Sensitivity Analysis of Time Length of Photovoltaic Output Power to Capacity Configuration of Energy Storage Systems


Abstract
:1. Introduction
2. Analysis of the Output Characteristics of Photovoltaic Power Stations
2.1. Output Power Level Statistics
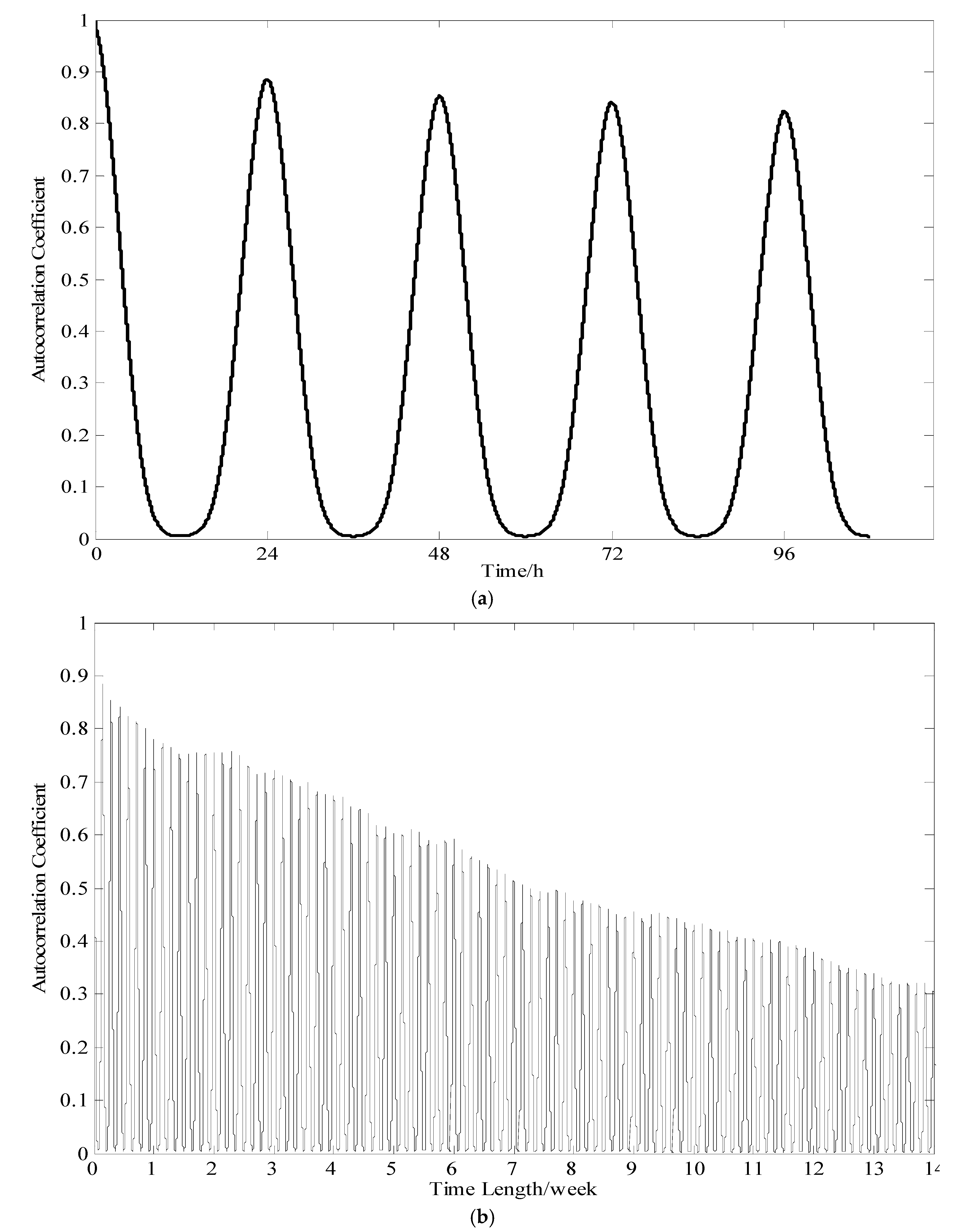
2.2. Output Data Autocorrelation Analysis
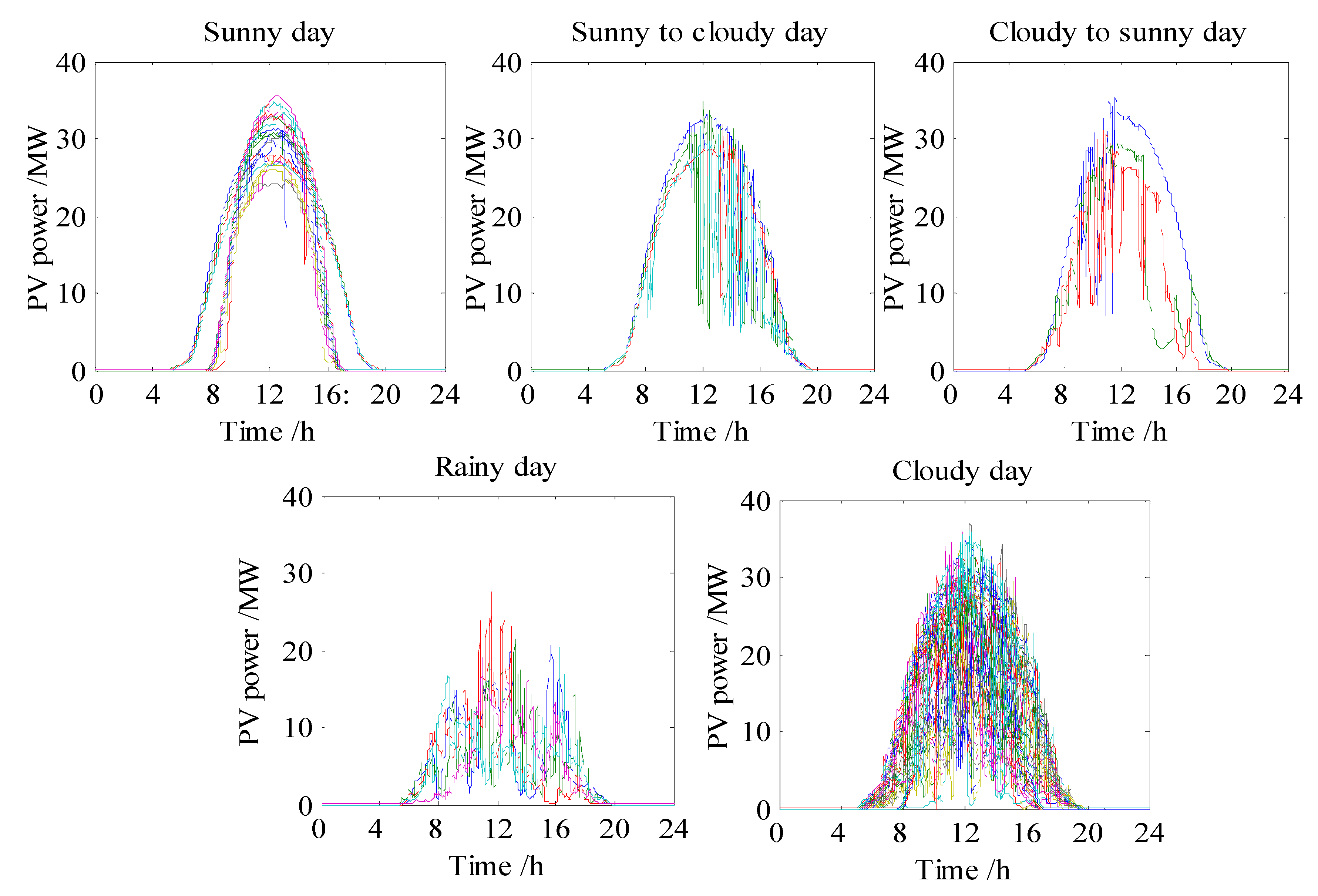
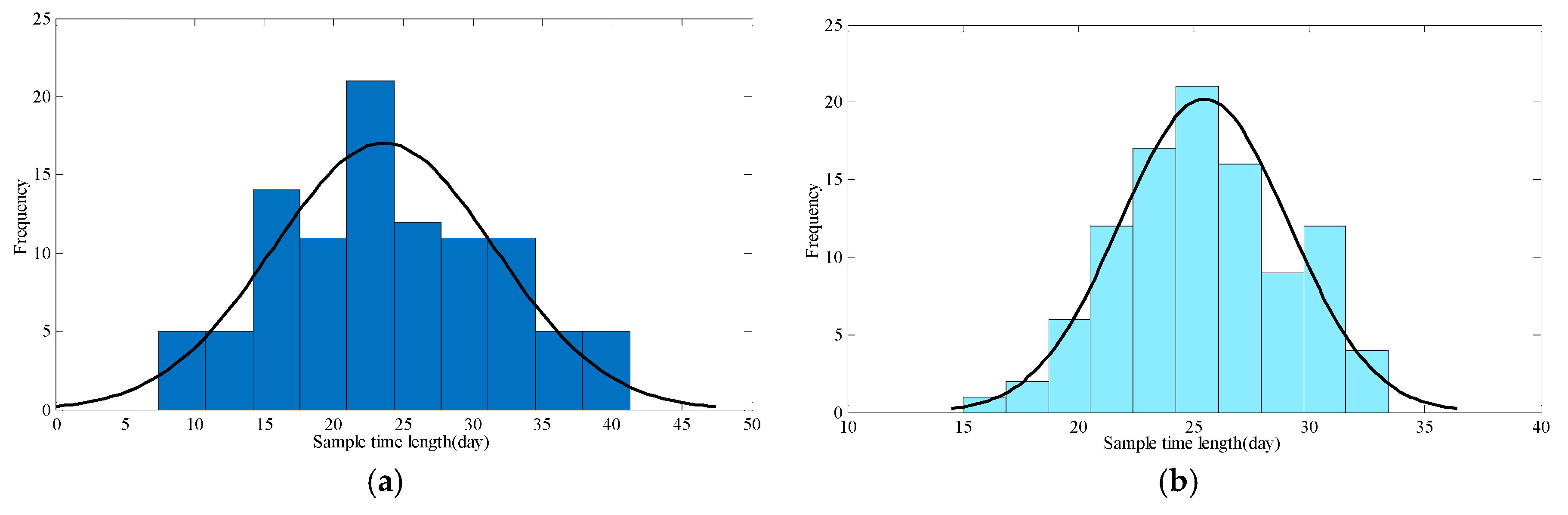
2.3. The Clustering Analysis of Similar Day of Operation Data of the PV Power Station
2.4. Based on the Optimal Sample Capacity Estimate to Determine the Length of Time
3. The Influence of the Time Length on the Capacity Configuration of the Energy Storage System
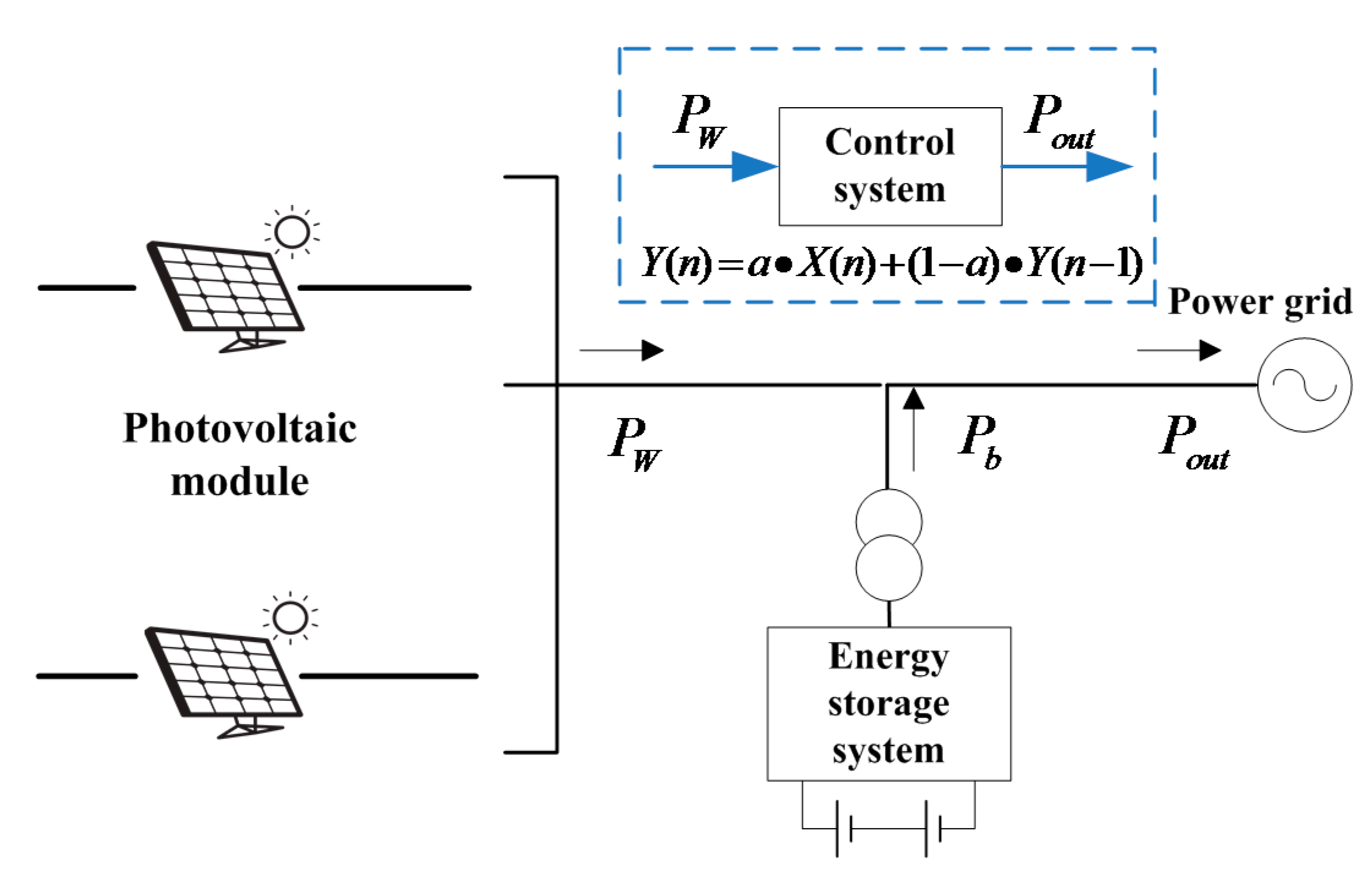
3.1. Smooth Control Principle of the First-Order Low-Pass Filter for Energy Storage Systems
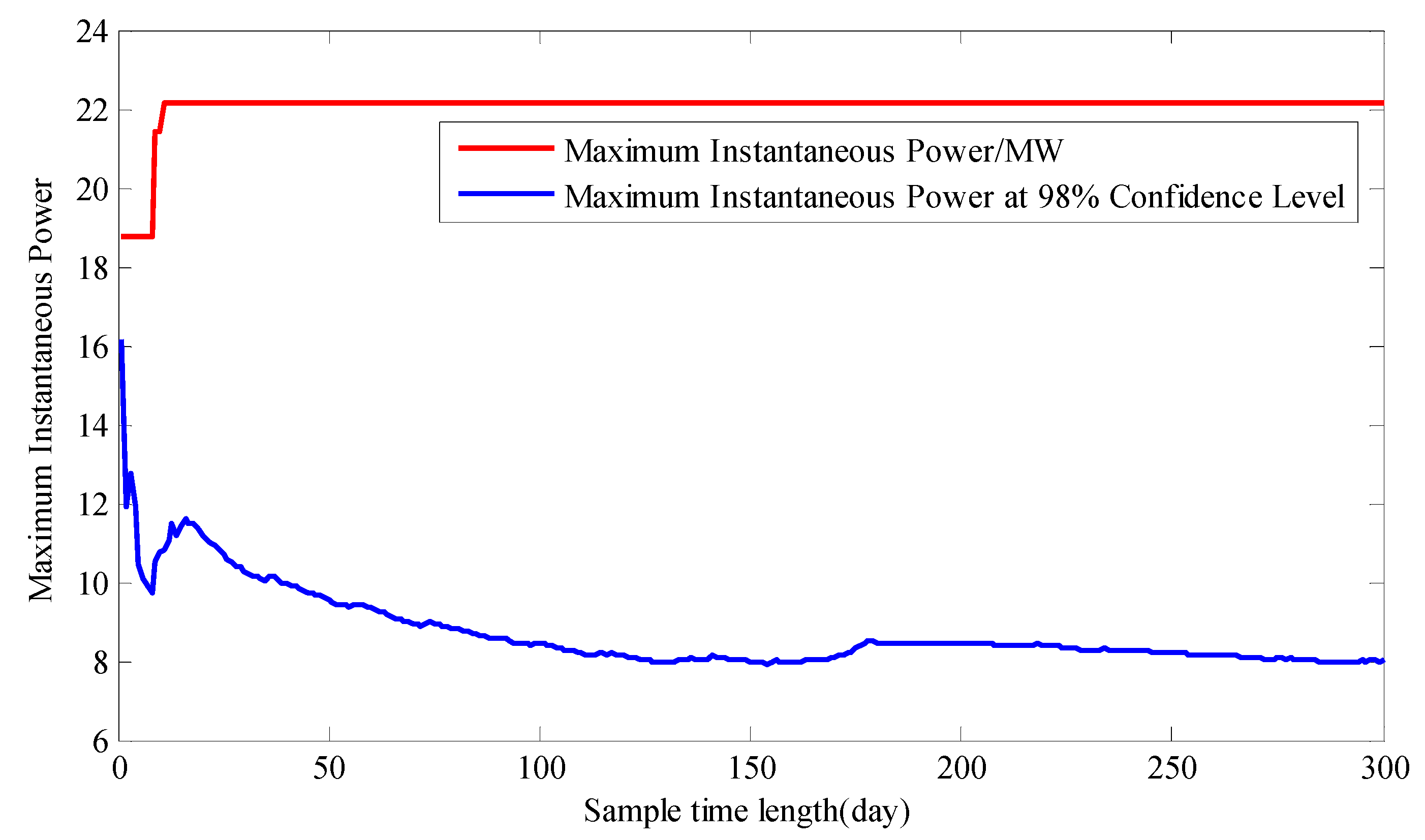
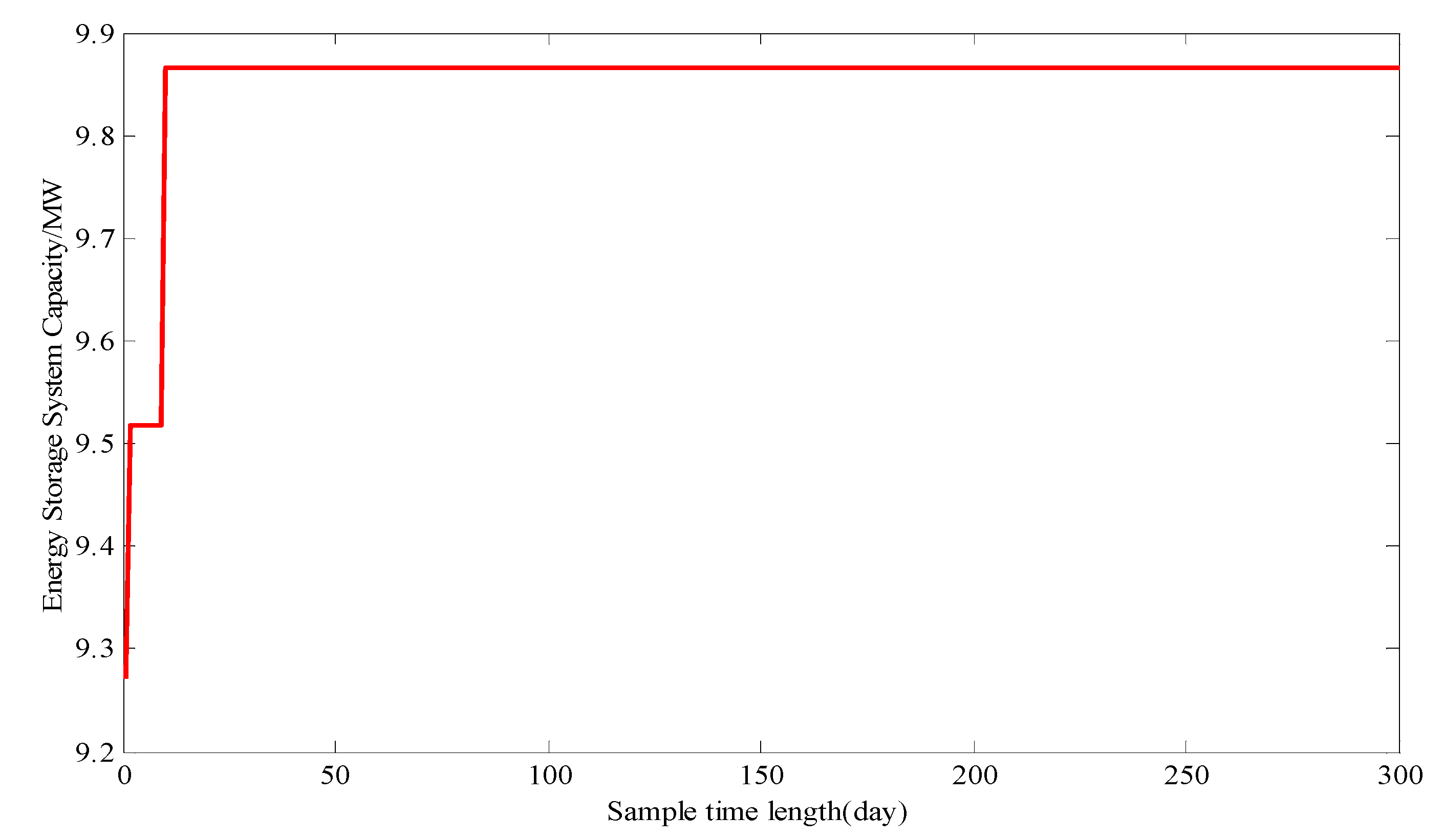
3.2. The Influence of the Sampling Time Length on the Capacity Configuration of Energy Storage Systems
4. Comparison and Analysis of Capacity Configuration of the Energy Storage System
4.1. Configure Capacity based on One-Year Historical Data
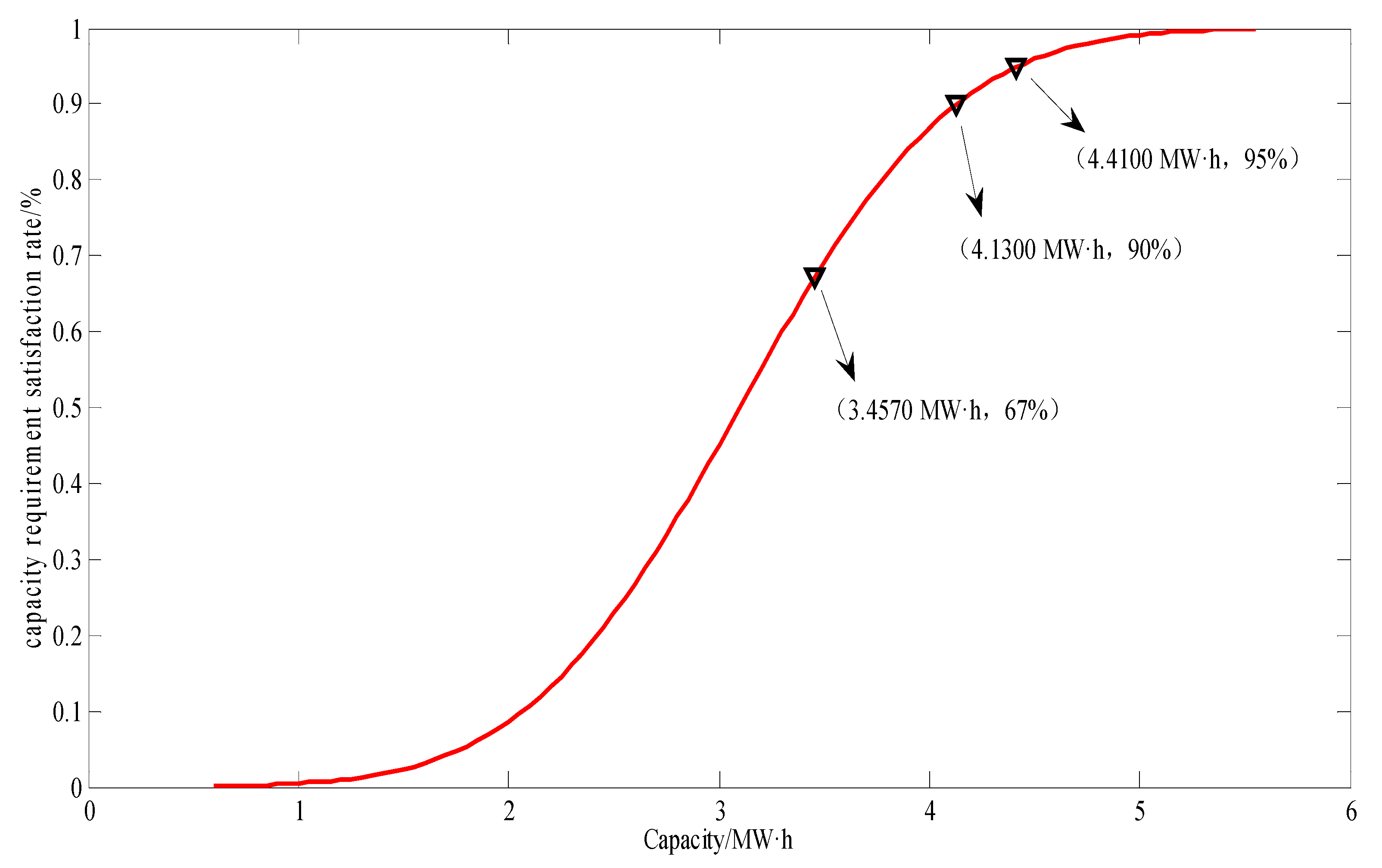
4.2. Configure Energy Storage Capacity Based on the Time Length Conclusion of PV Output Data
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Pinto, R.; Mariano, S.; Calado, M.; de Souza, J. Impact of Rural Grid-Connected Photovoltaic Generation Systems on Power Quality. Energies 2016, 9, 739. [Google Scholar] [CrossRef]
- Hong, Y.Y.; Lai, Y.M.; Chang, Y.R.; Lee, Y.D.; Liu, P.W. Optimizing Capacities of Distributed Generation and Energy Storage in a Small Autonomous Power System Considering Uncertainty in Renewables. Energies 2015, 8, 2473–2492. [Google Scholar] [CrossRef]
- Alghamdi, A.; Bahaj, A.B.; Wu, Y. Assessment of Large Scale Photovoltaic Power Generation from Carport Canopies. Energies 2017, 10. [Google Scholar] [CrossRef]
- Gulin, M.; Pavlović, T.; Vašak, M. A one-day-ahead photovoltaic array power production prediction with combined static and dynamic on-line correction. Sol. Energy 2017, 142, 49–60. [Google Scholar] [CrossRef]
- Yadav, A.K.; Chandel, S.S. Identification of relevant input variables for prediction of 1-minute time-step photovoltaic module power using Artificial Neural Network and Multiple Linear Regression Models. Renew. Sustain. Energy Rev. 2017, 77, 955–969. [Google Scholar] [CrossRef]
- Sichilalu, S.; Mathaba, T.; Xia, X. Optimal control of a wind–PV-hybrid powered heat pump water heater. Appl. Energy 2017, 185, 1173–1184. [Google Scholar] [CrossRef]
- Chen, W.L.; Tsai, C.T. Optimal Balancing Control for Tracking Theoretical Global MPP of Series PV Modules Subject to Partial Shading. IEEE Trans. Ind. Electron. 2015, 62, 4837–4848. [Google Scholar] [CrossRef]
- Abdelrazek, S.A.; Kamalasadan, S. Integrated PV Capacity Firming and Energy Time Shift Battery Energy Storage Management Using Energy-Oriented Optimization. IEEE Trans. Ind. Appl. 2016, 52, 2607–2617. [Google Scholar] [CrossRef]
- Liu, G.Q.; Yuan, Y.; Wang, M.; Dai, X.; Xu, L. Energy storage capacity determining of PV plant considering economic cost. Renew. Energy Resour. 2014, 1, 1–5. [Google Scholar]
- Zhu, L.; Yan, Z.; Yang, X.; Fu, Y.; Chen, J. Optimal configuration of battery capacity in microgrid composed of wind power and photovoltaic generation with energy storage. Power Syst. Technol. 2012, 12, 26–31. [Google Scholar]
- Hu, G.Z.; Duan, S.X.; Cai, T.; Chen, C.S. Sizing and cost analysis of photovoltaic generation system based on vanadium redox battery. Trans. Chin. Electron. Soc. 2012, 5, 260–267. [Google Scholar]
- Wu, X.G.; Liu, Z.Q.; Tian, L.T.; Ding, D.; Cheng, Z. Optimized capacity configuration of photovoltaic generation and energy storage device for stand-alone photovoltaic generation system. Power Syst. Technol. 2014, 5, 1271–1276. [Google Scholar]
- Han, X.; Liu, D.; Liu, J.; Kong, L. Sensitivity analysis of PV output power to capacity configuration of energy storage systems from time and space characteristics. Int. J. Energy Res. 2017. [Google Scholar] [CrossRef]
- Han, Z.H.; Zhu, X.X. Selection of training sample length in support vector regression based on information entropy. Proc. CSEE 2010, 20, 112–116. [Google Scholar]
- Gao, P.X. Parametric modeling sample size selection. J. Vib. Meas. Diagn. 1991, 4, 9–14. [Google Scholar]
- Shi, L.D.; Zhang, J.G.; Huang, S.Q. Investigating of random sample to determine the length of the data processing problem. Constr. Mach 1993, 4, 16–21. [Google Scholar]
- Heck, D.W.; Moshagen, M.; Erdfelder, E. Model selection by minimum description length: Lower-bound sample sizes for the Fisher information approximation. J. Math. Psychol. 2014, 60, 29–34. [Google Scholar] [CrossRef]
- Vallejos, R.; Osorio, F. Effective sample size of spatial process models. Spat. Stat. 2014, 9, 66–92. [Google Scholar] [CrossRef]
- Chun, Y.; Griffith, D.A. A quality assessment of eigenvector spatial filtering based parameter estimates for the normal probability model. Spat. Stat. 2014, 10, 1–11. [Google Scholar] [CrossRef]
- Rodrigues, E.M.G.; Godina, R.; Pouresmaeil, E.; Ferreira, J.R.; Catalão, J.P.S. Domestic appliances energy optimization with model predictive control. Energy Convers. Manag. 2017, 142, 402–413. [Google Scholar] [CrossRef]
- Oliveira, D.; Rodrigues, E.M.G.; Mendes, T.D.P.; Catalão, J.P.S.; Pouresmaeil, E. Model predictive control technique for energy optimization in residential appliances. In Proceedings of the IEEE International Conference on Smart Energy Grid Engineering, Oshawa, ON, Canada, 17–19 August 2015; pp. 1–6. [Google Scholar]
- Godina, R.; Rodrigues, E.M.G.; Pouresmaeil, E.; Matias, J.C.O.; Catalão, J.P.S. Model predictive control technique for energy optimization in residential sector. In Proceedings of the IEEE International Conference on Environment and Electrical Engineering, Florence, Italy, 7–10 June 2016. [Google Scholar]
- Oliveira, D.; Rodrigues, E.M.G.; Godina, R.; Mendes, T.D.P.; Catalão, J.P.S.; Pouresmaeil, E. Enhancing home appliances energy optimization with solar power integration. In Proceedings of the IEEE Region 8 International Conference on Computer as a Tool (EUROCON), Salamanca, Spain, 8–11 September 2015. [Google Scholar]
- Oliveira, D.; Rodrigues, E.M.G.; Godina, R.; Matias, J.C.O.; Catalão, J.P.S.; Pouresmaeil, E. MPC weights tunning role on the energy optimization in residential appliances. In Proceedings of the Power Engineering Conference, Wollongong, Australia, 27–30 September 2015; pp. 1–6. [Google Scholar]
- Han, X.; Liu, D.; Liu, J.; Kong, L. Sensitivity analysis of acquisition granularity of photovoltaic output power to capacity configuration of energy storage systems. Appl. Energy 2017, 203, 794–807. [Google Scholar] [CrossRef]
- Luo, B.; Yu, H.; Zhang, X.; Shen, Z.; Li, Q. On eigen-based signal combining using the autocorrelation coefficient. IET Commun. 2013, 6, 3091–3097. [Google Scholar] [CrossRef]
- Zárate-Miñano, R.; Milano, F. Construction of SDE-based wind speed models with exponentially decaying autocorrelation. Renew. Energy 2016, 94, 186–196. [Google Scholar] [CrossRef]
- Bhandary, M. On confidence interval of a common autocorrelation coefficient of two populations in multivariate data when the errors are autocorrelated. J. Stat. Manag. Syst. 2016, 19, 509–517. [Google Scholar] [CrossRef]
- Saygin, D.; Kempener, R.; Wagner, N.; Ayuso, M.; Gielen, D. The Implications for Renewable Energy Innovation of Doubling the Share of Renewables in the Global Energy Mix between 2010 and 2030. Energies 2015, 8, 5828–5865. [Google Scholar] [CrossRef]
- Brenna, M.; Dolara, A.; Foiadelli, F.; Lazaroiu, G.C.; Leva, S. Transient Analysis of Large Scale PV Systems with Floating DC Section. Energies 2012, 5, 3736–3752. [Google Scholar] [CrossRef]
- Fu, G.; Fu, J.; Xu, Y.; Chen, Z.; Lai, J. Accuracy enhancement of five-axis machine tool based on differential motion matrix: Geometric error modeling, identification and compensation. Int. J. Mach. Tools Manuf. 2015, 89, 170–181. [Google Scholar] [CrossRef]
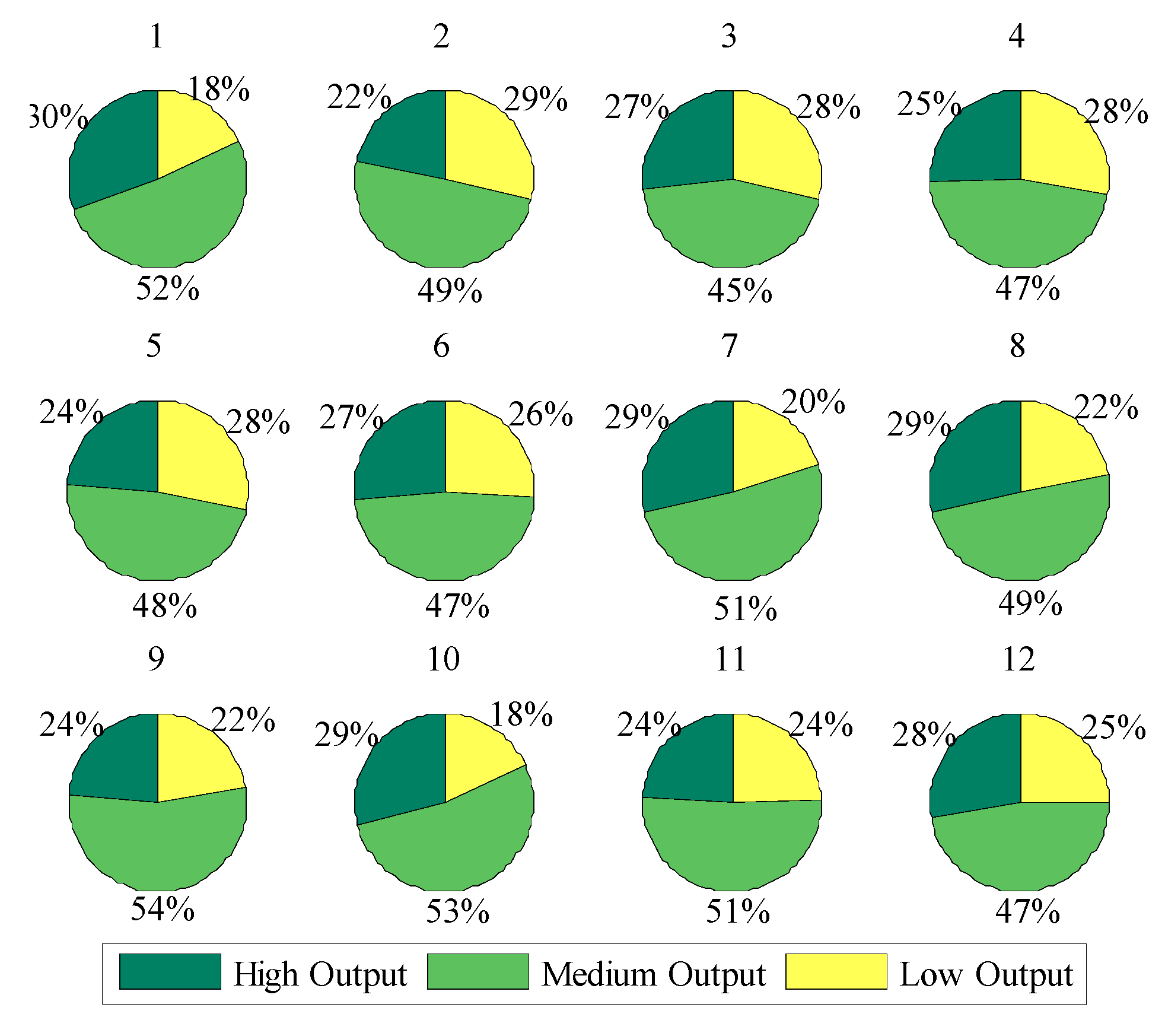



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Output Level | Definition |
|---|---|
| High output | The output level is higher than 60% of the installed capacity |
| Medium output | The output level is between 30% and 60% of the installed capacity |
| Low output | The output level is lower than 30% of the installed capacity |
| Allowable error accuracy | 0.15 | 0.2 | 0.25 | 0.3 |
| Time length/day | 79 | 55 | 31 | 23 |
| Installed Capacity/MW | 14 | 25 | 40 |
| Energy storage capacity/MW·h | 1.5583 | 2.7827 | 4.4523 |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Zheng, X. Sensitivity Analysis of Time Length of Photovoltaic Output Power to Capacity Configuration of Energy Storage Systems. Energies 2017, 10, 1616. https://doi.org/10.3390/en10101616
Wang M, Zheng X. Sensitivity Analysis of Time Length of Photovoltaic Output Power to Capacity Configuration of Energy Storage Systems. Energies. 2017; 10(10):1616. https://doi.org/10.3390/en10101616
Chicago/Turabian StyleWang, Mingqi, and Xinqiao Zheng. 2017. "Sensitivity Analysis of Time Length of Photovoltaic Output Power to Capacity Configuration of Energy Storage Systems" Energies 10, no. 10: 1616. https://doi.org/10.3390/en10101616