1. Introduction
Change detection is the process to find inconsistent regions in different temporal images of the same area [
1]. Recently, high resolution remote sensing (HRRS) images have become the major sources for change detection studies. The change detection technique is widely used in monitoring landscape conditions [
2], the influence of natural disasters [
3] and urban expansion, discovering the vegetation changes, assessing desertification [
4] and detecting other urban or natural environmental changes [
5,
6,
7]. In the past decades, numerous change detection methods have been developed and considerable studies have addressed the automatic and accurate detection of changes from multi-temporal images. The most general change detection framework in remote sensing comprises of feature extraction and decision making. At the feature level, some methods focus on the completeness of color, texture and structural information [
8,
9], while others intend to use object-based analysis and MRF to emphasis spatial information [
10,
11,
12]. At the decision level, most of these methods can be categorized into supervised, semi-supervised and unsupervised methods [
13,
14]. Supervised and semi-supervised methods obtain the change messages by learning from labelled samples, while unsupervised methods detect changes appearing in the observed region by comparing the distribution of pixel values. As an application-oriented research, change detection is a complicated process and is attracting more and more attention.
Supervised change detection methods sometimes detect land cover changes from classification results [
15]. If multitemporal ground truth information is available, supervised techniques can be applied. The ground truth is used to train classification models. Post-classification comparison techniques obtain the change message from multiple classification maps of different temporal images to detect category transitions [
16,
17]. Based on the set of reliable labelling samples, the supervised methods can obtain good performance and specific category transition. Molina et al. [
18] proposed to use a parametric multi-sensor Bayesian data fusion approach and a Support Vector Machine (SVM) for change detection problems. Wu et al. [
19] explored a scene change detection framework for HRRS images, with a bag-of-visual-words (BOVW) model and classification-based methods [
20]. Then, post-classification and compound classification were evaluated for their performances in the “from–to” change results. Nevertheless, whether or not the corresponding samples in the experimental dataset are correctly classified, some misclassified samples may result in errors on the post-classification change detection map. Almost all classifiers are sensitive to noise. Besides, preparing training samples for supervised classifiers is a complex, time consuming and expensive process. To avoid the bad effects of misclassified samples and consider the temporal correlation, some supervised methods stack multi-temporal images together and take into account the dependence between two images of the same area [
21,
22]. The general idea is to characterize pixels or objects by stacking the feature vectors of two images. Then, land-cover transition classifiers are carried out to recognize specific transitions provided by training samples. In [
22], Volpi et al. adopted the nonlinear SVMs to cope with the high intra-class variability, which achieved high detection accuracy in very high geometrical resolution images. In addition, to reduce the tedious workload of labelling, some semi-supervised change detection methods are proposed. Shao et al. [
23] proposed a novel and robust semi-supervised fuzzy C-means clustering algorithm to analyze the difference image. Chen et al. [
24] proposed a semisupervised context-sensitive method by analyzing the posterior of probabilistic Gaussian process classifier within an MRF model. An et al. [
25] proposed a novel semi-supervised SAR images change detection methods using random fields based on maximum entropy principle. The proposed model takes full advantages of the image information from both the labelled and the unlabelled samples, providing appropriate detection results even using a small number of labelled samples. All the aforementioned supervised and semi-supervised methods based on classification are intrinsically suitable to detect changes in multisensor/multisource data.
If no ground truth is available, unsupervised methods can be adopted. Unsupervised change detection methods detect land cover change based on the property of data, mainly referring to the difference image. Difference image-based unsupervised change detection mainly includes two pivotal steps: producing a difference image and analyzing the difference image to identify the pixels as changed or unchanged. The first step is to compare two co-registered multi-temporal images to create the difference image, in which different mathematical operators can be used (e.g., image differencing, image rationing, spectral gradient differencing, and change vector analysis). The second step is to separate the pixels of difference image into changed or unchanged classes to obtain the change detection map. Nielsen [
26] proposed the iteratively reweighted multivariate alteration detection (IR-MAD) method for change detection, which established the technique of canonical correlation analysis. Then, Marpu et al. [
27] improved the IR-MAD method by the usage of an initial change mask to eliminate strong changes. Liu et al. [
28] proposed a hierarchical scheme by considering spectral change information to identify the change classes. Considering reference samples are often not available in real applications, the proposed approach is designed in an unsupervised way. To detect changes in the increasing amount of available HRRS imagery, Leichtle et al. [
11] proposed an object-based approach using principal component analysis (PCA) and
k-means clustering for the discrimination of changed and unchanged buildings. Byun et al. [
29] introduced a novel unsupervised change detection approach based on image fusion. Shah-Hosseini et al. [
30] proposed two automatic kernel-based change detection algorithms based on kernel clustering and support vector data description algorithms in high dimensional Hilbert space. Sinha et al. [
31] proposed a rank-based metric selection process through computation of four difference-based indices using a Max–Min/Max normalization approach. Although these unsupervised methods do not need tedious and expensive annotations, certain objective factors such as the atmosphere conditions, sensor calibration, etc., can affect the derived difference image. Moreover, choosing an appropriate threshold to detect change areas is also a very difficult task. Most importantly, the change detection results of unsupervised methods are often unsatisfactory compared with supervised methods.
Considering many change detection methods only utilize the attribute information (color and texture), we further exploit the fact that, in detecting real-world changes, it is very likely that changes occur in a relatively large area, which means the spatially neighboring pixels belong to the same class (change or no change) [
14]. This prior, which can be modeled as MRFs, encourages piecewise smooth change detection and eliminates the “superpixel-noises” of active learning results. In either supervised and unsupervised methods, the integration of spatial and attribute information can significantly improve the detection results. To combine spectral and spatial information, Zhu et al. [
32] proposed to formulate saliency detection as a
maximum a posteriori (MAP) probability estimation problem, which could find the salient regions from the background through MRF learning. In [
33], the authors used multitask joint sparse representation and a stepwise MRF framework to effectively handle high data correlation and the spatial coherency. In [
34], Li et al. integrated the subspace multinomial logistic regression methods with the multilevel logistic Markov-Gibbs MRF, providing accurate characterization of hyperspectral imagery in both the spectral and the spatial domain. For change detection objective, Yousif et al. [
12] proposed the iterated conditional models framework to characterize the relationship between pixels’ class-labels in a nonlocal scale, which effectively preserved spatial details and reduced speckle effects in multi-temporal SAR images. These methods formulate the spatial constraints into MRF model, providing superior performance compared with results when only using attribute information.
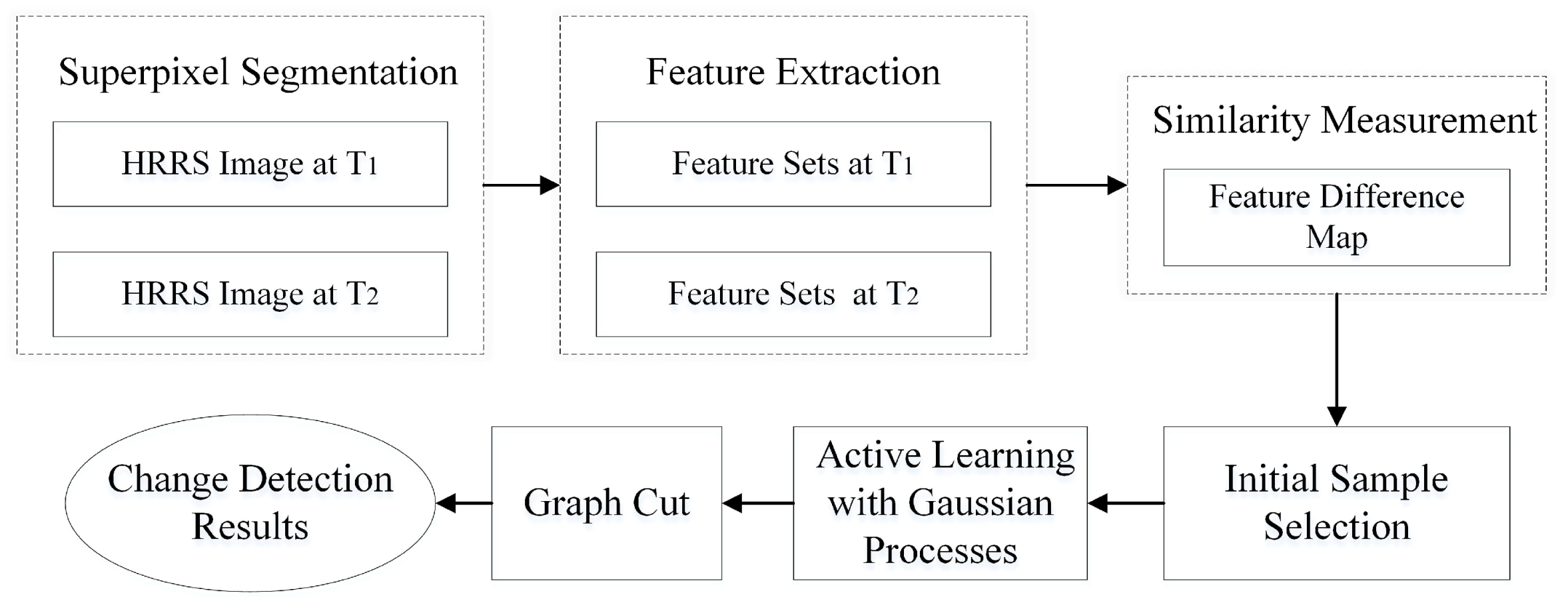
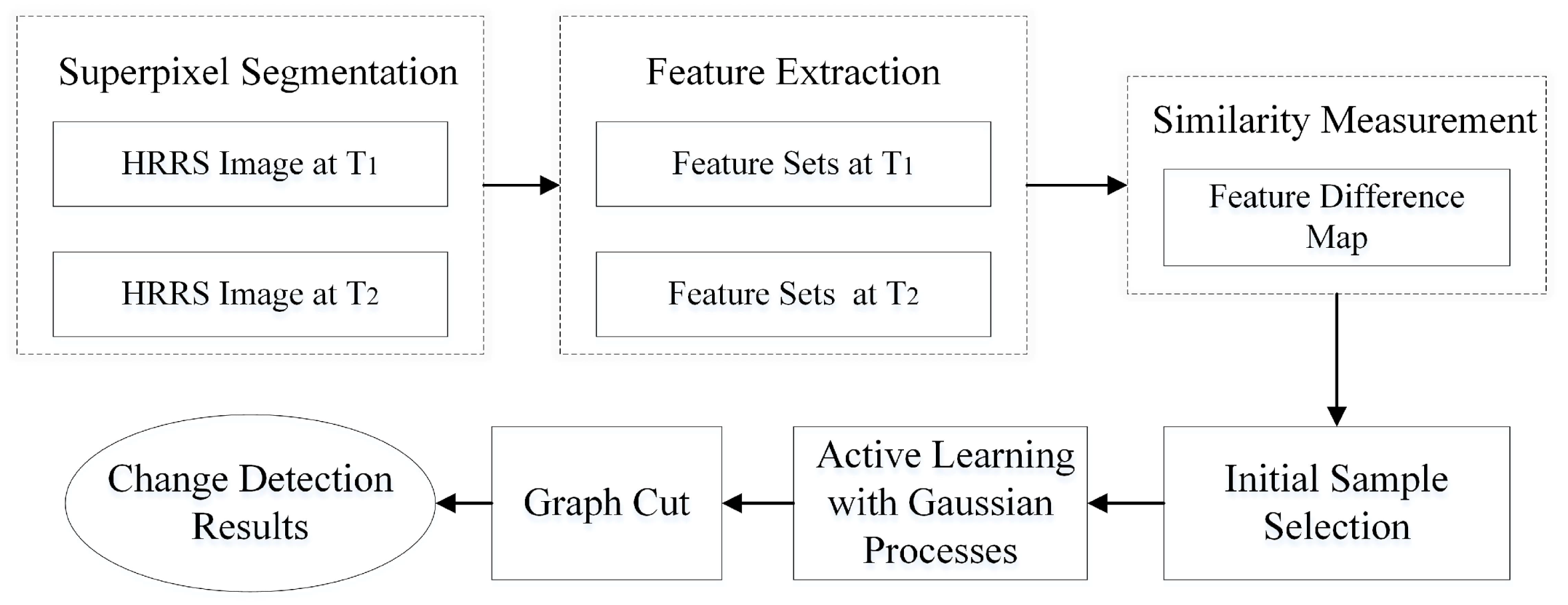
As mentioned above, it is a difficult task to construct the large training sample set for supervised methods, which may need extensive field investigations. However, whether a region has changed could be uncertain without human intervention for unsupervised methods. In this paper, our goal is to use the minimum labelling samples to obtain the most reliable change detection results. To reduce the workload of manual annotation, an active learning framework is proposed to improve the effectiveness of limited labelled training data. Active learning can label massive unlabelled instances with minimal cost by selecting the most informative samples from all unlabelled datasets. Then, more accurate change detection can be established with those informative samples. To further improve the detection results, the contextual information is used as spatial constraints to generate MRFs. More specifically, we firstly utilize a superpixel segmentation method, i.e., SLIC algorithm [
35], to over-segment one image and use it as a segmentation mask to be applied on another image for the corresponding objects. Then, we extract color and texture features to measure the similarity of corresponding superpixels using the histogram intersection kernel. Based on the feature similarity, we can find a limited number of the most representative superpixels by an unsupervised method, e.g.,
k-means clustering, and then manually annotate these representative superpixels with “change” or “no change” labels. Next, we can use these samples to train a weak binary classification model, i.e., a Gaussian process model. By using this model, we then select the most informative samples from the unlabelled dataset and manually label them to update the former weak classification model. After a few iterations, we can get a good classification model based on the informative training sample set. Finally, the classification results of pixels are formulated in MRFs. The final change labels from a posterior distribution are built on the active learning classifiers and on a spatial MRFs prior of the change labels.
Although there are many image classification methods using active learning, very few of them directly apply active learning in change detection problems. This study presents an interactive change detection system with active learning and MRFs. The main contributions of this paper are as follows:
An interactive object-based change detection framework is proposed, which uses active learning with Gaussian processes to update the change detection results iteratively. After the comprehensive analysis of the sample selection strategy in change detection, a new sample selection method is introduced by choosing the easiest one from several candidate samples with the consideration of the representativeness and the convenience of labelling.
The integration of attribute information (including color and texture) and contextual information. The contextual information is introduced to remove the “superpixel-noise” in the detection results of active learning. It is formulated as MRFs and can be efficiently solved by the min-cut-based integer optimization algorithm.
This paper is organized as follows. In
Section 2, we briefly review the background about active learning, Gaussian processes and MRFs. In
Section 3, we describe the interactive change detection framework using active learning and MRFs in detail. In
Section 4, the experimental results on multiple datasets are presented to show the performance of the proposed method. Finally, the conclusion is drawn in
Section 5.
5. Discussion
Change detection is a very important issue in the interpretation of multi-temporal HRRS imagery. In this paper, we firstly analyze the pros and cons of the typical supervised and unsupervised change detection methods and then we introduce an interactive change detection method based on active learning and MRFs. The objective is to use active learning to find the most informative samples and obtain the best change detection results. In our experiments, we use three different sample selection strategies to test the performance, and find out that the uncertainty measure can find the most informative samples under the same iteration setting. In our method, the manual annotation can be reduced substantially, and after the integration of attribute information and contextual information, a desirable detection result can be obtained.
In the original active learning model, based on the sample selection criteria in
Section 3.5.1, the most informative sample is the one in the front of the queue. However, this sample is often very difficult to label even for experts, but the labelling is the key problem for a good detection result. Thus we first select the front
m (e.g.,
) samples from the queue, and then select the most distinguished one for manually annotation from these candidates. This strategy is called labelling the easiest sample, which is described in
Section 3.5.2.
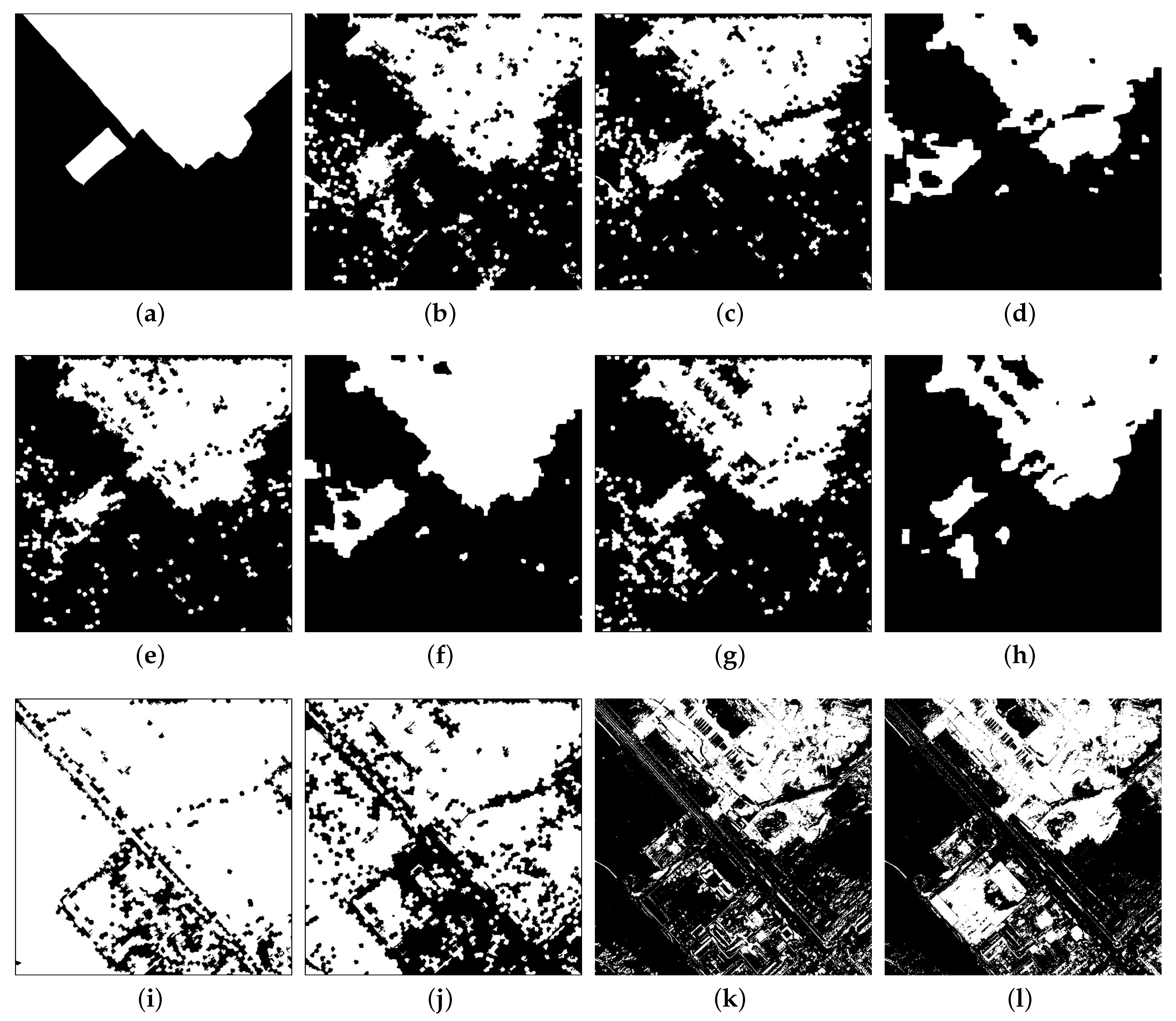
Table 3 shows the comparison of change detection results of the original active learning with our improved one. Under the same sample selection criterion, i.e., the uncertainty, the performance indexes of our improved active learning is relatively better than the original one on the two datasets, especially the Kappa coefficient, about 2.7% higher and 1.8%, respectively. Although this treatment does not change the essence of annotation, it makes the labelling more reliable. In addition, the spatial constraints using contextual information also greatly promote the performance, increasing the Kappa coefficient by 5.8% and 14.99%, respectively.
To further compare the change detection results, the McNemar test was employed [
59]. The confusion matrix is formed based on the agreements and disagreements of AL Uncertainty MRF and the other one method. The difference between two methods is significant when the test index,
p-value is less than 0.05. The proposed method (AL Uncertainty MRF) is compared with five representative methods, i.e., the typical supervised method (SVM), AL Uncertainty, AL Mean MRF, AL Impact MRF and the typical unsupervised method (IR-MAD).
Table 4 and
Table 5 are the McNemar’s test results for Datset 1 and Dataset 2, respectively.
denotes the number of pixels with the wrong detection for both AL Uncertainty MRF and other methods,
denotes the number of pixels that are correctly detected by AL Uncertainty MRF but wrongly detected by the other,
denotes the number of pixels that are wrongly detected by AL Uncertainty MRF but correctly detected by the other, and
is the number of pixels with the correct detection in both methods. Compared with the typical supervised and unsupervised methods (SVM and IR-MAD), the proposed AL Uncertainty MRF is much better. Compared with the improved AL Uncertainty, AL Uncertainty MRF also shows better performance, which illustrates the effectiveness of combining MRF. Furthermore, by comparing the active learning methods based on different sample selection strategies, we can also observe that the method based on uncertainty is the best one. In summary, the McNemar’s tests further show significant improvement of the AL Uncertainty MRF based method over the other five methods.
The above described active learning methods are all conducted on proper settings of parameters (
Section 4.2). The two key parameters for our method are object size and the number of iterations. The size of objects are obtained empirically, which is also related to the image resolution. Pixel-based change detection can also work with this active learning framework, but it is very time consuming.
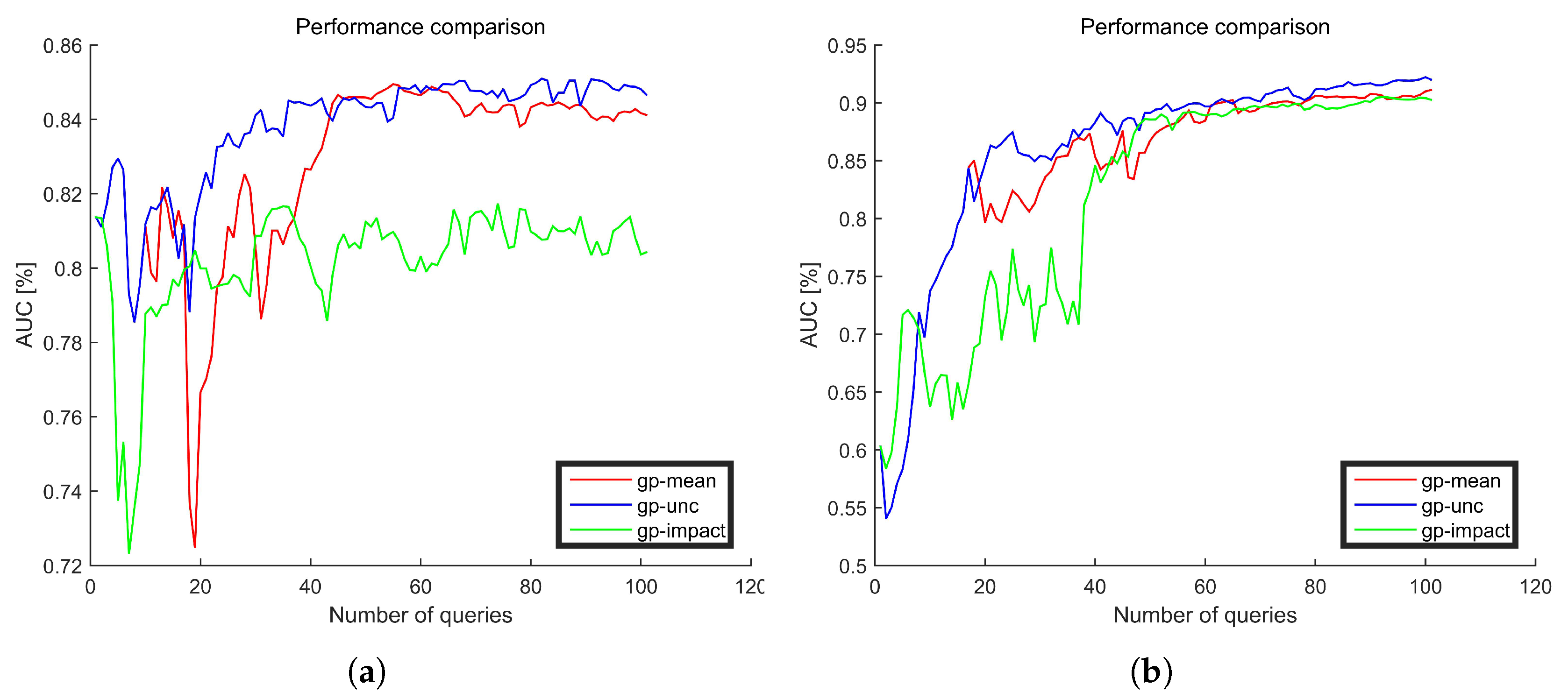
Figure 7 shows the gains of active learning after different number of iterations. Accuracies after every query are evaluated on disjoint test set using the area under receiver operator curves (AUC). Generally, the accuracy index first increases and then keeps stable with the increase of the number of iterations. There are some performance fluctuations for small numbers of iterations. The reason is that every added training sample plays a very important role in the model training when the number of samples is small. Thus if an inaccurate sample is selected for training the model, the performance will degrade. However, when the number of iterations is larger, the effect of limited inaccurate samples can also be reduced. This is why the performance finally improved. Generally, the performances of the Gaussian process based on the uncertainty (gp-unc, in blue) are relatively better than the Gaussian process based on the mean value (gp-mean, in red) for both two datasets. When adding a new training sample, the performance gains of different query strategies vary. Thus, adding new samples when the training sample set is not complete, the performance gain of gp-mean maybe better than gp-unc. However, after we add enough and complete training samples, the performances of different query strategies trend to be stable and the performance of gp-unc is relatively better than gp-mean (after number of queries above 80).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}