2.1. Simulated Populations
I constructed four simulated populations, the first of which had also been used and described in Roesch et al. [
1]. These populations are intended to examine estimator performance in the presence of a wider but still plausible set of suboptimal and latent population characteristics, in the form of nonlinear trends and fine-scale anomalies. A similar approach using different seed data and error assumptions was exploited in Roesch [
9]. The seed data for this study came from FIA plot data measured at least twice in the state of Georgia (USA) between 1995 and 2012, consisting of 7330 ground plots (set 1), most of which had two observed growth intervals for each component with remeasurement intervals that varied quite widely around the five-year target for these plots. First a null population (population 0) was constructed to represent a reasonable facsimile to the population of forested conditions from which set 1 could have been drawn. Population 0 consisted of 500 variance-interjected copies of set 1, resulting in a population of 3,665,000 hectares, of which 2,360,411 were forested at some time during the period of interest. The variance was interjected at two levels. In level 1, in order to maintain trend while adding variance to the seed, all values for each component on each hectare were multiplied by a unique random variate, drawn from an
N(1, 0.025) distribution. The second level of variance was introduced temporally by multiplying the result of step 1 for each annual value for each component on each hectare by a unique random variate drawn from an
N(1, 0.0025) distribution. The four test populations, 1 through 4, were then constructed from population 0. For each population, trend was introduced through the application of the formula:
For population 1, a mild (latent) nonlinear trend was introduced into each of the components of population 0 by multiplying each value in each year
t by
εt in (2) after setting
and
. Population 2 was constructed similarly to Population 1 except that increased harvesting pressure was introduced by setting
and
for the harvest component. Population 3 was constructed as in Population 1, except with an introduced catastrophic event of four times the amount of mortality of Population 1 in 2004. Population 4 was initially constructed in the same manner as Population 0 and then postulated climate change effects were simulated by increasing mortality and decreasing growth and recruitment, with harvest levels remaining the same as in Population 1. Although the potential rates of change are unknown and arbitrarily set for the purposes of this study, the justification for this effect comes from a general principle in ecology that assumes all species have a range of tolerance for any environmental factor (see e.g., Smith [
10]). Some of the members of any species exist near the edge of one or more of those ranges of tolerances. If climate changes in any way, some of the members of a species that cannot move will be in one or more out-of-tolerance zones, possibly resulting in decreasing growth and fecundity and increasing mortality. For live growth,
was set equal to 0.90 and
was set equal to −0.10. For entry,
was set equal to 0.95 and
was set equal to −0.05, and for mortality,
was set equal to 0.80 and
was set equal to 0.20. For clarity, these parameters values for each population are given in
Table 1.
Table A1,
Table A2,
Table A3 and
Table A4 in
Appendix A give the population distribution statistics for 1999–2011 for populations 1 through 4, respectively.
Table A1 is identical to
Table 1 in Roesch et al. [
1], because the same population is being described, while
Table A2,
Table A3 and
Table A4 are first presented here. The populations have been included as supplementary material to this manuscript in the file Pops_Roesch2016.zip. The populations can be obtained on DVD from the author upon request.
2.3. General Estimation Approach
To be clear, the problem to be solved is most easily thought of as a weighting problem. There is a set of plot observations in which each plot is observed every
y years (here, I happen to use
y = 10), and a decision has to be made with respect to how much of each change component should be attributed to each of the years within the observation interval. That decision can be partially based on the analyst’s assessment of the reliability of the ICE data. For instance, following a plot observation, the existing trees might grow prior to a harvest of some or all of the trees on the sample plot. Subsequently, some volume might remain on non-harvested trees which continue to grow. At some point in the interval, new trees might develop and grow prior to the next sample plot observation. A biometrician’s first instinct might be to try to use existing growth models to apportion those three categories of growth to the intervening years. At first blush, this might seem reasonable; however, one simply needs to look at the titles of publications in the growth and yield literature to realize how specific a growth model has to be in order to separate the trend from the noise in the data. Because of that requisite specificity, almost all of the funding for the development of growth models is applied to species of high commercial value. Therefore, large countries with a very diverse range of species and forest types will, at least for the foreseeable future, lack adequate growth models for many species and forest types. Additionally, there is always unobserved growth on trees that die or are harvested during the observation interval. In the case of a clearcut, most of this unobserved growth occurred on the prior stand, so it is reasonable to assume that it will usually far outweigh the observed growth because growth is observed only on trees present at the next plot observation. Roesch et al. [
1] discuss an estimation paradigm dubbed the (semi-centralized) Moving-Window Mean of Ratios (MWMOR) estimator, of which I use several variants in this paper. The estimator accounts for the specific timing of the plot observations and proportionally allocates growth observations to each growing season and portion of growing season spanned by the observation. The MWMOR estimator for component
C in year
t:
where:
the number of plots observing growth in year t,
the product of portion of year t growing season observed by plot i and the portion of plot i area within the area of interest, and
the value of component C observed on plot i, assignable to year t.
The theoretical properties of ratio estimators, including their variance estimators, were established more than five decades ago and have since become well known. The reader interested in these properties, or the appropriate estimators for variance, is referred to the treatises in Raj [
11], Walton and DeMars [
12], Cassel et al. [
13], or Cochran [
14].
Roesch [
9] demonstrated the utility of weighting the MWMOR estimator for fine-scale estimates. Weighting can be used to form a trend-distributed version of
by replacing
in Equation (3) with:
where
xi is the total value of a change component (such as live growth) observed over an interval of years
y = 1 to
Y, and
, where
vy is the sample mean initial volume for year
y. The variable
t indicates the general year within the population or estimation interval and the variable
y indicates the year within a particular sample plot’s remeasurement interval. Therefore,
y selects a panel-specific subset of
t. The underlying assumption of
is that the level of a change component during a particular year will be proportional to the standing volume at the beginning of the year. The trend-distributed estimator then takes the form:
Similarly, a weighting variant is used here to incorporate the remotely sensed information on the timing of harvests, and the corresponding allocation of the other components of change, within a remeasurement window. For comparison, a centralized mean estimator for harvest is used in which the weight is split evenly between the center two years of the observation interval for each plot.
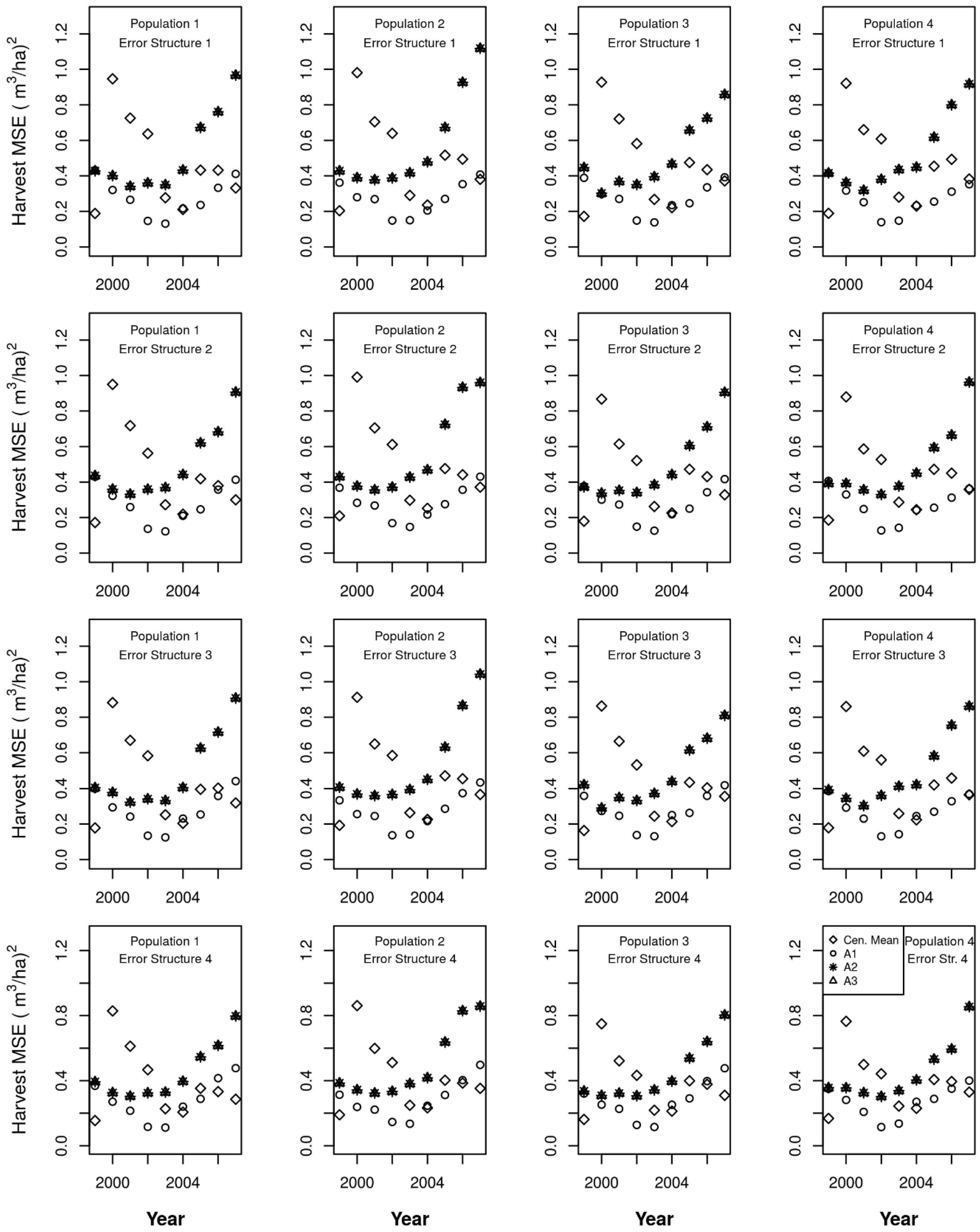
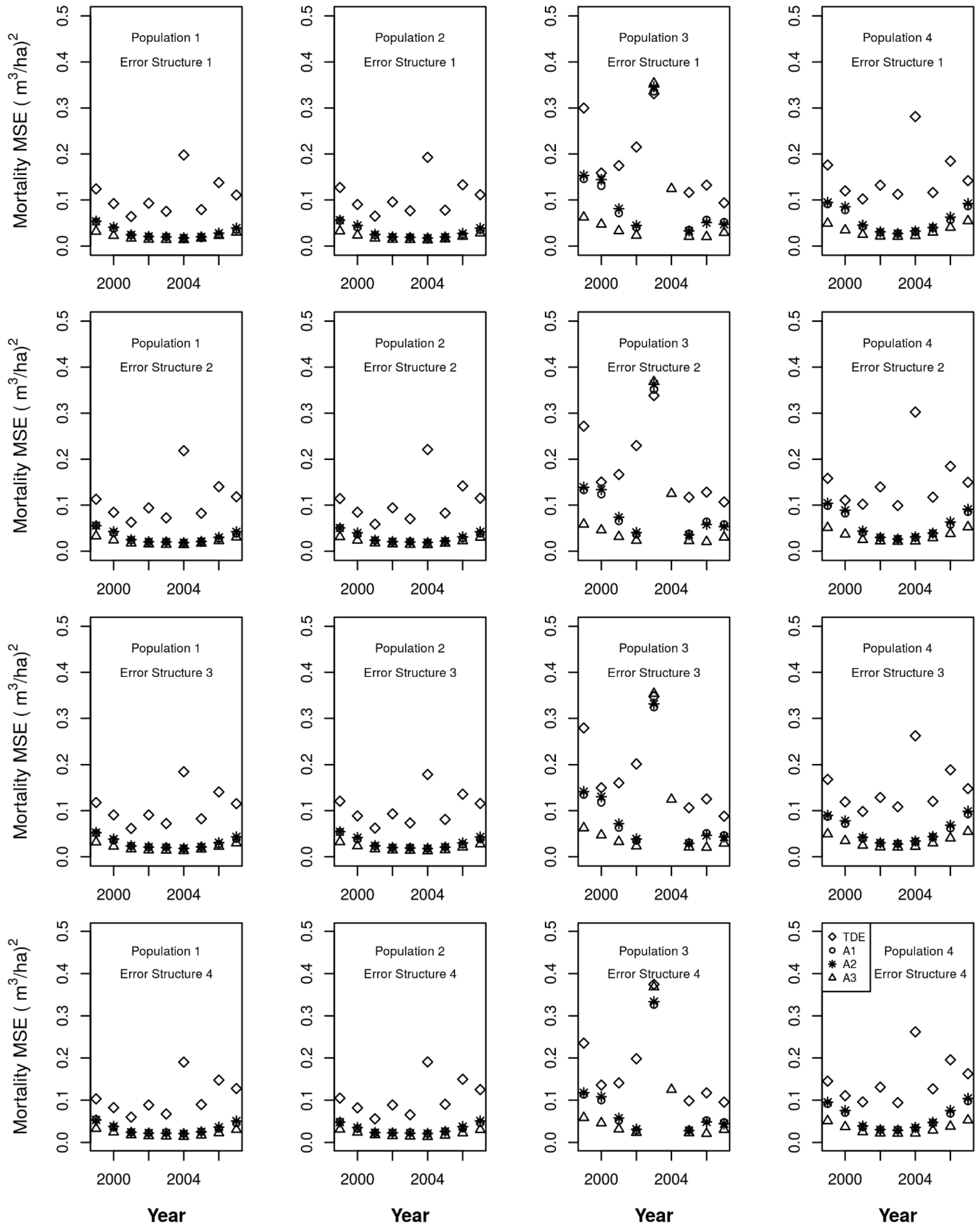
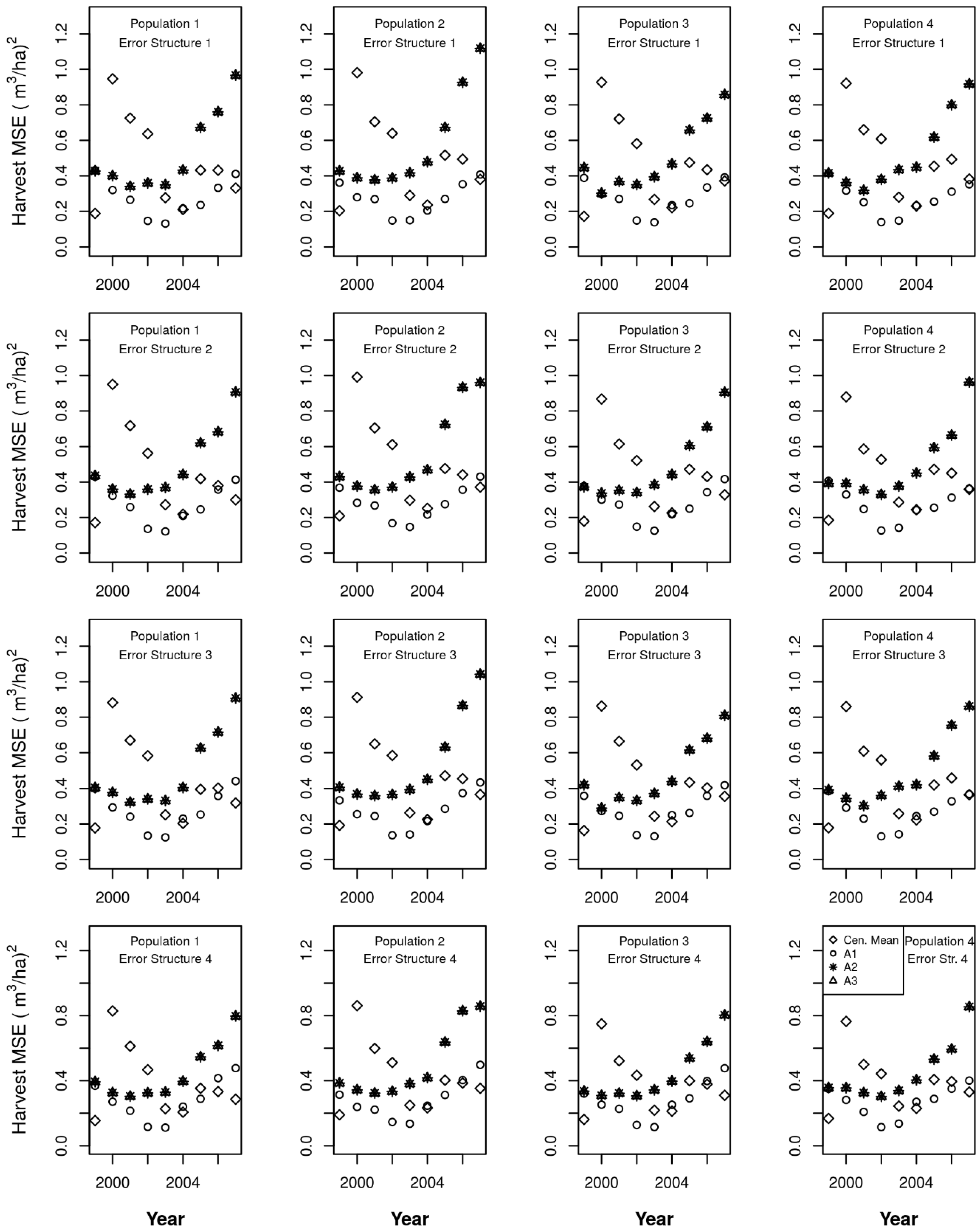
I compared three different levels of information that might be available from ICE observations, along with their related assumptions. In availability level 1 (A1), an ICE observation is made every two years and clearcuts are successfully identified 97.5% of the time, and there are no false positives. Other harvests are not identified by the ICE observation. Under this availability level, when a clearcut is identified, it is known to have occurred since the last plot visit, but may have been missed during intervening ICE observations.
Under availability level 2 (A2) an ICE observation is made every two years and every harvest (whether a partial harvest or a full harvest) is identified and assigned to the correct year, and there are no false positives. Also assume that proportional growth occurred before and after ICE harvest observations.
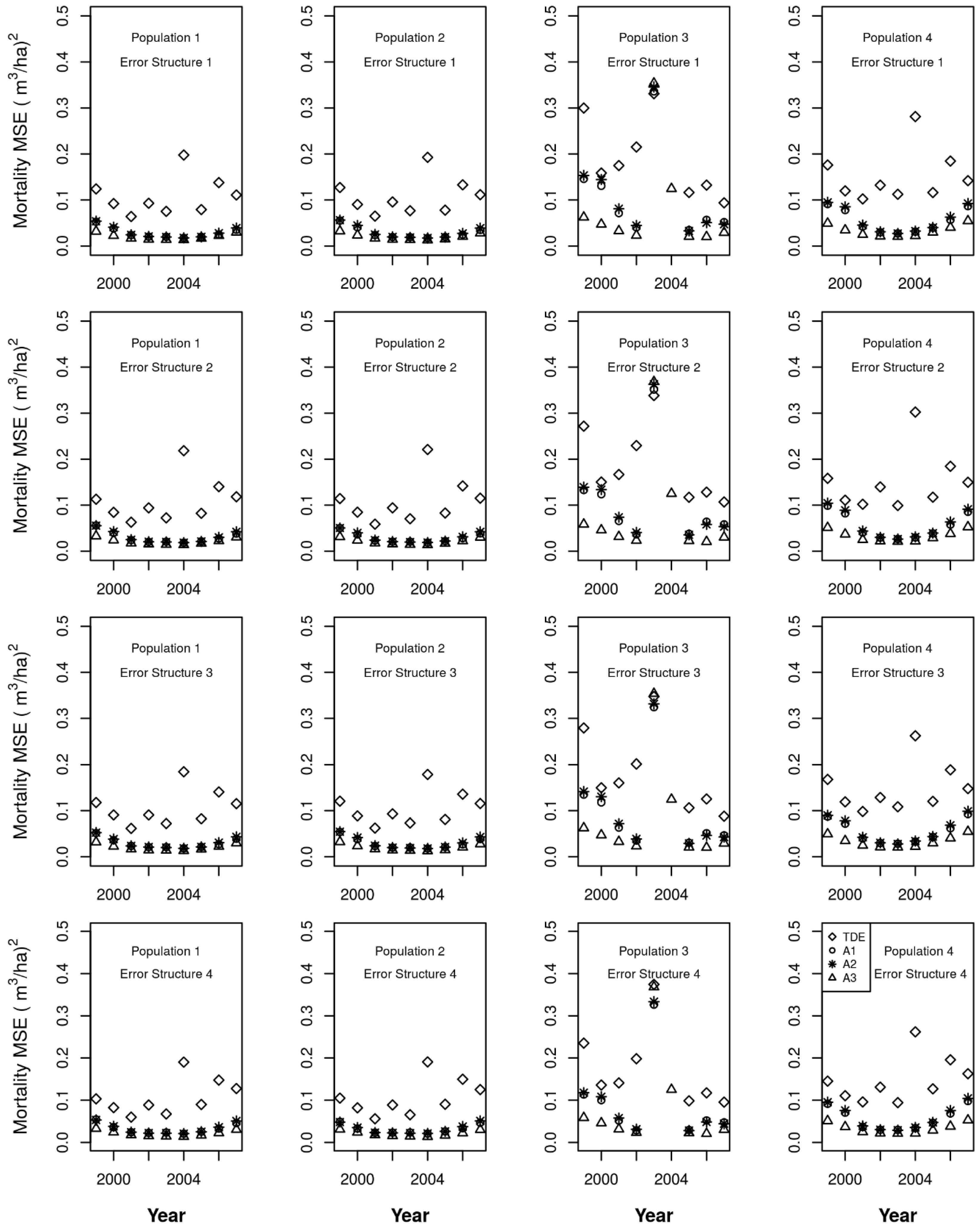
Availability level 3 (A3) reflects the same level of reliability as A2 with respect to harvest for ICE observations in which an ICE observation is made every two years and every harvest (whether a partial harvest or a full harvest) is identified and assigned to the correct year, and there are no false positives. Additionally, the ICE observations provide the same level of information on mortality, that is, all mortality trees can be identified, and there are no false positives.
Therefore, under availability level 1, I simplify the annual allocation problem by assuming that all observed growth occurred before the ICE clearcut observation. Under availability levels 2 and 3, for all harvests, I use an allocation that separates pre-harvest and post-harvest change based on an estimate of the proportion of volume harvested.
Each of these availability levels requires, at a minimum, the definition of two sets of weights, one set for the harvest component and the other for the remaining growth components. Additionally, each growth component could be assigned a unique set of weights if any auxiliary information contains enough detail.
Let
represent the weight for the harvest component under availability level α, for plot
i and year
t. (Naturally, the weight is equal to zero outside of the remeasurement interval.) Then, for each year in the estimation interval:
where
hi is the observation of cubic meter harvested volume on plot
i during the remeasurement interval. The estimator for the harvest component for year
t under availability level α is:
Weights must also be defined for the other components of change (live growth, entry, and mortality), to allocate the contribution to each year between the plot observation and the ICE-observed harvest. In simple cases, let
represent the weight defined for the other change components. The allocation for these other components of change on plot
i for year
t under α can be represented as:
where
oi is the observation of a specific component
o for plot
i during the interval. The estimator for the other components of change for year
t under α is:
2.3.1. Estimation of the Weights under α = A1:
Under the information availability of ICE observations of A1, when a clearcut is identified, it is known to have occurred since the last plot observation, but may have been missed during intervening ICE observations. To establish weights, I use the estimate of the probability of having missed the clearcut at previous ICE observations. Below, I use the fact that under this scenario, ICE data collected every two years will be in sync with about half of the plot observations collected under the panel design and out of sync with the other half, i.e. the first ICE observation after the plot observation will be in one year for half of the plots, and in two years for the other half of the plots.
I define
as the number of years of the first ICE observation of clearcut for plot
i since the previous plot measurement. Although it would be a rare event, I also define
as the year of the second ICE observation of clearcut for plot
i during the remeasurement interval, in order to estimate the weight for harvest. Additionally, when there are two ICE-identified clearcuts on plot
i, I define
ri,I as the proportion of total clearcut volume in the first clearcut, and
ri,II = 1 −
ri,I as the proportion of total clearcut volume in the second clearcut. For α = A1:
The proportion
ri,I would have to be estimated. An estimate might be obtained from the ICE data but it is not directly available from the sample plot data. Under A1, I do not assume that one can confidently estimate
ri,I from the images, so I set it equal to 0.5, before expanding to the estimation interval:
For the other components of change (live growth, entry, and mortality), the allocation to each year between plot observation and ICE-observed clearcut are as follows:
Again, placing the weights within the estimation interval:
2.3.2. Estimation of the Weights under α = A2:
Under availability level 2 (A2), I assume that I know if any harvest has occurred within the past two years and which year the harvest occurred. I further assume that I can estimate the proportion harvested to within ±5% (truncated at 0% and 100%), and proportional growth occurred before and after ICE harvest observations. Let
be the ICE-estimated proportion of volume harvested in year
y on plot
i. Then the weight for the harvest component under α = A2 is:
As above, the expansion to the entire estimation interval is:
To determine the allocation for the other components of change, let
be the first (in year
F,
yF) ICE-estimated proportion of volume harvested on plot
i, and
be the second (in year
S,
yS) ICE-estimated harvest proportion on plot
i. I set
if there is not an ICE-identified harvest during the interval, and I set
if there are not two ICE-identified harvests during the interval. The proportion remaining following the first harvest on plot
i is
. Likewise, the proportion remaining following the second harvest on plot
i is
. I calculate the annual allocation in three parts:
and
Summing the parts results in the annual proportion:
And, again, the weights within the estimation interval are:
2.3.3. Estimation of the Weights under α = A3:
Under availability level 3 (A3), the information available for harvest estimates is exactly the same as under A2 above and the same assumptions are used. The weight for the harvest component under α = A3 is:
Availability level A3 also provides information for mortality estimates that can be used in the same way as the harvest information is used above. The weight for the mortality component under
α = A3 is:
There is room for debate as to whether one should attempt to further adjust the components of entry and live growth due to this additional information on mortality. After all, the timing of mortality does affect both of these components. On the one hand, all forested populations have constant mortality, and it would seem that no modeled temporal adjustment in the other components would be helpful for this type of mortality. On the other hand, large mortality events do sometimes occur, leading to a loss of volume equivalent to that of some harvesting systems. In fact, one such event was built into Population 3 in this study. Because mortality is usually more consistently distributed throughout the population, I do not attempt to adjust the remaining components relative to observations of “normal” mortality, arbitrarily defined as those that are estimated to be less than one-half of the standing volume. I do adjust the remaining components relative to observations of mortality that are estimated to be greater than or equal to one-half of the standing volume in the same way that I adjusted those components relative to observations for harvest above. That is, to determine the allocation for these two other components of change, let
be the first (in year
F,
yF) ICE-estimated proportion of volume harvested or proportion dying that is greater than half of the standing volume (hereafter referred to as a large mortality event) on plot
i, and
be the second (in year
S,
yS) ICE-estimated harvest proportion or proportion of the standing volume lost during a large mortality event on plot
i. I set
if there is no harvest or large mortality event during the interval, and I set
if there are no two such events during the interval. The proportion remaining following the first event on plot
i is
. Likewise, the proportion remaining following the second event on plot
i is
. The same as for A2 above, I calculate the annual allocation in three parts:
and
Summing the parts results in the annual proportion:
And, again, the weights within the estimation interval are:
2.5. Estimation Systems
The estimators described above can be combined to define various estimation systems. Also, the noise in successive annual estimates can be reduced by using a filter to combine the information from successive observations. One common filter is known as the moving window estimator. In general, a moving window estimator for time
t, of size
s (an odd positive integer) is:
The estimation systems discussed here include:
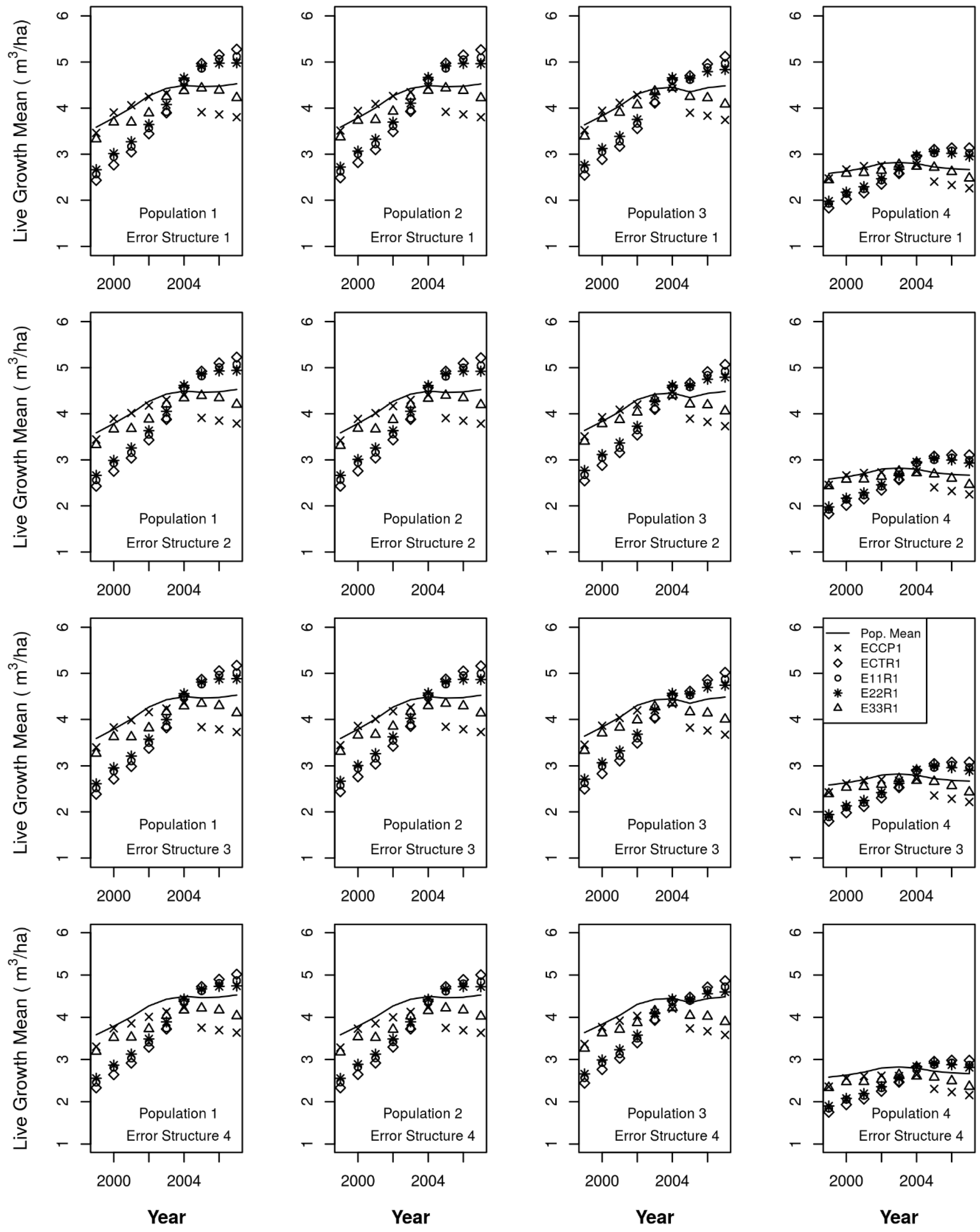
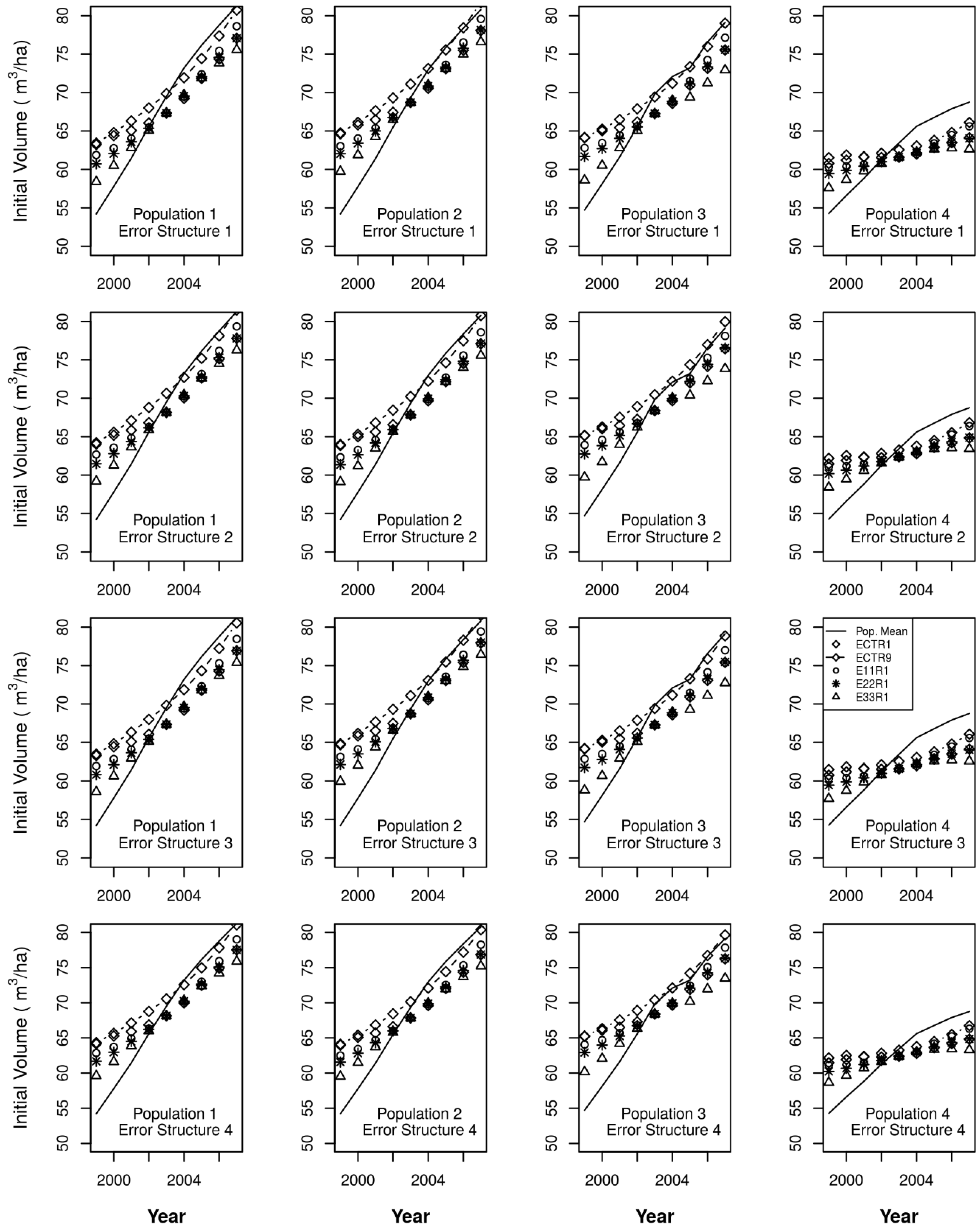
ECCP1 = CM for all components and for annual volume,
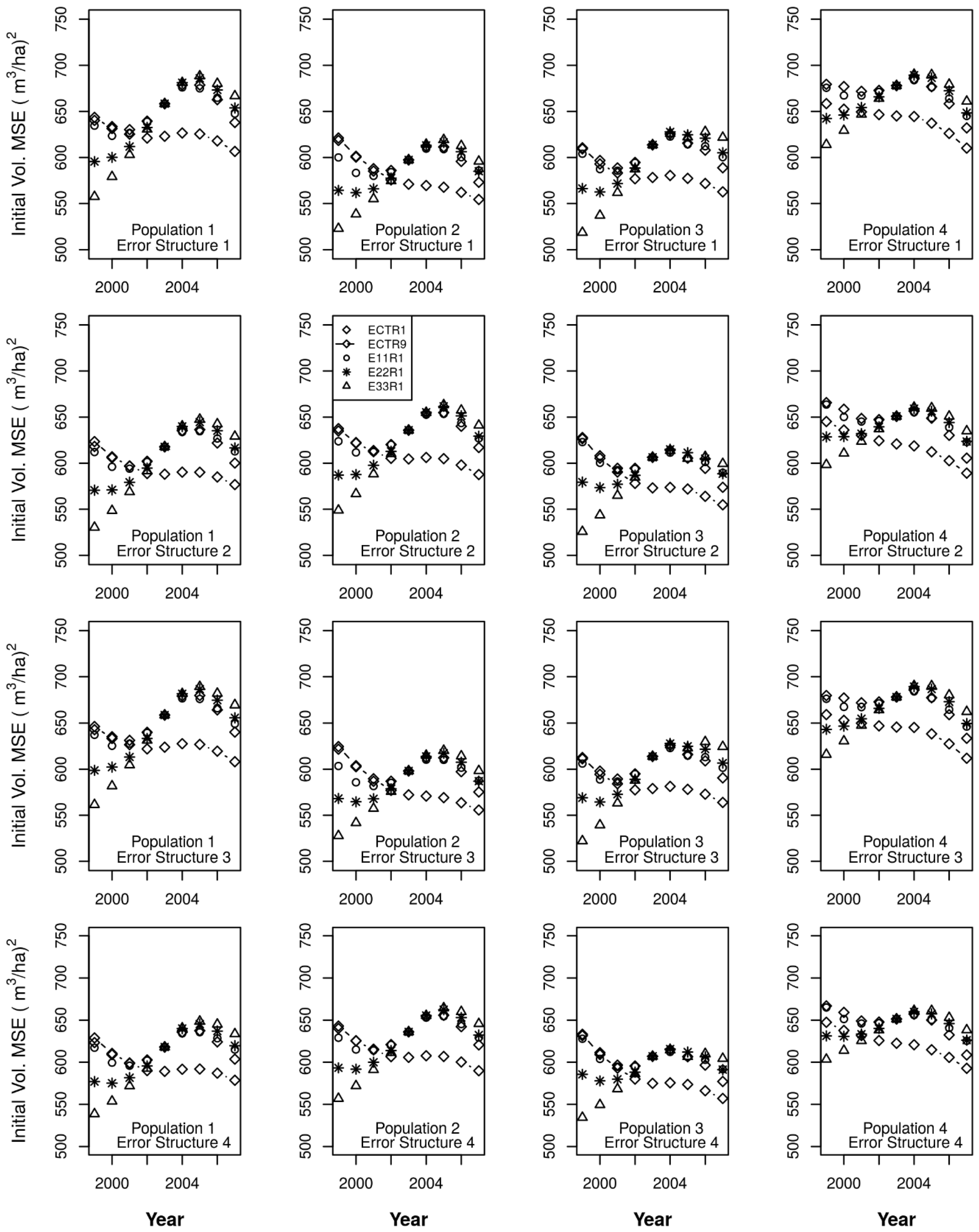
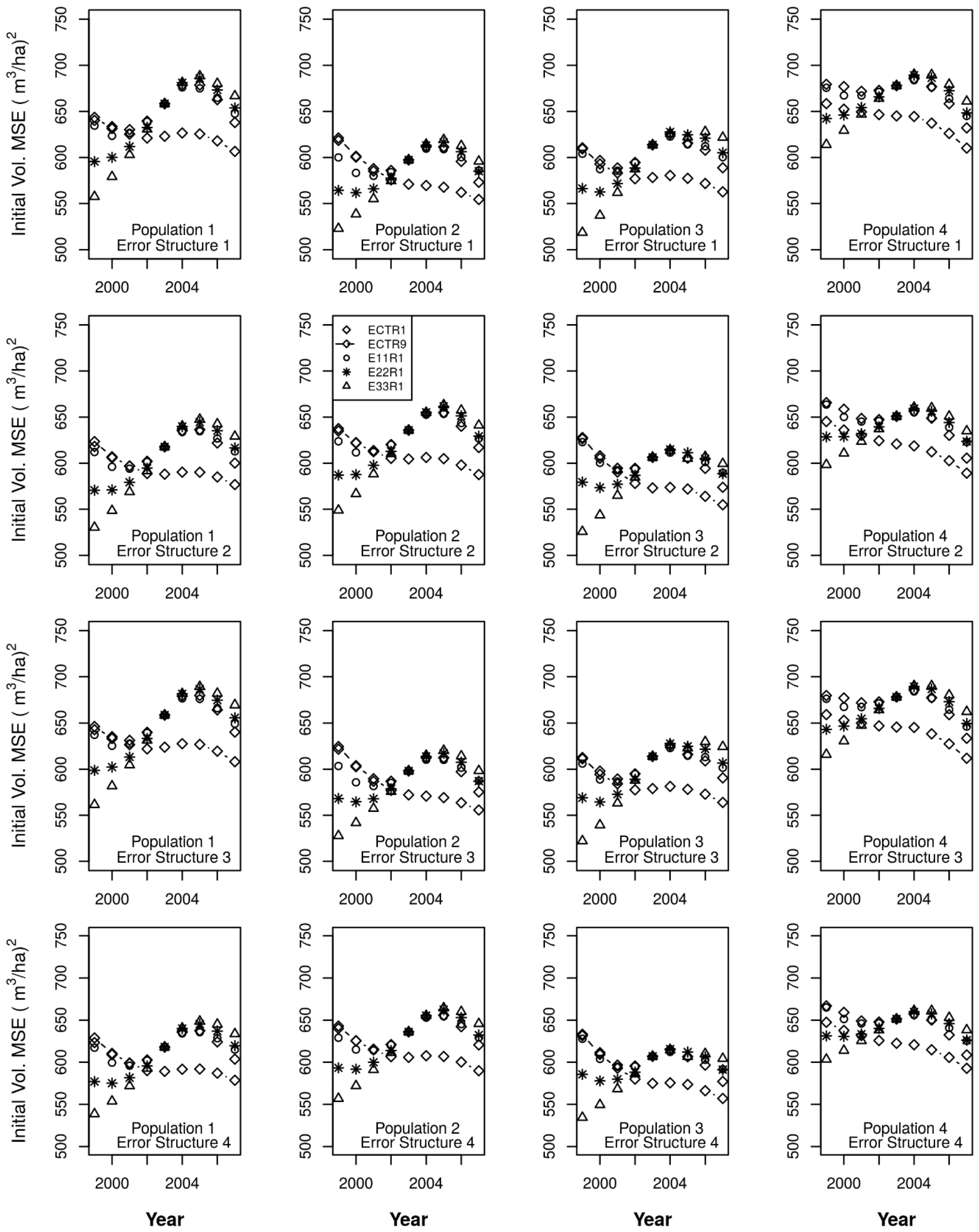
ECTR1 = CM for harvest, CT for the other change components, for annual volume,
E11R1 = ChA1 for harvest, C°A1 for the other change components, for annual volume,
E22R1 = ChA2 for harvest, C°A2 for the other change components, for annual volume,
E33R1 = ChA3 for harvest, CmA3 for harvest, C°A3 for the other change components, for annual volume,
ECTR9 = nine-year moving window on ECTR1.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}