
Transferring Pre-Trained Deep CNNs for Remote Scene Classification with General Features Learned from Linear PCA Network


Abstract
:
1. Introduction
- (1)
- By applying a shallow LPCANet to each spectral channel of the remote sensing images, we test the performance of LPCANet on extracting general features for pre-trained CNNs in spatial information.
- (2)
- Furthermore, we introduce quaternion algebra to LPCANet and design the linear quaternion PCANet (LQPCANet) to further extract general features for pre-trained CNNs from spectral information and test its performance for different remote sensing images.
- (1)
- We thoroughly investigate how the LPCANet and LQPCANet synthesize spatial and spectral information of the remote sensing imagery and how can them enhance generalization power of pre-trained deep CNNs for remote scene classification.
- (2)
- For future study, our proposed framework can serve as a simple but surprisingly effective baseline for empirically justifying advanced designs of transferring pre-trained deep CNNs to remote sensing images. We can take any pre-trained deep CNN as a starting point and improve the network further with our proposed method.
- (3)
- Our proposed features learning framework is under the “unsupervised settings”, which is an encouraging orientation in deep learning, and is more promising for remote sensing tasks compared with supervised or semi-supervised method.
2. Enhancing the Generalization Power of Pre-Trained Deep CNNs for Remote Scene Classification
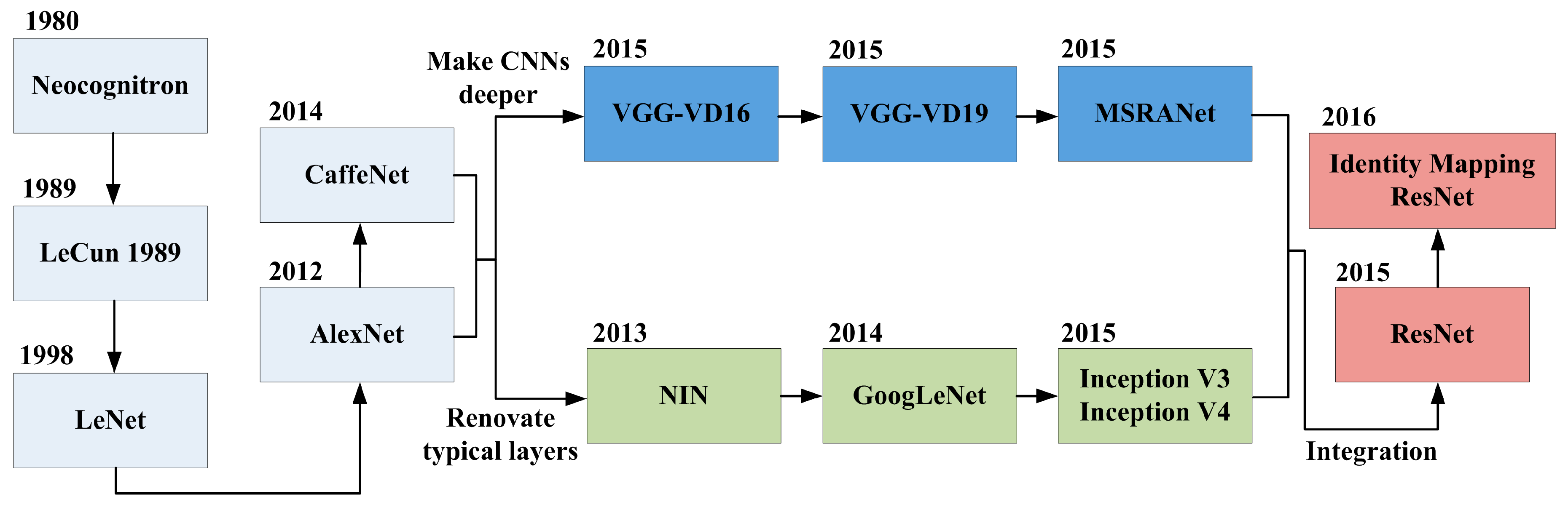
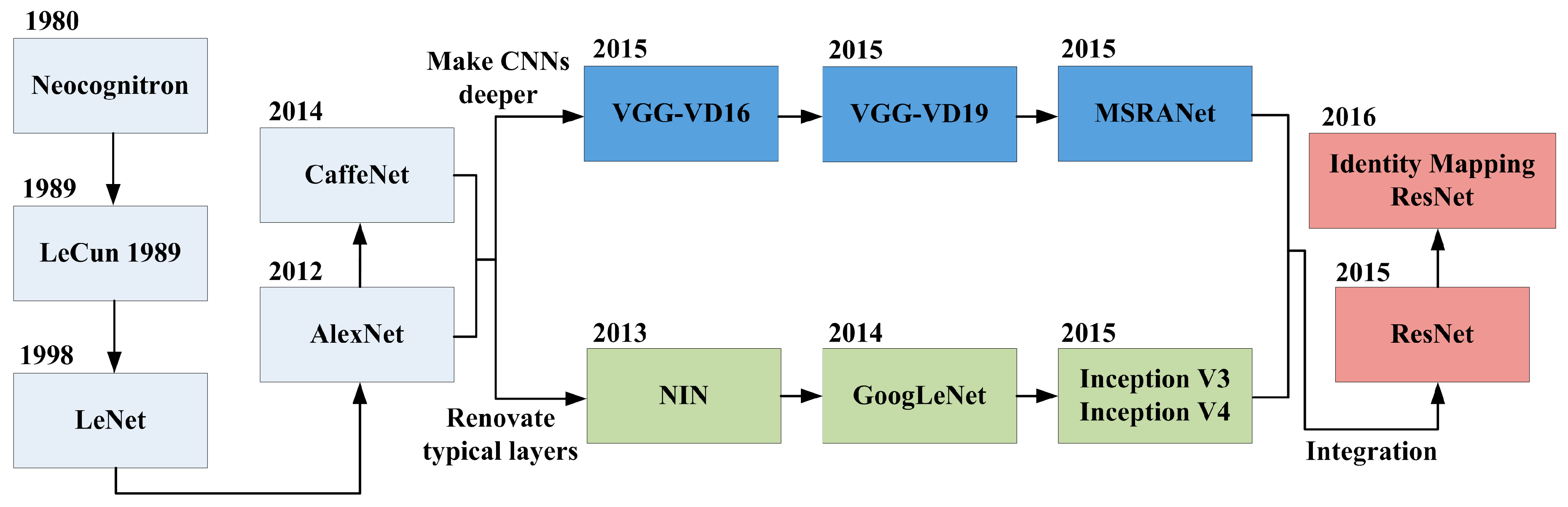
2.1. Pre-Trained Deep Convolutional Neural Networks
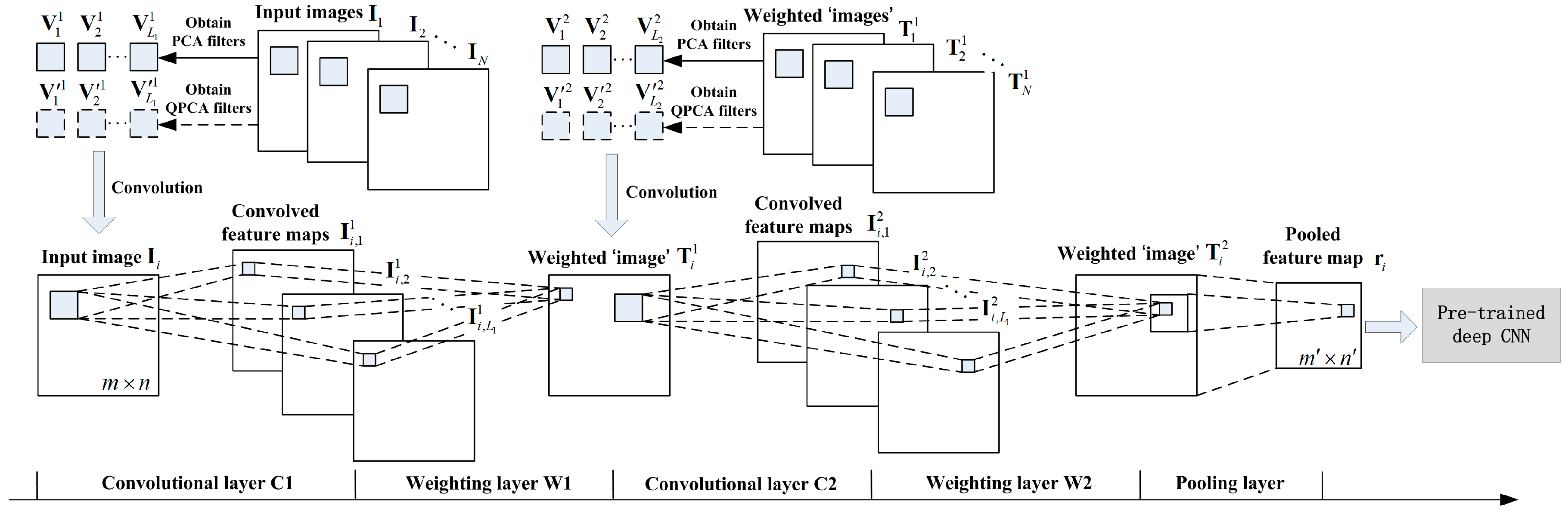
2.2. LPCANet and Its Quaternion Representation
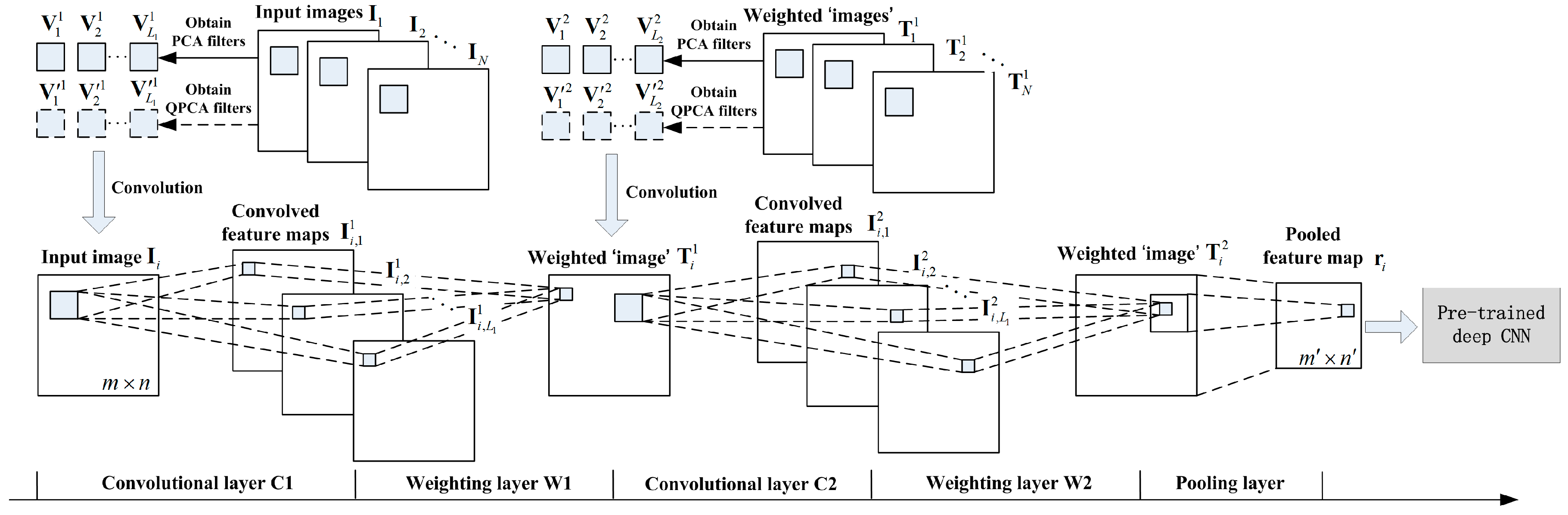
2.2.1. Learning PCA and QPCA Filters Bank from Remote Sensing Images
A. Learning PCA Filters Bank from Each Spectral Channel of Remote Sensing Images
B. Learning QPCA Filters Bank from Remote Sensing Images.
2.2.2. Encoding Feature Maps by Convolutional Operation
2.2.3. Feature Maps Weighing and Pooling
2.2.4. Multi-Stage Architecture
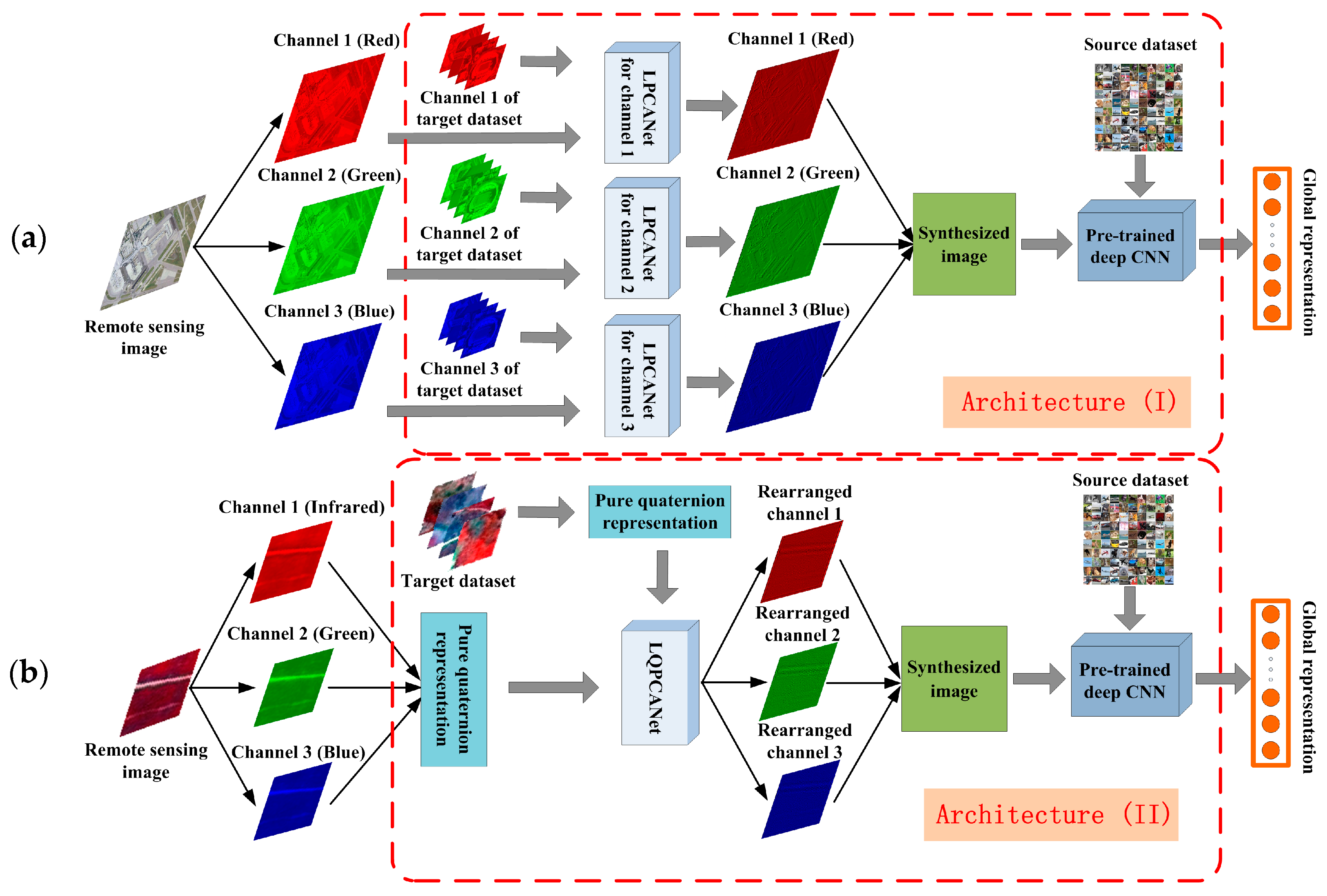
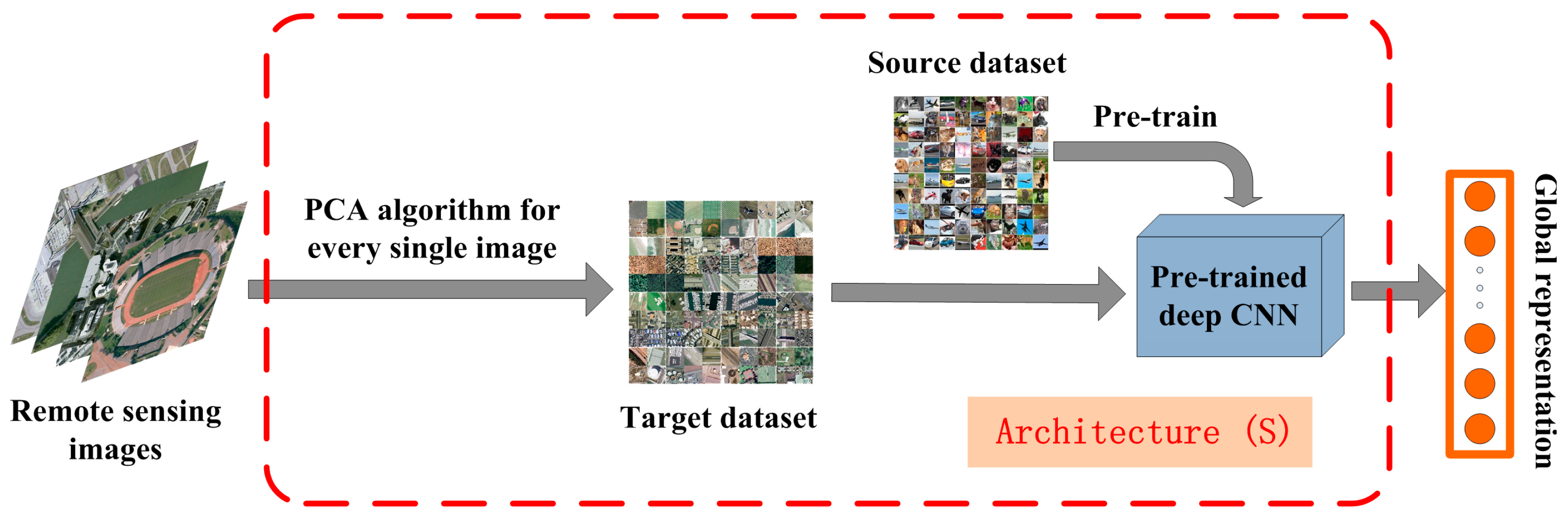
2.3. Methodology of Enhancing the Generalization Power of Pre-Trained Deep CNNs for Remote Scene Classification
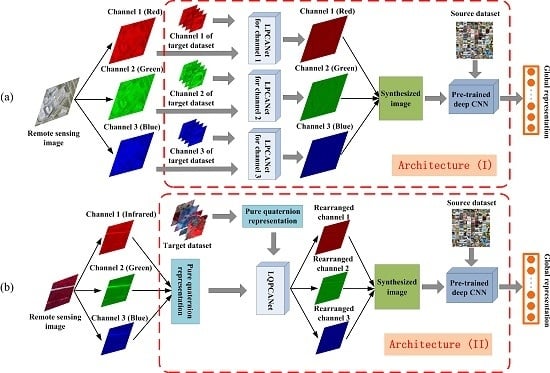
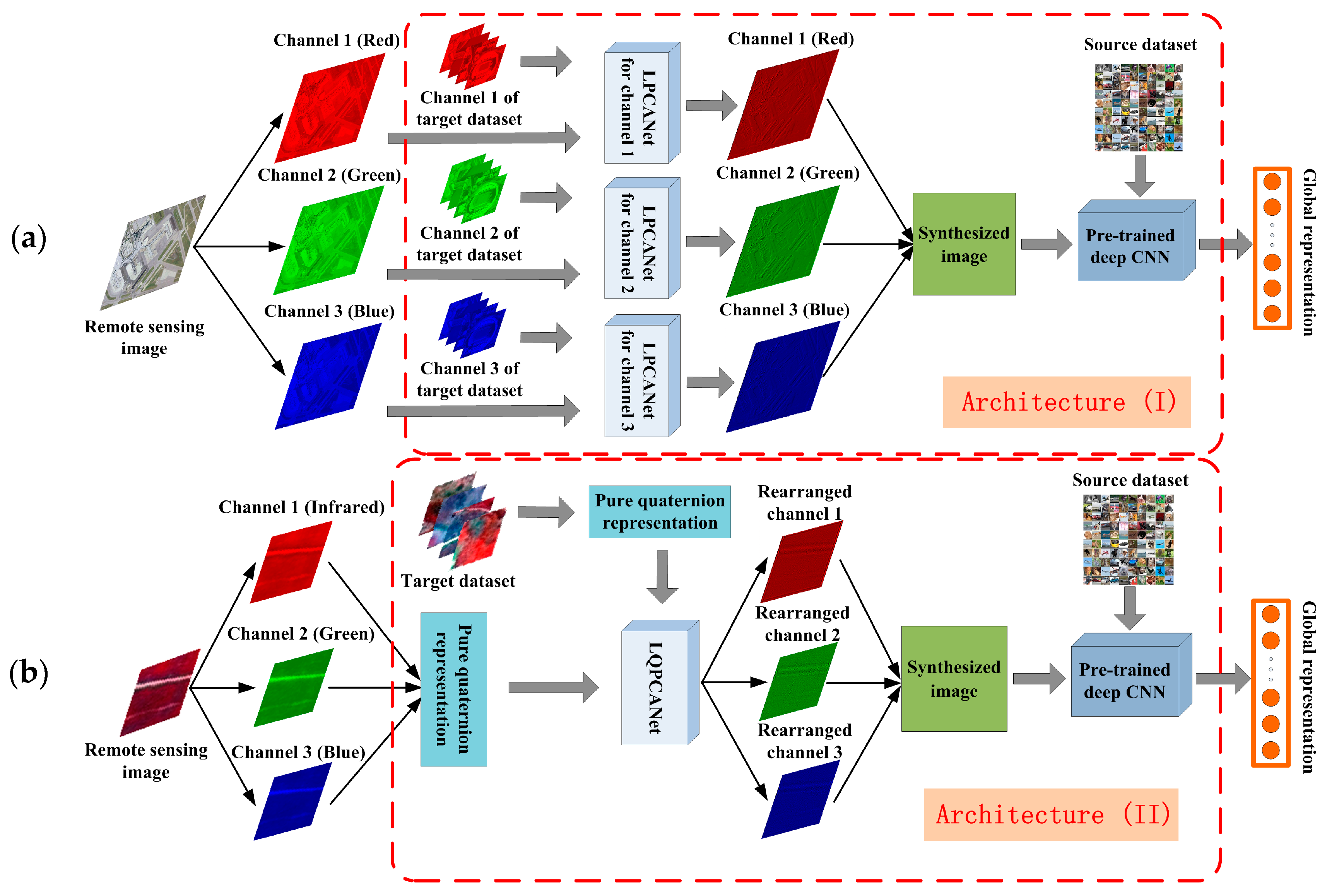
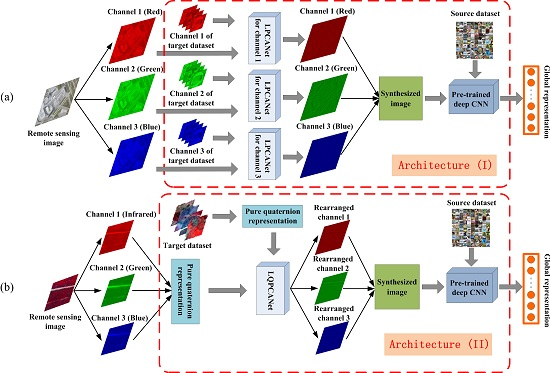
2.3.1. Architecture (I): Synthesizing Spatial Information of Remote Sensing Images to Extract General Features for Pre-Trained Deep CNNs
- Thus far, almost all successful pre-trained structures of deep CNNs are based on the ImageNet dataset. This results in the constraint that the number of spectral channels of input images should be and only be three when we use the pre-trained deep CNNs to extract global representation from them. This constraint limits the application range of pre-trained deep CNNs and causes inevitable information loss when the number of input images’ spectral channels is more than three.
- Data augmentation is a practical technique to improve the performance of deep CNNs by reducing overfitting in the training stage. However, in this paper, we use the pre-trained deep CNNs in a feedforward way without training on the remote sensing dataset. Because training a deep CNN on a small dataset helps little. Moreover, we usually cannot obtain the labels of remote sensing images in some case. Different from data augmentation, which enhances the generalization power of deep CNNs in supervised framework, LPCANet synthesizes the spatial information of remote sensing images and enhances the generalization power of pre-trained deep CNNs in an unsupervised manner.
- Compared with other remote sensing images such as SAR images, we prefer to apply Architecture (I) to optical remote sensing images. Because the spectral channels of daily natural images in the ImageNet dataset and optical remote sensing images in the target dataset are both red-green-blue, and the “distance” between them is relatively small.
2.3.2. Architecture (II): Further, Synthesizing Spectral Information of Remote Sensing Images to Extract General Features for Pre-Trained Deep CNNs
- Considering the constraint of the number of spectral channels that is discussed in Section 2.3.1, we should also obey this constraint in Architecture (II). Because the number of spectral channels of input images is fixed as three, in any case we apply pre-trained deep CNNs to extract global representation from them. Thus, the pure quaternion that contains three imaginary units is used to represent remote sensing images in practice.
- LQPCANet processes the pure quaternion representation of remote sensing images, rearranges the order of their spectral channels, and only maintains the relative relationship of them. Therefore, there is not some distinct spectral channel that we should represent it with some corresponding imaginary unit, when we transform the remote sensing images into pure quaternion form.
3. Experiments and Results
3.1. Experimental Setup
- 1
- UC Merced Land Use Dataset (http://vision.ucmerced.edu/datasets/landuse.html). Derived from United States Geological Survey (USGS) National Map, this dataset contains 2100 aerial scene images with 256 × 256 pixels, which are manually labeled as 21 land use classes, 100 for each class. Figure 8 shows one example image for each class. As shown in Figure 8, this dataset presents very small inter-class diversity among some categories, such as “dense residential”, “medium residential” and “sparse residential”. More examples and more information are available in [38].
- 2
- WHU-RS Dataset (http://www.tsi.enst.fr/~xia/satellite_image_project.html). Collected from Google Earth, this dataset is composed of 950 aerial scene images with 600 × 600 pixels, which are uniformly distributed in 19 scene classes, 50 for each class. The example images for each class are shown in Figure 9. We can see that images in both this dataset and UC Merced dataset are optical images (RGB color space). They are same in spectral information. However, compared with the images in UC Merced dataset, images in this dataset contain more detail information in space. The variation of scale and resolution of objects in a wide range within the images makes this dataset more complicated than the UC Merced dataset.
- 3
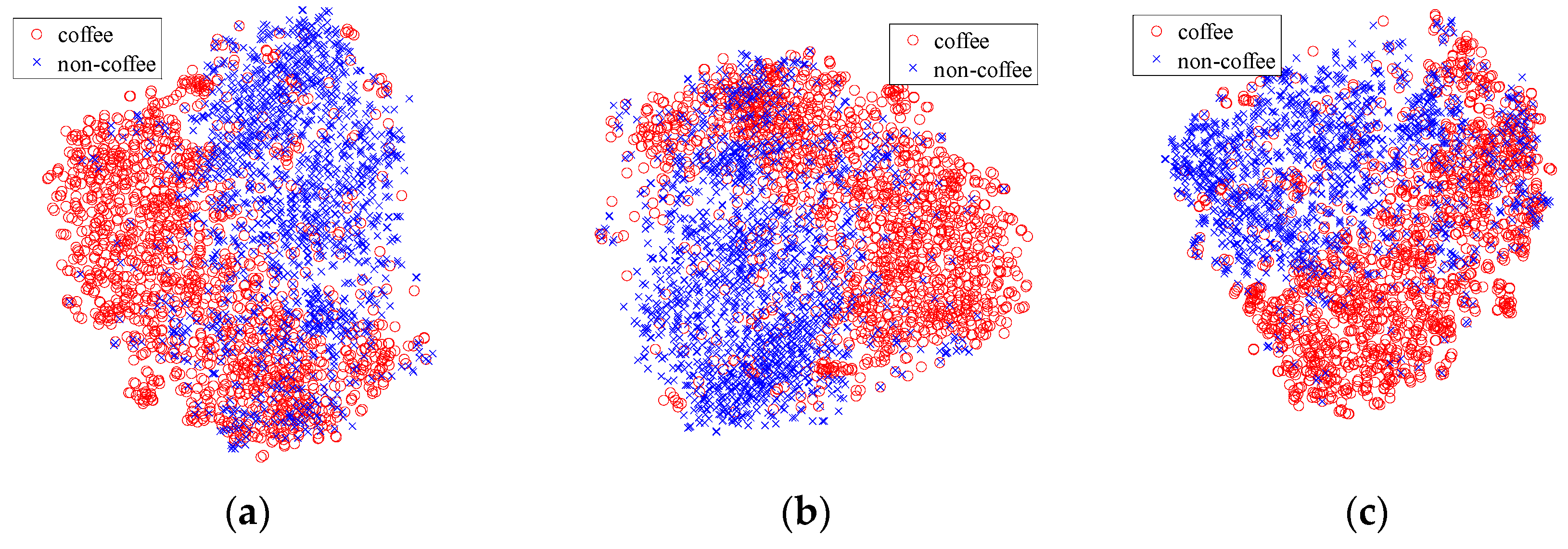
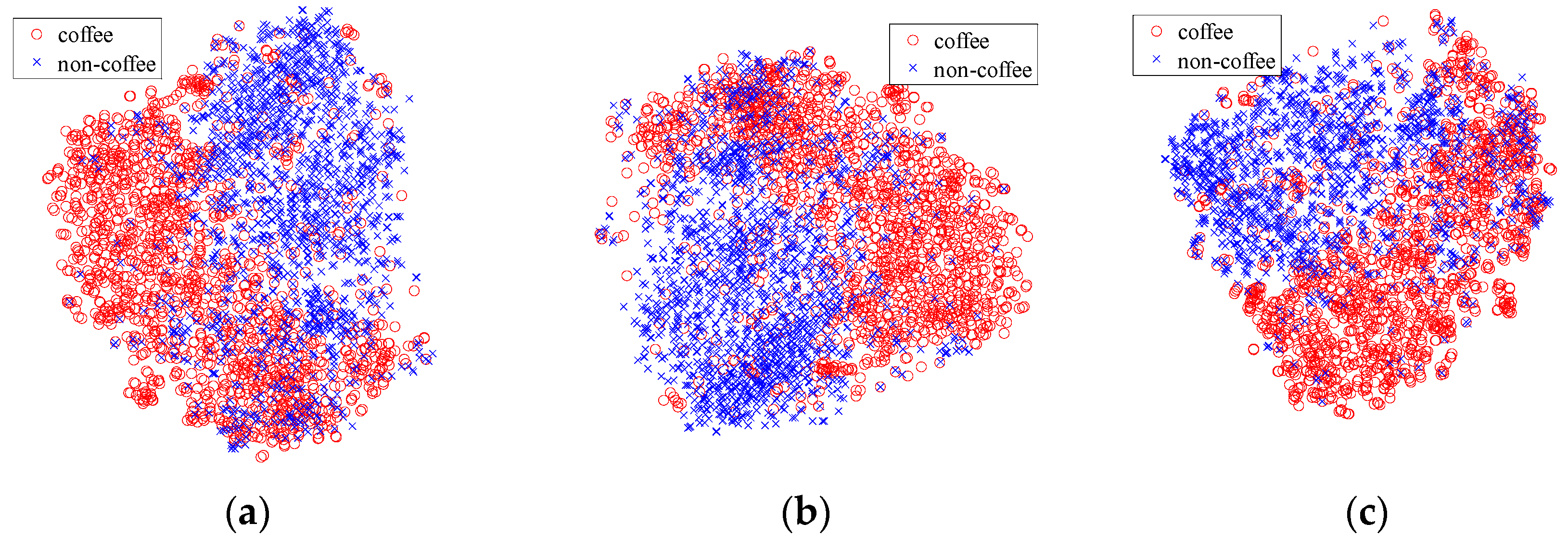
- Brazilian Coffee Scenes Dataset (www.patreo.dcc.ufmg.br/downloads/brazilian-coffee-dataset/). Taken by the SPOT sensor in the green, red, and near-infrared bands, over four counties in the State of Minas Gerais, Brazil, this dataset is released in 2015, and includes over 50,000 remote sensing images with 64 × 64 pixels, which are labeled as coffee (1438) non-coffee (36577) or mixed (12989) [25]. Figure 10 shows three example images for each of the coffee and non-coffee classes in false colors. To provide a balanced dataset for the experiments, 1438 images of both coffee and non-coffee classes are picked out, while images of mixed class are all discarded. Note that this dataset is very different from the former two datasets. Images in this dataset are not optical (green–red–infrared instead of red–green–blue).
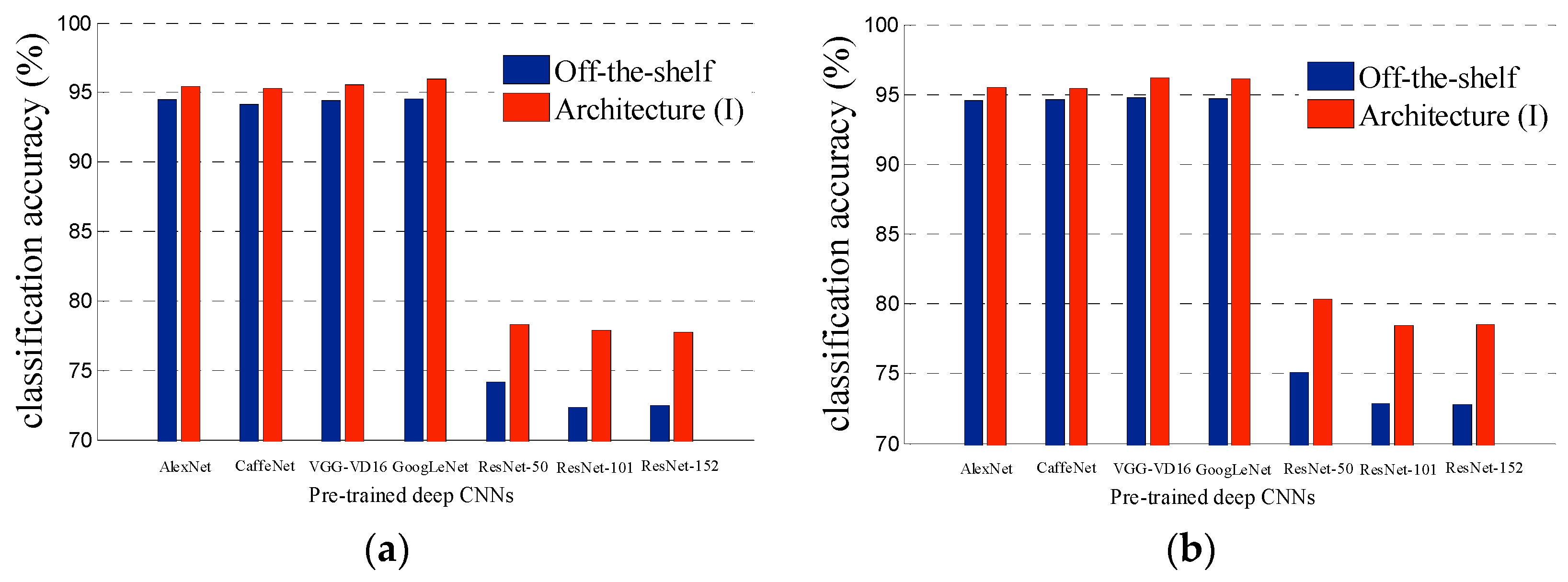
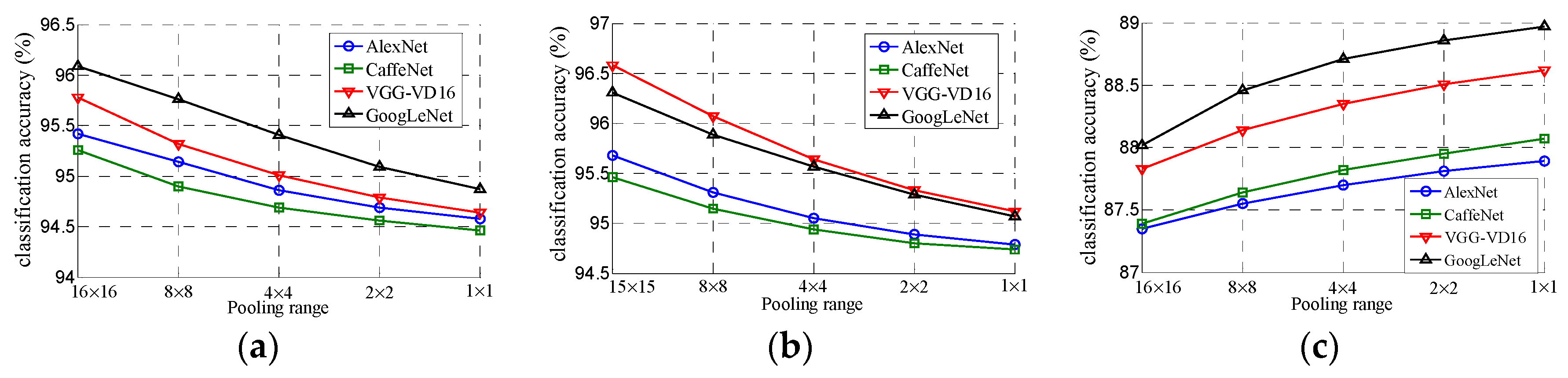
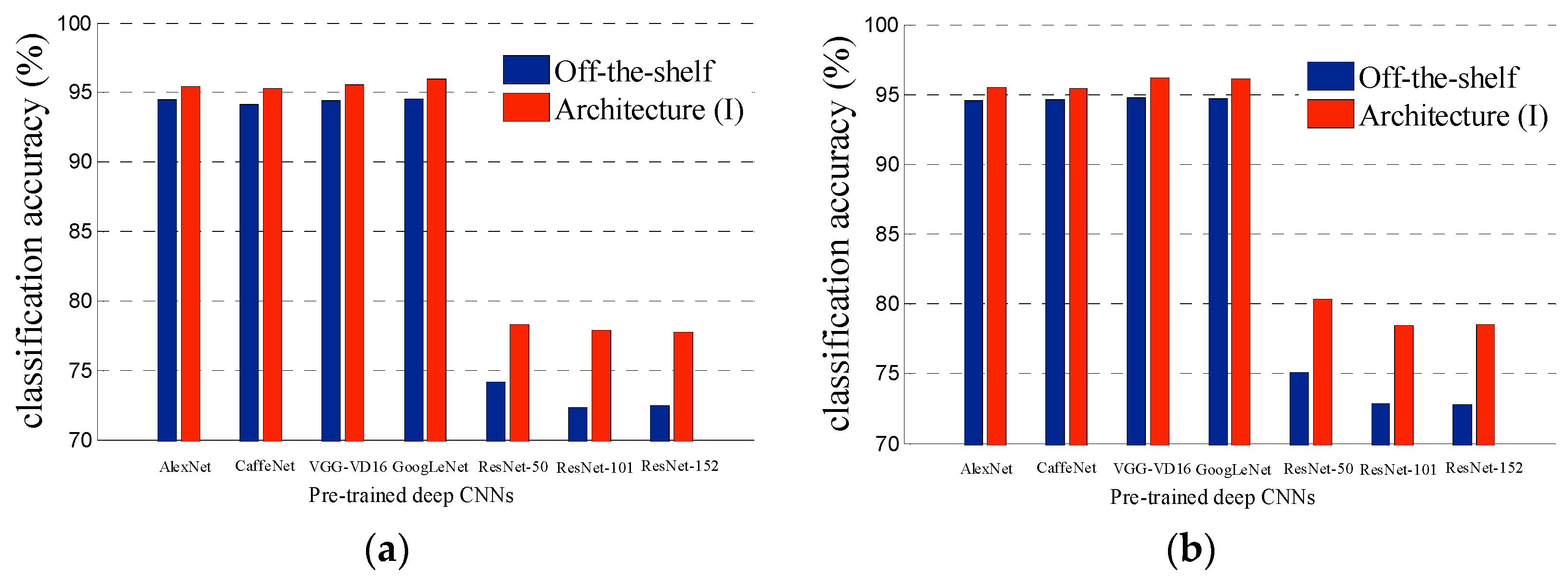
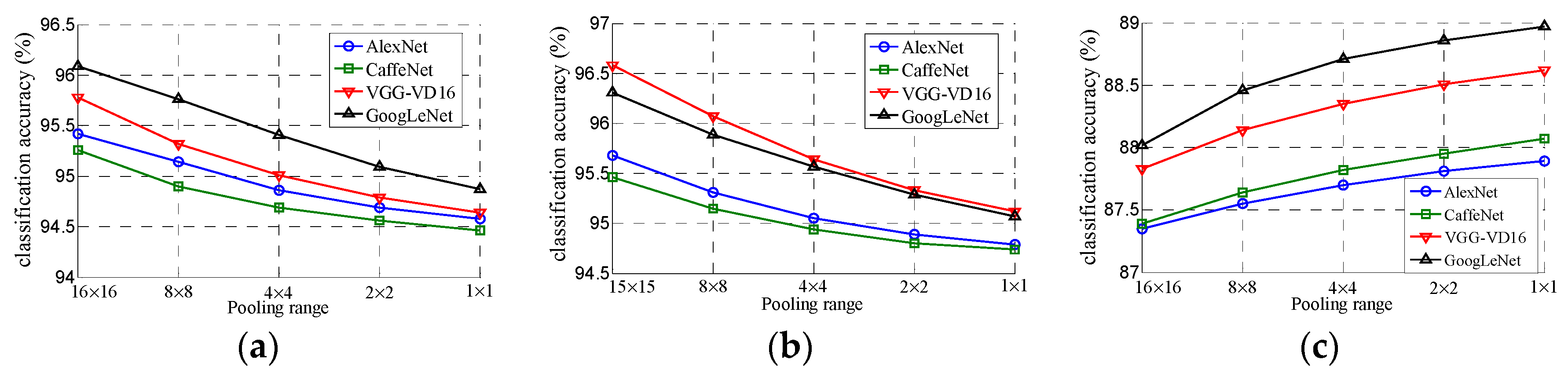
3.2. Experimental Results of Architecture (I)
3.3. Experimental Results of Architecture (II)
4. Discussion
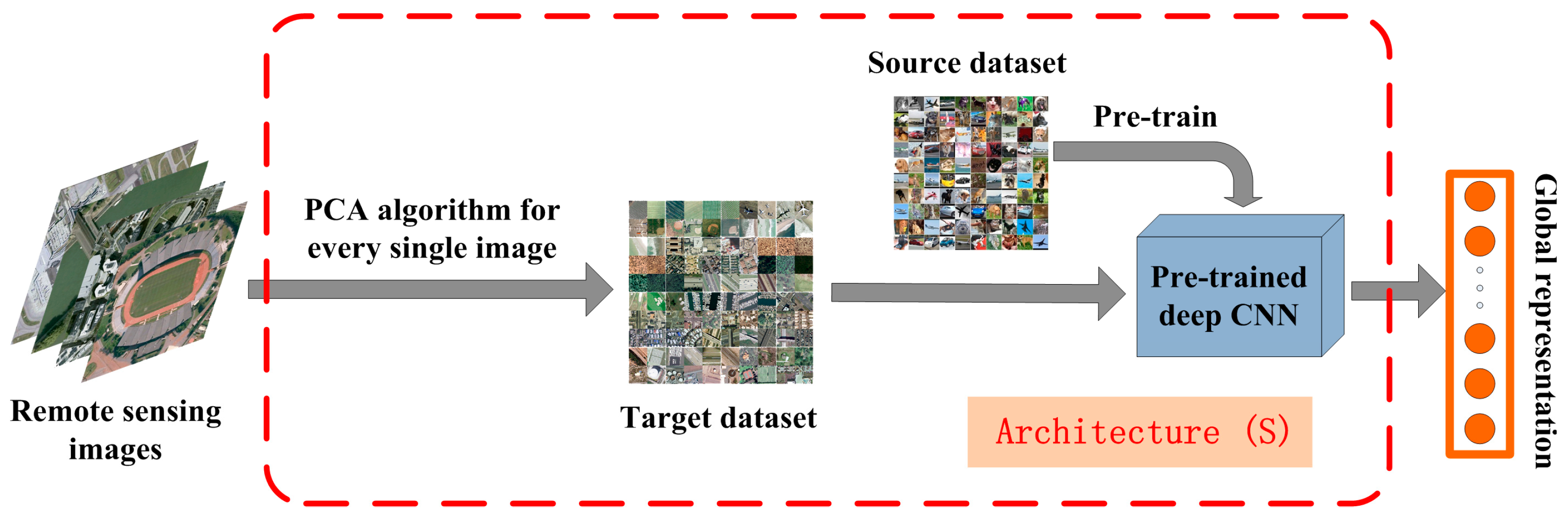
- In Table 1 and Table 5, we can see that the performances of pre-trained AlexNet, CaffeNet, VGG-VD16 and GoogLeNet are almost same in remote scene classification in condition of Off-the-shelf. There is obvious bottleneck for directly transferring pre-trained deep CNNs to the task of remote scene classification. Our proposed two architectures improve the performance of pre-trained CNNs in an unsupervised manner and provide a better starting point for further method (such as fine-tuning and feature fusing) to get better performance for remote scene classification.
- To our surprise, the most successful deep CNNs to date, ResNets, fail to obtain good experiment result when we transfer it for remote scene classification, no matter their layers are 50, 101 or 152. This phenomenon indicates that not all successful deep CNNs are suitable for transferring to the task of remote scene classification.
- The selection of our two proposed architectures depends on the target dataset in the transferring process, namely the remote sensing dataset when we transfer pre-trained deep CNNs for remote scene classification. When the spectral information of source and target datasets are the same, we use Architecture (I), and we prefer to Architecture (II) when their spectral information is different.
- Compared with directly transferring pre-trained deep CNNs for remote scene classification, our method provides a new way to optimize the transferring process. When we transfer any successful deep CNN explored in future for remote scene classification, we can make it a step further with our proposed method.
- The transferring strategy in our paper is limited by the spectral channels of input images for the deep CNNs pre-trained by everyday optical images. For remote sensing images whose spectral channels are more than three, their spectral dimensions must be reduces to three to fit the pre-trained deep CNNs transferred to them. With no doubt, this operation brings spectral information loss.
- In the remote sensing field, the scale of remote sensing datasets will be larger and larger. On the other hand, the structure of deep CNN will be optimized, and the parameters in it will be less and less. Therefore, in our proposed framework we could get more and more useful information from remote sensing datasets, obtain better generalization power of pre-trained deep CNNs and run into less overfitting.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wang, J.; Qin, Q.; Li, Z.; Ye, X.; Wang, J.; Yang, X.; Qin, X. Deep hierarchical representation and segmentation of high resolution remote sensing images. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 4320–4323.
- Nijim, M.; Chennuboyina, R.D.; Al Aqqad, W. A supervised learning data mining approach for object recognition and classification in high resolution satellite data. World Acad. Sci. Eng. Technol. Int. J. Comput. Electr. Autom. Control Inf. Eng. 2015, 9, 2472–2476. [Google Scholar]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 1873–1876.
- Zhou, W.; Shao, Z.; Diao, C.; Cheng, Q. High-resolution remote-sensing imagery retrieval using sparse features by auto-encoder. Remote Sens. Lett. 2015, 6, 775–783. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 439–451. [Google Scholar] [CrossRef]
- Xu, Y.; Huang, B. Spatial and temporal classification of synthetic satellite imagery: Land cover mapping and accuracy validation. Geo-Spat. Inf. Sci. 2014, 17, 1–7. [Google Scholar] [CrossRef]
- Yang, W.; Yin, X.; Xia, G.S. Learning high-level features for satellite image classification with limited labeled samples. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4472–4482. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Xia, G.S. Extreme value theory-based calibration for the fusion of multiple features in high-resolution satellite scene classification. Int. J. Remote Sens. 2013, 34, 8588–8602. [Google Scholar] [CrossRef]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised deep feature extraction for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1349–1362. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178.
- Zhao, L.J.; Tang, P.; Huo, L.Z. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Chen, S.; Tian, Y.L. Pyramid of spatial relatons for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1947–1957. [Google Scholar] [CrossRef]
- Negrel, R.; Picard, D.; Gosselin, P.H. Evaluation of second-order visual features for land-use classification. In Proceedings of the IEEE 12th International Workshop on Content-Based Multimedia Indexing, Klagenfurt, Austria, 18–20 June 2014; pp. 1–5.
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105.
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv, 2013; arXiv:1312.6229. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678.
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 4959–4962.
- Hamida, A.B.; Benoit, A.; Lambert, P.; Ben, A.C. Deep learning approach for remote sensing image analysis. In Proceedings of the Big Data from Space, Santa Cruz De Tenerife, Spain, 15–17 March 2016; p. 133.
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv, 2015; arXiv:1508.00092. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–29 June 2009; pp. 248–255.
- Nanni, L.; Ghidoni, S. How could a subcellular image, or a painting by Van Gogh, be similar to a great white shark or to a pizza? Pattern Recognit. Lett. 2017, 85, 1–7. [Google Scholar] [CrossRef]
- Penatti, O.A.B.; Nogueira, K.; dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 July 2015; pp. 44–51.
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, A.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 July 2015; pp. 1–19.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv, 2015; arXiv:1512.03385. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurones in the cat’s striate cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef] [PubMed]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 July 2015; pp. 5353–5360.
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv, 2013; arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. arXiv, 2015; arXiv:1512.00567. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv, 2016; arXiv:1602.07261. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279.
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 July 2015; pp. 5188–5196.
- Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Van der Maaten, L. Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar]
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the IEEE 2011 International Conference on Computer Vision, Providence, RI, USA, 20–25 June 2011; pp. 1465–1472.
- Jiang, Y.; Yuan, J.; Yu, G. Randomized spatial partition for scene recognition. In Computer Vision–ECCV 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 730–743. [Google Scholar]
- Xiao, Y.; Wu, J.; Yuan, J. mCENTRIST: A multi-channel feature generation mechanism for scene categorization. IEEE Trans. Image Process. 2014, 23, 823–836. [Google Scholar] [CrossRef] [PubMed]
- Avramović, A.; Risojević, V. Block-based semantic classification of high-resolution multispectral aerial images. Signal Image Video Process. 2016, 10, 75–84. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Kobayashi, T. Dirichlet-based histogram feature transform for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3278–3285.
- Ren, J.; Jiang, X.; Yuan, J. Learning LBP structure by maximizing the conditional mutual information. Pattern Recognit. 2015, 48, 3180–3190. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised feature learning via spectral clustering of multidimensional patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Liu, Z.; Bu, S.; Ren, J. Effective and efficient midlevel visual elements-oriented land-use classification using VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4238–4249. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Liu, T. Learning coarse-to-fine sparselets for efficient object detection and scene classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1173–1181.
- Hu, F.; Xia, G.S.; Hu, J.; Zhong, Y.; Xu, K. Fast binary coding for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2016, 8, 555. [Google Scholar] [CrossRef]
- Zhong, Y.; Fei, F.; Zhang, L. Large patch convolutional neural networks for the scene classification of high spatial resolution imagery. J. Appl. Remote Sens. 2016, 10, 025006. [Google Scholar] [CrossRef]
- Qi, K.; Liu, W.; Yang, C.; Guan, Q.; Wu, H. High Resolution Satellite Image Classification Using Multi-Task Joint Sparse and Low-Rank Representation; Preprints: Basel, Switzerland, 2016. [Google Scholar]
- Zhao, B.; Zhong, Y.; Zhang, L. A spectral–structural bag-of-features scene classifier for very high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2016, 116, 73–85. [Google Scholar] [CrossRef]
- Yu, H.; Yang, W.; Xia, G.S.; Liu, G. A Color-Texture-structure descriptor for high-resolution satellite image classification. Remote Sens. 2016, 8, 259. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Fei, F.; Zhang, L. Scene semantic classification based on random-scale stretched convolutional neural network for high-spatial resolution remote sensing imagery. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 763–766.
- Zou, J.; Li, W.; Chen, C.; Du, Q. Scene classification using local and global features with collaborative representation fusion. Inf. Sci. 2016, 348, 209–226. [Google Scholar] [CrossRef]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 806–813.
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pre-Trained Deep CNN | UC Merced | WHU-RS | Brazilian Coffee Scenes | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Off-the-Shelf | Architecture (I) | Off-the-Shelf | Architecture (I) | Off-the-Shelf | Architecture (I) | |||||||
| Ac (%) | SD | Ac (%) | SD | Ac (%) | SD | Ac (%) | SD | Ac (%) | SD | Ac (%) | SD | |
| AlexNet | 94.51 | 0.94 | 95.43 | 0.79 | 94.57 | 0.61 | 95.53 | 0.36 | 85.14 | 1.26 | 85.23 | 1.13 |
| CaffeNet | 94.12 | 1.05 | 95.26 | 0.67 | 94.67 | 0.75 | 95.47 | 0.69 | 84.97 | 1.54 | 85.12 | 1.08 |
| VGG-VD16 | 94.43 | 0.68 | 95.59 | 0.72 | 94.76 | 0.72 | 96.22 | 0.58 | 84.12 | 0.97 | 84.06 | 0.84 |
| GoogLeNet | 94.57 | 0.98 | 95.94 | 0.59 | 94.68 | 1.01 | 96.14 | 0.55 | 84.06 | 1.16 | 84.09 | 0.98 |
| ResNet-50 | 74.14 | 5.89 | 78.32 | 5.26 | 75.12 | 5.36 | 80.35 | 5.19 | 60.54 | 7.22 | 60.37 | 6.93 |
| ResNet-101 | 72.36 | 5.96 | 77.92 | 5.79 | 72.85 | 5.09 | 78.46 | 4.48 | 59.39 | 6.68 | 58.92 | 6.27 |
| ResNet-152 | 72.48 | 4.35 | 77.78 | 4.13 | 72.81 | 4.42 | 78.52 | 4.21 | 59.62 | 6.81 | 59.42 | 6.14 |
| Pre-Trained Deep CNN | Linear SVM | Softmax | ||
|---|---|---|---|---|
| With Aug | Without Aug | With Aug | Without Aug | |
| AlexNet | 95.85 | 95.43 | 96.01 | 95.78 |
| CaffeNet | 95.81 | 95.26 | 96.08 | 95.74 |
| VGG-VD16 | 96.15 | 95.59 | 96.26 | 95.90 |
| GoogLeNet | 96.67 | 95.94 | 96.95 | 96.03 |
| ResNet-50 | 79.22 | 78.32 | 79.54 | 78.58 |
| ResNet-101 | 78.64 | 77.92 | 79.52 | 78.65 |
| ResNet-152 | 78.83 | 77.78 | 79.30 | 78.59 |
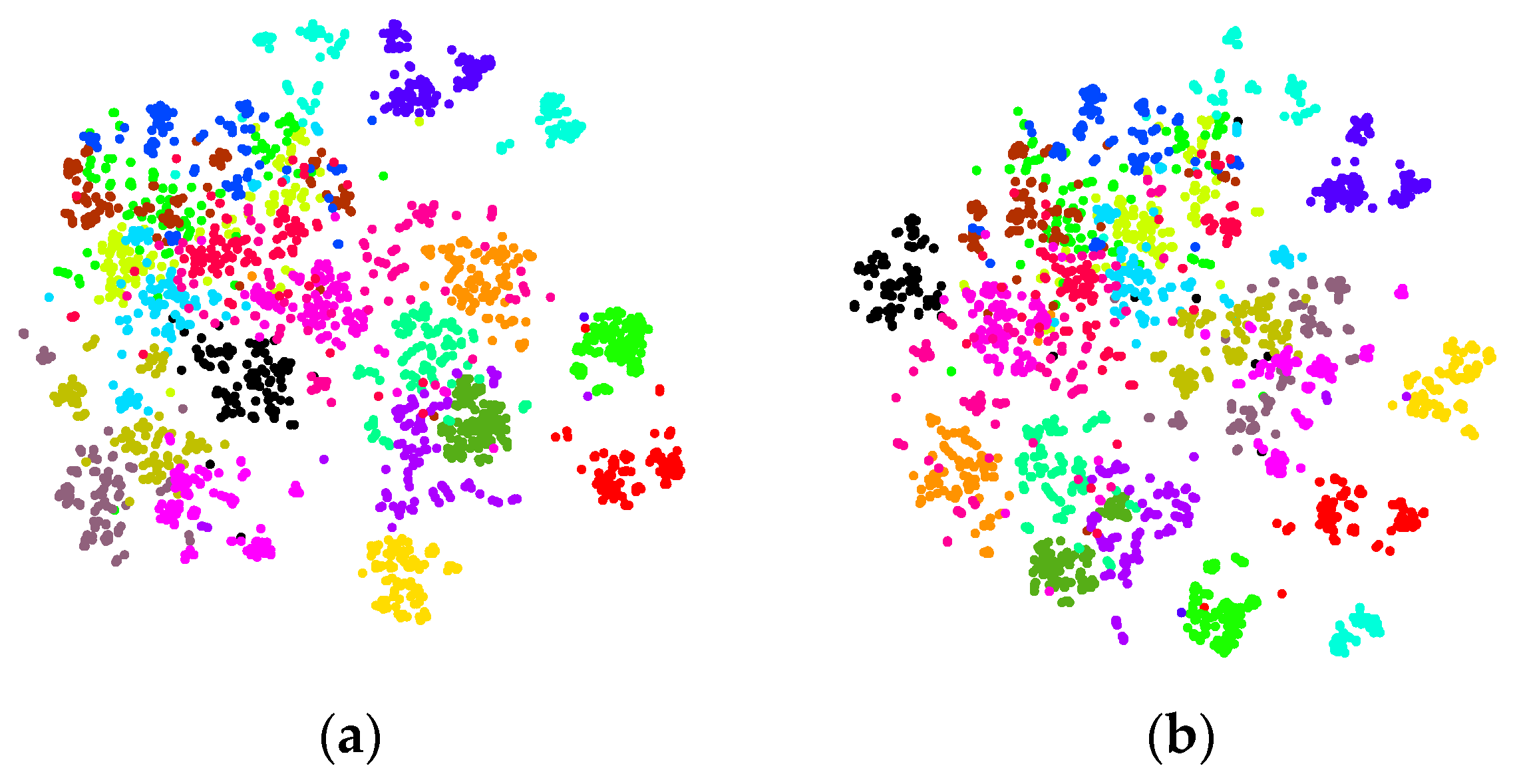
| Pre-Trained Deep CNN | Architecture (S) | Architecture (I) | off-the-Shelf |
|---|---|---|---|
| AlexNet | 92.25 | 95.43 | 94.51 |
| CaffeNet | 92.37 | 95.26 | 94.12 |
| VGG-VD16 | 92.71 | 95.59 | 94.43 |
| GoogLeNet | 93.16 | 95.94 | 94.57 |
| ResNet-50 | 72.85 | 78.32 | 74.14 |
| ResNet-101 | 70.79 | 77.92 | 72.36 |
| ResNet-152 | 70.92 | 77.78 | 72.48 |
| Method | Year | Reference | Accuracy |
|---|---|---|---|
| SCK | 2010 | [38] | 72.52 |
| SPCK++ | 2011 | [42] | 77.38 |
| BRSP | 2012 | [43] | 77.80 |
| UFL | 2014 | [5] | 81.67 |
| CCM-BOVW | 2014 | [11] | 86.64 |
| mCENTRIST | 2014 | [44] | 89.90 |
| MSIFT | 2014 | [45] | 90.97 |
| COPD | 2014 | [46] | 91.33 |
| Dirichlet | 2014 | [47] | 92.80 |
| VLAT | 2014 | [13] | 94.30 |
| MCMI-based | 2015 | [48] | 88.20 |
| PSR | 2015 | [12] | 89.10 |
| UFL-SC | 2015 | [49] | 90.26 |
| Partlets | 2015 | [50] | 91.33 |
| Sparselets | 2015 | [51] | 91.46 |
| Pre-trained CaffeNet | 2015 | [25] | 93.42 |
| FBC | 2016 | [52] | 85.53 |
| LPCNN | 2016 | [53] | 89.90 |
| MTJSLRC | 2016 | [54] | 91.07 |
| SSBFC | 2016 | [55] | 91.67 |
| CTS | 2016 | [56] | 93.08 |
| SRSCNN | 2016 | [57] | 95.10 |
| LGF | 2016 | [58] | 95.48 |
| Architecture (I) | — | — | 96.95 |
| Pre-Trained Deep CNN | UC Merced | WHU-RS | Brazilian Coffee Scenes | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Ar(II) | Ar(I) | OTS | Ar(II) | Ar(I) | OTS | Ar(II) | Ar(I) | OTS | |
| AlexNet | 95.14 | 95.43 | 94.51 | 95.31 | 95.53 | 94.57 | 87.55 | 85.23 | 85.14 |
| CaffeNet | 94.90 | 95.26 | 94.12 | 95.15 | 95.47 | 94.67 | 87.64 | 85.12 | 84.97 |
| VGG-VD16 | 95.32 | 95.59 | 94.43 | 96.07 | 96.22 | 94.76 | 88.14 | 84.06 | 84.12 |
| GoogLeNet | 95.76 | 95.94 | 94.57 | 95.89 | 96.14 | 94.68 | 88.46 | 84.09 | 84.06 |
| ResNet-50 | 77.06 | 78.32 | 74.14 | 79.15 | 80.35 | 75.12 | 68.85 | 60.37 | 60.54 |
| ResNet-101 | 76.65 | 77.92 | 72.36 | 78.38 | 78.46 | 72.85 | 68.26 | 58.92 | 59.39 |
| ResNet-152 | 76.89 | 77.78 | 72.48 | 78.10 | 78.52 | 72.81 | 68.44 | 59.42 | 59.62 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Luo, C.; Huang, H.; Zhao, H.; Wang, S. Transferring Pre-Trained Deep CNNs for Remote Scene Classification with General Features Learned from Linear PCA Network. Remote Sens. 2017, 9, 225. https://doi.org/10.3390/rs9030225
Wang J, Luo C, Huang H, Zhao H, Wang S. Transferring Pre-Trained Deep CNNs for Remote Scene Classification with General Features Learned from Linear PCA Network. Remote Sensing. 2017; 9(3):225. https://doi.org/10.3390/rs9030225
Chicago/Turabian StyleWang, Jie, Chang Luo, Hanqiao Huang, Huizhen Zhao, and Shiqiang Wang. 2017. "Transferring Pre-Trained Deep CNNs for Remote Scene Classification with General Features Learned from Linear PCA Network" Remote Sensing 9, no. 3: 225. https://doi.org/10.3390/rs9030225