Urban Niche Assessment: An Approach Integrating Social Media Analysis, Spatial Urban Indicators and Geo-Statistical Techniques

 ,
,  ,
,
Abstract
:1. Introduction
1.1. General Problem
1.2. Literature Review
1.3. Purpose of The Research
2. Materials and Methods
2.1. Study Area
2.2. Data Sources
2.2.1. Remote Sensing and Geographical Data
2.2.2. Google Street View Data
2.2.3. Flickr Data
2.3. Methods
- (a)
- identification of the location of individuals’ presence in the urban public space;
- (b)
- identification of the set of environmental variables that determine the habitat model and organization of a geo-database;
- (c)
- formulation of an ensemble of models based on regression and machine learning approaches for probabilistic prediction of the preferences of the individuals in the urban public spaces and evaluation of the performances of each model.
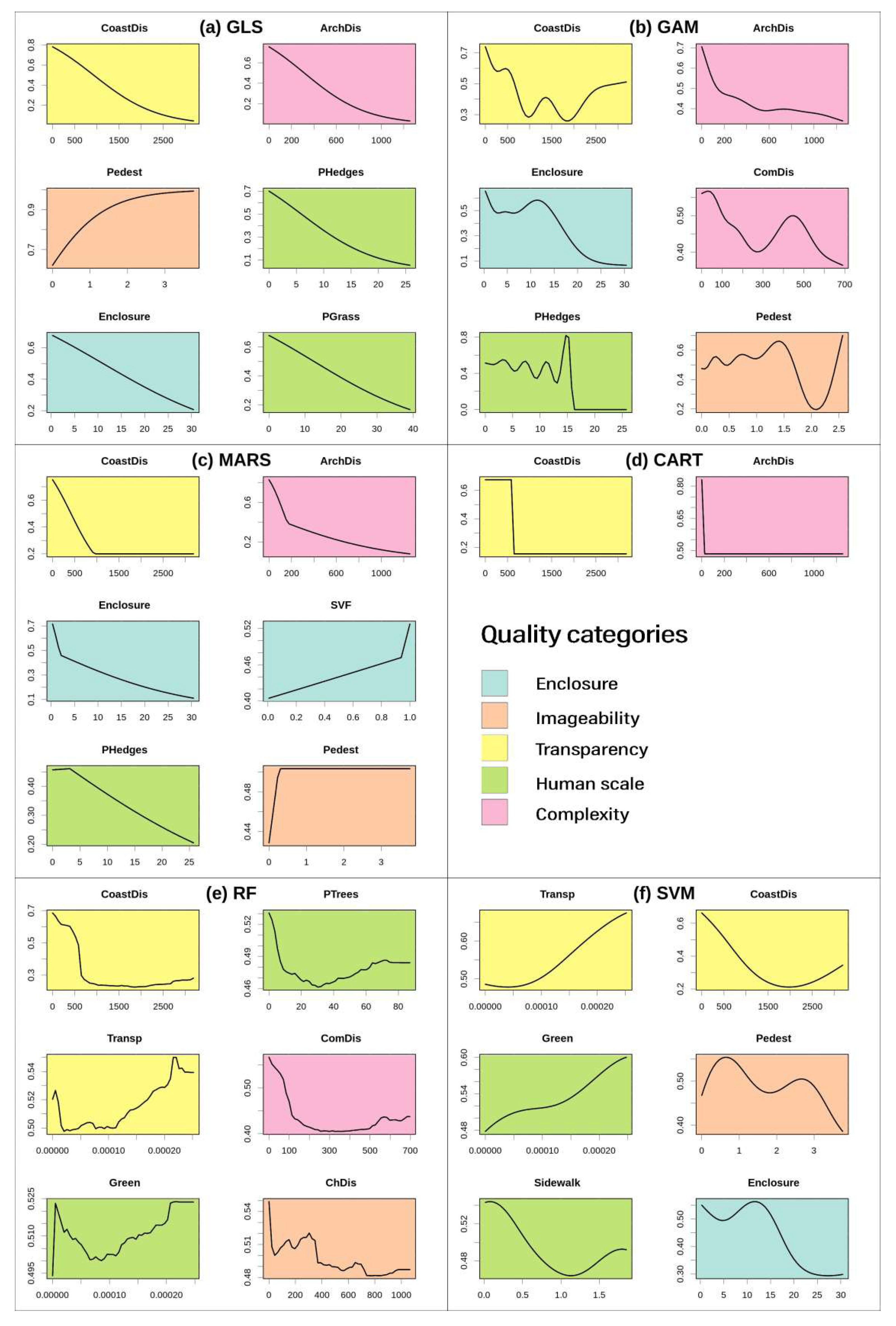
2.3.1. Assessment of Urban Niche Indicators
- (a)
- Enclosure. This category of indicators is characterized by the horizontal and vertical ratios between artificial and natural volumes (buildings and trees) with open spaces (streets and squares). Christopher Alexander et al. [29] (p. 106) stated that “outdoor space is positive when it has a distinct and definite shape, as definite as the shape of a room, and when its shape is as important as the shapes of the buildings which surround it”.
- (b)
- Imageability refers to the quality of a place that makes it distinct, recognizable and memorable. A place has high imageability when physical elements capture attention, evoke positive feelings related to the activity of walking [30].
- (c)
- Human scale. They are the urban elements that place the individual in relationship with nature.
- (d)
- Transparency. Transparency is defined as the degree to which people can see or perceive what lies beyond the edge of a road until their gaze reaches the horizon.
- (e)
- Complexity. Complexity results from varying building shapes, sizes, materials, and colors, but can also refer to diversity in jobs and land use (distribution of housing, offices, roads, etc.).
- (a)
- Enclosure: sky view factor; enclosure index.
- (b)
- Imageability: pedestrian index; distance from churches; pavement index.
- (c)
- Human scale: grass density, hedges density, trees density, green index, sidewalk index.
- (d)
- Transparency: transparency index, distance from coast-line.
- (e)
- Complexity: distance from commercials; distance from accommodation land use; distance from buildings with high architectural value.
- (i)
- Deep learning segmentation using GSV imagery was applied to the enclosure index, pedestrian index, cyclist index, road crowdedness index, building crowdedness index, and transparency index.
- (ii)
- Landscape ecology indicators were applied to multispectral remote sensing images for the grass density, hedges density, and trees density.
- (iii)
- The distance operator applied to data from OpenStreetMap database was applied to the urban points of interest (POIs), defined as commercials, accommodations, buildings with high architectural value, and churches.
- (iv)
- The sky view factor was calculated using LIDAR data.
2.3.2. Deep Learning Segmentation Using Google Street View Imagery
2.3.3. Landscape Ecology Indicators Applied to Multi-Spectral Aerial Images
2.3.4. Distance From The Urban Points of Interest (POIs)
2.3.5. Derivation of Sky-View Factors from LIDAR Data
2.4. Ecological Model of the Urban Human Niche (EMUHN)
2.4.1. Generating Pseudo-Absence Data
2.4.2. The Ensemble of Models
2.4.3. Ensemble Aggregation Method
3. Results
3.1. Mapping the Indicators of Urban Habitat Quality
3.1.1. Geotagged Photo Distribution
3.1.2. Deep Learning Segmentation Indexes
3.1.3. Indicators Derived From Geographic and Remote Sensing Data
3.2. Assessment of Features of The Urban Quality
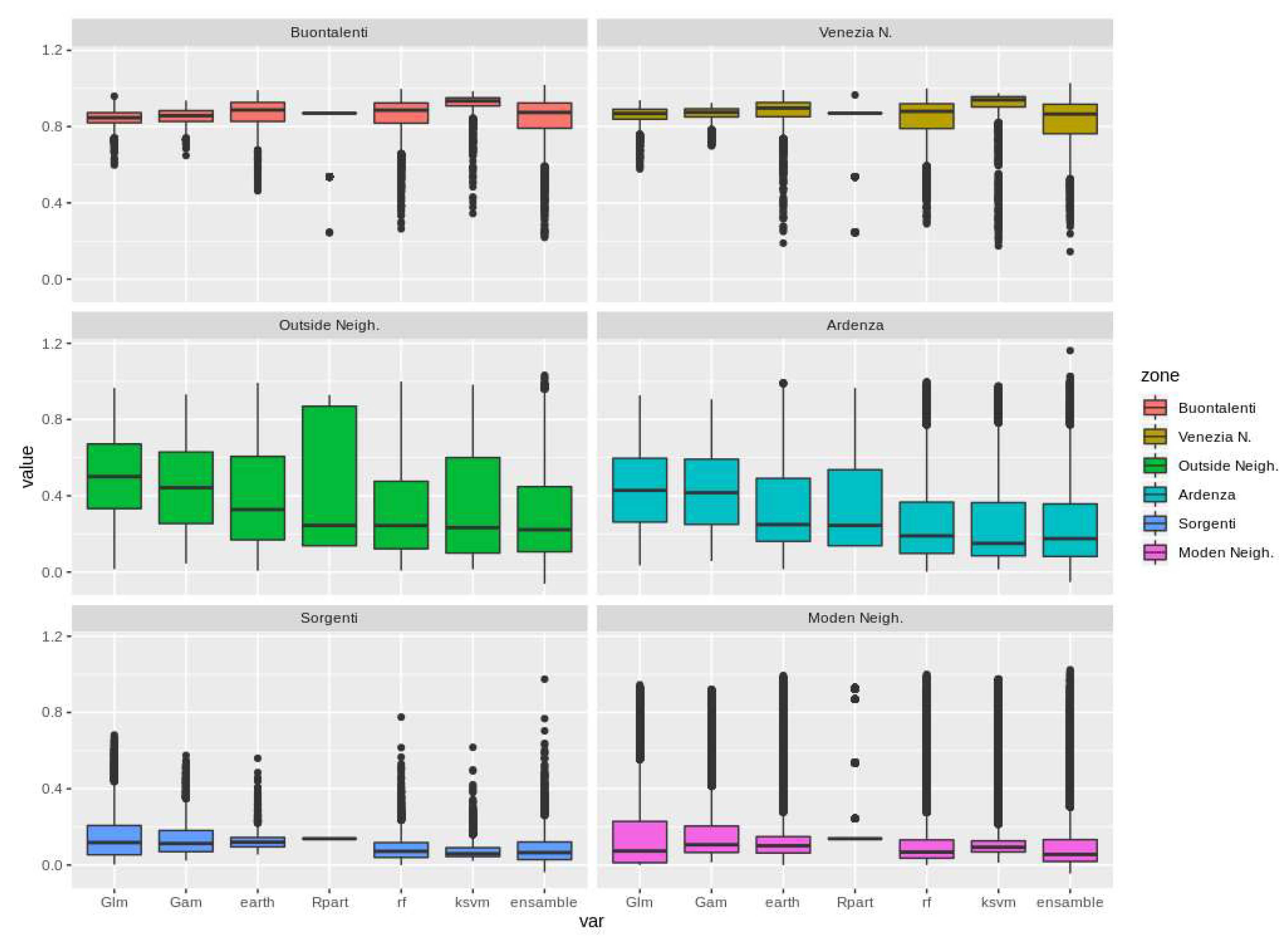
3.2.1. Model Evaluation
3.2.2. The Importance of Variables
3.2.3. The Response Curves
3.2.4. The Urban Quality Maps
4. Discussion
4.1. Have The Research Objectives Been Achieved?
4.2. Limitation of Study and Topics for Further Researches
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- United Nations. The State of World Population 2019; United Nations Population Fund: New York, NY, USA, 2019. [Google Scholar]
- Pallasmaa, J.; Mallgrave, H.F.; Robinson, S.; Gallese, V. Architecture and Empathy; Tidwell, P., Ed.; A Tapio Wirkkala-Rut Bryk Design Reader; Peripheral Projects: Espoo, Finland, 2015. [Google Scholar]
- Lynch, K. The Image of the City; Joint Center for Urban Studies: Cambridge, MA, USA, 1960. [Google Scholar]
- Sarkar, C.; Webster, C. Urban environments and human health: Current trends and future directions. Curr. Opin. Environ. Sustain. 2017, 25, 33–44. [Google Scholar] [CrossRef]
- Olsen, I.T. Sustainability of health care: A framework for analysis. Health Policy Plan. 1998, 13, 287–295. [Google Scholar] [CrossRef] [PubMed]
- Lyons, G.J.; Duggan, J. System dynamics modelling to support policy analysis for sustainable health care. J. Simul. 2015, 9, 129–139. [Google Scholar] [CrossRef] [Green Version]
- Griggs, D.; Stafford-Smith, M.; Gaffney, O.; Rockström, J.; Öhman, M.C.; Shyamsundar, P.; Noble, I. Policy: Sustainable development goals for people and planet. Nature 2013, 495, 305. [Google Scholar] [CrossRef] [PubMed]
- Cohen, D.A.; Inagami, S.; Finch, B. The built environment and collective efficacy. Health Place 2008, 14, 198–208. [Google Scholar] [CrossRef] [Green Version]
- Cohen, D.A.; Finch, B.K.; Bower, A.; Sastry, N. Collective efficacy and obesity: The potential influence of social factors on health. Soc. Sci. Med. 2006, 62, 769–778. [Google Scholar] [CrossRef]
- Nutsford, D.; Pearson, A.L.; Kingham, S. An ecological study investigating the association between access to urban green space and mental health. Public Health 2013, 127, 1005–1011. [Google Scholar] [CrossRef]
- Kleinert, S.; Horton, R. Urban design: An important future force for health and wellbeing. Lancet 2016, 388, 2848–2850. [Google Scholar] [CrossRef]
- Sallis, J.F.; Cerin, E.; Conway, T.L.; Adams, M.A.; Frank, L.D.; Pratt, M.; Davey, R. Physical activity in relation to urban environments in 14 cities worldwide: A cross-sectional study. Lancet 2016, 387, 2207–2217. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Yang, Y. Neighbourhood walkability: A review and bibliometric analysis. Cities 2019, 93, 43–61. [Google Scholar] [CrossRef]
- Joo, S.; Oh, C. A novel method to monitor bicycling environments. Transp. Res. Part A Policy Pract. 2013, 54, 1–13. [Google Scholar] [CrossRef]
- Salon, D. Estimating pedestrian and cyclist activity at the neighborhood scale. J. Transp. Geogr. 2016, 55, 11–21. [Google Scholar] [CrossRef]
- Neutens, T.; Schwanen, T.; Witlox, F. The prism of everyday life: Towards a new research agenda for time geography. Transp. Rev. 2011, 31, 25–47. [Google Scholar] [CrossRef]
- Jin, X.; Gallagher, A.; Cao, L.; Luo, J.; Han, J. The wisdom of social multimedia: Using flickr for prediction and forecast. In Proceedings of the 18th ACM international conference on Multimedia, Firenze, Italy, 25–29 October 2010; ACM: New York, NY, USA, 2010; pp. 1235–1244. [Google Scholar]
- Rybarczyk, G.; Banerjee, S.; Starking-Szymanski, M.D.; Shaker, R.R. Travel and us: The impact of mode share on sentiment using geo-social media and GIS. J. Locat. Based Serv. 2018, 12, 40–62. [Google Scholar] [CrossRef]
- Huang, Q.; Wong, D.W. Activity patterns, socioeconomic status and urban spatial structure: What can social media data tell us? Int. J. Geogr. Inf. Sci. 2016, 30, 1873–1898. [Google Scholar] [CrossRef]
- Cox, A.M.; Clough, P.D.; Marlow, J. Flickr: A first look at user behaviour in the context of photography as serious leisure. Inf. Res. 2008, 13, 13–21. [Google Scholar]
- Dunkel, A. Visualizing the perceived environment using crowdsourced photo geodata. Landsc. Urban Plan. 2015, 142, 173–186. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, C.; Kimmons, B. Detecting tourism destinations using scalable geospatial analysis based on cloud computing platform. Comput. Environ. Urban Syst. 2015, 54, 144–153. [Google Scholar] [CrossRef]
- Hauthal, E.; Burghardt, D. Using VGI for analyzing activities and emotions of locals and tourists. In Proceedings of the Link-VGI Workshop in Connection with the AGILE, Helsinki, Finland, 14 June 2016. [Google Scholar]
- Quercia, D.; Schifanella, R.; Aiello, L.M. The shortest path to happiness: Recommending beautiful, quiet, and happy routes in the city. In Proceedings of the 25th ACM Conference on Hypertext and Social Media, Santiago, Chile, 1–4 September 2014; ACM: New York, NY, USA, 2014; pp. 116–125. [Google Scholar]
- Alampi-Sottini, V.; Barbierato, E.; Bernetti, I.; Capecchi, I.; Cipollaro, M.; Sacchelli, S.; Saragosa, C. Urban landscape assessment: A perceptual approach combining virtual reality and crowdsourced photo geodata. Aestimum 2018, 147–171. [Google Scholar] [CrossRef]
- Li, Y.; Fei, T.; Huang, Y.; Li, J.; Li, X.; Zhang, F.; Kang, Y.; Wu, G. Emotional habitat: Mapping the global geographic distribution of human emotion with physical environmental factors using a species distribution model. Int. J. Geogr. Inf. Sci. 2020. [Google Scholar] [CrossRef]
- Peng, X.; Huang, Z. A novel popular tourist attraction discovering approach based on geo-tagged social media big data. ISPRS Int. J. Geo-Inf. 2017, 6, 216. [Google Scholar] [CrossRef] [Green Version]
- Ewing, R.; Handy, S. Measuring the unmeasurable: Urban design qualities related to walkability. J. Urban Des. 2009, 14, 65–84. [Google Scholar] [CrossRef]
- Alexander, C.; Ishikawa, S.; Silverstein, M. A Pattern Language; Oxford University Press: Oxford, UK, 1977. [Google Scholar]
- Yin, L. Street level urban design qualities for walkability: Combining 2D and 3D GIS measures. Comput. Environ. Urban Syst. 2017, 64, 288–296. [Google Scholar] [CrossRef]
- Yin, L.; Wang, Z. Measuring visual enclosure for street walkability: Using machine learning algorithms and Google Street View imagery. Appl. Geogr. 2016, 76, 147–153. [Google Scholar] [CrossRef]
- Zhou, H.; He, S.; Cai, Y.; Wang, M.; Su, S. Social inequalities in neighborhood visual walkability: Using Street View imagery and deep learning technologies to facilitate healthy city planning. Sustain. Cities Soc. 2019, 50, 101605. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Rodgers, J.C., III; Murrah, A.W.; Cooke, W.H. The Impact of Hurricane Katrina on the Coastal Vegetation of the Weeks Bay Reserve, Alabama from NDVI Data. Estuaries Coasts 2009, 32, 496–507. [Google Scholar] [CrossRef]
- Hyun, C.U.; Lee, J.S.; Lee, I. Assessment of hydrogen fluoride damage to vegetation using optical remote sensing data. Int. Arch. Photogramm. Remote Sen. Spat. Inf. Sci. 2013, 7, 115–118. [Google Scholar] [CrossRef] [Green Version]
- IGM, I. Airplane equipped with an UltraCam XP aerial digital cam-era installed on a gyrostabilized mount. In Proceedings of the Pattern Recognition: 7th Mexican Conference, MCPR 2015, Mexico City, Mexico, 24–27 June 2015; Springer: Berlin, Germany, 2015; Volume 9116, p. 145. [Google Scholar]
- Yang, P.P.J.; Putra, S.Y.; Li, W. Viewsphere: A GIS-based 3D visibility analysis for urban design evaluation. Environ. Plan. B Plan. Des. 2007, 34, 971–992. [Google Scholar] [CrossRef] [Green Version]
- Nasrollahi, N.; Shokri, E. Daylight illuminance in urban environments for visual comfort and energy performance. Renew. Sustain. Energy Rev. 2016, 66, 861–874. [Google Scholar] [CrossRef]
- Lindberg, F.; Grimmond, C.S.B. Continuous sky view factor maps from high resolution urban digital elevation models. Clim. Res. 2010, 42, 177–183. [Google Scholar] [CrossRef] [Green Version]
- Lindberg, F.; Grimmond, C.S.B.; Gabey, A.; Huang, B.; Kent, C.W.; Sun, T.; Chang, Y.Y. UMEP—An integrated tool for city-based climate services. In Proceedings of the 21st International Congress of Biometeorology, Durham, UK, 3–7 September 2017; p. 51. [Google Scholar]
- Wisz, M.S.; Guisan, A. Do pseudo-absence selection strategies influence species distribution models and their predictions? An information-theoretic approach based on simulated data. BMC Ecol. 2009, 9, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iturbide, M.; Bedia, J.; Herrera, S.; del Hierro, O.; Pinto, M.; Gutiérrez, J.M. A framework for species distribution modelling with improved pseudo-absence generation. Ecol. Model. 2015, 312, 166–174. [Google Scholar] [CrossRef] [Green Version]
- Gastón, A.; García-Viñas, J.I. Modelling species distributions with penalised logistic regressions: A comparison with maximum entropy models. Ecol. Model. 2011, 222, 2037–2041. [Google Scholar] [CrossRef]
- Hanspach, J.; Kühn, I.; Schweiger, O.; Pompe, S.; Klotz, S. Geographical patterns in prediction errors of species distribution models. Glob. Ecol. Biogeogr. 2011, 20, 779–788. [Google Scholar] [CrossRef]
- Domisch, S.; Kuemmerlen, M.; Jähnig, S.C.; Haase, P. Choice of study area and predictors affect habitat suitability projections, but not the performance of species distribution models of stream biota. Ecol. Model. 2013, 257, 1–10. [Google Scholar] [CrossRef]
- Anderson, R.P.; Raza, A. The effect of the extent of the study region on GIS models of species geographic distributions and estimates of niche evolution: Preliminary tests with montane rodents (genus Nephelomys) in Venezuela. J. Biogeogr. 2010, 37, 1378–1393. [Google Scholar] [CrossRef]
- Mateo, R.G.; Croat, T.B.; Felicísimo, Á.M.; Munoz, J. Profile or group discriminative techniques? Generating reliable species distribution models using pseudo-absences and target-group absences from natural history collections. Divers. Distrib. 2010, 16, 84–94. [Google Scholar] [CrossRef]
- Stamps, A.E., III. Evaluating enclosure in urban sites. Landsc. Urban Plan. 2001, 57, 25–42. [Google Scholar] [CrossRef]
- Janson, L.; Fithian, W.; Hastie, T.J. Effective degrees of freedom: A flawed metaphor. Biometrika 2015, 102, 479–485. [Google Scholar] [CrossRef] [Green Version]
- Merow, C.; Smith, M.J.; Edwards, T.C., Jr.; Guisan, A.; McMahon, S.M.; Normand, S.; Thuiller, W.; Wüest, R.O.; Zimmermann, N.E.; Elith, J. What do we gain from simplicity versus complexity in species distribution models? Ecography 2014, 37, 1267–1281. [Google Scholar] [CrossRef]
- Elith, J.; Ferrier, S.; Huettmann, F.; Leathwick, J. The evaluation strip: A new and robust method for plotting predicted responses from species distribution models. Ecol. Model. 2005, 186, 280–289. [Google Scholar] [CrossRef]
- Cortez, P.; Embrechts, M.J. Using sensitivity analysis and visualization techniques to open black box data mining models. Inf. Sci. 2013, 225, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Ramanathan, R.; Granger, C.W.J. Improved Methods of Combining Forecasts. J. Forecast. 1984, 3, 197–204. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing [Internet]; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
- Scales, K.L.; Miller, P.I.; Ingram, S.N.; Hazen, E.L.; Bograd, S.J.; Phillips, R.A. Identifying predictable foraging habitats for a wide-ranging marine predator using ensemble ecological niche models. Divers. Distrib. 2016, 22, 212–224. [Google Scholar] [CrossRef] [Green Version]
- García-Palomares, J.C.; Gutiérrez, J.; Mínguez, C. Identification of tourist hot spots based on social networks: A comparative analysis of European metropolises using photo-sharing services and GIS. Appl. Geogr. 2015, 63, 408–417. [Google Scholar] [CrossRef]
- Byrne, J.; Wolch, J. Nature, race, and parks: Past research and future directions for geographic research. Prog. Hum. Geogr. 2009, 33, 743–765. [Google Scholar] [CrossRef] [Green Version]
- Ye, J. Re-orienting geographies of urban diversity and coexistence: Analyzing inclusion and difference in public space. Prog. Hum. Geogr. 2019, 43, 478–495. [Google Scholar] [CrossRef]
- Shelton, T.; Poorthuis, A.; Zook, M. Social media and the city: Rethinking urban socio-spatial inequality using user-generated geographic information. Landsc. Urban Plan. 2015, 142, 198–211. [Google Scholar] [CrossRef]
- Guhathakurta, S.; Zhang, G.; Chen, G.; Burnette, C.; Sepkowitz, I. Mining Social Media to Measure Neighborhood Quality in the City of Atlanta. Int. J. E-Plan. Res. (IJEPR) 2019, 8, 1–18. [Google Scholar] [CrossRef]
- Olkiewicz, K.A.; Markowska-Kaczmar, U. Emotion-based image retrieval—An artificial neural network approach. In Proceedings of the International Multiconference on Computer Science and Information Technology, Wisła, Poland, 18–20 October 2010; pp. 89–96. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | Definition | Equations | Explanation |
|---|---|---|---|
| Enclosure index | Degree to which streets and other public spaces are visually defined by vertical elements (buildings, walls, trees) with respect to horizontal elements. | Bn number of building pixels; Tn number of tree pixels; Rd number of road pixels; Pv number of pavement pixels | |
| Pedestrian and cyclist index | Degree to which people can see or perceive soft human mobility with respect to unsustainable mobility. | Bc number of bicyclist pixels; Pd number of pedestrian pixels; and Car number of car pixels. | |
| Transparency index | Degree to which people can see what lies beyond the edge of a street or other public space. | Sky number of sky pixels; and TotPix total pixel number in the image. | |
| Green index | Extent to which the visibility of street vegetation can influence pedestrian psychological feelings. | Veg number of vegetation pixels. | |
| Sidewalk index | Extent to which the visibility of pavement and fences influences pedestrian psychological feelings of surfaces dedicated to walking with respect to surfaces planned for motor vehicles | Pav number of pavement pixels; and Fenc number of fences pixels. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bernetti, I.; Alampi Sottini, V.; Bambi, L.; Barbierato, E.; Borghini, T.; Capecchi, I.; Saragosa, C. Urban Niche Assessment: An Approach Integrating Social Media Analysis, Spatial Urban Indicators and Geo-Statistical Techniques. Sustainability 2020, 12, 3982. https://doi.org/10.3390/su12103982
Bernetti I, Alampi Sottini V, Bambi L, Barbierato E, Borghini T, Capecchi I, Saragosa C. Urban Niche Assessment: An Approach Integrating Social Media Analysis, Spatial Urban Indicators and Geo-Statistical Techniques. Sustainability. 2020; 12(10):3982. https://doi.org/10.3390/su12103982
Chicago/Turabian StyleBernetti, Iacopo, Veronica Alampi Sottini, Lorenzo Bambi, Elena Barbierato, Tommaso Borghini, Irene Capecchi, and Claudio Saragosa. 2020. "Urban Niche Assessment: An Approach Integrating Social Media Analysis, Spatial Urban Indicators and Geo-Statistical Techniques" Sustainability 12, no. 10: 3982. https://doi.org/10.3390/su12103982