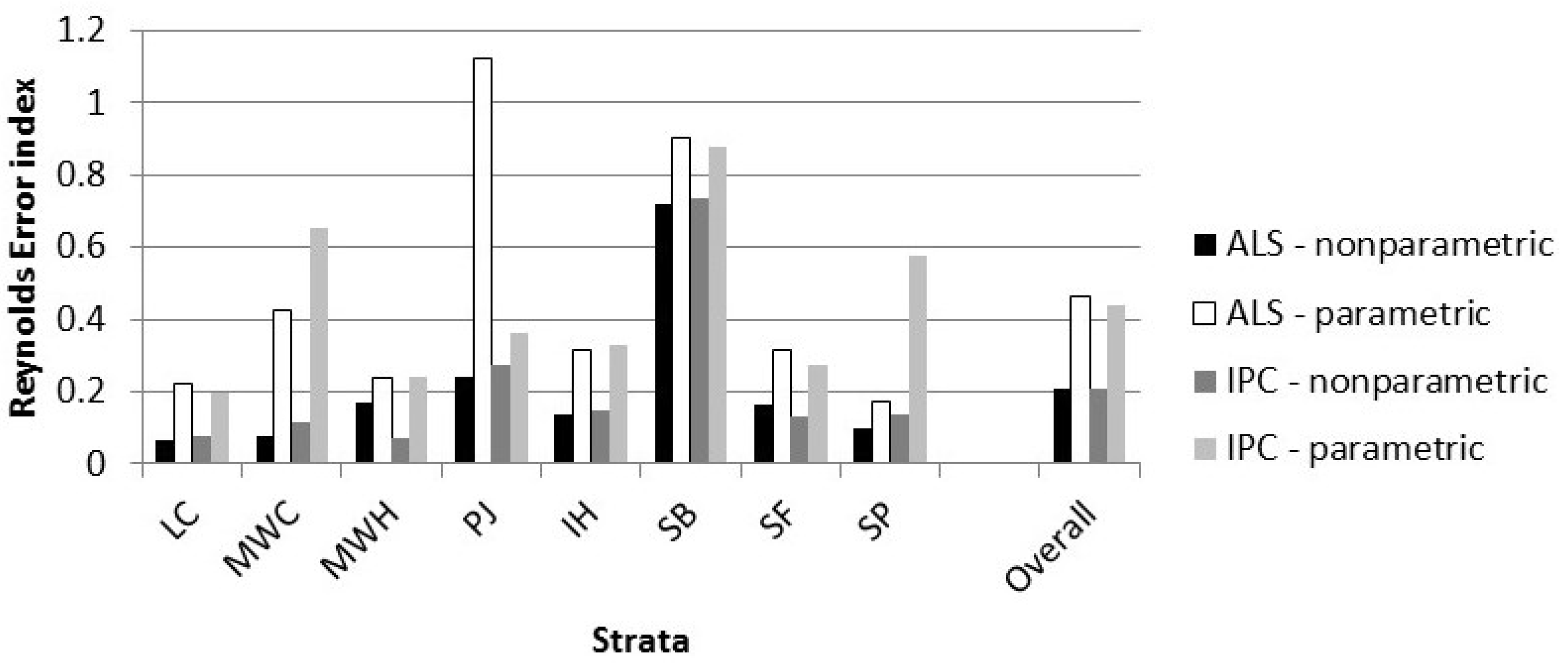
1. Introduction
Forest Resource Inventories in Ontario have been designed to meet long-term (20 year) strategic management planning needs and have traditionally contained photo-interpreted estimates of species composition, age, height, and site occupancy. Recent studies have shown that these data may be augmented with area-based estimates of growing stock (basal area, volume) and average tree size (height, diameter, volume) derived from either Airborne Laser Scanning (ALS) [
1,
2] or stereo image point clouds (IPC) [
3], to facilitate tactical (5-year) and operational (1-year) planning of forest operations. Since harvesting operations have become more mechanized and processing facilities are increasingly optimized for particular products and sizes of raw materials, there is considerable interest in adding information to inventories on the size assortment of the stems.
Modelling, or fitting size class distributions to empirical data, has received considerable attention. Much of the earlier work focused on selection and fitting of an appropriate distribution. Bailey and Dell [
4] proposed using the Weibull function for size class distributions. Most of the commonly used distribution functions are unimodal, while many forest size class distributions are irregular and not well characterized by a unimodal function. Mixture models combine two or more distribution functions, resulting in multi-modal distribution functions, which have been used to characterize more complex forests e.g., [
5]. Predicting the modeled size class distribution from ancillary data e.g., [
6] is generally the next step. This may include ensuring the size class distribution is compatible with other inventory attributes, including total stems and basal area [
7]. Alternatively, the Diameter at breast height (Dbh) and height distributions can be predicted together [
8]. The advantage of using a parametric distribution model is the typically low (one to four) number of parameters that have to be predicted; the key disadvantage is a restriction in model form [
9].
Nearest neighbour imputation methods have become popular in forest inventory efforts [
10]. Imputation is used to associate expensive but sparse data with inexpensive and spatially comprehensive data [
11]. The response variable is measured on a subset of the prediction units in the population (the reference data set), and auxiliary or predictor variables are available for the entire population. Generally, a prediction for a target unit is calculated from a weighted combination of the response variables from observations in the reference data set that are most similar, or nearest neighbours, to the target in terms of auxiliary variables. Nearest neighbour techniques can be used to predict categorical and continuous variables and univariate or multivariate response variables [
10]. This ability to predict multivariate response variables makes nearest neighbour imputation particularly promising for the prediction of probability density functions, particularly for complex stands with multiple species and a variety of tree sizes [
12]. The size class distributions for these stands tend to be multimodal and not easily represented by parametric functions [
10]. When the reference dataset is large, k-Nearest Neighbour (kNN), estimation shows promise in predicting relatively broad Dbh classes [
13]. However, in many forest inventory applications, ground observations are relatively few and are generally captured from small plot areas (typically 400 m
2). RandomForest, another nonparametric imputation method, has shown promise in forest application using ALS [
14].
ALS has been used to predict size class distributions. When height is the size attribute, early work [
15] focused on predicting the distribution of tree heights from the distribution of ALS return heights by first generating a canopy model for the calibration data. The canopy area model or three-dimensional canopy volume model was developed for the calibration data using stem-mapped data, including crown measurements. This canopy model was used to generate a theoretical distribution of ALS returns, which was then compared to the actual returns. More recent work [
16,
17] also predicted the distribution of canopy heights. Rather than requiring tree location in the calibration data, assumptions were made about the spatial arrangement of the trees. Another approach, particularly when diameter is the size attribute, is to predict the size class distribution directly from ALS data without first generating a crown map. Bollandsås
et al. [
18] used an ALS point density of ~0.7/m
2 in a Norwegian boreal forest to predict the deciles of the Dbh distribution using most similar neighbour (MSN) and seemingly unrelated regression (SUR). The MSN and SUR predictions generated an unbiased prediction of total basal area, but MSN was better at predicting the number of large trees. Some authors have also included predictors from aerial photographs. Packalén and Maltamo [
19] used ALS predictors as well as spectral values and textural features from aerial photos that had been radiometrically corrected against a Landsat 7 ETM.
Recently, ALS-like point clouds have been derived from stereo imagery using pixel matching. A previous study compared ALS and IPC for predicting forest inventory attributes in the Ontario boreal forest [
3]. Comparable accuracies were obtained for predictions of forest inventory attributes including basal area, merchantable stem volume, top height and quadratic mean Dbh, but they found some loss of precision with the IPC using an area-based modeling approach. To date, no studies have compared the use of ALS and IPC in the prediction of size class distributions.
The objective of this study was to investigate and compare the potential of ALS and IPC metrics to predict size class distributions for a management area in a northeastern Ontario boreal forest. Both parametric and nonparametric approaches are evaluated in this comparison.
3. Methods
3.1. Dependent Variables
The prediction unit was the 400-m
2 plot. The parametric dependent variable was relative basal area (BA), the fraction of total BA by 2-cm Dbh class on the 400-m
2 plot. The choice of 2-cm wide Dbh classes was somewhat arbitrary. For the calibration data, it led to an average of 9 Dbh classes with trees present. The lower limit for Dbh was 9 cm; the lower limit considered for merchantability. The total BA per hectare, as well as the fraction of basal area in trees with Dbh > 9 cm, were predicted [
31], and used herein to convert relative BA by Dbh class to BA by Dbh class.
The nonparametric dependent variable was the BA/ha by Dbh class on the 400-m2 plot. We considered predicting the relative BA by Dbh class, but these predictions would have required scaling to ensure that they summed to one. Since both the relative BA and the absolute BA would require scaling, it was decided to select the raw BA for modeling. These BA predictions were then converted to relative BA by dividing the BA by Dbh class by the sum of the predicted BA by Dbh class. Parametric and nonparametric predictions of relative BA were then compared.
3.2. Independent ALS and Optical CHM Predictors
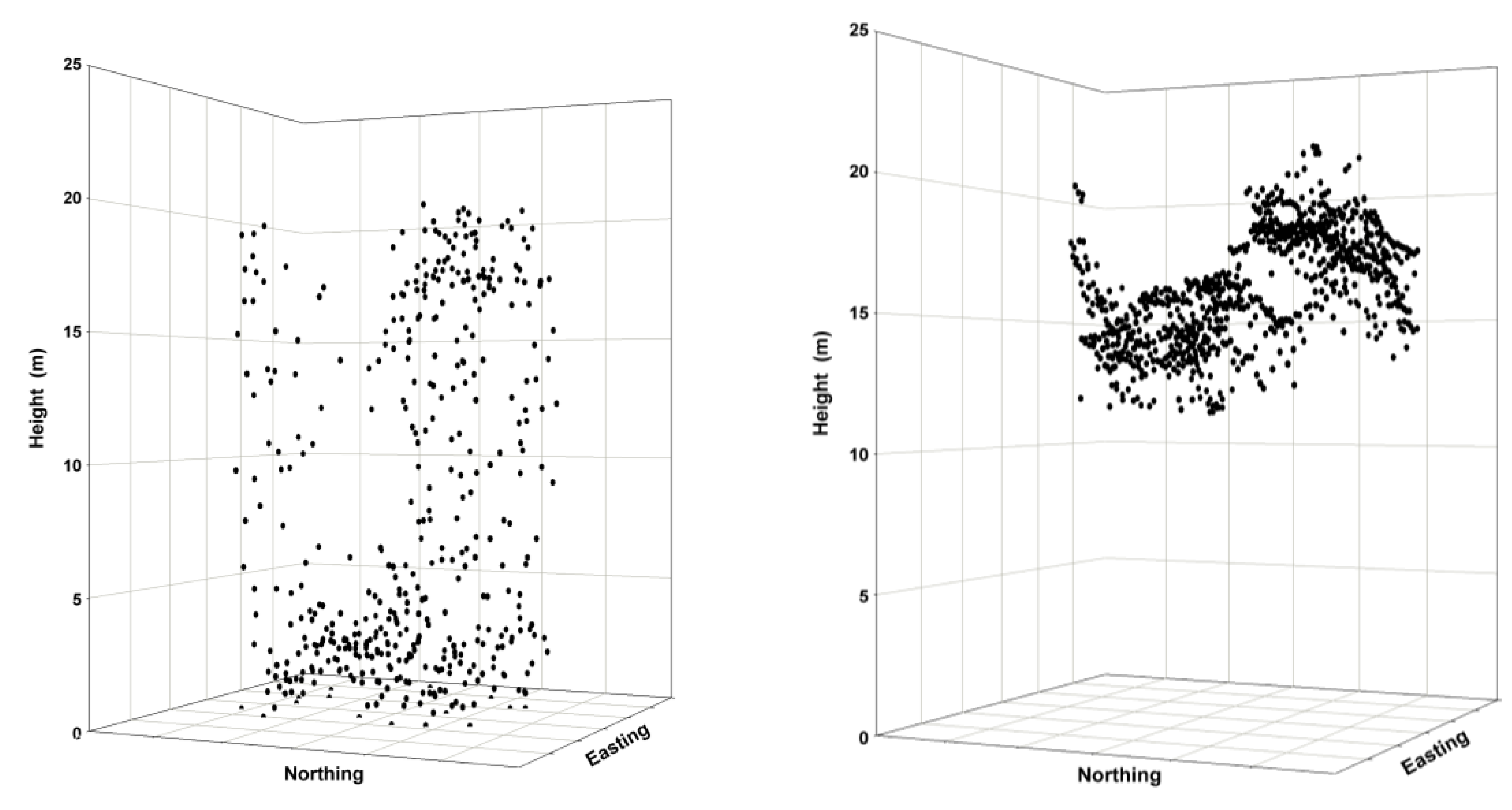
Both the ALS and IPC data require normalization against a DTM. The IPC point cloud is concentrated in the upper canopy envelope, compared to the ALS point cloud, which is distributed throughout the canopy (
Figure 2). The better canopy penetration of ALS makes it much more suitable to the generation of a DTM [
32] in a forested environment. For this study, a DTM was generated from the ALS data and the ALS and IPC data were normalized against this DTM.
The ALS predictor variables (
Table 5) were derived from point-cloud statistics following previously described methods [
2]. Veteran trees generally result in a few high ALS returns that have a large influence on some of the measures of spread, such as standard deviation of ALS returns (STD_DEV) and vertical complexity index (VCI). To reduce the influence of these trees on measures of spread, these statistics were calculated by first removing the top 5% of the ALS returns, and basing the statistic on the remaining 95% of returns. The remaining statistics were calculated using all ALS returns.
The IPC data were intersected with the ground plots and independent predictors were generated (
Table 5). Not all statistics generated with the ALS point clouds were generated from the IPC. Exceptions were the statistics that are dependent on ratios of the number of points distributed through the canopy (first return divided by all returns [DA], first and only return/all returns [DB], and coefficient of variation [CanCovar]), which could not be calculated for the IPC data.
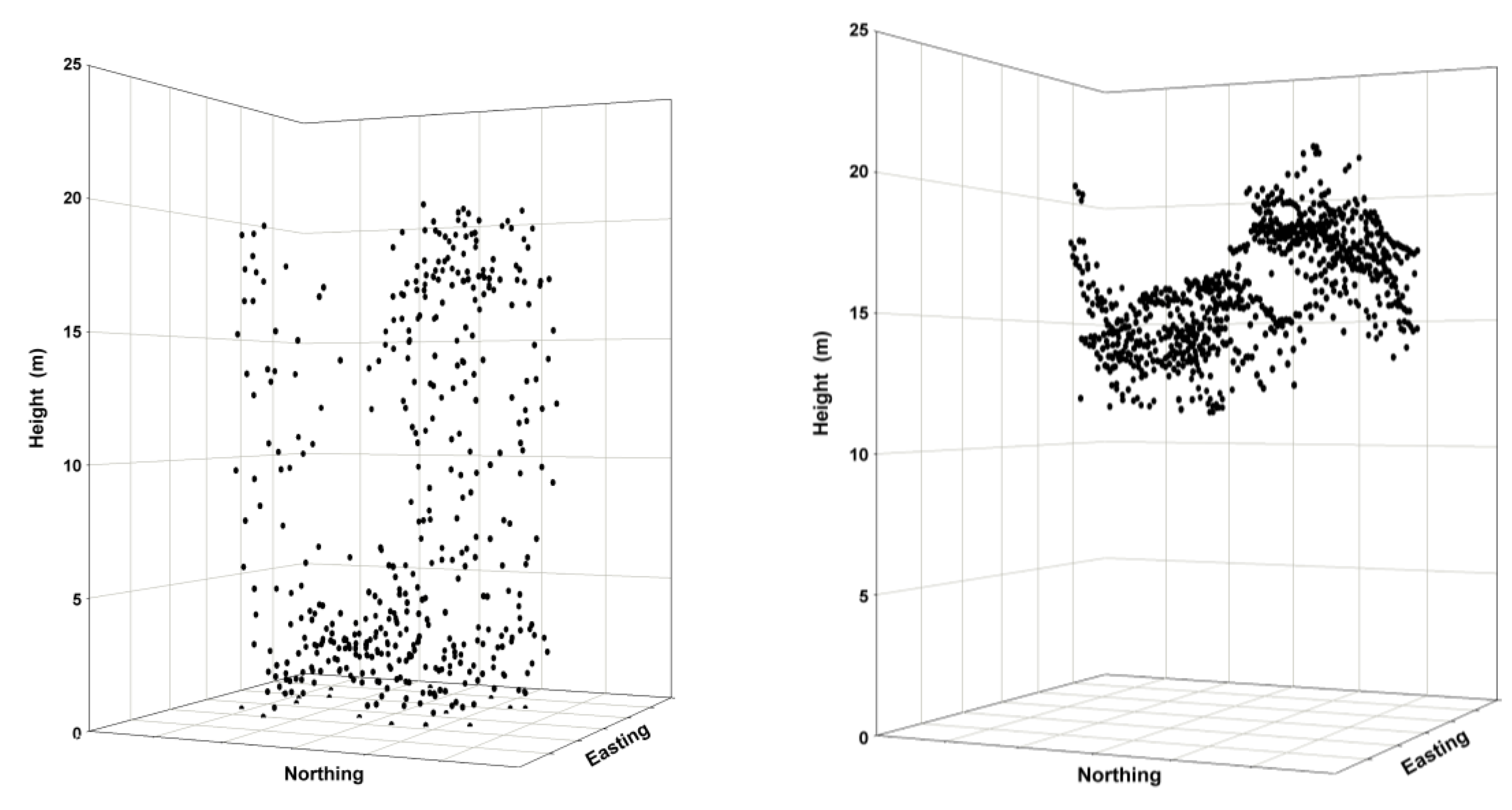
Figure 2.
Point clouds are illustrated as three-dimensional plots for a sample 400-m2 forested plot (ALS left panel; IPC right panel). ALS returns are distributed throughout the canopy and include the forest floor. In contrast, IPC elevation measures exist only for features shown on the image—in this case, the canopy surface. If a quality DTM exists, then the IPC-derived canopy surface measures can be translated into actual height values.
Figure 2.
Point clouds are illustrated as three-dimensional plots for a sample 400-m2 forested plot (ALS left panel; IPC right panel). ALS returns are distributed throughout the canopy and include the forest floor. In contrast, IPC elevation measures exist only for features shown on the image—in this case, the canopy surface. If a quality DTM exists, then the IPC-derived canopy surface measures can be translated into actual height values.
3.3. Parametric or Non-Linear Regression (NLS)
The choice of a 2-cm diameter class interval meant that some Dbh classes had no trees. These could either be treated as missing observations, and not used in the statistical analysis, or as zeroes, and used in the statistical analysis. In this study, we chose to set missing values to 0 for Dbh classes within the range of Dbhs for the plot. For example, if the Dbh range for a plot went from 10 to 32 cm, any Dbh classes within that interval with no trees had zero trees (no missing values). We set the relative frequency one size larger than the largest Dbh to zero as well. The result was that missing values were only allowed for Dbh classes > the largest Dbh class + 2 cm.
Our methods draw heavily from Cao [
6], who used the three-parameter Weibull (Equation (1)) to model Dbh distributions. The Weibull probability density function predicts the relative frequency of x, given location parameter “
a”, shape parameter “
b”, and scale parameter “
c”.
where
We used the parameter prediction method [
6]. First, we fit Equation (1) to each calibration plot using PROC NLIN in SAS, with
a = 9.0. Then we used stepwise regression (SAS routine GLMSELECT) to predict the parameters of the plot-level fit from ALS or IPC attributes by forest type. We used a logarithmic transformation to ensure the parameter predictions were always positive. We predicted the natural logarithm of the shape parameter (ln(
b)) and the scale parameter (ln(
c)) as linear combinations of the natural logarithm of the predictor variables (
X1 .. Xp-1) from
Table 5. The coefficients
b11 … b2p are estimated parameters.
Next, we fit the original model as a single equation expressing the difference between two cumulative density functions (
F(x)), with the location parameter
a set to 9.0 cm. We removed non-statistically significant (probability < 0.05) parameters from the model.
Model (3) was fit by forest type.
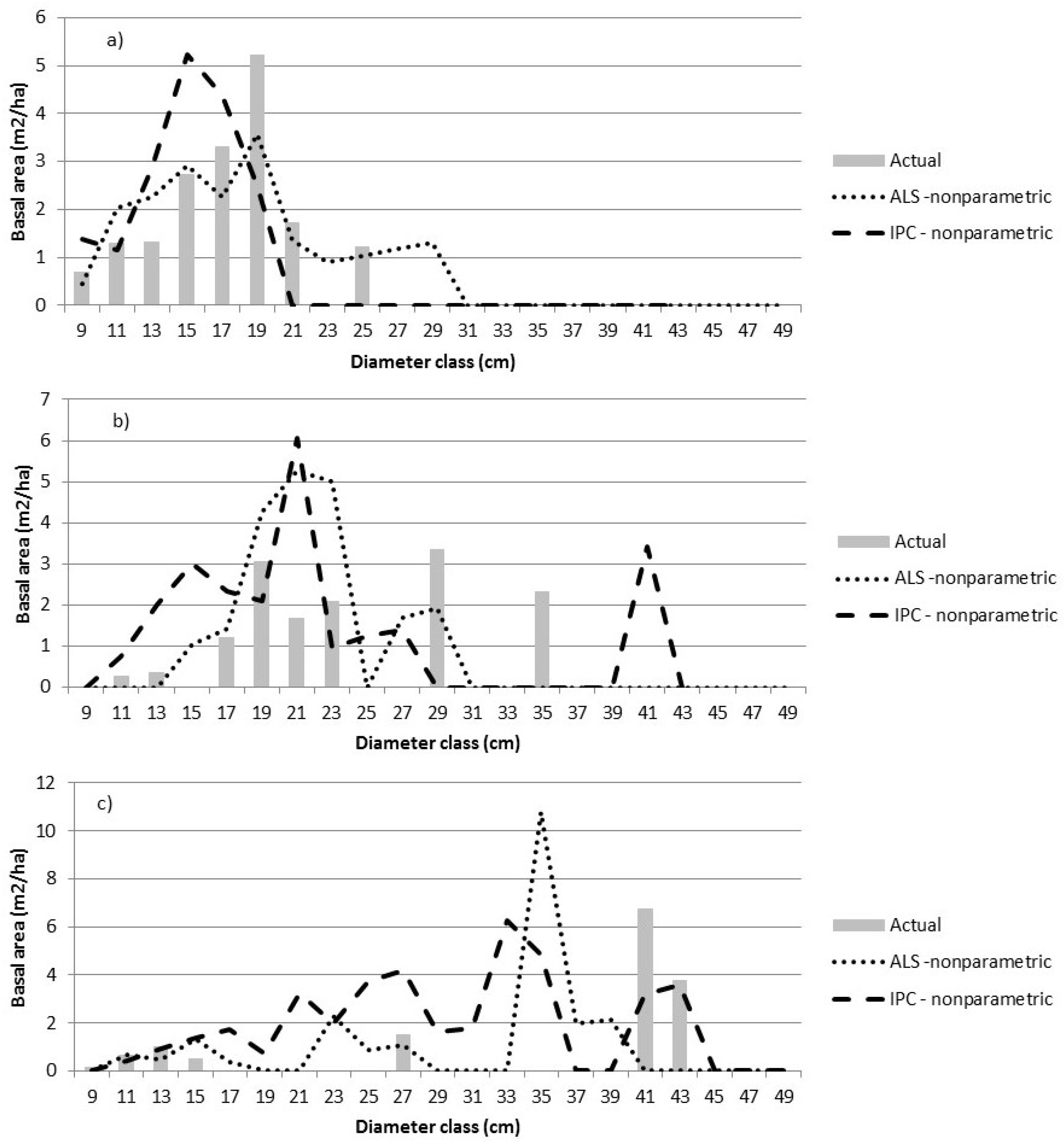
3.4. Non Parametric or RandomForest Nearest Neighbour Prediction
We used nearest neighbour methods [
11] to impute the size class distributions for the target prediction units. The distance measure to identify nearest neighbours was calculated using randomForest and the predictions are referred to as randomForest Nearest Neighbour (RFNN). RandomForest [
33] is a nonparametric technique that generates a “forest” of regression trees. Each regression tree is grown using binary partitioning so that at each node, the training data are split into two groups using a single predictor. This binary partitioning continues until each final group (“node” or “leaf”) contains a user-specified number of data points. Each tree is grown with a random subset of the training data and the decision variable at each node is drawn from a random subset of the potential predictor variables. The distance between a target prediction unit and each point in the reference data set is one minus the proportion of trees where the target prediction unit is in the same terminal node as the reference observation.
The R package yaImpute [
34] was used identify the nearest neighbour (
k = 1) in the reference dataset which was then used to impute the array of BA by 2 cm Dbh class, ranging from Dbh
9, Dbh
11, …, Dbh
69 where Dbh
i is the Dbh class (
i – 1) ≤ Dbh < (
i + 1). The function “yai” was used with method = “randomForest” and the supplied defaults, including the number of regression trees = 500 and mtry (the number of predictor variables picked a random) equal to the square root of the number of predictor variables. Unlike the parametric predictions, the data were not stratified by forest type.
3.5. Evaluating Fit
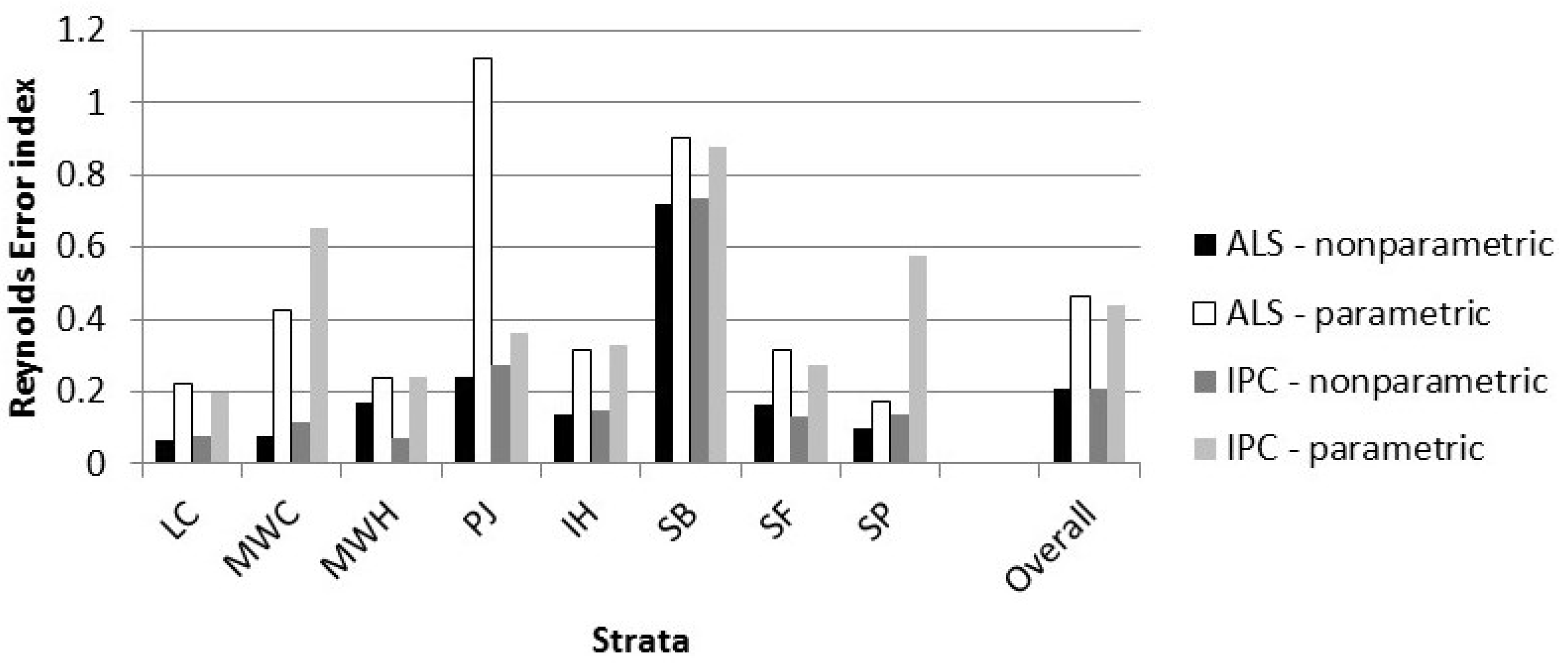
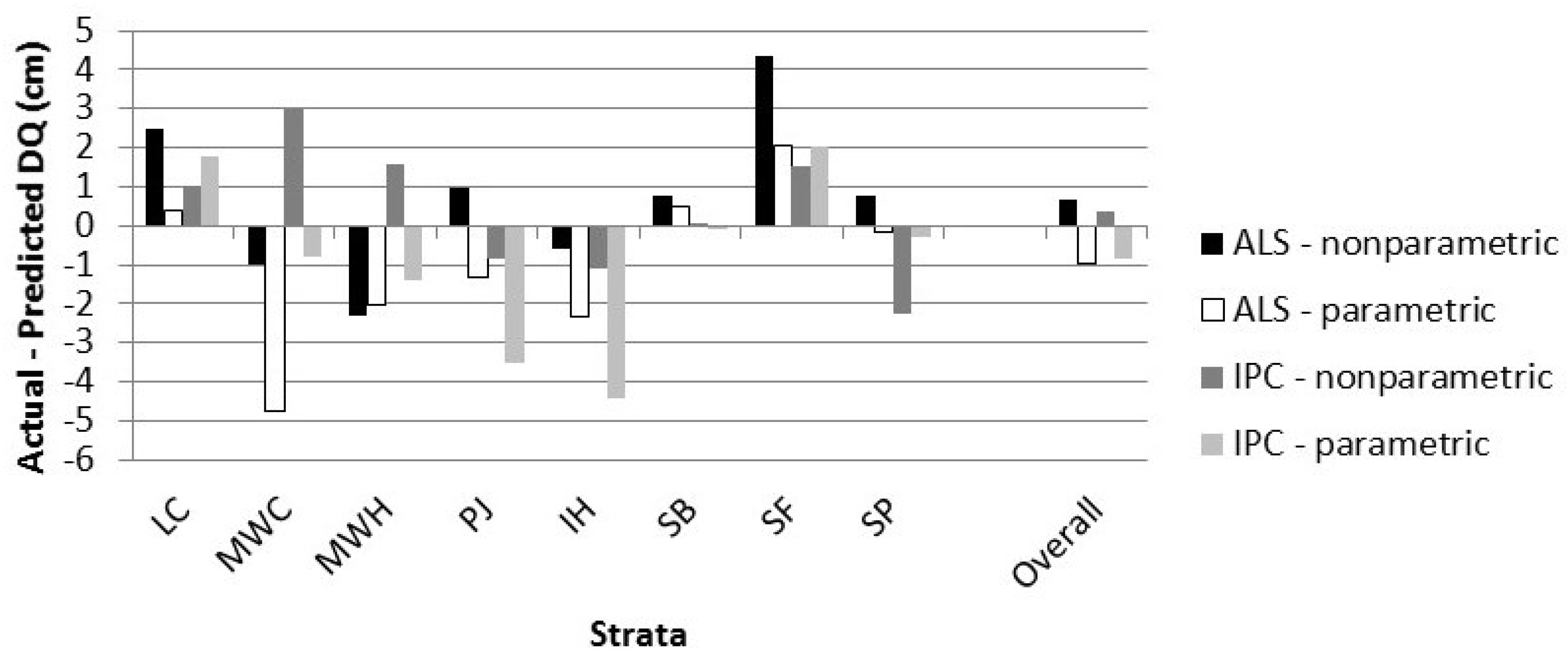
The predictions were evaluated by visually comparing the predicted and observed distributions as well as two measures of fit.
The first measure of fit was the index developed by Reynolds
et al. [
34], which was used to measure the closeness of Dbh predictions to the data. Let
be the cumulative density function (
cdf) of diameters (
x) on a plot predicted by the model and
be the observed
cdf. Let w(
x) be a weight function and N the number of trees/ha. The Reynolds error index is the following.
Reynolds
et al. [
35] suggested setting the weight to the volume of a tree in diameter class
x or the dollar value of the tree. We set the weight to the basal area of a tree with Dbh
x. The error index was calculated as the weighted absolute differences in frequencies summed over all diameter classes:
The statistical properties of the index are unknown but the smaller the index, the better the agreement between the predicted and observed distribution.
A second measure of fit was the closeness of the quadratic mean diameter (DQ) calculated from the predicted distribution compared to the actual DQ. This measure is relatively insensitive to the shape of the distribution.
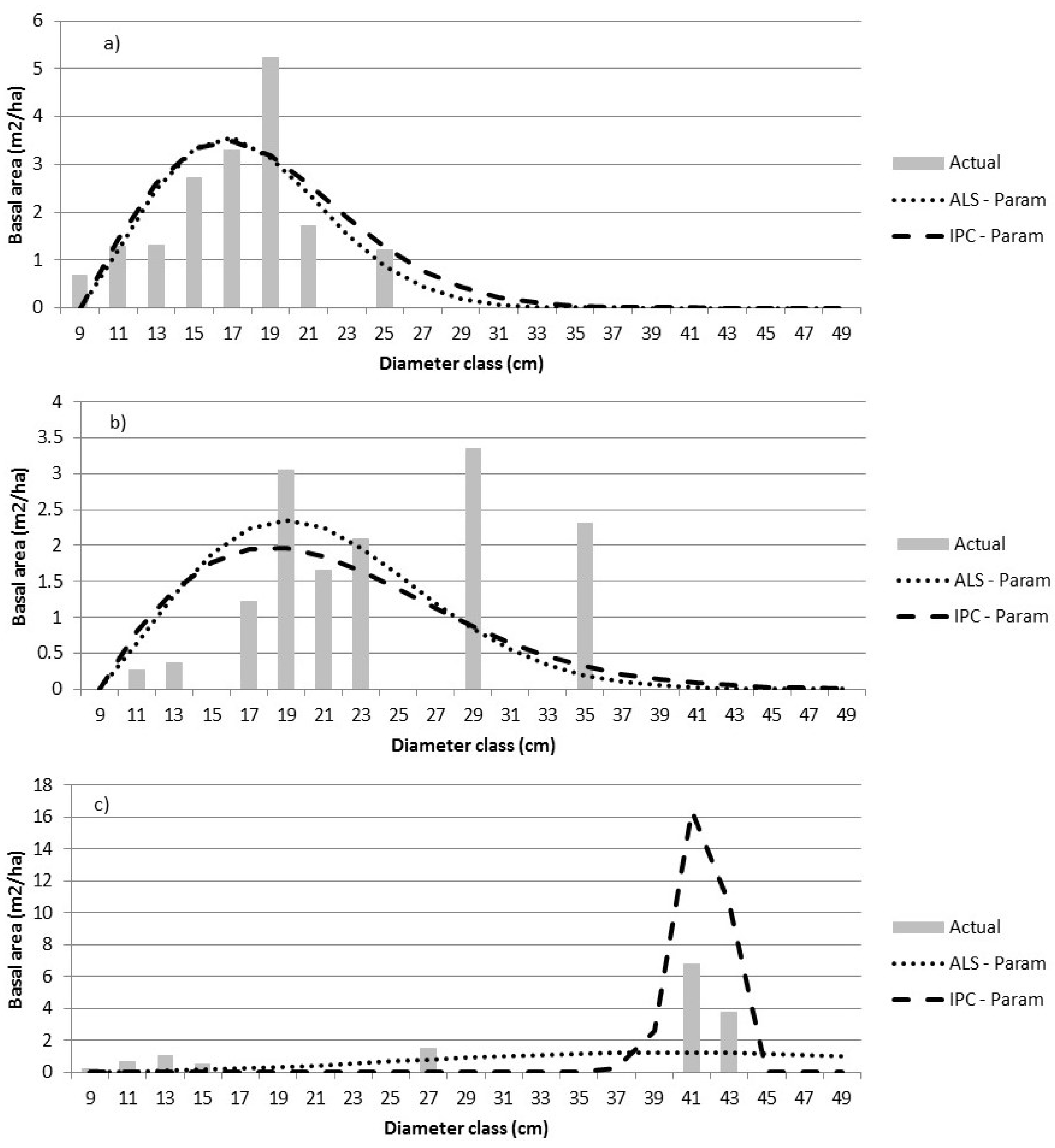
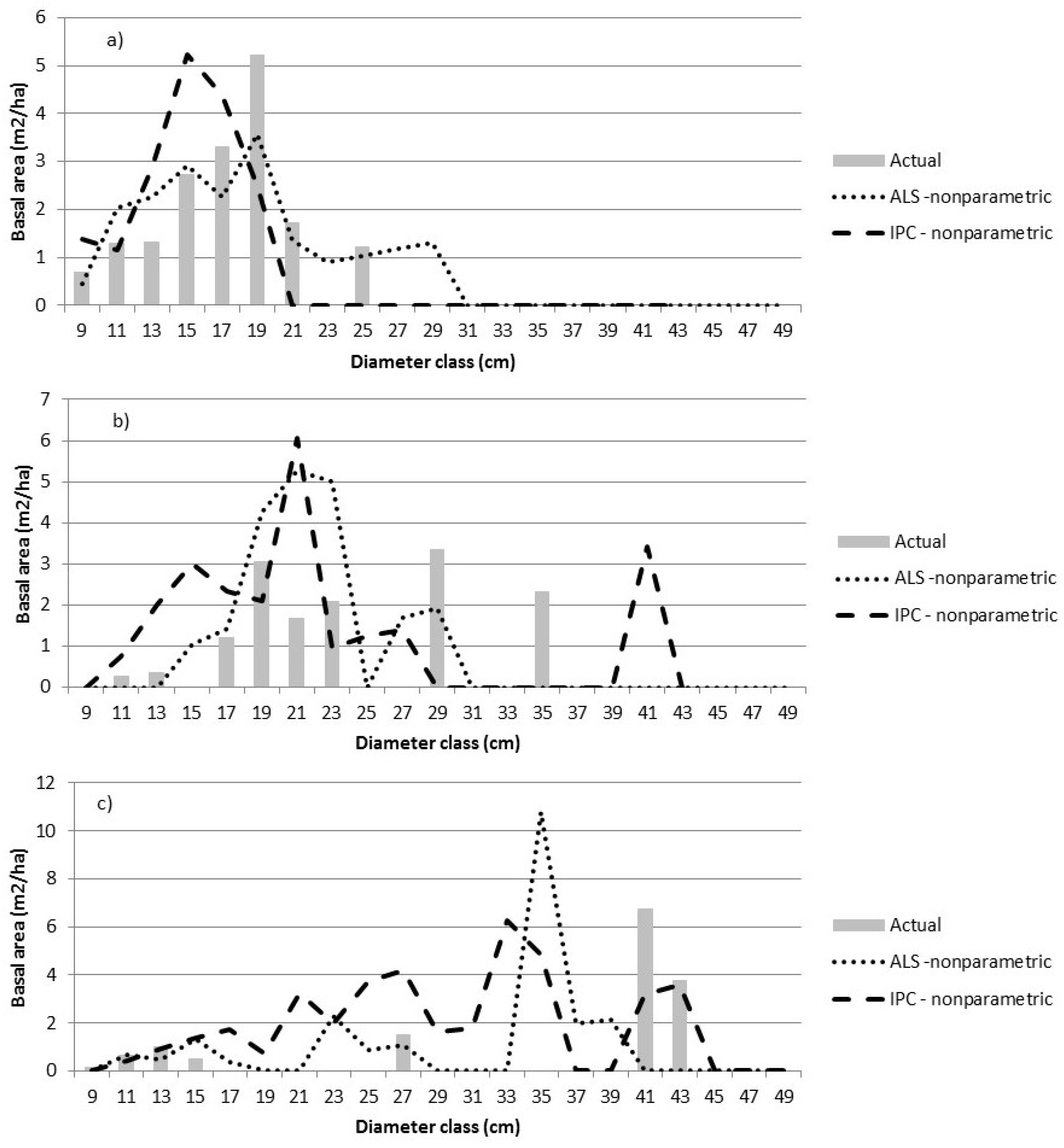
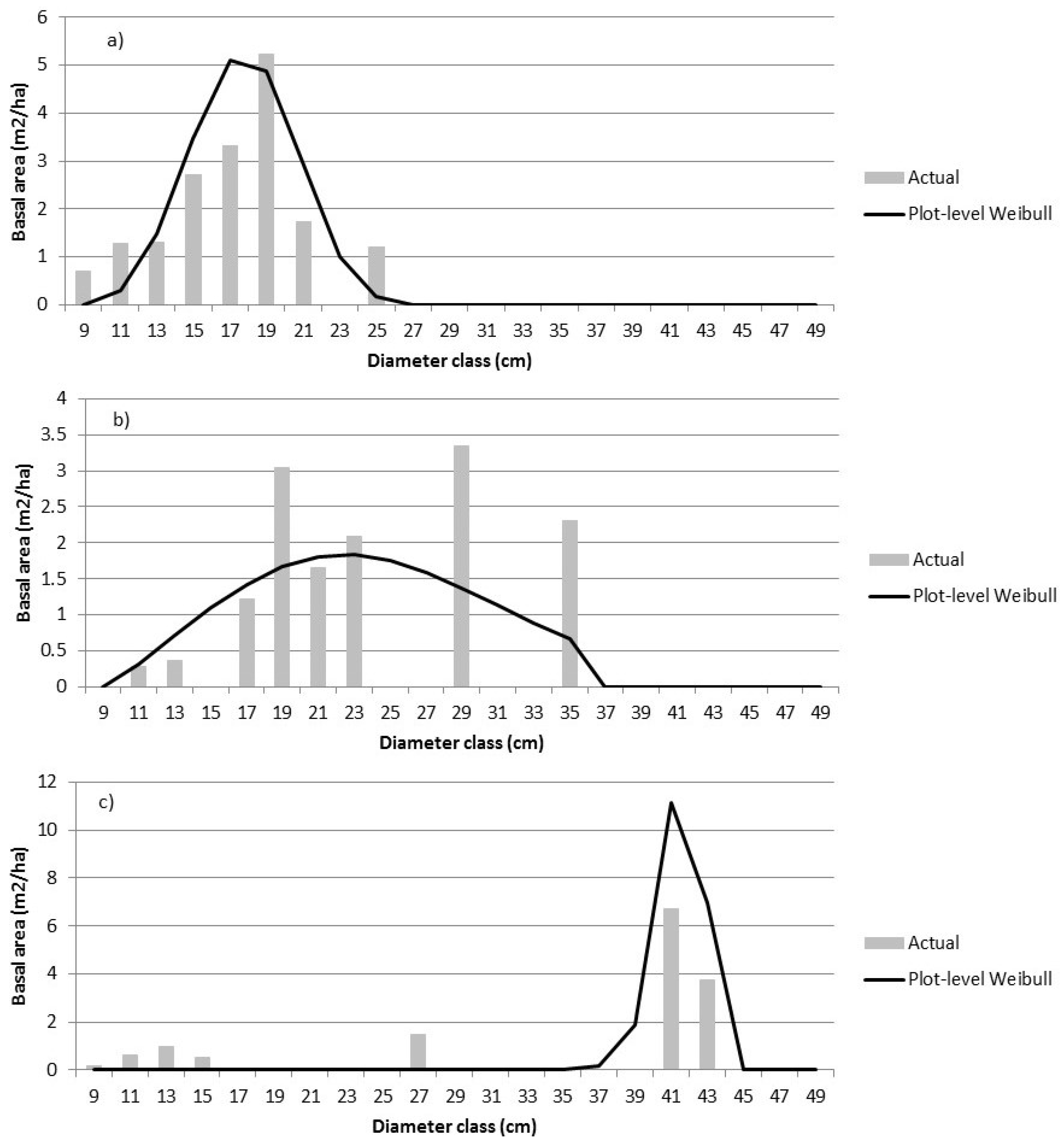
Our 400 m
2 prediction unit is relatively small, resulting in some jagged Dbh distributions (e.g.,
Figure 3c). Moreover, graphical summaries have limited usefulness when plots contain a relatively small (<40) number of trees [
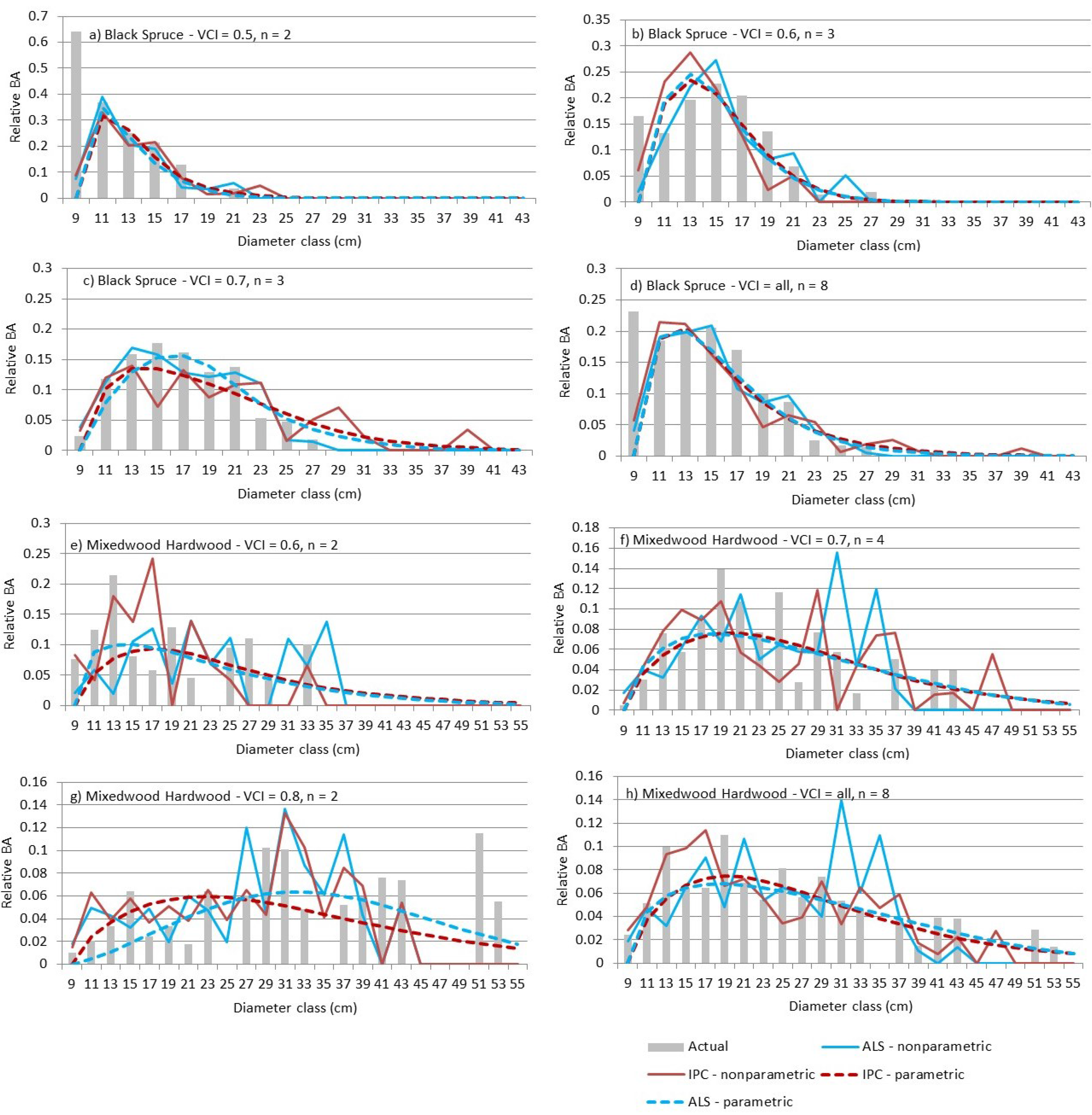
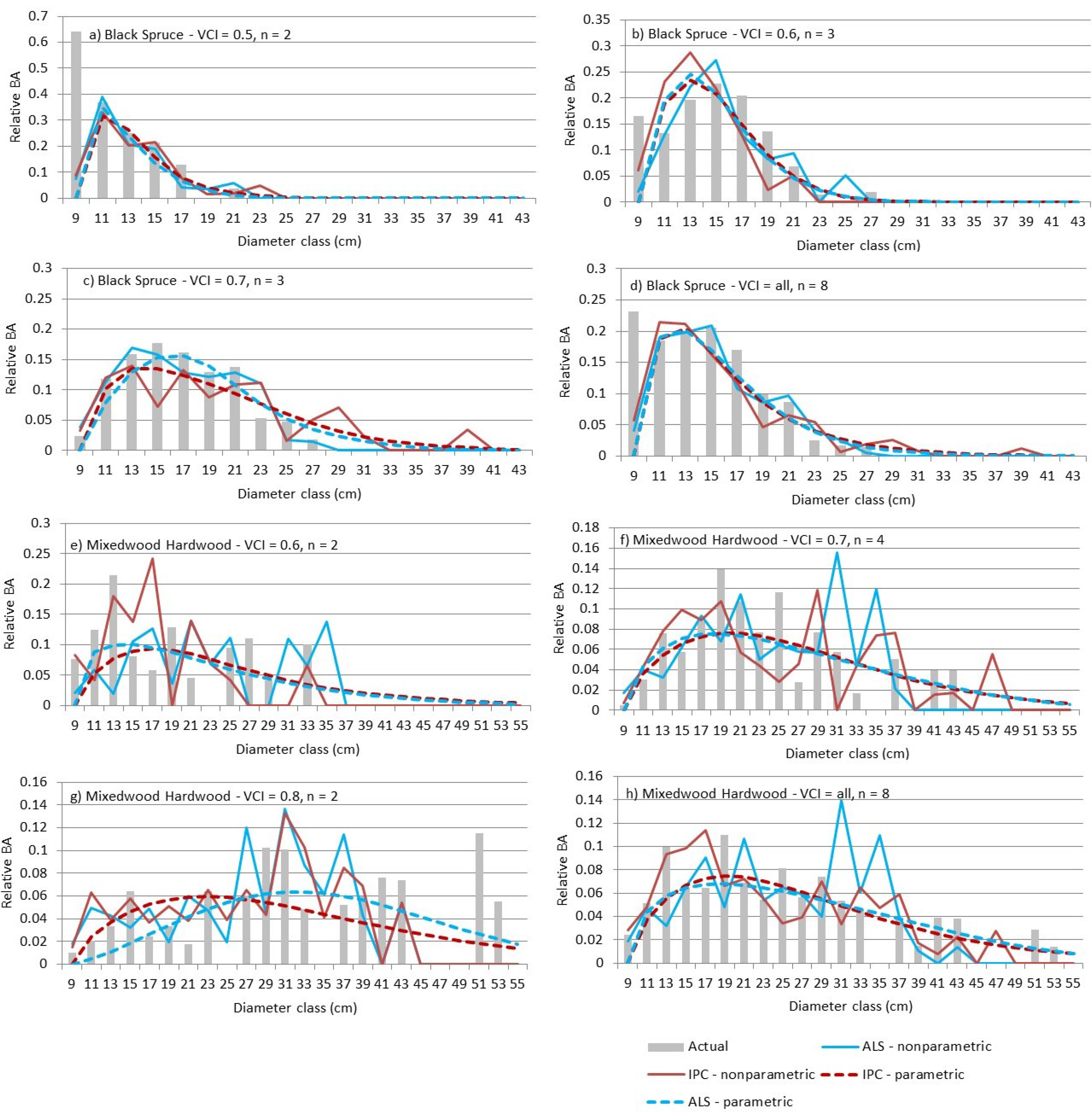
9]. Larger plots or areas of prediction, such as stands or blocks, may be expected to have smoother distributions. Therefore, we grouped validation plots by forest type as well as VCI class, a measure of the entropy of the vertical distribution of the ALS returns, to better assess prediction results.
The error index and DQ prediction errors were subjected to repeated measures analysis of variance. In this study, four error indices and four DQ prediction errors were calculated for each plot corresponding to two remote sensing methods (IPC
vs. ALS) and two prediction methods (SUR
vs. RFNN). The following hypotheses were tested.
H0: ALS = IPC. The error index does not depend on remote sensing technique (ALS vs. IPC).
H1: ALS ≠ IPC. The error index depends on remote sensing technique (ALS vs. IPC).
and
H0: SUR = RFNN. The error index does not depend on statistical technique (SUR vs. RFNN).
H1: SUR ≠ RFNN. The error index depends on statistical technique (SUR vs. RFNN).
As well, the interaction between remote sensing and statistical technique was tested. Similar hypotheses were tested for DQ prediction errors. Forest type was included as a fixed-effect, blocking variable.
5. Discussion
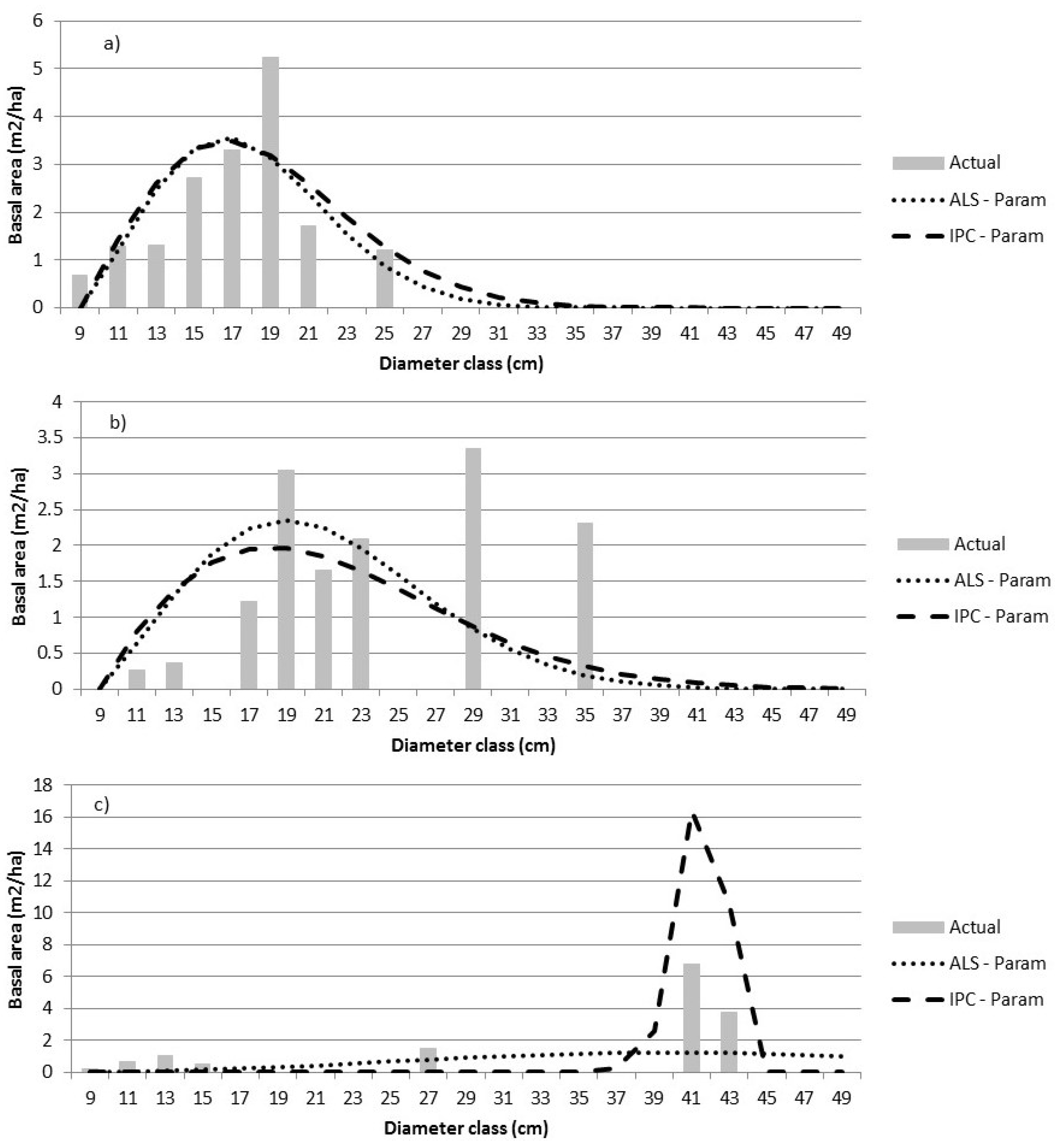
The differences between the ALS and IPC predictions are minor and not statistically significant when compared in terms of error index or DQ. Comparable results for ALS and IPC suggest that the choice of remote sensing can be based on other considerations. If an appropriate quality DTM is not available, IPC is not a viable option because the point cloud requires such a DTM for normalization. If a DTM is available, IPC may be the preferred method, since the point-cloud data may be generated at minimal additional cost when the same imagery is required for species interpretation to support inventory work.
The differences between parametric and nonparametric predictions when compared in terms of error index and DQ were statistically significant. Agreement between the actual and predicted size class distributions was poor for some plots, due in part to the small prediction unit size and relatively narrow Dbh class width used. Ground sampling is expensive and plot size is generally balanced by the number of samples. Prediction unit size is a function of the spatial resolution desired for the inventory attributes, and ~400 m
2 has been found to be a suitable size for both ALS [
2] and IPC [
3] predictions in the boreal forest. Larger prediction units may be used, but as the size increases, so does the cost of calibration and validation. Decisions regarding Dbh class width can affect parametric estimates. However, the resulting models can be used to predict the relative BA for any Dbh interval. In contrast, nonparametric imputation is tied to the Dbh class width associated with the training data—classes can be aggregated but not split. The inflexibility of the nonparametric predictions with respect to Dbh class width led to the choice of a relatively narrow Dbh class width. Alternatively, broader Dbh classes could have been used and finer intervals could be interpolated from the nonparametric predictions.
Parametric distributions have positive relative frequencies for all positive diameters, creating the need to truncate the right side of the distribution to avoid the over-estimation of BA into larger Dbh classes. Several options exist, including predicting the maximum Dbh for each pixel, setting relative frequencies below some threshold to zero, and capping predictions at the maximum observed Dbh in the calibration data. Parametric predictions often benefit from stratification into similar forest types, which can increase modeling costs. Nonparametric imputations generally use reference observations that are close or similar by some measure, obviating the need for stratification.
BA (m
2/ha) by Dbh class, rather than relative BA by Dbh class, is generally of interest. For the parametric models, this requires a prediction of total BA in trees larger than the minimum Dbh. For this study, those predictions were developed earlier [
31]. The error index and DQ used here to evaluate the predictions used relative BA.
This study deliberately focused on merchantable-sized trees (Dbh > 9.0 cm). Small errors in the BA associated with small trees can lead to unreasonably large estimates of stems/ha. A previous study [
31] derived estimates of total BA and the relative BA in merchantable-sized trees. The BA in smaller trees can thus be estimated. It could also be partitioned into size classes, but we have found that error rates are high.
Diameter distribution predictions are best suited to aggregates of prediction units (e.g., stands or other areas of interest), which complicates validation since the spatial definition and measurement of large plots on the ground can be difficult and prohibitively expensive. In this study, we attempted to get around this obstacle by aggregating and validating predictions by forest type or VCI class. Recent advancements in harvesting equipment (e.g., MultiDat
TM data loggers, [
37]) allow the measurement and recording of the stem diameter (and many other parameters, including stem taper and product volume) of each tree as it is harvested, presenting the best opportunity for validating inventory predictions.
Alternatively, a tree-based approach can be used. First, tree crowns are delineated using ALS [
38], and Dbh is estimated from the tree crowns [
39]. The relative accuracies of tree-based and area-based estimates vary, depending on the attribute [
40] and the degree to which crowns are visible from above, leading to research into combining tree- and area-based approaches (e.g., [
41]).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}