1. Introduction
Smartphone have become omnipresent personal computing platforms for users to access Internet services whenever and wherever. Recent surveys [
1,
2] show that as more and more private information and security information are stored in smartphones (e.g., 92.8% of Android smartphone users store private information in their smartphones), the risk of information leakage is becoming a major concern for the information society [
3]. The most common mechanism to address this problem is authentication. Smartphone users mainly adopt PIN-based passcodes, pattern-based passcodes, or fingerprints as the primary ways, which have been integrated into current smartphone systems. However, most passcodes are simple and easily guessed due to users’ preference for convenience and memorability [
4,
5]. Some recent studies also showed that users’ passcodes can be inferred through the smartphone onboard sensors [
6,
7], or through the smudges left on touchscreen surface [
8]. The fingerprint-based methods usually require auxiliary hardware, and it is only applied in iOS and a few Android devices. Recently, attackers were able to even get fingerprints from public events with help of a standard camera, and then use these fingerprints for smartphone authentication [
9].
Of various potential solutions, a particularly promising technique is the use of sensory data from the smartphone’s onboard sensors, which measures a user’s touch-input action characteristics when inputting passcodes [
10,
11]. Compared with biometric features for smartphone authentication such as face and touch-interaction behavior (e.g., touch-sliding behavior), onboard sensor behavior does not need special hardware and root access privilege on smartphones to obtain biometric data, and is less sensitive to users’ privacy. Thus it may provide a non-intrusive and implicit solution for enhancing the passcode-based authentication mechanisms.
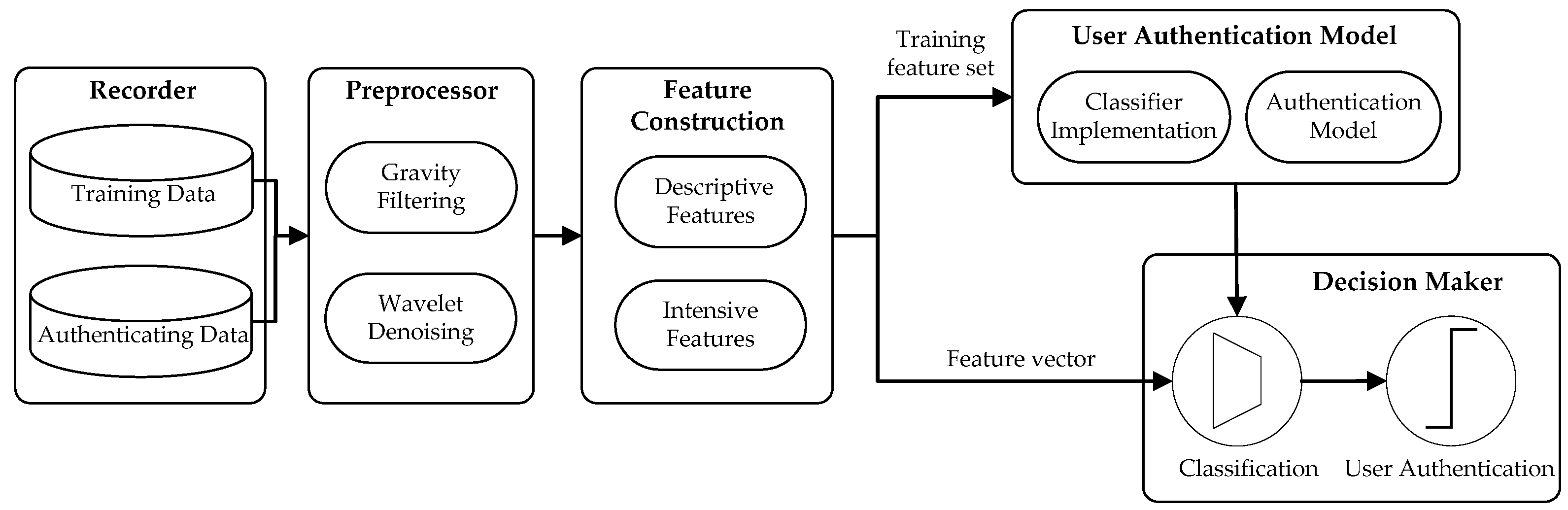
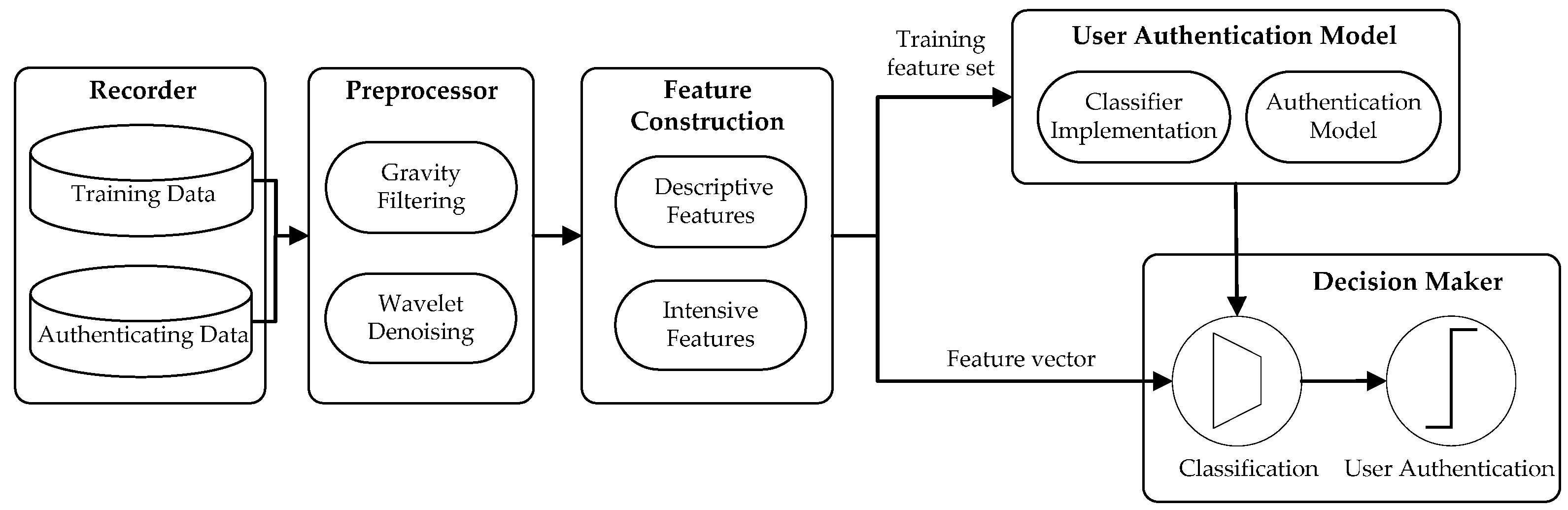
In this paper, we present a feasibility and applicability study of using motion-sensor behavior for user authentication on smartphones. The rationale behind our work is that touch-input actions from different users would generate different levels of posture and motion change of smartphones which may exhibit the unique behavioral characteristics of individuals. When a user input his/her passcode on smartphones, the sensory data from accelerometer and gyroscope are recorded. We extract descriptive and intensive features for accurate characterization of motion-sensor behavior induced by users’ passcode-input actions, and conduct an empirical feature study to measure the stability and discriminability of these features. We employ three types of one-class classifier to conduct the task of user authentication. We then perform extensive analyses using data from 48 participants with 129,621 passcode-input samples across various operational scenarios and different types of smartphones. We also examine the performance on usability with respect to passcode length, sensitivity with respect to training sample size, scalability with respect to the number of users, and flexibility with respect to smartphone screen size, to further analyze the effectiveness of the proposed approach. It should be noted that we do not propose our motion-sensor-behavior based authentication method as the sole authentication mechanism but rather as a complementary mechanism that can be used to improve security in smartphones. As an example, when a user unlocks his/her smartphone with a passcode, the passcode as well as the sensory characteristics will be examined. The main purpose and contributions of this paper are summarized as follows:
We present an empirical work analyzing motion-sensor data for smartphone authentication, and analyze the feasibility and applicability of authenticating a user based on the characteristics of motion-sensor data across various operational scenarios and different types of smartphones, which can be easily integrated with existing smartphone authentication mechanisms.
We model the behavior of accelerometer and gyroscope sensors by proposing descriptive and intensive features, such as descriptive statistics and information entropy of sensor-data sequences, to characterize a user’s passcode-input actions in a robust and accurate manner. These features could lead to a performance boost in stability and discriminability of authentication performance. We also employ three types of one-class classifier to build the authentication model, so that the model can be trained solely on the samples from the legitimate user, and we could examine whether an observed effect is specific to one type of classifier or holds for a range of classifiers.
We examine the proposed approach in terms of usability with respect to passcode length, sensitivity with respect to training sample size, scalability with respect to the number of users, and flexibility to screen size, to further examine the applicability and generalization capability of the proposed approach.
A public sensory behavior dataset is established (see
Section 4 for availability), not only for this study, but also to foster future research. This dataset contains high-quality behavior data of smartphone sensors from 48 subjects. To our knowledge, this study is the first to publish a shared sensory dataset for smartphone authentication.
This study systematically evaluates user authentication on smartphones by analyzing behavior of accelerometer and gyroscope sensors, and extensive analyses across various operational scenarios and different types of smartphones show the proposed approach can perform user authentication with a high degree of accuracy. These results suggest that sensory data could provide auxiliary authentication information, and this level of accuracy approaches sufficiency for two-factor authentication for passwords or PINs on smartphones.
The structure of the paper is as follows:
Section 2 introduces related work.
Section 3 introduces the model.
Section 4 describes the data acquisition process.
Section 5 introduces the process of data processing and feature extraction.
Section 6 details the authentication architecture.
Section 7 expounds on the classifier training and testing process, then explains the evaluation methodology.
Section 8 presents the experimental results.
Section 9 summaries this paper, and discusses future work.
4. Sensor-Data Acquisition
This section explains how we design passcode-input tasks, set up a data-collection platform, and recruit subjects to perform the tasks. Here we offer details regarding process of data acquisition, because these particulars can best reveal potential biases and confounds to experimental validity [
27]. Our dataset is available [
28].
4.1. Operational Scenarios
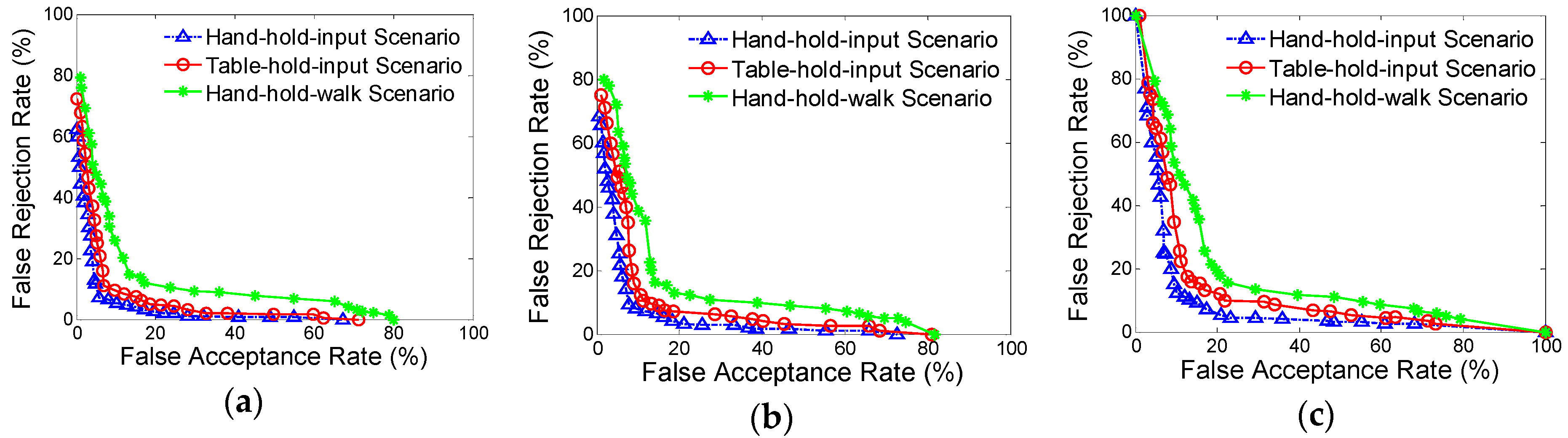
To systematically investigate the feasibility of using motion-sensor behavior for smartphone authentication, we design three types of operational scenarios for collecting motion-sensor data, which would roughly cover user’s routine passcode-input actions:
Hand-hold-input scenario: Users are asked to operate smartphone for authentication when sitting or standing steadily.
Table-hold-input scenario: Smartphones are placed on the desktop, and users were asked to perform authentication actions using a single hand.
Hand-hold-walk scenario: Users operate smartphones and perform passcode-input action for authentication when walking.
4.2. Apparatus
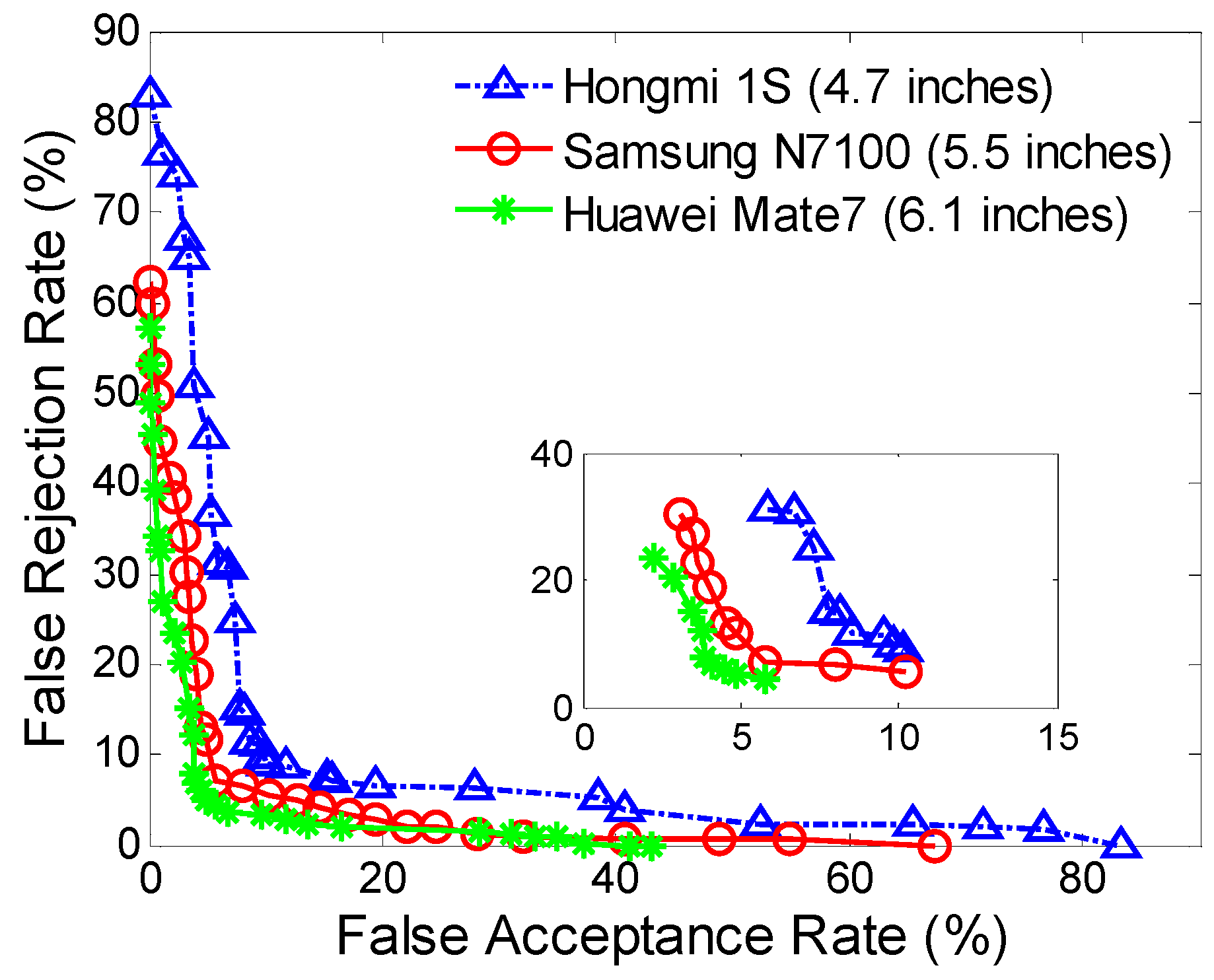
We establish a free experimental environment on Android smartphones and develop an App as uniform hardware and software platform for the collection of motion-sensor data. We set up three different types of smartphones, each operating on Android 4.4.x. The smartphones are a Huawei Mate7 with a 6.1-inch screen, 1.5 GHz processor, and 2 GB RAM; a Samsung N7100 with a 5.5-inch screen, 1.6 GHz processor, and 2 GB of RAM; and a HongMi 1s with a 4.7-inch screen, 1.6 GHz processor, and 1 GB of RAM.
The smartphone App, written in Java, prompts a user to conduct an authentication (
i.e., smartphone unlocking) task. During data collection, the application displays the task in a full-screen window on the smartphone, and records (1) the touch-input actions; (2) the motion-sensor data (
i.e., accelerometer and gyroscope) during touch-input actions; and (3) the timestamps of the operations. The default timing clock is used to timestamp touch-input actions [
29], which has a resolution of 10 ms, corresponding to 100 updates per second.
4.3. Stimulus Materials
Designing passcode-input tasks for such an evaluation is subtle. It is often more realistic to let subjects choose their own passcode inputs. Yet data collection becomes harder since different impostor samples would be needed for every task. Some studies suggest that letting subjects choose their own tasks makes it easier to distinguish them [
30,
31]. If this is true, then letting subjects choose their own tasks can bias the results of an experiment designed to assess performance on an arbitrary task. Thus we decide the same tasks would be undertaken by all subjects.
To make passcode-input tasks representative of typical and diverse combination of input actions, our stimulus materials consist of three passcodes with different lengths, 0-4-3-9, 0-1-4-7-8, and 0-1-4-3-6-7, and require subjects to type without hyphens to unlock the smartphone. The same passcodes are assigned to all subjects, as opposed to having each subject select passcodes of their own. The reasons for this choice are that: (1) Self-chosen passcodes may be of different lengths, which make users’ typing hard to compare; (2) Self-chosen passcodes may be easy to type (or particularly hard to type), which may introduce biases that are difficult to control; (3) Same passcode can make each subject be treated as impostor for other subjects, putting the authentication test on an equal basis; (4) Same passcode can reduce the effect of experimental control over unanticipated biases.
It is worthy of note that our passcodes are not unique. However, the passcode sequences span the keypad, and a finger typing this sequence travels both of the diagonals, and a vertical. Besides, since we had only one chance to accomplish every passcode, we chose a passcode from which we can learn most. The passcodes are chosen to cause smartphone users to perform a wide variety of finger movements on touchscreen.
4.4. Subjects
We recruited 48 volunteers (29 males and 19 females) from among students and faculty from our university. All subjects were skilled smartphone users with at least one year’s experience, and five of them were left-handed. The age ranged from 18 to 50 years (mean = 25.6, s.d. = 4.2).
4.5. Data Collection Process
Subjects are required to conduct fifty-four rounds of data collection (three operational scenarios × three smartphones × two rounds for each subject × three types of passcodes), and to wait at least one day between two rounds (ensuring that some day-to-day variation existed within our data). In each round of data collection, subjects are asked to type the passcode about 50 times on the number pad (under the application of smartphone unlocking). All 48 subjects remained in the study, and each subject contributed around 2,700 passcode-input samples (mean = 2721, median = 2758, min = 2601, max = 2822, and s.d. = 33.7). Subjects took between 90 and 120 days to complete the data collection, and the final dataset contains 129,621 authentication samples from 48 subjects. During data collection, when subjects input a passcode on the touchscreen, for each number of the passcode, the application records the tapped number, the timestamps of action starting (ACTION-DOWN) and action ending (ACTION-UP) (i.e., the down and up of a passcode-input action), and the data sequences of motion sensors during the period of ACTION-DOWN and ACTION-UP for the passcode-input action. For each motion sensor, three data sequences are collected to represent the data from three axes of the sensor.
Subjects are told that if they needed a break or needed to stretch their fingers, they were to do so after they have completed a task. This is intended to prevent artificially inconsistent passcode-input actions in the middle of a task. Subjects are admonished to focus on the task, as if they are unlocking their own smartphones, and to avoid distractions while the task is in progress. Besides, in the table-hold-input scenario, we observe that all subjects tap with her/his dominant hand. While in other two scenarios, we find that all the subjects hold the devices with one hand and type with the other hand, and the smartphone is in the portrait mode. In addition, to trigger the interaction in a natural way, the subjects are explained the purpose of the study after finishing all data collection.
9. Discussion and Conclusions
This work is the first study of evaluating and investigating motion-sensor data for smartphone authentication across various operational scenarios and different types of smartphones. Extensive experiments examine the reliability and practicability of the proposed approach, and show that the approach can achieve a FAR of 3.92% and FRR of 4.97% in some cases. However, this result is still less than the European standard for commercial biometric technology (which requiring a FAR of 0.001% and a FRR of 1% [
41]). Thus, further progress is needed before we can depend solely on motion-sensor behavior as a standalone authentication mechanism on smartphones. But these findings do suggest that sensory data could provide useful authentication information, and this level of accuracy approaches sufficiency for two-factor authentication for passwords or PIN numbers on smartphones.
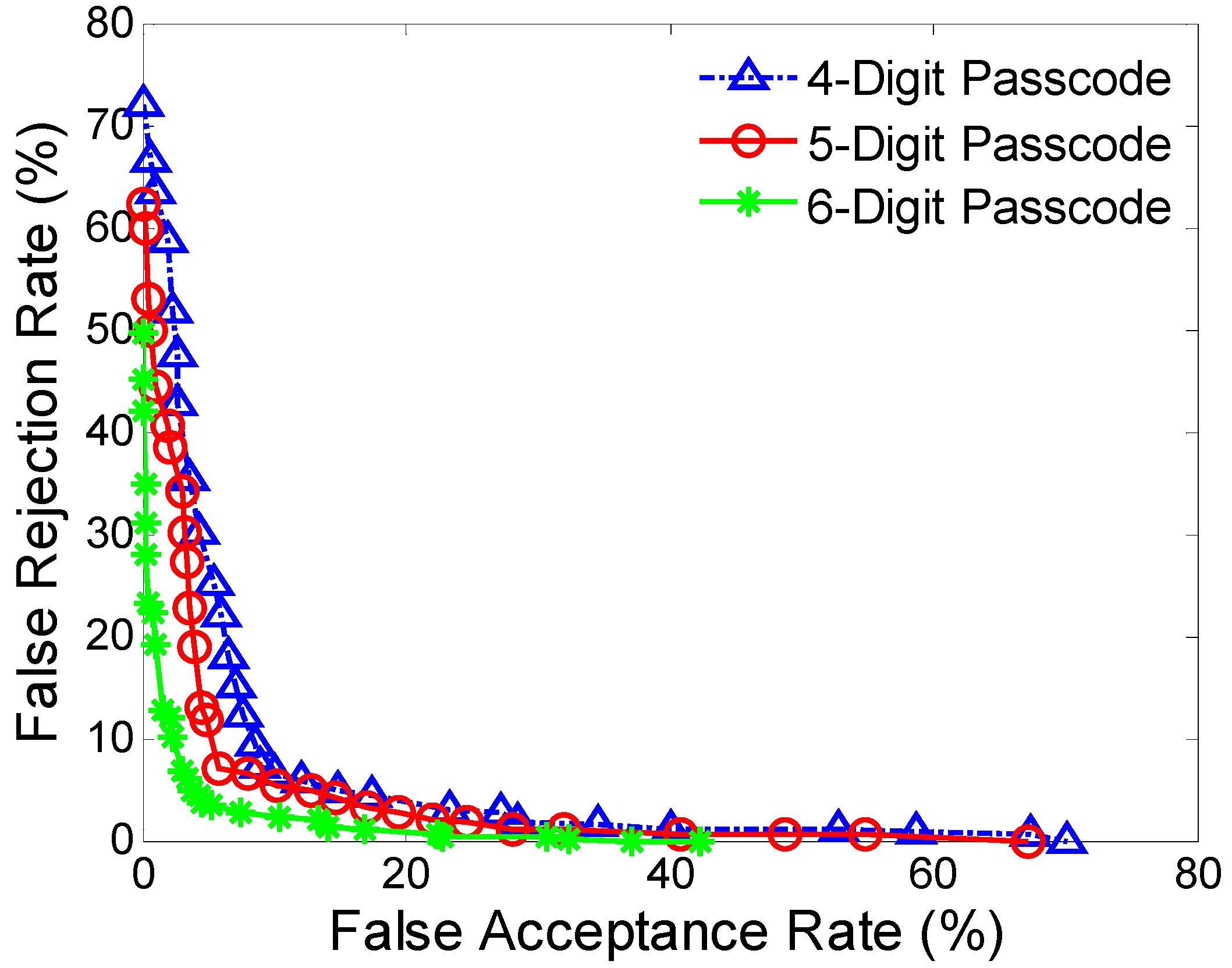
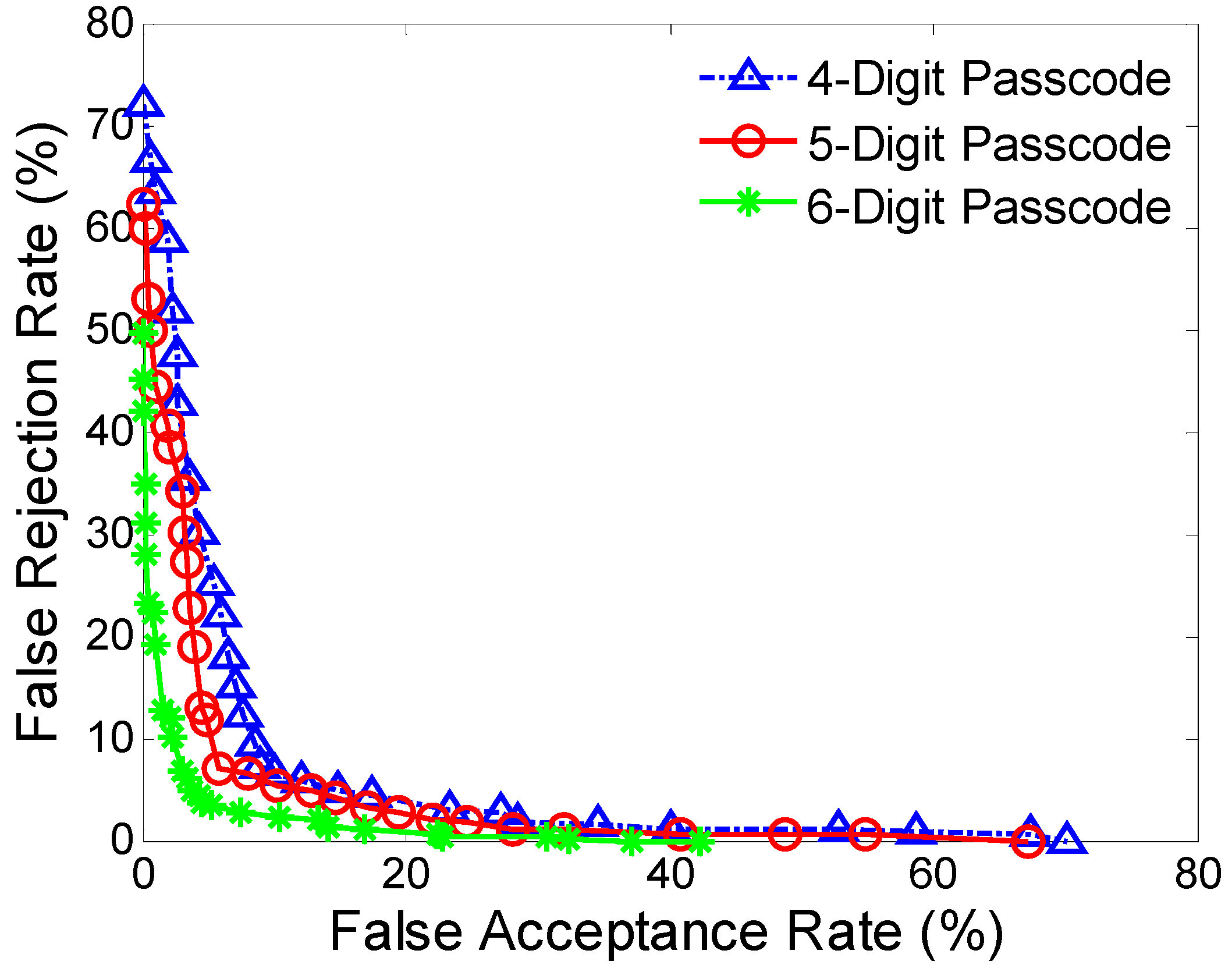
We analyze the effect of passcode length on authentication performance. The authentication accuracies become better as passcode length increases, and the reduced standard deviations indicate better robustness. However, we note that the time needed for completing an authentication increase with the increase of passcode length, which means a balance need to be made between authentication accuracy and authentication time. One possible way of improving this problem is to employ some newly developed tactics from “streaming classification” algorithms [
42,
43], by which we may be able to use less data to make authentication decisions with acceptable levels of accuracy.
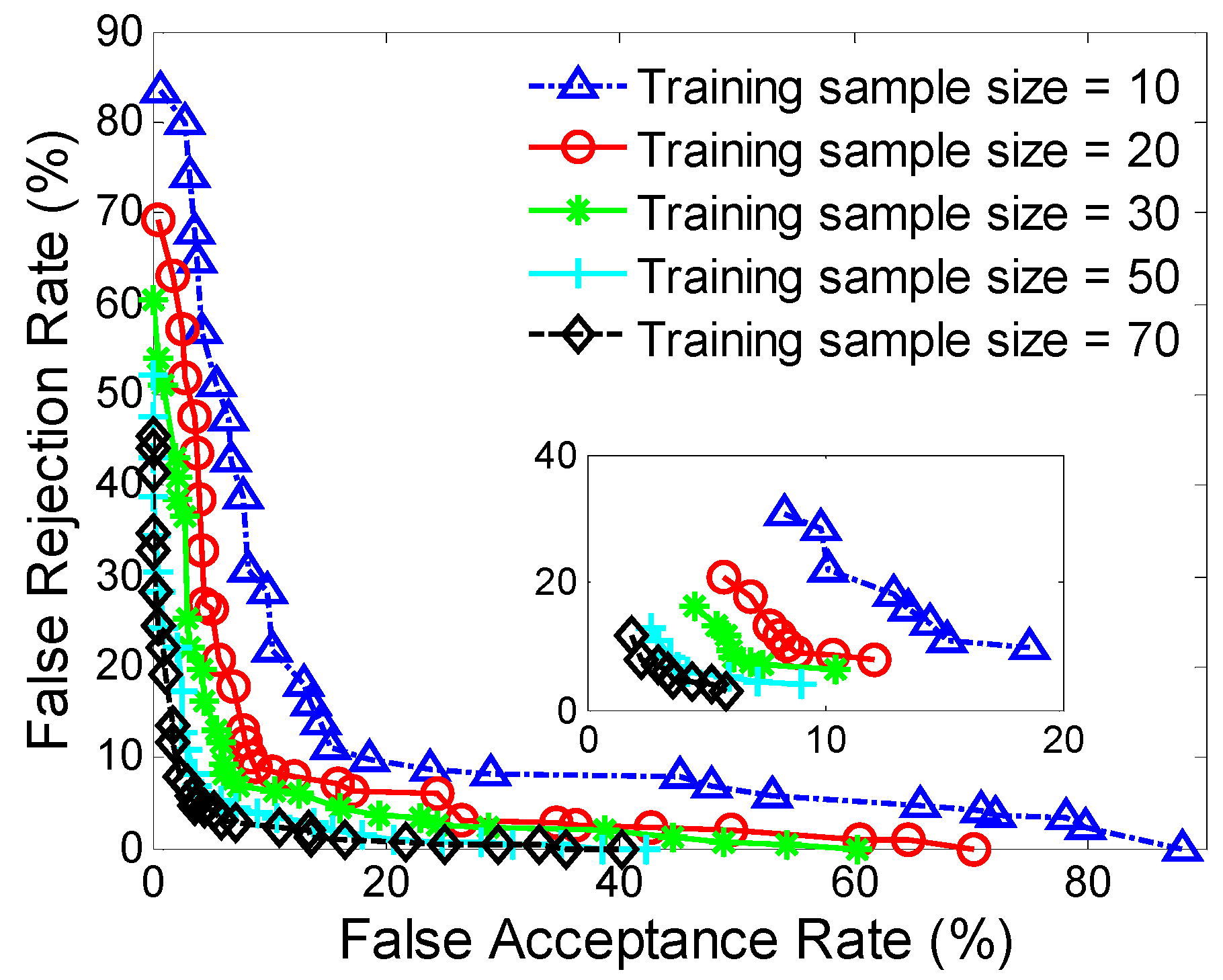
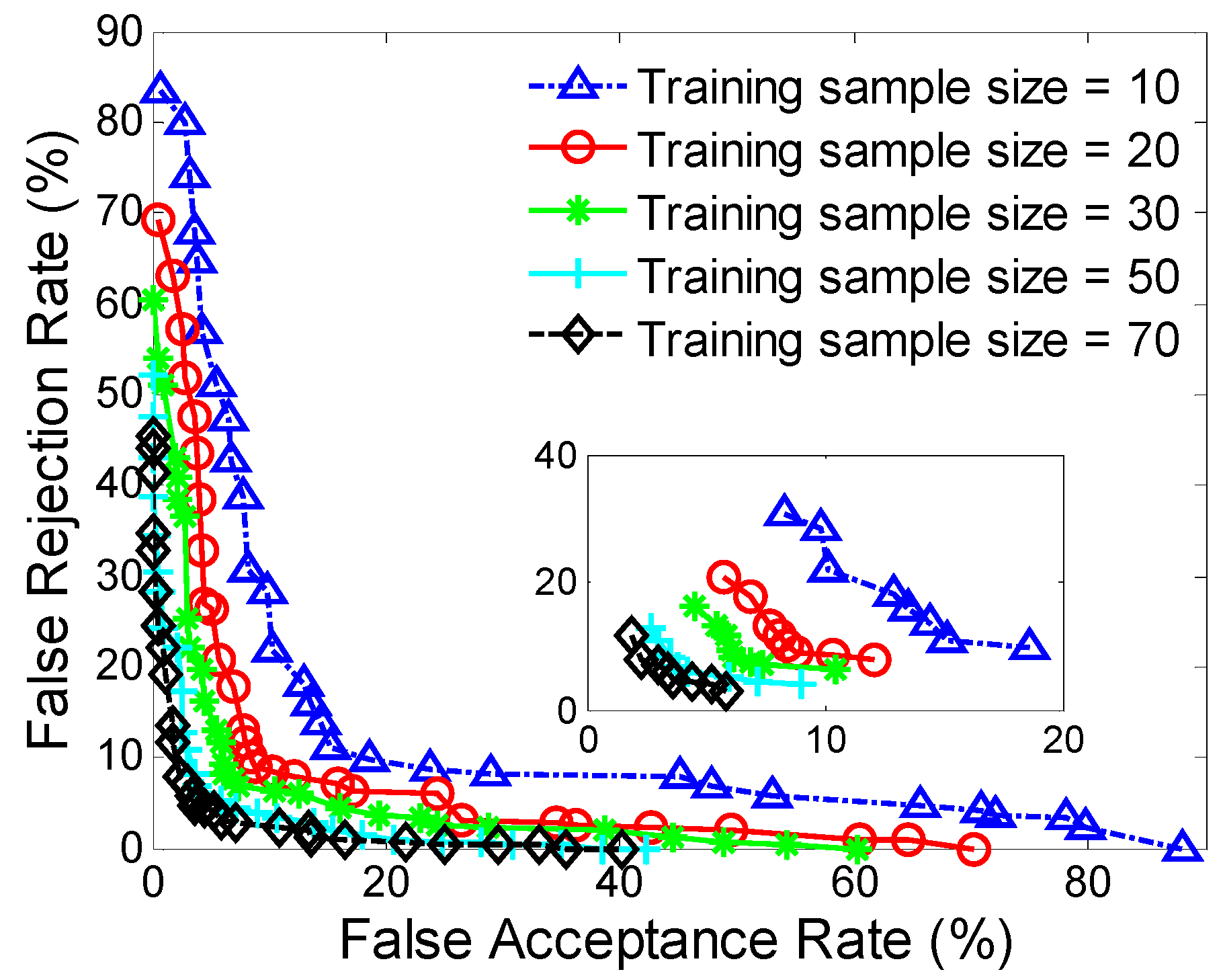
We examine the effect of training data size on smartphone authentication performance. The authentication accuracies improve as the training data size increases. However, a large training sample size will usually result in long training process for users and relatively-high computational complexity. In our evaluation, the FAR and FRR are less than about 9% when using 30 samples for model training, which indicates this technique supports the usage of a relatively small set of training data to authenticate users. One possible way to further decrease training data size while keeping accuracy may be to reduce the noise in raw data for obtaining higher quality data, which might build an accurate authentication model over smaller amounts of training data.
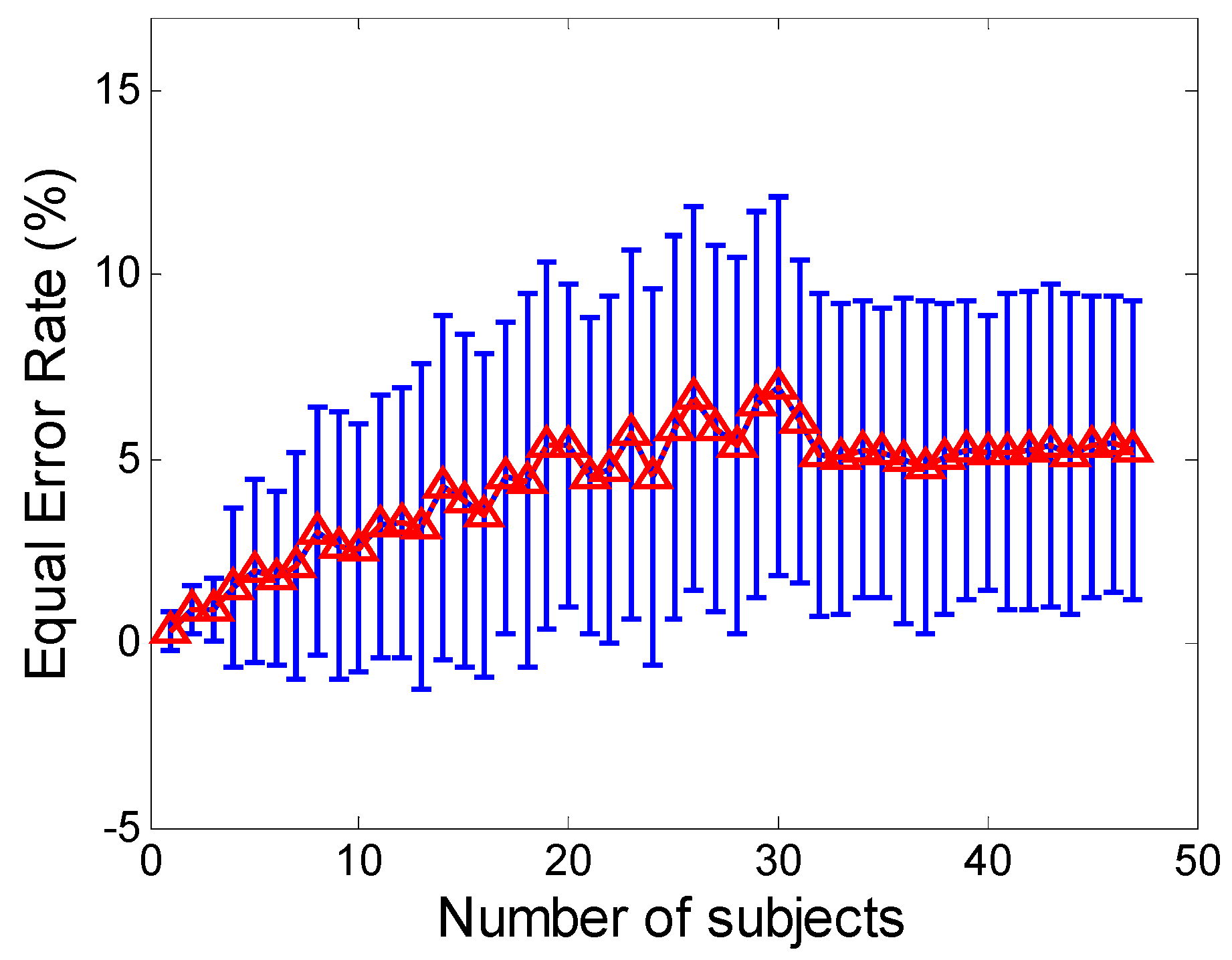
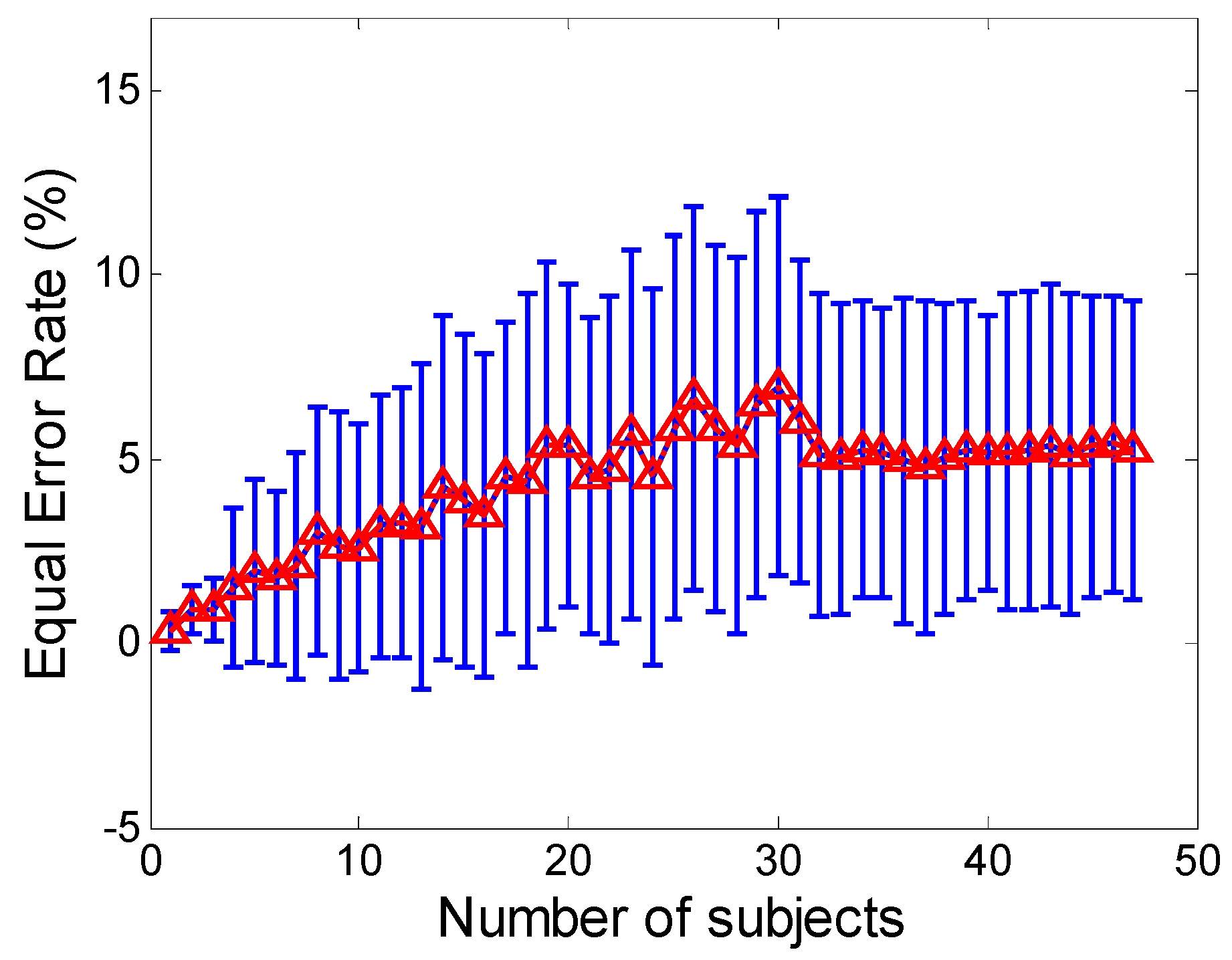
Another important issue about our approach concerns its scalability. We explore the authentication accuracy against different sizes of user space. The EER increases as the user space becomes larger, especially for the small sizes. There also observes the EER become relatively stable when the user size is larger than a certain number of users, and only small fluctuations with the error range are apparent. These results present that how the space of user profiles fills in as the number of users increases, and also demonstrate the influence of user space on sensor-based smartphone authentication may be minimal when the user space exceeds a certain size.
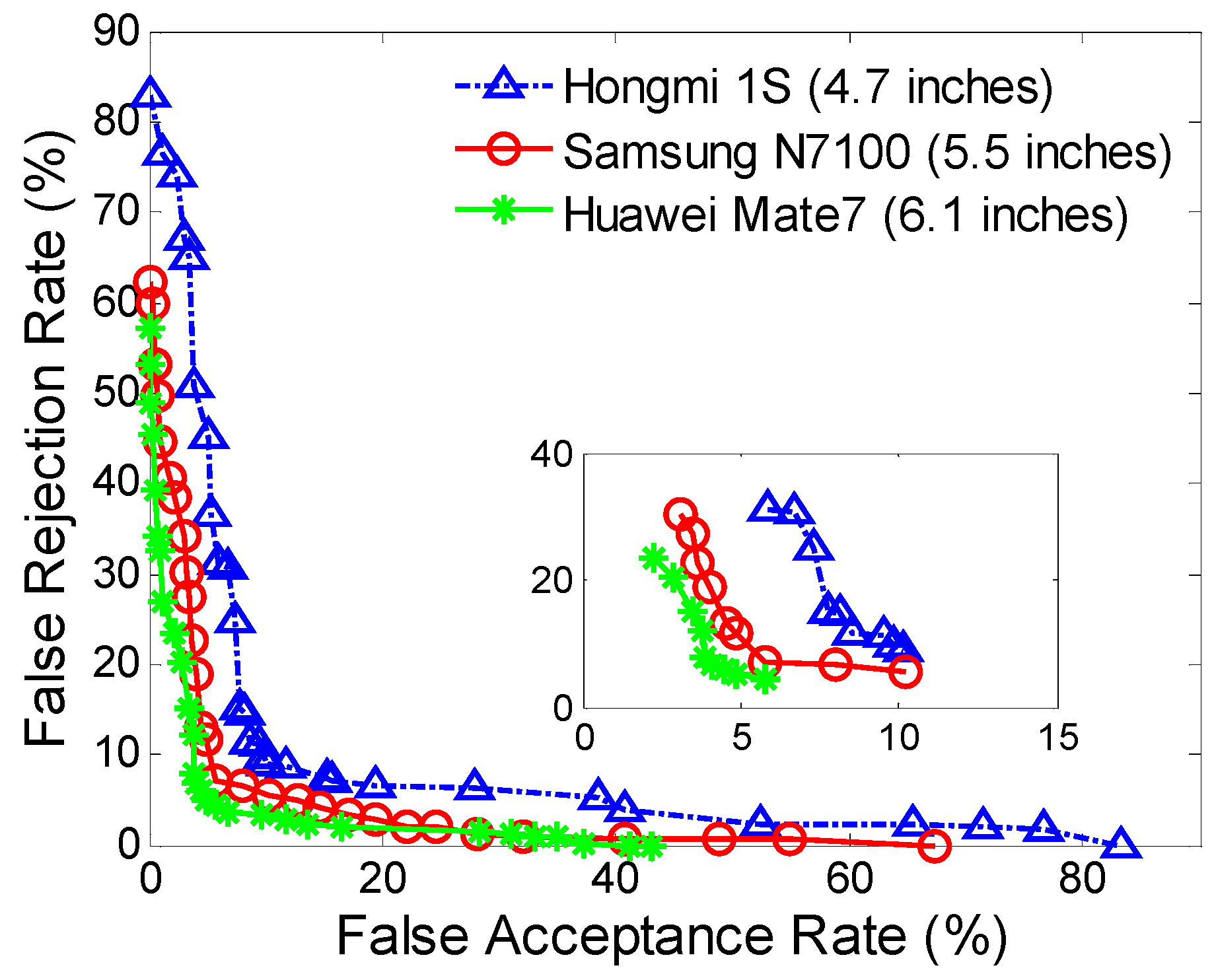
We explored the proposed approach across different types of smartphone screen sizes. The authentication with a larger screen size exhibits better accuracy than those with smaller screen sizes. This may be due to the fact that input actions on a larger area have better uniqueness and robustness than the ones on smaller areas. Currently, the mainstream smartphones have screen size around 5 inches; while in our evaluation, the authentication on the smartphones with screen sizes around 5 inches have a FAR of 5.01% and a FRR of 6.85%, which further presents a proof-of-concept analysis to demonstrate the effectiveness of this technique.
For authenticating a user’s identity through the motion-sensor behavior, one important thing is that the registration and authentication process should take place in a secure environment, to avoid impostors maliciously manipulating users’ profile data. In our system implementation, we consider a simple way to secure the profile data by storing it in an encrypted domain (using standard encryption techniques of AES), but this may lead to the risk of leaving the profile data exposed during each authentication. A securer way is to employ a transformation function to the profile data [
44], and only store the transformed profile data. Besides, during the profile generating phase, users’ identity should be checked in some alternative way, and the production of sensor-behavior samples should be limited to a few days, not to weeks or months.
When behavior-based techniques are utilized for user authentication, it may raise concerns about user’s privacy. At least users should be aware that they are under observation, and should also understand that every security policy must imply a limitation of their privacy in some way [
45]. Compared with other behavior-based authentication methods (e.g., keystroke dynamics may record users’ passwords and some sensitive textual information), the motion-sensor behavior analysis records the information of a smartphone’s posture and gesture change when the user inputs passcode on smartphone, and will have to be blurred for the privacy concern. The recorded sensor data would be stored in terms of sensor features and the corresponding timing information, and are made available exclusively to authentication process, which giving away little information about users’ smartphone activities and credentials.
There is still much space to improve the performance of sensor-based smartphone authentication. One way may be to analyze variability and noise in motion-sensor behavior, and then to develop effective methods to mitigate the impact of these factors, which are also critical to extract stable and discriminative behavior features. Other ways may be to clean the raw senor data of extraneous noise for obtaining high quality data, or to establish sophisticated pattern classifiers (e.g., the ensemble approach) that are robust to variable behavior data.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}