1. Introduction
Land use/land cover maps are important to determine vegetation distribution and to understand the variables promoting land cover change. The spatial distribution of vegetation has important implications on food security, trade, and environmental issues, like habitat loss and fragmentation. Land cover is also a key input variable to several models, for example, energy balance at the surface-atmosphere interface, hydrological cycle, and emissions of greenhouse gases. Key variables in biomass burning emission estimates are fuel load and emission factors, both highly dependent on land cover [
1].
Despite its importance, recent land cover maps at a national scale in Colombia, the area of interest in this study, are scarce. The best effort has been done by the Institute of Hydrology, Meteorology, and Environmental Studies (
Instituto de Hidrología,
Meteorología y Estudios Ambientales, IDEAM) [
2] following the Coordination of Information on the Environment (CORINE) land cover protocol, which requires multiple interpreters to update the geometry of polygons based on existing land cover maps and satellite images from 2003 to 2007. Other land cover maps for Colombia are available at the continental scale for South America [
3,
4,
5], Latin America and the Caribbean [
6,
7], and the globe [
8,
9,
10,
11,
12] (
Table 1).
Table 1.
Global and continental land cover maps for Colombia derived from satellite data.
Table 1.
Global and continental land cover maps for Colombia derived from satellite data.
| Study Name | Sensor | Resolution (m) | Year | Source |
|---|
| South America (Eva et al.) | SPOT-VGT 7 | 1000 | 1995–2000 | [3] |
| South America (Giri et al.) | Landsat | 30 | 2010 | [4] |
| South America (Hojas et al.) | Mainly MERIS 8 | 300 | 2008, 2010 | [5] |
| SERENA 1 | MODIS 4 | 500 | 2008 | [6] |
| Municipalities in LAC 2 | MODIS | 250 | 2001–2010 | [7] |
| GLOBCOVER | MERIS | 300 | 2004–2006 | [8] |
| GLC 2000 3 | SPOT VGT | 1000 | 2000 | [9] |
| MODIS 4 GLC C5 5 | MODIS | 500 | 2001–2012 (annual) | [10] |
| Global Land Cover 1 km | AVHRR 9 | 1000 | 1992–1993 | [11] |
| FROM-GLC 6 | Landsat | 30 | >2006 | [12] |
The generation of land cover maps using optical data in areas with persistent clouds is challenging [
13]. For instance, filtering daily Moderate Resolution Imaging Spectroradiometer (MODIS) data over Colombia for the entire year of 2008 resulted in an area of 4.1% without any valid information, mainly due to clouds along the Pacific coast and in the Andean cordilleras [
6]. At tropical latitudes MODIS acquires images at least every other day. The standardized data processing chain aggregates, for instance, all acquisitions over a 16-day period to generate a vegetation index composite. Data compositing is a viable approach to reduce the effect of invalid observations, data noise, or observations with high view or sun zenith angles by rule sets or statistical functions. Nevertheless, there are regions without any valid observation for the entire compositing period, e.g., due to persistent cloud cover. In MODIS data these pixels are flagged by the quality assurance science data set and the user has the flexibility to decide which quality level is acceptable and how to deal with invalid data for a particular application. For instance, temporal interpolation of data gaps is a frequently employed technique to reconstruct a continuous time series for land cover mapping, but the length of the period of missing data impacts the accuracy [
14].
A time series, in the context of remote sensing, is defined as the dense monitoring of surface dynamics over a defined period [
15]. The extraction of one pixel from this sequence of images ordered in time shows the temporal behavior of the land surface which may be decomposed in three components: the trend(s), the cyclic or other seasonal behavior, and irregular fluctuations [
16]. There are several computer programs to generate time series from satellite data. Harmonic Analysis for Time Series (HANTS), for instance, employs the Fast Fourier Transformation to model the general temporal behavior of a time series and iteratively substitutes invalid observations (mostly cloudy pixels in vegetation indices) defined by a threshold exceeding a negative deviation from the modeled data [
17]. The Timesat software models smooth time series by mathematical functions or filters, generally applying a fitting to the highest values of vegetation index values [
18,
19]. The Time Series Generator (TiSeG) applies user-defined quality settings to pixel-level quality information provided with each MODIS land product and generates spatial and temporal indices of data availability and gap length [
20,
21]. In a second step, data gaps may be masked or interpolated using generic temporal interpolation approaches, such as linear interpolation, cubic spline, or polynomial functions. An alternative approach employs stepwise interpolation of short data gaps by iteratively decreasing the data quality [
21]. There are recent studies employing time series models for land cover and land cover change mapping often employing complex time series models [
22,
23,
24]. The common question which all approaches address is how to identify, handle, and replace invalid observations.
In the context of classification, features are needed to distinguish the different land surface properties and land cover or vegetation classes. Commonly, spectral information from multiple portions of the electromagnetic spectrum is employed to distinguish different land cover classes. The spectral characteristics of dense green vegetation, for instance, are a low reflectance in the visible wavelengths and high values in the near infrared, which are fundamentally different from water, with generally low and decreasing reflectance in the visible to mid-infrared range of the electromagnetic spectrum. This multispectral information may be complemented by temporal information. In this context, time series describe the temporal properties of land surface types and may allow distinguishing between deciduous forests, typically described by a uni-modal curve of green-up, plateau, and senescence of a vegetation index, from an evergreen forest with constantly high values. In this respect, the phenological development of natural and managed vegetation plays a major role in image classification [
25,
26,
27,
28,
29]. Even though spectral and temporal properties for many land cover classes are well defined, it may be difficult to separate some classes, e.g., bare soil from urban areas. Information from the microwave range of the electromagnetic spectrum may improve separability of such classes, as the geometry of objects with strong backscattering at buildings is fundamentally different from the weak backscatter of bare soils. Information from Synthetic Aperture Radar (SAR) images may also be helpful for mapping regions of frequent cloud cover, such as Colombia, as long waves penetrate clouds and have shown potential to improve forest classifications by going well into the canopy [
30]. However, classifications from radar data alone have not shown promising results due to limited spectral resolution [
31,
32]. The horizontal (H) or vertical (V) orientation of electromagnetic fields, known as polarimetry, has been used in order to determine differences in land cover backscattering to overcome this limitation of radar images [
33,
34].
The objective of this study was to generate a land cover map from satellite image time series for the national territory of Colombia, which includes regions of frequent cloud cover. The primary goal was to generate an annual time series of vegetation index and spectral data to accurately classify eleven land cover classes of Colombia. In a second step, additional variables such as radar backscatter, precipitation, and elevation were added to improve the land cover map.
3. Study Area
The continental extension of Colombia is 1,141,748 km
2. The national territory is located in the neotropics, ranging from the Caribbean Sea (12° North) to the northern Amazon basin (4° South) and from the Orinoco river (67° West) to the Pacific Ocean (79° West). The country is commonly divided in five regions: Caribbean, dominated by grasslands, wetlands and bare soils; Pacific, made up of pluvial and very humid rain forest; Orinoco, dominated by savannas in a flat landscape; the rain forest area of the Amazon; and the Andes mountains, with highly modified natural ecosystems, an important crop extension, road networks, and built-up areas. Important activities promoting land use and change in Colombia are related to illegal cropping [
36], mining, agriculture, and deforestation [
37]. The main climate controls of this region with abrupt topography are: the Inter-tropical Convergence Zone (ITZC), the two low-level jet streams (Chocó and San Andrés), the feedback of the Amazon evapotranspiration, and the El Niño-Southern Oscillation (ENSO) [
38]. The topographic effect is important since approximately one third of the country (392,380 km
2) is covered by mountains. This includes Chocó-Darién moist forests, Northern Andean Montane Forests, and Santa Marta Montane Forests [
39].
6. Discussion and Conclusions
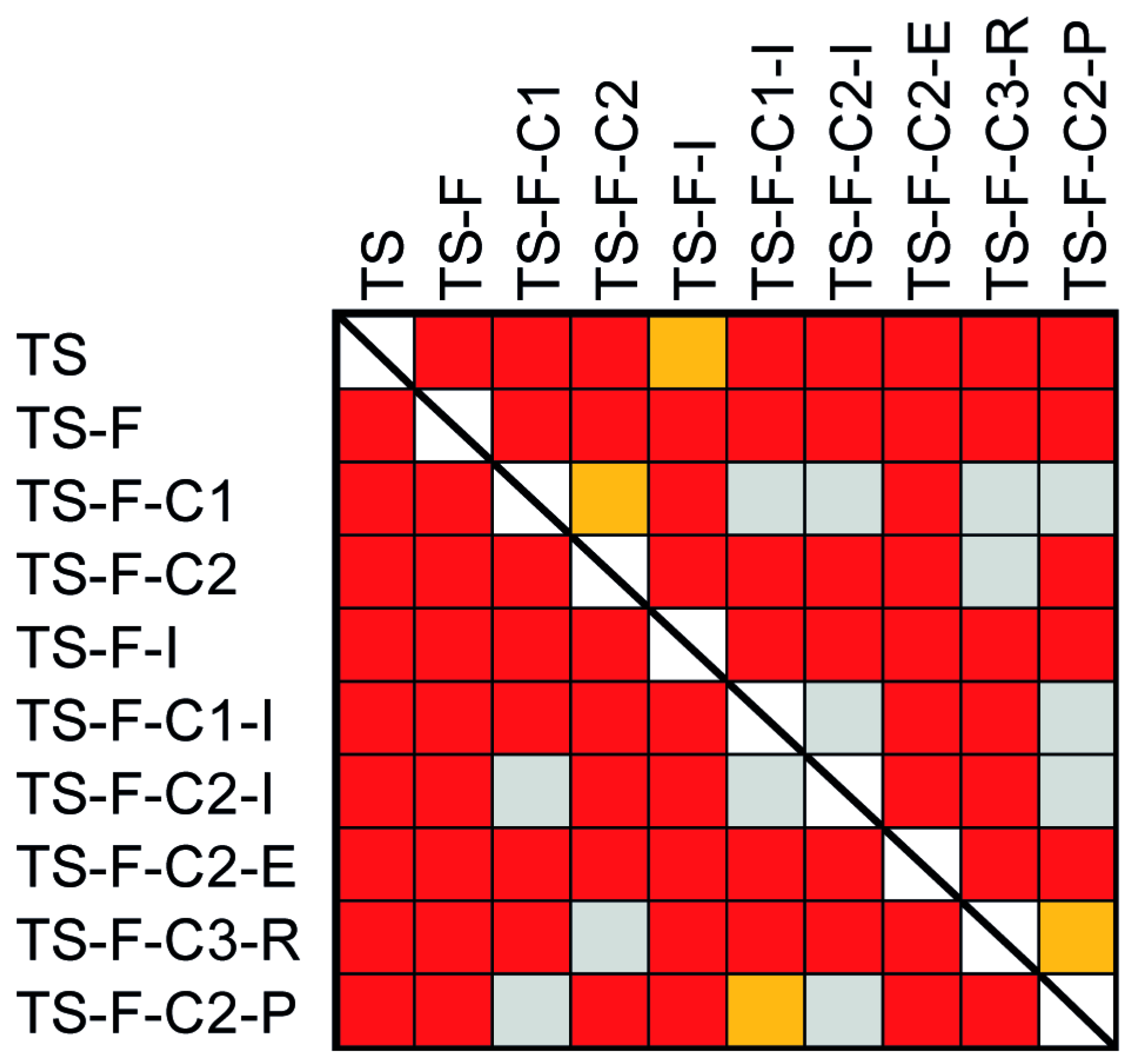
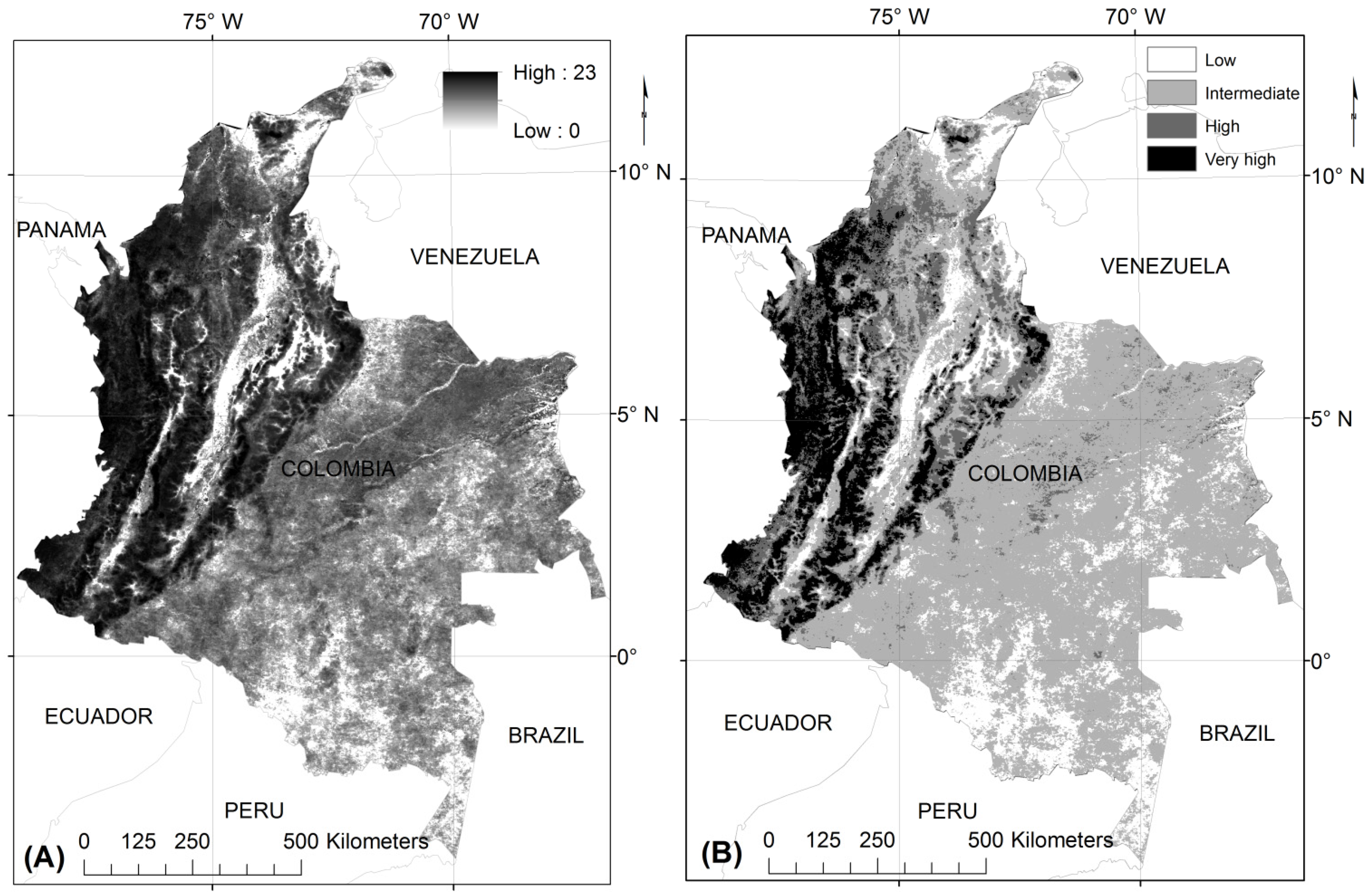
The high temporal resolution of MODIS with nearly daily observations in the tropics does not guarantee the existence of valid pixels in certain areas, mostly due to cloud formation. This study has shown that the number of invalid pixels in 2011 reduce by 54.5% when adding data from the previous and posterior year (2011 ± 1 year) and by 72.3% for 2011 ± 2 years. In addition, areas of no observations for the entire year 2011 (24,130 km2) reduced by 88% when integrating data from adjacent years (2011 ± 1 year) and by 94% for 2011 ± 2 years. This indicates that data integration over a longer period increases the possibility of valid data, thus aims at densification of information. The amount of valid pixels to be integrated from adjacent years into an annual time series will vary, e.g., due to the cloud content but will never be less than in the initial year. The effectiveness of this data integration approach may depend on the strength of seasonal dynamics; thus, land surface types with pronounced seasonal cycle, like deciduous forests, temperate grasslands, and croplands will benefit more than evergreen vegetation and barren areas. Therefore, we conclude that using a multi-year data integration is a viable approach for increasing the amount of valid data which is particularly useful for tropical and mountainous regions where cloud-free data is scarce.
Studies using daily MODIS data have shown that, for the year 2008, there were insufficient valid observations for 4.1% of the area of Colombia [
6]. This same study, however, allowed temporal interpolation across several months,
i.e., also performing image classification in area with just 3–4 valid observations for the entire year. Our results confirm these limitations of valid data availability (2.11%). Therefore, it will be difficult to implement recently-developed approaches for Landsat data [
23,
60] over Colombia as the simplest time series models require 12 valid observations.
The proposed multi-year data integration approach solves the difficulties of valid observations for a single year but is based on two important assumptions. First, it assumed that there are no notable temporal shifts among all years, such as a year with significantly earlier or later vegetation growth or differences in the magnitude of values in the time series, either due to natural variability, fire, or management in agricultural areas. Tests of temporal shifts, e.g., temporal cross-correlation [
61,
62,
63], may be restricted by only having a few observations. The second prerequisite is that there is no land cover change. Thus, the method may not be used for generating annual land cover updates as it integrates source data from various years.
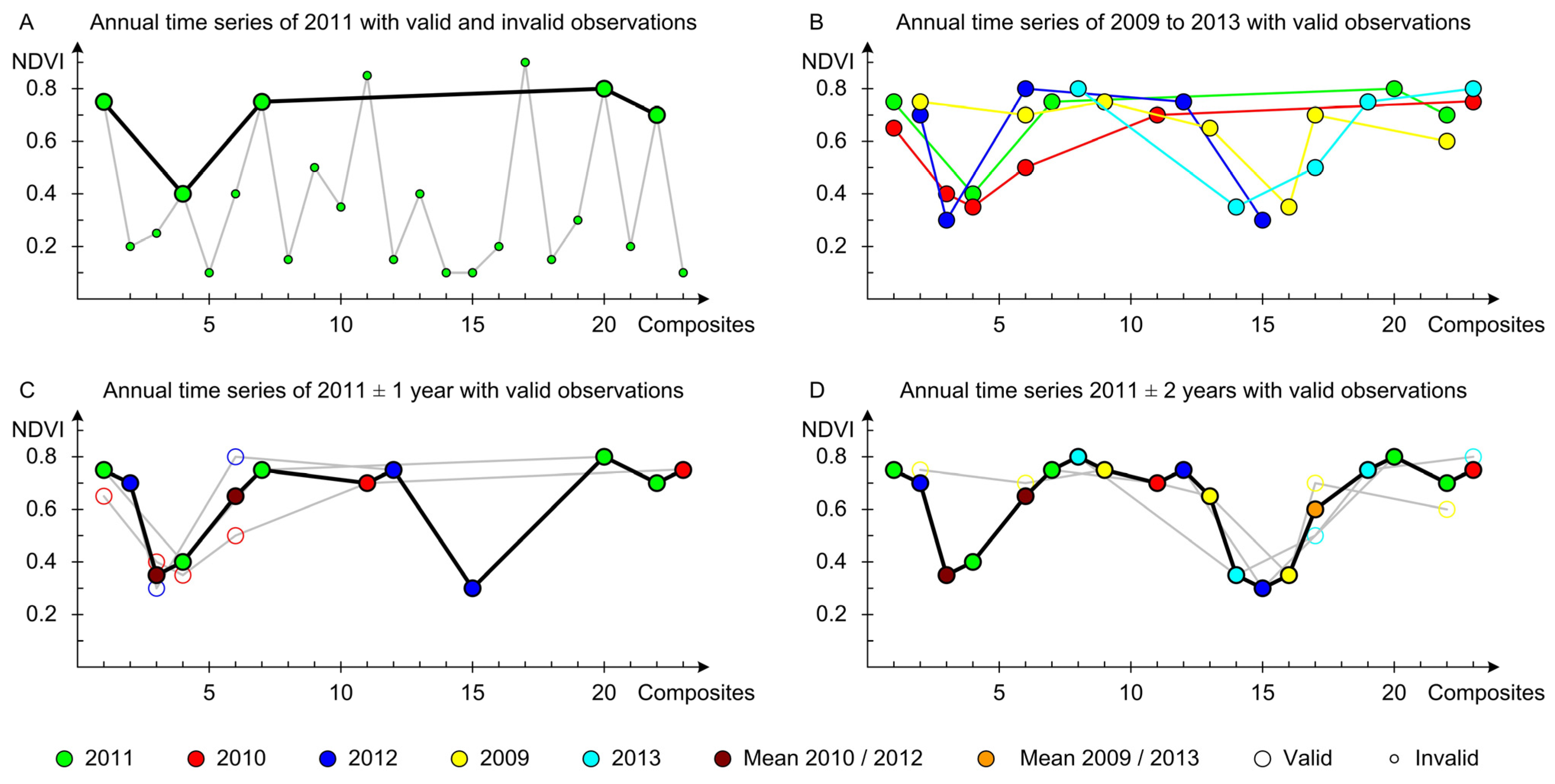
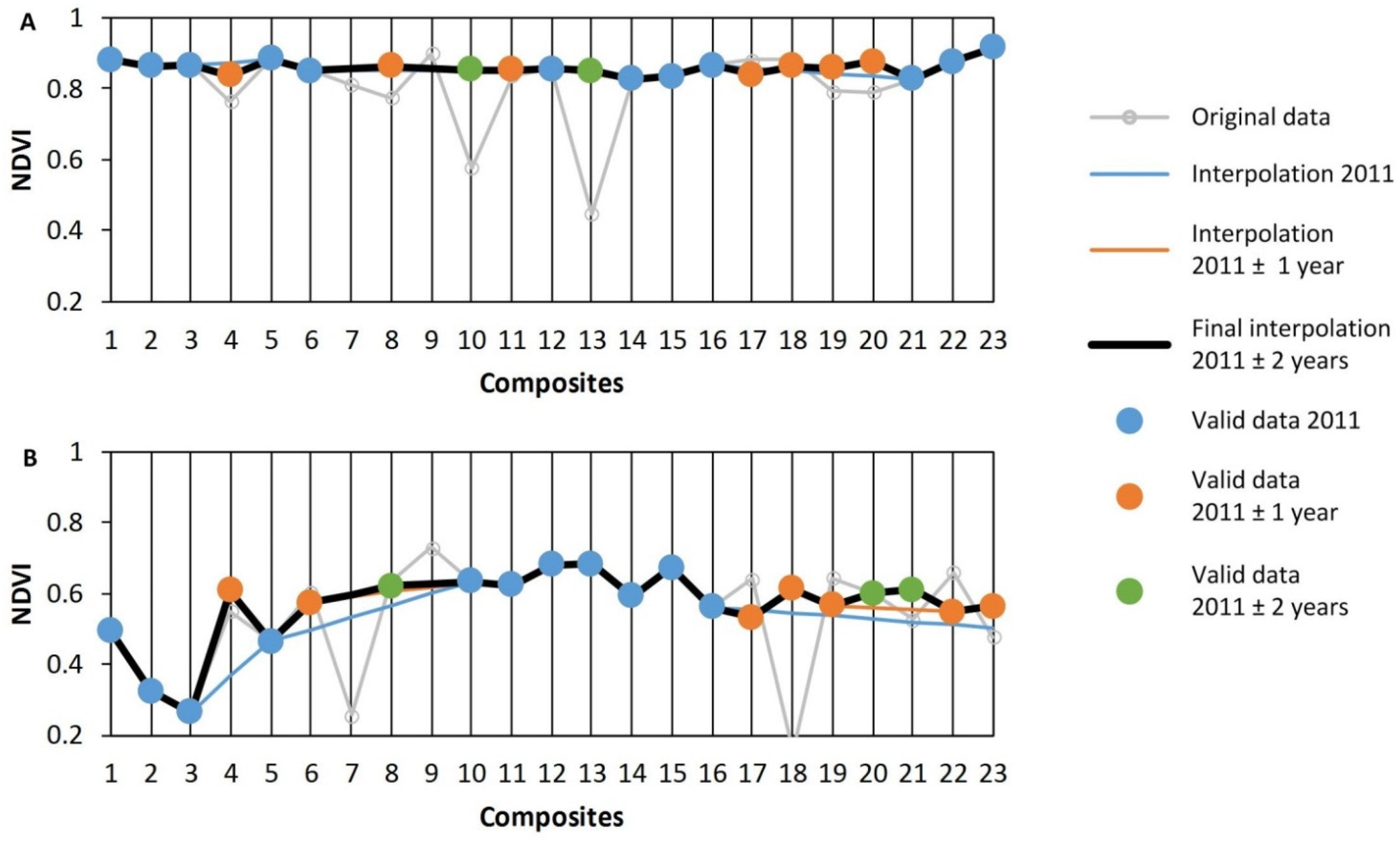
There could be several extensions and modifications to the approach as implemented in this study. For instance, data from more years could be integrated (Y
n ± 3, Y
n ± 4, Y
n ± 5,
etc.) but it should be considered that the likelihood of land cover change increases with adding more years. A viable approach to obtain a land cover map for the nominally most recent year could only consider previous years, e.g., generating a map for 2013 may iteratively integrate data from 2012, 2011, and maybe 2010. An alternative to data integration for an invalid observation (as shown in this approach) is the calculation of the mean, regardless of an existing valid observation in the previous iteration. This, for instance, would modify the value of the composite 1 in
Figure 1C to 0.7 instead of maintaining the value 0.75 from 2011. Instead of the proposed iterative approach that gives higher preference to Y
n ± 1 than Y
n ± 2, which more closely follows the logic of limiting the impact of possible land cover change in distant years, one could integrate data of multiple years all at once; thus, all have equal importance. For composite 6 with 0.65 (mean from 2010 and 2012) this approach would also include the value from 2009 resulting in 0.66. Another modification is the combination of this multi-year data integration approach with step-wise annual time series generation as described in Colditz
et al. [
21] that focuses on closing short data gaps which are not modified in following iterations, even if there is a valid value. For instance, an interpolation of gaps shorter or equal to two after the first round of data integration (
Figure 1C) closes the gap between composites 12 and 15 and, thus, does not permit integrating composites 13 (2009) and 14 (2013) in
Figure 1B.
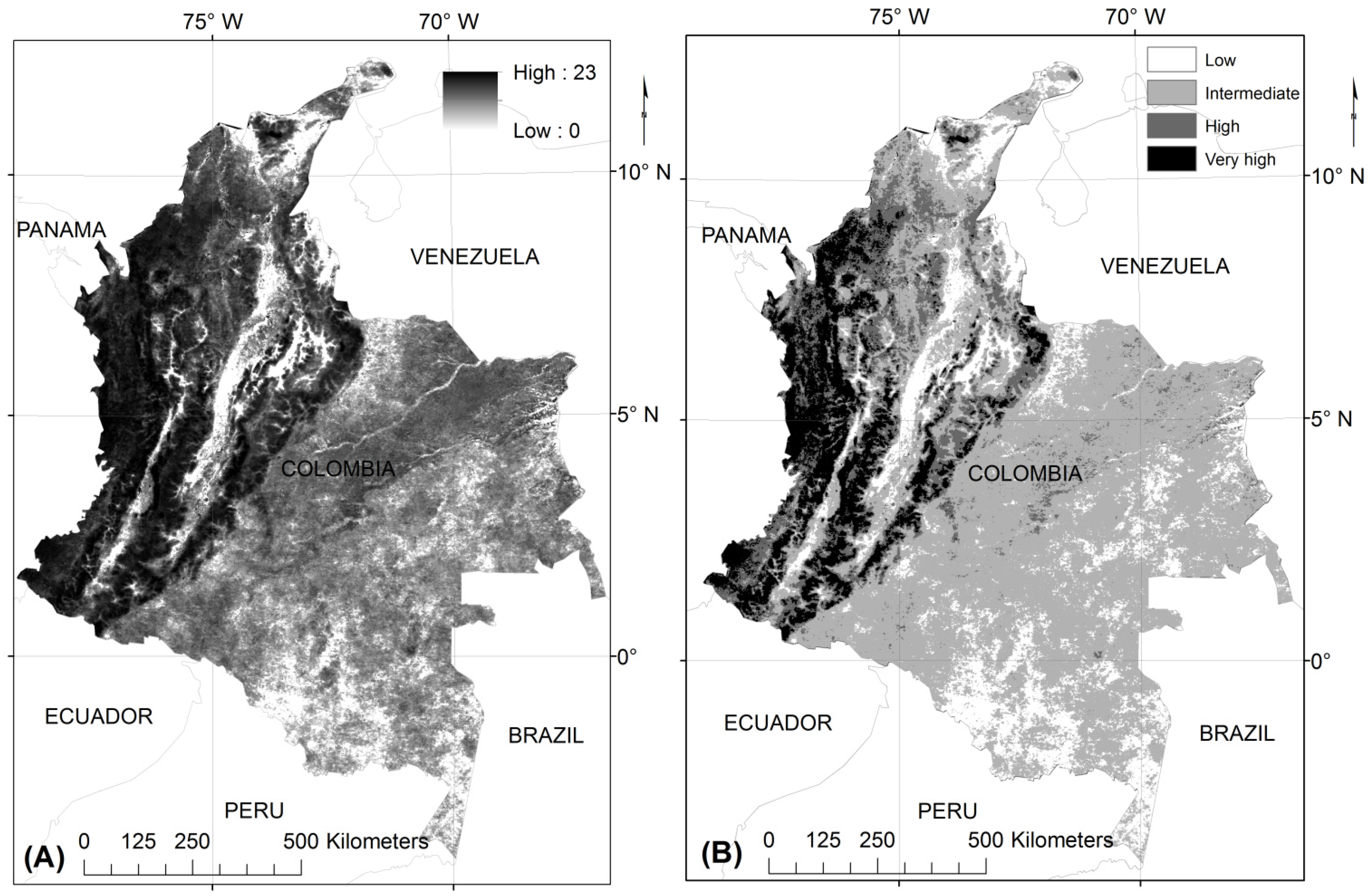
The comparison of land cover classifications based on various time series showed that the multi-year data integration approach as proposed in this study significantly improves map confidence and map accuracy. The Pacific region of Columbia, for instance, was highly favored using this approach shown by improving the classification of broadleaf forest. We recommend conducting further tests using this approach for vegetation and land cover classification, as well as for describing temporal dynamics in other tropical mountainous regions which suffer similar limitations with respect to cloud-free observations, such as in Central Africa and Indonesia. It also holds potential for other frequently cloud-covered areas such as temperate rain forests, e.g., in Western British Columbia, the Patagonian area of Chile, and the southern island of New Zealand.
Several regional to global land cover projects have integrated data of multiple years in order to increase data quality and fill periods of no available data [
64,
65,
66] for a given year, but no study has quantitatively analyzed the impact of data integration on classification accuracy. The accuracy between the number of additional years used for compositing differed only marginally; confidence-based assessment showed best results for 2011 ± 1 year and error matrix-based accuracy assessment indicated a better performance for 2011 ± 2 years. As noted above, integration over even longer periods introduces uncertainty due to potential land cover change. It was also shown that filtering a single year for all invalid observations may have adverse effects on classification accuracy. The number of missing observations was too high to build a stable decision tree and boosting could not be invoked due to a too low accuracy of a single classifier [
49].
Several other aspects may be considered to improve this result: training data may include mixed pixels to improve the classification of fragmented landscapes. A temporal match between reference data (to train and validate) and satellite data is desirable but difficult to achieve, as they are expensive to obtain and depend on specific sources or surveys. Some classes, such as páramo and secondary vegetation are defined from an ecosystem perspective and, thus, do not strictly link to land cover and have wide ambiguity in their interpretation which increases uncertainty in the map. The classification of cropland with coarse resolution data is difficult due to spatial, spectral, and temporal constraints which result in high errors. Most fields in tropical countries are smaller than a 500 m pixel. Crop types and agricultural practices vary on very small space, which causes a mix of the spectral and temporal signature. In the specific case of this study we found high ambiguity for coffee plantations as a sub-canopy crop along the Andes mountains, while palm oil, banana, and sugarcane are easily isolated in flat regions.
The addition of ancillary information only showed minor increases in accuracy for elevation and decreases when using other sources (precipitation, L-band radar data). This result may vary on the study area and classes to be classified, e.g., land cover classification of Colombia as a mountainous country can be improved with elevation data, while climatic gradients may be more helpful for countries with a high latitudinal range. Other tropical developing countries, rich in natural resources, with similar climatic characteristics may use these findings in order to assess land cover, understand the variables promoting land cover change and support sustainable development.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}