Deep Nonnegative Dictionary Factorization for Hyperspectral Unmixing


Abstract
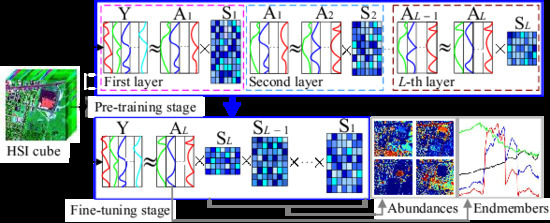
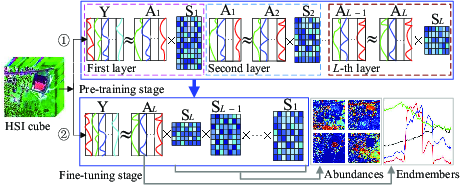
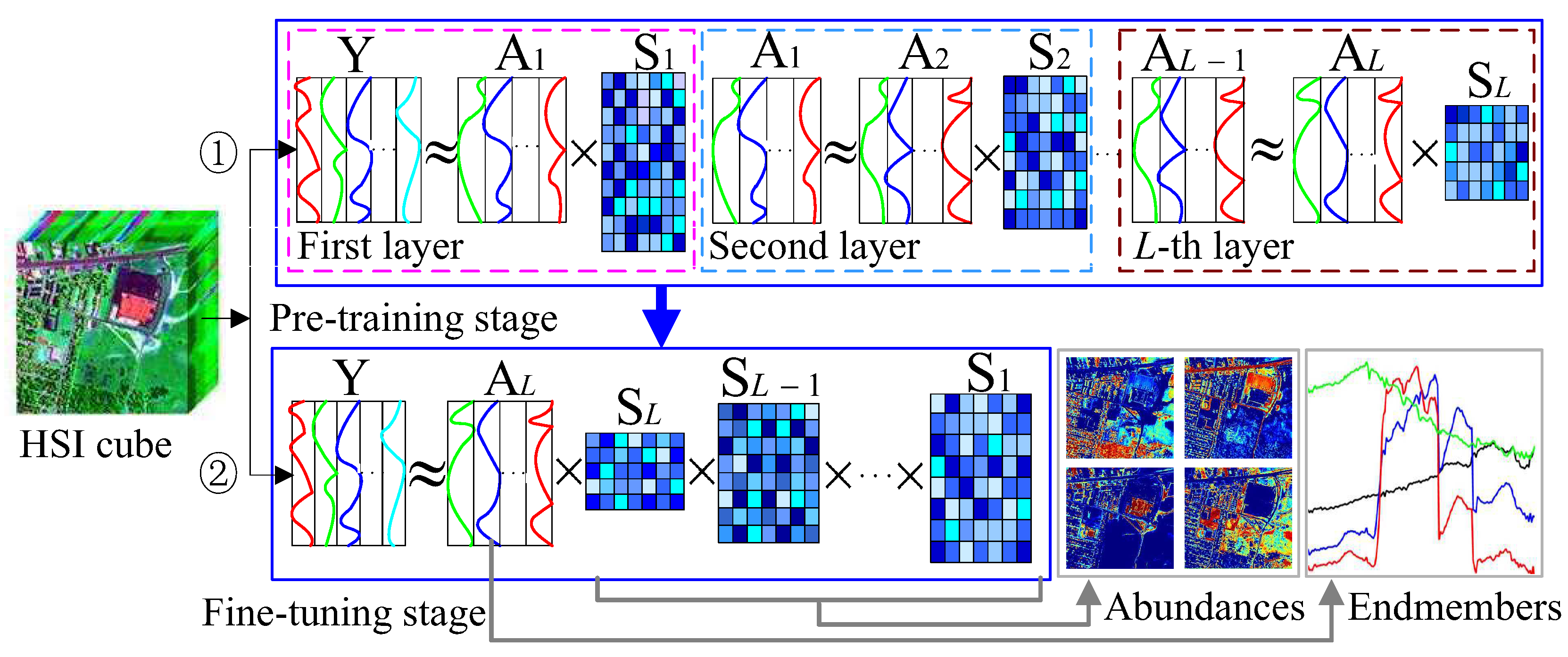
1. Introduction
- We propose a novel Deep Nonnegative Dictionary Factorization method for hyperspectral unmixing. By decomposing the learned dictionary layer by layer in our method, the multi-layer structured representation information implied in HSIs is expected to be captured and used to more accurately extract the target endmembers.
- Our method incorporates sparse constraint and self-supervised regularization into the deep factorization framework, by which the abundance sparseness prior, the sparsity-representation property of dictionaries, as well as the endmember signatures information presented in the data are jointly exploited to guide the unmixing.
- Our method consists of two stages, where the pre-training stage is designed to decompose the learned basis matrix layer by layer, and the fine-tuning stage are implemented to further optimize all the matrix factors obtained in the previous stage by reconstructing the original data via the production of these factors. Consequently, a set of dictionaries that capture the hierarchical representation relationship of the data are learned in a deep learning way.
2. Related Work
3. Methodology
3.1. Notation and Problem Definition
3.2. DNDF Model
3.3. Optimization and Implementation
| Algorithm 1: DNDF Algorithm For HU |
 |
4. Experiment
4.1. Experiment Setting
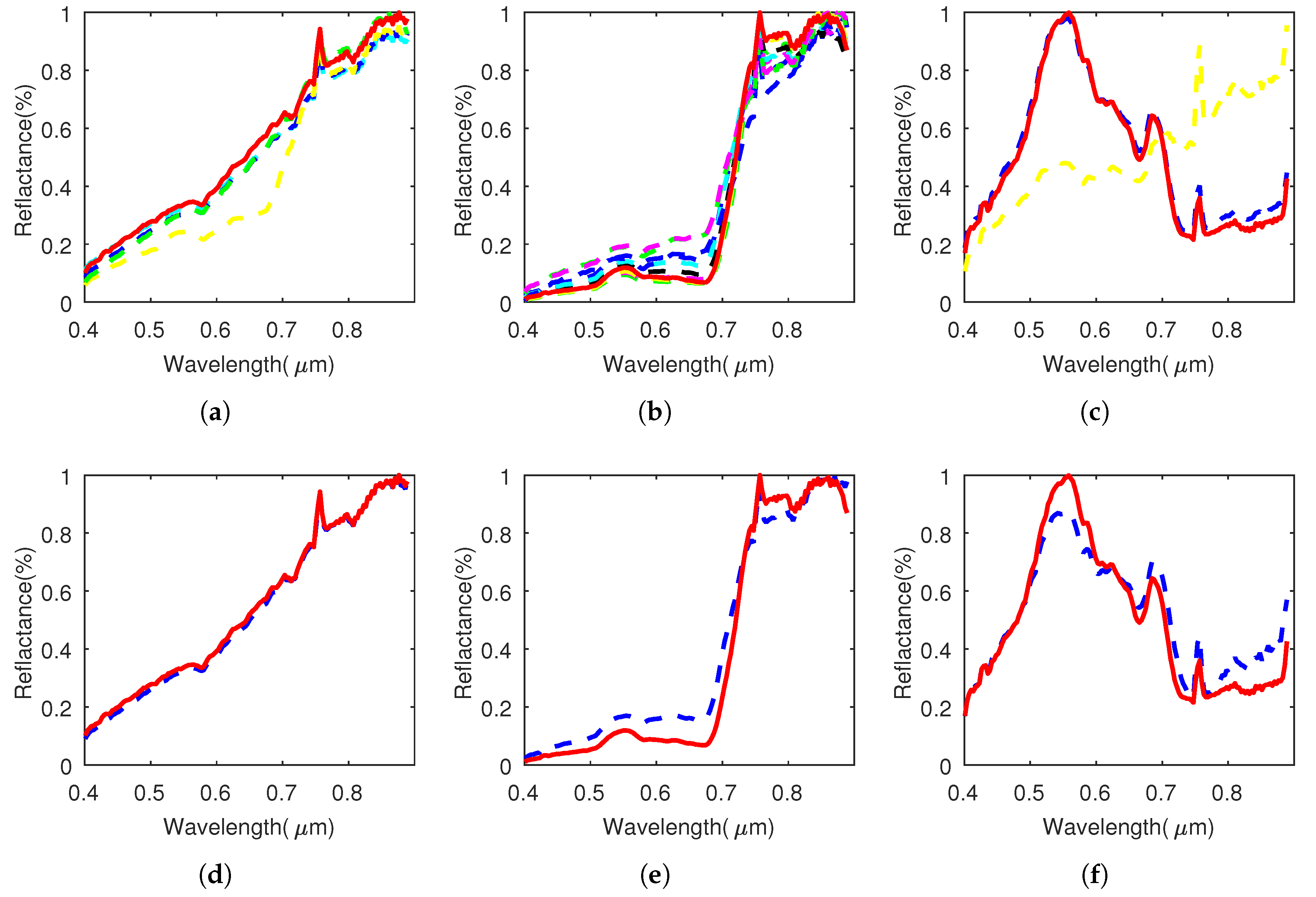
4.2. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HSI | Hyperspectral remote sensing image |
| HU | Hyperspectral unmixing |
| NMF | Nonnegative matrix factorization |
| DNDF | Deep nonnegative dictionary factorization |
| VCA | Vertex component analysis |
| FCLS | Fully constrained least squares |
| LMM | Linear spectrum mixture model |
| SAD | Spectral angle distance |
| RMSE | Root mean square error |
| MUR | Multiplicative update rule |
References
- Nalepa, J.; Myller, M.; Kawulok, M. Validating Hyperspectral Image Segmentation. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1264–1268. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Haut, J.M.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature Extraction With Multiscale Covariance Maps for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 755–769. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, X.; Li, X. Similarity Constrained Convex Nonnegative Matrix Factorization for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4810–4822. [Google Scholar] [CrossRef]
- Xiong, F.; Zhou, J.; Qian, Y. Material Based Object Tracking in Hyperspectral Videos. IEEE Trans. Image Process. 2020, 29, 3719–3733. [Google Scholar] [CrossRef]
- Chen, Q.; Sun, J.; Palade, V.; Shi, X.; Liu, L. Hierarchical Clustering Based Band Selection Algorithm for Hyperspectral Face Recognition. IEEE Access 2019, 7, 24333–24342. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Wang, N.; Du, B.; Zhang, L. An Endmember Dissimilarity Constrained Non-Negative Matrix Factorization Method for Hyperspectral Unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 554–569. [Google Scholar] [CrossRef]
- Zare, A.; Ho, K.C. Endmember Variability in Hyperspectral Analysis: Addressing Spectral Variability During Spectral Unmixing. IEEE Signal Process. Mag. 2014, 31, 95–104. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Algorithms for Non-negative Matrix Factorization. In Advances in Neural Information Processing Systems; Leen, T.K., Dietterich, T.G., Tresp, V., Eds.; MIT Press: Cambridge, MA, USA, 2001; pp. 556–562. [Google Scholar]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph Regularized Nonnegative Matrix Factorization for Data Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1548–1560. [Google Scholar]
- Wang, W.; Qian, Y. Adaptive L1/2 Sparsity-Constrained NMF With Half-Thresholding Algorithm for Hyperspectral Unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2618–2631. [Google Scholar] [CrossRef]
- Lu, Y.; Yuan, C.; Zhu, W.; Li, X. Structurally Incoherent Low-Rank Nonnegative Matrix Factorization for Image Classification. IEEE Trans. Image Process. 2018, 27, 5248–5260. [Google Scholar] [CrossRef]
- Yang, Z.; Xiang, Y.; Xie, K.; Lai, Y. Adaptive Method for Nonsmooth Nonnegative Matrix Factorization. IEEE Trans. Neural Net. Learn. Syst. 2017, 28, 948–960. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Song, R.; Mei, S.; Du, Q. Local Spectral Similarity Preserving Regularized Robust Sparse Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7756–7769. [Google Scholar] [CrossRef]
- Trigeorgis, G.; Bousmalis, K.; Zafeiriou, S.; Schuller, B.W. A Deep Matrix Factorization Method for Learning Attribute Representations. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 417–429. [Google Scholar] [CrossRef]
- Meng, Y.; Shang, R.; Shang, F.; Jiao, L.; Yang, S.; Stolkin, R. Semi-Supervised Graph Regularized Deep NMF With Bi-Orthogonal Constraints for Data Representation. IEEE Trans. Neural Net. Learn. Syst. 2019, 31, 3245–3258. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Q.; Yuan, Y. Hyperspectral Unmixing VIA L1/4 Sparsity-Constrained Multilayer NMF. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 2143–2146. [Google Scholar]
- Feng, X.; Li, H.; Li, J.; Du, Q.; Plaza, A.; Emery, W.J. Hyperspectral Unmixing Using Sparsity-Constrained Deep Nonnegative Matrix Factorization With Total Variation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6245–6257. [Google Scholar] [CrossRef]
- Qian, Y.; Jia, S.; Zhou, J.; Robles-Kelly, A. Hyperspectral Unmixing via L1/2 Sparsity-Constrained Nonnegative Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4282–4297. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y. Nonnegative Matrix Factorization: A Comprehensive Review. IEEE Trans. Knowl. Data Eng. 2013, 25, 1336–1353. [Google Scholar] [CrossRef]
- Miao, L.; Qi, H. Endmember Extraction From Highly Mixed Data Using Minimum Volume Constrained Nonnegative Matrix Factorization. IEEE Trans. Geosci. Remote Sens. 2007, 45, 765–777. [Google Scholar] [CrossRef]
- Lu, X.; Wu, H.; Yuan, Y.; Yan, P.; Li, X. Manifold Regularized Sparse NMF for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2815–2826. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, Y.; Zhang, L.; Xu, Y. Spatial Group Sparsity Regularized Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6287–6304. [Google Scholar] [CrossRef]
- Rajabi, R.; Ghassemian, H. Spectral Unmixing of Hyperspectral Imagery Using Multilayer NMF. IEEE Geosci. Remote Sens. Lett. 2015, 12, 38. [Google Scholar] [CrossRef]
- Fang, H.; Li, A.; Wang, T.; Xu, H. Hyperspectral unmixing using double-constrained multilayer NMF. Remote Sens. Lett. 2019, 10, 224–233. [Google Scholar] [CrossRef]
- Choo, J.; Lee, C.; Reddy, C.K.; Park, H. Weakly supervised nonnegative matrix factorization for user-driven clustering. Data Min. Knowl. Disc. 2015, 29, 1598–1621. [Google Scholar] [CrossRef]
- Heinz, D.C.; Chang, C.I. Fully constrained least squares linear spectral mixture analysis method for material quantification in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 529–545. [Google Scholar] [CrossRef]
- Zhu, F.; Wang, Y.; Fan, B.; Xiang, S.; Meng, G.; Pan, C. Spectral Unmixing via Data-Guided Sparsity. IEEE Trans. Image Process. 2014, 23, 5412–5427. [Google Scholar] [CrossRef]
- Zhu, F. Hyperspectral Unmixing: Ground Truth Labeling, Datasets, Benchmark Performances and Survey. arXiv 2017, arXiv:1708.05125. [Google Scholar]
- Jia, S.; Qian, Y. Constrained Nonnegative Matrix Factorization for Hyperspectral Unmixing. IEEE Trans. Geosci. Remote Sens. 2009, 47, 161–173. [Google Scholar] [CrossRef]
- Nascimento, J.M.P.; Bioucas-Dias, J.M. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Endmember | # Band | # Pixel | Wavelength | Sensor-Type |
|---|---|---|---|---|---|
| Samson | 3 | 156 | 0.401–0.889 m | SAMSON | |
| Jasper Ridge | 4 | 198 | 0.38–2.5 m | AVIRIS | |
| Wash. DC Mall | 5 | 191 | 0.4–2.5 m | HYDICE |
| Samson | DNDF-L1 | DNDF-L2 | GLNMF | SDNMF-TV | SGSNMF | MVCNMF | -NMF |
|---|---|---|---|---|---|---|---|
| Soil | 0.0220 | 0.0160 | 0.0275 | 0.1761 | 0.0097 | 0.3148 | 0.0279 |
| Tree | 0.0290 | 0.0316 | 0.0423 | 0.1310 | 0.0459 | 0.0734 | 0.0426 |
| Water | 0.1758 | 0.1567 | 0.2294 | 0.0922 | 0.2289 | 0.3204 | 0.3015 |
| Average | 0.0756 | 0.0681 | 0.0997 | 0.1331 | 0.0949 | 0.2365 | 0.1240 |
| Jasper Ridge | DNDF-L1 | DNDF-L2 | GLNMF | SDNMF-TV | SGSNMF | MVCNMF | -NMF |
| Tree | 0.0609 | 0.0729 | 0.1270 | 0.1026 | 0.1415 | 0.1752 | 0.1187 |
| Water | 0.0694 | 0.0659 | 0.1872 | 0.1088 | 0.2236 | 0.2980 | 0.2022 |
| Soil | 0.1173 | 0.2010 | 0.1170 | 0.1069 | 0.1385 | 0.1406 | 0.1324 |
| Road | 0.3754 | 0.1123 | 0.0697 | 0.4662 | 0.0483 | 0.1458 | 0.0690 |
| Average | 0.1558 | 0.1130 | 0.1252 | 0.1961 | 0.1380 | 0.1899 | 0.1306 |
| Wash. DC Mall | DNDF-L1 | DNDF-L2 | GLNMF | SDNMF-TV | SGSNMF | MVCNMF | -NMF |
| Tree | 0.0095 | 0.0321 | 0.1738 | 0.0993 | 0.1606 | 0.2372 | 0.1738 |
| Grass | 0.1128 | 0.1404 | 0.2585 | 0.1682 | 0.1425 | 0.2571 | 0.2688 |
| Street | 0.7073 | 0.5293 | 0.3887 | 0.4520 | 0.6963 | 0.5859 | 0.4195 |
| Roof | 0.2435 | 0.2632 | 0.1942 | 0.3645 | 0.2525 | 0.1663 | 0.1720 |
| Water | 0.0753 | 0.0462 | 0.0920 | 0.2509 | 0.1001 | 0.1117 | 0.0892 |
| Average | 0.2297 | 0.2023 | 0.2214 | 0.2670 | 0.2704 | 0.2716 | 0.2247 |
| Samson | DNDF | DNDF-SP | DNDF-SS | DNDF-L2 |
|---|---|---|---|---|
| Soil | 0.0169 | 0.0165 | 0.0164 | 0.0160 |
| Tree | 0.0325 | 0.0319 | 0.0321 | 0.0316 |
| Water | 0.1672 | 0.1635 | 0.1610 | 0.1567 |
| Average | 0.0722 | 0.0706 | 0.0698 | 0.0681 |
| Jasper Ridge | DNDF | DNDF-SP | DNDF-SS | DNDF-L2 |
| Tree | 0.0772 | 0.0742 | 0.0735 | 0.0729 |
| Water | 0.0686 | 0.0621 | 0.0666 | 0.0659 |
| Soil | 0.1979 | 0.2066 | 0.1764 | 0.2010 |
| Road | 0.1481 | 0.1327 | 0.1423 | 0.1123 |
| Average | 0.1230 | 0.1189 | 0.1147 | 0.1130 |
| Wash. DC Mall | DNDF | DNDF-SP | DNDF-SS | DNDF-L2 |
| Tree | 0.0427 | 0.0339 | 0.0447 | 0.0321 |
| Grass | 0.1483 | 0.1424 | 0.1465 | 0.1404 |
| Street | 0.5958 | 0.5686 | 0.5570 | 0.5293 |
| Roof | 0.2586 | 0.2594 | 0.2579 | 0.2632 |
| Water | 0.0478 | 0.0456 | 0.0384 | 0.0462 |
| Average | 0.2186 | 0.2100 | 0.2089 | 0.2023 |
| Data Sets | DNDF-L1 | DNDF-L2 | GLNMF | SDNMF-TV | SGSNMF | MVCNMF | -NMF |
|---|---|---|---|---|---|---|---|
| Samson | 262.04 | 42.41 | |||||
| Jasper Ridge | 583.24 | 54.52 | |||||
| Wash. DC Mall | 1229.91 | 89.43 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Liu, H. Deep Nonnegative Dictionary Factorization for Hyperspectral Unmixing. Remote Sens. 2020, 12, 2882. https://doi.org/10.3390/rs12182882
Wang W, Liu H. Deep Nonnegative Dictionary Factorization for Hyperspectral Unmixing. Remote Sensing. 2020; 12(18):2882. https://doi.org/10.3390/rs12182882
Chicago/Turabian StyleWang, Wenhong, and Hongfu Liu. 2020. "Deep Nonnegative Dictionary Factorization for Hyperspectral Unmixing" Remote Sensing 12, no. 18: 2882. https://doi.org/10.3390/rs12182882
APA StyleWang, W., & Liu, H. (2020). Deep Nonnegative Dictionary Factorization for Hyperspectral Unmixing. Remote Sensing, 12(18), 2882. https://doi.org/10.3390/rs12182882