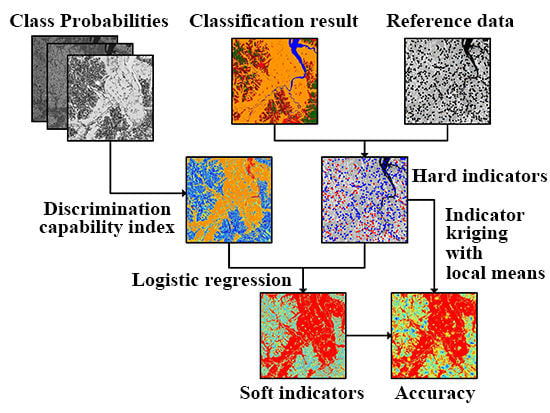
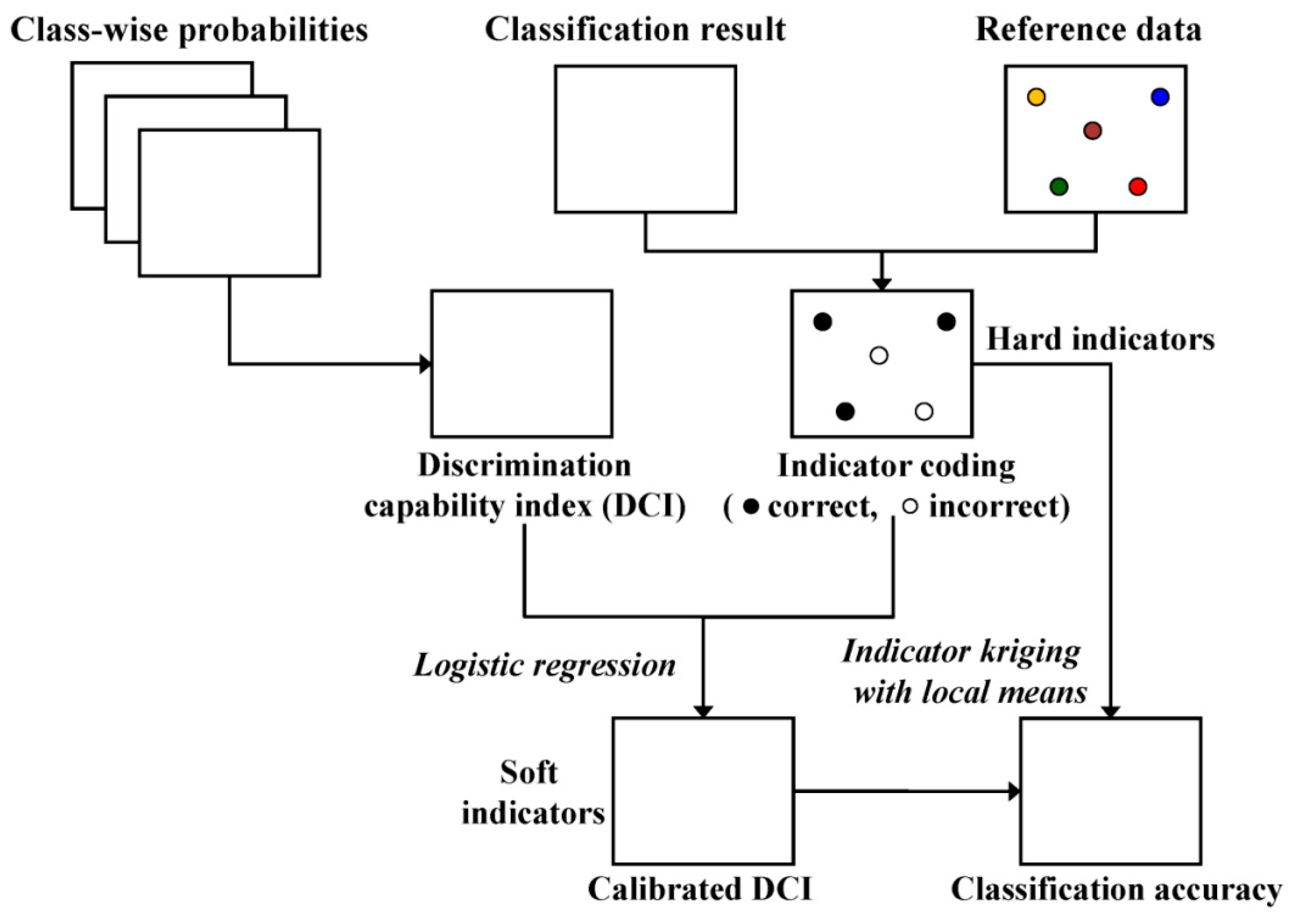
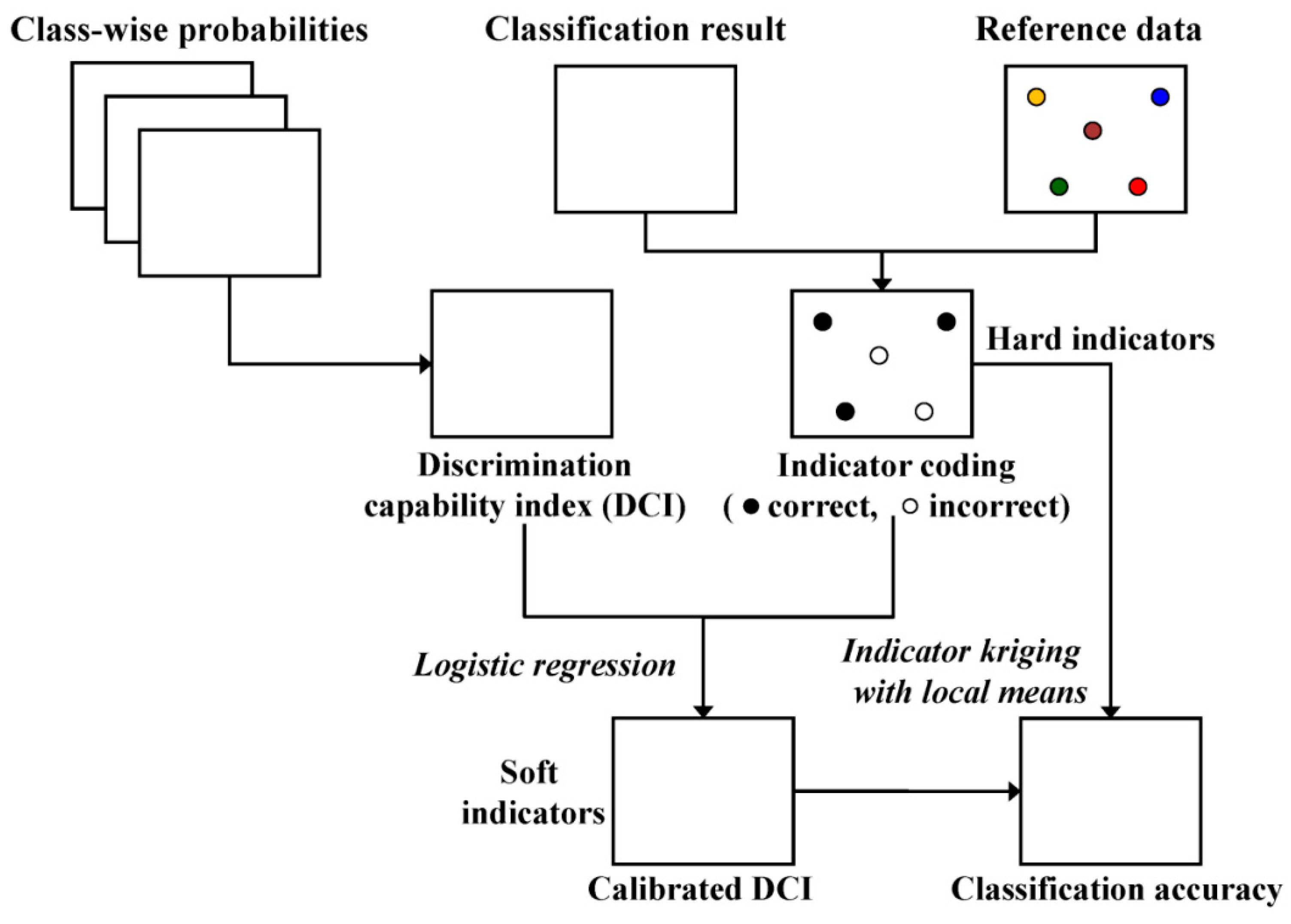
The geostatistical approach proposed in this paper for the spatial estimation of classification accuracy probability consists of three steps (
Figure 2): (1) generation of class-wise probabilities for land-cover classes by applying any probabilistic classification algorithm (probabilistic classification); (2) computation of DCI values (defining ambiguity level); and (3) application of indicator kriging with local means combined with logistic regression (integration and mapping). A detailed description on each of the steps is given hereafter.
3.1. Probabilistic Classification
In the first processing step, any probabilistic algorithm capable of generating class-wise
posteriori probabilities can be adopted. Bayesian probabilistic classifiers or machine learning algorithms can be applied to obtain class-wise probabilities, although some machine learning algorithms, such as support vector machines, require further post-processing to generate such
posteriori probabilities. In this study, a multilayer neural network (MLP) was adopted as the main classifier, on the basis of our previous study [
20].
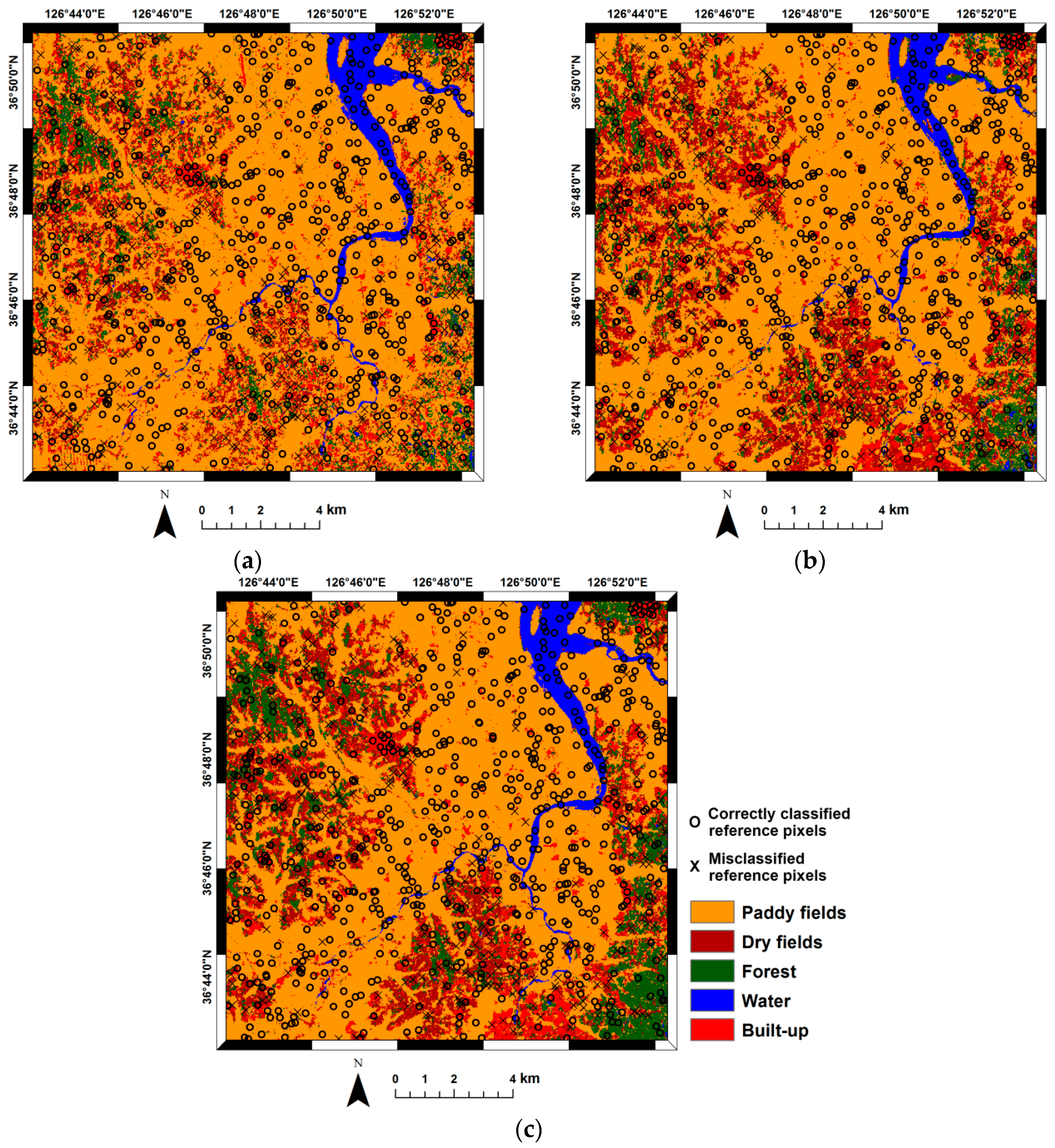
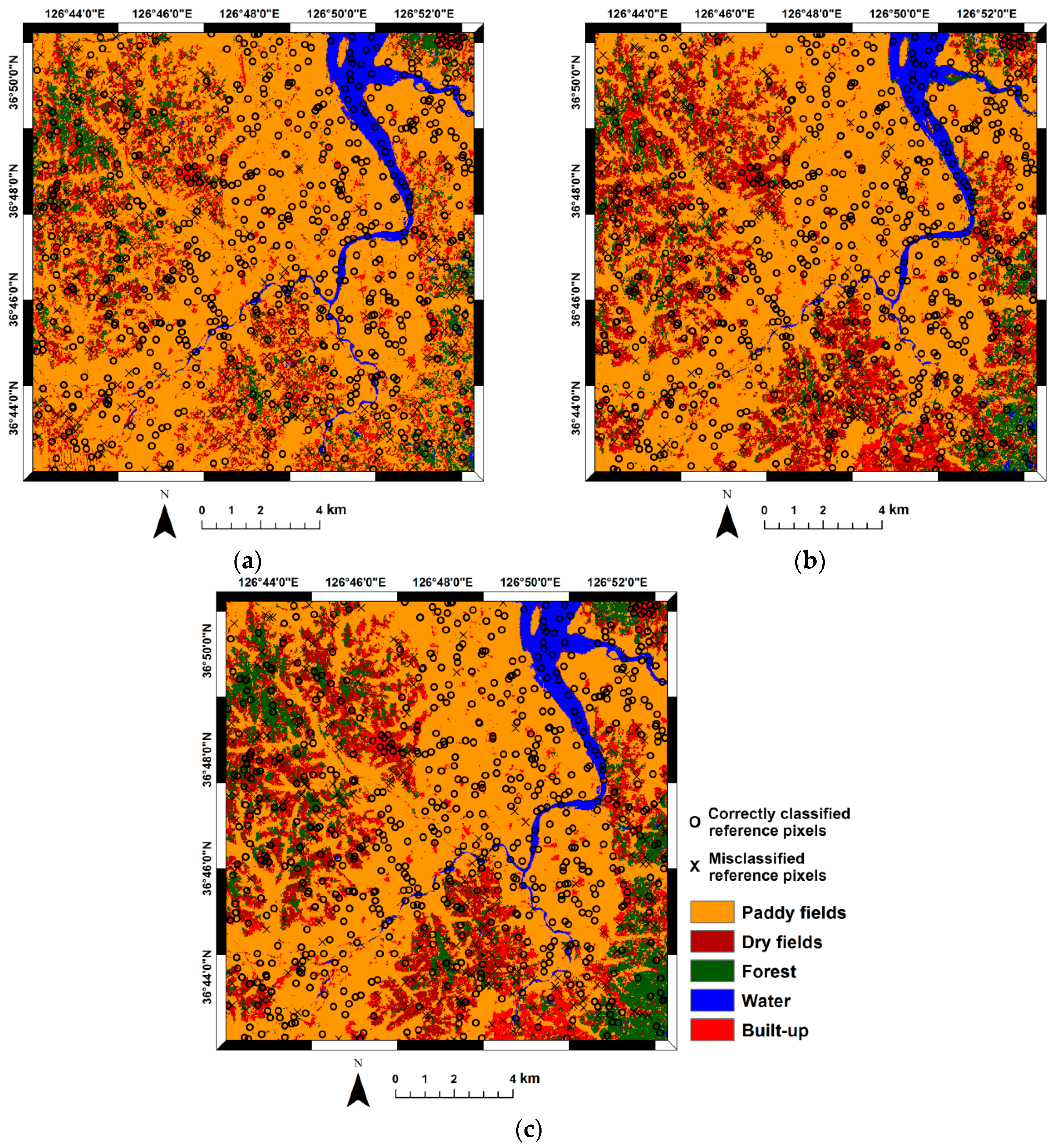
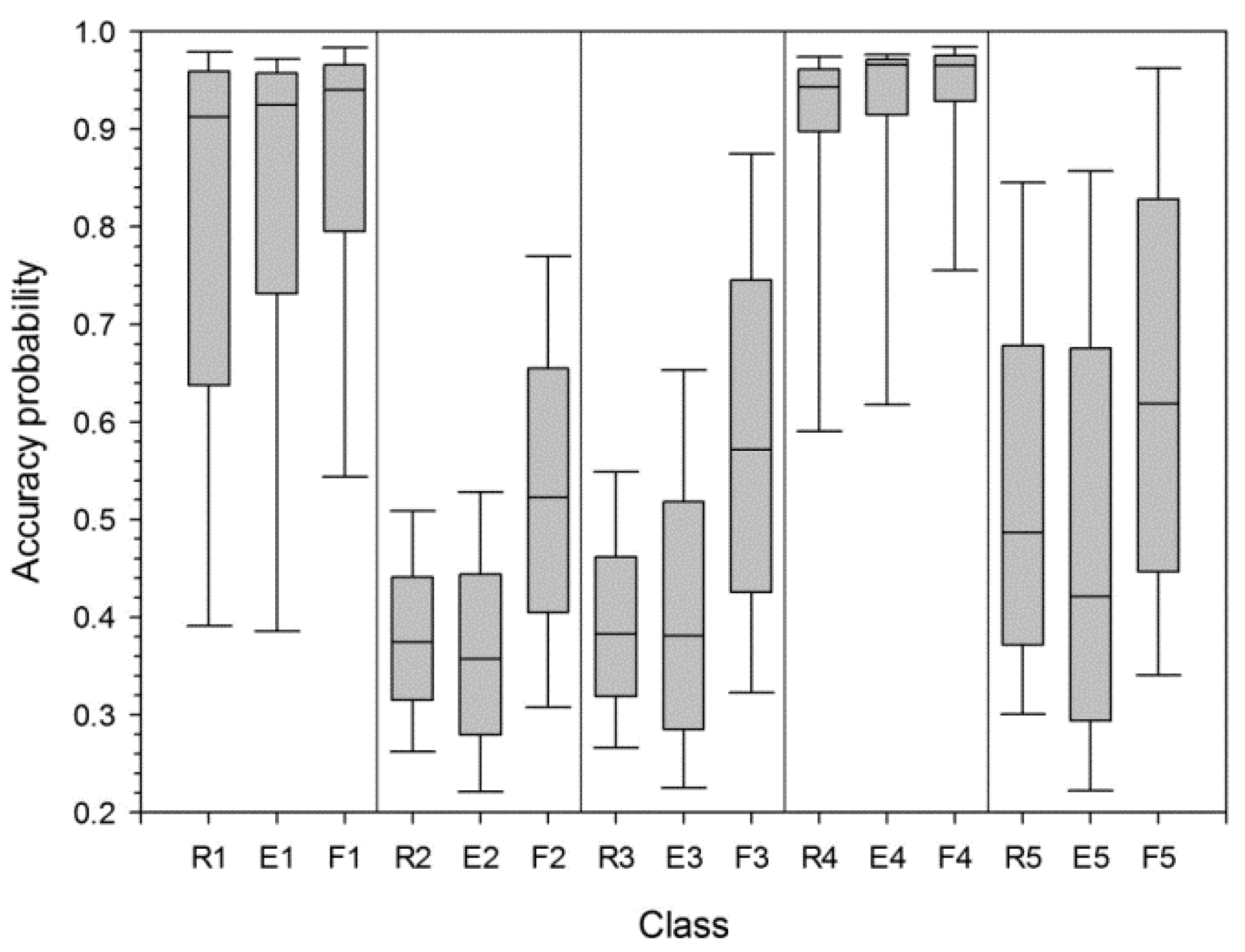
For comparison purposes, the following three classification scenarios were considered, based on: (1) Radarsat-1 features only; (2) ENVISAT ASAR features only; and (3) fusion of (1) and (2). The reason for choosing these scenarios is to highlight the effects of data fusion on classification performance by comparing the spatial distributions of classification accuracy. A concatenating fusion approach was adopted to combine the Radarsat-1 and ENVISAT ASAR features and, thereafter, the stacked multi-sensor features were used as inputs for MLP-based classification. Note that any advanced feature- or decision-level fusion technique could be applied for data fusion. However, the simple concatenating approach was selected in this study, because the main purpose here is to demonstrate the effectiveness of the proposed approach, not to select the best classifier or fusion technique.
For traditional pixel-based accuracy assessment, accuracy statistics including overall accuracy, user’s accuracy, producer’s accuracy, and the Kappa coefficient were computed from the confusion matrix. The statistical significance of the differences in classification accuracy was evaluated using the McNemar test [
21].
3.2. Defining Ambiguity Level
To quantify the ambiguity in class assignment, a DCI is derived from the class-wise
posteriori probabilities. In this study, the DCI is defined as the difference between the largest and the second largest
posteriori probabilities as:
where
is one among the
K possible land-cover classes and
is a feature set at a certain pixel
u in the study area.
and
are the most probable and the second most probable classes, respectively.
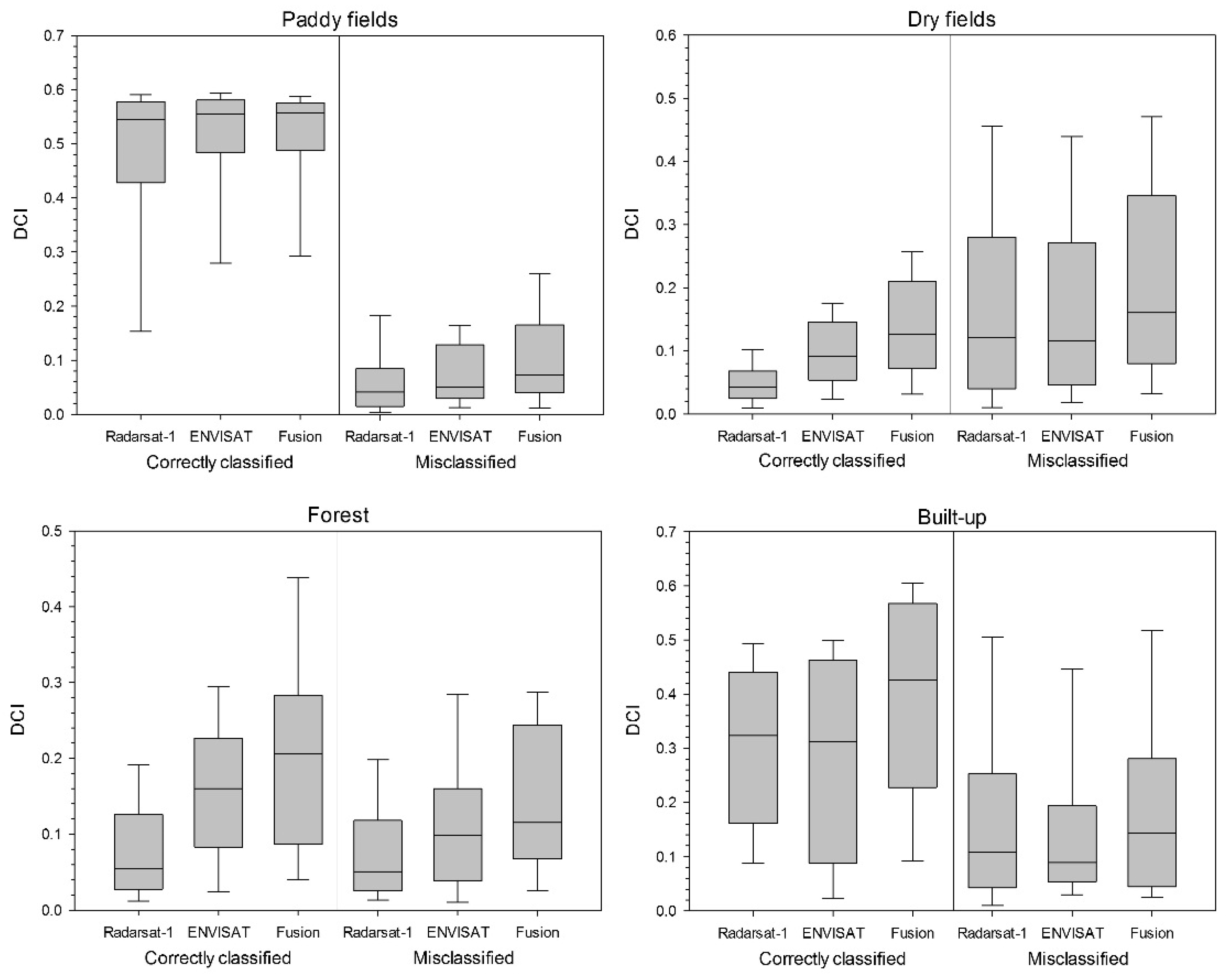
A large DCI value indicates that the class was assigned more unambiguously. The basic assumption adopted in this study is that any locations with larger DCI values are likely to have a higher accuracy level. However, the DCI provides information only on the quality of classification based on a certain input feature set and the classification algorithm used, not on the classification accuracy that can only be quantified from reference data. Therefore, another processing step is required to link the DCI values to the classification results obtained using reference data that provide actual classification accuracy (i.e., 1 or 0).
3.3. Integration and Mapping
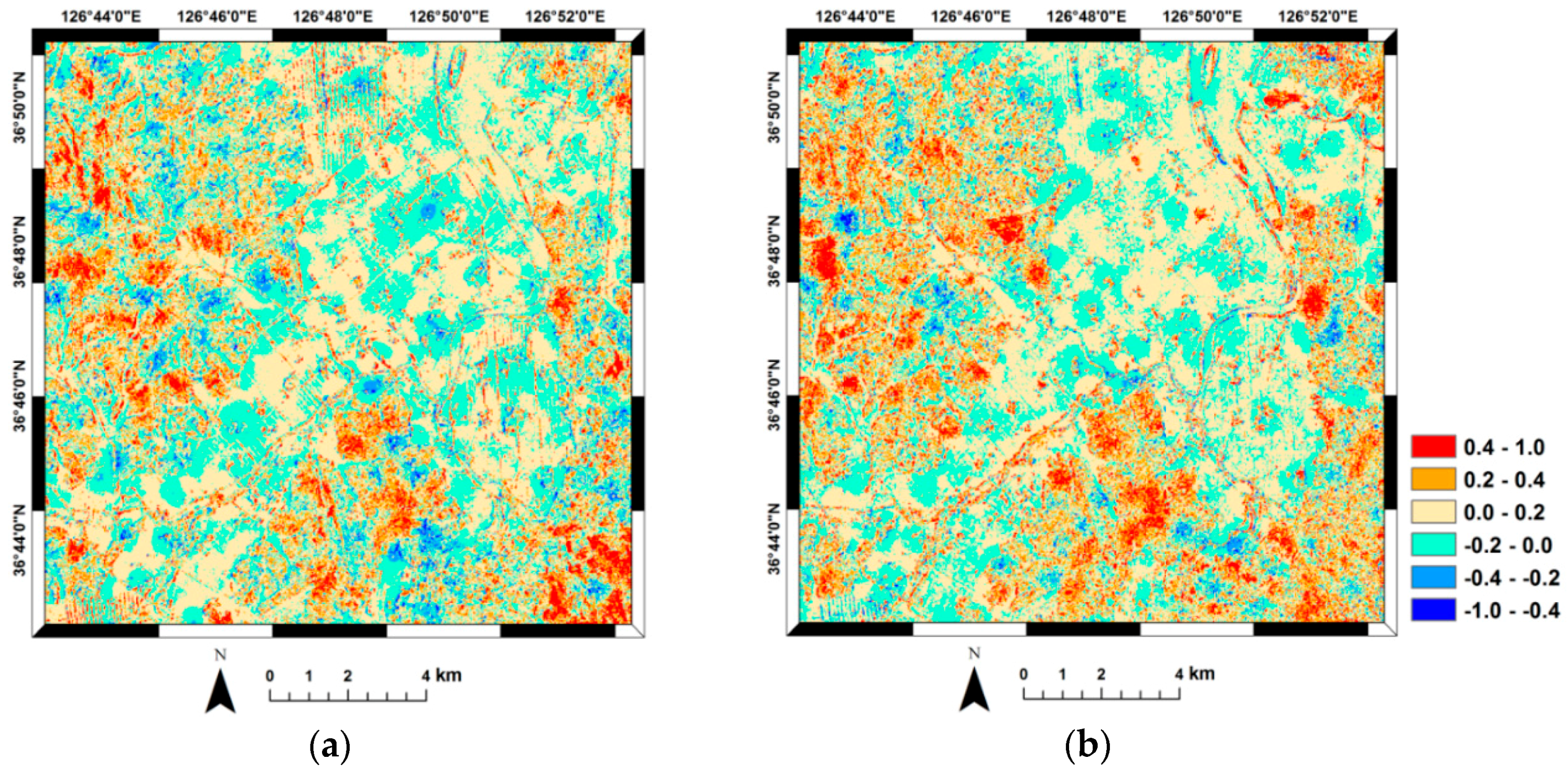
This step involves the incorporation of classification accuracy probabilities derived at a small number of reference pixels into the image-derived exhaustive DCI values for estimating the spatial distribution of classification accuracy probabilities across the entire image.
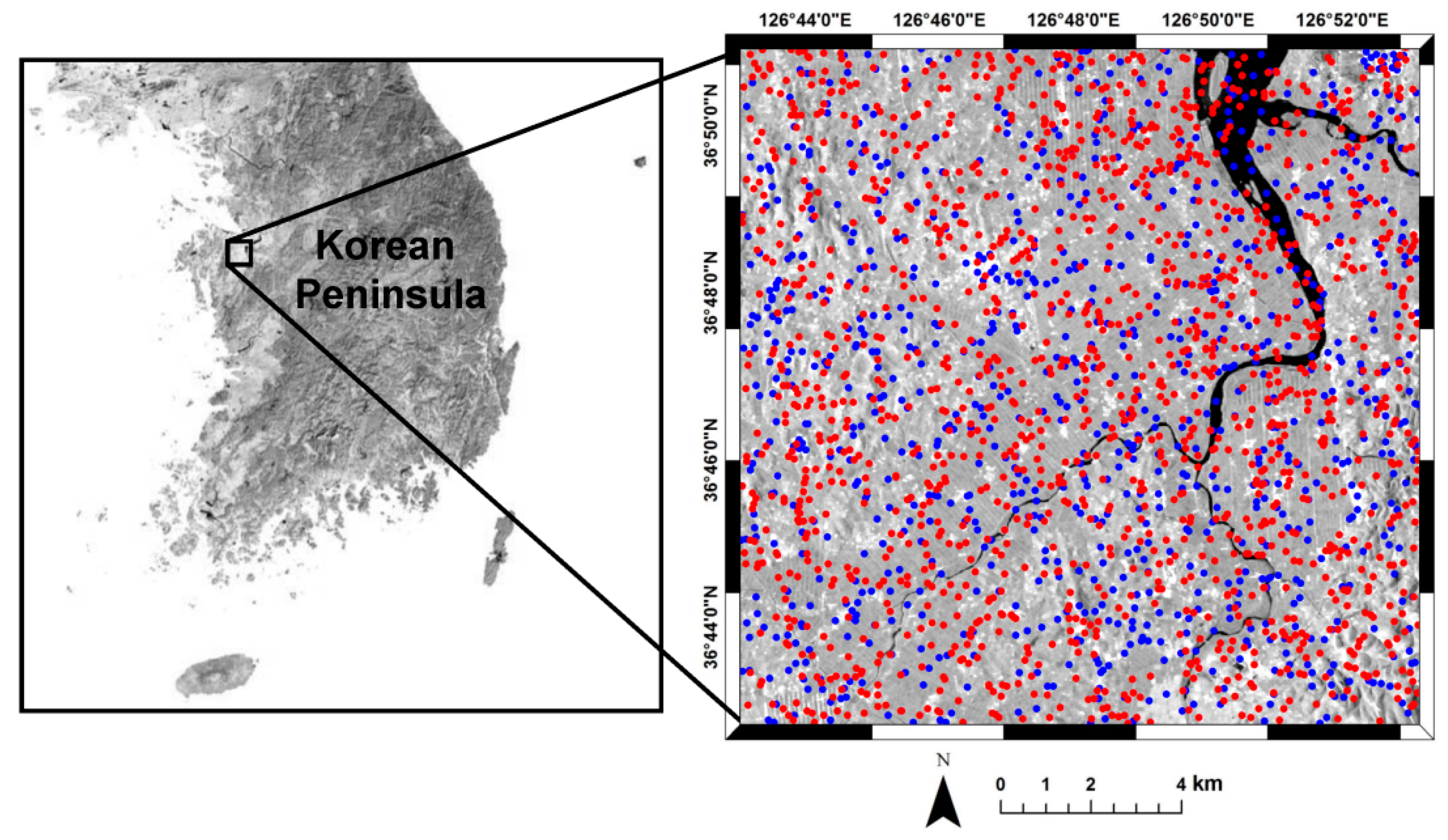
Suppose that there are
n reference pixels
where true land-cover types are known and the DCI values are available at all pixels in the study area. The binary information on classification accuracy (correct or incorrect) at the reference pixels amounts to direct (hard) measurements of classification accuracy. Meanwhile, the DCI values provide indirect (soft) information on classification accuracy. Using both direct and indirect information, the unknown classification accuracy probabilities are estimated over the study area within an indicator framework [
19]. Applications of the indicator geostatistical framework for remote sensing data classification have been previously reported in the literature [
22,
23,
24].
The indicator approach begins with indicator coding of the available information. The binary indicators at the reference pixels (
) are defined as:
The DCI values are then calibrated or transformed into soft indicators (probabilities) to be used as local means in kriging of the above indicator-coded hard data. The soft indicator probabilities are derived from quantitative relationships between the DCI values and the hard indicator data at the reference pixels. In this study, logistic regression is adopted for calibrating the DCI values, as it is suitable for regression with a binary dependent variable [
25]. In the context of this case study, the data on the dependent and independent variables are the hard indicator data and the DCI values at the reference pixels, respectively. More specifically, the calibrated DCI value at a certain pixel
u in the study area (DCI_cal(
u)) is defined by the following formula [
25]:
where a and b are the intercept and the regression coefficient of DCI in the linear logistic model, respectively.
As logistic model predictions, the calibrated DCI values range between 0 and 1 and can, thus, be regarded as soft probabilities. Calibrated DCI values, however, need not revert to 0 or 1 at the reference pixels; hence, do not fully reproduce the corresponding hard indicator data on classification accuracy. It is, therefore, necessary to integrate both the hard indicator data and the soft DCI-derived probabilities (soft indicators) for estimating classification accuracy over the entire image.
In this work, hard and soft indicators are integrated via simple indicator kriging with local means. The constant mean in simple kriging is replaced by the soft indicators (
i.e., calibrated DCI). The classification accuracy probability (
) at an arbitrary pixel in the study area is estimated as the conditional expectation of an indicator random variable (
) from of nearby hard and soft indicator data as:
where
j(
u) is the soft probability derived from the DCI (
i.e., calibratd DCI),
is a simple kriging weight, and
n(
u) is the number of hard indicators within a predefined search window. The neighboring hard and soft indicators are denoted as (info).
The simple kriging weight (
) is obtained by solving the following simple indicator kriging system [
24]:
where
is the covariance function of the residuals (
).
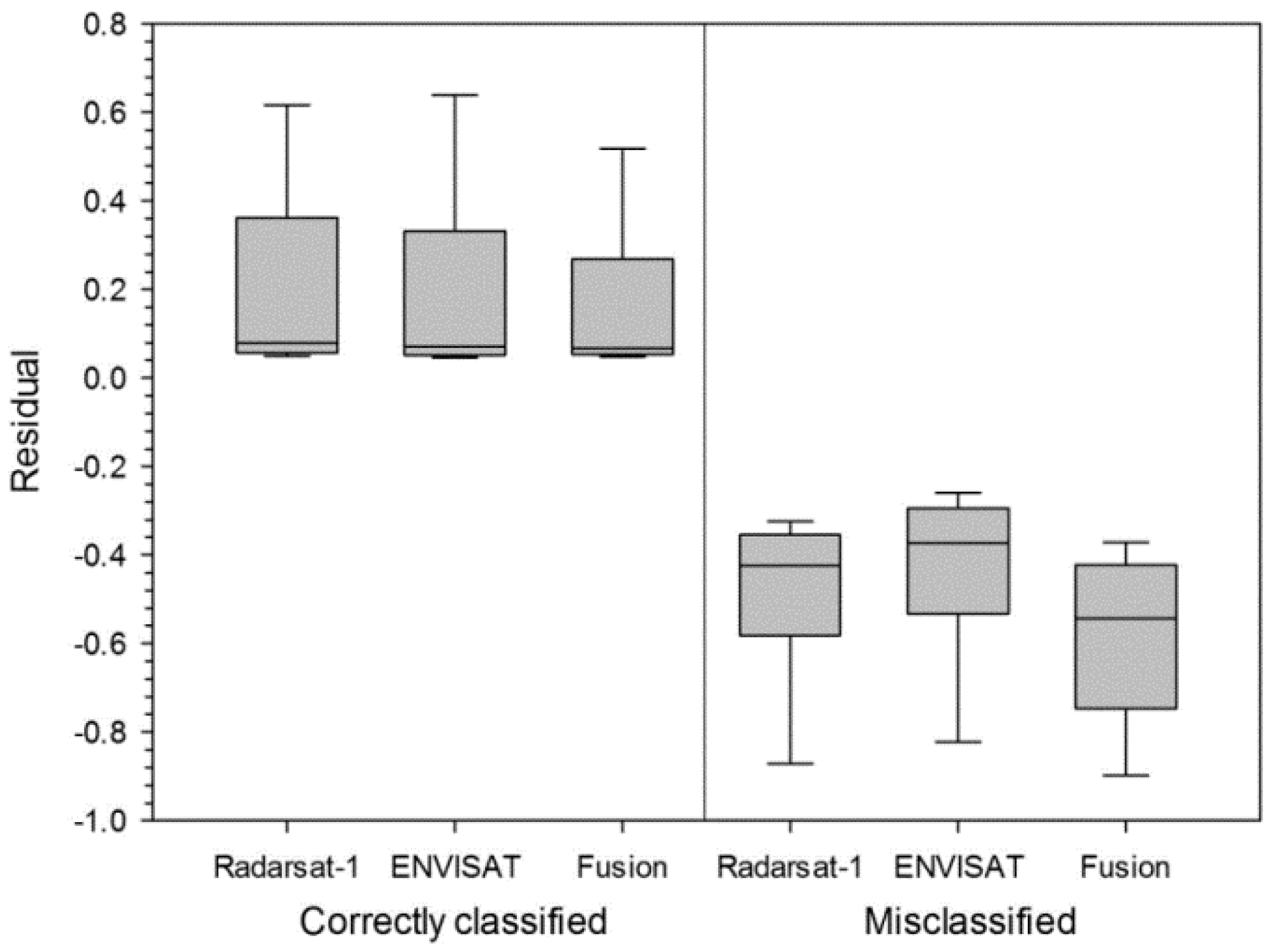
As denoted in Equations (4) and (5), the estimate of simple indicator kriging with local means is a weighted sum of the soft indicators available at all pixels and the simple kriging estimate of residuals. By interpolating the residuals through kriging, the difference or discrepancy between hard and soft indicators can be accounted for in the classification accuracy probability estimates. The accuracy value (1 or 0) at the reference pixels is reproduced because of the exactitude property of kriging [
26]. At other locations, the accuracy probability is affected by both the soft probabilities and residuals at the nearby reference pixels. As the estimation location gets farther away from the reference pixels, the impact of the soft probability becomes dominant and the estimated classification accuracy, thus, approaches to soft probability [
26]. Since kriging is a non-convex interpolator [
27], indicator kriging estimates that should be valued between 0 and 1 might have values less than 0 or greater than 1. These values are reset to the closest bound, 0 and 1 by adopting the common correction procedure [
26,
27].







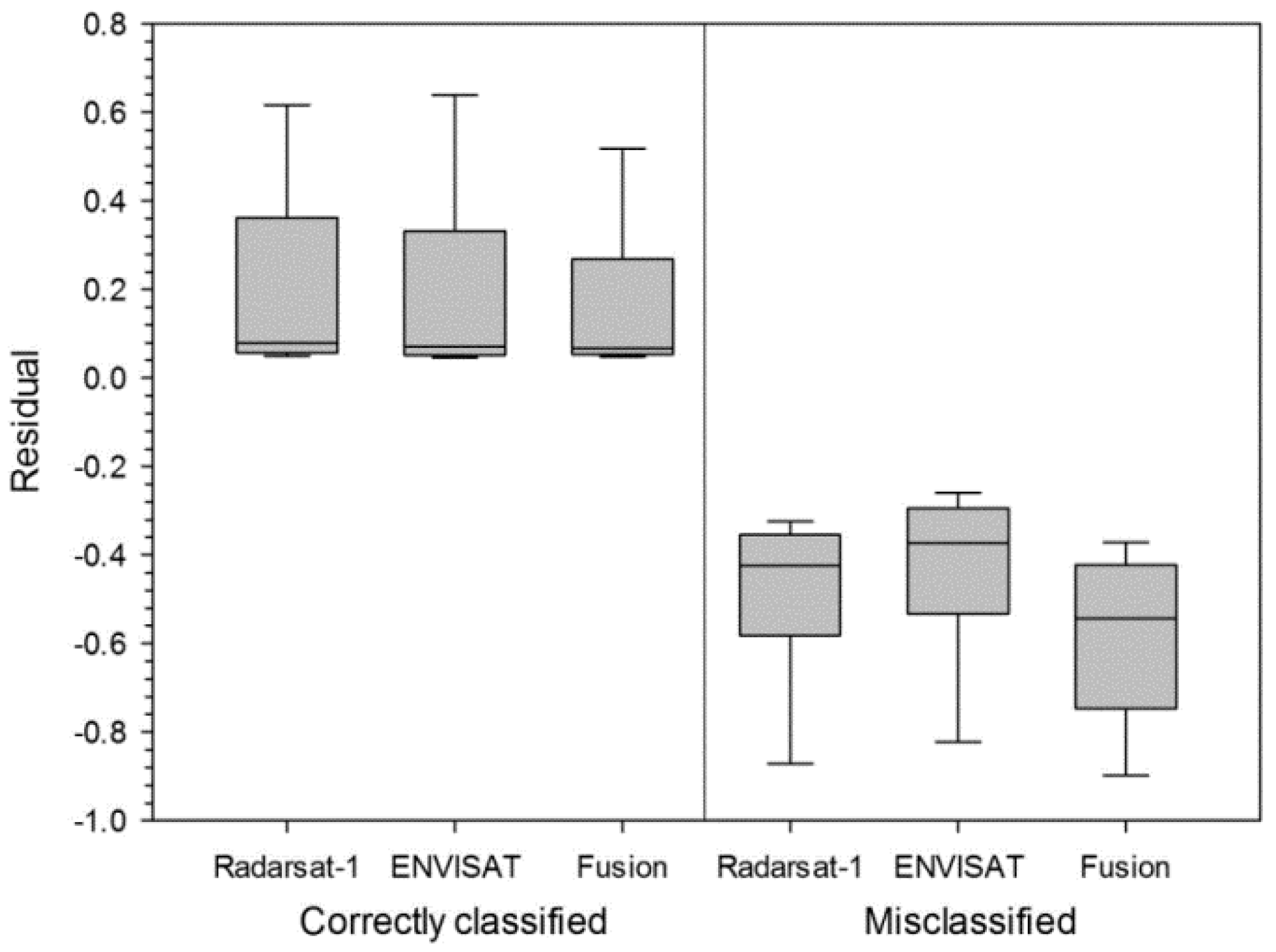
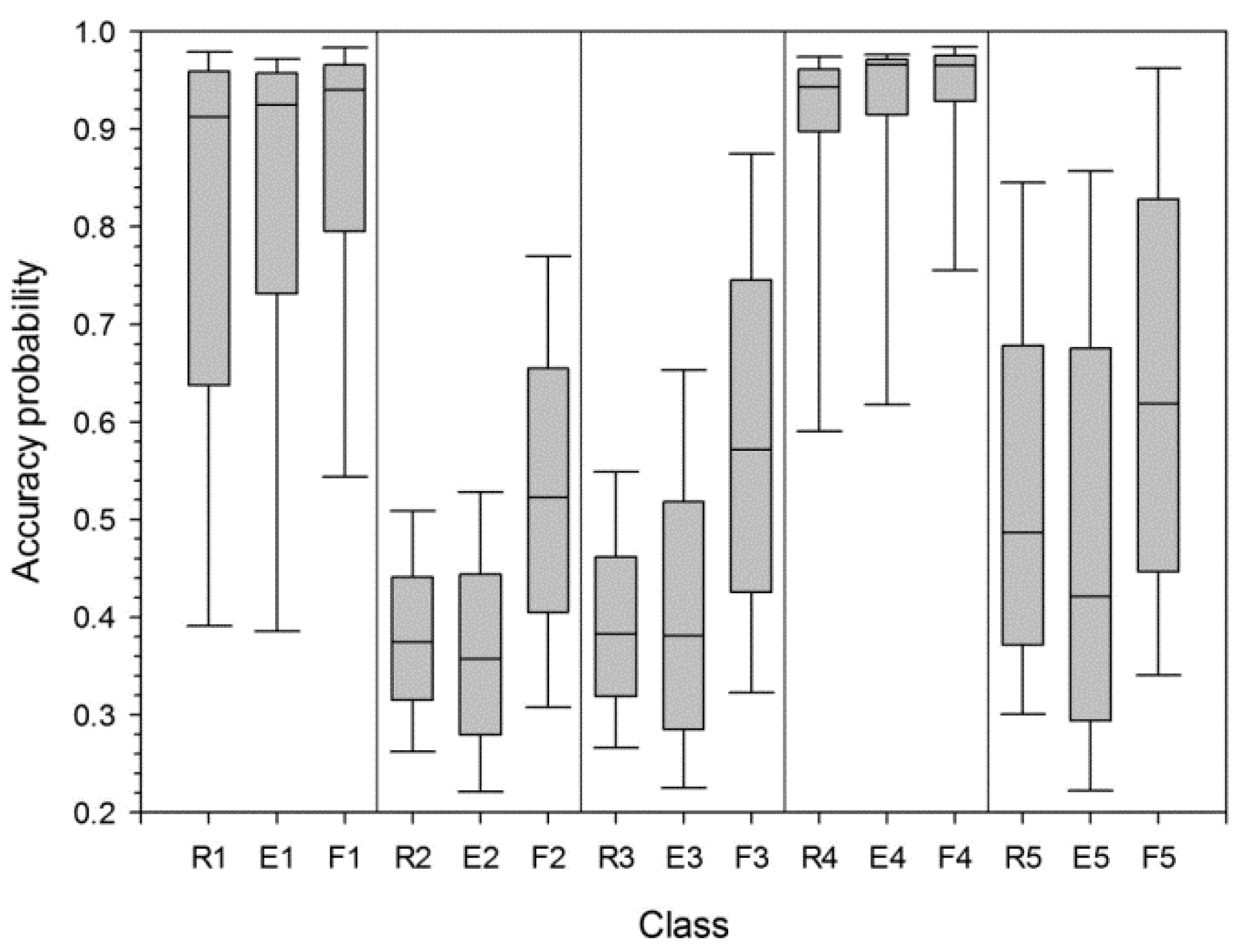
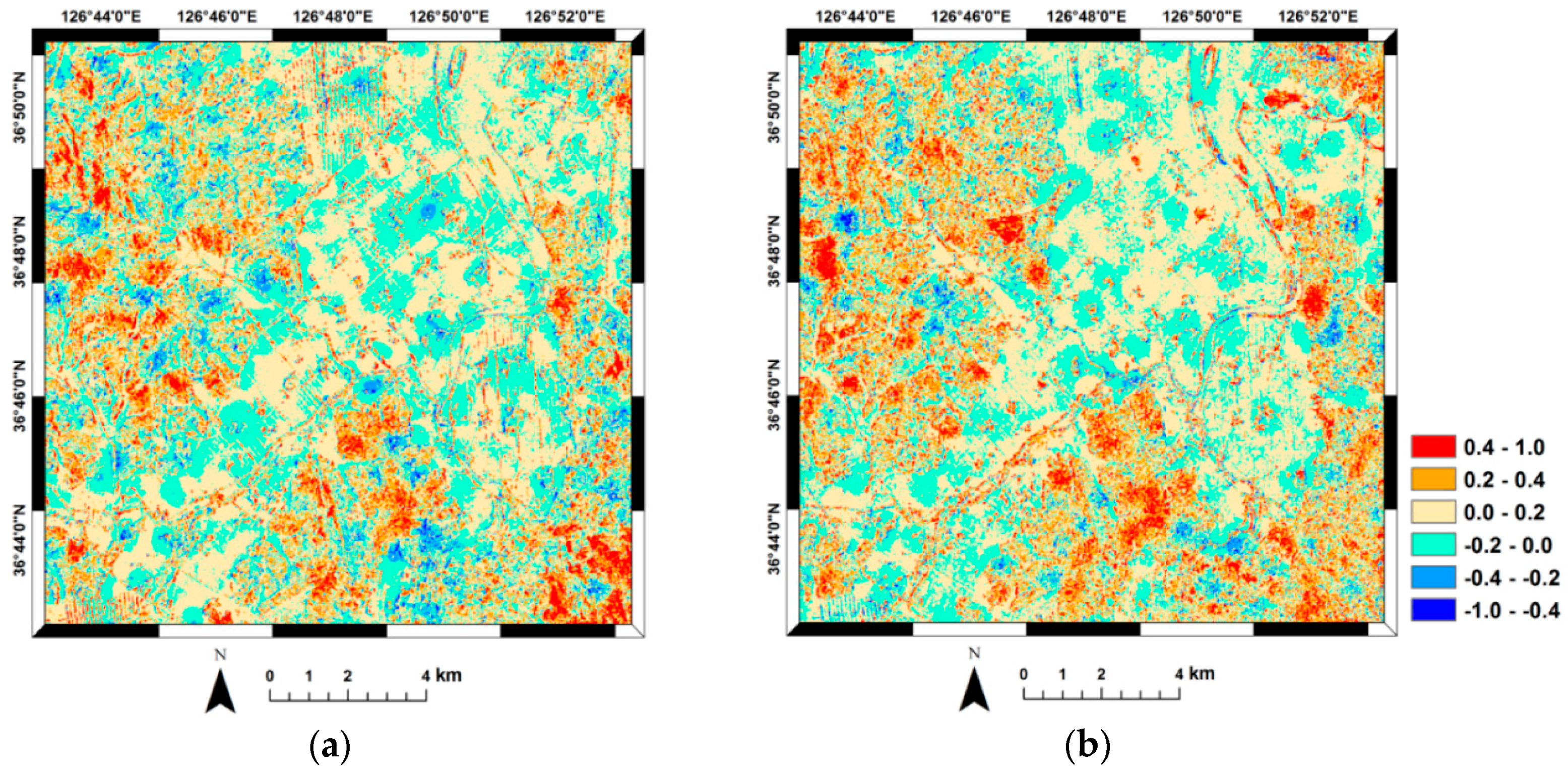

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}