Towards Operational Satellite-Based Damage-Mapping Using U-Net Convolutional Network: A Case Study of 2011 Tohoku Earthquake-Tsunami



Abstract

1. Introduction
- (1)
- The superior performance of deep learning algorithms is limited to the size of the available training sets and the size of the considered networks. One of the most significant challenges for applying the deep learning technique to disaster damage-mapping practice is that thousands of training images of damaged targets are commonly beyond reach in disaster tasks, which is particularly true for earthquakes and landslides, where only a few samples are available [21]. Therefore, an algorithm that works with notably few training samples and yields more precise results is highly in demand.
- (2)
- The previous method mainly focuses on assessing the accuracy of deep learning algorithms in classifying the damage from remote-sensing images [22,23,24,25]. Although damage assessment is essential and indispensable because it can improve our perception of which algorithm or scheme can achieve the best accuracy and should be used for damage-mapping practice, from this viewpoint, the damage assessment is a more theoretical argumentation. To satisfy the requirements of disaster emergency response, a framework that integrates accuracy assessment and damage-mapping is urgently needed. The scientific value of previous works is significantly reduced because they only focus on the damage assessment without providing the damage-mapping demonstration, and many manual steps must be implemented to successfully derive the damage-mapping results of these methods, which is impractical in disaster response considering the time cost.
- (3)
- The mainstream application of convolutional neural networks is on classification tasks, where the output to an image is a single class label. However, in many real application tasks, the desired output should also include localization, which requires that the algorithm can assign the output class label into specific pixels [26]. Damage-mapping is a task that highly depends on the location information, whereas the framework proposed in previous work can only output the label of tiles, and the label information requires an additional procedure to project to a map [5,22,24]. This lag or gap dramatically increases the time cost of the actual disaster response.
- (4)
- The accuracy of the class label has a significant effect on the accuracy. The previous method mostly uses the patch-based label, where a single label is assigned to a large patch [5,22]. However, this patch contains many unrelated pixels. Theoretically, the pixel-based labelling method [25] is more precise. However, it has not been applied to the practice of damage-mapping.
- (5)
- To rapidly respond to a disaster, a high-efficiency commercial platform that can implement our deep learning algorithm and visualize the geospatial-based damage-mapping products is highly required.
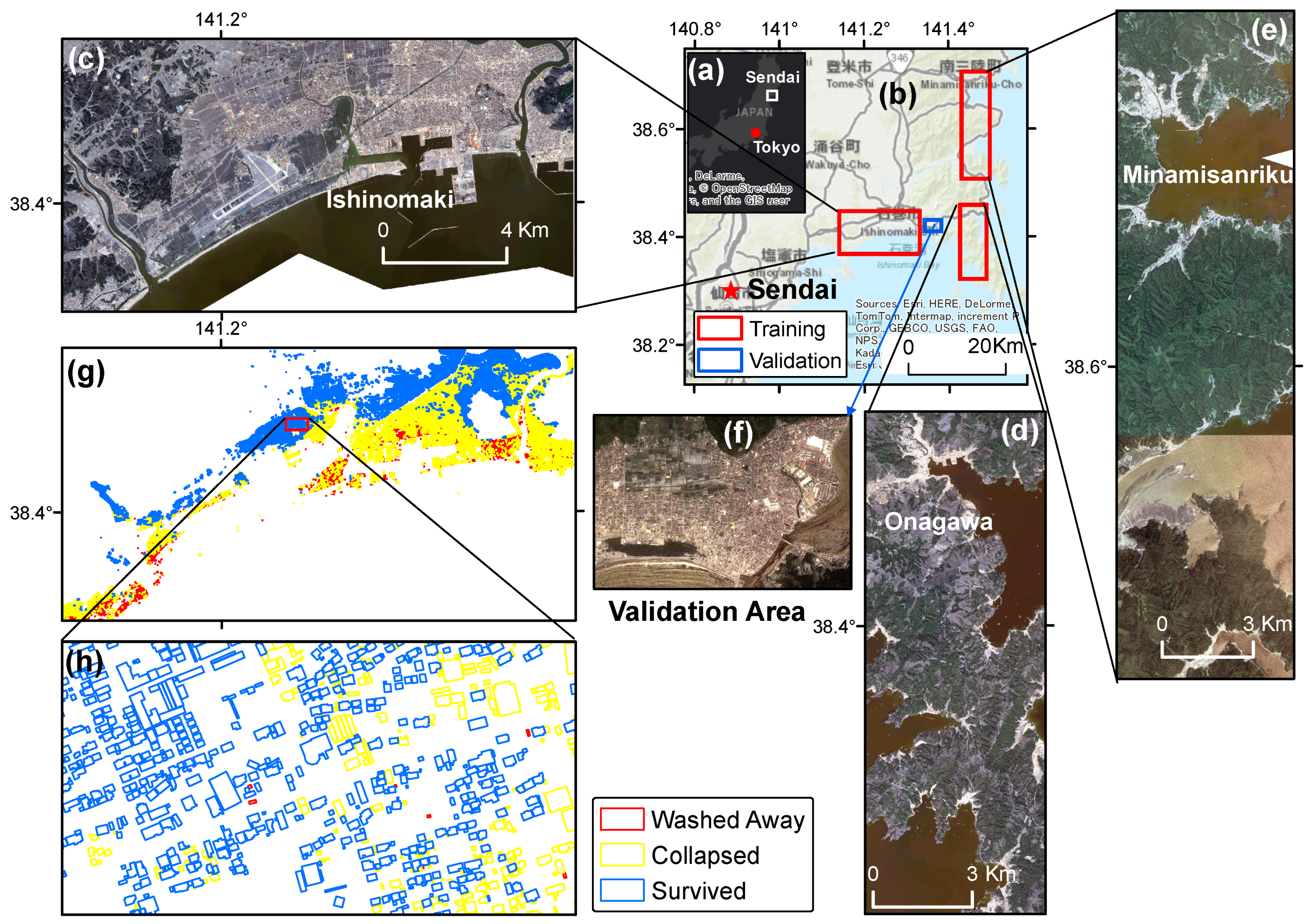
2. Case Study and Datasets
3. Methodology
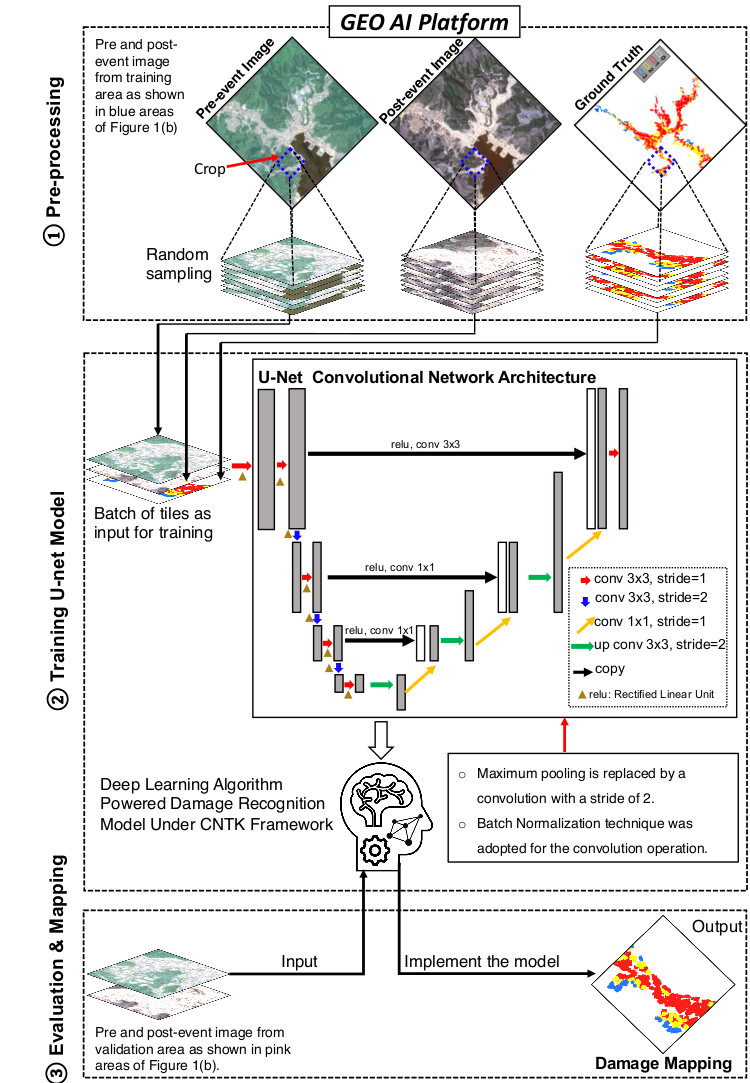
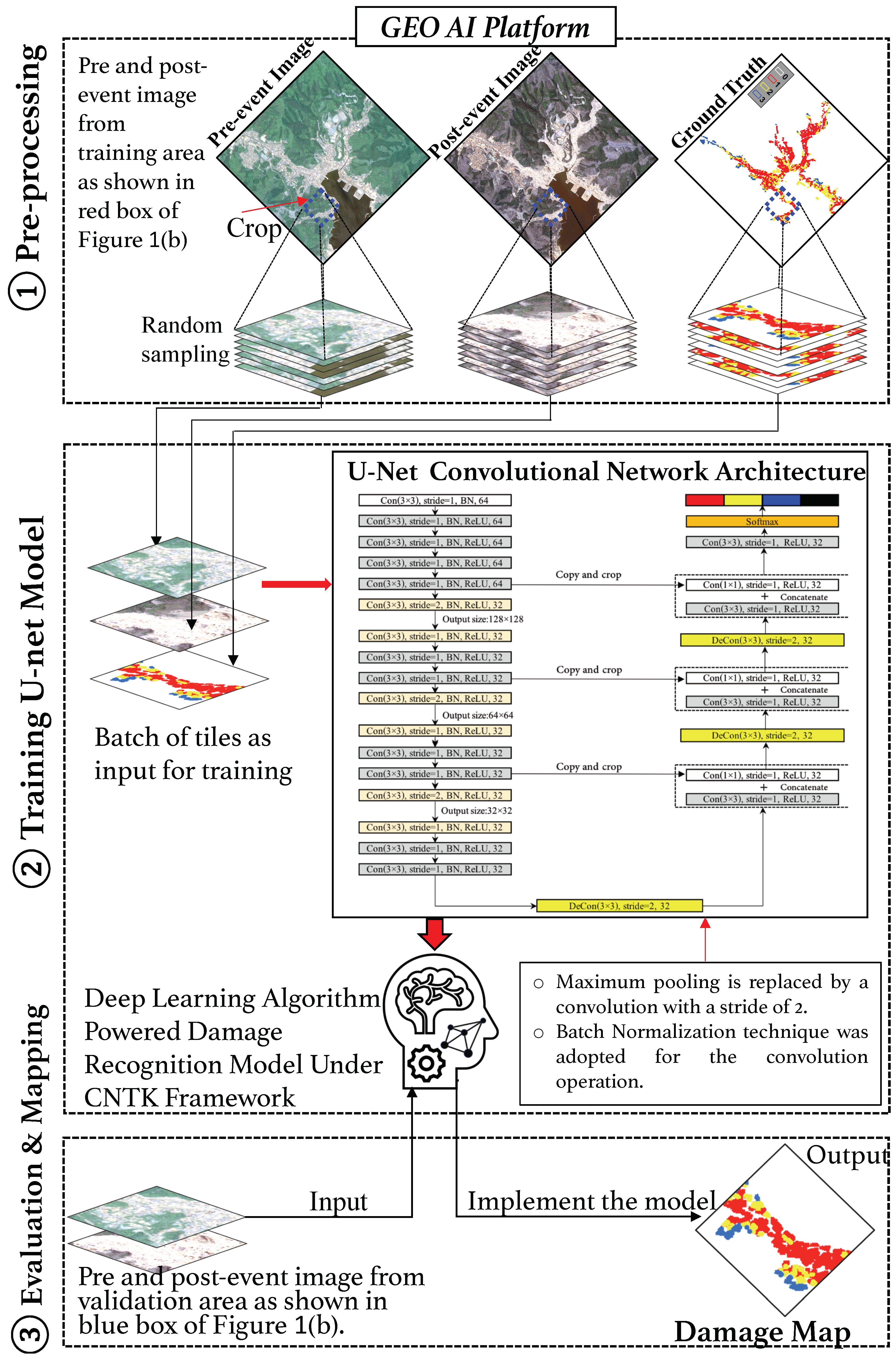
3.1. Pre-Processing HR Images and Ground-Truth Data
3.2. Preparation of Datasets for Training
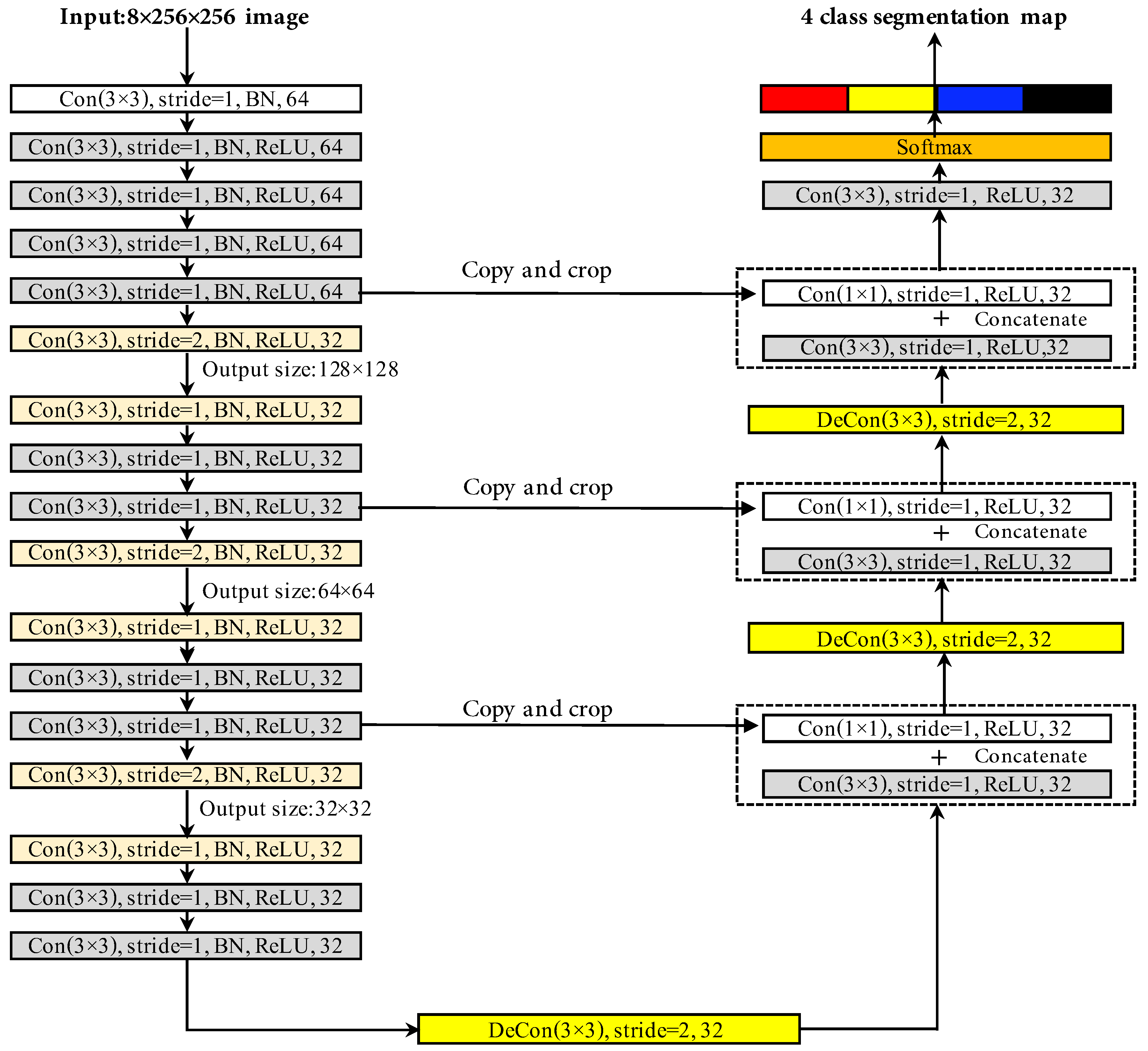
3.3. U-Net Neural Network Architecture
- Compared with U-net [26], the batch normalization operation is used in this work as shown in Figure 3a,b. Batch normalization is a new technique to accelerate deep network training by alleviating the internal covariate shifting issue while training a notably deep neural network. It normalizes its inputs for every minibatch using the minibatch mean/variance and de-normalizes it with a learned scaling factor and bias. Batch normalization uses a long-term running mean and variance estimate, and the estimate is calculated during training by low-pass filtering minibatch statistics [31]. Many studies have demonstrated that batch normalization can significantly reduce the number of iterations to converge and improves the final performance [34]. In this study, BN is used in every convolutional operation, and the time constant of the low-pass filter is set to 4096.
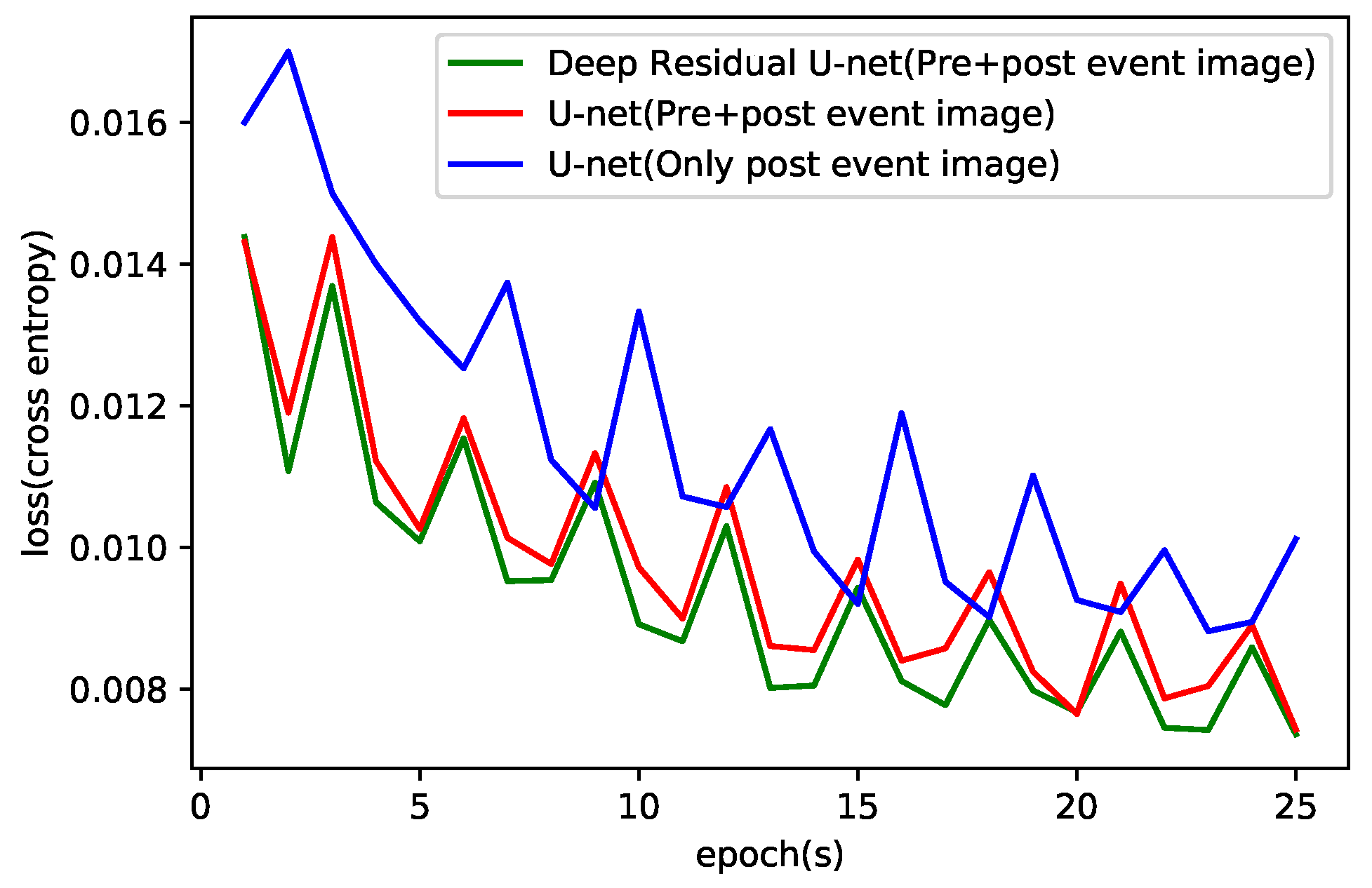
3.4. Training Damage Recognition Model
3.5. Evaluating the Performance of Damage Recognition Model
3.6. Damage Mapping and Visualization
3.7. Experiment Environment
4. Results and Discussions
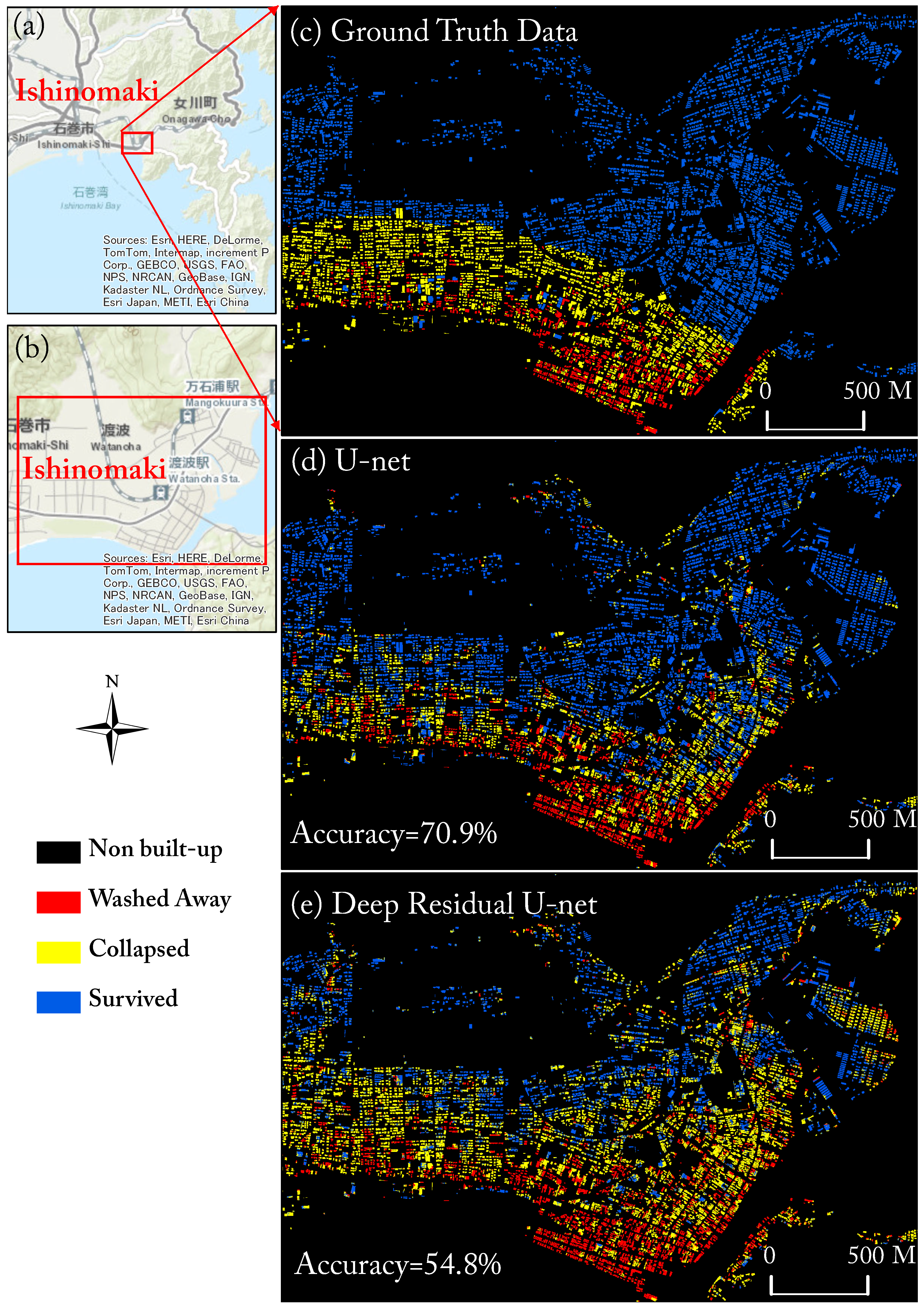
4.1. Accuracy Assessment of Damage-Mapping
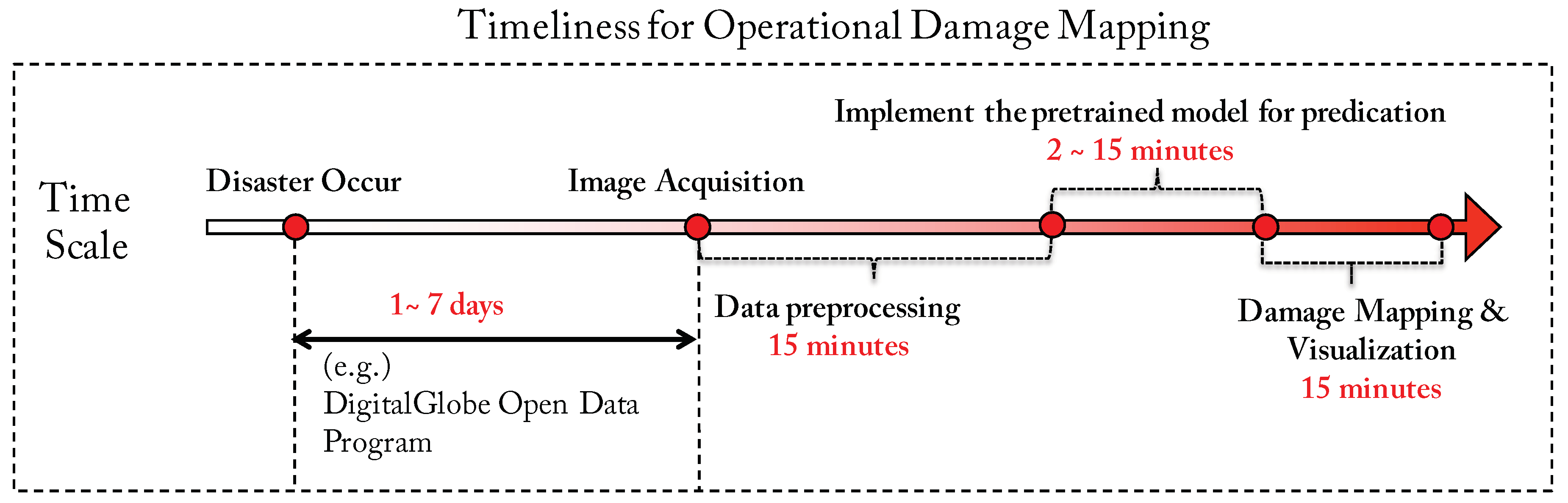
4.2. Timeliness Estimation for Operational Damage-Mapping
4.3. Contribution of the Proposed Framework for Accelerating Operational Damage-Mapping Practice
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| HR | High-Resolution |
| GeoAI | Geospatial Artifical Intelligence |
| CNTK | Computational Network Toolkit |
| BN | Batch Normalization |
| RMSprob | Root Mean Square Prop |
| ReLU | Rectified Linear Unit |
References
- Mori, N.; Takahashi, T.; 2011 Tohoku Earthquake Tsunami Joint Survey Group. Nationwide post event survey and analysis of the 2011 Tohoku Earthquake Tsunami. Coast. Eng. J. 2012, 54, 1250001-1–1250001-27. [Google Scholar] [CrossRef]
- Ruangrassamee, A.; Yanagisawa, H.; Foytong, P.; Lukkunaprasit, P.; Koshimura, S.; Imamura, F. Investigation of tsunami-induced damage and fragility of buildings in Thailand after the December 2004 Indian Ocean tsunami. Earthq. Spectra 2006, 22, 377–401. [Google Scholar] [CrossRef]
- Suppasri, A.; Koshimura, S.; Imai, K.; Mas, E.; Gokon, H.; Muhari, A.; Imamura, F. Damage characteristic and field survey of the 2011 Great East Japan Tsunami in Miyagi Prefecture. Coast. Eng. J. 2012, 54, 1250005-1–1250005-30. [Google Scholar] [CrossRef]
- Schultz, C.H.; Koenig, K.L.; Noji, E.K. A medical disaster response to reduce immediate mortality after an earthquake. N. Engl. J. Med. 1996, 334, 438–444. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Gao, C.; Singh, S.; Koch, M.; Adriano, B.; Mas, E.; Koshimura, S. A Framework of Rapid Regional Tsunami Damage Recognition From Post-event TerraSAR-X Imagery Using Deep Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 43–47. [Google Scholar] [CrossRef]
- Moya, L.; Yamazaki, F.; Liu, W.; Yamada, M. Detection of collapsed buildings from lidar data due to the 2016 Kumamoto earthquake in Japan. Nat. Hazards Earth Syst. Sci. 2018, 18, 65–78. [Google Scholar] [CrossRef]
- Chen, S.W.; Wang, X.S.; Sato, M. Urban damage level mapping based on scattering mechanism investigation using fully polarimetric SAR data for the 3.11 East Japan earthquake. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6919–6929. [Google Scholar] [CrossRef]
- Trekin, A.; Novikov, G.; Potapov, G.; Ignatiev, V.; Burnaev, E. Satellite imagery analysis for operational damage assessment in Emergency situations. arXiv, 2018; arXiv:1803.00397. Available online: https://arxiv.org/abs/1803.00397 (accessed on 1 September 2018).
- Digital Globe. Open Data Program. 2017. Available online: https://www.digitalglobe.com/opendata (accessed on 24 August 2018).
- Mas, E.; Bricker, J.; Kure, S.; Adriano, B.; Yi, C.; Suppasri, A.; Koshimura, S. Field survey report and satellite image interpretation of the 2013 Super Typhoon Haiyan in the Philippines. Nat. Hazards Earth Syst. Sci. 2015, 15, 805–816. [Google Scholar] [CrossRef]
- Gokon, H.; Koshimura, S. Mapping of building damage of the 2011 Tohoku earthquake tsunami in Miyagi Prefecture. Coast. Eng. J. 2012, 54, 1250006. [Google Scholar] [CrossRef]
- Gamba, P.; Casciati, F. GIS and image understanding for near-real-time earthquake damage assessment. Photogramm. Eng. Remote Sens. 1998, 64, 987–994. [Google Scholar]
- Yusuf, Y.; Matsuoka, M.; Yamazaki, F. Damage assessment after 2001 Gujarat earthquake using Landsat-7 satellite images. J. Indian Soc. Remote Sens. 2001, 29, 17–22. [Google Scholar] [CrossRef]
- Rathje, E.M.; Woo, K.S.; Crawford, M.; Neuenschwander, A. Earthquake damage identification using multi-temporal high-resolution optical satellite imagery. IEEE Int. Geosci. Remote Sens. Symp. 2005, 7, 5045–5048. [Google Scholar] [CrossRef]
- Bai, Y.; Adriano, B.; Mas, E.; Koshimura, S. Building Damage Assessment in the 2015 Gorkha, Nepal, Earthquake Using Only Post-Event Dual Polarization Synthetic Aperture Radar Imagery. Earthq. Spectra 2017, 33, S185–S195. [Google Scholar] [CrossRef]
- Thomas, J.; Kareem, A.; Bowyer, K.W. Automated poststorm damage classification of low-rise building roofing systems using high-resolution aerial imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3851–3861. [Google Scholar] [CrossRef]
- Anniballe, R.; Noto, F.; Scalia, T.; Bignami, C.; Stramondo, S.; Chini, M.; Pierdicca, N. Earthquake damage mapping: An overall assessment of ground surveys and VHR image change detection after L’Aquila 2009 earthquake. Remote Sens. Environ. 2018, 210, 166–178. [Google Scholar] [CrossRef]
- Ranjbar, H.R.; Ardalan, A.A.; Dehghani, H.; Saradjian, M.R. Using high-resolution satellite imagery to proide a relief priority map after earthquake. Nat. Hazards 2018, 90, 1087–1113. [Google Scholar] [CrossRef]
- Duarte, D.; Nex, F.; Kerle, N.; Vosselman, G. Satellite Image Classification of Building Damages Using Airborne and Satellite Image Samples in a Deep Learning Approach. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2018, IV-2, 89–96. [Google Scholar] [CrossRef]
- Alidoost, F.; Arefi, H. Application of Deep Learning for Emergency Response and Disaster Management. In Proceedings of the AGSE Eighth International Summer School and Conference, University of Tehran, Tehran, Iran, 29 April–4 May 2017; pp. 11–17. [Google Scholar]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Environ. 2018, 115, 2564–2577. [Google Scholar] [CrossRef]
- Fujita, A.; Sakurada, K.; Imaizumi, T.; Ito, R.; Hikosaka, S.; Nakamura, R. Damage detection from aerial images via convolutional neural networks. In Proceedings of the Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8 May–12 May 2017; pp. 8–12. [Google Scholar] [CrossRef]
- Vetrivel, A.; Gerke, M.; Kerle, N.; Nex, F.; Vosselman, G. Disaster damage detection through synergistic use of deep learning and 3D point cloud features derived from very high resolution oblique aerial images, and multiple-kernel-learning. ISPRS J. Photogramm. Remote Sens. 2018, 140, 45–59. [Google Scholar] [CrossRef]
- Cao, Q.D.; Choe, Y. Deep Learning Based Damage Detection on Post-Hurricane Satellite Imagery. arXiv, 2018; arXiv:1807.01688. [Google Scholar]
- Kemker, R.; Salvaggio, C.; Kanan, C.W. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 60–77. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, Massachusetts, 8–12 June 2015; pp. 3431–3440. [Google Scholar]
- Microsoft. Geospatial AI on Azure. 2018. Available online: http://aka.ms/dsvm/geoai/docs (accessed on 25 August 2018).
- National Police Agency of Japan. Police Countermeasures and Damage Situation Associated with 2011 Tohoku District-Off the Pacific Ocean Earthquake. Available online: https://www.npa.go.jp/news/other/earthquake2011/pdf/higaijokyo_e.pdf (accessed on 18 June 2018).
- Ministry of Land, Infrastructure and Transportation (MLIT), Survey of Tsunami Damage Condition. Available online: http://www.mlit.go.jp/toshi/toshi-hukkou-arkaibu.html (accessed on 20 Novermber 2014).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning-Volume, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Fifteenth IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic Segmentation of Small Objects and Modeling of Uncertainty in Urban Remote Sensing Images Using Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 680–688. [Google Scholar] [CrossRef]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv, 2014; arXiv:1412.6806. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can Semantic Labeling Methods Generalize to Any City? the inria aerial image labeling benchmark. In Proceedings of the IEEE International Symposium on Geoscience and Remote Sensing (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar] [CrossRef]
- Hinton, G.; Srivastava, N.; Swersky, K. Rmsprop: Divide the Gradient by a Running Average of Its Recent Magnitude. COURSERA: Neural Networks for Machine Learning. Available online: https://www.coursera.org/lecture/neural-networks/rmsprop-divide-the-gradient-by-a-running -average-of-its-recent-magnitude-YQHki (accessed on 1 September 2018).
- Seide, F.; Agarwal, A. CNTK: Microsoft’s open-source deep-learning toolkit. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; p. 2135. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Vienna, Austria, 29 March–1 April 2015; Springer: Berlin/Heidelberg, Germany; pp. 345–359. [Google Scholar]
- Yamazaki, F.; Iwasaki, Y.; Liu, W.; Nonaka, T.; Sasagawa, T. Detection of damage to building side-walls in the 2011 Tohoku, Japan earthquake using high-resolution TerraSAR-X images. In Proceedings of the Image and Signal Processing for Remote Sensing XIX, Dresden, Germany, 23–25 September 2013. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Acquisition Time | Sensor | Spectral Bands | Ground Sample Distance |
|---|---|---|---|---|
| Pre-disaster | 13 May 2009 | WorldView-2 | 4-band multispectral | 0.6 m |
| 9 November 2006 | ||||
| 17 February 2006 | ||||
| 18 July 2004 | ||||
| Post-disaster | 8 June 2011 | |||
| 6 April 2011 | ||||
| 18 July 2011 |
| U-Net Model | Deep Residual U-net Model | ||||||
|---|---|---|---|---|---|---|---|
| Omission Error | Commission Error | F-score | Omission Error | Commission Error | F-Score | ||
| Washed Away | 39.0% | 75.6% | 0.35 | 35.2% | 85.6% | 0.24 | |
| Collapsed | 51.2% | 66.2% | 0.40 | 48.6% | 72.3% | 0.36 | |
| Survived | 22.7% | 29.9% | 0.76 | 51.9% | 28.2% | 0.58 | |
| Overall Accuracy = 70.9% | Overall Accuracy = 54.8% | ||||||
| Disaster Event | Occur Date | Data Available Time | Time Gap (Day) |
|---|---|---|---|
| 2017 Santa Rosa Wildfires | 8 October 2017 | 10 October 2017 | 2 |
| 2017 Southern Mexico Earthquake | 8 September 2017 | 8 September 2017 | 1 |
| 2017 Monsoon in Nepal, India | 14 August 2017 | 17 August 2017 | 3 |
| 2017 Sierra Leone Mudslide | 14 August 2017 | 15 August 2017 | 1 |
| 2017 Mocoa Landslide | 1 April 2017 | 8 April 2017 | 7 |
| 2017 Tropical Cyclone Enawo | 7 March 2017 | 10 March 2017 | 3 |
| 2016 Ecuador Earthquake | 16 April 2015 | 17 April 2015 | 1 |
| 2015 Nepal Earthquake | 25 April 2015 | 26 April 2015 | 1 |
| 2010 Haiti Earthquake | 12 January 2010 | 12 January 2010 | 3 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, Y.; Mas, E.; Koshimura, S. Towards Operational Satellite-Based Damage-Mapping Using U-Net Convolutional Network: A Case Study of 2011 Tohoku Earthquake-Tsunami. Remote Sens. 2018, 10, 1626. https://doi.org/10.3390/rs10101626
Bai Y, Mas E, Koshimura S. Towards Operational Satellite-Based Damage-Mapping Using U-Net Convolutional Network: A Case Study of 2011 Tohoku Earthquake-Tsunami. Remote Sensing. 2018; 10(10):1626. https://doi.org/10.3390/rs10101626
Chicago/Turabian StyleBai, Yanbing, Erick Mas, and Shunichi Koshimura. 2018. "Towards Operational Satellite-Based Damage-Mapping Using U-Net Convolutional Network: A Case Study of 2011 Tohoku Earthquake-Tsunami" Remote Sensing 10, no. 10: 1626. https://doi.org/10.3390/rs10101626
APA StyleBai, Y., Mas, E., & Koshimura, S. (2018). Towards Operational Satellite-Based Damage-Mapping Using U-Net Convolutional Network: A Case Study of 2011 Tohoku Earthquake-Tsunami. Remote Sensing, 10(10), 1626. https://doi.org/10.3390/rs10101626