Tile-Level Annotation of Satellite Images Using Multi-Level Max-Margin Discriminative Random Field



Abstract
:1. Introduction
2. Multi-Level Max-Margin Discriminative Topic Model Based on MedLDA
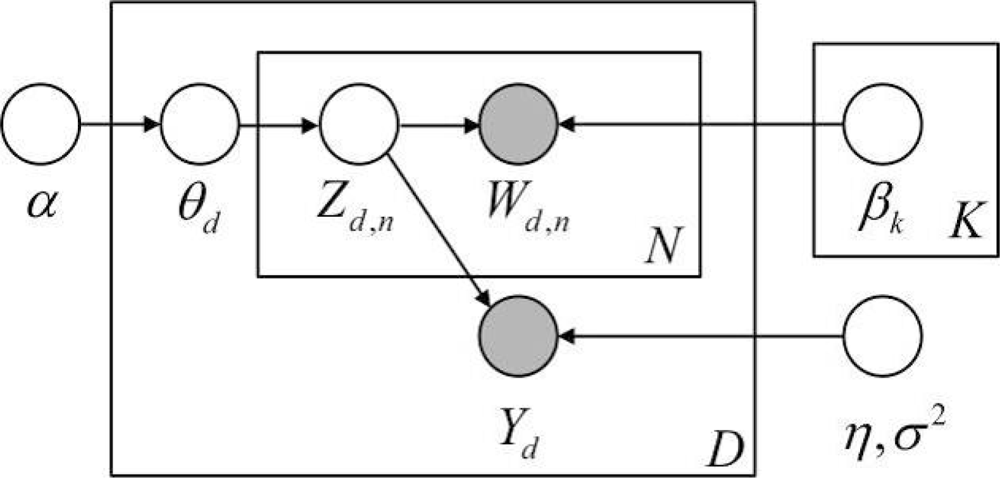
2.1. MedLDA Model
- (1)
- Draw topic proportions θ|α ∼ Dir(α);
- (2)
- For each of the N words wn:
- (a)
- Draw a topic assignment zn|θ ∼ Multinomial(θ);
- (b)
- Draw a word wn from P(wn|zn,β), a multinomial probability conditioned on the topic zn, namely wn|zn,β1:K ∼ Multinomial(βzn).
- (3)
- Draw a response variable y|z1:N,η,σ2 ∼ N(ηT Z̄,σ2), where
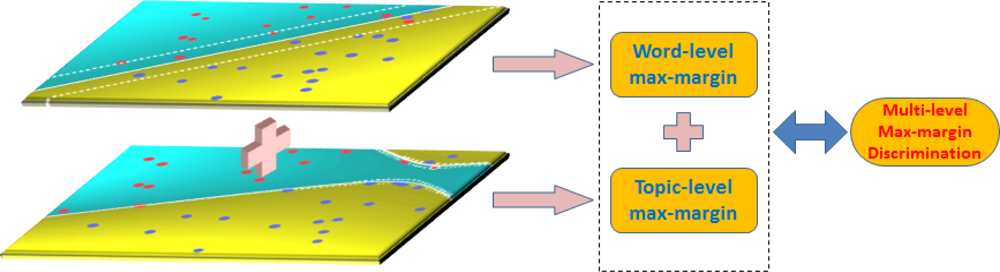
2.2. Multi-Level Max-Margin Discriminative Topic Model
3. M3DA-Based Random Field
3.1. Conditional Random Field
3.2. M3DA-Based Random Field
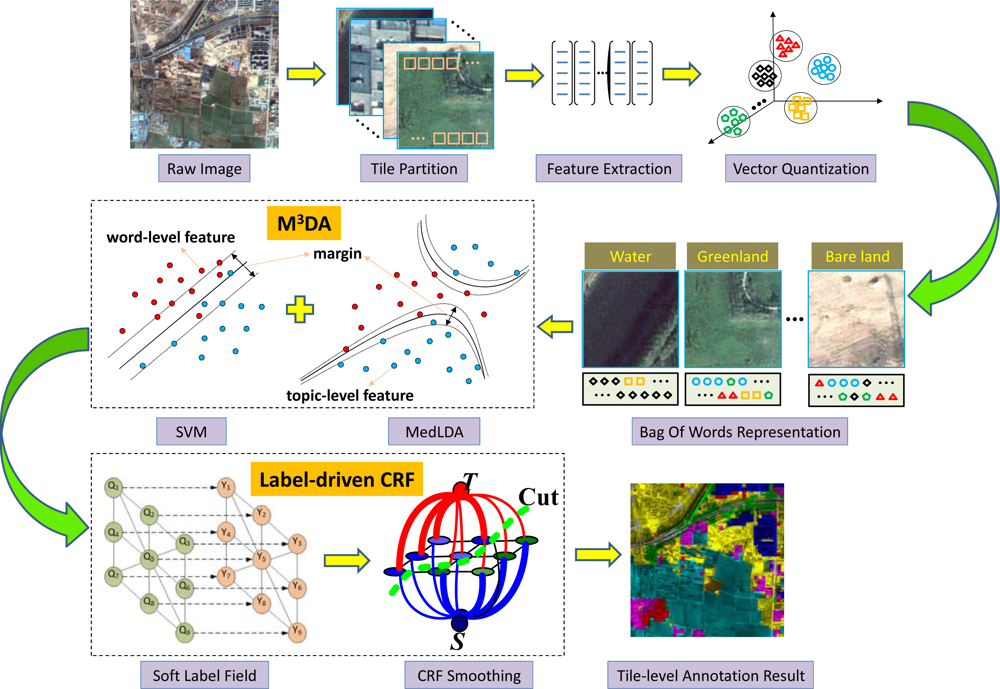
4. Tile-Level Annotation Algorithm and Experimental Result Analysis
4.1. M3DA-RF Based Tile-level Annotation Algorithm of Satellite Images

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input: original high-resolution image IO |
| Output: the annotation image IA |
|
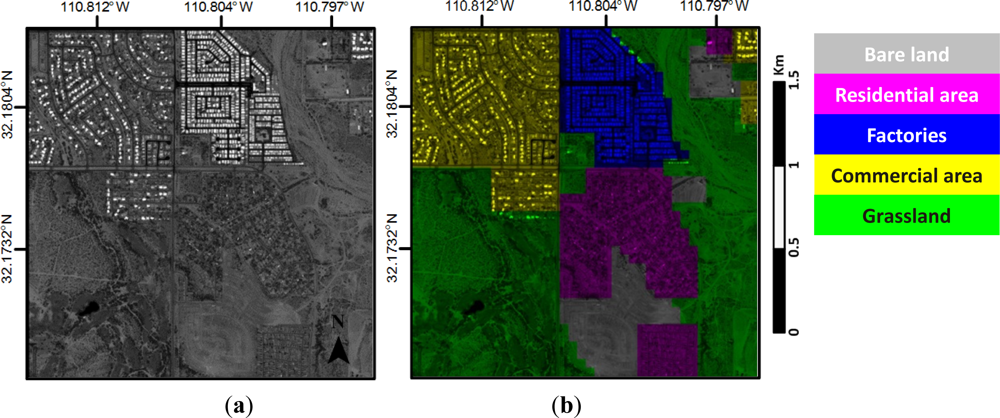
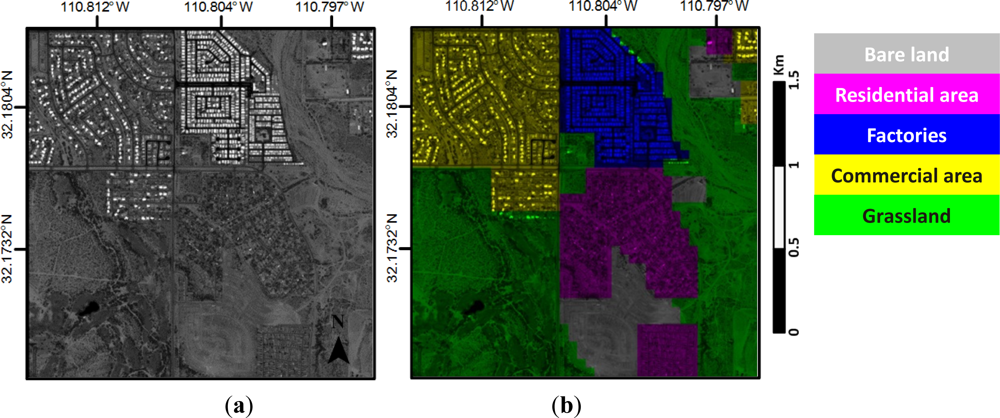
4.2. Experimental Data and Settings
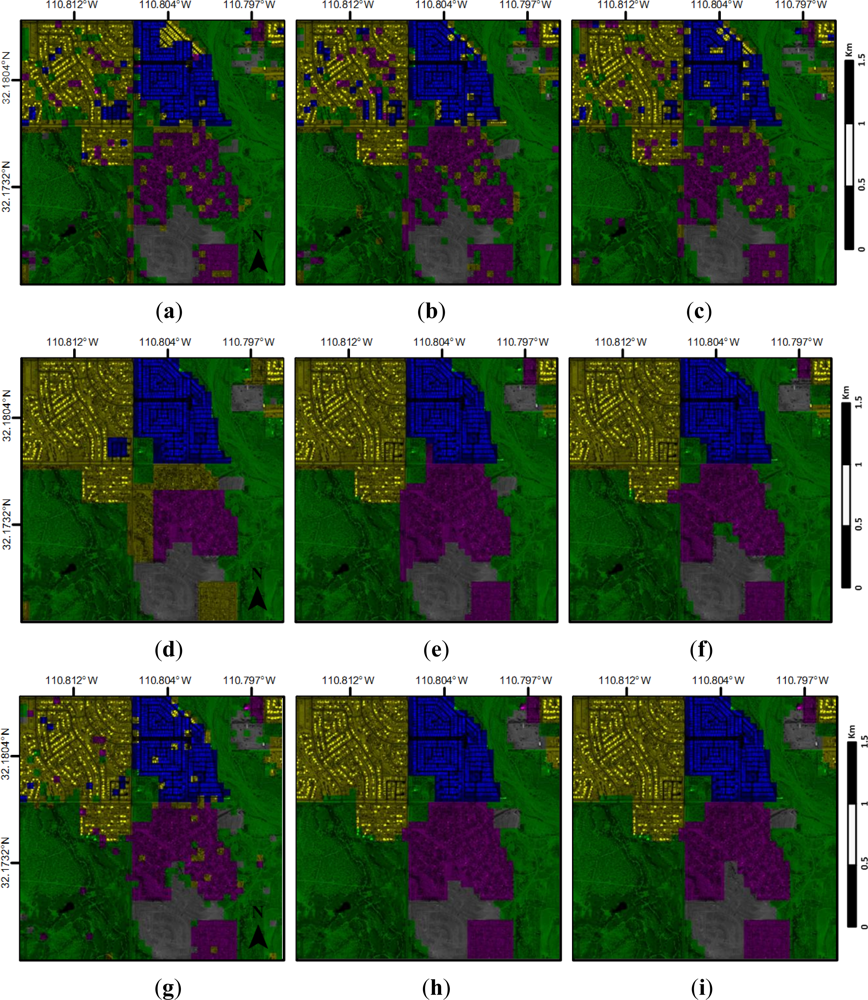
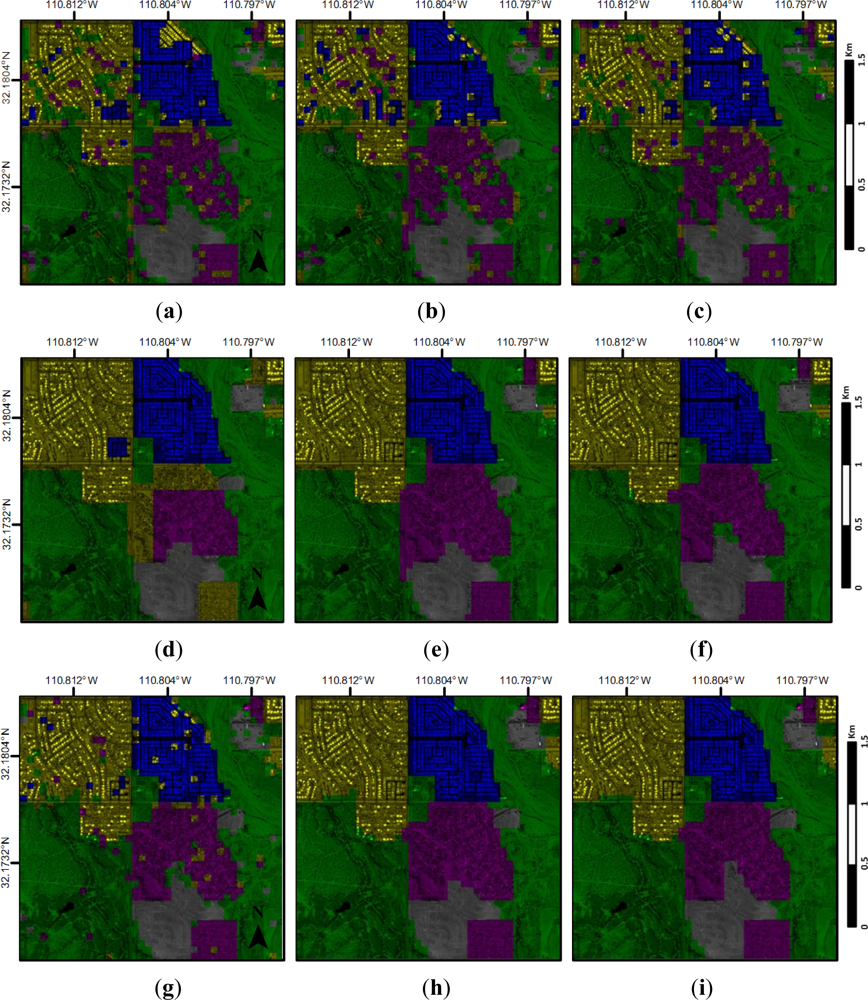
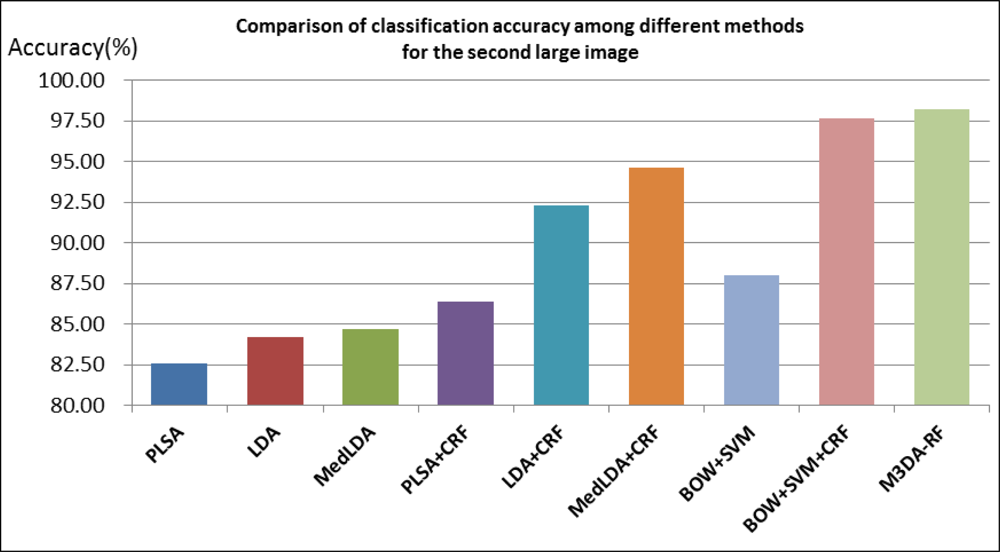
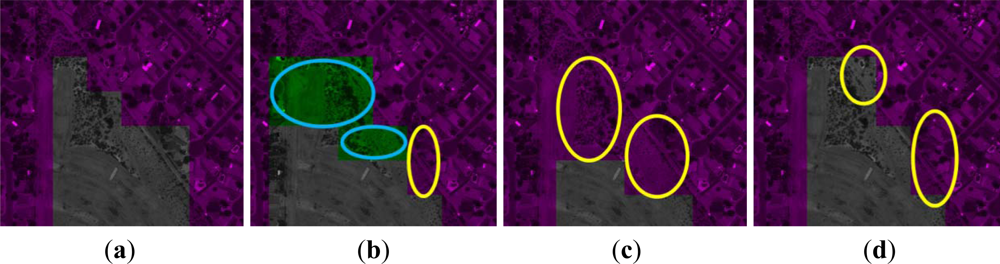
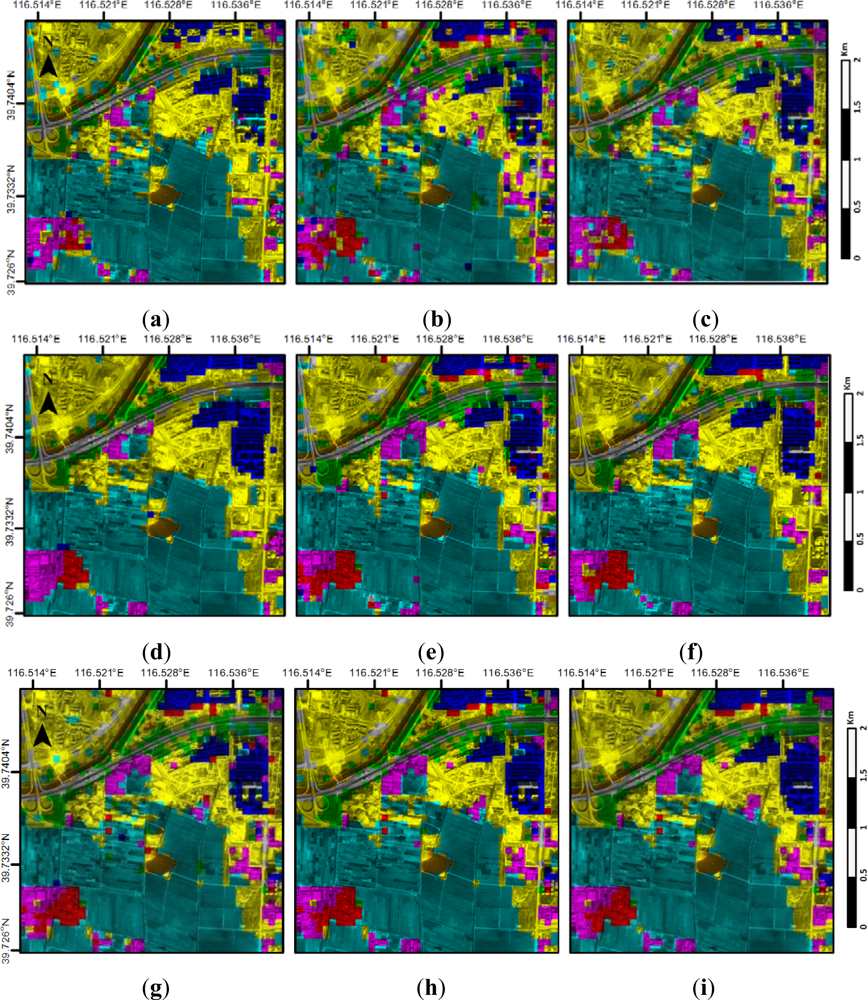
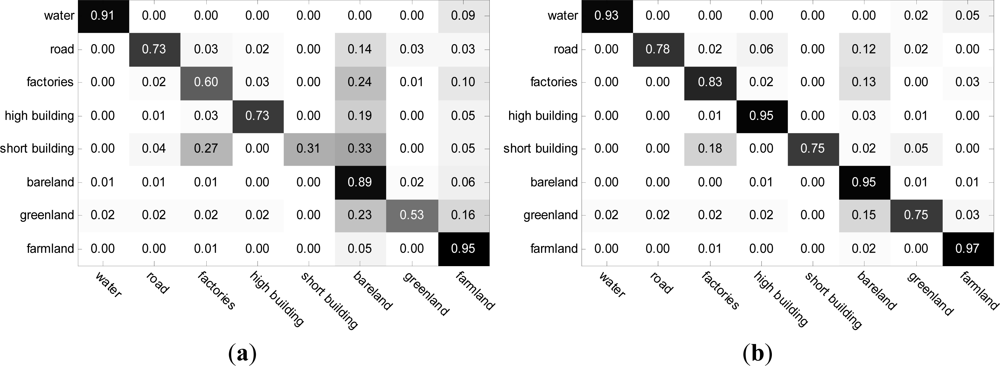
4.3. Annotation Results and Analysis
5. Discussion
6. Conclusion
Acknowledgments
- Conflict of InterestThe authors declare no conflict of interest.
References
- Yi, W.; Tang, H.; Chen, Y. An object-oriented semantic clustering algorithm for high-resolution remote sensing images using the aspect model. IEEE Geosci. Remote Sens. Lett. 2011, 8, 522–526. [Google Scholar]
- Hofmann, T. Unsupervised learning by probabilistic latent semantic analysis. Mach. Learn. 2001, 42, 177–196. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Larlus, D.; Jurie, F. Latent mixture vocabularies for object categorization and segmentation. Image Vis. Comput. 2009, 27, 523–534. [Google Scholar]
- Lienou, M.; Maitre, H.; Datcu, M. Semantic annotation of satellite images using latent dirichlet allocation. IEEE Geosci. Remote Sens. Lett. 2010, 7, 28–32. [Google Scholar]
- Xu, K.; Yang, W.; Liu, G.; Sun, H. Unsupervised satellite image classification using markov field topic model. IEEE Geosci. Remote Sens. Lett. 2013, 10, 130–134. [Google Scholar]
- Wang, X.; Grimson, E. Spatial Latent Dirichlet Allocation. Proceedings of 21st Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2007; pp. 1577–1584.
- Verbeek, J.; Triggs, B. Region Classification with Markov Field Aspect Models. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8.
- Yang, W.; Dai, D.; Triggs, B.; Xia, G.-S. SAR-based terrain classification using weakly supervised hierarchical Markov aspect models. IEEE Trans. Image Process. 2012, 21, 4232–4243. [Google Scholar]
- Zhu, J.; Ahmed, A.; Xing, E.P. MedLDA: Maximum Margin Supervised Topic Models for Regression and Classification. Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1257–1264.
- Blei, D.M.; McAuliffe, J.D. Supervised Topic Models. Proceedings of 21st Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2007; pp. 121–128.
- Zhao, B.; Li, F.; Xing, E. Image Segmentation with Topic Random Field. Proceedings of 11th European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 785–798.
- Lafferty, J.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. Proceedings of the 29th International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001.
- Delong, A.; Osokin, A.; Isack, H.N.; Boykov, Y. Fast approximate energy minimization with label costs. Int. J. Comput. Vis. 2012, 96, 1–27. [Google Scholar]
- Kolmogorov, V.; Zabin, R. What energy functions can be minimized via graph cuts? IEEE Trans. Patt. Anal. Mach. Int 2004, 26, 147–159. [Google Scholar]
- Wang, Y.; Mori, G. Max-Margin Latent Dirichlet Allocation for Image Classification and Annotation. Proceedings of 22nd British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011.


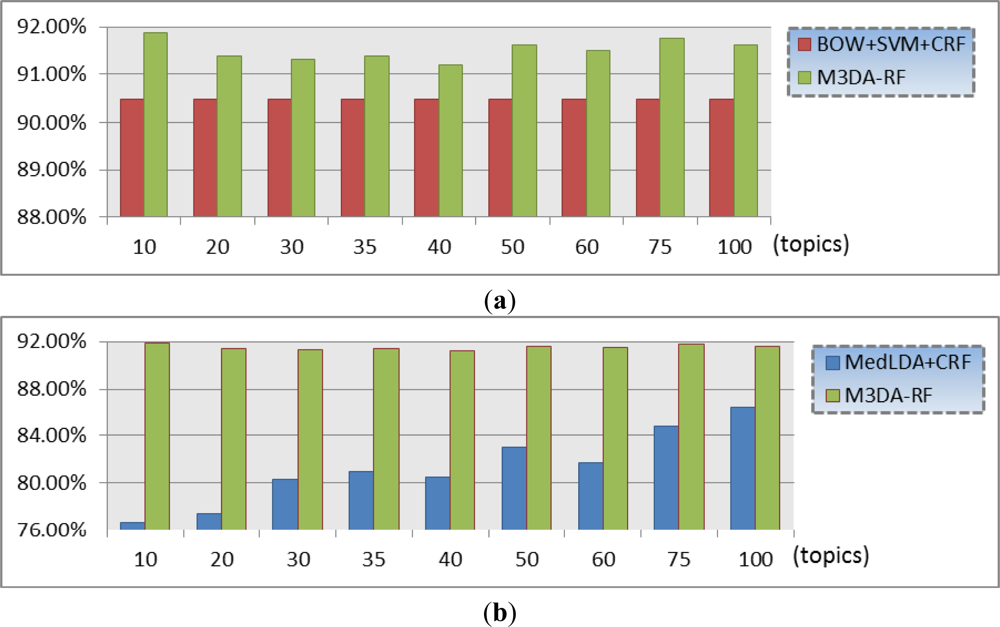
| Topics | 10 | 20 | 30 | 35 | 40 | 50 | 60 | 75 | 100 |
|---|---|---|---|---|---|---|---|---|---|
| Method | |||||||||
| PLSA | 68.06% | 69.44% | 71.38% | 72.25% | 73.5% | 73.13% | 73.69% | 73.94% | 74.44% |
| LDA | 69.38% | 73.13% | 74.56% | 76.13% | 74.94% | 75.94% | 76.38% | 77.94% | 78.5% |
| MedLDA | 71.4% | 73.6% | 76.4% | 77.6% | 79% | 79.4% | 80.1% | 83.18% | 83.93% |
| PLSA+CRF | 72% | 73% | 75.75% | 76.88% | 76.94% | 77.44% | 78.125% | 78.81% | 78.81% |
| LDA+CRF | 71.88% | 78.18% | 79.13% | 80.06% | 80.5% | 81% | 80.81% | 82.31% | 83.5% |
| MedLDA+CRF | 76.69% | 77.44% | 80.31% | 81% | 80.5% | 83% | 81.69% | 84.75% | 86.44% |
| M3DA-RF | 91.88% | 91.38% | 91.31% | 91.38% | 91.19% | 91.63% | 91.5% | 91.75% | 91.63% |
© 2013 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Hu, F.; Yang, W.; Chen, J.; Sun, H. Tile-Level Annotation of Satellite Images Using Multi-Level Max-Margin Discriminative Random Field. Remote Sens. 2013, 5, 2275-2291. https://doi.org/10.3390/rs5052275
Hu F, Yang W, Chen J, Sun H. Tile-Level Annotation of Satellite Images Using Multi-Level Max-Margin Discriminative Random Field. Remote Sensing. 2013; 5(5):2275-2291. https://doi.org/10.3390/rs5052275
Chicago/Turabian StyleHu, Fan, Wen Yang, Jiayu Chen, and Hong Sun. 2013. "Tile-Level Annotation of Satellite Images Using Multi-Level Max-Margin Discriminative Random Field" Remote Sensing 5, no. 5: 2275-2291. https://doi.org/10.3390/rs5052275