Short-Term Wind Power Forecasting Based on Clustering Pre-Calculated CFD Method

Abstract
:1. Introduction
2. Wind Turbine Clustering Algorithms
2.1. K-Means Clustering
- (a)
- Randomly place k points into the space represented by the objects that are being clustered. These points represent the initial cluster centroids.
- (b)
- Assign each object to the cluster that has the closest centroid.
- (c)
- Recalculate the positions of the k centroids, according to the distance between points and centroids.
- (d)
- Repeat steps b and c until the centroids no longer move, and J stabilizes to its minimum value.
2.2. Hierarchical Agglomerative Clustering
- (a)
- Assign each item to a single cluster and calculate the distance between every two items to form a distance matrix with size m × m.
- (b)
- Find the most similar (the closest) pair of clusters Cp, Cq, which fulfills , and then merge them into one cluster, so now there are m-1 clusters in total.
- (c)
- Compute the similarities (distances) between the new cluster and each of the previous clusters.
- (d)
- Repeat steps b and c until the number of clusters is reduced to k.
2.3. Spectral Clustering
- (a)
- Build the similarity matrix S of data set X = {x1, x2, …, xm}, S µ ∈ Rm×m, and Sij is the weight vector connecting the i-th and the j-th data point, where
- (b)
- Define a diagonal matrix J, the (i, i) element of J is computed as the summation of all the items in the i-th row of matrix S. Then construct the Laplacian matrix L = J−1/2SJ−1/2.
- (c)
- Compute the k largest eigenvectors in matrix L, and then construct the eigenvector space Y via the stack of column vectors, Y = {y1, y2, …, yk} ∈ Rm×k.
- (d)
- Normalize the items in matrix Y, and then obtain the normalized matrix Z. The items in Z are calculated by Equation (4).
- (e)
- Take the items in each row of Z as a single point, and try to classify the m points in eigenvector space into k clusters, by using K-means or other classical clustering methods.
3. Wind Turbine Clustering Models
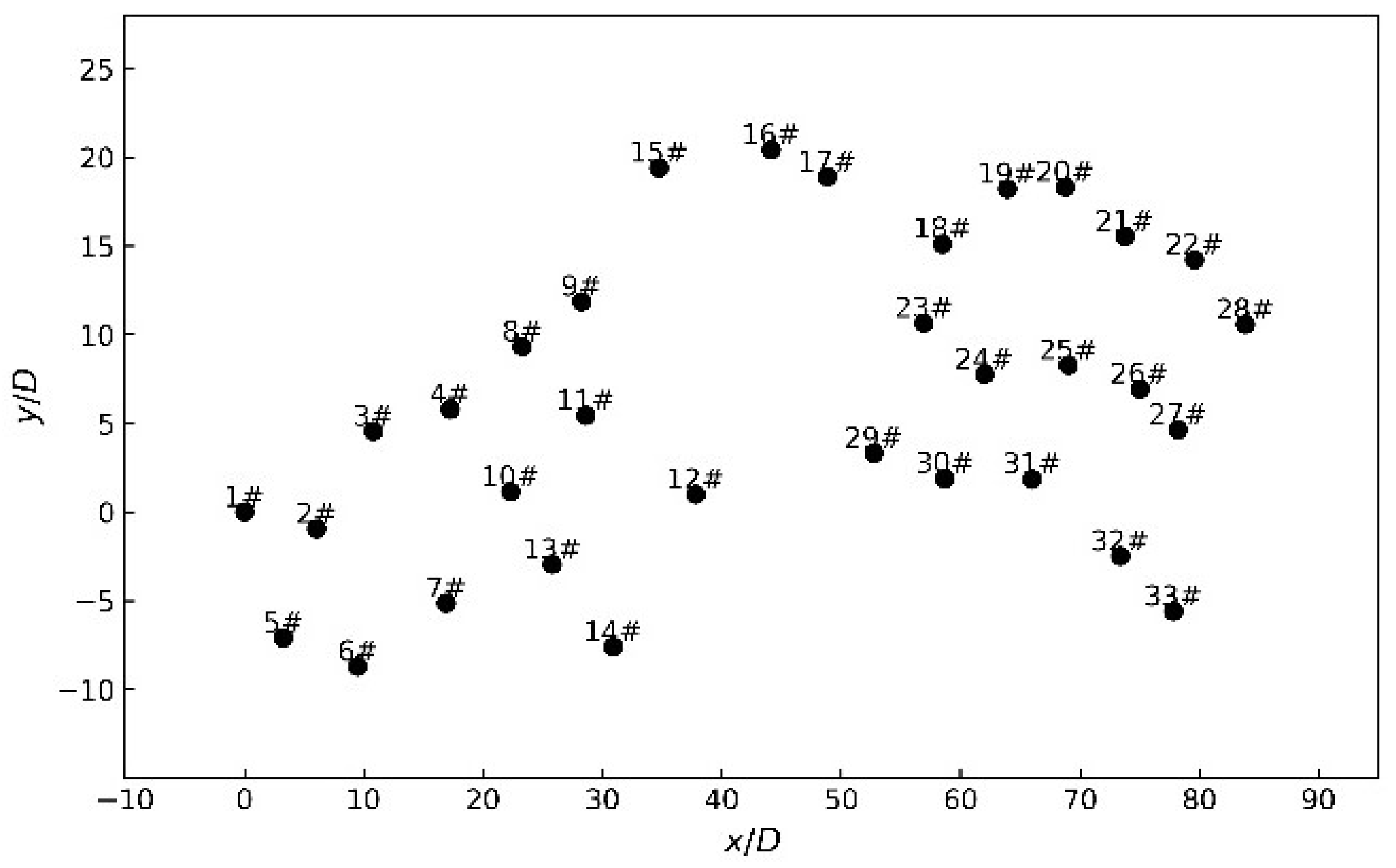
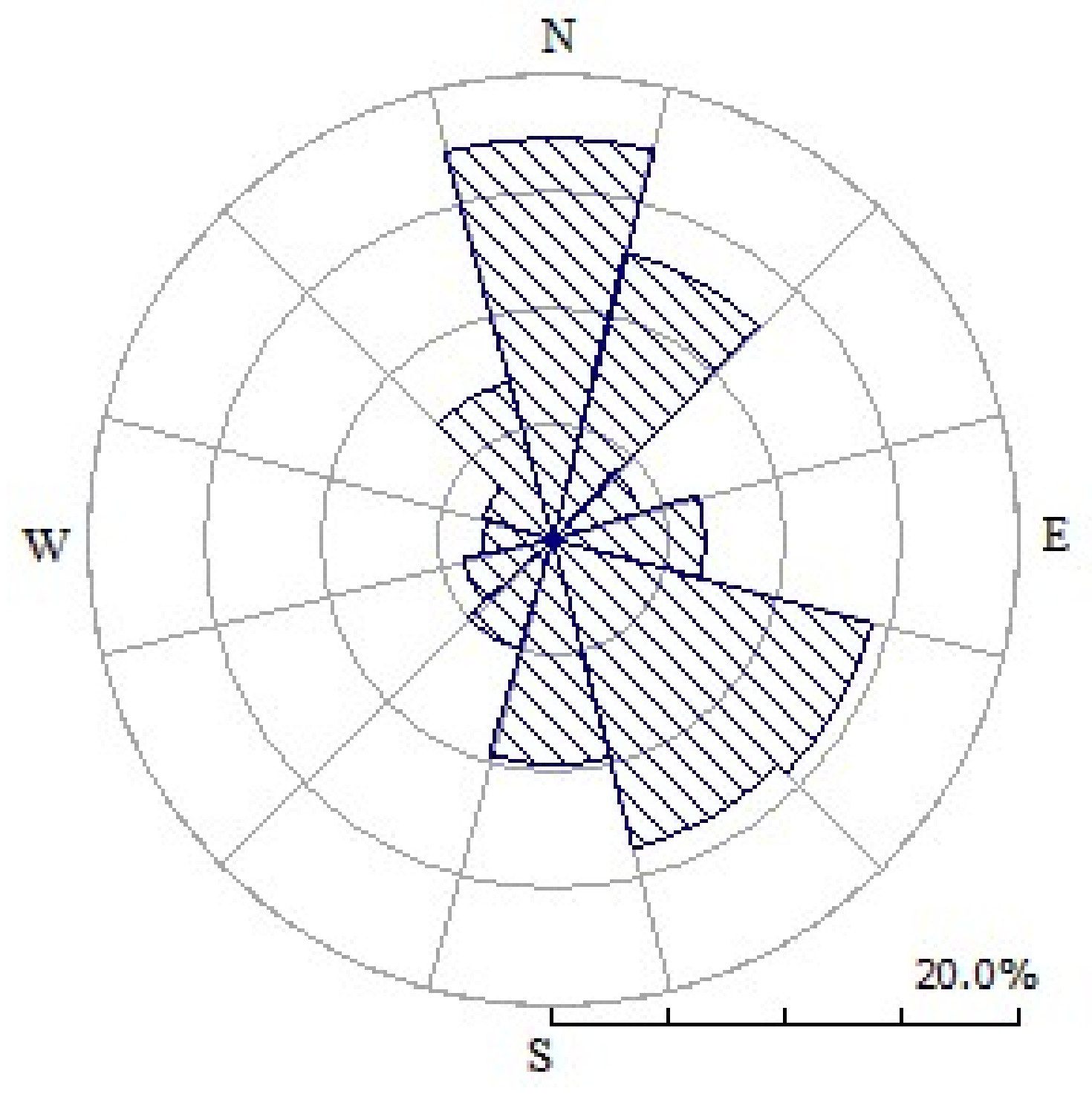
3.1. Wind Farm and Input Data Description
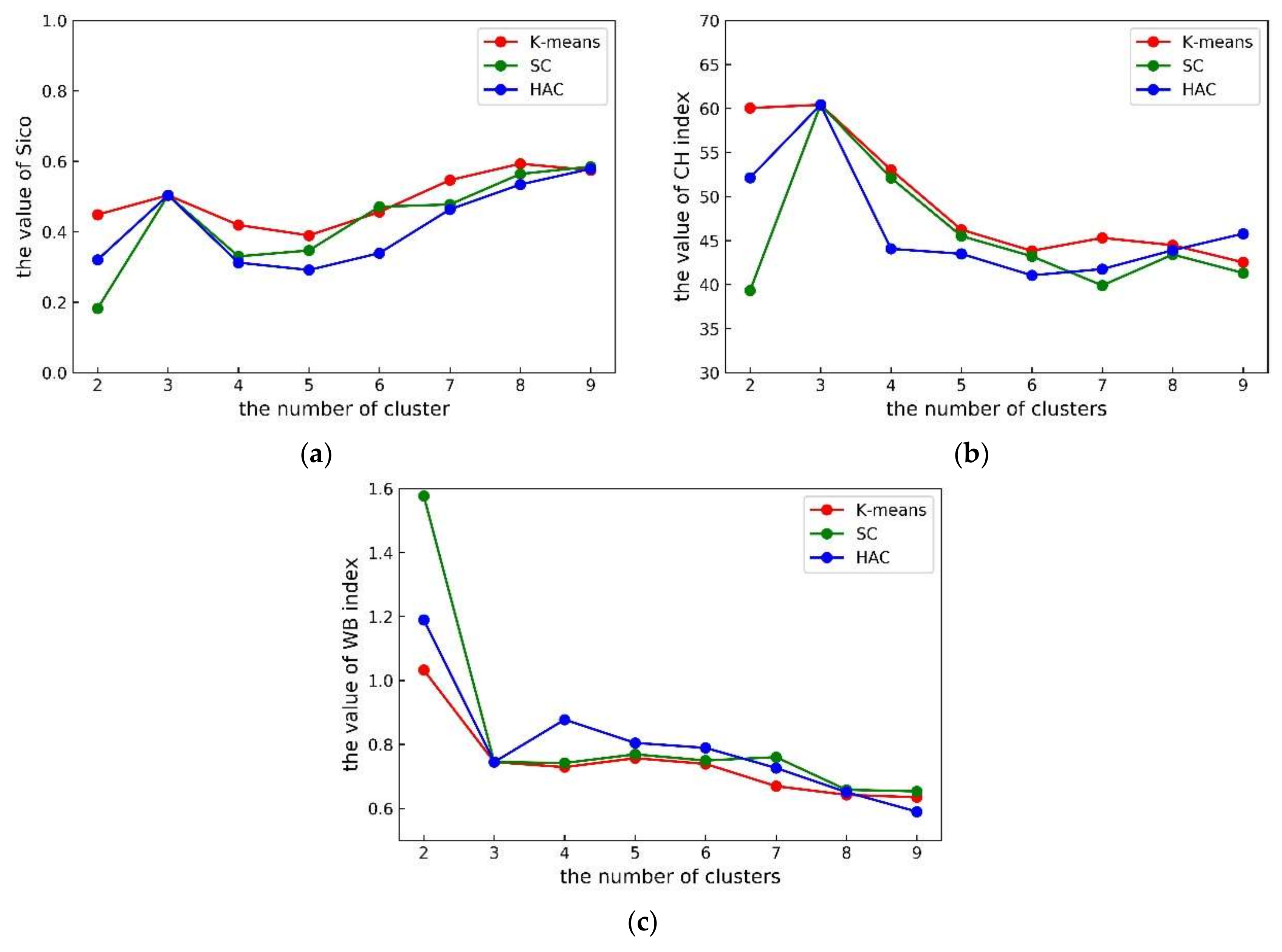
3.2. Criteria Used to Assess Clustering Effectiveness
3.2.1. Silhouette Coefficient
3.2.2. Calinski-Harabaz and within-between Indices
3.3. Wind Turbine Clustering Analysis
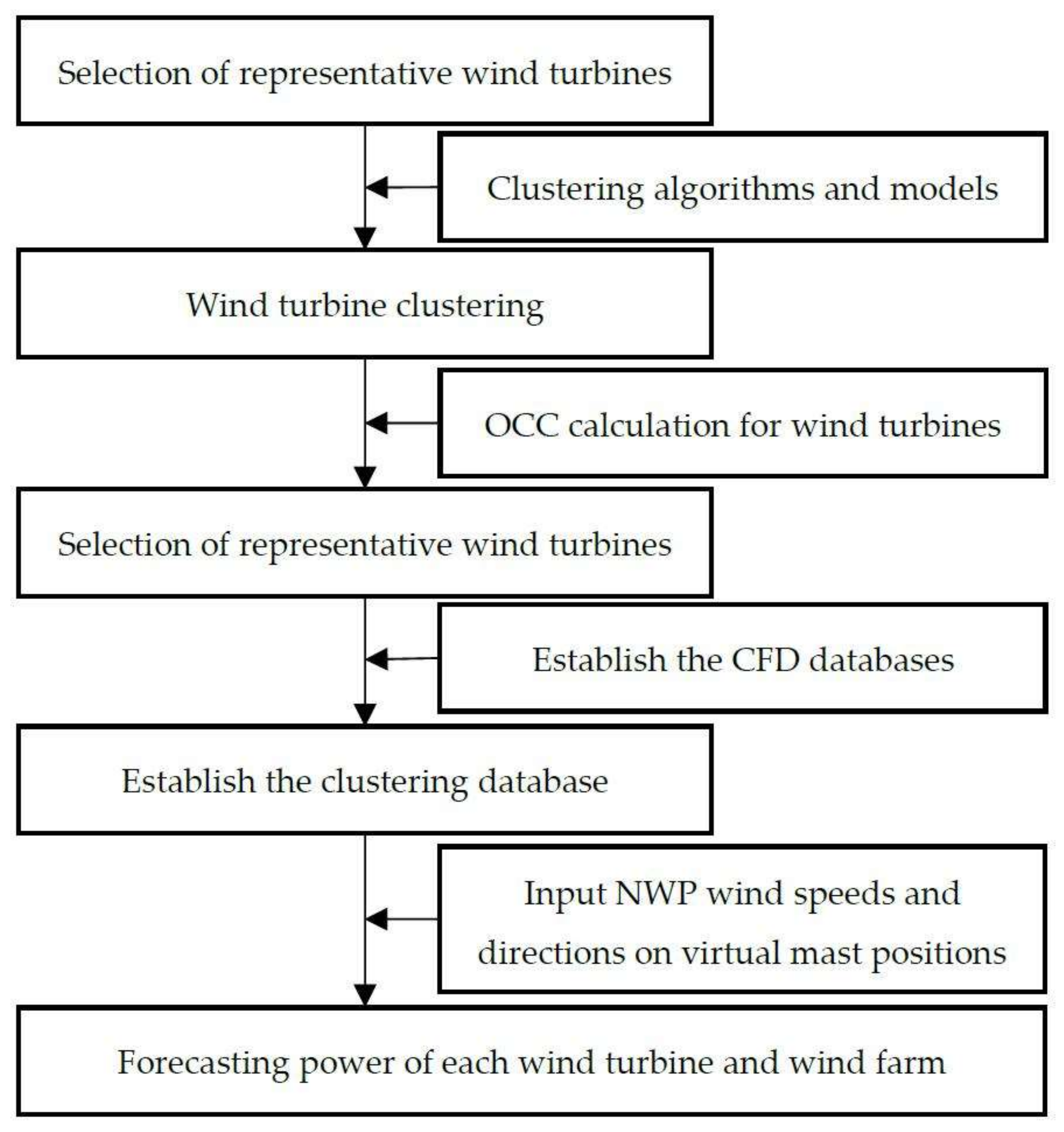
4. Clustering Pre-Calculated CFD-Based WPF
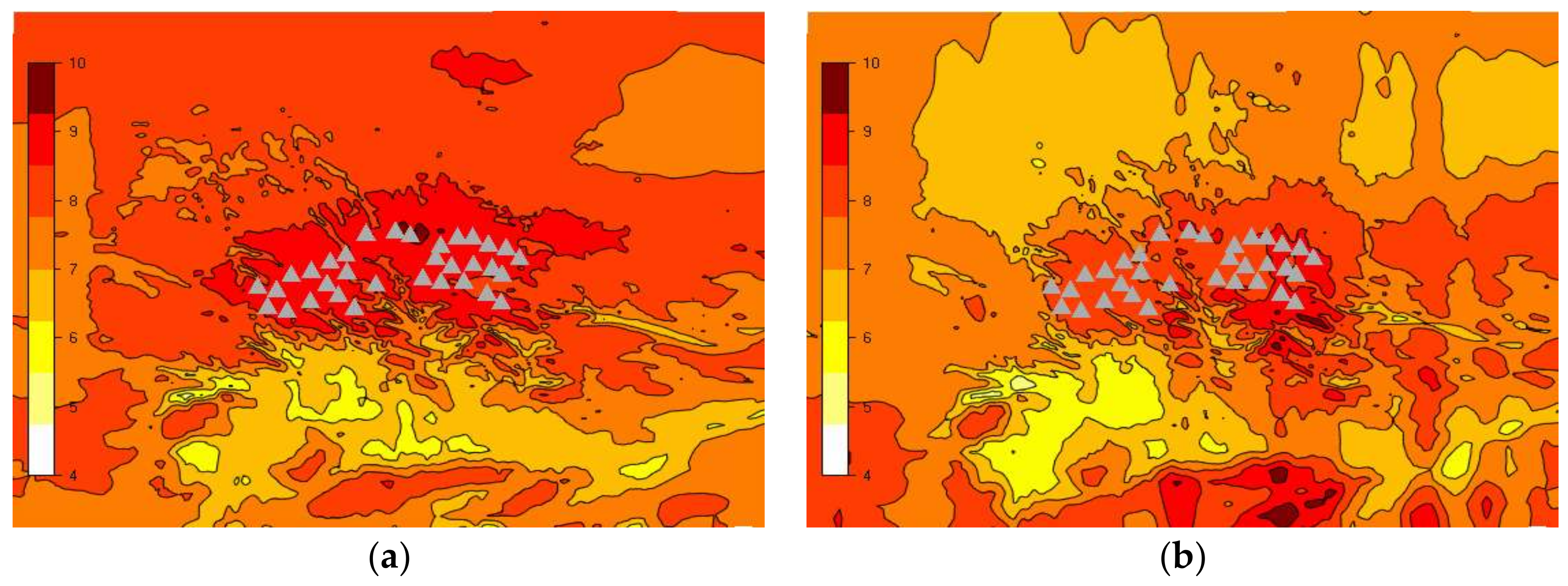
4.1. CFD Database of Flow Field Characteristics
4.2. WPF Model Based on Clustering CFD Database
4.3. Case Analysis for Clustering WPF Method
4.3.1. The Final Clustering Scheme for WPF
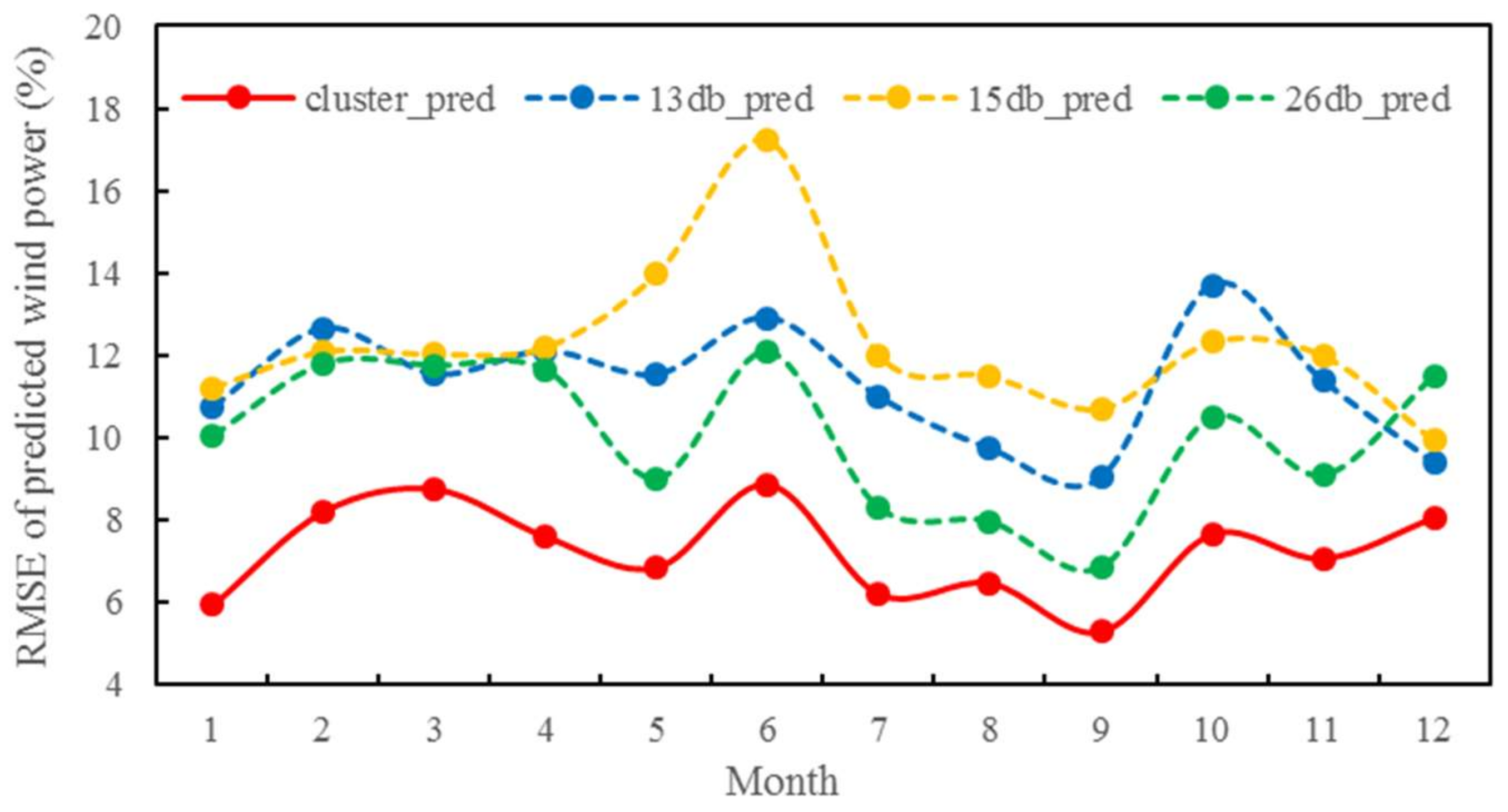
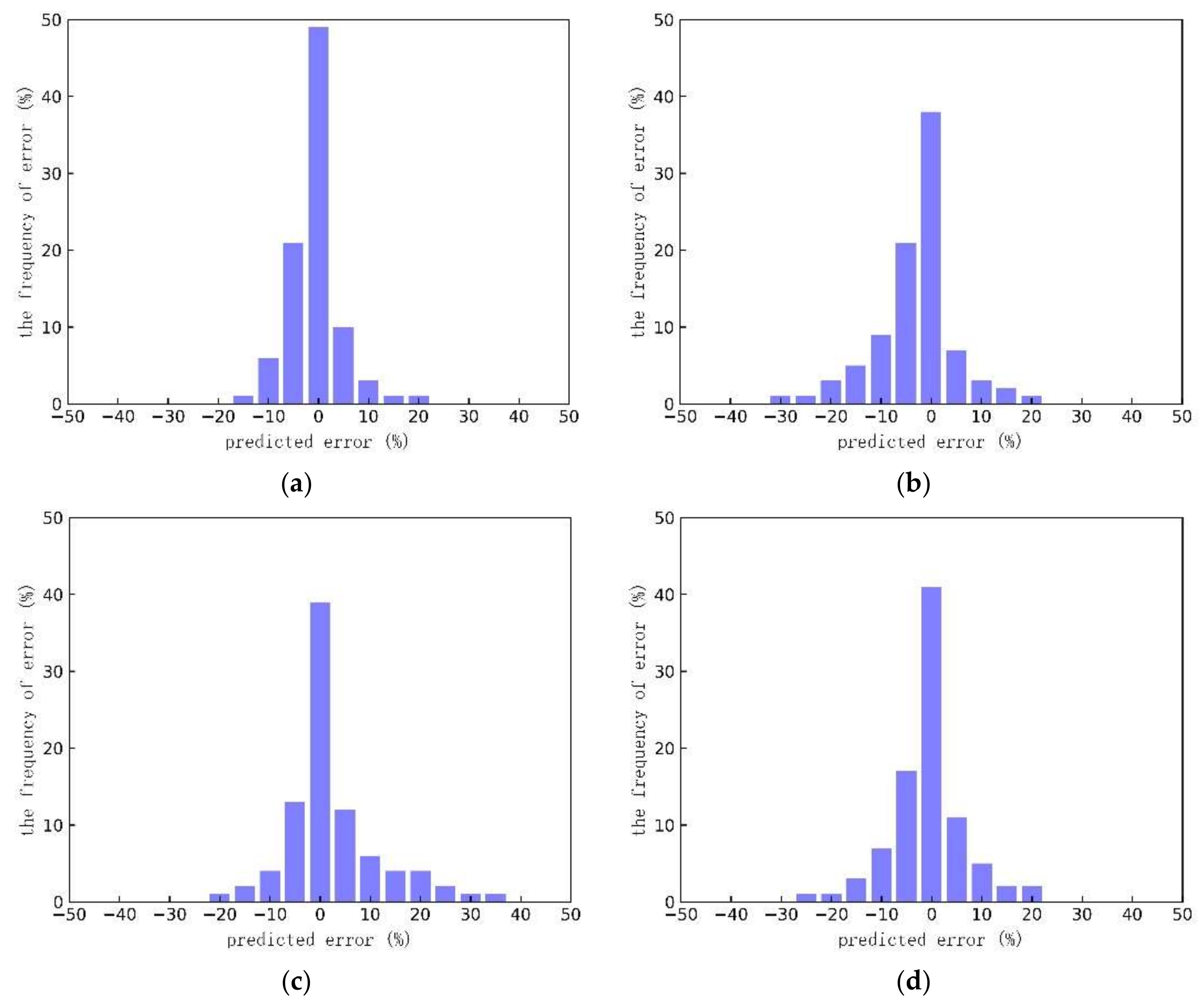
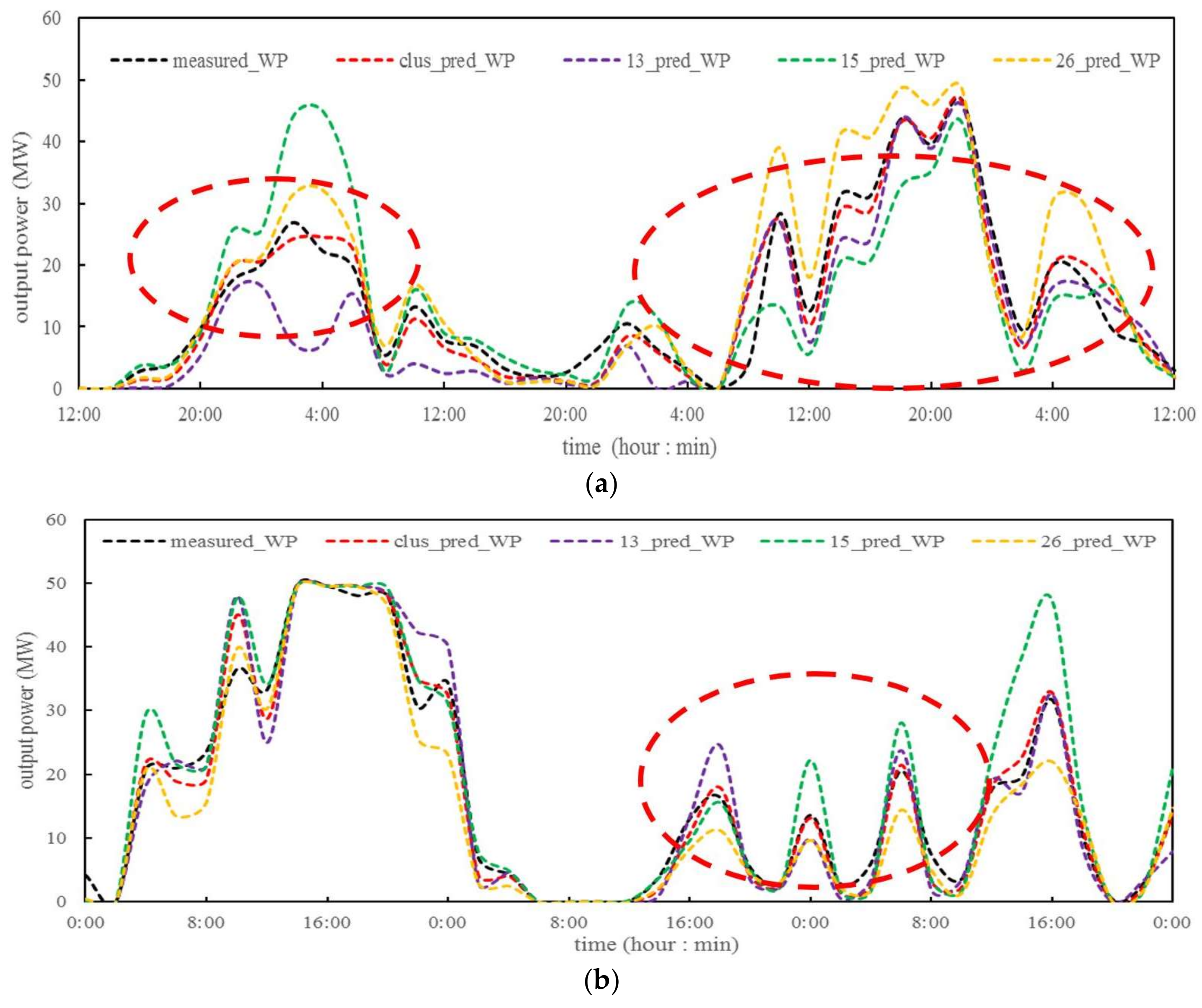
4.3.2. WPF Analysis for Optimal Clustering Scheme
5. Conclusions
- (1)
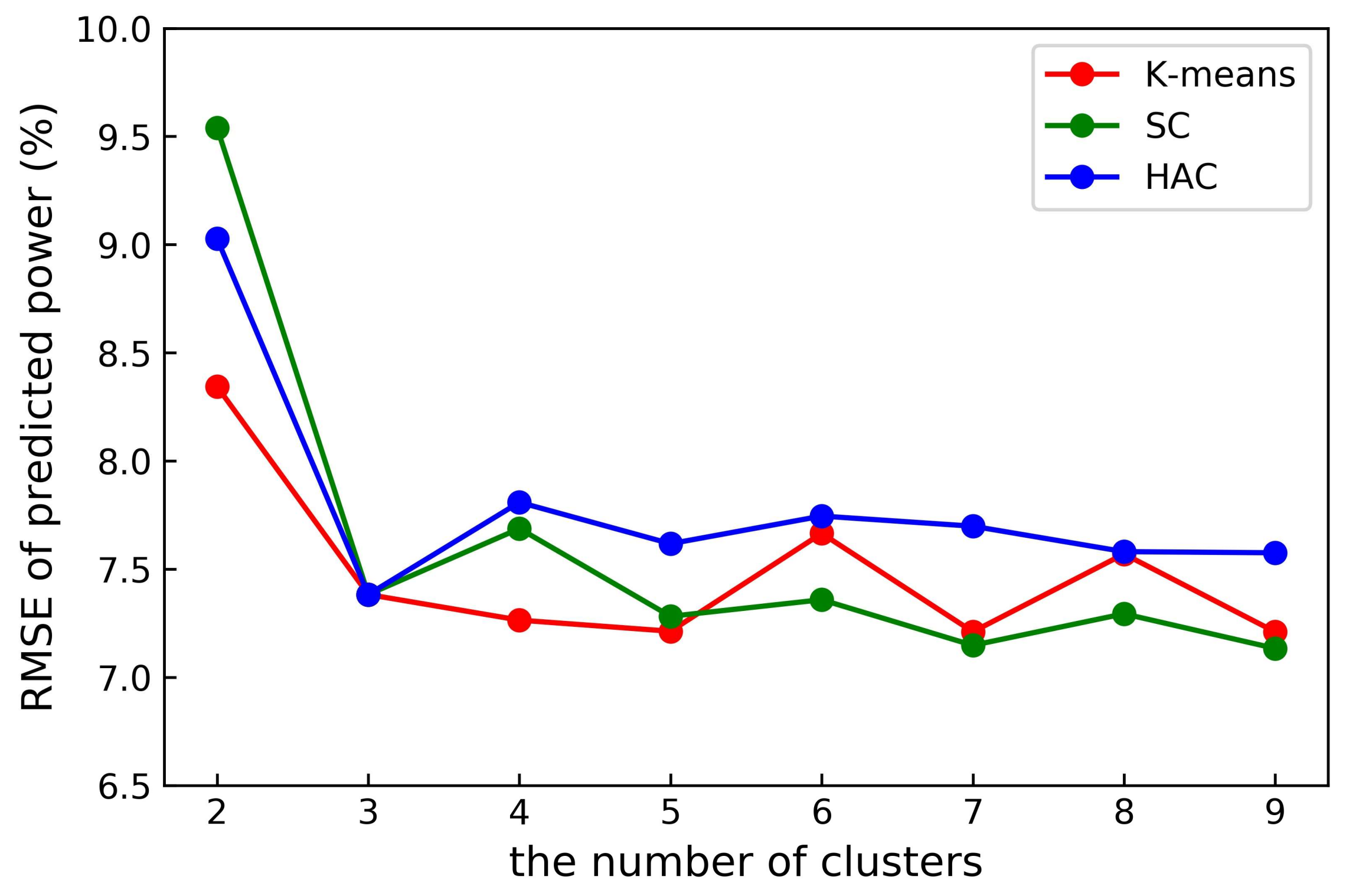
- The analysis of WPF error confirmed the effectiveness of the three measures (Silhouette Coefficient, Calinski-Harabaz and WB indices) for assessing clustering performance proposed in this paper, and the three clustering evaluation indices are all in close agreement.
- (2)
- For a given cluster number k, K-means method gives the best clustering results, SC ranks the second, and HAC is a little worse than the other two methods. For k is three, all three clustering methods give the same clustering performance, in fact they share exact the same clustering scheme.
- (3)
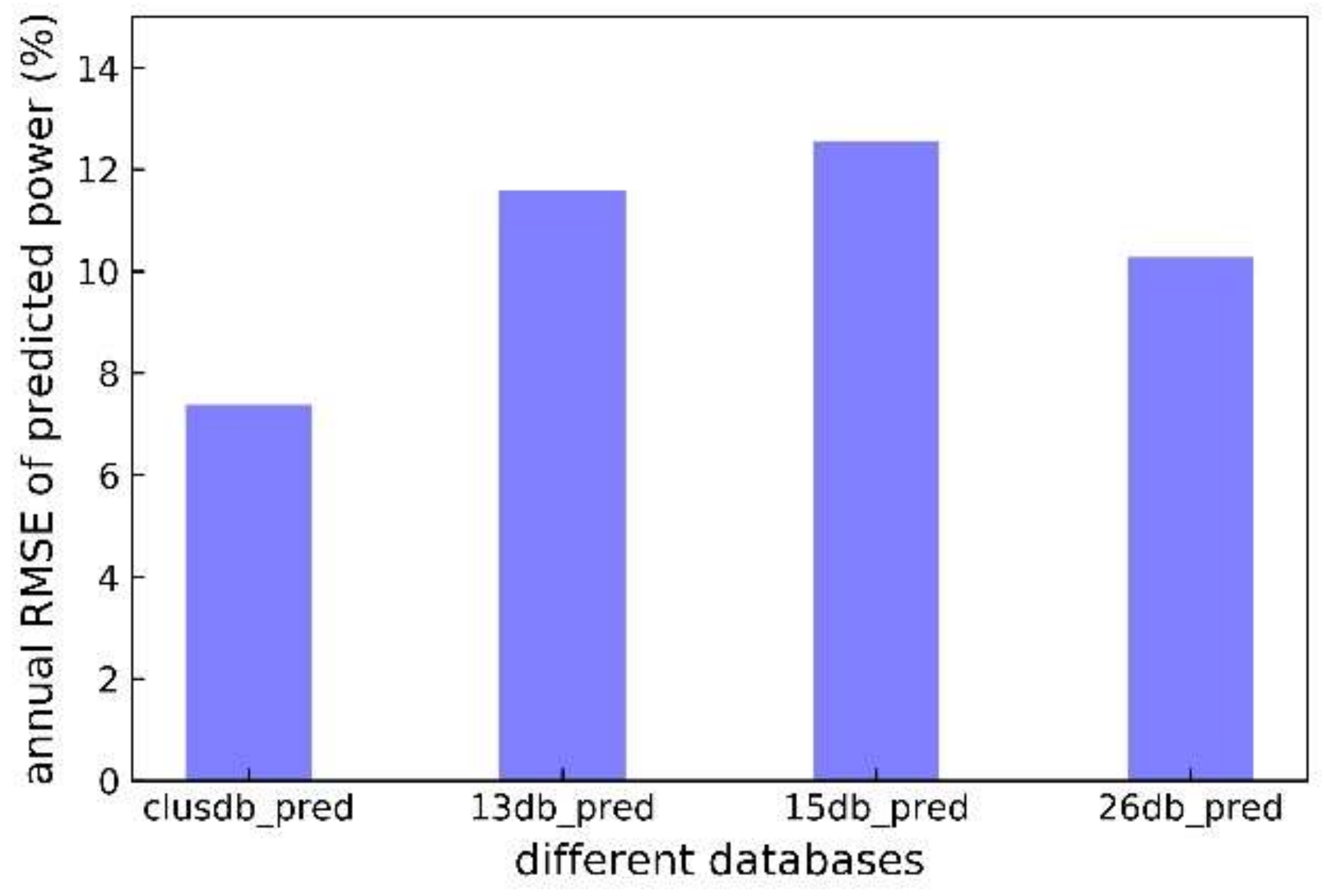
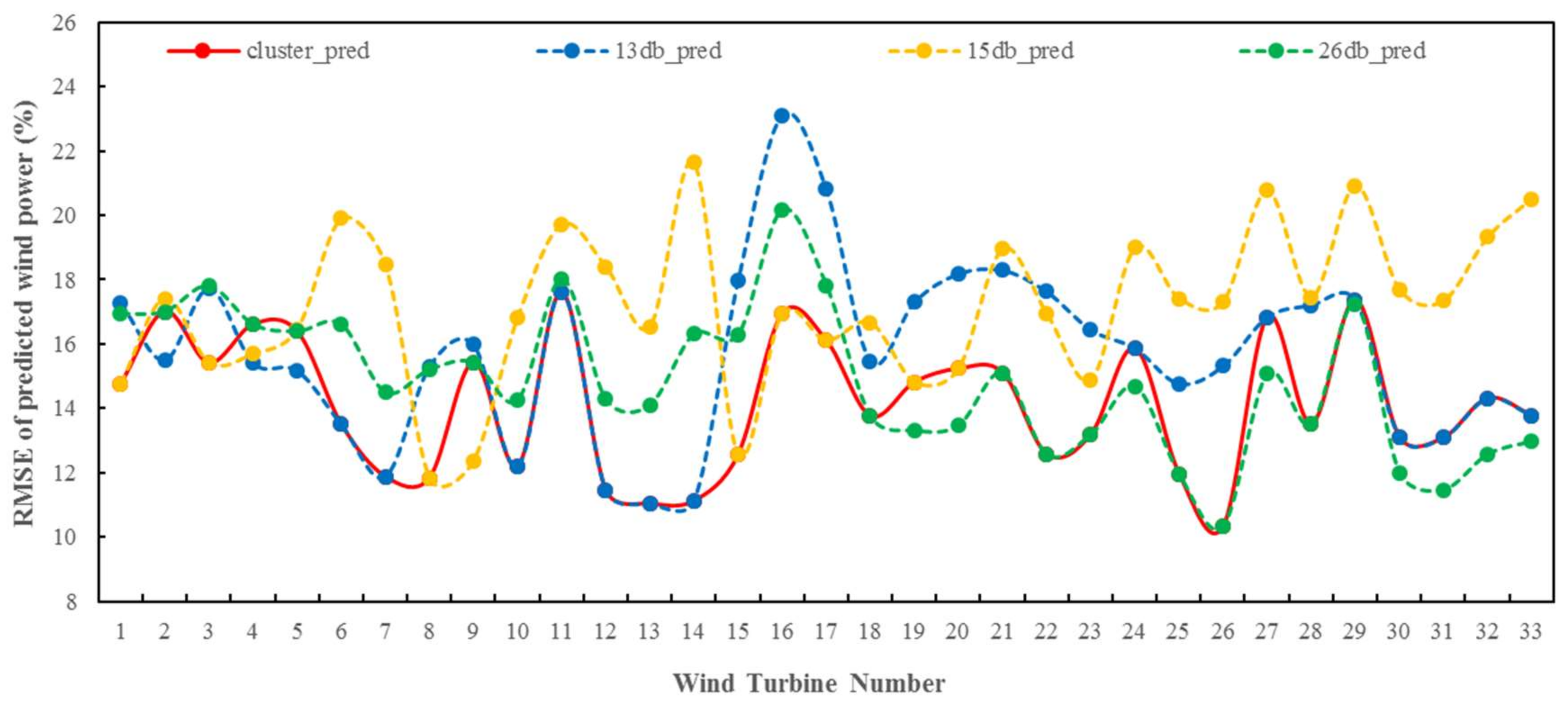
- For different temporal scales (yearly, monthly or daily) and spatial scales (wind farm or wind turbine), the clustering approach always produces more accurate forecasts power than those from single sub-databases, and can decrease the annual forecasting RMSE of the whole wind farm by up to 5.2%.
- (4)
- Use of clustering database dramatically improves the distribution of forecasting errors. The errors within [−10%, 10%] are 14.4% higher than 15# sub-database. The clustering database produces more accurate wind power predictions for different short-term variation scenarios than the other sub-databases.
Acknowledgments
Author Contributions
Conflicts of Interest
Nomenclature
| WPF | wind power forecasting |
| CFD | computational fluid dynamics |
| CPFF | CFD pre-calculated flow fields |
| CPCC | clustering pre-calculated CFD |
| SCADA | supervisory control and data acquisition |
| HAC | hierarchical agglomerative clustering |
| SC | spectral clustering |
| RANS | reynold averaged navier-stokes |
| DES | detached eddy simulation |
| LES | large eddy simulation |
| Sico | silhouette coefficient |
| CH | calinski-harabaz |
| WB | within-between |
| SSW | sum of squares within |
| SSB | sum of squares between |
| OCC | overall correlation coefficient |
| NWP | numerical weather prediction |
| RMSE | root mean square error |
References
- Lauha, F.; Limig, Q.; Steve, S.; Sgruti, S. Global Wind Report Annual Market Update 2016; Global Wind Energy Council: Brussels, Belgium, 2017. [Google Scholar]
- Lu, X.; McElroy, M.B.; Peng, W.; Liu, S.; Nielsen, C.P.; Wang, H. Challenges faced by China compared with the US in developing wind power. Nat. Energy 2016, 1, 16061. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, C.; Song, X.; Zhou, Y.; Chen, W. The impacts of wind technology advancement on future global energy. Appl. Energy 2016, 184, 1033–1037. [Google Scholar] [CrossRef]
- Lund, H. Large-scale integration of wind power into different energy systems. Energy 2005, 30, 2402–2412. [Google Scholar] [CrossRef]
- Lei, M.; Shiyan, L.; Chuanwen, J.; Hongling, L.; Yan, Z. A review on the forecasting of wind speed and generated power. Renew. Sustain. Energy Rev. 2009, 13, 915–920. [Google Scholar] [CrossRef]
- Ren, G.; Liu, J.; Wan, J.; Guo, Y.; Yu, D. Overview of wind power intermittency: Impacts, measurements, and mitigation solutions. Appl. Energy 2017, 204, 47–65. [Google Scholar] [CrossRef]
- Jung, J.; Broadwater, R.P. Current status and future advances for wind speed and power forecasting. Renew. Sustain. Energy Rev. 2014, 31, 762–777. [Google Scholar] [CrossRef]
- Colak, I.; Sagiroglu, S.; Yesilbudak, M. Data mining and wind power prediction: A literature review. Renew. Energy 2012, 46, 241–247. [Google Scholar] [CrossRef]
- Wang, H.-Z.; Li, G.-Q.; Wang, G.-B.; Peng, J.-C.; Jiang, H.; Liu, Y.-T. Deep learning based ensemble approach for probabilistic wind power forecasting. Appl. Energy 2017, 188, 56–70. [Google Scholar] [CrossRef]
- Shuang-Lei, F.; Wei-Sheng, W.; Chun, L.; Hui-zhu, D. Study on the physical approach to wind power prediction. Proc. CSEE 2010, 30, 1–6. [Google Scholar]
- Al-Yahyai, S.; Charabi, Y.; Gastli, A. Review of the use of Numerical Weather Prediction (NWP) Models for wind energy assessment. Renew. Sustain. Energy Rev. 2010, 14, 3192–3198. [Google Scholar] [CrossRef]
- Lange, M.; Focken, U. Physical Approach to Short-Term Wind Power Prediction; Springer: New York, NY, USA, 2006. [Google Scholar]
- Landberg, L. Short-term prediction of the power production from wind farms. J. Wind Eng. Ind. Aerodyn. 1999, 80, 207–220. [Google Scholar] [CrossRef]
- Ye, L.; Zhao, Y.; Zeng, C.; Zhang, C. Short-term wind power prediction based on spatial model. Renew. Energy 2017, 101, 1067–1074. [Google Scholar] [CrossRef]
- Marjanovic, N.; Wharton, S.; Chow, F.K. Investigation of model parameters for high-resolution wind energy forecasting: Case studies over simple and complex terrain. J. Wind Eng. Ind. Aerodyn. 2014, 134, 10–24. [Google Scholar] [CrossRef]
- Murali, A.; Rajagopalan, R. Numerical simulation of multiple interacting wind turbines on a complex terrain. J. Wind Eng. Ind. Aerodyn. 2017, 162, 57–72. [Google Scholar] [CrossRef]
- Politis, E.S.; Prospathopoulos, J.; Cabezon, D.; Hansen, K.S.; Chaviaropoulos, P.; Barthelmie, R.J. Modeling wake effects in large wind farms in complex terrain: The problem, the methods and the issues. Wind Energy 2012, 15, 161–182. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, D.; Rocha, A.; Santos, C.S.; Pereira, R. Wind resource modelling in complex terrain using different mesoscale–microscale coupling techniques. Appl. Energy 2013, 108, 493–504. [Google Scholar] [CrossRef]
- Castellani, F.; Vignaroli, A. An application of the actuator disc model for wind turbine wakes calculations. Appl. Energy 2013, 101, 432–440. [Google Scholar] [CrossRef]
- Castellani, F.; Astolfi, D.; Mana, M.; Piccioni, E.; Becchetti, M.; Terzi, L. Investigation of terrain and wake effects on the performance of wind farms in complex terrain using numerical and experimental data. Wind Energy 2017, 20, 1277–1289. [Google Scholar]
- Göçmen, T.; Van der Laan, P.; Réthoré, P.-E.; Diaz, A.P.; Larsen, G.C.; Ott, S. Wind turbine wake models developed at the technical university of Denmark: A review. Renew. Sustain. Energy Rev. 2016, 60, 752–769. [Google Scholar] [CrossRef] [Green Version]
- Sanderse, B. Aerodynamics of Wind Turbine Wakes; ECN-E–09-016; Energy Research Center of the Netherlands (ECN): Petten, The Netherlands, 2009; Volume 5, p. 153. [Google Scholar]
- Castellani, F.; Astolfi, D.; Mana, M.; Burlando, M.; Meißner, C.; Piccioni, E. Wind Power Forecasting techniques in complex terrain: ANN vs. ANN-CFD hybrid approach. J. Phys. Conf. Ser. 2016, 753, 082002. [Google Scholar] [CrossRef]
- Li, L.; Liu, Y.; Yang, Y.; Han, S. Short-term wind speed forecasting based on CFD pre-calculated flow fields. Proc. CSEE 2013, 33, 27–32. [Google Scholar]
- Li, L.; Liu, Y.-Q.; Yang, Y.-P.; Shuang, H.; Wang, Y.-M. A physical approach of the short-term wind power prediction based on CFD pre-calculated flow fields. J. Hydrodyn. Ser. B 2013, 25, 56–61. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y.; Li, L.; Han, S.; Infield, D. Numerical weather prediction wind correction methods and its impact on computational fluid dynamics based wind power forecasting. J. Renew. Sustain. Energy 2016, 8, 033302. [Google Scholar] [CrossRef] [Green Version]
- Lin, L.; Chen, Y.; Wang, N. Clustering wind turbines for a large wind farm using spectral clustering approach based on diffusion mapping theory. In Proceedings of the 2012 IEEE International Conference on Power System Technology (POWERCON), Auckland, New Zealand, 30 October–2 November 2012; pp. 1–6. [Google Scholar]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Yan, J.; Liu, Y.; Han, S.; Qiu, M. Wind power grouping forecasts and its uncertainty analysis using optimized relevance vector machine. Renew. Sustain. Energy Rev. 2013, 27, 613–621. [Google Scholar] [CrossRef]
- Liu, D.; Wang, J.; Wang, H. Short-term wind speed forecasting based on spectral clustering and optimised echo state networks. Renew. Energy 2015, 78, 599–608. [Google Scholar] [CrossRef]
- Dong, L.; Wang, L.; Khahro, S.F.; Gao, S.; Liao, X. Wind power day-ahead prediction with cluster analysis of NWP. Renew. Sustain. Energy Rev. 2016, 60, 1206–1212. [Google Scholar] [CrossRef]
- Li, S.; Ma, H.; Li, W. Typical solar radiation year construction using k-means clustering and discrete-time Markov chain. Appl. Energy 2017, 205, 720–731. [Google Scholar] [CrossRef]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.D.; Silverman, R.; Wu, A.Y. An efficient k-means clustering algorithm: Analysis and implementation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 881–892. [Google Scholar] [CrossRef]
- Zepeda-Mendoza, M.L.; Resendis-Antonio, O. Hierarchical agglomerative clustering. In Encyclopedia of Systems Biology; Springer: New York, NY, USA, 2013; pp. 886–887. [Google Scholar]
- Day, W.H.; Edelsbrunner, H. Efficient algorithms for agglomerative hierarchical clustering methods. J. Classif. 1984, 1, 7–24. [Google Scholar] [CrossRef]
- Ding, C.; He, X. Cluster merging and splitting in hierarchical clustering algorithms. In Proceedings of the Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 139–146. [Google Scholar]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Proc Nips 2001, 14, 849–856. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Zhao, Q.; Fränti, P. WB-index: A sum-of-squares based index for cluster validity. Data Knowl. Eng. 2014, 92, 77–89. [Google Scholar] [CrossRef]
- Yakhot, V.; Orszag, S.A. Renormalization group analysis of turbulence. I. Basic theory. J. Sci. Comput. 1986, 1, 3–51. [Google Scholar] [CrossRef]
- Larsen, G.C. A Simple Stationary Semi-Analytical Wake Model; Risø National Laboratory for Sustainable Energy, Technical University of Denmark: Roskilde, Denmark, 2009. [Google Scholar]
- Kuo, J.Y.; Romero, D.A.; Amon, C.H. A mechanistic semi-empirical wake interaction model for wind farm layout optimization. Energy 2015, 93, 2157–2165. [Google Scholar] [CrossRef]
- Liu, C.; Pei, Z.Y.; Wang, B.; Dong, C.; Feng, S.L.; Fan, G.F.; Shi, Y.G.; Fan, G.Y.; Guo, L. Function Specification of Wind Power Forecasting; China Electric Power Press: Beijing, China, 2011. [Google Scholar]
- Ouyang, T.; Zha, X.; Qin, L. A combined multivariate model for wind power prediction. Energy Convers. Manag. 2017, 144, 361–373. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster I | Cluster II | Cluster III | |||
|---|---|---|---|---|---|
| WT | OCC (%) | WT | OCC (%) | WT | OCC (%) |
| 2 | 89.30 | 6 | 90.52 | 1 | 92.11 |
| 4 | 90.58 | 7 | 93.38 | 3 | 91.92 |
| 5 | 89.86 | 10 | 93.37 | 8 | 93.55 |
| 9 | 91.62 | 11 | 89.46 | 15 | 93.77 |
| 18 | 92.63 | 12 | 93.83 | 16 | 91.53 |
| 21 | 87.50 | 13 | 93.84 | 17 | 90.14 |
| 22 | 91.99 | 14 | 92.83 | 19 | 92.39 |
| 23 | 92.81 | 24 | 91.59 | 20 | 92.02 |
| 25 | 92.59 | 27 | 91.01 | ||
| 26 | 92.84 | 29 | 90.50 | ||
| 28 | 91.64 | 30 | 93.73 | ||
| 31 | 93.69 | ||||
| 32 | 92.78 | ||||
| 33 | 92.68 | ||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Liu, Y.; Li, L.; Infield, D.; Han, S. Short-Term Wind Power Forecasting Based on Clustering Pre-Calculated CFD Method. Energies 2018, 11, 854. https://doi.org/10.3390/en11040854
Wang Y, Liu Y, Li L, Infield D, Han S. Short-Term Wind Power Forecasting Based on Clustering Pre-Calculated CFD Method. Energies. 2018; 11(4):854. https://doi.org/10.3390/en11040854
Chicago/Turabian StyleWang, Yimei, Yongqian Liu, Li Li, David Infield, and Shuang Han. 2018. "Short-Term Wind Power Forecasting Based on Clustering Pre-Calculated CFD Method" Energies 11, no. 4: 854. https://doi.org/10.3390/en11040854
APA StyleWang, Y., Liu, Y., Li, L., Infield, D., & Han, S. (2018). Short-Term Wind Power Forecasting Based on Clustering Pre-Calculated CFD Method. Energies, 11(4), 854. https://doi.org/10.3390/en11040854