Short-Term Electricity-Load Forecasting Using a TSK-Based Extreme Learning Machine with Knowledge Representation



Abstract
:1. Introduction
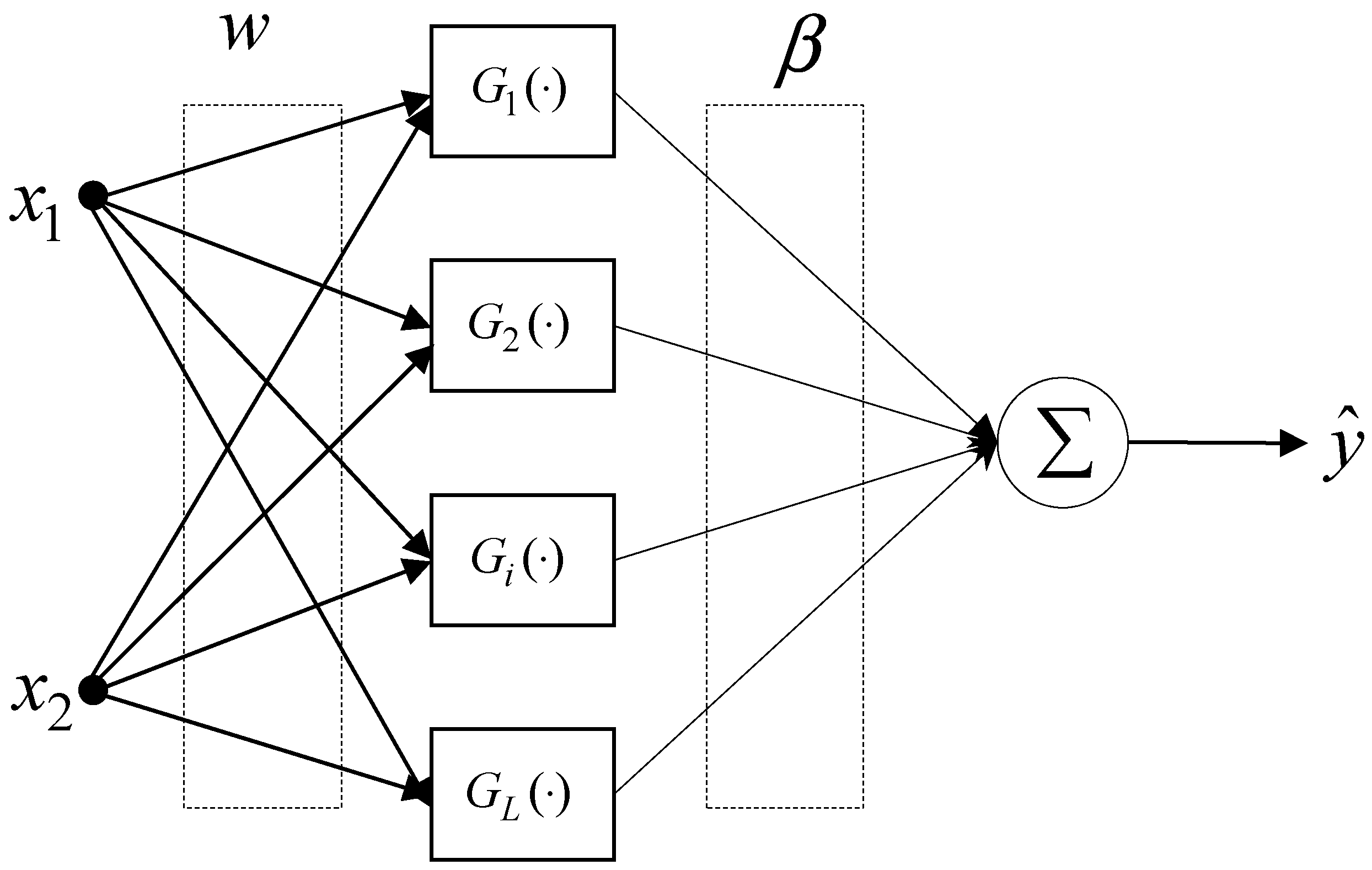
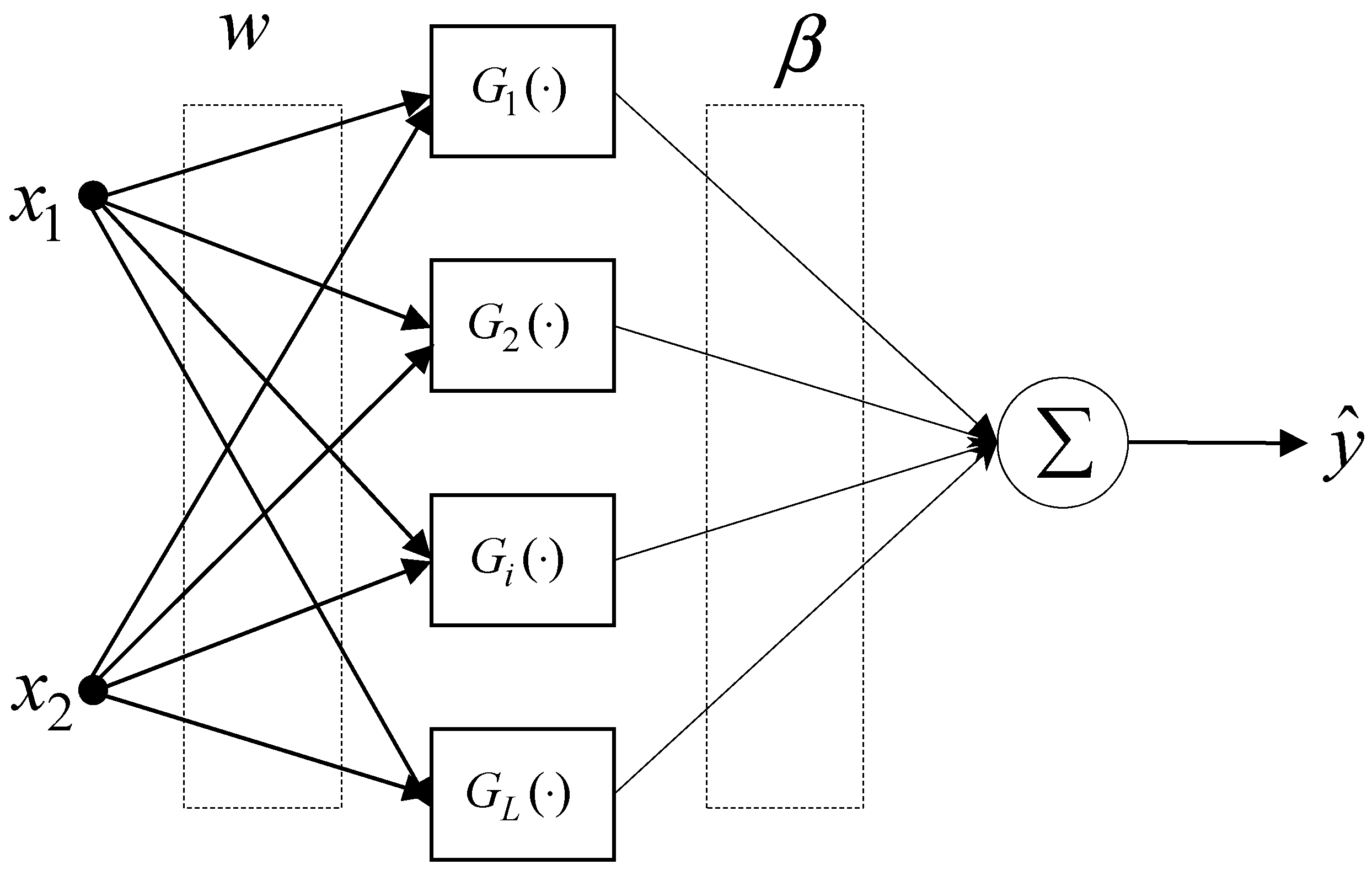
2. ELM as an Intelligent Predictor
- Randomly assign hidden node parameters .
- Calculate the hidden-layer output matrix .
- Calculate the output weights using a LSE:
3. Design of TSK-Based ELM for Short-Term Electricity-Load Forecasting
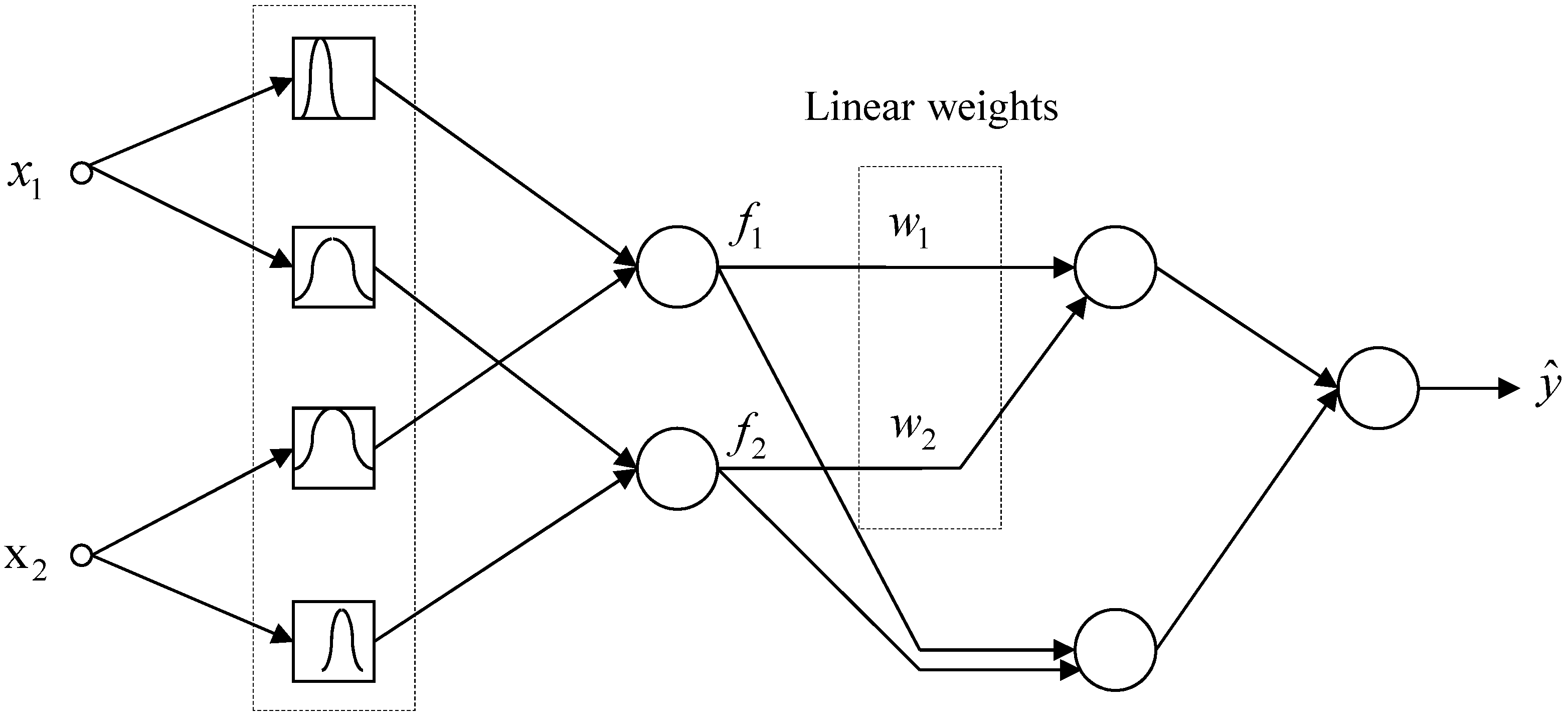
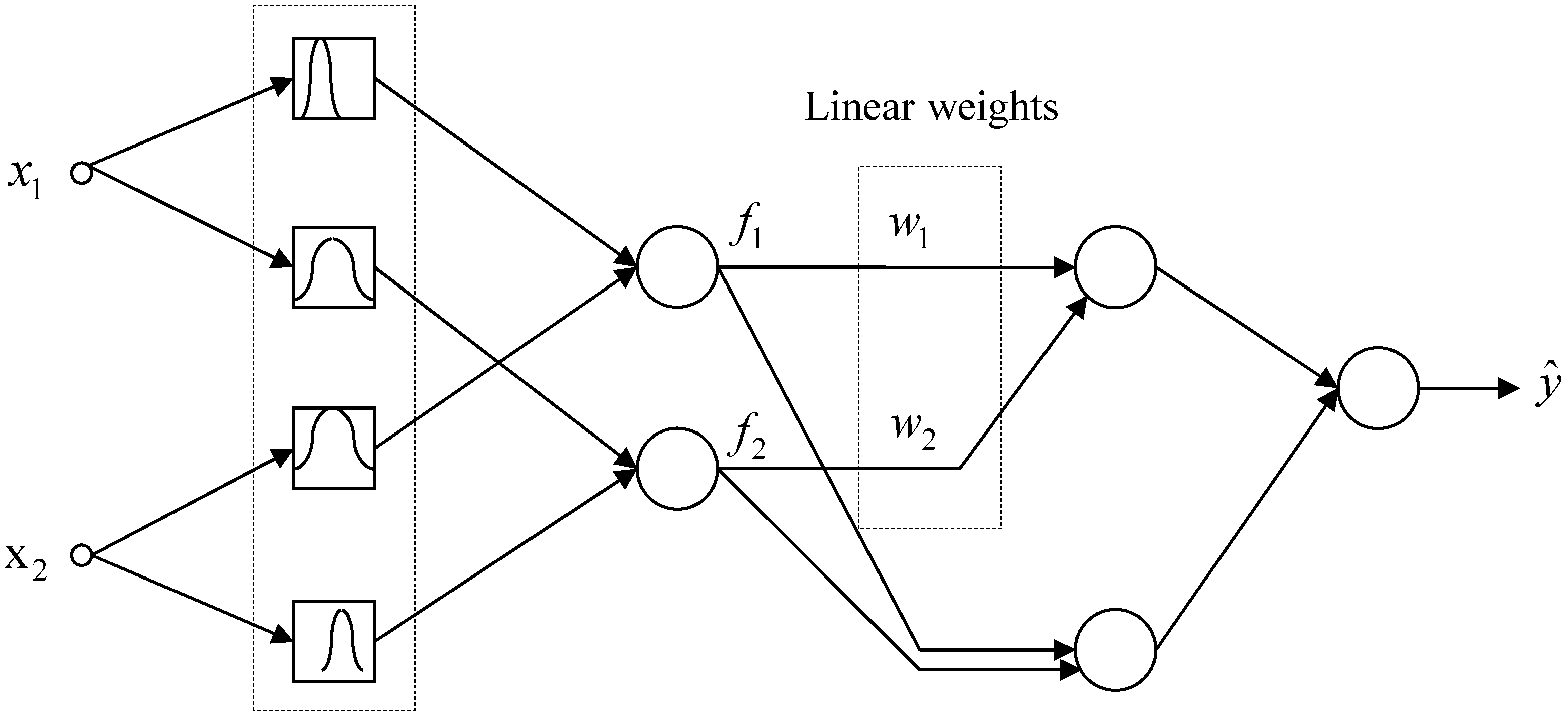
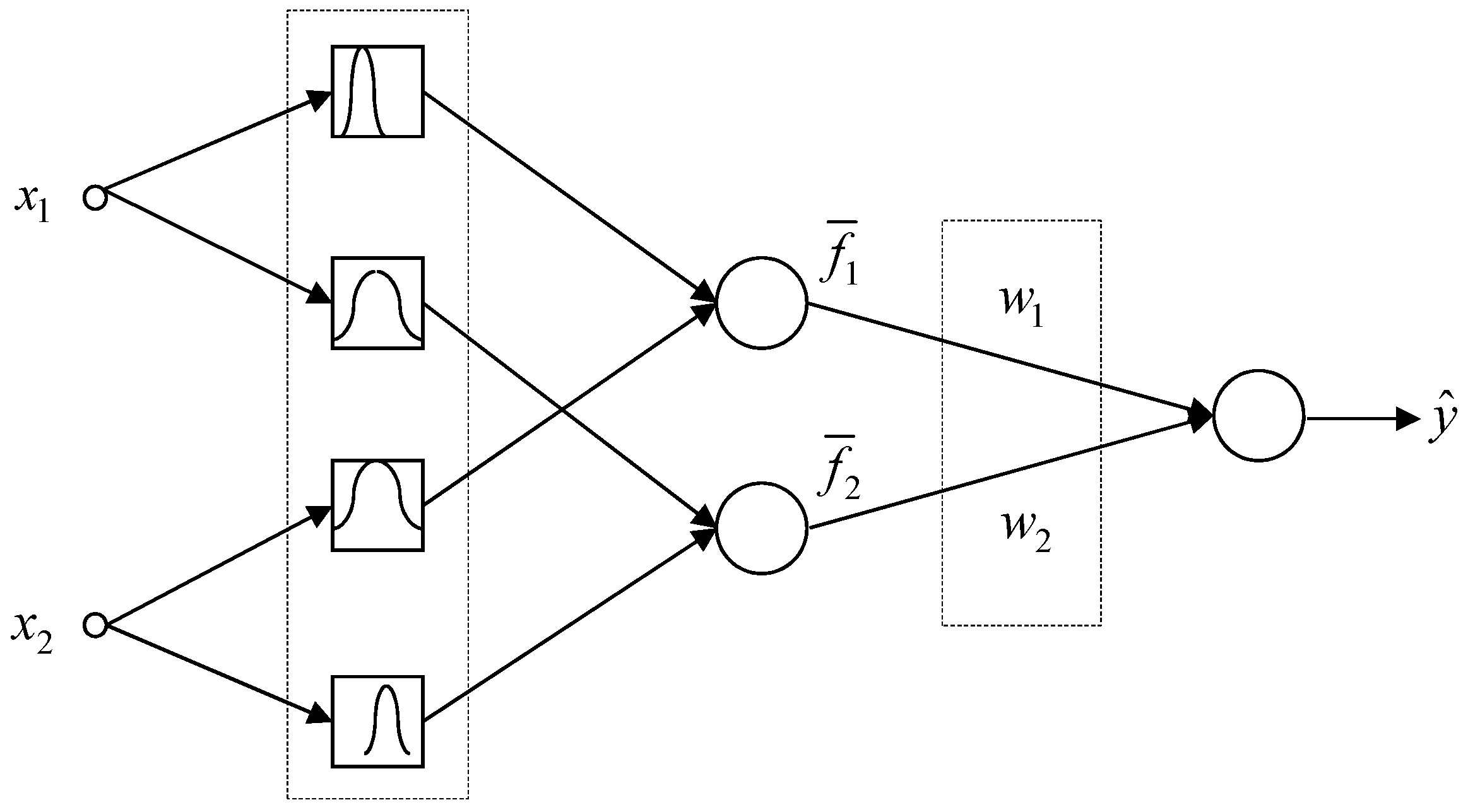
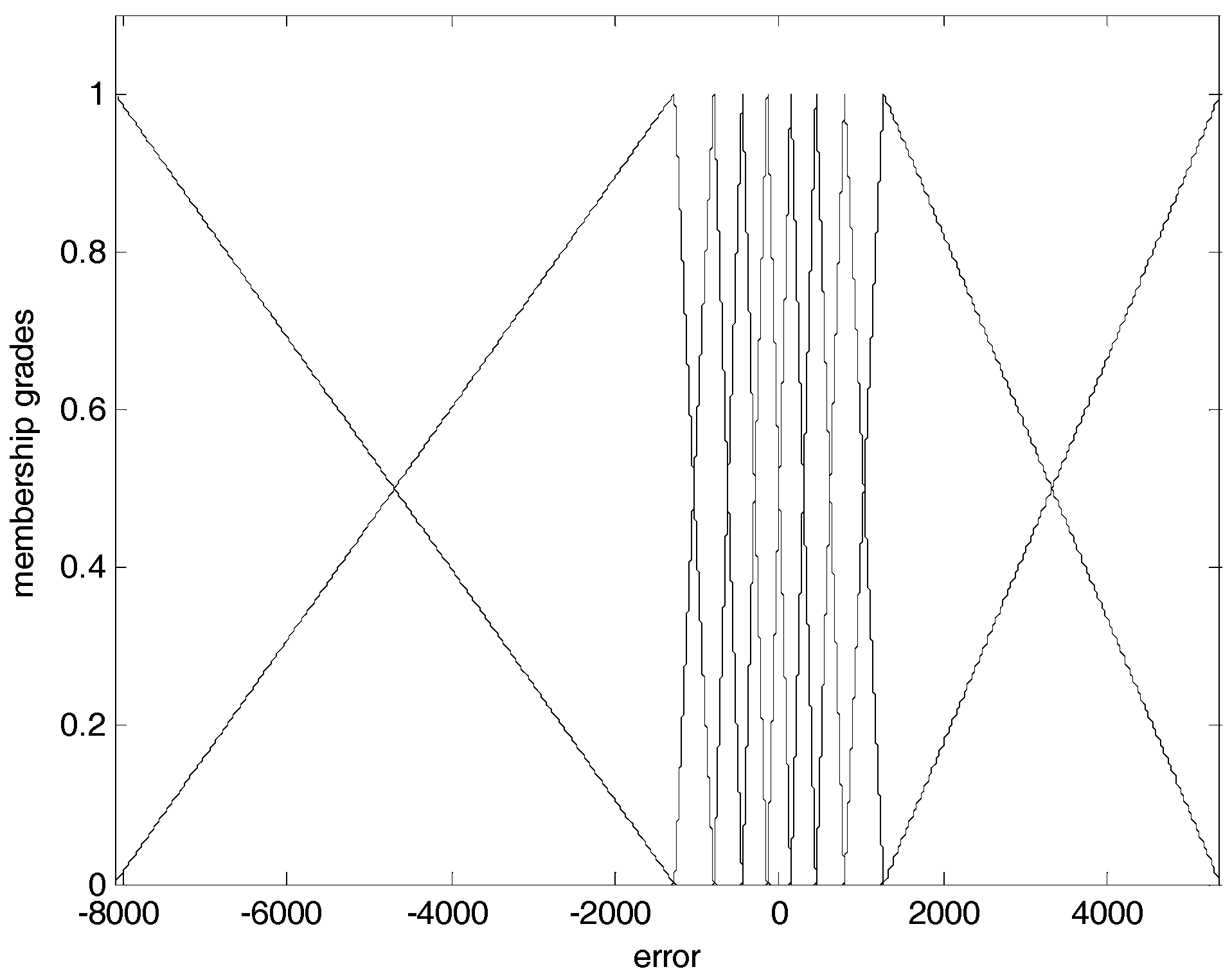
3.1. TSK-ELM Architecture and Knowledge Representation
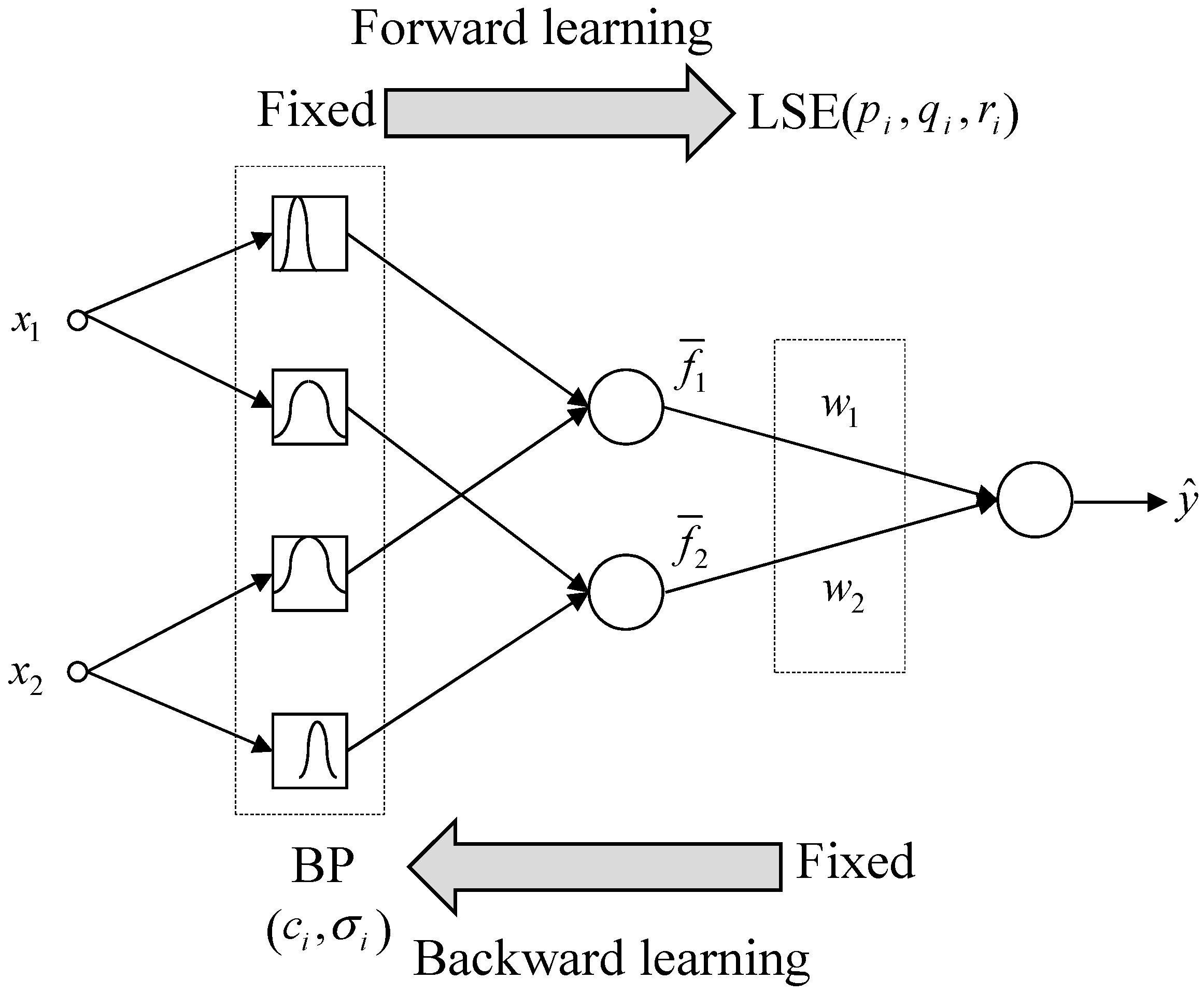
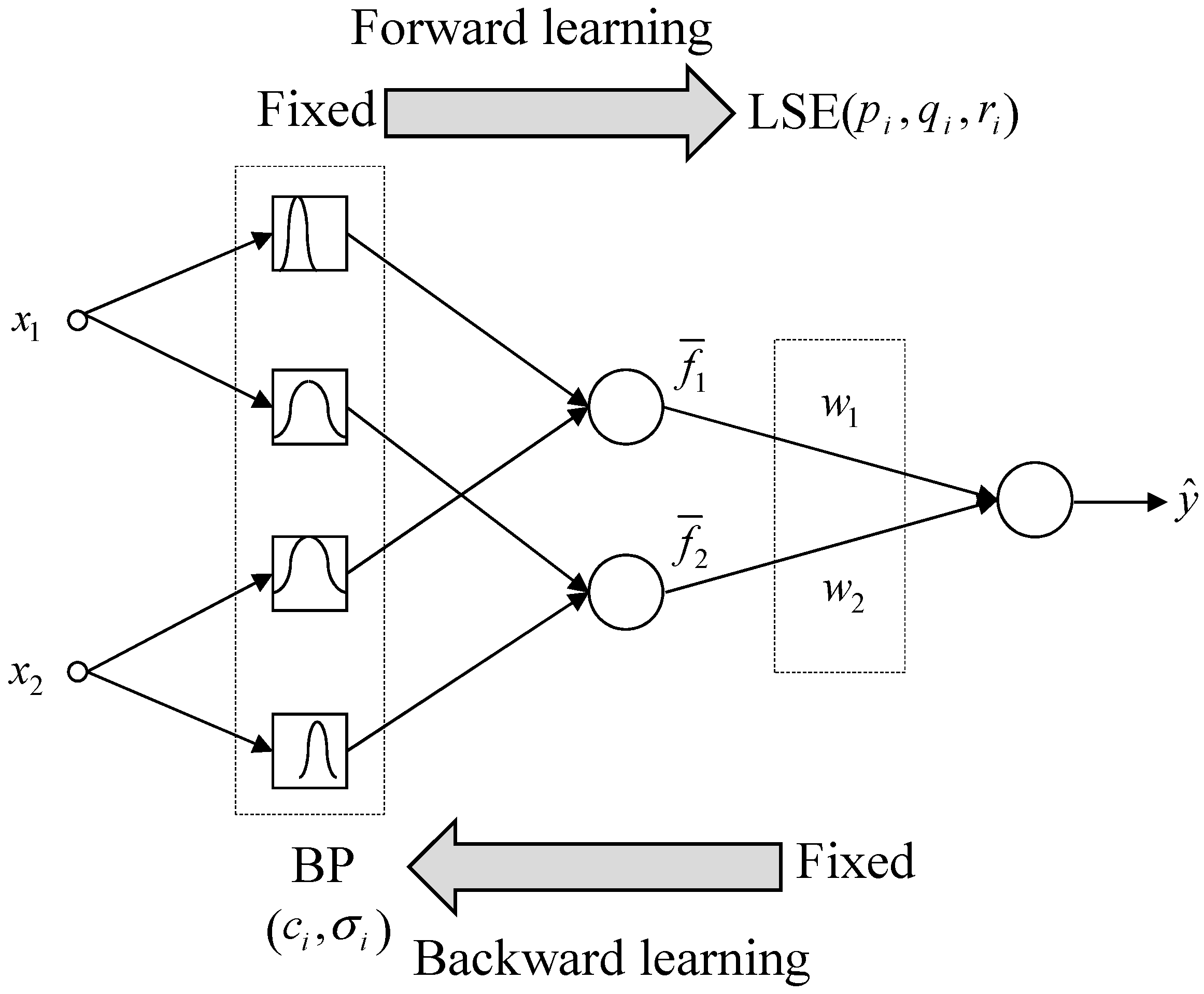
3.2. TSK-ELM’s Fast Learning and Hybrid-Learning
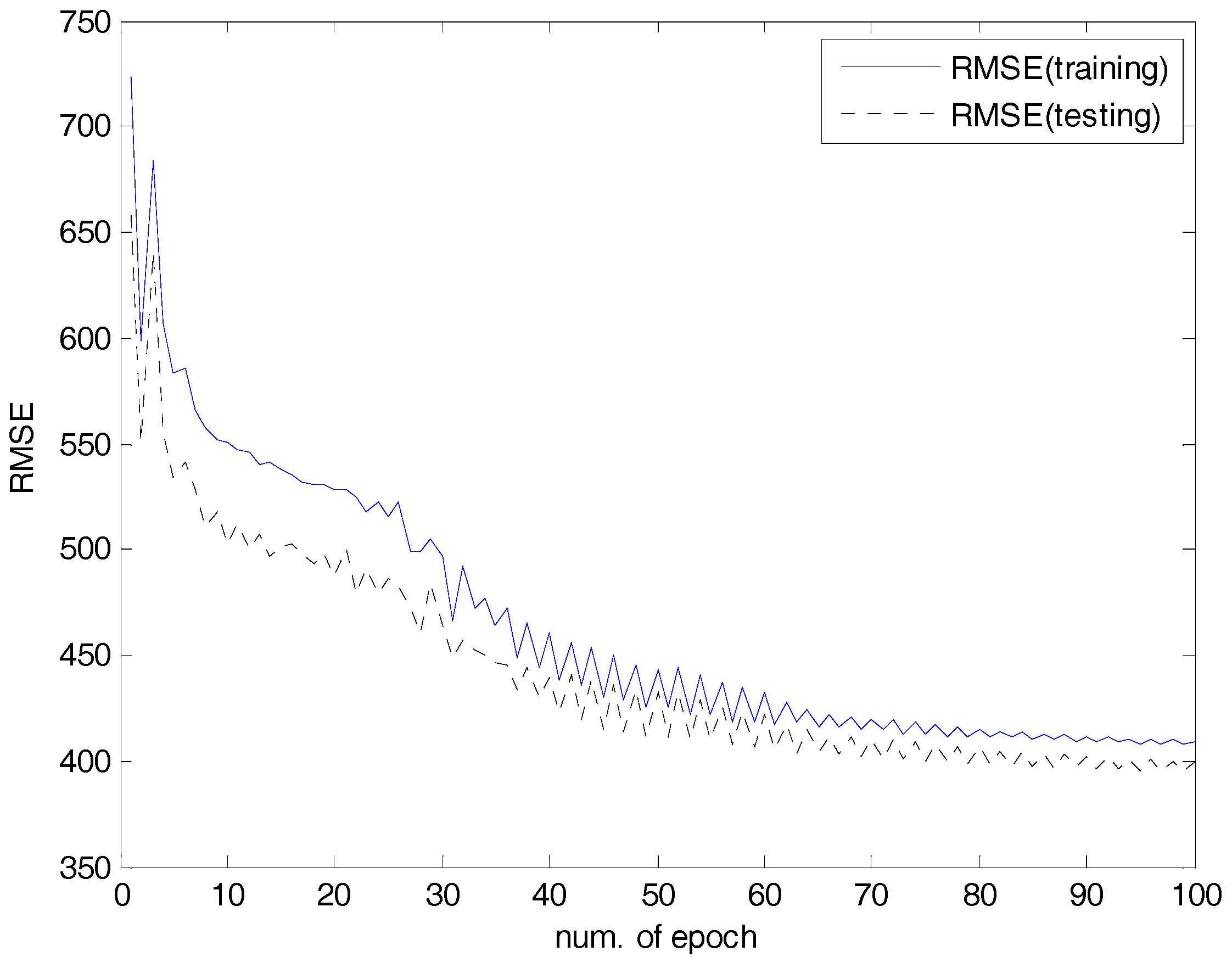
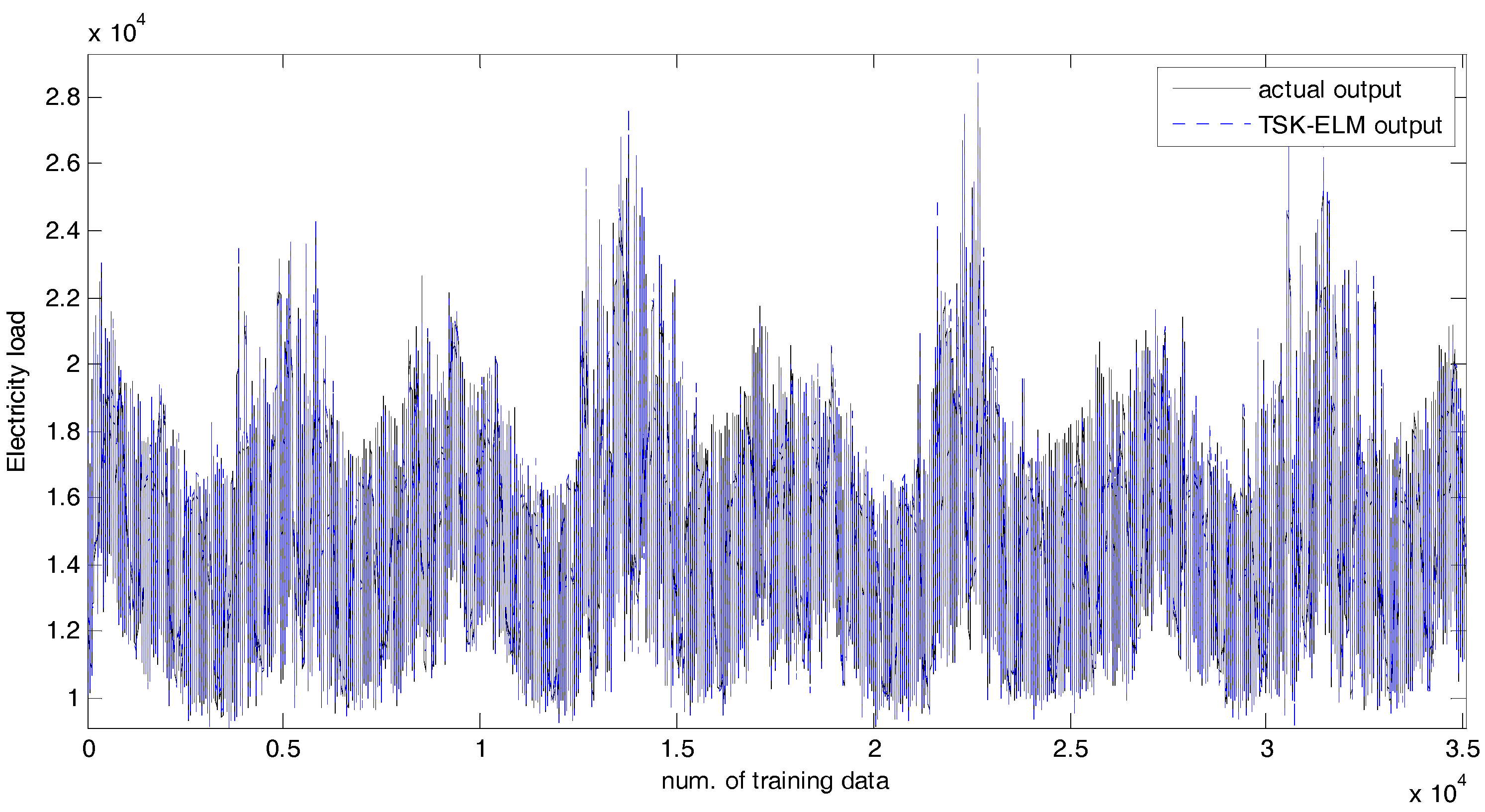
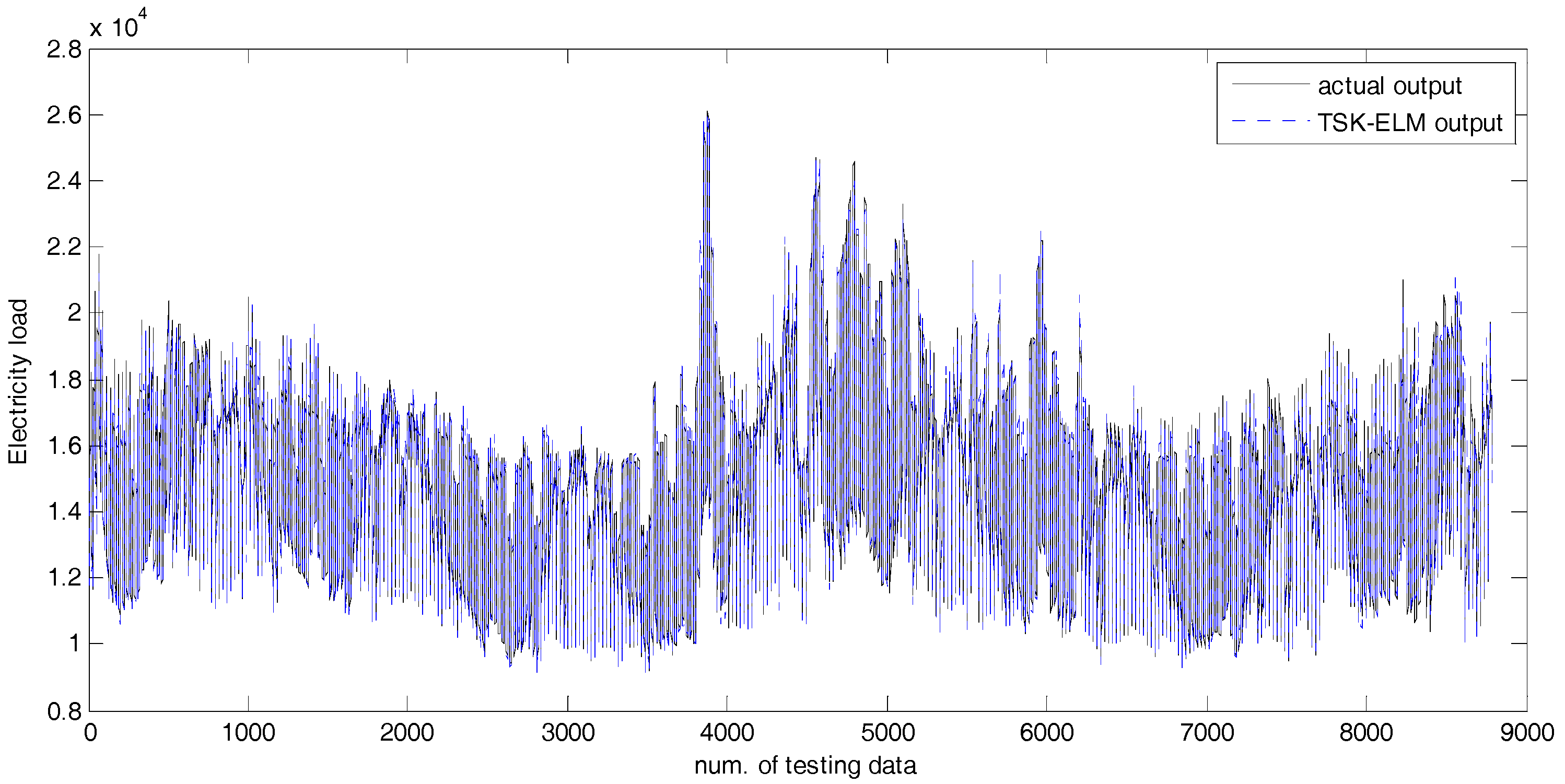
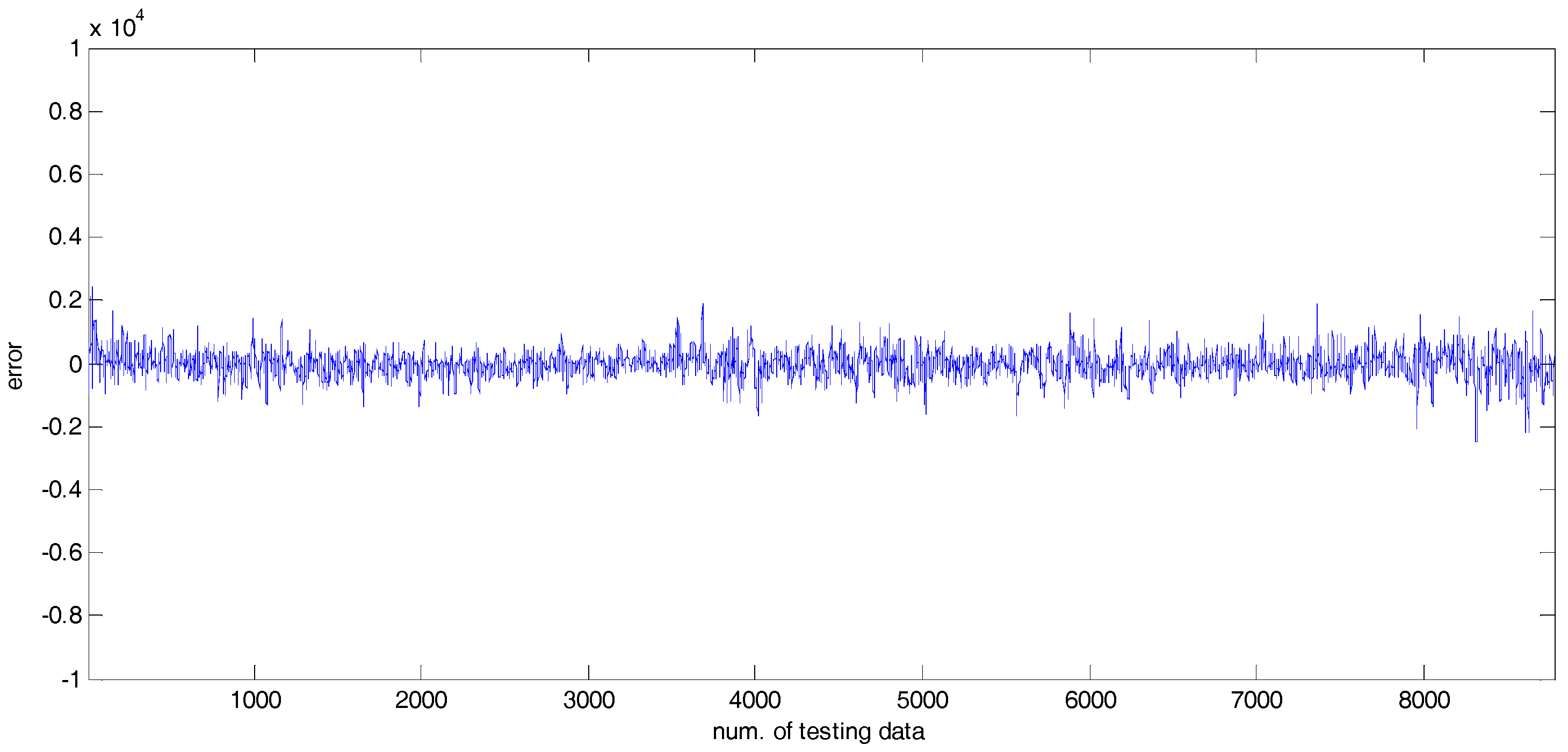
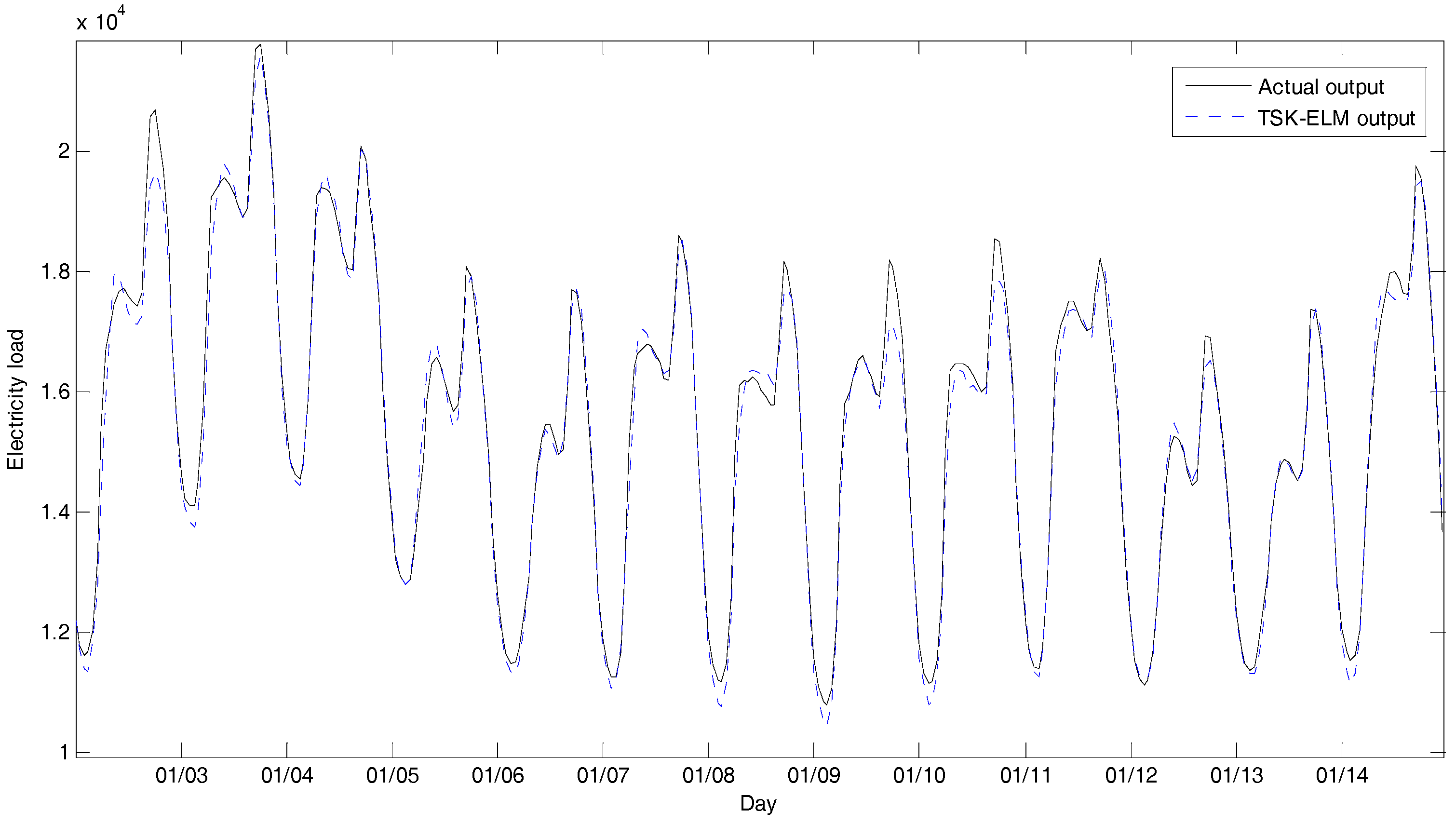
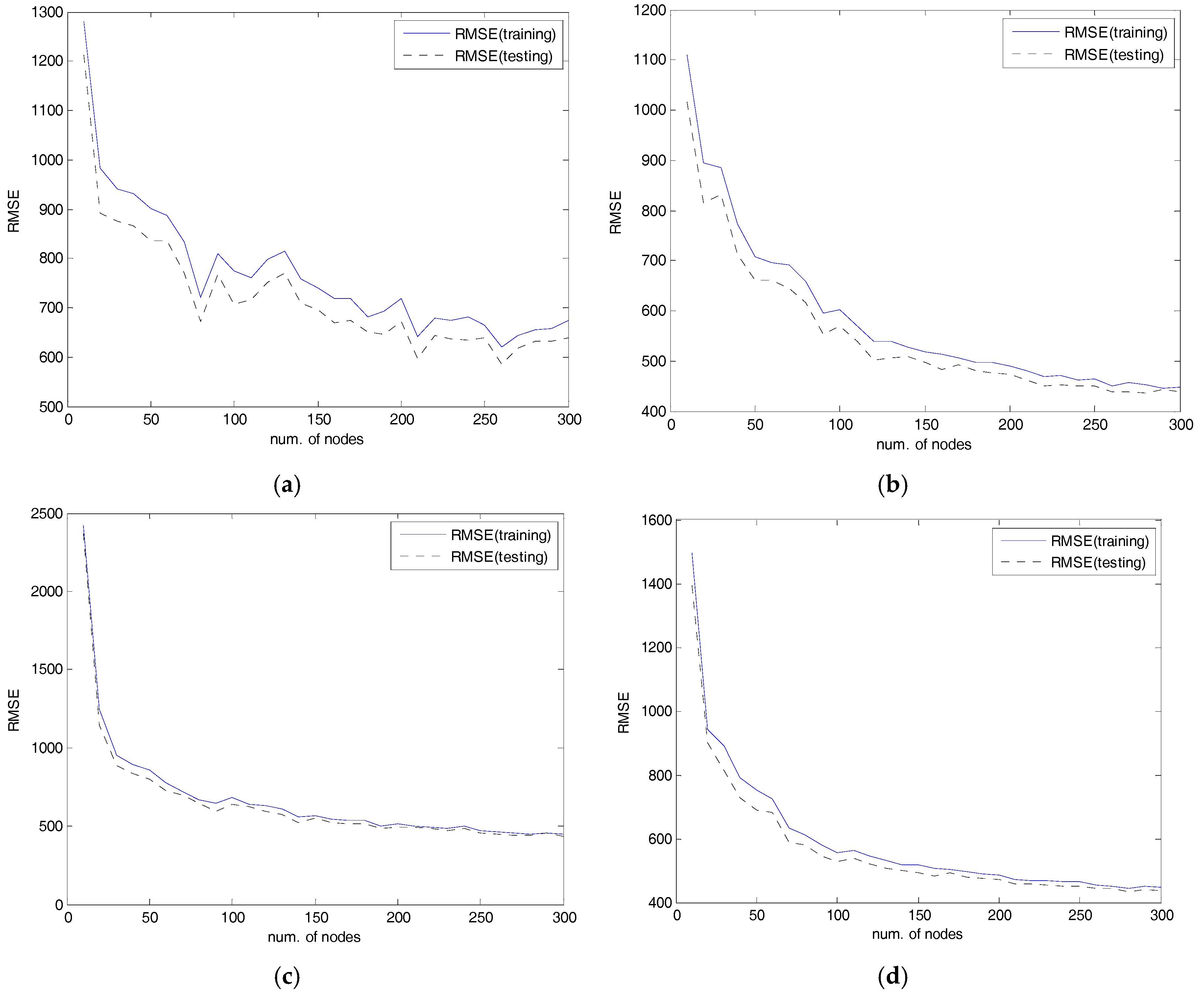
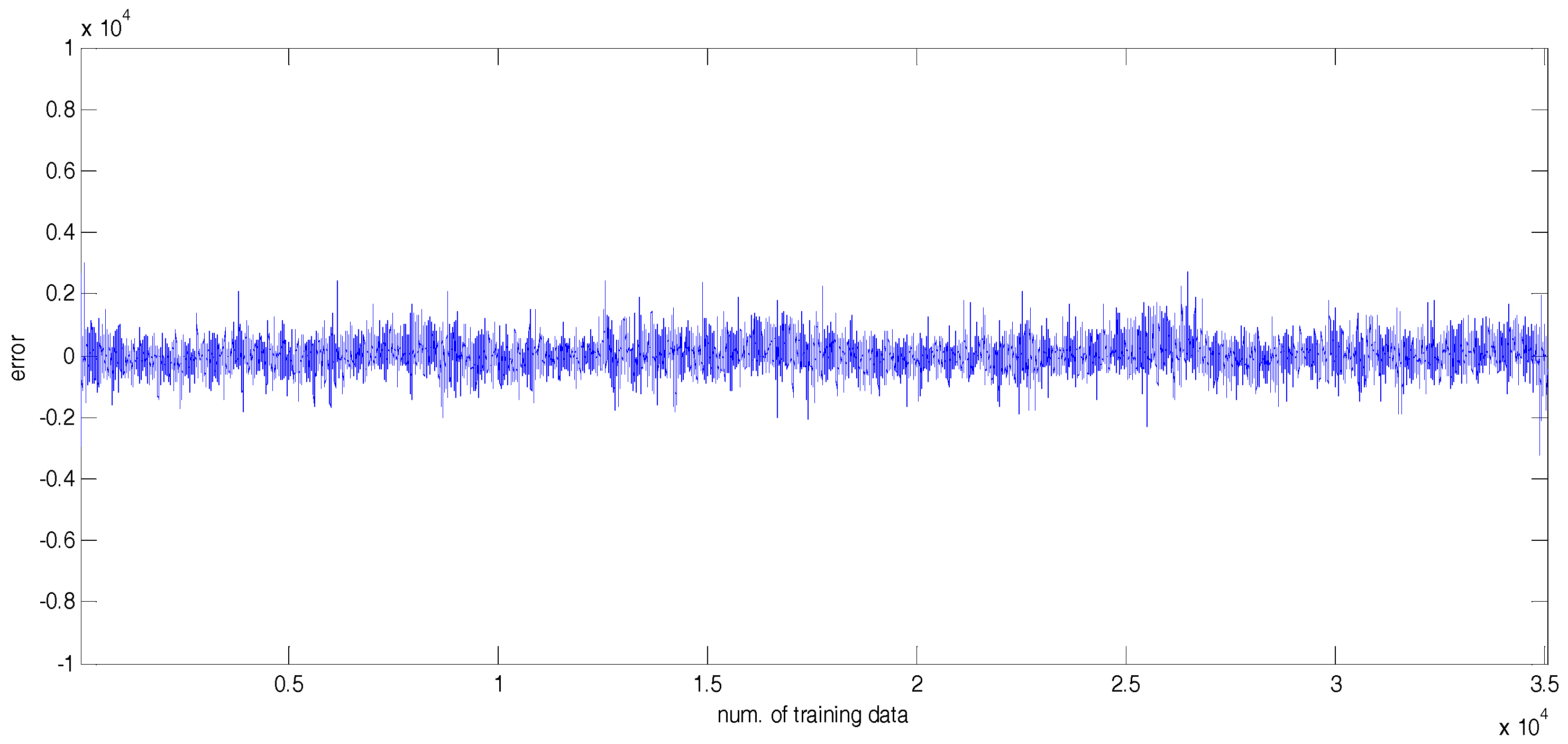
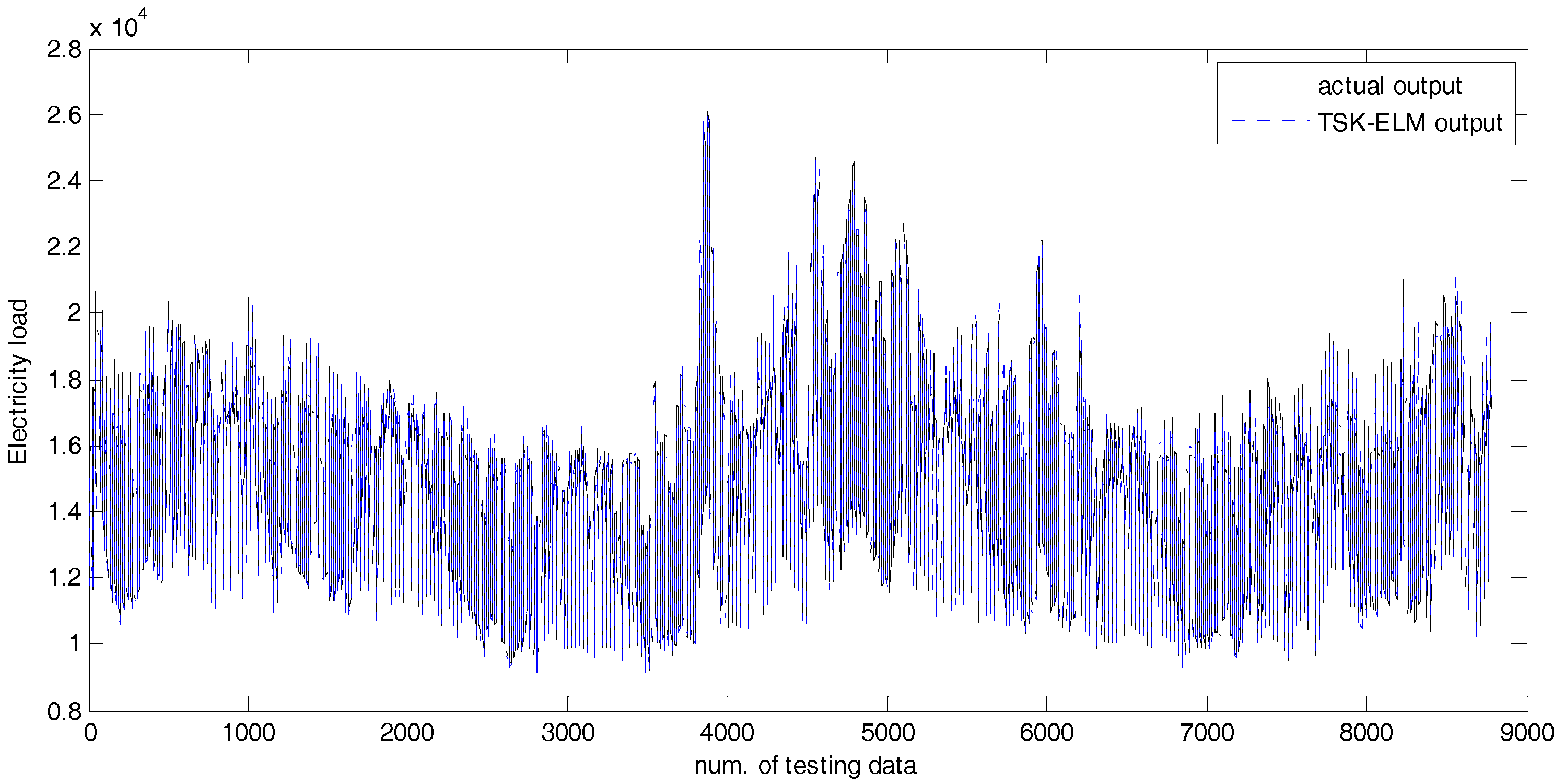
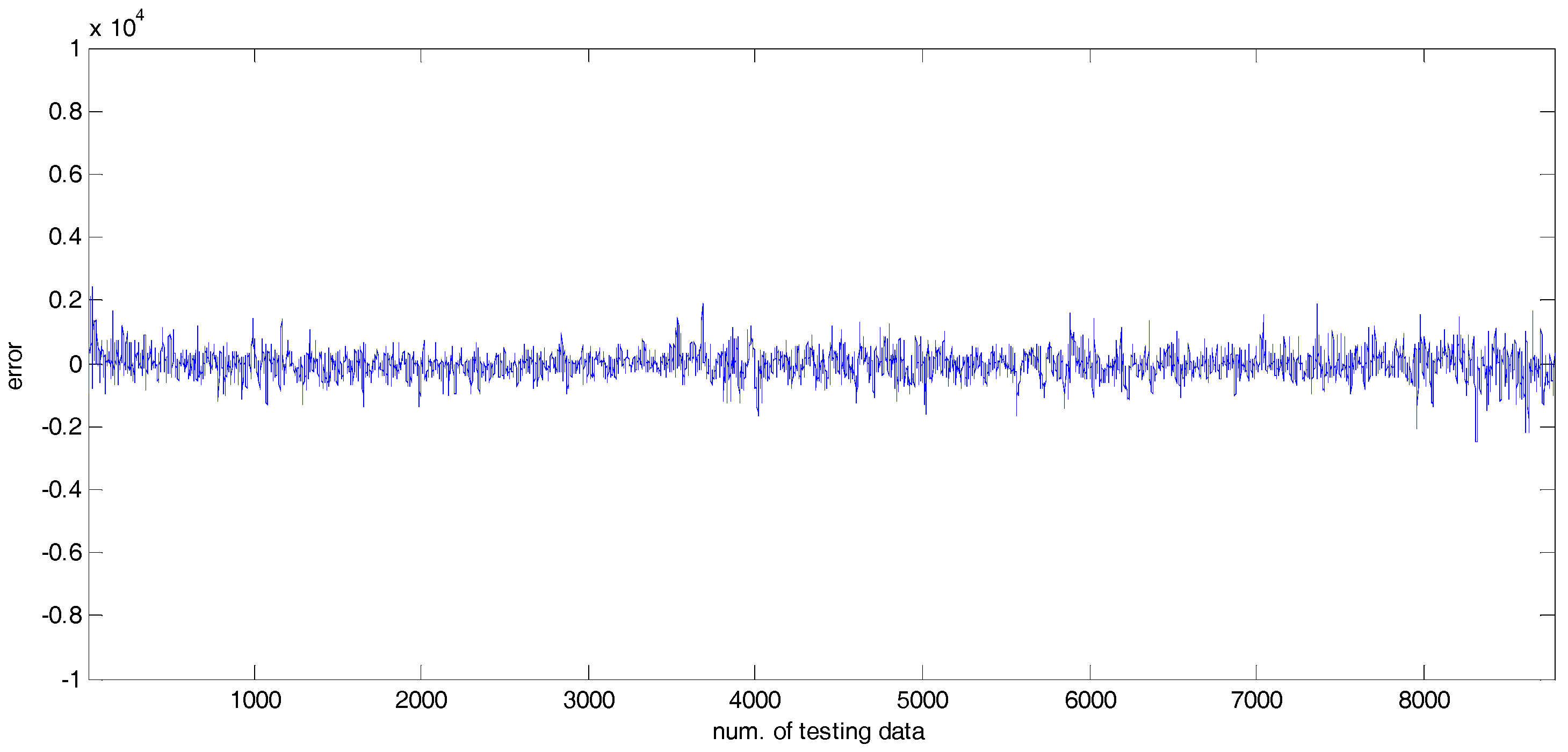
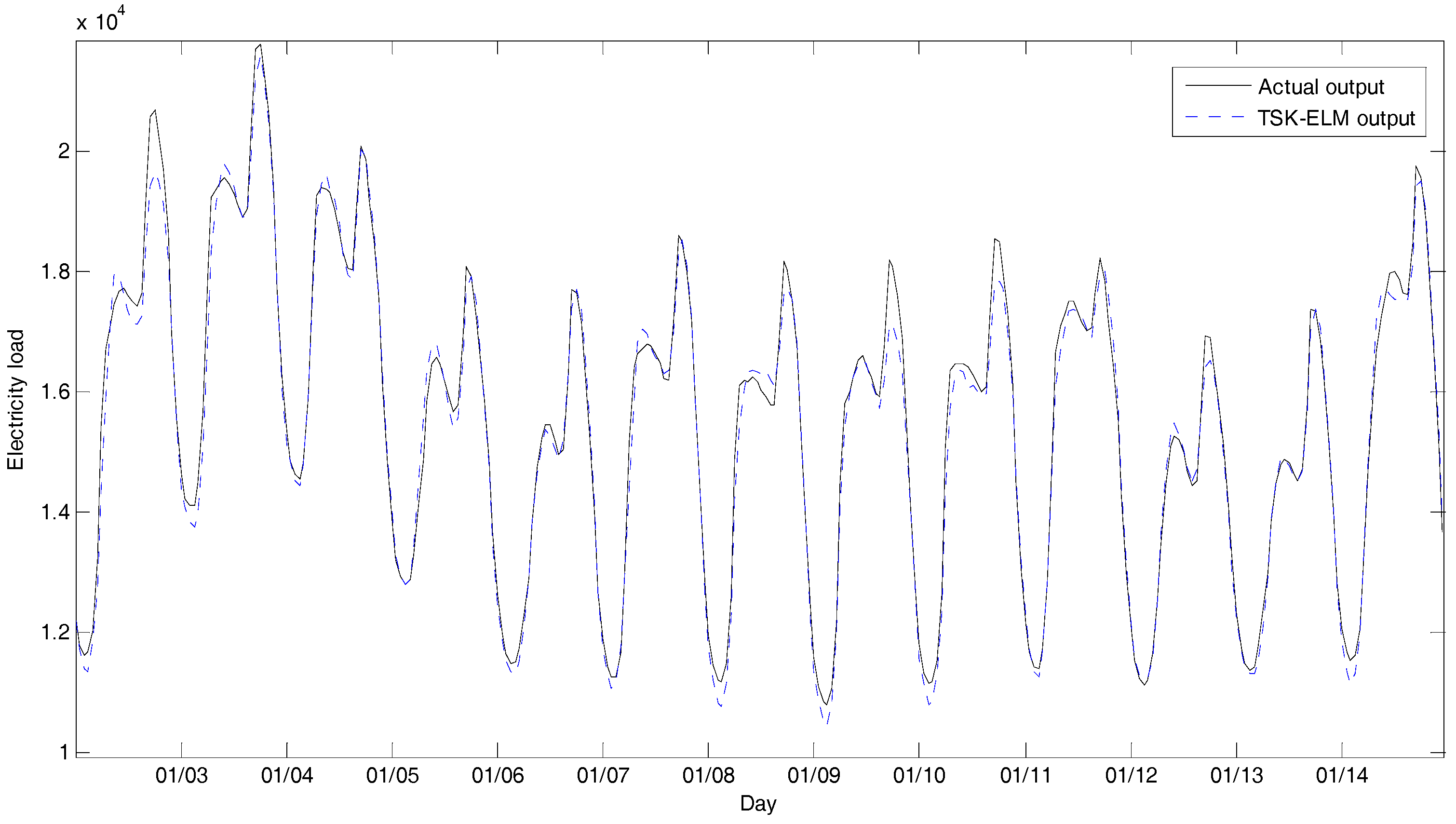
4. Experimental Results
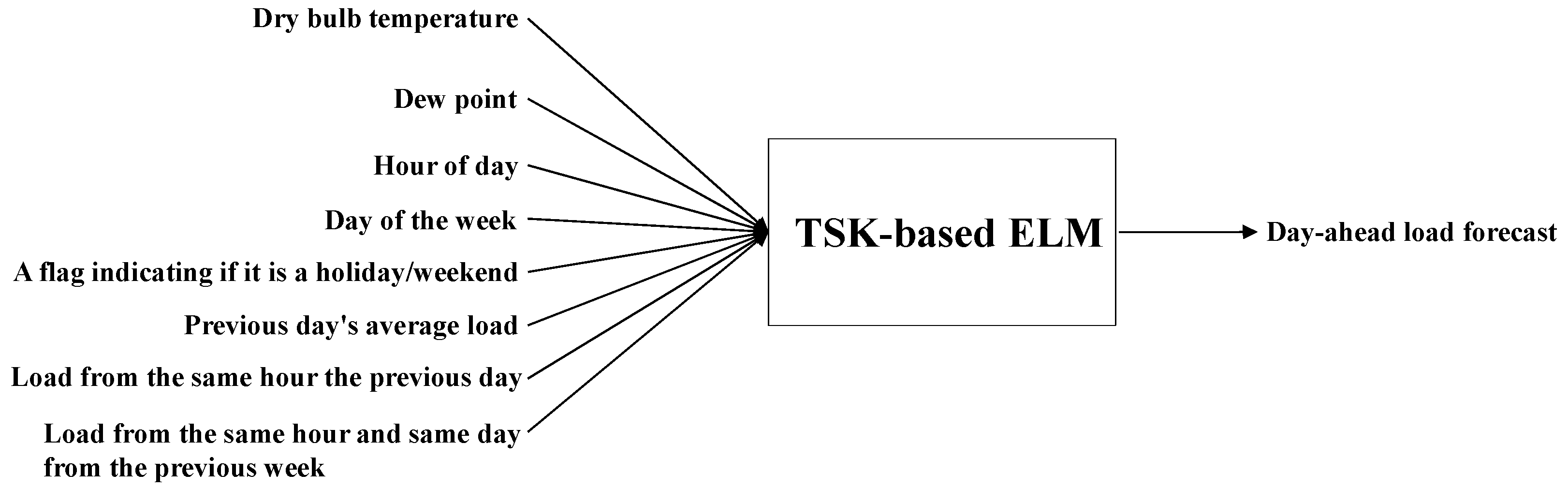
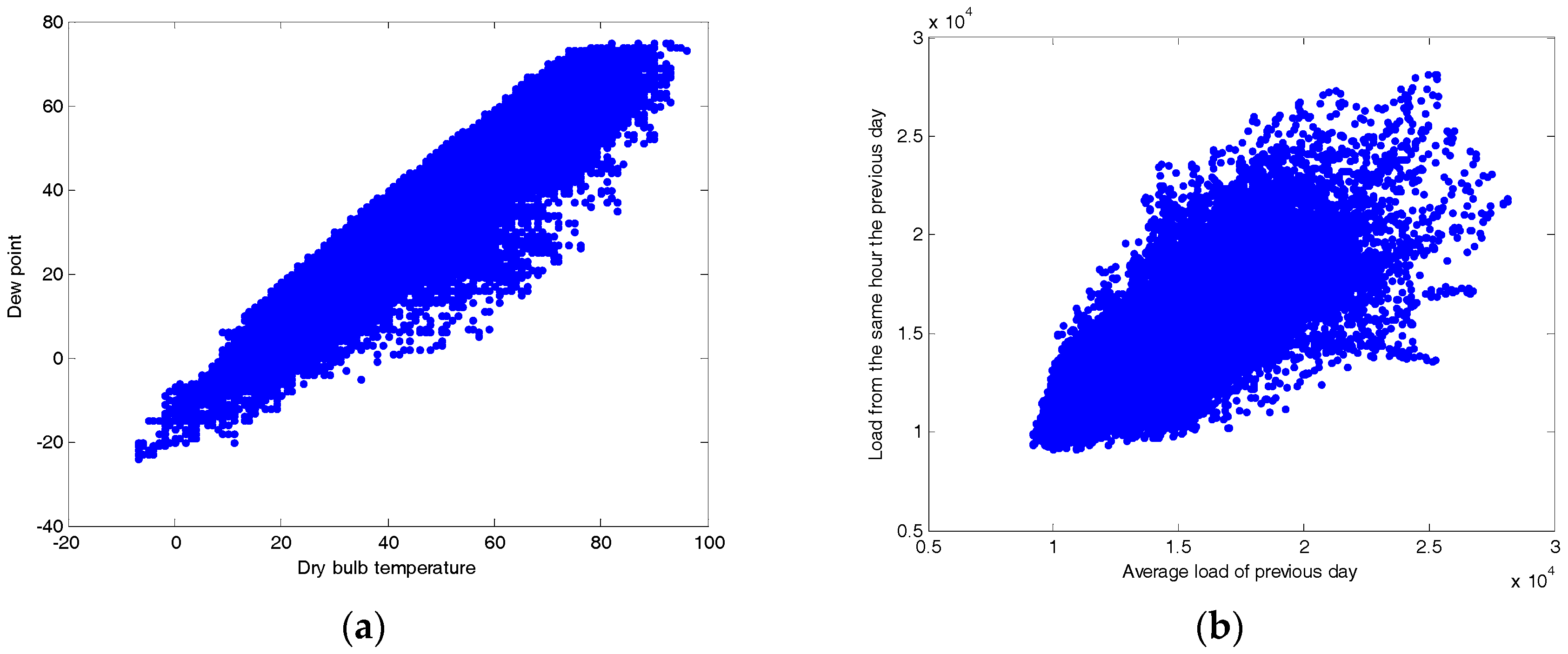
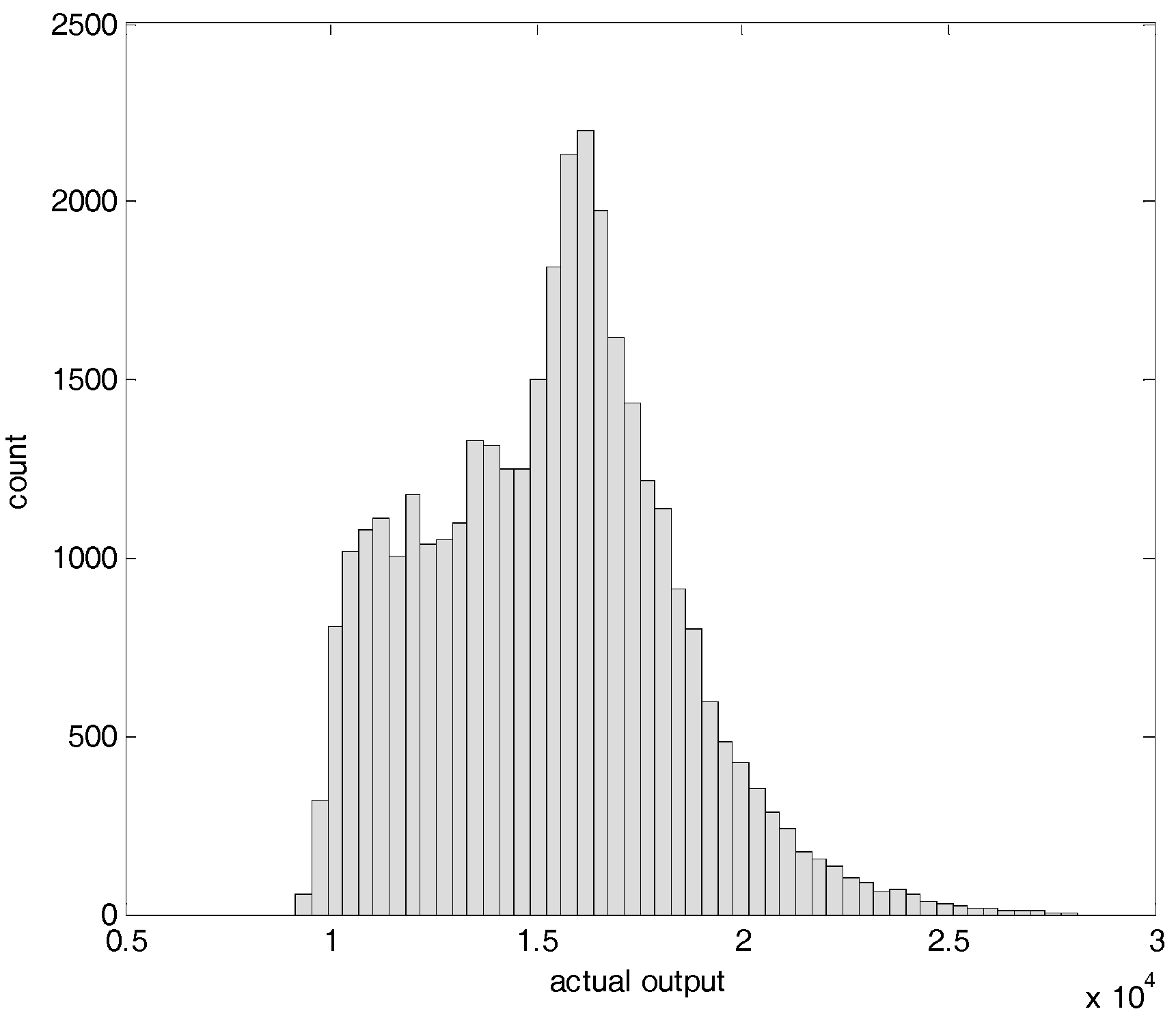
4.1. Training and Testing Data Sets
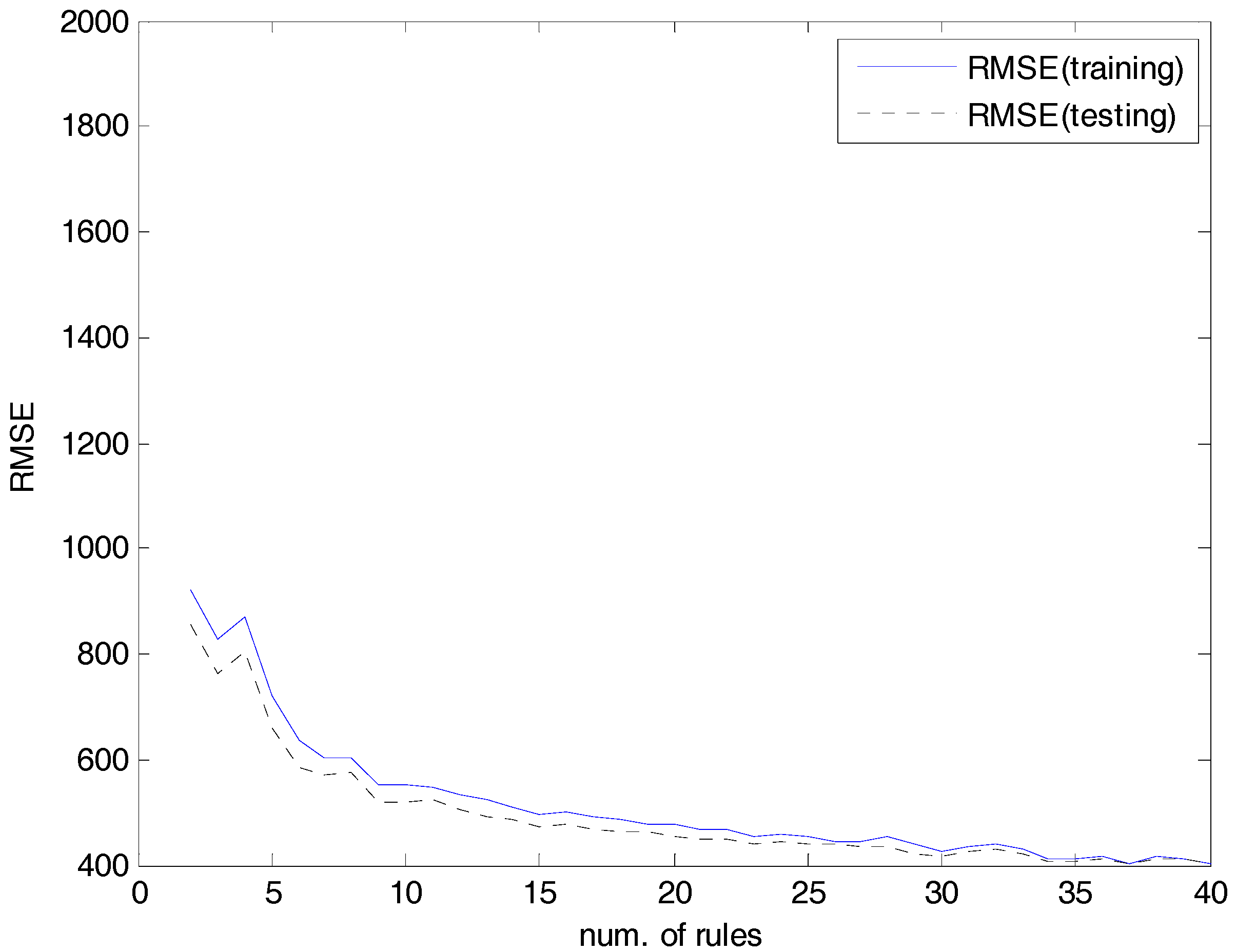
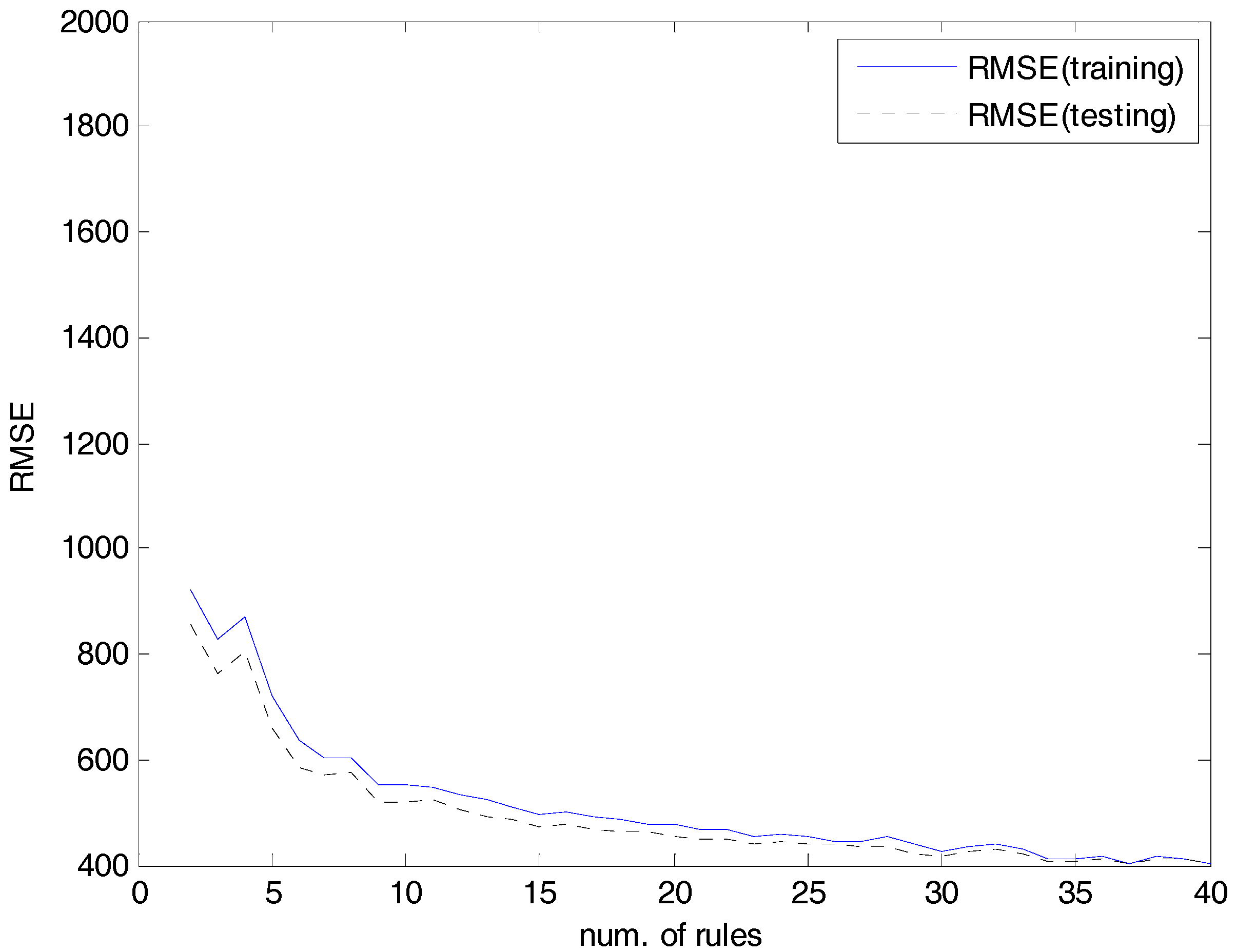
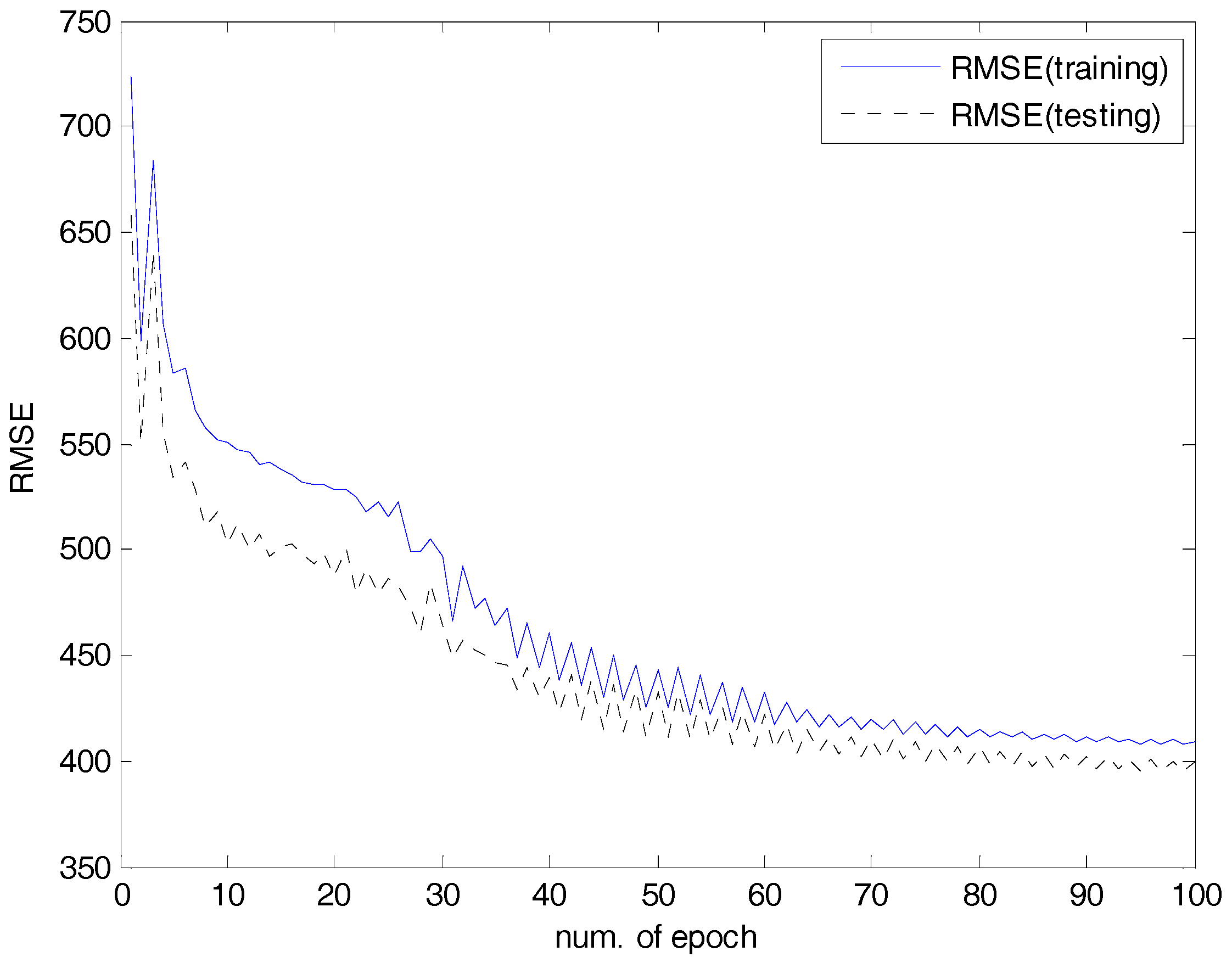
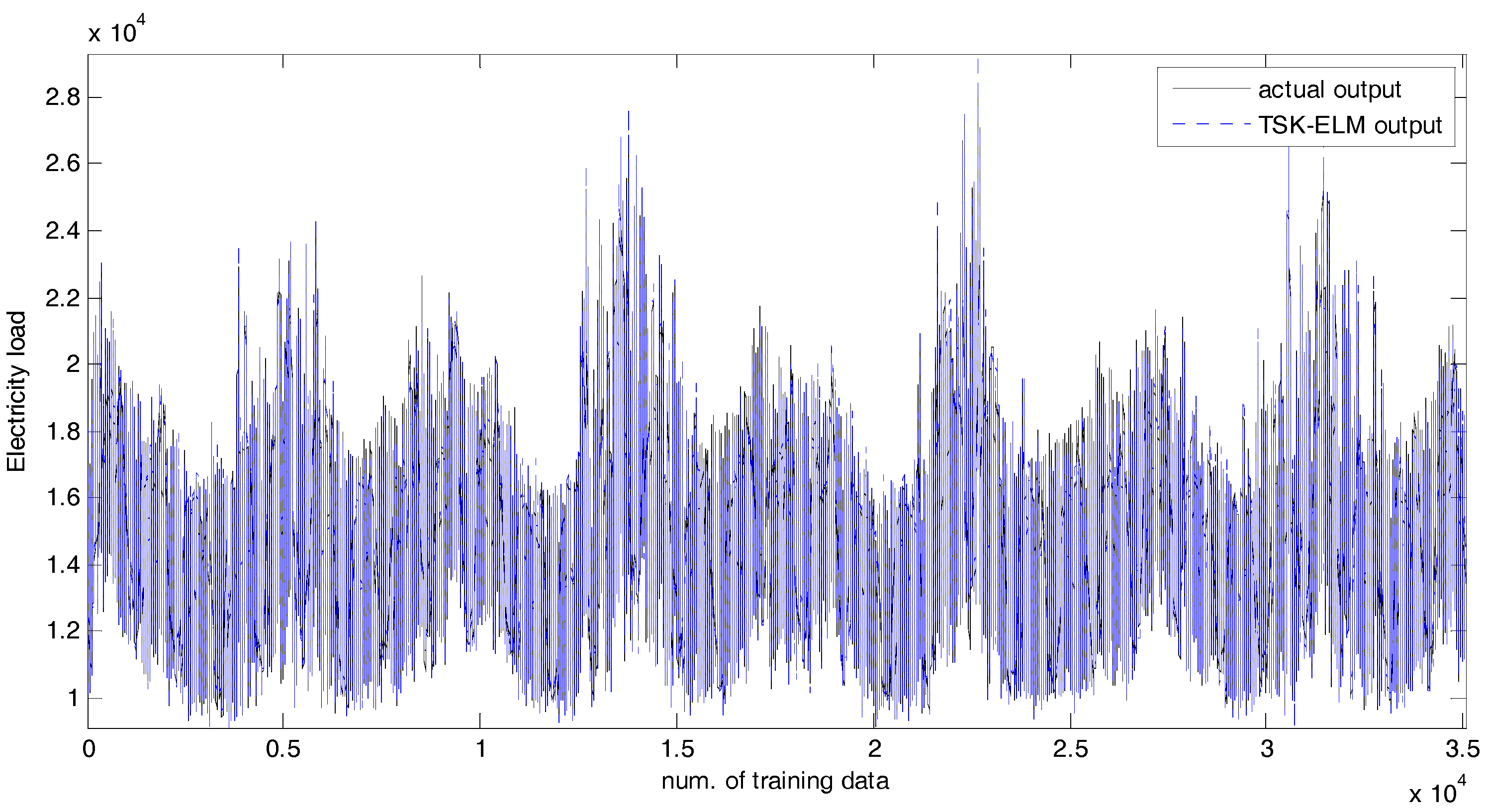
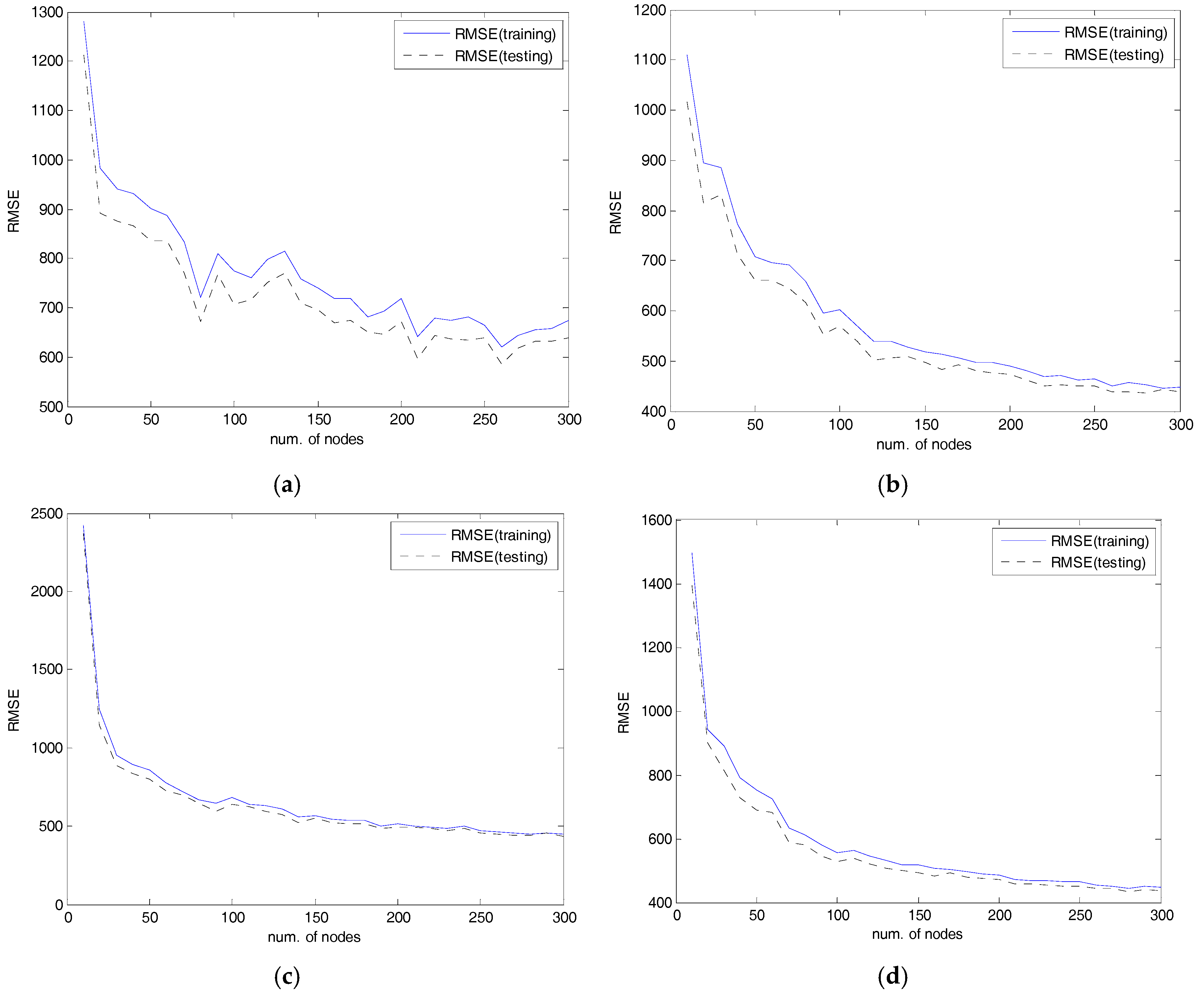
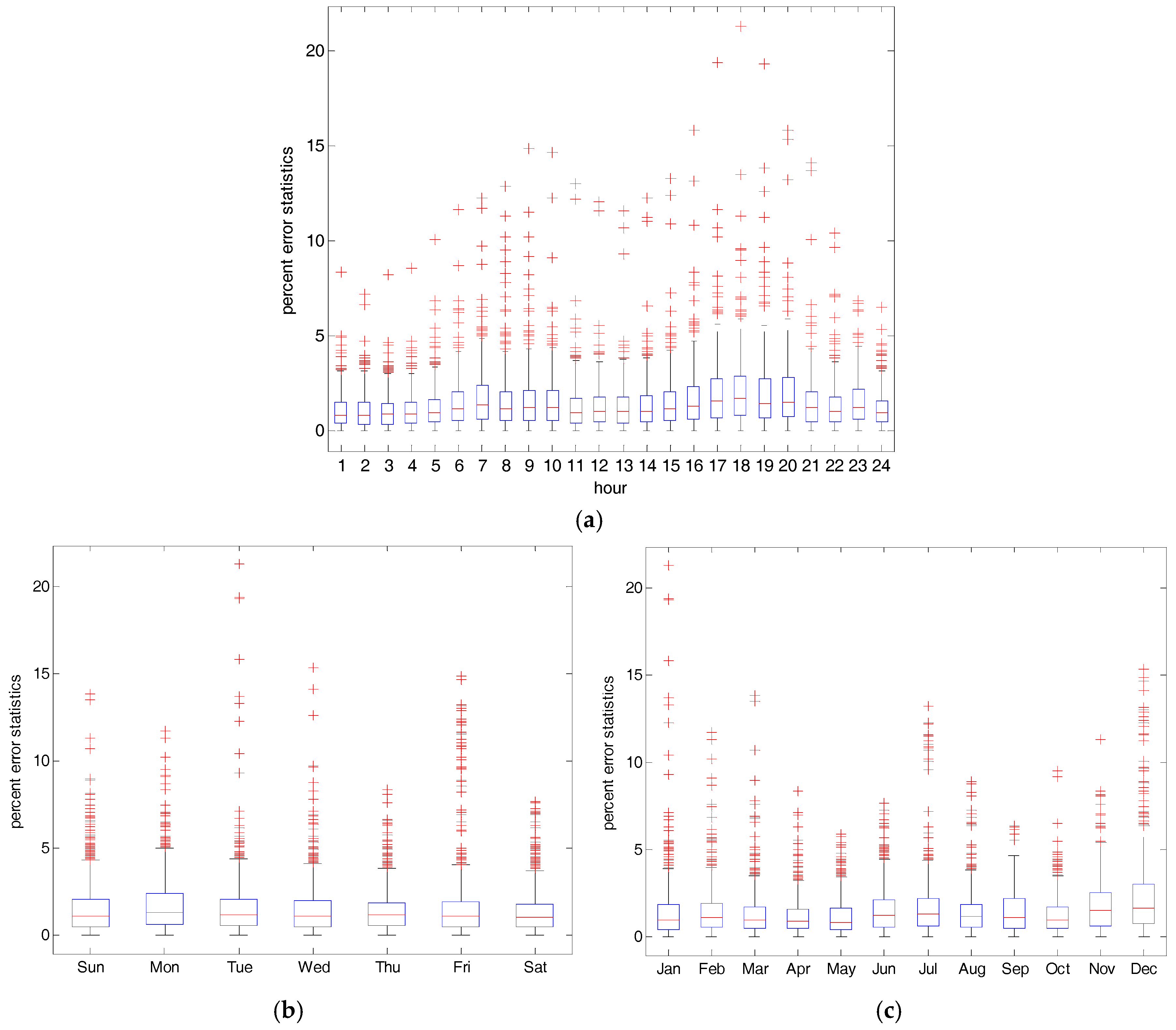
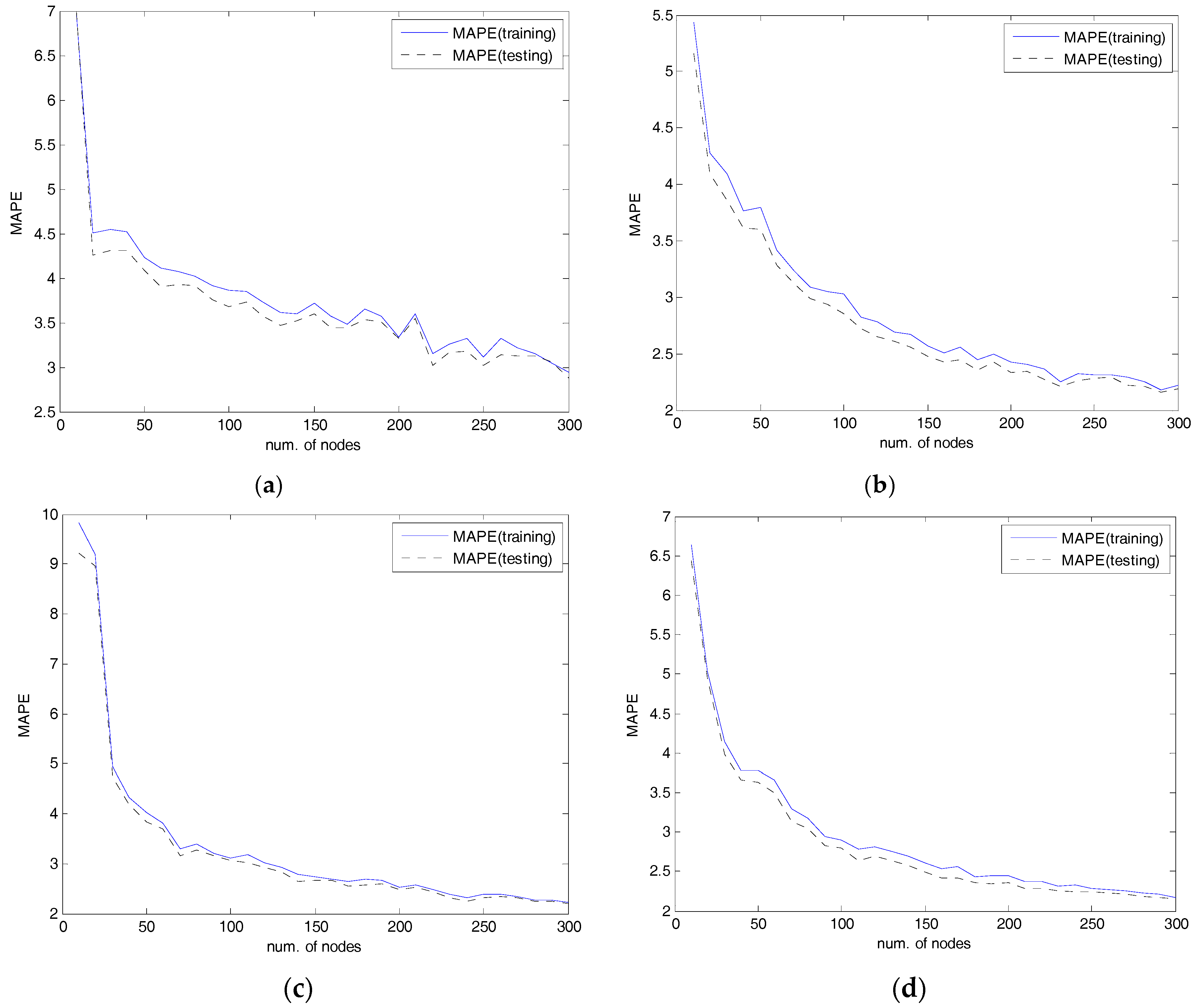
4.2. Experiments and Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kyriakides, E.; Polycarpou, M. Short Term Electric Load Forecasting: A Tutorial. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2007; pp. 391–418. [Google Scholar]
- Zhang, Y.; Yang, R.; Zhang, K.; Jiang, H.; Jason, J. Consumption behavior analytics-aided energy forecasting and dispatch. IEEE Intell. Syst. 2017, 32, 59–63. [Google Scholar] [CrossRef]
- Dong, Y.; Ma, X.; Ma, C.; Wang, J. Research and application of a hybrid forecasting model based on data decomposition for electrical load forecasting. Energies 2016, 9, 1050. [Google Scholar] [CrossRef]
- Huang, N.; Lu, G.; Xu, D. A permutation importance-based feature selection method for short-term electricity load forecasting using random forest. Energies 2016, 9, 767. [Google Scholar] [CrossRef]
- Bennett, C.; Stewart, R.A.; Lu, J. Autoregressive with exogenous variables and neural network short-term load forecast models for residential low voltage distribution networks. Energies 2014, 7, 2938–2960. [Google Scholar] [CrossRef]
- Hernandez, L.; Baladron, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J. Short-term load forecasting for microgrids based on artificial neural networks. Energies 2013, 6, 1385–1408. [Google Scholar] [CrossRef]
- Amjady, N.; Keynia, F. A new neural network approach to short term load forecasting of electrical power systems. Energies 2011, 4, 488–503. [Google Scholar] [CrossRef]
- Goude, Y.; Nedellec, R.; Kong, N. Local short and middle term electricity load forecasting with semi-parametric additive models. IEEE Trans. Smart Grid 2014, 5, 440–446. [Google Scholar] [CrossRef]
- Guo, H. Accelerated continuous conditional random fields for load forecasting. IEEE Trans. Knowl. Data Eng. 2015, 27, 2023–2033. [Google Scholar] [CrossRef]
- Yu, C.N.; Mirowski, P.; Ho, T.K. A sparse coding approach to household electricity demand forecasting in smart grids. IEEE Trans. Smart Grid 2017, 8, 738–748. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, P.; Chu, Y.; Li, W.; Wu, Y.; Ni, L.; Bao, Y.; Wang, K. Short-term electrical load forecasting using the support vector regression model to calculate the demand response baseline for office buildings. Appl. Energy 2017, 195, 659–670. [Google Scholar] [CrossRef]
- Ren, Y.; Suganthan, P.N.; Amaratunga, G. Random vector functional link network for short-term electricity load demand forecasting. Inf. Sci. 2016, 367–368, 1078–1093. [Google Scholar] [CrossRef]
- Lopez, C.; Zhong, W.; Zheng, M. Short-term electric load forecasting based on wavelet neural network, particle swarm optimization and ensemble empirical mode decomposition. Energy Procedia 2017, 105, 3677–3682. [Google Scholar] [CrossRef]
- Zhang, R.; Dong, Z.Y.; Xu, Y.; Meng, K.; Wong, K.P. Short-term load forecasting of Australian national electricity market by an ensemble model of extreme learning machine. IET Gener. Transm. Distrib. 2013, 7, 391–397. [Google Scholar] [CrossRef]
- Golestaneh, F.; Pinson, P.; Gooi, H.B. Very short-term nonparametric probabilistic forecasting of renewable energy generation-with application to solar energy. IEEE Trans. Power Syst. 2016, 31, 3850–3863. [Google Scholar] [CrossRef]
- Li, S.; Wang, P.; Goel, L. A novel wavelet-based ensemble method for short-term load forecasting with hybrid neural networks and feature selection. IEEE Trans. Power Syst. 2016, 31, 1788–1798. [Google Scholar] [CrossRef]
- Cecati, C.; Kolbusz, J.; Rozycki, P.; Siano, P.; Wilamowski, B.M. A novel RBF training algorithm for short-term electric load forecasting and comparative studies. IEEE Trans. Ind. Electron. 2015, 62, 6519–6529. [Google Scholar] [CrossRef]
- Li, S.; Wang, P.; Goel, L. Short-term load forecasting by wavelet transform and evolutionary extreme learning machine. Electr. Power Syst. Res. 2015, 122, 96–103. [Google Scholar] [CrossRef]
- Yang, Z.; Ce, L.; Lian, L. Electricity price forecasting by a hybrid model, combining wavelet transform, ARMA and kernel-based extreme learning machine methods. Appl. Energy 2017, 190, 291–305. [Google Scholar] [CrossRef]
- Li, S.; Goel, L.; Wang, P. An ensemble approach for short-term load forecasting by ELM. Appl. Energy 2016, 170, 22–29. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- ISO. New England. Available online: https://en.wikipedia.org/wiki/ISO_New_England (accessed on 13 October 2017).
- Mathworks. Available online: https://www.mathworks.com/videos/electricity-load-and-price-forecasting-with-matlab-81765.html (accessed on 13 October 2017).
- Zhang, R.; Lan, Y.; Huang, G.B.; Xu, Z.B. Universal approximation of extreme learning machine with adaptive growth of hidden nodes. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 365–371. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Bai, Z.; Kasun, L.L.C.; Vong, C.M. Local receptive fields based extreme learning machine. IEEE Comput. Intell. Mag. 2015, 10, 18–29. [Google Scholar] [CrossRef]
- Neumann, K.; Steil, J.J. Optimizing extreme learning machines via ridge regression and batch intrinsic plasticity. Neurocomputing 2013, 102, 23–30. [Google Scholar] [CrossRef]
- Deng, Z.; Choi, K.S.; Cao, L.; Wang, S. T2FELA: Type-2 fuzzy extreme learning algorithm for fast training of interval type-2 TSK fuzzy logic system. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 664–676. [Google Scholar] [CrossRef] [PubMed]
- Jang, J.S.R.; Sun, C.T.; Mizutani, E. Neuro-Fuzzy and Soft Computing: A Computational Approach to Learning and Machine Intelligence; Prentice Hall: Upper Saddle River, NJ, USA, 1997. [Google Scholar]
- Han, Y.H.; Kwak, K.C. A design of an improved linguistic model based on information granules. J. Inst. Electron. Inf. Eng. 2010, 47, 76–82. [Google Scholar]
- Pedrycz, W. Conditional fuzzy clustering in the design of radial basis function neural networks. IEEE Trans. Neural Netw. 1998, 9, 601–612. [Google Scholar] [CrossRef] [PubMed]
- Lee, M.W.; Kwak, K.C. A design of incremental granular networks for human-centric system and computing. J. Korean Inst. Inf. Technol. 2012, 10, 137–142. [Google Scholar]
- Kwak, K.C.; Kim, S.S. Development of quantum-based adaptive neuro-fuzzy networks. IEEE Trans. Syst. Man. Cybern. Part B 2010, 40, 91–100. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C. Time Series Analysis: Forecasting and Control, 4th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Han, J.S.; Kwak, K.C. Image classification using convolutional neural network and extreme learning machine classifier based on ReLU function. J. Korean Inst. Inf. Technol. 2017, 15, 15–23. [Google Scholar]
- Pal, S.; Sharma, A.K. Short-term load forecasting using adaptive neuro-fuzzy inference system. Int. J. Novel Res Electr. Mech. Eng. 2015, 2, 65–71. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
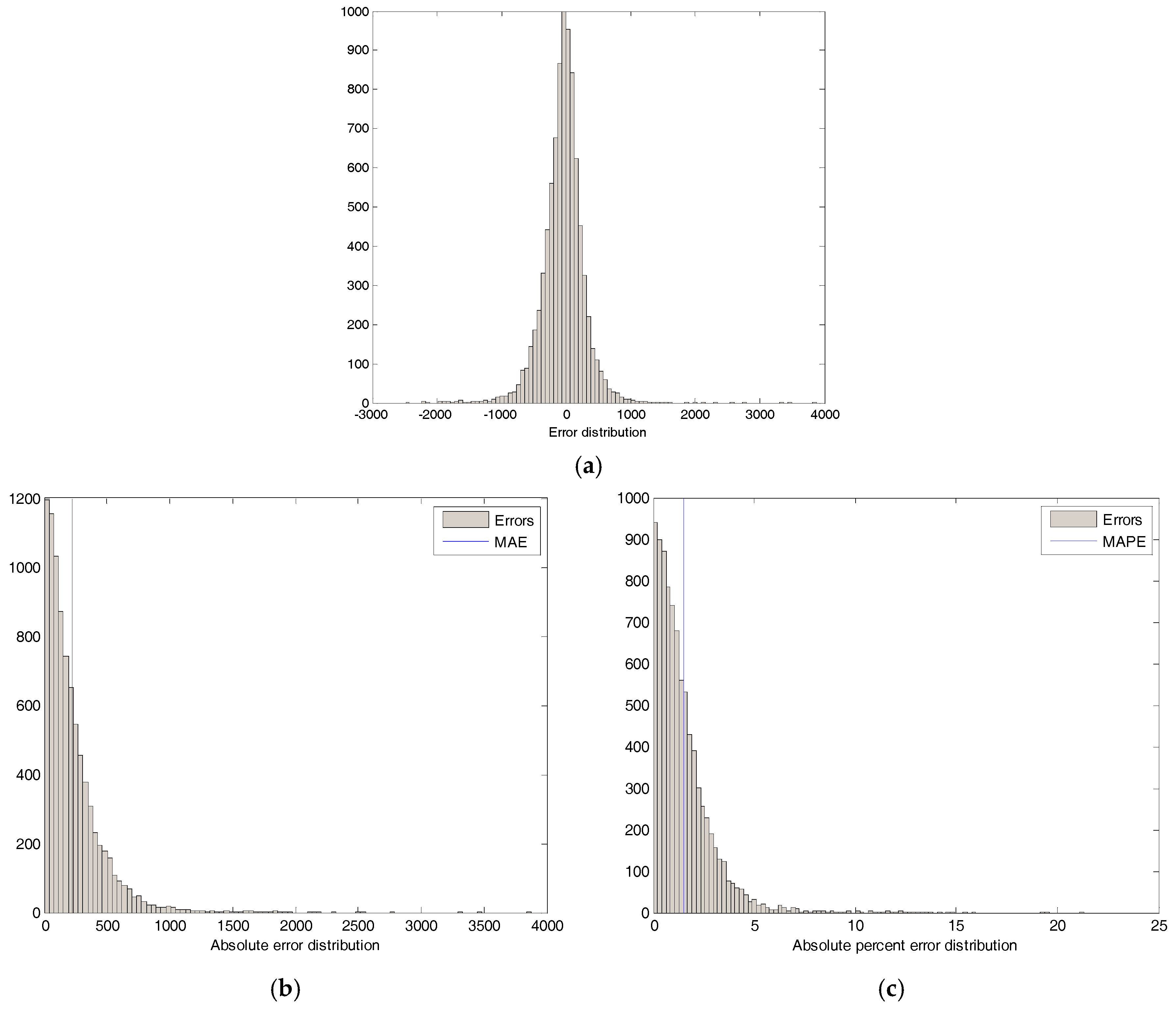{kind=link}
| Method | No. of Node | RMSE (Training) | RMSE (Testing) |
|---|---|---|---|
| LR [33] | - | 1044.5 | 928.98 |
| RBFN(CFCM) [30] | 100 | 983.64 | 926.43 |
| LM [29] | 100 * | 1005.61 | 980.59 |
| IRBFN [31] | 450 | 647.10 | 450.60 |
| ELM (ReLU) [34] | 260 | 620.35 | 586.11 |
| ELM (Sigmoid) [21] | 270 | 451.56 | 438.52 |
| ELM (RBF) [21] | 300 | 449.88 | 433.99 |
| ELM (sin) [21] | 270 | 443.16 | 435.07 |
| TSK-ELM (FCM) | 36 * | 468.79 | 450.60 |
| TSK-ELM(SC) | 36 * | 487.38 | 478.79 |
| TSK-ELM (without learning) | 36 * | 402. 89 | 400.86 |
| TSK-ELM (with learning) | 5 * | 409.31 | 398.58 |
| 10 * | 359.24 | 349.61 | |
| 36 * | 292.93 | 331.16 |
| Method | No. of Node | MAPE(%)-Training | MAPE(%)-Testing |
|---|---|---|---|
| ELM (ReLU) [34] | 300 | 2.94 | 2.87 |
| ELM (Sig) [21] | 290 | 2.18 | 2.15 |
| ELM (RBF) [21] | 300 | 2.23 | 2.19 |
| ELM (sin) [21] | 300 | 2.16 | 2.14 |
| ANFIS [35] | 36 * | 3.32 | 3.27 |
| TSK-ELM (without learning) | 36 * | 2.01 | 1.99 |
| TSK-ELM (with learning) | 5 * | 1.96 | 1.95 |
| 10 * | 1.72 | 1.70 | |
| 36 * | 1.38 | 1.49 |
| Method | No. of Node | MAE(MWh)-Training | MAE (MWh)-Testing |
|---|---|---|---|
| ELM (ReLU) [34] | 300 | 445.54 | 427.08 |
| ELM (Sig) [21] | 290 | 331.06 | 320.69 |
| ELM (RBF) [21] | 300 | 338.91 | 326.21 |
| ELM (sin) [21] | 300 | 328.71 | 319.18 |
| ANFIS [35] | 36 * | 500.84 | 483.11 |
| TSK-ELM (without learning) | 36 * | 306.62 | 298.21 |
| TSK-ELM (with learning) | 5 * | 300.53 | 292.14 |
| 10 * | 264.65 | 257.19 | |
| 36 * | 213.72 | 227.48 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeom, C.-U.; Kwak, K.-C. Short-Term Electricity-Load Forecasting Using a TSK-Based Extreme Learning Machine with Knowledge Representation. Energies 2017, 10, 1613. https://doi.org/10.3390/en10101613
Yeom C-U, Kwak K-C. Short-Term Electricity-Load Forecasting Using a TSK-Based Extreme Learning Machine with Knowledge Representation. Energies. 2017; 10(10):1613. https://doi.org/10.3390/en10101613
Chicago/Turabian StyleYeom, Chan-Uk, and Keun-Chang Kwak. 2017. "Short-Term Electricity-Load Forecasting Using a TSK-Based Extreme Learning Machine with Knowledge Representation" Energies 10, no. 10: 1613. https://doi.org/10.3390/en10101613
APA StyleYeom, C.-U., & Kwak, K.-C. (2017). Short-Term Electricity-Load Forecasting Using a TSK-Based Extreme Learning Machine with Knowledge Representation. Energies, 10(10), 1613. https://doi.org/10.3390/en10101613