
Interframe Saliency Transformer and Lightweight Multidimensional Attention Network for Real-Time Unmanned Aerial Vehicle Tracking

Abstract
:1. Introduction
- We present a novel interframe saliency transformer that adaptively aggregates temporal contextual information, focusing on the dependencies between salient regions and their corresponding interframe response maps. This approach endows the algorithm with spatiotemporal correlation to enhance its ability to perceive foreground information;
- We developed the lightweight multidimensional attention network that establishes inter-dimensional dependencies with a remarkably low computational overhead, encoding both channel-wise and spatial information to enhance saliency and discriminative capability of features;
- Comprehensive evaluations on four benchmarks have validated the promising performance of SiamITL compared with other state-of-the-art (SOTA) trackers. In the speed test, SiamITL exhibits real-time performance with a speed of 32 frames per second (FPS) on real embedded platforms.
2. Related Work
3. Proposed Method
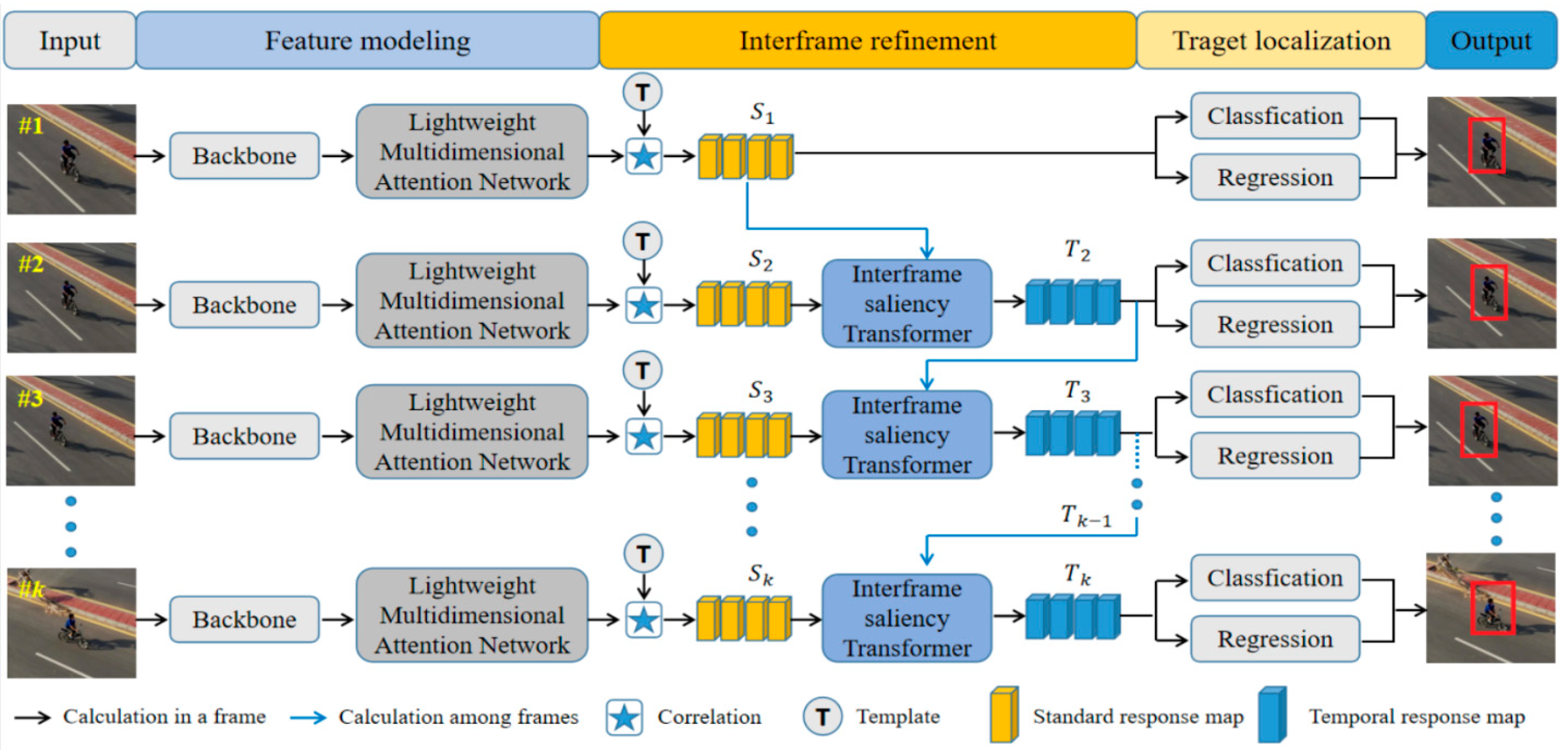
3.1. Overview
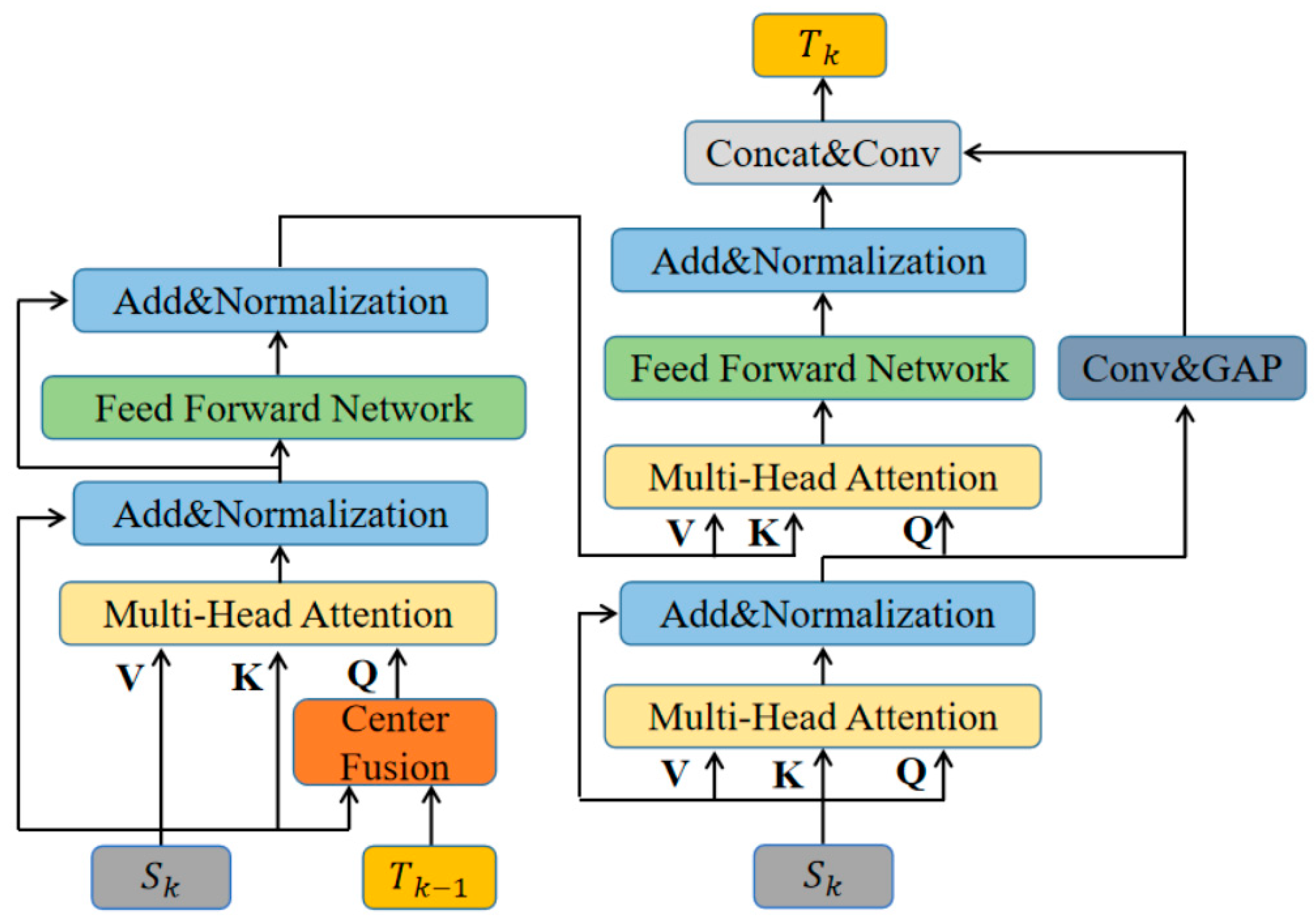
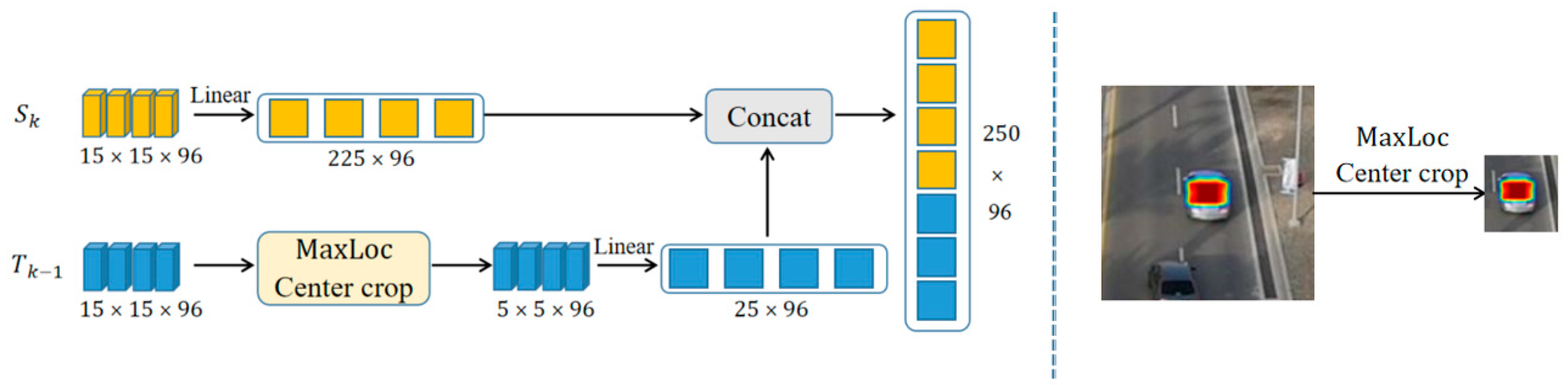
3.2. Interframe Saliency Transformer
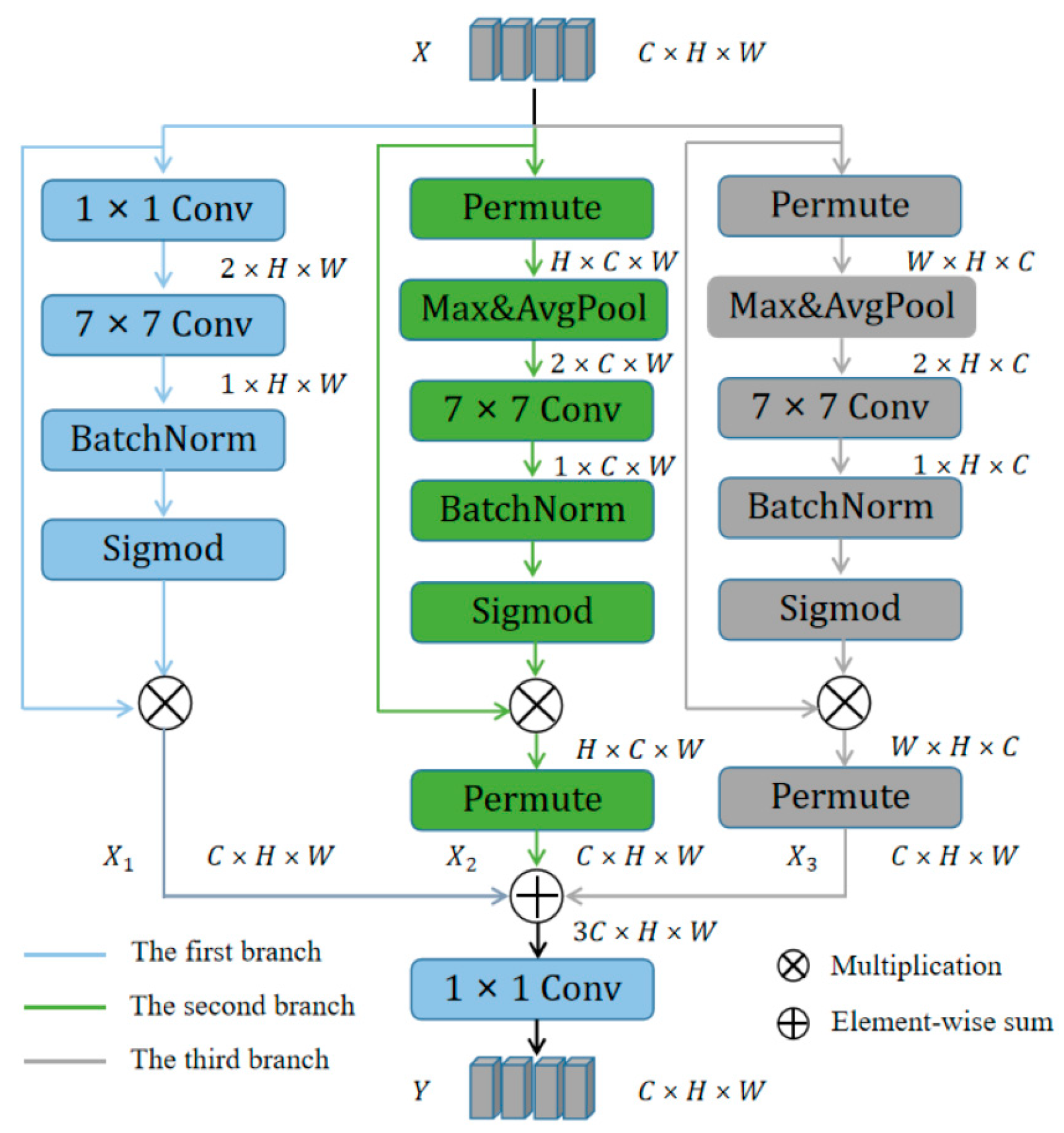
3.3. Lightweight Multidimensional Attention Network
4. Results
4.1. Implementation Details
4.2. Evaluation Index
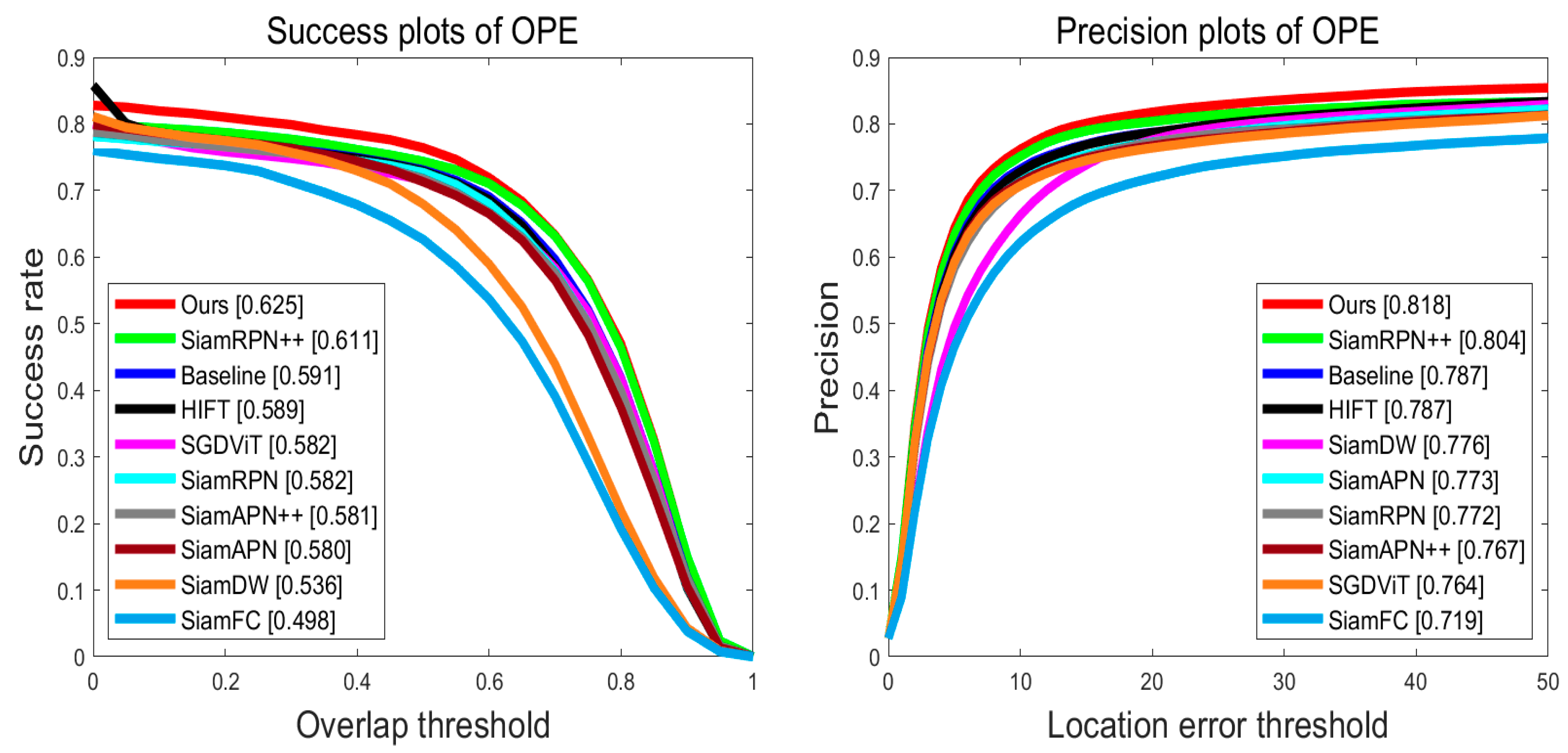
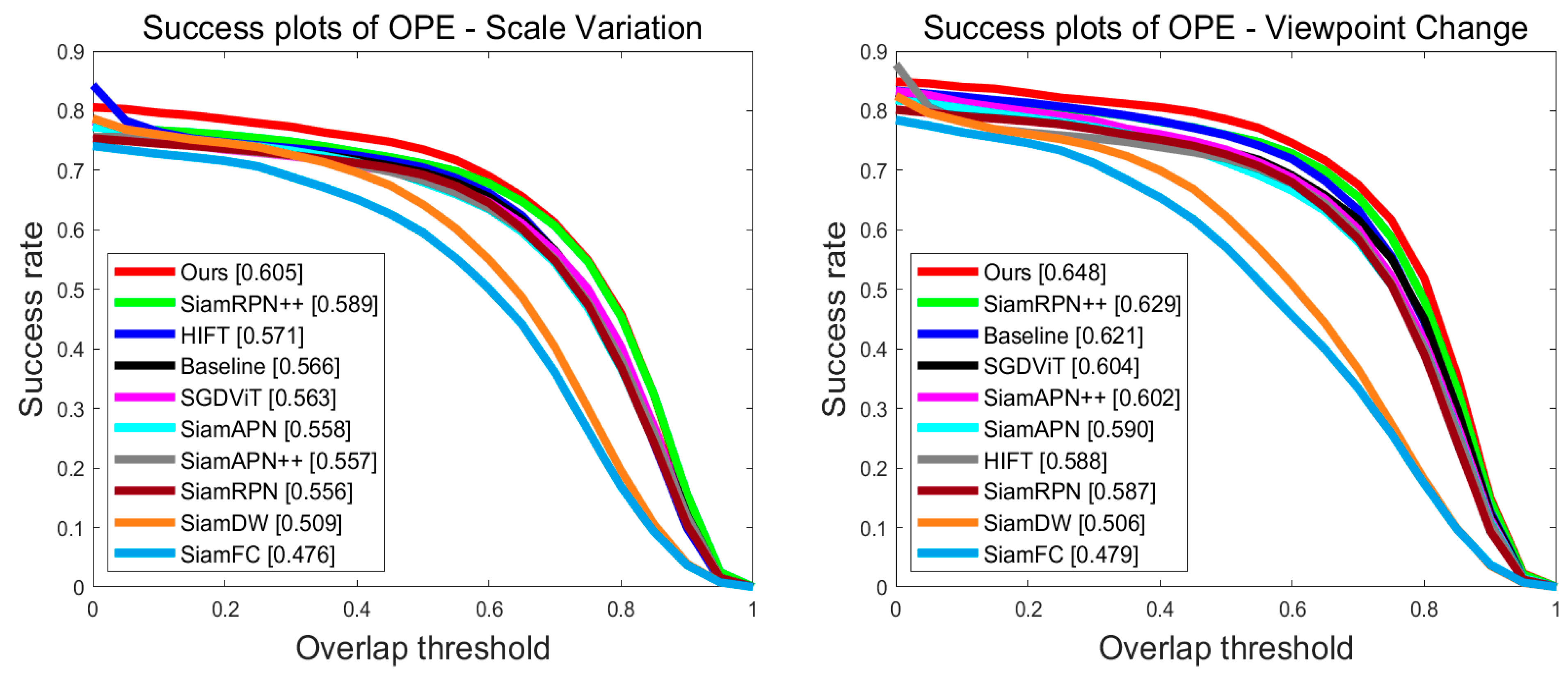
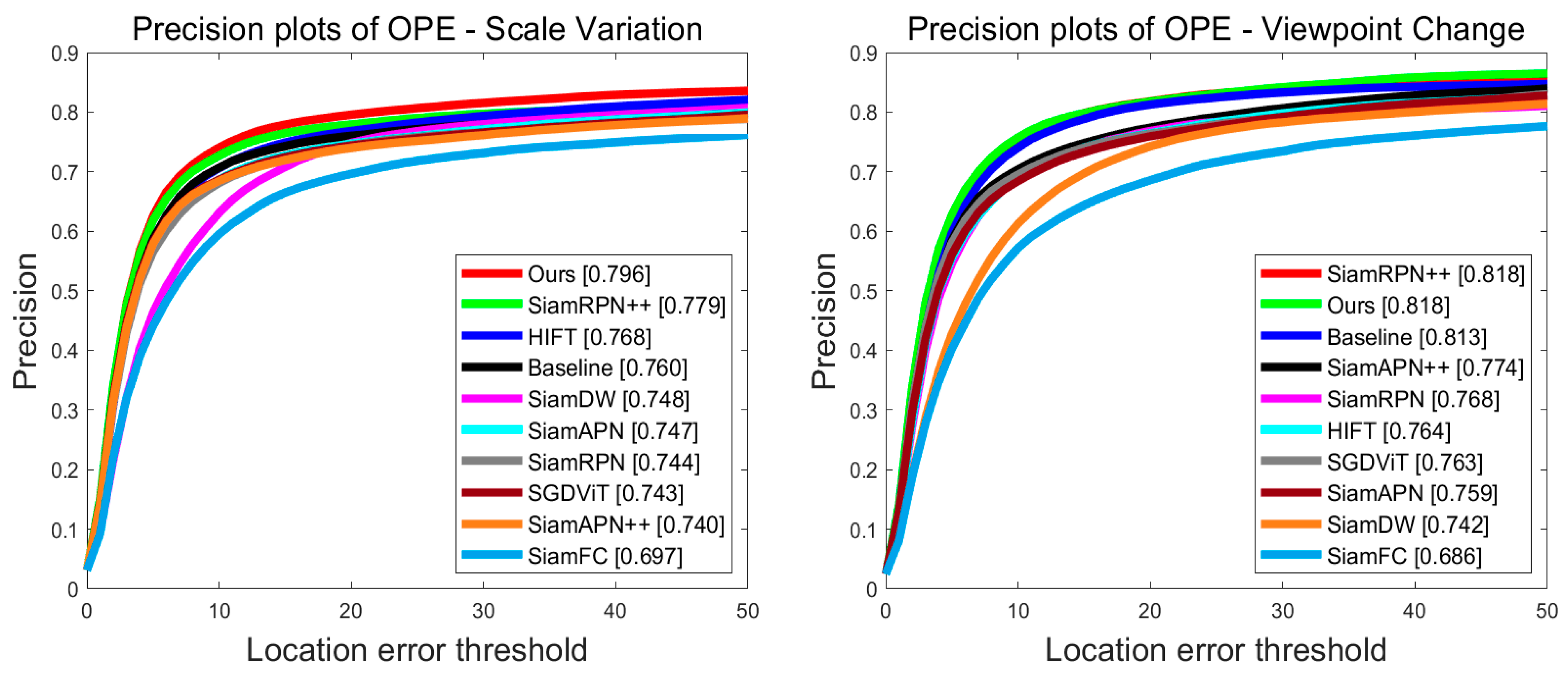
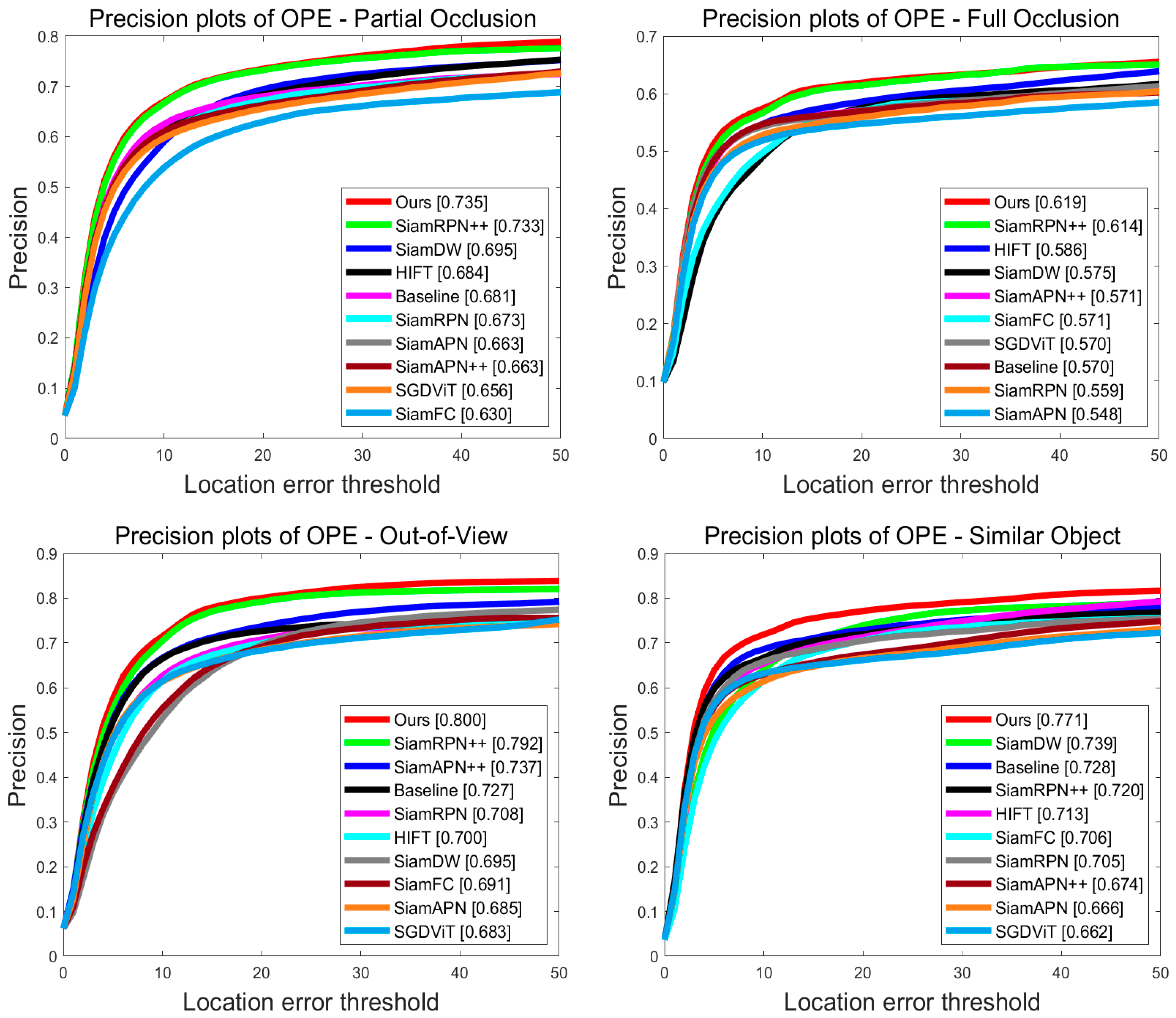
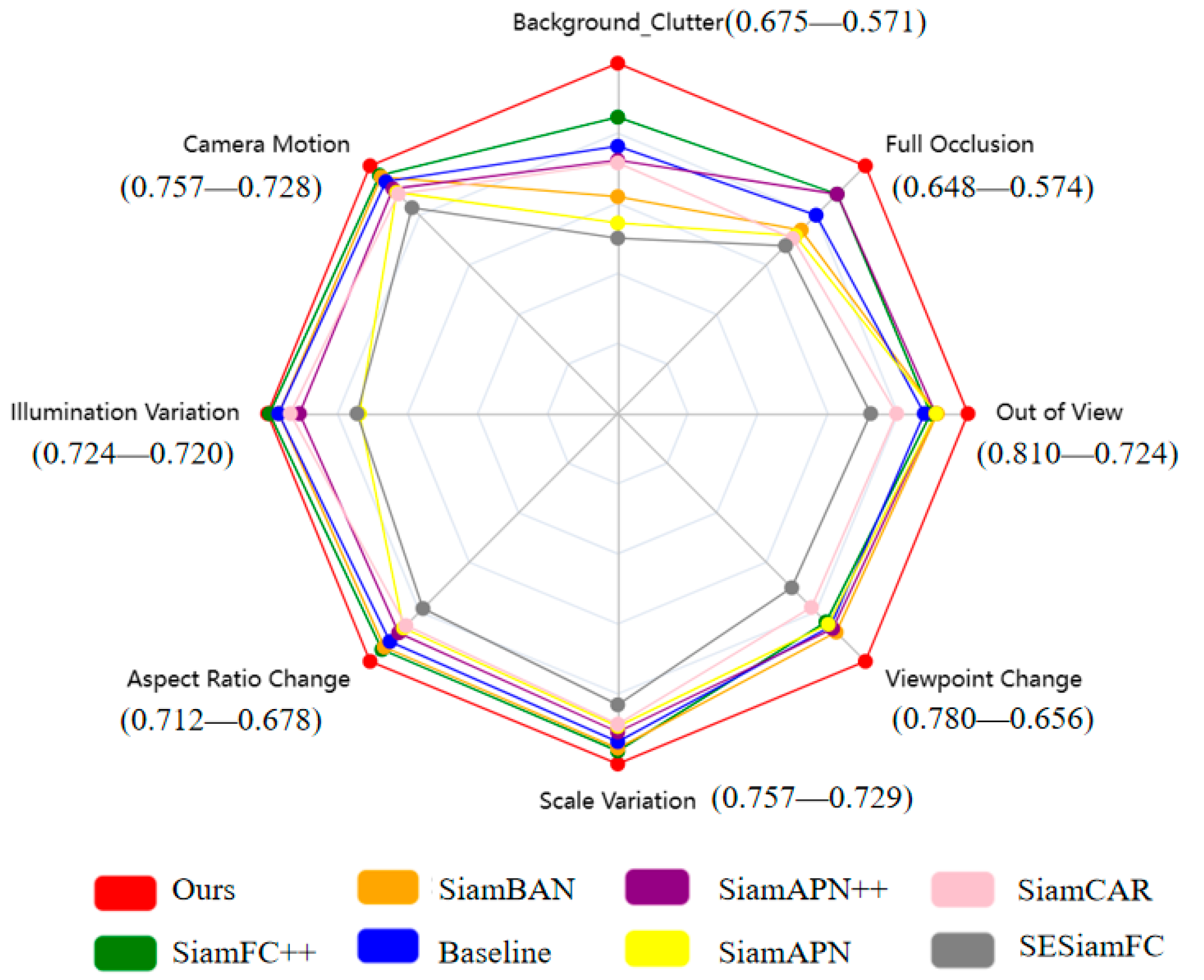
4.3. Experiments on the UAV123 Benchmark
4.4. Experiments on the UAV20L Benchmark
4.5. Experiments on the DTB70 Benchmark
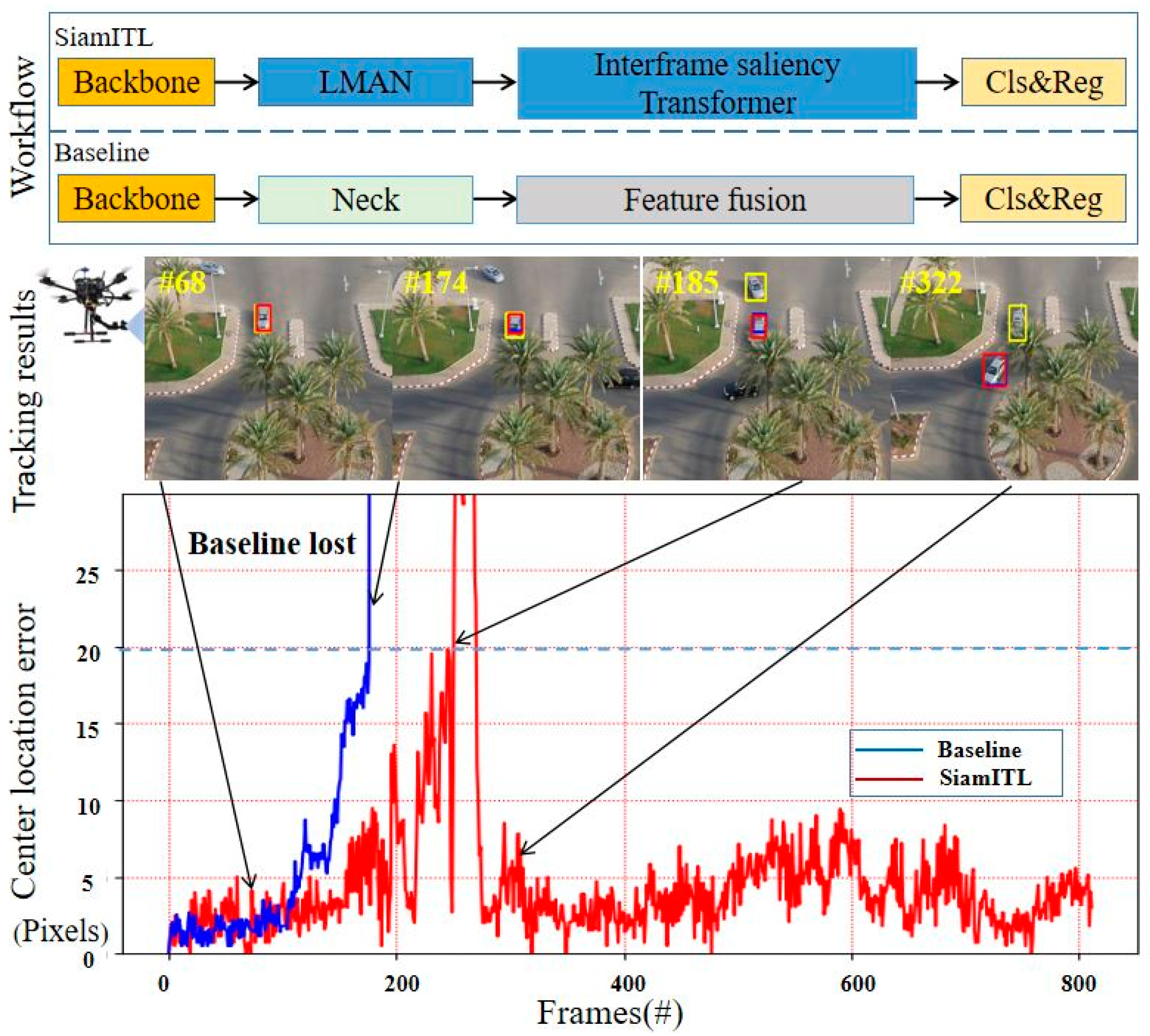
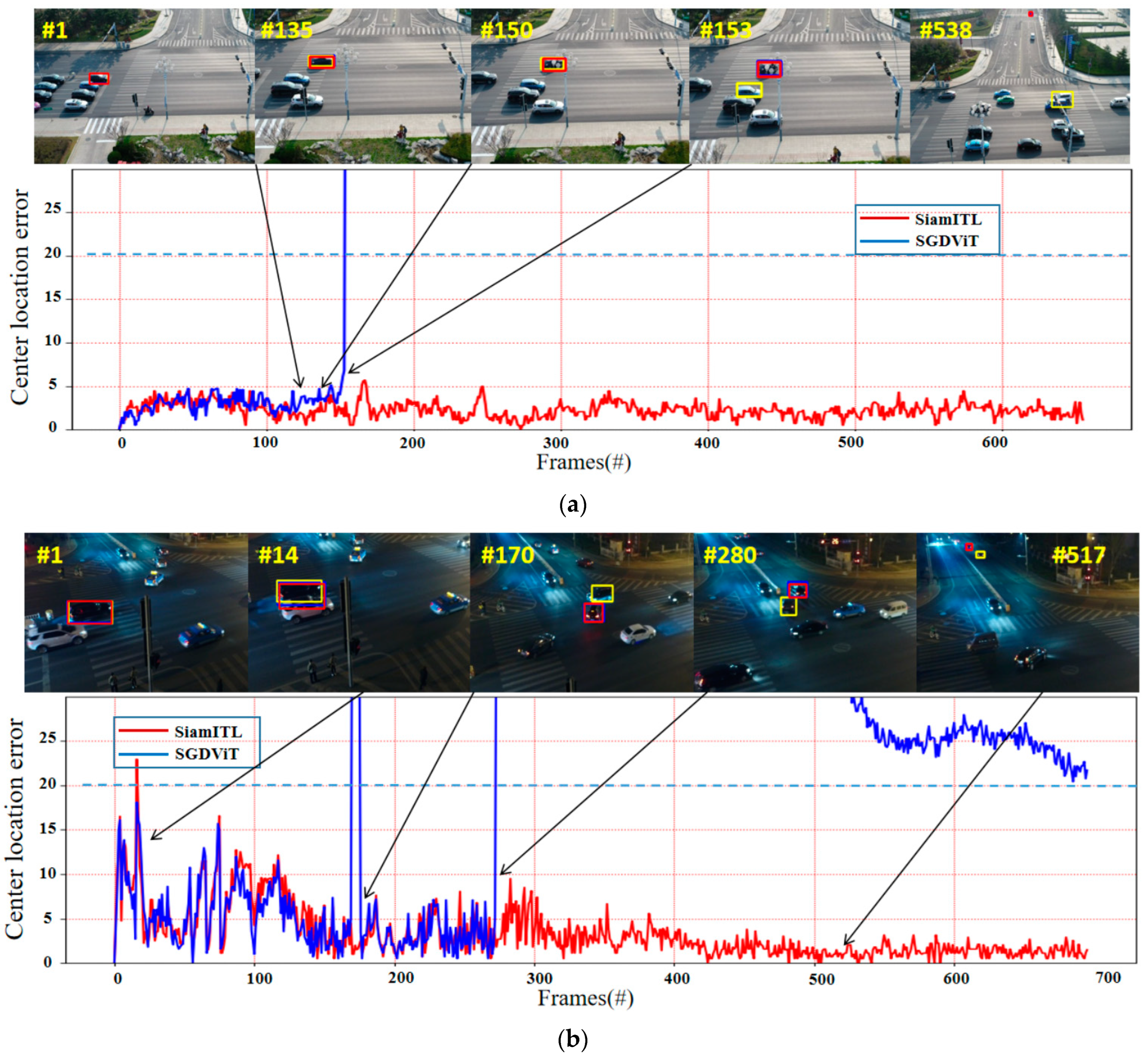
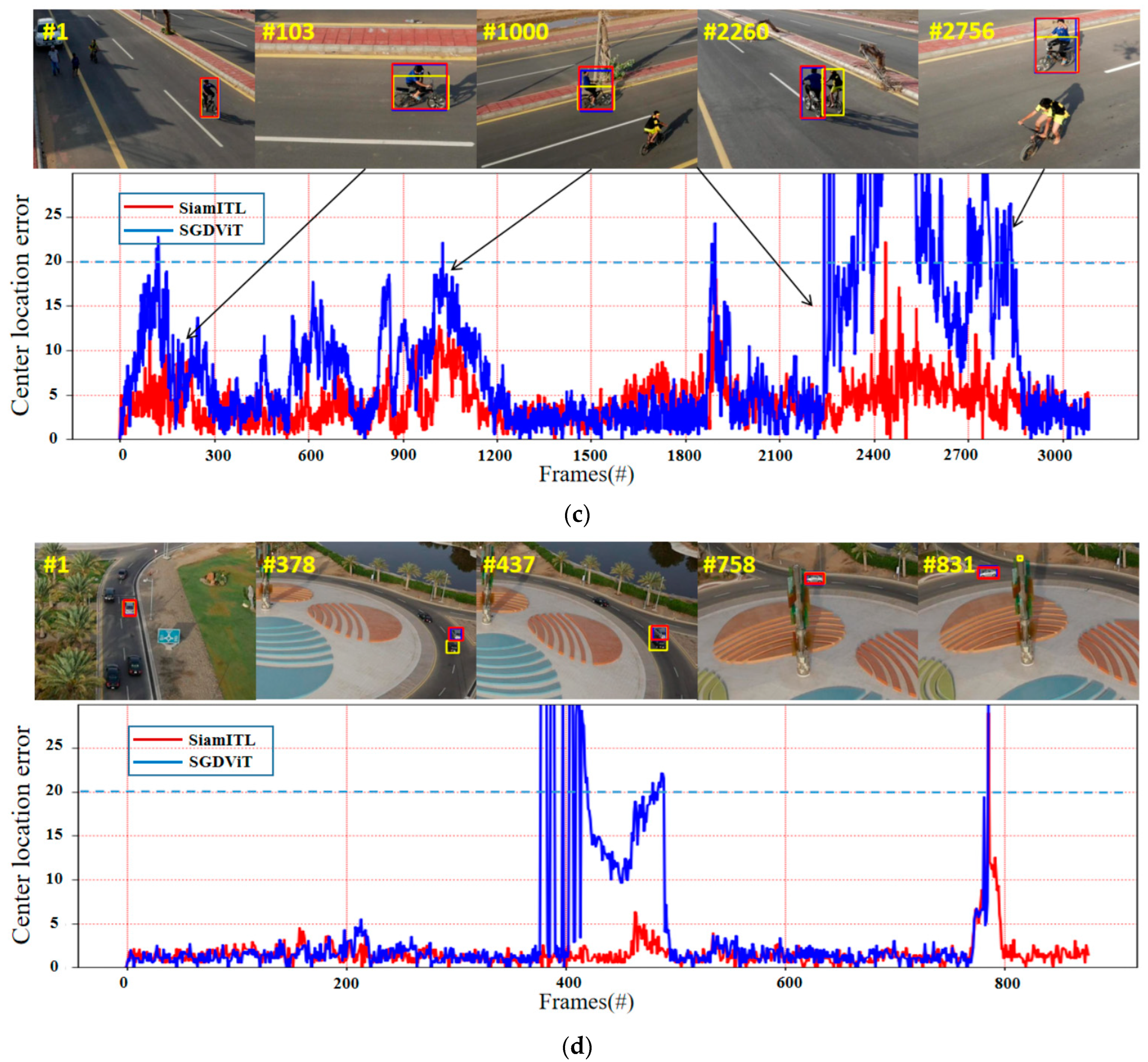
4.6. Qualitative Evaluation
4.7. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, B.; Fu, C.; Ding, F.; Ye, J.; Lin, F. All-Day Object Tracking for Unmanned Aerial Vehicle. IEEE Trans. Mob. Comput. 2022, 22, 4515–4529. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Song, J.; Xu, Y. Object Tracking Based on Satellite Videos: A Literature Review. Remote Sens. 2022, 14, 3674. [Google Scholar] [CrossRef]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep learning for unmanned aerial vehicle-based object detection and tracking: A survey. IEEE Geosci. Remote Sens. Mag. 2021, 10, 91–124. [Google Scholar] [CrossRef]
- Lee, D.; Kim, G.; Kim, D.; Myung, H.; Choi, H.-T. Vision-based object detection and tracking for autonomous navigation of underwater robots. Ocean. Eng. 2012, 48, 59–68. [Google Scholar] [CrossRef]
- Marvasti-Zadeh, S.M.; Cheng, L.; Ghanei-Yakhdan, H.; Kasaei, S. Deep learning for visual tracking: A comprehensive survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 3943–3968. [Google Scholar] [CrossRef]
- Fu, C.; Li, B.; Ding, F.; Lin, F.; Lu, G. Correlation filters for unmanned aerial vehicle-based aerial tracking: A review and experimental evaluation. IEEE Geosci. Remote Sens. Mag. 2021, 10, 125–160. [Google Scholar] [CrossRef]
- Fu, C.; Lu, K.; Zheng, G.; Ye, J.; Cao, Z.; Li, B.; Lu, G. Siamese object tracking for unmanned aerial vehicle: A review and comprehensive analysis. arXiv 2022, arXiv:2205.04281. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Su, Y.; Liu, J.; Xu, F.; Zhang, X.; Zuo, Y. A Novel Anti-Drift Visual Object Tracking Algorithm Based on Sparse Response and Adaptive Spatial-Temporal Context-Aware. Remote Sens. 2021, 13, 4672. [Google Scholar] [CrossRef]
- Li, Y.; Fu, C.; Ding, F.; Huang, Z.; Lu, G. AutoTrack: Towards High-Performance Visual Tracking for UAV with Automatic Spatio-Temporal Regularization. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11920–11929. [Google Scholar] [CrossRef]
- Huang, Z.; Fu, C.; Li, Y.; Lin, F.; Lu, P. Learning aberrance repressed correlation filters for real-time UAV tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2891–2900. [Google Scholar]
- Javed, S.; Danelljan, M.; Khan, F.S.; Khan, M.H.; Felsberg, M.; Matas, J. Visual object tracking with discriminative filters and siamese networks: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 6552–6574. [Google Scholar] [CrossRef] [PubMed]
- Tao, R.; Gavves, E.; Smeulders, A.W.M. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P. Fully-convolutional siamese networks for object tracking. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–16 October 2016; Part II 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Bo, L.; Yan, J.; Wei, W.; Zheng, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4282–4291. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8126–8135. [Google Scholar]
- Tang, F.; Ling, Q. Ranking-based siamese visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8741–8750. [Google Scholar]
- Howard, A.; Zhmoginov, A.; Chen, L.C.; Sandler, M.; Zhu, M. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation. 2018. Available online: https://research.google/pubs/pub48080/ (accessed on 18 July 2023).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, I. [Google Scholar]
- Thangavel, J.; Kokul, T.; Ramanan, A.; Fernando, S. Transformers in Single Object Tracking: An Experimental Survey. arXiv 2023, arXiv:2302.11867. [Google Scholar]
- Deng, A.; Han, G.; Chen, D.; Ma, T.; Liu, Z. Slight Aware Enhancement Transformer and Multiple Matching Network for Real-Time UAV Tracking. Remote Sens. 2023, 15, 2857. [Google Scholar] [CrossRef]
- Fu, C.; Peng, W.; Li, S.; Ye, J.; Cao, Z. Local Perception-Aware Transformer for Aerial Tracking. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 12122–12129. [Google Scholar]
- Fu, C.; Cai, M.; Li, S.; Lu, K.; Zuo, H.; Liu, C. Continuity-Aware Latent Interframe Information Mining for Reliable UAV Tracking. arXiv 2023, arXiv:2303.04525. [Google Scholar]
- Li, S.; Fu, C.; Lu, K.; Zuo, H.; Li, Y.; Feng, C. Boosting UAV tracking with voxel-based trajectory-aware pre-training. IEEE Robot. Autom. Lett. 2023, 8, 1133–1140. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2013; JMLR Workshop and Conference Proceedings. pp. 315–323. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Fan, H.; Lin, L.; Yang, F.; Chu, P.; Deng, G.; Yu, S.; Bai, H.; Xu, Y.; Liao, C.; Ling, H. Lasot: A high-quality benchmark for large-scale single object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5374–5383. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 445–461. [Google Scholar]
- Li, S.; Yeung, D.Y. Visual object tracking for unmanned aerial vehicles: A benchmark and new motion models. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Isaac-Medina, B.; Poyser, M.; Organisciak, D.; Willcocks, C.G.; Breckon, T.P.; Shum, H. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. SiamAPN++: Siamese attentional aggregation network for real-time UAV tracking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3086–3092. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Yao, L.; Fu, C.; Li, S. SGDViT: Saliency-Guided Dynamic Vision Transformer for UAV Tracking. arXiv 2023, arXiv:2303.04378. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. Hift: Hierarchical feature transformer for aerial tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15457–15466. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12549–12556. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6668–6677. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6269–6277. [Google Scholar]
- Yan, B.; Peng, H.; Wu, K.; Wang, D.; Fu, J.; Lu, H. Lighttrack: Finding lightweight neural networks for object tracking via one-shot architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15180–15189. [Google Scholar]
- Cao, Z.; Huang, Z.; Pan, L.; Zhang, S.; Liu, Z.; Fu, C. TCTrack: Temporal Contexts for Aerial Tracking. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14778–14788. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trackers | Backbone | Overall | Model_Size (MB) | FPS_GPU (FPS) | FPS_Xavier (FPS) | |
|---|---|---|---|---|---|---|
| Pre. | Suc. | |||||
| SiamAPN | AlexNet | 0.692 | 0.518 | 118.7 | 180.4 | 34.5 |
| SGDViT | AlexNet | 0.703 | 0.519 | 183.0 | 115.8 | 23.0 |
| SiamAPN++ | AlexNet | 0.703 | 0.533 | 187.1 | 175.2 | 34.9 |
| HiFT | AlexNet | 0.763 | 0.566 | 82.1 | 127.7 | 31.2 |
| SiamSTM | Slight-ViT | 0.742 | 0.580 | 31.1 | 193.2 | 36.0 |
| Ours | MobilenetV2 | 0.769 | 0.588 | 65.4 | 160.3 | 32.3 |
| Trackers | Overall | OCC | SOA | OOV | ARV | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pre. | Suc. | Pre. | Suc. | Pre. | Suc. | Pre. | Suc. | Pre. | Suc. | |
| SiamAPN | 0.784 | 0.586 | 0.654 | 0.474 | 0.658 | 0.480 | 0.756 | 0.557 | 0.715 | 0.569 |
| LightTrack [40] | 0.761 | 0.587 | 0.617 | 0.438 | 0.642 | 0.466 | 0.768 | 0.586 | 0.755 | 0.603 |
| SiamAPN++ | 0.790 | 0.594 | 0.713 | 0.517 | 0.682 | 0.495 | 0.772 | 0.590 | 0.728 | 0.575 |
| HiFT | 0.802 | 0.594 | 0.662 | 0.455 | 0.700 | 0.485 | 0.812 | 0.596 | 0.770 | 0.610 |
| SGDViT | 0.806 | 0.603 | 0.755 | 0.526 | 0.735 | 0.524 | 0.778 | 0.588 | 0.723 | 0.573 |
| TCTrack [41] | 0.813 | 0.626 | 0.751 | 0.540 | 0.728 | 0.535 | 0.894 | 0.641 | 0.769 | 0.619 |
| Ours | 0.824 | 0.629 | 0.782 | 0.552 | 0.746 | 0.542 | 0.883 | 0.663 | 0.765 | 0.633 |
| NO. | IST | LMAN | Overall | BC | SV | FO | OOV |
|---|---|---|---|---|---|---|---|
| 1 | × | × | 0.723 | 0.515 | 0.709 | 0.519 | 0.709 |
| 2 | √ | × | 0.736 | 0.565 | 0.728 | 0.557 | 0.742 |
| 3 | × | √ | 0.752 | 0.640 | 0.743 | 0.615 | 0.781 |
| 4 | √ | √ | 0.769 | 0.675 | 0.757 | 0.648 | 0.810 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, A.; Han, G.; Chen, D.; Ma, T.; Wei, X.; Liu, Z. Interframe Saliency Transformer and Lightweight Multidimensional Attention Network for Real-Time Unmanned Aerial Vehicle Tracking. Remote Sens. 2023, 15, 4249. https://doi.org/10.3390/rs15174249
Deng A, Han G, Chen D, Ma T, Wei X, Liu Z. Interframe Saliency Transformer and Lightweight Multidimensional Attention Network for Real-Time Unmanned Aerial Vehicle Tracking. Remote Sensing. 2023; 15(17):4249. https://doi.org/10.3390/rs15174249
Chicago/Turabian StyleDeng, Anping, Guangliang Han, Dianbing Chen, Tianjiao Ma, Xilai Wei, and Zhichao Liu. 2023. "Interframe Saliency Transformer and Lightweight Multidimensional Attention Network for Real-Time Unmanned Aerial Vehicle Tracking" Remote Sensing 15, no. 17: 4249. https://doi.org/10.3390/rs15174249