
Localization-Free Detection of Replica Node Attacks in Wireless Sensor Networks Using Similarity Estimation with Group Deployment Knowledge

Abstract
:1. Introduction
2. Related Works
3. Preliminaries
3.1. Network Assumptions
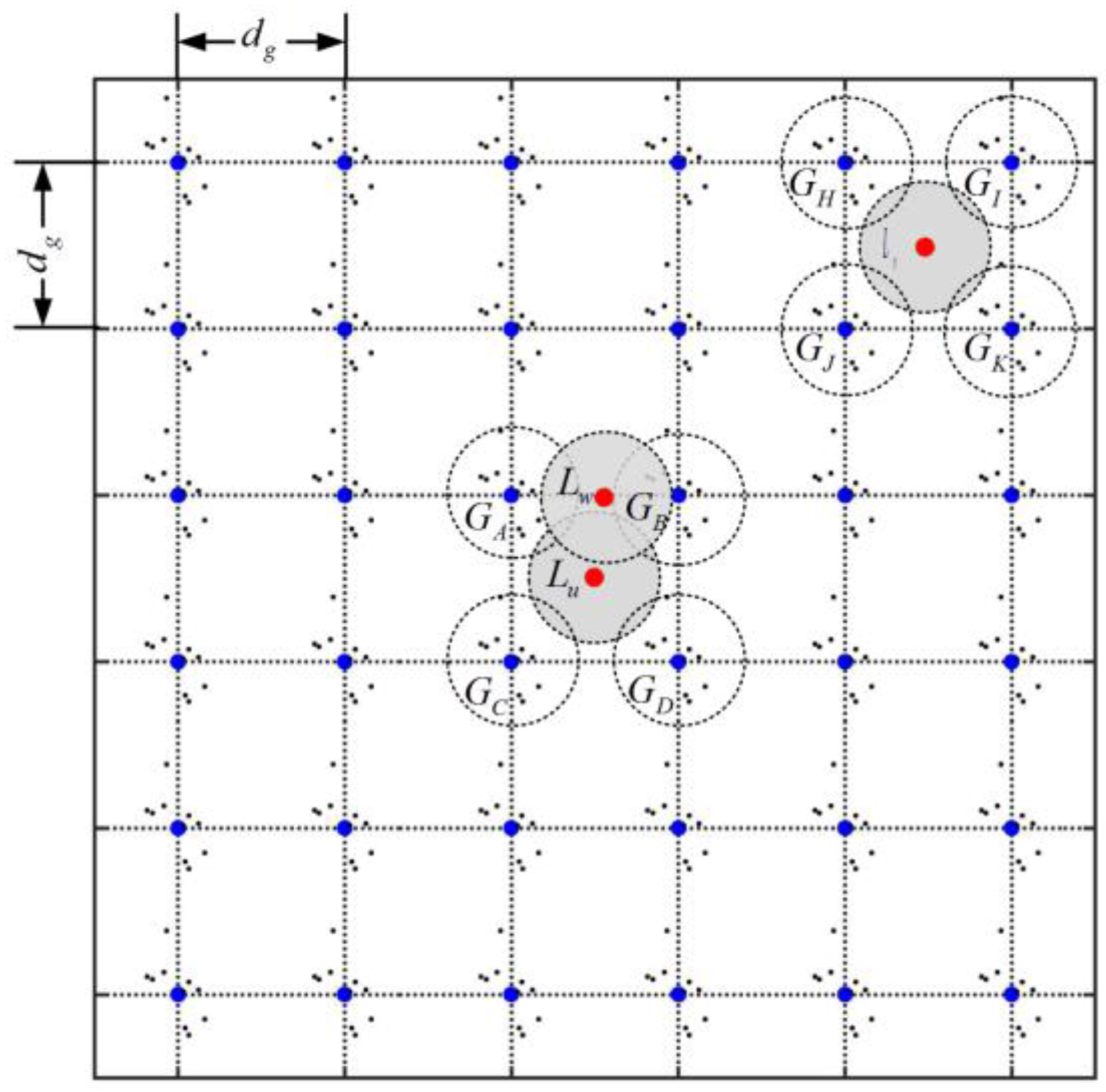
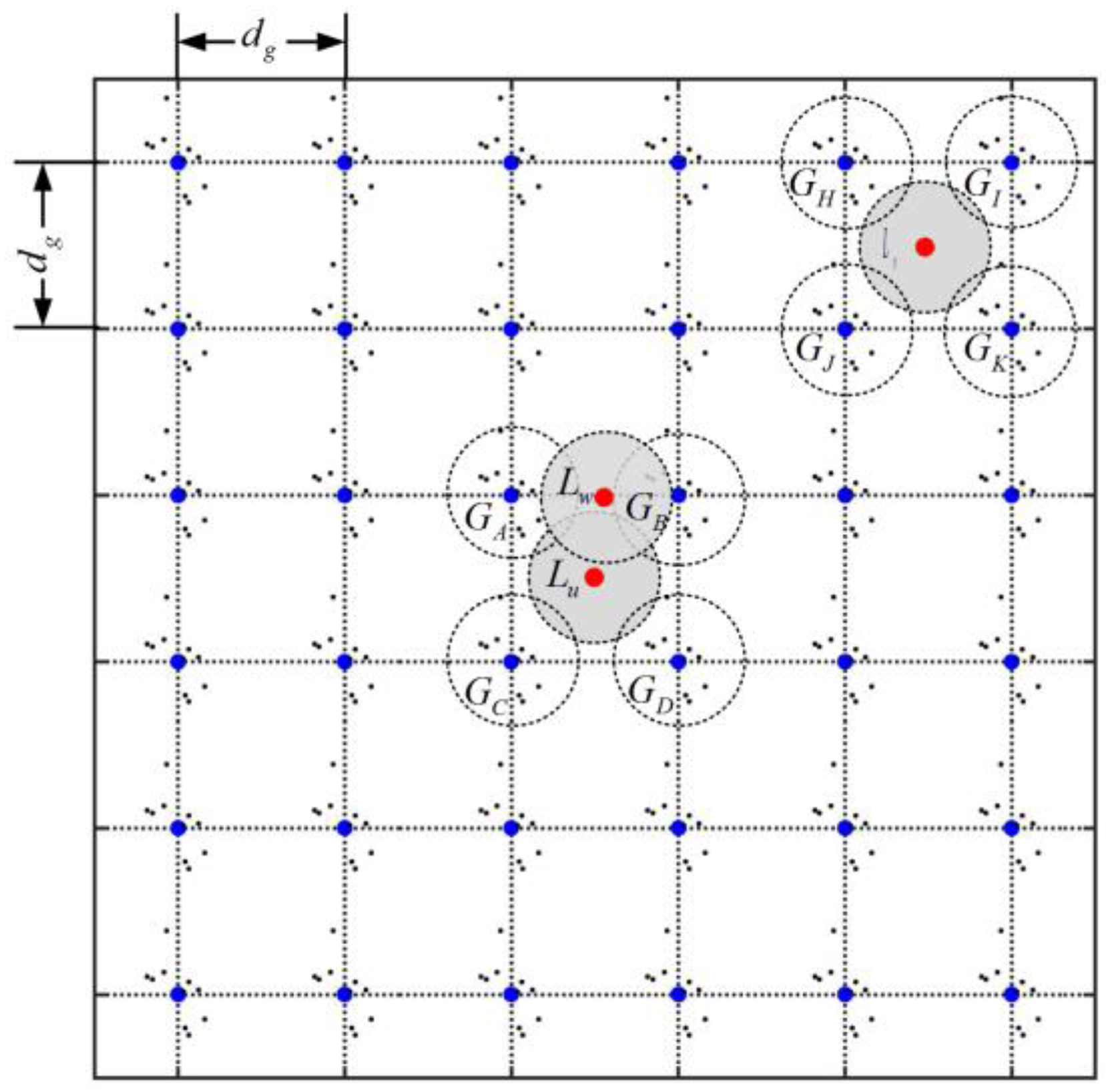
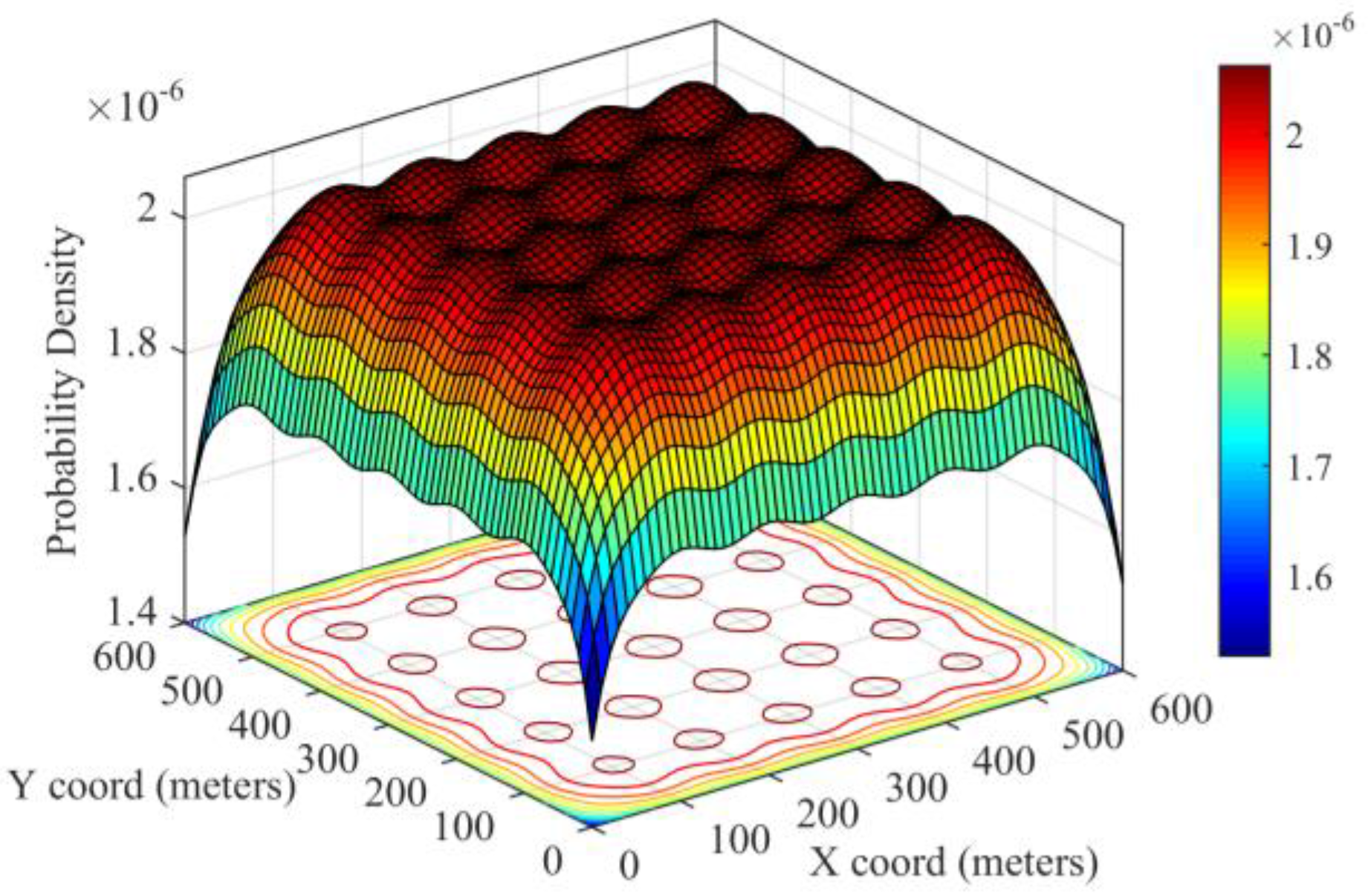
3.2. Sensor Deployment Strategies
3.3. Attack Model
4. Localization-Free Replica Detection Based on Similarity Estimation
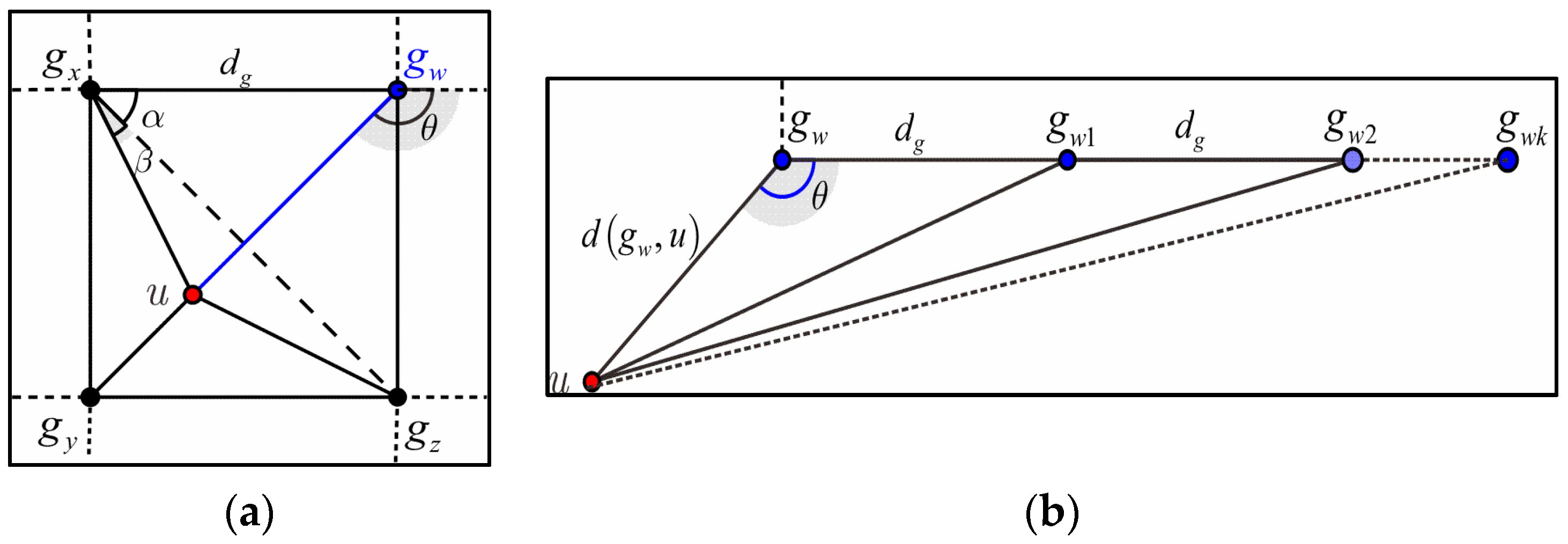
4.1. Problem Statement
4.2. Neighborhood-Based Detection Metric
4.3. Protocol Description
4.4. Obtaining the Replica Detection Threshold
- Step 1.
- We obtain the actual physical position , where , and derive the actual DNV for the selected nodes, represented as:
- Step 2.
- We collect the field of LCQ message from the N selected nodes, and compute the corresponding estimated position where . Then we derive the estimated DNV for the selected nodes, represented as:
- Step 3.
- We collect the IDs field of the LCQ message from the selected nodes, and derive the ONV for them: .
- Step 4.
- We derive the NV-LS of and , denoted by and , respectively, where , and . Then we can compute the deviation between and caused by the network uncertainties and measurement errors, represented as:
5. Security Analysis
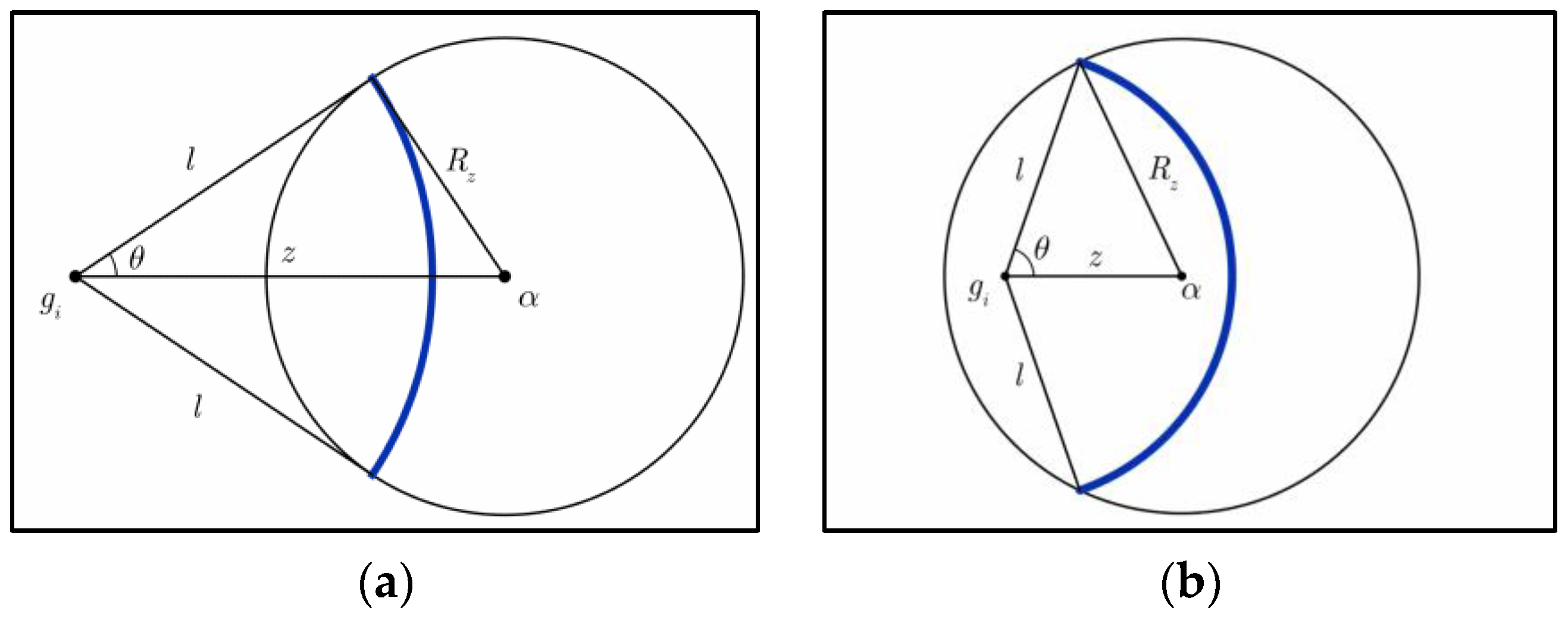
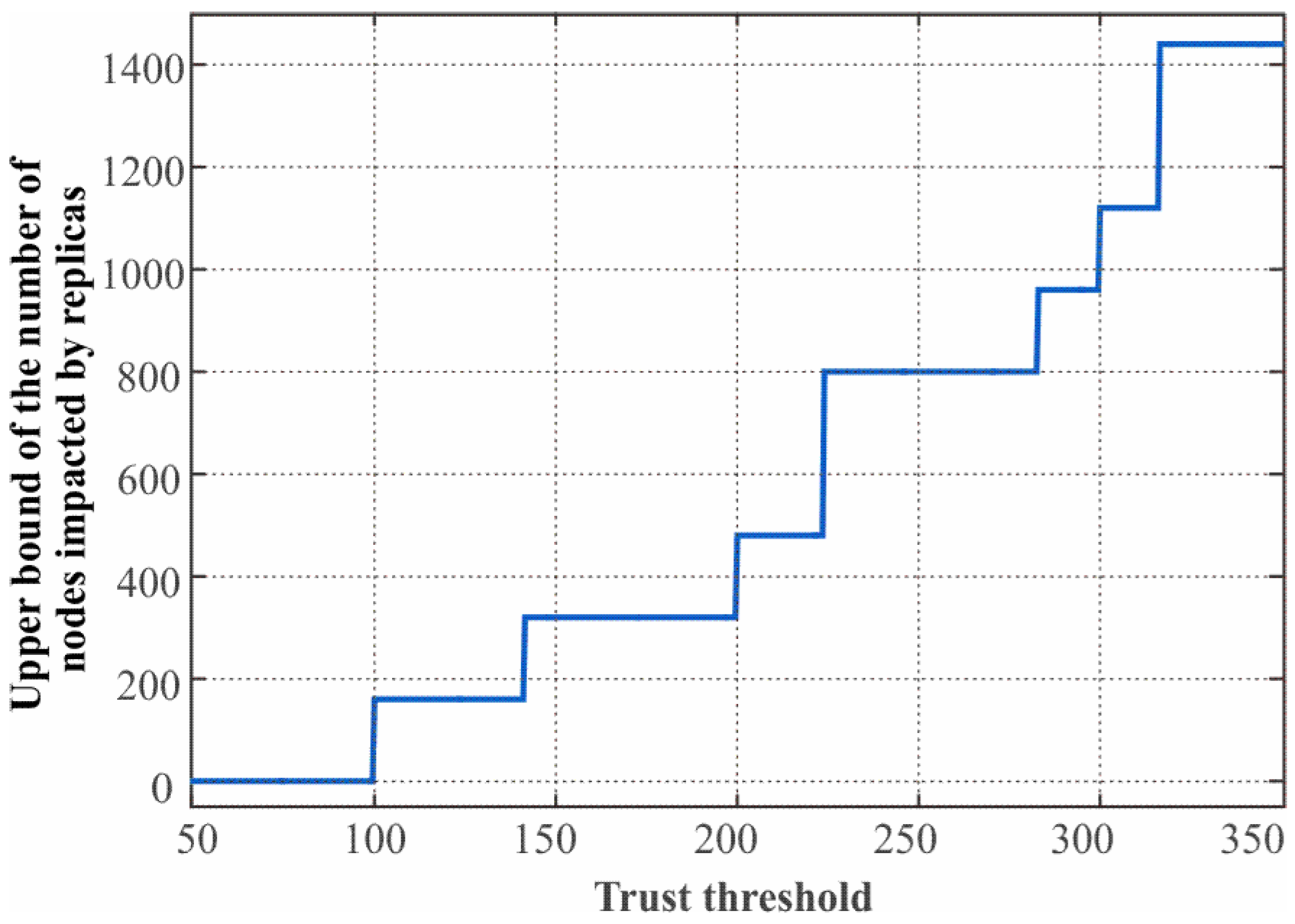
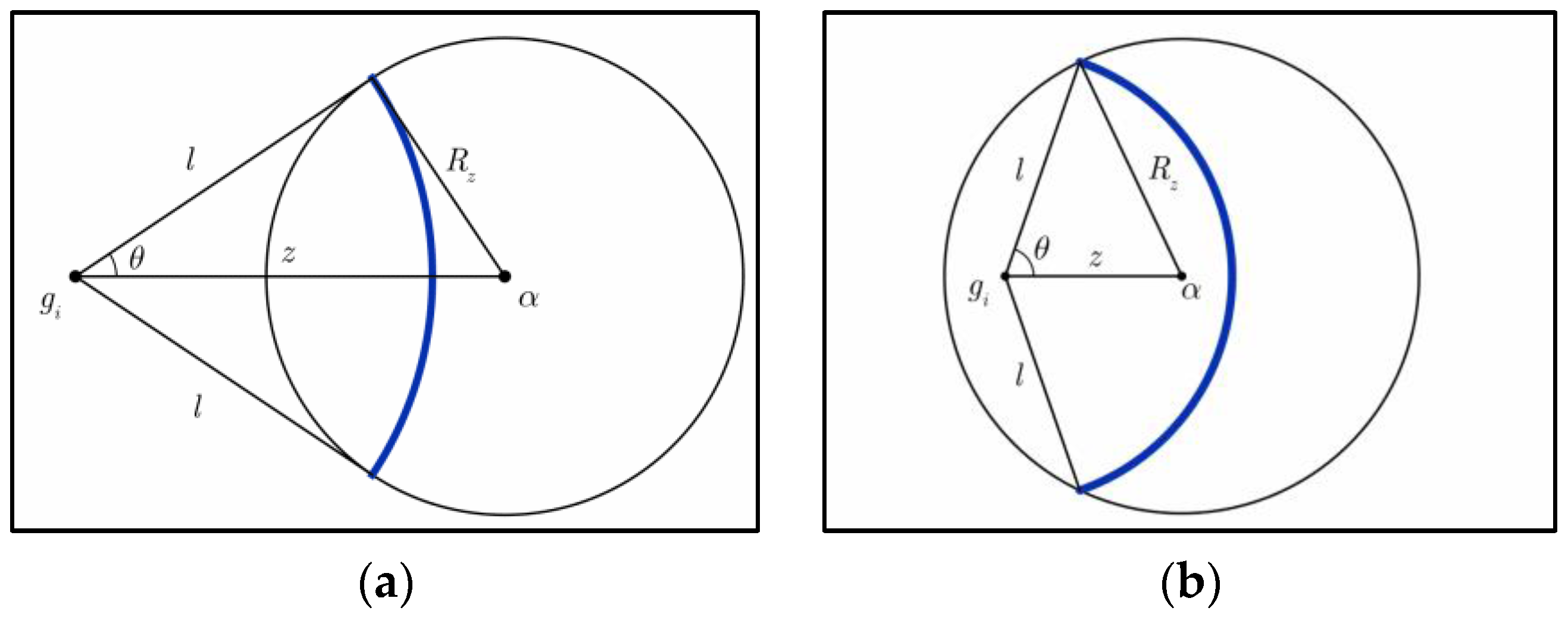
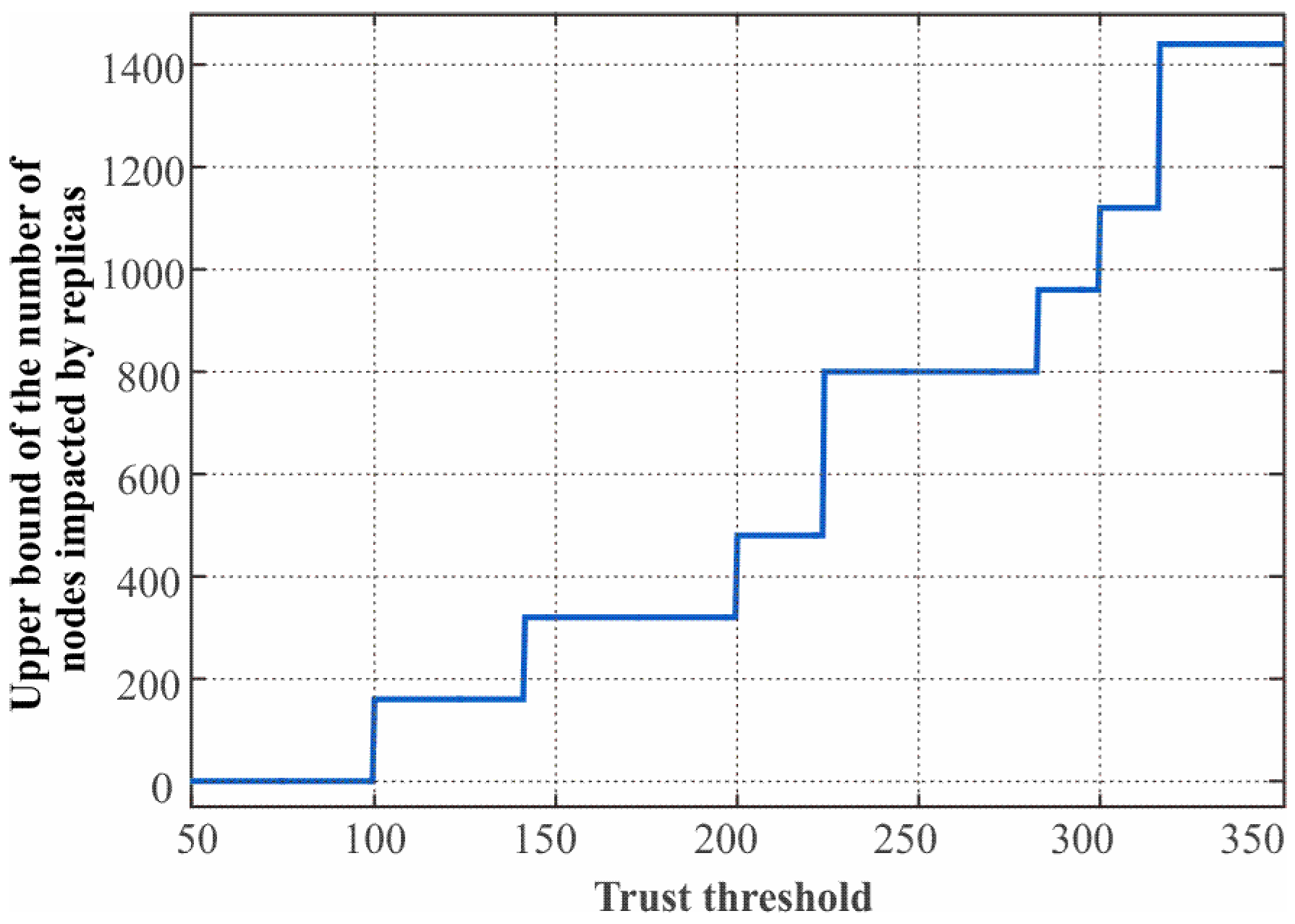
5.1. Limitation of the Impact Range of Node Replica Attack
5.2. Defense Capacity Analysis on Location Claim-Based Detection
6. Performance Evaluation
6.1. Communication, Computation, and Storage Overhead
6.2. Experimental Setup and Methodology
- Step 1.
- After deployment, we randomly pick k () nodes from the network topology, and mark them as compromised nodes. Let denote the locations of these k compromised nodes.
- Step 2.
- For each compromised node, we generate r replica nodes and place them D meters away from their original compromised nodes. denote the locations of compromised node i’s (i = 1, 2, …, k) replicas, where .
- Step 3.
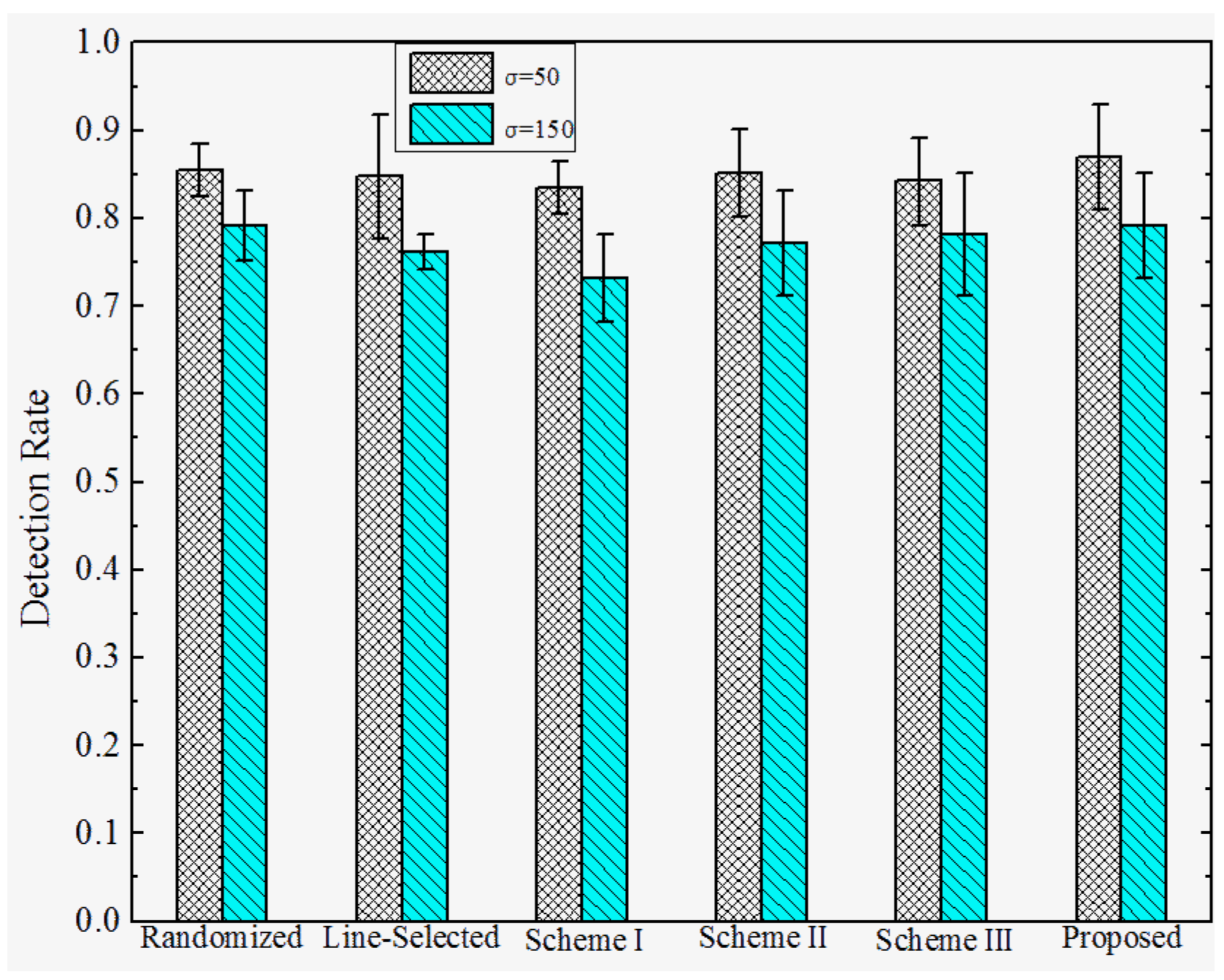
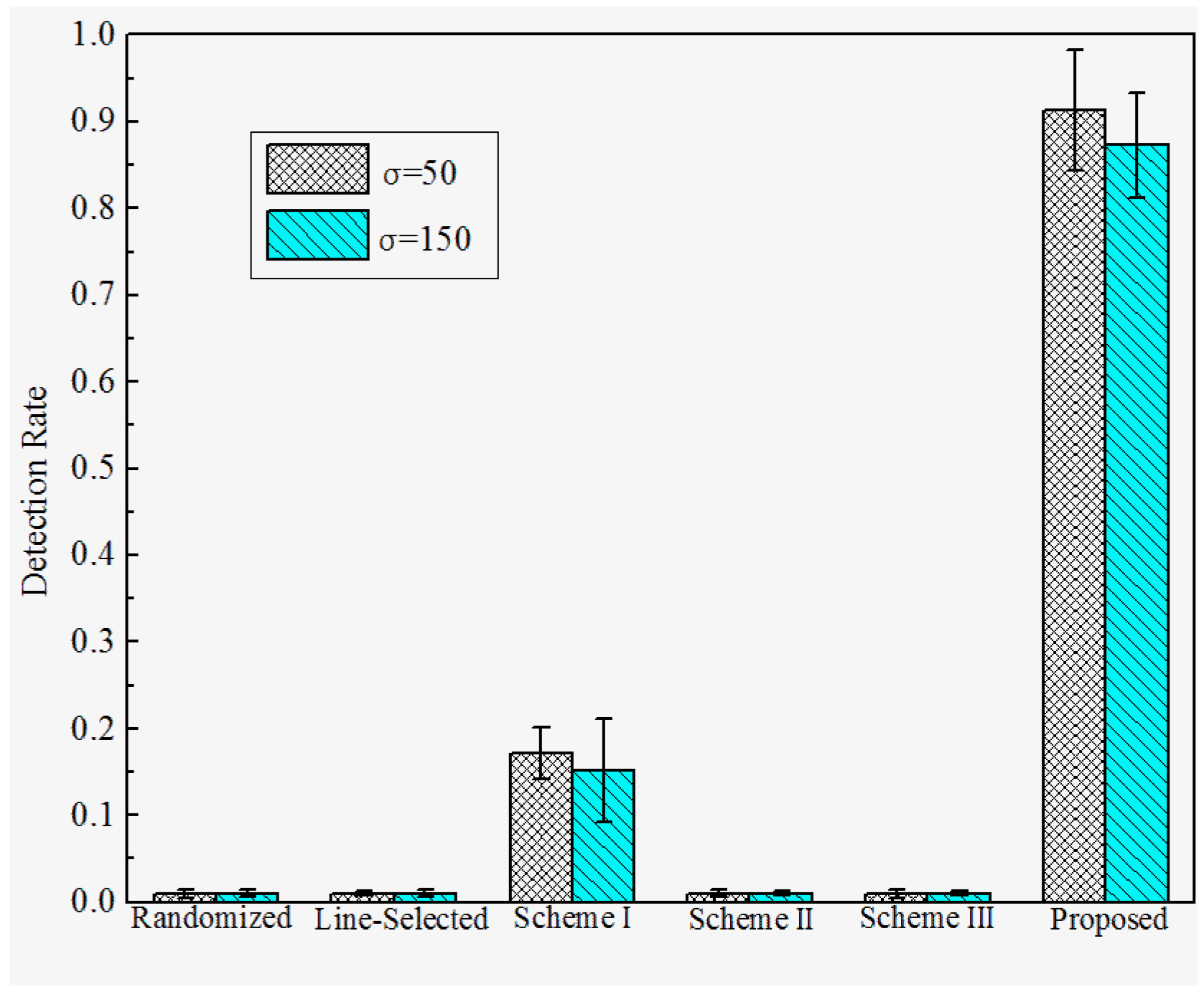
- In attack strategy I, the replica node modifies its group identity GID to the nearest group while keeping its NID the same with its origins. In attack strategy II, the replica nodes keep their field consistent with the IDs field in their LCQ message. In attack strategy III, the replica nodes make their field the same with their original compromised nodes, and keep their IDs field consistent with the field in the LCQ message.
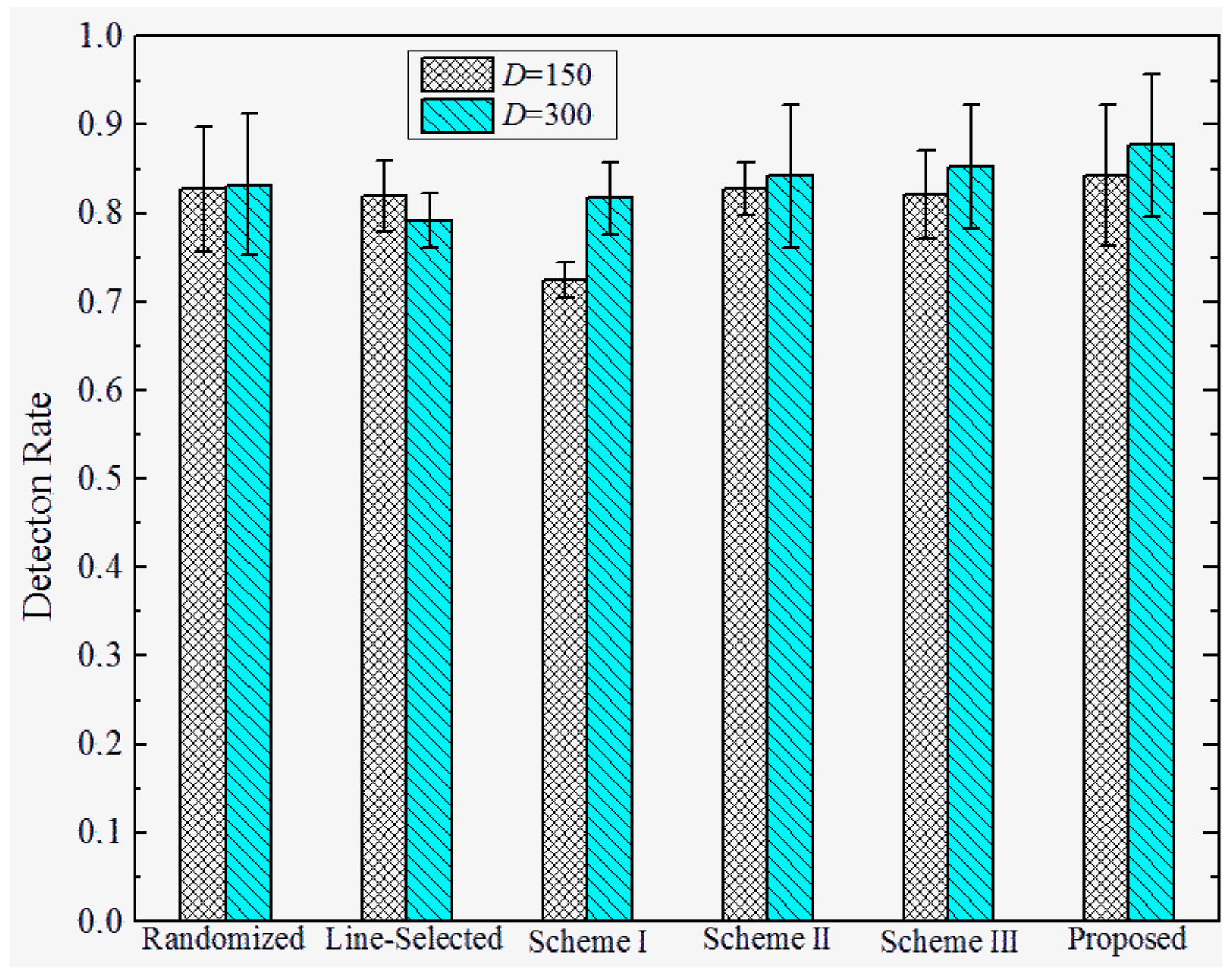
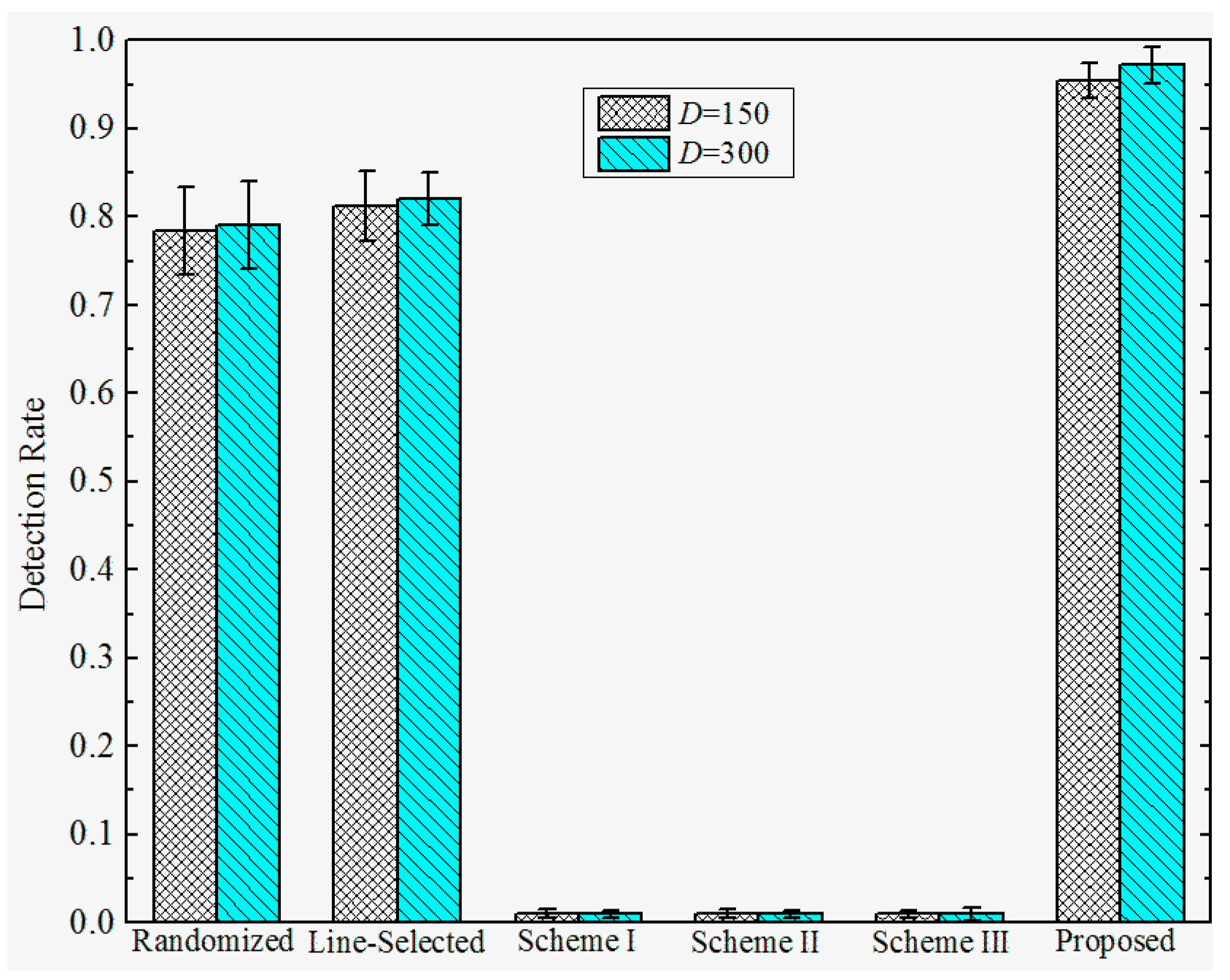
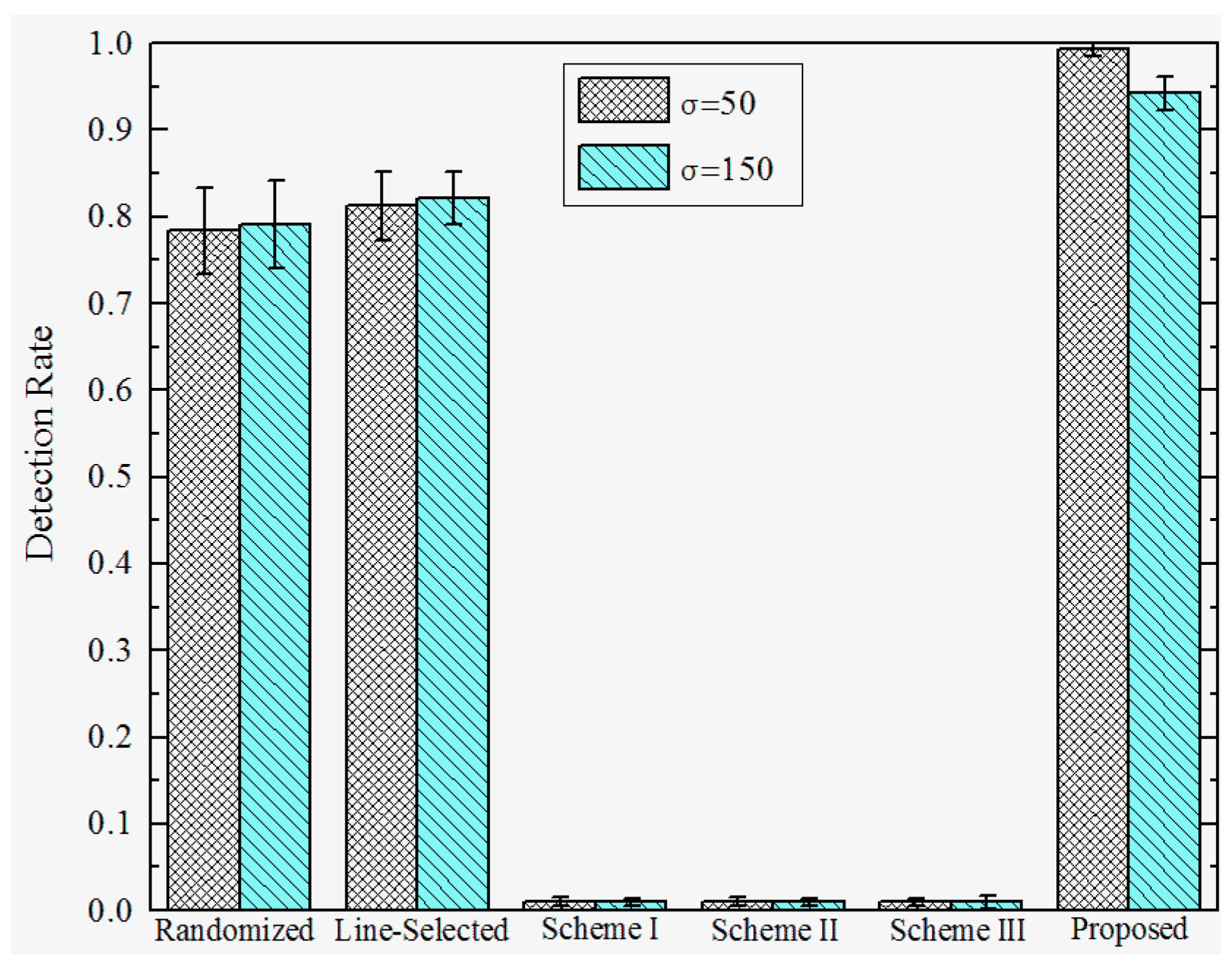
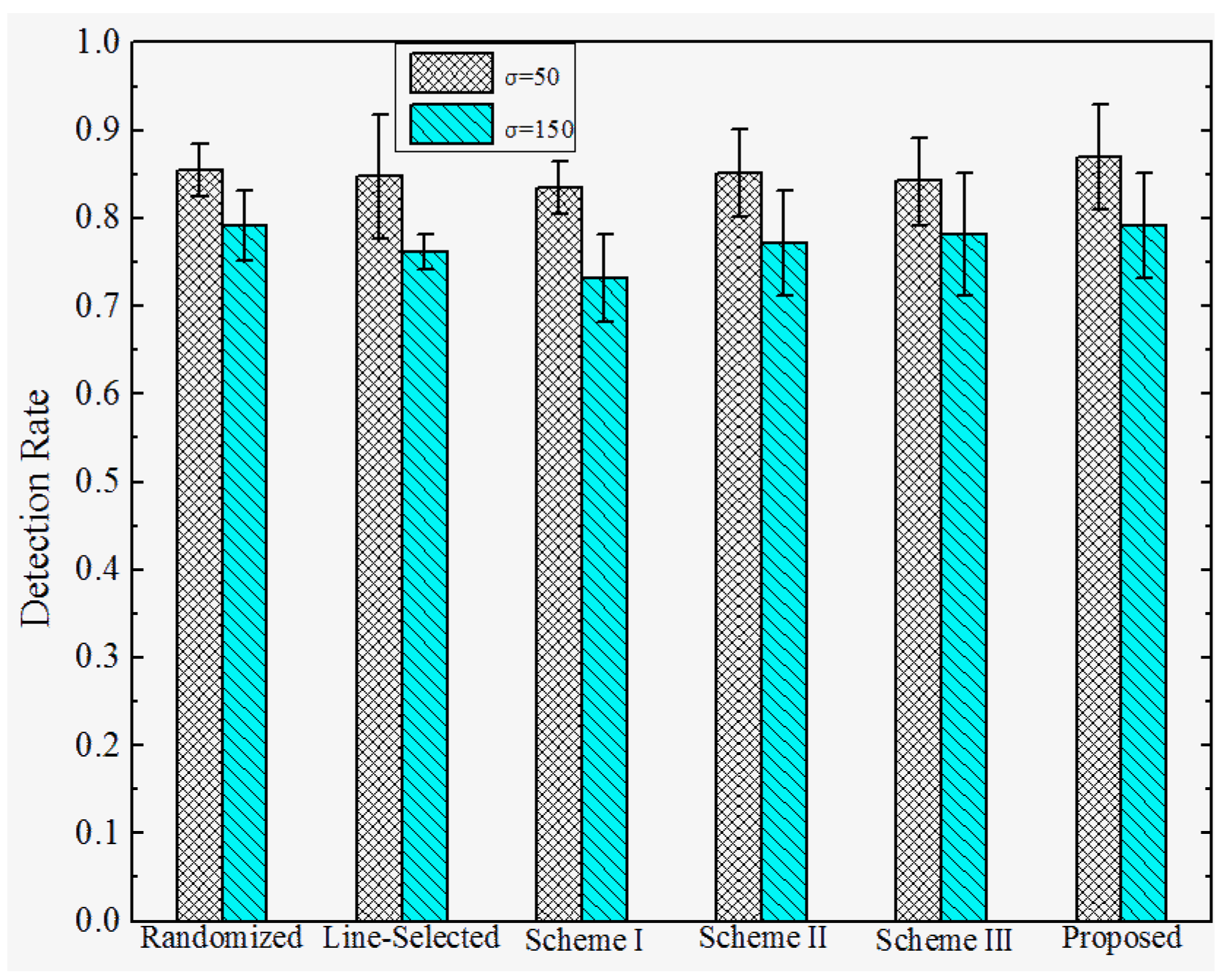
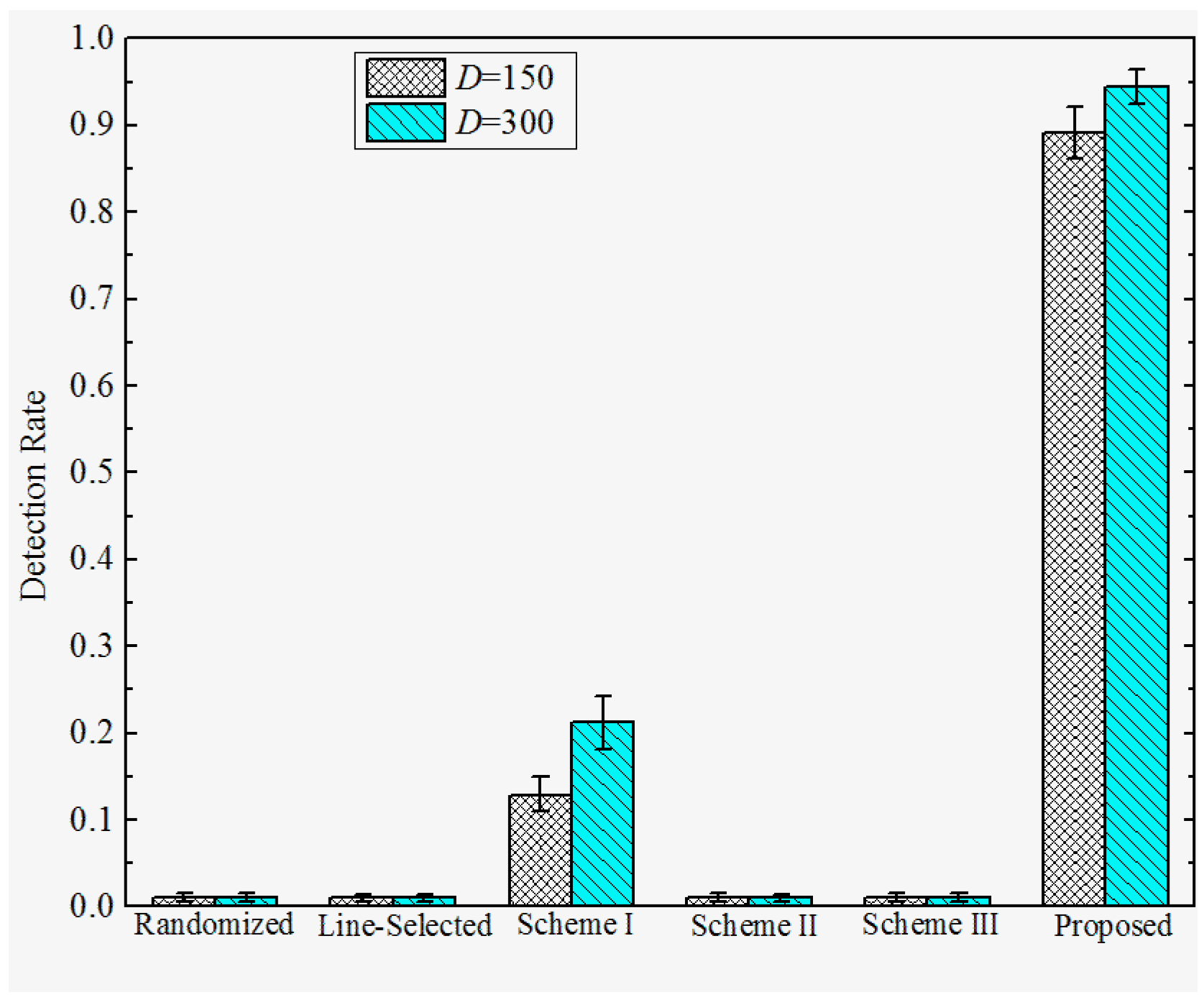
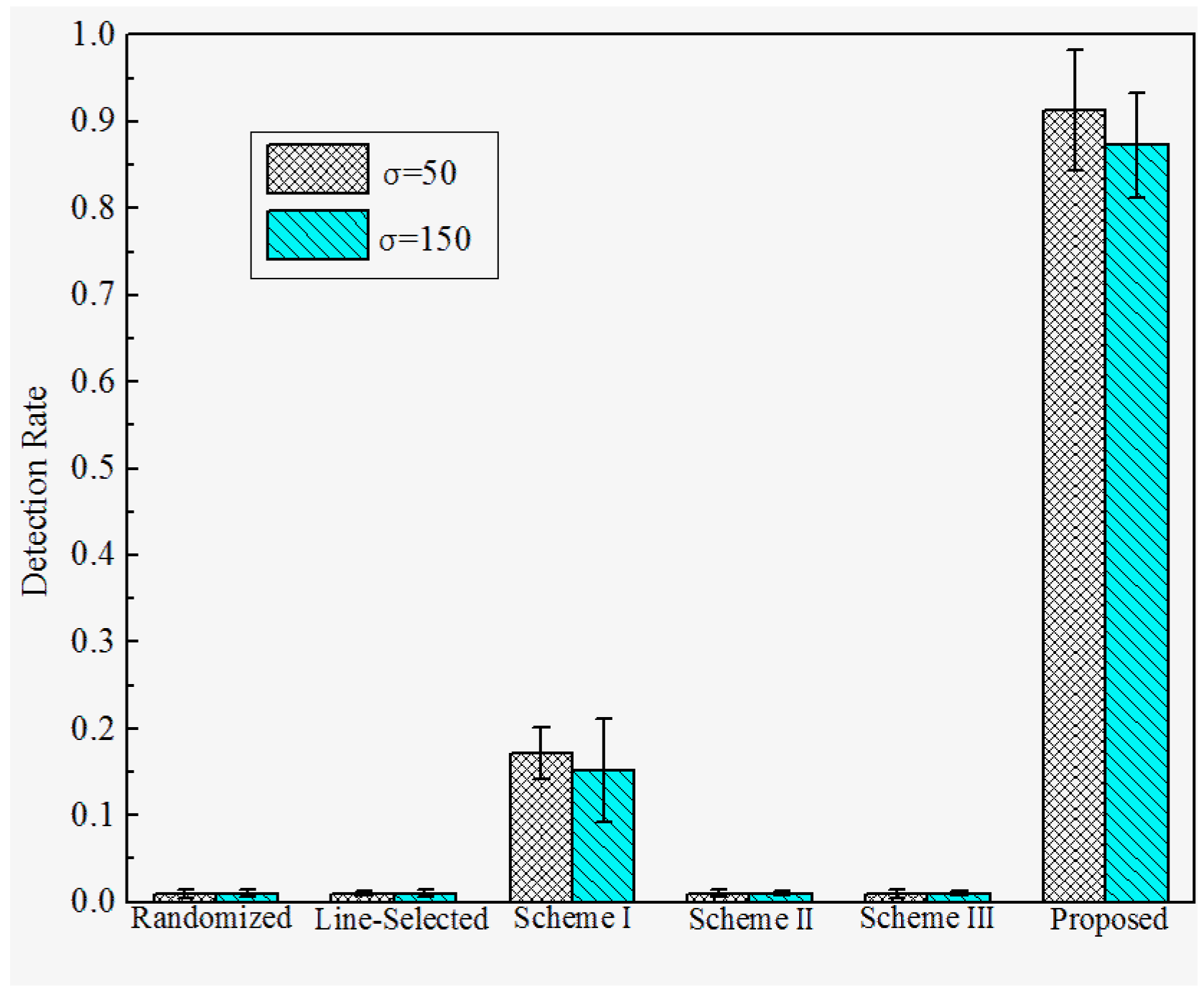
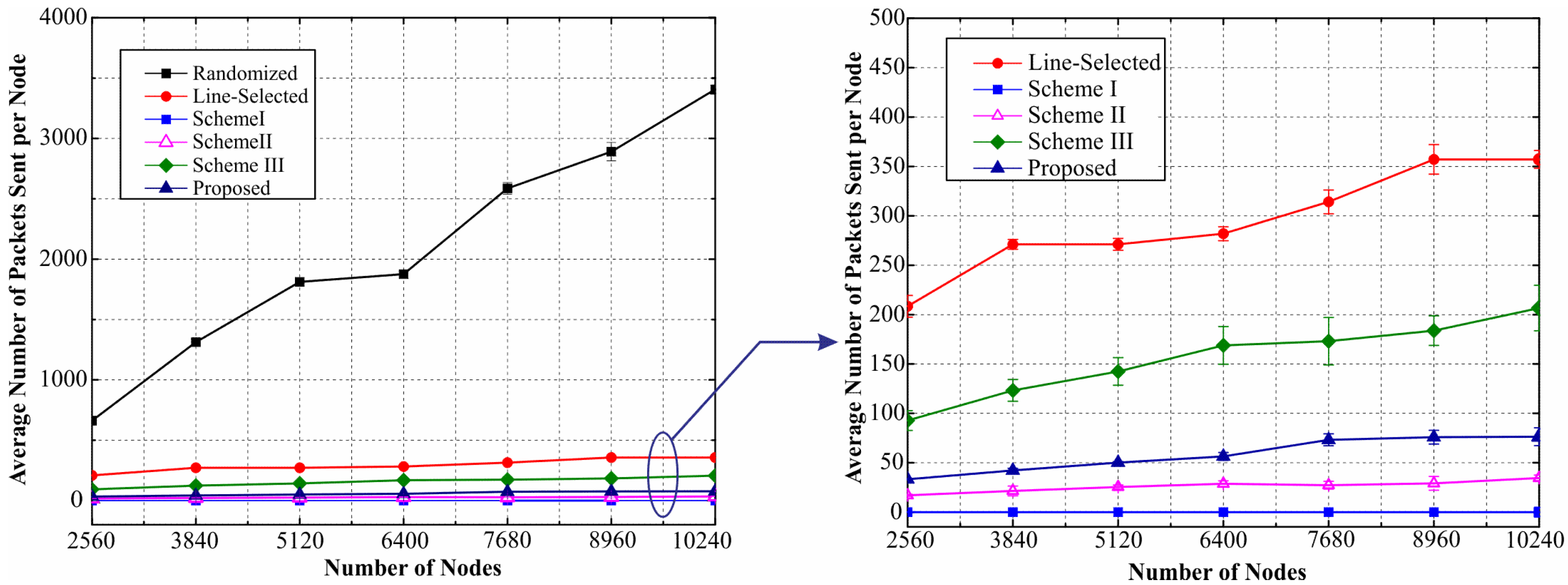
6.3. Results and Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Fu, Z.; Wu, X.; Guan, C.; Sun, X.; Ren, K. Toward Efficient Multi-Keyword Fuzzy Search Over Encrypted Outsourced Data With Accuracy Improvement. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2706–2716. [Google Scholar] [CrossRef]
- Fu, Z.; Ren, K.; Shu, J.; Sun, X.; Huang, F. Enabling Personalized Search over Encrypted Outsourced Data with Efficiency Improvement. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2546–2559. [Google Scholar] [CrossRef]
- Xie, S.; Wang, Y. Construction of Tree Network with Limited Delivery Latency in Homogeneous Wireless Sensor Networks. Wirel. Pers. Commun. 2014, 78, 231–246. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, X.; Sun, X.; Wang, Q. A Secure and Dynamic Multi-keyword Ranked Search Scheme over Encrypted Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 340–352. [Google Scholar] [CrossRef]
- Fu, Z.; Sun, X.; Liu, Q.; Zhou, L.; Shu, J. Achieving Efficient Cloud Search Services: Multi-keyword Ranked Search over Encrypted Cloud Data Supporting Parallel Computing. IEICE Trans. Commun. 2015, 98, 190–200. [Google Scholar] [CrossRef]
- Parrno, B.; Perrig, A.; Gligor, V.D. Distributed detection of node replication attacks in sensor networks. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 8–11 May 2005; pp. 49–63.
- Zhu, B.; Addada, V.G.K.; Setia, S.; Jajodia, S.; Roy, S. Efficient Distributed Detection of Node Replication Attacks in Sensor Networks. In Proceedings of the Computer Security Applications Conference, Miami Beach, FL, USA, 10–14 December 2007; pp. 257–267.
- Conti, M.; Pietro, R.D.; Mancini, L.V. A randomized, efficient and distributed protocol for the detection of nodes replication attacks in wireless sensor networks. In Proceedings of the ACM International Symposium on Mobile Ad Hoc Networking and Computing, ACM MobiHoc, Montreal, QC, Canada, 9–14 September 2007; pp. 80–89.
- Abinaya, P.; Geetha, C. Dynamic detection of node replication attacks using X-RED in wireless sensor networks. In Proceedings of the International Conference on Information Communication and Embedded Systems (ICICES2014), Chennai, India, 27–28 February 2014; pp. 1–4.
- Choi, H.; Zhu, S.; Potra, T.F.L. SET: Detecting node clones in sensor networks. In Proceedings of the Third International Conference on Security and Privacy in Communication Networks and the Workshops (SecureComm 2007), Nice, France, 17–21 September 2007; pp. 341–350.
- Ho, J.-W.; Liu, D.; Wright, M.; Das, S. K. Distributed detection of replica node attacks with group deployment knowledge in wireless sensor networks. Ad Hoc Netw. 2009, 7, 1476–1488. [Google Scholar] [CrossRef]
- Charikar, M. Similarity estimation techniques from rounding algorithms. In Proceedings of the Thirty-Fourth ACM Symposium on Theory of Computing, Montreal, QC, Canada, 19–21 May 2002; pp. 380–388.
- Zanca, G.; Zorzi, F.; Zanella, A.; Zorzi, M. Experimental comparison of RSSI-based localization algorithms for indoor wireless sensor networks. In Proceedings of the Workshop on Real-World Wireless Sensor Networks, Glasgow, UK, 1 April 2008.
- Sastry, N.; Shankar, U.; Wagner, D. Secure verification of location claims. In Proceedings of the ACM Workshop on Wireless Security, San Diego, CA, USA, 19 September 2003.
- Farah, K.; Nabila, L. The MCD Protocol for Securing Wireless Sensor Networks against Nodes Replication Attacks. In Proceedings of the Proceedings of International Conference on Advanced Networking Distributed Systems and Applications, Bejaia, Algeria, 17–19 June 2014; pp. 58–63.
- Guo, C.; Guo, S.; Yang, Y.; Fei, W. Replication attack detection with monitor nodes in clustered wireless sensor networks. In Proceedings of the 2015 IEEE 34th International Performance Computing and Communications Conference (IPCCC), Nanjing, China, 14–16 December 2015; pp. 1–8.
- Ho, Y.S.; Ma, R.L.; Sung, C.E.; Tsai, I.C.; Kang, L.W.; Yu, C.M. Deterministic detection of node replication attacks in sensor networks. In Proceedings of the 2015 IEEE International Conference on Consumer Electronics, Taipei, Taiwan, 6–8 June 2015; pp. 468–469.
- Douceur, J.R. The Sybil Attack. In Presented at the Revised Papers from the First International Workshop on Peer-to-Peer Systems, Cambridge, MA, USA, 7–8 March 2002.
- Pecori, R. S-Kademlia: A trust and reputation method to mitigate a Sybil attack in Kademlia. Comput. Netw. 2016, 94, 205–218. [Google Scholar] [CrossRef]
- Katz, J.; Lindell, A. Aggregate message authentication codes. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 8–11 April 2008; pp. 155–169.
- Chan, H.; Perrig, A.; Song, D. Random key predistribution schemes for sensor networks. In Proceedings of the IEEE Symposium on Research in Security and Privacy, Berkeley, CA, USA, 11–14 May 2003; pp. 197–213.
- Eschenauer, L.; Gligor, V.D. A key-management scheme for distributed sensor networks. In Proceedings of the 9th ACM Conference on Computer and Communication Security, Washington, DC, USA, 18–22 November 2002; pp. 41–47.
- Perrig, A.; Szewczyk, R.; Tygar, J.D.; Wen, V.; Culler, D.E. SPINS: Security protocols for sensor networks. Wirel. Netw. 2002, 8, 521–534. [Google Scholar] [CrossRef]
- Lei, F.; Wenliang, D.; Peng, N. A beacon-less location discovery scheme for wireless sensor networks. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; pp. 161–171.
- Yang, L.; Ding, C.; Wu, M. RPIDA: Recoverable Privacy-preserving Integrity-assured Data Aggregation Scheme for Wireless Sensor Networks. KSII Trans. Internet Inf. Syst. 2015, 37, 2808–2814. [Google Scholar]
- Oliveira, L.B.; Aranha, D.F.; Gouvêa, C.P.L.; Scott, M.; Câmara, D.F.; López, J. TinyPBC: Pairings for authenticated identity-based non-interactive key distribution in sensor networks. Comput. Commun. 2011, 34, 485–493. [Google Scholar] [CrossRef]
- Kumar, P.; Reddy, L.; Varma, S. Distance measurement and error estimation scheme for RSSI based localization in Wireless Sensor Networks. In Proceedings of the Fifth IEEE Conference on Wireless Communication and Sensor Networks (WCSN), Allahabad, India, 15–19 December 2009; pp. 1–4.
- NIST. Special Publication 800-57: Recommendation for Key Management. Available online: http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-57pt1r4.pdf (accessed on 15 December 2015).
- Diffie, W.; Hellman, M.E. Exhaustive Cryptanalysis of the NBS Data Encryption Standard; The Institute of Electrical and Electronics Engineering: Long Beach, CA, USA, 1977. [Google Scholar]
- Levis, P.; Lee, N.; Welsh, M.; Culler, D. TOSSIM: Accurate and scalable simulation of entire TinyOS applications. In Proceedings of the 1st International Conference on Embedded Networked Sensor Systems, Los Angeles, CA, USA, 5–7 November 2003.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| the communication radius of sensor nodes and beacons | secret key shared between node i and j | ||
| the trust threshold | secret key shared between node i and BS | ||
| the threshold of confliction detection | the certification signed by BS | ||
| the threshold of replica detection | LAQ/LAR | the location authentication request/reply | |
| the derived neighboring vector | NAN | the node authentication needed request | |
| the observed neighboring vector | LCQ/LCD | the location claim request/decision | |
| private/public key of BS |
| Scheme | Communication Overhead |
|---|---|
| Randomized Multicast [6] | |
| Line-selected Multicast [6] | |
| Location Claim Scheme I [11] | Negligible |
| Location Claim Scheme II [11] | |
| Location Claim Scheme III [11] | |
| Our proposed scheme |
| Scheme | Computation Overhead |
|---|---|
| Randomized Multicast [6] | |
| Line-selected Multicast [6] | |
| Location Claim Scheme I [11] | Negligible |
| Location Claim Scheme II [11] | |
| Location Claim Scheme III [11] | |
| Our proposed scheme |
| Scheme | Claim Storage Overhead |
|---|---|
| Randomized Multicast [6] | |
| Line-selected Multicast [6] | |
| Location Claim Scheme I [11] | Negligible |
| Location Claim Scheme II [11] | |
| Location Claim Scheme III [11] | |
| Our proposed scheme | Negligible |
| Parameter | Value |
|---|---|
| Power decay in reference distance (A) | 55 dB |
| Maximum data rate | 250 Kbps |
| Packet size | 36 Bytes |
| Average radio noise floor | −110 dBm |
| Standard deviation for WGN | 4.0 dB |
| Receiving Sensitivity | −105 dBm |
© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, C.; Yang, L.; Wu, M. Localization-Free Detection of Replica Node Attacks in Wireless Sensor Networks Using Similarity Estimation with Group Deployment Knowledge. Sensors 2017, 17, 160. https://doi.org/10.3390/s17010160
Ding C, Yang L, Wu M. Localization-Free Detection of Replica Node Attacks in Wireless Sensor Networks Using Similarity Estimation with Group Deployment Knowledge. Sensors. 2017; 17(1):160. https://doi.org/10.3390/s17010160
Chicago/Turabian StyleDing, Chao, Lijun Yang, and Meng Wu. 2017. "Localization-Free Detection of Replica Node Attacks in Wireless Sensor Networks Using Similarity Estimation with Group Deployment Knowledge" Sensors 17, no. 1: 160. https://doi.org/10.3390/s17010160