
Integrating Auto-Associative Neural Networks with Hotelling T2 Control Charts for Wind Turbine Fault Detection


Abstract
:1. Introduction
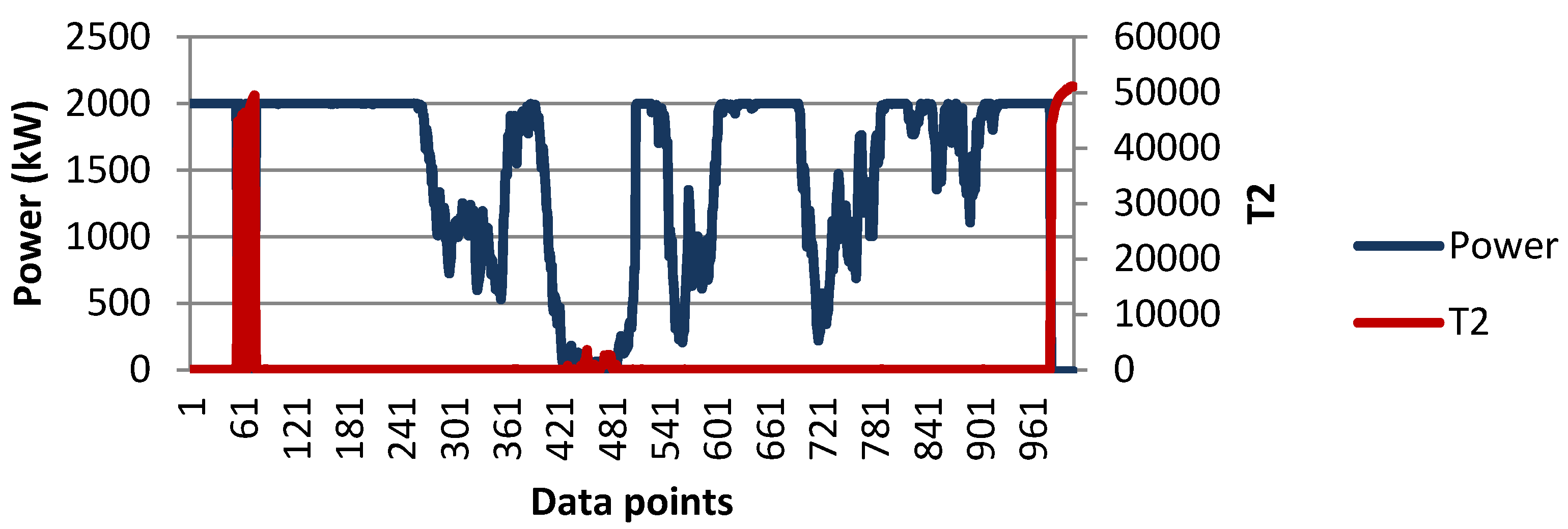
2. Dataset Description

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Components or Subsystems | Name of Attributes | Unit | Minimum | Maximum | Average | Standard Deviation |
|---|---|---|---|---|---|---|---|
| 1 | Meteorology | Wind speed | m/s | 0.3 | 26.5 | 12.19 | 5.97 |
| 2 | Rotor system | Pitch angle | ° | −2.3 | 89.5 | 69.67 | 33.53 |
| 3 | Gearbox | Gear bearing temperature | °C | 15 | 89 | 33.89 | 19.04 |
| 4 | Gearbox | Gear oil temperature | °C | 17 | 79 | 32.25 | 15.43 |
| 5 | Converter | Power output | kW | −21.5 | 2000.8 | 328.81 | 695.76 |
| 6 | Generator | Generator bearing temperature | °C | 12 | 78 | 28.86 | 20.24 |
| 7 | Generator | Generator speed | rpm | 0 | 1972 | 427.86 | 784.43 |
| 8 | Rotor system | Rotor speed | rpm | 0 | 16.3 | 3.43 | 6.54 |
| Description | Detected | Log Type |
|---|---|---|
| Pause pressed on keyboard | 21 January 2009, 02:56:29 | Alarm log |
| Start auto-outyawing | 23 February 2009, 05:02:32 | Alarm log |
| High wind speed: 25.1 m/s | 13 March 2009, 09:41:26 | Alarm log |
3. Research Methodology

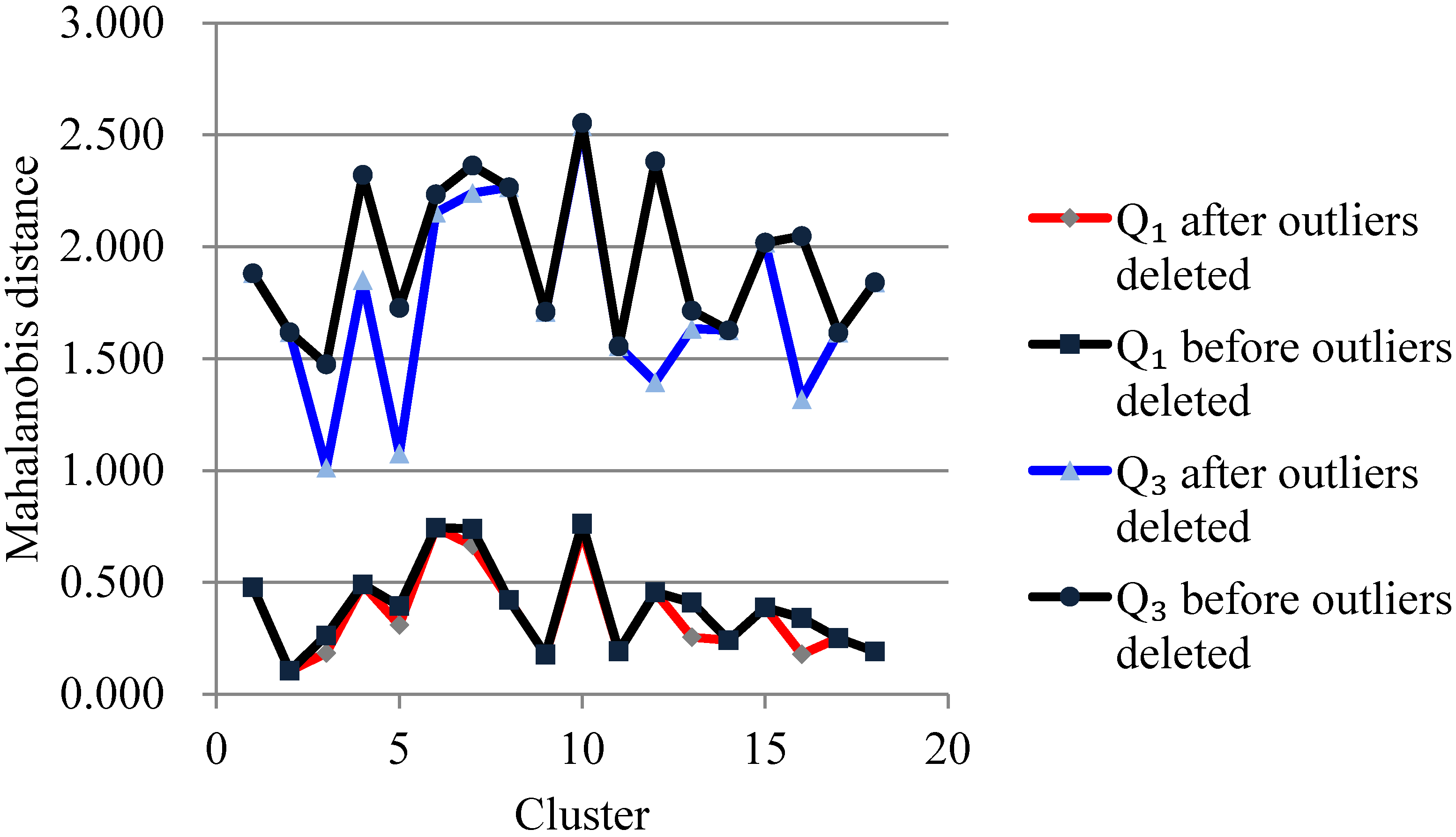
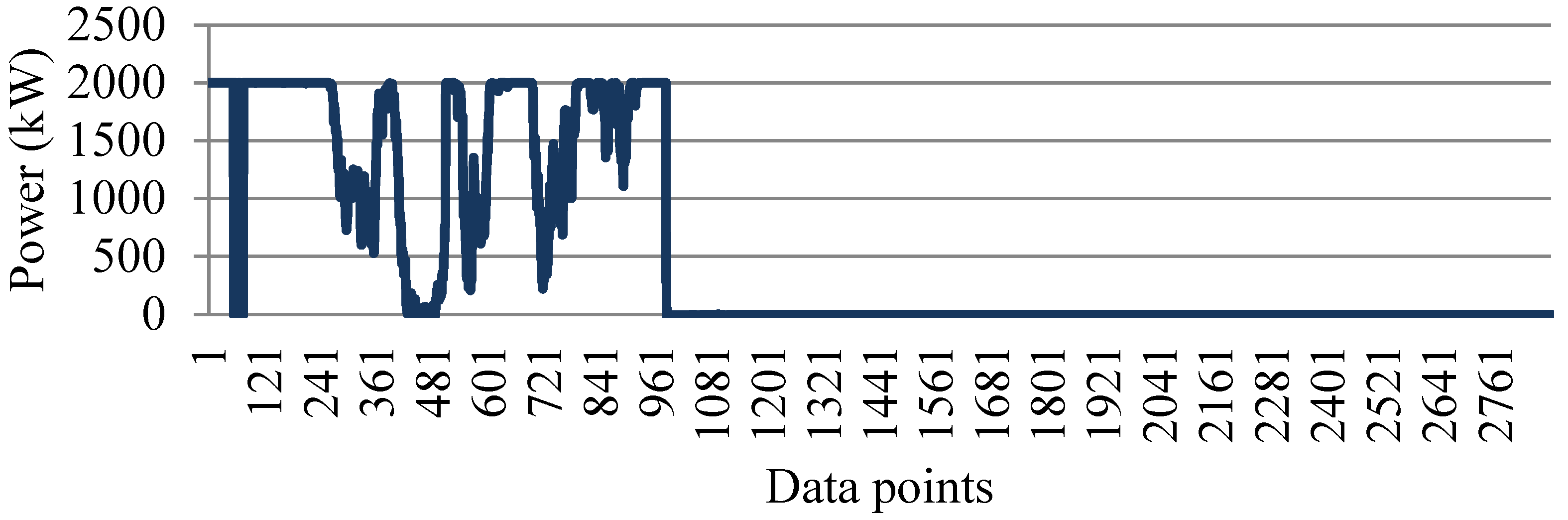
3.1. Processing Outliers
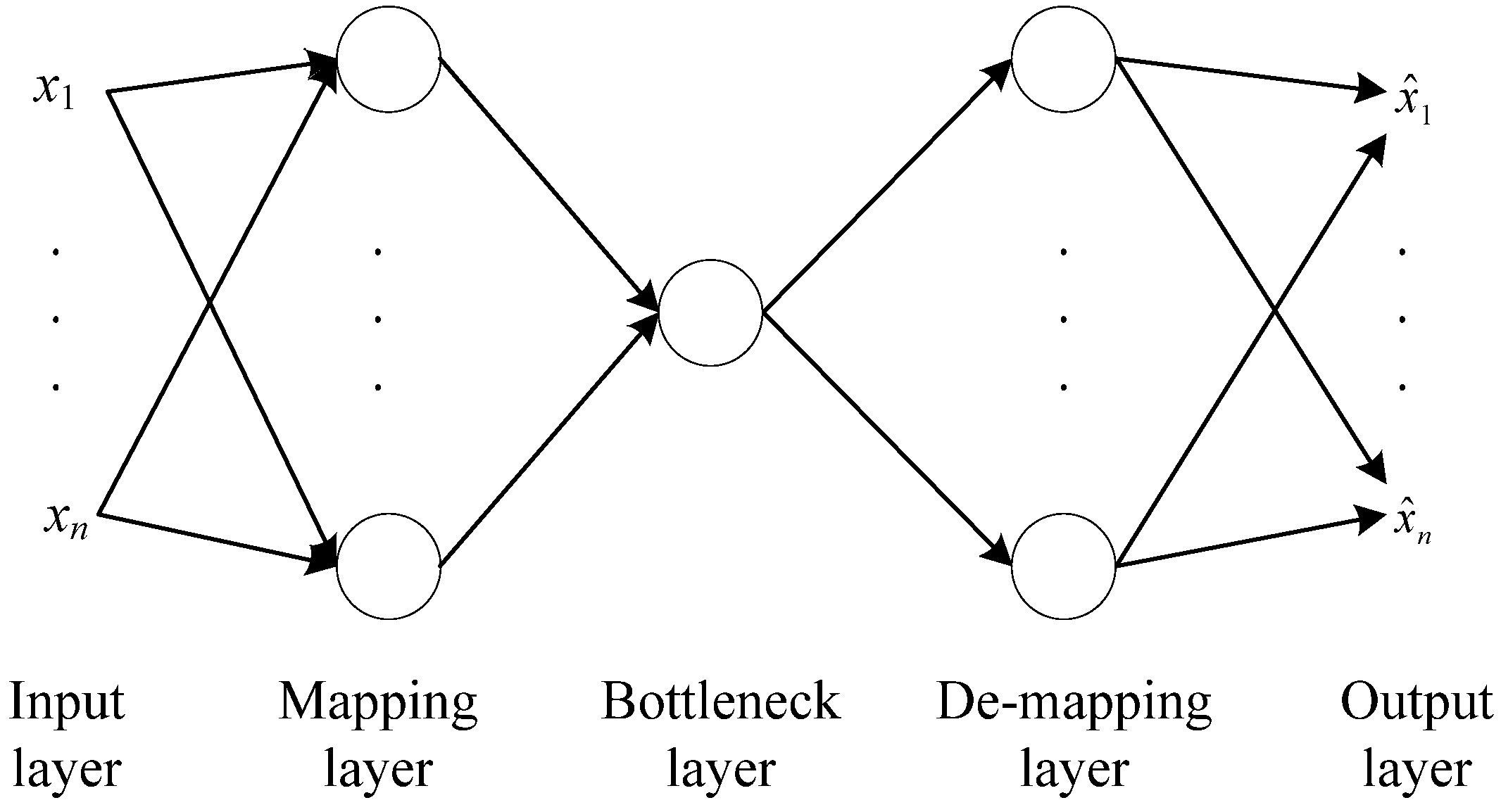
3.2. Auto-Associative Neural Networks (AANN) Model
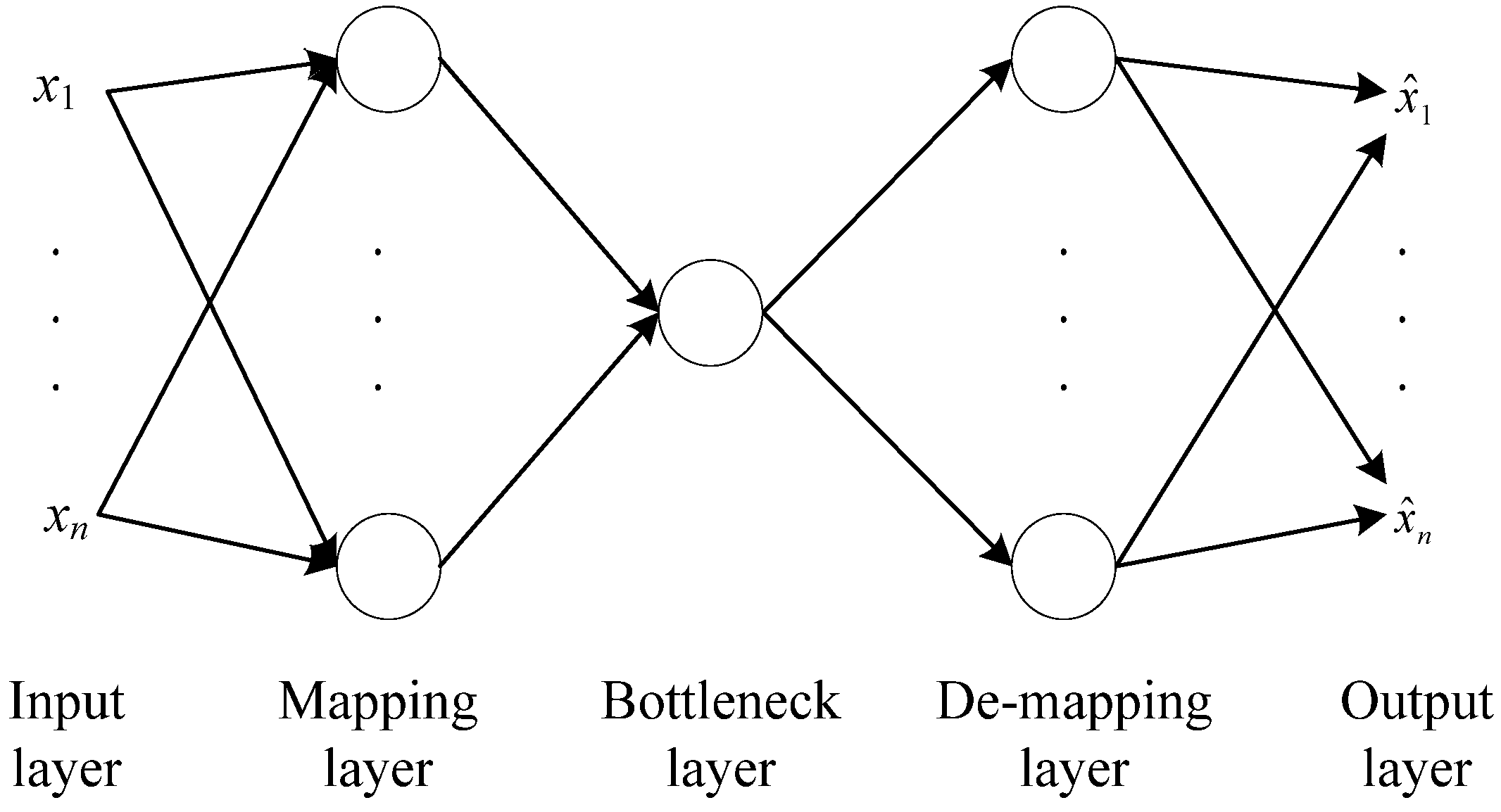
3.3. Hotelling T2 Control Charts
4. Results and Discussion
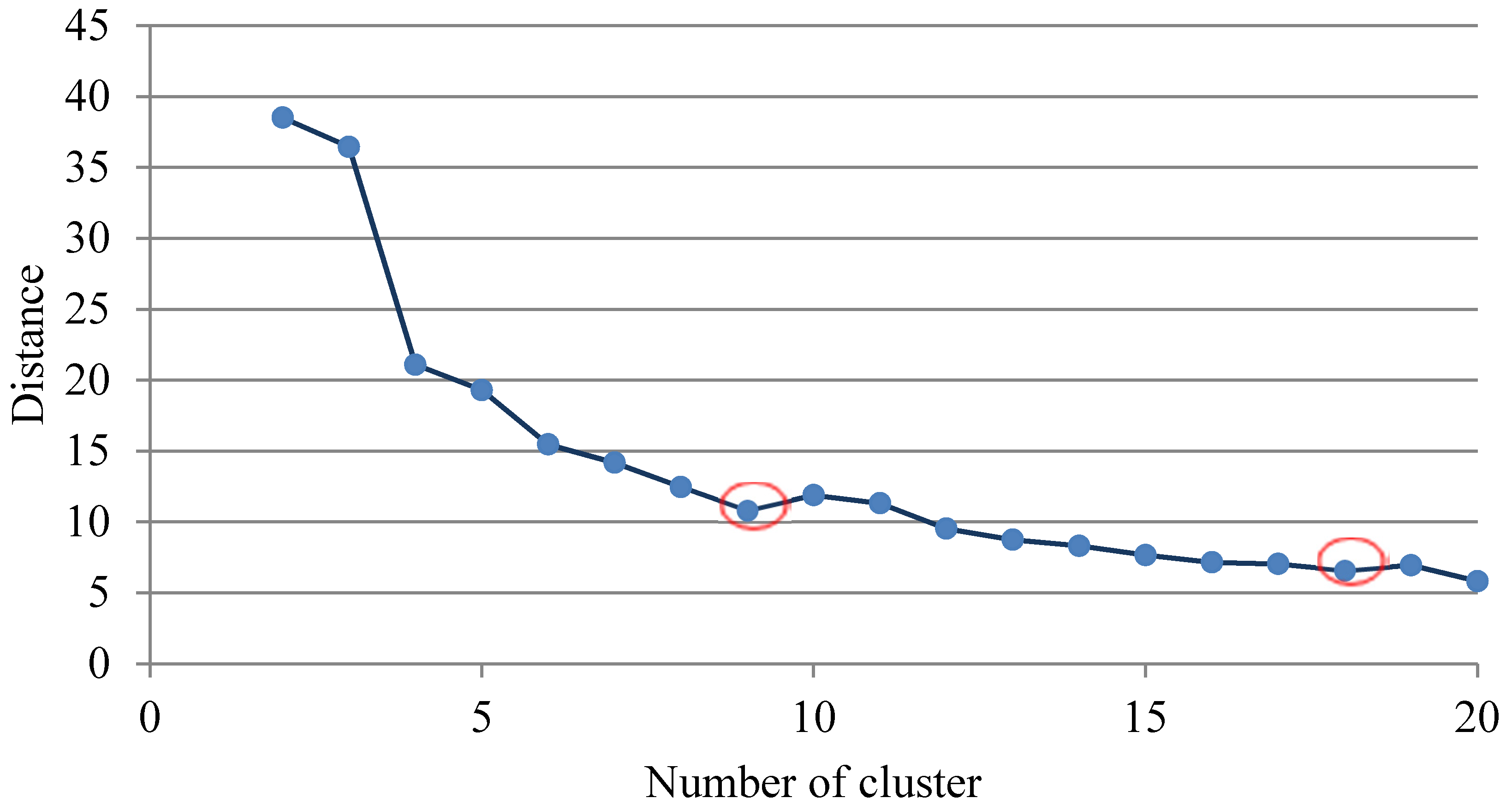
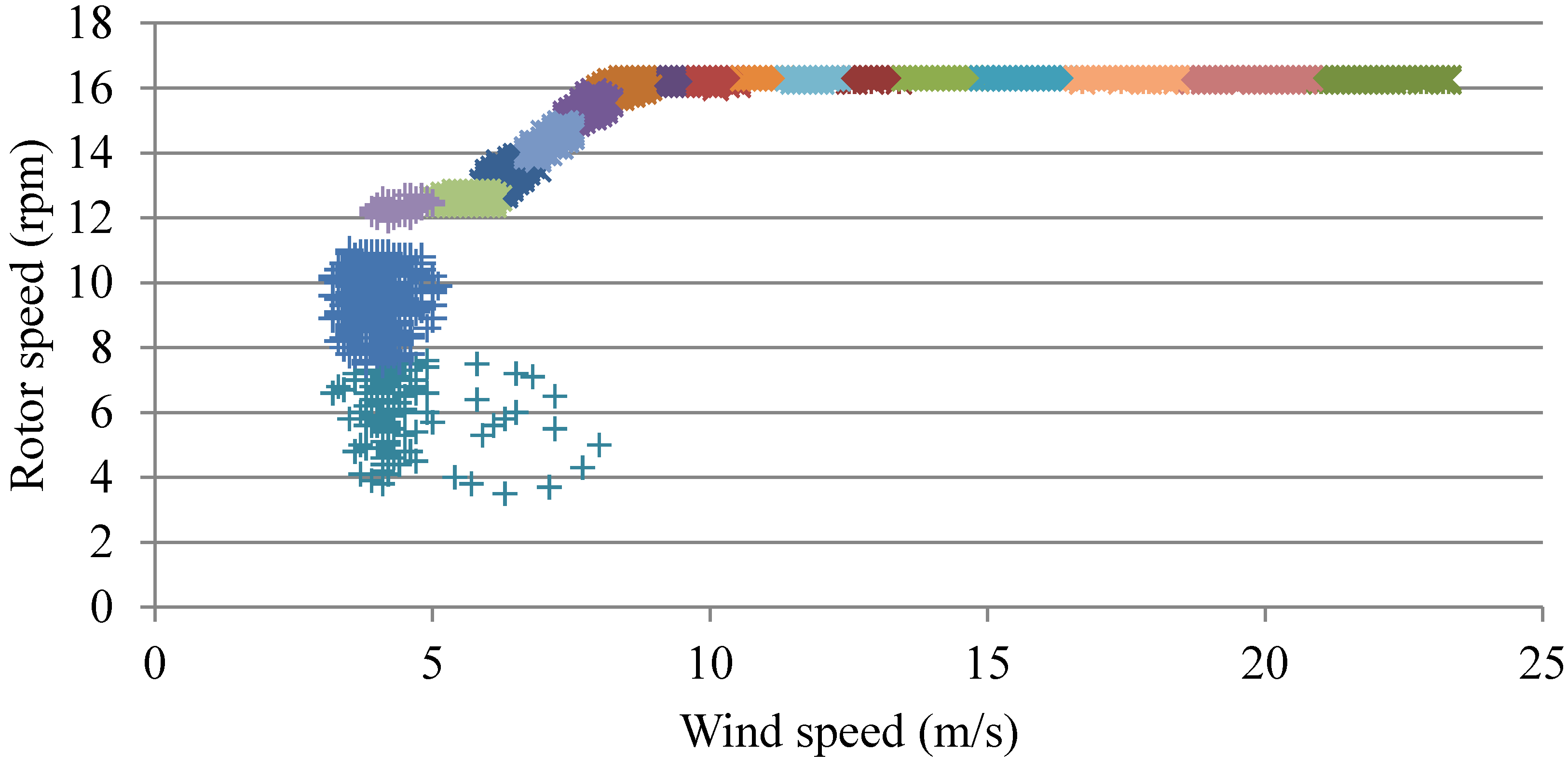
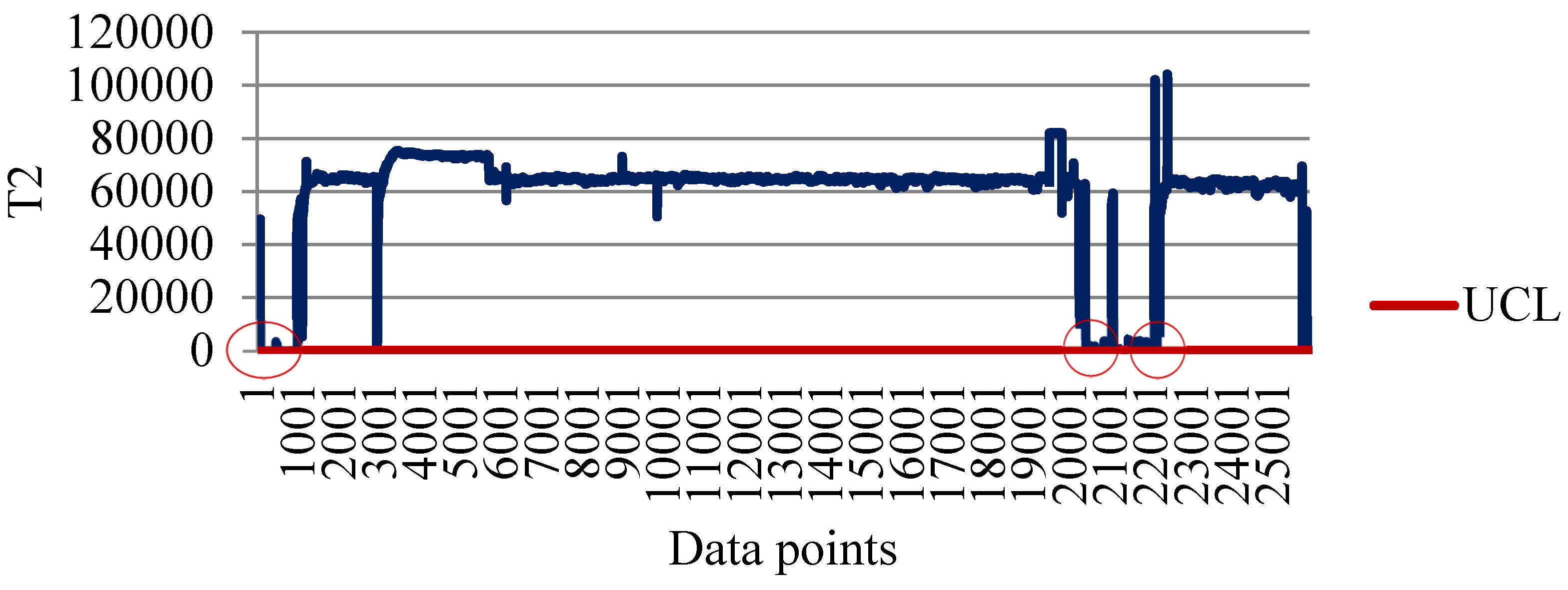
4.1. Clustering for Processing Outliers
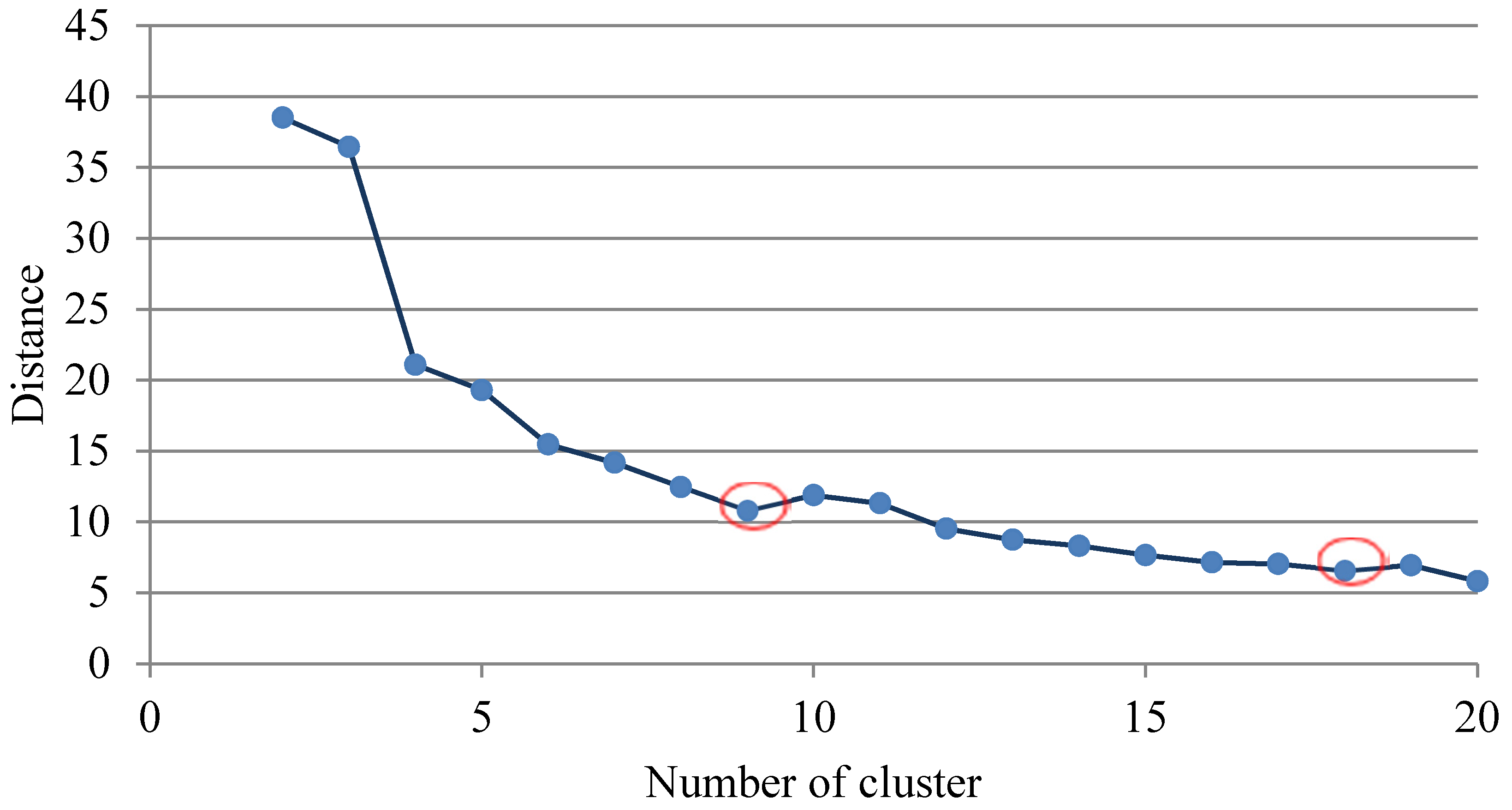
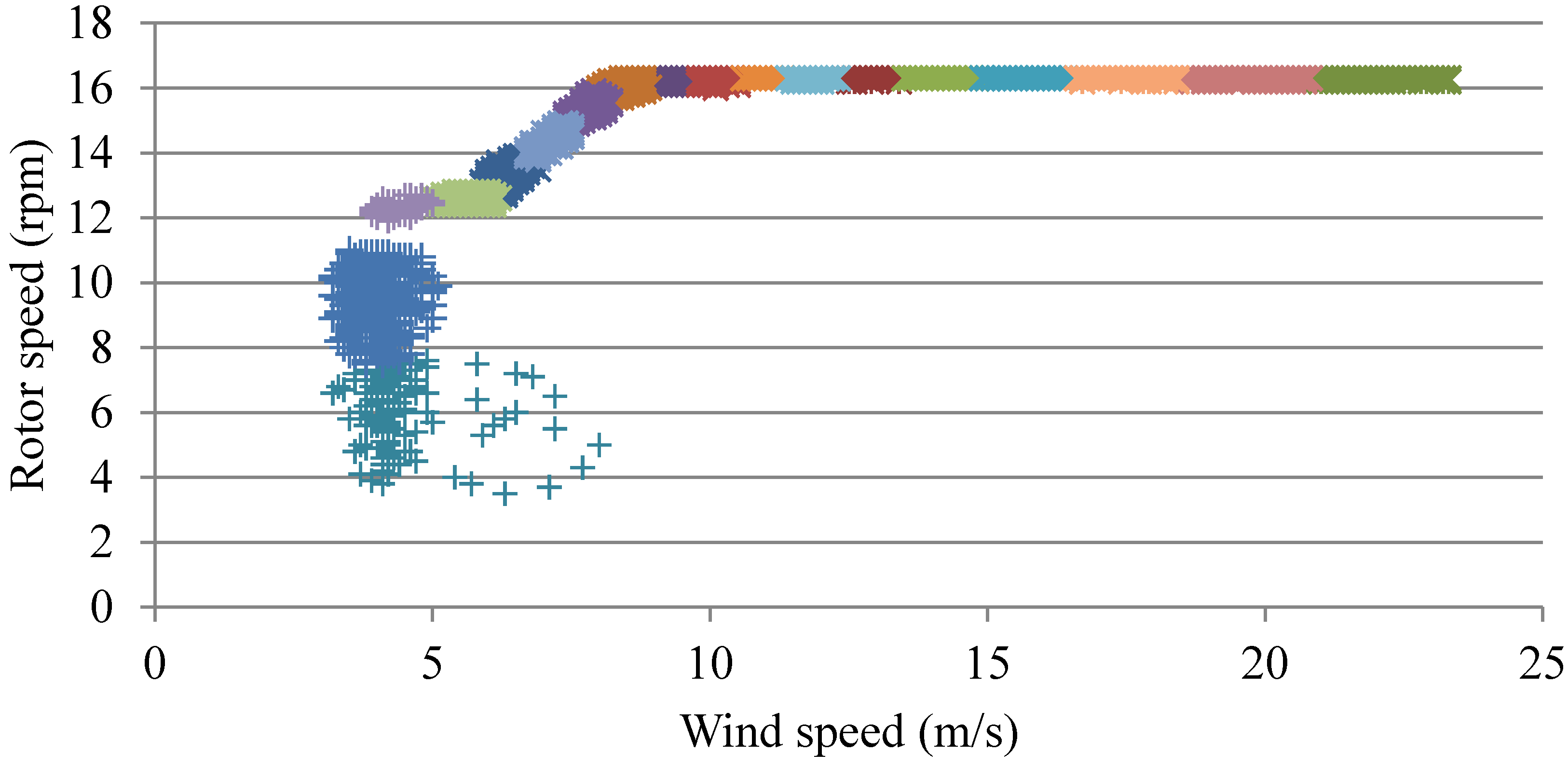
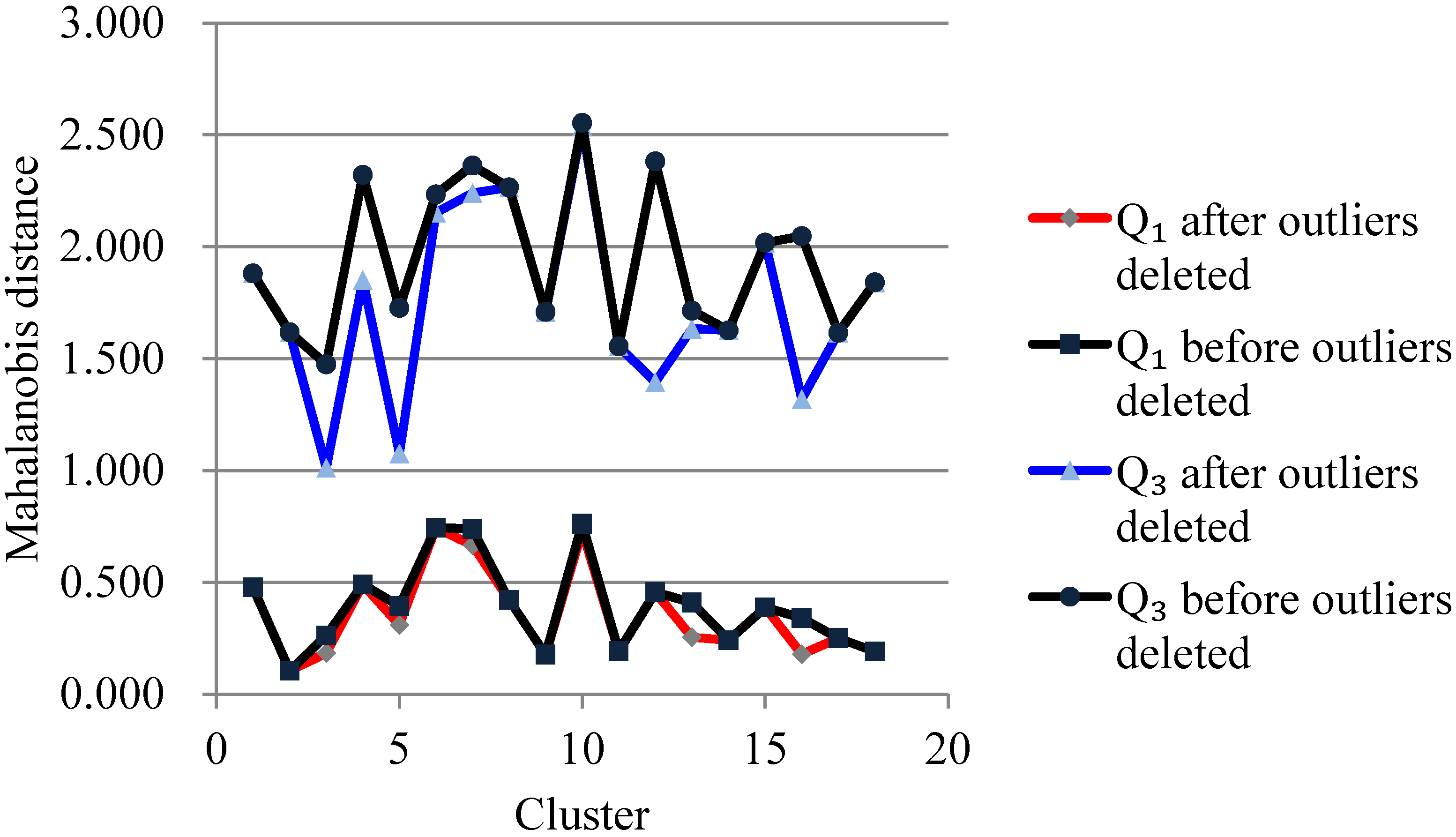
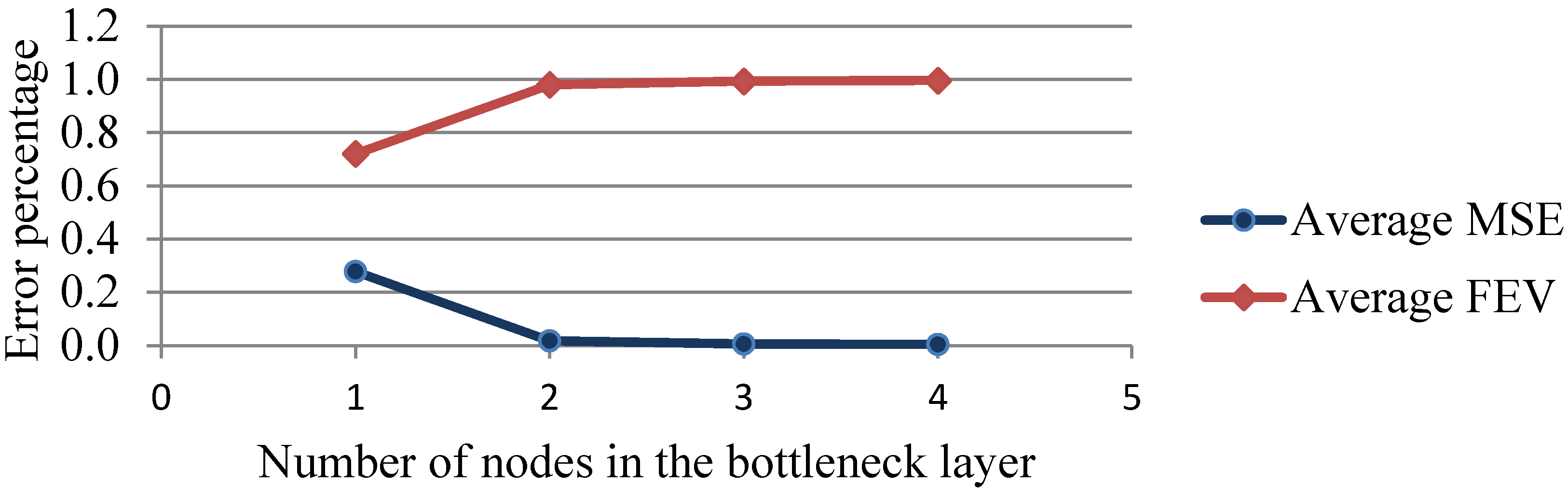
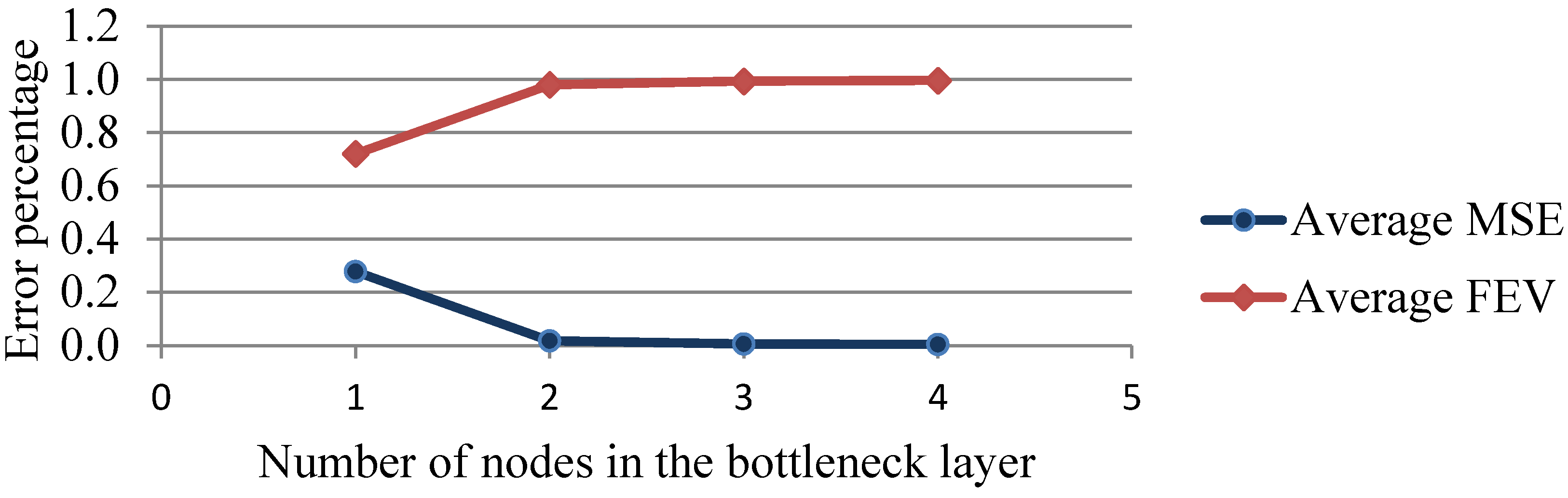
4.2. Training AANN
| Structure | Mean Square Error (MSE) | Fraction of Explained Variance (FEV) |
|---|---|---|
| 8-9-1-9-8 | 0.3211 | 0.6805 |
| 8-10-1-10-8 | 0.2704 | 0.7292 |
| 8-11-1-11-8 | 0.1911 | 0.8015 |
| 8-12-1-12-8 | 0.3285 | 0.6713 |
| 8-9-2-9-8 | 0.0139 | 0.9843 |
| 8-10-2-10-8 | 0.0167 | 0.9809 |
| 8-11-2-11-8 | 0.0183 | 0.9764 |
| 8-12-2-12-8 | 0.0205 | 0.9783 |
| 8-9-3-9-8 | 0.0063 | 0.9938 |
| 8-10-3-10-8 | 0.0062 | 0.9915 |
| 8-11-3-11-8 | 0.0060 | 0.9926 |
| 8-12-3-12-8 | 0.0050 | 0.9946 |
| 8-9-4-9-8 | 0.0050 | 0.9960 |
| 8-10-4-10-8 | 0.0052 | 0.9943 |
| 8-11-4-11-8 | 0.0022 | 0.9974 |
| 8-12-4-12-8 | 0.0035 | 0.9965 |
| Number of Nodes in the Bottleneck Layer | Average MSE | Average FEV |
|---|---|---|
| 1 | 0.2778 | 0.7206 |
| 2 | 0.0173 | 0.9800 |
| 3 | 0.0059 | 0.9931 |
| 4 | 0.0040 | 0.9961 |
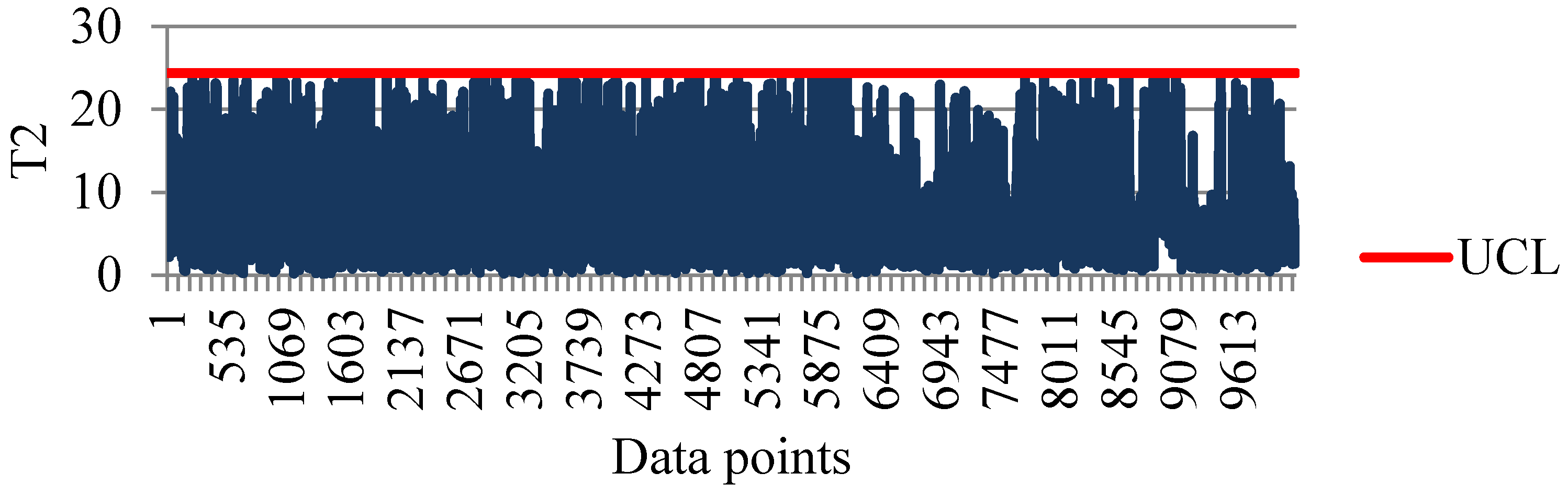
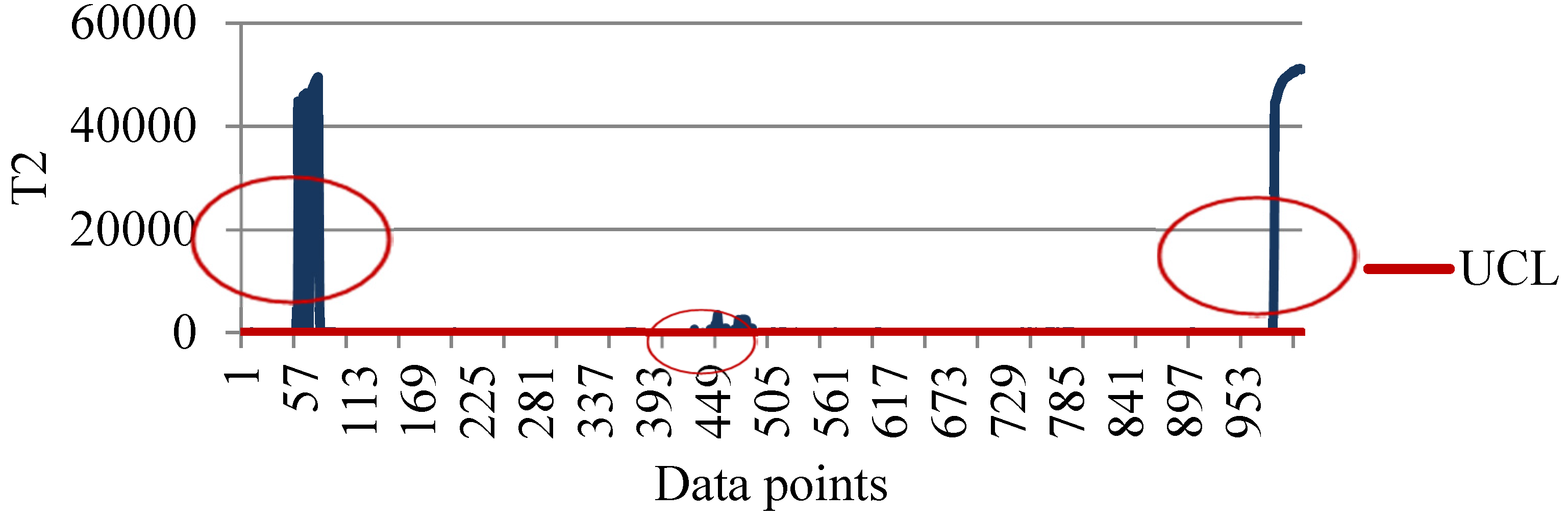
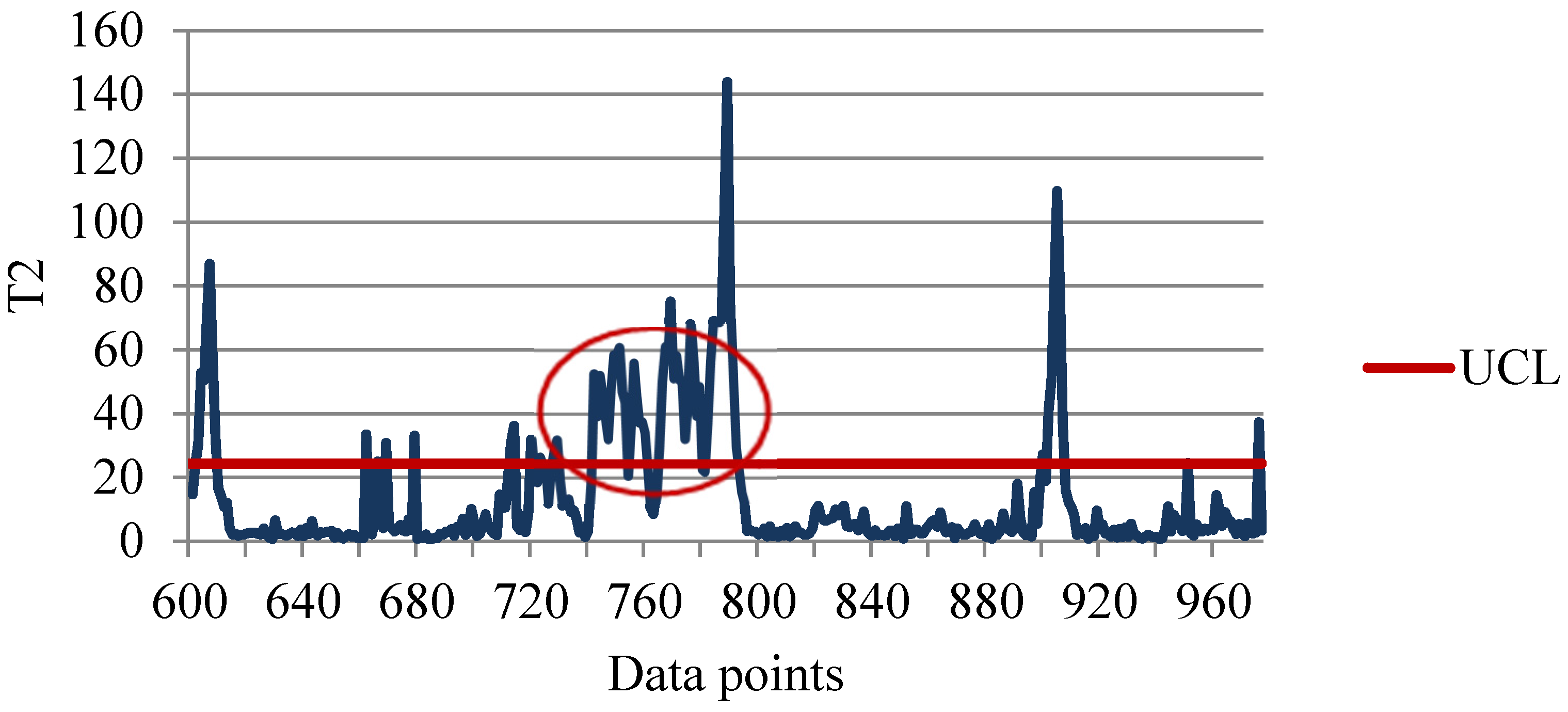
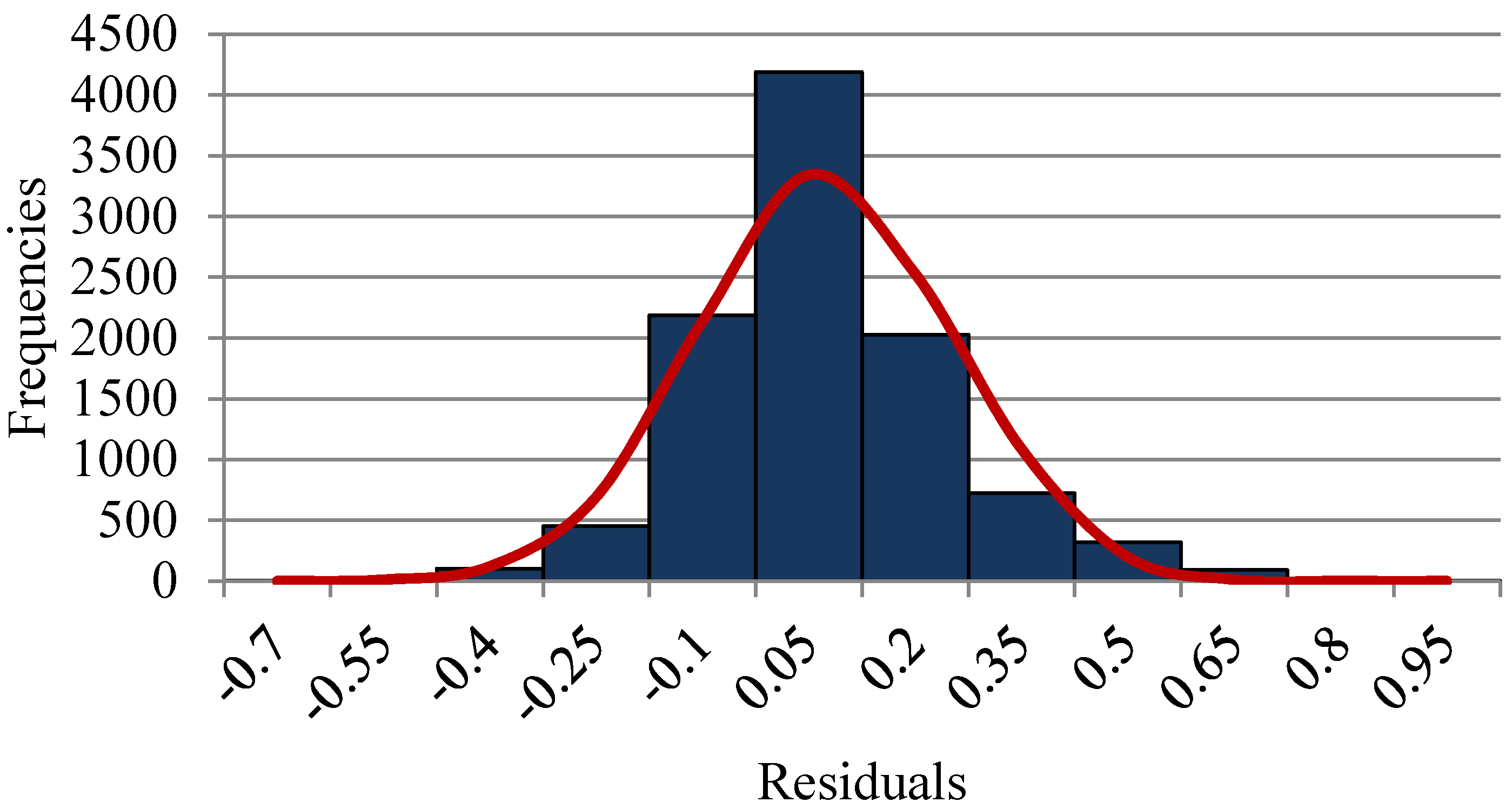
4.3. Constructing Hotelling T2 Control Charts
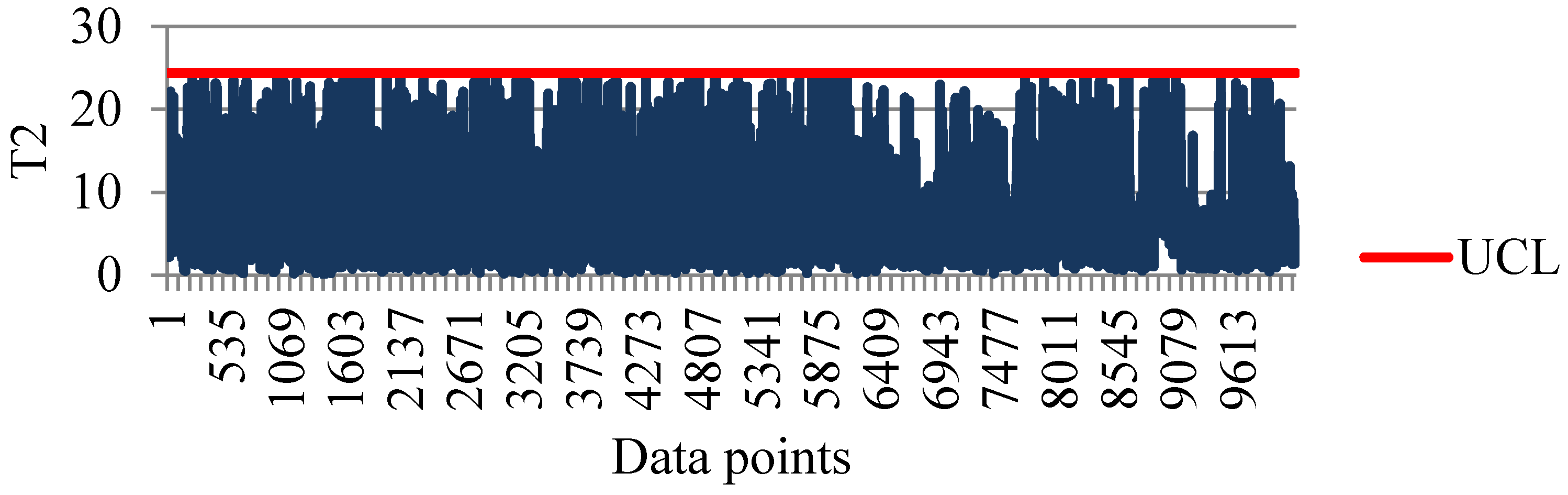
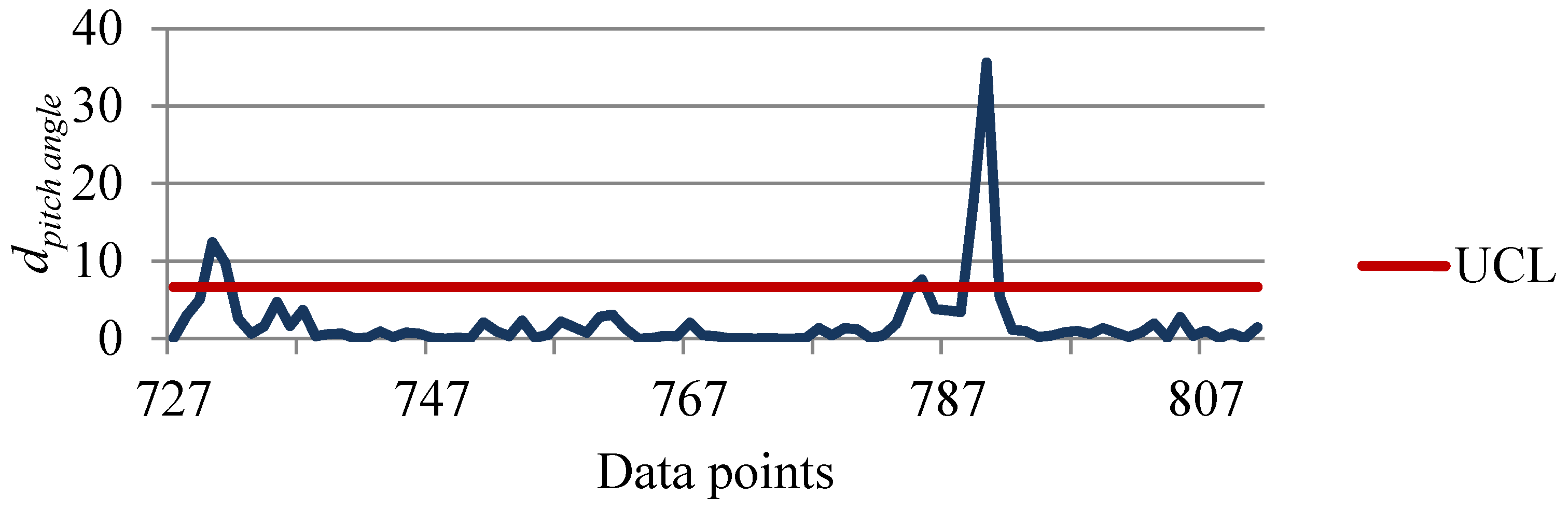
4.4. Detecting Potential Attributes Contributing to Faults


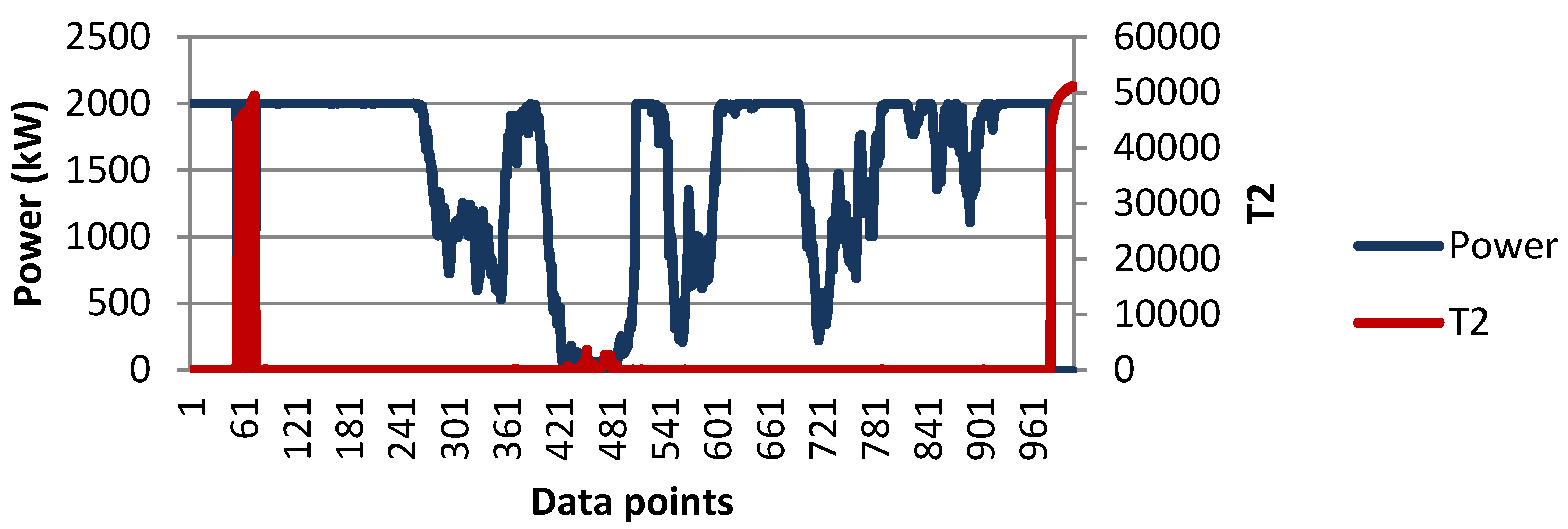
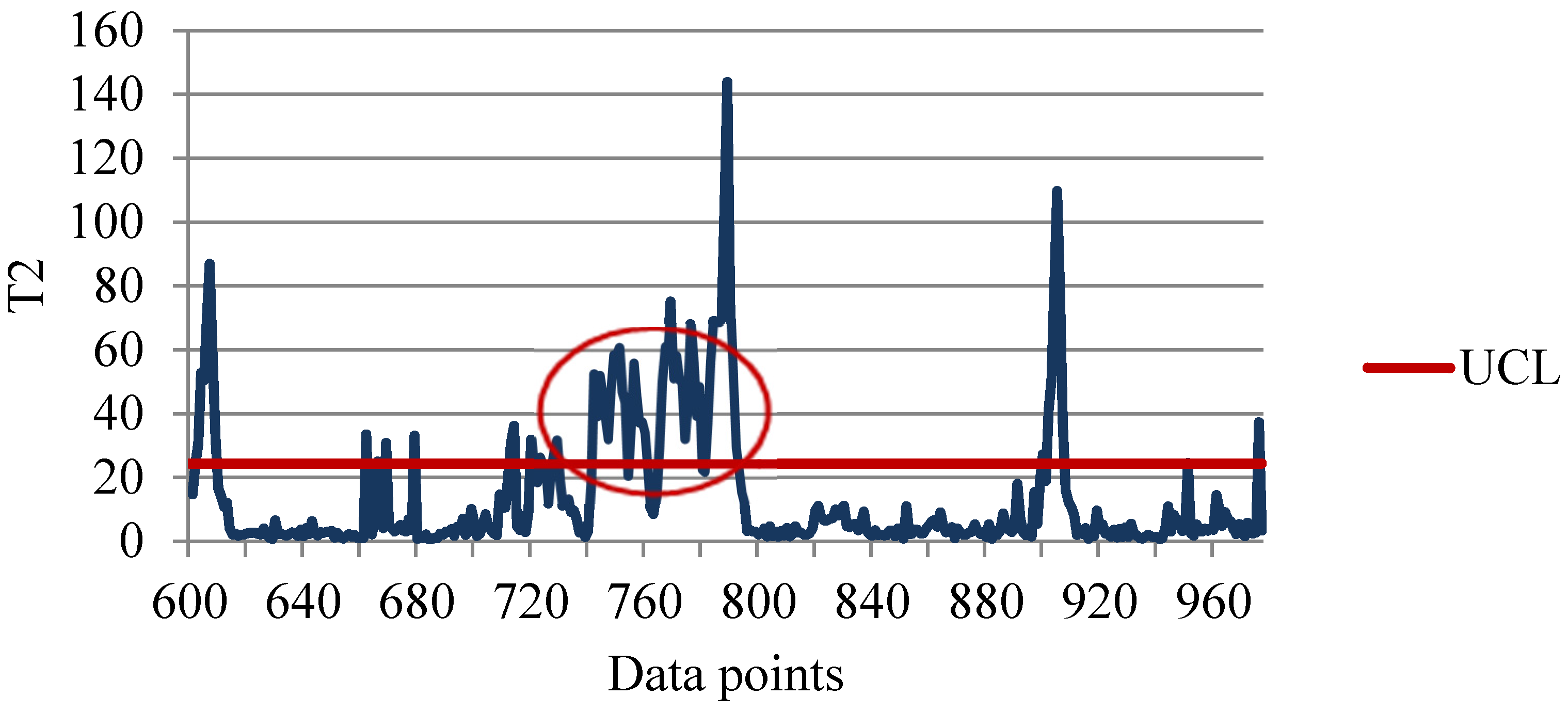
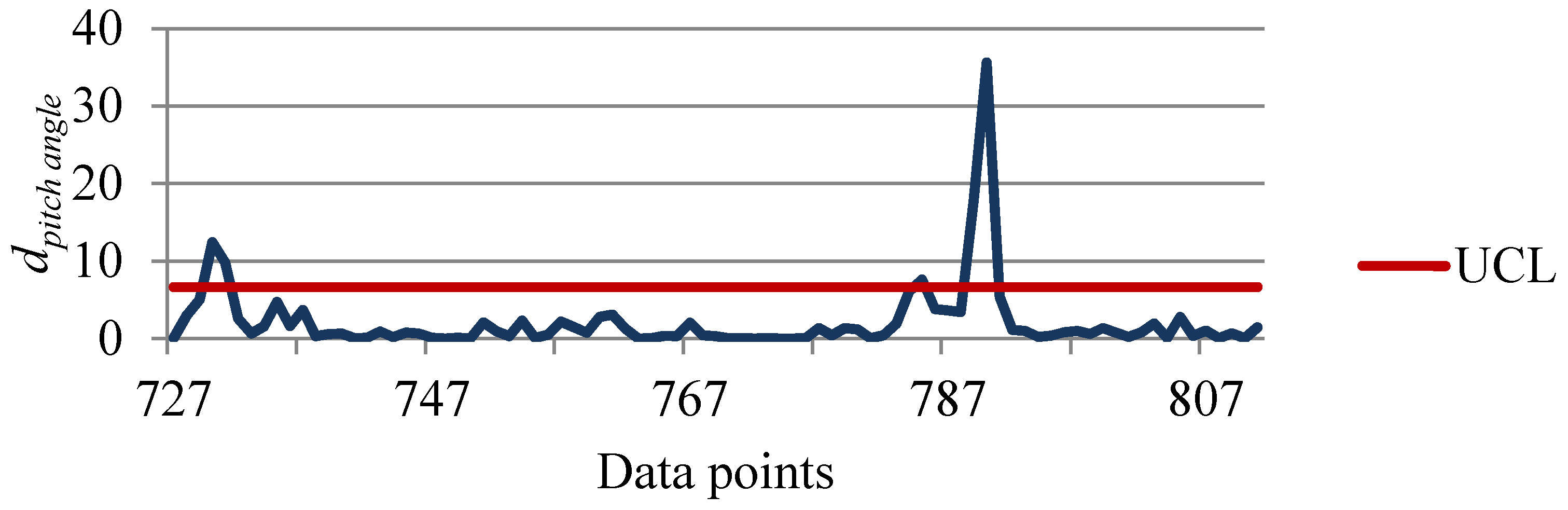
4.5. Advantages of Obtained Results Using the Proposed Methodology
| Period | Potential Attributes | Identified Component |
|---|---|---|
| 1–7 January 2009 | ABF | Undetermined |
| 22–27 May 2009 | ABCD | Generator |
| 1–4 June 2009 | ABDC | Generator |
| 29 June–8 July 2009 | ABDC | Generator |
| 18–20 July 2009 | ABCD | Generator |
| 26–30 July 2009 | BCD | Undetermined |
| 2–10 August 2009 | ABCD | Generator |
| 31 August–4 September 2009 | ABCD | Generator |
| 10–14 September 2009 | BCDA | Generator |
| 28–29 September 2009 | BCAD | Blade pitch |
| 15–24 October 2009 | ABCD | Undetermined |
| 10–13 November 2009 | ABDC | Blade pitch |
| 28–30 November 2009 | ABDC | Undetermined |
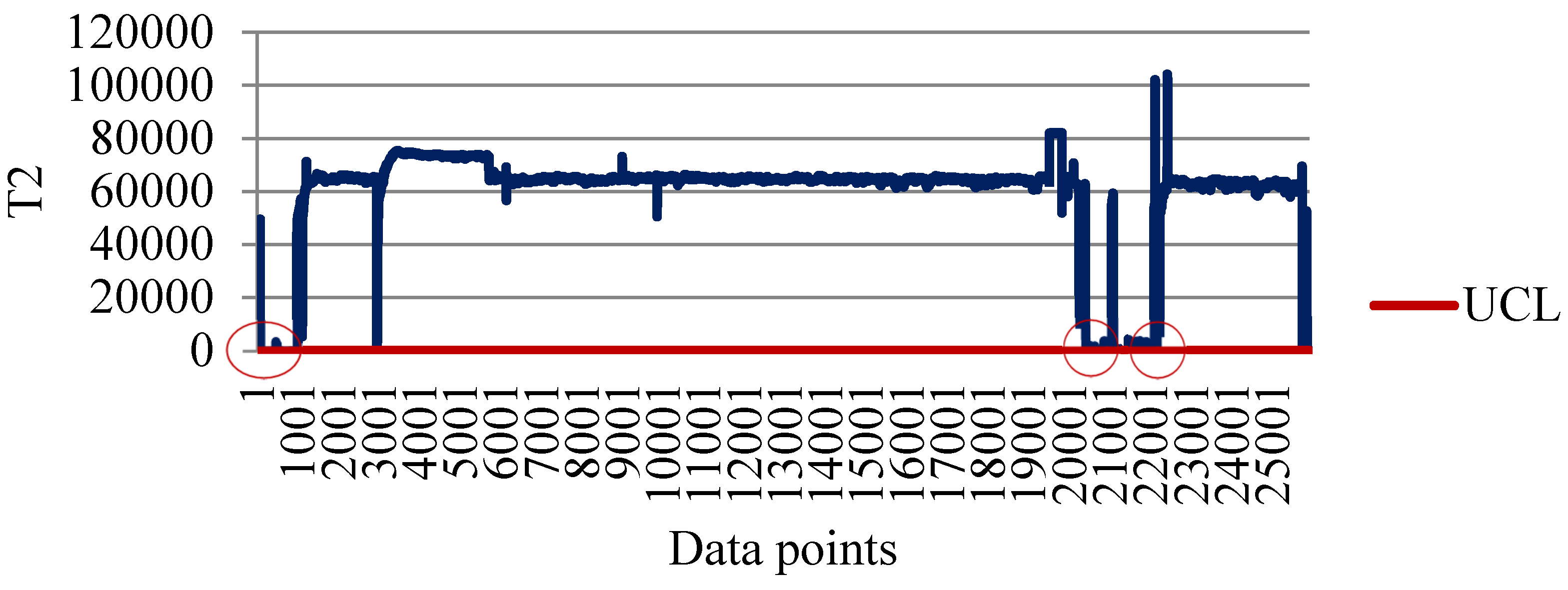
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tchakoua, P.; Wamkeue, R.; Ouhrouche, M.; Slaoui-Hasnaoui, F.; Tameghe, T.A.; Ekemb, G. Wind turbine condition monitoring: State-of-the-art review, new trends, and future challenges. Energies 2014, 7, 2595–2630. [Google Scholar]
- Kusiak, A.; Zhang, Z.; Verma, A. Prediction, operations, and condition monitoring in wind energy. Energy 2013, 60, 1–12. [Google Scholar] [CrossRef]
- Márquez, F.P.G.; Tobias, A.M.; Pérez, J.M.P.; Papaelias, M. Condition monitoring of wind turbines: Techniques and methods. Renew. Energy 2012, 46, 169–178. [Google Scholar] [CrossRef]
- Kusiak, A.; Verma, A. Monitoring wind farms with performance curves. IEEE Trans. Sustain. Energy 2013, 4, 192–199. [Google Scholar] [CrossRef]
- Montgomery, D.C. Introduction to Statistical Quality Control, 7th ed.; Wiley: New York, NY, USA, 2013. [Google Scholar]
- Yang, H.-H.; Huang, M.-L.; Huang, P.-C. Detection of wind turbine faults using a data mining approach. J. Energy Eng. 2015. [Google Scholar] [CrossRef]
- Yampikulsakul, N.; Byon, E.; Huang, S.; Sheng, S.; You, M. Condition monitoring of wind power system with nonparametric regression analysis. IEEE Trans. Energy Convers. 2014, 29, 288–299. [Google Scholar]
- Marvuglia, A.; Messineo, A. Monitoring of wind farms’ power curves using machine learning techniques. Appl. Energy 2012, 98, 574–583. [Google Scholar] [CrossRef]
- Kusiak, A.; Zheng, H.; Song, Z. Models for monitoring wind farm power. Renew. Energy 2009, 34, 583–590. [Google Scholar] [CrossRef]
- Kusiak, A.; Zheng, H.; Song, Z. On-line monitoring of power curves. Renew. Energy 2009, 34, 1487–1493. [Google Scholar] [CrossRef]
- Kramer, M.A. Nonlinear principal component analysis using auto-associative neural networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- Bayba, A.J.; Siegel, D.N.; Tom, K. Application of Auto-Associative Neural Networks to Health Monitoring of the CAT 7 Diesel Engine; ARL-TN-0472; U.S. Army Research Laboratory: Adelphi, MD, USA, 2012. [Google Scholar]
- Muthuraman, S.; Twiddle, J.; Singh, M.; Connolly, N. Condition monitoring of SSE gas turbines using artificial neural networks. Insight 2012, 54, 436–439. [Google Scholar] [CrossRef]
- Uluyol, O.; Parthasarathy, G. Multi-Turbine Associative Model for Wind Turbine Performance Monitoring. In Proceedings of the Annual Conference of the Prognostics and Health Management Society, Minneapolis, MN, USA, 23–27 September 2012.
- Kim, K.; Parthasarathy, G.; Uluyol, O.; Foslien, W.; Sheng, S.; Fleming, P. Use of SCADA Data for Failure Detection in Wind Turbines. In Proceedings of the Energy Sustainability Conference and Fuel Cell Conference, Washington, DC, USA, 7–10 August 2011.
- Schlechtingen, M.; Santos, I.F. Comparative analysis of neural network and regression based condition monitoring approaches for wind turbine fault detection. Mech. Syst. Signal Process. 2011, 25, 1849–1875. [Google Scholar] [CrossRef]
- Worden, K.; Staszewski, W.J.; Hensman, J.J. Natural computing for mechanical systems research: A tutorial overview. Mech. Syst. Signal Process. 2011, 25, 4–111. [Google Scholar] [CrossRef]
- Santos, P.; Villa, L.F.; Reñones, A.; Bustillo, A.; Maudes, J. An SVM-based solution for fault detection in wind turbines. Sensors 2015, 15, 5627–5648. [Google Scholar] [CrossRef] [PubMed]
- Kusiak, A.; Zhang, Z. Short-horizon prediction of wind power: A data-driven approach. IEEE Trans. Energy Convers. 2010, 25, 1112–1122. [Google Scholar] [CrossRef]
- Zaher, A.; McArthur, S.D.J.; Infield, D.G.; Patel, Y. Online wind turbine fault detection through automated SCADA data analysis. Wind Energy 2009, 12, 574–593. [Google Scholar] [CrossRef]
- Schlechtingen, M.; Santos, I.F.; Achiche, S. Wind turbine condition monitoring based on SCADA data using normal behavior models. Part 1: System description. Appl. Soft Comput. 2013, 13, 259–270. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3th ed.; Morgan Kaufmann Publishers: Waltham, MA, USA, 2011. [Google Scholar]
- Kerschen, G.; Golinval, J.-C. Feature extraction using auto-associative neural networks. Smart Mater. Struct. 2004, 13, 211–219. [Google Scholar] [CrossRef]
- Sanz, J.; Perera, R.; Huerta, C. Fault diagnosis of rotating machinery based on auto-associative neural networks and wavelet transforms. J. Sound Vib. 2007, 302, 981–999. [Google Scholar] [CrossRef]
- Dervilis, N.; Choi, M.; Taylor, S.G.; Barthorpe, R.J.; Park, G.; Farrar, C.R.; Worden, K. On damage diagnosis for a wind turbine blade using pattern recognition. J. Sound Vib. 2014, 333, 1833–1850. [Google Scholar] [CrossRef]
- Bulunga, M.L. Change-point Detection in Dynamical Systems Using Auto-Associative Neural Networks. Master’s Thesis, Faculty of Engineering, Stellenbosch University, Stellenbosch, South Africa, March 2012. [Google Scholar]
- Harrou, F.; Nounou, M.N.; Nounou, H.N.; Madakyaru, M. Statistical fault detection using PCA-based GLR hypothesis testing. J. Loss Prevent. Proc. 2013, 26, 129–139. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.-H.; Huang, M.-L.; Yang, S.-W. Integrating Auto-Associative Neural Networks with Hotelling T2 Control Charts for Wind Turbine Fault Detection. Energies 2015, 8, 12100-12115. https://doi.org/10.3390/en81012100
Yang H-H, Huang M-L, Yang S-W. Integrating Auto-Associative Neural Networks with Hotelling T2 Control Charts for Wind Turbine Fault Detection. Energies. 2015; 8(10):12100-12115. https://doi.org/10.3390/en81012100
Chicago/Turabian StyleYang, Hsu-Hao, Mei-Ling Huang, and Shih-Wei Yang. 2015. "Integrating Auto-Associative Neural Networks with Hotelling T2 Control Charts for Wind Turbine Fault Detection" Energies 8, no. 10: 12100-12115. https://doi.org/10.3390/en81012100