
Texture Retrieval from VHR Optical Remote Sensed Images Using the Local Extrema Descriptor with Application to Vineyard Parcel Detection


Abstract
:
1. Introduction
2. Studied Sites and Data
3. Texture Retrieval from VHR Optical Remote Sensing Images
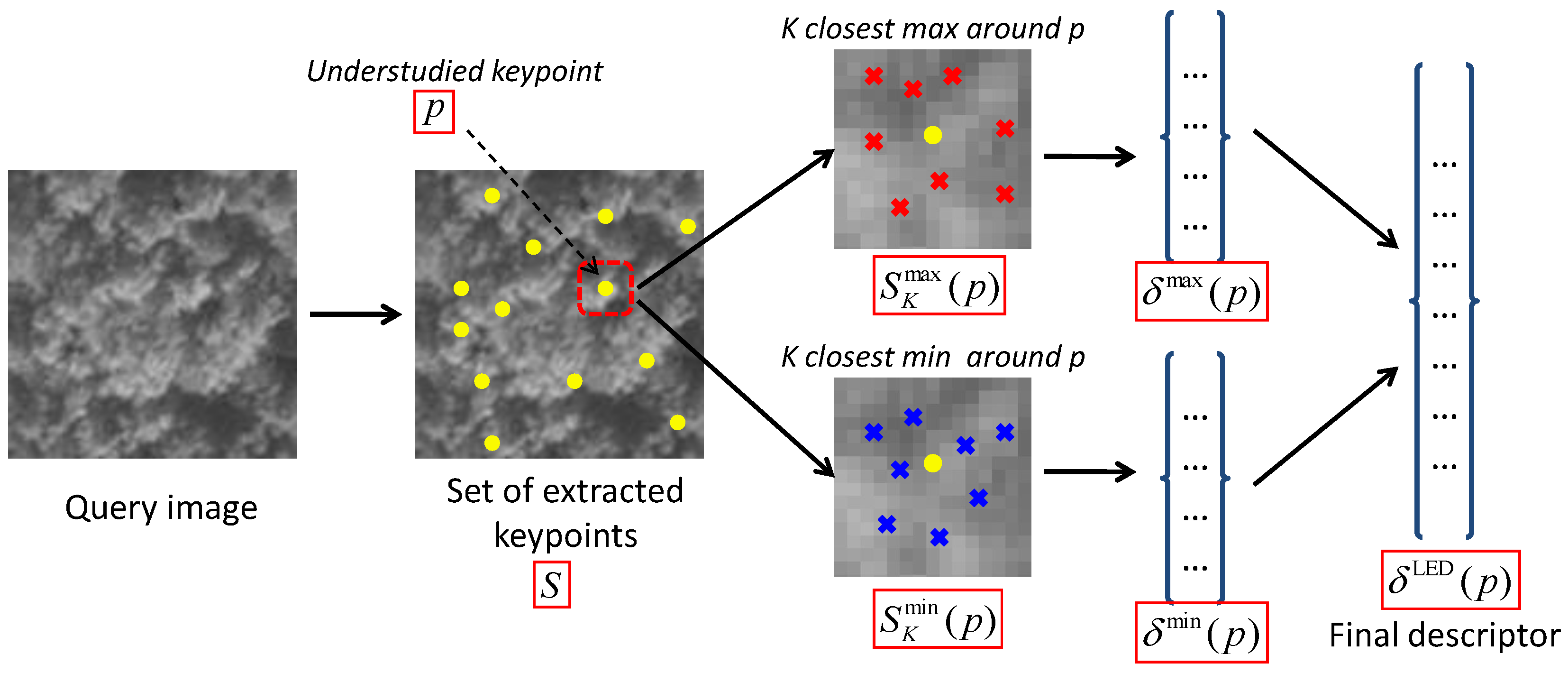
3.1. Extraction of the Local Extrema Descriptor
3.2. Dissimilarity Measure for Retrieval
3.3. Proposed Retrieval Algorithm
| Algorithm 1: Proposed retrieval algorithm. |
 |
3.4. Retrieval Results
- (1)
- three statistical local texture descriptors: the gray-level co-occurrence matrix (GLCM) [1,5,6], the Gabor filter banks (GFB) [2,7,8] and the local Weber descriptor (WLD) [3,11]. The GLCM and GFB appear to be two of the most widely-used methods for texture analysis in remote sensing imagery. They have been adopted for the vine detection task within the last ten years [5,6,7,8]. Meanwhile, the WLD is one of the most recent local descriptors in computer vision;
- (2)
- three distribution models of wavelet coefficients: the multivariate Gaussian model (MGM), the spherically-invariant random vectors (SIRV) and the Gaussian copula-based model (GCM) [12,13]. These methods are the most recent wavelet-based techniques proposed for tackling texture-based retrieval and vine detection tasks. They are considered to give state-of-the-art retrieval performance for our two databases;
- (3)
- the pointwise (PW) descriptor proposed in our early work [16]. This descriptor only exploits the radiometric and spatial information from local extrema points. Gradient features are not considered. Our LED can be considered as the improved version of PW by integrating gradient features and taking into account the rotation-invariant property. The comparison to the PW descriptor allows us to validate the significant role of gradient features to characterize textural features in this study of vine cultivation.
- GLCM [1,5,6]: From the neighborhood around each keypoint, compute four co-occurrence matrices along four main directions (, , and ) with the distance between pairwise pixels set to two and the number of gray levels set to eight, then extract five Haralick textural parameters for each matrix including the contrast, correlation, homogeneity, energy and entropy in order to create the 20-feature GLCM descriptor for each keypoint.
- WLD [3,11]: Following the related paper, the differential excitation ξ and the quantized gradient orientation Φ for the image are first calculated using the neighborhood. A 2D histogram is constructed for the window around each keypoint. Then, the 1D WLD descriptor is generated by setting , and (dedicated parameters of WLD; see [3]). Therefore, the dimension of WLD is 72.
3.5. Sensitivity to Parameters
4. Application to Vineyard Parcel Detection
4.1. Supervised Classification Algorithm
| Algorithm 2: Proposed supervised classification algorithm. |
 |
4.2. Evaluation Criteria
- true positives (TP): the number of vine points correctly detected (i.e., good detections),
- true negatives (TN): the number of non-vine points correctly detected,
- false positives (FP): the number of non-vine points incorrectly detected as vine (i.e., false alarms),
- false negatives (FN): the number of vine points incorrectly detected as non-vine (i.e., missed detections).
- ratio between the number of good detections (GD) and bad detections (BD) including false alarms (FA) and missed detections (MD):
- percentage of total errors (TE) consisting of false alarms and missed detections:
- percentage of overall accuracy (OA):
4.3. Experimental Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| VHR | very high resolution |
| LED | local extrema-based descriptor |
| GLCM | gray-level co-occurrence matrix |
| GFB | Gabor filter bank |
| WLD | Weber local descriptor |
| MGM | multivariate Gaussian model |
| SIRV | spherically-invariant random vector |
| GCM | Gaussian copula-based model |
| SIFT | scale-invariant feature transform |
| SURF | speed up robust features |
| PW | pointwise |
| ARR | average retrieval rate |
| TP | true positives |
| TN | true negatives |
| FP | false positives |
| FN | false negatives |
| GD | good detection |
| BD | bad detection |
| FA | false alarm |
| MD | missed detection |
| TE | total error |
| OA | overall accuracy |
References
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 3, 610–621. [Google Scholar] [CrossRef]
- Jain, A.K.; Farrokhnia, F. Unsupervised texture segmentation using Gabor filters. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Los Angeles, CA, USA, 4–7 November 1990; pp. 14–19.
- Chen, J.; Shan, S.; He, C.; Zhao, G.; Pietikäinen, M.; Chen, X.; Gao, W. WLD: A robust local image descriptor. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1705–1720. [Google Scholar] [CrossRef] [PubMed]
- Van de Wouwer, G.; Scheunders, P.; van Dyck, D. Statistical texture characterization from discrete wavelet representation. IEEE Trans. Image Process. 1999, 8, 592–598. [Google Scholar] [CrossRef] [PubMed]
- Warner, T.A.; Steinmaus, K. Spatial classification of orchards and vineyards with high spatial resolution panchromatic imagery. Photogramm. Eng. Remote Sens. 2005, 71, 179–187. [Google Scholar] [CrossRef]
- Kayitakire, F.; Hamel, C.; Defourny, P. Retrieving forest structure variables based on image texture analysis and IKONOS-2 imagery. Remote Sens. Environ. 2006, 102, 390–401. [Google Scholar] [CrossRef]
- Delenne, C.; Rabatel, G.; Deshayes, M. An automatized frequency analysis for vine plot detection and delineation in remote sensing. IEEE Geosci. Remote Sens. Lett. 2008, 5, 341–345. [Google Scholar] [CrossRef]
- Rabatel, G.; Delenne, C.; Deshayes, M. A non supervised approach using Gabor filter for vine-plot detection in aerial images. Comput. Electron. Agric. 2008, 62, 159–168. [Google Scholar] [CrossRef]
- Ruiz, L.A.; Fdez-Sarría, A.; Recio, J.A. Texture feature extraction for classification of remote sensing data using wavelet decomposition: A comparative study. In Proceedings of the 20th ISPRS Congress, London, UK, 21 June 2004; pp. 1109–1114.
- Ranchin, T.; Naert, B.; Albuisson, M.; Boyer, G.; Astrand, P. An automatic method for vine detection in airborne imagery using the wavelet transform and multiresolution analysis. Photogramm. Eng. Remote Sens. 2001, 67, 91–98. [Google Scholar]
- Cui, S.; Dumitru, C.O.; Datcu, M. Ratio-detector-based feature extraction for very high resolution SAR image patch indexing. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1175–1179. [Google Scholar]
- Regniers, O.; Da Costa, J.P.; Grenier, G.; Germain, C.; Bombrun, L. Texture based image retrieval and classification of very high resolution maritime pine forest images. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium—IGARSS, Melbourne, Australia, 21–26 July 2013; pp. 4038–4041.
- Regniers, O.; Bombrun, L.; Guyon, D.; Samalens, J.C.; Germain, C. Wavelet-based texture features for the classification of age classes in a maritime pine forest. IEEE Geosci. Remote Sens. Lett. 2015, 12, 621–625. [Google Scholar] [CrossRef]
- Pham, M.T.; Mercier, G.; Michel, J. Wavelets on graphs for very high resolution multispectral image segmentation. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 2273–2276.
- Pham, M.T.; Mercier, G.; Michel, J. Textural features from wavelets on graphs for very high resolution panchromatic Pléiades image classification. Revue française de photogrammétrie et de télédétection 2014, 208, 131–136. [Google Scholar]
- Pham, M.T.; Mercier, G.; Michel, J. Pointwise graph-based local texture characterization for very high resolution multispectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1962–1973. [Google Scholar] [CrossRef]
- Pham, M.T.; Mercier, G.; Michel, J. PW-COG: An effective texture descriptor for VHR satellite imagery using a pointwise approach on covariance matrix of oriented gradients. IEEE Trans. Geosci. Remote Sens. 2016, in press. [Google Scholar] [CrossRef]
- Tuytelaars, T.; Mikolajczyk, K. Local invariant feature detectors: A survey. In Foundations and Trends® in Computer Graphics and Vision; Now Publishers Inc.: Hanover, MA, USA, 2008; Volume 3, pp. 177–280. [Google Scholar]
- Mardia, K.V.; Jupp, P.E. Directional Statistics; John Wiley and Sons, Ltd.: Hoboken, NJ, USA, 2000; Volume 494. [Google Scholar]
- Förstner, F.; Moonen, B. A metric for covariance matrices. In Geodesy-The Challenge of the 3rd Millennium; Springer: Berlin, Germany, 2003; pp. 299–309. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Forest | Bare Soil | Urban | Vine Fields | Total |
|---|---|---|---|---|---|
| Pessac 22-08-12 | 66 | 53 | 147 | 179 | 445 |
| Emilion 03-09-13 | 44 | 32 | 27 | 881 | 984 |
| Method | Pessac 22-08-12 | Emilion 03-09-13 |
|---|---|---|
| MGM | 77.51 | 78.35 |
| SIRV | 60.58 | 60.16 |
| GCM | 76.88 | 75.91 |
| GLCM | 54.56 | 64.57 |
| GFB | 61.37 | 62.39 |
| WLD | 64.38 | 73.88 |
| PW | 78.24 | 83.18 |
| LED (K = 15, Mahalanobis) | 83.42 | 87.90 |
| LED (K = 20, Mahalanobis) | 83.78 | 88.18 |
| LED (K = 15, Riemannian) | 85.63 | 89.01 |
| LED (K = 20, Riemannian) | 85.79 | 89.43 |
| Class/Method | MGM | GCM | GLCM | WLD | PW | LED (K = 20) | LED (K = 20) |
|---|---|---|---|---|---|---|---|
| Mahalanobis | Riemannian | ||||||
| Equation (8) | Equation (9) | ||||||
| Pessac 22-08-12 | |||||||
| Forest | 96.51 | 94.54 | 61.61 | 88.84 | 79.08 | 90.12 | 92.37 |
| Bare soil | 95.76 | 92.48 | 56.53 | 61.76 | 76.76 | 74.96 | 77.75 |
| Urban | 73.78 | 75.28 | 48.37 | 57.97 | 83.00 | 95.97 | 94.64 |
| Vineyard | 43.99 | 42.22 | 51.75 | 48.94 | 74.13 | 74.07 | 78.34 |
| ARR | 77.51 | 76.88 | 54.56 | 64.38 | 78.24 | 83.78 | 85.79 |
| Emilion 03-09-13 | |||||||
| Forest | 93.71 | 84.12 | 79.20 | 83.73 | 90.88 | 94.35 | 97.93 |
| Bare soil | 99.71 | 96.25 | 76.26 | 78.80 | 80.99 | 83.82 | 85.69 |
| Urban | 86.93 | 87.51 | 52.84 | 79.73 | 88.59 | 98.87 | 96.40 |
| Vineyard | 33.05 | 39.75 | 49.96 | 53.25 | 72.28 | 75.68 | 77.69 |
| ARR | 78.35 | 75.91 | 64.57 | 73.88 | 83.18 | 88.18 | 89.43 |
| Method | FA | MD | GD | |||
|---|---|---|---|---|---|---|
| (Points) | (Points) | (Points) | (%) | (%) | ||
| MGM | 6011 | 676 | 32,177 | 4.8119 | 13.41 | 86.59 |
| GCM | 5160 | 1035 | 31,818 | 5.1361 | 12.42 | 87.58 |
| GLCM | 2469 | 8200 | 24,653 | 2.3107 | 21.39 | 78.61 |
| GFB | 6316 | 5159 | 27,694 | 2.4134 | 23.01 | 76.99 |
| WLD | 6026 | 858 | 31,995 | 4.6477 | 13.80 | 86.20 |
| PW | 667 | 5557 | 26,696 | 4.2892 | 12.48 | 87.52 |
| Proposed | 412 | 4708 | 28,145 | 5.4971 | 10.26 | 89.74 |
| Method | FA | MD | GD | |||
|---|---|---|---|---|---|---|
| (Points) | (Points) | (Points) | (%) | (%) | ||
| MGM | 2714 | 1496 | 16,230 | 3.4828 | 16.34 | 83.66 |
| GCM | 2309 | 1408 | 16,768 | 4.5112 | 13.04 | 86.96 |
| GLCM | 2010 | 4589 | 13,587 | 2.0589 | 23.14 | 76.86 |
| GFB | 2224 | 5749 | 12,427 | 1.5586 | 27.96 | 72.04 |
| WLD | 3704 | 1836 | 16,340 | 2.9495 | 19.43 | 80.57 |
| PW | 618 | 4699 | 13,477 | 2.5347 | 18.65 | 81.35 |
| Proposed | 1270 | 1688 | 16,488 | 5.5740 | 10.37 | 89.63 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, M.-T.; Mercier, G.; Regniers, O.; Michel, J. Texture Retrieval from VHR Optical Remote Sensed Images Using the Local Extrema Descriptor with Application to Vineyard Parcel Detection. Remote Sens. 2016, 8, 368. https://doi.org/10.3390/rs8050368
Pham M-T, Mercier G, Regniers O, Michel J. Texture Retrieval from VHR Optical Remote Sensed Images Using the Local Extrema Descriptor with Application to Vineyard Parcel Detection. Remote Sensing. 2016; 8(5):368. https://doi.org/10.3390/rs8050368
Chicago/Turabian StylePham, Minh-Tan, Grégoire Mercier, Oliver Regniers, and Julien Michel. 2016. "Texture Retrieval from VHR Optical Remote Sensed Images Using the Local Extrema Descriptor with Application to Vineyard Parcel Detection" Remote Sensing 8, no. 5: 368. https://doi.org/10.3390/rs8050368
APA StylePham, M.-T., Mercier, G., Regniers, O., & Michel, J. (2016). Texture Retrieval from VHR Optical Remote Sensed Images Using the Local Extrema Descriptor with Application to Vineyard Parcel Detection. Remote Sensing, 8(5), 368. https://doi.org/10.3390/rs8050368