
Spatial and Spatio-Temporal Models for Modeling Epidemiological Data with Excess Zeros

Abstract
:1. Introduction
2. Models for Data with Excess Zeros
2.1. Hurdle Models
2.2. Zero-Inflated Models
2.3. Model Choice between a Hurdle Model and a Zero-Inflated Model
2.4. Spatial and Spatio-Temporal Models with Excess Zeros
2.5. Software Tools and Implementation
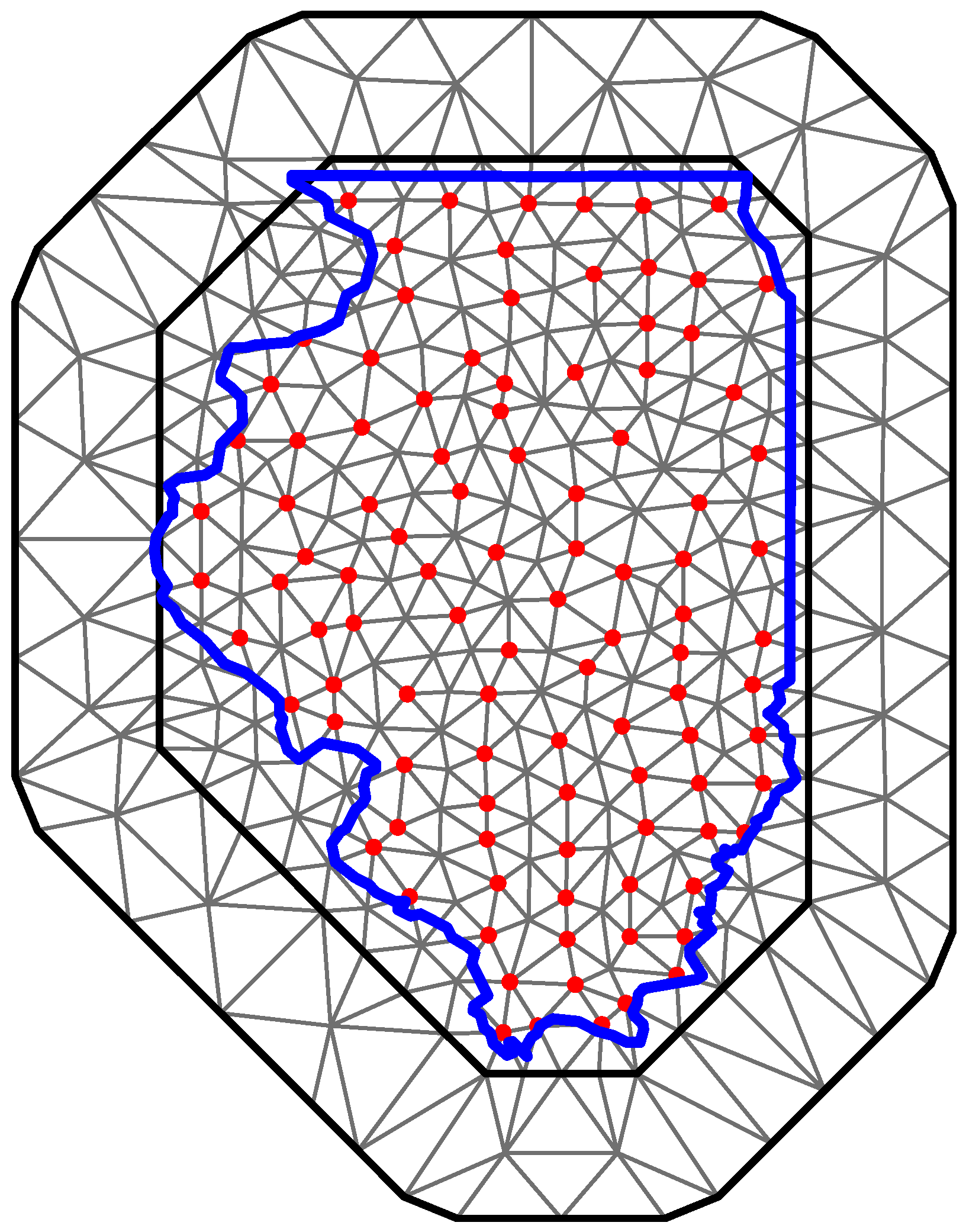
3. Case Study: Lyme disease in Illinois
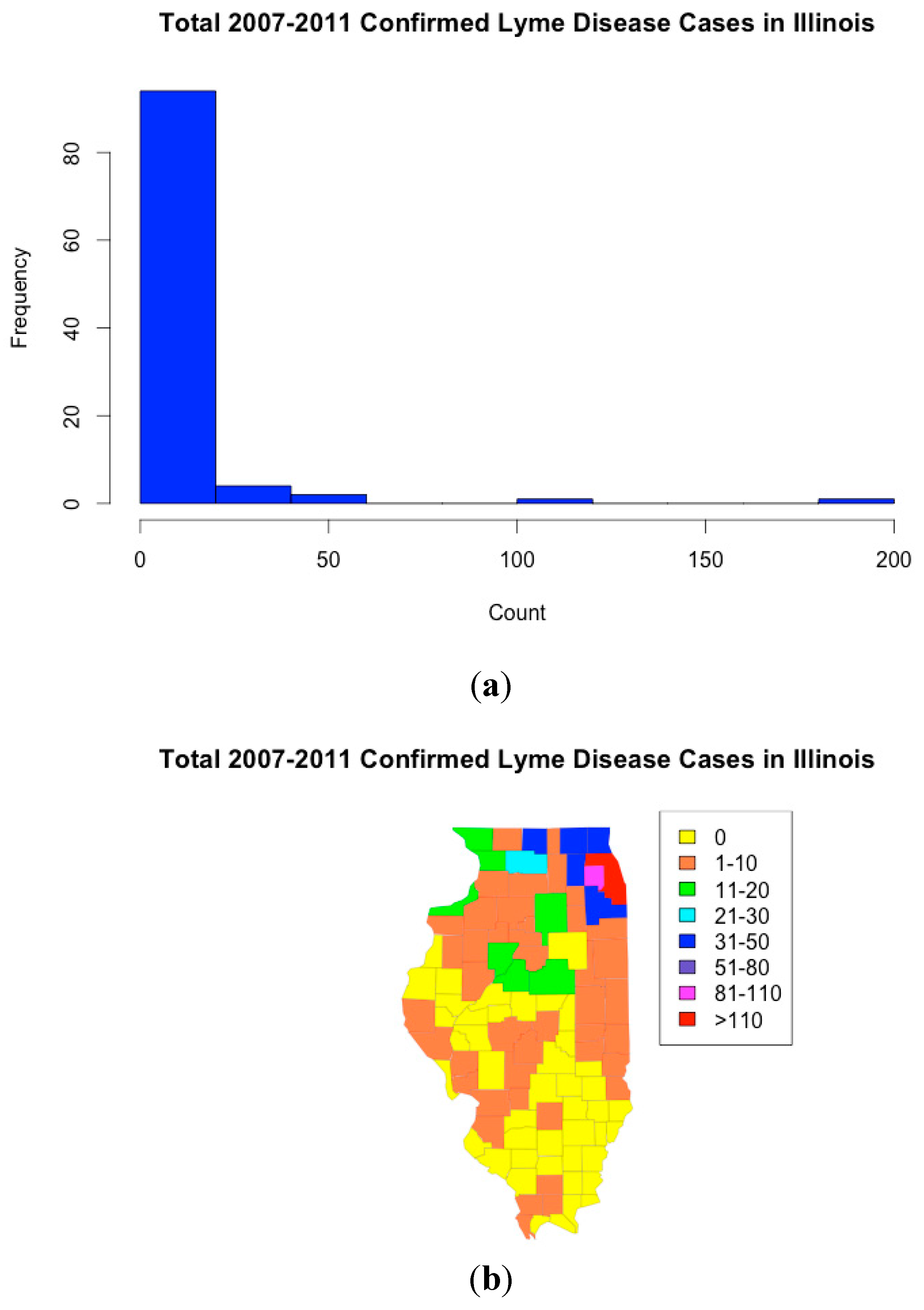

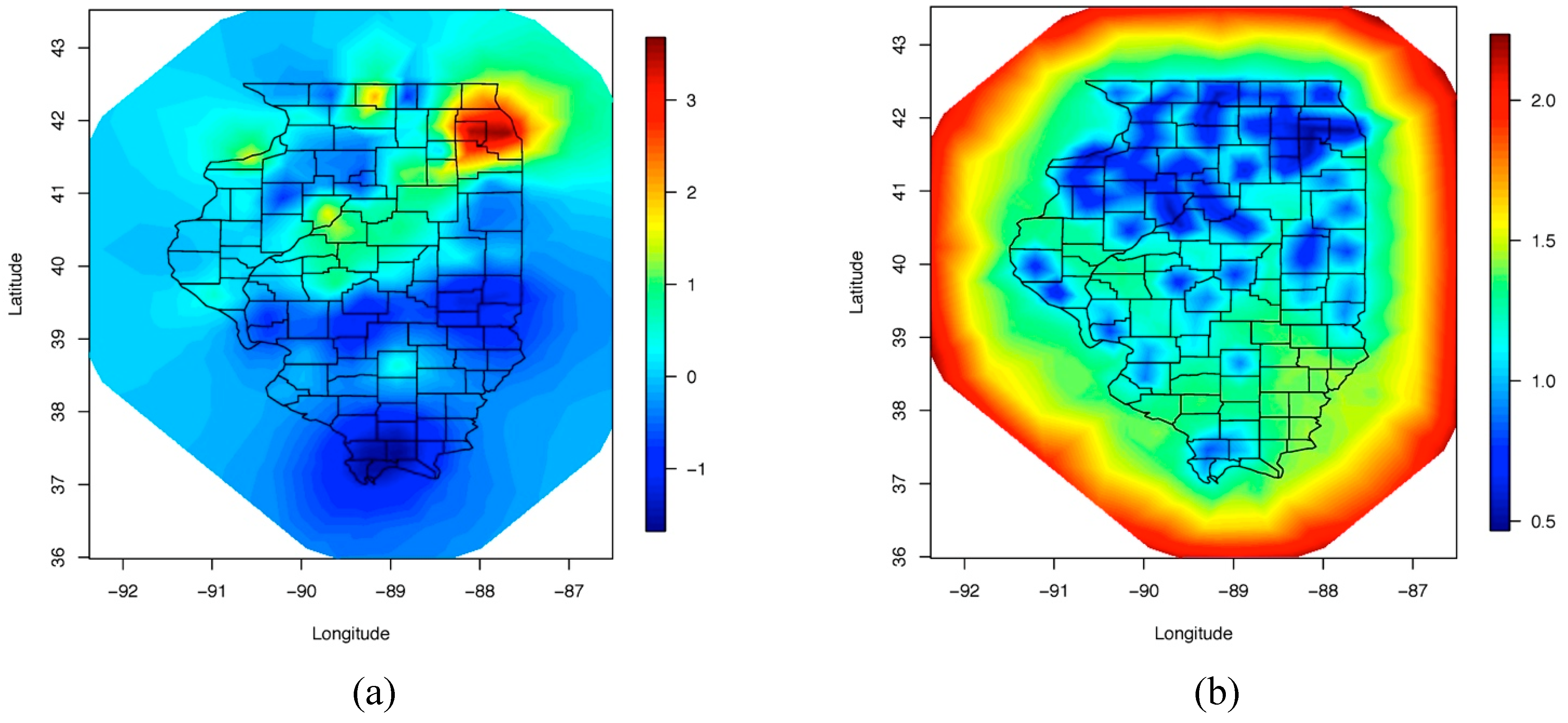
4. Results and Discussion

{kind=link}
{kind=link}
{kind=link}
| Model | DIC | Effective p |
|---|---|---|
| Spatial Poisson Hurdle | 404 | 42.94 |
| Spatial Zero-Inflated Poisson | 360 | 48.54 |
| Spatial Poisson Hurdle with Probability Model | 380 | 44.84 |
| Spatial Negative Binomial Hurdle | 459 | 11.85 |
| Spatial Zero-Inflated Negative Binomial | 420 | 11.53 |
| Spatial Neg. Bin. Hurdle with Probability Model | 435 | 13.84 |
| Coefficient | Mean | Standard Deviation | 95% CI |
|---|---|---|---|
| Truncated Poisson | |||
| Intercept | −3.2931 | 1.6830 | (−6.6478, −0.0008) |
| Elevation | 0.0051 | 0.0019 | (0.0014, 0.0089) |
| Population per square mile | −0.0007 | 0.0056 | (−0.0120, 0.0102) |
| Zero-Inflation Probability | |||
| Intercept | 7.4643 | 1.8093 | (4.1338, 11.2494) |
| Elevation | −0.0097 | 0.0022 | (−0.0143, −0.0056) |
| Population per square mile | −0.0025 | 0.0086 | (−0.0196, 0.0143) |
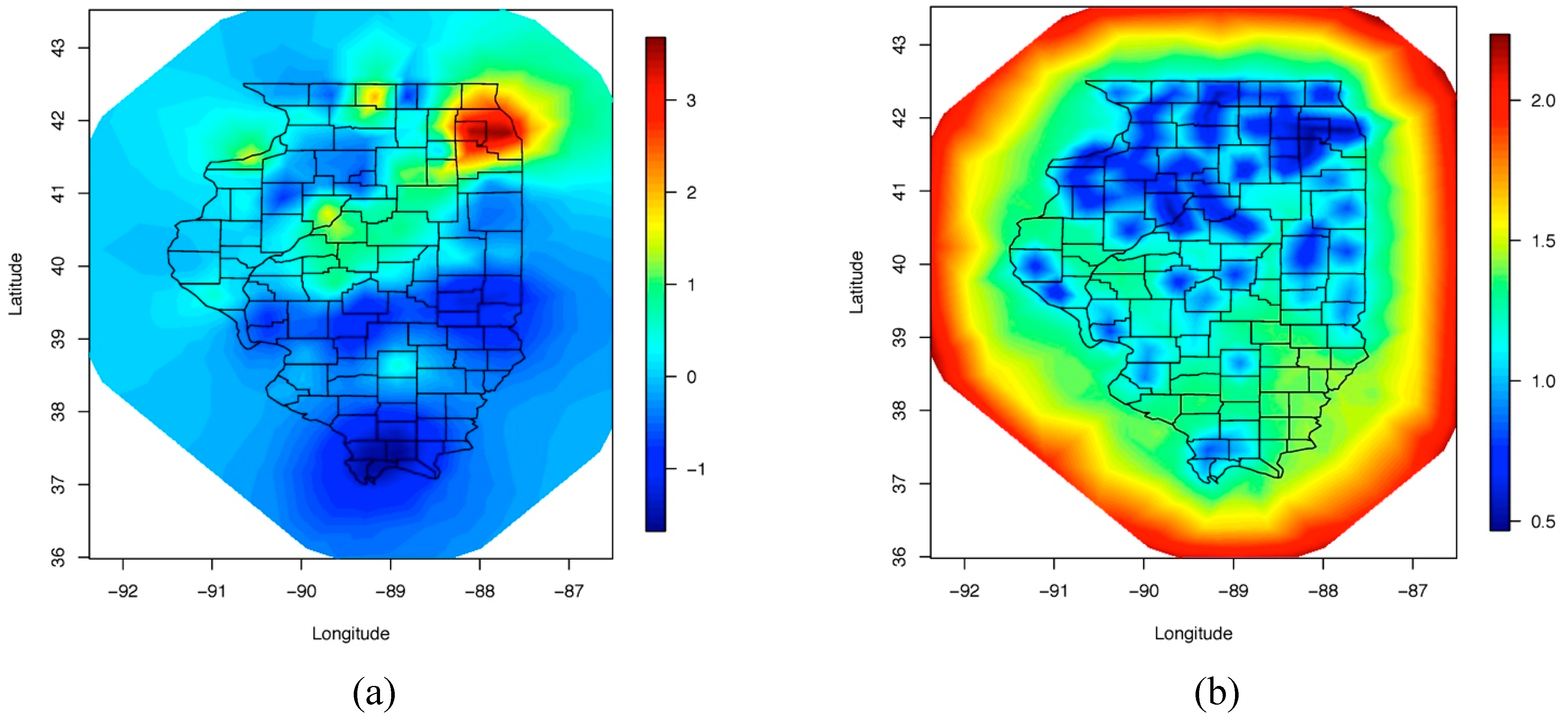
5. Conclusions
Supplementary Files
Supplementary File 1Conflicts of Interest
References
- Lawson, A.B. Statistical Methods in Spatial Epidemiology; John Wiley & Sons: West Sussex, UK, 2013. [Google Scholar]
- Cohen, A. Estimation in mixtures of discrete distributions. In Proceedings of the International Symposium on Discrete Distributions, Montreal, QC, Canada; Pergamon Press: New York, NY, USA, 1963; pp. 373–378. [Google Scholar]
- Lambert, D. Zero-inflated Poisson regression with an application to defects in manufacturing. Technometrics 1992, 34, 1–14. [Google Scholar]
- Hilbe, J.M. Modeling Count Data; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar]
- Cragg, J.G. Some statistical models for limited dependent variables with application to the demand for durable goods. Econometrica 1971, 39, 829–844. [Google Scholar] [CrossRef]
- Mullahy, J. Specification and testing of some modified count data models. J. Econom. 1986, 33, 341–365. [Google Scholar] [CrossRef]
- Cameron, A.C.; Trivedi, P.K. Regression Analysis of Count Data; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Elliott, P.; Wartenberg, D. Spatial epidemiology: Current approaches and future challenges. Environ. Health Perspect. 2004, 112, 998–1006. [Google Scholar] [CrossRef] [PubMed]
- Berliner, L.M. Hierarchical Bayesian time series models. In Maximum Entropy and Bayesian Methods; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1996; pp. 15–22. [Google Scholar]
- Arab, A.; Hooten, M.B.; Wikle, C.K. Hierarchical spatial models. In Encyclopedia of GIS; Springer Science & Business Media: New York, NY, USA, 2008; pp. 425–431. [Google Scholar]
- Cressie, N.; Wikle, C.K. Statistics for Spatio-temporal Data; John Wiley & Sons: New Jersey, NJ, USA, 2011. [Google Scholar]
- Banerjee, S.; Carlin, B.P.; Gelfand, A.E. Hierarchical Modeling and Analysis for Spatial Data, 2nd ed.; CRC Press: Florida, FL, USA, 2015. [Google Scholar]
- Wikle, C.K.; Anderson, C.J. Climatological analysis of tornado report counts using a hierarchical Bayesian spatiotemporal model. J. Geophys. Res. Atmos. 2003, 108. [Google Scholar] [CrossRef]
- Agarwal, D.K.; Gelfand, A.E.; Citron-Pousty, S. Zero-inflated models with application to spatial count data. Environ. Ecol. Stat. 2002, 9, 341–355. [Google Scholar] [CrossRef]
- Neelon, B.; Gosh, P.; Loebs, P. A spatial Poisson hurdle model for exploring geographic variation in emergency department visits. J. Roy. Stat. Soc. A 2013, 176, 389–413. [Google Scholar] [CrossRef] [PubMed]
- Oleson, J.J.; Wikle, C.K. Predicting infectious disease outbreak risk via migratory waterfowl vectors. J. Appl. Stat. 2013, 40, 656–673. [Google Scholar] [CrossRef]
- Amek, N.; Bayoh, N.; Hamel, M.; Lindblade, K.A.; Gimnig, J.; Laserson, K.F.; Slutsker, L.; Smith, T.; Vounatsou, P. Spatio-temporal modeling of sparse geostatistical malaria sporozoite rate data using a zero inflated binomial model. Spat. Spatiotemporal Epidemiol. 2011, 2, 283–290. [Google Scholar] [CrossRef] [PubMed]
- Musenge, E.; Chirwa, T.F.; Kahn, K.; Vounatsou, P. Bayesian analysis of zero inflated spatiotemporal HIV/TB child mortality data through the INLA and SPDE approaches: Applied to data observed between 1992 and 2010 in rural North East South Africa. Int. J. Appl. Earth Obs. 2013, 22, 86–98. [Google Scholar] [CrossRef] [PubMed]
- Cressie, N. Statistics for Spatial Data: Wiley Series in Probability and Statistics; John Wiley & Sons: New Jersey, NJ, USA, 1993. [Google Scholar]
- Arab, A.; Holan, S.H.; Wikle, C.K.; Wildhaber, M.L. Semiparametric bivariate zero-inflated Poisson models with application to studies of abundance for multiple species. Environmetrics 2012, 23, 183–196. [Google Scholar] [CrossRef]
- Rue, H.; Martino, S.; Chopin, N. Approximate Bayesian inference for latent Gaussian models by using integratednested Laplace approximations. J. Roy. Stat. Soc. B 2009, 71, 319–392. [Google Scholar] [CrossRef]
- Blangiardo, M.; Cameletti, M.; Baio, G.; Rue, H. Spatial and spatio-temporal models with R-INLA. Spat. Spatiotemporal Epidemiol. 2013, 7, 39–55. [Google Scholar] [CrossRef] [PubMed]
- Quiroz, Z.C.; Prates, M.O.; Rue, H. A Bayesian approach to estimate the biomass of anchovies off the coast of Perú. Biometrics 2015, 71, 208–217. [Google Scholar] [CrossRef] [PubMed]
- Spiegelhalter, D.; Best, N.; Carlin, B.; Van Der Linde, A. Bayesian measures of model complexity and fit. J. Roy. Stat. Soc. B 2002, 64, 583–639. [Google Scholar] [CrossRef]
- Radolf, J.D.; Caimano, M.J.; Stevenson, B.; Hu, L.T. Of ticks, mice and men: understanding the dual-host lifestyle of Lyme disease spirochaetes. Nat. Rev. Microbial. 2012, 10, 87–99. [Google Scholar] [CrossRef] [PubMed]
- Mead, P.S. Epidemiology of Lyme disease. Infect. Dis. Clin. North Am. 2015, 29, 187–210. [Google Scholar] [CrossRef] [PubMed]
- Center for Disease Control and Prevention: Reported Cases of Lyme Disease by State or Locality, 2004–2013. Available online: http://www.cdc.gov/lyme/stats/chartstables/reportedcases_statelocality.html (accessed on 20 June 2015).
- Tran, P.; Waller, L. Variability in results from negative binomial models for lyme disease measured at different spatial scales. Environ. Res. 2015, 136, 373–380. [Google Scholar] [CrossRef] [PubMed]
- Lindgren, F.; Rue, H. Bayesian Spatial and Spatiotemporal Modelling with R-INLA. Available online: http://inla.googlecode.com/hg-history/5cba347753615e2bfdab62141acd4d6e858136bd/r-inla.org/papers/jss/lindgren.pdf (accessed on 4 July 2015).
- Diuk-Wasser, M.A.; Hoen, A.G.; Cislo, P.; Brinkerhoff, R.; Hamer, S.A.; Rowland, M.; Cortinas, R.; Vourc’h, G.; Melton, F.; Hickling, G.J.; et al. Human risk of infection with Borrelia burgdorferi, the Lyme disease agent, in Eastern United States. Am. J. Trop. Med. Hyg. 2012, 86, 320–327. [Google Scholar] [CrossRef] [PubMed]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arab, A. Spatial and Spatio-Temporal Models for Modeling Epidemiological Data with Excess Zeros. Int. J. Environ. Res. Public Health 2015, 12, 10536-10548. https://doi.org/10.3390/ijerph120910536
Arab A. Spatial and Spatio-Temporal Models for Modeling Epidemiological Data with Excess Zeros. International Journal of Environmental Research and Public Health. 2015; 12(9):10536-10548. https://doi.org/10.3390/ijerph120910536
Chicago/Turabian StyleArab, Ali. 2015. "Spatial and Spatio-Temporal Models for Modeling Epidemiological Data with Excess Zeros" International Journal of Environmental Research and Public Health 12, no. 9: 10536-10548. https://doi.org/10.3390/ijerph120910536