1. Introduction
Load forecasting is of upmost significance and affects the construction and operation of power systems. In the preparation of the power system planning stage, if the load forecasting result is lower than the real demand, the installed and distribution capacities of the planned power system will be insufficient. The power generated will not be able to meet electricity demand of the community it serves, and the entire system will not be able to operate in a stable manner. Conversely, if the load forecast is too high, it will result in power generation, transmission, and distribution, at a larger scale, that cannot be fully used in the real power system. The investment efficiency and the efficiency of the resource utilization will be reduced in this situation. Therefore, effective and reliable power load forecasting can promote a balanced development of the power system while improving the utilization of energy. There are various power load forecasting methods and, commonly, load forecasting is classified into short-term, medium-term, and long-term, based on the application field and forecasting time. Among these categories, short-term load forecasting (STLF) is an essential tool for the planning and operation [
1,
2] of energy systems and it has thus been a major area of research during the past few decades.
According to existing research, concern mostly focuses on the point forecasting of STLF. Additionally, the relative algorithms can be mainly classified into three major categories: traditional statistical techniques, computational intelligent methods, and multimodule hybrid models [
3].
In the early stages of research, traditional statistical techniques were extensively employed for point forecasting of STLF, such as linear regression methods [
4,
5], exponential smoothing [
6], Kalman filters [
7], and other linear time-series models. In general, most of the traditional statistical approaches have been involved in linear analysis and have mainly considered linear factors in time series. However, the short-term load series are a mixture of multiple components which include linear and non-linear factors. Therefore, the traditional statistical approaches encounter difficulties when dealing with the STLF, and the forecasting accuracy is often unsatisfactory. With the development of machine learning and artificial intelligence, an increased number of non-linear computational intelligent methods have been applied to STLF, such as neural network models (NN) [
8,
9], expert systems [
10] and support vector machines (SVM) [
11,
12]. These approaches have been proved to have advantages in dealing with the non-linear problems of STLF compared to traditional statistical methods, thereby eliciting improved performances in most cases. Most importantly, a key point that influences the performance of computational intelligent methods is the setting of related parameters in algorithms. At this time, efficient hybrid models appeared. In hybrid models, different modules were introduced to improve the performance and accuracy of STLF [
13,
14,
15,
16,
17,
18,
19]. Among existing reviews in the literature, two popular and efficient modules include the data preprocessing and optimization modules. In the case of the data preprocessing modules, a multiwavelet transform was used in combination with a three-layer feed-forward neural network to extract the training data and predict the load in [
13]. Fan et al. [
14] used empirical mode decomposition (EMD) to decompose electric load data, generating high-frequency series and residuals for the forecasting of support vector regression (SVR) and autoregression (AR), respectively. The results showed that the hybrid methods can perform well by eliciting good forecasting accuracy and interpretability. In the case of the optimization modules, AlRashidi et al. [
15] employed the particle swarm optimizer (PSO) to fine-tune the model parameters, and the forecasting problem was presented in a state space form. Wang et al. [
16] proposed a hybrid forecasting model combining differential evolution (DE) and support vector regression (SVR) for load forecasting, where the DE algorithm was used to choose the appropriate parameters for SVR.
However, as mentioned above, the current research on STLF mainly concentrates on point forecasting in which the accuracy is usually measured by the errors between the predicted and the target values. With power system growth and the increase in its complexity, point forecasting might not be able to provide adequate information support for power system decision making. An increasing number of factors, such as load management, energy conversion, spot pricing, independent power producers and non-conventional energy, make point forecasting undependable in practice. In addition to the fact that most of these point forecasting models do not elicit the required precision, they are also not adequately robust. They fail to yield accurate forecasts when quick exogenous changes occur. Other shortcomings are related to noise immunity, portability, and maintenance [
20].
In general, point forecasting cannot properly handle uncertainties associated with load datasets in most cases. To avoid such imperfection, interval prediction (IP) of STLF is an efficient way to deal with the forecast uncertainty in electrical power systems. Prediction intervals (PIs) not only provide a range in which targets are highly likely to be covered, but they also provide an indication of their accuracy, known as the coverage probability. Furthermore, the PIs can take into account more uncertain information and the result of (PIs) commonly form a double output (upper bounds and lower bounds) which can reflect more uncertain information and provide a more adequate basis for power system planning.
With the development of artificial intelligence technology, the interval prediction methods based on NN have been proved to be efficient techniques. According to existing research, the popular techniques for constructing PIs are Bayesian [
21], delta [
22], bootstrap [
23], and mean–variance estimation [
24]. In the literature, the Bayesian technique [
25] is used for the construction of NN-based PIs. Error bars are assigned to the predicted NN values using the Bayesian technique. Even if the theories are effective in the construction of PIs, the calculation of the Hessian matrix will result in the increase of model complexity and computation cost. In [
26], the delta technique was applied to construct PIs for STLF, and a simulated annealing (SA) algorithm was introduced to improve the performance of PIs through the minimization of a loss function. In [
27], according to bootstrap, error output, resampling, and multilinear regression, were used with STLF for the construction of confidence intervals with NN models. In [
24], a mean–variance estimation-based method used NN to estimate the characteristics of the conditional target distribution. Additive Gaussian noise with non-constant variance was the key assumption of the method for PI construction.
Considering most of the existing research studies of PIs by NN mentioned above, the PIs were usually calculated depending on the point forecasting. The NNs were first trained by minimizing an error-based cost function, and the PIs were then constructed depending on the outcomes of trained and tuned NNs. It may be questionable to construct PIs in this way. Furthermore, it is a more reasonable way to output the upper and lower bounds directly [
28]. Compared with the Bayesian, delta, and bootstrap techniques, this approach can output the PIs without being dependent on point prediction. However, in traditional research approaches, the cost function mainly aims at guaranteeing coverage probability (CP). However, a satisfactory coverage probability can be achieved easily by assigning sufficiently large and small values to the upper and lower bounds of the PIs. Thus, the prediction interval width (PIW) is another key characteristic which needs to be considered fully. These two goals, that is, achieving a higher CP and a lower PIW, should be considered in a comprehensive manner when the NN parameters are determined.
Therefore, in this study, a hybrid, lower upper bound estimation (LUBE) based on multi-objective optimization is proposed. The requirements for higher CP and lower PIW constitute a typical case of the Pareto optimization problem. In the present study, a significant and valid approach was used to solve the Pareto optimization problem is the multi-objective optimization [
29]. There are many algorithms in the literature for solving multi-objective optimizations. For the GA, the most well-regarded multi-objective algorithm is the non-dominated sorting genetic algorithm (NSGA) [
30]. Other popular algorithms include the multi-objective particle swarm optimization (MOPSO) [
31,
32], multi-objective ant colony optimization (MOACO) [
33], multi-objective differential evolution (MODE) [
34], multi-objective grasshopper optimization (MOGO) [
35], multi-objective evolution strategy (MOES) [
36], multi-objective sine cosine (MOSC) [
37], and multi-objective ant lion [
38]. All these algorithms are proved to be effective in identifying non-dominated solutions for multi-objective problems. According to the “no free lunch theorem” for optimization [
39,
40], there is no algorithm capable of solving optimization algorithms for all types of problems. This theorem logically proves this and proposes new algorithms, or improves the current ones.
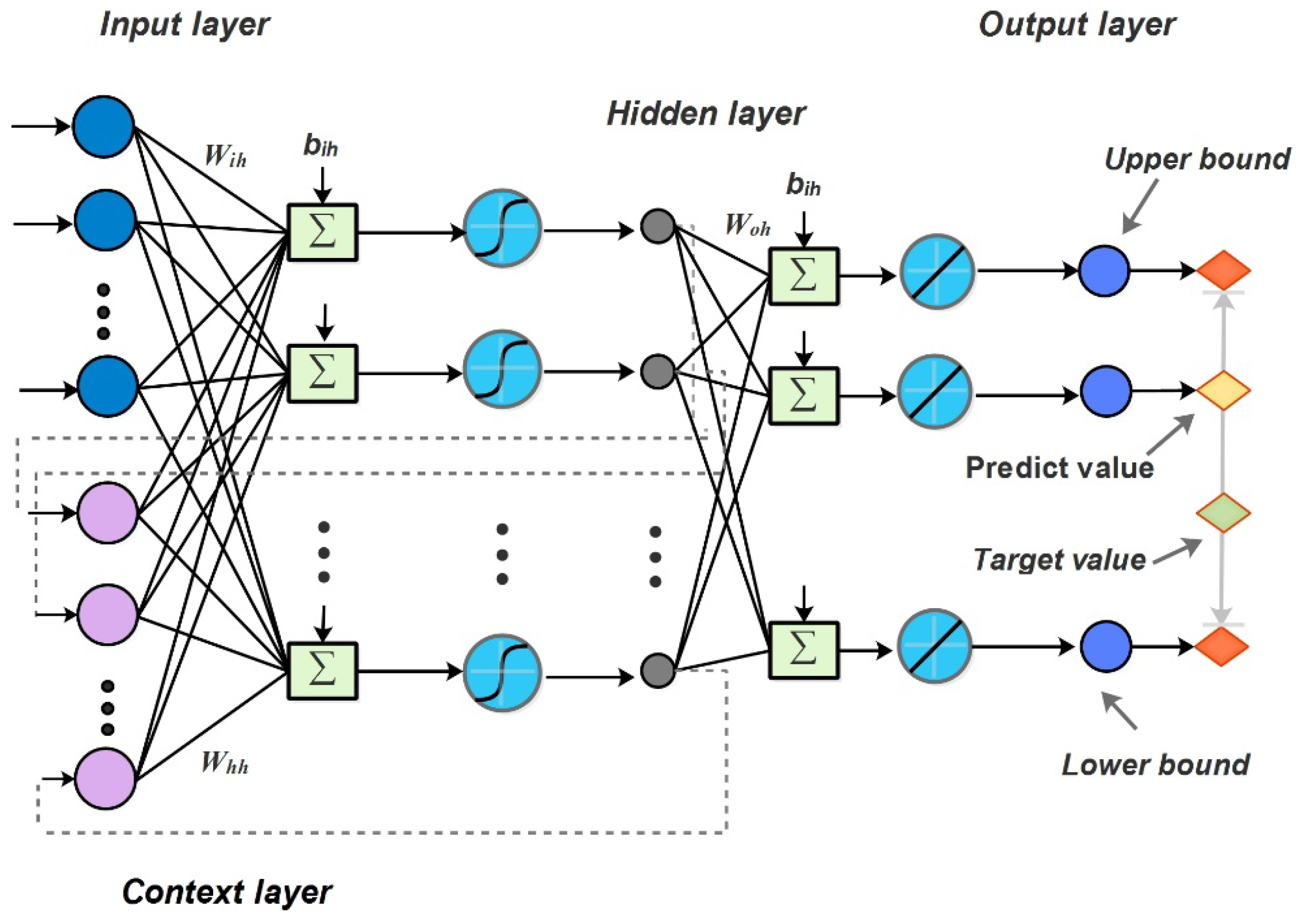
In this study, to achieve a better performance in STLF, one of the novel recurrent neural networks, the Elman neural network (ENN) [
41], is applied to construct the structure of a modified LUBE. The Elman neural network has already been extensively used in time-series forecasting [
42,
43,
44]. As a type of recurrent neural network, ENN exhibits superiority on the time delay information because of the existence of the undertaking layer which can connect hidden NN layers and store the historical information in the training process. This structure design of NN commonly leads to a better performance in time-series forecasting.
In traditional STLF, most of the methods construct the training set of the model directly using the original data. However, data in the natural world often receives a lot of noise interference, which will cause more difficulties for desired STLF. Furthermore, improving the signal-to-noise ratio of the training dataset will help the effective training of the model. Amongst the existing denoising methods, empirical mode decomposition (EMD) [
45] is extensively used, which is an adaptive method introduced to analyze non-linear and non-stationary signals. In order to alleviate some reconstruction problems, such as “mode mixing” of EMD, some other versions [
46,
47,
48] are proposed. Particularly, the problem of different number of modes for different realizations of signal and noise need to be considered.
Summing up the above, in this study, a hybrid interval prediction system is proposed to solve the STLF problem based on the modified Lower and Upper bound estimate (LUBE) technique, by incorporating the use of a data preprocessing module, an optimization module, and a prediction module. In order to verify the performance of the proposed model, we choose as the experimental case the power loads of four states in Australia. The elicited results are compared with those from basic benchmark models. In summary, the primary contributions of this study are described below:
- (1)
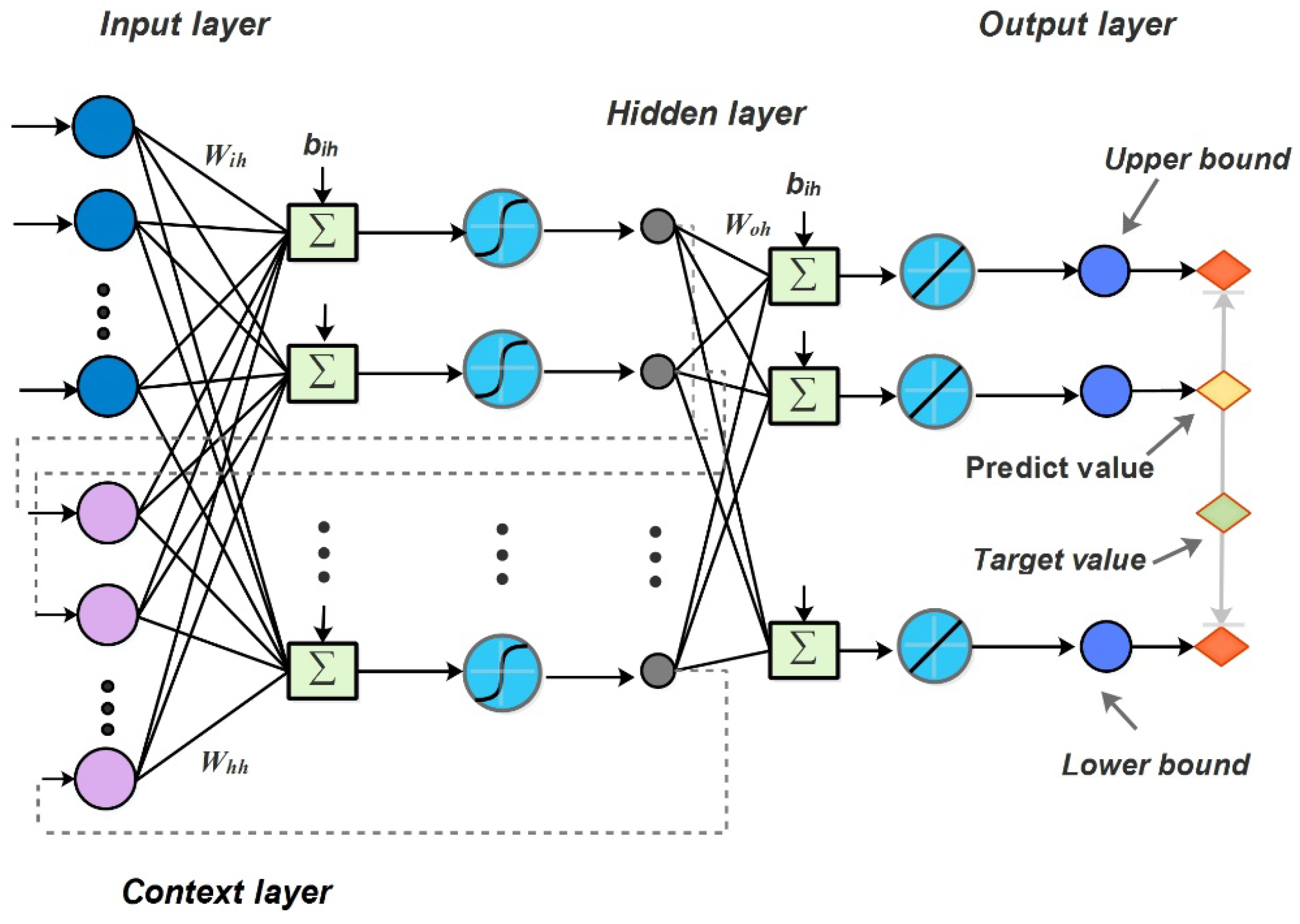
A modified LUBE technique is proposed based on a recurrent neural network, which is able to consider previous information of former observations in STLF. The contest layer of ENN can store the outputs of a former hidden layer, and then connect the input layer in the current period. Comparison of the traditional interval predictive model with the basic neural network, this mechanism can improve the performance of time series forecasting methods, such as STLF.
- (2)
A more convincing optimization technique based on multi-objective optimization is proposed for LUBE. In LUBE, besides CP, PIW should also be considered in the construction of the cost function. In this study, the novel multi-objective optimization method MOSSA is employed in the optimization module to balance the conflict between higher CP and lower PIW, and to train the parameters in ENN. With this method, the structure of neural networks can provide a better performance in interval prediction.
- (3)
A novel and efficient data preprocessing method is introduced to extract the valuable information from raw data. In order to improve the signal noise ratio (SNR) of the input data, an efficient method is used to decompose the raw data into several empirical modal functions (IMFs). According to the entropy theory, the IMFs with little valuable information are ignored. The performance of the proposed model trained with processed data improves significantly.
- (4)
The proposed hybrid system for STLF can provide powerful theoretical and practical support for decision making and management in power grids. This hybrid system is simulated and tested depending on the abundant samples involving different regions and different times, which indicate its practicability and applicability in the practical operations of power grids compared to some basic models.
The rest of this study is organized as follows: The relevant methodology, including data preprocessing, Elman neural network, LUBE, and multi-objective algorithms, are introduced in
Section 2.
Section 3 discusses our proposed model in detail. The specific simulation, comparisons and analyses of the model performances are shown in
Section 4. In order to further understand the features of the proposed model, several points are discussed in
Section 5. According to the results of our research, conclusions are outlined in
Section 6.
3. Proposed Interval Prediction Model for Short-Term Load Forecasting (STLF)
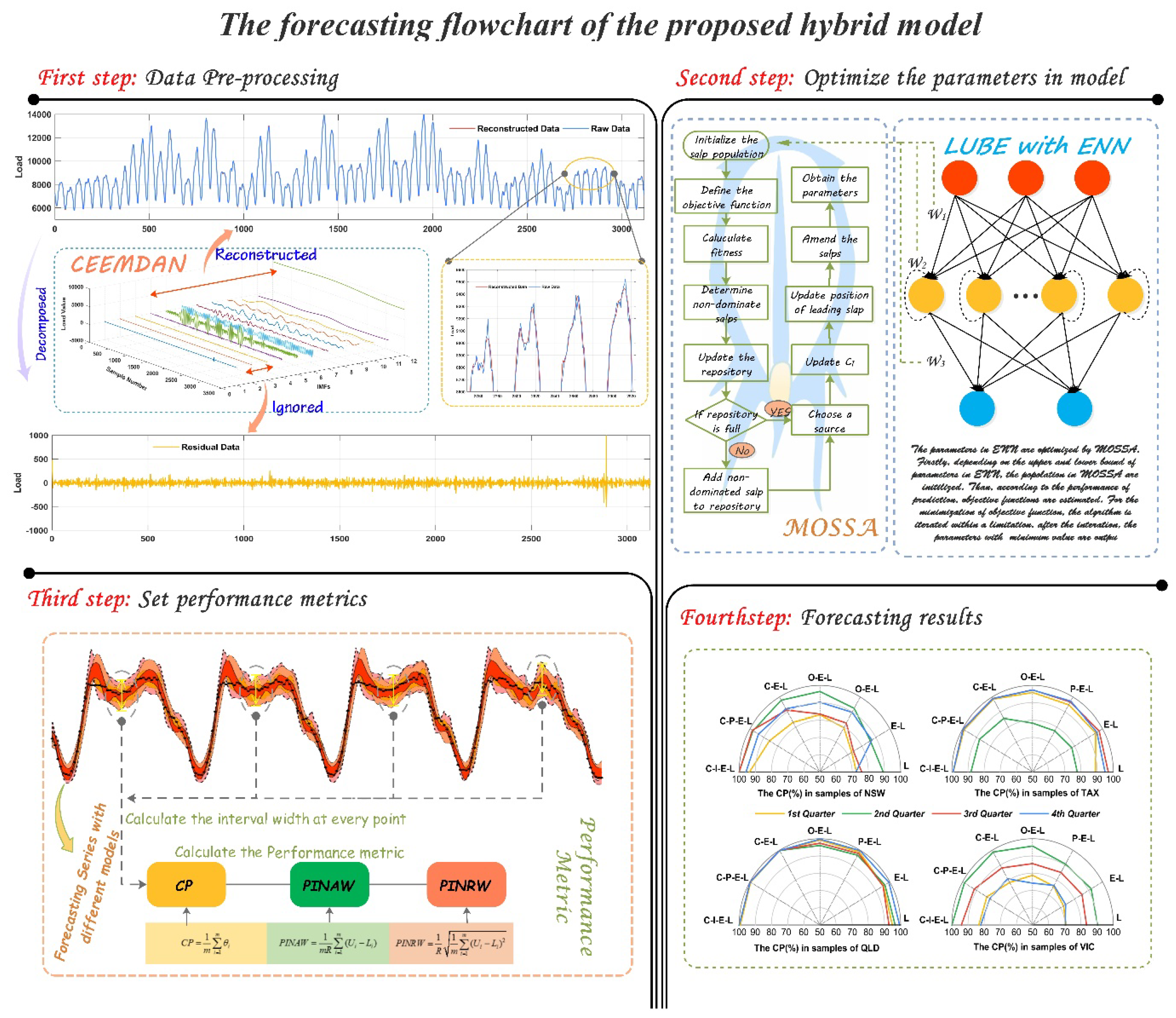
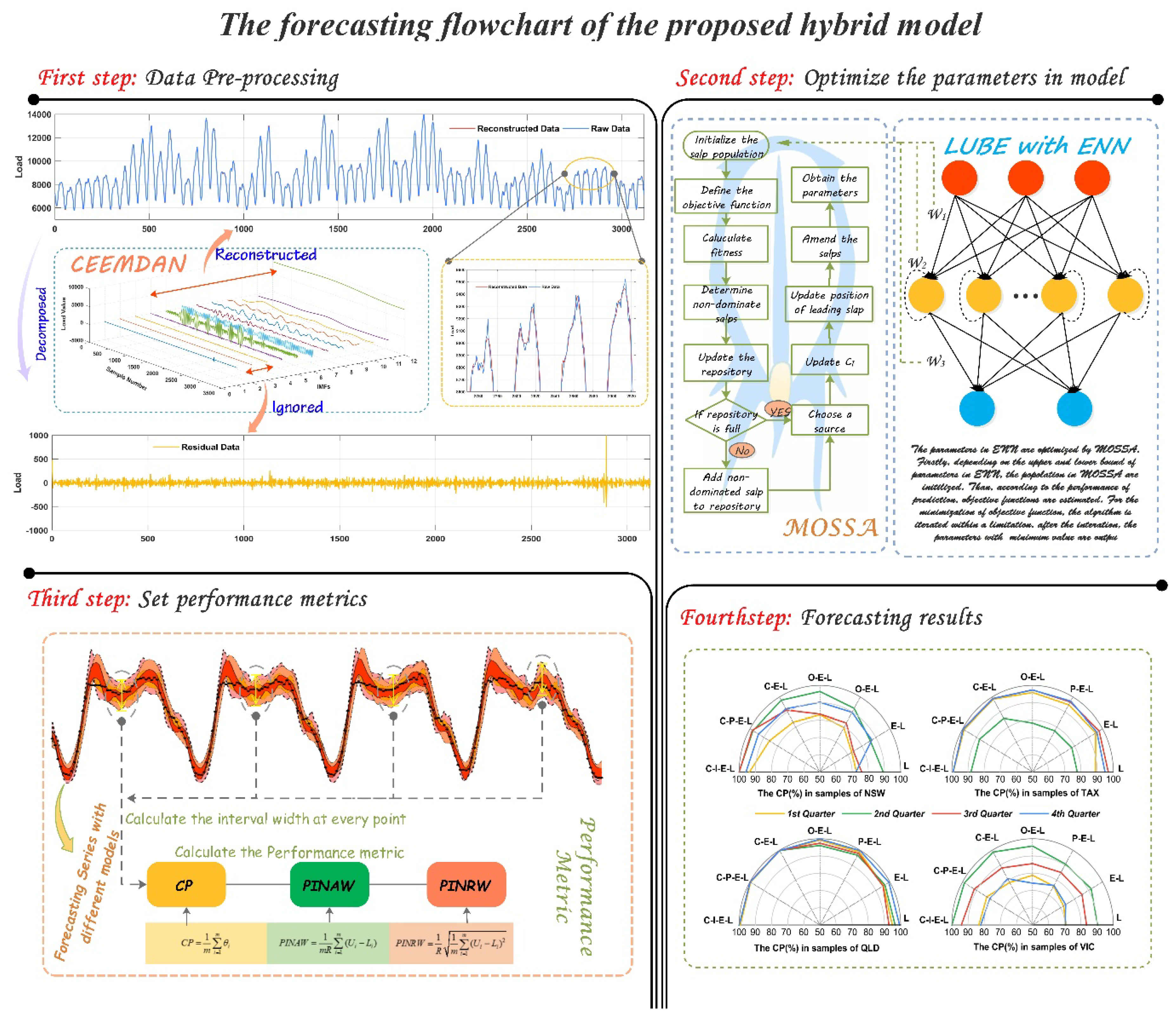
In this paper, we proposed a hybrid model for interval prediction based on the data preprocessing, multi-objective optimization algorithm and LUBE to solve the problem of STLF. This hybrid model consist of two stages: data de-noising and model prediction.
In the first stage, the main task is to refine the original data. The raw power load data is affected by many internal and external factors in the collection process. Therefore, a lot of unrelated information is integrated in the data. Several pieces of information will further affect the quality of the power load data, and increase the difficulty of accurate forecasting of the power load. In the neural network model, the performance of the model is directly affected by the quality of the data. As a type of machine learning algorithm, the neural network uses its multilayered structure to learn the relevant interdependencies of the data and determine the structural parameters of the prediction model, so as to achieve fitting and forecasting. However, if the input set of the model contains too much noise and “false information”, the model will be seriously affected in the training process, and some problems will emerge, such as the overfitting problem. Therefore, we introduced CEEMDAN to eliminate useless information in the raw data. As mentioned above, CEEMDAN can decompose the data series into several IMFs with different frequencies, as shown in
Figure 2. Because the IMFs are extracted with envelope curves depending on the extremum, some of the IMFs have higher frequencies, just as the first few IMFs that are shown in
Figure 2. In addition, the other IMFs also have lower frequencies and represent the trend factors, thereby formulating the vital basis for time-series prediction. In the actual operations, we can remove the IMFs with higher frequencies, which effectively represent noise to refine the original data. In order to determine which IMFs ought to be abandoned, we calculated the entropy of each IMF and removed the IMFs with lower entropy. After the denoising process, the refined data are transferred to next stage as the input data for training in the predictive model.
In the second stage, the main interval prediction model was proposed. In our hybrid interval prediction model, the PI is output dependent on LUBE, which is based on the multi-output of the Elman neural network (E–LUBE). In the training process, the input set of E–LUBE is constructed as indicated in Formula (16), while the output set is constructed as indicated in Formula (17), where
m and
s respectively denote the number of features and the numbers of samples, and
denotes the interval width coefficient. In the case of the STLF problem,
m indicates the number of previous time-points that we use to forecast the predictive value.
According to a trained model, when a new series
Xi,
i = 1, …,
m, is input into the model,
Xm+1 with an upper bound
and a lower bound
will be output. This is the basic mechanism of interval prediction for STLF in this study. However, in traditional multi-output neural networks, the loss function is always the mean-square-error (MSE), which is a key criterion for point forecasting. In this study, we introduced two new criteria (PIW and CP) to construct the loss function, considering the main purpose of our interval prediction. The traditional neural network parameters were determined by using a gradient descent algorithm, but for two of the set criteria, the calculation of the gradient was difficult. Therefore, we employed MOSSA to realize the multi-objective parameter optimization. Furthermore, the optimization problem can be expressed as,
where
is a set of parameters in E–LUBE, including the weight and bias.
When the parameters are determined in the training process, the entire model can be applied to the test set to verify the performance of interval prediction.
4. Simulations and Analyses
In order to validate the performance of the proposed hybrid model in STLF, four electrical load datasets collected from four states in Australia are used in our research. The four states include New South Wales (NSW), Tasmania (TAX), Queensland (QLD) and Victoria (VIC), and the specific location is showed in
Figure 3. The experiments in this study consist of two parts: experiment I and experiment II. For experiment I, the load data of four states are modeled with interval width coefficient
, and for the experiment II, the interval width coefficient
is set as 0.025 for further analysis. In order to verify the superiority of the proposed hybrid model, several benchmark models which include basic LUBE (LUBE), LUBE with Elman neural network (E–LUBE), E–LUBE with point optimization (PO–E–LUBE), E–LUBE with interval optimization (IO–E–LUBE), and models integrated with CEEMDAN, are exhibited. For persuasive comparability and fairness, the hyper-parameters in each model are consistent, as shown in
Table 1. All experiments have been carried out in MATLAB 2016a on a PC with the configuration of Windows 7 64-bit, Inter Core i5-4590 CPU @ 3.30GHz, 8GB RAM.
4.1. Data Descriptions
For each state, we considered the data using half an hour interval in four quarters. The data used in this paper can be obtained on the website of Australian energy market operator (
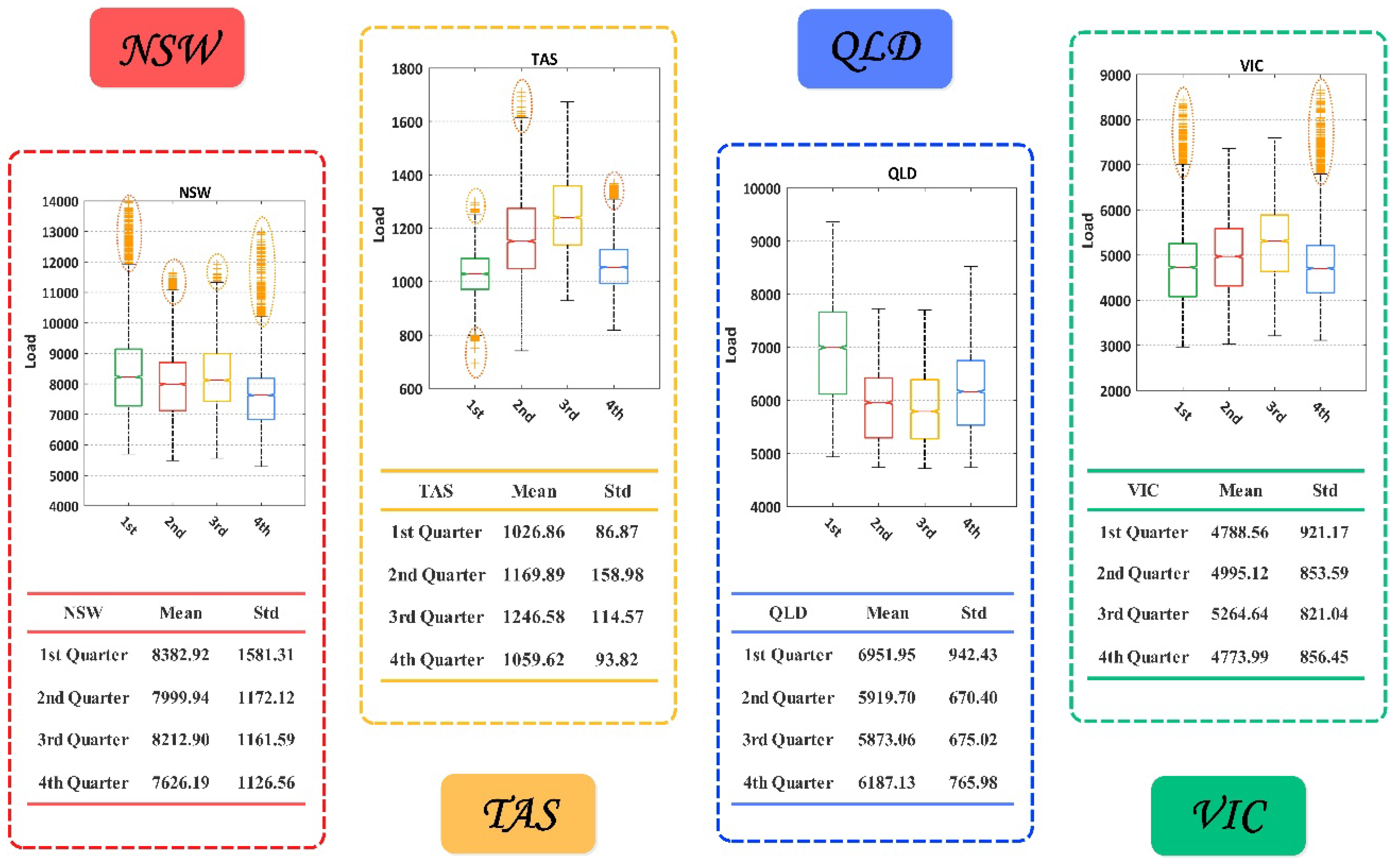
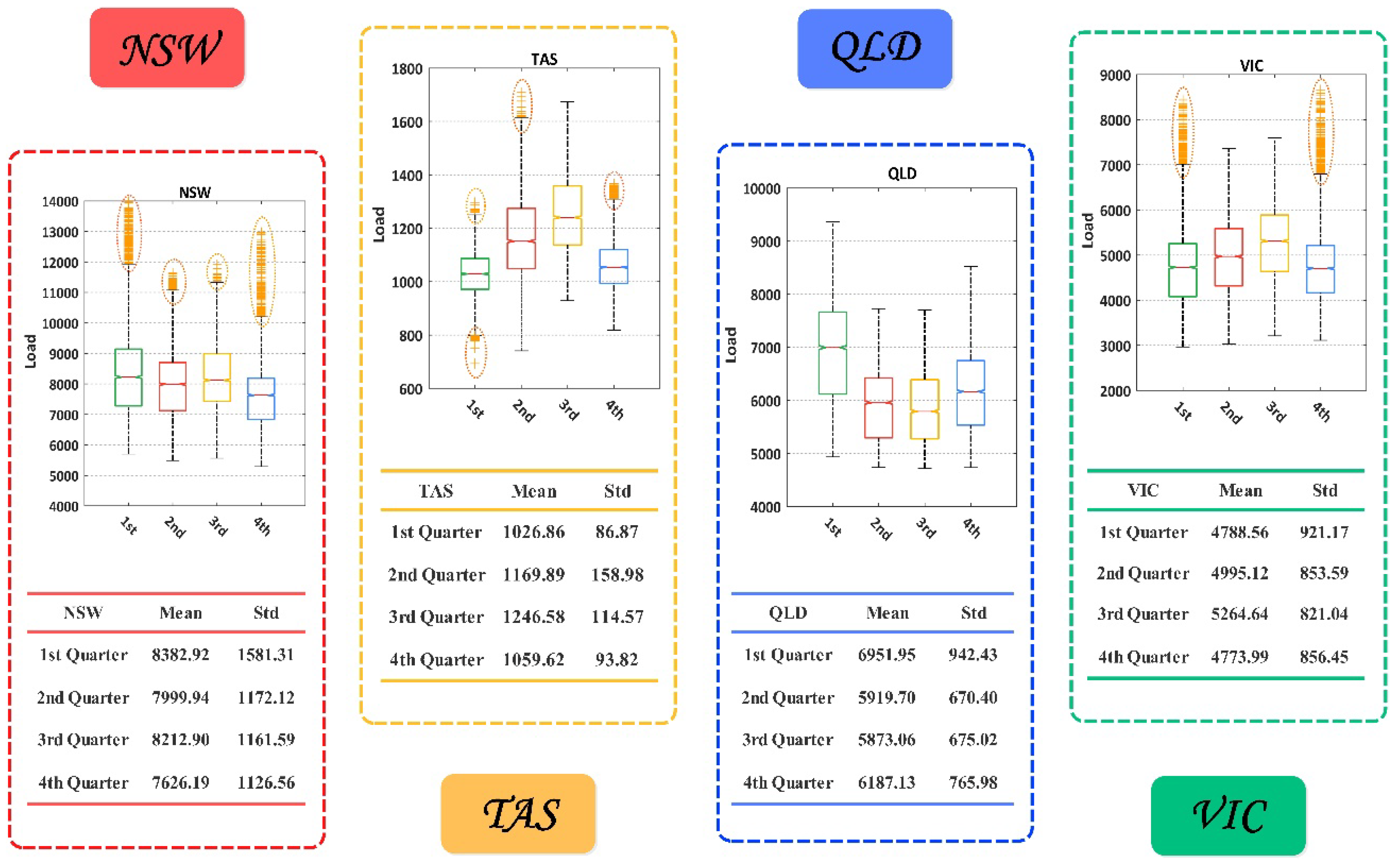
http://www.aemo.com.au/). We chose data from the whole of 2017 from 1 January 2017 0:30 am to 31 December 2017 0:00 am to construct dataset. In each state, the total sample number is 17,520. For each quarter, the number of samples were 4320, 4358, 4416, 4416 respectively. In order to control the comparability, we selected 1200 samples to test the trained model, and used the rest in each quarter to train the models. The proportion of train sets versus the test sets was approximately equal to 3:1. The description of the data characteristics are shown in
Figure 4. Considering the structure of the neural network in this study, we set six input neurons, 13 hidden neurons, and three output neurons. Specifically, the output set was formulated in accordance with Formula (17).
During data preprocessing, the input data were divided into several IMFs depending on CEEMDAN, as displayed in
Figure 2. According to the energy entropy of each IMF shown in
Figure 3, we ignored the IMFs which contained high frequencies, and summed the rest of the IMFs to reconstruct the input set, as shown in
Figure 1.
4.2. Performance Metrics
In order to comprehensively assess the performance of the models, some metrics were employed. These metrics primarily focused on the coverage of the real value in the prediction interval and the width of the interval.
4.2.1. Coverage Probability
Coverage probability [
50] is usually considered as a basic feature of PIs and CP is calculated according to the ratio of the number of target values covered by PIs:
where
m denotes the number of samples, and
is a binary index which measures whether the target value is covered by PIs:
where
denote the
ith target value and
,
represent the
ith lower bound and the upper bound, respectively.
A larger CP means more targets are covered by the constructed PIs and a too small CP indicates the unsatisfied coverage behaviors. To have valid PIs, CP should be larger or at least equal to the nominal confidence level of PIs. Furthermore, in this paper, CP is also an important factor in the process of parameter optimization by the multi-objective optimization algorithm.
4.2.2. Prediction Interval (PI) Normalized Average width and PI Normalized Root-Mean-Square Width
In research studies on interval prediction, more attention is usually paid to CP. However, if the lower and upper bounds of the PIs are expanded from either side, any requirement for a larger CP can be satisfied, even for 100%. However, in some cases, a narrower interval width is necessary for a more precise support for electric power supply. Therefore, the width between the lower and upper bounds should be controlled so that the PIs are more convincing. In this study, the prediction interval width (PIW) is another factor in the process of parameter optimization. With CP and PIW, two objects compose the solution space within which the Pareto solution set is estimated.
In order to eliminate the impact of dimension, some relative indexes should be introduced to improve the comparability of width indicators. Inspired by the mean absolute percentage error (MAPE) in point forecasting, we employed PI normalized average width (PINAW) and PI normalized root-mean-square width (PINRW) [
50]:
where
R equals to the maximum minus minimum of the target values. Normalization by the range
R is able to improve comparability of PIs constructed using different methods and for different types of datasets.
4.2.3. Accumulated Width Deviation (AWD)
Accumulated width deviation (AWD) is a criterion that measure the relative deviation degree, and it can be obtained by the cumulative sum of
AWDi [
55]. The calculation formula of AWD is expressed as Equations (23) and (24), where
α denotes the interval width coefficient and
Ii represents the
i-th prediction interval.
4.3. Experiment I: Cases with Larger Width Coefficients
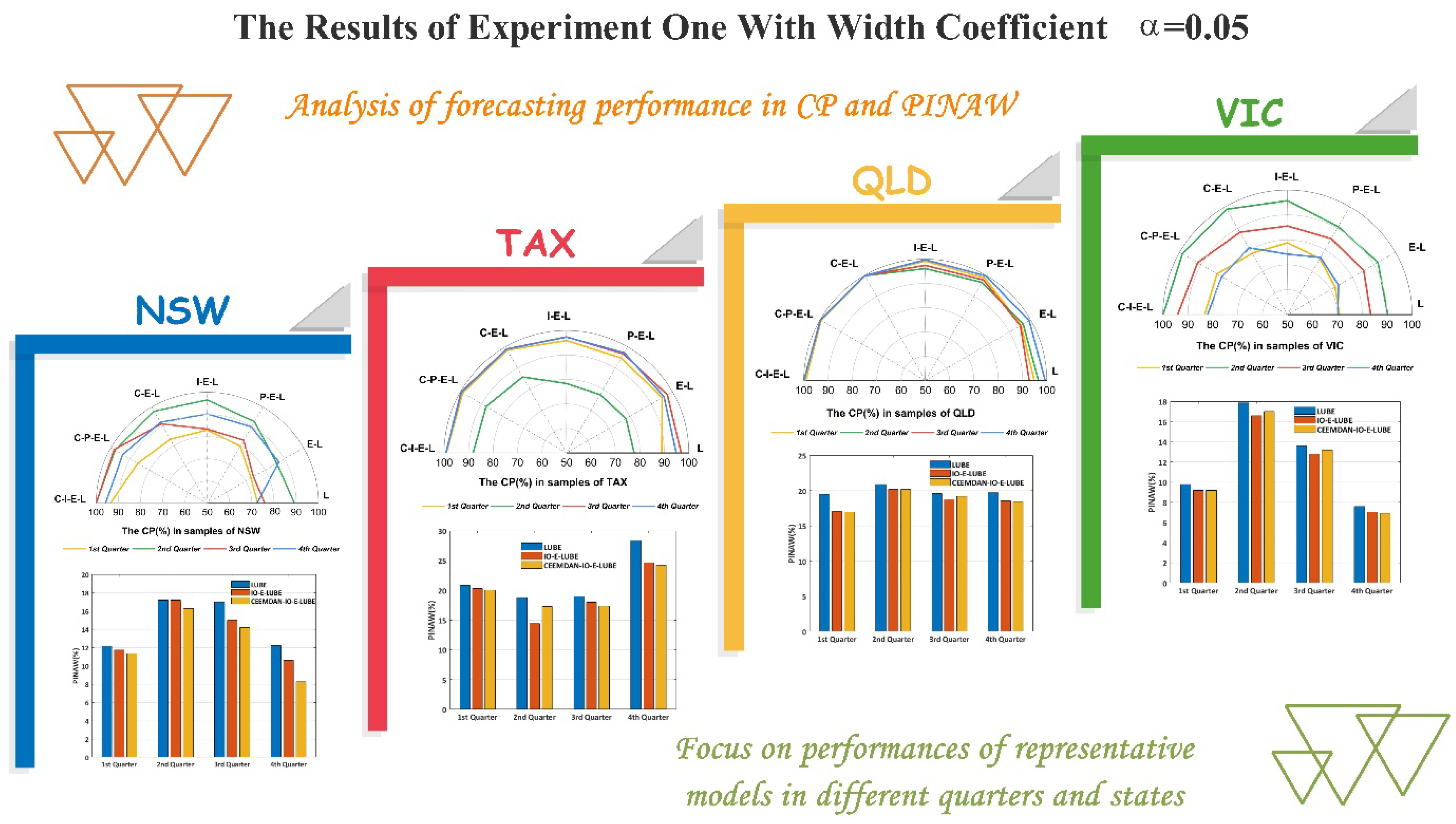
In this experiment, we set the interval width coefficient , which is equivalent to setting the output to for a single sample in the training process of the neural network. Based on this structure, the PIs can be output given an input test set. In order to guarantee the diversity of the samples, we studied four different quarterly data for four different states.
The models involved in our research can be divided into three groups for better explanations for the impact of different components. The first group included LUBE and E–LUBE, and the difference between them were the structures of the neural network. The structure of LUBE consisted of three layers which were similar to the traditional BP neural network. Moreover, in the E–LUBE, an extra context layer was added to the structure so that we could validate the impact of the context layer in prediction by comparing the performance of these two models. The second group included the PO–E–LUBE and IO–E–LUBE, and the difference between them included the optimization algorithm in the training process. PO–E–LUBE used the error and variance of point prediction to construct the cost function in MOSSA, whereby the target of minimizing the cost function effectively denotes a requirement for better prediction accuracy. In addition, IO–E–LUBE employed the CP and PIW of the interval prediction to construct the cost function in multi-objective optimization, while the target of minimizing such a cost function denoted the requirements for a better performance in interval coverage, which is more rational for our goal of interval prediction. The comparison between such models can reflect the influence of different cost functions in the parameter optimization process. Furthermore, in the first group, the parameters of the neural network are determined by a conventional gradient descent algorithm, and in the second group, the parameters are determined by a heuristic optimization algorithm. Therefore, the impact of different optimization algorithms can be shown by comparing the models in different groups. In addition, in the third group, the data preprocessing is introduced. Based on the models in the first two groups, CEEMDAN was used to refine the input dataset. The results of the models in this group will display the effect of data preprocessing in the hybrid model.
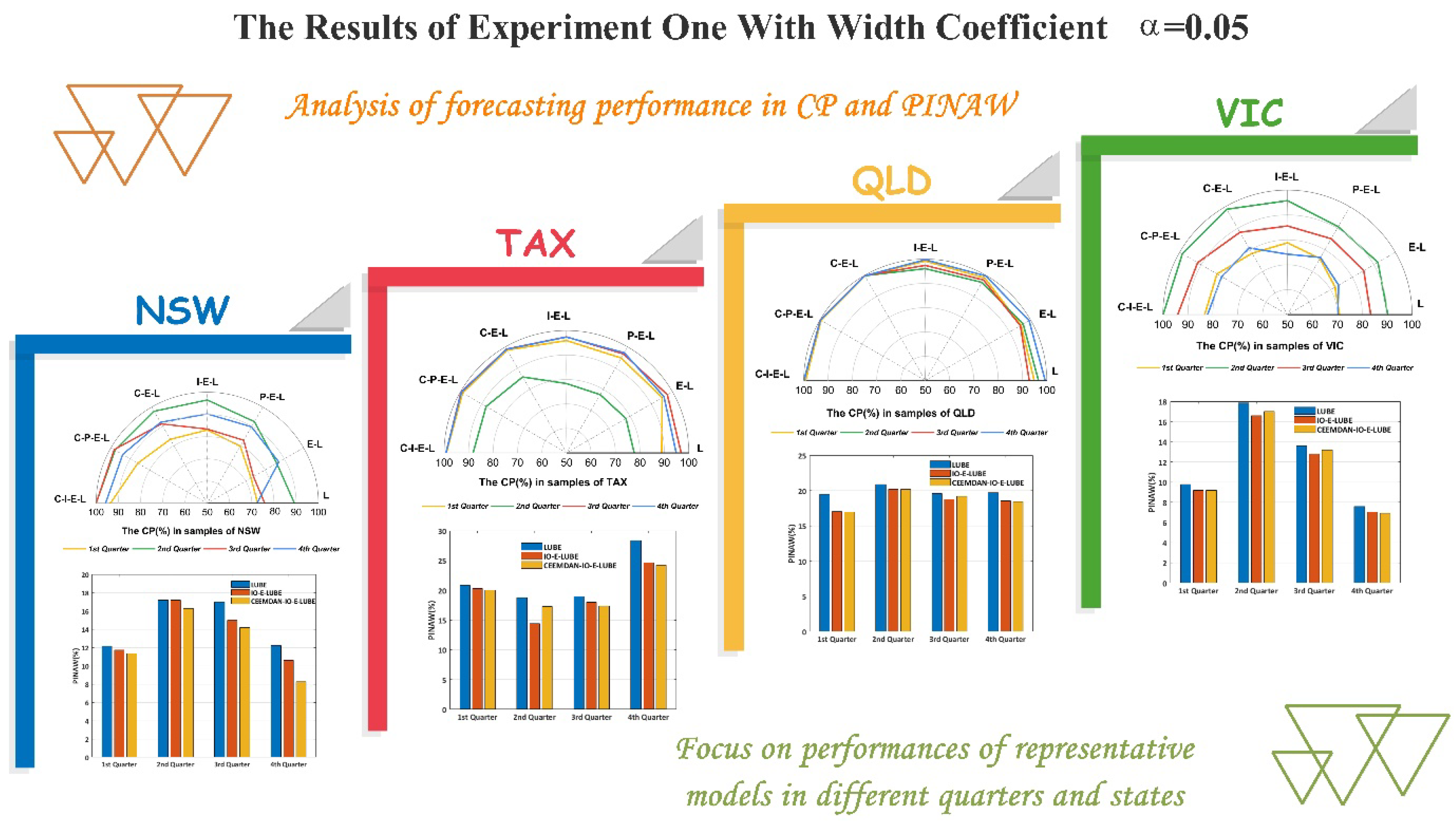
The simulation results are shown in
Table 2 and
Table 3. Also shown in
Figure 5 are the principal indices of interval prediction, namely, CP and PINAW. Based on the conducted comparisons referred to earlier, several conclusions can be inferred:
- (1)
By comparing the models in the first group, we can conclude that the E–LUBE is superior to LUBE in most cases, such as the fourth quarter in NSW and the first quarter in TAX, as shown in
Table 2 and
Figure 5. The CP of E–LUBE reached 87.17%, while the CP of LUBE was 72.36% for the fourth quarter in NSW. The rate of improvement was more than 15% with the maintenance of PINAW and PINRW. However, in some cases, the improvement is not remarkable, such as the fourth quarter in QLD, as shown in
Table 3 and
Figure 5. The performances of these two models are almost the same. In general, the performance of E–LUBE is better than LUBE, which means that E–LUBE with an extra context layer can improve the performance. In theory, the context layers are able to provide more information compared to previous outputs of hidden layers. This superiority has been proved in our experiments. However, owing to the instability of the parameters in the neural network, the improvement is not adequately remarkable in a few cases.
- (2)
In terms of the optimization methods, and according to the results shown in
Figure 5, and
Table 2 and
Table 3, the CPs of the second group (PO–E–LUBE and IO–E–LUBE) perform better than E–LUBE in most cases. E–LUBE uses the gradient descent algorithm, which is sensitive to the initialization, in order to obtain the parameters in NN. Furthermore, the models in the second group use the heuristic swarm optimization algorithm which can synthesize the initialization results using an adequate population size. Thus, the models in the second groups should have elicited better performances in theory unless the random initializations of E–LUBE are perfect. Moreover, within the second group, IO–E–LUBE has a larger CP value than PO–E–LUBE, with low levels of PINAW and PINRW. It is just the influence of the cost function that makes such a difference. The main object of the interval prediction is a larger CP value along with a narrow width. Therefore, the IO should have an advantage
- (3)
Incorporation of CEEMDAN in the hybrid models is improved the performances significantly because of the denoising preprocessing. In most cases, the CPs are larger than 80% and 90%, which means more than 80% target load values are covered by the predicted intervals. Furthermore, in some cases, the CPs can reach 100%, such as the second and third quarters in NSW, and the second quarter in QLD. Such accuracy can ensure that the power supply meets the demand. Compared with the original LUBE and E–LUBE, the hybrid model we proposed (CEEMDAN–IO–E–LUBE) elicited a significant improvement in the elicited results of interval prediction.
- (4)
With a larger width coefficient, the CPs of our models were almost satisfactory. The smallest CP was more than 70%, and the largest CP was able to reach 100%, which is perfect for interval prediction in STLF. However, the PINAW and PINRW were almost all larger than 10, and even reached the value of 20 in second quarter in QLD. But the proposed model still outperforms other models.
- (5)
Considering the accumulated width deviation (AWD), for a larger width coefficient, the proposed model (CEEMDAN-IO-E-LUBE) has a smaller AWD compared with other benchmark models in most cases. According to the definition of AWD, a smaller AWD means more target values fall into the predicted intervals. For the results in which the target values are over the bounds, the deviations are relatively small. In this experiment, the AWDs of the proposed model are satisfactory in most case. For some cases, the AWDs is even closed to 0, which means almost all target load values fall into the predicted intervals. According to these predicted intervals, load dispatch will be more rational.
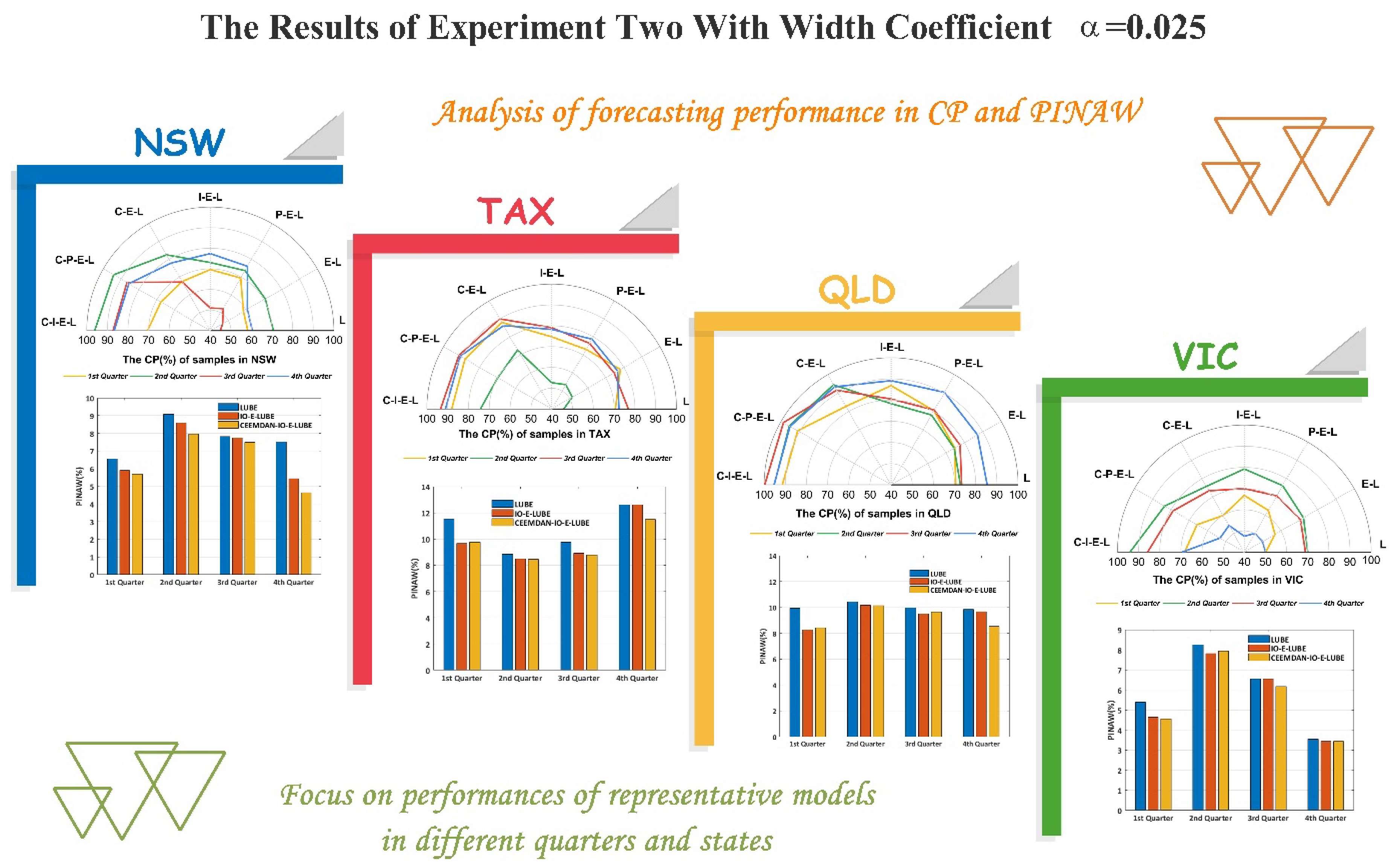
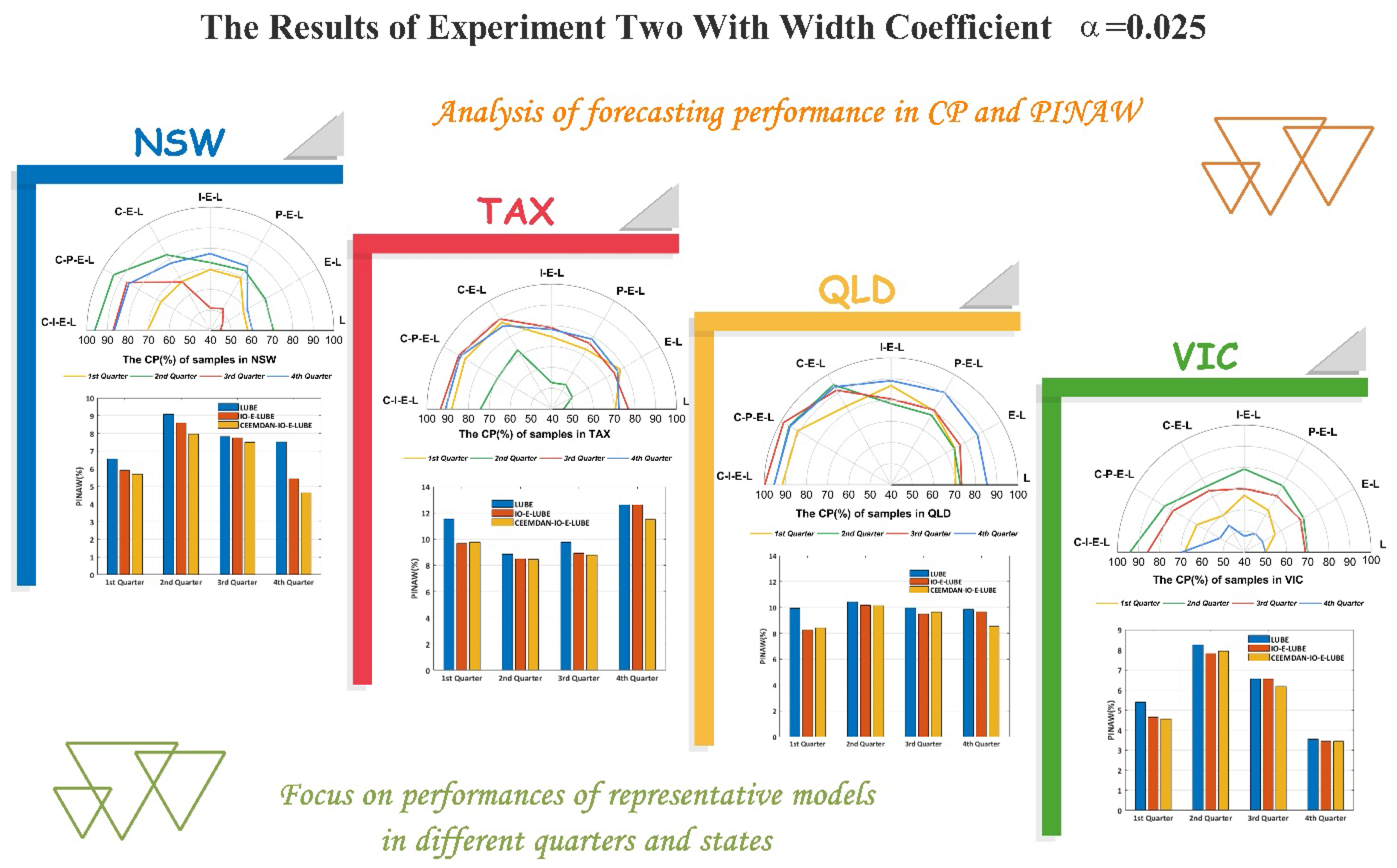
4.4. Experiment II: Cases with Smaller Width Coefficients
In this experiment, we set the interval width coefficient
, which means we set the output to be
for a single sample in the training process of the neural network. With a narrow width coefficient, the lower and upper bounds were closer to the target value in the training process, which can provide more valuable information in practice. However, a narrow bound might lead to the increase of CP. Thus, a smaller width coefficient requires the models to have better predictive properties. The results of this simulation are shown in
Table 4 and
Table 5, and in
Figure 6. Correspondingly, the following conclusions can be drawn:
- (1)
As
Table 4 and
Figure 6 show, the distinction of the models is similar to experiment I. The CPs of the original LUBE and E–LUBE are the smallest among the models in our simulation, and our proposed model CEEMDAN–IO–E–LUBE elicits the best performance
- (2)
For some benchmark models in this experiment, with a narrow bound in the training process, the performance was not adequately satisfactory. As the cases of the third quarter in NSW denote and the second quarter in TAX show the CPs of LUBE and E–LUBE are close to 50%, which is not conclusive in practice. However, based on the hybrid mechanism we proposed, the performances were improved significantly. The minimum CP values of CEEMDAN–IO–E–LUBE can reach 70%, and the maximum is close to 100%, such as in the third quarter in QLD. Such results show that the predicted intervals can better cover actual electricity demand data and economize spinning reserve in power grid.
- (3)
With a smaller width coefficient, the CPs decreased while the PINAW and PINRW are reduced. For the benchmark models, the results mostly display smaller CPs and larger PINAW or PINRW. However, the proposed model is able to demonstrate larger CPs with smaller PINAW and PINRW values, which is equivalent to a good performance in interval prediction. In some cases, the CP values were larger than 95% with PINAW and PINRW values less than 10. In such cases, the CPs are satisfactory and the widths of the PIs are most appropriate.
- (4)
In terms of AWD in this experiment, the proposed model still showed a relatively small AWD compared with other benchmark models, which means the proposed model has a better performance at predicted accuracy. Compared with experiment I, the AWDs in this experiment are bigger. For a smaller width coefficient, the predicted interval will be narrower, which means there will be more target points falling outside the intervals. In some situations, a narrower predicted interval is necessary. The proposed model is able to provide a better performance on the condition of the requirement of a narrower predicted interval of electric load.
4.5. Comparisons and Analyses
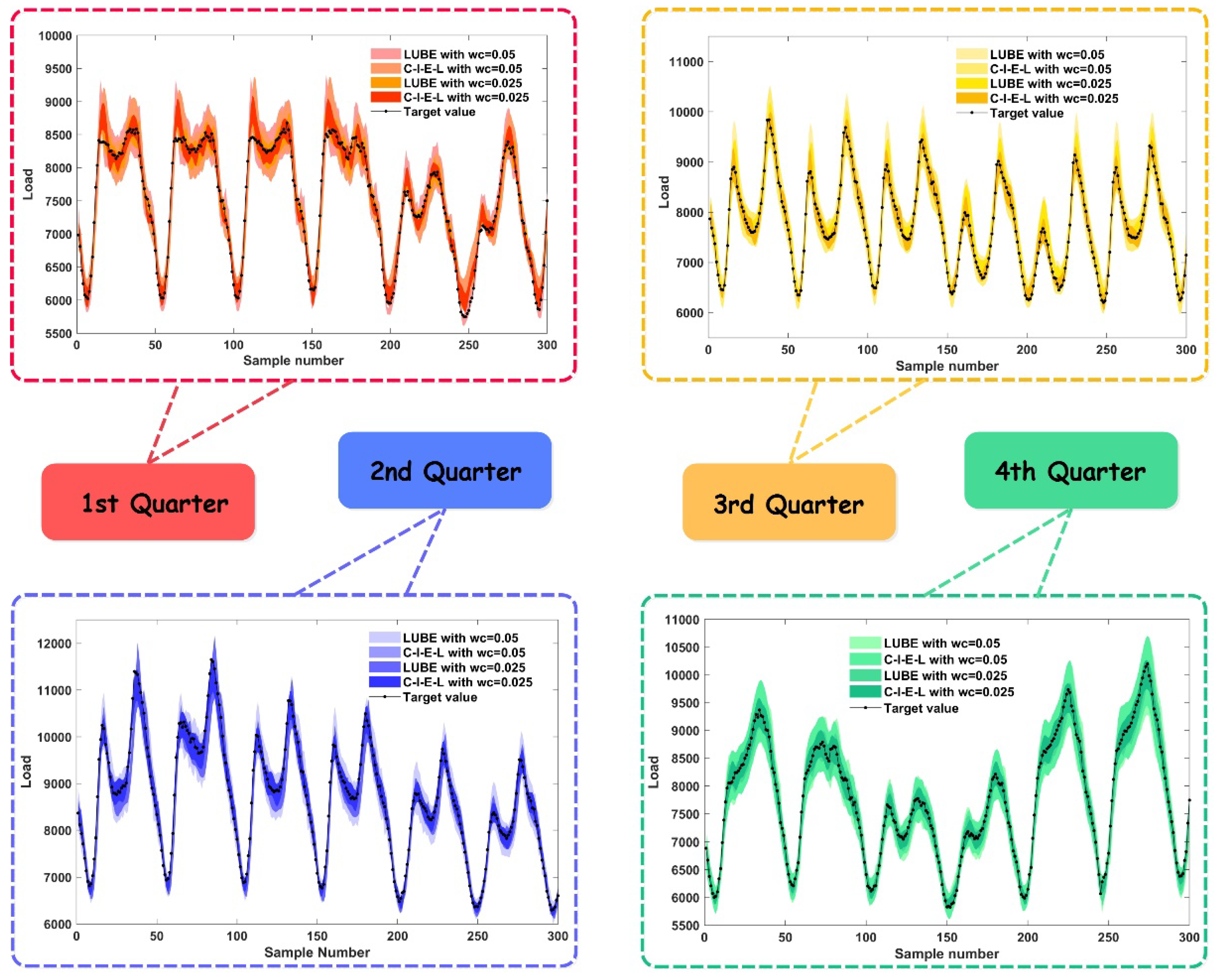
According to the comparison of the above two experimental results, the width coefficient has a significant influence on performance, as shown in
Figure 7. From one perspective, for most models, a coefficient with a larger width may lead to a larger and more satisfactory CP value, but the index about the width of PI may not be desired. From another perspective, for most models, a narrower width coefficient may elicit the desired PINAW and PINRW values, but the CP is not good enough. Considering such a situation, the proposed models alleviate the contradiction. Even though the CP value of the proposed model will decline when the width coefficient decreases, comprehensive performance is satisfactory. In some exceptional cases, owing to the complexity and instability of the datasets, the performance of the proposed models is not adequate, as the description in
Figure 3 shows.
6. Conclusions
STLF is the basic work of power system planning and operation. However, the power load has regularity and certain randomness at the same time, which increases the difficulty of desired and reliable STLF. Moreover, compared with the prediction of specific points, interval prediction may provide more information for decision making in STLF. In this study, based on LUBE, we developed a novel hybrid model including data preprocessing, a multi-objective salp algorithm, and E–LUBE. In theory, such a hybrid model can reduce the influence of noise in a dataset and the parameter optimization process is more effective and efficient in E–LUBE.
In our proposed approach, we used a multi-objective optimization algorithm to search for the parameters of the neural network and reconstructed the cost function with double interval criterions instead of point criterions (such as MSE) in the traditional method. As
Table 2,
Table 3,
Table 4 and
Table 5 show, by comparing it with traditional methods, the proposed approach provides a higher CP and a lower interval width at the same time, which makes up for the lower CP and higher interval width of traditional methods.
In order to verify the performance of the proposed model and validate the impact of the constituent components in a hybrid model, we collected 16 samples involving four states using four quarters in Australia, and set several model comparisons in experiments
Furthermore, according to the comparison and analyses results, the conclusions are summarized as follows: (a) an efficient data preprocessing method was applied herein. Depending on the decomposition and reconstruction, this method can significantly improve the model performance in STLF. (b) Compared to the traditional prediction models based on neural networks, the newly developed E–LUBE method has an advantage in terms of comprehensive performance in interval prediction. It can be validated that the context layer with the information of the former hidden layer can improve model performance. (c) The introduction of the novel multi-objective algorithm MOSSA optimized the process of parameter search. The new cost function was based on a double-objective interval index that outperformed the traditional single-objective point error index (such as MSE) in interval prediction. (d) For STLF based on the E–LUBE mechanism, the width coefficient is an important factor. A larger width coefficient may lead to satisfactory CPs, and a smaller width coefficient may result in a satisfactory interval width. Therefore, in practice, the decision maker needs to adjust the width coefficient for specific demands. For example, we chose the width coefficient with a minimum interval width at the same time that the minimum demand of CP was guaranteed. (e) No matter how complex is the dataset, the proposed model always provides the best performance compared to benchmark models. However, because of the complexity of the data itself, some of the performance is not remarkable. In general, the proposed model provided a desired result in most cases.
Furthermore, in a power grid operator the proposed method has a strong practical application significance. A highly accurate forecasting method is one of the most important approaches used in improving power system management, especially in the power market [
58]. In actual operation, for secure power grid dispatching, a control center has to make a prediction for the subsequent load. According to historical data, the dataset for the predictive model involved can be constructed. The results of the predictive model are able to provide the upper bound and lower bound of the load at some point in the future. Depending on the upper bound and lower bound, the control center can adjust the quantity of electricity on each charging line. Therefore, such a hybrid approach which can provide more accurate results can ensure the safe operation of the power grid and improve the economic efficiency of power grid operation.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}