CloudScout: A Deep Neural Network for On-Board Cloud Detection on Hyperspectral Images

 , , , , ,
, , , , ,  and
and
Abstract
:1. Introduction
- Preliminary decision taken directly on board, without the need for a human operator;
- Mission reconfigurability, changing only the weights of the network [6];
- Continuous improvement of results, in terms of accuracy and precision, through new generated data.
2. Aim of the PhiSat-1 Mission
- Maximum memory footprint of 5 MB: to update the network with respect to the uplink bandwidth limitation during the life of the mission;
- Minimum accuracy of 85%: to increase the quality of each prediction even in particular situations, e.g., clouds on ice, or clouds on salt-lake;
- Maximum FP of 1.2%: to avoid the loss of potentially good images.
3. Methods
3.1. Machine Learning Accelerators Overview
- A
- TPU: TPU is an innovative hardware accelerator dedicated to a particular data structure: Tensors [16]. Tensors are a base type of the TensorFlow framework [17] developed by Google. The standard structures and the dedicate libraries for GPU and VPU make tensors and consequently TensorFlow very powerful tools in the ML world. The Coral Edge TPU is an example of an edge hardware accelerator whose performances are very promising, especially in the static images processing acceleration e.g., CNN, Fully Convolutional Network (FCN).The best performances of this hardware platform are reached exploiting TensorFlow Lite and 8 bits integer quantization, even if the latter could have a big impact on the model metrics.
- B
- GPU: GPUs [18] are the most widely used to carry out both inference and training process of the typical ML models. Their computational power is entrusted to the parallel structure of the hardware that computes operations among matrices at a very high rate. Nvidia and AMD lead the market of the GPU for ML training, using respectively CUDA Core (Nvidia) and Stream processor (AMD), as shown in [14,15]. Moreover, several frameworks allow to use the potentiality offered by GPUs, including TensorFlow, TensorFlow Lite, and PyTorch. This hardware can quantize the model and run inferences supporting a wide range of computational accuracies e.g., 32 and 16 bits floating point, 16, 8, 4, and 2 bits integer. On the other hand, these solutions consume huge power, reaching a peak of 100 W and therefore cannot be used for on the edge applications.
- C
- FPGA: FPGAs are extremely flexible hardware solutions, which could be completely customized. This customizability, however, represents the bottleneck for a fast deployment [19]. In fact, the use of an FPGA requires many additional design steps compared to COTS Application-Specific Integrate Circuit (ASIC), including the design of the architecture of the hardware accelerator and the quantization of the model, for approaches exploiting fixed-point representation. FPGAs are produced by numerous companies such as Xilinx, MicroSemi, Intel. Some FPGAs, like RTG4 or Brave, are also radiation-hard/tolerance, which means these boards can tolerate the radiations suffered during the life of the mission as explained in [20,21].
- D
- VPU: VPUs represent a new class of processors able to increase the speed of visual processing as CNN, Scale-Invariant Feature Transform (SIFT) [22], Sobel and similar. The most promising accelerators in this category are the Intel Movidius Myriad VPUs. At the moment, there exist two versions of this accelerator, the Myriad 2 [23] and the Myriad-X. The core of both processors is the computational engine that uses groups of specialized vectors of Very Long Instruction Word (VLIW) processors called Streaming Hybrid Architecture Vector Engine (SHAVE)s capable of consuming only a few watts (W) [24,25]. Myriad 2 has 12 SHAVEs instead the Myriad-X has 18 SHAVEs. The Myriad 2 and Myriad-X show better performance when they accelerate CNNs model or other supported layers than mobile CPUs or general-purpose low-power processors.To reduce the computational effort, all the registers and operation within the processor use 16 bits floating point arithmetic. Moreover, the Myriad 2 processor has already passed the radiation tests at CERN [6].
3.2. Eyes of Things
- Convolutional layers
- Pooling layers
- Add and subtraction layers
- Dropout layers
- Fully connected layers
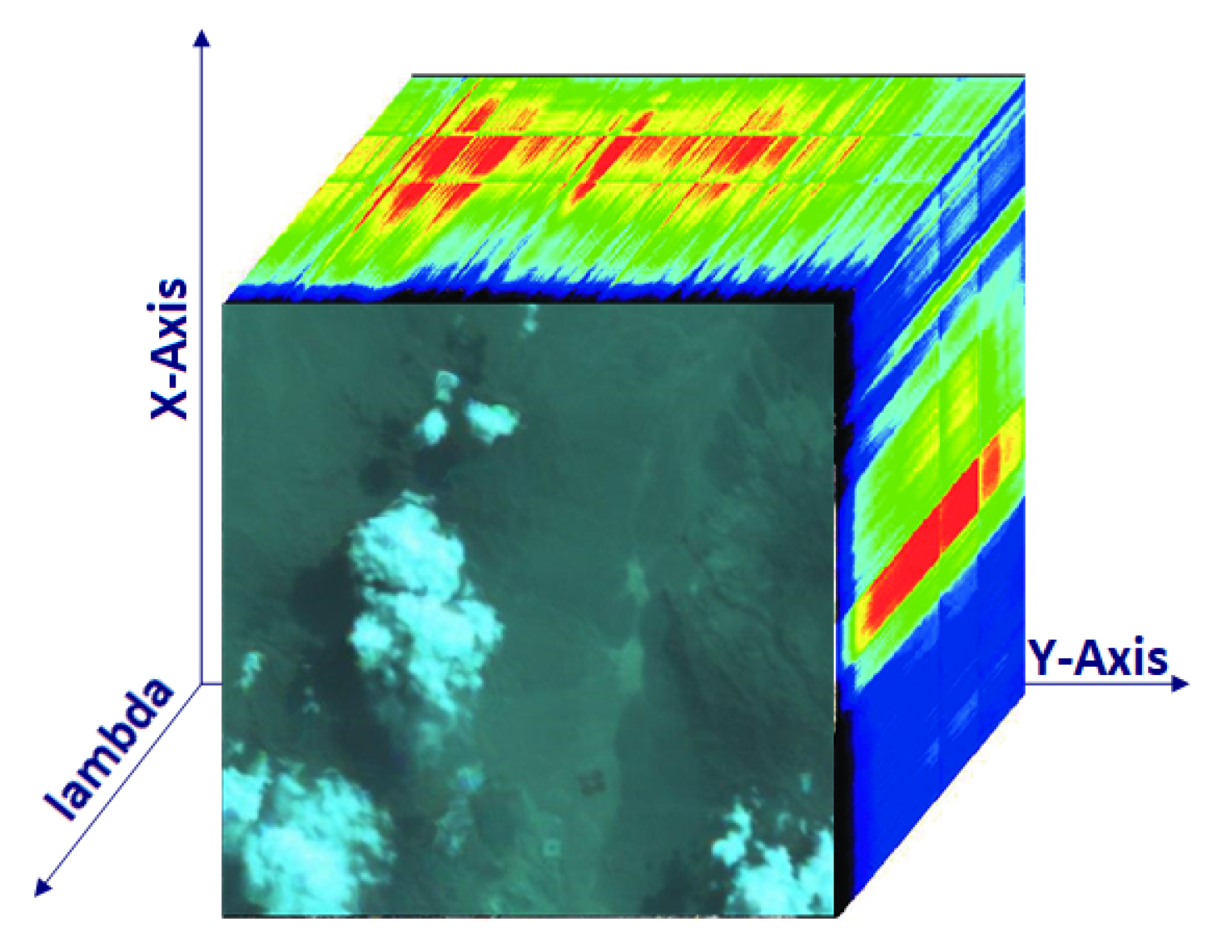
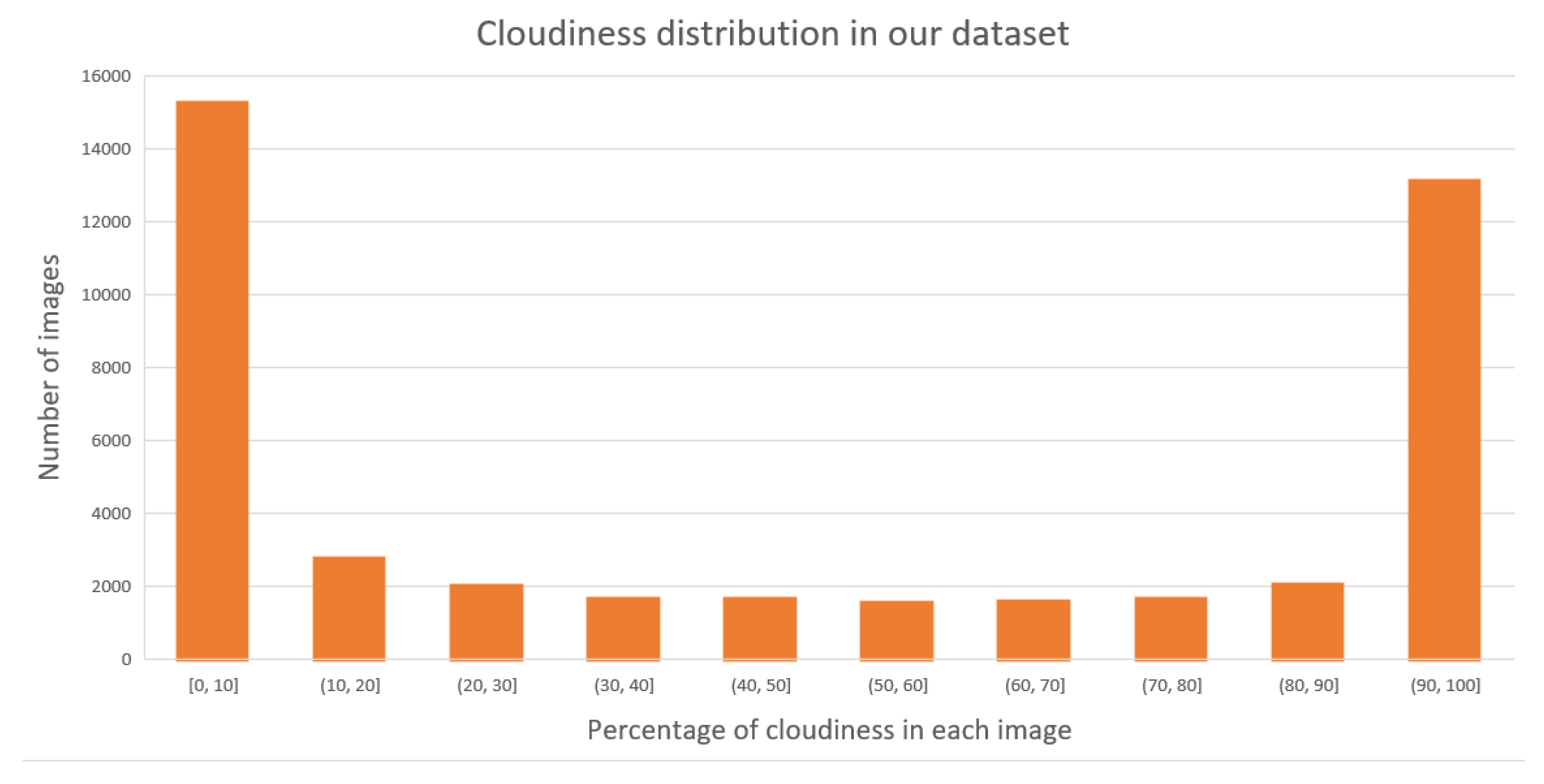
3.3. Dataset and Training Preparation
3.3.1. Satellite Selection
- Level-0 saves raw-data and appends them with annotation and meta-data;
- Level-1 is divided into three sub-steps: A, B, C. Step A decompresses the mission-relevant Level-0 data. Step B applies radiometric correction, then step C applies geometric corrections;
- Level-2 applies atmospheric correction and, if required, some other filters or scene classification.
- The data are provided by a member of the CloudScout mission consortium, Sinergise Ltd.;
- The Sentinel-2 spatial resolution (10 to 60 m) is compatible with HyperScout-2 (75 m). The downscale does not deteriorate the quality of the information;
- The swath of both satellites is about 300 km;
- 10 of the 13 bands of Sentinel-2 are compatible with HyperScout-2 camera both in wavelength and Signal-to-Noise Ratio (SNR);
- Sinergise provides also a tool to convert saturation images into radiance images.
3.3.2. Preliminary Trainig Phase
- Label the original dataset with the selected threshold;
- Compute the minimum between the number of cloudy and not cloudy images, call it N;
- Sample cloudy and not cloudy images, call it training set;
- Sample cloudy and not cloudy images, call it validation set;
- Exploit all the remaining images to populate the test set.
3.4. CloudScout Network
3.4.1. EoT NCSDK
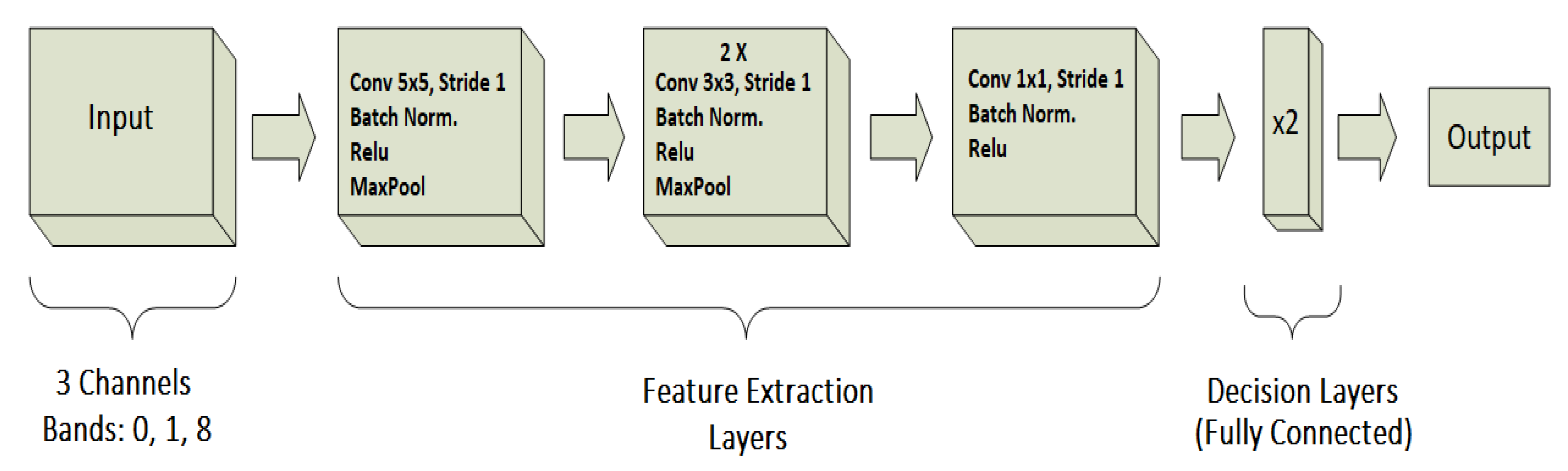
3.4.2. CloudScout Network Structure
- train the CNN model against the dataset with labels generated by using TH30 dataset to improve the recognition of the shape of the clouds;
- train the CNN model against the dataset with labels generated by using TH70 dataset to improve the accuracy of the decision layers.
4. Results
- In Figure 8 the network recognises ice as a continuum of the cloud. To avoid this behaviour, a possible solution could be to use a thermal band that provides high-quality cloud contours.
- The CloudScout network was not trained to recognise the fog, even if in some cases it could represent a big obstacle to visibility. This phenomenon is observable in Figure 9. Here, the image is fully covered by fog as further shown by the cloud mask, but our network does not interpret the fog as cloud obtaining, in fact, just a 1% probability of cloudiness in this picture.
- Another reason for wrong classifications is the use of a fixed threshold to define an image cloudy or not. Indeed, as shown in Figure 10, the cloudiness inside the image is about 65%. This value is very close to the threshold selected for this project (70%). To achieve a better result for all the borderline cases should be useful to increase the granularity of the classification, developing a segmentation network.
5. Discussion
- Relaxing Bandwidth limitations: as described in Section 1, the introduction of DNNs onboard Earth Observation satellites allows filtering data produced by sensors according to the Edge computing paradigm. In particular, cloud-covered images can be discarded mitigating bandwidth limitations. More detailed information on these aspects is provided in [6,7,8].However, producing a binary response (cloudy/not cloudy) leads to a complete loss of data when clouds are detected, preventing the applications of cloud removal techniques, described in [37,38,39]. Such approaches allow reconstructing the original contents by exploiting low-rank decomposition using temporal information of different images, spatial information of different locations, or frequency contents of other bands. Such methods are generally performed on ground because of their high complexity.To enable the use of these approaches and to the reduction of downlink data through filtering data on the edge, DNN-based approaches performing image segmentation can be exploited [40]. In this way, pixel-level information on the presence of clouds can be exploited to improve compression performance through the substitution of cloudy areas through completely white areas. In this way, the application of cloud removal techniques can be performed after data downlink.The implementation of a segmentation DNN for on-board cloud-detection represents a future work.
- Power-consumption/inference time: The use of DNNs allows leveraging modern COTS hardware accelerators featuring enhanced performance/throughput trade-offs compared to space-qualified components [6]. Table 5 shows the proposed model can perform an inference in 325 ms with an average power consumption of 1.8 W. Such reduced power consumption represents an important outcome for CubeSats, for which the limited power budget represents an additional limitation for downlink throughput [41].
- Training procedure: This work proposes to exploit a synthetic dataset for the training of the DNN model in view of the lack of data due by the novelty of the HyperScout 2 imager [11].Despite the functionality of the proposed approach has still to be demonstrated through the validation by means of HyperScout 2 data, the methodology described might be exploited in near future to realize a preliminary training of new applications used for novel technology for which a proper dataset is not available. Moreover, thanks to the possibility to reconfigure hardware accelerators for DNNs, the model can be improved after the launch thanks to a fine-tuning process performed through the actual satellite data [6].
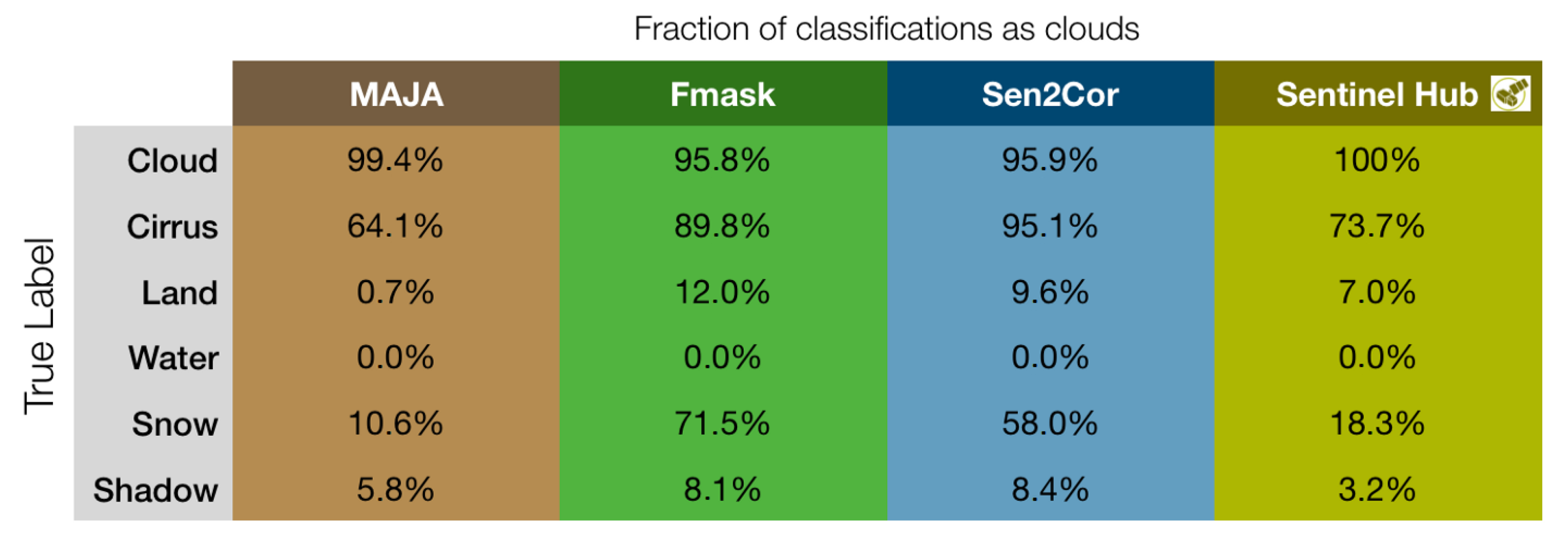
- Cloud detection performance: There are different cloud detection techniques for satellite images, both at the pixel and image level. Yang at al. [42] divide the cloud detector techniques into three categories:
- -
- Threshold methods: some of the most known thresholding-based techniques are ISCPP [43], APOLLO [44], MODIS [45], ACCA [46], and some new methods which work well when ice and clouds coexist. However, these methods are very expensive for the CPU because of the application of several custom filters on the images. Hence, they are not good candidates to be used directly on-board.
- -
- Multiple image-based methods: Zhu and Woodcock [47] use multiple sequential images to overcome the limitations of thresholding-like algorithms. Again, processing this information requires an amount of power that is hardly available on board. In addition, this method requires the use of a large amount of memory.
- -
- Learning-base methods: these methods are the most modern. They exploit all the ML techniques such as Support Vector Machines (SVM) [48], Random Forest (RF) [49], and NN as our CloudScout or [42]. Contrary to SVM and RF methods, NNs have a standard structure that allows building ad-hoc accelerators able to speed up the inference process by reducing energy consumption.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sweeting, M.N. Modern small satellites-changing the economics of space. Proc. IEEE 2018, 106, 343–361. [Google Scholar] [CrossRef]
- Madry, S.; Martinez, P.; Laufer, R. Conclusions and Top Ten Things to Know About Small Satellites. In Innovative Design, Manufacturing and Testing of Small Satellites; Springer: Berlin, Germany, 2018; pp. 105–111. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Li, H.; Zheng, H.; Han, C.; Wang, H.; Miao, M. Onboard spectral and spatial cloud detection for hyperspectral remote sensing images. Remote Sens. 2018, 10, 152. [Google Scholar] [CrossRef] [Green Version]
- Hagolle, O.; Huc, M.; Pascual, D.V.; Dedieu, G. A multi-temporal method for cloud detection, applied to FORMOSAT-2, VENμS, LANDSAT and SENTINEL-2 images. Remote Sens. Environ. 2010, 114, 1747–1755. [Google Scholar] [CrossRef] [Green Version]
- Furano, G.; Meoni, G.; Dunne, A.; Moloney, D.; Ferlet-Cavrois, V.; Tavoularis, A.; Byrne, J.; Buckley, L.; Psarakis, M.; Voss, K.O.; et al. Towards the use of Artificial Intelligence on the Edge in SpaceSystems: Challeng-es and Opportunities. IEEE Aerosp. Electron. Syst. 2020. forthcoming. [Google Scholar]
- Kothari, V.; Liberis, E.; Lane, N.D. The Final Frontier: Deep Learning in Space. In Proceedings of the 21st International Workshop on Mobile Computing Systems and Applications, Austin, TX, USA, 3–4 March 2020; pp. 45–49. [Google Scholar]
- Denby, B.; Lucia, B. Orbital Edge Computing: Nanosatellite Constellations as a New Class of Computer System. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 939–954. [Google Scholar]
- Deniz, O.; Vallez, N.; Espinosa-Aranda, J.; Rico-Saavedra, J.; Parra-Patino, J.; Bueno, G.; Moloney, D.; Dehghani, A.; Dunne, A.; Pagani, A.; et al. Eyes of Things. Sensors 2017, 17, 1173. [Google Scholar] [CrossRef] [Green Version]
- Pastena, M.; Domínguez, B.C.; Mathieu, P.P.; Regan, A.; Esposito, M.; Conticello, S.; Dijk, C.V.; Vercruyssen, N. ESA Earth Observation Directorate NewSpace initiatives. Session V. 2019. Available online: https://digitalcommons.usu.edu/smallsat/2019/all2019/92/ (accessed on 7 July 2020).
- Esposito, M.; Conticello, S.S.; Pastena, M.; Carnicero Domínguez, B. HyperScout-2: Highly Integration of Hyperspectral and Thermal Sensing for Breakthrough In-Space Applications. In Proceedings of the ESA Earth Observation ϕ-Week 2019, Frascati, Italy, 9–13 September 2019. [Google Scholar]
- Esposito, M.; Conticello, S.; Pastena, M.; Domínguez, B.C. In-orbit demonstration of artificial intelligence applied to hyperspectral and thermal sensing from space. In CubeSats and SmallSats for Remote Sensing III; International Society for Optics and Photonics: San Diego, CA, USA, 2019; Volume 11131, p. 111310C. [Google Scholar]
- Benelli, G.; Meoni, G.; Fanucci, L. A low power keyword spotting algorithm for memory constrained embedded systems. In Proceedings of the 2018 IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), Verona, Italy, 8–10 October 2018; pp. 267–272. [Google Scholar]
- Reuther, A.; Michaleas, P.; Jones, M.; Gadepally, V.; Samsi, S.; Kepner, J. Survey and benchmarking of machine learning accelerators. arXiv 2019, arXiv:1908.11348. [Google Scholar]
- Wang, Y.E.; Wei, G.Y.; Brooks, D. Benchmarking TPU, GPU, and CPU platforms for deep learning. arXiv 2019, arXiv:1907.10701. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Nickolls, J.; Dally, W.J. The GPU Computing Era. IEEE Micro 2010, 30, 56–69. [Google Scholar] [CrossRef]
- Dinelli, G.; Meoni, G.; Rapuano, E.; Benelli, G.; Fanucci, L. An FPGA-Based Hardware Accelerator for CNNs Using On-Chip Memories Only: Design and Benchmarking with Intel Movidius Neural Compute Stick. Int. J. Reconfigurable Comput. 2019, 2019, 7218758. [Google Scholar] [CrossRef] [Green Version]
- Baze, M.P.; Buchner, S.P.; McMorrow, D. A digital CMOS design technique for SEU hardening. IEEE Trans. Nucl. Sci. 2000, 47, 2603–2608. [Google Scholar] [CrossRef]
- Sterpone, L.; Azimi, S.; Du, B. A selective mapper for the mitigation of SETs on rad-hard RTG4 flash-based FPGAs. In Proceedings of the 2016 16th European Conference on Radiation and Its Effects on Components and Systems (RADECS), Bremen, Germany, 19–23 September 2016; pp. 1–4. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Barry, B.; Brick, C.; Connor, F.; Donohoe, D.; Moloney, D.; Richmond, R.; O’Riordan, M.; Toma, V. Always-on Vision Processing Unit for Mobile Applications. IEEE Micro 2015, 35, 56–66. [Google Scholar] [CrossRef]
- Rivas-Gomez, S.; Pena, A.J.; Moloney, D.; Laure, E.; Markidis, S. Exploring the vision processing unit as co-processor for inference. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Vancouver, BC, Canada, 21–25 May 2018; pp. 589–598. [Google Scholar]
- Myriad2VPU. Available online: https://www.movidius.com/myriad2 (accessed on 7 July 2020).
- Antonini, M.; Vu, T.H.; Min, C.; Montanari, A.; Mathur, A.; Kawsar, F. Resource Characterisation of Personal-Scale Sensing Models on Edge Accelerators. In Proceedings of the First International Workshop on Challenges in Artificial Intelligence and Machine Learning for Internet of Things, New York, NY, USA, 16–19 November 2019; pp. 49–55. [Google Scholar]
- Li, W.; Liewig, M. A Survey of AI Accelerators for Edge Environment. In World Conference on Information Systems and Technologies; Springer: Berlin, Germany, 2020; pp. 35–44. [Google Scholar]
- Deschamps, P.; Herman, M.; Tanre, D. Definitions of atmospheric radiance and transmittances in remote sensing. Remote Sens. Environ. 1983, 13, 89–92. [Google Scholar] [CrossRef]
- Sinergise Ltd. Available online: https://www.sinergise.com/en (accessed on 7 July 2020).
- Intel Movidius SDK. Available online: https://movidius.github.io/ncsdk/ (accessed on 7 July 2020).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Quantized neural networks: Training neural networks with low precision weights and activations. J. Mach. Learn. Res. 2017, 18, 6869–6898. [Google Scholar]
- Krishnamoorthi, R. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv 2018, arXiv:1806.08342. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Ji, T.Y.; Yokoya, N.; Zhu, X.X.; Huang, T.Z. Nonlocal tensor completion for multitemporal remotely sensed images’ inpainting. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3047–3061. [Google Scholar] [CrossRef]
- Kang, J.; Wang, Y.; Schmitt, M.; Zhu, X.X. Object-based multipass InSAR via robust low-rank tensor decomposition. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3062–3077. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; He, W.; Yokoya, N.; Huang, T.Z. Blind cloud and cloud shadow removal of multitemporal images based on total variation regularized low-rank sparsity decomposition. ISPRS J. Photogramm. Remote Sens. 2019, 157, 93–107. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Selva, D.; Krejci, D. A survey and assessment of the capabilities of Cubesats for Earth observation. Acta Astronaut. 2012, 74, 50–68. [Google Scholar] [CrossRef]
- Yang, J.; Guo, J.; Yue, H.; Liu, Z.; Hu, H.; Li, K. Cdnet: Cnn-based cloud detection for remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6195–6211. [Google Scholar] [CrossRef]
- Rossow, W.B.; Garder, L.C. Cloud detection using satellite measurements of infrared and visible radiances for ISCCP. J. Clim. 1993, 6, 2341–2369. [Google Scholar] [CrossRef]
- Gesell, G. An algorithm for snow and ice detection using AVHRR data An extension to the APOLLO software package. Int. J. Remote Sens. 1989, 10, 897–905. [Google Scholar] [CrossRef]
- Wei, J.; Sun, L.; Jia, C.; Yang, Y.; Zhou, X.; Gan, P.; Jia, S.; Liu, F.; Li, R. Dynamic threshold cloud detection algorithms for MODIS and Landsat 8 data. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 566–569. [Google Scholar]
- Zhong, B.; Chen, W.; Wu, S.; Hu, L.; Luo, X.; Liu, Q. A cloud detection method based on relationship between objects of cloud and cloud-shadow for Chinese moderate to high resolution satellite imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4898–4908. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Automated cloud, cloud shadow, and snow detection in multitemporal Landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sens. Environ. 2014, 152, 217–234. [Google Scholar] [CrossRef]
- Latry, C.; Panem, C.; Dejean, P. Cloud detection with SVM technique. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 448–451. [Google Scholar]
- Deng, J.; Wang, H.; Ma, J. An automatic cloud detection algorithm for Landsat remote sensing image. In Proceedings of the 2016 4th International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Guangzhou, China, 4–6 July 2016; pp. 395–399. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | |
|---|---|
| Number of Images | 31,926 |
| Data augmentation used | Mirror |
| Flip X axis | |
| Flip Y axis | |
| Noise injection | |
| Validation | |
| Number of Images | 5986 |
| Data augmentation used | Mirror |
| Test | |
| Number of Images | 5180 |
| Data augmentation used | none |
| Training | |
|---|---|
| Number of Images | 26,834 |
| Data augmentation used | Mirror |
| Flip X axis | |
| Flip Y axis | |
| Noise injection | |
| Validation | |
| Number of Images | 5032 |
| Data augmentation used | Mirror |
| Test | |
| Number of Images | 11,226 |
| Data augmentation used | none |
| ROC analysis: | |
| TPR | 0.83 |
| FPR | 0.02 |
| False Positive | 1.03 % |
| EoT board (Myriad 2) accuracy | 92 % |
| Cloudy | Not Cloudy | |
|---|---|---|
| Cloudy | 32.5 % | 1 (FP)% |
| Not Cloudy | 6.8 (FN) % | 59.7 % |
| EoT board (Myriad 2) Inference Time | 325 ms |
| Model memory footprint | 2.1 MB |
| Power consumption per inference | 1.8 W |
| Cloudy | Not Cloudy | |
|---|---|---|
| Cloudy | 2 | 2 (FP) |
| Not Cloudy | 6 (FN) | 14 |
| Name | Clouds % | Prob. of Cloudiness % (Net Output) |
|---|---|---|
| Aral Sea clouds and ice Figure 8 | 35% | 99 % |
| Bonneville clouds Figure 9 | 87% | 1 % |
| Algeria mixed clouds and shadows | 98% | 0 % |
| Erie ice clouds Figure 10 | 65% | 96 % |
| Pontchartrain clouds | 72% | 1 % |
| Amadeus January clouds | 78% | 1 % |
| Aral Sea clouds | 87% | 2 % |
| Aral Sea thin clouds | 90% | 0% |
| Aral Sea no clouds | 0% | 0% |
| Pontchartrain sun glint | 3% | 0% |
| Caspian sea cloud | 64% | 0% |
| Alps snow no clouds | 9% | 0% |
| Bonneville clouds shadows Figure 11 | 56% | 1% |
| Greenland snow ice no-cloud | 2% | 18% |
| Alps snow cloud no-shadow | 44% | 12% |
| Amadeus no clouds | 0% | 0% |
| Alps snow cloud shadow | 22% | 0% |
| Greenland snow ice clouds | 85% | 99% |
| Amadeus no-clouds | 3% | 0% |
| Bonneville no clouds | 29% | 0% |
| Erie ice no-clouds | 0% | 9% |
| Amadeus clouds | 99% | 100% |
| Pontchartrain small clouds | 14% | 0% |
| Pontchartrain clouds over water Figure 12 | 66% | 2% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giuffrida, G.; Diana, L.; de Gioia, F.; Benelli, G.; Meoni, G.; Donati, M.; Fanucci, L. CloudScout: A Deep Neural Network for On-Board Cloud Detection on Hyperspectral Images. Remote Sens. 2020, 12, 2205. https://doi.org/10.3390/rs12142205
Giuffrida G, Diana L, de Gioia F, Benelli G, Meoni G, Donati M, Fanucci L. CloudScout: A Deep Neural Network for On-Board Cloud Detection on Hyperspectral Images. Remote Sensing. 2020; 12(14):2205. https://doi.org/10.3390/rs12142205
Chicago/Turabian StyleGiuffrida, Gianluca, Lorenzo Diana, Francesco de Gioia, Gionata Benelli, Gabriele Meoni, Massimiliano Donati, and Luca Fanucci. 2020. "CloudScout: A Deep Neural Network for On-Board Cloud Detection on Hyperspectral Images" Remote Sensing 12, no. 14: 2205. https://doi.org/10.3390/rs12142205