1. Introduction
It is well known that before the fiber production line starts, the production parameters must be determined. If the fiber performance needed is changed, the corresponding production parameters must be changed, too. If there is an approach to find the relationship between fiber performance and production parameters, the fiber production can be optimized. However, the fiber production line is a large-scale production system that has multiple processes, different modes and complex conditions, so it is difficult to complete the above task. Since the 1960s, a large amount of basic theory research has been applied on fiber production. The traditional optimization methods of this system involve controlling the production equipment, improving the production processes and optimizing the fiber performance. However, most of them are applied to controlling production, such as the control of winding machines [
1], the coagulation bath [
2] and the stretching process [
3]. In recent years, there has been some research in building mathematic models of the production process, which uses simulation technologies to find the accurate description and calculation for every step or a part of the fiber production, but not the whole process. Tan tried to find the relationship between diameter distributions and the viscosity and elasticity of meltblown fibers [
4]. Gou gave a two-dimensional model of dry spinning polymer fibers [
5]. Lee gave a numerical reduction model of optical fibers [
6]. Kadi gave a review of the influence from mechanical behavior [
7]. Arafeh used a neuro-fuzzy logic approach to model the material process [
8]. Although these research results are accurate and correct, they have not considered the interaction influence among multiple steps. In addition, if the production mode or the equipment condition is changed, this research must be re-modified in order to adapt to the new production process.
In order to find the relationship between the fiber performance and production parameters in the method of a black box, neural networks and multi-objective evolutionary algorithm are mentioned here, and both algorithms have been applied on industrial problems successfully for many years. There are some reviews for different neural networks [
9,
10,
11,
12,
13]. The multi-objective evolutionary algorithm is an area for multiple criteria decision making, which is used to make an optimal decision in the presence of trade-offs between two or more conflicting objectives. It has been successfully used in pattern recognition, adaptive control and prediction problems [
14,
15]. Some similar research in this field has been done, such as Liu adopting an adaptive neuro fuzzy inference system (ANFIS) to perform parameter prediction [
16], Deng using intelligent decision support tools to design production [
17], Yu using a fuzzy neural network to predict the fabric hand [
18] and Yang using a neural network approach to optimize the mechanical characteristics of short glass fiber [
19]. However, most of the existing results about prediction problems are always a matter of one-way prediction.
Based on neural networks and a multi-objective evolutionary algorithm, this paper develops an approach to predict both fiber performance and production parameters, and its final target is to optimize fiber production. This approach only depends on the production parameters and their corresponding fiber performance, so it remains unaffected when the production modes or the equipment conditions are changed. The prediction in this paper consists of the bi-directional prediction process, which includes the prediction of the fiber performance by the production parameters and the prediction of the production parameters by the fiber performance. If these two prediction processes are regarded as two irrelevant parts, they can be solved by many kinds of algorithms, but there may be some problems. Because the forward prediction is based on the production process, it is a forward process in nature, which means it can be seen as an independent prediction. However, backward reasoning is complex, because it is a reverse process in nature. For example, different production parameters can achieve same fiber performance, and this situation will affect the backward reasoning results, which means that one-way prediction is not enough to solve this backward reasoning. In a word, comparing with the forward prediction, which can be solved by different algorithms simply, backward reasoning is too complex to be realized by the same algorithms as the forward prediction, because of the missing data, the conflict data, the interaction influences and other problems. In order to avoid those problems, the forward prediction and backward reasoning are designed together in the bi-directional prediction approach in this paper, and in addition, the prediction approach adopted in this paper is a bi-directional prediction approach, whose backward reasoning is based on the forward prediction.
In order to solve the accuracy problem, through experiments and data analysis, this paper uses hybrid intelligent algorithms, including a particle swarm optimization algorithm with a K-means algorithm to optimize the clustering and to increase the accuracy of the forward prediction. Backward reasoning, as mentioned before, is based on the forward prediction, and it can be seen as a multi-objective evolutionary problem. This paper uses a multi-objective evolutionary algorithm, the clustering results and the forward prediction to achieve the backward reasoning results.
The remainder of this paper is organized as follows. In
Section 2, we give the introduction of the fiber production and the bi-directional prediction optimization, including the production process, the production parameters, the fiber performance and the design of the forward prediction and backward reasoning. In
Section 3, the implementation, simulation results and error analysis of the bi-directional prediction approach are given, which is applied to design polyester filament parameters. Finally, concluding remarks are given in
Section 4.
2. Fiber Production and Bi-Directional Prediction Optimization
2.1. Fiber Production Process
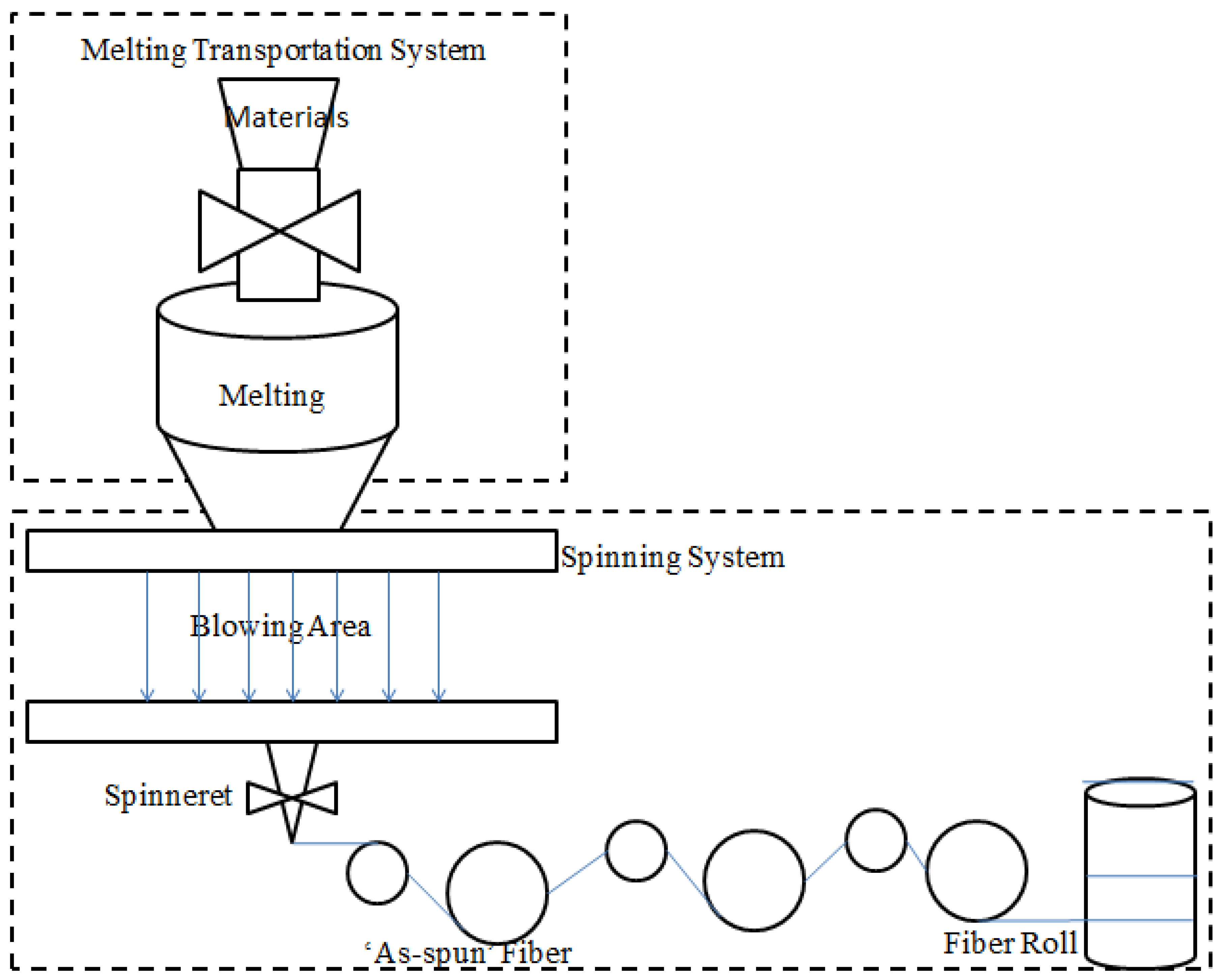
The production of fiber is a complex production line, which generally consists of two systems: the melting transportation system and the spinning system. The melting transportation system is used to convert the fiber materials to liquid, and this is accomplished by the following spinning system. The spinning system includes a quenching area and a stretching process. The quenching area is used to help the liquid to solidify in the streams, which are called ‘as-spun’ fibers [
20,
21], and then, the ‘as-spun’ fibers can be stretched in the stretching process, according to the stretching ratio. Although different fibers ask for different combinations of equipment and materials, the basic production processes are similar. The production process of polyester staple fiber is depicted in
Figure 1.
In order to produce fibers with good performance, the optimization of fiber production always depends on the adjusting and controlling of production parameters. Because the production line consists of several processes, there are numerous production parameters that need to be determined in every process. In addition, all the processes have interaction influences on each other. The traditional approaches, which follow experience, are not accurate enough to solve the problems above, and the mathematic models are not adaptable enough to solve for differential fibers. Therefore, if we can find a way to achieve the bi-directional prediction results with hybrid intelligent algorithms, the production parameters can be determined and fiber production can be optimized.
Figure 1.
The process of fiber production.
Figure 1.
The process of fiber production.
First of all, the selection of the key production parameters and fiber performance is the foundation of this paper. At the beginning of production, the materials will be melted into liquid according to a predefined viscosity and temperature; this process belongs to the chemical category, so it is not taken into account in this paper. After this process, the materials will enter the quenching area and the stretching process. These two processes are the most important ones in this paper, so all the parameters of these processes are considered in the bi-directional prediction approach.
In the bi-directional prediction approach, the prediction of fiber performance by production parameters is a forward prediction process and the prediction of production parameters by fiber performance is a backward reasoning process.
2.2. Fiber Production Process Overall Design of Bi-Directional Prediction Approach
As mentioned above, the bi-directional prediction approach consists of the forward prediction and backward reasoning.
2.2.1. Forward Prediction
Because fiber production is a positive process, the forward prediction is a positive process, too. It stands to reason that when the parameters of fiber production are changed, the corresponding fiber performance will be changed accordingly. In addition, production is a long-term process, which means that the predetermined production parameters usually need not be changed once in production. Because of the production conditions and environment conditions, there must be a small disturbance between the real production parameters and the presupposed production parameters. In other words, the real measured production parameters of production, at the same time, are not the same, but they are similar. Therefore, if the production parameters are similar, there must be little difference between the fiber performances. Meanwhile, though the production parameters of every production process are unstable, the fiber performance must also have incredibly small variations, which means they all have the characteristic of aggregation.
From the above analysis, the relationship between the production parameters and the fiber performance can be assumed as a many-to-many problem. Because there is a characteristic of aggregation in the production parameters and their corresponding fiber performance, this many-to-many problem can be simplified to a one-to-one problem by a clustering algorithm. In order to solve this one-to-one problem, this paper developed neural networks based on a clustering algorithm to fulfill the function of the forward prediction.
2.2.2. Backward Reasoning
The prediction of production parameters by fiber performance is a reverse process, so the prediction process can be seen as backward reasoning. Compared with the forward prediction process, the backward reasoning process is more complex. Traditional prediction approaches will meet some problems, as follows. Firstly, the variety of fiber performance is more inadequate than the production parameters. Secondly, because the production has several processes and every process of the whole production is not independent of each other, it is possible that similar fiber performance can sometimes be achieved with different production parameters, which means that backward reasoning cannot be simplified to a one-to-one problem; it is a one-to-many problem. The one stands for the fiber performance, and the many stands for the production parameters. Therefore, traditional neural networks based on a clustering algorithm, which is used in the forward prediction process, are not suitable for backward reasoning.
In order to solve the above problems, backward reasoning consists of not only itself, but also the clustering results and the forward prediction. First, we use the clustering results as the foundation of backward reasoning. Since the clustering results are based on the production parameters, it can keep the variety of fiber performance without changing its structure and avoid the influences of the missing and conflict data. Secondly, in order to solve the one-to-many problem, the multi-objective evolutionary algorithm is used in it to find the optimal answer in the many part, and the forward prediction is used to calculate the objectives.
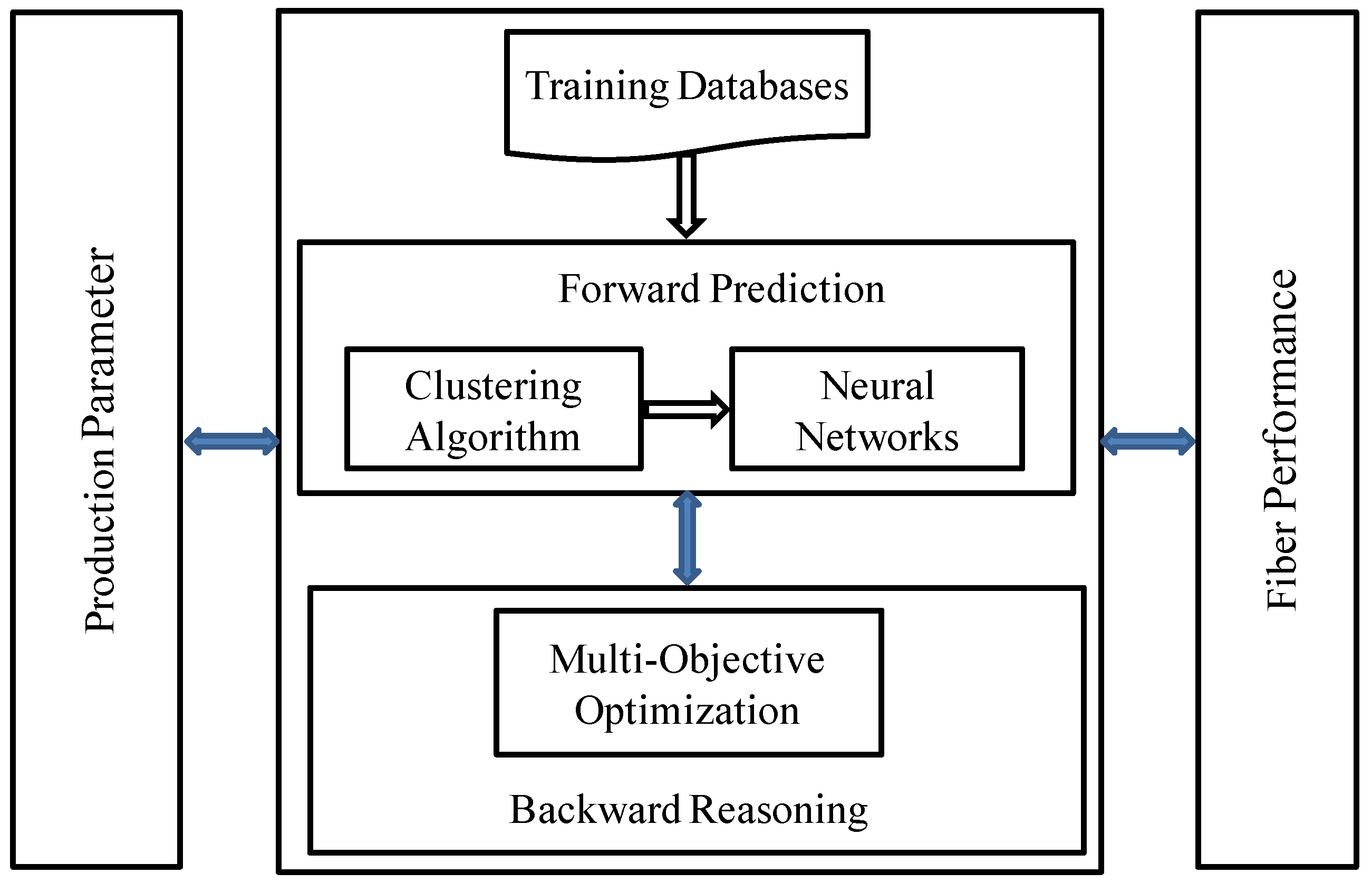
Figure 2 is the overall chart of the bi-directional prediction approach above.
Figure 2.
The overall chart of the bi-directional prediction approach.
Figure 2.
The overall chart of the bi-directional prediction approach.
2.3. Design and Improvement of the Bi-Directional Prediction Approach
The design and improvement of the bi-directional prediction approach will be divided into three parts: the clustering process, the forward prediction and backward reasoning.
2.3.1. Design of the Clustering Process
As mentioned above, the bi-directional prediction is composed of the forward prediction and backward reasoning. Backward reasoning depends on the forward prediction, and the forward prediction is based on the positive clustering result; so, the clustering result is the most important point in the bi-directional prediction approach.
The clustering algorithm is an important tool for data analysis and an unsupervised classification algorithm, which can classify the unlabeled data automatically. Up to now, a lot of algorithms have been proposed and applied in clustering problems, but they all have a common problem, that the result is the locally optimal solution. In order to solve this problem, this paper uses some hybrid intelligent algorithms to optimize traditional clustering algorithms. Compared with other clustering algorithms, the particle swam optimization algorithm (PSO) with its multifarious particles can get the global optimal solution more efficiently [
22,
23], and the K-means algorithm is good at optimizing the local optimal solution [
24,
25].
Firstly, the whole clustering process will be operated by every kind of fiber performance, which can optimize the clustering results. All the training data are preprocessed to be the same order as Equation (1); this normalization approach can avoid the effects of the difference across different data kinds and increases the clustering efficiency and accuracy. The preprocess effect is relieved by Equation (2), where
X* is the initial data and
X is the processed data.
Secondly, we use the PSO function and multifarious particles to find the preliminary result. The selection of the initial particles of the PSO function is random in the training data, and the initial particles include the input data and the output data of every center. The selection in training data can avoid the generation of invalid centers, and including the output data can avoid the error of data mutations. The fitness of the PSO function is the key point, and the calculation of the
i-th fitness is as shown in Equation (3), where
xj is the
j-th training input data,
n is the number of training input data,
Xi is the
i-th particle and
m is the number of particles.
is the calculation of the Euclidean distance between
xj and
Xi.
Thirdly, the particle updating functions are as shown in Equation (4), where
w is the speed factor,
r1 and
r2 are random numbers between 0 and 1,
Pbest and
Gbest are the best particle and the global best particle, respectively,
t is the step number of this updating and
nstep is the total iterative times of the whole clustering process. Equation (4) shows the traditional particle updating functions [
22].
Through iterative analysis and calculation, all the particles will be directed to the best result, which means that most of the particles will be similar to each other. When the similarity of the particles reaches a certain high degree, the best particle is nearer to the global optimal solution. However, all the initial particles are different in their centers’ order with respect to each other, so the similarity is difficult to judge by the particles themselves. However, the fitness of every particle stands for both the cluster accuracy and its particle, so the similarity of the fitness can stand for the similarity of the particles. Then, the K-means function is added to increase the accuracy of the optimal solutions and to optimize the clustering result.
In addition, a mutation operator is used to make particles that are far from the local optimal solution. Because the mutation operator can lead the particles to be both better and worse, the mutation operator is used on all the particles, except the optimal particle. Then, the optimal particle can just keep being optimized.
Finally, we calculate the output centers according to the input centers and the training output data, as shown in Equation (5), where
Yj is the
j-th output center,
Xj is the
j-th input center,
xi is the training input data, which are clustered into the
j-th input center,
yi is the corresponding training output data of
xi and
n is the number of training data in the
j-th center. The numerator of the coefficient calculation is the exponent of the distance between the input data and the input center, and its denominator is the total of all the distance factors. This cannot only keep the inverse proportion between the coefficient and the distance, but also avoid the effect from the coefficients’ order of magnitude. In this function, the closer the input data is to the input center, the bigger the coefficient of the corresponding output data will be weighted, which means it can decrease the effect from some data that have similar production parameters and performance with a large difference.
The steps of the clustering algorithm are as follows.
- Step 1:
Preprocess the training data by Equation (1).
- Step 2:
Select the initial particles randomly in the training data and calculate the initial fitness by Equation (3) of all the particles and the initial Pbest and Gbest with their particle as the local and global optimal one.
- Step 3:
Update the particles by Equation (4) and make sure that all velocities of particles are less than Vmax.
- Step 4:
Calculate the fitness of all the particles by Equation (3) and update Pbest and its local optimal particle. If Pbest < Gbest, then Gbest = Pbest, and update its globally optimal particle.
- Step 5:
Regard the Pbest particle as the optimal particle; other particles have the mutation operator. The rate of the mutation operator is 10%, and the mutations will change into another particle selected in the training data randomly.
- Step 6:
If all the steps are over, or two thirds of the fitness values are similar to the global best particle’s, then use the K-means function to optimize the global best particle three times; else, return to Step 3.
- Step 7:
Calculate the output centers as in Equation (5) by the global best particle, and output the clustering result. During the calculation, if there is no training data in one center, then this center will be deleted from the final clustering result.
2.3.2. Design and Improvement of the Neural Networks
Traditional neural networks can do prediction, but this prediction is point prediction, which conveys little information about the prediction accuracy [
10,
11]. Radial basis function neural networks based on a Gaussian function are used here to optimize the prediction accuracy and avoid the point prediction [
26,
27]. There are some traditional difficulties in this kind of algorithm: the calculation of σ and the calculation of weight [
7,
9].
Firstly, the value of σ in the radial basis function neural networks shows the width of each center, and the final fitness value of each clustering result shows the average distance of all the centers. Therefore, this paper uses the final fitness value of each clustering result to calculate the value of σ by Equation (6), where
m is the number of kinds of fiber performance, and factor 2 enlarges the width of every center by the average distances as the maximum distance.
Secondly, the traditional function to calculate the weight of every output center relies on the value of σ. Although the calculation of σ is improved and simplified, in this paper, it is an average value. In order to reduce the prediction errors, this paper also improves the function of weight value, which can assure that the total value of all the weights is one and the prediction value is within the range. The traditional Gaussian function is as shown in Equation (7), while the improved Gaussian function is as shown in Equation (8), where
wij is the
j-th output center’s weight of the
i-th output kind,
X is the input data,
Cij is the
j-th input center of the
i-th output kind,
σ is a constant,
m is the number of output kinds and
n is the clustering amount.
The steps of the clustering algorithm are as follows.
- Step 1:
Preprocess the input production parameters by Equation (1).
- Step 2:
Calculate the σ by Equation (5) and the weights by Equation (7).
- Step 3:
Add up the production of every center and its weight.
- Step 4:
Relieve the preprocess effect by Equation (2), and get the prediction result of the fiber performance.
2.3.3. Design and Improvement of the Multi-Objective Evolutionary Algorithm
Backward reasoning is a one-to-many problem; in other words, there is more than one production parameter set that can achieve the target fiber performance. As mentioned above, the foundation of backward reasoning is the positive clustering result based on output classes. Therefore, every clustering result can be seen as a subset, and every local optimal solution can be seen as a sub-goal. A multi-objective evolutionary algorithm is a good tool to solve this kind of problem and find the globally optimal solution [
28,
29]. The non dominated sorting genetic algorithm (NSGA)-II [
28,
30] algorithm has been one of the most popular algorithms to solve this kind of problems in recent years.
The backward reasoning process based on the multi-objective evolutionary algorithm is shown as follows:
- Step 1:
According to the input data in backward reasoning, select the high similarity output centers and their corresponding input centers in the positive clustering results by the classes of the output data and save the deviations between the input data and the centers. All of the corresponding input centers are candidate solutions.
- Step 2:
Optimize all of the candidate solutions by the selection process, the genetic operator and replacement process. Calculate the fitness of every objection by Equation (9) of the solution, where
Sij is the
j-th output of the
i-th solution’s forward prediction result,
Xj is the
j-th output of the input fiber performance,
m is the number of the solutions and
n is the number of fiber performance kinds.
- Step 3:
Select the better solutions to be the optimized solution sets by two rules. Firstly, calculate the better number of other solutions, which is in total better than this solution, solution by solution. The in total better solution means that every fitness value in it is smaller than the corresponding fitness value in this solution. Secondly, from the better numbers, small to big, calculate the total value of all the fitness solutions by the solutions that have the same better number, and choose the one that has a smaller value to fulfill the new solution set, until the set is full.
- Step 4:
If all the steps are over, then relieve the preprocess effect and output the final solution set; else, return to step 2.
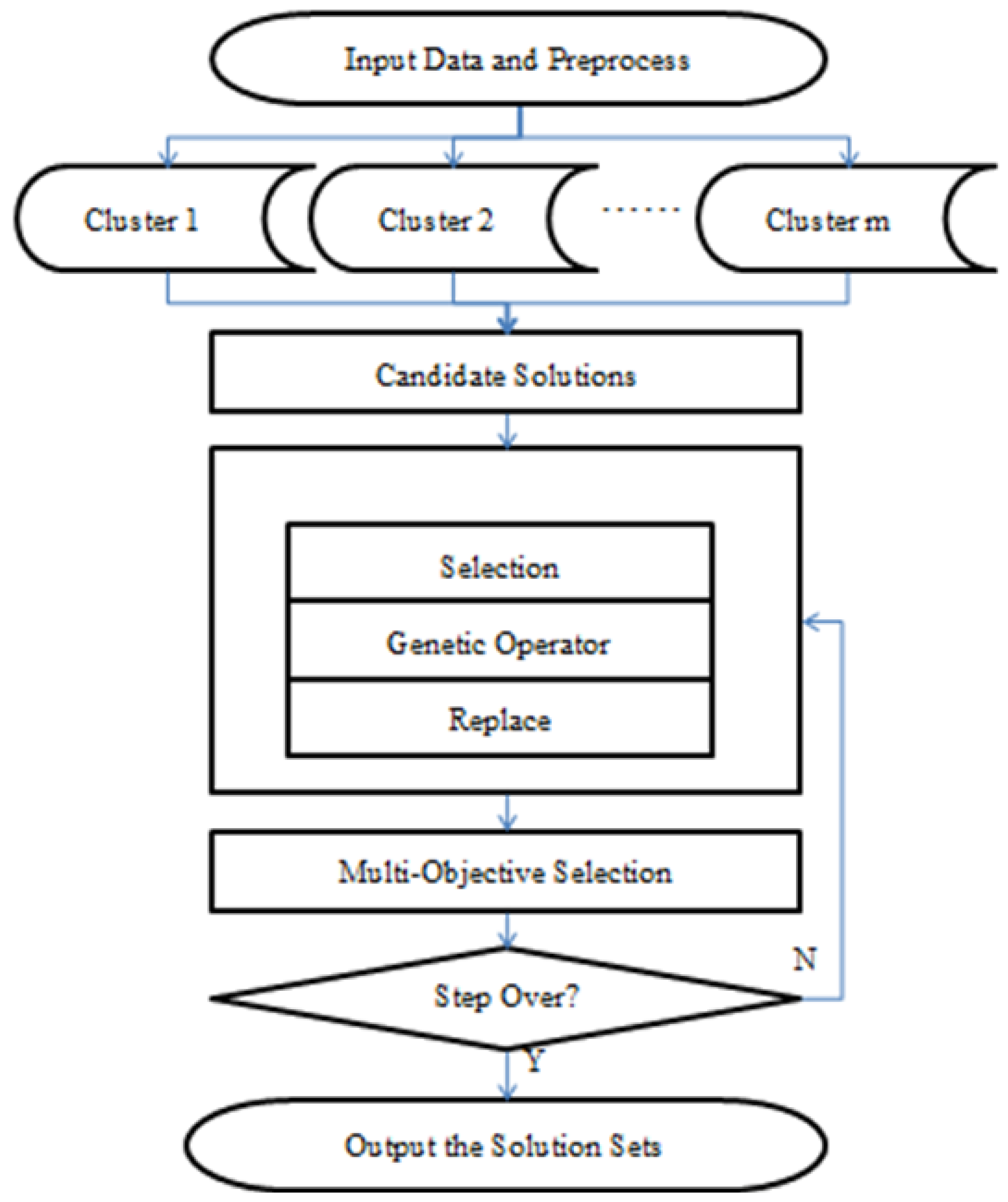
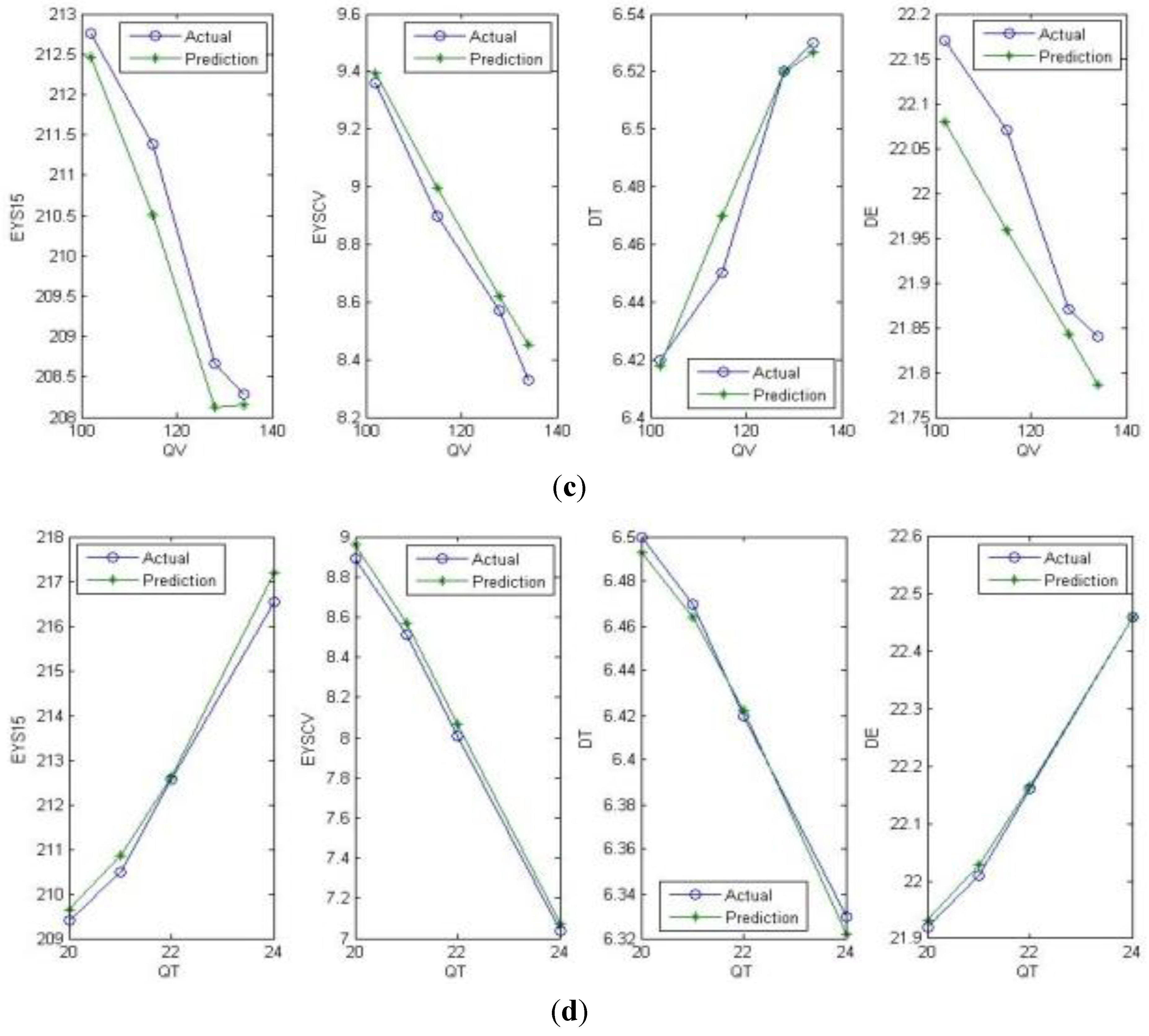
Figure 3 is the overall chart of the algorithm above.
Figure 3.
The overall chart of backward reasoning.
Figure 3.
The overall chart of backward reasoning.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}