Integration of Satellite Imagery, Topography and Human Disturbance Factors Based on Canonical Correspondence Analysis Ordination for Mountain Vegetation Mapping: A Case Study in Yunnan, China


Abstract
:
1. Introduction
- ➢ To quantify the relationships between vegetation SDP and topography and human disturbance attributes by using ordination analysis;
- ➢ To map mountain vegetation by integrating ordination models into remote sensing (Landsat Thematic Mapper) image analysis;
- ➢ To test the effectiveness of this mapping approach by evaluating its accuracy against two alternative classification strategies: (1) ordinary image classification without ancillary information (null model); and (2) classification with a DEM as extra input channel; and finally;
- ➢ To determine whether the significant differences of the two mountain zones are determinant in the outcomes of the experimental procedures.
2. Material and Methods
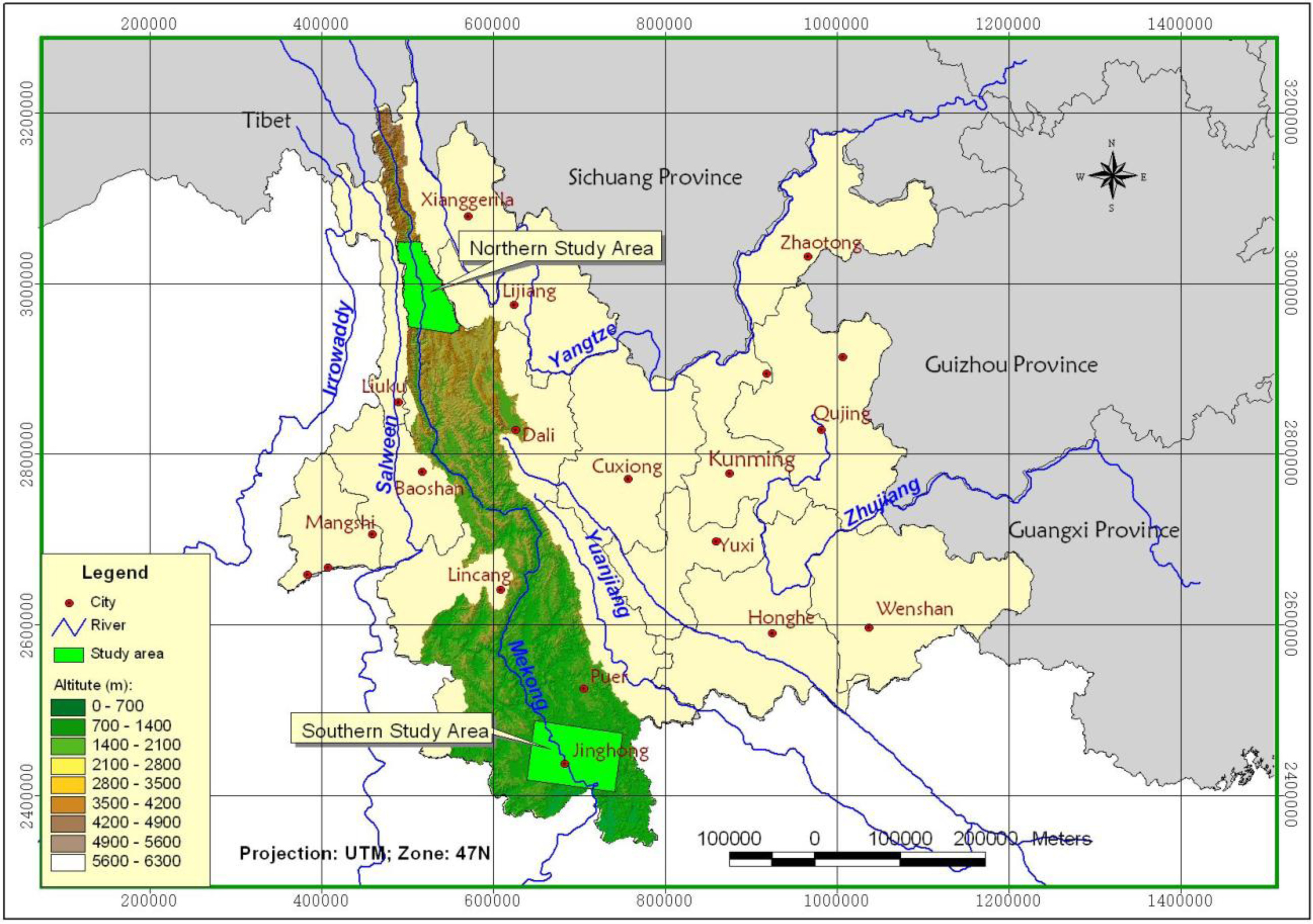
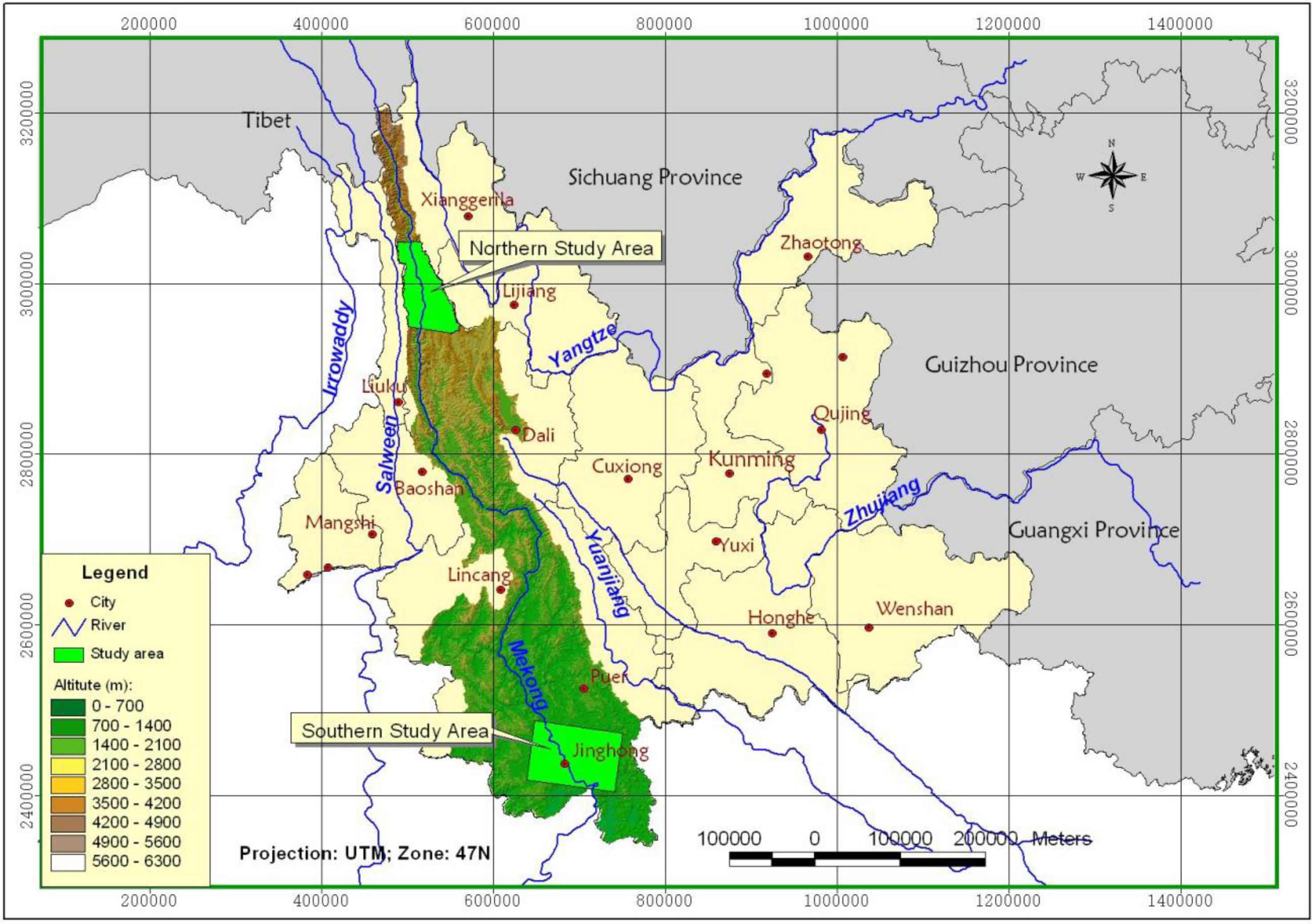
2.1. Study Area
2.2. Software
2.3. Data
2.3.1. Image Data
2.3.2. Vegetation Data
2.3.3. DEM, Topographic Maps and Derived Attributes
2.3.4. Human Disturbance Factors
2.3.5. Training and Validation Data
2.3.6. Classification Algorithm Selection
2.4. Methods
2.4.1. Outline
Stage 1: Ordination Analysis
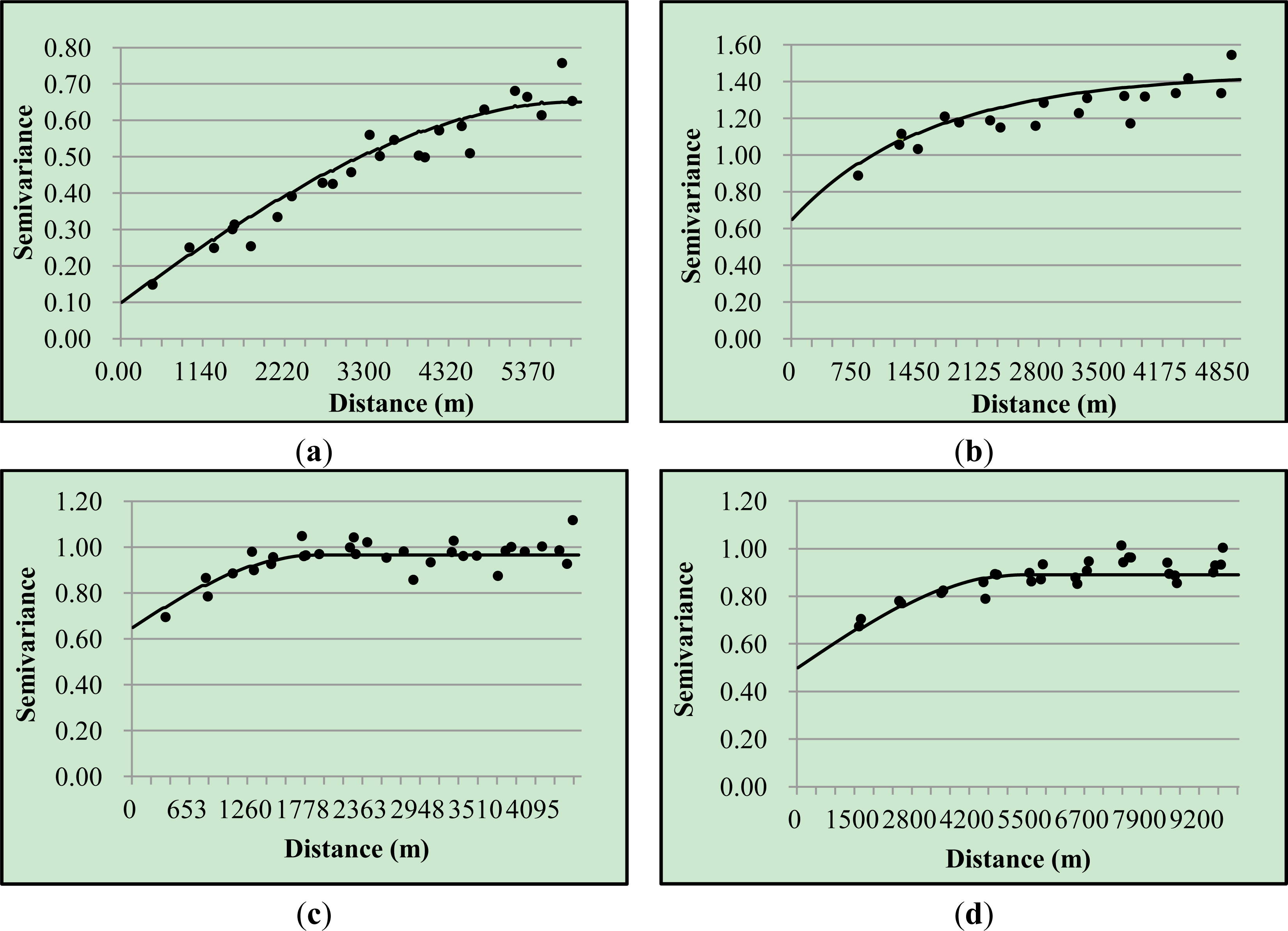
Stage 2: Spatial Interpolation of CCA Axes Scores
Stage 3: Image Classification
2.4.2. Accuracy Assessment
3. Results
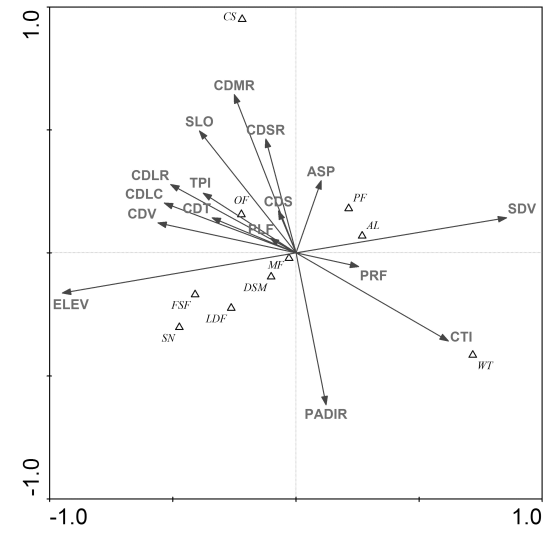
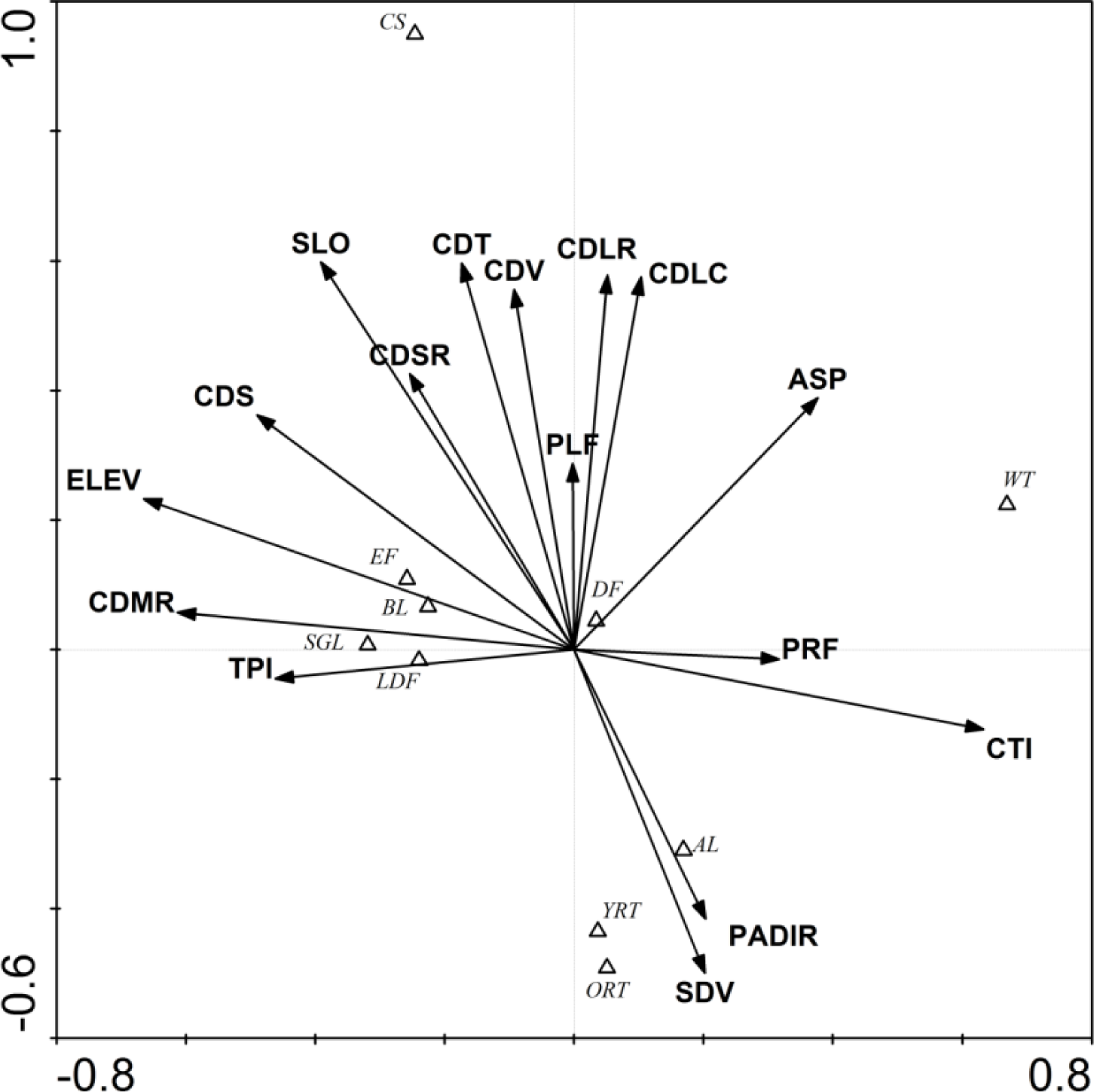
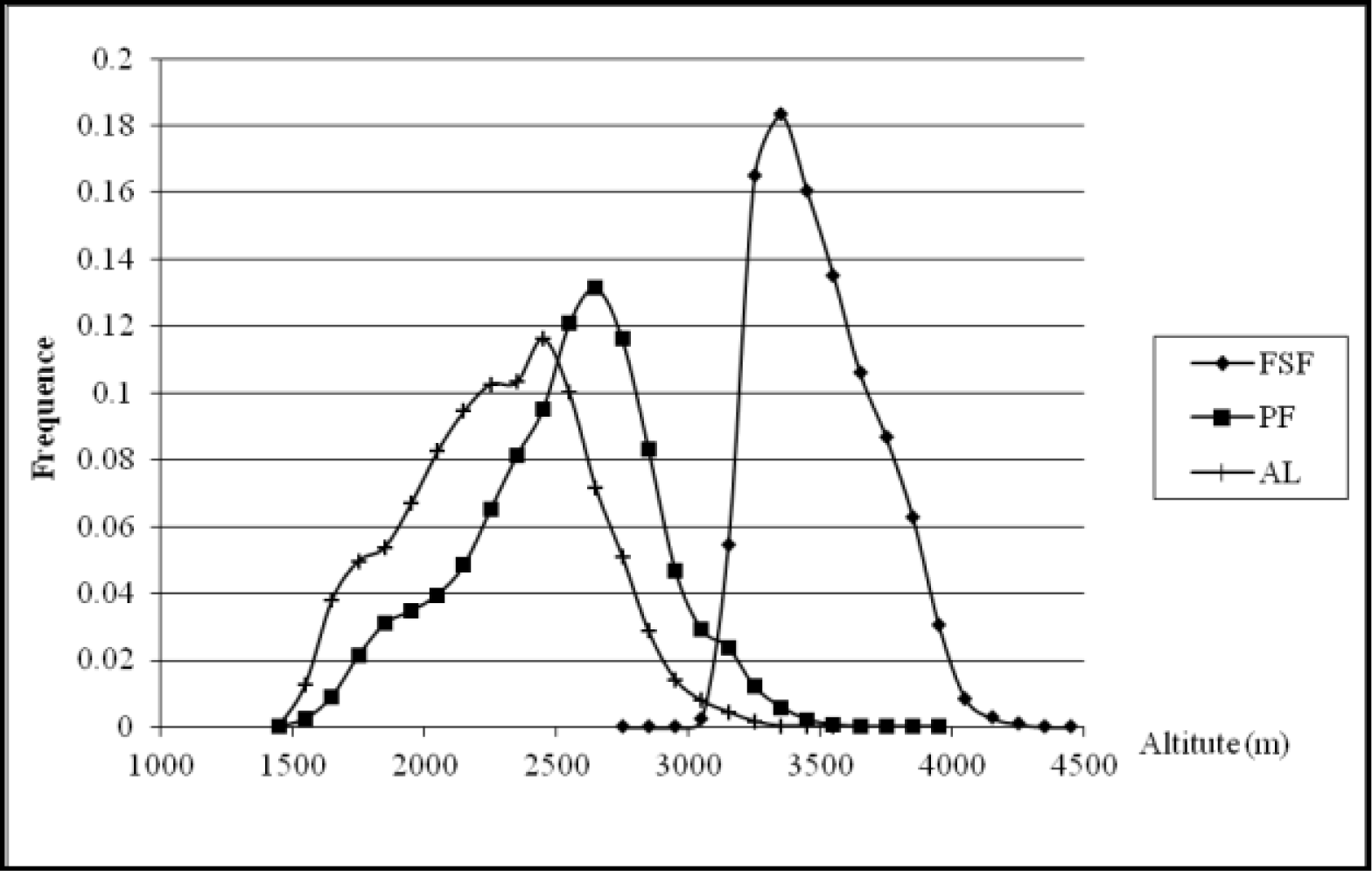
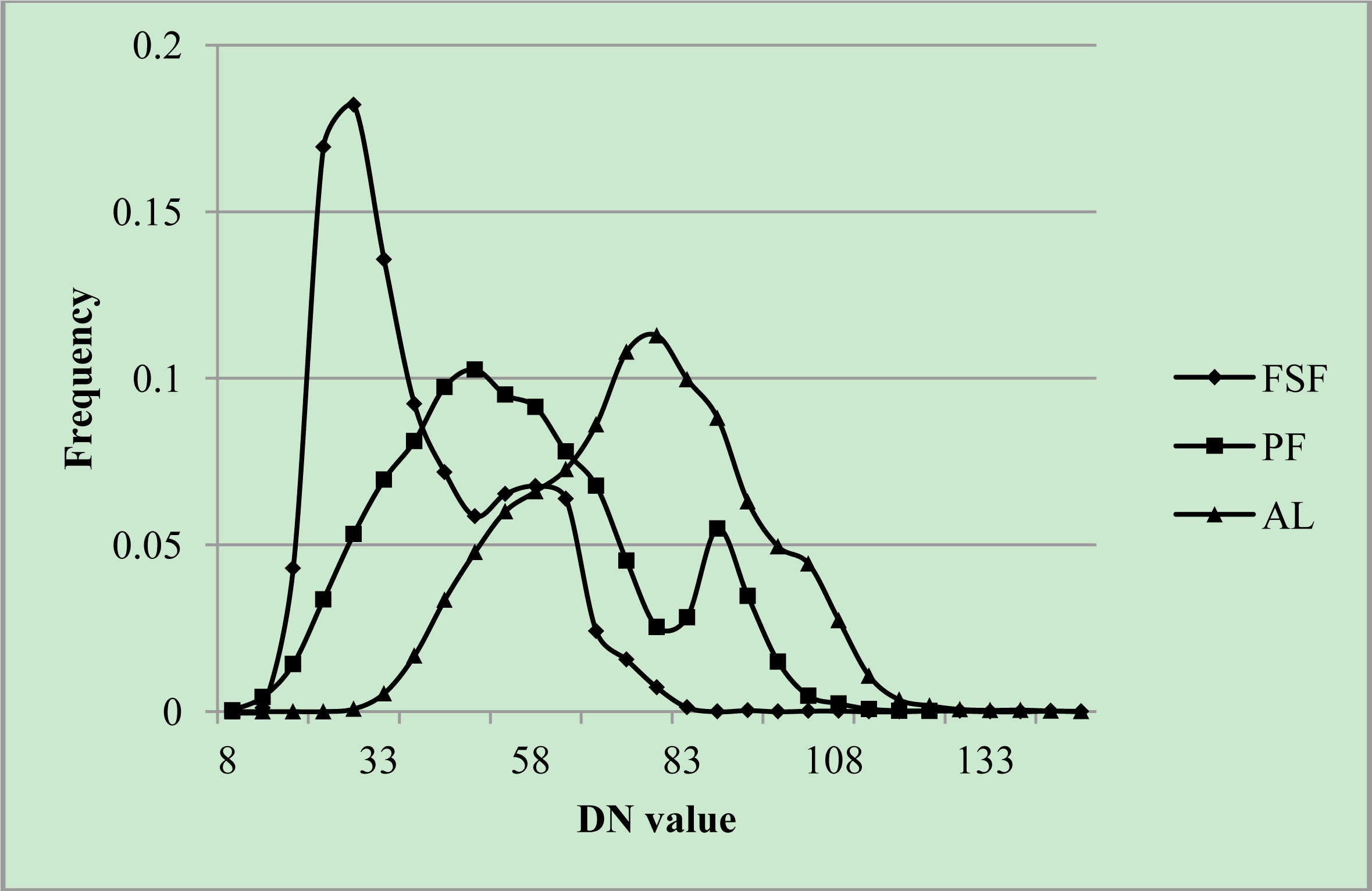
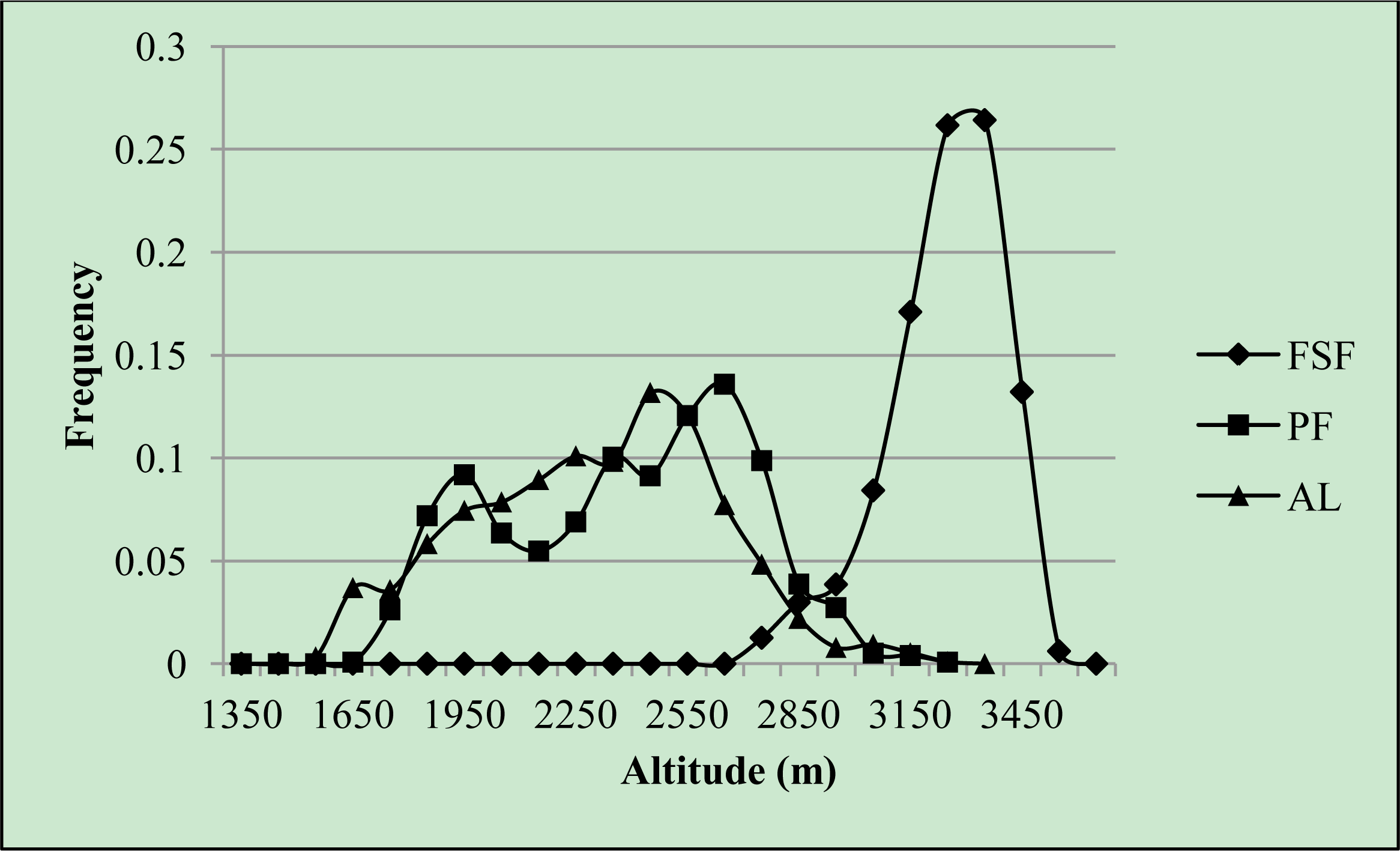
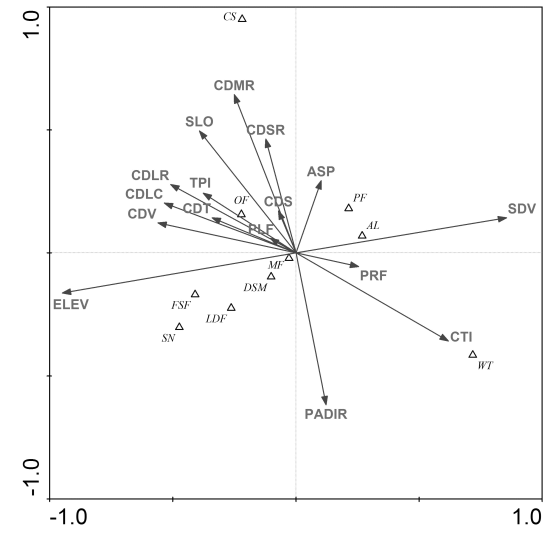
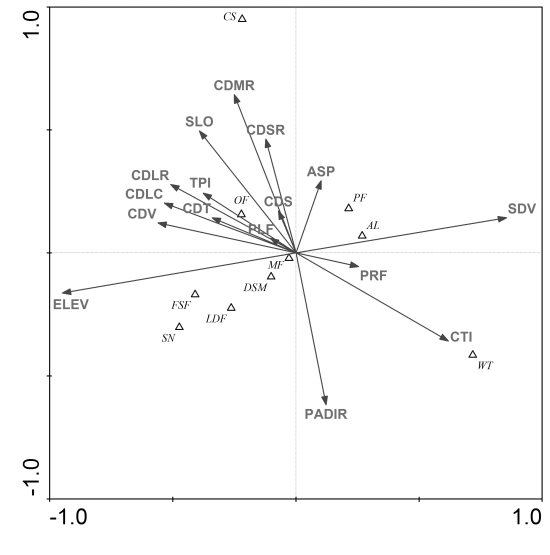
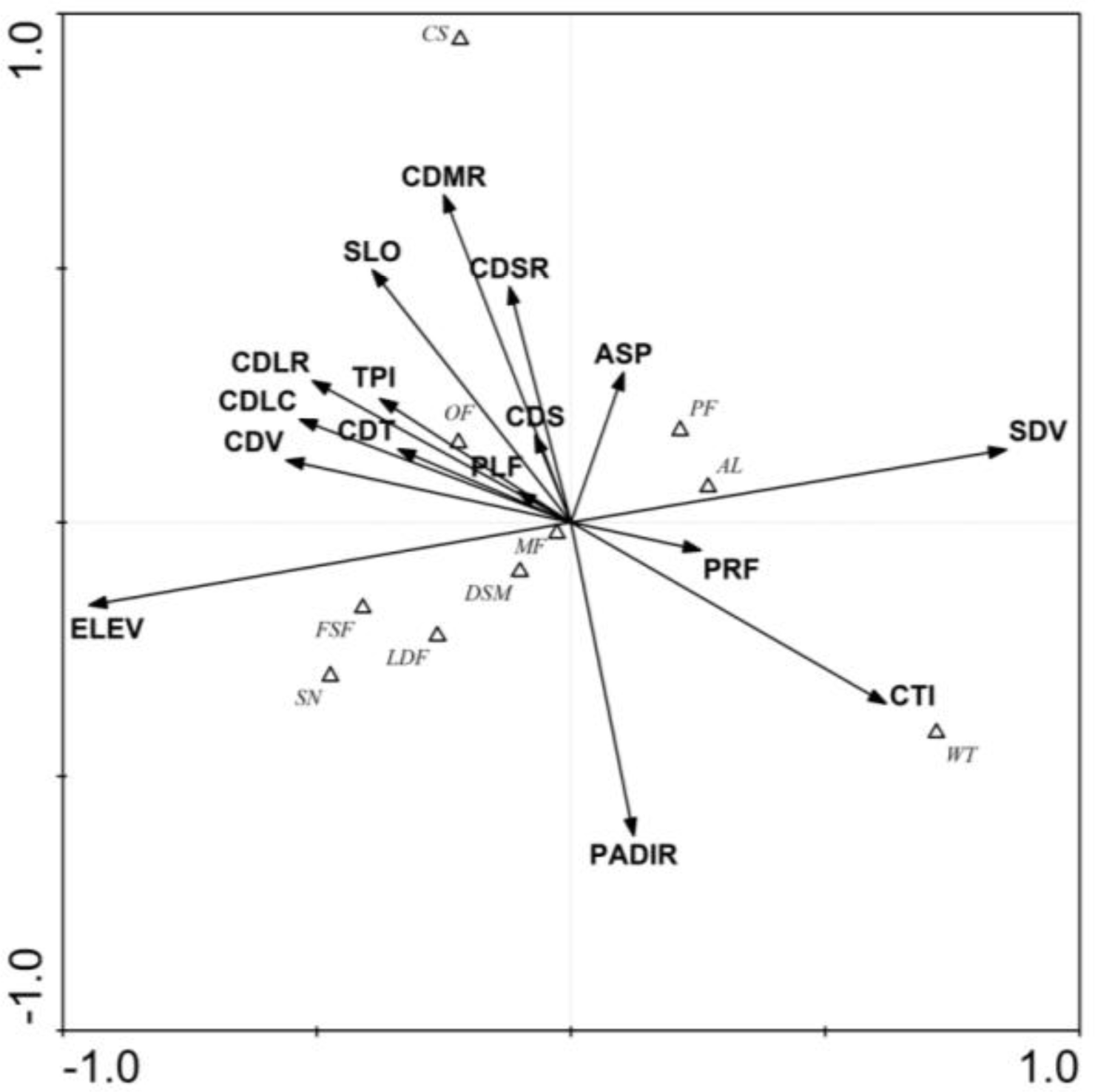
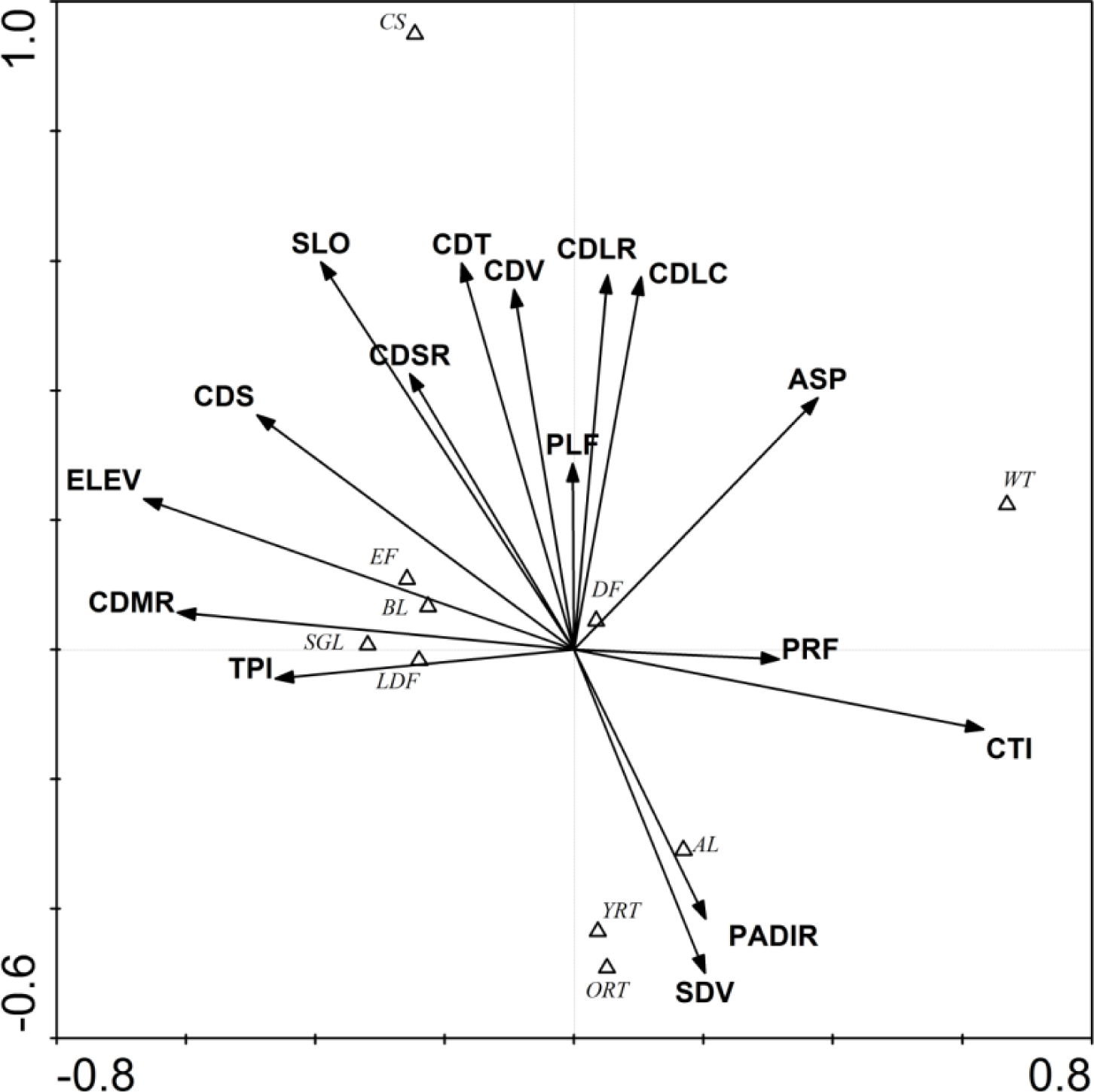
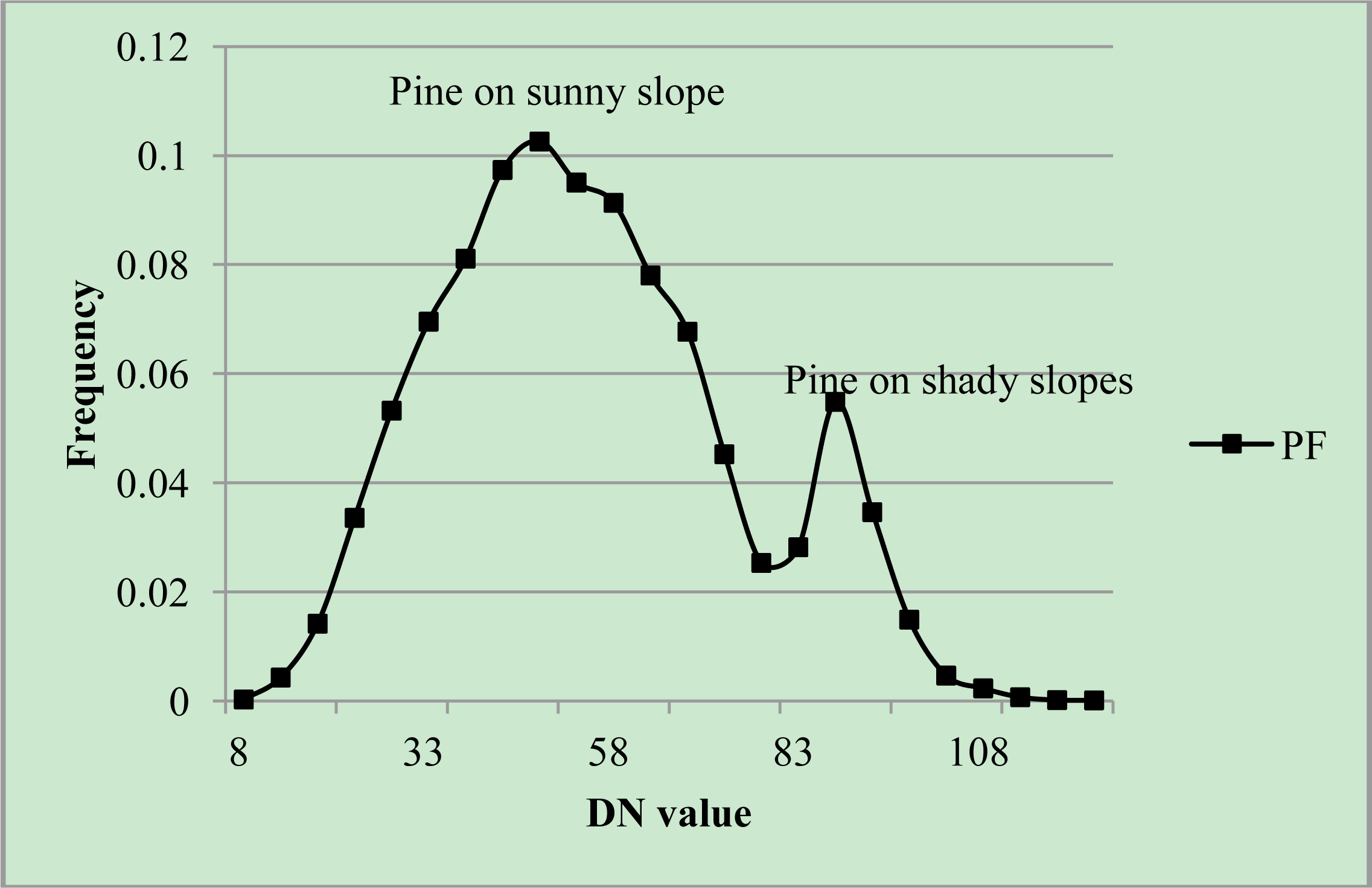
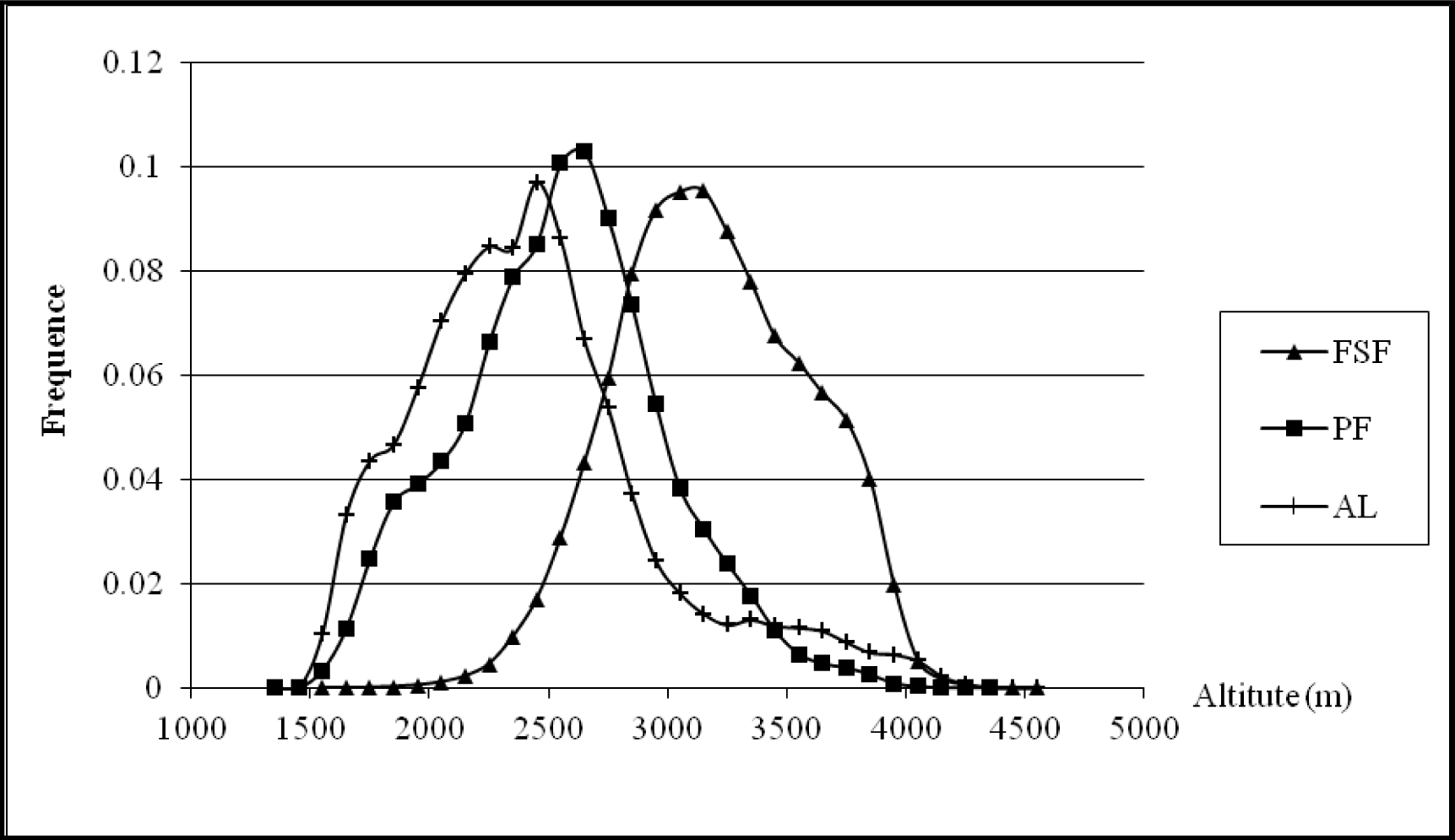
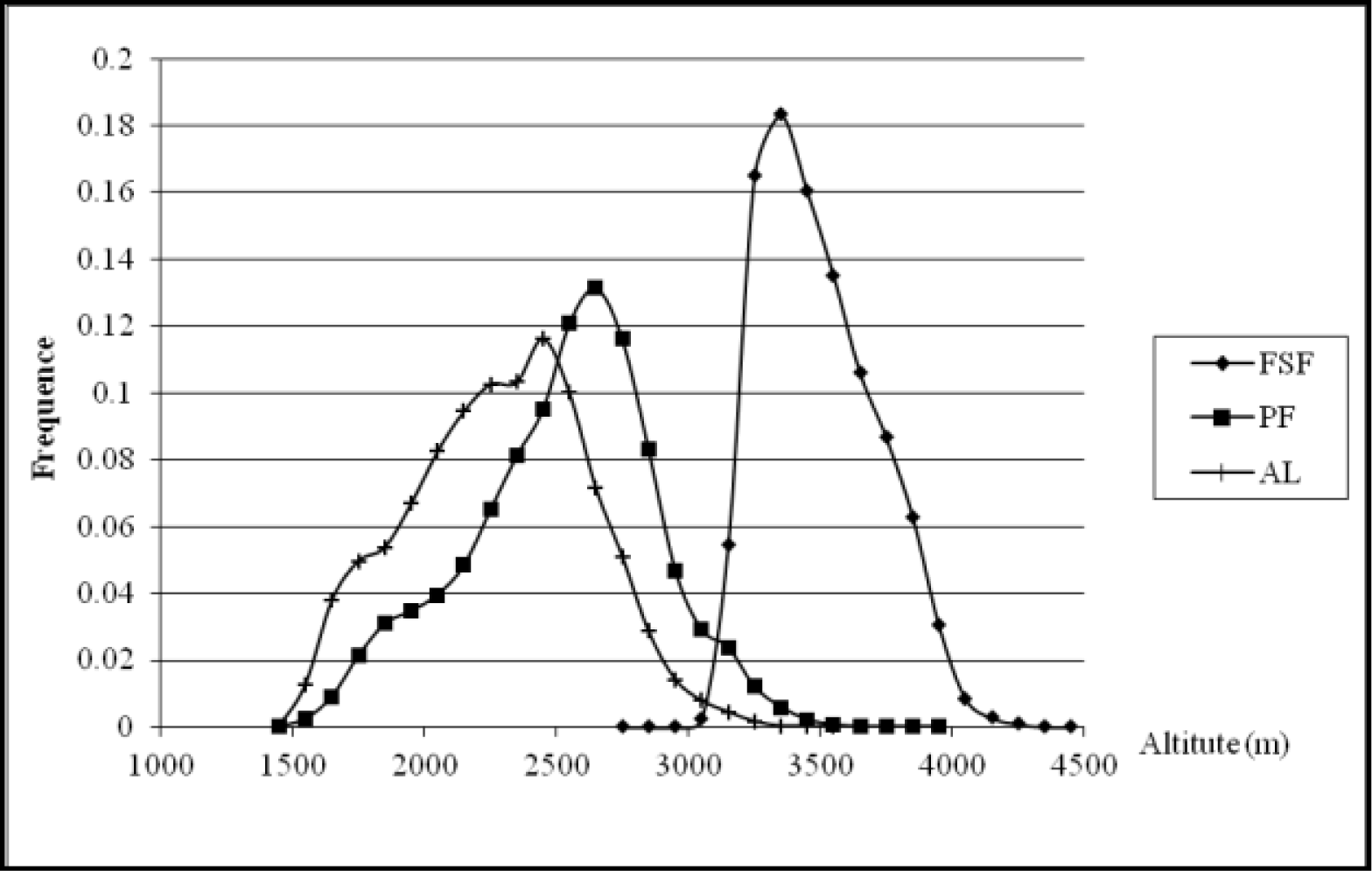
3.1. Ordination Results
3.2. Image Classification
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Itten, K.I.; Meyer, P. Geometric and radiometric correction of TM-data of mountainous forested areas. IEEE Trans. Geosci. Remote Sens 1992, 31, 764–770. [Google Scholar]
- Gu, D.; Gillespie, A.R.; Adams, J.B.; Week, R. A statistical approach for topographic correction of satellite images by using spatial context information. IEEE Trans. Geosci. Remote Sens 1999, 37, 236–246. [Google Scholar]
- Dymond, C.C.; Johnson, E.A. Mapping vegetation spatial patterns from modeled water, temperature and solar radiation gradients. ISPRS J. Photogramm. Remote Sens 2002, 57, 69–85. [Google Scholar]
- Cantón, Y.; Barrio, G.D.; Solé-Benet, A.; Lázaro, R. Topographic controls on the spatial distribution of ground cover in the Tabernas badlands of SE Spain. Catena 2004, 55, 341–365. [Google Scholar]
- Deng, Y.X.; Chen, X.F.; Chuvieco, E.; Warner, T.; Wilson, J.P. Multi-scale linkages between topographic attributes and vegetation indices in a mountainous landscape. Remote Sens. Environ 2007, 111, 122–134. [Google Scholar]
- Brown, D.G. Predicting vegetation types at treeline using topographic and biophysical disturbance variables. J. Veg. Sci 1994, 5, 641–656. [Google Scholar]
- Crave, E.; Gascuel-Odoux, C. The influence of topography on time and space distribution of soil surface water content. Hydrol. Process 1997, 11, 203–210. [Google Scholar]
- Gómez-Plaza, A.; Martínez-Mena, M.; Alvadalejo, J.; Castillo, V.M. Factors regulating spatial distribution of soil water content in small semiarid catchments. J. Hydrol 2001, 253, 211–226. [Google Scholar]
- Western, A.W.; Grayson, R.B.; Blöschl, G.; Willgoose, G.R.; McMahon, T.A. Observed spatial organization of soil moisture and its relation to terrain indices. Water Resour. Res 1999, 35, 797–810. [Google Scholar]
- Frank, T.D. Mapping dominant vegetation communities in the Colorado Rocky Mountain front range with Landsat Thematic Mapper and digital terrain data. Photogramm. Eng. Remote Sens 1988, 54, 1727–1734. [Google Scholar]
- Smith, J.A.; Lin, T.L.; Ranson, K.J. The Lambertian assumption and Landsat data. Photogramm. Eng. Remote Sens 1980, 46, 1183–1189. [Google Scholar]
- Civco, D.L. Topographic normalization of Landsat Thematic Mapper digital imagery. Photogramm. Eng. Remote Sens 1989, 55, 1303–1309. [Google Scholar]
- Gu, D.; Gillespie, A. Topographic normalization of Landsat TM images of forest based on subpixel sun-canopy-sensor geometry. Remote Sens. Environ 1998, 64, 166–175. [Google Scholar]
- Dymond, J.R; Shepherd, J.D. Correction of the topographic effect in remote sensing. IEEE Trans. Geosci. Remote Sens 1999, 37, 2618–2610. [Google Scholar]
- Gao, Y.; Zhang, W. A simple empirical topographic correction method for ETM+ imagery. Int. J. Remote Sens 2009, 30, 2259–2275. [Google Scholar]
- Soenen, S.A.; Peddle, D.R.; Cobure, C.A. SCS + C: A modified sun-canopysensor topographic correction in forested terrain. IEEE Trans. Geosci. Remote Sens 2005, 43, 2148–2159. [Google Scholar]
- Soenen, S.A.; Peddle, D.R.; Cobure, C.A.; Hall, R.J.; Hall, F.G. Improved topographic correction of forest image data using a 3-D canopy reflectance model in multiple forward mode. Int. J. Remote Sens 2008, 29, 1007–1027. [Google Scholar]
- Huang, H.; Gong, P.; Clinton, N.; Hui, F. Reduction of atmospheric and topographic effect on Landsat TM data for forest classification. Int. J. Remote Sens 2008, 29, 5623–5642. [Google Scholar]
- Cuo, L.; Vogler, J.B.; Fox, J.M. Topographic normalization for improving vegetation classification in a mountainous watershed in Northern Thailand. Int. J. Remote Sens 2010, 31, 3037–3050. [Google Scholar]
- Reese, H.; Olsson, H. C-correction of optical satellite data over alpine vegetation areas: A comparison of sampling strategies for determining the empirical c-parameter. Remote Sens. Environ 2011, 115, 1387–1400. [Google Scholar]
- Teillet, P.M.; Guindon, B.; Goodenough, D.G. On the slope-aspect correction of multispectral scanner data. Can. J. Remote Sens 1982, 8, 84–106. [Google Scholar]
- Hutchinson, C.F. Techniques for combining Landsat and ancillary data for digital classification improvement. Photogramm. Eng. Remote Sens 1982, 48, 123–130. [Google Scholar]
- Elummoh, A.; Shrestha, R.P. Application of DEM data to Landsat image classification: Evaluation in a tropical wet-dry landscape of Thailand. Photogramm. Eng. Remote Sens 2000, 66, 297–304. [Google Scholar]
- Dorren, L.K.A.; Maier, B.; Sejimonsbergen, A.C. Improved Landsat-based forest mapping in steep mountainous terrain using object-based classification. For. Ecol. Manag 2003, 183, 31–46. [Google Scholar]
- Wulder, M.A.; Franklin, S.E.; White, J.C.; Cranny, M.C.; Dechka, J.A. Inclusion of topographic variables in an unsupervised classification of satellite imagery. Can. J. Remote Sens 2004, 30, 137–149. [Google Scholar]
- Liu, Q.J.; Takamura, T.; Takeuchi, N. Mapping of boreal vegetation of a temperate mountain in China by multitemporal Landsat TM imagery. Int. J. Remote Sens 2002, 23, 3385–3405. [Google Scholar]
- Brown, D.C.E.C.; Story, M.H.; Thompson, C.C.K.; Timothy, G.S.; James, R.I. National park vegetation mapping using multitemporal Landsat 7 data and a decision tree classifier. Remote Sens. Environ 2003, 85, 316–327. [Google Scholar]
- Ren, G.; Zhu, A.; Wang, W.; Xiao, W.; Huang, Y.; Li, G.; Li, D.; Zhu, J. A hierarchical approach coupled with coarse DEM information for improving the efficiency and accuracy of forest mapping over very rugged terrains. For. Ecol. Manag 2009, 258, 26–34. [Google Scholar]
- Mather, P.M. A computationally-efficient maximum-likelihood classifier employing prior probabilities for remotely-sensed data. Int. J. Remote Sens 1985, 6, 369–376. [Google Scholar]
- Maselli, F.; Conese, C.; Petkov, L.; Resti, R. Inclusion of prior probabilities derived from a nonparametric process into the maximum likelihood classifier. Photogramm. Eng. Remote Sens 1992, 58, 833–839. [Google Scholar]
- Maselli, F.; Conese, C.; de Tiziana, F.; Maurizio, R. Integration of ancillary data into a maximum-likelihood classifier with nonparametric priors. ISPRS J. Photogramm. Remote Sens 1995, 50, 2–11. [Google Scholar]
- Foody, G.M.; Campbell, N.A.; Trodd, N.M.; Wood, T.F. Derivation and applications of probabilistic measures of class membership from the maximum-likelihood classification. Photogramm. Eng. Remote Sens 1992, 58, 1335–1341. [Google Scholar]
- McIver, D.K.; Friedl, M.A. Using prior probabilities in decision-tree classification of remotely sensed data. Remote Sens. Environ 2002, 81, 253–261. [Google Scholar]
- Zhang, Z.; de Clercq, E.M.; Ou, X.; de Wulf, R.R.; Verbeke, L.P.C. Mapping dominant communities vegetation in Meili Snow Mountain, Yunnan Province, China using satellite imagery and plant community data. Geocarto Int 2008, 23, 135–153. [Google Scholar]
- Pfeffer, K.; Pebesma, E.J.; Burrough, P.A. Mapping alpine vegetation using vegetation observation and topographic attributes. Landsc. Ecol 2003, 18, 759–776. [Google Scholar]
- Turner, M.G.; Gardner, R.H.; O’Neill, R.V. Landscape Ecology in Theory and Practice: Pattern and Process; Springer: New York, NY, USA, 2001. [Google Scholar]
- Hörsch, B. Modeling the spatial distribution of montane and subalpine forests in the central Alps using digital elevation models. Ecol. Model 2003, 168, 267–282. [Google Scholar]
- Farina, A. Emerging Processes in the Landscape. In Principles and Methods in Landscape Ecology, 3rd ed; Springer: Dordrecht, The Netherlands, 2006; pp. 110–128. [Google Scholar]
- Sherman, R.; Mullen, R.; Li, H.; Fang, Z.D.; Wang, Y. Spatial patterns of plant diversity and communities in alpine ecosystems of the Hengduan Mountains, northwest Yunnan, China. Plant Ecol 2008, 1, 117–136. [Google Scholar]
- Ohmann, J.; Spies, T.A. Regional gradient analysis and spatial pattern of woody plant communities of Oregon forests. Ecol. Monogr 1998, 68, 151–182. [Google Scholar]
- Begon, M.; Townsend, C.R.; Happer, J.L. The Nature of the Community: Patterns in Space and Time. In Ecology—from Individuals to Ecosystems, 4th ed; Blackwell: Malden, MA, USA, 2006; pp. 469–498. [Google Scholar]
- Gauch, H.G.J. Multivariate Analysis in Community Ecology; Cambridge University Press: Cambridge, UK, 1982. [Google Scholar]
- Thomas, V.; Treitz, P.; Dennis, J.; John, M.; Peter, L.; McCaughey, H.J. Image classification of a northern peatland complex using spectral and plant community data. Remote Sens. Environ 2002, 84, 83–89. [Google Scholar]
- Bio, A.M.F. Does Vegetation Suit Our Models? Data and Model Assumptions and the Assessment of Species Distribution in Space, Faculty of Geographic Science, Utrecht, The Netherlands, 2000; p. 195. [Google Scholar]
- Dirnböck, T.; Dullinger, S.; Gottfried, M.; Ginzler, C.; Grabherr, G. Mapping alpine vegetation based on image analysis, topographic variables and Canonical correspondence analysis. Appl. Veg. Sci 2003, 6, 85–96. [Google Scholar]
- Franklin, J.; Woodcock, C.E. Multiscale Vegetation Data for the Mountains of Southern California: Spatial and Categorical Resolution. In Scale in Remote Sensing and GIS; Quattorchi, D.A., Goodchild, M.F., Eds.; CRC-Lewis Publishers: Boca Raton, FL, USA, 1997; pp. 141–171. [Google Scholar]
- Dirnböck, T.; Hobbs, R.J.; Caccetta, P.A. Vegetation distribution in relation to topographically driven process in south-western Australia. Appl. Veg. Sci 2002, 5, 147–158. [Google Scholar]
- Guisan, A.; Zimmermann, N.E. Predictive habitat distribution models in ecology. Ecol. Model 2000, 135, 147–168. [Google Scholar]
- Horning, N.; Robinson, J.A.; Sterling, E.J.; Turner, W.; Spector, S. Measuring and Monitoring Land Cover, Land Use, and Vegetation Characteristics. In Remote Sensing for Ecology and Conservation; Oxford University Press: Oxford, UK, 2010; pp. 81–119. [Google Scholar]
- Pu, Y.S; Zhang, Z.Y. A strategic study on biodiversity conservation in Xishuangbanna. J. For. Res 2001, 12, 25–30. [Google Scholar]
- Anderson, D.M.; Salick, J.; Moseley, R.K.; Ou, X. Conserving the sacred medicine mountains: A vegetation analysis of Tibetan sacred sites in Northern Yunnan. Biodivers. Conserv 2005, 14, 3065–3091. [Google Scholar]
- Mittermeier, R.A.; Myers, N.; Thomsen, J.B.; Fonseca, G.A.B.D.; Olivieri, S. Biodiversity hotspots and major tropical wilderness areas. Conserv. Biol 1998, 12, 516–520. [Google Scholar]
- Salick, J.; Amend, A.; Anderson, D.; Hoffmeister, K.; Gunn, B.; Fang, Z. Tibetan sacred sites conserve old growth trees and cover in the eastern Himalayas. Biodivers. Conserv 2007, 16, 693–706. [Google Scholar]
- Deng, M.; Zhang, P.; Zhao, B.; Wang, Y. The Forest in Lanping Pumi Autonomous County; Yuannan Ethnic Press: Kunming, China, 1997. (In Chinese) [Google Scholar]
- Verbeke, L.P.C.; Vancoillie, F.M.B.; de Wulf, R.R. Reusing back-propagation artificial neural networks for land cover classification in tropical savannahs. Int. J. Remote Sens 2004, 25, 2747–2771. [Google Scholar]
- Gitas, Z.; Devereux, B.J. The role of topographic correction in mapping recently burned Mediterranean forest areas from Landsat TM images. Int. J. Remote Sens 2006, 27, 41–54. [Google Scholar]
- Zhang, Z.; de Wulf, R.R.; van Coillie, F.M.B.; Verbeke, L.P.C.; de Clercq, E.M.; Ou, X. The influence of different topographic correction strategies on vegetation classification accuracy in the Lancang watershed, China. J. Appl. Remote Sens 2011, 5. [Google Scholar] [CrossRef]
- Wilson, J.P.; Gallant, J.C. Terrain Analysis Principles and Applications; John Wiley and Sons: New York, NY, USA, 2000. [Google Scholar]
- Pinder, J.E.; Kroh, G.C.; White, J.D.; Basham May, A.M. The relationship between vegetation types and topography in Lassen Volcanic National Park. Plant Ecol 1997, 131, 17–29. [Google Scholar]
- Zhang, Z.; Wang, W.; Ou, X.; Wu, W. The correlation between vegetation spatial pattern and environmental factors in Meili Snow Mountain, China. J. Yunnan Univ 2009, 31, 311–315. (In Chinese) [Google Scholar]
- Shen, Z.; Zhang, X. The spatial pattern and topographic interpretation of the forest vegetation at Dalaoling Region in the Three Gorges. Acta Bot. Sin 2000, 42, 1089–1095. (In Chinese) [Google Scholar]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modeling: A review of hydrological, geomorphological, and biological application. Hydrol. Process 1991, 5, 3–30. [Google Scholar]
- Jenness, J. Topographic Position Index ( tpi_jen.avx) Extension for ArcView 3.x, v. 1.3a. Jenness Enterprises, 2006. Available online: http://www.jennessent.com/arcview/tpi.htm (accessed on 18 July 2007).
- Shen, Z.; Zhang, X.; Jin, X. Gradient analysis of the influence of mountain topography on vegetation pattern. Acta Phytoecol. Sin 2000, 24, 430–435. (In Chinese) [Google Scholar]
- McCune, B.; Keon, D. Equations for potential annual direct incident radiation and heat load. J. Veg. Sci 2002, 13, 603–606. [Google Scholar]
- Serneels, S.; Lambin, E.F. Proximate causes of land-use change in Narok District Kenya: A spatial statistical model. Agric. Ecosyst. Environ 2001, 85, 65–81. [Google Scholar]
- Geist, H.J.; Lambin, E.F. Proximate causes and underlying driving forces of tropical deforestation. BioScience 2002, 52, 143–150. [Google Scholar]
- Overmars, K.; Verburg, P.H. Analysis of land use drivers at the watershed and household level: Linking two paradigms at the Philippine forest fringe. Int. J. Geogr. Inf. Sci 2005, 19, 125–152. [Google Scholar]
- Mottet, A.; Ladet, S.; Coque, N.; Gibon, A. Agricultural land-use change and its drivers in mountain landscapes: A case study in the Pyrenees. Agric. Ecosyst. Environ 2006, 114, 296–310. [Google Scholar]
- McCoy, J.; Johnston, K. Using ArcGIS’ Spatial Analyst; ESRI Press: Redlands, CA, USA, 2001. [Google Scholar]
- Long, H.L.; Liu, Y.S.; Wu, X.Q.; Dong, G.H. Spatial-temporal dynamic patterns of farmland and rural settlements in Su-Xi-Chang region: Implications for building a new countryside in coastal China. Land Use Policy 2009, 26, 322–333. [Google Scholar]
- Deffontaines, J.P.; Thenail, C.; Baudry, J. Agricultural systems and landscape patterns: How can we build a relationship. Landsc. Urban Plann 1995, 31, 3–10. [Google Scholar]
- Nagendra, H.; Southworth, J.; Tucker, C. Accessibility as adeterminant of landscape transformation in western Honduras: Linking pattern and process. Landsc. Ecol 2003, 18, 141–158. [Google Scholar]
- Aspinall, R. Modelling land use change with generalized linear models—A multi-model analysis of change between 1860 and 2000 in Gallatin Valley, Montana. J. Environ. Manag 2004, 72, 91–103. [Google Scholar]
- Rutherford, G.N.; Bebi, P.; Edwards, P.J.; Zimmermann, N.E. Assessing land-use statistics to model land cover change in a mountainous landscape in the European Alps. Ecol. Model 2008, 212, 460–471. [Google Scholar]
- Foltête, J.C.; Berthier, K.; Cosson, J.F. Cost distance defined by a topological function of landscape. Ecol. Model 2008, 210, 104–114. [Google Scholar]
- Schneider, K.; Robbins, P. Exercise 3: Modeling Access to Health Care: Anisotropic Cost Distance. Exploration in Geographic Information Systems Technology. In GIS and Mountain Environments; United Nations Institute of Training and Research, Clark University: Worcester, MA, USA, 1995; Volume 5. [Google Scholar]
- Rees, W.G. Least-cost paths in mountainous terrain. Comput. Geosci 2004, 30, 203–209. [Google Scholar]
- LaRue, M.A.; Nielsen, C.K. Modelling potential dispersal corridors for cougars in midwestern North America using least-cost path methods. Ecol. Model 2008, 212, 372–381. [Google Scholar]
- Eastman, J.R. Pushbroom algorithms for calculating distances in raster grids. Proc. Autocarto 1989, 9, 288–297. [Google Scholar]
- Lillesand, T.M.; Kiefer, R.W.; Chipman, J.W. Digital Image Processing. In Remote Sensing and Image Interpretation, 5th ed; John Wiley & Sons: New York, NY, USA, 2004; pp. 482–557. [Google Scholar]
- Atkinson, P.M.; Tatnall, A.R.L. Neural networks in remote sensing. Int. J. Remote Sens 1997, 18, 699–709. [Google Scholar]
- Mas, J.F.; Flores, J.J. The application of artificial neural networks to the analysis of remotely sensed data. Int. J. Remote Sens 2008, 29, 617–663. [Google Scholar]
- Benediktsson, J.A.; Swain, P.H.; Ersoy, O.K. Neural network approaches versus statistical methods in classification of mutisource remote sensing data. IEEE Trans. Geosci. Remote Sens 1990, 28, 540–551. [Google Scholar]
- Leps, J.; Smilauer, P. Multivariate Analysis of Ecological Data Using of CANOCO; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Parker, A.J. Comparative gradient structure and forest cover types in Lassen Volcanic and Yosemite National Parks, California. Bull. Torrey Bot. Soc 1995, 122, 58–68. [Google Scholar]
- Parker, A.J. Forest/environment relationship in Yosemite National Park, Califonia. Vegetatio 1989, 82, 41–54. [Google Scholar]
- Shen, Z. A multi-scale study on the vegetation-environment relationship of a mountain forest transect. Acta Ecol. Sin 2002, 22, 461–470. (In Chinese) [Google Scholar]
- Ter Braak, C.J.F.; Šmilauer, P. CANOCO Reference Manual and CanoDraw for Windows User’s Guide: Software for Canonical Community Ordination (Version 4.5); Microcomputer Power: Ithaca, NY, USA, 2002; p. 500. [Google Scholar]
- Ter Braak, C.J.F. Canonical correspondence analysis: A new eigenvector technique for multivariate direct gradient analysis. Ecology 1986, 67, 1167–79. [Google Scholar]
- Wagner, H.H. Direct multi-scale ordination with canonical correspondence analysis. Ecology 2004, 85, 342–351. [Google Scholar]
- Legendre, P.; Legendre, L. Numerical Ecology, 2nd ed; Elsevier: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Burrough, P.A.; McDonnell, R.A. Principles of Geographical Information Systems; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Wagner, H.H. Spatial covariance in plant communities: Integrating ordination, geostatistics, and variance testing. Ecology 2003, 84, 1045–1057. [Google Scholar]
- Johnston, K.; ver Hoef, J.M.; Krivoruchko, K.; Lucas, N. Using ArcGIS’ Geostatistical Analyst; ESRI Press: Redlands, CA, USA, 2001. [Google Scholar]
- Webster, R.; Oliver, M.A. Geostatistics for Environmental Scientists, 2nd ed; John Wiley & Sons: New York, NY, USA, 2007. [Google Scholar]
- Cressie, N. Statistics for Spatial Data, Revised ed; John Wiley & Sons: New York, NY, USA, 1993; p. 900. [Google Scholar]
- Guillemette, N.; St-Hilaire, A.; Ouarda, T.B.M.J.; Bergeron, N.; Robichaud, É.; Bilodeau, L. Feasibility study of a geostatistical modelling of monthly maximum stream temperatures in a multivariate space. J. Hydrol 2009, 364, 1–12. [Google Scholar]
- Dayhoof, J.E. Neural Network Architectures; Van Nostrand Reinhold: New York, NY, USA, 1990. [Google Scholar]
- Zhang, Z.; Verbeke, L.P.C.; de Clercq, E.M.; Ou, X.; de Wulf, R.R. Vegetation change detection using artificial neural networks with ancillary data in Xishuangbanna, Yunnan Province, China. Chin. Sci. Bull 2007, 52, 232–243. [Google Scholar]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices; Lewis Publisher: Boca Raton, FL, USA, 1999. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas 1960, 1, 37–40. [Google Scholar]
- Congalton, R.G.; Oderwald, R.G.; Mead, R.A. Assessing Landsat classification accuracy using discrete multivariate analysis statistical techniques. Photogramm. Eng. Remote Sens 1983, 46, 1671–1678. [Google Scholar]
- Van Coillie, F. Design and Application of Artificial Neural Networks for Digital Image Classification of Tropical Savanna Vegetation, Ghent University, Ghent, Belgium, 2003.
- Schowengerdt, R.A. Thematic Classification. In Remote Sensing, Models and Methods for Image Processing, 3rd ed; Academic Press: New York, NY, USA, 2007; pp. 387–455. [Google Scholar]
- Fahsi, A.; Tsegaye, T.; Tadesse, W.; Coleman, T. Incorporation of digital elevation models with Landsat-TM data to improve land cover classification accuracy. For. Ecol. Manag 2000, 128, 57–64. [Google Scholar]
- Yunnan Statistic Bureau. Yunnan Statistical Yearbook 2004; Yunnan Statistical Press: Kunming, China, 2004. (In Chinese) [Google Scholar]
- Li, H.M.; Aide, T.M.; Ma, Y.X.; Liu, W.J.; Cao, M. Demand for rubber is causing the loss of high diversity rain forest in SW China. Biodivers. Conserv 2007, 16, 1731–1745. [Google Scholar]
- Liu, W.J.; Hu, H.B.; Ma, Y.X.; Li, H.M. Environmental and socioeconomic impacts of increasing rubber plantations in Menglun Township, southwest China. Mt. Res. Dev 2006, 26, 245–253. [Google Scholar]
- Xu, J.C.; Fox, J.; Vogler, J.B.; Zhang, P.F.; Fu, Y.S.; Yang, L.X.; Qian, J.; Leisz, S. Land-use and land-cover change and farmer vulnerability in Xishuangbanna Prefecture in Southwestern China. Environ. Manag 2005, 36, 404–413. [Google Scholar]
- Xu, J.C.; Fox, J.; Lu, X.; Podger, N.; Leisz, S.; Ai, X. Effects of swidden cultivation, state polices and customary institutions on land cover in Hani Village, Yunnan. Mt. Res. Dev 1999, 19, 123–132. [Google Scholar]
- Rerkasem, K.; Yimyam, K.; Rerkasem, B. Land use transformation in the mountainous mainland Southeast Asia region and the role of indigenous knowledge and skills in forest management. For. Ecol. Manag 2009, 257, 2035–2043. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Areas | Path/Row | Date | Sensor | Number of Classes | Number of Subclasses |
|---|---|---|---|---|---|
| Northern study area | 132-41 | 26 December 2003 | Thematic Mapper 5 | 10 | 41 |
| Southern study area | 130-45 | 1 March 2004 | Thematic Mapper 5 | 10 | 46 |
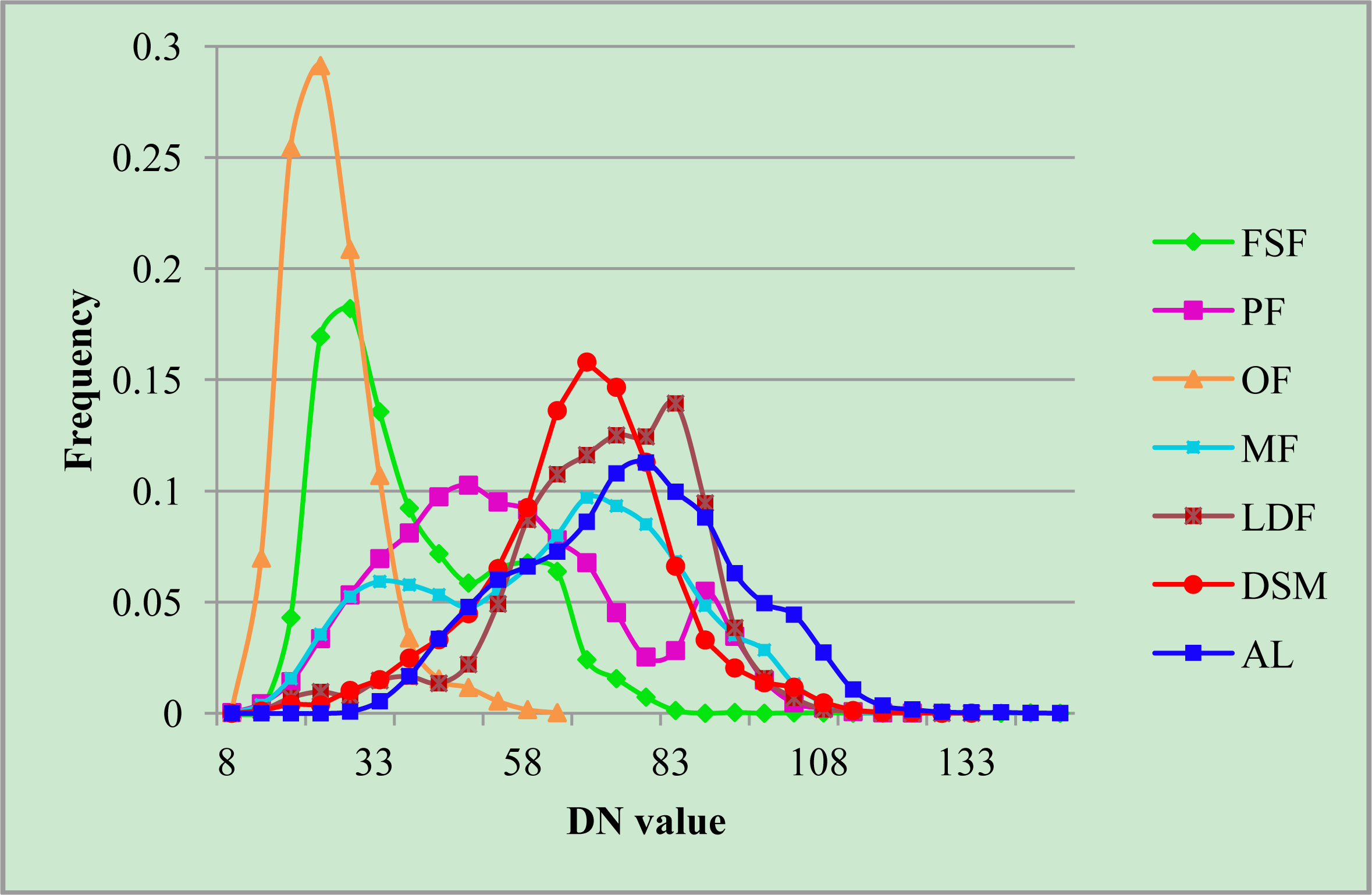
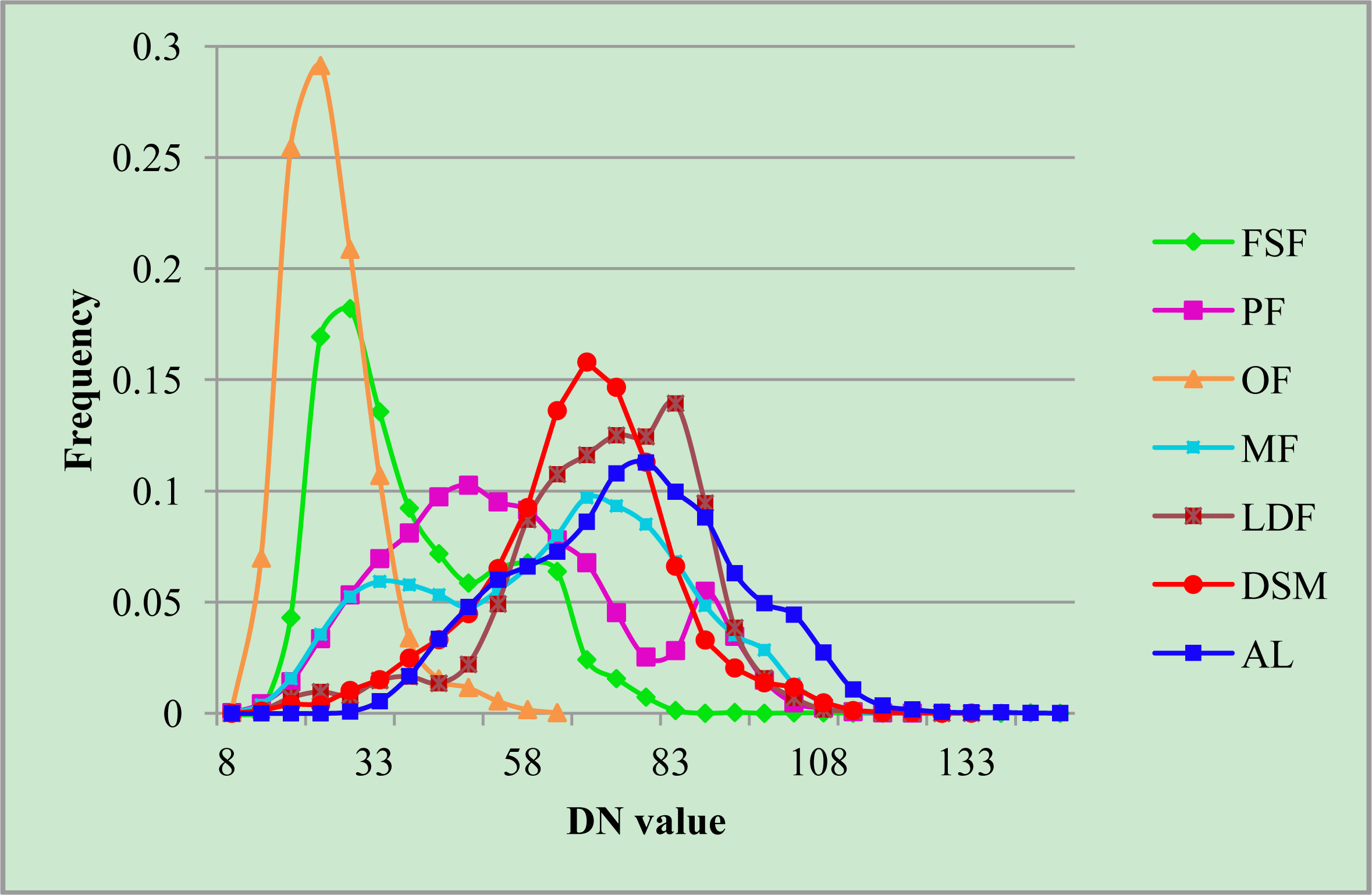
| Code | Classes | Dominant Species |
|---|---|---|
| FSF | Fir and spruce forest | Picea likiangensis, Picea brachytyla, Abies georgei, Abies georgei var. smithii, Abies forrestii, Abies ferreana. |
| PF | Pine forest | Pinus yunnanensis, Pinus densata, Pinus armandi, Corylus yunnanensis |
| OF | Oak forest | Quercus aquifolioides, Quercus gilliana, Quercus pannosa. |
| MF | Mixed forests | Pinus yunnanensis, Pinus armandii, Quercus aquifolioides, Quercus gilliana, Betula utilis, Acer cappadocicum, Acer davidii, Picea likiangensis, Picea brachytyla, Sorbus sp., Abies georgei, Pseudotsuga forrestii, Tsuga sp., Abies georgei var. smithii, Abies forrestii. |
| LDF | Low density forest and tall shrubs | Pinus yunnanensis, Salix myrtillacea, Corylus yunnanensis. |
| DSM | Dwarf shrub and meadow | Elsholtzia capituligera, Incarvillea arguta, Bauhinia brachycarpa, Rhododendron tapetiforme, Rhododendron telmateium, Rhododendron phaeochrysum, Salix annulifera, Salix hirticaulis, Salix myrtillacea, Vitex microphylla, Potentilla sp., Polystichum sp., Juncus sp., Carex sp., Poa sp., Plantago sp., Heleocharis yokoscensis, Polygonum lapathifolium, Polygonum calostachyum. |
| AL | Agricultural land | Juglans sp., Zea mays L. |
| SN | Snow | |
| WT | Water | |
| CS | Cast shadow |
| Code | Classes | Dominant Species |
|---|---|---|
| ORT | Old rubber trees | Hevea brasiliensis |
| YRT | Young rubber trees | Hevea brasiliensis |
| EF | Evergreen forest | Cyclobalanopsis delavayi, Castanopsis hystrix, Castanopsis mekongensis, Lithocarpus truncatus, Litsea glutinosa, Actinodaphne henryi, Schima wallichii, Syzygium yunnanensis, Elaeocarpus austro-yunnanensis, Paramichelia baillonii, Engelhardtia sp. Machilus salicina, Symplocos cochinchinensis, Olea rosea, Aporusa sp. Pinus khasya var. langbianensis, Lithocarpus sp. Quercus dentata, Betula alnoides, Quercus acutissima, Cyclobalanopsis kerrii, Quercus variabilis. |
| LDF | Low density forest and tall shrubs | Pinus khasya var. langbianensis, Pyrus pashia, Phoebe minutiflora, Myrica esculenta, Colona floribunda and Vaccinium bracteatum. |
| DF | Deciduous forest | Ficus altissima, Toona sinensis, Nephelium chryseum, Altingia excelsa, Bischofia javanica, Colona floribunda, Bombax ceiba, Erythrina stricta, Bauhinia variegata, Dendrocalamus strictus, D. brandisii, Cephalostachyum pergracile, Indosasa sinica, Schizostachyum funghomii, and Dinochloa puberula. |
| SGL | Shrub and grass land | Trema orientalis, Dalbergia obtusifolia, Docynia indica, Eurya groffii, Saccharum sinense, Leucosceptrum canum, Eupatorium coelestinum. |
| AL | Agricultural land | |
| BL | Burned land | |
| WT | Water | |
| CS | Cloud and shadow | |
| Code | Factors | Descriptions |
|---|---|---|
| ELEV | Elevation | Elevation is one of most important topographic factors in regulating mountain vegetation patterns [39,59,60]. |
| SLO | Slope | Slope also is one of important topographic factors for mountain vegetation patterns because it will influence features such as soil moisture, wind, and solar radiation [37,59–61]. |
| ASP | Aspect | Vegetation spatial distribution can be affected by slope aspect [3,4,59]. |
| PRF | Slope profile curvature | This index measures the rate of change of potential gradient and hence is important for characterizing changes in flow velocity and sediment transport processes [58]. It also potentially indicates soil moisture [37]. |
| PLF | Planiform curvature | This index is related to converging/diverging flow and soil water content [62]. |
| TPI | Topographic position index | Topographic position index is the basis of the topography classification system and is simply the difference between a cell elevation value and the average elevation of the neighborhood around that cell [63]. This index can affect the vegetation patterns in mountainous areas [4,59,64]. |
| CTI | Compound topographic index | CTI is a steady state wetness index [62]. Wetness index has been shown to affect vegetation spatial patterns [3,4]. |
| PADIR | Potential annual direct incident radiation | PADIR is a solar index, and was developed by McCune and Keon [65]. Solar radiation is the primary atmospheric control over soil moisture status between precipitation events in vegetation not receiving melt water and appears to influence the local adaptation of vegetation [3]. |
| Code | Proximate Drivers | Unit |
|---|---|---|
| SDV | Surface density of villages | km2 |
| CDV | Cost distance to villages | m |
| CDT | Cost distance to towns | m |
| CDLC | Cost distance to Lancang River | m |
| CDMR | Cost distance to mid-class level river | m |
| CDS | Cost distance to streams | m |
| CDLR | Cost distance to large (wide) roads | m |
| CDSR | Cost distance to small (narrow) roads | m |
| The Northern Study Area | The Southern Study Area | ||||
|---|---|---|---|---|---|
| Code of Classes | Number of Training Pixels | Number of Validation Pixels | Code of Classes | Number of Training Pixels | Number of Validation Data |
| FSF | 2,779 | 2,736 | ORT | 3,302 | 3,321 |
| PF | 9,540 | 9,594 | YRT | 1,727 | 1,695 |
| OF | 1,813 | 1,815 | EF | 23,866 | 23,981 |
| MF | 4,539 | 4,423 | LDF | 2,386 | 2,383 |
| LDF | 6,319 | 6,230 | DF | 2,472 | 2,439 |
| DSM | 6,898 | 6,933 | SGL | 4,838 | 4,710 |
| AL | 23,851 | 23,800 | AL | 9,310 | 9,408 |
| SN | 3,912 | 3,777 | BL | 1,715 | 1,623 |
| WT | 1,138 | 1,176 | WT | 1,217 | 1,250 |
| CS | 2,327 | 2,383 | CS | 241 | 267 |
| Study Areas | DCA1 | DCA2 | DCA3 | DCA4 | Dispersion of All EV | |
|---|---|---|---|---|---|---|
| Northern study area | Eigenvalues (EV) | 1.000 | 1.000 | 0.826 | 0.067 | 9.000 |
| Lengths of gradient | 0.000 | 0.000 | 4.877 | 4.151 | ||
| Southern study area | Eigenvalues (EV) | 1.000 | 0.842 | 0.444 | 0.077 | 9.000 |
| Lengths of gradient | 0.000 | 6.501 | 6.087 | 5.619 |
| Code | Variables | Northern Study Area (n = 2,085) | Southern Study Area (n = 2,986) | ||
|---|---|---|---|---|---|
| p-Level | F Value | p-Level | F Value | ||
| ELEV | Elevation | 0.002 | 21.88 | 0.002 | 13.05 |
| SDV | Surface density of villages | 0.002 | 3.52 | 0.002 | 12.84 |
| CTI | Compound topographic index | 0.002 | 18.09 | 0.002 | 8.29 |
| CDLC | Cost distance to Lancang River | 0.002 | 15.23 | 0.018 | 2.49 |
| PADIR | Potential annual direct incident radiation | 0.002 | 17.16 | 0.002 | 4.95 |
| SLO | Slope angle | 0.002 | 4.93 | 0.002 | 4.41 |
| CDLR | Cost distance to large roads | 0.002 | 5.05 | 0.002 | 12.60 |
| CDMR | Cost distance to mid-class level river | 0.002 | 7.21 | 0.002 | 4.81 |
| CDV | Cost distance to villages | 0.018 | 2.51 | 0.002 | 5.52 |
| CDT | Cost distance to towns | 0.002 | 6.49 | 0.002 | 5.80 |
| CDSR | Cost distance to small roads | 0.002 | 2.71 | 0.002 | 4.22 |
| TPI | Topographic position index | 0.01 | 2.81 | 0.108 | 1.59 |
| CDS | Cost distance to streams | 0.036 | 2.11 | 0.002 | 3.97 |
| PRF | Slope profile curvature | 0.094 | 1.63 | 0.302 | 1.15 |
| ASP | Slope aspect | 0.002 | 3.92 | 0.002 | 6.66 |
| PLF | Slope planiform curvature | 0.846 | 0.49 | 0.762 | 0.62 |
| Study Areas | Variance Explained | Partially Explained by Topographic Attributes | Partially Explained by Human Disturbance Attributes | The Shared Explained Variance |
|---|---|---|---|---|
| Northern study area | 41.41% | 17.76% | 12.83% | 10.82% |
| Southern study area | 37.57% | 14.71% | 15.63% | 7.23% |
| Classification Number | Classification and Training Strategies | Data Used | Overall Accuracy (OA) (n = 62,867) | Kappa (n = 62,867) |
|---|---|---|---|---|
| N1 | ANN by training 10 classes | 7 bands | 83.69% | 0.7996 |
| N2 | ANN Training 41 subclasses | 7 bands | 91.09% | 0.8878 |
| N3 | ANN by training 41 subclasses | 7 bands, DEM | 95.3% | 0.9412 |
| N4 | ANN by training 41 subclasses | 7 bands, 4 CCA interpolated axes | 96.49% | 0.9561 |
| Classification Number | Classification and Training Strategies | Data Used | Overall Accuracy (OA) (n = 62,867) | Kappa (n = 62,867) |
|---|---|---|---|---|
| S1 | ANN by training 10 classes | 7 bands | 85.97% | 0.8021 |
| S2 | ANN by training 46 subclasses | 7 bands | 90.1% | 0.8631 |
| S3 | ANN by training 46 subclasses | 7 bands, DEM | 93.49% | 0.9103 |
| S4 | ANN by training 46 subclasses | 7 bands, 4 CCA interpolated axes | 96.45% | 0.9500 |
| Pair-Wise | N1 | N2 | N3 | N4 |
|---|---|---|---|---|
| N1 | ||||
| N2 | −5.64 *** | |||
| N3 | −7.04 *** | −2.42 * | ||
| N4 | −6.87 *** | −2.79 ** | −0.54 |
| Pair-Wise | S1 | S2 | S3 | S4 |
|---|---|---|---|---|
| S1 | ||||
| S2 | −3.53 *** | |||
| S3 | −5.40 *** | −2.20 * | ||
| S4 | −8.23 *** | −4.45 *** | −2.03 * |
| Code | Northern Study Area | Southern Study Area | ||||||
|---|---|---|---|---|---|---|---|---|
| Axis1 | Axis2 | Axis3 | Axis4 | Axis1 | Axis2 | Axis3 | Axis4 | |
| ELEV | −0.95 *** | −0.16 | 0.14 | 0.14 | −0.67 *** | 0.23 * | −0.52 *** | 0.14 |
| SLO | −0.39 *** | 0.50 *** | −0.47 *** | 0.10 | −0.39 *** | 0.60 *** | 0.49 *** | 0.19 |
| ASP | 0.10 | 0.29 ** | 0.09 | 0.01 | 0.38 *** | 0.39 *** | −0.05 | −0.17 |
| TPI | −0.38 *** | 0.24 * | −0.23 * | −0.12 | 0.63 *** | −0.12 | −0.28 ** | −0.03 |
| PRF | 0.25 * | −0.06 | 0.20 * | 0.18 | −0.46 *** | −0.05 | 0.16 | −0.23 * |
| PLF | −0.10 | 0.06 | −0.02 | −0.09 | 0.00 | 0.29 ** | 0.12 | −0.34 *** |
| CTI | 0.62 *** | −0.36 *** | 0.64 *** | 0.08 | 0.32 ** | −0.01 | −0.16 | 0.35 *** |
| PADIR | 0.12 | −0.62 *** | −0.53 *** | 0.02 | 0.20 * | −0.42 *** | −0.09 | 0.70 *** |
| CDT | −0.34 *** | 0.14 | −0.18 | 0.51 *** | −0.17 | 0.60 *** | 0.01 | 0.36 *** |
| CDV | −0.56 *** | 0.12 | 0.01 | 0.40 *** | −0.09 | 0.56 *** | 0.21 * | 0.36 *** |
| CDSR | −0.12 | 0.46 *** | −0.09 | 0.28 ** | −0.25 * | 0.43 *** | 0.34 *** | 0.21 * |
| CDS | −0.07 | 0.17 | −0.33 *** | −0.09 | −0.49 *** | 0.36 *** | 0.38 *** | 0.13 |
| CDMR | −0.25 * | 0.64 *** | 0.09 | 0.20 * | −0.61 *** | 0.06 | 0.05 | −0.03 |
| CDLC | −0.53 *** | 0.20 * | −0.01 | 0.71 *** | 0.10 | 0.57 *** | −0.50 *** | 0.07 |
| CDLR | −0.51 *** | 0.28 ** | 0.05 | 0.55 *** | 0.05 | 0.58 *** | 0.07 | 0.39 *** |
| SDV | 0.86 *** | 0.14 | −0.23 * | −0.35 *** | 0.20 * | −0.50 *** | −0.21 * | −0.39 *** |
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Zhang, Z.; Van Coillie, F.; Ou, X.; De Wulf, R. Integration of Satellite Imagery, Topography and Human Disturbance Factors Based on Canonical Correspondence Analysis Ordination for Mountain Vegetation Mapping: A Case Study in Yunnan, China. Remote Sens. 2014, 6, 1026-1056. https://doi.org/10.3390/rs6021026
Zhang Z, Van Coillie F, Ou X, De Wulf R. Integration of Satellite Imagery, Topography and Human Disturbance Factors Based on Canonical Correspondence Analysis Ordination for Mountain Vegetation Mapping: A Case Study in Yunnan, China. Remote Sensing. 2014; 6(2):1026-1056. https://doi.org/10.3390/rs6021026
Chicago/Turabian StyleZhang, Zhiming, Frieke Van Coillie, Xiaokun Ou, and Robert De Wulf. 2014. "Integration of Satellite Imagery, Topography and Human Disturbance Factors Based on Canonical Correspondence Analysis Ordination for Mountain Vegetation Mapping: A Case Study in Yunnan, China" Remote Sensing 6, no. 2: 1026-1056. https://doi.org/10.3390/rs6021026