1. Introduction
Optimal reactive power dispatch (ORPD) is an important problem in power system operation. The economy of grid operation has two main aspects to consider: active (Watt) and reactive (Var) power control problems. The Watt problem concerns regulating and controlling the output of the generation units to reduce the overall costs of production. On the other hand, the Var is considered a more complex problem due to the nature of control variables involved in its operation, where it focuses on different voltage control aspects of the grid components (i.e., tap-changing transformers, reactive compensators, etc.) to reduce the overall grid losses, and improve voltage balance. ORPD is considered a pivotal problem in this manner, which aims to solve highly constrained, nonconvex, and nonlinear optimization problems that possess both discrete and continuous control variables to achieve important goals, such as minimizing active power losses and voltage deviations, while improving the voltage stability index of the grid. These types of operational issues emerge due to the complexity arising in grid modernization. Specifically, an optimal reactive power dispatch is essential to help maintain the voltage level in loading conditions by reducing the voltage deviation and power quality issues that emerge from the stochastic fluctuations of the power output. The latter due to the unpredictability of sources such as renewable energy and electric vehicle integration.
Recent years have witnessed growing attention on the metaheuristics and population-based techniques to solve various problems in power system operation and control. These modern approaches have been widely recognized to overwhelm the traditional gradient-based optimization methodologies that have been used for a long time [
1]. The gradient-based approaches to reactive power planning and operation have many valid drawbacks and criticisms. One is that solving a large number of gradient variables requires intensive computations and tends to converge very slowly [
2]. Another aspect of its drawback is that the gradient solution to the objective function is utilized as a search method is based on too many assumptions. for example, the active and reactive power are not directly influenced by voltage levels and phase Angles
ϴ [
3]. This is unacceptable since
ϴ is considered one of the factors that determine the active power loss due to its link to the variation of the real power in the system. Therefore, the inconsistencies in formulating its mathematical representation lack adequate modeling accuracy, leading to repercussions in its search juncture.
On the other hand, metaheuristic approaches allow abstract-level description that provide non-specificity, which is useful for solving a wide range of problems that are presided over by the metaheuristics’ upper-level strategies which influence greater search capabilities. They are based on utilizing search capabilities, mainly embodied as a form of memory, to be re-evaluated by successive iterations to steer their search process. This has helped to rapidly escalate its use in the literature to solve a variety of engineering and scientific-based, real-life problems. Many traditional and bio-inspired optimization algorithms have touched on different aspects of the ORPD problem in the literature, such as genetic algorithms (GA) [
4,
5], particle swarm optimization (PSO) [
6,
7,
8,
9], evolutionary programming (EP) [
1,
10], Tabu search [
11], dynamic programming (DP) [
12,
13], harmony search optimization (HSO) [
14], gravitational search algorithm (GSA) [
15,
16,
17], and grey wolf optimizer (GWO) [
18]. Some of these methodologies show superior performance in reaching a near-global optimum while greatly prevailing over the difficulty that arises due to the nonconvexity and nonlinearity nature of such problems.
The significant contribution of this paper is to develop a new hybridization of two naturally-inspired metaheuristics techniques, particle swarm optimization (PSO) and artificial physics optimization (APO), then solve and optimize the complexity and nonlinearity of the ORPD problem and test it on various IEEE test systems to evaluate its search capacity. The PSO is an evolutionary metaheuristic algorithm that imitates the complex social behavior of flocking birds or fish schooling and was firstly introduced by Kennedy and Eberhard [
19]. It utilizes a set of potential solutions (known as particles) to explore the search space, where every possible solution (or particle) modifies its position via the learning-by-experience concept from the history of its position and its neighboring particles. The use of PSO, either as a stand-alone or by hybridization with another metaheuristic methodology, has been extensively considered to solve complex problems in various engineering disciplines, including studies related to optimal reactive power dispatch. However, in this paper, we present a new form of hybridization with the APO that has not been applied to the ORPD problem before. The APO is a probabilistic population-influenced algorithm inspired by physics-based swarm intelligence, also known as physicomimetics [
20]. In APO, each solution is looked at as an individual that exhibits physical properties such as mass, force, velocity, and position. Derived mainly from Newton’s second law, every particle (solution) can be optimized as the best solution based on the iterative relocations of the population, where a particle’s movement is influenced by the force and inertia of other particles (possible solutions). Recent literature shows the powerful capabilities of APO in solving various kind of problems as a stand-alone algorithm or when hybridized with other algorithms [
21,
22,
23] and it exhibits solid search performance and fast convergence. Hybrid APO–PSO has been used in a previous study to solve dynamic power security analysis [
22], but has never been applied to the ORPD problem. Our overall goal is to produce an intact algorithm that combines the global search capabilities of APO with the strong local exploratory search performance of PSO, while improving its convergence characteristics. The APO exhibits flexible and wide-range search features that enhance its global population diversity, adding a powerful searching-mixture when combined with PSO. After building the mathematical representation of each algorithm, we validate the performance of the hybridized algorithm on the IEEE 30, IEEE 57, and IEEE 118 bus test systems, and compare with the results of previously published reports using other methods to verify its capabilities.
This paper is organized as follow.
Section 1 presents literature on the metaheuristics methodologies used in power systems and provides insight into the problem.
Section 2 provides the mathematical representation and modeling of the ORPD problem.
Section 3 describes the mathematical representation and framework for the APO, the PSO, and the hybrid APO–PSO and its application to solve the ORPD problem.
Section 4 provides an analysis of the results and compares them with the reported results in the literature.
Section 5 concludes the paper and provides suggestions for future studies to be carried out in this area.
3. Mathematical Framework of the Metaheuristic Algorithms
A thorough discussion on the APO and PSO algorithms and their hybridization is presented in this section.
3.1. Artificial Physics Optimization (APO)
APO, as a naturally inspired metaheuristic methodology, is well presented in [
20,
26]. APO is based on the idea that an exerted force may result in either attractive or repulsive aggregation of physical entities (namely the particles or solutions) leading to a movement that represents the search to find local and global optima. Specifically, the process is based on three main observations: initializations, calculation of force, and motion of particles. At the initialization step, particles are sampled stochastically within a multidimensional decision space. The central presumption of APO is based on treating the particles (possible solutions) as physical entities that exhibit mass, position, and velocity, with the mathematical representation of the mass mapped as the fitness function. The mathematical representation of the mass (fitness) function is expressed as follow:
when
f(
x) € [−
,
], then;
Equations (24) and (25) can be mapped into the interval (0, 1) through an elementary transformation function. The mass functions can be rewritten as
where the function
f (
) is the objective function value at the position of the best received value for the individual (swarm particle), while
f (
) refers to the function value of the worst individual swarm reported:
where
S = {1; population of
N agents}
Once each particle’s mass is identified, a velocity vector will be produced. The inevitable changes in velocity in the iteration process are controlled by the level and amount of force exerted on the particle, which is the second stage of the algorithm; calculation of the force, which is based on the mass of the particle and its distance from its neighbors. The force exerted on a particle
i via another particle
j can be found via:
where
is the
kth force quantity enforced on particle
i via particle
j in their dimensions;
and
are the
kth dimension coordinates for the swarm particles
i and
j;
is the distance between these coordinates. Sgn(r) represents the signum function, while
G(
r) denotes the gravitational factor that follow the changes iteratively with
. Both of them can be expressed as:
The
g can be assumed as any value to provide simplicity and flexibility when experimenting. In our studies, we assumed these values based on studies presented in [
25]. The total force exerted on all particles can be rewritten mathematically as:
The third stage is understanding the motion principles of the particles in the decision space, where the computed force is utilized to determine the velocity of the particles that are used to find (and then update iteratively) the respective positions of the particles. Such motions are set in either two- or three-dimensional space, in which particles can be locally spotted, and can be mathematically represented as
where
and
are the
kth components of particle
i’s velocity and distance at iteration
t. Beta is a uniformly distributed random number distributed on the interval (0, 1), while
w is the user-specified inertia weight that can be iteratively updated, usually between 0.1 to 0.99. The inertia influences how two velocity values iteratively change. Larger values of
w is a good indication of greater velocity changes, while small values is only used when we only want to facilitate a local search. Each particle identifies the information of its neighbors, while the physical attractiveness/repulsiveness rule serves as the search strategy in this algorithm to guide the population to search within the region of a possible solution in accordance with their fitness function. The high accuracy and ability to map the particle’s mass as a fitness function influence the whole optimization process, to which the relationship is proportionally related; the more accurately the objective function is designed, the bigger mass will be produced, which leads to a higher level of attractiveness, or in other words, more optimized searching strength, as particles will be naturally attracted to higher masses.
The iteration process in the APO leads to the updating of all particles’ positions, and accordingly, the objective fitness function is adjusted to those new positions. Then, the fitness function identifies a new best individual and marks its position vector as the best solution. In this way, the second and third steps of the algorithm, force calculation and motion, are iteratively performed until a stopping criterion is achieved. Such criteria may be a predetermined number of executed iterations or reaching several successive iterations with no difference in the value of the best obtained particle position.
3.2. Particle Swarm Optimization (PSO)
PSO is a population-based, bio-inspired metaheuristic algorithm that was established by Kennedy and Eberhart in 1995 [
19]. It is based on the concept of evolutionary computational method, where a system of study is started with an initial population of randomized solutions, updated iteratively in the process of searching for the local and global optima. The candidate solutions, known as particles, fly in the decision space with the velocity obtained in its previous best solutions, as well as its group’s best results. Both the velocity and position of each particle are updated accordingly using the following mathematical formulas:
where
(
t) and
(
t) are vector representations in the solution space for both the velocity and position of particle
i, while Pbest and gbest are the best individual and global optimal obtained solutions. The performance of PSO as a validated and well-proven metaheuristic technique is widely spread in the literature in different fields of study. This is due to its powerful searching capacity and premature convergence without the need to find local optimal.
Figure 1 shows the basic concept of the searching methodology and motion principle for particle
i in PSO, where
V(
t),
Xm, and
X are three vectors describing the coordinates of the best solution in the decision space.
3.3. Hybridization of APO and PSO to Solve the ORPD Problem
The primary goal of establishing a hybridization of APO and PSO is to combine their individual strengths to form an optimized algorithm that utilizes the global search capabilities of APO with the strong local exploratory search performance of PSO, while improving its convergence performance. In other words, such hybridization aims to form a successful partnership among the local and global searching capabilities of the two algorithms to overcome any shortages each one may face if performed alone. Talbi et al. (2009) provide extensive analysis of the concept of integrating two metaheuristic techniques, which can be achieved on either lowly or highly heterogeneous integration [
27,
28]. This work combines the two algorithms as a low-heterogeneity routine. Successful implementation of the hybridization requires modifying the particles’ velocity and position equations, as follows:
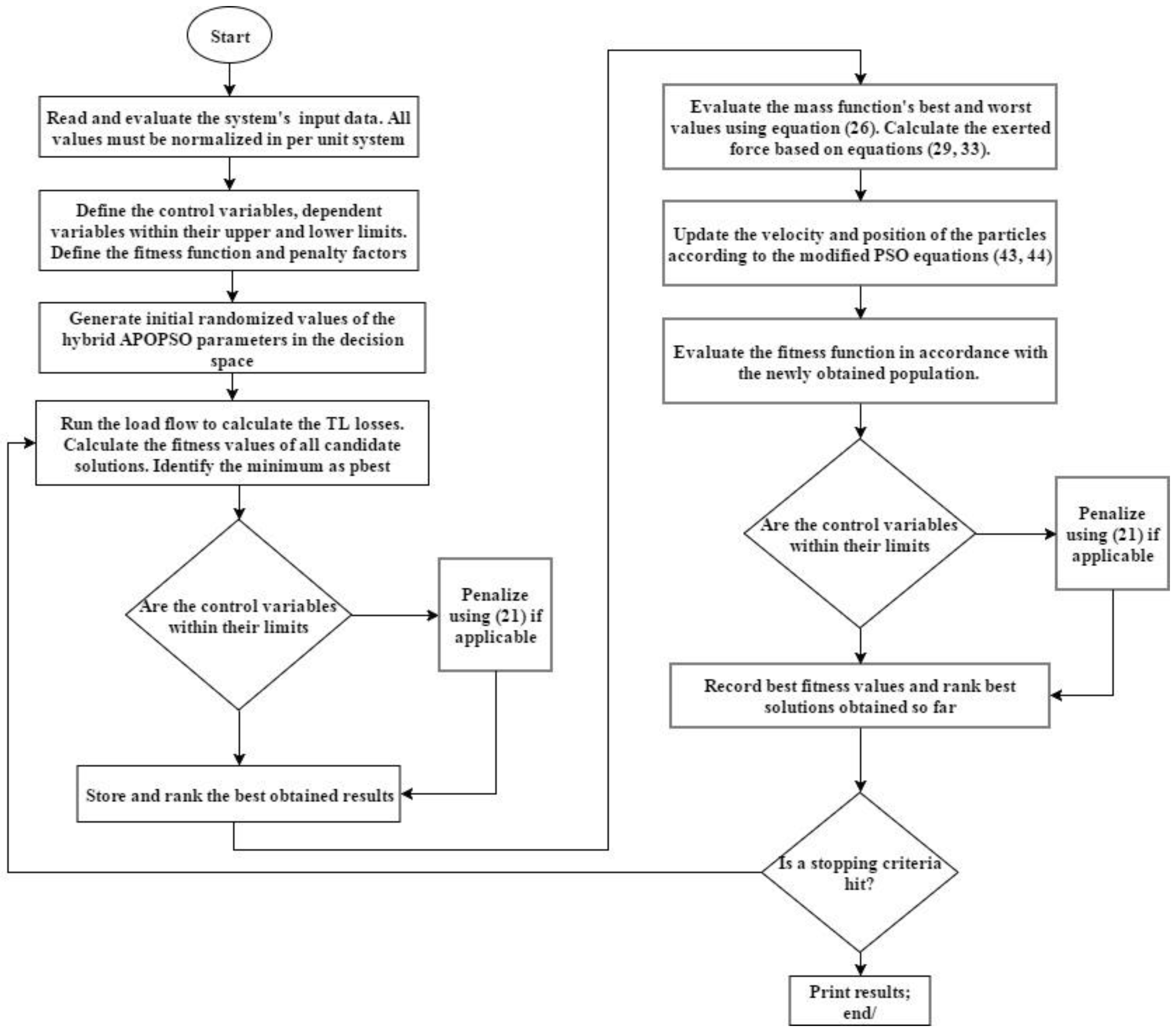
In our proposed APOPSO to solve the ORPD, we first define the dependent and control variables with their respective limits over a defined fitness function. Then, we randomly initialize the input values of the population (particles or swarms). Each particle represents a candidate solution. After the initialization step, we establish the best and worst values of the load flow and rank the obtained results. After that, the mass function given in Equation (26) will be assessed according to those results, and a force calculated using Equations (29) and (33) will be exerted on the particles, then their velocity and positions are updated based on Equations (36) and (37) and the distance between them according to (30), then ranking the newly produced results according to their fitness values. The process is repeated iteratively, and in each iteration we check whether there is a violation that occurred at any level to ensure proper operation within the limits. The iteration process stops updating the velocities and positions once an ending criterion is met.
Figure 2 shows the flowchart of the proposed APOPSO algorithm. The pseudocode of the combined algorithm is as follows:
Step 1: Read and evaluate the input data [Tr, Qc, ….]. All values must be normalized in per unit system.
Step 2: 2.1: Define the independent (control) variables X within their specific boundary levels; 2.2: Define the dependent variables Y within their specific boundary levels; 2.3: Define the fitness function with its associated penalty factors.
Step 3: Generate an initial randomized population with
N agents in the decision space. Specify the desired number of iterations to be performed. It should be noted that the initial positions of the population must be strictly within their boundary levels.
The initialized value of the
kth control parameter in an
ith particle (candidate solution) can be found using the following mathematical expression:
Rand is a number randomly allocated in the interval [0–1], while
and
are the boundary limits of the control variable
d. The
ith particles corresponding to the optimal dispatch problem can be rearranged in a vector form as follows:
At
i = 1, 2, ……,
N.
Step 4: Run the system’s load flow to calculate the transmission line losses. Calculate the fitness values of all candidate solutions using the mass function. Select the minimally obtained result as best.
Step 5: Check if the control variables are within their boundary limits. If yes, proceed to step 6. If no, then penalize using the penalty function in Equation (21). The penalization is considered only for the multiobjective case studies.
Step 6: Evaluate the mass function’s best and worst values using Equation (26). Calculate the force based on as in Equation (33).
Step 7: Update the velocity and position of the particles according to the modified PSO Equations (38) and (39).
Step 8: Evaluate the fitness function by newly obtained population information. Check if the control variables are within their boundary limits. If yes, proceed to Step 9. If no, then penalize using the quadratic penalty function in Equation (21).
Step 9: Record the best fitness values and rank the best obtained solutions.
Step 10: Repeat Steps 4–9 until a stopping criterion is achieved.
Step 11: Print best results and end.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}