3.1. Disturbance Attenuation and Convergence
This subsection focuses on solving the first part of Problem 1, i.e., finding a proper observer gain L such that (10) is an L2 disturbance attenuation observer if disturbance w ≠ O, and is globally convergent if w ≡ O. The result is summarized as following Theorem 1, which is the first main result of this paper.
Theorem 1.
Consider state-observer (10) of MHTGR dynamics (5). Suppose that observer gain matrix
F of observer (10) takes the form as:
where both
F1 and
F2 are positive scalars. Choose the evaluation signal corresponding to observer (10) as:
where
e1 and
e3 are defined in equation (11). Since δ
ρr0 = 0, it is not loss of generality to assume that:
where
,
x4,0 and δ
ρr0 are the initial values of
,
x4 and δ
ρr respectively. Then, state-observer (10) is an
L2 disturbance attenuation observer when
w ≠
O if:
- (a)
, and
- (b)
both positive scalars F1 and F2 are large enough.
Proof:
Substituting (19) into the observation error dynamics (12), and it is easy to see that:
From assumption (21) and the 4
th equation of (22), we have:
Substituting Equation (23) into (22), we can obtain that:
It is clear that the first two equations of (24) govern the observation error dynamics related to thermal-hydraulics of the MHTGR, and the other two equations is related to the neutron kinetics.
Choosing the Lyapunov function corresponding to the first two equations of (24) as:
and differentiating (25) along the trajectory given by the first two equations of (24):
To formulate the Lyapunov function for the entire observation error dynamics, we need to analyze the property of term
e1e3 in the following. Differentiate
e1e3 along the trajectory determined by (24), and we can see that:
From differential Equation (27), we have:
where
c0 is the initial value of term
e1e3, and:
Suppose observer gains
L1 and
L2 are large enough so that:
and:
where both
ε1 and
ε2 are positive scalars.
Substituting inequalities (30) and (31) into (28):
where σ ∈ (0,
t).
From inequality (32), if:
it is clear that
e1e3 < 0. Further, if:
then, from inequality (32), it is clear that
e1e3 < 0 when:
Since the inlet and outlet helium temperatures of the MHTGR can be measured, it is feasible to set:
i.e.:
where
e10 and
e30 are the initial values of
e1 and
e3 respectively. Based upon (33) and (34), it is so clear that
e1e3 < 0 for any
t > 0 if inequality (31) is satisfied. Since
e1e3 can be negative definite for any
t > 0, it is then possible for us to construct the whole Lyapunov function and guarantee the
L2 disturbance attenuation performance for observer (10). The detail derivation is given as follows.
If we choose the Lyapunov function for the entire observation error dynamics as:
and then differentiate it along the trajectory given by the observation error dynamics:
For the MHTGR, we have the following physical relationship,
i.e.:
It is natural to assume that:
and then from the negative definite property of
e1e3, there must be a large enough
F1 satisfying:
where
ε3 is a positive scalar.
Based upon inequalities (36), (38) and (39), we have:
From Definition 1, we can see that observer (10) has the performance of F2 disturbance attenuation, which completes the proof of this theorem. ☐
Remark 1:
Here, it is clear that if
e1 ≠ 0 (
t > 0), then there must exist a gain
F2 such that inequality (31) is well satisfied. Otherwise, substitute
e1 = 0 (
t > 0) to the first two equations of (24):
Since the dynamics of δ
Tdin are related directly with the variations of the outlet helium temperature and the mean steam temperature in the secondary loop of the steam generator, which means that it has no direct relationship with
e3 and δ
Tr, Equation (41) can be only satisfied if δ
Tdin = δ
Tr =
e3 = 0, which contradicts with
w ≠
O. Thus, it is no loss of generality to suppose that there exists a large enough
F2 such that inequality (31) is satisfied. ☐
Remark 2:
Observer gains F1 and F2 are large enough means that inequalities (30), (31) and (39) are all satisfied. The function of F2 is to guarantee that e1e3 < 0 for any t > 0, and the function of gain L1 is to guarantee the disturbance attenuation performance of observer (10). Moreover, from inequality (39), it is clear that smaller L2 gain γ needs larger observer gain F1. ☐
From Theorem 1, we know that state-observer (10) has the L2 disturbance attenuation performance when w ≠ O. The following Theorem 2, which is the second main result of this paper, gives the sufficient condition for state-observer (10) to be globally convergent.
Theorem 2.
Consider state-observer (10) of MHTGR dynamics (5) with gain matrix F taking the form as (19). Suppose (21) is well satisfied, and assume that w = O. Then observer (10) is globally convergent if conditions a) and b) in Theorem 1 are both satisfied.
Proof:
Substitute
w =
O to (24), and the observation error dynamics can then be written as:
Choose the Lyapunov function of the first two equations of (42) as (25), and differentiate it along the trajectory given by (42):
Moreover, differentiating
e1e3,
i.e.:
From (44), it is clear that:
where
c0 is the initial value of term
e1e3, and κ is also defined by (29).
In the following, we should discuss in the cases of e1 ≠ 0 and e1 = 0 for any t > 0.
If
e1 ≠ 0 (
t > 0), then there exists large enough observer gains
F1 and
F2 are so that inequalities (30) and:
where
ε4 is a positive scalar, are well satisfied, then from (45) and assumption (21), we have:
where
σ ∈ (0,
t).
Similarly to the proof of Theorem 1, we set the Lyapunov function of the entire error system (42) as (35), and then differentiate it along the trajectory given by (42):
Also, from the negative definition of
e1e3, there must exist a large enough
F1 satisfying:
where
ε5 is a positive scalar. Substitute (49) to (48), we have:
From inequality (50), Equations (23) and (42), observation error
e must be in the set defined by:
in which any
e must converge to origin. From the Lassalle’s invariance principle, observer (10) is globally convergent in the case of
e1 ≠ 0 (
t > 0).
Furthermore, if
e1 = 0 for any
t > 0, then from (42):
Then substituting the 1st equation of (52) into the other three equations, we can easily see that e1 = 0 means that the observation error e must in the set defined by (51). Also from the Lassalle’s invariance principle, observer (10) is globally convergent in the case of e1 = 0 (t > 0).
This completes the proof of Theorem 2. ☐
Remark 3:
In Theorem 2, observer gains F1 and F2 are large enough means that inequalities (30), (46) and (49) are all well satisfied. ☐
Theorems 1 and 2 give us the solution to the first part of Problem 1 raised in
Section 2,
i.e., the method of adjusting the gain matrix
F of observer (10) so that it is globally convergent in the case of
e1 = 0 (
t > 0), and is the
L2 disturbance attenuation observer in the case of
e1 ≠ 0 (
t > 0). In the following, we shall focus on whether observer (10) can recover the performance a well-designed power-level regulator of the MHTGR.
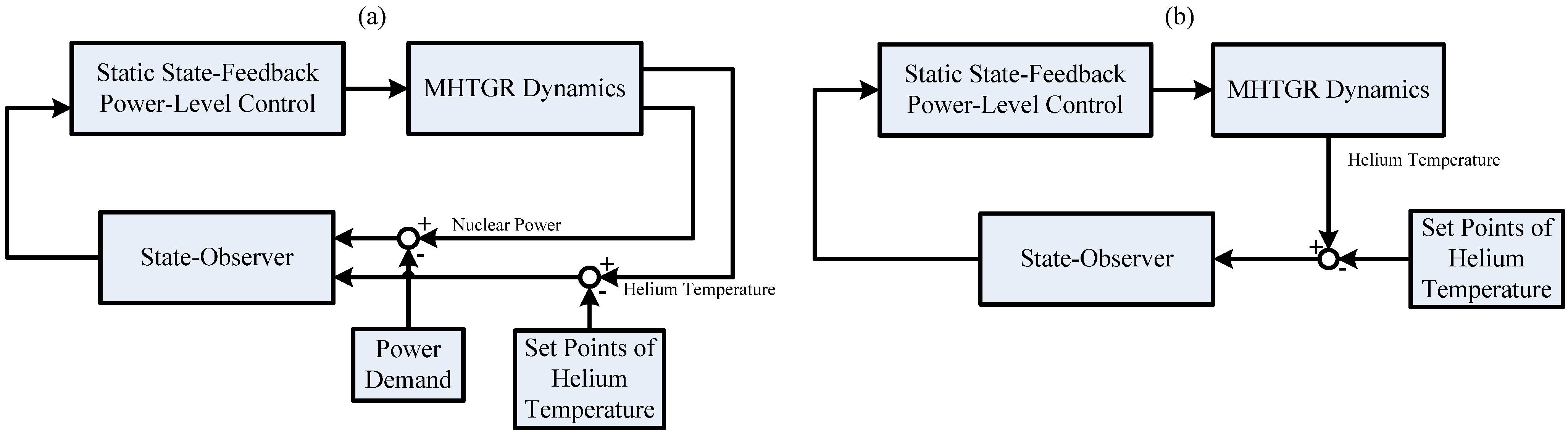
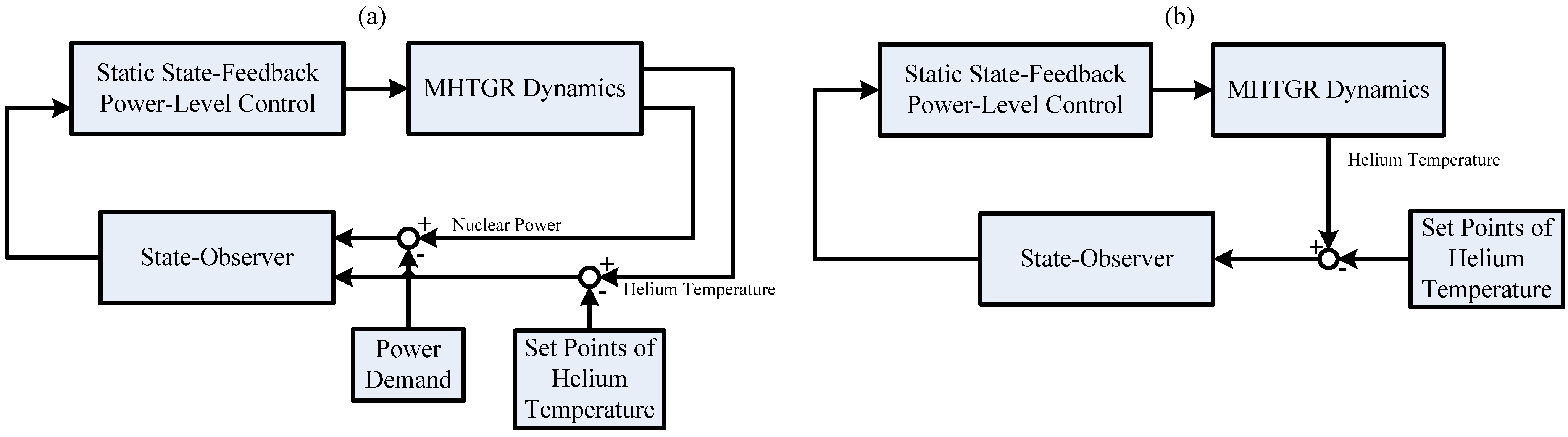
3.2. Performance Recovery
Here, observer (10) can recover the performance of a well-designed state-feedback power-level control if the dynamic output feedback power-level control strategy composed of this static state-feedback power-level regulator and observer (10) still keeps the key characteristics of this static state-feedback regulator such as the L2 disturbance attenuation performance and asymptotic stability. Before giving the theoretical result about performance recovery, the definition of L2 disturbance attenuator is given as follows:
Definition 2.
Consider nonlinear system (14) with evaluation signal defined as:
Control input
u is said to be an
L2 disturbance attenuator if there is a semi-positive smooth function
Σ(
x) such that following
ϑ-dissipation inequality:
is satisfied, where
Q(
x) is a semi-positive function, and
is a positive scalar called the
L2 gain from disturbance
w to evaluation signal
ξ. □
The following theorem, i.e., the 3rd main result of this paper tells us under what conditions can observer (10) recover the performance of an L2 disturbance attenuator.
Theorem 3.
Consider MHTGR dynamics (5) with state-observer (10), and assume that the MHTGR is in the normal power operation,
i.e.:
where both a and b are given positive scalars. Suppose that static state feedback power-level control of the MHTGR taking the form:
is an
L2 disturbance attenuator if disturbance
w ≠
O,
i.e., there exists a semi-positive differentiable function
W1 and an evaluation signal
υ =
υ(
x) such that:
where
S is a semi-positive function, and
ς is a positive scalar denoting the
L2 gain from
w to
υ. Here, we assume that there exists a positive scalar
M1 such that:
Therefore dynamic output feedback power-level control:
where observer gain matrix
F satisfies (19), is an
L2 disturbance attenuator in case of
w ≠
O, if conditions (a) and (b) in Theorem 1 are both satisfied and:
- (c)
function
Θ satisfies:
where
L is a positive scalar and
x1,
x2 R
n satisfying (55) are two state-vectors of the MHTGR dynamics.
Proof:
First, we shall prove that dynamic output feedback power-level control law (59) can recover the
L2 disturbance attenuation performance of static state-feedback controller (56) if conditions (a), (b) and (c) of this theorem are all satisfied. Since condition (a) is satisfied and observer gain
F2 is high enough, it is quite clear that from the proof of Theorem 1 that
e1e3 is definitely negative. The Lyapunov function for the entire system composed of MHTGR dynamics (5) and power-level control (59) can be chosen as:
where
Ve is determined by (35).
Differentiate
V1 along the trajectory given by (5) and (59), we have:
Further, from (60) and (58), we have:
where:
Based upon (55), ||
e||
U is definitely bounded and there must exist a large enough gain
F1 such that:
where
ε6 is a positive scalar, then:
Because of the negative definition of e1e3 and from the Definition 2, dynamic output feedback control strategy (59) is clearly an L2 disturbance attenuator. This completes the proof of Theorem 3. ☐
In the following, we shall explore whether observer (10) can recover the performance of a global asymptotic stabilizer. Before giving the result, the inverse Lyapunov lemma is introduced as follows:
Lemma 1 [
18]. Consider an autonomous nonlinear system:
where
χ ∈ R
n is the state vector,
ω:
D ⊂ R
n → R
n is local Lipchitz, and
ω(
O) =
O. Here, suppose that
χ =
O is a asymptotic stable steady point, and
RA ⊂
D is the attracting domain of
χ =
O. Therefore, for all
χ ∈
RA, there is smooth positive definite function
ϒ(
χ) and a continuous positive definite function
W(
χ) such that:
and for any
c > 0, {
ϒ(
χ) ≤
c} is a compact subset of
RA. If steady point
χ =
O is globally asymptotically stable,
i.e.,
D =
RA = R
n, then conditions (70) and (71) respectively change to:
Based upon Lemma 1, the following theorem, which is the 4th main result of this paper, gives us the sufficient condition for observer (10) to recover the performance of a globally asymptotic stabilizer.
Theorem 4.
Consider MHTGR dynamics (5) with state-observer (10), and assume that the MHTGR is in normal power operation,
i.e., (55) is satisfied. Suppose that static state feedback power-level control of the MHTGR (56) is a globally asymptotic stabilizer if disturbance
w =
O,
i.e., there is a smooth positive definite function
W2(
x) and a continuous positive definite function
E(
x) such that:
Moreover, we assume that there exists a positive scalar
M2 such that:
Therefore, dynamic output feedback power-level controller (59) is still a globally asymptotic stabilizer in case of
w ≡
O, if conditions (a) and (b) in Theorem 1 and (c) in Theorem 2 are all satisfied.
Proof:
Similarly to the proof of Theorem 3, the whole Lyapunov function can be chosen as:
where
Ve is determined by (35) whose negative definition is provided by large enough observer gain
F2.
Differentiate
V2 along the trajectory given by (5) and (59):
Substituting (60) and (76) into (78), we have:
and it is clear that there must exist a large enough
F1 such that:
where
ε7 is a positive scalar. Then, based on inequalities (79) and (80) we have:
which denotes the globally asymptotic stabilizing ability of dynamic output feedback power-level control (59). This completes the proof of Theorem 4. ☐
Remark 4:
Here, “enough high gains” is quite different from “very high gains”. Actually, in Theorem 3, observer gains F1 and F2 are high enough means that both inequalities (67) and (31) hold. Similarly, in Theorem 4, F1 and F2 are high enough means that (80) and (46) are satisfied. ☐
Remark 5:
Since we have assumed that inequality (55) holds, i.e., the MHTGR runs at the normal power operation state, it is clear that inequalities (60), (58) and (76) are all easily satisfied in a practical engineering case. ☐
Theorems 1, 2, 3 and 4 give the main properties of observer (10) with the gain matrix defined by (19),
i.e., if the observer gains are high enough, then it can recover the
L2 disturbance attenuation performance in case of
w ≠
O and provide globally asymptotic stabilization performance in case of
w =
O. Now, we have solved Problem 1 raised in
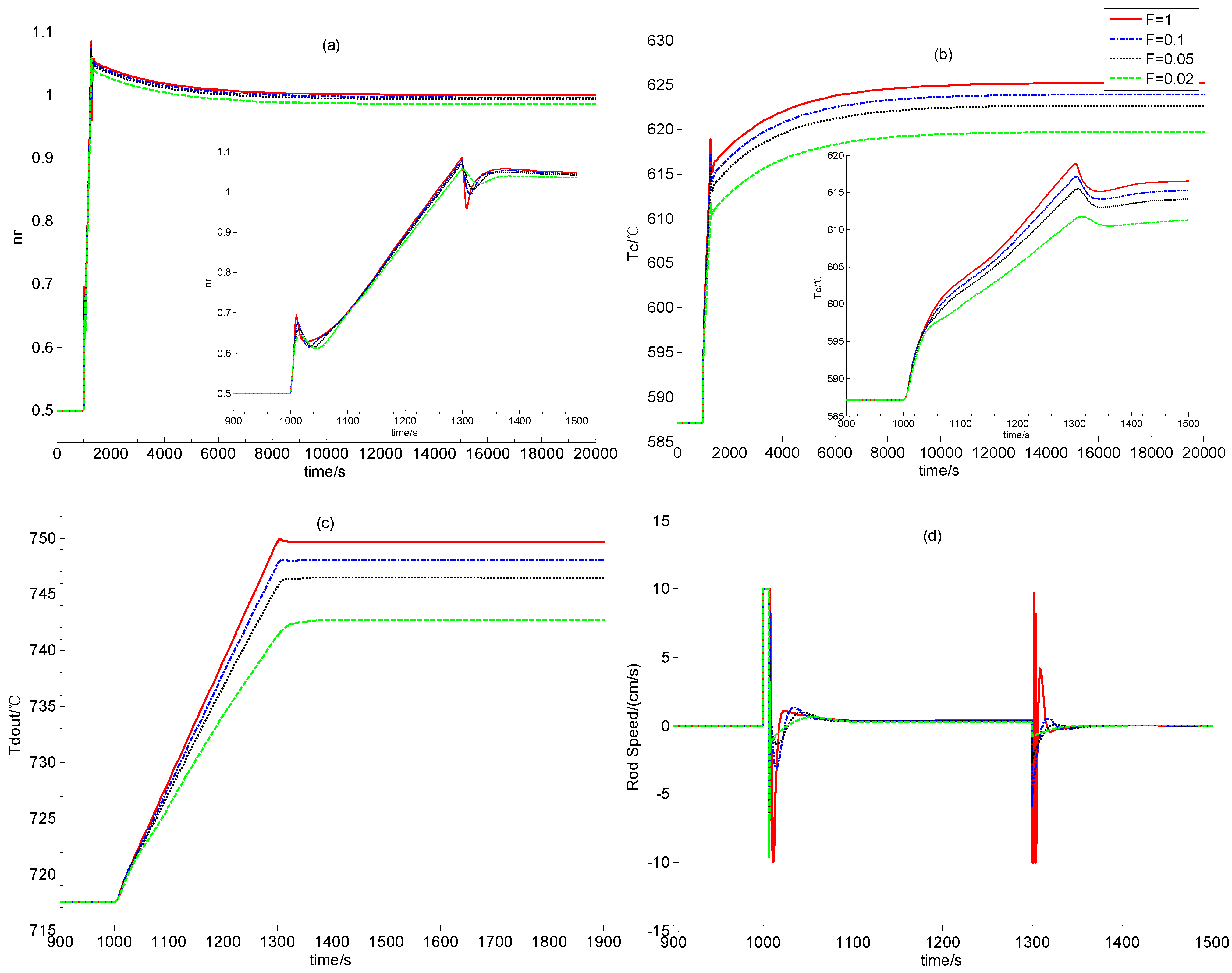
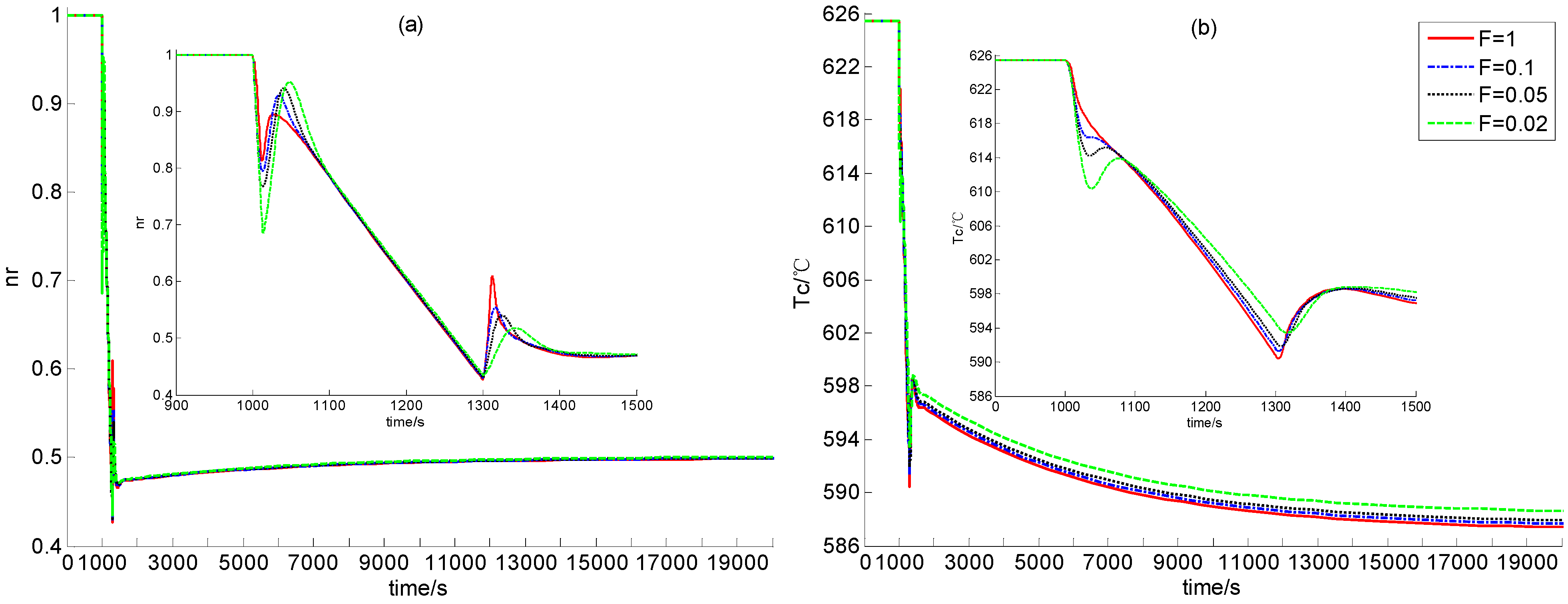
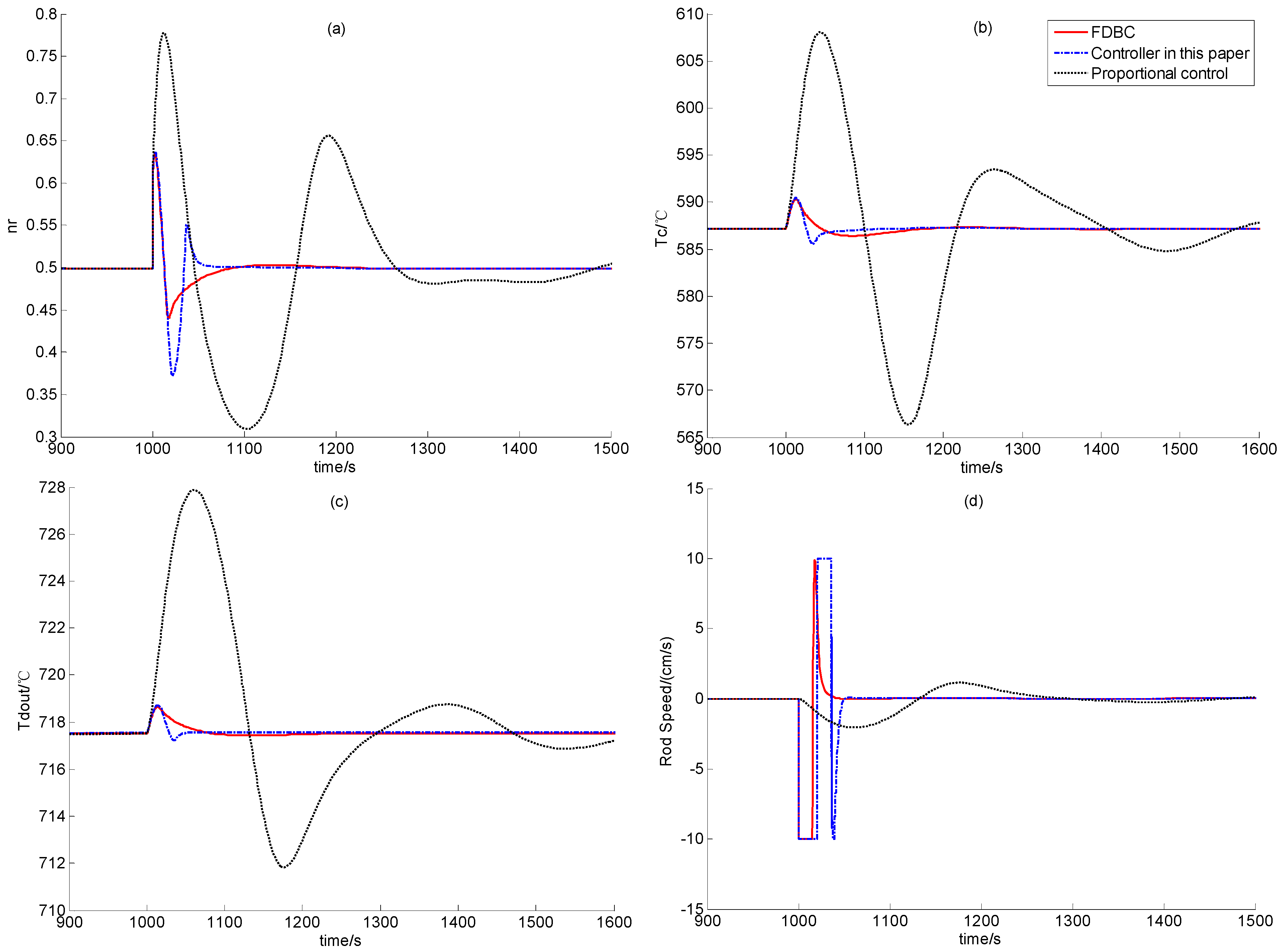
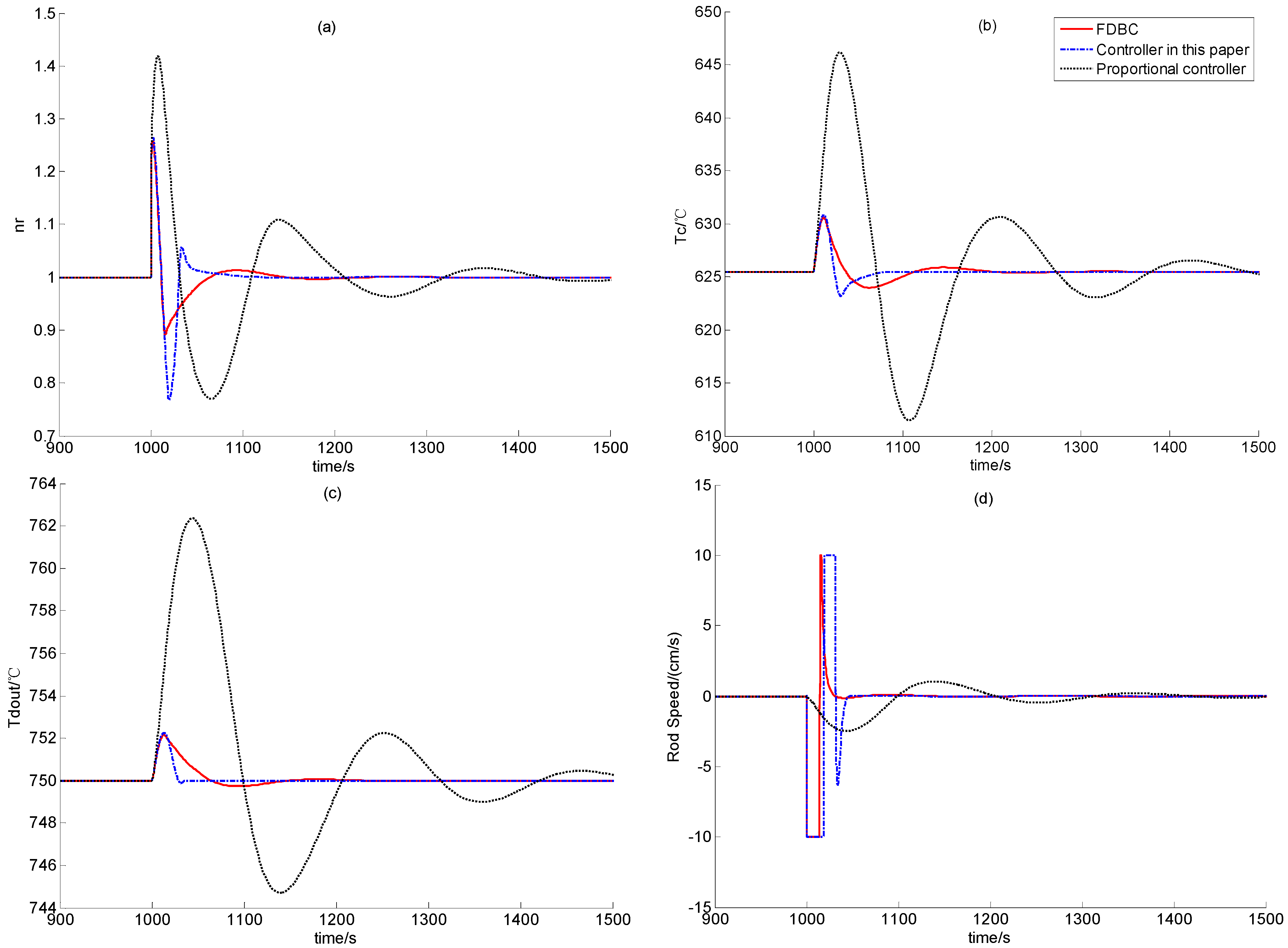
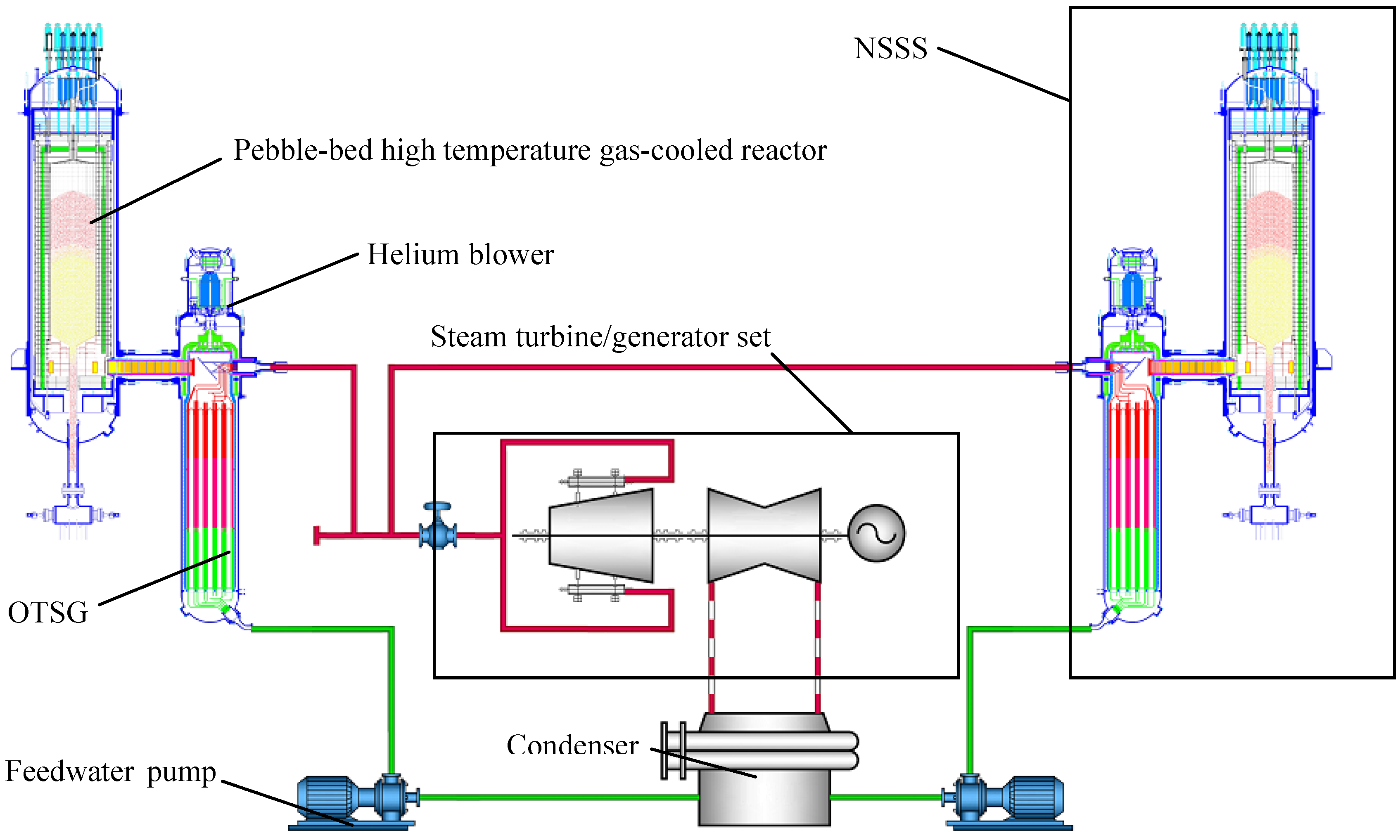
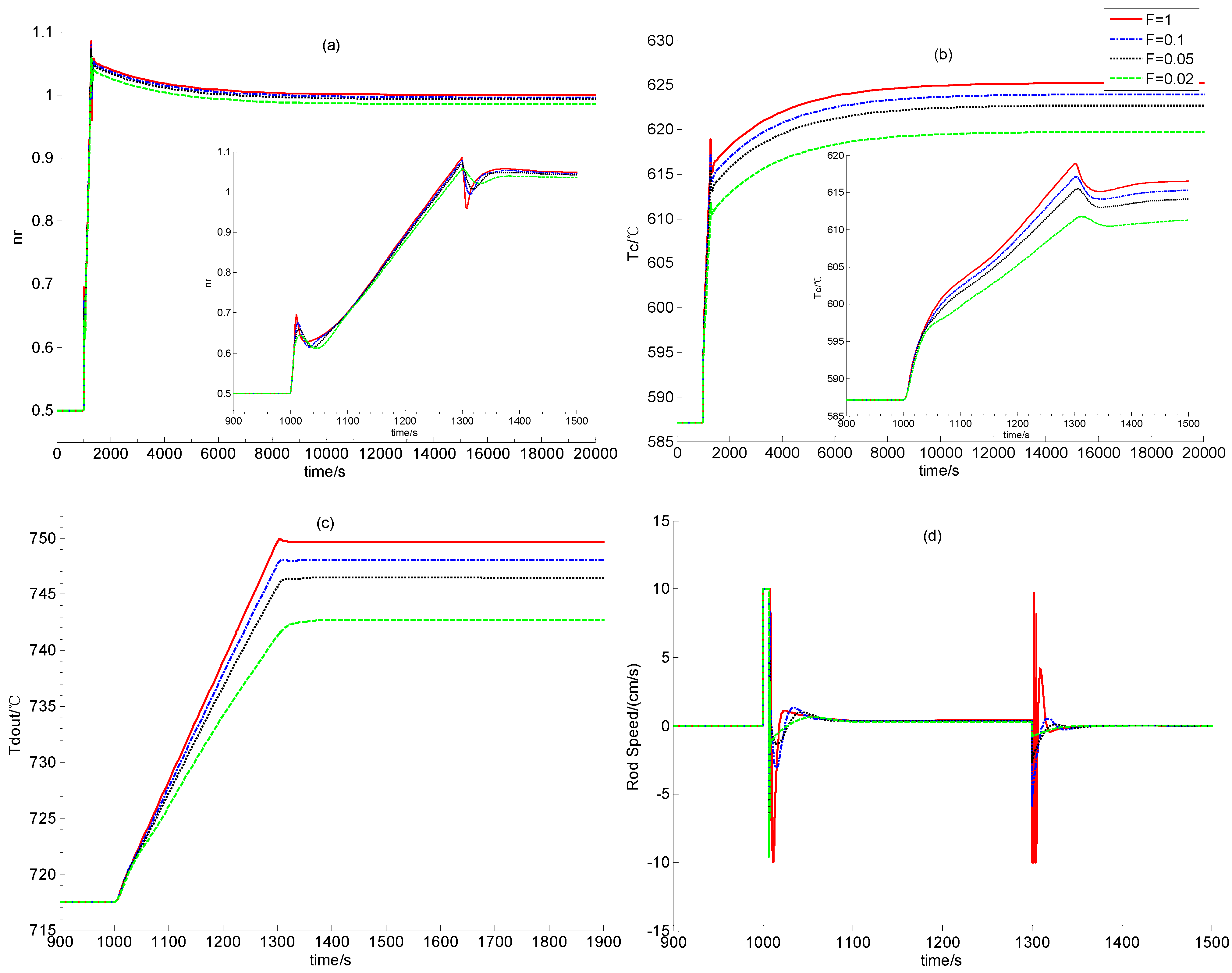
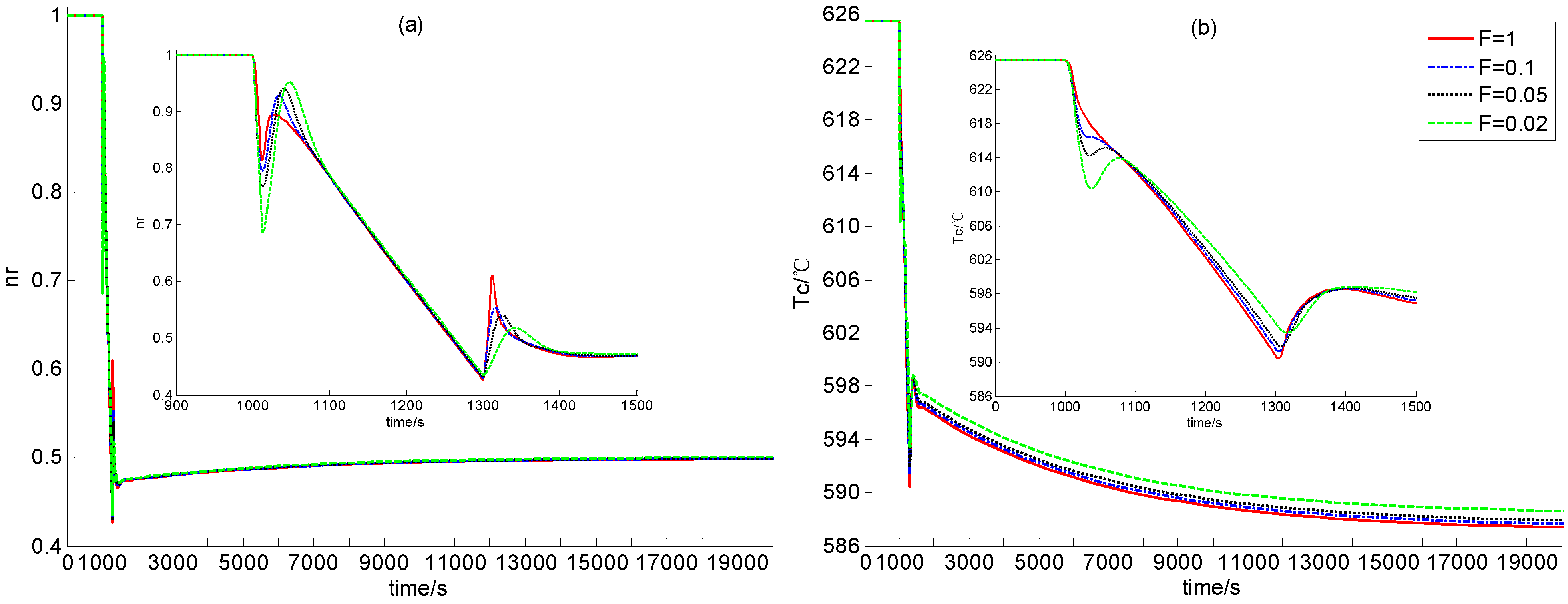
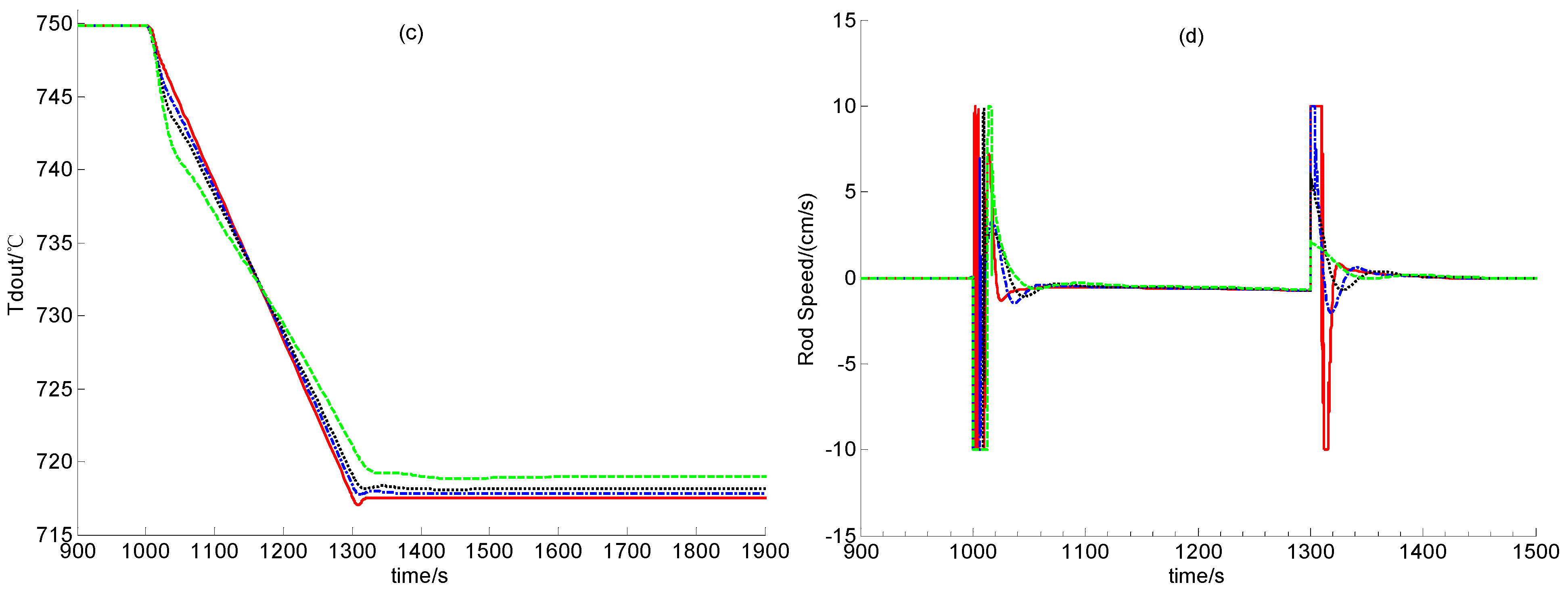
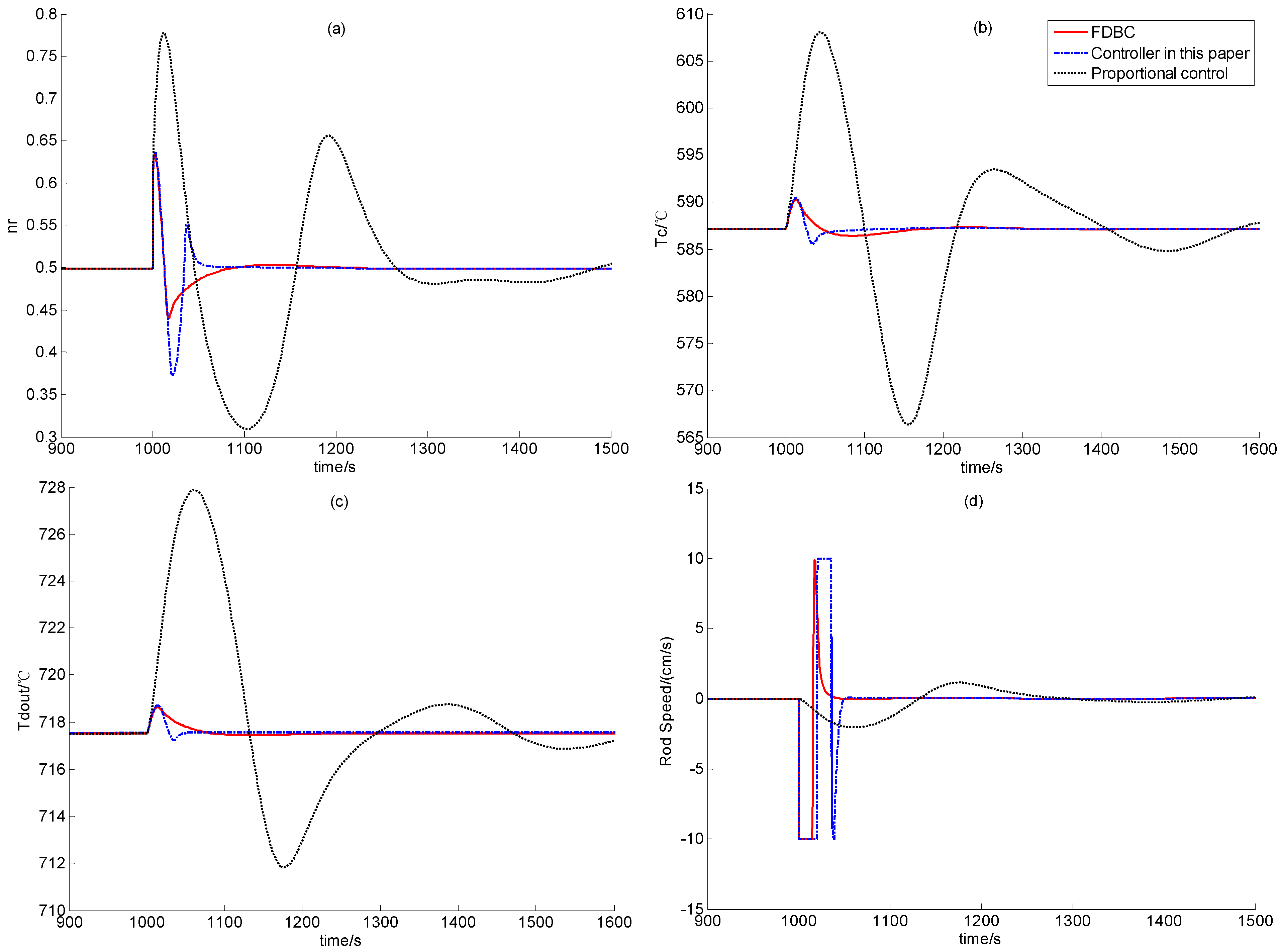
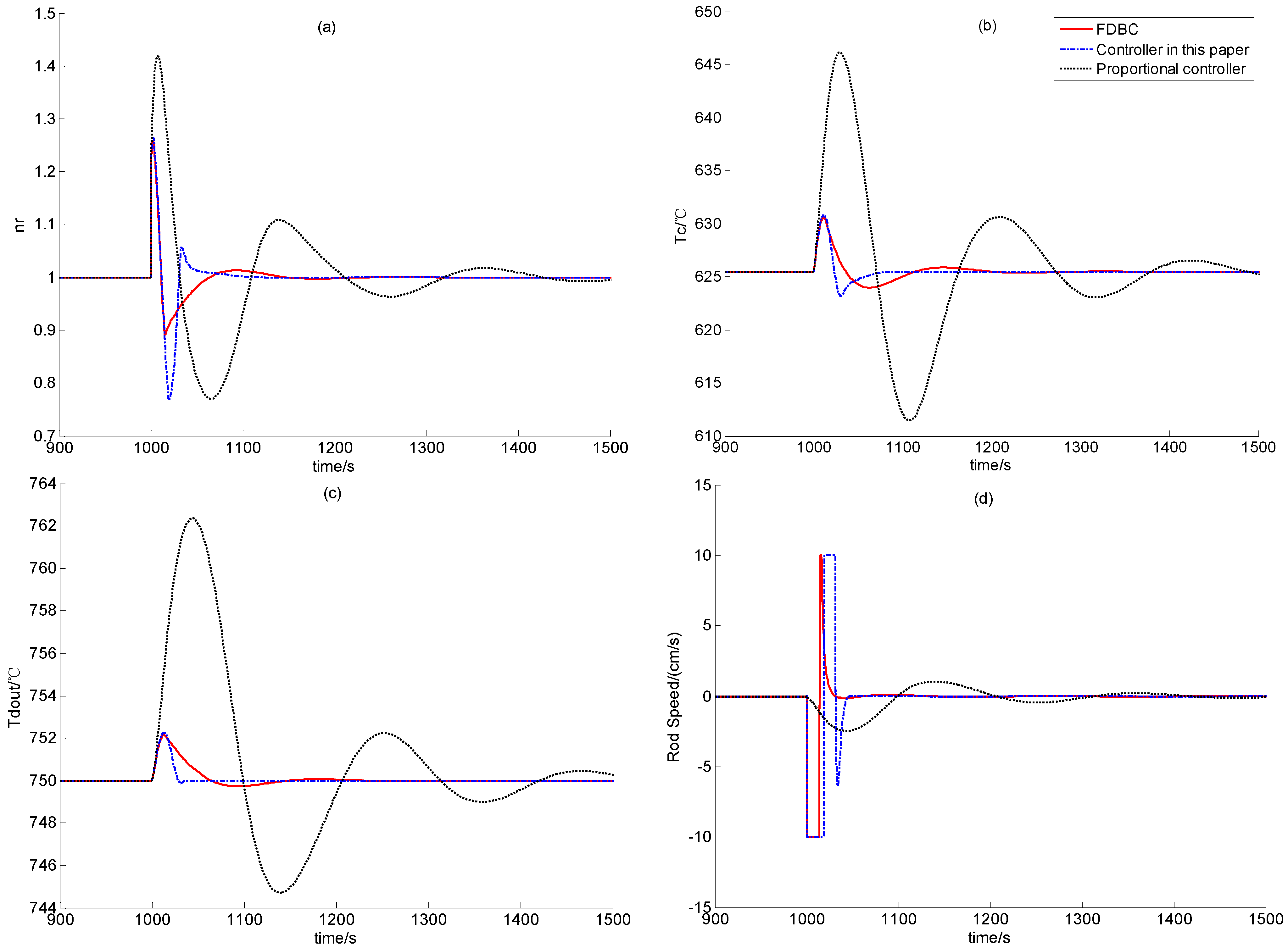
Section 2. In the following, the feasibility of dynamic output feedback power-level control strategy (59) is verified through numerical simulation.


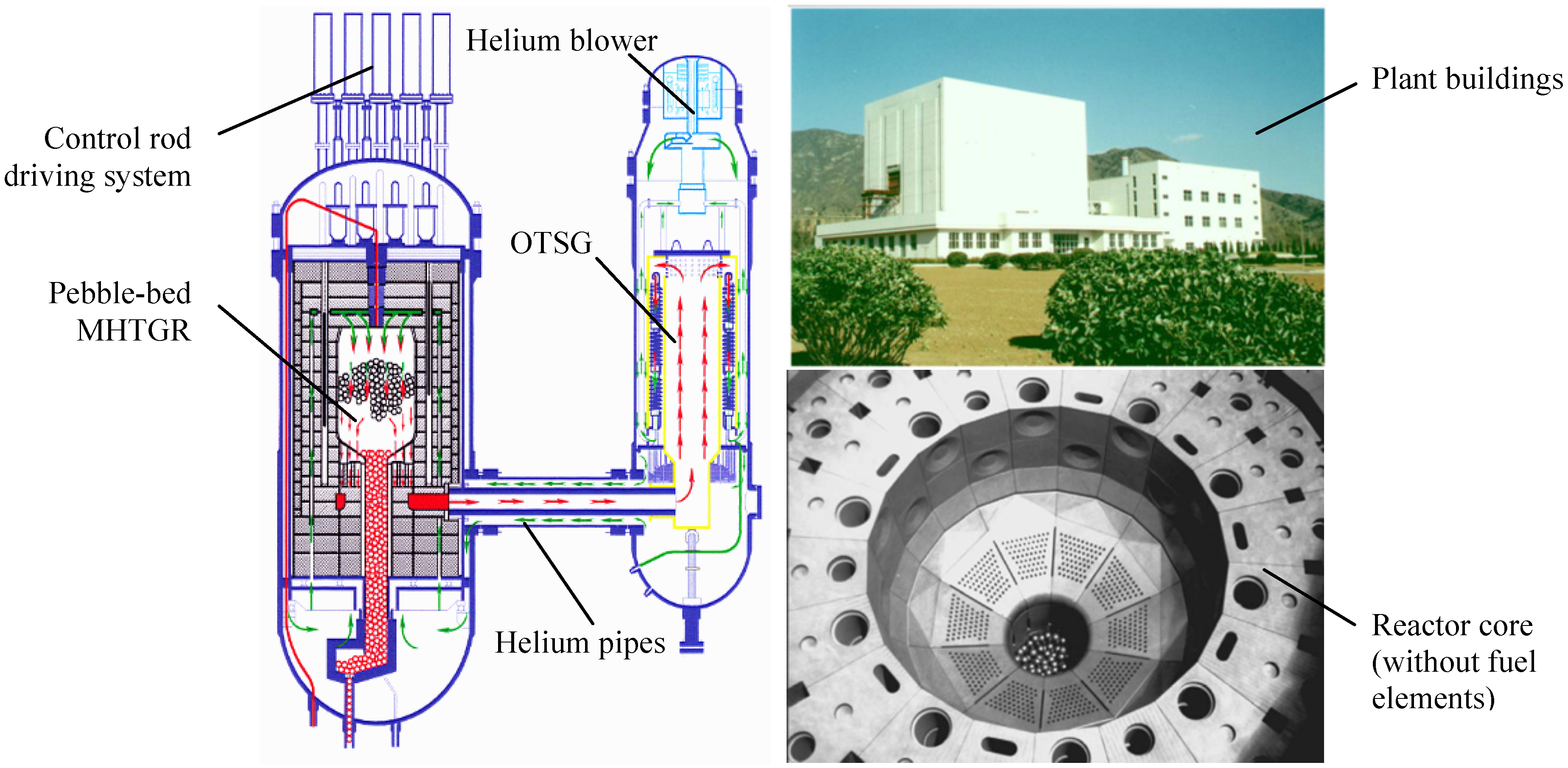{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}