The cloud and cloud-shadow masking method described here, called SPOTCASM (SPOT Cloud and Shadow Masking), is based on the method of le Hégarat-Mascle and André [
8], but also includes the following new components: masking water bodies from images before searching for clouds and shadows; limiting the shadow search area by assuming that clouds are at similar heights; filtering possible clouds to remove very small objects; and, using the watershed-from-markers transform to grow cloud and cloud-shadow segments from marker pixels [
10]. These last two ideas use morphological image processing techniques often used for extracting features from images [
11]. Parts of the le Hégarat-Mascle and André [
8] method that were adapted include: identifying linear threshold lines in 2-dimensional space based on the distribution of pixels; limiting the search for cloud-shadows to the appropriate direction from possible clouds; and, comparing the possible cloud and shadow pairs to determine which are valid.
SPOTCASM is implemented with a script written in the Python programming language, using functions from the standard Python library [
12,
13], as well as from the following freely-available open-source Python modules: Numpy [
14], Scipy [
15], GDAL [
16], Pymorph [
11,
17] and Mahotas [
18]. The program is open-source and available online under the GNU General Public License, Version 3 [
19]. As many components of the method make use of morphological image processing, it is appropriate to describe this first.
3.1. Morphological Image Processing
Morphological image processing is based on exploiting the geometric structures within images, and can be used to design algorithms for automatic object recognition or feature extraction. The following section describes some of the fundamental components of the technique that are used in the new cloud and shadow masking method, summarized from the work of Dougherty and Lotufu (2003) [
11]. The fundamental idea of morphological image processing is erosion, which is to probe an image with a structuring element, and observe where the element fits and where it does not (a structuring element, similar to a filter kernel, is defined by its size, shape, pixel values, and the position of its origin). This concept is straightforward for binary images, where a structuring element can fit or not fit at different pixel locations, resulting in the features in an image shrinking, or being eroded. Applying the concept to grayscale images is more complex, but it can be simplified if only flat (binary) structuring elements are considered, resulting in the erosion of an image by the structuring element
g being the same as applying a moving-minimum filter with a kernel
g: it removes isolated pixels with large values (bright pixels) and erodes image features that are collections of bright pixels. The opposite of morphological erosion is dilation, which is the same as a moving-maximum filter, and has the effect of removing isolated pixels with small values (dark pixels) and erodes image features that are collections of dark pixels.
Many useful morphological image processing methods have been developed by combining erosion and dilation. For example, morphological opening (erosion followed by dilation) removes bright features smaller than the structuring element, while maintaining bright features larger than the structuring element. Morphological closing (dilation followed by erosion) removes small dark features while maintaining larger dark features. If an image contains noise consisting of both bright and dark features, they can be removed by applying an opening followed by a closing. Furthermore, if the noisy features are a mixture of different spatial sizes, it can be useful to repeat the opening-closing with structuring elements of increasing size, termed an alternating sequential filter (ASF). This removes high frequencies within image objects that are larger than the largest structuring element used, while maintaining the edges of these objects, and is used in the SPOTCASM method.
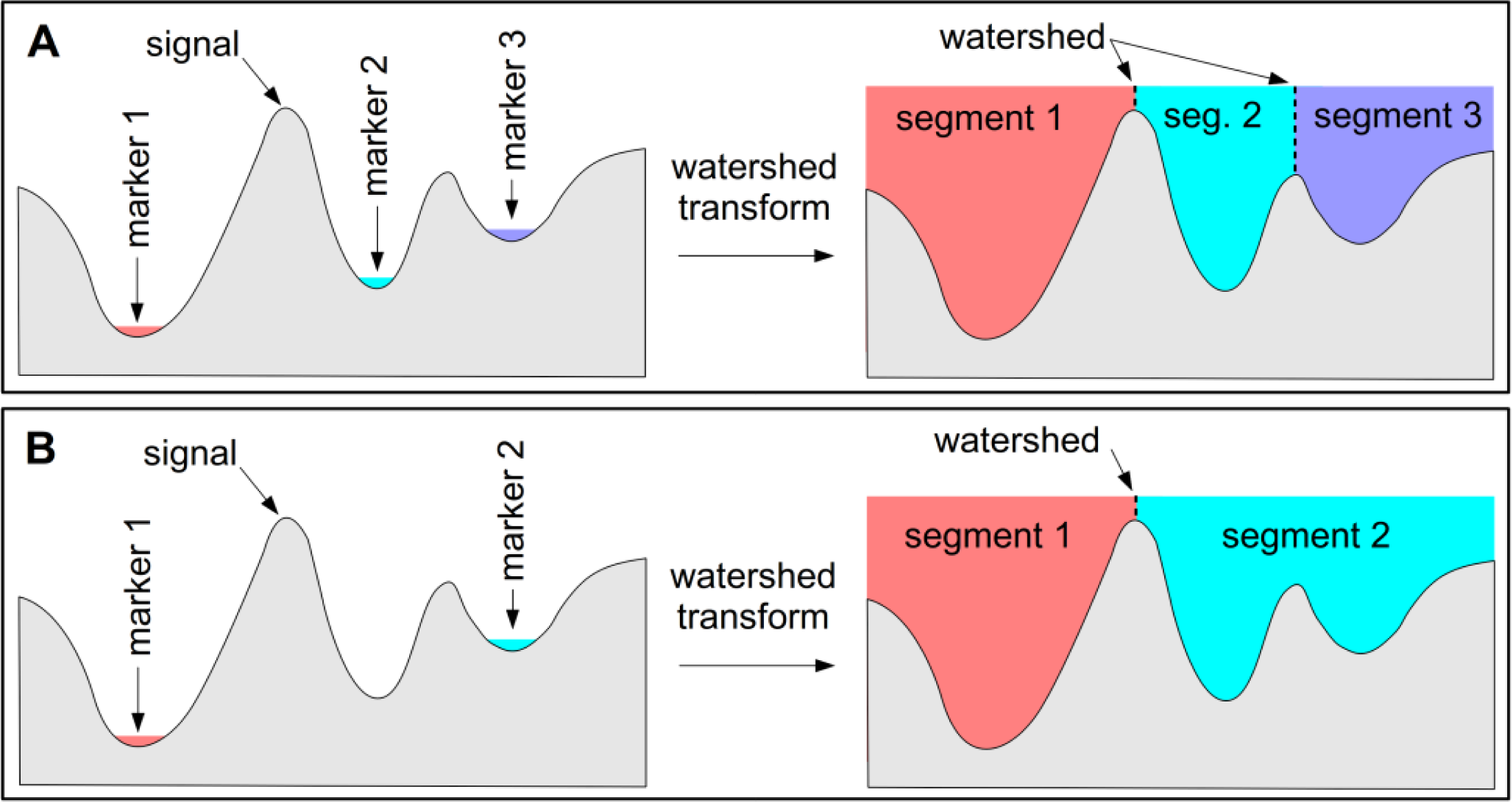
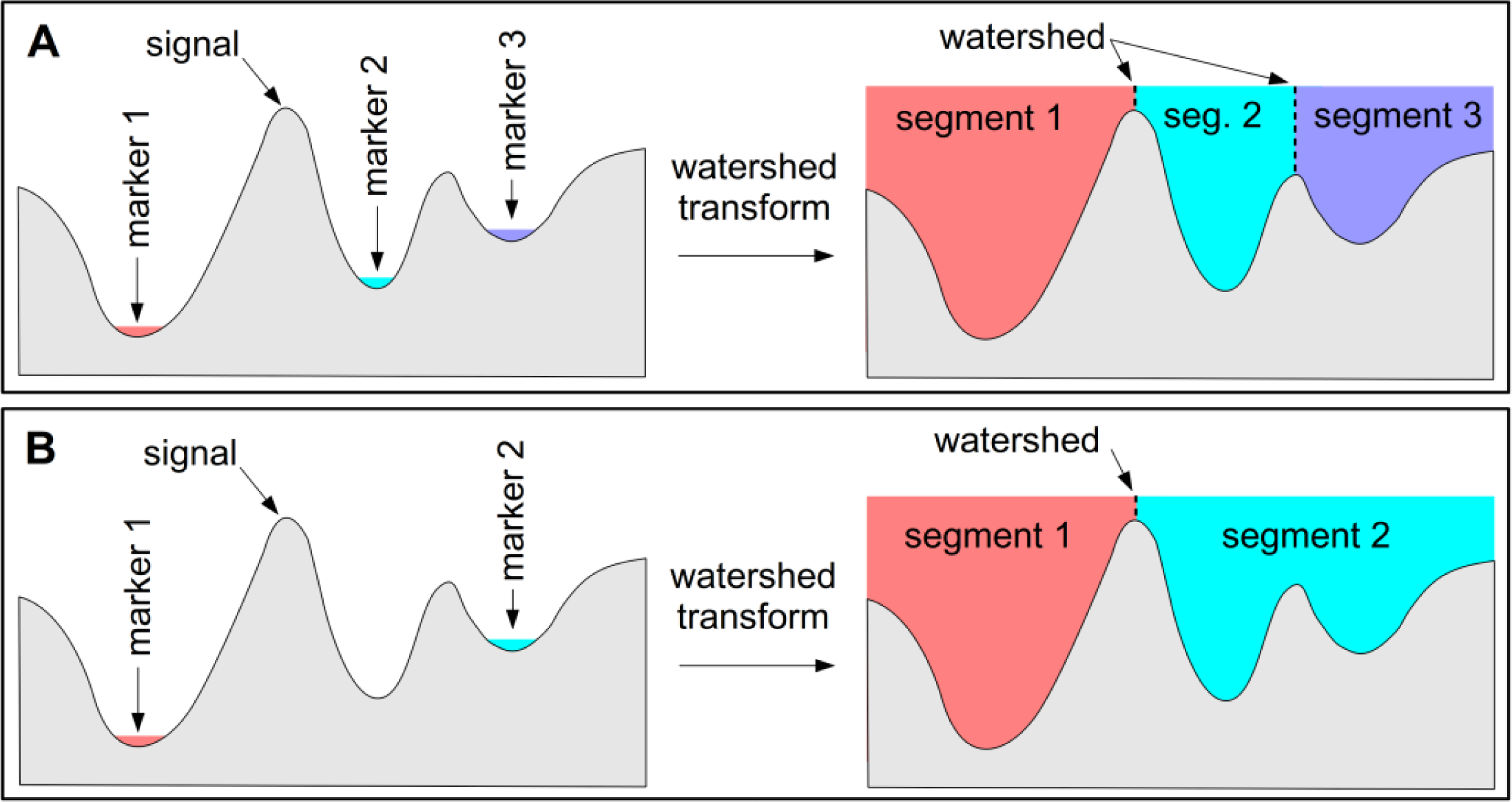
The watershed transform is a more complex morphological technique for image segmentation or feature extraction that can also be used for identifying peaks and troughs in one-dimensional signals. It is best explained by considering the flooding simulation of a signal, where holes are punched in each minima or trough and the signal is flooded by gradually immersing it in water (
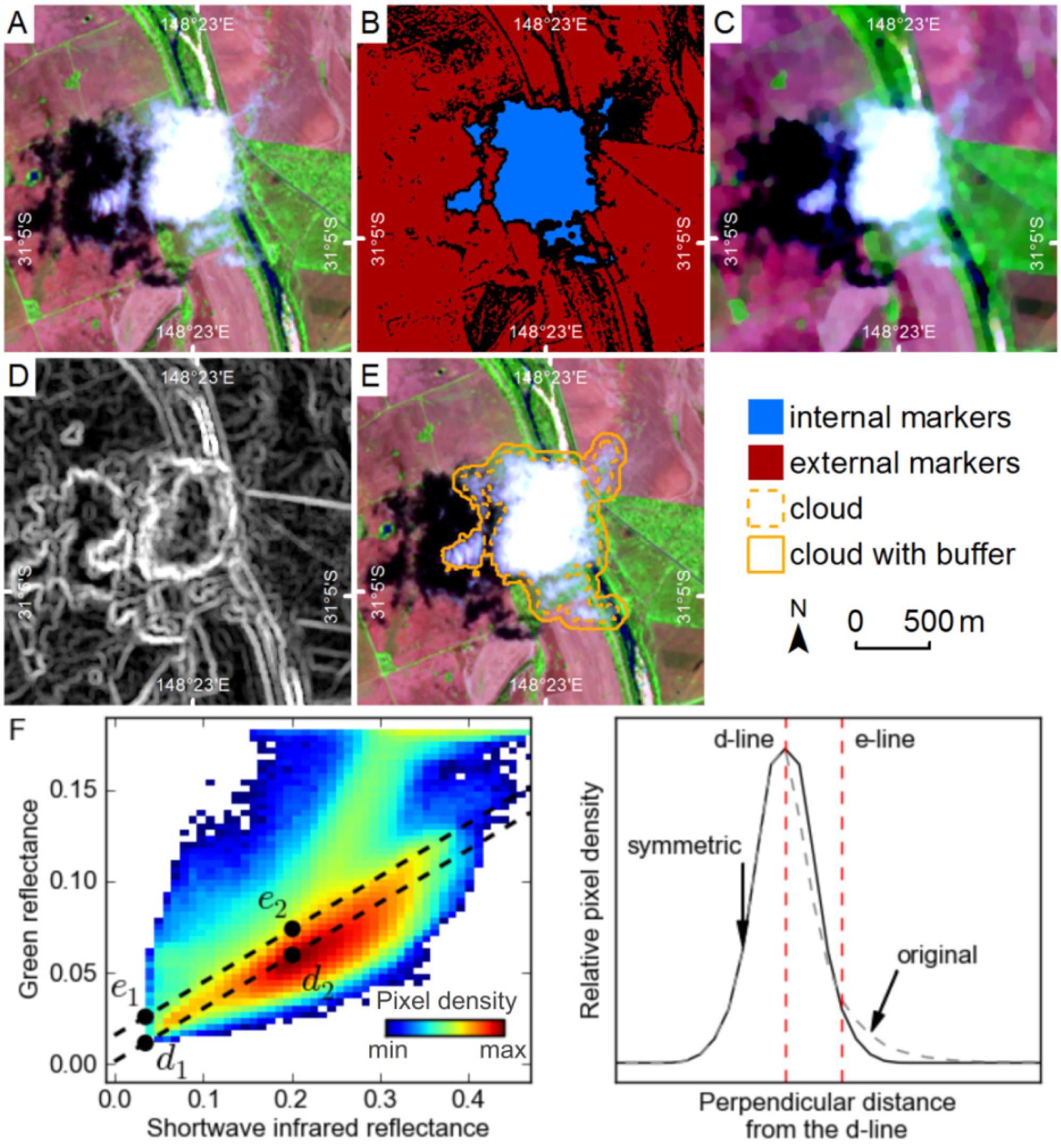
Figure 3A). The watershed lines are the points at which the waters from different basins meet. When applying the watershed transform to an image it is common to apply it to the morphological gradient (dilation minus erosion) of the image, which is a form of edge detection used to define potential watershed lines between image features. When the morphological gradient of an image is viewed as a topographic surface flooded from the minima, an image is commonly over-segmented due to minima from image noise. While this can be somewhat improved through filtering, the best improvement is gained when a set of minima are selected to act as markers. Applying the watershed-from-markers transform greatly reduces over-segmentation, though it makes it necessary to identify marker pixels for each image object (
Figure 3B). In the case of feature extraction, it is necessary to identify internal markers for the features, and also external markers for the background pixels against which the features sit. The watershed-from-markers transform is used in several steps of the SPOTCASM method.
3.2. Image Selection and Pre-Processing
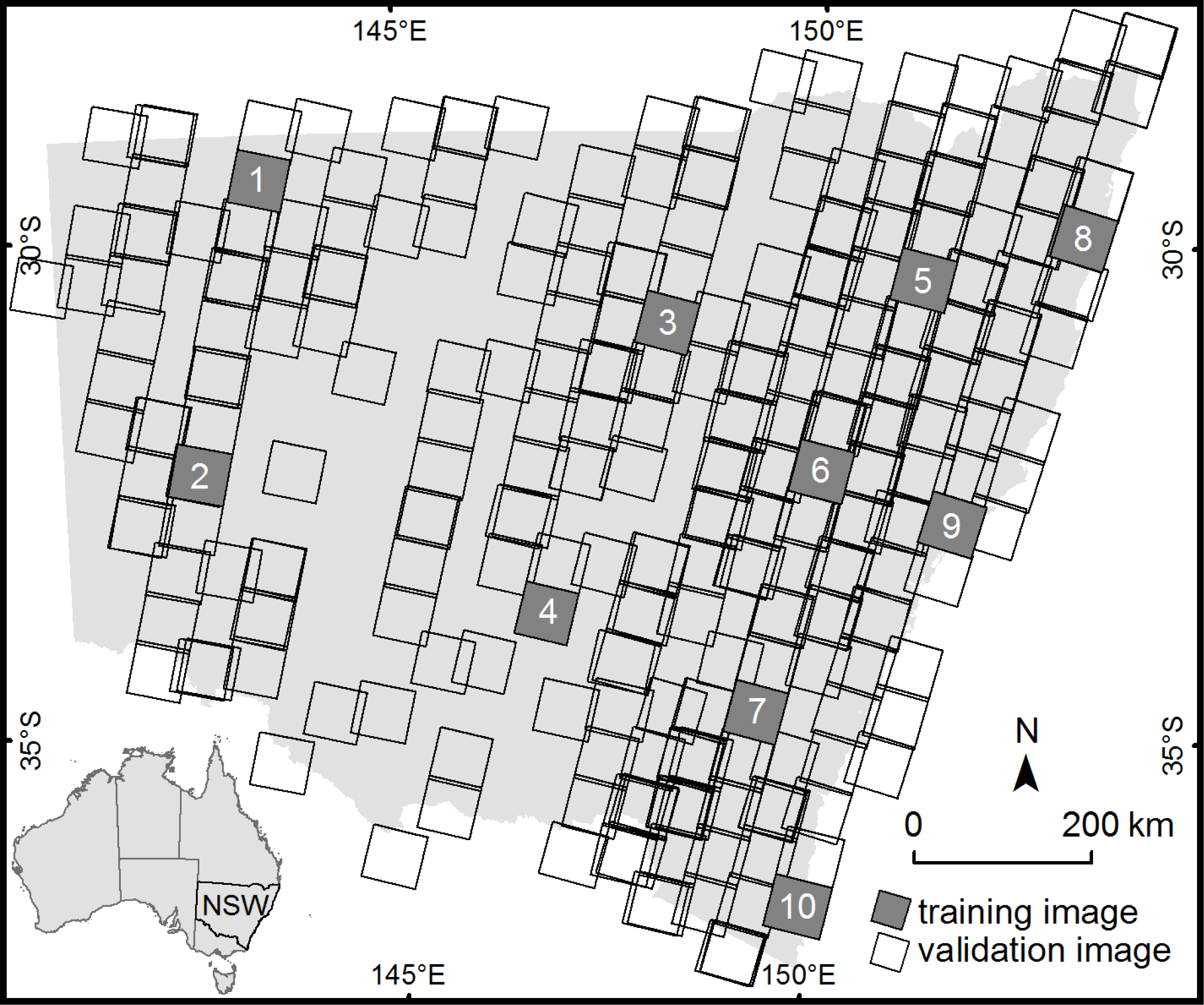
SPOTCASM was developed primarily for the OEH SPOT5 HRG image archive. Over 300 SPOT5 HRG images are required to cover NSW, an area of over 800,000 km2 that has a large variety of landcover types including subtropical rainforest, alpine herbfields and arid shrublands. Acquisition of imagery is generally in the southern hemisphere summer, to enhance the discrimination between tree canopy foliage and herbaceous or understory foliage.
SPOTCASM uses as input a SPOT5 HRG image, converted to surface reflectance [
20], and the image metadata file that contains the sun and satellite angles at the time of acquisition. The surface reflectance images were corrected for variations in atmospheric conditions, sensor location, and sun elevation, but were not corrected for topography to avoid changing the reflectance of clouds to conform to the ground elevation. It was convenient to use surface reflectance imagery rather than top of atmosphere reflectance as surface reflectance is a standard product for all OEH SPOT5 HRG imagery. It also has the advantage of normalizing the reflectance of surface features, allowing reflectance values to be compared over large areas and times. Although the atmospheric correction makes the assumption that features are at the ground surface, which is incorrect for cloud pixels, the effect is relatively minor.
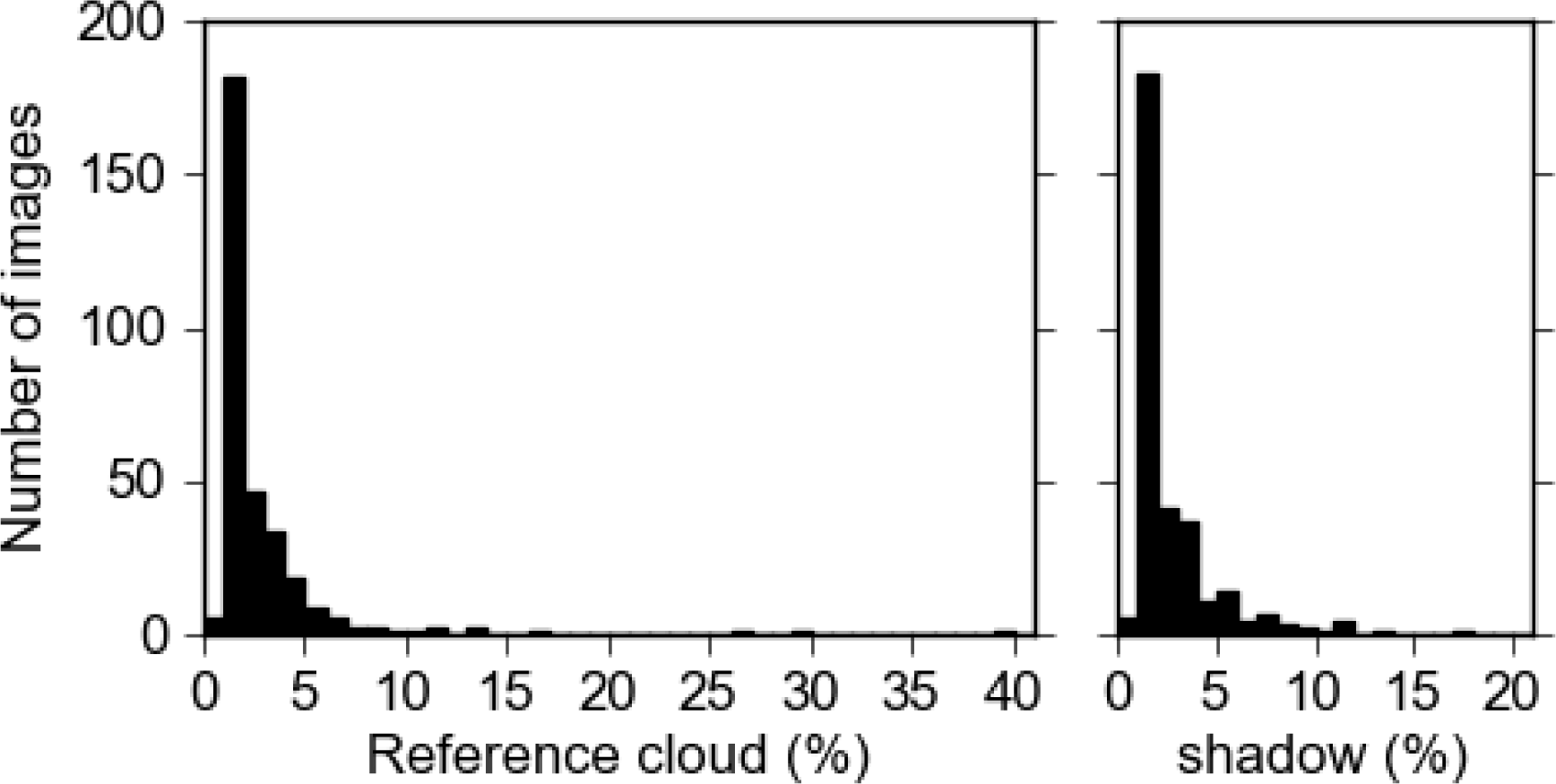
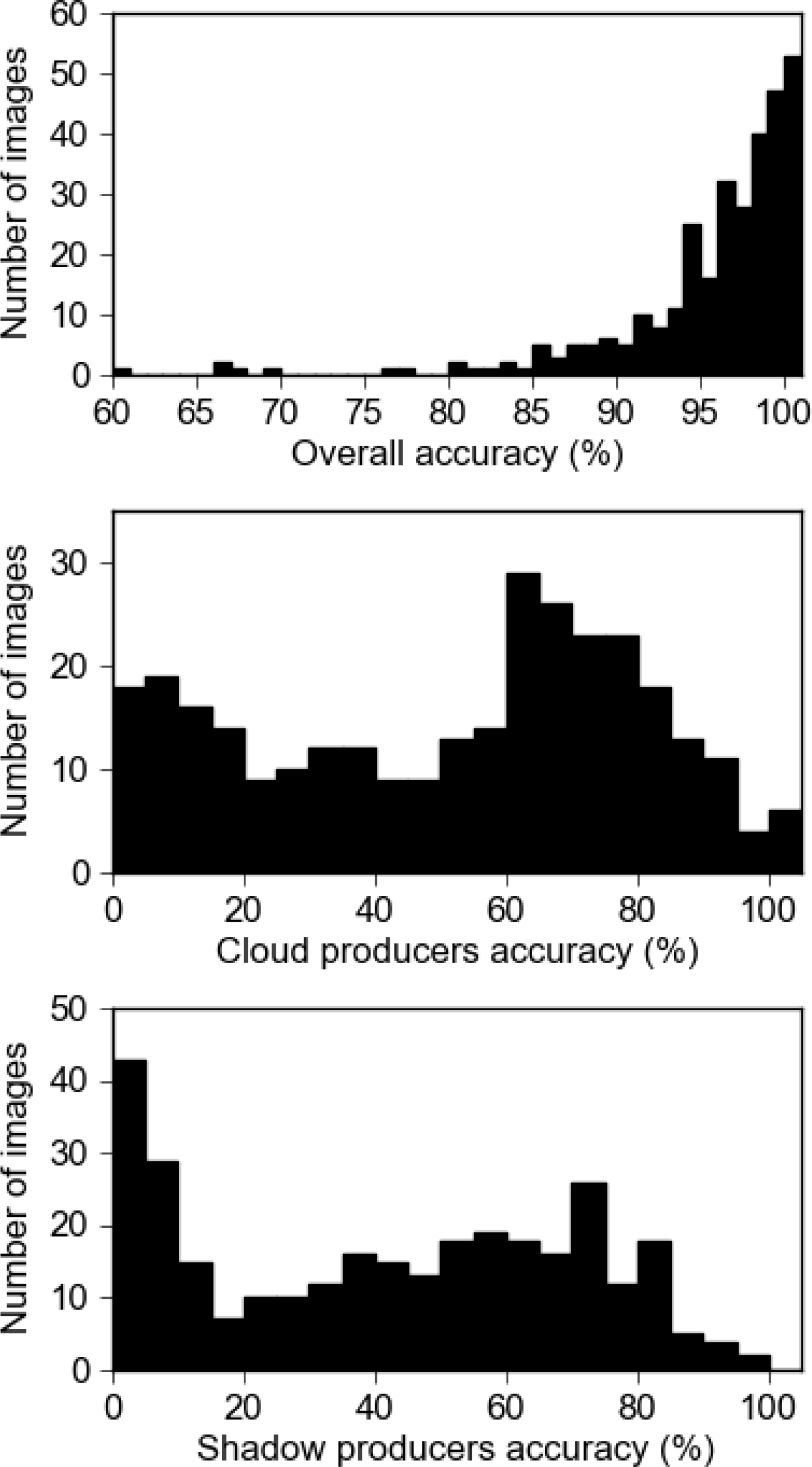
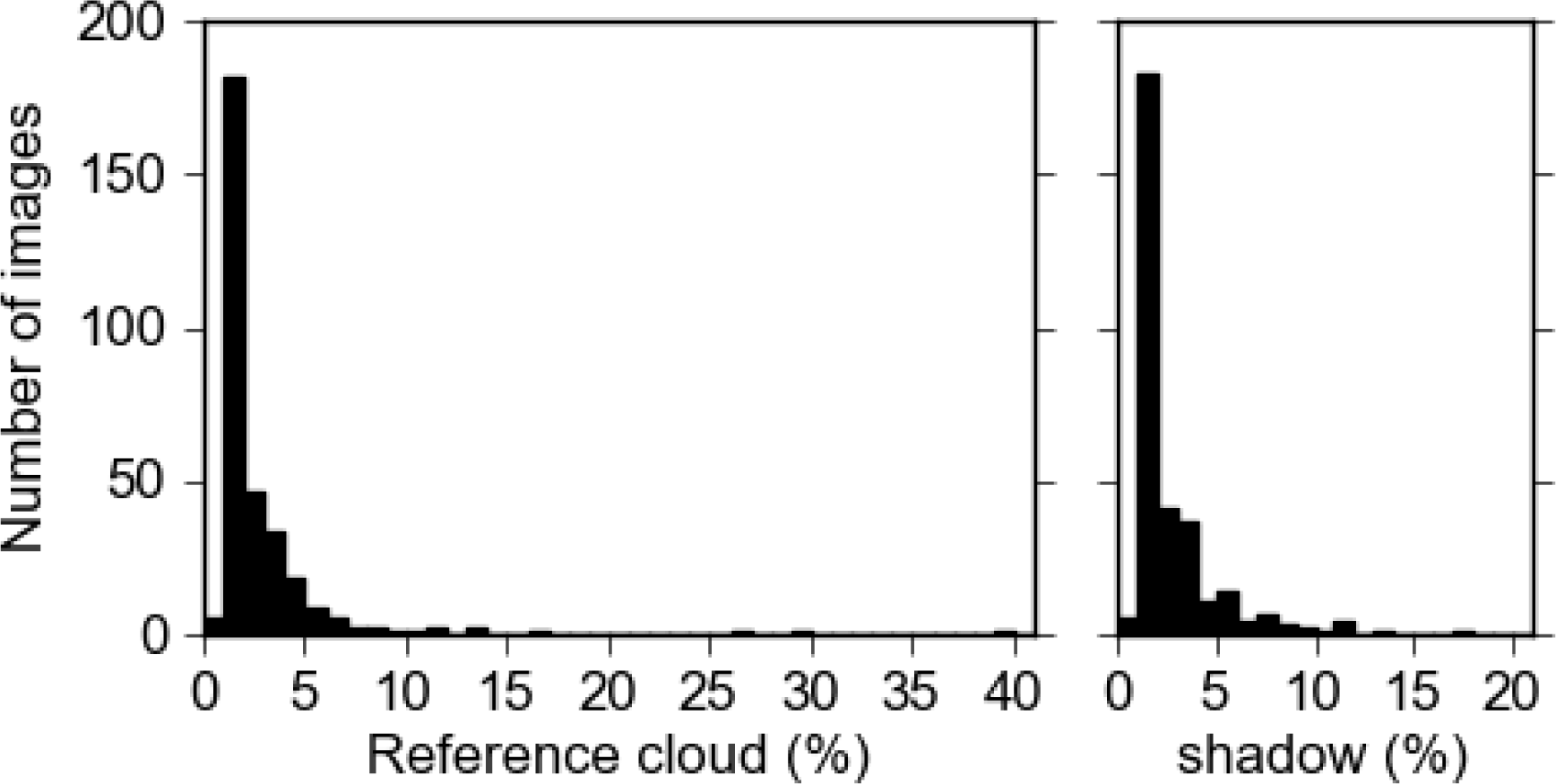
Cloud and cloud-shadow masks have been generated for each of the 313 archived images through manual editing. As OEH require a single summer image coverage for NSW they choose images with no or low cloud cover, resulting in 60% of the 313 cloudy images having less than 1% cloud and 1% shadow (
Figure 4).
Ten of the cloudy images were selected to train SPOTCASM, due to restrictions in available time and computing resources. They were chosen to represent the variety of land cover conditions across NSW, with more images selected from the eastern part of the state, which was more often cloudy (
Figure 1). They were used to test the method as it developed, through visual inspection of results at each stage. Although the manually edited masks were useful in checking the results, they could not effectively be used to optimize the methods parameters, as the manually defined edges and buffering of clouds (especially thin clouds), meant that the reference masks contained many non-cloud pixels.
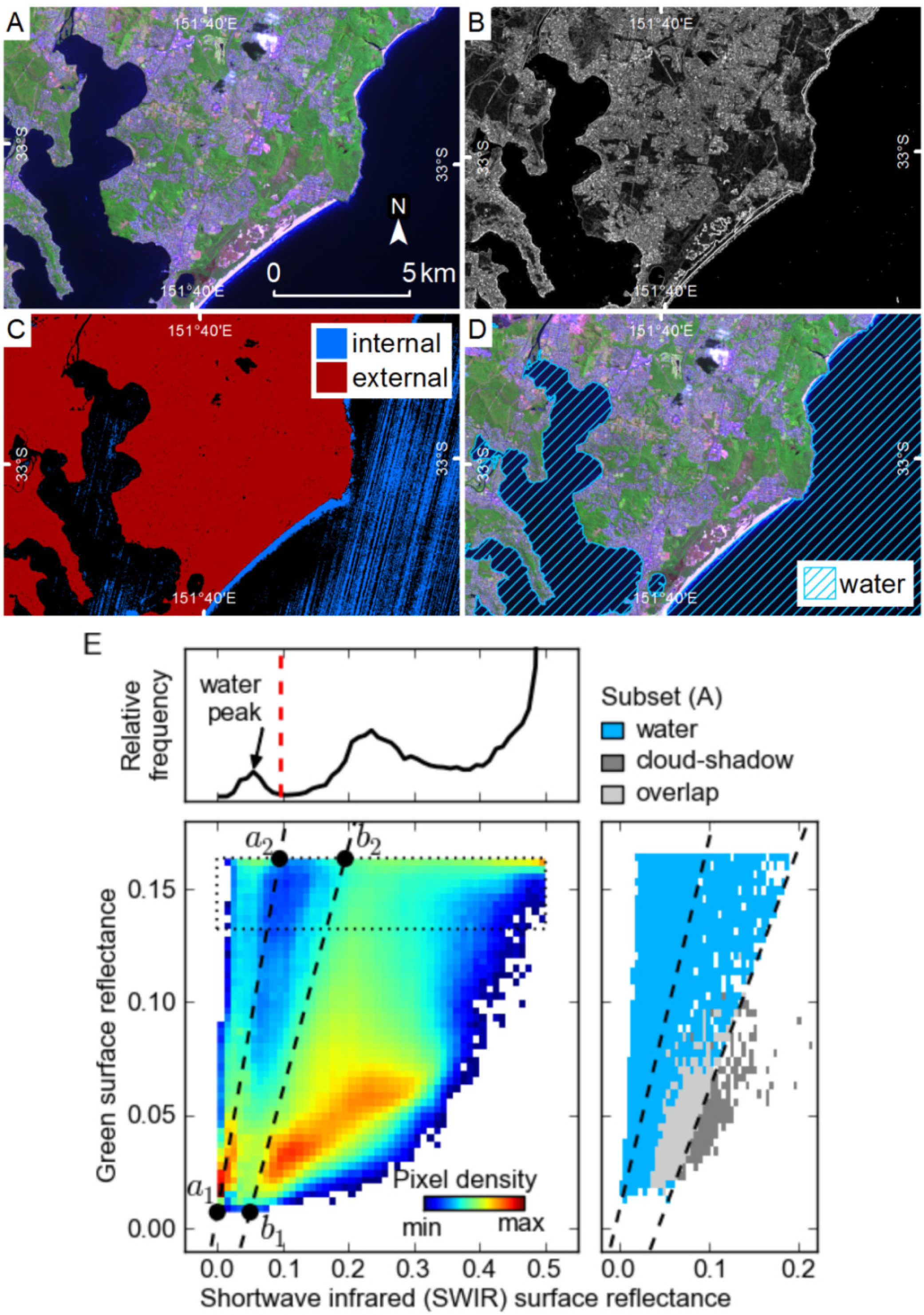
3.4. Masking Water
As most water pixels in SPOT5 HRG data are spectrally similar to cloud-shadows, and others are spectrally similar to clouds that are in shadow, a method to identify the majority of water pixels and remove them from further processing, without removing cloud or cloud-shadow pixels, was developed. Existing methods of water masking could not be used, as they have difficulty in distinguishing water from cloud-shadows [
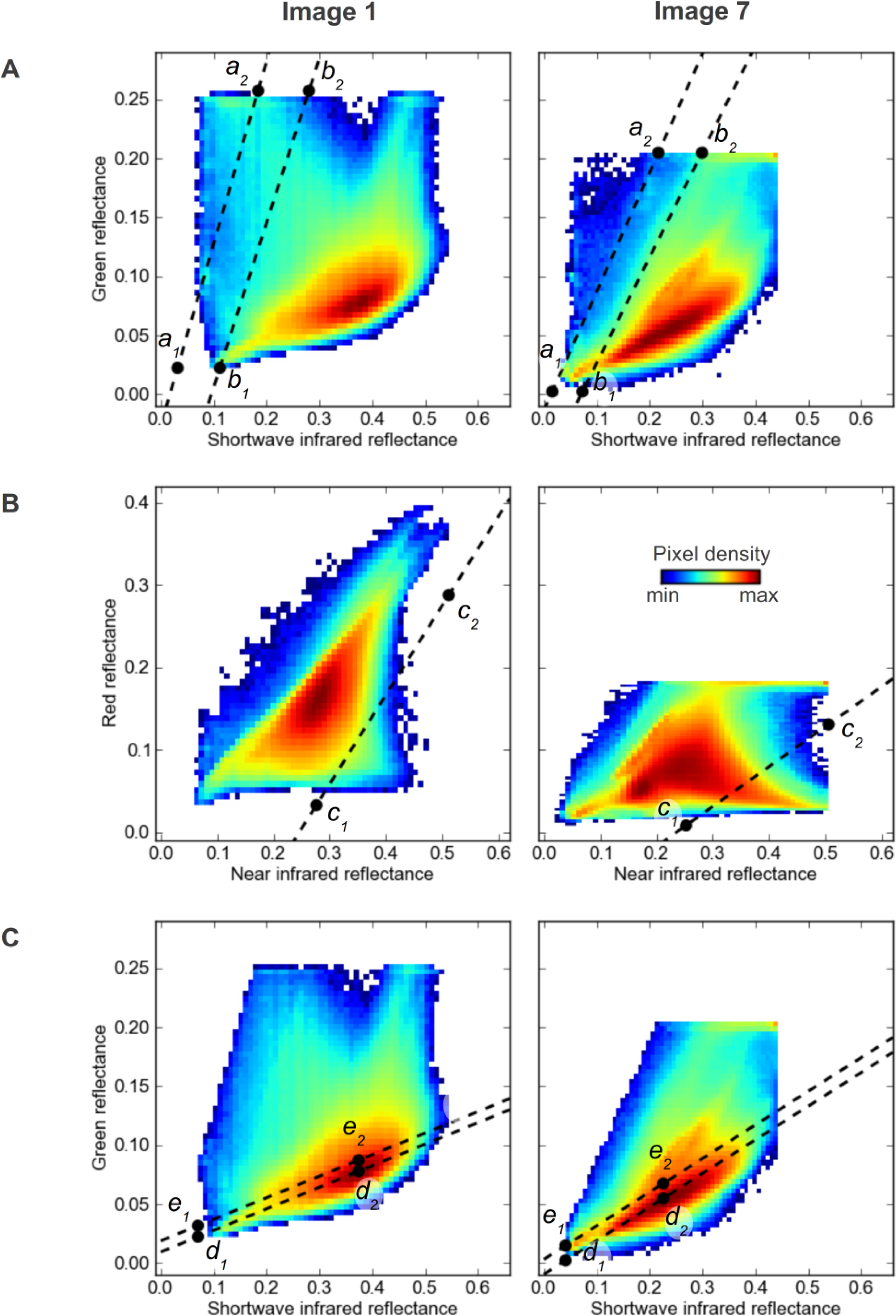
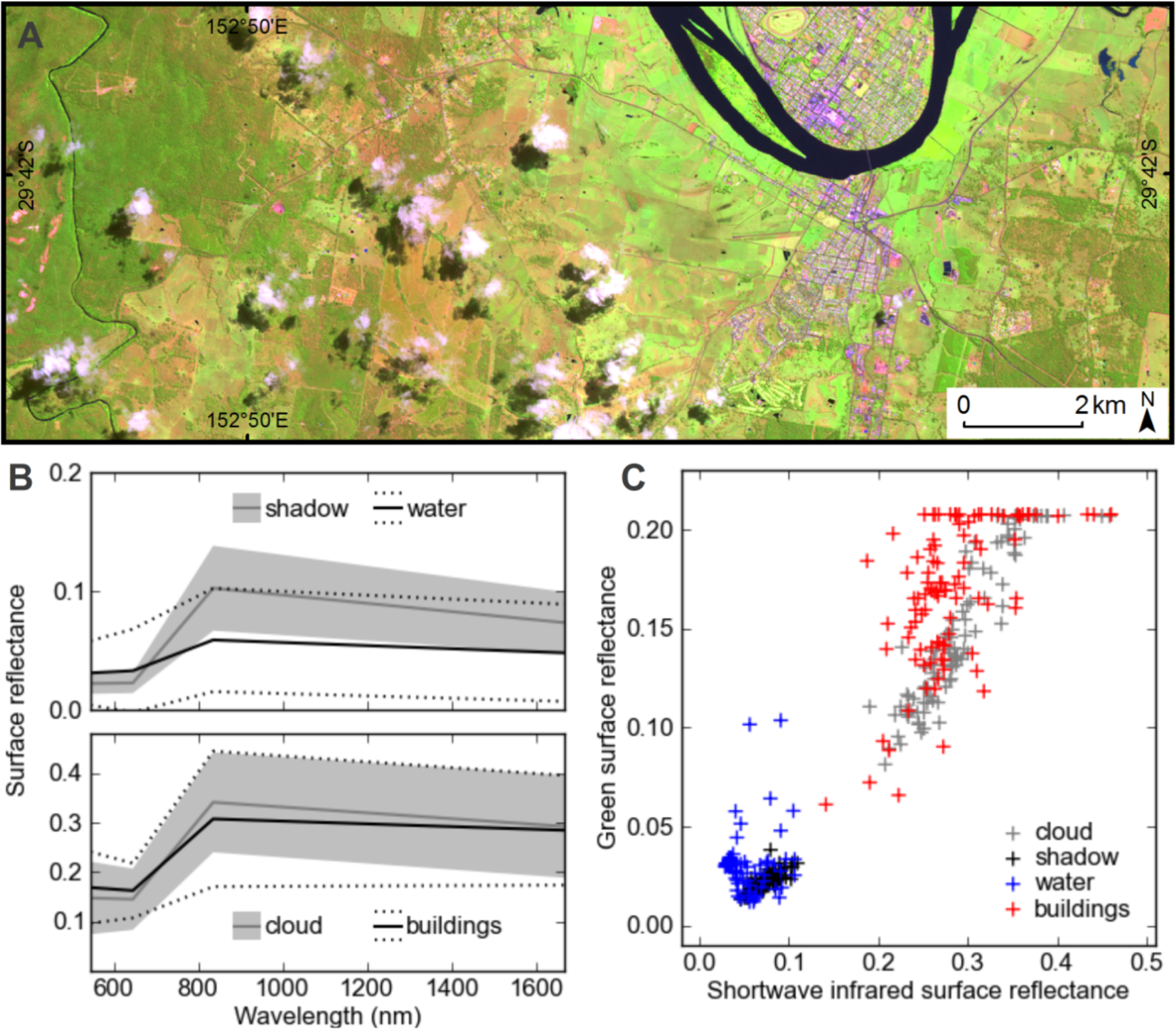
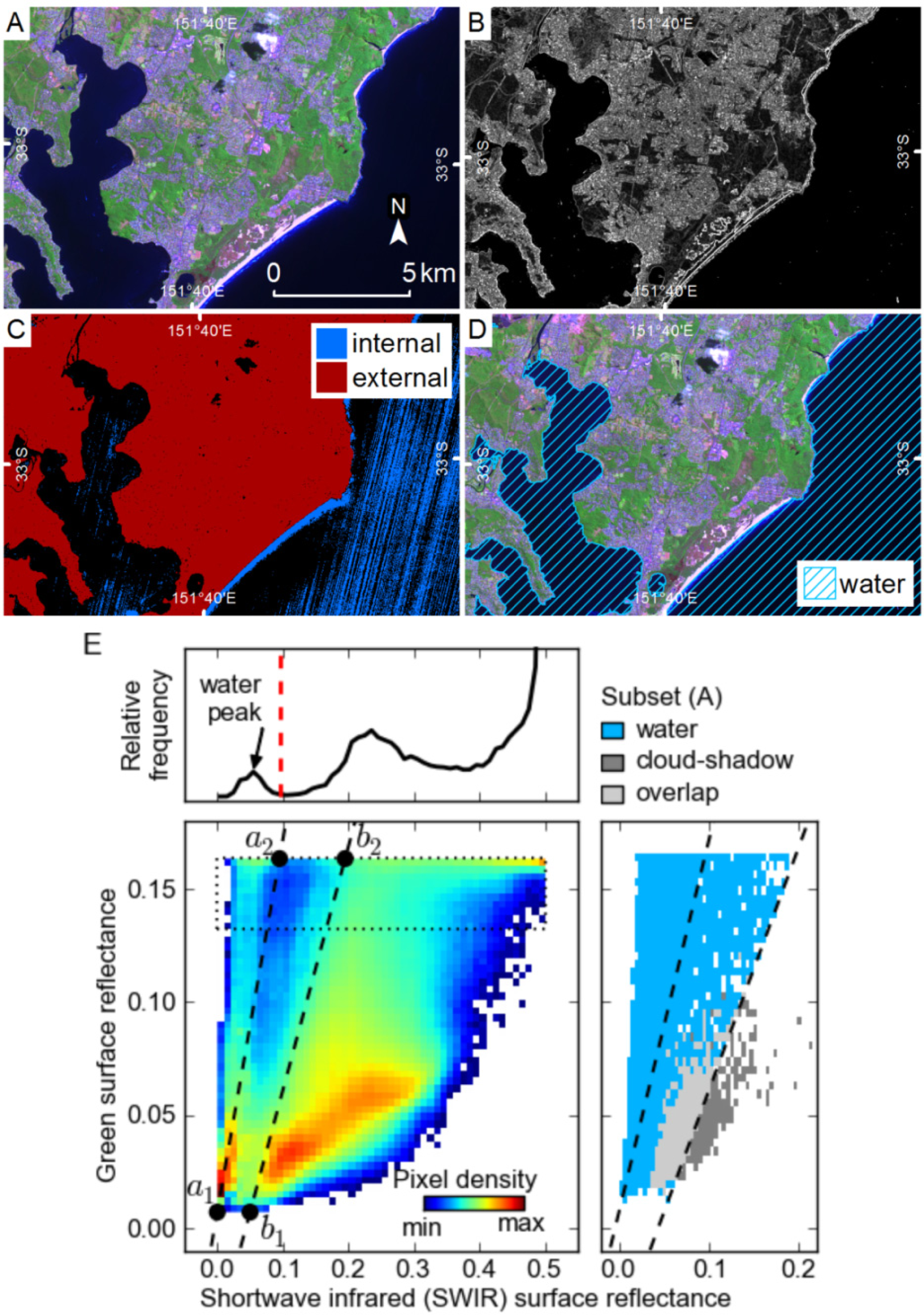
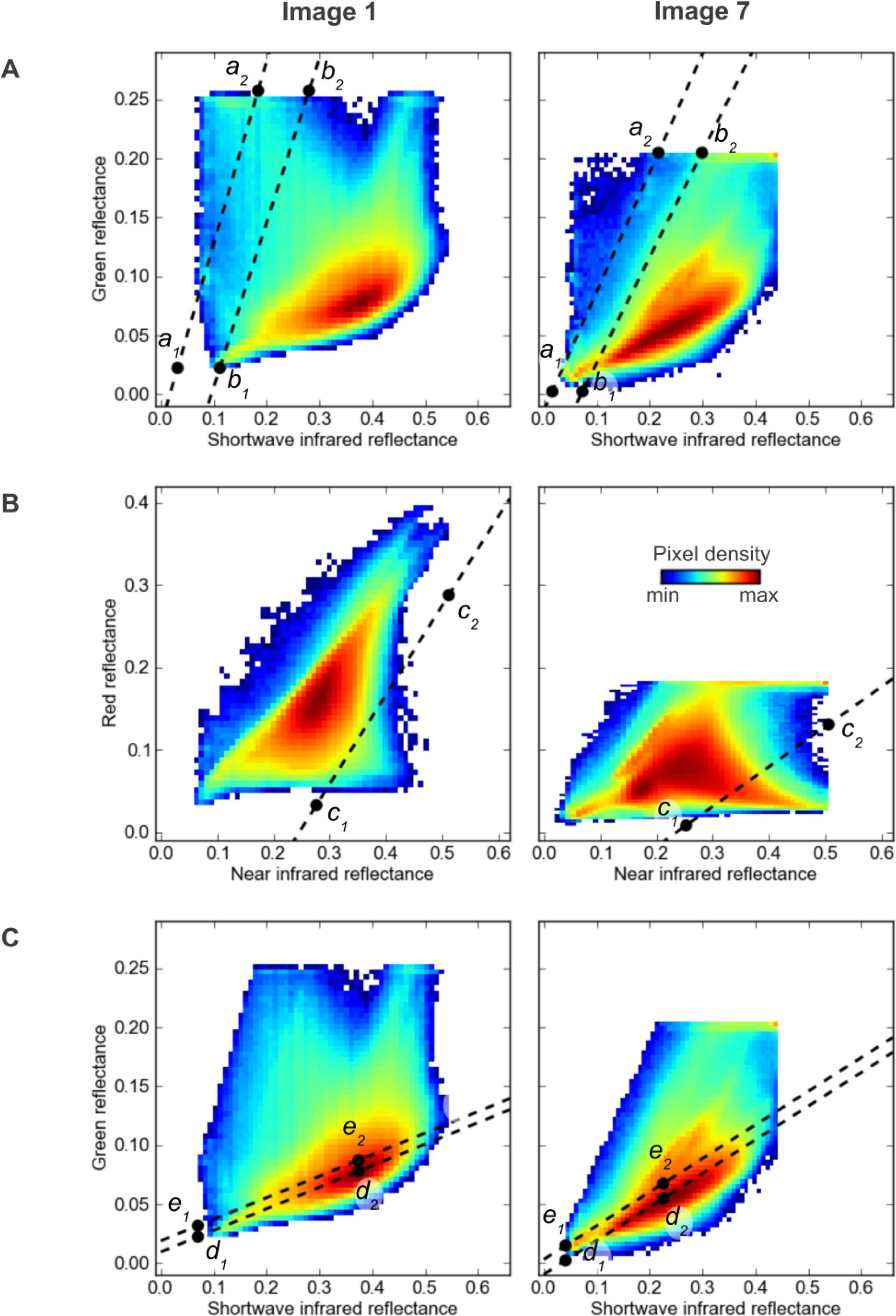
21]. Pixels in the water mask are also used as external markers when growing cloud and shadow segments with the watershed transform. For each image this method defines linear thresholds in green-SWIR space based on features in the 2-dimensional (2D) histogram constructed from those image bands. An example of this method for image 9 is shown in
Figure 6, and two further examples of the thresholds and 2D histograms from images 1 and 7 are shown in
Figure 7A.
Firstly, a threshold is defined as line
a (
a1−
a2) where pixels above
a are used as internal markers for water. The second threshold is line
b (
b1−
b2) where pixels below line
b are external markers for water. Identifying thresholds in this way allows them to vary slightly between images that have different reflectance characteristics, examples of which are shown in
Figures 6E and
7A. The points
a1,
a2,
b1 and
b2 are determined by analysis of the 2D histogram according to the following criteria:
a1 is positioned at half the minimum SWIR reflectance, and the minimum green reflectance;
a2 is defined by the location of the left edge of the rightmost peak in the top 20% of the 2D histogram, and the maximum green reflectance;
b1 and
b2 are
a1,
a2 offset in the SWIR dimension, such that
b1 is positioned at the minimum SWIR plus 10% of the maximum SWIR reflectance, and
b2 is positioned at
a2 plus 20% of the maximum SWIR reflectance. Line
a is positioned to threshold all pixels with a high ratio of green to SWIR reflectance, which includes most water and snow. The position of
a1 ensures that shadow pixels with very low reflectance values are not included; while the position of
a2 ensures that clouds with lower than normal SWIR reflectance (e.g., clouds in shadow) are not included.
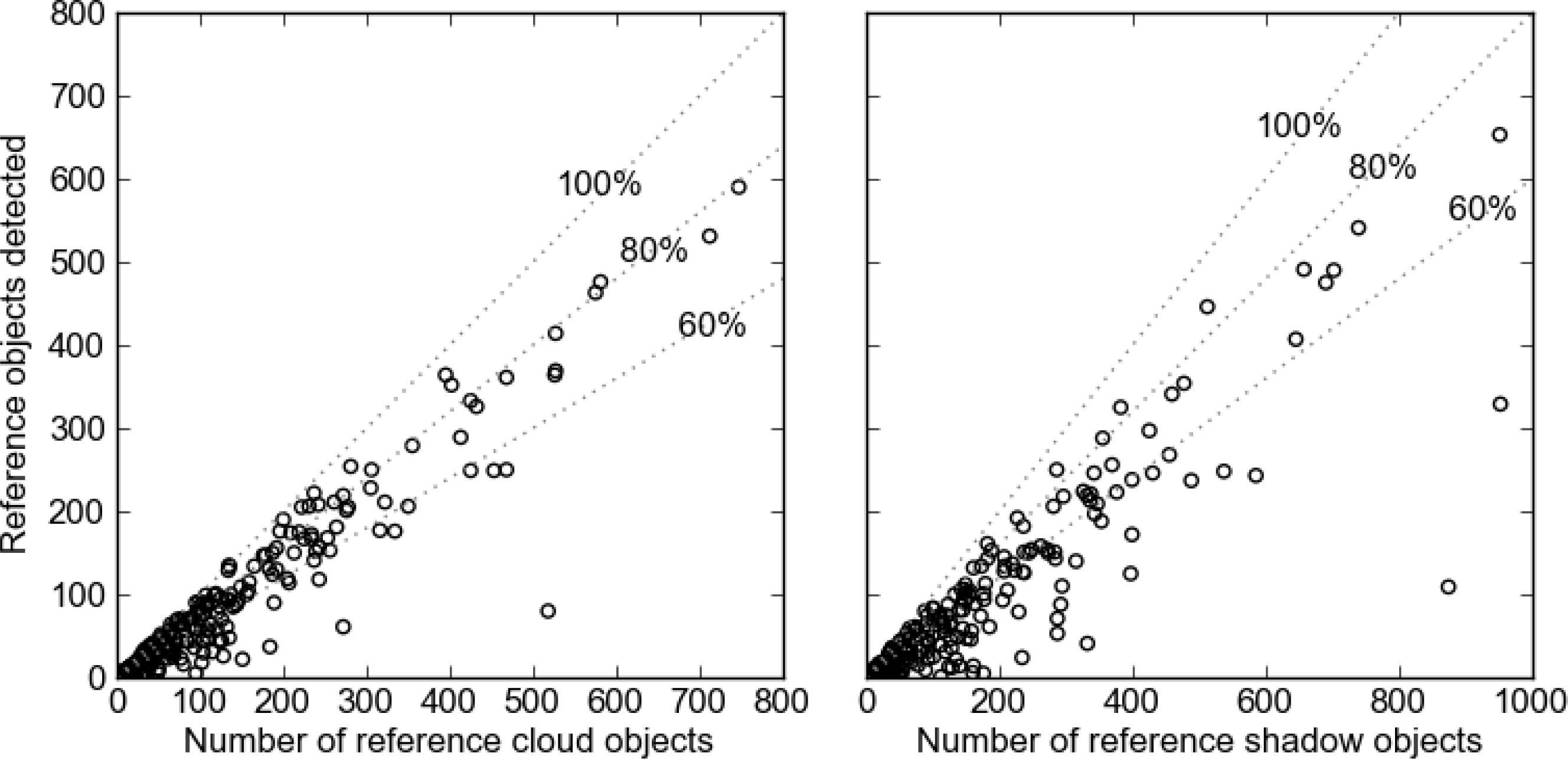
The markers defined by these thresholds are then used in a watershed-from-markers transform to generate a mask of water segments, based on the sum of the morphological gradient of the four bands. This approach grows segments from pixels that are definitely water, to the edge of the water features, and does not include omission errors that would result from attempting to define all water pixels with a threshold (
Figure 6). The position of
b1 and
b2 is not highly critical to the end result as the morphological gradient at the edge of water bodies is usually quite prominent, and the external markers are only needed as a guide. The resulting water mask does omit some water pixels that have very low reflectance similar to shadows, but it identifies most large water bodies relatively well.
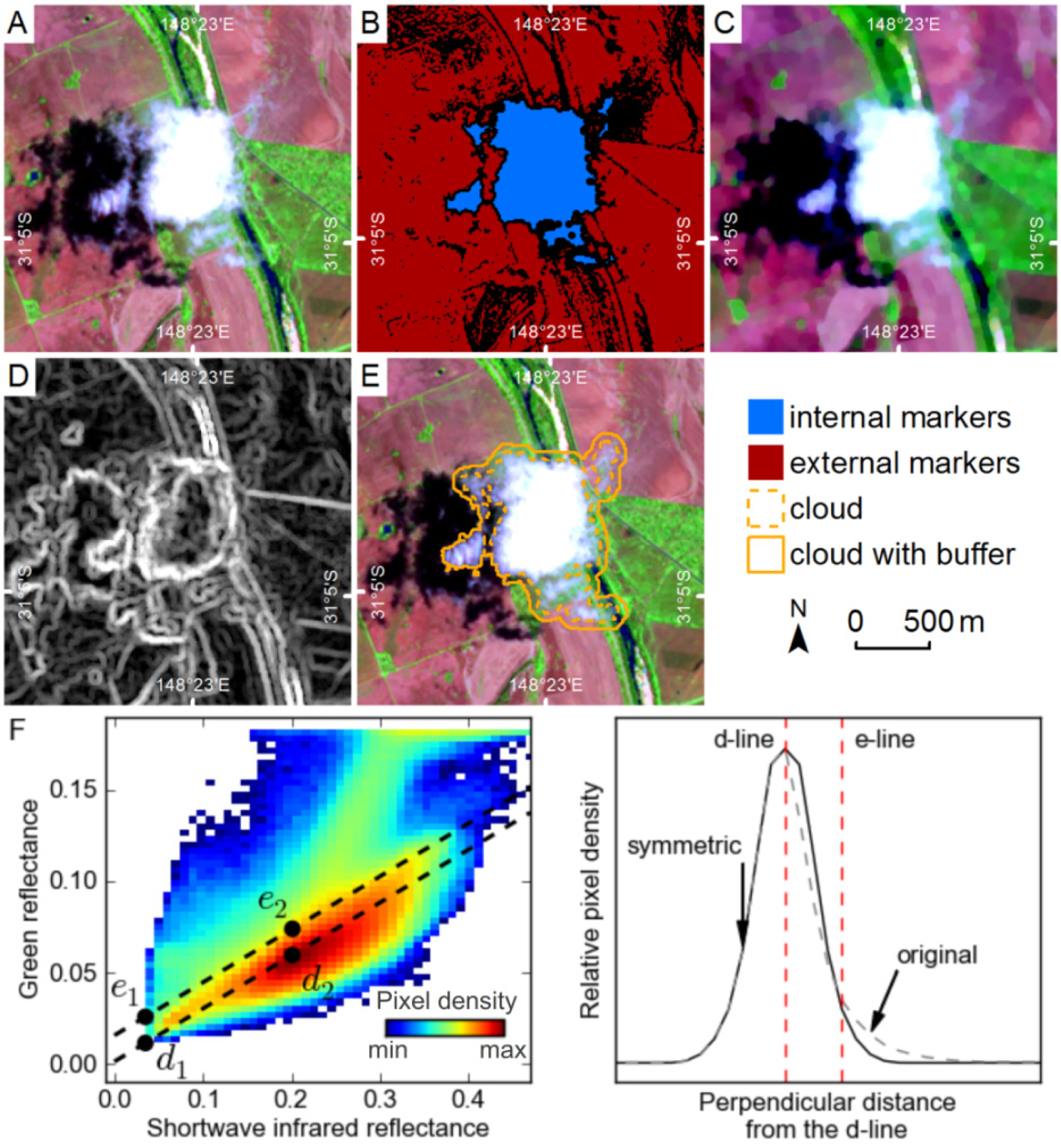
3.6. Identifying Possible Clouds
Marker pixels for clouds are defined by a threshold for each image in green-SWIR space based on features in the 2D histogram constructed from those image bands (
Figures 7C and
8F), using a modified version of the method described by le Hégarat-Mascle and André [
8]. The threshold is defined by the following steps. Firstly,
d is identified as the line through the points
d1 and
d2, where
d1 is the minimum mid-IR and minimum green reflectance, and
d2 is the position of greatest density in the 2D histogram, after the lower 20% of values in each dimension are masked to remove the influence of shadows (
Figure 8F). Line
d is an approximation of the “soil line” identified by le Hégarat-Mascle and André [
8]. Secondly, the 2D histogram is rotated by the slope of the line
d, and the 1D signal perpendicular to the line is extracted (
Figure 8F). The left-hand side of the peak in this signal (the side with greater SWIR reflectance) is not influenced by clouds, while the right-hand side of the peak contains the cloud pixels (
Figure 8F). The right-hand side of the peak is discarded, and replaced by a reversed copy of the left-hand side, which makes the peak symmetric (
Figure 8F). This modified histogram is then analyzed to calculate the position where 95% of the histogram is to the right. The distance from the peak to this position is used to offset points
d1 and
d2 to points
e1 and
e2 (
Figure 8F). Internal marker pixels for clouds are then defined as those that have reflectance values above line
e. To avoid pixels with very low reflectance being included as cloud markers, a second threshold is applied where pixels with green reflectance values less than the mean green reflectance for the whole image are removed from the cloud markers.
The threshold defined by the line e may include many other highly reflective features, such as urban structures. As many of these features are small they can be removed through morphological erosion with a 5 by 5 pixel disk-shaped structuring element. This introduces a detection limit for clouds by removing valid marker pixel objects smaller than the structuring element (50 m by 50 m).
External markers for clouds are a combination of the water and vegetation mask pixels; pixels below line
d in 2D green-SWIR space, pixels with green reflectance values less than the mean green reflectance for the whole image, and pixels more than 500 m from internal marker pixels (this limits cloud growth over reflective ground that might lack external markers). Cloud segments are grown from the internal and external markers (
Figure 8B) using the watershed transform on the sum of the morphological gradient for each band (
Figure 8D), after an ASF has been applied (
Figure 8C). The ASF removes image noise due to small objects, and enhances the edges of larger objects, while summing the morphological gradient for all bands means object edges in any band influence the segments produced by the watershed transform.
3.7. Identifying Possible Cloud-Shadows
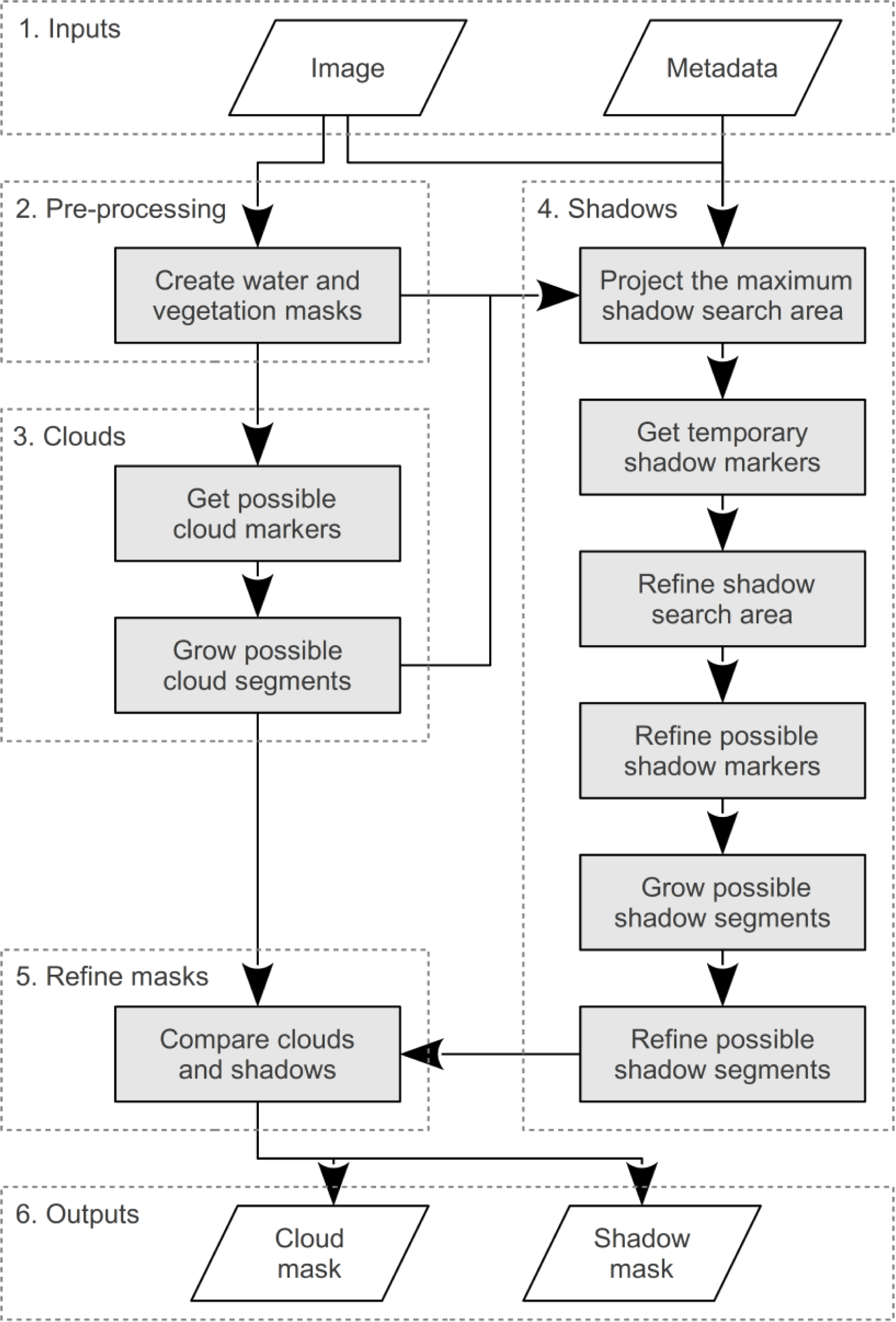
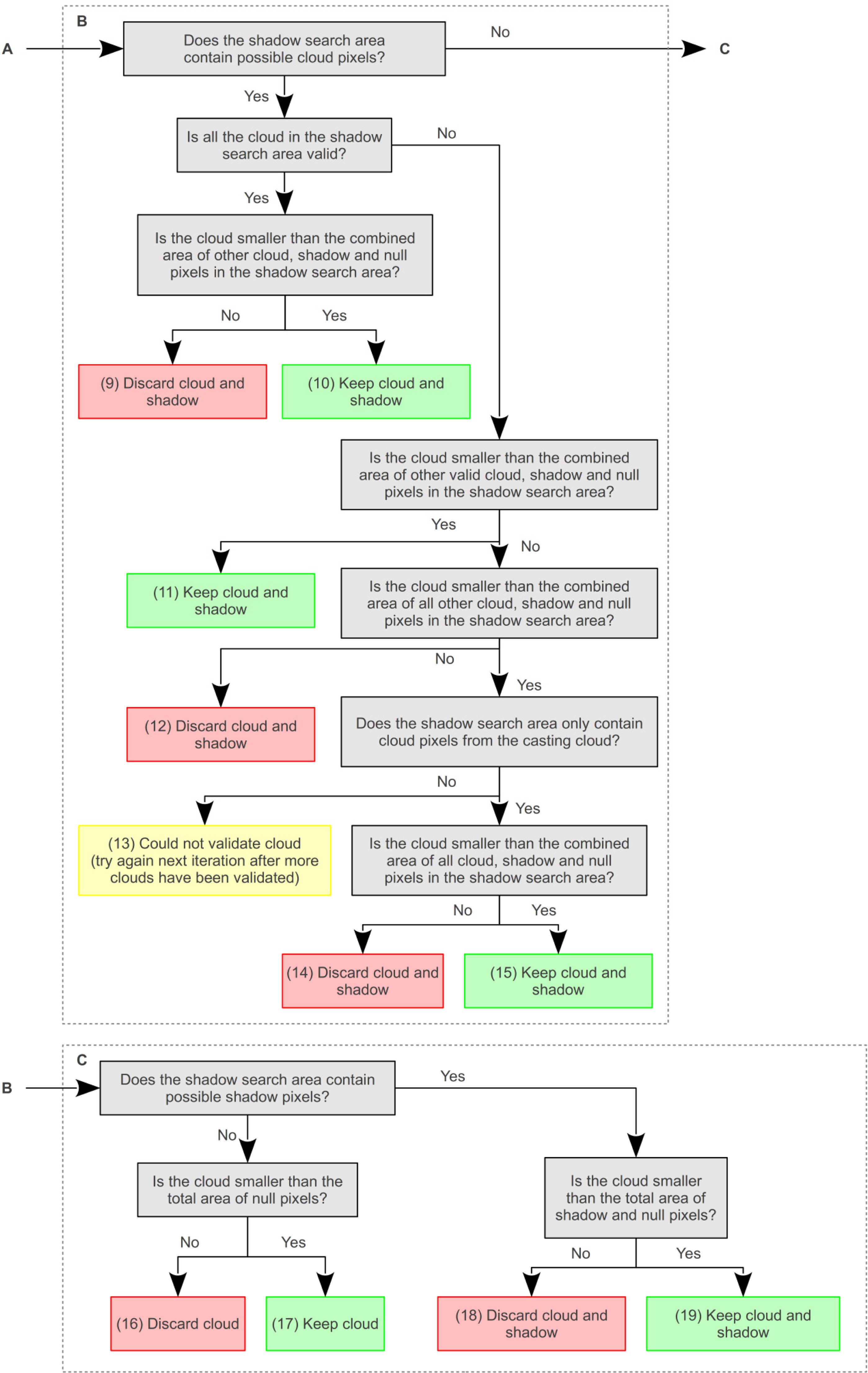
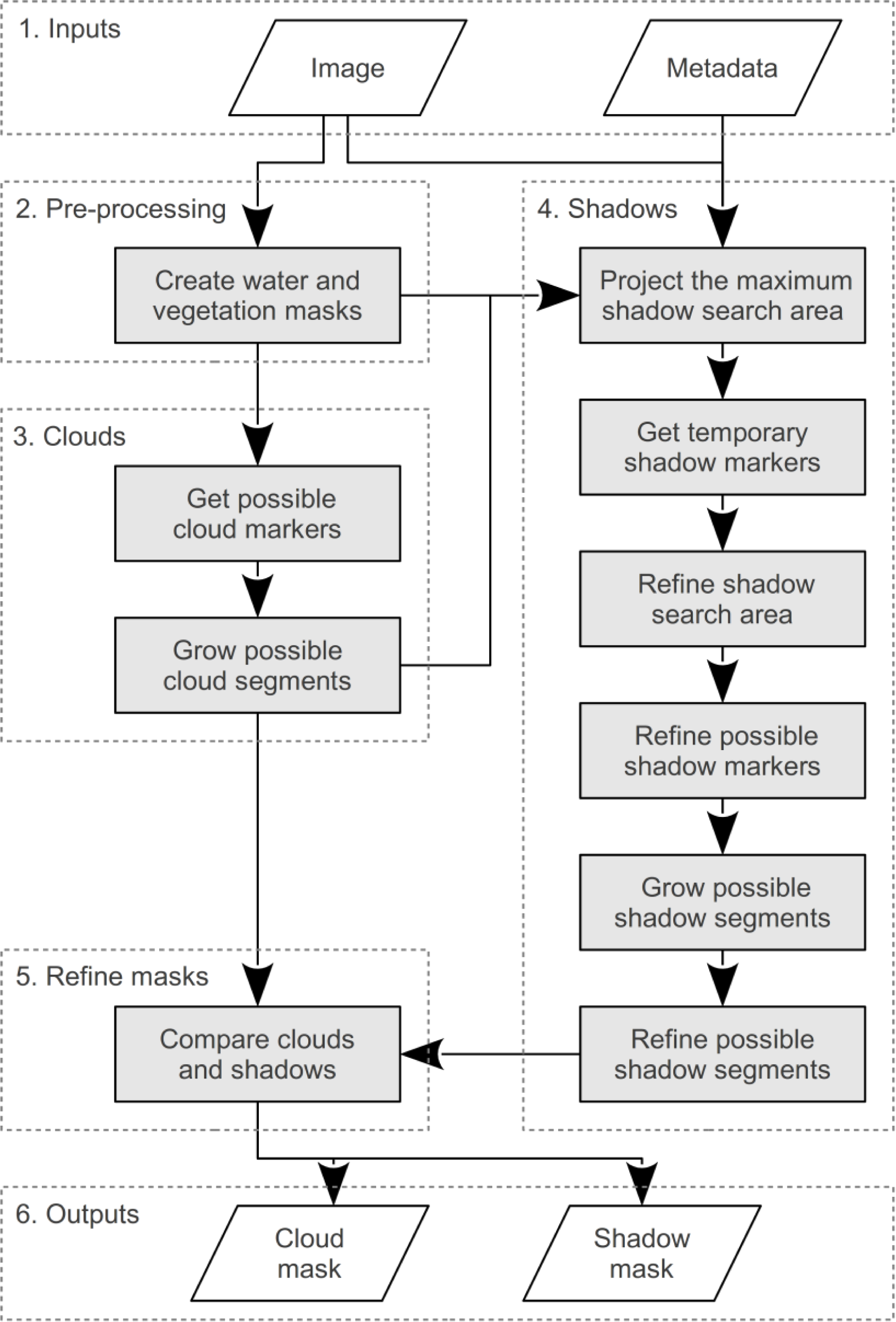
The following six steps (
Figure 4) are used to identify possible cloud-shadows, each of which is described in more detail below: (1) The maximum shadow search area is calculated using the possible cloud pixels and the sun and sensor angles; (2) Temporary shadow markers are identified as all dark objects in the maximum shadow search area; (3) The maximum shadow search area is reduced by determining the optimum cloud-shadow offset distance, through comparing the possible cloud pixels and temporary shadow markers, and assuming that all clouds are at a similar height; (4) New shadow markers are defined for each of the refined shadow search areas; (5) Possible shadow segments are grown with the watershed transform using the new markers; and (6) Some of the possible shadow segments are discarded if they are too small or if they are not sufficiently darker than neighboring pixels.
The maximum cloud-shadow search area is defined by the location of the possible cloud pixels, the apparent solar azimuth and a range of possible cloud heights, in an approach similar to other methods [
6,
8]. Apparent solar azimuth (
ϕa) is calculated using
Equation (1).
where
ϕs is the solar azimuth,
θs is the solar zenith,
ϕv is the viewer (sensor) azimuth, and
θv is the viewer zenith. Each of these inputs is taken from the image metadata file, with the approximation at the scene center used to simplify calculations. This approximation does not affect results, as other assumptions regarding flat ground and flat cloud surfaces have a greater influence on shadow location than within scene variation in sun and sensor view angles. The maximum horizontal distance between clouds and shadows is calculated using
Equation (2).
where
h is maximum cloud height, and
d is the maximum horizontal distance between a cloud and its shadow. A maximum cloud height of 12 km was used, based on previous work [
6,
20], and observations of maximum cloud-shadow offsets in imagery from NSW. This may need to be increased to 18 km if processing images from the tropics [
6,
22]. A minimum cloud-height of zero was used, allowing for the case where cloud and shadow pixels are adjacent. The maximum shadow search area was buffered by 100 m by dilating with a disk-shaped structuring element, merging closely spaced areas into regions, and ensuring that shadow identification is not limited by the angle approximations and the assumption of flat ground and flat cloud surfaces.
Temporary shadow marker pixels are identified for each continuous region in the maximum shadow search area. They are defined using a NIR threshold, calculated by comparing the 1-dimensional histogram of NIR values from within a region with that from the surrounding pixels within a 500 m buffer. The NIR band is used as cloud shadows appeared to be consistently dark in this band compared to a variety of landcover types. As the surrounding pixels do not contain any cloud-shadows, the difference between the two histograms represents the NIR values of the shadow pixels, and an initial threshold is defined as the median value of the difference between the histograms. In regions that have generally low NIR reflectance, this initial threshold performs well in defining cloud-shadow pixels. In highly reflective regions however, the initial threshold should ideally be increased to capture more shadow pixels. These cases are identified by the presence of a distinct trough between the shadow peak and the main peak when the two histograms are added. Where this trough is identified, the initial threshold is increased to the value at the location of the trough instead of the median value of the difference.
The temporary shadow marker pixels contain any dark pixels that are in the maximum shadow search area, which can include false positives such as topographic shadow or dark patches of vegetation. By making the assumption that all clouds within an image are at approximately the same height, these errors can be reduced by using the temporary markers to calculate an optimum cloud-shadow horizontal offset, which is then used to calculate a refined shadow search area. This is implemented by iteratively shifting cloud marker pixels in the shadow direction, and for each shift calculating the percentage of cloud marker pixels that are coincident with shadow marker pixels. The position at which this percentage is at a maximum is the optimum cloud-shadow offset distance. To allow for some variation in cloud height and surface relief, this best-fit value is assigned an uncertainty of ±40 m.
New shadow markers are then determined for each possible cloud by calculating a NIR threshold for the pixels in its refined shadow search area, according to the following steps. Firstly, the percentage of pixels in the search area expected to be shadow is calculated as the number of cloud pixels divided by the number of search area pixels multiplied by 100. If the search area includes pixels off the image edge, the percentage is reduced by multiplying by the number of valid search area pixels divided by the total number of search area pixels. Secondly, a NIR threshold is calculated, such that half the expected percentage of pixels in the search area have values less than the threshold. Halving the expected percentage creates a threshold that includes only the darkest pixels as internal markers, and reduces false positives.
External markers for shadows are a combination of the pixels defined by the water and vegetation masks, and extra pixels based on local thresholds for pixels neighboring the internal markers according to the following steps. Internal markers for shadows are buffered by 500 m through dilating with a disk shaped structuring element. Local thresholds are calculated as half way between the maximum reflectance for internal marker pixels and the median reflectance for all other pixels in the buffered region, for both band 3 (NIR) and band 4 (SWIR). All pixels with reflectance values greater than these thresholds are external markers for shadows. The SWIR threshold was necessary to remove some non-shadow objects that were not sufficiently dark in the NIR alone.
Possible shadow segments are grown from the internal and external markers using the watershed transform on the sum of the morphological gradient for each band, after an ASF has been applied, following the method used for clouds. The segments are refined by size, with all segments less than 4 pixels in size removed to reduce commission of false positives from small shadows cast by tall buildings and trees, and from small water bodies that were missed by the water mask. They are further refined by only including shadows that are darker than the surrounding pixels. Shadows are deemed sufficiently dark if the mean reflectance of band 3 (NIR) for shadow pixels is at least 20% less than the mean for pixels in a 5 pixel buffer around that shadow. The value of 20% was determined by examining the reflectance of shadows and their surrounding pixels in the 10 training images. It was set to screen out obvious non-shadows without resulting in omission of real shadows.
3.8. Refining Clouds and Shadows
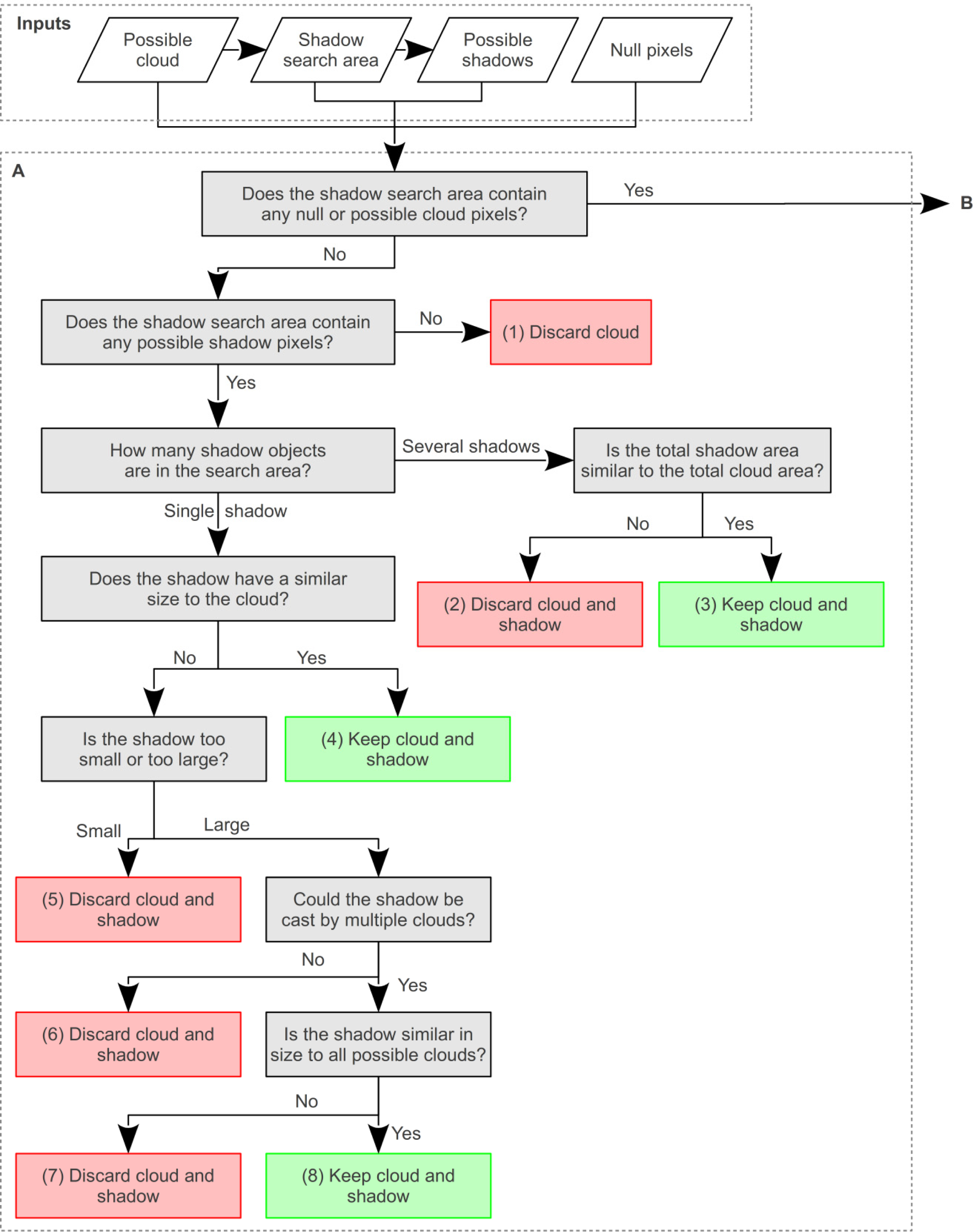
Possible cloud and shadow segments are refined through iteratively checking that each cloud object has a similar number of possible shadow pixels within the expected area, defined by the apparent solar azimuth and the best-fit cloud-shadow offset distance. This process is complicated by numerous factors, such as: the presence of possible cloud objects within the shadow search area; shadow search areas that extend off the image edge; single cloud objects that cast multiple shadow objects; and, single shadow objects that are cast by multiple cloud objects. A decision tree is used to identify whether these complicating factors are relevant to a particular cloud, before rules are applied to determine if a cloud or shadow is valid (
Figure 9).
A degree of uncertainty is incorporated into any comparison of cloud and shadow size, by including a tolerance factor. When a possible cloud object has a single possible shadow object in the expected area, and no complicating factors, the cloud is considered valid if
Equations (3) and
(4) are true.
where
C is the size of the possible cloud (pixels),
S is the size of the possible shadow (pixels) and
t is the tolerance factor. After experimentation across the training images,
t was set at a value of 4. This was found to be a good compromise between tolerating some variation in size (that is expected when the shadow of a 3-dimensional object is projected into a topographically varying surface) and discarding clouds and shadows that varied too greatly in size. Where
Equation (3) is false, the possible cloud is deemed too large to have cast the possible shadow, and they are both discarded. Where
Equation (4) is false, the possible shadow is too large for the possible cloud. If the shadow could not have been cast by additional possible clouds (checked through creating a cloud search area for the possible shadow through reversing the cloud-shadow offset distance and angle) then both possible cloud and shadow are discarded. If the possible shadow could have been cast by more than one possible cloud then the total number of cloud pixels in the cloud search area is compared to the number of shadow pixels using
Equations (3) and
(4) before accepting or rejecting the possible clouds and shadows.
When multiple shadows are present in the shadow search area the shadow size is calculated as the sum of all possible shadow pixels within the shadow search area, before using
Equations (3) and
(4). When null pixels are present in the shadow search area, these are included in the shadow size calculation, but
Equation (4) is not used as the area obscured by null pixels may be much larger than the cloud size.
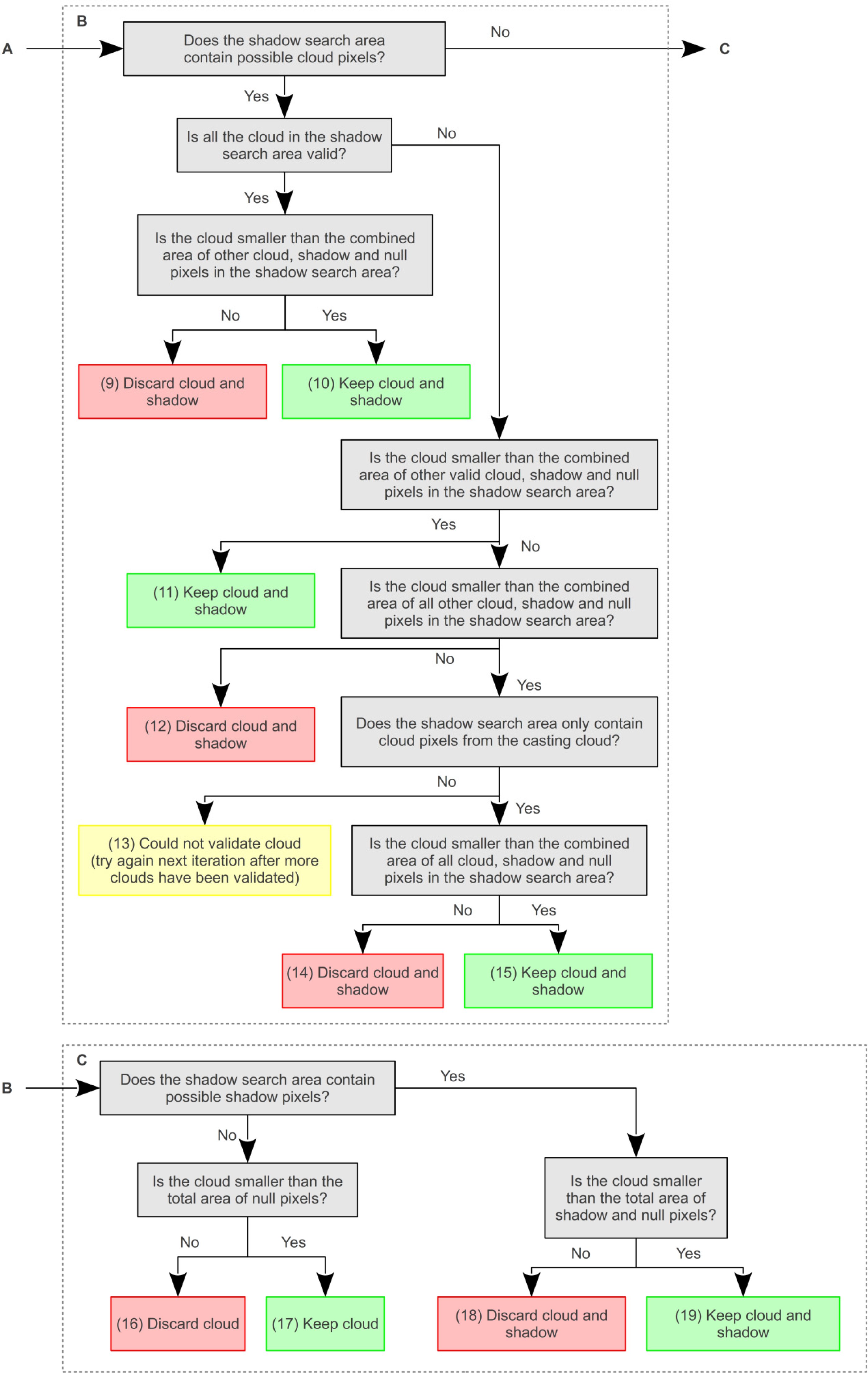
When other possible clouds are present in the shadow search area a different sequence of tests is used. Firstly, all the pixels from clouds that are in the shadow search area and have already been accepted are included in the calculation of shadow size. If
Equation (4) is true and the cloud size is smaller than this shadow size the cloud and shadow(s) are accepted, otherwise a second step is used. This requires all cloud pixels that are in the shadow search area to be added to the shadow size even if they are yet to be validated, before testing with
Equation (4). If
Equation (4) is false and the cloud is larger than the shadow size, then the cloud and shadow(s) are rejected, otherwise the third step is used. This tests whether the cloud pixels within the shadow search area only belong to the cloud being validated. If this is the case, the cloud may be obscuring part of its own shadow, and both cloud and shadow(s) are accepted. If other clouds are present, then the cloud cannot be validated until the other clouds are validated first. Once all clouds have been tested, those that could not be validated are tested again, and iterations continue until all cloud has been accepted or rejected.
Other approaches to refining the clouds and shadows, such as comparing their shape [
8] may perform better with discrete pairs of matching clouds and shadows. However, it is difficult to compute for all the complex situations described above and shown in
Figure 9. Once the cloud and shadow masks have been finalized, they are buffered by 5 pixels through dilating with an 11 by 11 disk shaped structuring element. Any overlap created by the cloud and shadow buffering is attributed to clouds.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}