
Enhancement of ELDA Tracker Based on CNN Features and Adaptive Model Update


Abstract
:
1. Introduction
- The exemplar-based model is quite discriminative and specific, because it trains a linear discriminant analysis (LDA) classifier using one positive example and massive negative examples. Besides, to improve its discriminative ability, the ELDA tracker applies histograms of oriented gradient (HoG) features [10] as the appearance representation of the object [9].
- On the other hand, the adaptivity of the exemplar-based model is improved by combining an ensemble of detectors. Each detector (object model) is built based on a positive example; thus, the exemplar-based model can be considered as a template-based method. Model (or template) updating is very important to build a robust tracker.
- (1)
- Discriminative ability
- (2)
- Adaptivity
2. Related Work
2.1. Exemplar-Based Tracker
2.2. Appearance Representations in Tracking-By-Detection Methods
2.2.1. Discriminative Models
2.2.2. Generative Model
2.3. LDA
2.4. Deep Networks in Tracking
2.5. Differences with ELDA
- (1)
- Representation scheme. The proposed method uses CNN features for object representation, while ELDA uses HoG features. Many recent works have proven to have better performance of CNN features in object detection and many other computer vision tasks;
- (2)
- Search mechanism. Both methods adopt the dense sampling search mechanism. However, our method samples the candidate windows on the conv5 feature maps; while ELDA samples the windows on the original image. The step length of the sliding window of the proposed method, corresponding to the ordinal image, is not a fixed value, as seen in Section 3.2;
- (3)
- Object model update. ELDA selects all of the models in a fixed time window to build the short-term object models; while our method selects a small number of models by considering their discriminative abilities and correlation among them. The models in our method are more compact.
- (4)
- Background model. The ELDA tracker builds the background model as a single Gaussian model; while the proposed method builds it as a Gaussian mixture model to improve its adaptivity in complex scenes.
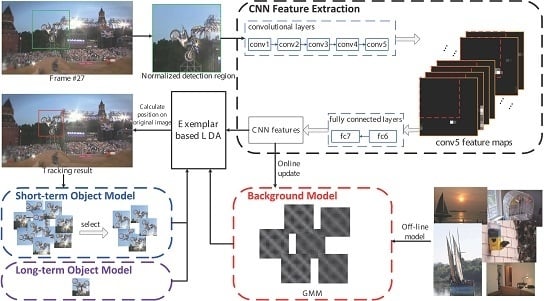
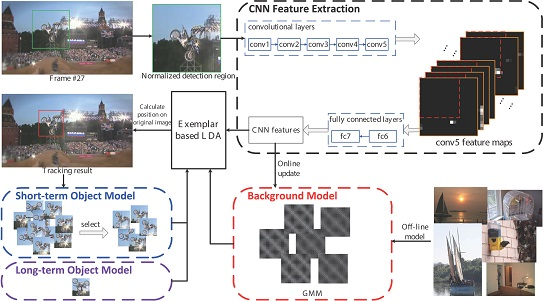
3. Our Method
3.1. ELDA Tracker
3.2. Appearance Representations
| Algorithm 1 Two-step CNN feature extraction |
Input:
|
Output:
|
|
3.3. Object Model Update
| Algorithm 2 Object model updating algorithm |
Input:
|
Output:
|
|
3.4. Background Model Update
4. Experimental Results
4.1. Implementation Details
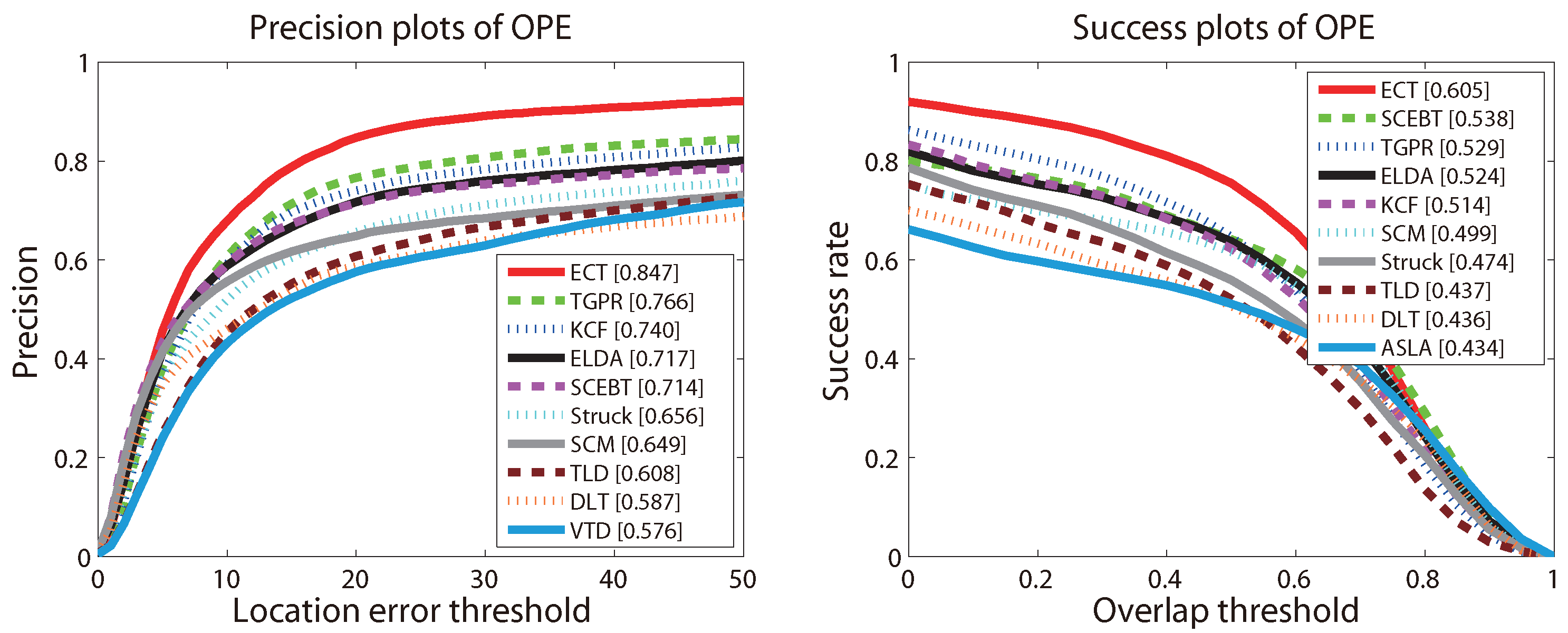
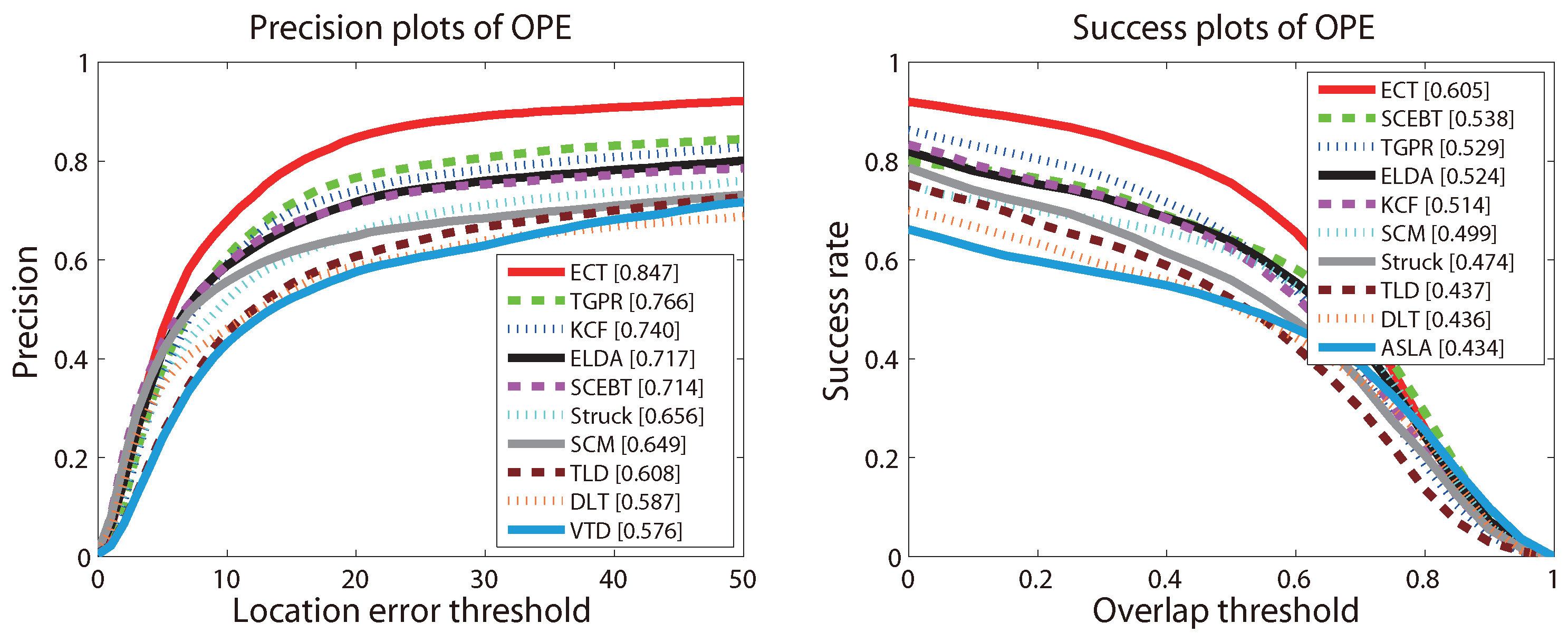
4.2. Overall Performance
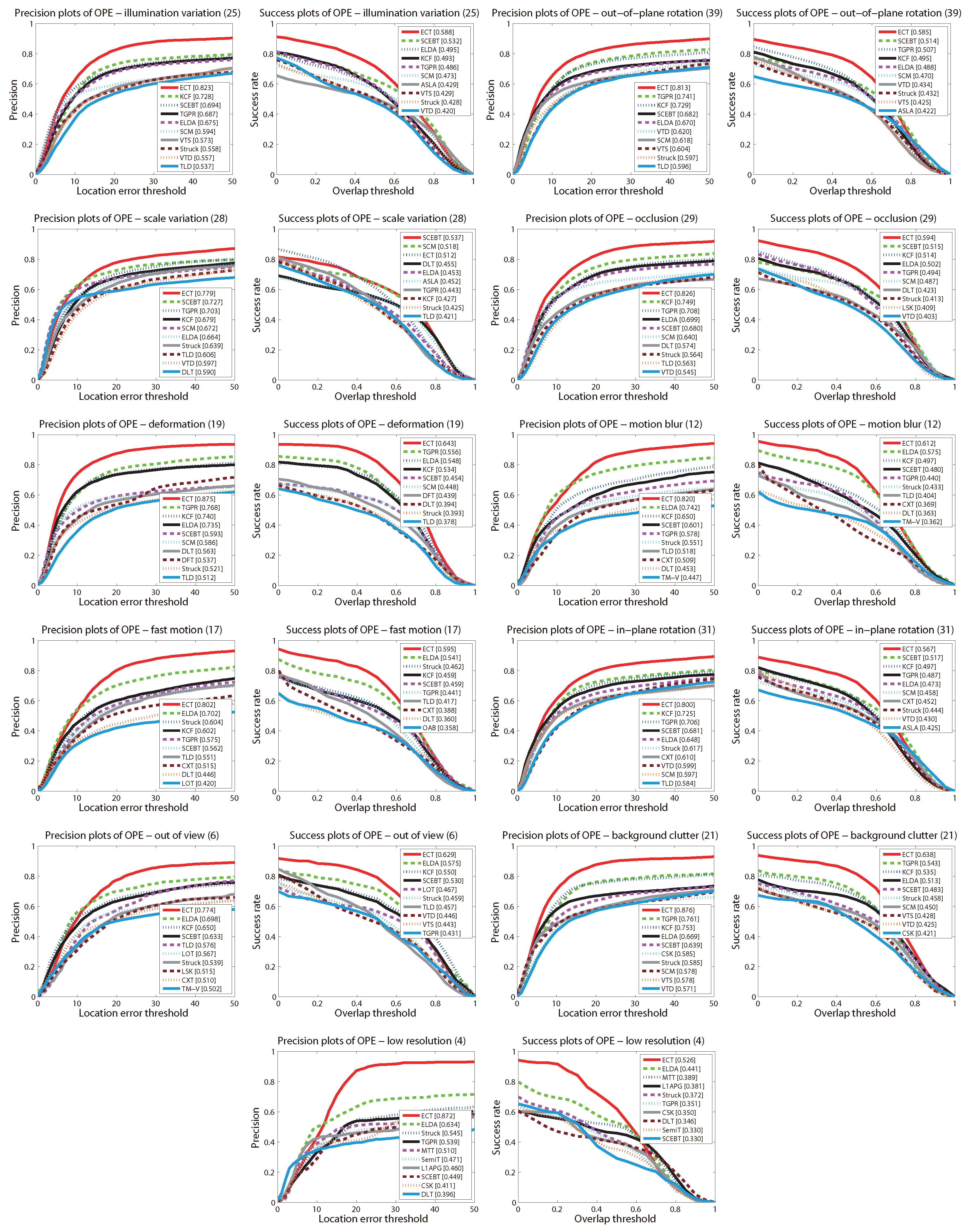
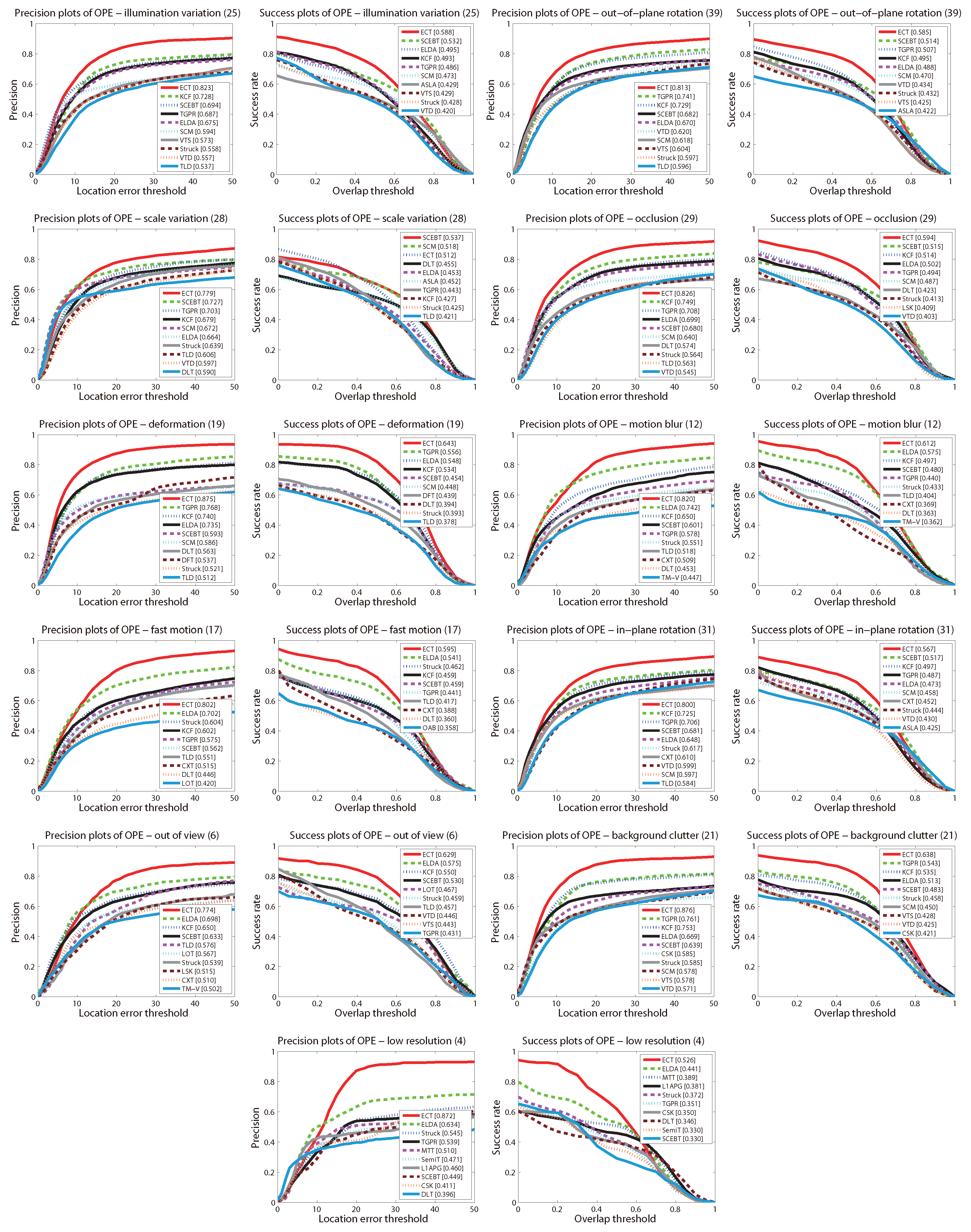
4.3. Quantitative Comparison
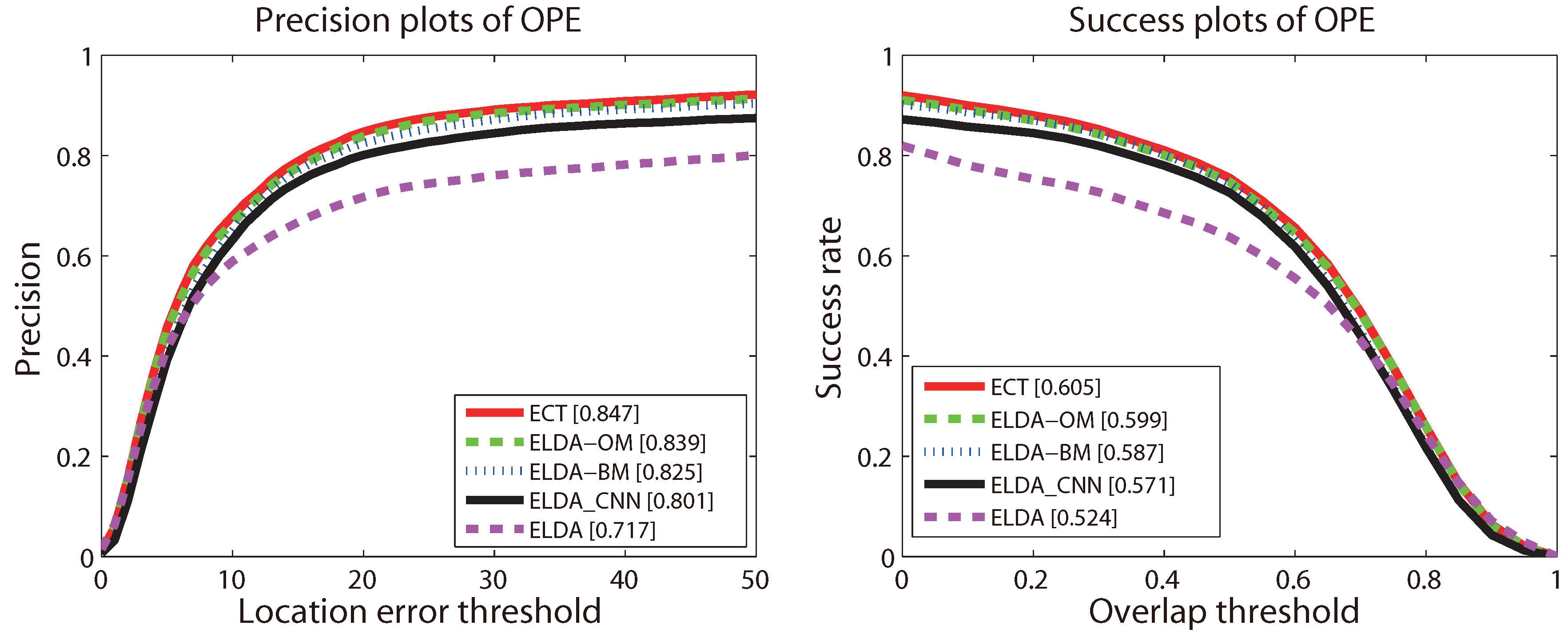
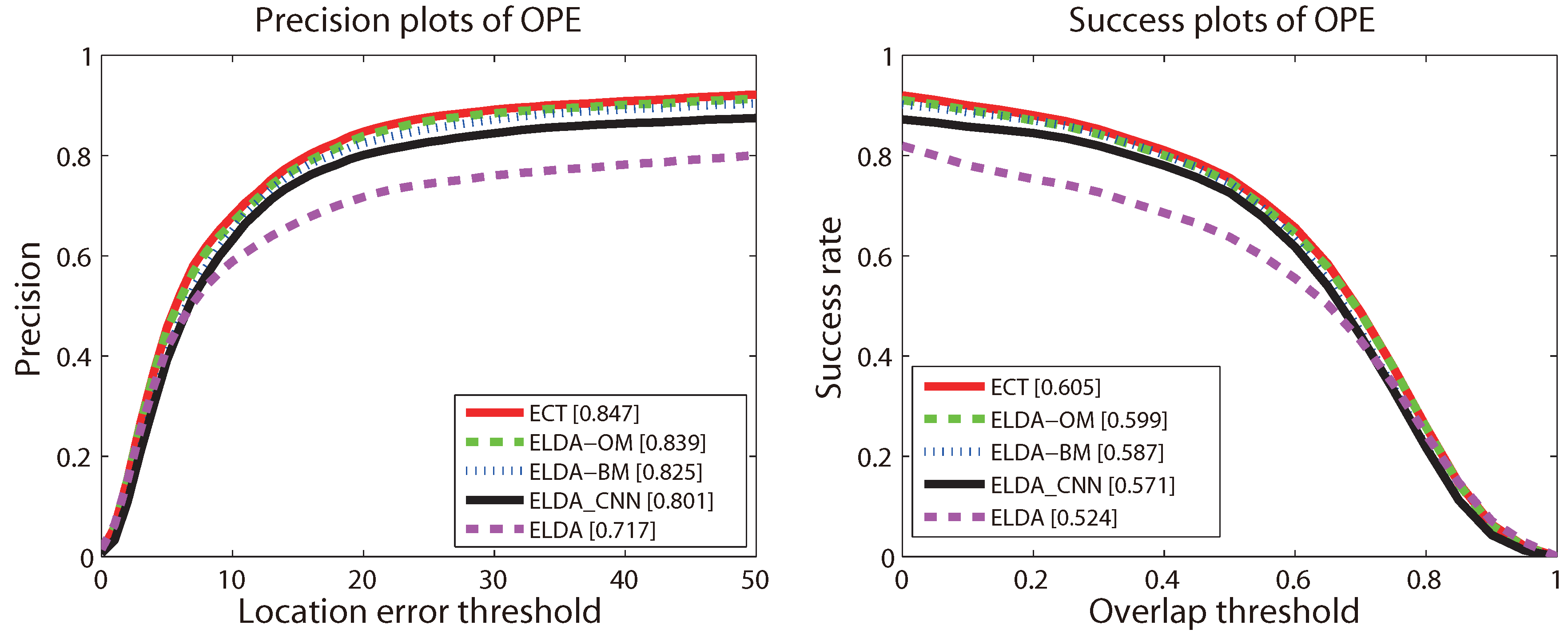
4.4. Evaluation of Components
- ELDA_CNN: replacing the HoG representation in ELDA with CNN features;
- ECT-OM: removing the proposed object model from ECT;
- ECT-BM: removing the proposed background model from ECT;
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| AUC | area under the curve |
| CNN | convolutional neural networks |
| ELDA | exemplar-based linear discriminant analysis |
| HoG | histograms of oriented gradients |
| GMM | Gaussian mixture model |
| IOU | intersection over union |
| LDA | linear discriminant analysis |
| NMS | non-maximum suppression |
| OPE | one-pass evaluation |
| SIFT | scale-invariant feature transform |
References
- Gao, H.; Li, J. Detection and Tracking of a Moving Target Using SAR Images with the Particle Filter-Based Track-Before-Detect Algorithm. Sensors 2014, 14, 10829–10845. [Google Scholar] [CrossRef] [PubMed]
- Xue, M.; Yang, H.; Zheng, S.; Zhou, Y.; Yu, Z. Incremental Structured Dictionary Learning for Video Sensor-Based Object Tracking. Sensors 2014, 14, 3130–3155. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.J.; Kim, Y.G. A Target Model Construction Algorithm for Robust Real-Time Mean-Shift Tracking. Sensors 2014, 14, 20736–20752. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Wang, Y.; Wu, H. A coded aperture compressive imaging array and its visual detection and tracking algorithms for surveillance systems. Sensors 2012, 12, 14397–14415. [Google Scholar] [CrossRef] [PubMed]
- Qin, L.; Snoussi, H.; Abdallah, F. Object Tracking Using Adaptive Covariance Descriptor and Clustering-Based Model Updating for Visual Surveillance. Sensors 2014, 14, 9380–9407. [Google Scholar] [CrossRef] [PubMed]
- Pan, S.; Shi, L.; Guo, S. A Kinect-Based Real-Time Compressive Tracking Prototype System for Amphibious Spherical Robots. Sensors 2015, 15, 8232–8252. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2411–2418.
- Babenko, B.; Yang, M.H.; Belongie, S. Viusal tracking with online multiple instance learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 983–990.
- Gao, C.; Chen, F.; Yu, J.G.; Huang, R.; Sang, N. Robust Visual Tracking Using Exemplar-based Detectors. IEEE Trans. Circuits Syst. Video Technol. 2015. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 25 June 2005; Volume 1, pp. 886–893.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems (NIPS); 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Machine Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale Orderless Pooling of Deep Convolutional Activation Features. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 392–407.
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014.
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable Object Detection using Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2147–2154.
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 184–199.
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. Proc. BMVC 2014. arXiv:1405.3531. [Google Scholar]
- Malisiewicz, T.; Gupta, A.; Efros, A.A. Ensemble of exemplar-SVMs for object detection and beyond. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 89–96.
- Hariharan, B.; Malik, J.; Ramanan, D. Discriminative decorrelation for clustering and classification. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 459–472.
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. 2006, 38. [Google Scholar] [CrossRef]
- Yang, H.; Shao, L.; Zheng, F.; Wang, L.; Song, Z. Recent advances and trends in visual tracking: A review. Neurocomputing 2011, 74, 3823–3831. [Google Scholar] [CrossRef]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [PubMed]
- Grabner, H.; Grabner, M.; Bischof, H. Real-time tracking via on-line boosting. In Proceedings of the British Machine Vision Conference (BMVC), Edinburgh, UK, 4–7 September 2006.
- Grabner, H.; Leistner, C.; Bischof, H. Semi-supervised on-line boosting for robust tracking. In Proceedings of the 10th European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008; pp. 234–247.
- Stalder, S.; Grabner, H.; Van Gool, L. Beyond semi-supervised tracking: Tracking should be as simple as detection, but not simpler than recognition. In Proceedings of the International Conference on Computer Vision (ICCV) Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1409–1416.
- Zhang, K.; Zhang, L.; Yang, M.H. Real-time compressive tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 864–877.
- Hare, S.; Saffari, A.; Torr, P.H.S. Struck: Structured output tracking with kernels. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 263–270.
- Viola, P.; Jones, M. Robust real-time object detection. Int. J. Comput. Vis. 2001, 4, 51–52. [Google Scholar]
- Kalal, Z.; Matas, J.; Mikolajczyk, K. P-N learning: Bootstrapping binary classifiers by structural constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 49–56.
- Dinh, T.B.; Vo, N.; Medioni, G. Context tracker: Exploring supporters and distracters in unconstrained environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 1177–1184.
- Ma, C.; Liu, C. Two dimensional hashing for visual tracking. Comput. Vis. Image Underst. 2015, 135, 83–94. [Google Scholar] [CrossRef]
- Tang, F.; Brennan, S.; Zhao, Q.; Tao, H. Co-tracking using semi-supervised support vector machines. In Proceedings of the International Conference on Computer Vision (ICCV), Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8.
- Song, S.; Xiao, J. Tracking revisited using RGBD camera: Unified benchmark and baselines. In Proceedings of the International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 233–240.
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Bai, X.; Liu, W.; Latecki, L.J. Similarity Fusion for Visual Tracking. Int. J. Comput. Vis. 2016. [Google Scholar] [CrossRef]
- Sun, L.; Liu, G. Visual object tracking based on combination of local description and global representation. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 408–420. [Google Scholar] [CrossRef]
- Bouachir, W.; Bilodeau, G.A. Collaborative part-based tracking using salient local predictors. Comput. Vis. Image Underst. 2015, 137, 88–101. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, H.; Sun, X.; Lu, X. Sparse coding based visual tracking: Review and experimental comparison. Pattern Recognit. 2012, 46, 1772–1788. [Google Scholar] [CrossRef]
- Ross, D.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental Visual Tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Liu, B.; Huang, J.; Kulikowsk, C. Robust tracking using local sparse appearance model and k-selection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 1313–1320.
- Jia, X.; Lu, H.; Yang, M.H. Visual tracking via adaptive structural local sparse appearance model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 6–21 June 2012; pp. 1822–1829.
- Zhong, W.; Lu, H.; Yang, M.H. Robust object tracking via sparsity-based collaborative model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 6–21 June 2012; pp. 1838–1845.
- Zhang, T.; Ghanem, B.; Liu, S.; Ahuja, N. Roubst visual tracking via multi-task sparse learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 6–21 June 2012; pp. 2042–2049.
- Bao, C.; Wu, Y.; Ling, H.; Ji, H. Real time robust L1 tracker using accelerated proximal gradient approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 6–21 June 2012; pp. 1830–1837.
- Wang, B.; Tang, L.; Yang, J.; Zhao, B.; Wang, S. Visual Tracking Based on Extreme Learning Machine and Sparse Representation. Sensors 2015, 15, 26877–26905. [Google Scholar] [CrossRef] [PubMed]
- Kwon, J.; Lee, K.M. Tracking by sampling trackers. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1195–1202.
- Kwon, J.; Lee, K.M. Visual tracking decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1269–1276.
- Godec, M.; Roth, P.M.; Bischof, H. Hough-based tracking of non-rigid objects. Comput. Vis. Image Underst. 2013, 117, 1245–1256. [Google Scholar] [CrossRef]
- Wang, H.; Sang, N.; Yan, Y. Real-Time Tracking Combined with Object Segmentation. In Proceedings of the International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 4098–4103.
- Wen, L.; Du, D.; Lei, Z.; Li, S.Z.; Yang, M.H. JOTS: Joint Online Tracking and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2226–2234.
- Baudat, G.; Anouar, F. Generalized discriminant analysis using a kernel approach. Neural Comput. 2000, 12, 2385–2404. [Google Scholar] [CrossRef] [PubMed]
- Krzanowski, W.; Jonathan, P.; Mccarthy, W.; Thomas, M. Discriminant analysis with singular covariance matrices: Methods and applications to spectroscopic data. Appl. Stat. 1995, 44, 101–115. [Google Scholar] [CrossRef]
- Ye, J.; Janardan, R.; Li, Q. Two-dimensional linear discriminant analysis. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 13–18 December 2004; pp. 1569–1576.
- Rao, C.R. The utilization of multiple measurements in problems of biological classification. J. R. Stat. Soc. Ser. B (Methodol.) 1948, 10, 159–203. [Google Scholar]
- Fan, J.; Xu, W.; Wu, Y.; Gong, Y. Human tracking using convolutional neural networks. IEEE Trans. Neural Netw. 2010, 21, 1610–1623. [Google Scholar] [PubMed]
- Wang, N.; Yeung, D.Y. Learning a deep compact image representation for visual tracking. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–10 December 2013; pp. 809–817.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2008 (VOC2008) Results. Available online: http://host.robots.ox.ac.uk/pascal/VOC/voc2008/index.html (accessed on 14 April 2016).
- Wang, N.; Yeung, D.Y. Ensemble-based tracking: Aggregating crowdsourced structured time series data. In Proceedings of the 31th International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 806–813.
- Gao, J.; Ling, H.; Hu, W.; Xing, J. Transfer learning based visual tracking with Gaussian processes regression. In 13th Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 188–203.
- Li, H.; Li, Y.; Porikli, F. DeepTrack: Learning Discriminative Feature Representations by Convolutional Neural Networks for Visual Tracking. In Proceedings of the British Machine Vision Conference (BMVC), Nottingham, UK, 1–5 September 2014.
- Zhang, K.; Liu, Q.; Wu, Y.; Yang, M.H. Robust Visual Tracking via Convolutional Networks without Learning. IEEE Trans. Image Process. 2015, 25, 1779–1792. [Google Scholar]
- Wang, N.; Li, S.; Gupta, A.; Yeung, D.Y. Transferring Rich Feature Hierarchies for Robust Visual Tracking. Comput. Vis. Pattern Recognit. 2015. arXiv:1501.04587. [Google Scholar]
- Wang, N.; Shi, J.; Yeung, D.Y.; Jia, J. Understanding and Diagnosing Visual Tracking Systems. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | p@5 | p@10 | p@15 | p@20 | p@25 |
|---|---|---|---|---|---|
| Struck [29] | 0.355 | 0.519 | 0.605 | 0.656 | 0.690 |
| SCM [44] | 0.416 | 0.557 | 0.617 | 0.649 | 0.670 |
| ELDA [9] | 0.416 | 0.589 | 0.667 | 0.717 | 0.744 |
| SCEBT [61] | 0.433 | 0.591 | 0.673 | 0.714 | 0.740 |
| KCF [36] | 0.365 | 0.592 | 0.697 | 0.740 | 0.767 |
| TGPR [62] | 0.384 | 0.607 | 0.713 | 0.766 | 0.791 |
| DLT [58] | 0.349 | 0.461 | 0.540 | 0.587 | 0.613 |
| ECT | 0.457 | 0.679 | 0.788 | 0.847 | 0.876 |
| Methods | [email protected] | [email protected] | [email protected] | [email protected] | [email protected] |
|---|---|---|---|---|---|
| Struck [29] | 0.669 | 0.614 | 0.559 | 0.476 | 0.354 |
| SCM [44] | 0.681 | 0.656 | 0.616 | 0.548 | 0.440 |
| ELDA [9] | 0.727 | 0.685 | 0.637 | 0.555 | 0.431 |
| SCEBT [61] | 0.738 | 0.690 | 0.642 | 0.581 | 0.482 |
| KCF [36] | 0.730 | 0.683 | 0.623 | 0.524 | 0.393 |
| TGPR [62] | 0.769 | 0.716 | 0.646 | 0.539 | 0.377 |
| DLT [58] | 0.591 | 0.558 | 0.507 | 0.442 | 0.358 |
| ECT | 0.852 | 0.810 | 0.755 | 0.656 | 0.488 |
| Methods | DLT | DeepTrack | CNT | SO-DLT | ECT |
|---|---|---|---|---|---|
| TP | 0.587 | 0.83 | 0.612 | 0.819 | 0.847 |
| ASR | 0.436 | 0.63 | 0.471 | 0.602 | 0.605 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, C.; Shi, H.; Yu, J.-G.; Sang, N. Enhancement of ELDA Tracker Based on CNN Features and Adaptive Model Update. Sensors 2016, 16, 545. https://doi.org/10.3390/s16040545
Gao C, Shi H, Yu J-G, Sang N. Enhancement of ELDA Tracker Based on CNN Features and Adaptive Model Update. Sensors. 2016; 16(4):545. https://doi.org/10.3390/s16040545
Chicago/Turabian StyleGao, Changxin, Huizhang Shi, Jin-Gang Yu, and Nong Sang. 2016. "Enhancement of ELDA Tracker Based on CNN Features and Adaptive Model Update" Sensors 16, no. 4: 545. https://doi.org/10.3390/s16040545