Fully Connected Conditional Random Fields for High-Resolution Remote Sensing Land Use/Land Cover Classification with Convolutional Neural Networks


Abstract
:1. Introduction
2. CNN and Fully Connected CRF
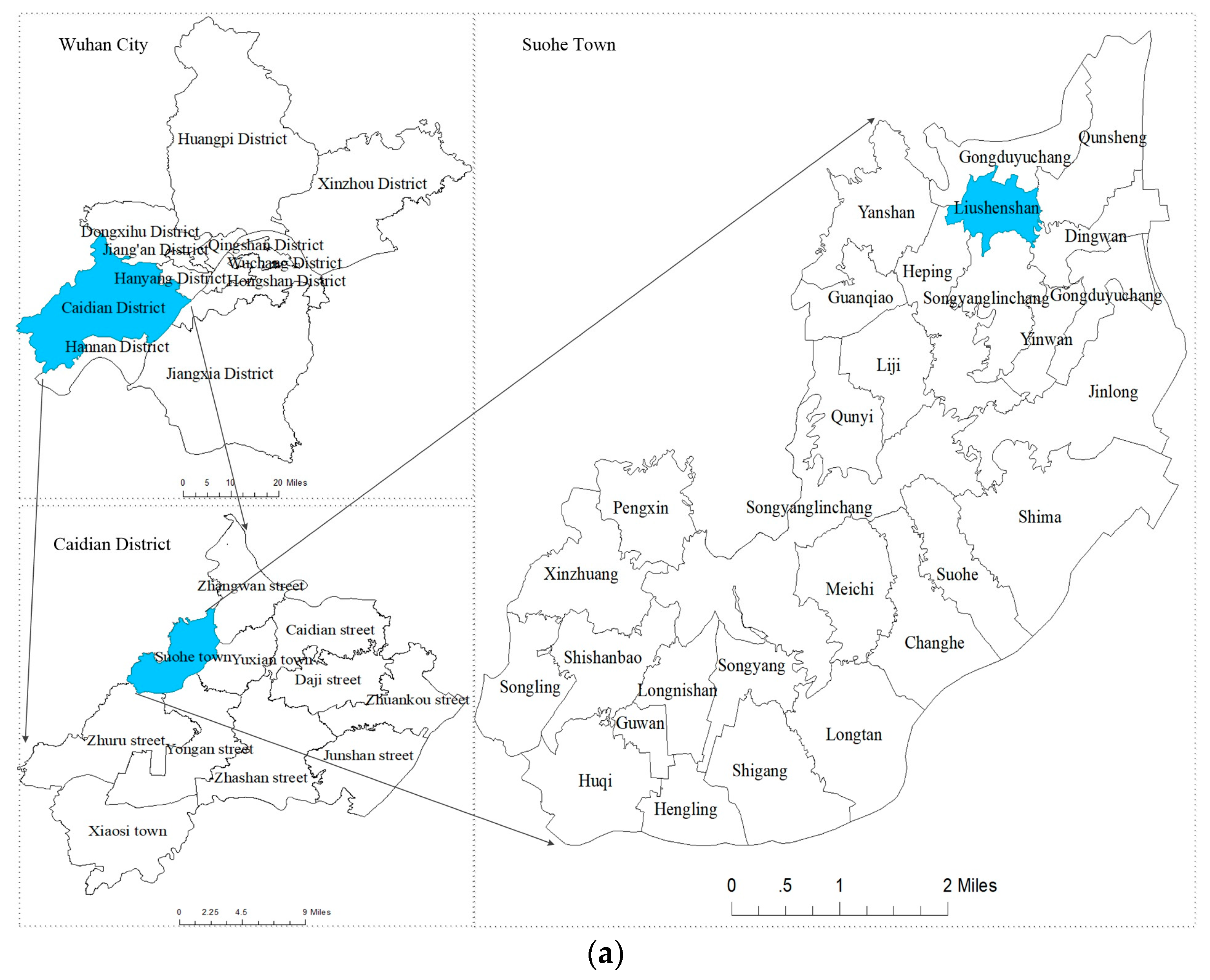
2.1. Data and Manual Labeling
2.2. CNN Architecture
2.3. Feature Descriptors
2.4. Fully Connected CRF
2.5. Work Flow of Proposed Method
3. Results
3.1. Experimental Results and Discussion
3.2. Parameter Sensitivity Analysis
3.3. Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nogueira, K.; Penatti, O.A.B.; Santos, J.A.D. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2016, 61, 539–556. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Review [PDF]. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Nogueira, K.; Miranda, W.O.; Santos, J.A.D. Improving Spatial Feature Representation from Aerial Scenes by Using Convolutional Network. In Proceedings of the 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Bahia, Brazil, 26–29 August 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 289–296. [Google Scholar]
- Yue, J.; Zhao, W.; Mao, S.; Liu, H. Spectral–spatial classification of hyperspectral images using deep convolutional neural networks. Remote Sens. Lett. 2015, 6, 468–477. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 55. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep Supervised Learning for Hyperspectral data Classification Through Convolutional Neural Networks. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 4959–4962. [Google Scholar]
- Volpi, M.; Tuia, D. Dense Semantic Labeling of Subdecimeter Resolution Images with Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 881–893. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land Use Classification in Remote Sensing Images by Convolutional Neural Networks. Acta Ecol. Sinica 2015, 28, 627–635. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 1097–1105. [Google Scholar] [CrossRef]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. In Proceedings of the British Machine Vision Conference 2014, Nottingham, UK, 1–5 September 2014; BMVA Press, 2014. [Google Scholar]
- Xie, M.; Jean, N.; Burke, M.; Ermon, S. Transfer learning from deep features for remote sensing and poverty mapping. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Paolo Alto, CA, USA, 2016; pp. 3929–3935. [Google Scholar]
- Penatti, O.A.B.; Nogueira, K.; Santos, J.A.D. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 44–51. [Google Scholar]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Shao, G. Object-Based Land-Cover Mapping with High Resolution Aerial Photography at a County Scale in Midwestern USA. Remote Sens. 2014, 6, 11372–11390. [Google Scholar] [CrossRef] [Green Version]
- Lucieer, V. Object-oriented classification of side-scan sonar data for mapping benthic marine habitats. Int. J. Remote Sens. 2008, 29, 905–921. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar]
- Qian, Y.; Ye, M. Hyperspectral imagery restoration using nonlocal spectral-spatial structured sparse representation with noise estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 499–515. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral-Spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Rother, C.; Kolmogorov, V.; Blake, A. GrabCut: Interactive foreground extraction using iterated graph cuts. In Proceedings of the 31st International conference on computer graphic and interactive techniques SIGGRAPH ’04 ACM SIGGRAPH, Los Angeles, CA, USA, 8–12 August 2004; ACM Trans Graphics: New York, NY, USA, 2004; Volume 23, pp. 309–314. [Google Scholar]
- Shotton, J.; Winn, J.; Rother, C.; Criminisi, A. Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context. Int. J. Comput. Vis. 2009, 81, 2–23. [Google Scholar] [CrossRef]
- Lucchi, A.; Li, Y.; Boix, X.; Smith, K.; Fua, P. Are spatial and global constraints really necessary for segmentation? In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- He, X.; Zemel, R.S.; Carreira-Perpindn, M. Multiscale conditional random fields for image labeling. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Ladicky, L.; Russell, C.; Kohli, P.; Torr, P.H. Associative hierarchical crfs for object class image segmentation. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Lempitsky, V.; Vedaldi, A.; Zisserman, A. Pylon Model for Semantic Segmentation. In Proceedings of the Neural Information Processing Systems NIPS 2011, Granada, Spain, 12–17 December 2011; pp. 1485–1493. [Google Scholar]
- Delong, A.; Osokin, A.; Isack, H.N.; Boykov, Y. Fast approximate energy minimization with label costs. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Gonfaus, J.M.; Boix, X.; Van de Weijer, J.; Bagdanov, A.D.; Serrat, J.; Gonzàlez, J. Harmony potentials for joint classification and segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Matikainen, L.; Karila, K. Segment-Based Land Cover Mapping of a Suburban Area—Comparison of High-Resolution Remotely Sensed Datasets Using Classification Trees and Test Field Points. Remote Sens. 2011, 3, 1777–1804. [Google Scholar] [CrossRef] [Green Version]
- Chi, M.; Feng, R.; Bruzzone, L. Classification of hyperspectral remote-sensing data with primal SVM for small-sized training dataset problem. Adv. Space Res. 2008, 41, 1793–1799. [Google Scholar] [CrossRef]
- Huang, M.J.; Shyue, S.W.; Lee, L.H.; Kao, C.C. A Knowledge-based Approach to Urban Feature Classification Using Aerial Imagery with Lidar Data. Photogramm. Eng. Remote Sens. 2008, 74, 1473–1485. [Google Scholar] [CrossRef]
- Salem, S.A.; Salem, N.M.; Nandi, A.K. Segmentation of retinal blood vessels using a novel clustering algorithm (RACAL) with a partial supervision strategy. Med. Biol. Eng. Comput. 2007, 45, 261–273. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Orlando, J.I.; Prokofyeva, E.; Blaschko, M.B. A Discriminatively Trained Fully Connected Conditional Random Field Model for Blood Vessel Segmentation in Fundus Images. IEEE Trans. Biomed. Eng. 2016, 64, 16–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wagner, S.A. SAR ATR by a combination of convolutional neural network and support vector machines. IEEE Trans. Aerosp. Electron. Syst. 2018, 52, 2861–2872. [Google Scholar] [CrossRef]
- Gerke, M. Use of the Stair Vision Library Within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen); Technical Report, University of Twente; Researche Gate: Berlin, Germany, 2015. [Google Scholar]
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. Marta gans: Unsupervised representation learning for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2016, 14, 2092–2096. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LULC | Land Use and Land Cover |
| DSM | Digital Surface Model |
| UAV | Unmanned Aerial Vehicle |
| NDSM | Normalized Digital Surface Model |
| dCNN | Convolutional Neural Networks |
| SVM | Support Vector Machine |
| FC-CRF | Fully connected Conditional Random Fields |
| Overall Accuracy | OA |
| Method | Feature Descriptors | Classifier |
|---|---|---|
| FCNN-SVM | Fine-tuned CNN–Equation (2) | SVM |
| SD-SVM | Spectral feature and NDSM combined with SVM–Equation (3) | SVM |
| CMP-SVM | Concatenating probability vector–Equation (4) | SVM |
| FCNN-FCCRF | Fine-tuned CNN–Equation (2) | FC-CRF |
| SD-FCCRF | Spectral feature and NDSM combined with SVM–Equation (3) | FC-CRF |
| CMP-FCCRF | Concatenating probability vector–Equation (4) | FC-CRF |
| Classification Method | Confusion Matrix (%) | OA (%) | ||||
|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | |||
| SD-SVM | C1 | 82.28 | 6.69 | 3.81 | 7.23 | 81.07 ± 0.6050 |
| C2 | 11.78 | 85.11 | 2.60 | 0.51 | ||
| C3 | 13.91 | 0.99 | 77.78 | 7.32 | ||
| C4 | 9.85 | 1.30 | 7.10 | 81.74 | ||
| FCNN-SVM | C1 | 76.13 | 8.84 | 7.09 | 7.95 | 78.89 ± 0.3141 |
| C2 | 11.38 | 86.54 | 0.86 | 1.22 | ||
| C3 | 12.71 | 1.25 | 75.77 | 10.28 | ||
| C4 | 7.11 | 0.81 | 3.68 | 88.40 | ||
| CMP-SVM | C1 | 80.34 | 9.04 | 3.69 | 6.93 | 83.29 ± 0.1192 |
| C2 | 7.67 | 90.13 | 1.17 | 1.02 | ||
| C3 | 10.32 | 1.05 | 80.02 | 8.62 | ||
| C4 | 6.66 | 0.80 | 5.02 | 87.51 | ||
| SD-FCCRF | C1 | 86.09 | 6.05 | 1.83 | 6.03 | 83.03 ± 1.1030 |
| C2 | 10.19 | 87.47 | 2.00 | 0.35 | ||
| C3 | 13.07 | 0.42 | 79.50 | 7.02 | ||
| C4 | 7.59 | 1.24 | 6.39 | 84.78 | ||
| FCNN-FCCRF | C1 | 79.42 | 8.62 | 5.34 | 6.62 | 80.06 ± 0.4239 |
| C2 | 9.31 | 89.19 | 0.70 | 0.81 | ||
| C3 | 11.79 | 0.62 | 77.71 | 9.88 | ||
| C4 | 6.18 | 0.61 | 2.63 | 90.58 | ||
| CMP -FCCRF | C1 | 83.34 | 9.04 | 1.75 | 5.87 | 84.73 ± 0.1566 |
| C2 | 6.04 | 92.51 | 0.80 | 0.65 | ||
| C3 | 9.72 | 0.67 | 81.23 | 8.38 | ||
| C4 | 4.58 | 0.72 | 4.48 | 90.22 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, B.; Wang, C.; Shen, Y.; Liu, Y. Fully Connected Conditional Random Fields for High-Resolution Remote Sensing Land Use/Land Cover Classification with Convolutional Neural Networks. Remote Sens. 2018, 10, 1889. https://doi.org/10.3390/rs10121889
Zhang B, Wang C, Shen Y, Liu Y. Fully Connected Conditional Random Fields for High-Resolution Remote Sensing Land Use/Land Cover Classification with Convolutional Neural Networks. Remote Sensing. 2018; 10(12):1889. https://doi.org/10.3390/rs10121889
Chicago/Turabian StyleZhang, Bin, Cunpeng Wang, Yonglin Shen, and Yueyan Liu. 2018. "Fully Connected Conditional Random Fields for High-Resolution Remote Sensing Land Use/Land Cover Classification with Convolutional Neural Networks" Remote Sensing 10, no. 12: 1889. https://doi.org/10.3390/rs10121889