A Bibliometric Analysis and Visualization of Medical Big Data Research





Abstract
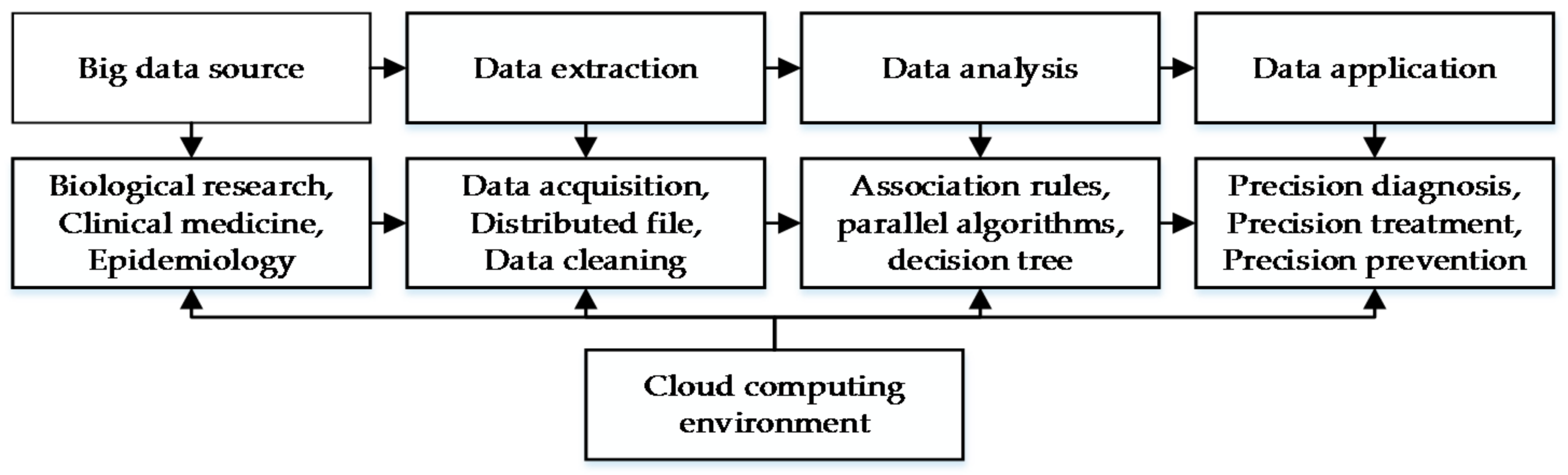
:1. Introduction
2. Data and Methods
3. Results
3.1. The Current Status of MBD Study
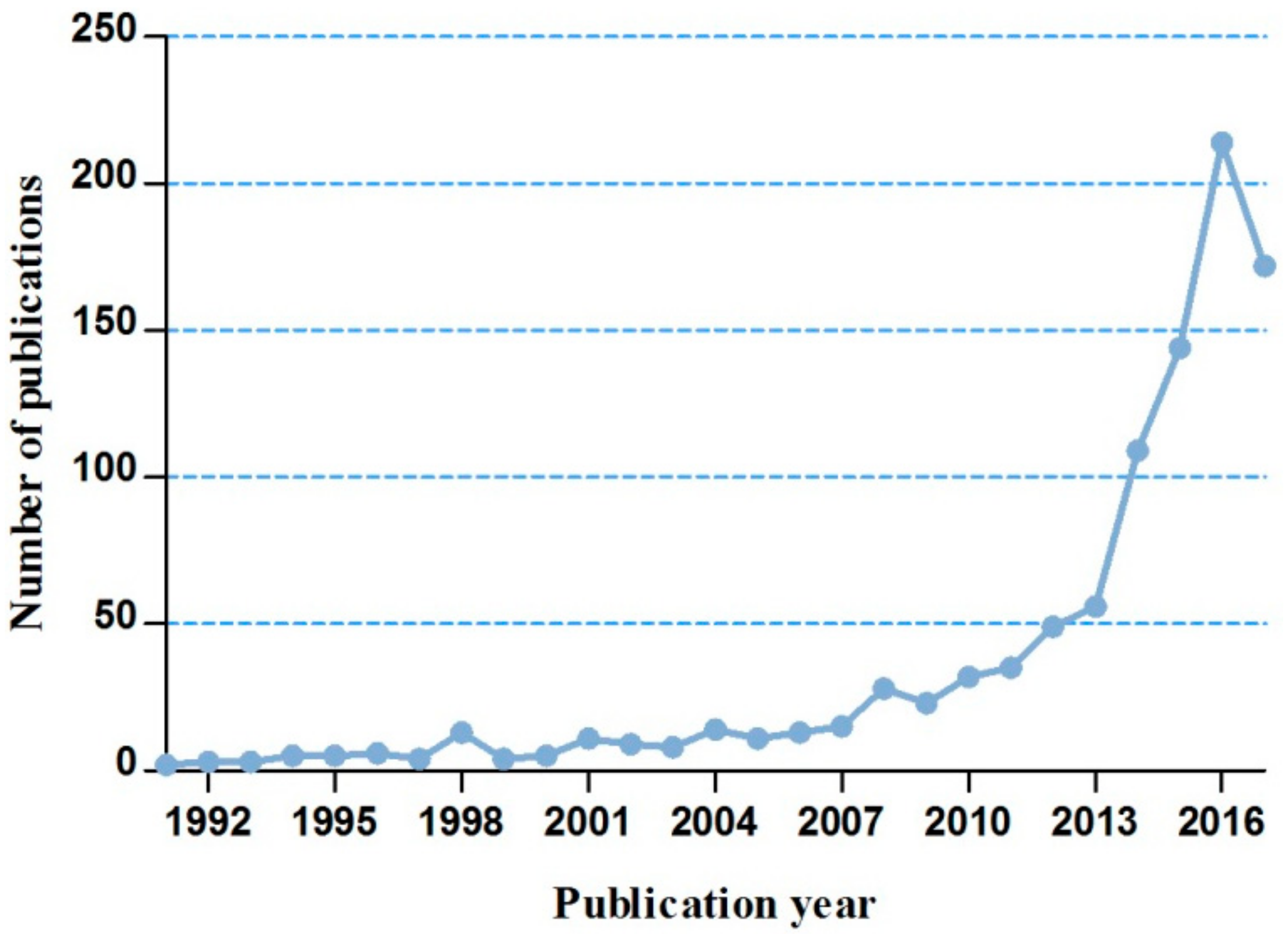
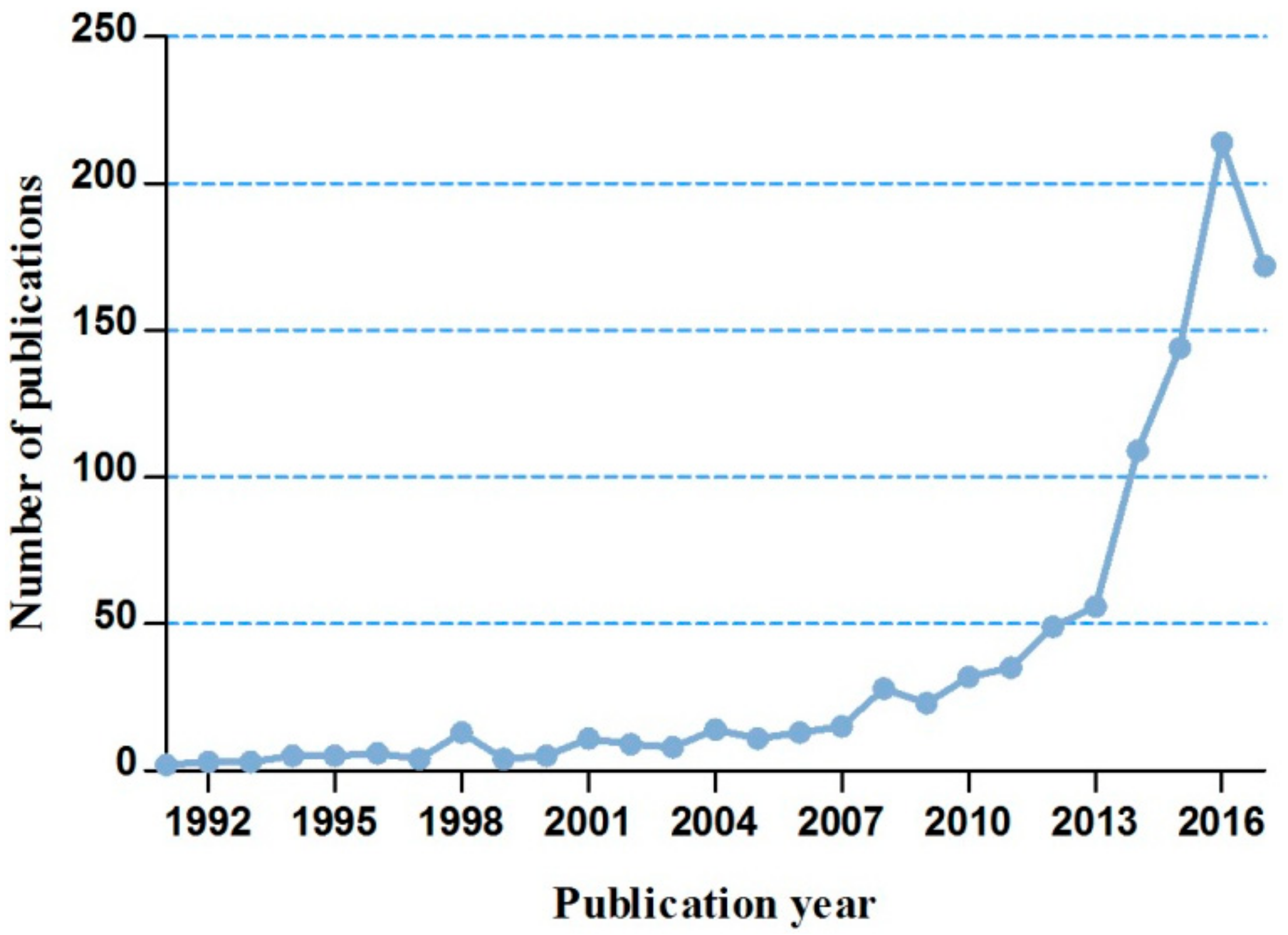
3.1.1. The Annual Trends of MBD-Related Publications
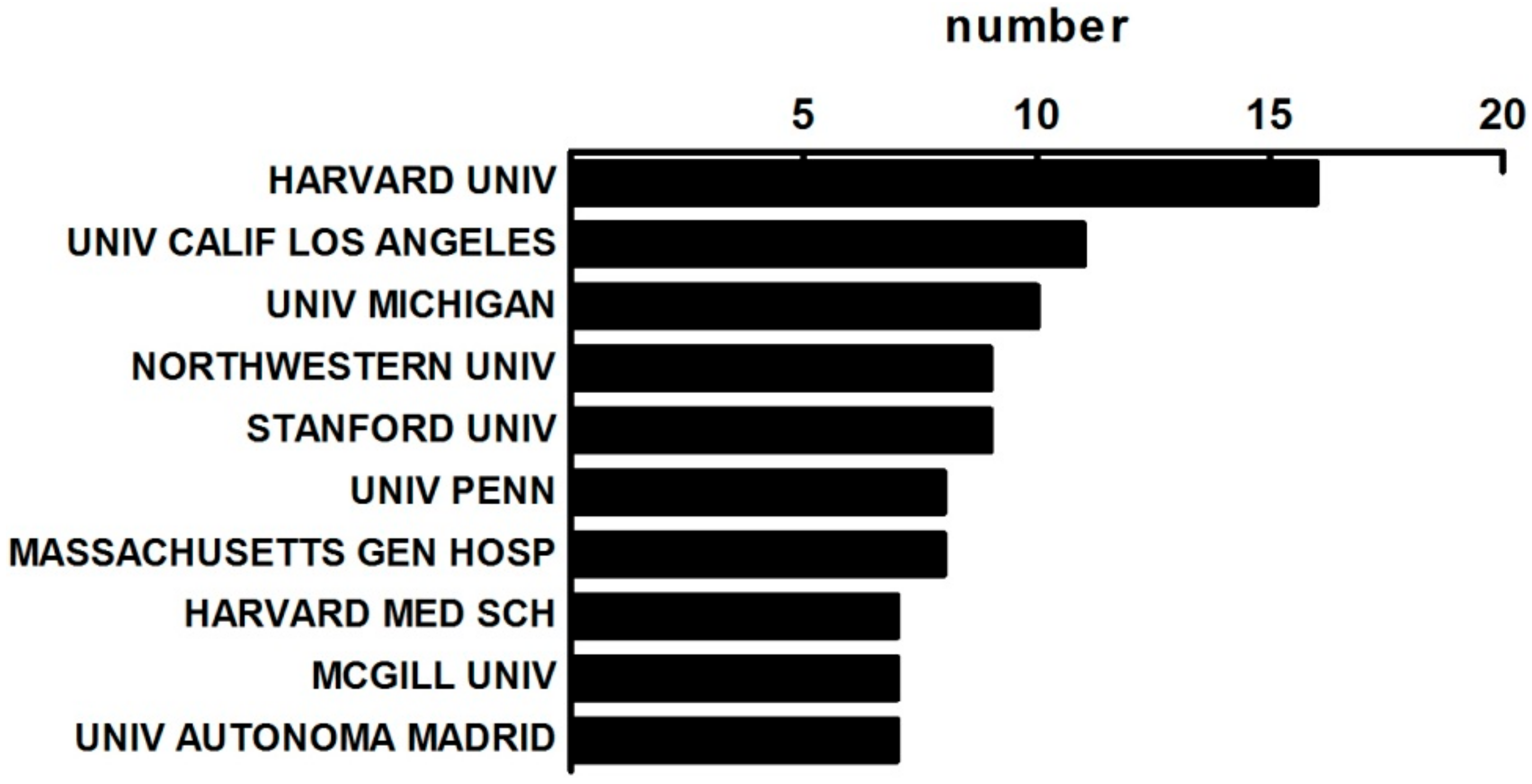
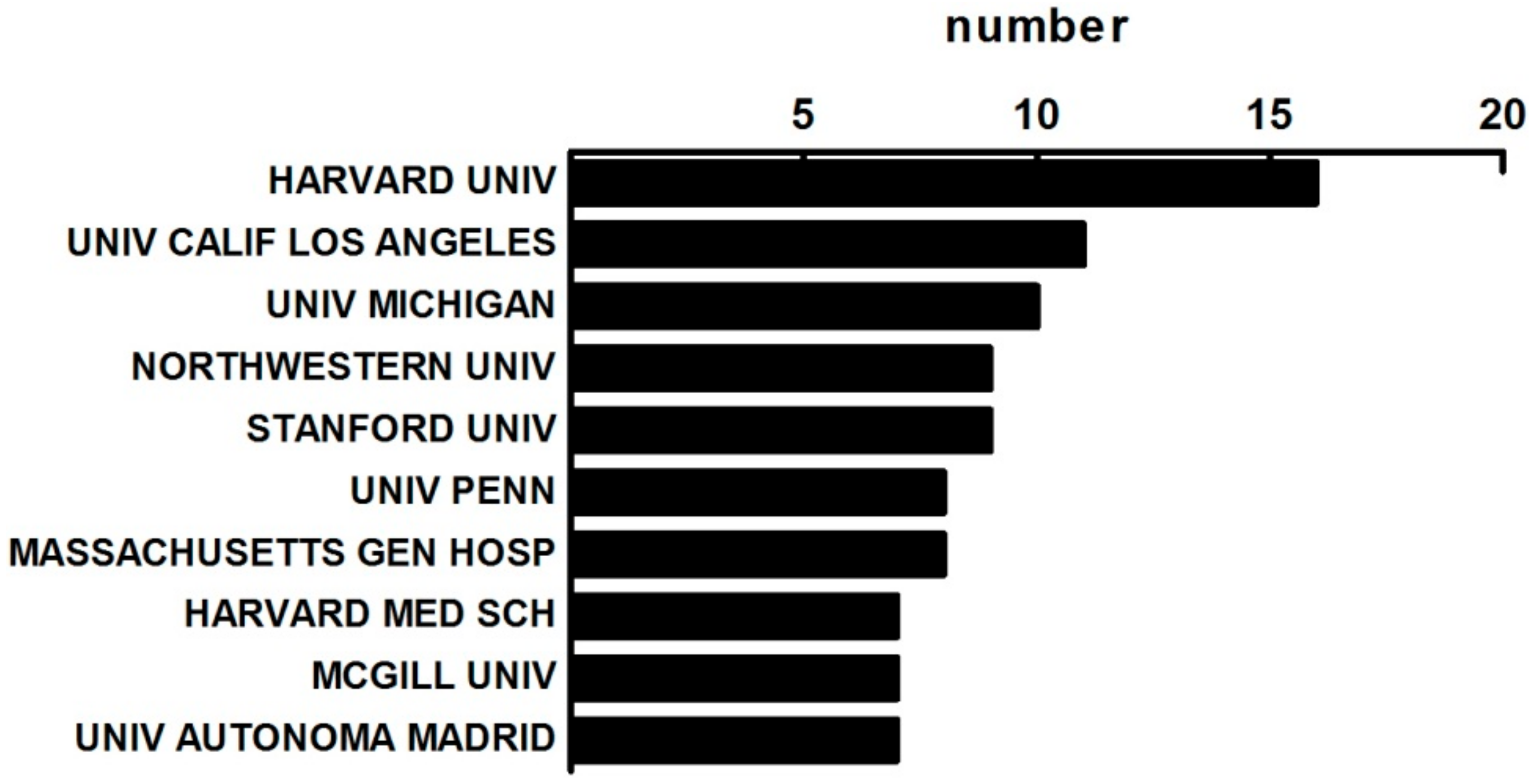
3.1.2. The Distribution of Institutes on MBD Study
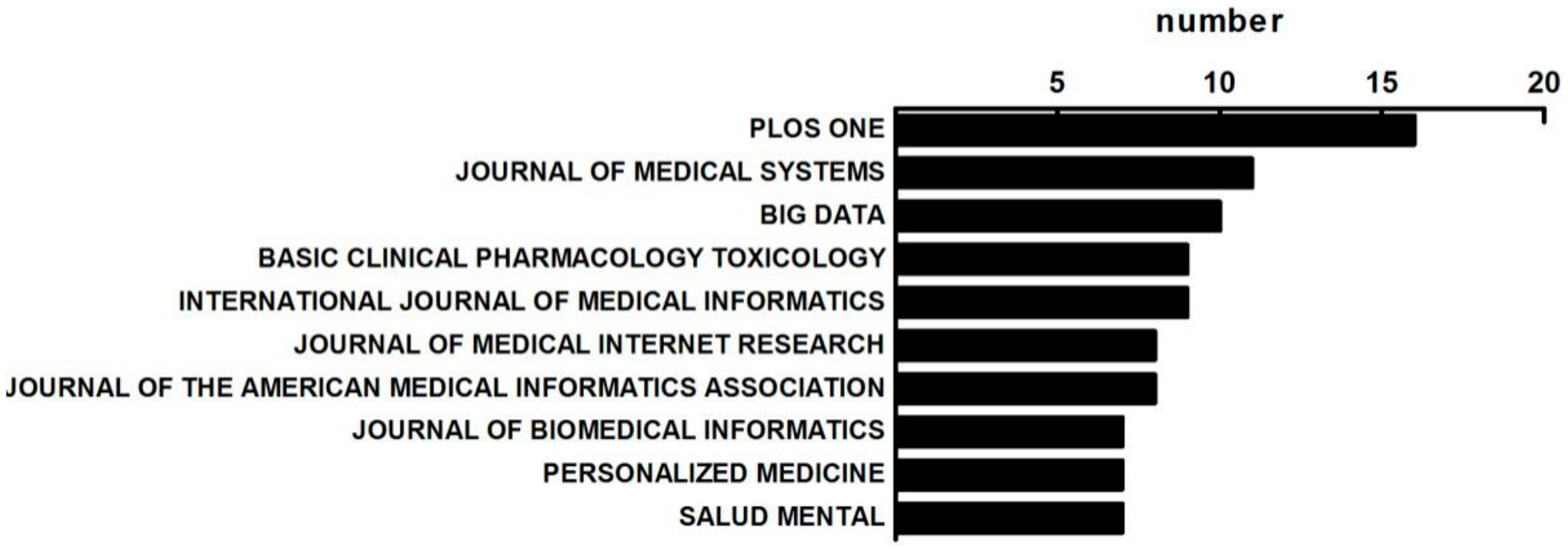
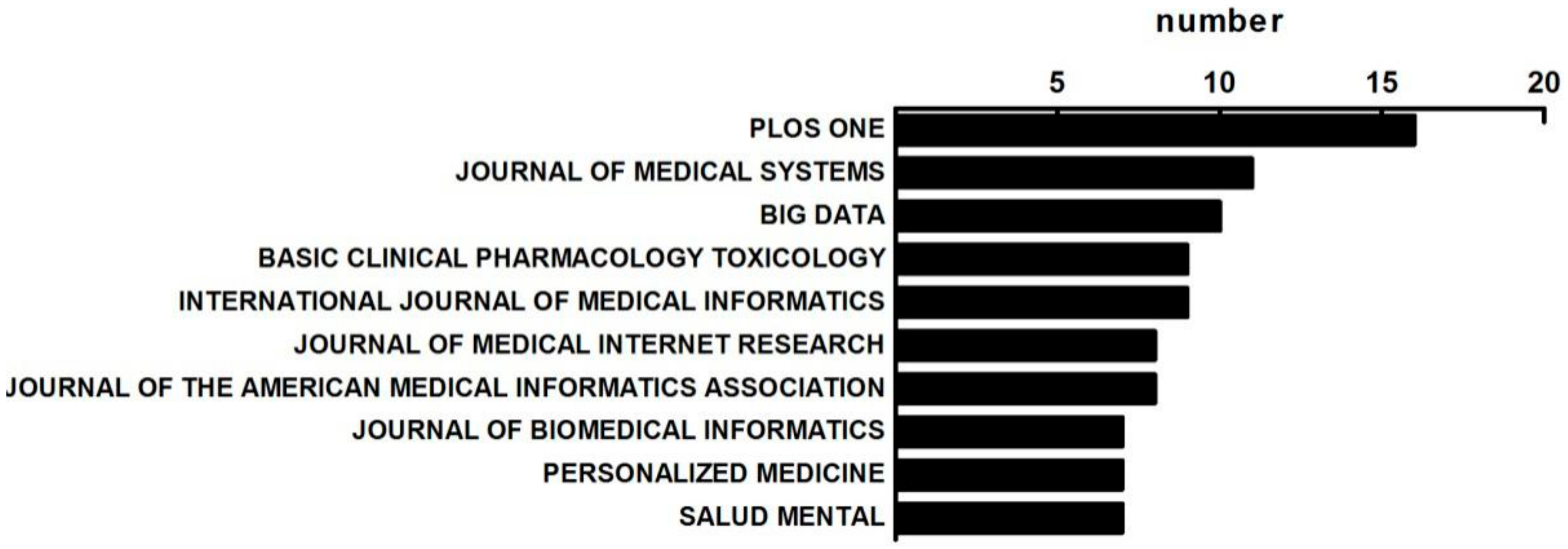
3.1.3. The Distribution of Published Journals on MBD Study
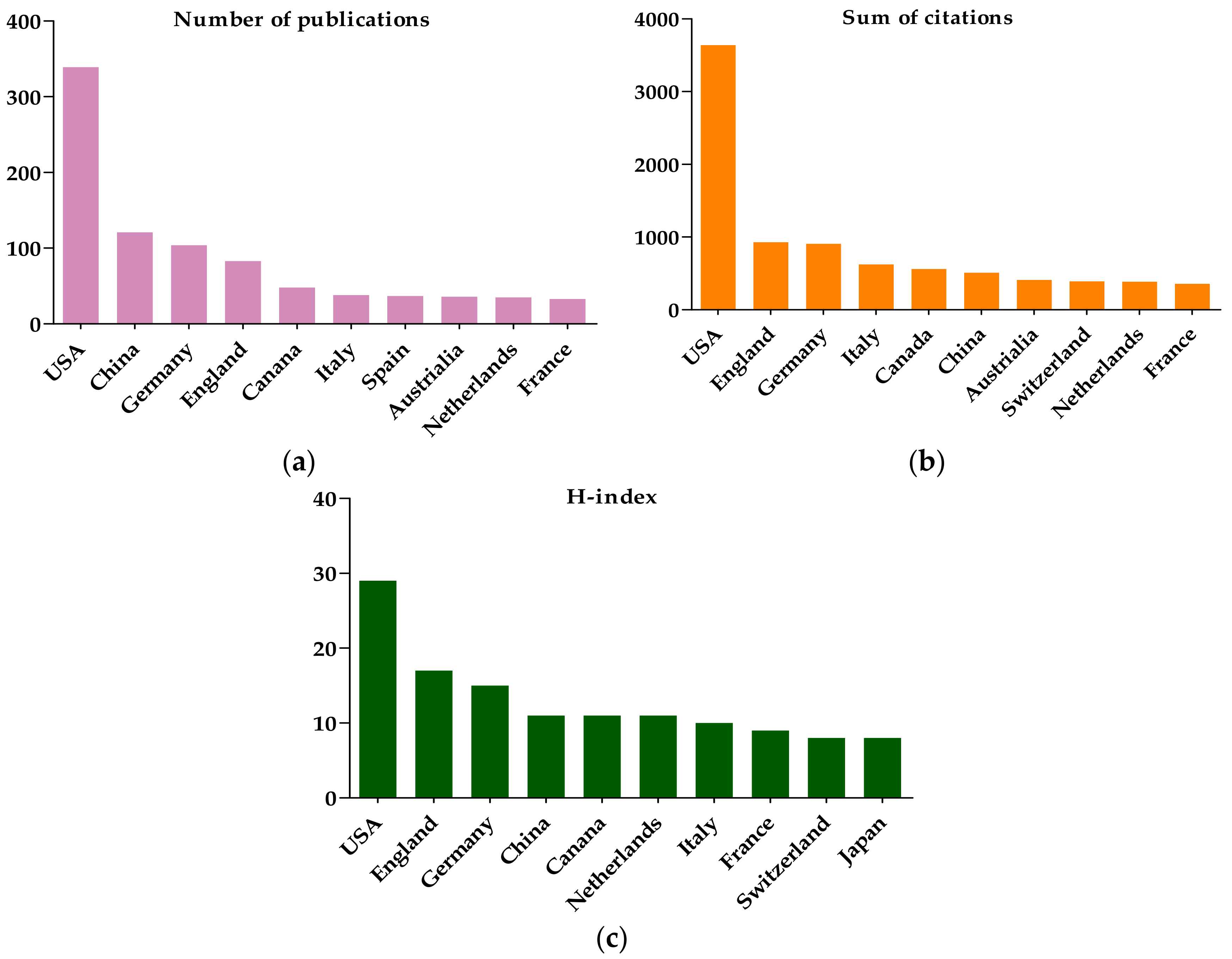
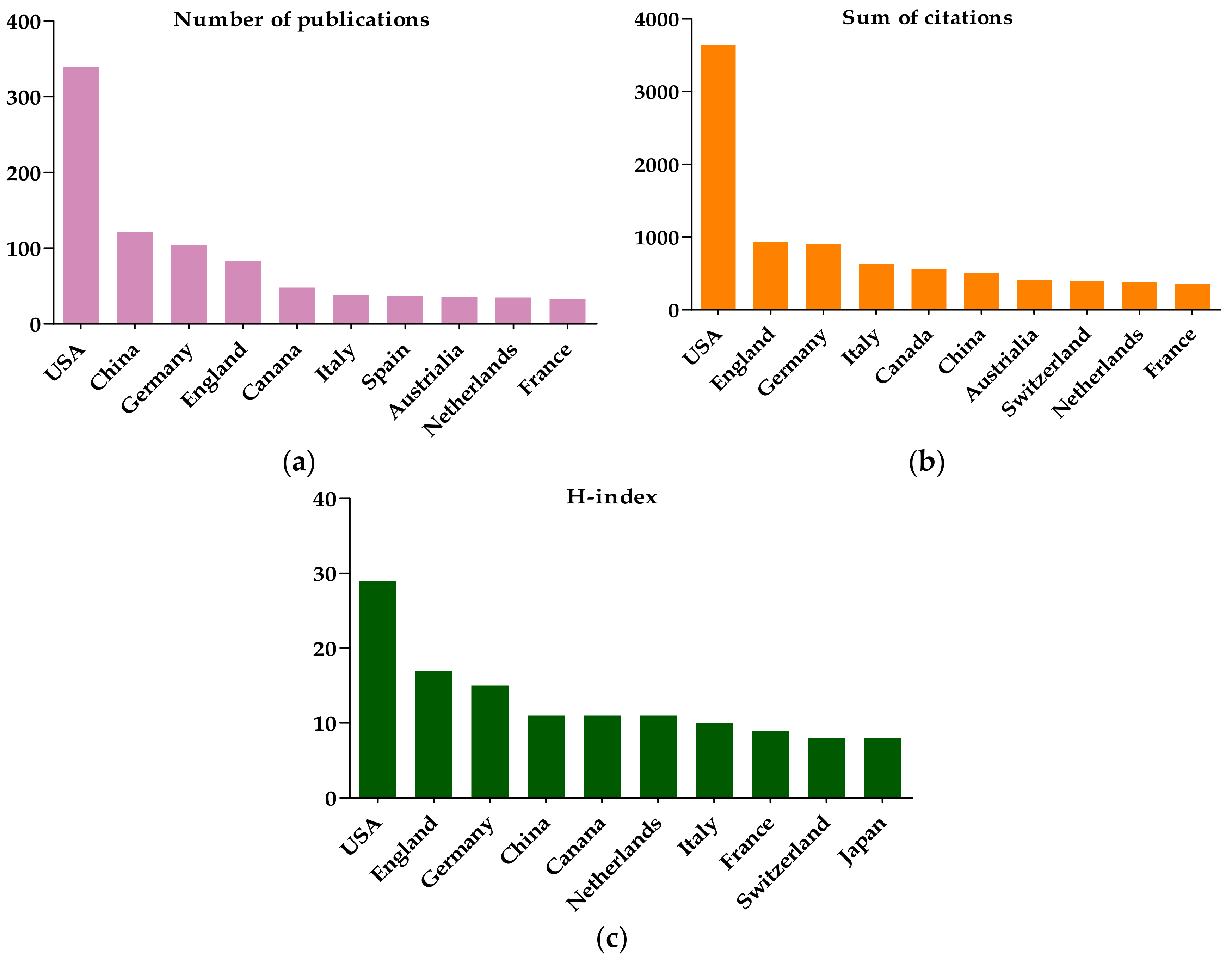
3.1.4. The Citation and H-Index Analysis
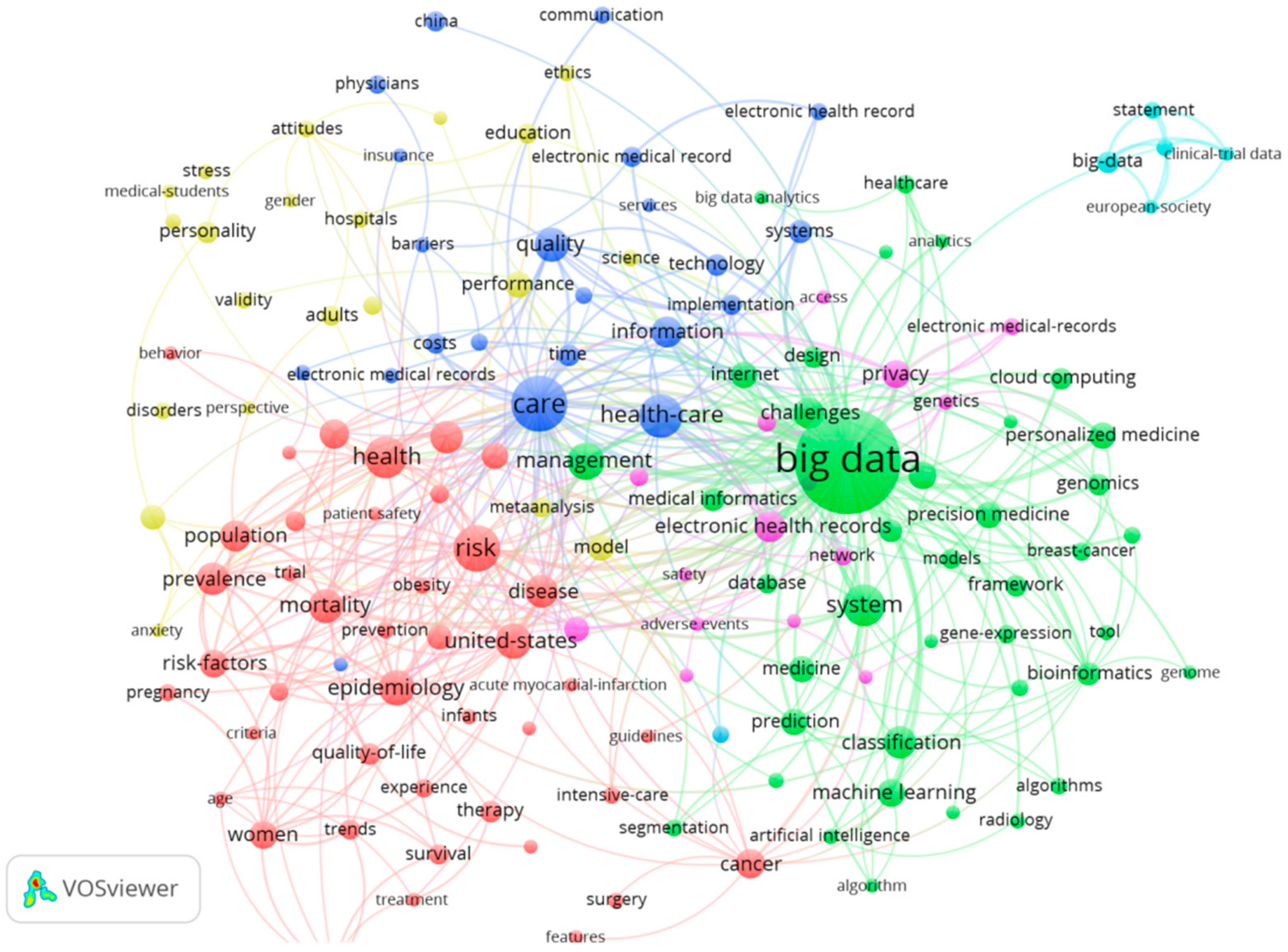
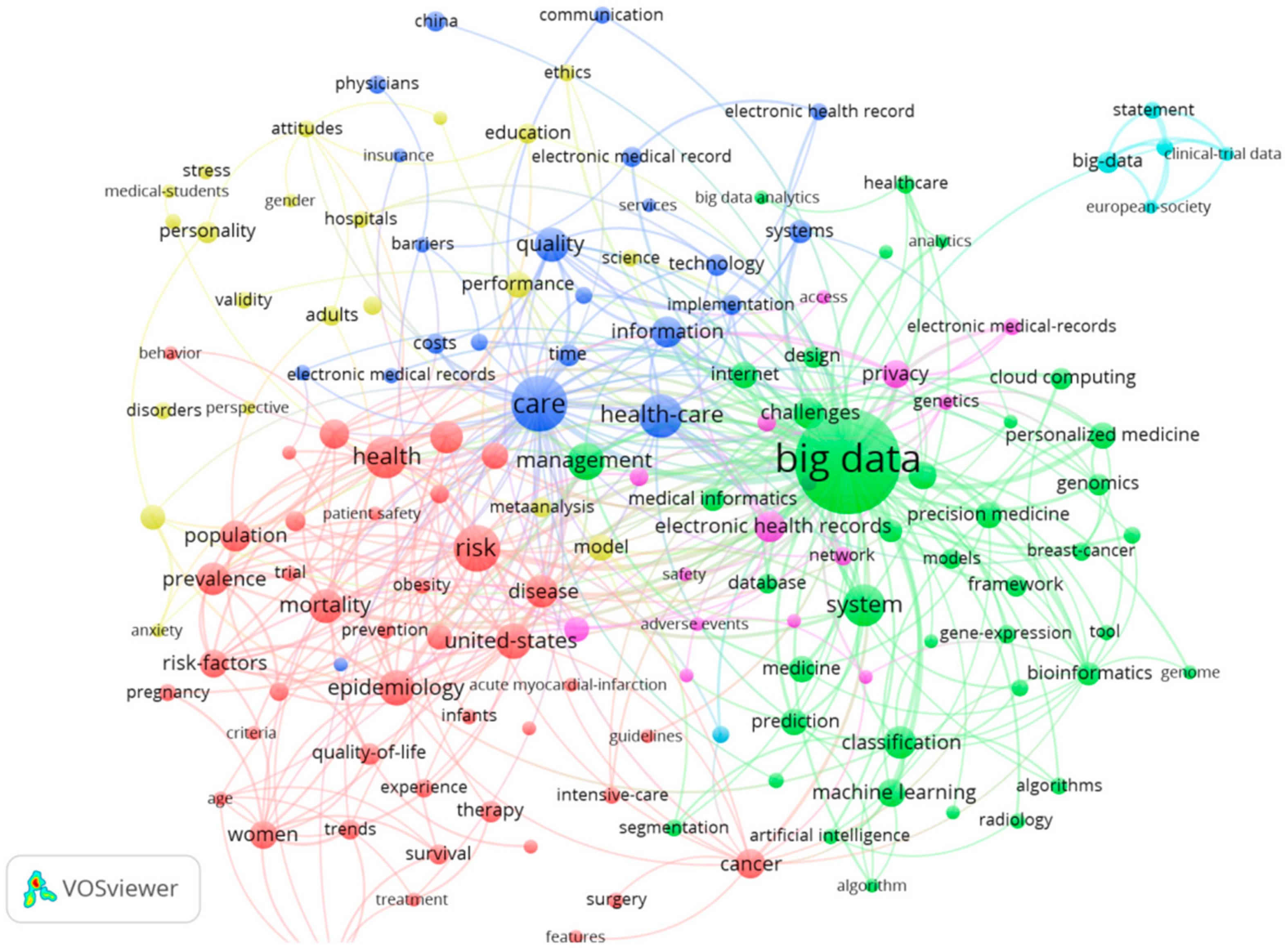
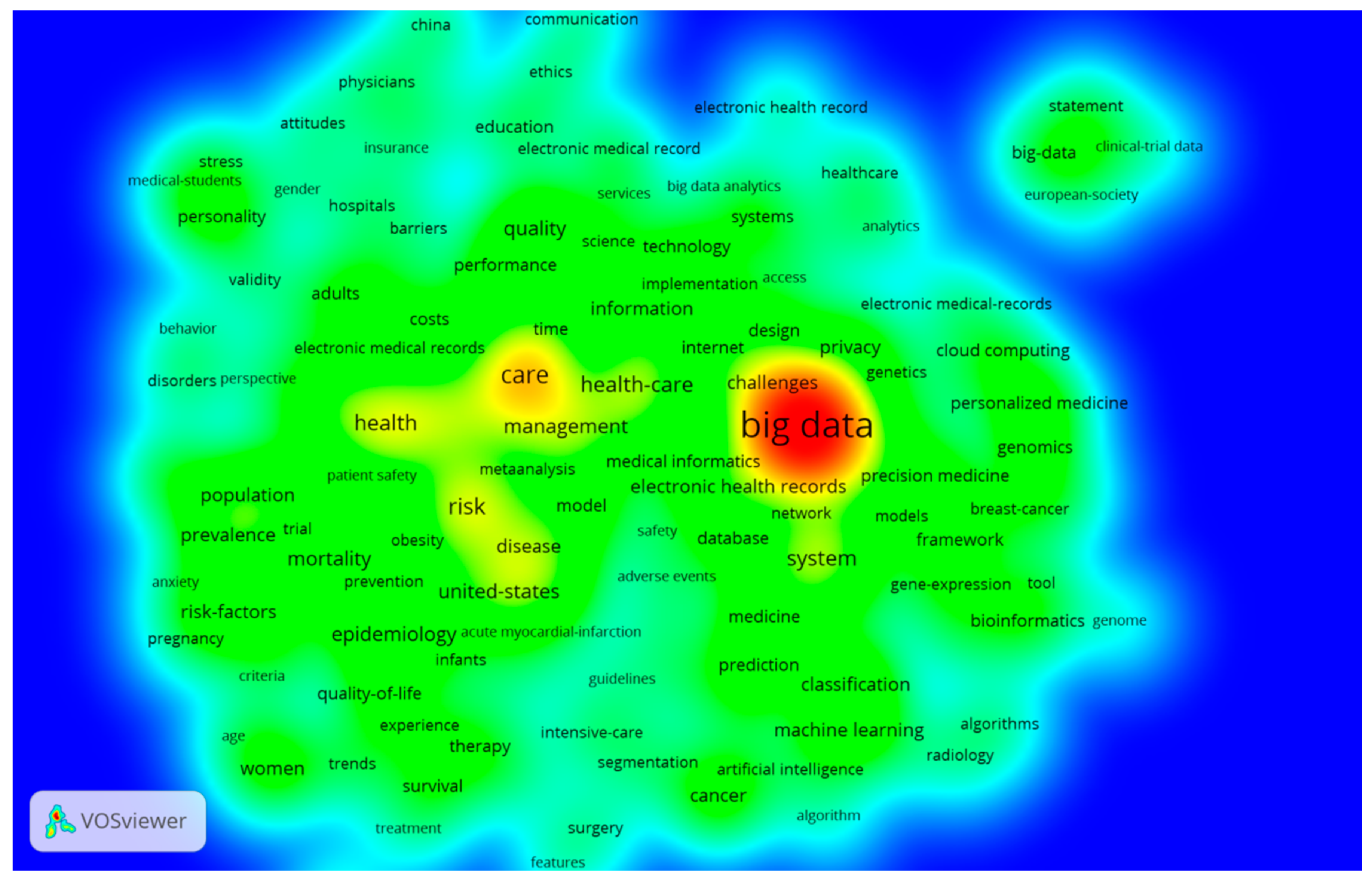
3.2. The Keywords Analysis of Research Hotspots on MBD Study
3.3. The Co-Authorship Analysis on MBD
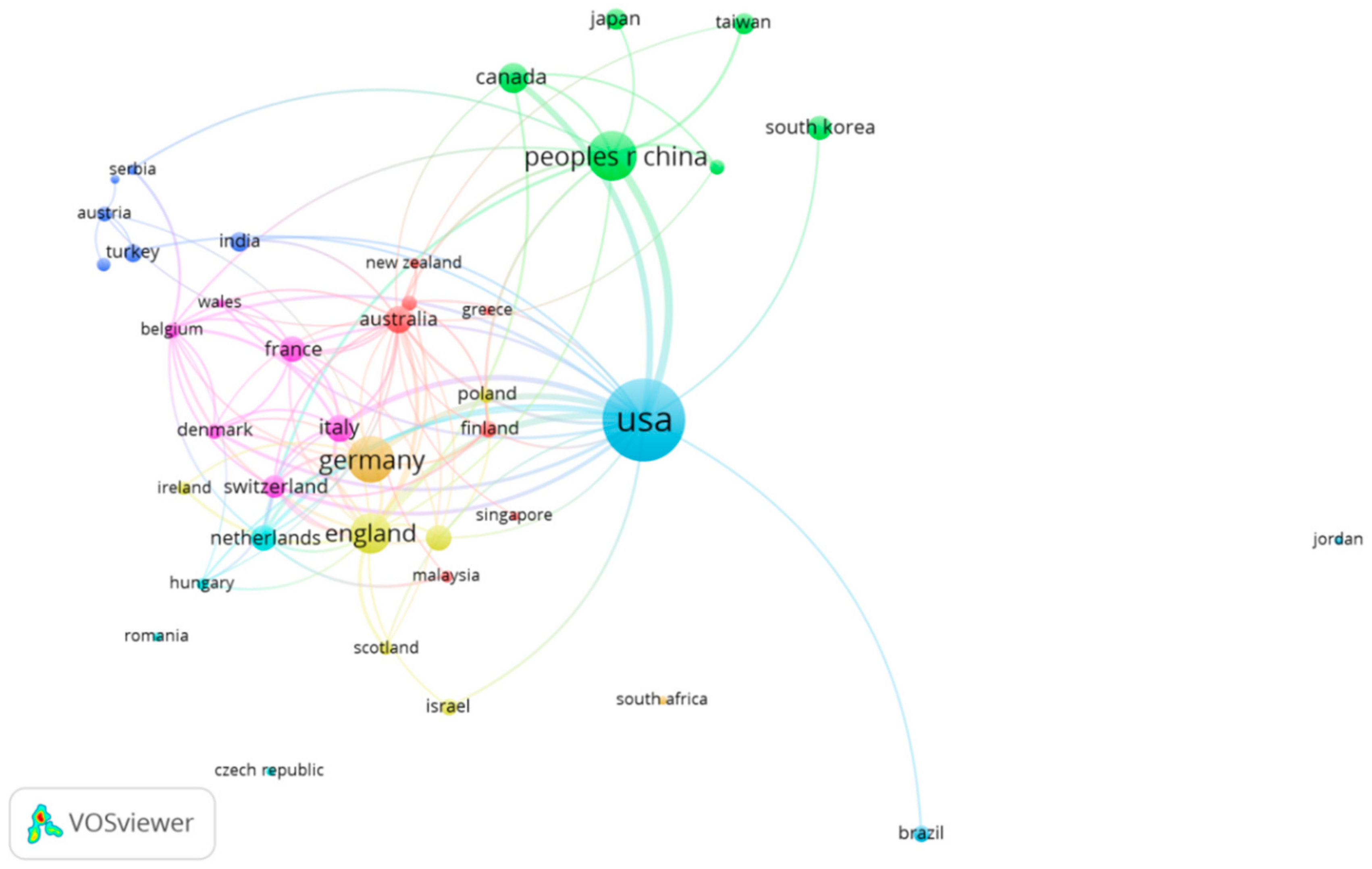
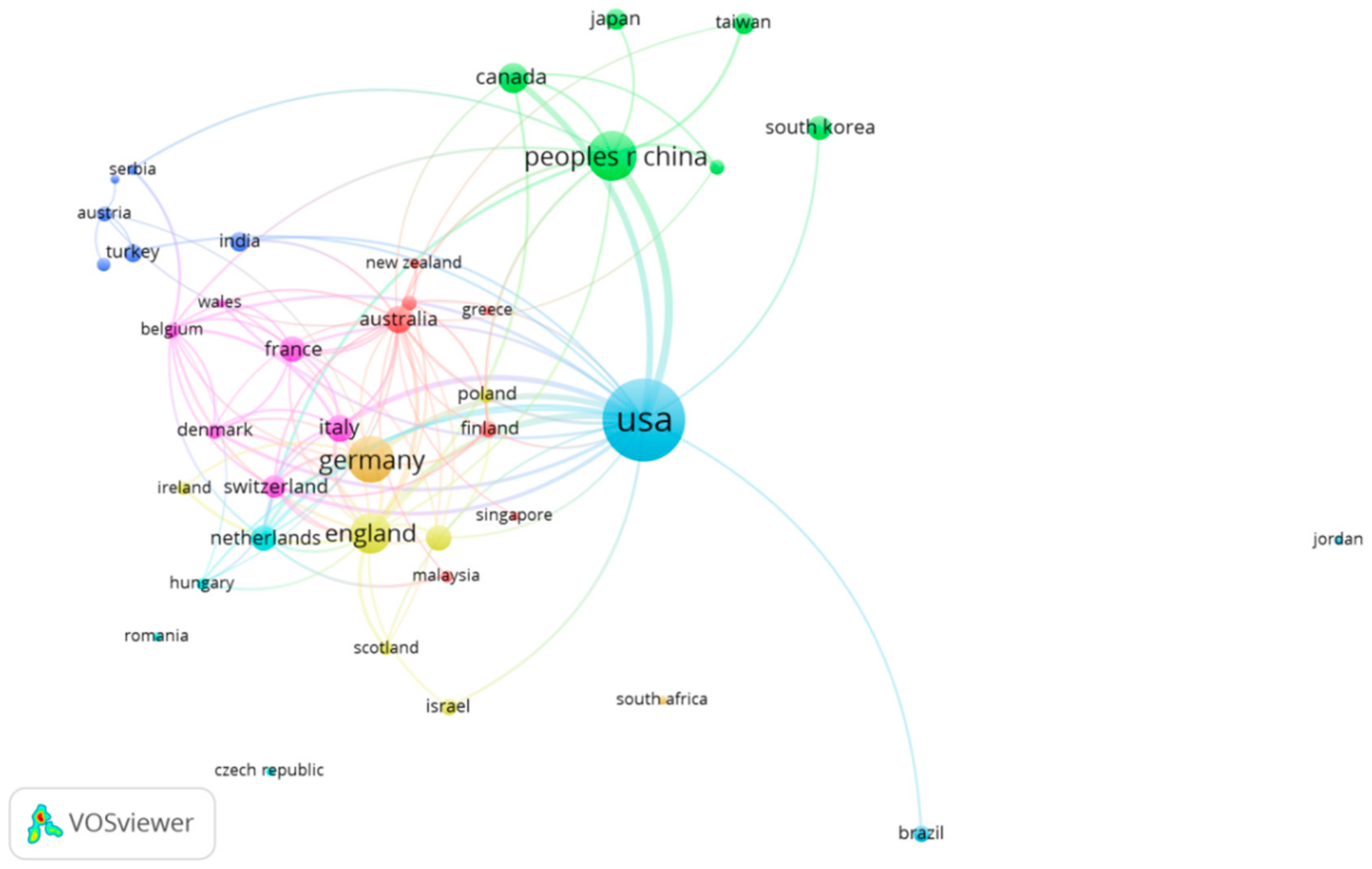
3.3.1. The Country Co-Authorship Analysis
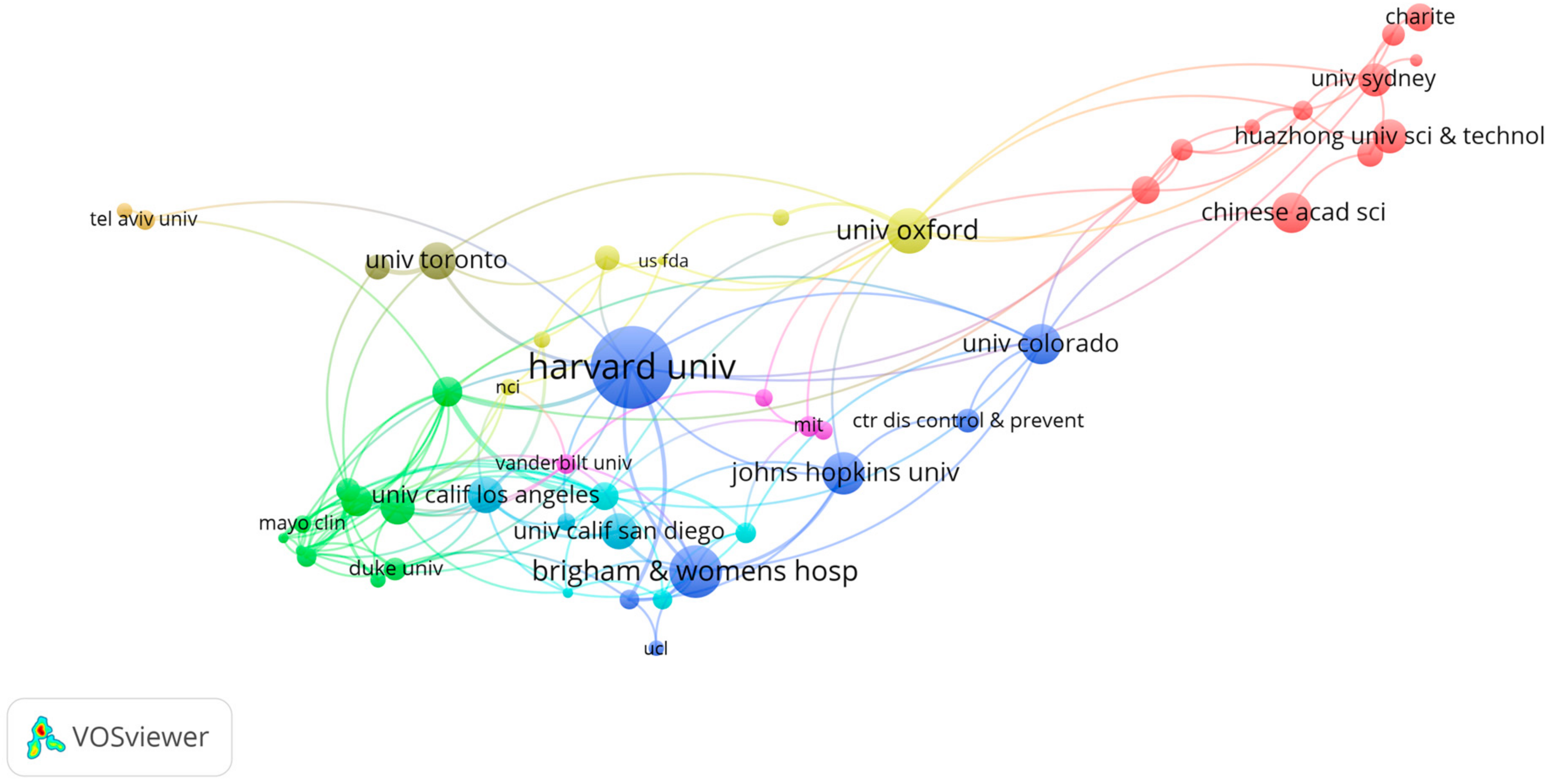
3.3.2. The Institute Co-Authorship Analysis
3.3.3. The Highly Cited MBD-Related Publications
3.4. The Co-Citation Analysis on MBD-Related Publications
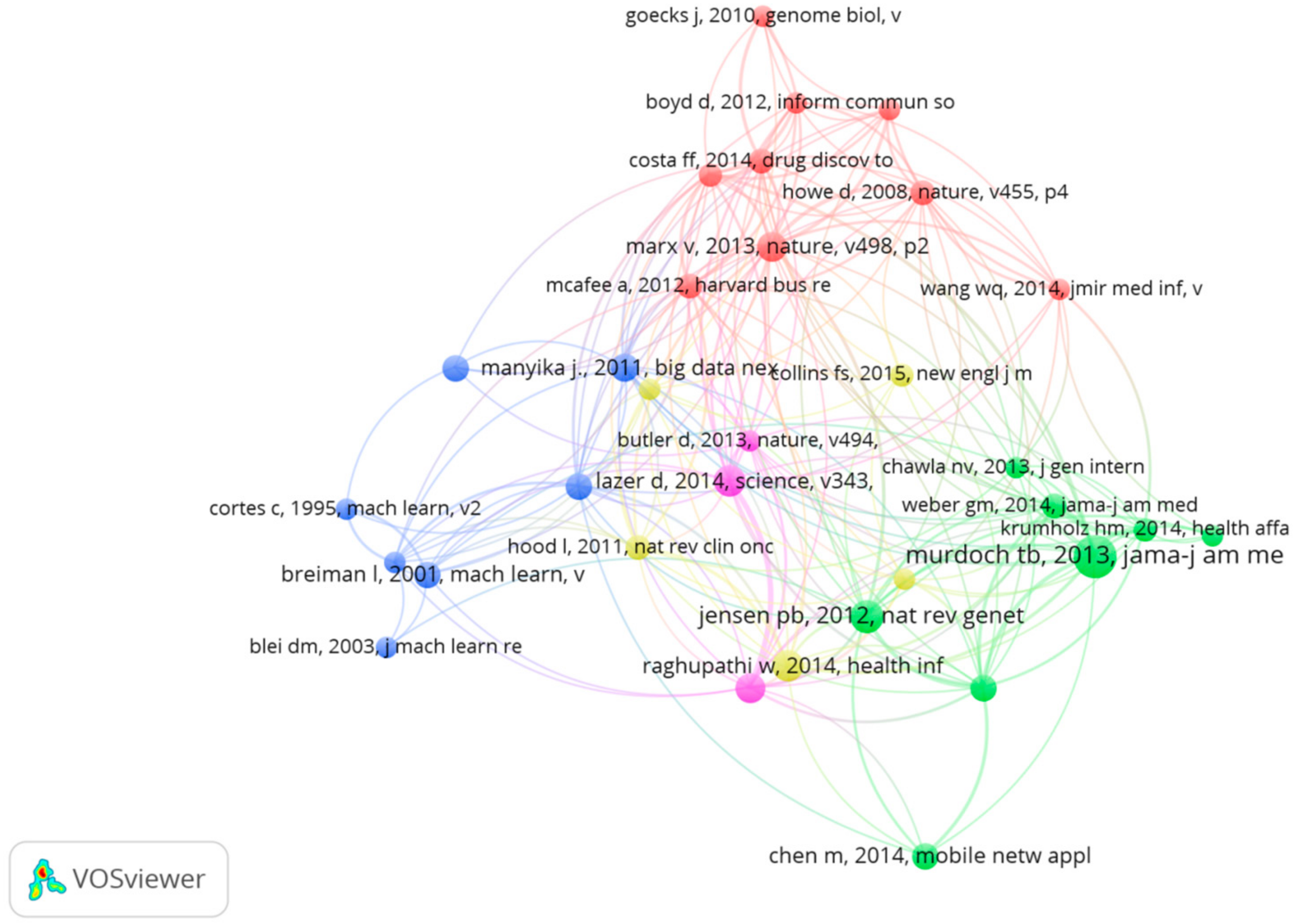
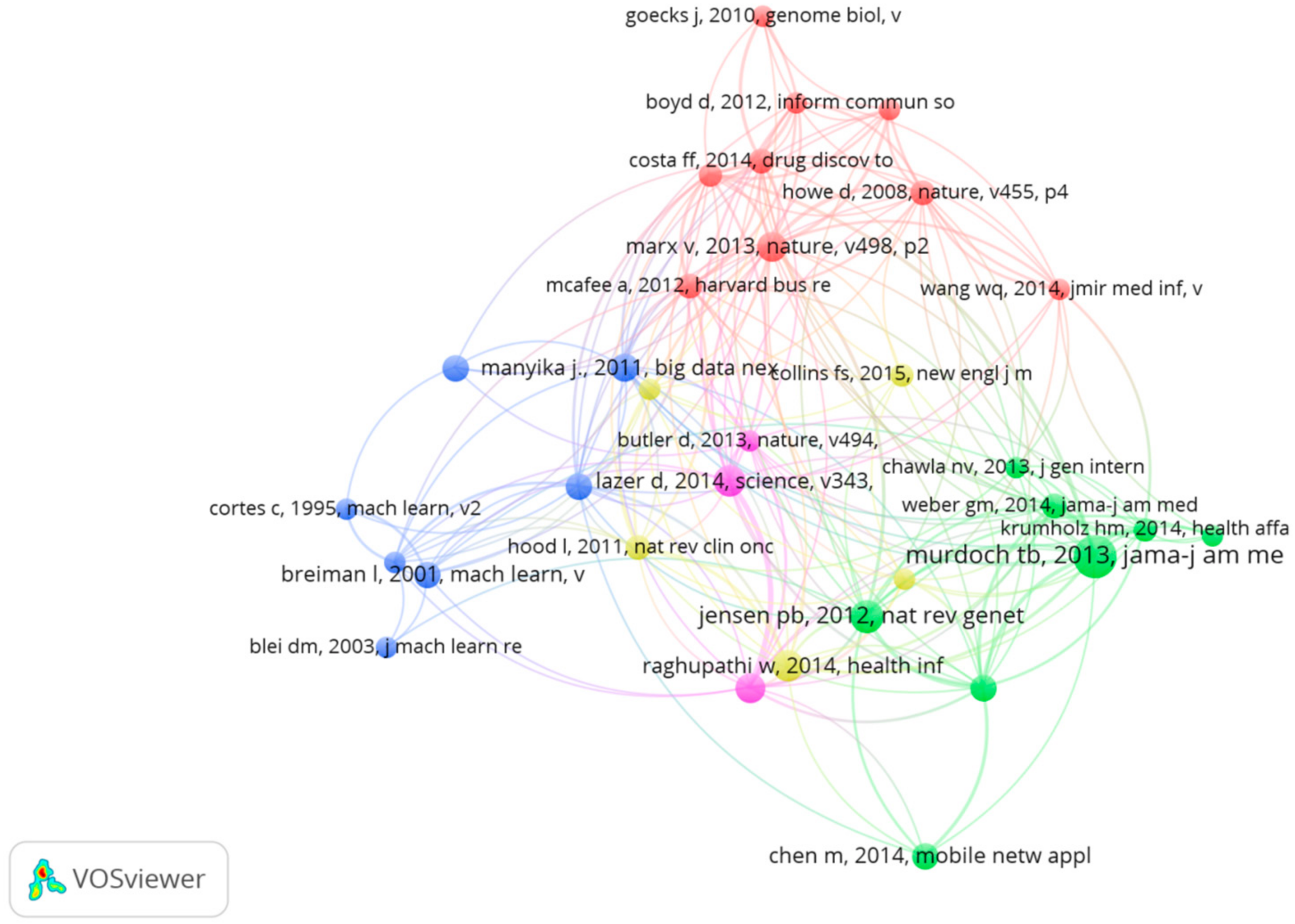
3.4.1. The Reference Co-Citation Analysis
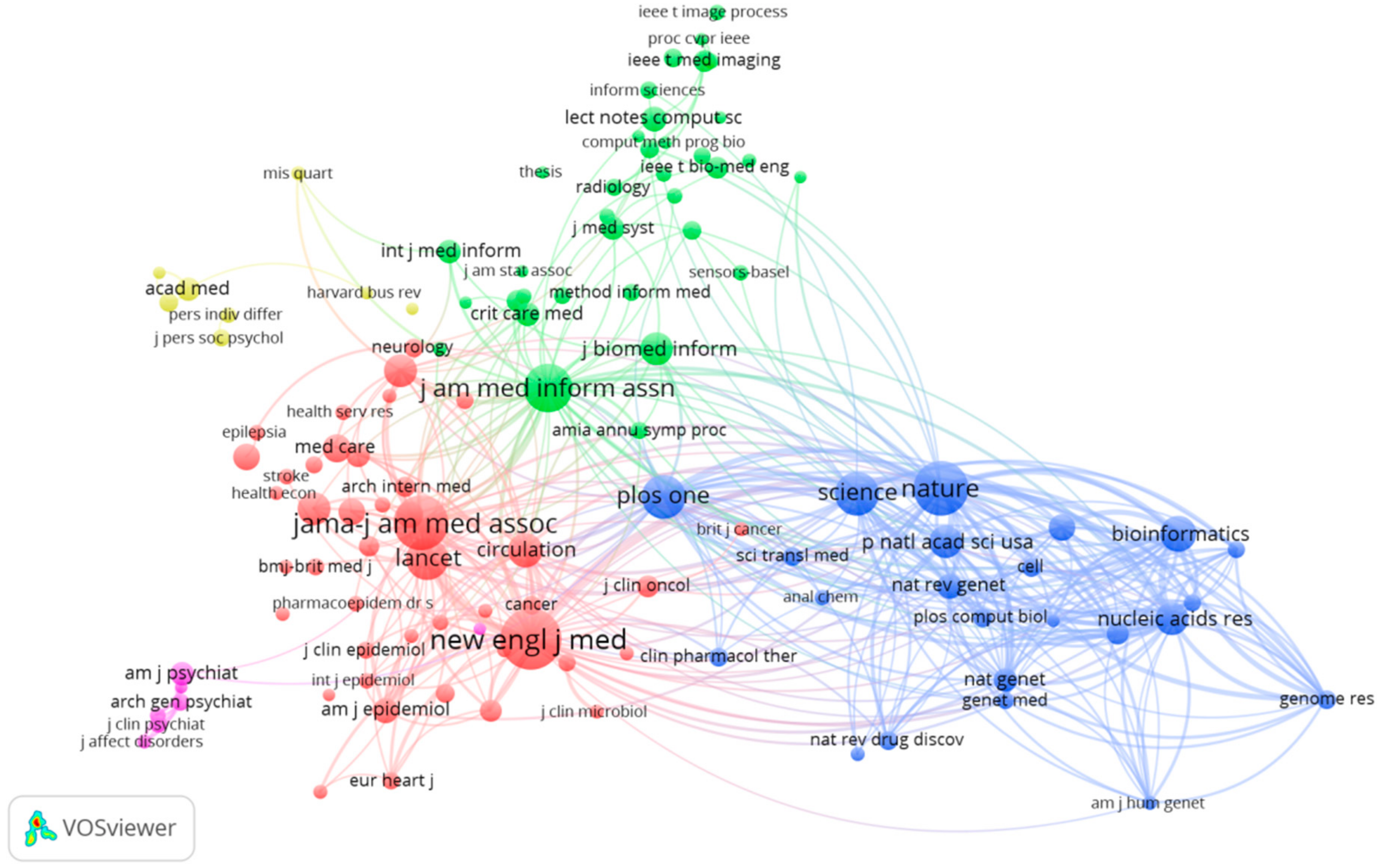
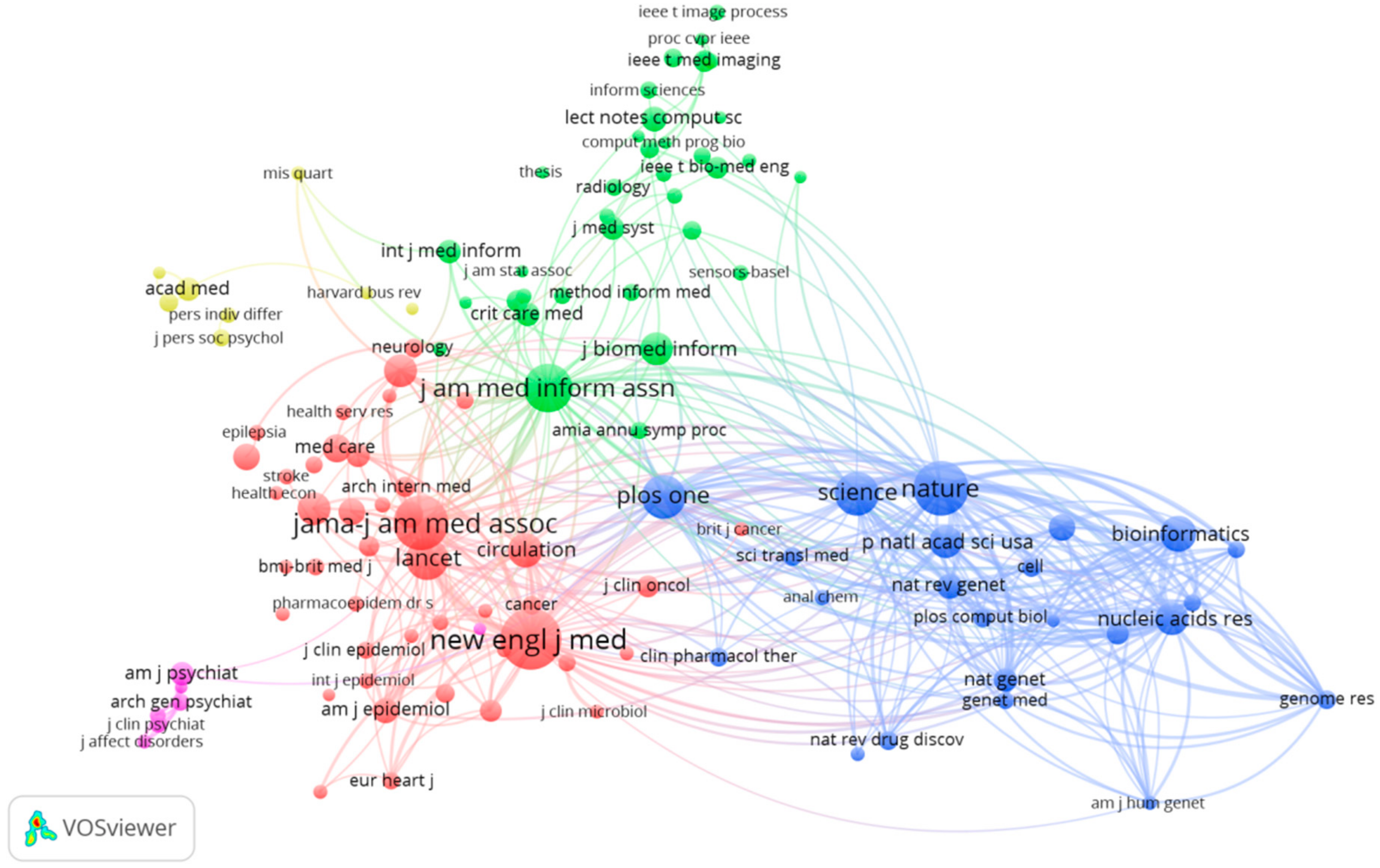
3.4.2. The Journal Co-Citation Analysis
4. Discussions and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Jin, X.L.; Wah, B.W.; Chen, X.Q.; Wang, Y.Z. Significance and challenges of big data research. Big Data Res. 2015, 2, 59–64. [Google Scholar] [CrossRef]
- Binder, H.; Blettner, M. Big data in medical science-A biostatistical view. Dtsch. Arztebl. Int. 2015, 112, 137–142. [Google Scholar] [PubMed]
- Katal, A.; Wazid, M.; Goudar, R.H. Big data: Issues, challenges, tools and good practices. In Proceedings of the Sixth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2013; pp. 404–409. [Google Scholar]
- Wamba, S.F.; Akter, S.; Edwards, A.; Chopin, G.; Gnanzou, D. How ‘big data’ can make big impact: Findings from a systematic review and a longitudinal case study. Int. J. Prod. Econ. 2015, 165, 234–246. [Google Scholar] [CrossRef]
- Alles, M.G. Drivers of the use and facilitators and obstacles of the evolution of big data by the audit profession. Account. Horiz. 2015, 29, 439–449. [Google Scholar] [CrossRef]
- Huwe, T.K. Big data, big future. Comput. Lib. 2012, 32, 20–22. [Google Scholar]
- Li, G.J.; Cheng, X.Q. Research status and scientific thinking of big data. Bull. Chin. Acad. Sci. 2012, 6, 647–657. [Google Scholar]
- Jee, K.; Kim, G.H. Potentiality of big data in the medical sector: Focus on how to reshape the healthcare system. Healthc. Inform. Res. 2013, 19, 79–85. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Davis, D.A. Bringing big data to personalized healthcare: A patient-centered framework. J. Gen. Intern. Med. 2013, 28, 660–665. [Google Scholar] [CrossRef] [PubMed]
- Antman, E.M.; Benjamin, E.J.; Harrington, R.A.; Houser, S.R.; Peterson, E.D.; Bauman, M.A.; Brown, N.; Bufalino, V.; Califf, R.M.; Creager, M.A.; et al. Acquisition, analysis, and sharing of data in 2015 and beyond: A survey of the landscape. J. Am. Heart Assoc. 2015, 4, e002810. [Google Scholar] [CrossRef] [PubMed]
- Merigó, J.M. Academic research in innovation: A country analysis. Scientometrics 2016, 108, 559–593. [Google Scholar] [CrossRef]
- Železnik, D.; Vošner, H.B.; Kokol, P. A bibliometric analysis of the Journal of Advanced Nursing, 1976–2015. J. Adv. Nurs. 2017, 73, 2407–2419. [Google Scholar] [CrossRef] [PubMed]
- Merigó, J.M.; Mas-Tur, A.; Roig-Tierno, N.; Ribeiro-Soriano, D. A bibliometric overview of the Journal of Business Research between 1973 and 2014. J. Bus. Res. 2015, 68, 2645–2653. [Google Scholar] [CrossRef]
- Osareh, F. Bibliometrics, citation analysis and co-citation analysis: A review of literature I. Libri 2009, 49, 149–158. [Google Scholar] [CrossRef]
- Yeung, A.W.K.; Goto, T.K.; Leung, W.K. A bibliometric review of research trends in neuroimaging. Curr. Sci. 2017, 112, 725–734. [Google Scholar] [CrossRef]
- Sweileh, W.M.; Al-Jabi, S.W.; Sawalha, A.F.; AbuTaha, A.S.; Saed, H.Z. Bibliometric analysis of publications on Campylobacter: (2000–2015). J. Health Popul. Nutr. 2016, 35, 35–39. [Google Scholar] [CrossRef] [PubMed]
- Merigó, J.M.; Blanco-Mesa, F.; Gil-Lafuente, A.M.; Yager, R.R. Thirty years of the International Journal of Intelligent Systems: A bibliometric review. Int. J. Intell. Syst. 2017, 32, 526–554. [Google Scholar] [CrossRef]
- Merigó, J.M.; Yang, J.B. A bibliometric analysis of operations research and management science. Omega 2016, 97, 1–16. [Google Scholar] [CrossRef]
- Kostoff, R.N. The underpublishing of science and technology results. Scientist 2000, 14, 6. [Google Scholar]
- Liu, W.S.; Liao, H.C. A bibliometric analysis of fuzzy decision research during 1970–2015. Int. J. Fuzzy Syst. 2017, 19, 1–14. [Google Scholar] [CrossRef]
- Yu, D.J.; Liao, H.C. Visualization and quantitative research on intuitionistic fuzzy studies. J. Intell. Fuzzy Syst. 2016, 30, 3653–3663. [Google Scholar] [CrossRef]
- Powell, T.H.; Kouropalatis, Y.; Morgan, R.E.; Karhu, P. Mapping knowledge and innovation research themes: Using bibliometrics for classification, evolution, proliferation and determinism. Int. J. Entrep. Innov. Manag. 2016, 20, 174–199. [Google Scholar] [CrossRef]
- Garousi, V.; Mantyla, M.V. Citations, research topics and active countries in software engineering. Comput. Sci. Rev. 2016, 19, 56–77. [Google Scholar] [CrossRef]
- Chen, C.M. CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature. J. Assoc. Inf. Sci. Tech. 2006, 57, 359–377. [Google Scholar] [CrossRef]
- Chen, C.M.; Hu, Z.; Liu, S.; Tseng, H. Emerging trends in regenerative medicine: A scientometric analysis in CiteSpace. Expert Opin. Biol. Ther. 2012, 12, 593–608. [Google Scholar] [CrossRef] [PubMed]
- Van Eck, N.J.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef] [PubMed]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. Science mapping software tools: Review, analysis, and cooperative study among tools. J. Assoc. Inf. Sci. Tech. 2011, 62, 1382–1402. [Google Scholar] [CrossRef]
- Bates, D.W.; Saria, S.; Ohnomachado, L.; Shah, A.; Escobar, G. Big data in health care: Using analytics to identify and manage high-risk and high-cost patients. Health Affair. 2014, 33, 1123–1131. [Google Scholar] [CrossRef] [PubMed]
- Tahamtan, I.; Afshar, A.S.; Ahamdzadeh, K. Factors affecting number of citations: A comprehensive review of the literature. Scientometrics 2016, 107, 1195–1225. [Google Scholar] [CrossRef]
- Bertolibarsotti, L.; Lando, T. A theoretical model of the relationship between the h-index and other simple citation indicators. Scientometrics 2017, 111, 1–34. [Google Scholar]
- Bornmann, L.; Daniel, H.D. What do we know about the h index? J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1381–1385. [Google Scholar] [CrossRef]
- Díaz, I.; Cortey, M.; Olvera, À.; Segalés, J. Use of H-index and other bibliometric indicators to evaluate research productivity outcome on swine diseases. PLoS ONE 2016, 11, e0149690. [Google Scholar] [CrossRef] [PubMed]
- Li, H.J.; An, H.Z.; Wang, Y.; Huang, J.C.; Gao, X.Y. Evolutionary features of academic articles co-keyword network and keywords co-occurrence network: Based on two-mode affiliation network. Phys. A 2016, 450, 657–669. [Google Scholar] [CrossRef]
- Gu, D.X.; Li, J.J.; Li, X.G.; Liang, C.Y. Visualizing the knowledge structure and evolution of big data research in healthcare informatics. Int. J. Med. Inform. 2017, 98, 22–32. [Google Scholar] [CrossRef] [PubMed]
- Pinto, M.; Pulgarín, A.; Escalona, M.I. Viewing information literacy concepts: A comparison of two branches of knowledge. Scientometrics 2014, 98, 2311–2329. [Google Scholar] [CrossRef]
- Chung, K.F. Personalised medicine in asthma: Time for action. Eur. Respir. Rev. 2017, 26, 170064. [Google Scholar] [CrossRef] [PubMed]
- Schulkes, K.J.G.; Nguyen, C.; van den Bos, F.; Hamaker, M.E.; van Elden, L.J. Patient-centered outcome measures in lung cancer trials. Lung 2016, 94, 647–652. [Google Scholar] [CrossRef] [PubMed]
- Reyes, G.L.; Gonzalez, C.N.B.; Veloso, F. Using co-authorship and citation analysis to identify research groups: A new way to assess performance. Scientometrics 2016, 108, 1171–1191. [Google Scholar] [CrossRef]
- Von Haehling, S.; Anker, S.D. Cachexia as a major underestimated and unmet medical need: Facts and numbers. J. Cachexia Sarcopenia Muscle 2010, 1, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Robinson, P.B.; Sexton, E.A. The effect of education and experience on self-employment success. J. Bus. Ventur. 1994, 9, 141–156. [Google Scholar] [CrossRef]
- Regan, M.M.; Neven, P.; Giobbie-Hurder, A.; Goldhirsch, A.; Ejlertsen, B.; Mauriac, L.; Forbes Fracs, J.F.; Lang, I.; Wardley, A.; Rabaglio, M.; et al. Assessment of letrozole and tamoxifen alone and in sequence for postmenopausal women with steroid hormone receptor-positive breast cancer: The BIG 1-98 randomised clinical trial at 8.1 years median follow-up. Lancet Oncol. 2011, 12, 1101–1108. [Google Scholar] [CrossRef]
- Zhang, B.T.; Muhlenbein, H. Balancing accuracy and parsimony in genetic programming. Evol. Comput. 1995, 3, 17–38. [Google Scholar] [CrossRef]
- Small, H. Co-citation in the scientific literature: A new measure of the relationship between two documents. J. Am. Soc. Inform. Sci. 1973, 24, 265–269. [Google Scholar] [CrossRef]
- Boyack, K.W.; Klavans, R. Co-citation analysis, bibliographic coupling, and direct citation: Which citation approach represents the research front most accurately? J. Assoc. Inf. Sci. Technol. 2010, 61, 2389–2404. [Google Scholar] [CrossRef]
- Murdoch, T.B.; Detsky, A.S. The inevitable application of big data to health care. JAMA J. Am. Med. Assoc. 2013, 309, 1351–1352. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.P.; Hu, J.M.; Gao, Y.; Zhang, Y.K. A journal co-citation analysis of library and information science in China. Scientometrics 2011, 86, 657–670. [Google Scholar] [CrossRef]
- Mirnezami, R.; Nicholson, J.; Darzi, A. Preparing for Precision Medicine. N. Engl. J. Med. 2012, 366, 489–491. [Google Scholar] [CrossRef] [PubMed]
- Hammer, M.J. Precision medicine and the changing landscape of research ethics. Oncol. Nurs. Forum 2016, 43, 149–150. [Google Scholar] [CrossRef] [PubMed]
- Jameson, J.L.; Longo, D.L. Precision medicine—Personalized, problematic, and promising. N. Engl. J. Med. 2015, 372, 2229–2234. [Google Scholar] [CrossRef] [PubMed]
- Wishart, D.S. Emerging applications of metabolomics in drug discovery and precision medicine. Nat. Rev. Drug Discov. 2016, 17, 473–484. [Google Scholar] [CrossRef] [PubMed]
- Aronson, S.J.; Rehm, H.L. Building the foundation for genomics in precision medicine. Nature 2015, 526, 336–342. [Google Scholar] [CrossRef] [PubMed]
- Costa, F.F. Big data in biomedicine. Drug Discov. Today 2014, 19, 433–440. [Google Scholar] [CrossRef] [PubMed]
- Kayaalp, M. Patient privacy in the era of big data. Balk. Med. J. 2017. [Google Scholar] [CrossRef] [PubMed]
- Cios, K.J.; Moore, G.W. Uniqueness of medical data mining. Artif. Intell. Med. 2002, 26, 1–24. [Google Scholar] [CrossRef]
- Huang, T.; Lan, L.; Fang, X.; An, P.; Min, J.; Wang, F. Promises and challenges of big data computing in health sciences. Big Data Res. 2015, 2, 2–11. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Document | Frequency | Proportion |
|---|---|---|
| Article | 807 | 81.7 |
| Review | 98 | 10.7 |
| Editorial material | 36 | 3.6 |
| Proceedings paper | 25 | 2.5 |
| Meeting abstract | 12 | 1.2 |
| Book chapter | 5 | 0.5 |
| Letter | 2 | 0.2 |
| Book review | 1 | 0.1 |
| Correction | 1 | 0.1 |
| News item | 1 | 0.1 |
| Total | 988 | 100 |
| Rank | Keywords | Frequency | Total Link Strength |
|---|---|---|---|
| 1 | Big data | 203 | 597 |
| 2 | Care | 70 | 220 |
| 3 | Risk | 50 | 172 |
| 4 | Health-care | 45 | 152 |
| 5 | System | 43 | 139 |
| 6 | Health | 43 | 121 |
| 7 | Management | 34 | 94 |
| 8 | The United States | 33 | 123 |
| 9 | Epidemiology | 32 | 118 |
| 10 | Quality | 31 | 95 |
| Periods | Keywords |
|---|---|
| Before 2000 | mortality, care, internet, women, intensive care system |
| 2001–2010 | Diagnosis, impact, the United States, clinical trial, quality of life, risk, model, predication, cost, stress, death, anxiety, simulation, complication, birth, association, cohort, breast cancer |
| After 2010 | Personalized medicine, machine learning, framework, database, datasharing, statement, privacy, personality, China, data mining |
| Title | Journal | Authors | Year | Citation | IN | CN |
|---|---|---|---|---|---|---|
| Cachexia as a major underestimated and unmet medical need: facts and numbers | Journal of Cachexia Sarcopenia and Muscle | von Haehling & Anker | 2010 | 216 | 1 | 1 |
| The effect of education and experience on self-employment success | Journal of Business Venturing | Robinson & Sexton | 1994 | 190 | 2 | 2 |
| Assessment of letrozole and tamoxifen alone and in sequence for postmenopausal women with steroid hormone receptor-positive breast cancer: the BIG 1-98 randomised clinical trial at 8.1 years median follow-up | Lancet Oncology | Regan et al. | 2011 | 157 | 14 | 9 |
| Balancing accuracy and parsimony in genetic programming | Evolutionary Computation | Zhang & Muhlenbein | 1995 | 113 | 1 | 1 |
| Galactomannan detection for invasive aspergillosis in immunocompromized patients | Cochrane Database of Systematic Reviews | Leeflang, Debets-Ossenkopp & Visser | 2008 | 112 | 1 | 1 |
| Meta-analysis in clinical trials revisited | Contemporary Clinical Trials | DerSimonian & Laird | 2015 | 105 | 1 | 1 |
| Evaluation of noise-induced hearing loss in young people using a web-based survey technique | Pediatrics | Chung, Des Roches & Meunier | 2005 | 98 | 2 | 1 |
| Big data in health care: Using analytics to identify and manage high-risk and high-cost patients | Health Affairs | Bates, Saria & Ohno-Machado | 2014 | 96 | 5 | 1 |
| Multimorbidity and quality of life: A closer look | Health and Quality of Life Outcomes | Fortin, Dubois & Hudon | 2007 | 92 | 1 | 1 |
| ‘Big data’, Hadoop and cloud computing in genomics | Journal Biomedical Informatics | O’Driscoll, Daugelaite & Sleator | 2013 | 90 | 1 | 1 |
| Frequency | Betweenness Centrality | Author | Year |
|---|---|---|---|
| 29 | 0.16 | Murdoch TB | 2013 |
| 17 | 0.04 | Jensen PB | 2012 |
| 15 | 0 | Lazer D | 2014 |
| 15 | 0 | Raghupathi W | 2014 |
| 14 | 0.04 | Marx V | 2013 |
| 13 | 0 | Ginsberg J | 2009 |
| 11 | 0 | Mayer-schonberger V | 2013 |
| 11 | 0 | Manyika J | 2011 |
| 10 | 0.08 | Bates DW | 2014 |
| 9 | 0.02 | Dean J | 2008 |
| Frequency | Centrality | Sources | Subject |
|---|---|---|---|
| 253 | 0.25 | JAMA-J AM MED ASSOC | Computer science, healthcare sciences& Services, Information science &Library Science, Medical Informatics |
| 240 | 0.18 | NEW ENGL J MED | General & Internal Medicine |
| 177 | 0.24 | LANCET | General & Internal Medicine |
| 163 | 0.10 | NATURE | Science & Technology |
| 162 | 0.10 | PLOS ONE | Science &Technology |
| 134 | 0.13 | SCIENCE | Science & Technology |
| 132 | 0.14 | J AM MED INFORM ASSN | Computer Science |
| Health Care Sciences & Services | |||
| Information Science & Library Science | |||
| Medical Informatics | |||
| 114 | 0.09 | BRIT MED J | General & Internal Medicine |
| 86 | 0.09 | HEALTH AFFAIRS | Health Care Sciences & Services |
| 84 | 0.06 | ANN INTERN MED | General & Internal Medicine |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, H.; Tang, M.; Luo, L.; Li, C.; Chiclana, F.; Zeng, X.-J. A Bibliometric Analysis and Visualization of Medical Big Data Research. Sustainability 2018, 10, 166. https://doi.org/10.3390/su10010166
Liao H, Tang M, Luo L, Li C, Chiclana F, Zeng X-J. A Bibliometric Analysis and Visualization of Medical Big Data Research. Sustainability. 2018; 10(1):166. https://doi.org/10.3390/su10010166
Chicago/Turabian StyleLiao, Huchang, Ming Tang, Li Luo, Chunyang Li, Francisco Chiclana, and Xiao-Jun Zeng. 2018. "A Bibliometric Analysis and Visualization of Medical Big Data Research" Sustainability 10, no. 1: 166. https://doi.org/10.3390/su10010166
APA StyleLiao, H., Tang, M., Luo, L., Li, C., Chiclana, F., & Zeng, X.-J. (2018). A Bibliometric Analysis and Visualization of Medical Big Data Research. Sustainability, 10(1), 166. https://doi.org/10.3390/su10010166