1. Introduction
Thanks to the powerful advantage in collecting both spectrum and images of ground objects on the earth surface, hyperspectral imaging is a popular technique in many application fields, including environment monitoring [
1,
2], precision agriculture [
3,
4], mine exploration [
5,
6] and so on. However, many challenging problems exist in the hyperspectral imagery (HSI) processing, especially the “curse of dimensionality” [
7,
8,
9]. The problem results from numerous bands and strong intra-band correlations and it indicates that achieving higher classification accuracy requires more training samples. However, collecting too many training samples is expensive and time-consuming [
10,
11]. Therefore, dimensionality reduction is an alternative way to conquer the above problem and to promote the applications of HSI data.
Usually, dimensionality reduction can be classified into two main groups: band selection and feature extraction [
12,
13]. Feature extraction reduces the dimensionality of HSI data through transforming it into a low-dimensional feature space, whereas band selection selects a proper band subset from the original band set [
14,
15]. In this study, we focus on band selection because we believe band selection inherits the original spectral meanings of HSI data when compared to feature extraction.
The research history of band selection starts from the birth of hyperspectral imaging technique. Many classical methods from information theory were introduced into the hyperspectral community. The entropy-based methods select a band subset aiming for maximal information entropy or relative entropy [
16,
17]. The effects from intra-band correlations are usually neglected in the entropy-based methods, and the representative bands are prone to be highly correlated and do not necessarily perform well in realistic applications [
18]. Meanwhile, intra-class divergences can be maximized to formulate the distance measure based methods using Euclidean, Spectral Information Divergence (SID), Mahalanobis distances and so on [
18,
19]. The methods outperform the entropy-based methods in many instances but the selected band subsets vary greatly across different distance measurements. In addition, some measurements such as Spectral Angle Mapping (SAM) do not consider the intra-band correlations and these methods might bring about unstable results in band selection. The intra-band correlation based methods select a proper band subset that has minimal band correlations, and typical examples are the mutual information method [
20], the joint band-prioritization and band-decorrelation method [
21], the semi-supervised band clustering method [
22] and the column subset selection method [
23]. These methods perform better than all classical methods, but they rely heavily on prior knowledge of intra-band and still have some respective disadvantages. For example, the band clustering algorithms typically involve complex combinatorial optimization leading to a plethora of heuristics, and the choices of clustering centers highly affect the result of representative bands [
22].
With the maturity of artificial intelligence, many relevant algorithms have been adopted to solve the band selection problem. The particle swarm optimization based methods implement a defined iterative searching criterion function to obtain a proper band subset that maximizes the intra-class separabilities. Typical algorithms are the simple particle swarm optimization algorithm using the searching criterion function of minimum estimated abundance covariance [
24], the parallel particle swarm optimization algorithm [
25], and the improved particle swarm optimization algorithm [
26]. The particle swarm optimization based methods have lower computational complexity and smaller parameter tuning works, but the methods are easily encountered in local minima and could not guarantee successful global optimization. The ant colony optimization based methods implement a positive feedback scheme and continually update the pheromones to optimize the band subset combination. The representative algorithms are the parallel ant colony optimization algorithm [
27] and the specific ant colony algorithm for urban data classification [
28]. Because they lack sufficient initial information, the ant colony based methods usually take long computational times to obtain a stable optimal solution. The complex networks based methods input the HSI dataset into complex networks and find an appropriate band subset that has best qualification for differentiating all ground objects [
29,
30]. The band subset from complex networks performs better in identifying different ground objects than classical methods, whereas the high computational complexity in constructing and analyzing the complex network hinders its applications in realistic works. Other artificial intelligence based methods in recent literature include the progressive band selection method [
31], the constrained energy minimization based method [
32] and the supervised trivariate mutual information based method [
33]. From the above, most artificial intelligence based methods could not perfectly balance the computational speeds and the optimization solutions. In addition, the estimated band subset is difficult to physically interpret because of the complicated searching strategy adopted.
More recently, the popularity of compressive sensing brings about new perspectives for band selection and many sparsity-based algorithms have been presented in the literature [
34,
35,
36]. The sparsity theory states that each band vector (
i.e., the hyperspectral image in each band is reshaped as a band vector in the column format) can be sparsely represented using only a few non-zero coefficients in a proper basis or dictionary [
37,
38]. Sparse representation could uncover underlying features within the HSI band collection and help selecting a proper band subset. The Sparse Nonnegative Matrix Factorization (SNMF) based methods originate from the idea of “blind source separation”, and simultaneously factorize the HSI data matrix into a dictionary and a sparse coefficient matrix [
36]. The band subset is then estimated from the sparse coefficient matrix. The examples of SNMF based methods are the improved SNMF with thresholded earth’s mover distance algorithm [
39] and the constrained nonnegative matrix factorization algorithm [
40]. The SNMF based methods stand on low rank approximations and have a great degree of flexibility in capturing the variances among different band vectors. Unfortunately, the band subset from SNMF based methods can be hard to interpret and its physical or geometric meaning is unclear. Different from the SNMF based methods, the dictionaries in sparse coding based methods are learned or manually defined in advance. The sparse coding based methods integrate the regular band selection models with sparse representation model of band vectors to estimate the proper representative bands. Typical methods are the sparse representation based (SpaBS) method [
35], the sparse support vector machine method [
41], the sparse constrained energy minimization method [
42], the discriminative sparse multimodal learning based method [
43], the multitask sparsity pursuit method [
44] and the least absolute shrinkage and selection operator based method [
45]. Similar with SNMF, the band subset from sparse coding has unclear physical or geometric explanations. When the dictionary in sparse coding is set to be equal to the HSI data matrix, all band vectors can be assumed to be sampled from several independent subspaces and the Sparse Subspace Clustering (SSC) model is then formulated. Typical methods include the collaborative sparse model based method [
34] and the Improved Sparse Subspace Clustering (ISSC) method [
46]. The SSC based methods combine the sparse coding model with the subspace clustering approach, and the benefit of clustering renders that the achieved band subset is easy to interpret. Nevertheless, the clustering center in the methods is difficult to uniquely determine because it depends on the number of clusters.
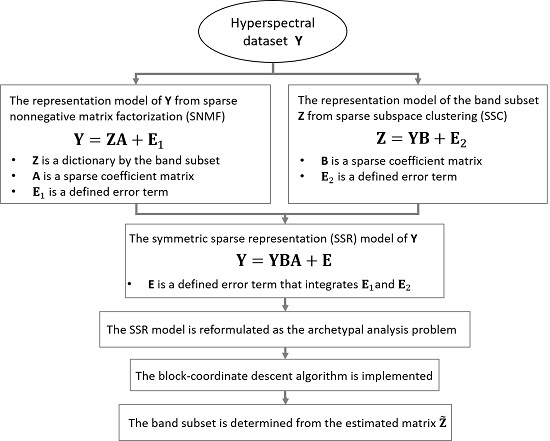
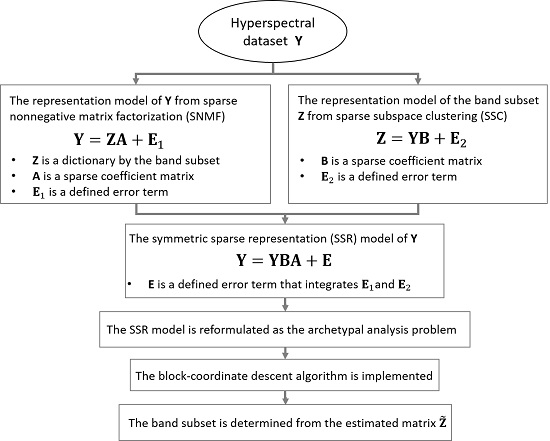
In this study, different from previous works, a Symmetric Sparse Representation (SSR) method is proposed to investigate the band selection problem. The aim of SSR is to combine the advantages of SNMF and SSC, while avoiding their respective disadvantages. Compared with the SNMF and SSC, the SSR method favors the following three main innovations:
- (1)
SSR combines the assumptions of SNMF and SSC and integrates benefits from both methods. The SNMF regards that each band vector can be sparsely represented by the aimed band subset with a sparse and nonnegative coefficient vector, and it explains that each band vector in HSI data can be regarded as a convex combination of the aimed band subset, even though the band subset is undetermined. The SSC assumes that each selected band vector can be sparsely represented in the feature space spanned by all the band vectors, and each selected band vector is a convex combination of all the band vectors in HSI data. The SSR combines symmetric assumptions of both SNMF and SSC together, and then it could integrate the advantages of SNMF and the virtues of SSC.
- (2)
The SSR method has clearer geometric interpretations than many current methods. SSR formulates the band selection problem into the optimization program of archetypal analysis. Archetypal analysis gives the SSR a clear geometric meaning that selecting the representative bands is to find archetypes (
i.e., representative corners) of the minimal convex hull containing the HSI band points (
i.e., a band vector corresponds to a high-dimensional band point). In contrast, the current sparsity-based methods including SNMF and sparse coding based method could capture low-rank feature of HSI band set, but the meanings of selected bands are difficult to interpret [
47].
- (3)
The SSR method does not involve any tuning works of inner parameters and this feature makes it easier to implement SSR in realistic applications. Particularly, the SSR does not have the clustering procedure, and hence the estimated SSR band subset avoids negative effects from the clustering approaches that exist in SNMF and SSC.
The rest of this paper is organized as follows.
Section 2 presents the band selection procedure using the proposed SSR method.
Section 3 describes experimental results of SSR in band selection for classification on two widely used HSI datasets.
Section 4 discusses the performance of SSR compared to four other methods.
Section 5 states the conclusions.
4. Discussions
This section discusses the performances of SSR compared to the four other state-of-the-art methods from
Section 3.2 in detail. Three experiments have been designed using Indian Pines and PaviaU datasets to compare the SSR method to SID, MVPCA, SpaBS and SNMF. Three quantitative measures, AIE, ACC and ARE, show that SSR outperforms the four other methods. SSR assumes that the selected bands and the original HSI bands are symmetrically sparsely represented by each other. The two sparse representation assumptions interpret band selection as finding archetypes (
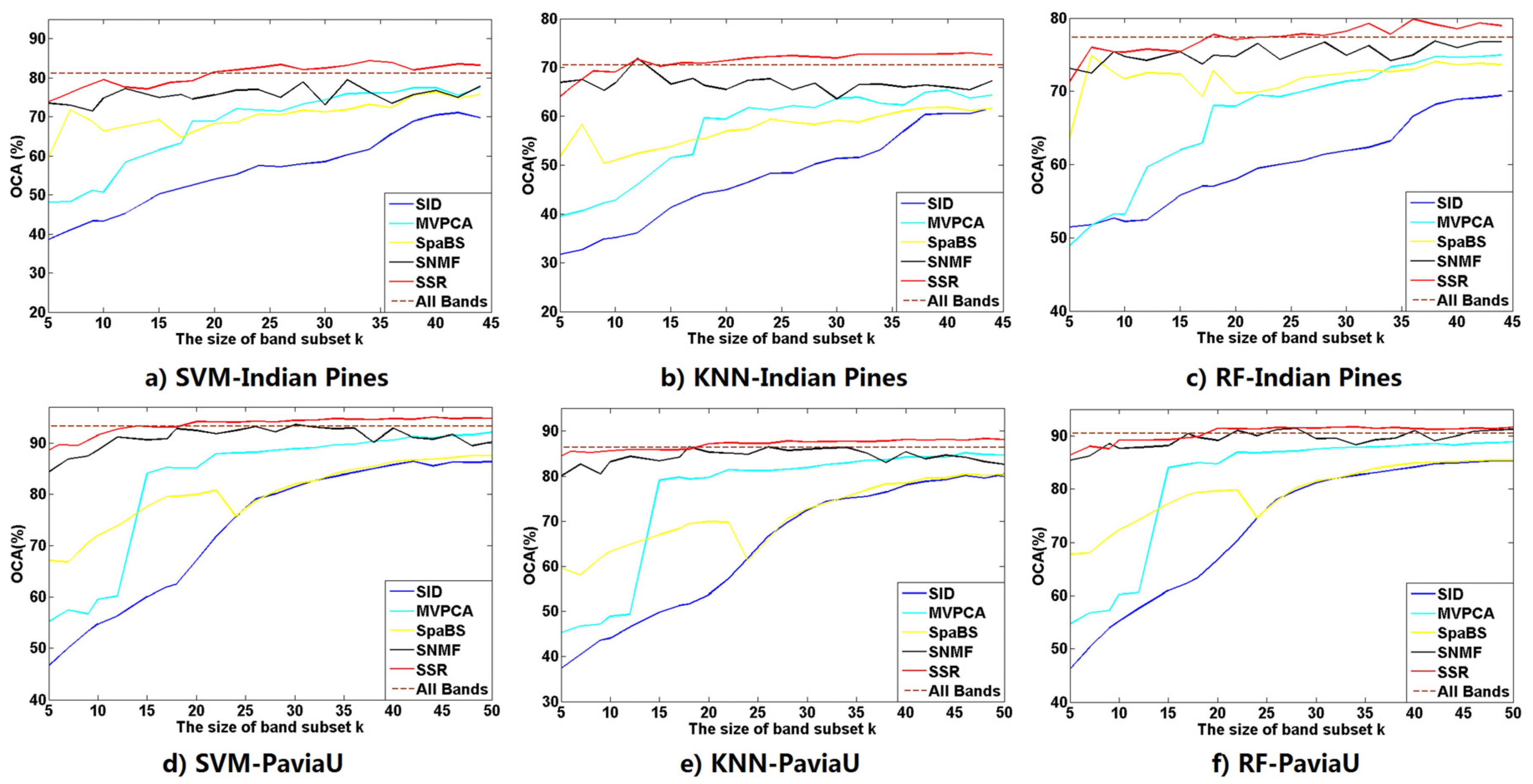
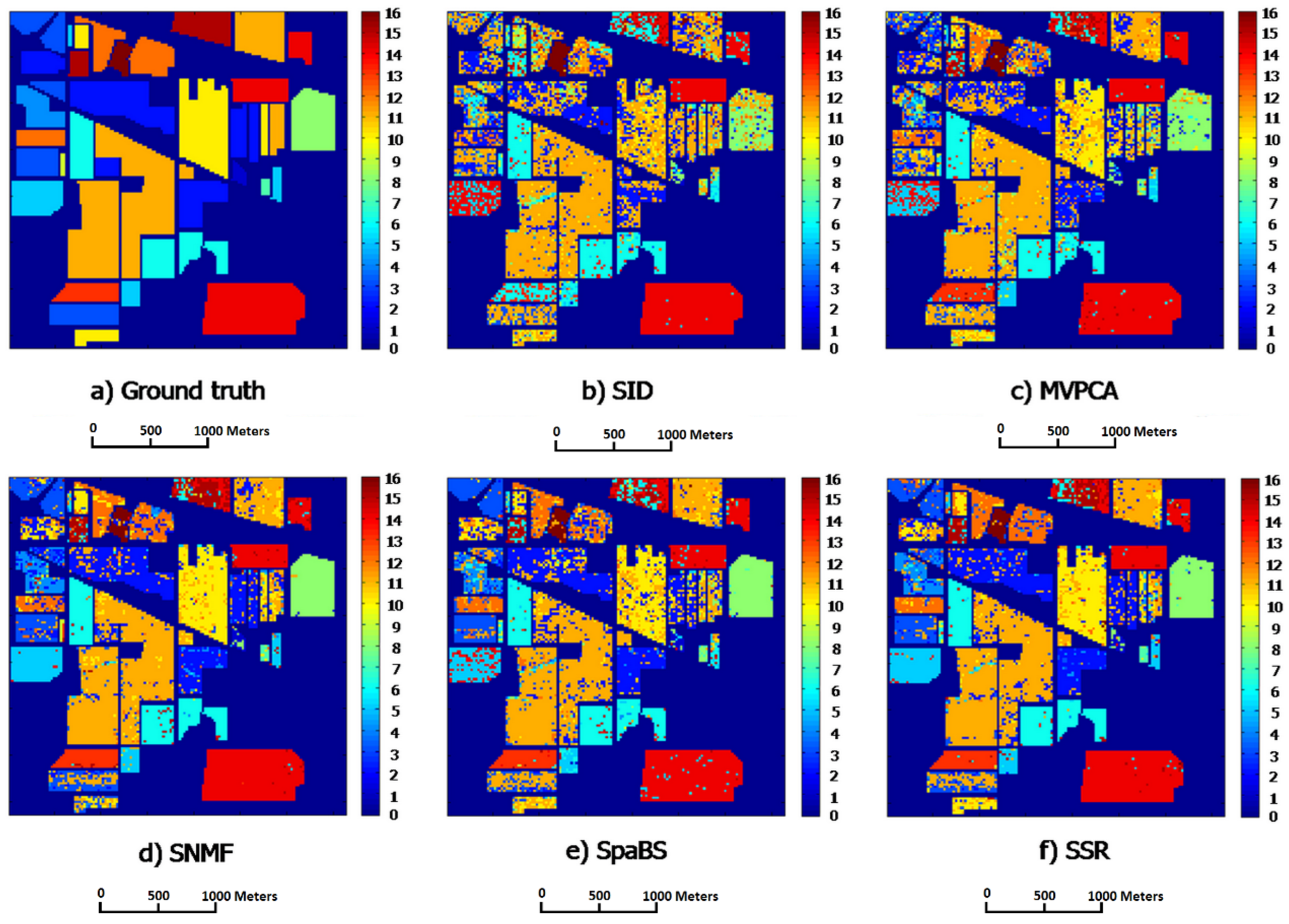
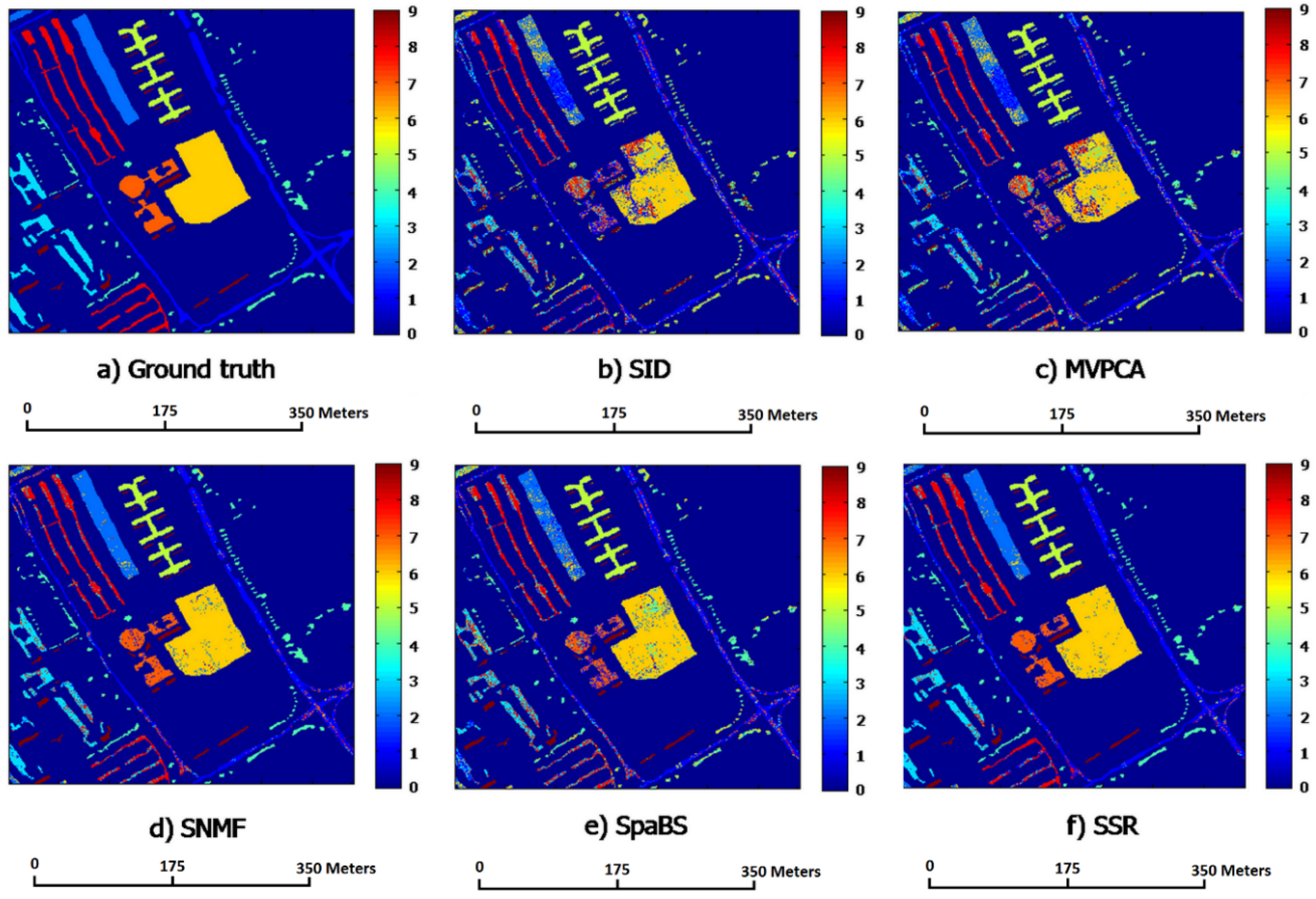
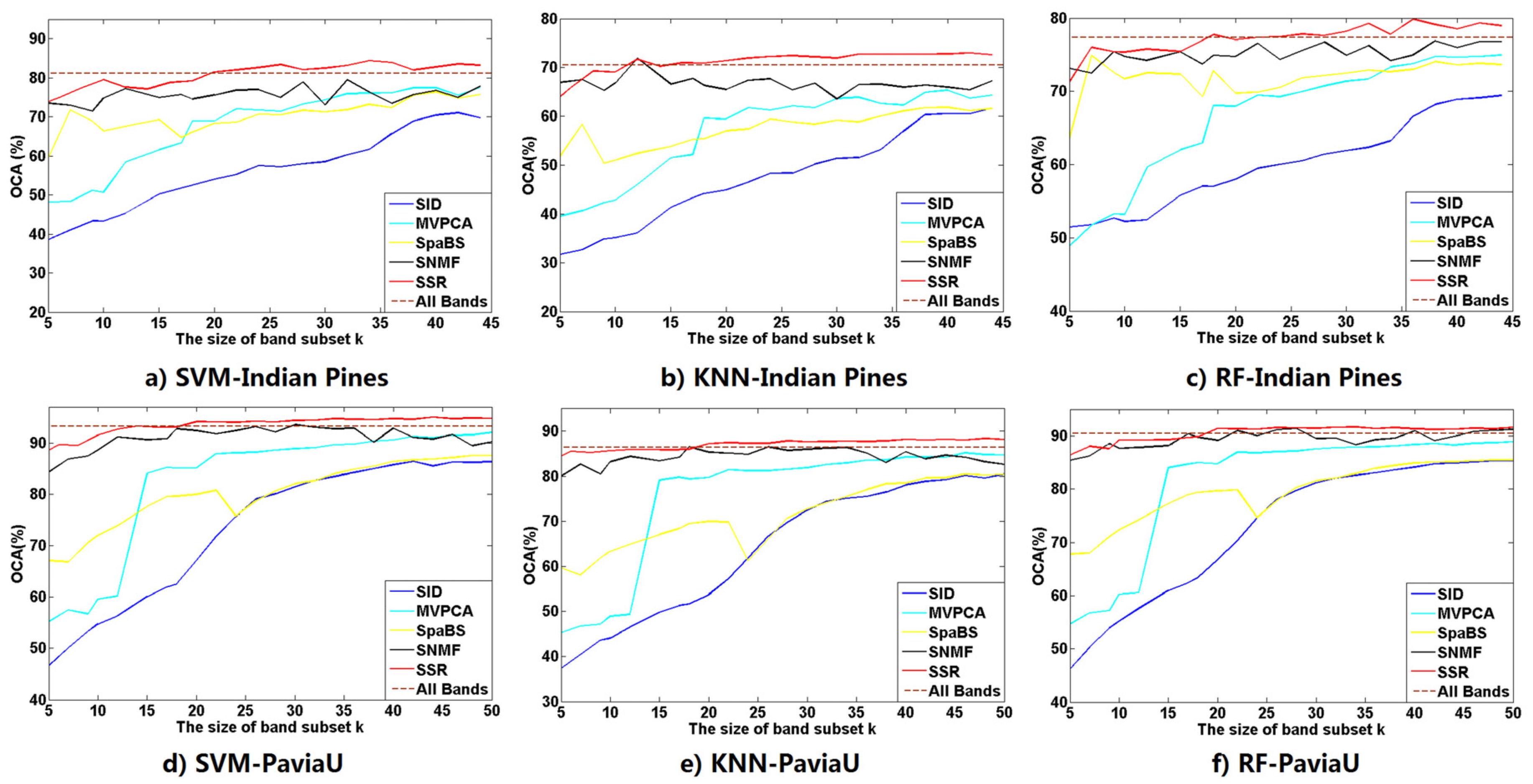
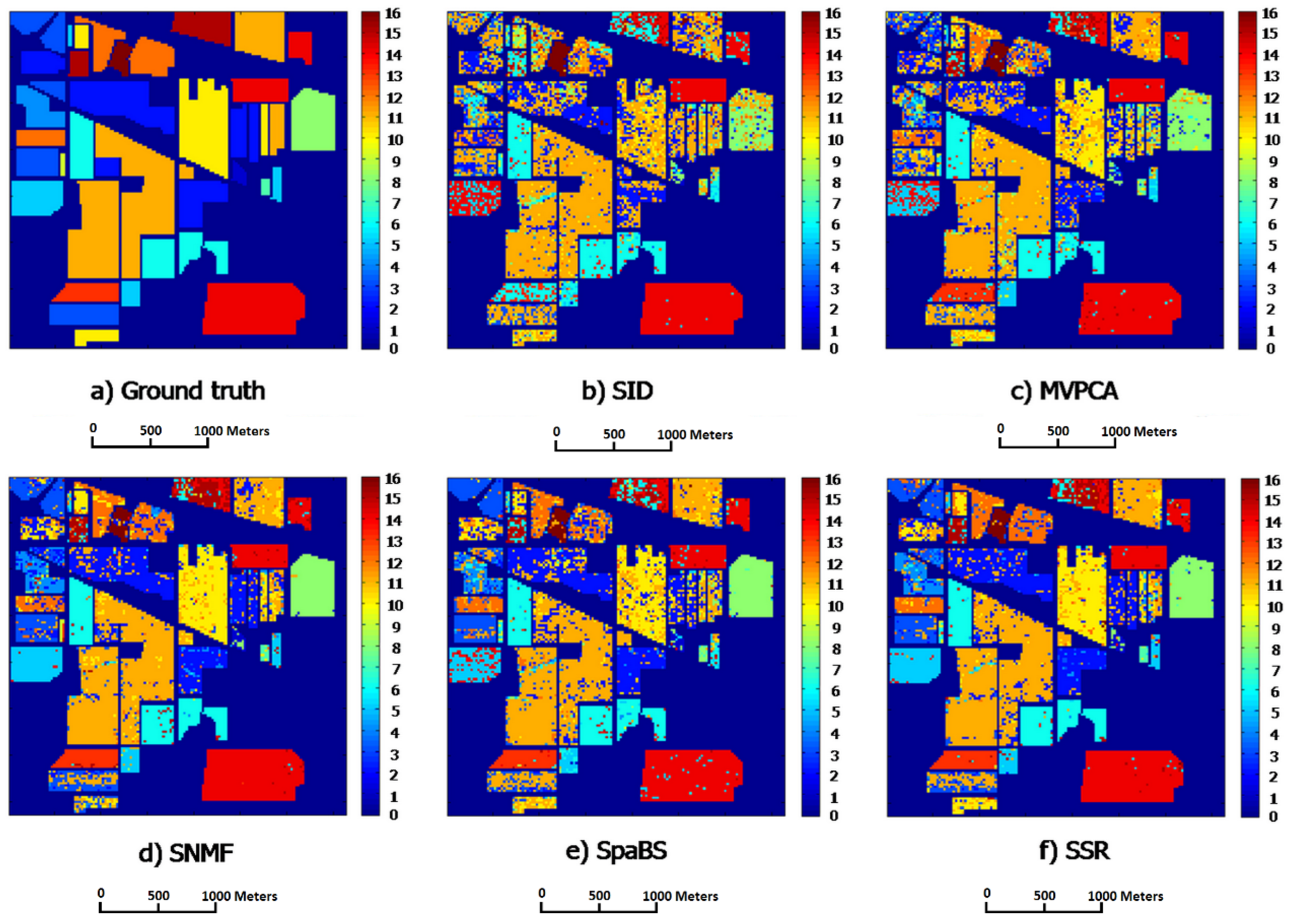
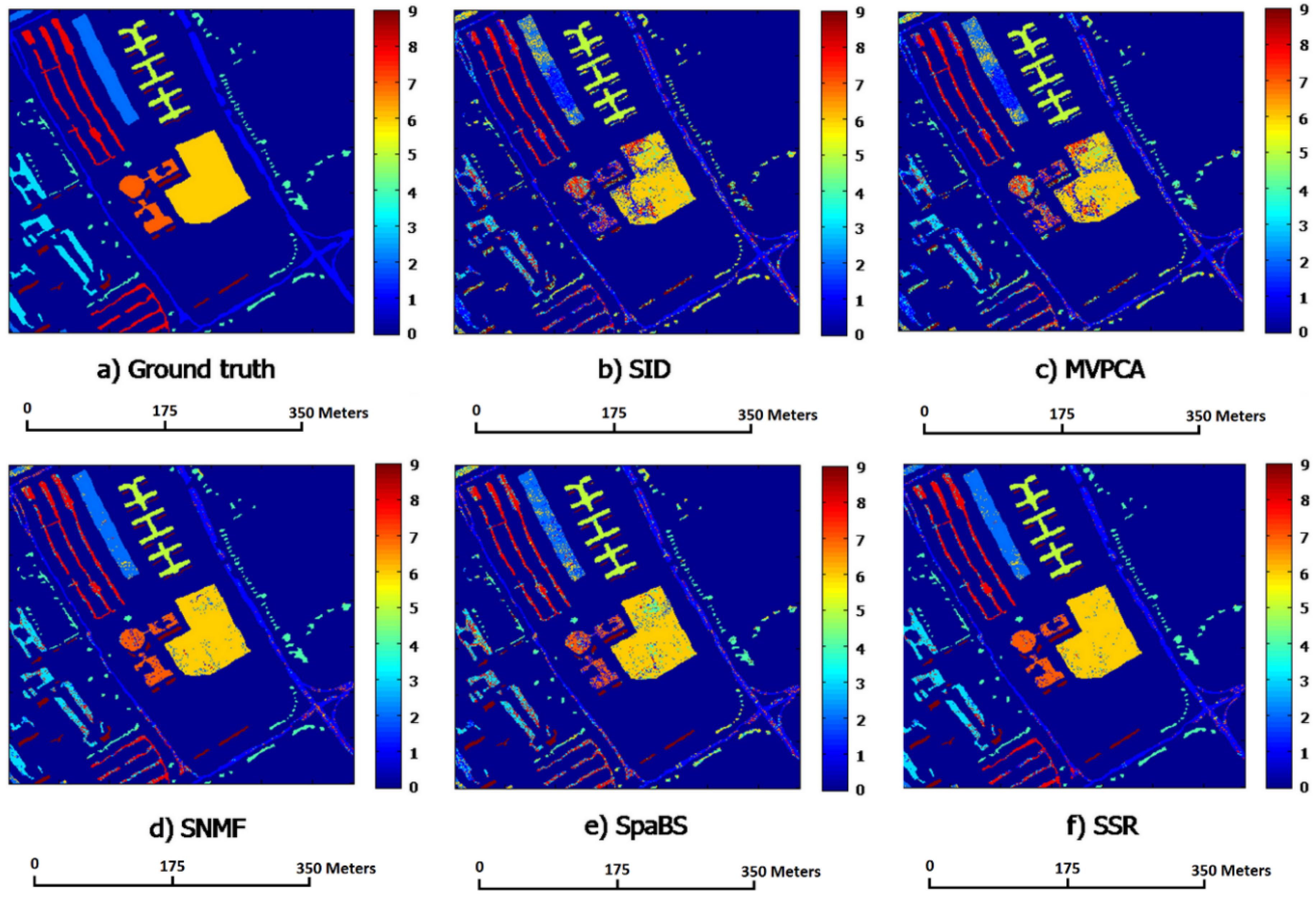
i.e., representative corners) of the minimal convex hull containing the HSI band points. Hence, the SSR subset has high information amount, high intra-class separabilities and low intra-band correlations. The SSR satisfies the requirements of band subset selection and is more appropriate for band selection than the four other methods, especially SID and MVPCA.
The classification and computation experiments compare classification and computational performances of the SSR band subset with those of the four other methods. The SID has the fastest computational speeds whereas its band subset obtains worst ACAs and OCAs. The fastest speed of SID results from its lowest computational complexity in computing the diagonal elements of its similarity matrix. The SpaBS has better classification accuracies, ACAs and OCAs, than SID but it costs the longest computational time. The reason for that is the extremely high complexity of dictionary learning using K-SVD algorithm. The slower computational speed of MVPCA than SSR results from the lower computation in principal component analysis transformation. The SSR behaves best among all five methods in classification accuracies OCAs and ACAs while it takes the second shortest computational times. Moreover, compared with the four other methods, the SSR band subsets exclusively achieve better OCAs than the original band sets on both HSI datasets, when having a larger size k than a certain value. This implies that SSR could select a proper band subset and could help solve the “curse of dimensionality” problem in HSI classification.
However, we have to clarify that SSR requires no more parameter setting work, except the size of band subset k. We did manually estimate the size of band subset and did not carefully investigate a proper size for the selected bands. Aside from the size problem of a band subset, SSR is the best candidate among all five methods for selecting a proper band subset from HSI bands because of its comprehensive performances in classification and computation. The reason we did not explore setting a proper size for the SSR method is that different estimation criteria in various methods renders it confusing, and even difficult, to estimate a unique and proper size. The unification of all current estimation methods of band subset size is then the first significant problem we aim to solve in future work. One big possible uncertainty of SSR in band selection for HSI classification is the effect from atmospheric calibration on both HSI datasets. We decided to make no atmospheric correction in this manuscript to facilitate comparison with other methods. Nevertheless, atmospheric calibration does make clear effects in classification results of HSI datasets. Therefore, the second aim of our future work is to carefully analyze the effects of atmospheric calibration on the classification performance of SSR and continue to ameliorate classification results of the SSR band subset in realistic classification applications.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}