1. Introduction
Woody cover encroachment/expansion/conversion is altering grassland and savannah systems around the world [
1,
2,
3,
4,
5,
6,
7,
8]. The alteration is a complex phenomenon that influences both human and natural systems and their corresponding services. The increase or decrease in the amount of trees and shrubs enhances the livelihood of some fauna, while endangering other species. Woody plants affect both the hydrological and carbon cycles [
9,
10]. Changes in the percentage of woody cover on the landscape affect water usage and carbon storage. Therefore, it is important that land managers have access to accurate quantifications of woody cover on the landscape.
The discussion of how to best manage areas within the Southern Great Plains has been ongoing for decades [
11]. Resources have been spent on grazing techniques and management strategies in the hopes of controlling and possibly reversing the spread of woody plants [
12]. However, there is not one model that can explain how all savannahs will respond to activities like grazing and controlled burns [
13,
14,
15,
16]. The ideal combination of spraying, cutting, grazing, and burning to manage woody cover is unclear. Some land managers promote rangeland health through fire and grazing intensity [
17], while other land use management activities focus on biodiversity and ecosystem services [
5] or recreational hunting. These management goals can lead to a range of woody cover densities.
The level of herbaceous plant diversity has decreased as the climate continues to change and land managers attempt to adjust [
6]. Areas with reduced species richness may be more susceptible to encroachment by exotic species [
18]. Drought events combined with higher average temperatures have led to increases in tree mortality [
19,
20].
To understand the impacts that woody cover encroachment/expansion/conversion are having on grassland dynamics, accurate measurements of percent woody cover are necessary. Remotely sensed data provides the unique spectral, spatial, and temporal resolutions necessary to characterize woody cover before and after management activities around the world [
21,
22,
23,
24,
25,
26,
27]. Aerial photograph and digital image records stretch back decades, providing information on how the landscape has changed over time. Combining data sources, researchers are able to quantify the amount of woody cover in a region and calculate trends in land cover change.
Various methods exist to identify woody cover using remotely sensed data. Thematic land cover and land use products, such as the National Land Cover Database (NLCD), classify pixels as different woody cover types, but do so based on a percentage of a pixel being that cover type. For example, a pixel would be classified as deciduous forest if that pixel is predominately composed of trees greater than 5 m in height, the trees make up more than 20% of the cover in the pixel, and more than 75% of the trees shed foliage [
28]. NLCD also offers a tree canopy product for 2001 and 2011. The two products specify the amount of tree canopy in each 30 m pixel. The United States Forest Service (USFS) employed different methodologies to model percent tree canopy in 2001 and 2011. The technique used in 2001 is similar to the methodology described in this paper to estimate percent woody cover [
29]. In 2011, USFS estimated percent tree canopy using random forests [
30]. Due to the difference in procedures, the authors (26) do not recommend performing change detection using the 2001 and 2011 products. Other studies, employing a variety of algorithms, have attempted to model continuous woody cover.
Spectral mixture analysis decomposes pixels into proportions of cover types based on endmembers [
9,
31]. Accurate estimates of continuous woody cover have been created for areas composed of one type of woody cover (deciduous vs. evergreen), but areas of mixed woody cover exhibit weaker correlation coefficients. Stepwise regressions have been used to create relationships between Landsat variables and percent canopy cover [
32]. However, it is difficult to create one linear equation for the entire range of percent woody cover and for areas of mixed species. A recent study used Phased Array type L-band Synthetic Aperture Radar (PALSAR) mosaic data from 2010 and Landsat 5 and 7 data from 1984 to 2010 to develop time series of juniper forest maps to examine juniper encroachment in Oklahoma [
33,
34].
Two datasets containing estimates of continuous woody cover at a 30 m spatial resolution are publicly available. The Global Land Cover Facility has produced a global Landsat Vegetation Continuous Fields (VCF) tree cover layer for 2000, 2005, and 2010. To calculate tree cover, a piecewise linear function using Moderate Resolution Imaging Spectroradiometer (MODIS) surface reflectance and temperature data was created. The model was then fit to every Landsat tile using the Cubist regression tree algorithm [
35]. The model achieved an overall root mean square error of 17.4% for North and Central America when compared to Light Detection and Ranging (LiDAR) measurements across four sampled biomes.
The second dataset produced by the Web-Enabled Landsat Data (WELD) project calculated the amount of tree cover present between 2006 and 2010 [
36]. The WELD project visually identified tree crowns using QuickBird, Ikonos, and imagery on Google Earth acquired across the conterminous United States (CONUS). Aggregating the high resolution image data to 30 m pixels made it possible to extract information from seasonal and monthly Landsat products. A Classification and Regression Tree (CART) algorithm mined the Landsat information to estimate the percentage of trees in each Landsat pixel. No clear estimation of error, in regards to the WELD continuous tree cover product, is stated. Since the VCF and WELD woody cover products extend over very large areas, the world, and CONUS, respectively, over and under estimations may occur at regional scales.
The main goal of this research is to develop an affordable, efficient, and accurate way of modeling continuous woody cover for regional studies. To accomplish this goal, we will first examine how well an algorithm, trained with woody cover information from a single county, extrapolates over a number of adjacent counties within the same ecoregion. We are applying previously established calibration and validation techniques using fine resolution image data (1–2 m) with a small footprint to estimate woody cover over large areas represented by coarser moderate resolution data (30 m) [
29,
37]. The second goal is to compare and contrast these newly derived detailed and continuous woody cover results to the freely available WELD and VCF woody cover products that are only available for a limited number of years or periods. There is currently only one WELD product available and three VCF products spaced at five-year intervals.
2. Methods
2.1. Southern Great Plains Study Area
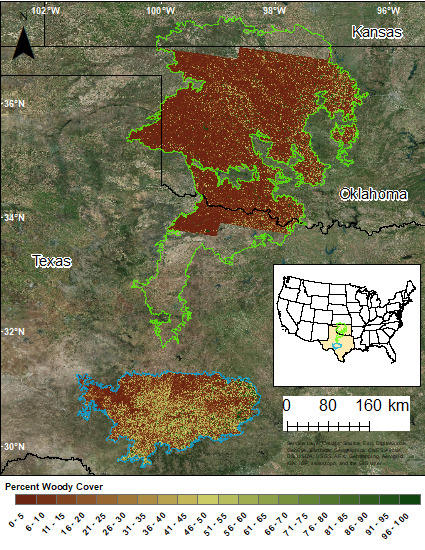
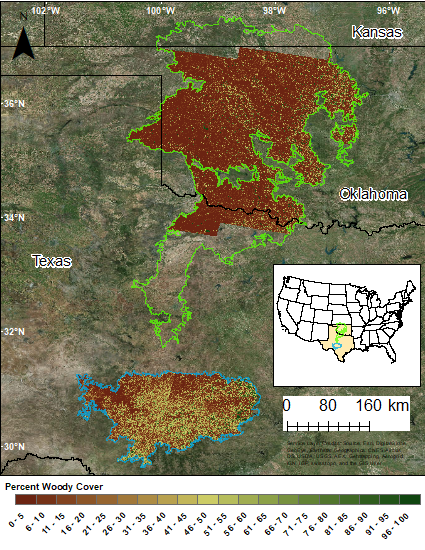
The focus areas of this study are two ecoregions within the Southern Great Plains: Edwards Plateau, located in central Texas, and the Rolling Red Plains located mainly in western Oklahoma and north central Texas. Nine Landsat tiles cover the area of interest (
Figure 1).
Edwards Plateau covers around 33,500 km
2 with elevation ranging from 240 m to 1200 m. Precipitation, closely related to elevation, varies between 375 and 875 mm per year. The soils are shallow and mainly composed of surface clay turning into rocky clay or solid limestone rock further below the surface. The Plateau contains a variety of short, medium, and tall grasses. Edwards Plateau used to have more fires resulting in a savannah with live oak (
Quercus fusiformis) as its primary woody species [
38]. Reduced fire frequency and intensity have resulted in more woody cover represented by live oak (
Quercus fusiformis), honey mesquite (
Prosopis glandulosa), and dense stands of Ashe juniper (
Juniperus ashei).
The majority of the Edwards Plateau study area is contained within four Landsat tiles. Path 29 along Rows 38 and 39 covers the western part of the Plateau. Path 28 along Rows 38 and 39 captures the eastern part of the Plateau.
The Rolling Red Plains cover around 269,359 km
2 with elevation ranging from 274 m to around 853 m. Mean precipitation varies between 500 and 890 mm annually. The majority of the region is composed of Reddish Prairie and Reddish Chestnut soils [
39]. Specific parts of the Plains are composed of Lithosols, Regosols, and Alluvial soils. In the past, the southern portion of the Plains was dominated by a mixture of bluestem (
Schizachyrium) and needlegrass (
Stipa), while the northern portion was dominated by a combination of oak (
Quercus) and bluestem (
Schizachyrium) [
39]. Now, the region’s woody cover is mainly composed of fragmented stands of Ash Juniper and Eastern Redcedar (
Juniperus virginiana L.) [
5], with an understory of various grasses, prickly pear (
Consolea Lem.), and thorny scrub.
A portion of the Rolling Red Plains ecoregion is contained within five Landsat tiles. The region is composed of three parts: western, central, and eastern. Path 29 along Rows 35 and 36 covers the western part of the Plains. Path 28 along Rows 35 and 36 captures the central part of the Plains. Only one tile, Path 27 Row 35, covers the eastern part of the Plains.
2.2. Overview of Data and Modeling Approach
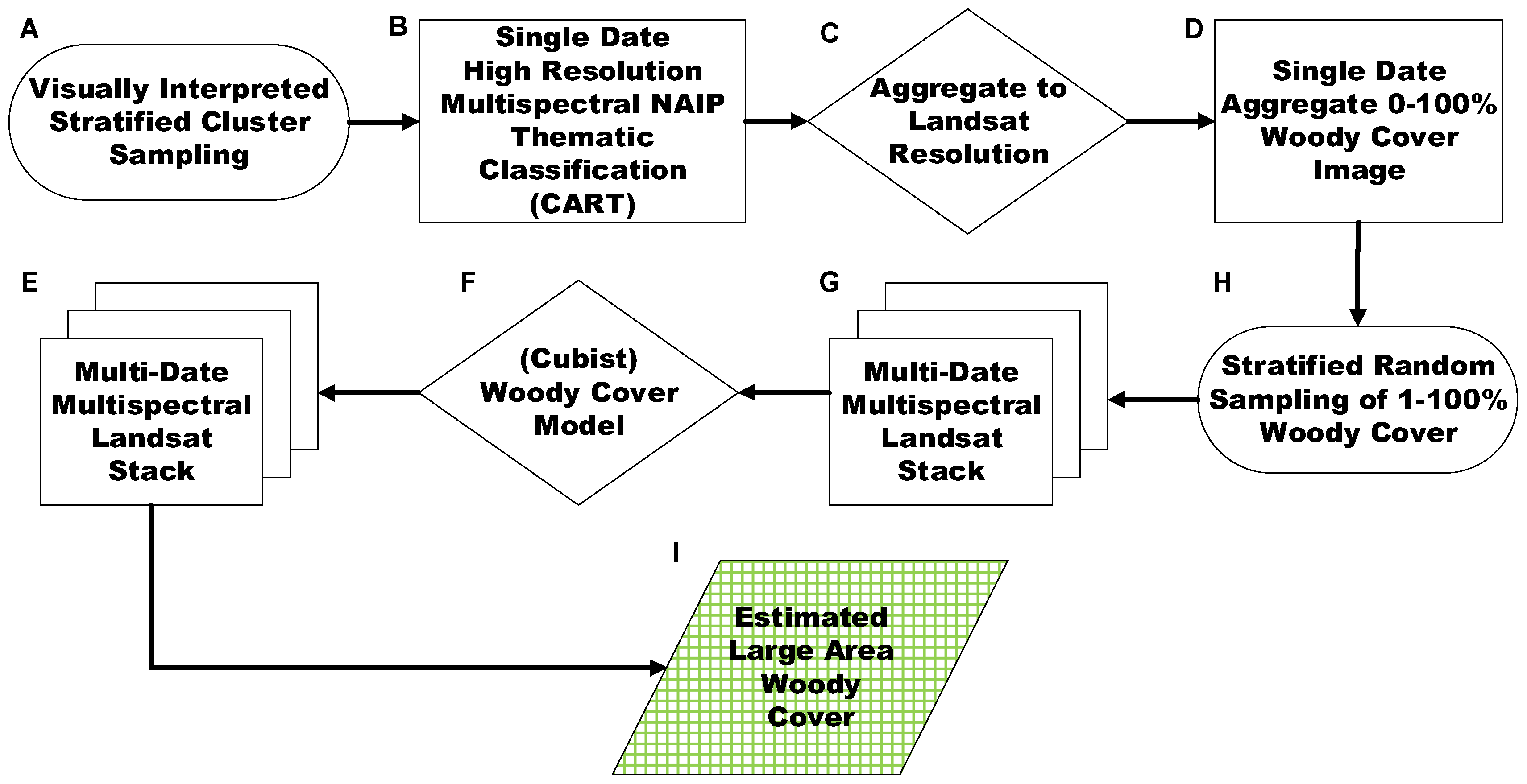
We explored several approaches to derive woody cover for these ecoregions, including linear spectral mixture models, multivariate regression, and vegetation indices. This manuscript only reports the best approach (
Figure 2) and results that follow. Some lessons learned about other approaches are included in the discussion section.
2.3. NAIP and LANDSAT Data Acquisition
We downloaded National Agriculture Imagery Program (NAIP) county mosaics from the Geospatial Data Gateway (
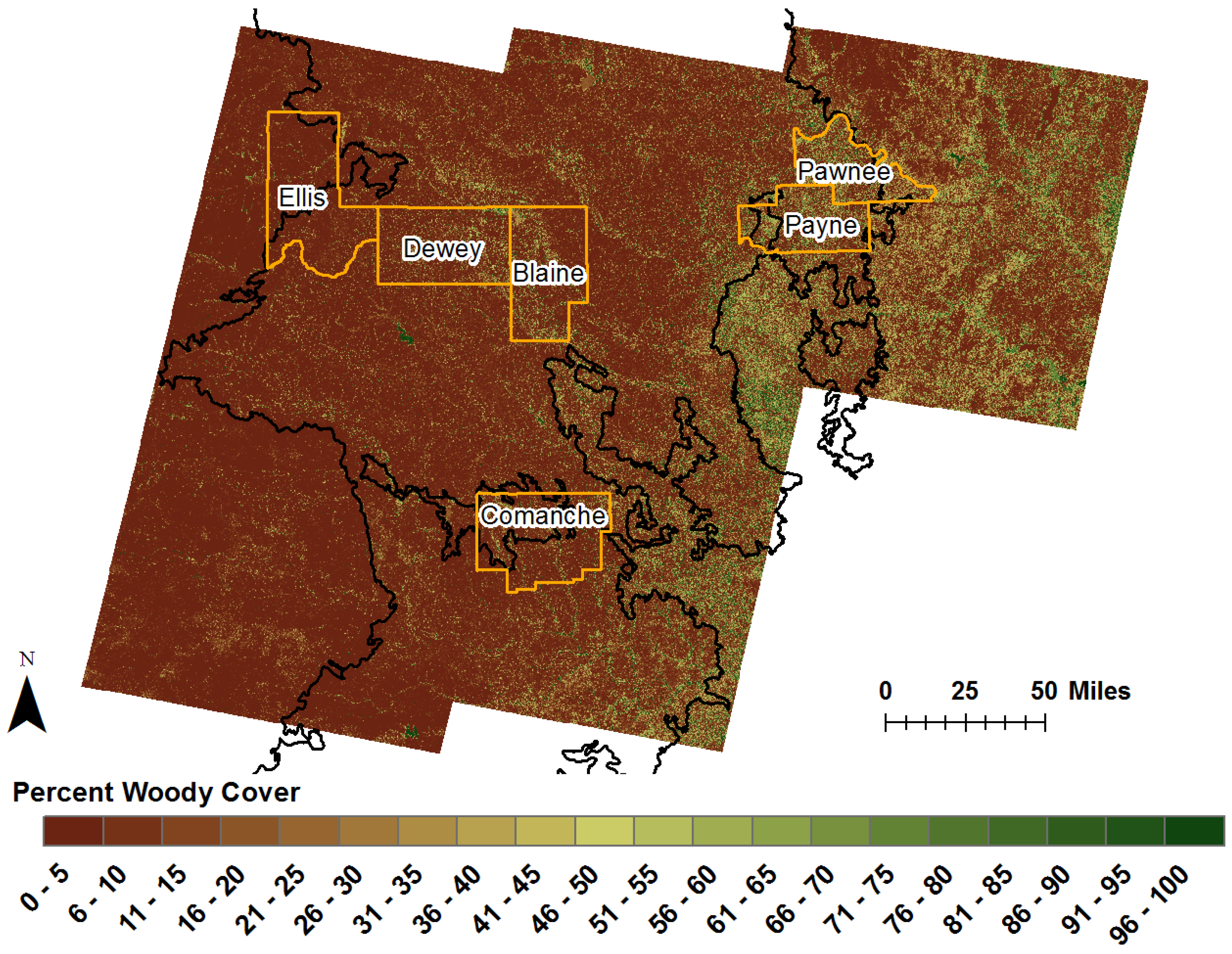
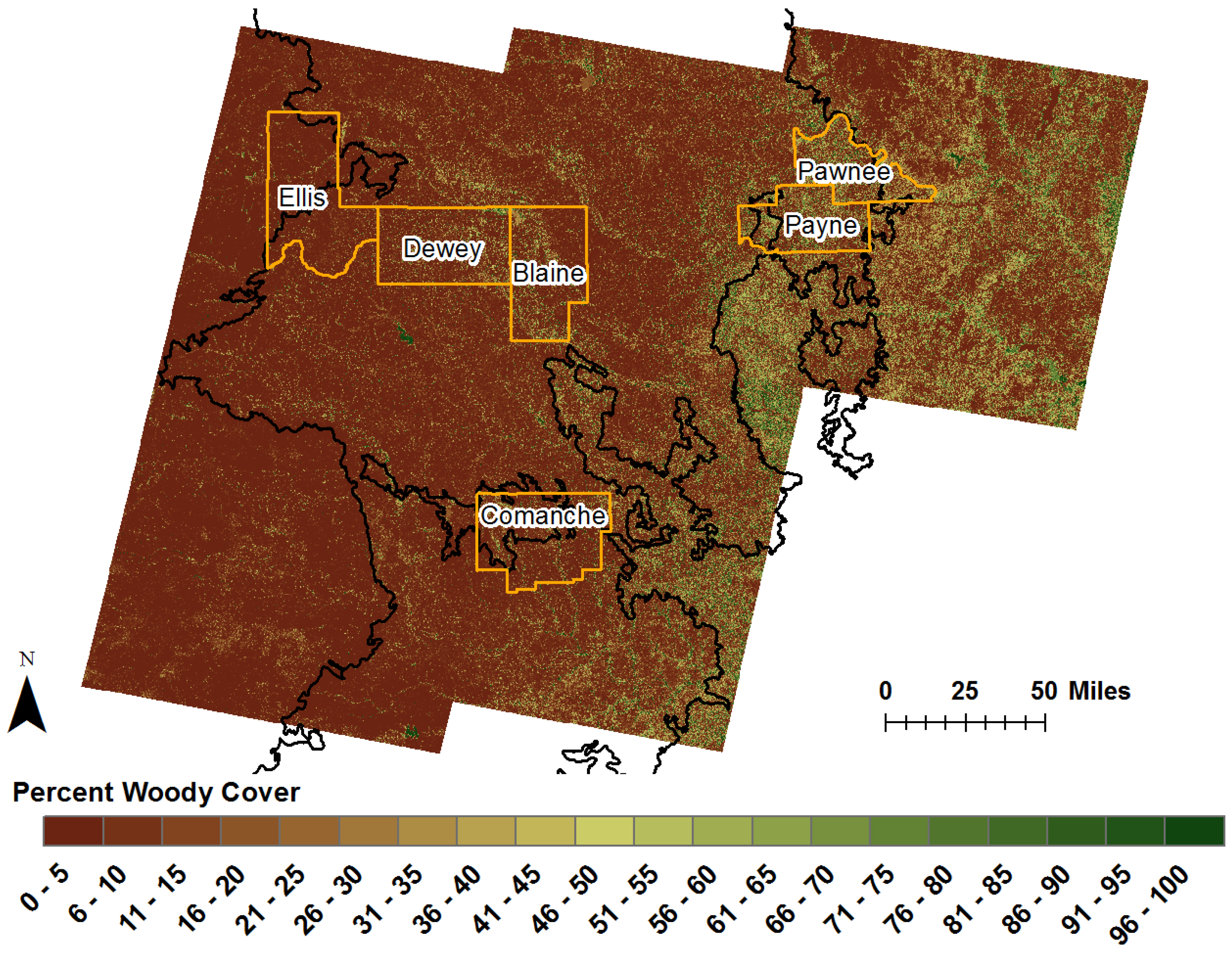
https://gdg.sc.egov.usda.gov/). We selected ten counties in total, with at least two counties located in each of the five portions of the study areas. The 2004 Color infrared mosaics (blue, green, red, NIR) for Edwards Plateau have a spatial resolution of 1 m. Two counties, Schleicher and Sutton, are located in the western portion of Edwards Plateau. The other two counties, Menard and Gillespie, are located in the eastern portion of the Plateau. The 2004 natural color mosaics (blue, green, and red) for the Rolling Red Plains have a spatial resolution of 2 m. Two counties, Ellis and Dewey, are located in the western portion of the Rolling Red Plains. Two counties, Blaine and Comanche, are located in the central portion of the Plains, while the final two counties, Payne and Pawnee, are located in the eastern portion of the ecoregion (
Table 1).
We downloaded a selection of Orthorectified and atmospherically corrected 30 m Landsat 5 image data using the USGS EarthExplorer (
http://earthexplorer.usgs.gov/) and Land Satellites Data System (LSDS) Science Research and Development (LSRD) Bulk Ordering tool (
http://espa.cr.usgs.gov/). The acquired products include Surface reflectance, Normalized Difference Vegetation Index (NDVI), Enhanced Vegetation Index (EVI), Soil Adjusted Vegetation Index (SAVI), Modified Soil Adjusted Vegetation Index (MSAVI), and Normalized Difference Moisture Index (NDMI) for three dates during the year under investigation. Tiles in the same path and acquired on the same day were stitched together using the Mosaic to New Raster tool in ArcGIS (ESRI; Redlands, CA, USA).
To capture the phenological cycle of woody cover and better quantify the amount of woody cover, the selected Landsat data represent the beginning of the growing season, the peak of the growing season, and the end of the growing season (
Table 2).
We used image data from 2004 for two reasons. First, cloud-free Landsat data is available for both ecoregions at the key points of the phenological cycle. Secondly, NAIP data is present for both ecoregions. The NAIP datasets have different spatial and spectral resolutions, adding another level of analysis about estimation accuracy addressed later in the paper. We compared products created for 2004 to the closest VCF (2005) and WELD (2006–2010) estimates available. Additionally, we also created Cubist-based woody cover products for 2005 and 2006 to compare coincident years of VCF and WELD products (
Appendix A).
We acquired the National Agricultural Statistics Service (NASS) National 2014 Cultivated Layer (
https://www.nass.usda.gov/Research_and_Science/Cropland/Release/index.php). The National Cultivated Layer contains information from 2010 to 2014. NASS considered active cropland any pixels classified as cultivated in 2014 or as cultivated in two out of the five years. We masked areas of cropland using the cultivated layer to avoid accidentally classifying the locations as woody cover.
For consistency, between study areas, we used the 2014 Cultivated Layer. The oldest crop data layers available for the two study areas were produced in 2006 (Oklahoma) and 2008 (Texas). Comparison of the 2006 and 2008 crop masks with the 2014 Cultivated Layer revealed that less than 2% of the area in each county reverted from cultivated to non-cultivated. Some of the reversion may be due to the 2006 and 2008 masks being coarser (56 m resolution) than the 2014 layer (30 m). The 2014 Cultivated Layer provided a stable view of the region as it contained five years of data compared to the snapshots documented by the yearly crop data layers.
2.4. Thematic Classification of High Resolution Data
Using ArcMap to perform visual interpretation, we selected 60 NAIP pixels representing woody cover and 60 NAIP pixels representing other cover (
Figure 3). We made sure to select woody cover pixels from different canopies within a cluster of canopies. We used a stratified cluster sampling strategy to randomly select pixels from each class and cluster in order to capture signal variation throughout the image and for efficiency (A in
Figure 2). Depending on the acquisition date of the fine resolution image data, we also selected pixels representing shadows (other class), grass (other class), or senesced trees (woody cover class) if those classes were present in the NAIP image. We used the Multi-Resolution Land Characteristics Consortium (MRLC) National Land Cover Dataset (NLCD) Mapping Sampling Tool, located in ERDAS Imagine, to select 30 random training pixels from each class, while reserving the remaining 30 pixels from each class for assessment. We then sampled information from every band of the NAIP images also using the MRLC tool.
SEE5, Classification and Regression Tree (CART) software (
https://www.rulequest.com/see5-info.html), ingested the sampled information to determine what data to use to separate each class. SEE5 mines through a dataset to find patterns, creates the branches of the CART, and produces a thematic output (B in
Figure 2). The algorithm winnows layers deemed insignificant. Boosting was performed with a maximum of ten iterations to achieve the most accurate and unbiased CART result. The software used the 30 random pixels reserved from each class to assess the accuracy of each CART. Error matrices were created to calculate the overall user accuracy, overall kappa, producer’s accuracy for each class, user’s accuracy for each class, and kappa coefficients for each class [
40]. The final output is a separate binary land cover raster product for each county in the study (
Figure 4).
2.5. Reclass and Aggregation of High Resolution Woody Classification
We merged pixels classified as other, grass, or shadow into one class and combined the pixels representing senesced trees with the woody cover class. The goal was to produce a binary classification containing only woody cover, represented as ones, and other cover, represented as zeroes.
We aggregated the NAIP pixels (1–2 m resolution), classified as woody cover, to calculate the percentage of woody cover present in a Landsat pixel (30 m resolution). The aggregated woody cover was then masked using the NASS cultivated layer to remove any pixels representing cropland (C in
Figure 2). We used pixels from these rasters to train the Cubist algorithm, to assess the Cubist algorithm, and to compare the Cubist, WELD, and VCF products.
2.6. Cubist Training and Validation
In a similar vein to SEE5, Cubist is a tool that creates rule-based trees with the output being continuous data (e.g., percent woody cover) instead of thematic values (e.g., woody or not woody) (
https://www.rulequest.com/cubist-info.html). Cubist, in this case using the sampled Landsat data, creates various sets of conditions. Depending on what conditions a pixel meets, the software applies a specific linear equation to that pixel to estimate woody cover in that location. Cubist has a number of adjustable settings to fine tune the final modeled output, including a composite option that averages the value of a case based on similar cases and the option to produce an unbiased ruleset.
The stratified sampling strategy option of the MRLC NLCD Mapping Sampling Tool selected 700,000 geographically random pixels, a little more than 1% of the pixels in an average Landsat tile, from each county separately, to train the Cubist algorithm. We set the tool to select pixels, from the aggregated woody cover raster created in
Section 2.5, representing woody cover from 1–100%, at 1% increments. The tool used the pixels to sample information from the three Landsat datasets, which included 18 bands of surface reflectance data and 15 indices for each portion of the study area.
Using an iterative process, we ran Cubist a number of times with the same input data and settings, but a different number of training pixels to test if the accuracy changed. The results indicated that the accuracy of the Cubist estimates did not improve much beyond 700,000 training pixels. The software reserved the remaining pixels in each county for validation.
The Cubist software ingested the Landsat information extracted by the training pixels. We selected the “Let Cubist Decide” option and allowed the algorithm to extrapolate 1% to account for the lack of a 0% percent estimation. We did not train a 0% class due to possible confusion related to the variability of soil signatures across the ecoregions.
Cubist assessed the output model using average absolute error magnitude, relative error magnitude, and a correlation coefficient calculated using the reserved validation pixels. The average absolute error magnitude, measured in percent woody cover, is the absolute value of the difference between the reference measurements and the predicted measurements. The relative error magnitude is the average absolute error magnitude divided by the difference between the reference measurements and the mean of the reference measurements. Good models have a value below one. The Pearson correlation coefficient measures the relationship between the reference measurements and the predicted measurements [
41].
We performed Cubist woody cover estimates portion by portion (West, Central, East) for the two major study areas. We stitched the portion estimates together, to encompass fully the two regions, using ArcGIS.
We took the following steps to make sure the comparison of the three woody cover products, Cubist, VCF, and WELD, was stringent and thorough. First, we randomly selected 1,000,000 pixels from each county’s aggregated thematic NAIP classification to capture the full range of woody cover. Second, we compared the three products using randomly selected pixels not used for training or assessing the Cubist models compared, as we selected the pixels from another county in the same portion of an ecoregion. This allowed us to determine how well the Cubist estimates performed outside of the county used for sampling, along with how well the estimates compared to the currently available woody cover products. We calculated average absolute errors and correlation values to compare the three products.
We also calculated average errors for each woody cover product at 20 percent intervals 20%, 21–40%, 60%, 80%, and 100%, to examine if certain models over- or under-estimated different levels of woody cover.
4. Discussion
Based on the results of this woody cover assessment and research, the Cubist model-based approach does an excellent job of estimating woody cover at the ecoregion scale. However, the VCF and WELD results, for the region, are better than the Cubist models for the 1–20% woody cover interval. The VCF underestimates by 6% on average and the WELD underestimates by 3% on average, while the Cubist overestimates by 10% on average. Acquisition of the training data during peak greenness leads to the overestimation in the Cubist model. Based on the rate of woody cover growth, the majority of woody cover encroachment should appear in the 1–20% interval. To accurately measure encroachment in the region, we need to fine-tune the Cubist model for the low cover interval. In the future, we may explore training using only pixels from 1–20% to see if this improves the estimates created by Cubist.
We must point out that we designed our technique to estimate woody cover across an ecoregion. This means that we accounted for trees and shrubs, no matter their height. The VCF and WELD products model tree cover, not woody cover, across the continental United States. This means that the VCF and WELD models may not account for all shrubs due to height. This may explain the high levels of underestimation by the VCF and WELD products for the 61–80% and 81–100% intervals.
The Cubist technique outperformed other approaches to derive woody cover for these ecoregions, including linear spectral mixture models, multivariate regression, and vegetation indices. The other methods listed above fail to capture the variability of woody cover across the landscape. Linear spectral mixture models need a clear vegetation signal to estimate woody cover, but the ecoregions in the study area contain various types of woody cover. Multivariate regression attempts to create a single equation to model the full range of woody cover, while the Cubist technique creates different equations to account for various ranges of cover related to a variety of species. Vegetation indices are a great input for the modelling algorithms, but attempting to threshold the indices across the entire landscape, to capture all the woody cover, is difficult due to variability in soil and woody type. Cubist integrates the best of all these approaches into an algorithm that can handle the variety of woody cover occurring over a large region.
Image data availability for the area of study is a limitation of the methodology described in this paper. Accurately distinguishing woody cover from other cover types requires high resolution data acquisition at the proper time of year. Avoidance of certain periods of acquisition, such as peak vegetation greenness, minimizes confusion between grass and woody cover. Availability of Landsat scenes throughout the year is equally important to accurately measuring percent woody cover. Our methodology requires scenes from the beginning, middle, and end of the year to capture the phenological cycle of woody cover of both deciduous broadleaf and evergreen species (e.g., oak and juniper) in the area of interest. We wanted to perform a more direct comparison of products by running Cubist for 2005, but NAIP data were unavailable. However, we verified that only a small number of fires occurred in the study area between 2004 and 2005, with a majority of them being low severity [
42]. In addition, estimates may not be precise enough for certain applications because of the levels of error present.
Another strength of the Cubist technique is the ability to apply it to any year where both high spatial resolution data and Landsat data are available. Without presenting all results in this manuscript, we also modelled woody cover for the period of 1994–1995 and 2014–2015 using the process described in this paper. We trained the 1994–1995 models with black and white/color infrared DOQQs, with a pixel size of 1m, and Landsat 5 data. The 1994–1995 Cubist models achieved, on average, an average absolute error of 14%, a relative error of 0.55, and a correlation coefficient of 0.74. We trained the 2014–2015 models with 1m natural color NAIP data and Landsat 8 data. The 2014–2015 Cubist models achieved, on average, an average absolute error of 11%, a relative error of 0.48, and a correlation coefficient of 0.82.
Ranchers and land managers provided with accurate and timely estimates of woody cover can make informed decisions on where to rotate cattle and remove woody cover. Studies from around the world show declines in the ability for soil to store carbon in areas where woody encroachment levels have increased [
4,
43]. In the short term, woody encroachment increases carbon sequestration, but in the long term, it inhibits herbaceous plant growth [
3]. Not only do woody plants alter the physical landscape, they also change the access to water resources below the surface. The roots of woody plants can access water resources that grasses cannot, making it possible for woody plants to outcompete grasses and exacerbate encroachment [
2]. The ability to create year-to-year percent woody cover maps will help managers get ahead of woody cover expansion.
The EPA reports, that in the future, Texas and Oklahoma will most likely see increases in average temperatures and decreases in average precipitation [
44,
45]. Dry, hot conditions do not directly translate to decreases in woody cover encroachment [
1]. However, if the likelihood of drought does increase, it could lead to greater chances for wildfires. Managers can use year-to-year percent woody cover maps to identify areas that need plant removal or controlled burns to avoid catastrophic uncontrolled fires.
In a future paper, we will use estimates of woody cover from two dates, to compute the change in woody cover for each pixel in the two ecoregions. Measuring change comes with an inherent propagation of error. Cubist produces a raster indicating the possible amount of percent woody cover error for each pixel based on the equation used at that location. Our first inclination is to compute an average absolute error in percent woody cover for each pixel using the average absolute error from the two estimations. Other studies have converted continuous data into categories to handle the error propagation problem [
46,
47,
48]. Building on the idea of categories and fuzzy classifications, we may bin the average absolute errors from each date into ordinal ratings (ex., excellent, good, acceptable, poor, bad). Using the ratings, we would report each pixel’s rating from each date when presenting the amount of percent woody cover change. We would then relate the changes in woody cover to variables such as precipitation, temperature, soil characteristics, fire patterns, and management practices.
5. Conclusions
This research demonstrates that it is possible to create temporally relevant estimates of woody cover using high resolution image data and multi-season Landsat. Current woody cover products only cover a limited time span, 2000–2010, and only certain years, 2000, 2005, and 2010. The methodology laid out in this research allows a user to calculate the percentage of woody cover in an area for any year in the Landsat time series. The results also show that the Cubists estimates tend to be better than the VCF and WELD woody cover products for all parts of a Landsat tile. This was consistently true when we compared the uncertainty between Cubist-based woody cover with VCF and WELD-based woody cover for the years 2004, 2005, and 2006 (
Appendix A shows Years 2005 and 2006). The producers of the VCF and WELD products know that errors exist in their products as they are trying to map large, variable areas, the world, and the United States, respectively. However, the methods in this research provide a technician with the means of using a single county of NAIP data to better model regional woody cover over two Landsat tiles.
Accurate woody cover models also provide us with the means of examining the impacts of woody plant expansion or loss on the hydrological cycle. Using our estimates in coordination with the Mapping Evapotranspiration with the high Resolution and Internalized Calibration (METRIC) model, we can calculate evapotranspiration and examine the correlation to woody cover. We can also asses how the amount of evapotranspiration changes over a region with the increase or decrease of woody cover.
Going forward, we plan to use woody cover estimates produced with this methodology to examine the rate of woody cover expansion or loss across Edwards Plateau and the Rolling Red Plains and compare these with results recently published by Wang et al. [
34]. The ability to model woody cover nearly every 16 days via Landsat allows us to determine the best temporal interval at which to study this phenomenon. We can determine how quickly specific management activities are changing the landscape, measure how swiftly an area recovers from fire, and study how changes in climate are altering the region.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}