1. Introduction
According to the prediction of the International Energy Agency (IEA), global crude oil can be exploited for 45 years, and coal can be exploited for 230 years [
1]. Solar energy has increasingly replaced traditional fossil fuel energy because of the global energy crisis and environmental deterioration. As an important technology path for the utilization of solar energy, photovoltaic (PV) power systems have been rapidly developed in recent years. By 2015, the global PV installed capacity reached 227 GW. With a total installed PV capacity of 43.18 GW, China has become the country with the largest installed capacity of photovoltaic power generation in the world. Notably, the new installed capacity has reached 15.13 GW, and the installed capacity of PV power stations is 37.12 GW [
2]. However, the operational stability and power quality of the power grid have been seriously influenced by the large-scale integration of PV power stations [
3,
4]. PV consumption has become an important obstacle for further improvements in the PV industry. Currently, PV power forecasting is an effective way of solving this problem. On one hand, power generation information can be provided for the coordinated control and optimal dispatching of the power grid, which can play a significant role in solving voltage fluctuations when a large number of PV systems are connected to the power grid [
5]. On the other hand, the PV absorption ability can be promoted to increase the rate of return on investments in PV power stations. PV power forecasting includes ultrashort-term (0~6 h), short-term (6~24 h) and mid-and-long-term (>24 h) methods. From the perspective of power grid operation, it is more beneficial for emergency management and prevention to have a short prediction period [
6]. Therefore, ultrashort-term power forecasting for PV power stations should be given increased attention.
Traditionally, PV power forecasting methods can be categorized into direct forecasting and indirect forecasting methods. Usually, direct forecasting models are regression models of instantaneous power generation established using associated data, such as irradiance, temperature, humidity and wind speed data. These data are supplied by PV power stations or numerical weather prediction (NWP). Modeling methods include artificial neural network (ANN) [
7,
8,
9], support vector machine (SVM) [
10,
11] and multivariate regression [
12] methods, among others. Indirect forecasting models comprise two continuous processes. One is the prediction of the solar irradiation intensity or other meteorological information. The other is the calculation of instantaneous PV power using prediction data. Nephogram processing methods (including cloud tracking images [
13], ground-based sky images [
14], geostationary satellite imagery [
15], etc.), time series analysis [
16,
17], fuzzy logic [
18], and hidden Markov models [
19] are all suitable irradiation intensity forecasting methods.
Because of complementary advantages of different algorithms and the associated high forecasting accuracy, hybrid forecasting has gradually become a new research direction [
20,
21,
22,
23,
24]. Typically, hybrid forecasting is a two-step process that includes the classification and recognition of weather types and the regression and forecasting of PV power generation. K-means clustering [
25] and fuzzy c-means [
26] are used for clustering of weather types. Self-organizing map (SOM), learning vector quantization (LVQ) [
27], gray correlation coefficient [
28], generalized weather class (GWC) and SVM [
29] methods are effective approaches for weather pattern recognition. In addition, support vector regression (SVR) [
27], support vector machines optimized with genetic algorithms (GA-SVM) [
28], and particle swarm-optimized SVR (PSO-SVR) [
30] can be selected as corresponding regression algorithms.
The acquisition accuracy and frequency of PV data have improved with the development of online monitoring technology. Currently, it is possible to establish a real-time PV forecasting mechanism for power grid regulation. In this paper, a novel ultrashort-term forecasting model is proposed that can predict PV power every 5 min. Modeling data from the meteorological service and online monitoring system are reliable and actual, which can reflect the real situation and improve forecast ability in rolling mode.
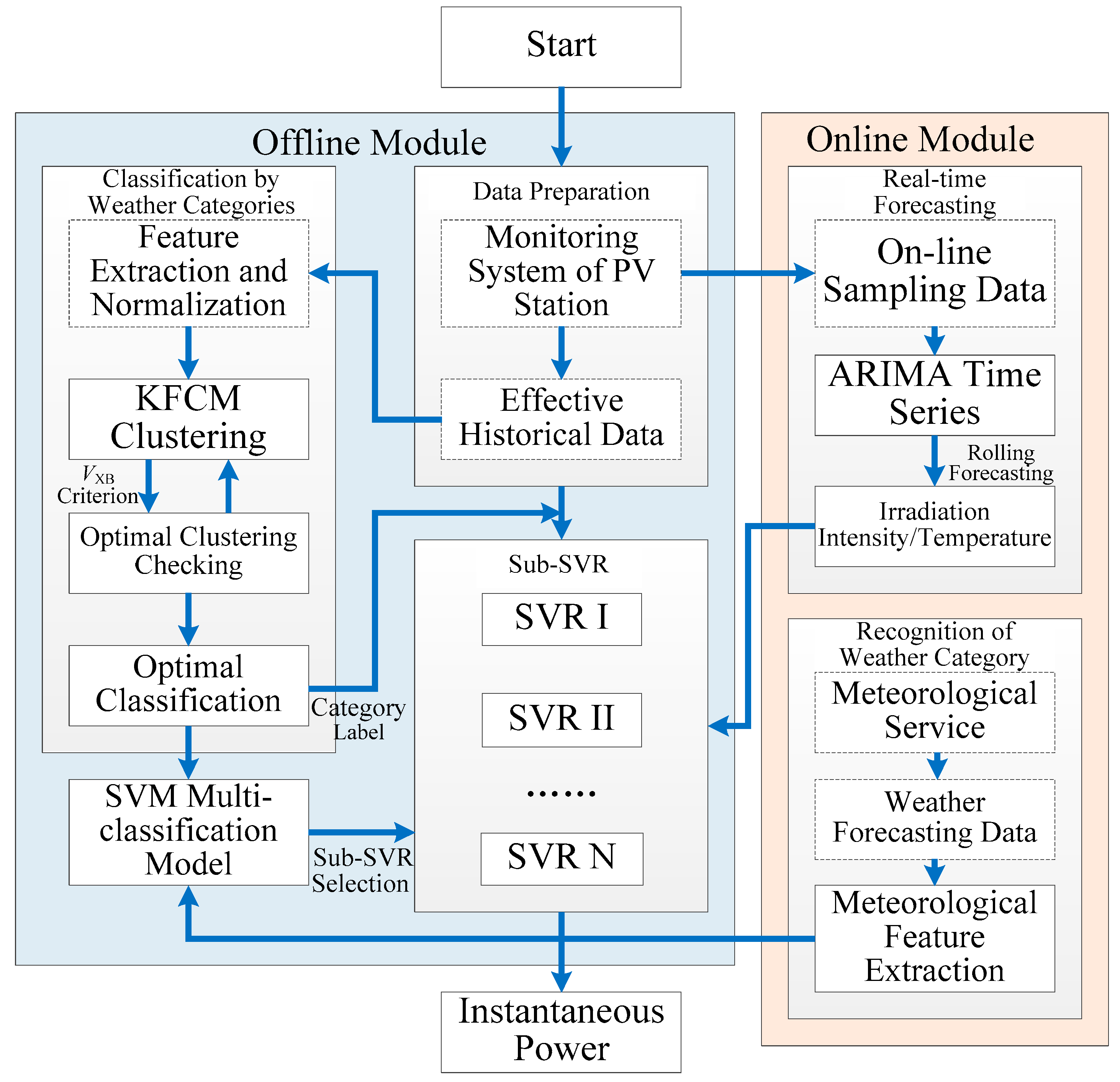
This model can be divided into offline modeling and online forecasting. The offline modeling is based on the processing of historical data and establishment of a regression model. Real-time modeling is performed in online forecasting. In offline modeling, weather classification and pattern recognition are performed to eliminate interference and increase the forecasting accuracy. The kernel fuzzy c-means (KFCM) method is adopted to classify the characteristic data of different weather conditions, and an SVM is used to construct the weather recognition model. Subsequently, several SVR submodels (sub-SVRs) are established for power forecasting. In online forecasting, the autoregressive integrated moving average (ARIMA) can be used to predict solar irradiation and temperature using monitoring data (the sampling period is 5 min) from PV power stations in a step-by-step process in a rolling forecasting mode. Finally, real-time instantaneous PV power (forecast period is also 5 min) can be acquired by previously established sub-SVRs. The performance of the proposed model is verified using historical data from PV power stations in Wujiang District, Jiangsu Province, China.
2. Correlation Analysis of PV Generation Factors
Generally, geographical location and meteorological conditions strongly affect the generation of PV power stations. However, the geographical location of a PV power station, layout and arrangement of PV cell panels, global system efficiency and other factors known before the construction of a PV power plant affect generation. Therefore, only the local meteorological conditions are adopted for modeling PV power generation. To reflect the operational status over time, online monitoring systems have been widely applied in many PV power stations.
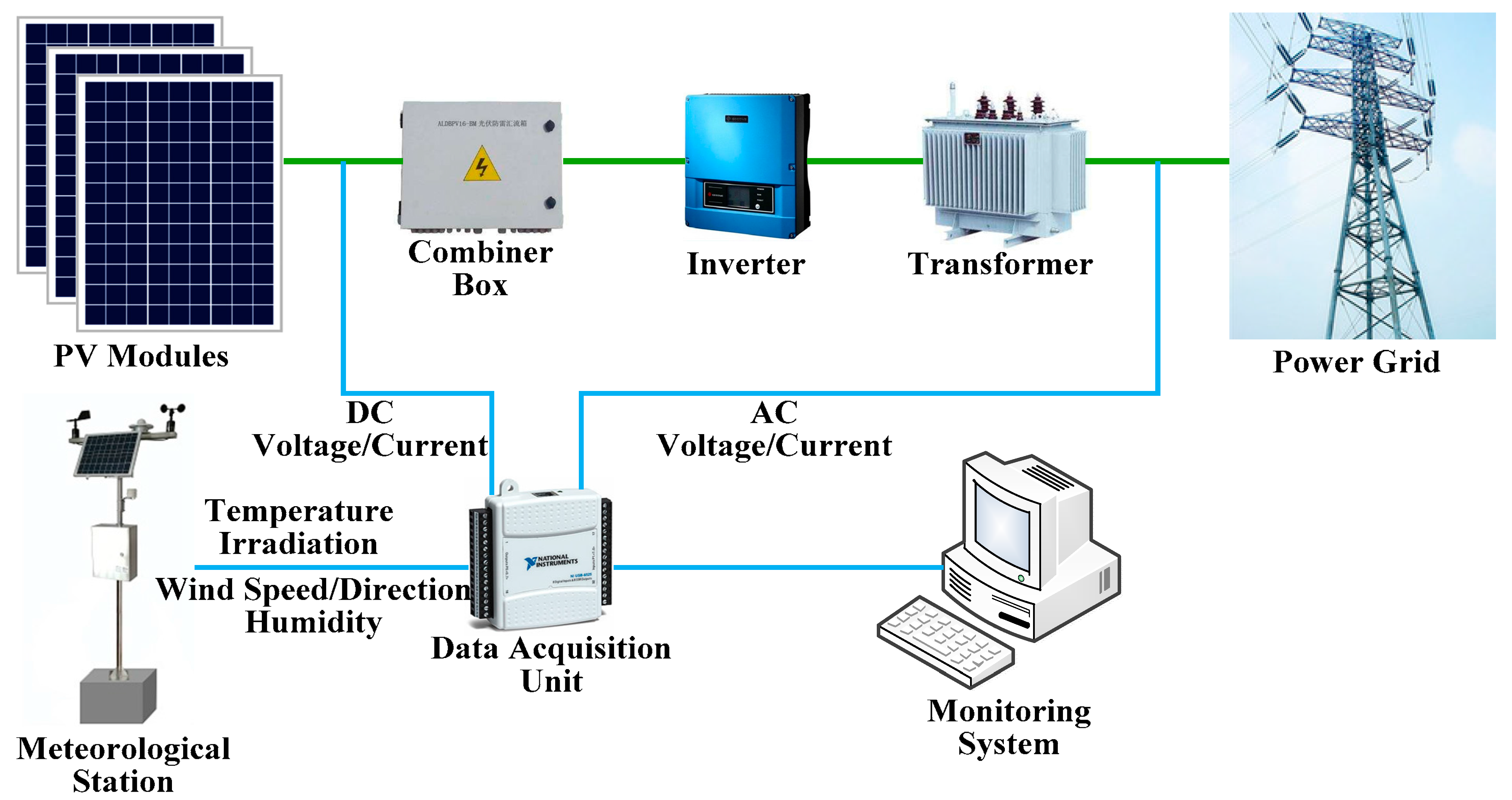
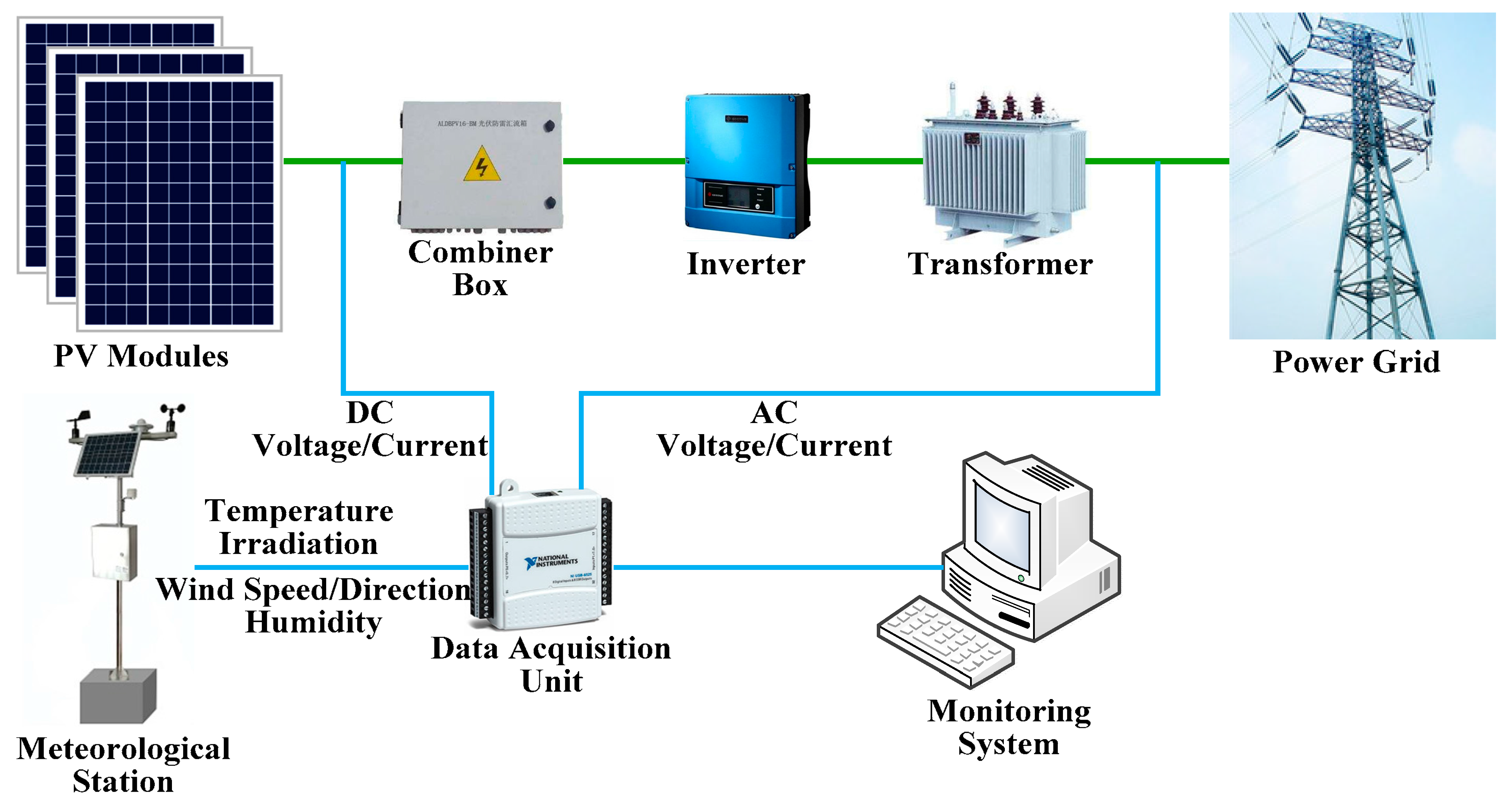
Figure 1 depicts the scheme of a monitoring system that can collect important electrical and meteorological information.
Specifically, these meteorological data include the irradiation intensity, temperature, wind speed and direction, etc. In theory, meteorological factors, especially the irradiation intensity and temperature, have influence on the instantaneous power generation of a PV power station.
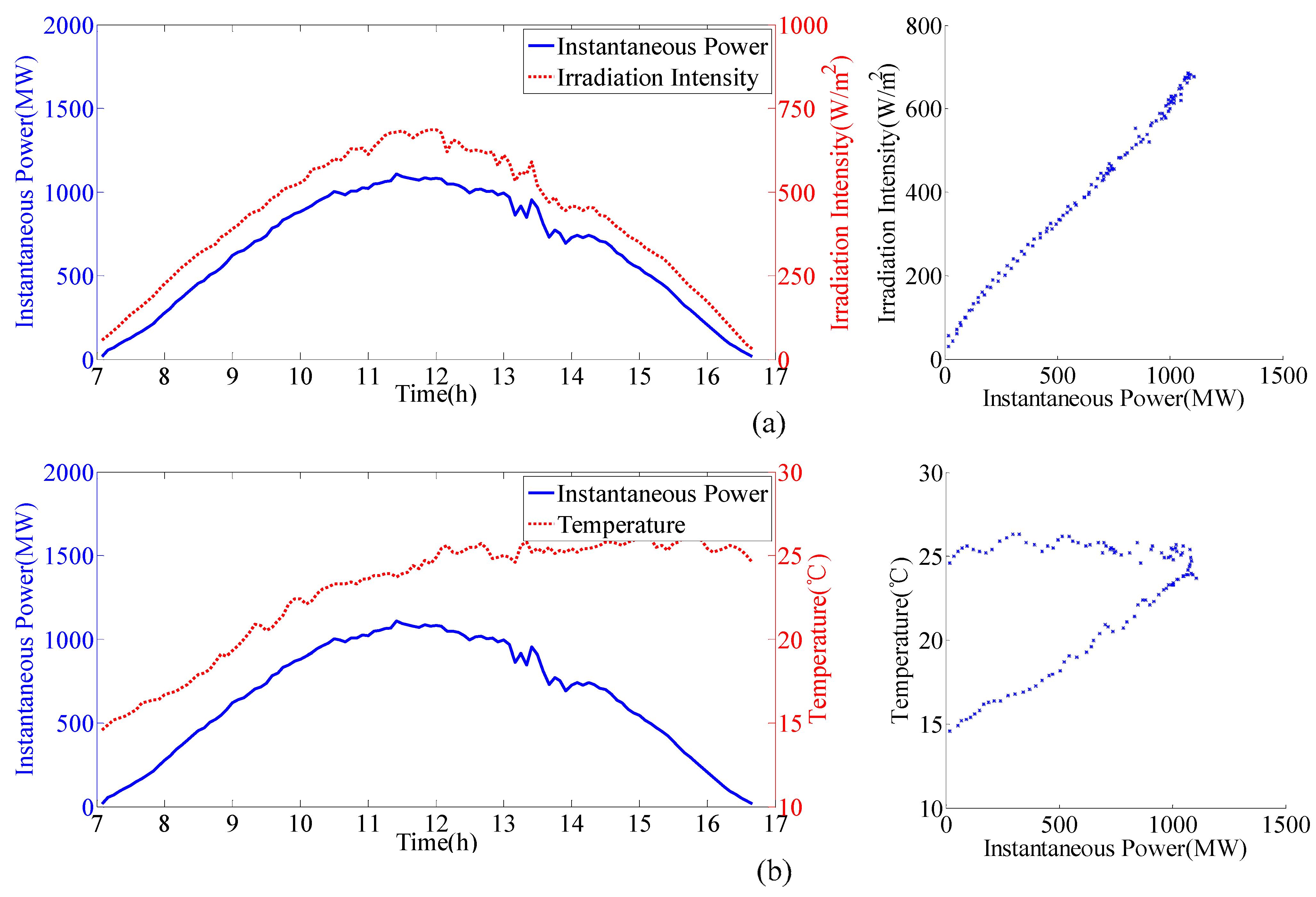
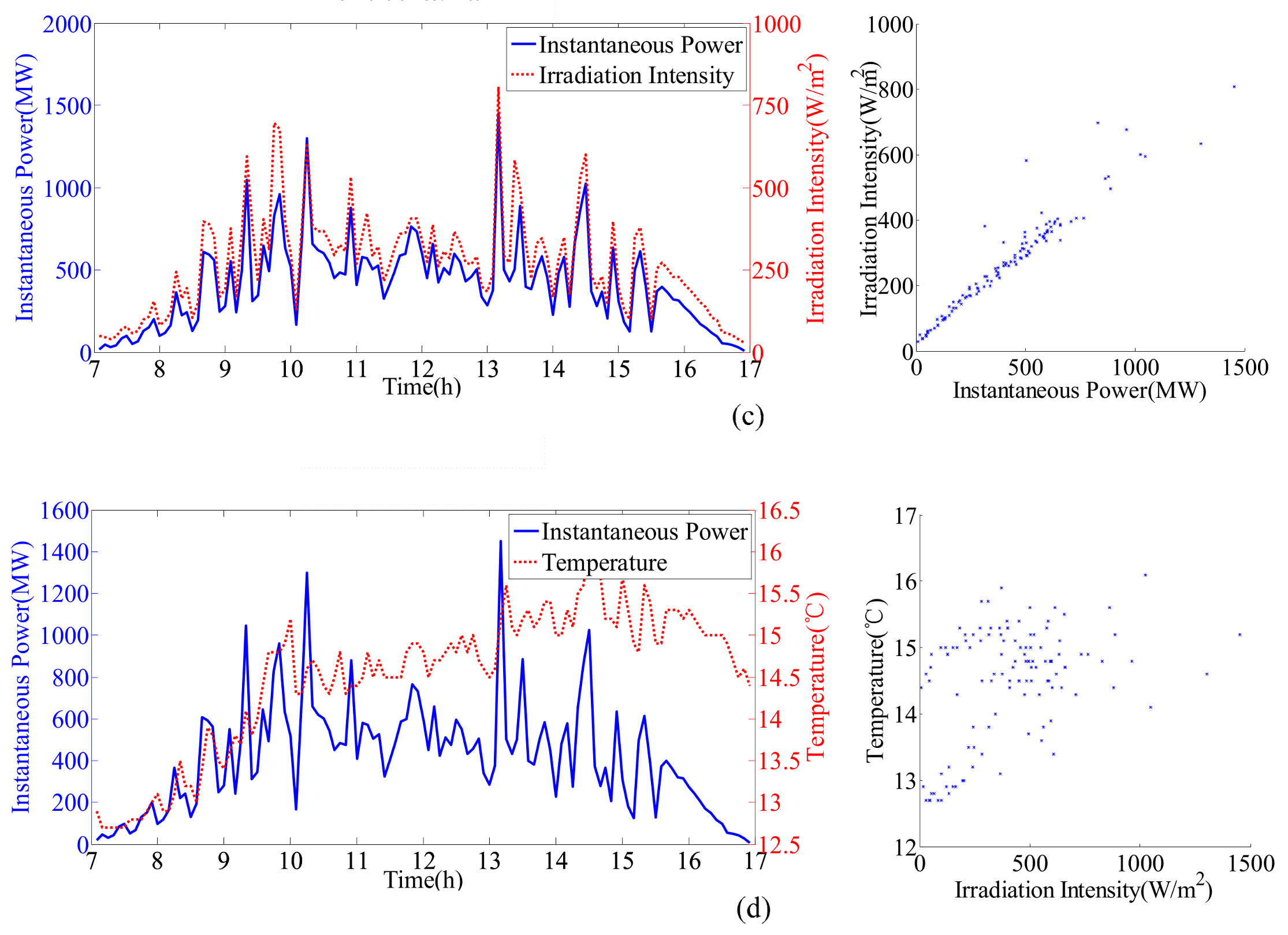
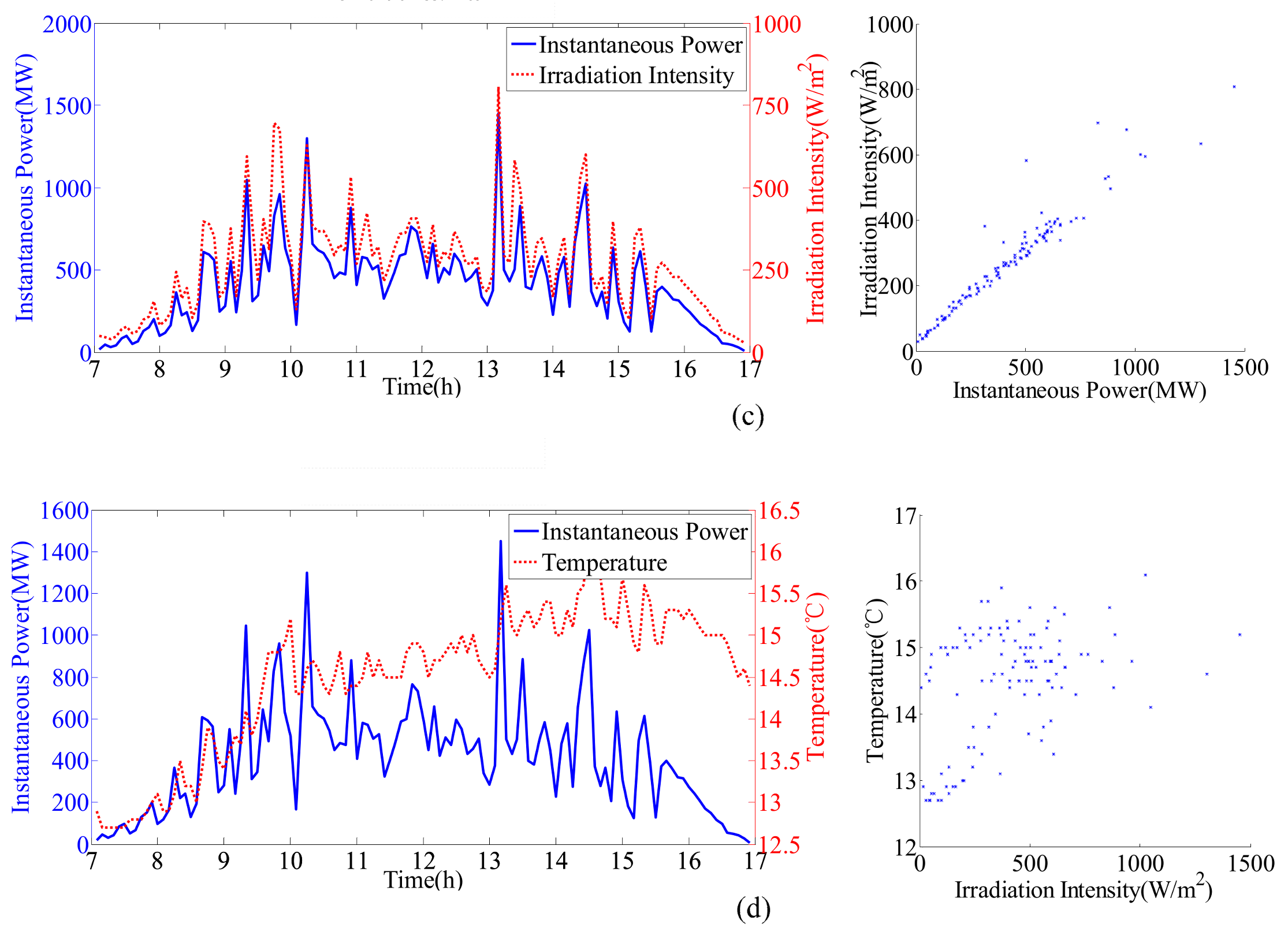
Figure 2 shows the curve and scatter of the irradiation intensity, temperature and instantaneous power under different sunny and cloudy days. From the scatter diagram, an obvious linear relation between radiation intensity and instantaneous power is shown on both sunny and cloudy days. However, there is not a clear relationship between temperature and instantaneous power. Meanwhile, weather type has a certain influence on this relationship. For example, the scatter points are more concentrated on sunny rather than cloudy days. Therefore, a strong positive correlation exists between the radiation intensity and instantaneous power, while temperature has a weaker correlation with instantaneous power.
The selection of reasonable data is a prerequisite for building an accurate regression model. As shown in
Figure 2, the irradiation intensity and temperature directly influences power generation in all weather conditions. In addition, to improve the computational accuracy and efficiency, other monitoring meteorological data must be considered. Therefore, it is necessary to perform correlation analysis to independently explore the correlation degrees between meteorological factors and instantaneous power. Pearson correlation analysis is chosen in this study, and the related results are shown in
Table 1. Note that the sine and cosine values of wind direction are adopted.
Table 1 shows that irradiation intensity and temperature have higher correlations with power generation than others do. Moreover, the correlations of wind speed and direction are sufficiently small and can be eliminated from the regression model. As a result, irradiation intensity and temperature are adopted as the training datasets of the SVR model.
3. Hybrid Forecasting Model
3.1. Data Verification and Cleaning
The training data were collected from a PV power station in Wujiang District, Jiangsu Province, China. This power station has three grid-connected points, and its total installed capacity is 10 MW. Currently, a comprehensive monitoring system has been set up at this station, and nearby independent weather stations collect real-time weather information for the system. Power metering devices are installed at grid-connected points to collect power information, which is sampled at an interval of 5 min. The period of the modeling data spans from April 2016 to February 2017, for almost a total of nine months, amounting to 295 days. There are 31,397 samples when nighttime samples with instantaneous power values of 0 are removed. The samples
include temperature
, irradiation intensity
and instantaneous power
. Generally, some inaccurate data exist in a database due to sensor failure, data acquisition module failure and system error. These data have negative effects on weather pattern recognition and regression modeling. Therefore, they must be eliminated in advance. In this paper, the inaccurate and incorrect data are cleaned using residual processing based on SVR. As noted in
Table 1,
has a relatively high relationship with
and
. Thus,
and
(
and
are
ith and
jth samples) should not significantly deviate over similar ranges of
and
. Otherwise, these samples can be regarded as incorrect samples.
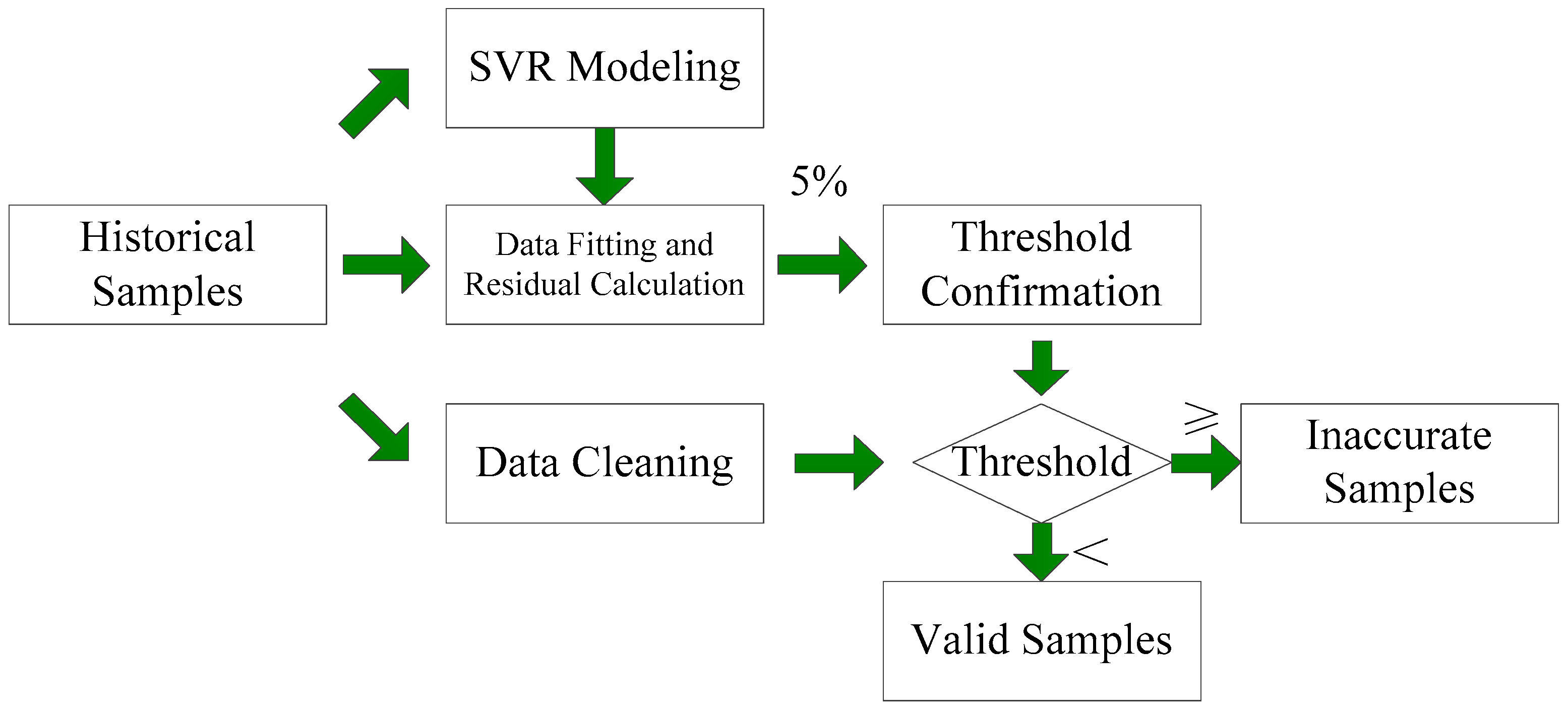
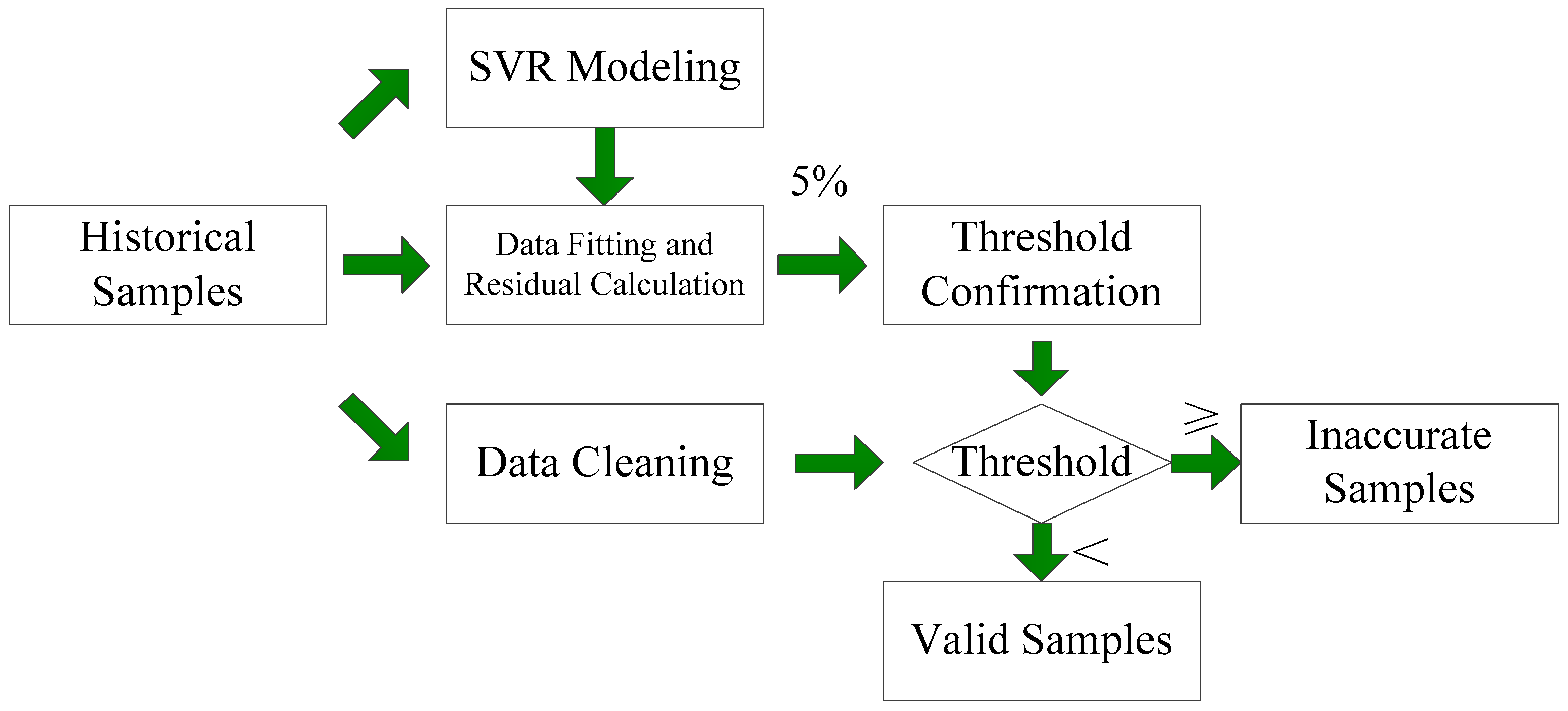
Figure 3 shows the data cleaning process. First, all the historical samples are used to establish the SVR model with inputs
and
and output
. Then, fitting residuals can be calculated. Second, the samples with maximum residuals of 5% are considered to be inaccurate and are used to establish a corresponding threshold. Finally, samples are eliminated if their residuals are greater than the threshold. Remaining samples are used in the forecasting model.
3.2. Hybrid Forecasting Model
The hybrid forecasting model contains an offline module for historical data processing and an online module for real-time forecasting. The integrated model is shown in
Figure 4. The main functions of the offline module are as follows:
the classification of historical samples according to meteorological characteristics;
the establishment of regression submodels (sub-SVRs);
the effective identification of weather types and selection of sub-SVRs.
The main functions of the online module are as follows:
Rolling forecasting is a forecasting mode. Predicted value can be obtained by a time series model. Simultaneously, this time series model can be extended and corrected by the actual value for further forecasting step by step.
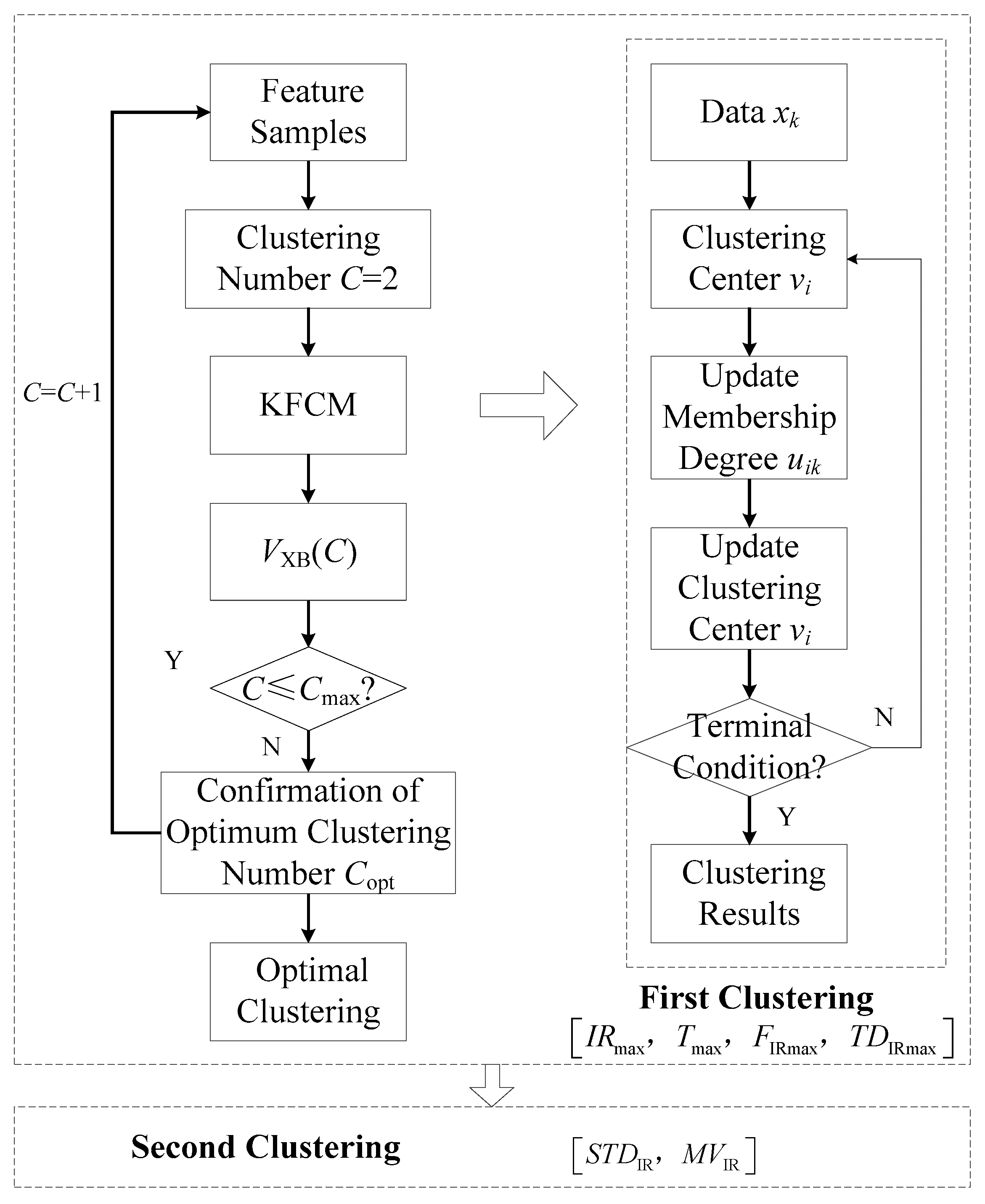
Data verification and cleaning, weather identification and sub-SVRs establishment are all included in the offline module, while time series forecasting and regression are performed in the online module. The classified regression model has better accuracy than the overall model due to the advantage of eliminating the interference of unknown factors on other weather conditions. In this paper, KFCM and SVM are selected to identify weather types. The real-time forecasting of irradiation intensity and temperature is achieved using the ARIMA method. The instantaneous power of the PV station is obtained using sub-SVRs. The processing steps are as follows:
- Step 1.
Meteorological feature selection: The feature vectors of the KFCM model are calculated. is the maximum irradiance, and is the maximum temperature. , , and are the maximum fluctuation, mean fluctuation, standard deviation of fluctuate on and maximum third derivative, respectively. They are standardized by the Z-score method.
- Step 2.
Clustering and optimization: An unsupervised clustering model is established using KFCM. In addition, the VXB indicator is selected to determine the optimal clustering number. Both historical samples and meteorological features are denoted by category labels.
- Step 3.
Establishment of the sub-SVR model: the historical samples in one category are used to construct the SVR submodel. Additionally, several submodels are established.
- Step 4.
Multiclassification modeling: An SVM recognition model is established using meteorological features. To obtain the category attributes on target days, the features calculated from the NWP service are input into the SVM model. Corresponding submodels are selected according to the category label of the target day.
- Step 5.
Time series modeling: The ARIMA time series model is established using some data, including and , collected by the online PV monitoring system on the target day. Then, new predicted values of the time series can be obtained via rolling forecasting.
- Step 6.
Instantaneous power forecasting: The predicted values are input into the corresponding sub-SVR models and yield the final instantaneous power .
3.3. Feature Selection for Weather Identification
As discussed above, the temperature and irradiation intensity play major roles in PV power generation. Additionally, irradiation fluctuation is the most important factor that influences PV power forecasting due to the random interference caused by meteorological conditions. Therefore, in weather identification, the fluctuation indexes of irradiance are used as the main features in weather clustering under different fluctuation conditions. In this paper, six features are selected for modeling. The first three are as follows:
maximum irradiance ,
maximum temperature ,
the maximum fluctuation .
Generally, the derivative of irradiance can be used to describe the irradiance fluctuation. However, for discrete data with a constant sampling rate, the first difference
is typically adopted to replace the first derivative:
where
is the number of sampling points. The final three features include the following variables:
the fluctuation mean value , which is the average of ,
the fluctuation standard deviation of , and
the maximum third derivative
of
. The third derivative is more sensitive to rapid weather changes than are the other derivatives [
31].
and can reflect maximum instantaneous power. Other features reflect weather fluctuations.
The Z-score method is adopted to eliminate data dimensionality:
where
and
are the features before and after standardization, respectively, and
and
are the mean value and standard deviation of the features.
3.4. KFCM Clustering and Optimization
To classify historical data, feature samples are used to establish the KFCM clustering model. To enhance the separation, the KFCM method transforms the feature space into a high-dimensional space via nonlinear mapping. Therefore, KFCM can overcome the shortcoming of K-means and fuzzy c-means such as local optimum and sensitive to abnormal data. To assess the clustering effectiveness, a cluster validity index must be determined. In this study, the Xie–Beni index [
32]
is used to evaluate the clustering performance:
where
C and
n are the clustering number and sample number, respectively;
is the membership degree;
is the
jth sample;
is the
ith clustering center; and
is the minimum resulting value. At this value, KFCM displays the best performance, and the corresponding value of
C is the optimal clustering number. Considering the practical application of model refinement methods, KFCM clustering must be hierarchically executed. Specifically, the first clustering step is executed in accordance with the features (
). Then, the initial results are clustered again with the remaining features (
). The KFCM process is shown in
Figure 5.
The process is as follows:
- Step 1.
Data preparation: the samples in the first clustering include .
- Step 2.
The initial clustering number is C = 2.
- Step 3.
KFCM is executed as follows:
- Step a.
Initialization of KFCM clustering centers ,
- Step b.
Membership degrees
are calculated by the following equation:
where
xk is the sample, and
K is the Gaussian kernel function:
is the kernel parameter.
- Step c.
New clustering centers are updated as follows:
- Step d.
KFCM terminal conditions: When the minimum variation in clustering centers or the cycle number threshold is met, the cycle is stopped. Otherwise, the cycle continues from Steps a to d.
- Step 4.
The clustering validity coefficient is calculated using Formula (3).
- Step 5.
C = C + 1; if , proceed to step 3. Otherwise, proceed to step 6.
- Step 6.
The optimum clustering number Copt is determined by the minimum VXB(C).
- Step 7.
A second clustering process will be executed to classify the results of the first clustering using and based on steps 1–6.
3.5. SVM Recognition and the Sub-SVR Model
As a machine learning algorithm, SVM is widely used in data classification, pattern recognition and fault diagnosis. The core concept of SVM is to construct an optimal separating hyperplane so that the distance between the hyperplane and the sample nearest the hyperplane is the maximum distance. For classification problem
, samples can be accurately separated into two categories by the optimal hyperplane
. Therefore, the construction of the optimal hyperplane can be transformed into an optimization problem:
The SVM constraint condition is given by Label (8):
where
is the normal vector of the optimal hyperplane and
,
and
, are the threshold, penalty parameter and slack variable, respectively.
The Lagrange multiplier method can be used to solve this optimization problem. For nonlinear classification, samples in low-dimensional space are mapped into high-dimensional space using the function
. The kernel function
is the same as that used in the KFCM method. The objective function can be expressed as follows:
where
is the Lagrange multiplier.
SVR is an important branch of SVM. The main concept of SVR is to map linearly inseparable samples into high-dimensional space for linear regression. Ultimately, the nonlinear regression function can be obtained. The sub-SVR model in this paper is a combination of several independent SVR models.
3.6. ARIMA Model
Generally, the ARIMA model can be expressed as ARIMA(p, q, d), where p is the autoregressive order, q is the moving average order, and d is the difference order. The ARIMA process is as follows:
- Step 1.
Differential processing: The stationary time series data [XAt] are obtained from the original time series [Xt] based on a difference method. In this paper, two ARIMAs are established based on the irradiance intensity sequence [Xt-IR] and the temperature sequence [Xt-T].
- Step 2.
Model identification and
p and
q confirmation: An autocorrelation function (ACF) and a partial correlation function (PACF) are calculated for [
XAt]. Then, the model type (AR, MA, or ARMA) will be determined according to the ACF and PACF. In general, the ARIMA model can be expressed as follows:
where
is the autoregressive coefficient,
is the moving average coefficient, and
is a white noise series, which represents independent error. The Akaike information criterion (AIC) is commonly used to confirm
p and
q.
- Step 3.
Parameter estimation: After parameter estimation, ARIMA(p, q, d) is established.
- Step 4.
Data forecasting: Single-step forecasting is performed to obtain predictions of the irradiance intensity and temperature using the ARIMA model.
Rolling forecasting is adopted for the ARIMA method in this paper because it uses monitoring data to correct the real-time ARIMA model and improve the forecasting accuracy. In this paper, the sampling interval of the PV monitoring system is 5 min. Therefore, the predictive value is acquired by ARIMA model at a 5-min interval. For example, the temperature sequence is the first n monitoring samples on the target day. First, the ARIMA forecasting model is established using . Then, the predicted temperature value can be obtained. Second, actual monitoring sample can be acquired 5 min later and is added to to update the ARIMA model. Finally, the next predicted value is obtained by the new ARIMA model, and the model is updated again. The remainder of the process is performed in the same manner.
4. Modeling and Evaluation
According to the data cleaning and modeling processes described in
Section 3.1 and
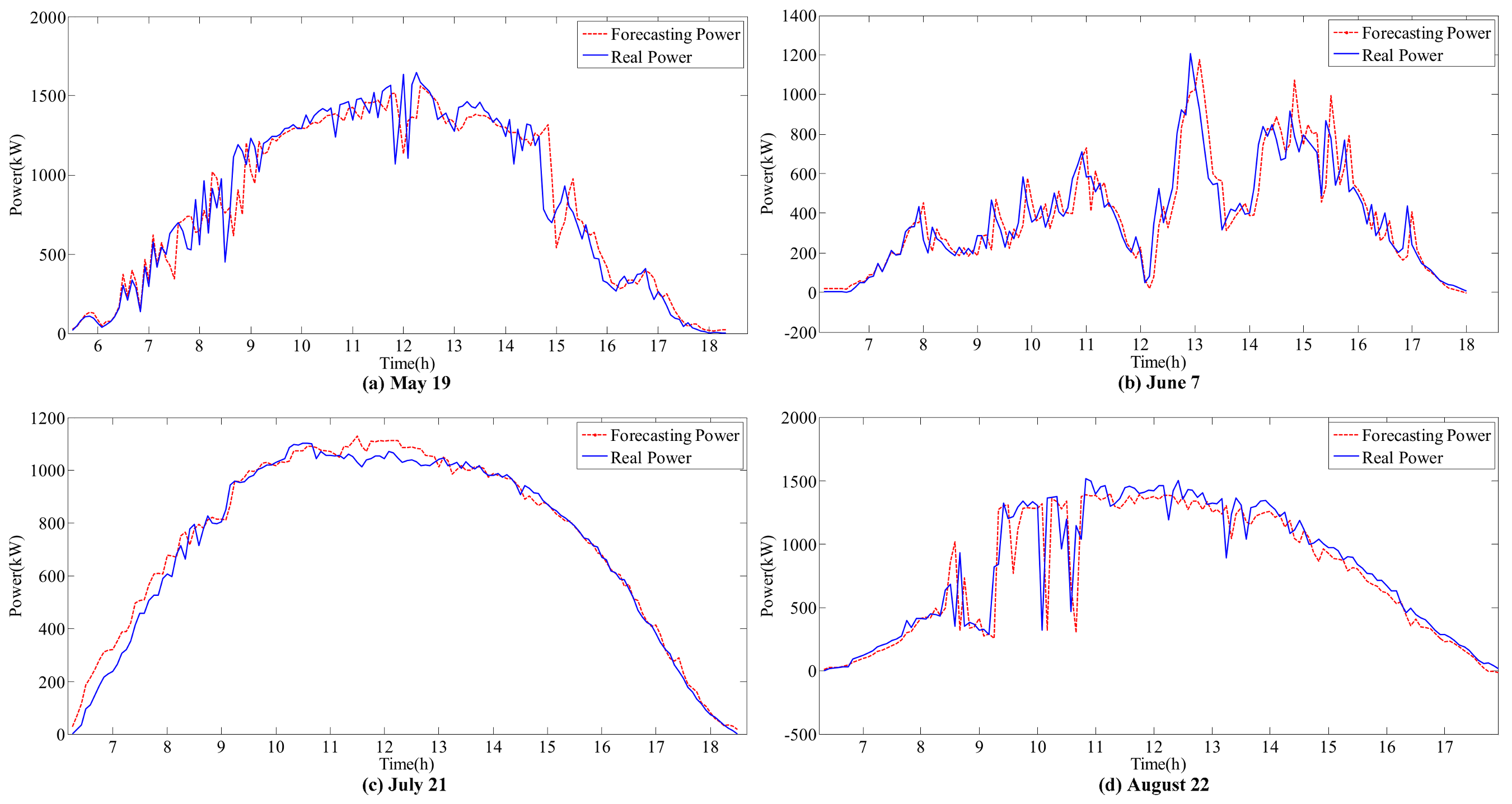
Section 3.2, the PV generation forecasting model is established. Four typical weather conditions, sunny (21 July), cloudy (19 May), rainy (7 June) and overcast (22 August), are selected as the test dataset (586 samples). The remaining 30,811 samples are used as the training dataset.
4.1. Data Verification and Cleaning Based on SVR
As shown in
Figure 3, the sub-SVR model should be established using the training dataset with irradiation intensity
and temperature
inputs and instantaneous power
as the output. The model parameters should be optimized using a cross-validation method. Penalty parameter
c and kernel parameter
g are set to 194.02 and 0.0098, respectively. Then, the training samples are fitted by the SVR model to calculate the residuals. Finally, the residuals are ranked in descending order. The samples in the highest 5% of residuals are removed as abnormal samples, and the remaining samples are regarded as valid samples. To evaluate the fitting precision of PV instantaneous power, the mean absolute percentage error (
) is chosen to measure the global error, while the root mean square error (
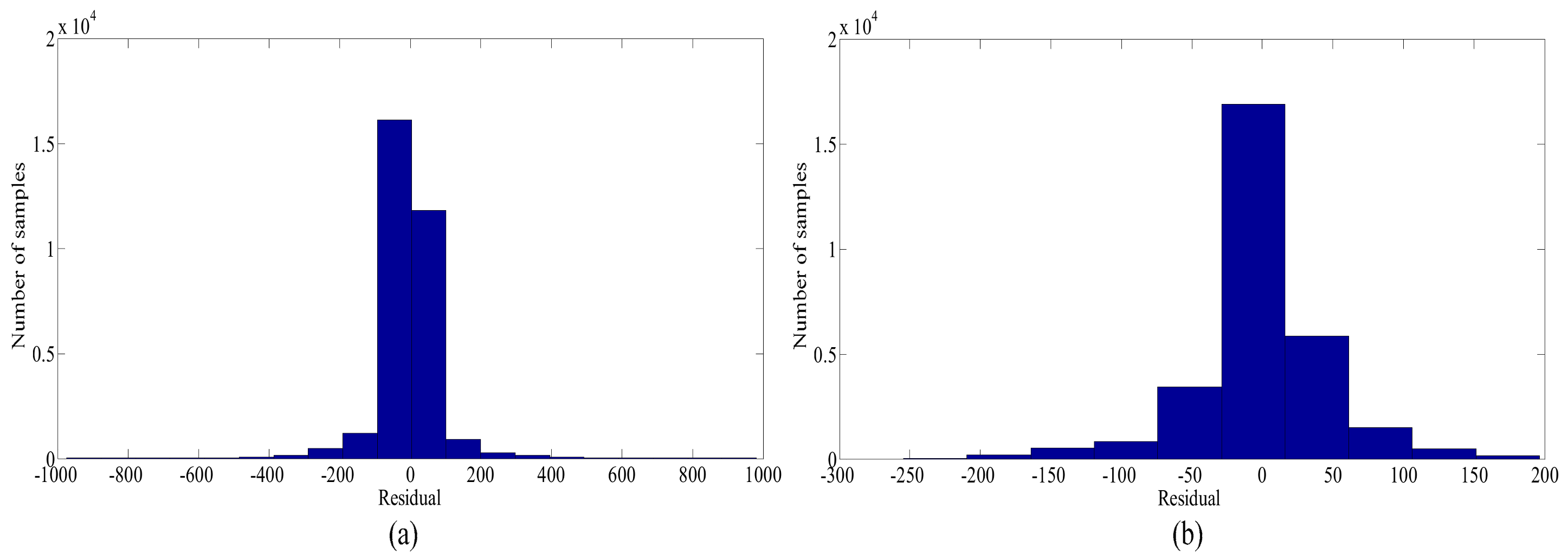
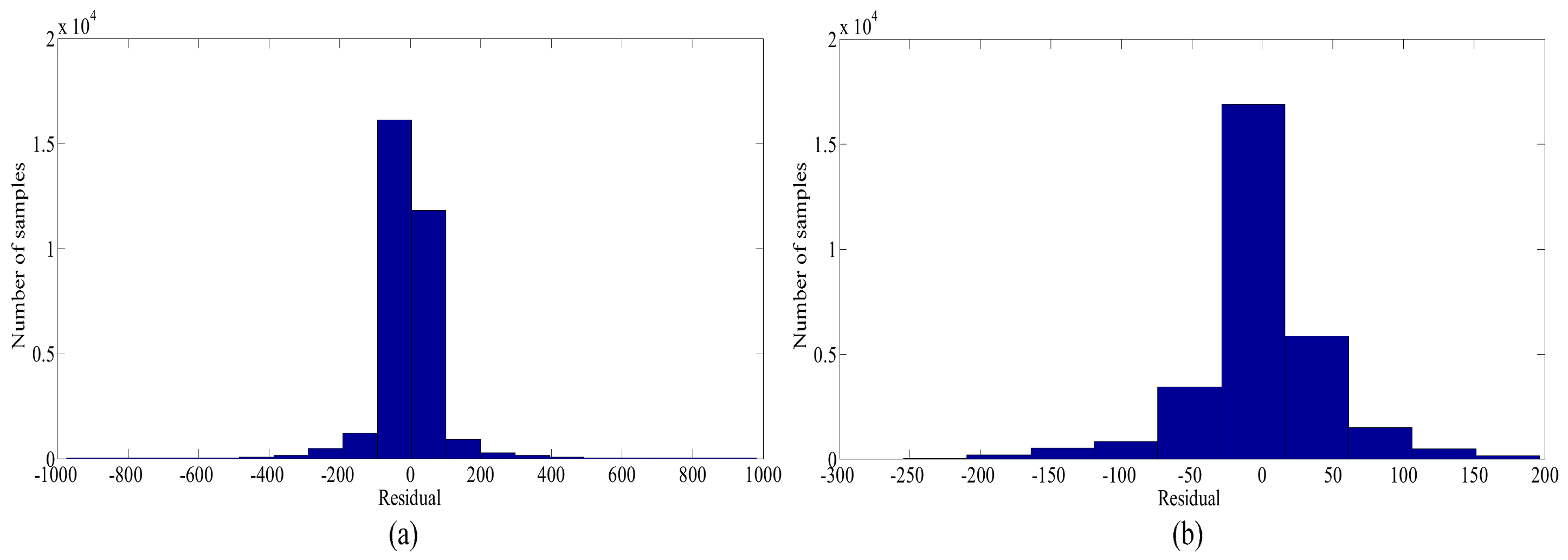
) is chosen to measure the difference between predicted and real values. The histograms of the residual distribution before and after cleaning are shown in
Figure 6.
and
are shown in
Table 2:
Figure 6 and
Table 2 show that
and
decrease, and the residual distribution becomes more reasonable.
4.2. Weather Identification and Regression Submodel Establishment
After data cleaning, daily meteorological features are extracted from the modeling dataset using the methods presented in
Section 3.3. Notably, 261 valid days are used (
). These feature days are categorized to label the modeling data. Next, a hierarchical clustering model is established, as discussed in
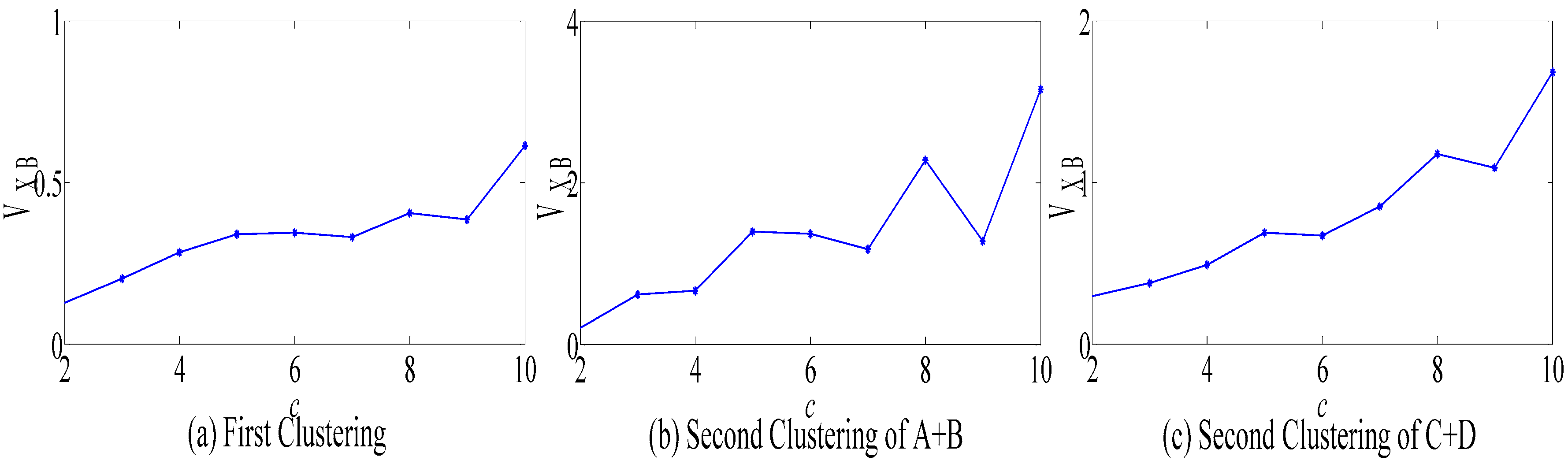
Section 3.4. In general, an overly large clustering number can negatively affect the clustering performance. Therefore, the maximum clustering number is set to
Cmax = 10. The variation of
is shown in
Figure 7. Notably, when
C = 2,
is at a minimum. Therefore, the optimal clustering number of the two layers is 2. Moreover, all the feature days are divided into four categories. The clustering results are shown in
Table 3.
After labeling the 261 feature days, these days are used to establish the multiclassification SVM model for weather type identification. Specifically, 183 days are selected for training, and the remaining 78 days are used as the test dataset. Through cross-validation, the penalty parameter
c = 111.4305 and the kernel parameter
g = 0.00156 are obtained. The results of the weather type test are shown in
Table 4.
In
Table 4, the SVM model misclassifies four days that belong to category B, resulting in a 94.78% classification accuracy. Thus, the SVM accuracy is high enough for weather recognition, and this model can identify the weather types on target days. Therefore, corresponding sub-SVR models can be reasonably selected.
4.3. ARIMA Time Series Forecasting and Sub-SVRs
According to
Section 3.2, two essential steps should be completed by the online module: sub-SVR selection and regression and ARIMA modeling and forecasting.
In the first step, 29,829 data samples over 261 days are classified into A, B, C and D classes by KFCM. The sub-SVR model is established using samples with the same label. Four submodels (SUB-A, SUB-B, SUB-C and SUB-D) with irradiation intensity and temperature inputs and output instantaneous power as the output are obtained. Subsequently, weather type identification is performed. The weather information on target days is input into the SVM multiclassification model to obtain the category attribute. The target days selected include 19 May, 7 June, 21 July, and 22 August. The category labels obtained for these four days using the SVM model are B, C, D and B, which correspond to submodels SUB-B, SUB-C, SUB-D and SUB-B, respectively.
In the second step, the hybrid forecasting models based on ARIMA time series and sub-SVR are established in accordance with the process described in
Section 3.6, and rolling forecasting is adopted. To meet the requirements of time series modeling and engineering applications, two ARIMA models are established using the first 20 values of
and
(
I = 1~20), which are obtained from the online PV monitoring system on the target days. The sampling interval is 5 min. For example, on 21 July, the first monitoring values appeared at 6:15 a.m. The first 20 monitoring values (
,
) are collected from 6:15 a.m. to 7:55 a.m. Then, ARIMA modeling and forecasting begin. Subsequently, two time series models, ARIMA
IR and ARIMA
T, can be constructed to forecast irradiation intensity and temperature, respectively. Model parameters
p,
q and
d are set to 1. Then, the subsequent values of
and
(5 min later at 8:00 a.m.) can be predicted using the ARIMA
IR and ARIM
AT models. These predicted values are input into the submodel SUB-D to obtain the predicted instantaneous power
. In addition, the new actual monitoring values
and
can be used in real time to modify the ARIMA
IR and ARIM
AT models.
and
are obtained from the PV monitoring system at 8:00 a.m. Then, the next predicted values,
,
and
(8:05 a.m.), can be similarly obtained. The instantaneous power
is forecasted in real time via a rolling cycle. The forecasts of
and
and the regression of
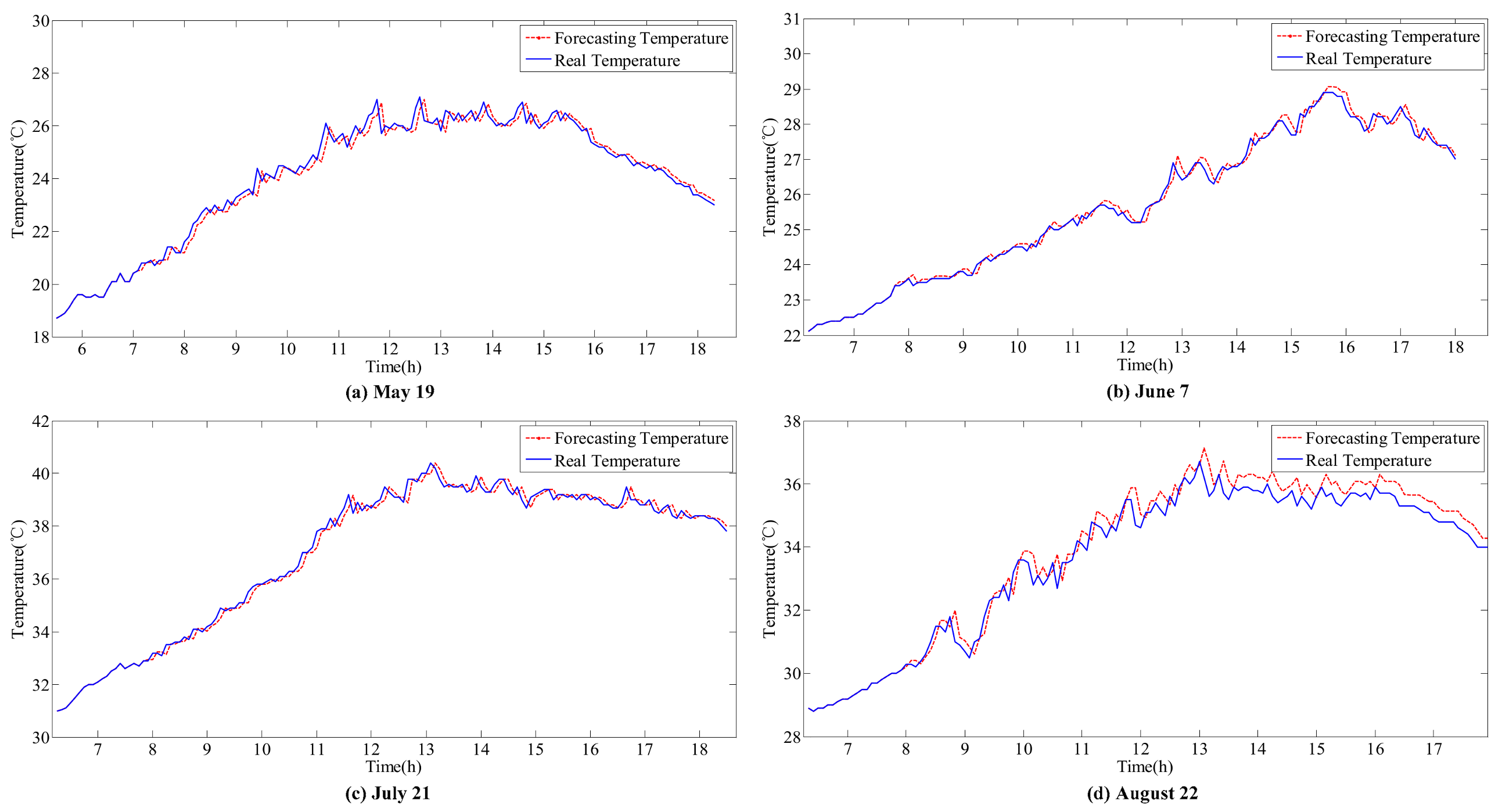
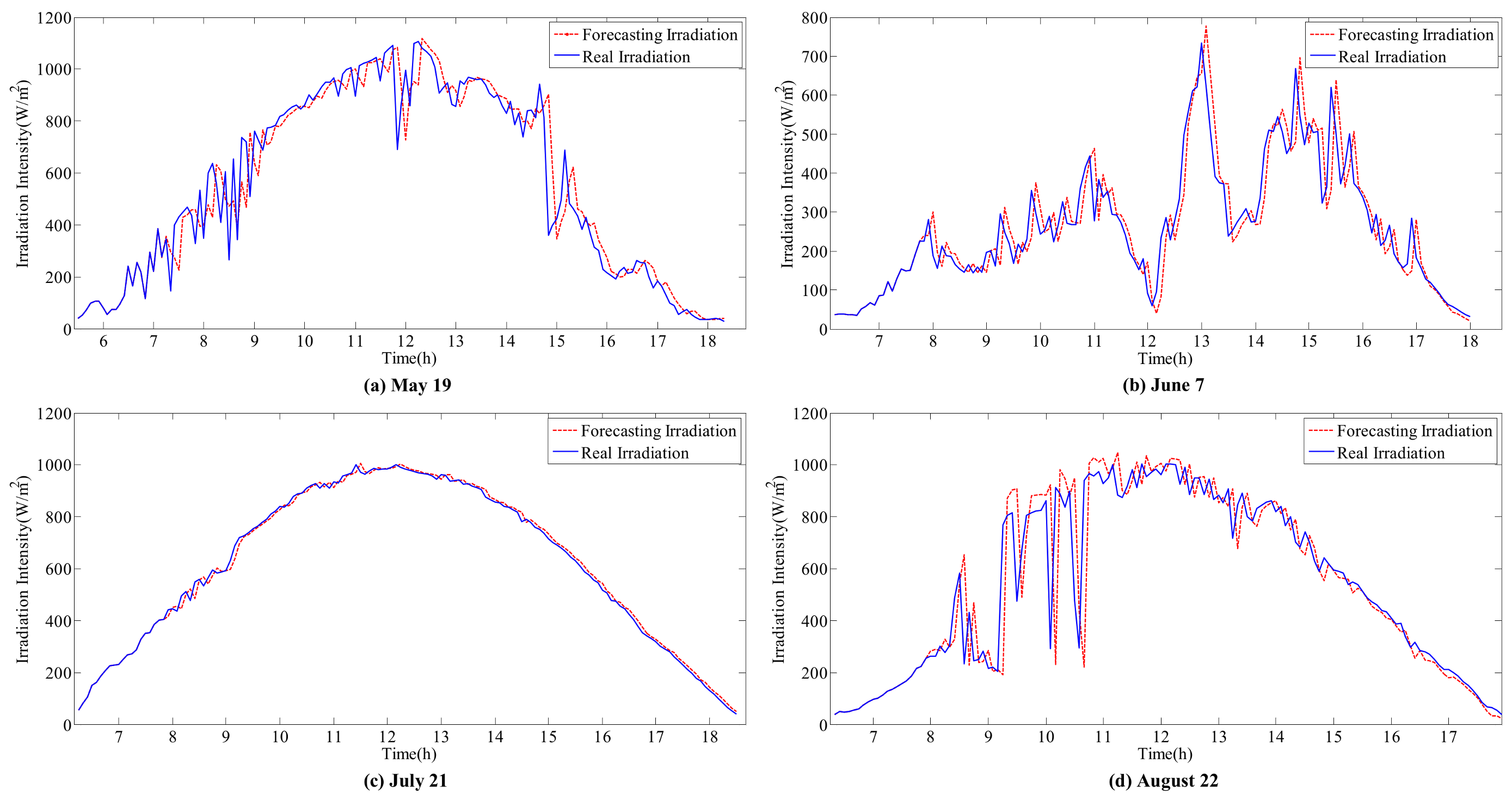
by the hybrid forecasting models on four target days are shown in
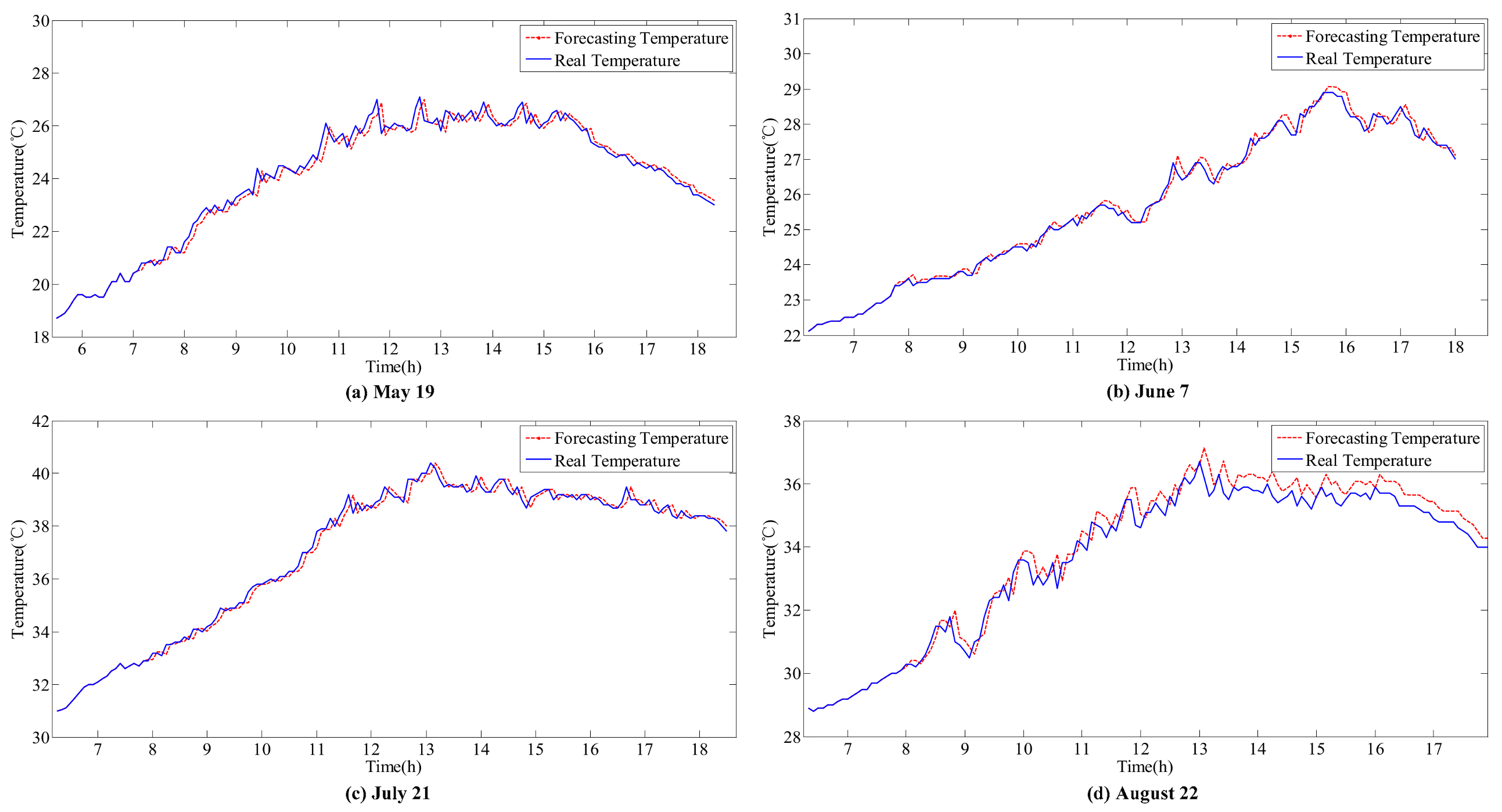
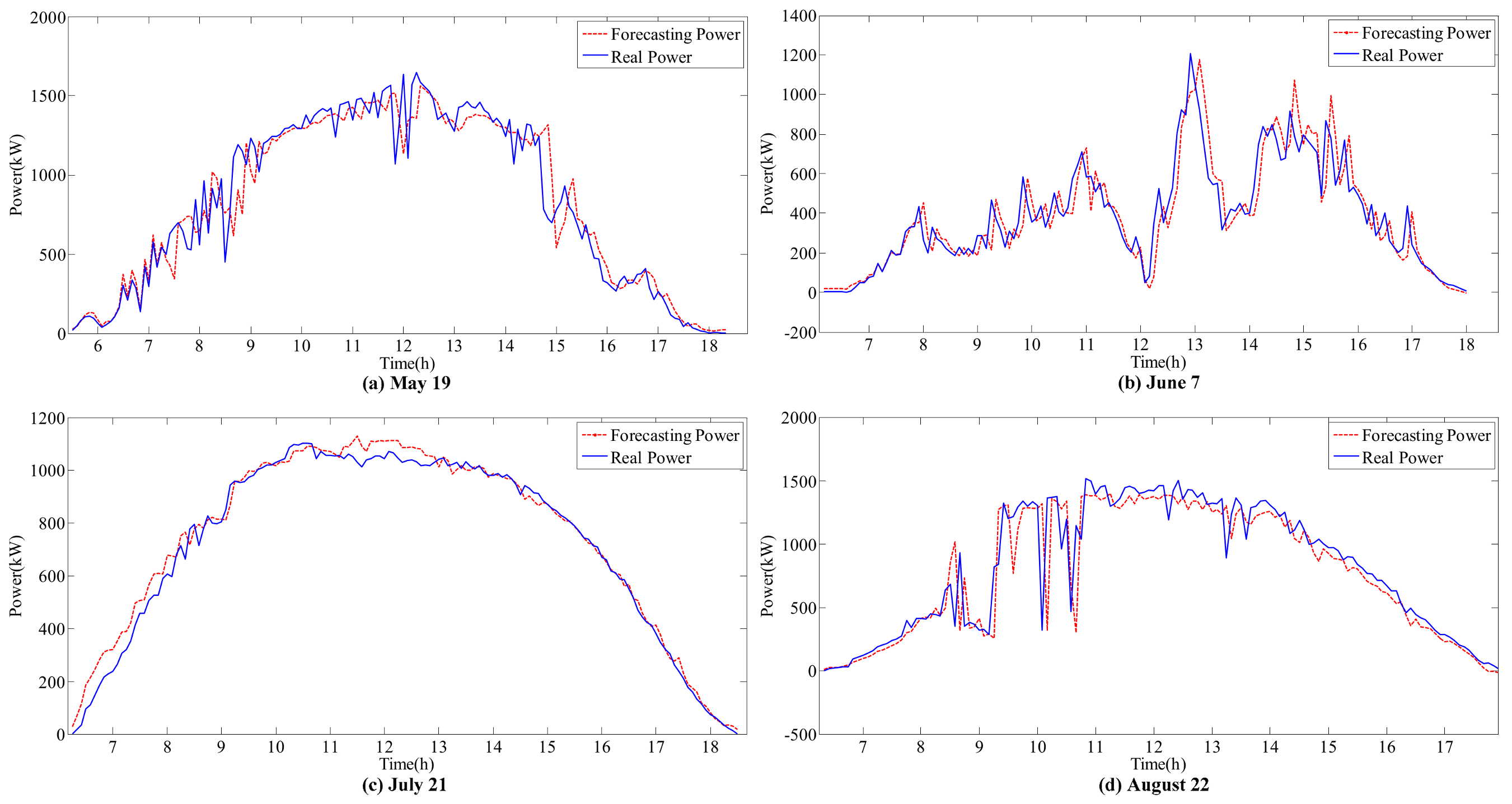
Figure 8,
Figure 9 and
Figure 10. Additionally, the forecasting accuracy is shown in
Table 5. Moreover, for comparison of different forecasting algorithms, four different regression models are established: the sub-SVR model, a global SVR model (G-SVR), a back propagation neural network submodel (S-BPNN) and a global BPNN model (G-BPNN). The global models are established using all the training data, while submodels are established using the classified data. The forecasting results are shown in
Table 6.
The following conclusions can be obtained from the forecasting results:
The accurate forecasting results of IR and T can be used as inputs in the sub-SVR to improve the forecasting performance of P. As a result, the forecasted and actual curves are similar.
IR and T are relatively stable on the sunny day (21 July), and the variation trends are clear. Reasonable forecasting results can be obtained with the ARIMA models. The curves of forecasted IR and T are coincident with the actual monitoring curves on the sunny day. However, in other weather conditions, errors can be observed in the forecasting results for various reasons.
The effect of variations in
T on
P is considered in this hybrid model. For instance, on 21 July, the peak value of
IR occurs at approximately 12 p.m. However, the peak value of
P appears between 10 p.m. and 11 p.m. On one hand,
IR is stable and does not considerably affect the fluctuation in
P. On the other hand, the increase in temperature during this period decreases
P. This result is reflected by the forecasting curve in
Figure 8,
Figure 9 and
Figure 10c.
In the ARIMA models, T is more stable than IR under all weather conditions, with higher forecasting accuracy. However, the correlation between IR and P is higher than the correlation between T and P. Thus, the influence of IR on P is larger than that of T. Meanwhile, volatility will considerably affect the time series fitting ability of ARIMA. Therefore, the forecasting accuracy of the hybrid model depends on the processing of IR volatility.
Generally, SVR has an advantage in processing fluctuant data relative to BPNN. However, because it is sunny on 21 July, T and IR are more stable than other days, and forecasting performances of G-BPNN and G-SVR are approximate. Except for this day, the G-SVR model has better fitting and forecasting ability than the G-BPNN model. Moreover, the submodels can improve the forecasting accuracy by excluding interference factors under different weather conditions. Therefore, the hybrid forecasting model proposed is a reasonable choice.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}