Short-Term Wind Speed Forecasting Based on Low Redundancy Feature Selection


Abstract
1. Introduction
2. Structure and Methodology of the New Hybrid Model
2.1. Complementary Ensemble Empirical Mode Decomposition (CEEMD)
- (a)
- The local maximum and minimum points of the original signal are connected by a cubic spline to obtain the upper envelope and the lower envelope .
- (b)
- The sequence is obtained by averaging two envelopes.
- (c)
- The first component h1 is obtained by removing m1 from S:
- (d)
- Repeat the above steps with h1 until the number of extrema and zero crossings is equal or differ at most by one, and the mean value of and is zero. The remaining signal is the first Intrinsic Mode Functions (IMF).
- (e)
- Remove IMF1 from the original S and repeat the iterations above until the signal cannot be decomposed, the remaining signal is the remainder function.
- (a)
- Two groups of white noise signals with the same amplitude and opposite phase are introduced into the original signal respectively, get two generated signals and ;
- (b)
- Decomposition two groups of sequences with EMD method, obtain two groups of IMFs and . Then obtain the IMFs of CEEMD by averaging the components of the two groups of IMFs:
- (c)
- Repeat the above steps with the data which removed the IMFs until the signal cannot be decomposed. The remainder function is the remainder of the signal, and the final decomposition result of CEEMD is:
2.2. Conditional Mutual Information (CMI)
2.3. Outlier-Robust Extreme Learning Machine (ORELM)
- (a)
- The implicit layer node parameters, namely the weight matrix and the threshold are randomly generated, where ;
- (b)
- Calculate the output matrix of the hidden layer [32]:
- (c)
- Parameter initialization: , where represents penalty coefficient, , the Lagrange multiplier ;
- (d)
- This constraint optimization problem is solved by using the augmented Lagrange multiplier (ALM) method, execute the following iteration process until the loop parameter k reaches the maximum number of iterations:
2.4. Forecasting Accuracy Evaluations
3. The Composition of Data Sets
3.1. The Features of The Input Set
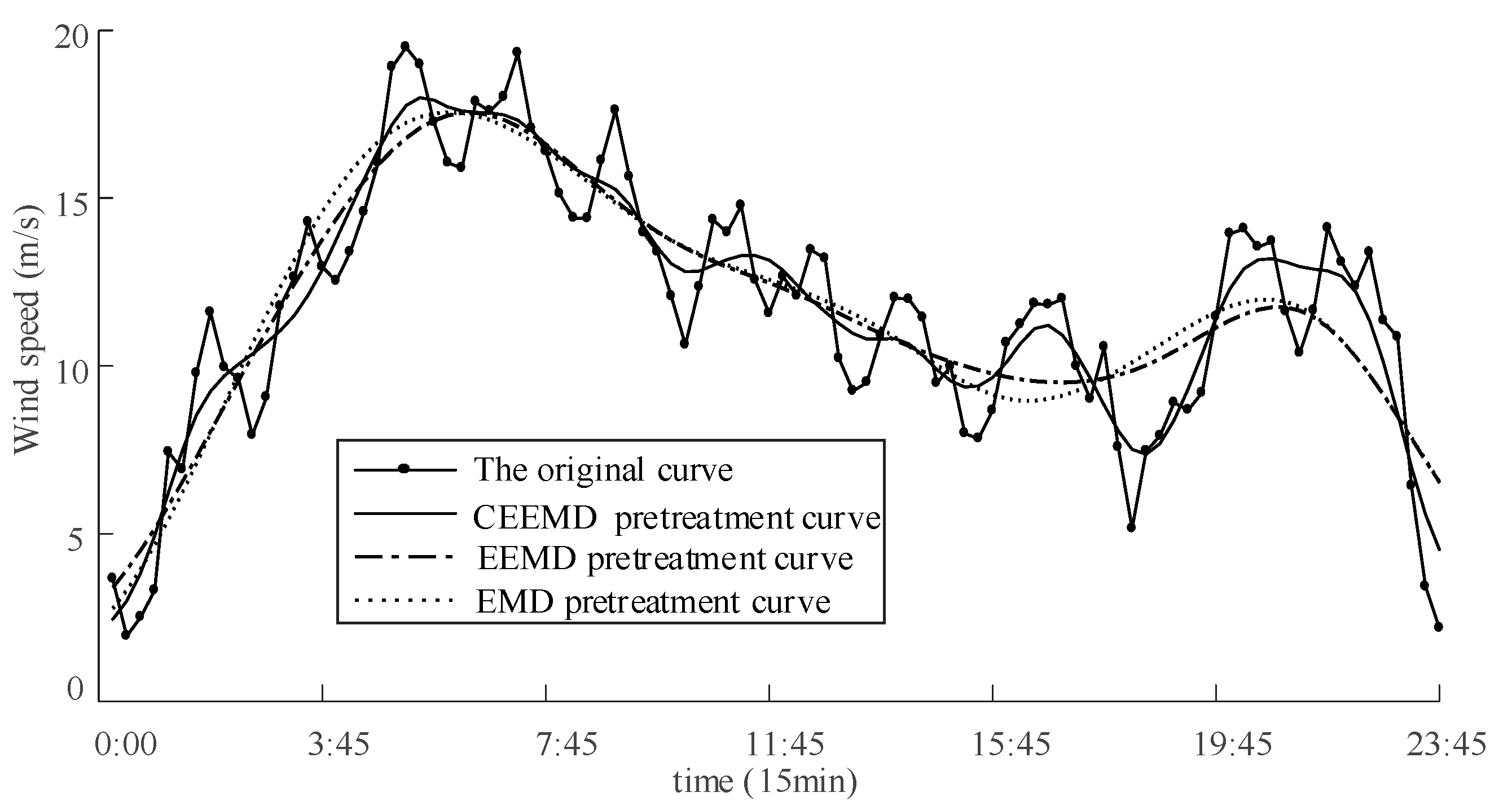
3.2. Data Preprocessing
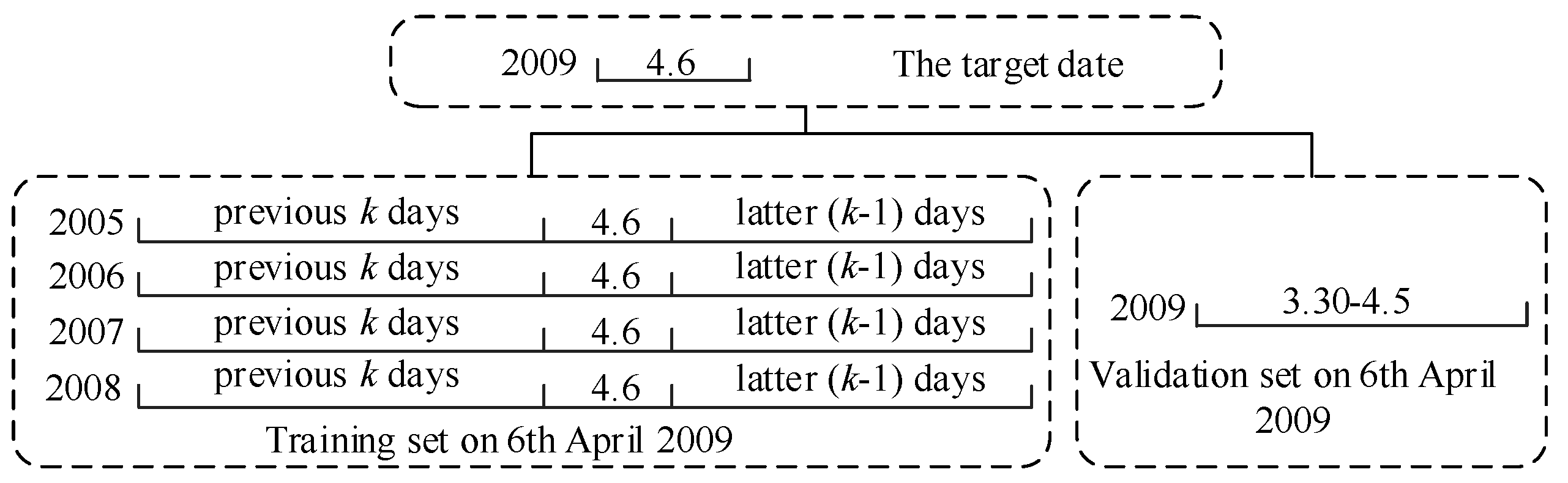
3.3. Data Set Construction
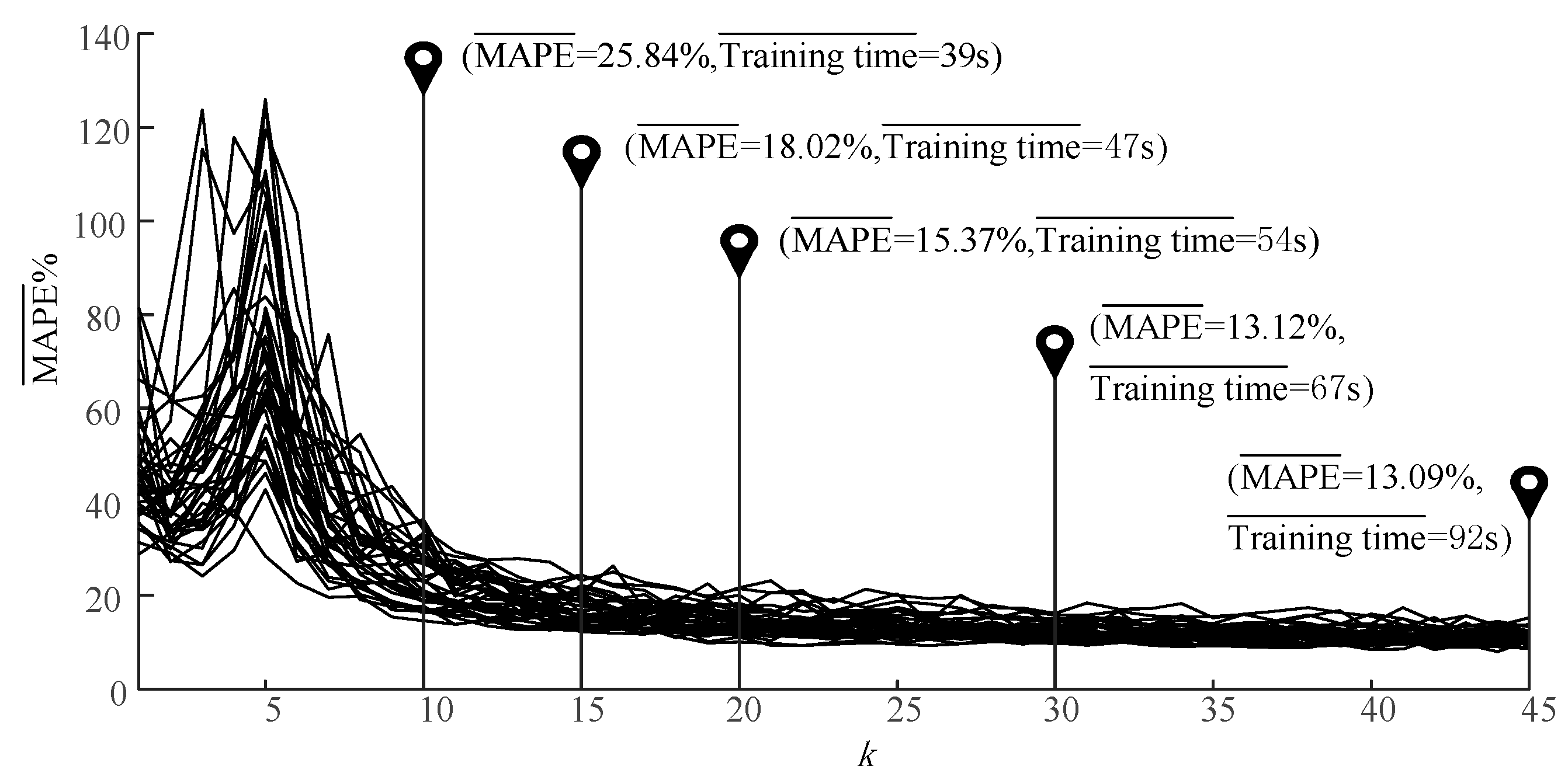
3.4. Data Set Determination
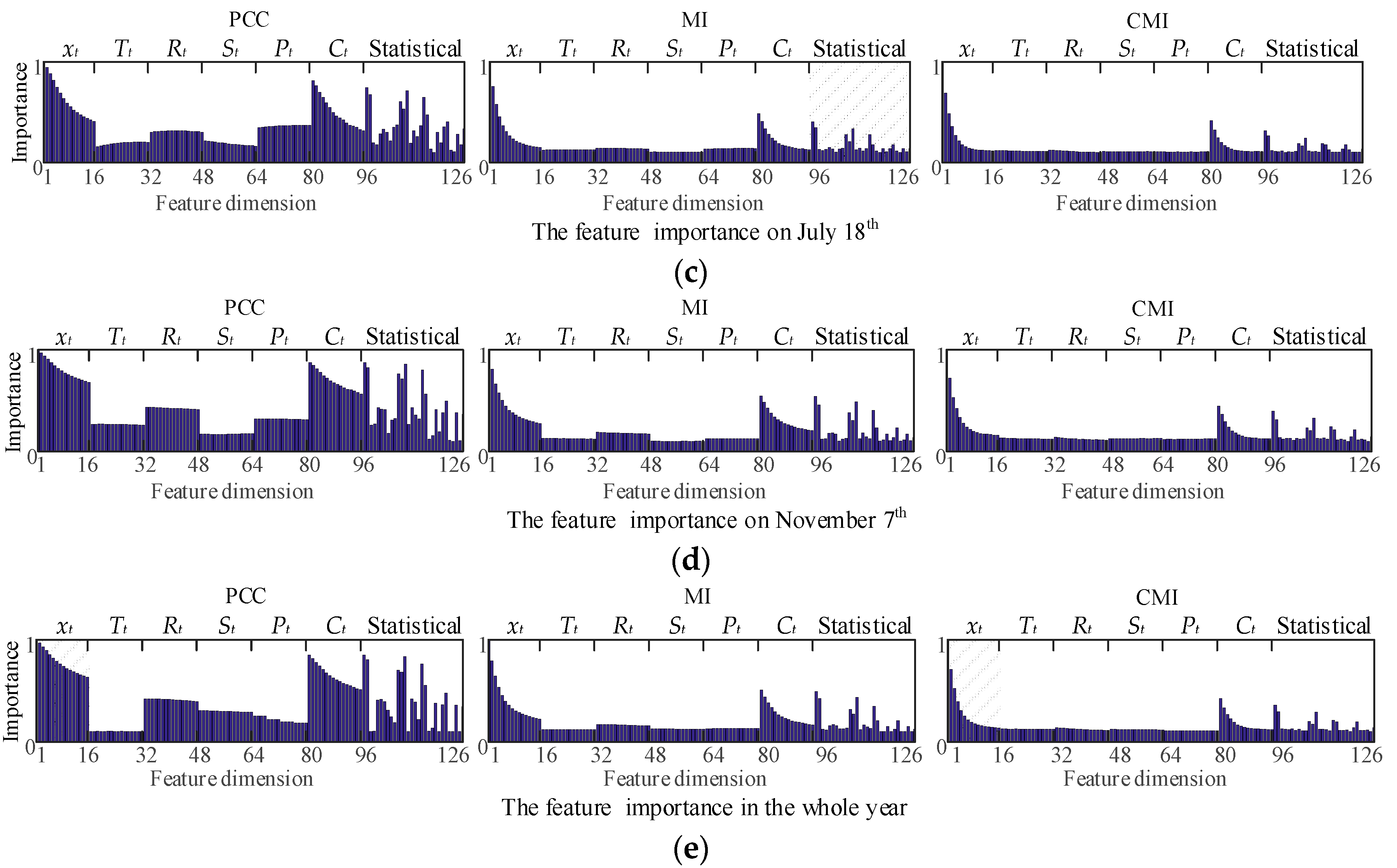
4. Time-Sharing Low Redundancy Feature Selection
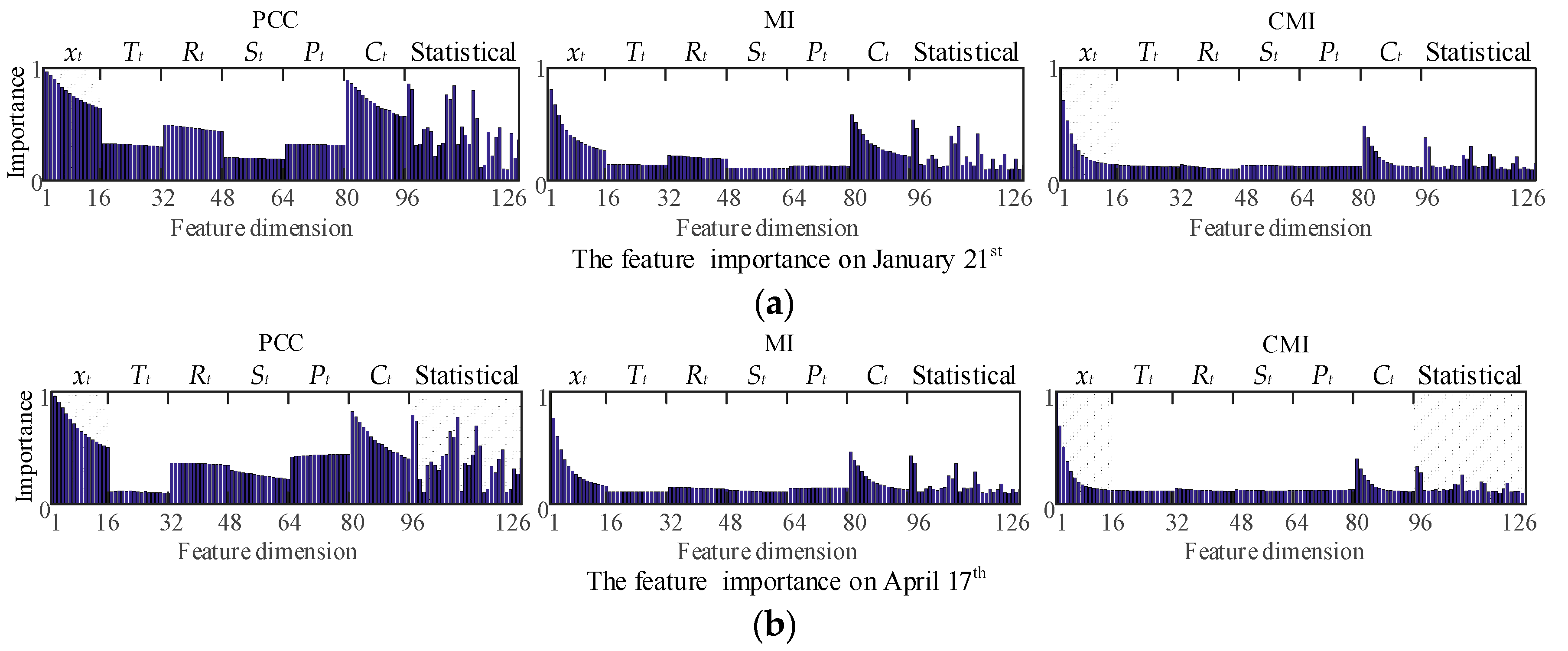
4.1. Analysis of Feature Correlation
4.2. Forward Feature Selection
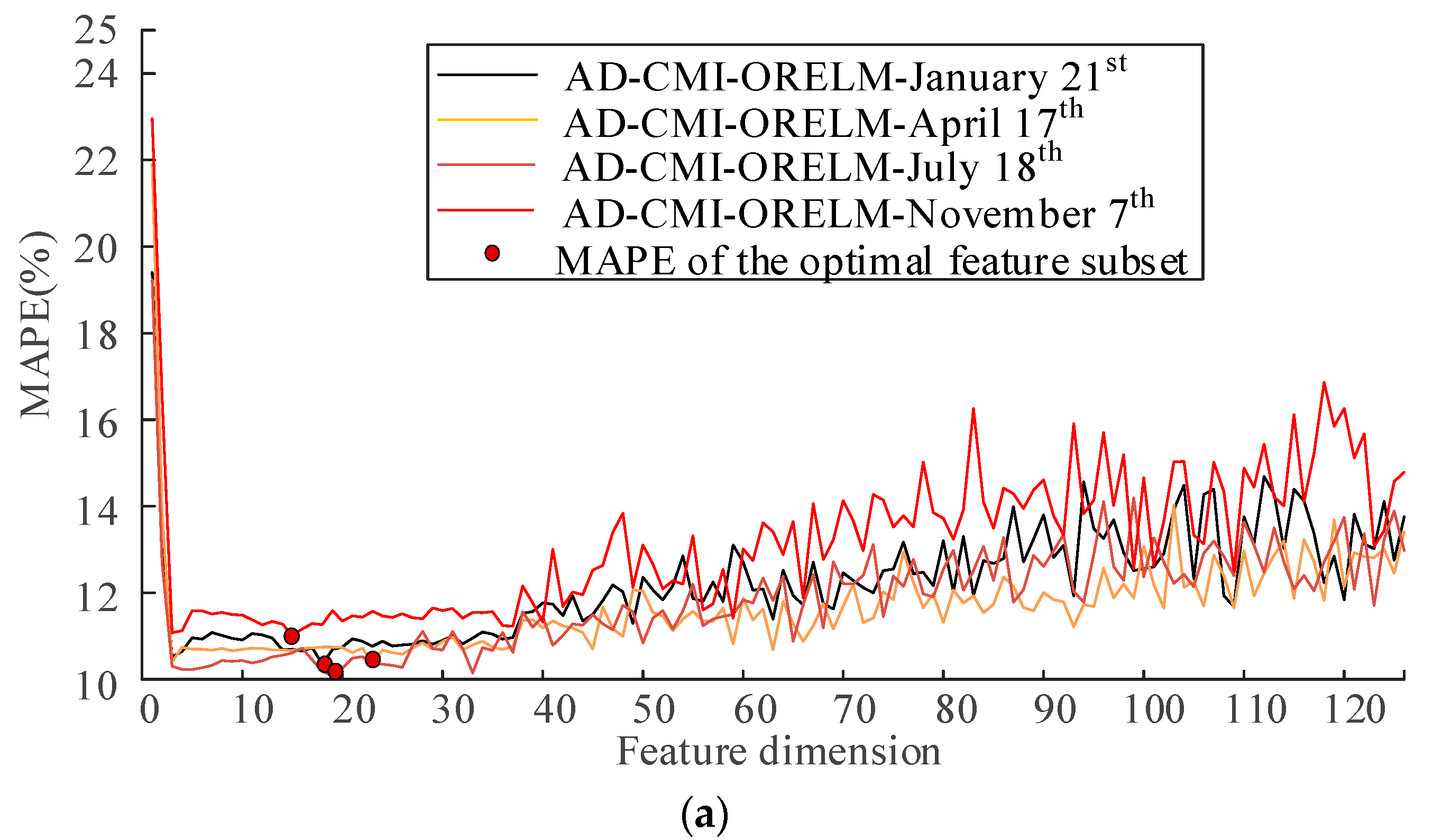
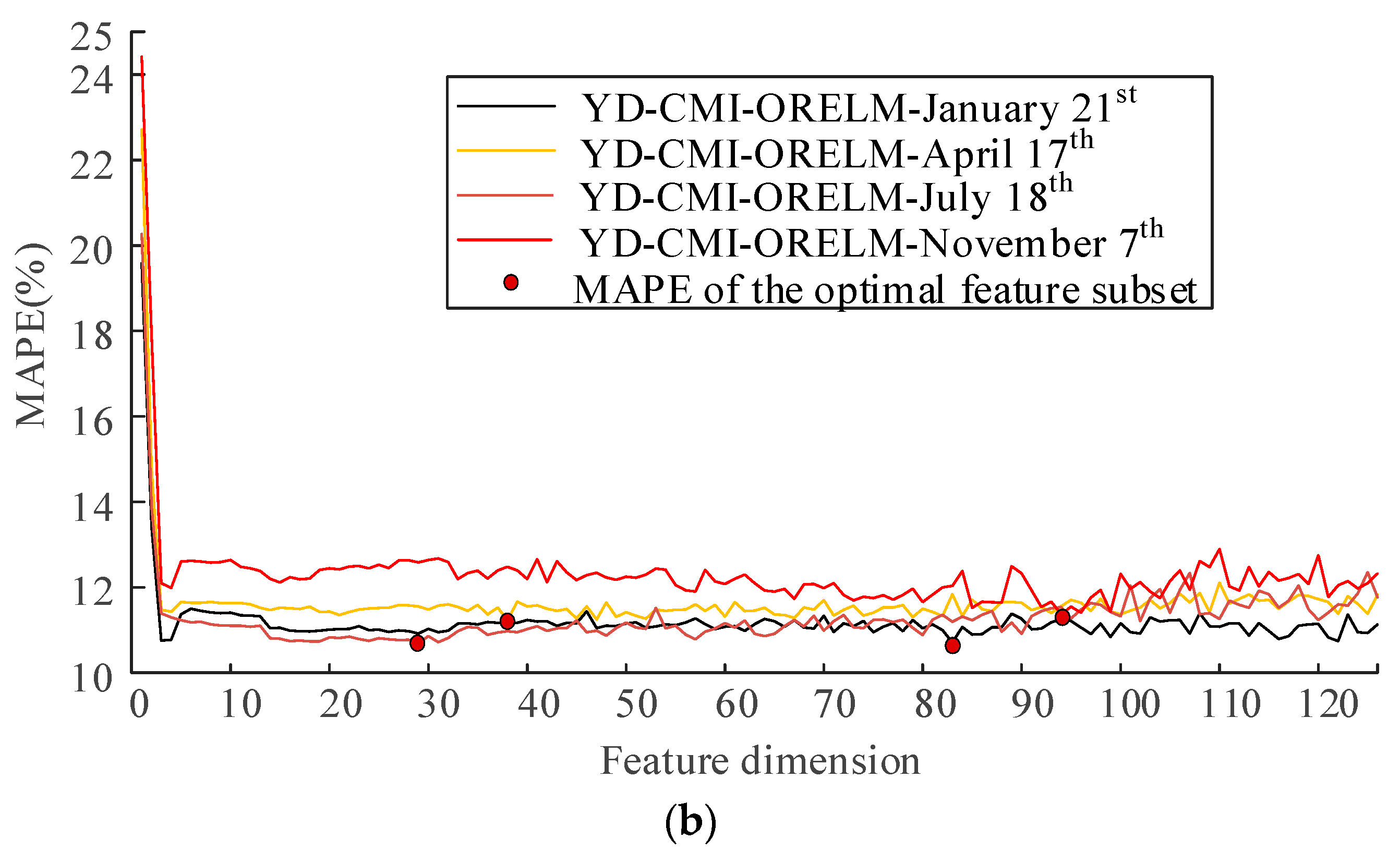
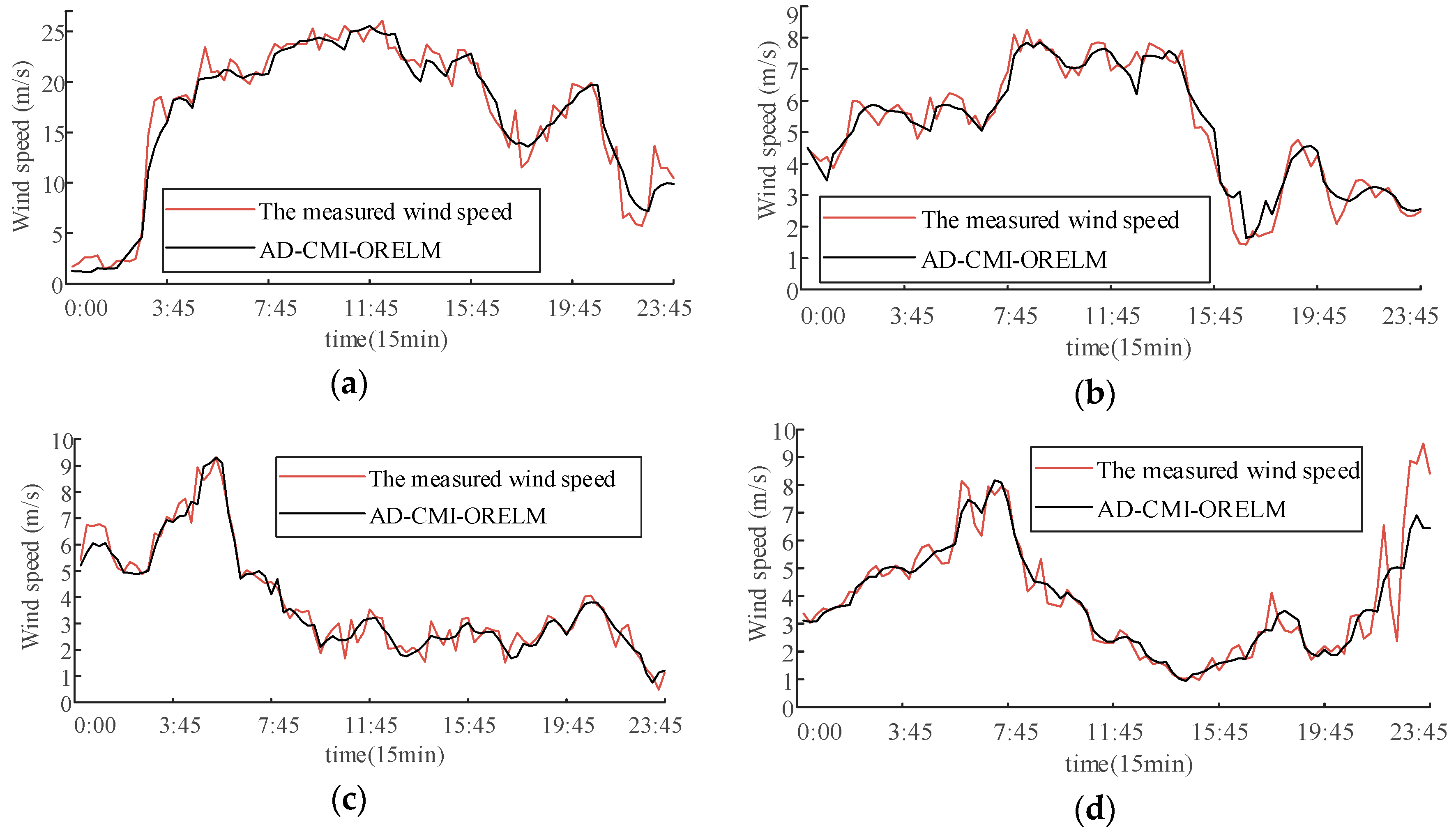
5. Predictive Effect and Model Comparison
6. Conclusions
- (1)
- A low redundancy feature selection is carried out with the CMI method, which reduced the effect of redundancy between features on prediction accuracy and complexity of a model.
- (2)
- Building prediction model with ORELM, which improves the generalization performance of the prediction model based on the high prediction efficiency by adding the standard parameter adjustment training error and output layer weight into the target function of ELM.
- (3)
- The targeted feature selection process and modeling are carried out on different forecast days, overcomes the shortcoming of carrying out feature selection with annual data, which is difficult to show the correlation between wind speed and complex meteorological factors in different time periods, improved the pertinence and prediction of wind speed forecasting model.
Author Contributions
Funding
Conflicts of Interest
References
- Men, Z.X.; Yee, E.; Lien, F.S.; Wen, D.Y.; Chen, Y.S. Short-term wind speed and power forecasting using an ensemble of mixture density neural networks. Renew. Energy 2016, 87, 203–211. [Google Scholar] [CrossRef]
- Ye, L.; Zhao, Y.; Zeng, C.; Zhang, C. Short-term wind power prediction based on spatial model. Renew. Energy 2017, 101, 1067–1074. [Google Scholar] [CrossRef]
- Wang, H.Z. Deep learning based ensemble approach for probabilistic wind power forecasting. Appl. Energy 2017, 118, 56–70. [Google Scholar] [CrossRef]
- Jadidoleslam, M.; Ebrahimi, A.; Latify, M.A. Probabilistic Transmission Expansion Planning to Maximize the Integration of Wind Power. Renew. Energy 2017, 114, 866–878. [Google Scholar] [CrossRef]
- Yin, H.; Dong, Z.; Chen, Y.; Ge, J.; Lai, L.L.; Vaccaro, A.; Meng, A. An effective secondary decomposition approach for wind power forecasting using extreme learning machine trained by crisscross optimization. Energy Convers. Manag. 2017, 150, 108–121. [Google Scholar] [CrossRef]
- Yuan, X.; Tan, Q.; Lei, X.; Yuan, Y.; Wu, X. Wind Power Prediction Using Hybrid Autoregressive Fractionally Integrated Moving Average and Least Square Support Vector Machine. Energy 2017, 129, 122–137. [Google Scholar] [CrossRef]
- Wang, J.; Song, Y.; Liu, F.; Hou, R. Analysis and application of forecasting models in wind power integration: A review of multi-step-ahead wind speed forecasting models. Renew. Sustain. Energy Rev. 2016, 60, 960–981. [Google Scholar] [CrossRef]
- Ssekulima, E.B.; Anwar, M.B.; Al Hinai, A.; El Moursi, M.S. Wind speed and solar irradiance forecasting techniques for enhanced renewable energy integration with the grid: A review. IET Renew. Power Gener. 2016, 10, 885–989. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, J.; Liu, F. Multistep Forecasting for Short-Term Wind Speed Using an Optimized Extreme Learning Machine Network with Decomposition-Based Signal Filtering. J. Energy Eng. 2016, 142, 04015036. [Google Scholar] [CrossRef]
- Guo, Z.; Zhao, W.; Lu, H.; Wang, J. Multi-step forecasting for wind speed using a modified EMD-based artificial neural network model. Renew. Energy 2012, 37, 241–249. [Google Scholar] [CrossRef]
- Chen, D.; Lin, J.; Li, Y. Modified complementary ensemble empirical mode decomposition and intrinsic mode functions evaluation index for high-speed train gearbox fault diagnosis. J. Sound Vib. 2018, 424, 192–207. [Google Scholar] [CrossRef]
- Niu, M.; Wang, Y.; Sun, S.; Li, Y. A novel hybrid decomposition-and-ensemble model based on CEEMD and GWO for short-term PM 2.5, concentration forecasting. Atmos. Environ. 2016, 134, 168–180. [Google Scholar] [CrossRef]
- Wang, Y.W.; Feng, L.Z. A new feature selection method for handling redundant information in text classification. Front. Inf. Technol. Electron. Eng. 2018, 19, 221–234. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, L. Hybrid feature selection using component co-occurrence based feature relevance measurement. Expert Syst. Appl. 2018, 102, 83–99. [Google Scholar] [CrossRef]
- Lin, Y.; Hu, Q.; Liu, J.; Li, J.; Wu, X. Streaming Feature Selection for Multilabel Learning Based on Fuzzy Mutual Information. IEEE Trans. Fuzzy Syst. 2017, 25, 1491–1507. [Google Scholar] [CrossRef]
- Li, S.; Wang, P.; Goel, L. A Novel Wavelet-Based Ensemble Method for Short-Term Load Forecasting with Hybrid Neural Networks and Feature Selection. IEEE Trans. Power Syst. 2016, 31, 1788–1798. [Google Scholar] [CrossRef]
- Liu, D.; Wang, J.; Wang, H. Short-term wind speed forecasting based on spectral clustering and optimised echo state networks. Renew. Energy 2015, 78, 599–608. [Google Scholar] [CrossRef]
- Feng, C.; Cui, M.; Hodge, B.M.; Zhang, J. A data-driven multi-model methodology with deep feature selection for short-term wind forecasting. Appl. Energy 2017, 190, 1245–1257. [Google Scholar] [CrossRef]
- Hu, Q.; Su, P.; Yu, D.; Liu, J. Pattern-Based Wind Speed Prediction Based on Generalized Principal Component Analysis. IEEE Trans. Sustain. Energy 2014, 5, 866–874. [Google Scholar] [CrossRef]
- Poncela, M.; Poncela, P.; Perán, J.R. Automatic tuning of Kalman filters by maximum likelihood methods for wind energy forecasting. Appl. Energy 2013, 108, 349–362. [Google Scholar] [CrossRef]
- Erdem, E.; Shi, J. ARMA based approaches for forecasting the tuple of wind speed and direction. Appl. Energy 2011, 88, 1405–1414. [Google Scholar] [CrossRef]
- Ma, X.; Jin, Y.; Dong, Q. A generalized dynamic fuzzy neural network based on singular spectrum analysis optimized by brain storm optimization for short-term wind speed forecasting. Appl. Soft Comput. 2017, 54, 296–312. [Google Scholar] [CrossRef]
- Gouveia, H.T.; de Aquino, R.R.; Ferreira, A.A. Enhancing Short-Term Wind Power Forecasting through Multiresolution Analysis and Echo State Networks. Energies 2018, 11, 824. [Google Scholar] [CrossRef]
- Bonanno, F.; Capizzi, G.; Sciuto, G.L. A neuro wavelet-based approach for short-term load forecasting in integrated generation systems. In Proceedings of the International Conference on Clean Electrical Power, Alghero, Italy, 11–13 June 2013; pp. 772–776. [Google Scholar]
- Chen, Y.; Cai, K.; Tu, Z.; Nie, W.; Ji, T.; Hu, B.; Chen, C.; Jiang, S. Prediction of benzo[a]pyrene content of smoked sausage using back-propagation artificial neural network. J. Sci. Food Agric. 2018, 98, 3022–3030. [Google Scholar] [CrossRef] [PubMed]
- Noorollahi, Y.; Jokar, M.A.; Kalhor, A. Using artificial neural networks for temporal and spatial wind speed forecasting in Iran. Energy Convers. Manag. 2016, 115, 17–25. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Zhang, K.; Luo, M. Outlier-robust extreme learning machine for regression problems. Neurocomputing 2015, 151, 1519–1527. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Yeh, J.R.; Shieh, J.S.; Huang, N.E. Complementary ensemble empirical mode decomposition: A novel noise enhanced data analysis method. Adv. Adapt. Data Anal. 2010, 2, 135–156. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: New York, NY, USA, 1991; pp. 155–183. [Google Scholar]
- Peng, X.; Zheng, W.; Zhang, D.; Liu, Y.; Lu, D.; Lin, L. A novel probabilistic wind speed forecasting based on combination of the adaptive ensemble of on-line sequential ORELM (Outlier Robust Extreme Learning Machine) and TVMCF (time-varying mixture copula function). Energy Convers. Manag. 2017, 138, 587–602. [Google Scholar] [CrossRef]
- Li, H.; Zhou, M.; Guo, Q.; Wu, R.; Xi, J. Compressive sensing-based wind speed estimation for low-altitude wind-shear with airborne phased array radar. Multidimens. Syst. Signal Process. 2016, 7, 1–14. [Google Scholar] [CrossRef]
- Groves, G.V. Determination of Air Density Temperature & Winds at High Altitudes; University Coll: London, UK, 1966. [Google Scholar]
- NWTC Information Portal. Available online: http://wind.nrel.gov/MetData/ (accessed on 15 June 2018).
- Mu, Y.; Liu, X.; Wang, L. A Pearson’s correlation coefficient based decision tree and its parallel implementation. Inf. Sci. 2018, 435, 40–58. [Google Scholar] [CrossRef]
- Huang, N.; Peng, H.; Cai, G.; Chen, J. Power Quality Disturbances Feature Selection and Recognition Using Optimal Multi-Resolution Fast S-Transform and CART Algorithm. Energies 2016, 9, 927. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Types | Historical Features | Numbers |
|---|---|---|
| Wind speed (xt) | xt−1,xt−2,xt−3,…,xt−16 | 1–16 |
| Temperature (Tt) | Tt−1,Tt−2,Tt−3,…,Tt−16 | 17–32 |
| Relative humidity (Rt) | Rt−1,Rt−2,Rt−3,…,Rt−16 | 33–48 |
| Absolute humidity (St) | St−1,St−2,St−3,…,St−16 | 49–64 |
| atmospheric pressure (Pt) | Pt−1,Pt−2,Pt−3,…,Pt−16 | 65–80 |
| Wind shear (Ct) | Ct−1,Ct−2,Ct−3,…,Ct−16 | 81–96 |
| Feature Types | Statistical Features | Numbers |
|---|---|---|
| Wind speed (xt) | max(xt−1, xt−2, xt−3,…, xt−16); min(xt−1, xt−2, xt−3,…, xt−16); mean(xt−1, xt−2, xt−3,…, xt−16); std(xt−1, xt−2, xt−3,…, xt−16); var(xt−1, xt−2, xt−3,…, xt−16) | 97–101 |
| Temperature (Tt) | max(Tt−1, Tt−2, Tt−3,…, Tt−16); min(Tt−1, Tt−2, Tt−3,…, Tt−16); mean(Tt−1, Tt−2, Tt−3,…, Tt−16); std(Tt−1, Tt−2, Tt−3,…, Tt−16); var(Tt−1, Tt−2, Tt−3,…, Tt−16) | 102–106 |
| Relative humidity (Rt) | max(Rt−1, Rt−2, Rt−3,…, Rt−16); min(Rt−1, Rt−2, Rt−3,…, Rt−16); mean(Rt−1, Rt−2, Rt−3,…, Rt−16); std(Rt−1, Rt−2, Rt−3,…, Rt−16); var(Rt−1, Rt−2, Rt−3,…, Rt−16) | 107–111 |
| Absolute humidity (St) | max(St−1, St−2, St−3,…, St−16); min(St−1, St−2, St−3,…, St−16); mean(St−1, St−2, St−3,…, St−16); std(St−1, St−2, St−3,…, St−16); var(St−1, St−2, St−3,…, St−16) | 112–116 |
| atmospheric pressure (Pt) | max(Pt−1, Pt−2, Pt−3,…, Pt−16); min(Pt−1, Pt−2, Pt−3,…, Pt−16); mean(Pt−1, Pt−2, Pt−3,…, Pt−16); std(Pt−1, Pt−2, Pt−3,…, Pt−16); var(Pt−1, Pt−2, Pt−3,…, Pt−16) | 117–121 |
| Wind shear (Ct) | max(Ct−1, Ct−2, Ct−3,…, Ct−16); min(Ct−1, Ct−2, Ct−3,…, Ct−16); mean(Ct−1, Ct−2, Ct−3,…, Ct−16); std(Ct−1, Ct−2, Ct−3,…, Ct−16); var(Ct−1, Ct−2, Ct−3,…, Ct−16) | 122–126 |
| Pretreatment Method | EMD | EEMD | CEEMD | Raw Data |
|---|---|---|---|---|
| MAPE | 31.96% | 29.79% | 24.23% | 38.16% |
| RMSE (m/s) | 1.5211 | 1.4013 | 1.1465 | 1.9902 |
| Periods of Time | Analysis Methods | 1–10 Dimensional Features | 11–20 Dimensional Features | 21–30 Dimensional Features |
|---|---|---|---|---|
| 21 January | PCC | 1,2,3,4,81,5,82,97,109,6 | 83,98,114,7,84,8,107,85,9,10 | 86,108,11,87,12,88,13,14,89,15 |
| MI | 1,2,3,81,4,97,82,5,109,98 | 83,6,114,84,7,107,8,85,9,10 | 86,108,11,87,12,13,88,14,15,89 | |
| CMI | 1,2,3,81,4,82,97,5,83,109 | 98,6,84,114,107,7,121,115,85,8 | 108,9,86,10,11,87,12,88,13,126 | |
| 17 April | PCC | 1,2,3,4,81,5,97,82,109,6 | 98,83,7,114,84,8,85,9,107,10 | 86,108,11,12,87,13,88,14,89,15 |
| MI | 1,2,3,4,81,97,5,82,98,109 | 83,6,7,84,114,8,107,85,9,108 | 10,86,11,87,12,88,13,121,115,14 | |
| CMI | 1,2,3,81,4,97,82,5,98,109 | 83,6,84,114,7,115,121,107,85,108 | 8,9,86,10,87,11,33,34,126,120 | |
| 18 July | PCC | 1,2,3,4,81,82,5,97,109,83 | 6,98,114,84,7,107,85,8,9,86 | 108,10,87,11,115,12,88,13,89,14 |
| MI | 1,2,3,81,4,82,97,5,98,109 | 83,6,84,114,107,7,85,8,86,9 | 108,10,87,11,121,115,88,12,13,89 | |
| CMI | 1,2,3,81,4,82,97,5,98,83 | 109,6,84,107,114,115,121,7,85,108 | 8,86,9,10,120,126,87,11,122,116 | |
| 7 November | PCC | 1,2,3,4,97,81,5,109,82,6 | 98,7,83,114,8,84,9,107,10,85 | 11,12,86,108,13,14,87,15,16,88 |
| MI | 1,2,3,4,81,97,5,109,82,98 | 6,83,114,7,107,8,84,9,85,10 | 11,86,12,108,13,14,87,15,16,88 | |
| CMI | 1,2,3,81,4,97,82,5,109,98 | 83,6,114,84,7,107,8,115,121,108 | 85,9,10,86,11,12,13,14,87,15 | |
| YD | PCC | 1,2,3,4,5,97,81,109,6,82 | 98,7,83,8,114,84,9,10,85,11 | 107,12,108,86,13,14,87,15,16,88 |
| MI | 1,2,3,4,81,97,5,82,109,98 | 6,83,7,114,84,8,107,9,85,10 | 11,108,86,12,13,87,14,88,15,16 | |
| CMI | 1,2,3,81,4,97,82,5,98,109 | 83,6,84,7,114,107,121,115,8,85 | 9,108,86,10,11,87,12,13,88,14 |
| Periods of Time | Analysis Methods | AD-ORELM | AD-ELM | AD-BPNN | |||
|---|---|---|---|---|---|---|---|
| MAPE | DIM | MAPE | DIM | MAPE | DIM | ||
| 21 January | PCC | 10.45% | 17 | 11.56% | 14 | 11.39% | 103 |
| MI | 10.44% | 17 | 11.33% | 21 | 11.40% | 118 | |
| CMI | 10.34% | 18 | 11.00% | 19 | 11.03% | 116 | |
| 17 April | PCC | 10.75 | 22 | 12.19 | 10 | 11.93 | 34 |
| MI | 10.76 | 23 | 11.99 | 18 | 11.98 | 90 | |
| CMI | 10.37 | 23 | 11.56 | 21 | 11.87 | 30 | |
| 18 July | PCC | 10.20 | 17 | 11.73 | 16 | 11.88 | 24 |
| MI | 10.23 | 19 | 11.82 | 15 | 11.97 | 106 | |
| CMI | 10.08 | 19 | 11.37 | 17 | 11.44 | 44 | |
| 7 November | PCC | 11.25 | 15 | 12.19 | 15 | 12.50 | 88 |
| MI | 11.20 | 14 | 12.68 | 52 | 12.76 | 55 | |
| CMI | 11.02 | 15 | 12.51 | 15 | 12.64 | 59 | |
| Periods of Time | Analysis Methods | YD-ORELM | YD-ELM | YD-BPNN | |||
|---|---|---|---|---|---|---|---|
| MAPE | DIM | MAPE | DIM | MAPE | DIM | ||
| 21 January | PCC | 11.11% | 106 | 11.62% | 125 | 11.90% | 120 |
| MI | 10.93% | 113 | 11.63% | 88 | 11.83% | 121 | |
| CMI | 10.71% | 83 | 11.51% | 109 | 11.62% | 68 | |
| 17 April | PCC | 11.34% | 83 | 12.77% | 53 | 12.46% | 67 |
| MI | 11.23% | 97 | 12.72% | 20 | 12.43% | 111 | |
| CMI | 11.23% | 38 | 12.32% | 56 | 12.38% | 61 | |
| 18 July | PCC | 10.99% | 22 | 12.29% | 22 | 12.34% | 21 |
| MI | 10.99% | 20 | 12.22% | 21 | 12.29% | 29 | |
| CMI | 10.70% | 29 | 12.16% | 16 | 12.24% | 27 | |
| 7 November | PCC | 11.52% | 81 | 12.50% | 63 | 12.97% | 69 |
| MI | 11.42% | 62 | 12.72% | 95 | 12.90% | 57 | |
| CMI | 11.37% | 94 | 12.65% | 103 | 12.81% | 75 | |
| Periods of Time | Analysis Method | Historical Features | Statistical Features | ||||
|---|---|---|---|---|---|---|---|
| xt | Ct | xt | Rt | St | Pt | ||
| 21 January | PCC | 8 | 4 | 2 | 2 | 1 | 0 |
| MI | 8 | 4 | 2 | 2 | 1 | 0 | |
| CMI | 7 | 4 | 2 | 2 | 2 | 1 | |
| 17 April | PCC | 10 | 6 | 2 | 3 | 1 | 0 |
| MI | 11 | 6 | 2 | 3 | 1 | 0 | |
| CMI | 9 | 6 | 2 | 3 | 2 | 1 | |
| 18 July | PCC | 7 | 5 | 2 | 2 | 1 | 0 |
| MI | 9 | 5 | 2 | 2 | 1 | 0 | |
| CMI | 7 | 5 | 2 | 2 | 2 | 1 | |
| 7 November | PCC | 8 | 3 | 2 | 1 | 1 | 0 |
| MI | 7 | 3 | 2 | 1 | 1 | 0 | |
| CMI | 7 | 4 | 2 | 1 | 1 | 0 | |
| Periods of Time | Analysis Methods | AD-ORELM | AD-ELM | AD-BPNN | AD-CART | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE (m/s) | MAPE | DIM | RMSE (m/s) | MAPE | DIM | RMSE (m/s) | MAPE | DIM | RMSE (m/s) | MAPE | DIM | ||
| 21 January | PCC | 1.7284 | 11.42% | 17 | 1.8966 | 12.84% | 14 | 1.7655 | 12.51% | 103 | 1.6725 | 11.03% | 32 |
| MI | 1.6987 | 11.33% | 17 | 1.7187 | 12.52% | 21 | 1.7295 | 12.44% | 118 | ||||
| CMI | 1.5056 | 10.81% | 18 | 1.6244 | 12.03% | 19 | 1.7083 | 12.37% | 116 | ||||
| 17 April | PCC | 0.5545 | 9.68% | 22 | 0.5655 | 11.96% | 10 | 0.5097 | 11.49% | 34 | 0.5261 | 9.75% | 25 |
| MI | 0.5118 | 9.77% | 23 | 0.5401 | 11.81% | 18 | 0.6424 | 11.9% | 90 | ||||
| CMI | 0.4545 | 9.17% | 23 | 0.5005 | 11.43% | 21 | 0.5024 | 11.41% | 30 | ||||
| 18 July | PCC | 0.5054 | 11.54% | 17 | 0.5481 | 13.22% | 16 | 0.5468 | 13.43% | 24 | 0.4855 | 11.09% | 27 |
| MI | 0.5021 | 11.15% | 19 | 0.5476 | 13.12% | 15 | 0.5015 | 12.94% | 106 | ||||
| CMI | 0.4141 | 11.06% | 19 | 0.4603 | 12.74% | 17 | 0.4439 | 12.66% | 44 | ||||
| 7 November | PCC | 0.4561 | 10.37% | 15 | 0.4211 | 11.49% | 15 | 0.4972 | 12.28% | 88 | 0.372 | 10.41% | 20 |
| MI | 0.3988 | 10.45% | 14 | 0.453 | 11.61% | 52 | 0.4484 | 11.89% | 55 | ||||
| CMI | 0.3269 | 9.72% | 15 | 0.3704 | 10.95% | 15 | 0.4154 | 11.52% | 59 | ||||
| Seasons | Analysis Methods | AD-ORELM | AD-ELM | AD-BPNN | AD-CART | ||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (m/s) | MAPE | RMSE (m/s) | MAPE | RMSE (m/s) | MAPE | RMSE (m/s) | MAPE | ||
| Spring | PCC | 1.3397 | 11.23% | 1.3878 | 11.82% | 1.397 | 12.06% | 1.3482 | 11.16% |
| MI | 1.3474 | 11.15% | 1.3927 | 11.79% | 1.3856 | 11.92% | |||
| CMI | 1.2881 | 10.72% | 1.3241 | 11.36% | 1.3328 | 11.17% | |||
| Summer | PCC | 0.5894 | 11.32% | 0.6633 | 12.45% | 0.6648 | 12.45% | 0.5872 | 11.3% |
| MI | 0.5911 | 11.27% | 0.6519 | 12.40% | 0.6467 | 12.49% | |||
| CMI | 0.5321 | 10.84% | 0.5864 | 11.86% | 0.5942 | 11.89% | |||
| Autumn | PCC | 0.5290 | 10.88% | 0.5843 | 11.97% | 0.5798 | 11.98% | 0.4957 | 10.83% |
| MI | 0.5204 | 10.95% | 0.5774 | 11.96% | 0.5760 | 12.02% | |||
| CMI | 0.4684 | 10.25% | 0.5175 | 11.28% | 0.4995 | 11.46% | |||
| Winter | PCC | 0.9491 | 11.63% | 0.9825 | 12.54% | 0.9858 | 12.89% | 0.943 | 11.25% |
| MI | 0.9521 | 11.71% | 0.9908 | 12.75% | 0.9832 | 12.89% | |||
| CMI | 0.9026 | 10.93% | 0.9493 | 12.02% | 0.9375 | 12.27% | |||
| Feature | Seasons | Range of Variation | Variance Value |
|---|---|---|---|
| Wind speed | Spring | [0.29, 32.48] | 22.34 |
| Summer | [0.29, 31.57] | 10.30 | |
| Autumn | [0.25, 30.52] | 7.12 | |
| Winter | [0.25, 32.65] | 21.76 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, N.; Xing, E.; Cai, G.; Yu, Z.; Qi, B.; Lin, L. Short-Term Wind Speed Forecasting Based on Low Redundancy Feature Selection. Energies 2018, 11, 1638. https://doi.org/10.3390/en11071638
Huang N, Xing E, Cai G, Yu Z, Qi B, Lin L. Short-Term Wind Speed Forecasting Based on Low Redundancy Feature Selection. Energies. 2018; 11(7):1638. https://doi.org/10.3390/en11071638
Chicago/Turabian StyleHuang, Nantian, Enkai Xing, Guowei Cai, Zhiyong Yu, Bin Qi, and Lin Lin. 2018. "Short-Term Wind Speed Forecasting Based on Low Redundancy Feature Selection" Energies 11, no. 7: 1638. https://doi.org/10.3390/en11071638
APA StyleHuang, N., Xing, E., Cai, G., Yu, Z., Qi, B., & Lin, L. (2018). Short-Term Wind Speed Forecasting Based on Low Redundancy Feature Selection. Energies, 11(7), 1638. https://doi.org/10.3390/en11071638