Adjustment of Measurements with Multiplicative Errors: Error Analysis, Estimates of the Variance of Unit Weight, and Effect on Volume Estimation from LiDAR-Type Digital Elevation Models

Abstract
: Modern observation technology has verified that measurement errors can be proportional to the true values of measurements such as GPS, VLBI baselines and LiDAR. Observational models of this type are called multiplicative error models. This paper is to extend the work of Xu and Shimada published in 2000 on multiplicative error models to analytical error analysis of quantities of practical interest and estimates of the variance of unit weight. We analytically derive the variance-covariance matrices of the three least squares (LS) adjustments, the adjusted measurements and the corrections of measurements in multiplicative error models. For quality evaluation, we construct five estimators for the variance of unit weight in association of the three LS adjustment methods. Although LiDAR measurements are contaminated with multiplicative random errors, LiDAR-based digital elevation models (DEM) have been constructed as if they were of additive random errors. We will simulate a model landslide, which is assumed to be surveyed with LiDAR, and investigate the effect of LiDAR-type multiplicative error measurements on DEM construction and its effect on the estimate of landslide mass volume from the constructed DEM.1. Introduction
Theory and methods of adjustment have been developed, both with the advance of measurement technology and with our deepened understanding of measurement errors. Although manufacturers of surveying instruments would always provide accuracy specifications [1], these specified numbers may not correctly reflect the nature of the errors of collected measurements. To understand the performance of a surveying instrument in practice, or equivalently, to obtain the accuracy of the instrument for a specific set of measurements, Airy [2] and Helmert [3] invented the theory and methods of variance component estimation, which has since become one of the important topics in statistics, geodesy and beyond (see e.g., [4–6]). If measurements are supposed to contain outliers, outlier detection and robust statistics are developed (see e.g., [7–13]). If prior information is available, Bayesian statistics and least squares collocation are accordingly borne naturally. To precisely determine the best trajectory of an object in motion, the theory and methods of optimal filtering, smoothing and control are incepted with the celebrated publication of Kalman [14]. Recently, with the advance of space observation technology such as global positioning system (GPS) and interferometric synthetic aperture radar (InSAR) (see e.g., [15–17]) and their wide applications, we have to handle observational models that contain real-valued and integer unknowns, which have been coined as mixed integer (linear) models by Xu [18].
Almost all theory and methods of adjustment have been developed on the basis of the following mathematical or functional model:
The observational model (4) is called a multiplicative error model, which is widely known as a generalized linear model in statistics (see e.g., [27,28]). In engineering, it is also called a multiplicative speckle model (see e.g., [21,24]). The most widely used method in statistics to handle such a model is the quasi-likelihood method, which was invented by Wedderburn [27]. Quasi-likelihood has since become a standard method for parameter estimation in the model (4) and been widely applied in practice (see e.g., [29–32]). Mathematically, the method directly solves a set of nonlinear equations for the unknown parameters without any link to an objective function. As a result, Wedderburn [27] showed that the method is equivalent to maximum likelihood, if and only if the joint probability density function (pdf) of measurements is of exponential class. Unlike Wedderburn [27], Xu and Shimada [33] did not assume any pdf for the measurements with multiplicative errors. Instead, they directly started with the least squares (LS) method and derived the bias-corrected LS method for parameter estimation in the model (4).
A digital elevation model (DEM) is a numerical or digital representation of the topography of the Earth. A number of mathematical interpolators have been proposed for the construction of a DEM on the (implicit) assumption that the measurements are contaminated with additive random errors (see e.g., [34–36]). Recently, robust methods have also been proposed to construct a DEM by allowing the measurements to contain a certain percent of erroneous data (outliers) (see e.g., [37,38]). DEMs have found important applications in hazard assessment for disaster prevention and/or mitigation, for example, in landslide analysis [39,40], in construction of hazard maps [41] and to help reconstruct the history of hydrological and glacial events (see e.g., [42]). Practically, a DEM can be constructed by using remote sensing techniques such as (In)SAR and light detection and ranging (LiDAR). Although (In)SAR and LiDAR measurements have been well known to be of speckle (or multiplicative) noise, they have been used to construct a DEM as if these types of measurements were of additive random errors (see e.g., [37,39,43–45]). One of the purposes of this paper is to extend the methods of DEM construction to the case in which measurements are contaminated with multiplicative random errors and investigate their effect on the estimate of volume computed from LiDAR-type DEM, which can be important in practical hazard evaluation of landslides.
Although the errors of GPS, EDM and VLBI baselines and measurements of InSAR and LiDAR have been shown to be of multiplicative nature, almost nothing can be found in the geodetic and DEM literature, except for Xu et al. [46]. In this paper, we will limit ourselves to the model of multiplicative errors and substantially extend the work of Xu and Shimada [33]. We will not assume any pdf for the measurements with multiplicative errors. The paper is organized as follows: Section 2 will briefly outline three LS-based methods for parameter estimation. We will focus on analytical error analysis of all adjusted quantities of interest in Section 3, which further supplements the work of Xu and Shimada [33] in the sense that they mainly discussed parameter estimation and stochastic/numerical simulations. The error analysis of quantities other than model parameters is not covered by Xu et al. [46] either. In Section 4, we will derive the estimators of variance of unit weight in association with the three LS-based methods. Finally, we will simulate an example of DEM construction from LiDAR-type data contaminated with multiplicative random errors and investigate their effect on the estimate of volume from the constructed DEM.
2. Parameter Estimation in the Model with Multiplicative Errors
2.1. Representation of Models with Multiplicative Errors
As in the case of adjustment with additive random errors, given a set of measurements with multiplicative errors, we have the corresponding adjustment model as follows:
2.2. The Three LS-Based Methods for Parameter Estimation
When the ordinary LS method is applied to the linear model (7) with multiplicative errors, we have the following minimization problem:
If the random errors ε(i = 1, 2, …, n) in the model (7) are assumed to be statistically independent with the same variance, the measurements yi(i = 1, 2, …, n) are still statistically independent but are no longer of the same variance or weight. In this case, the weight matrix of the measurements yi(i = 1, 2, …, n) now depends on the unknown parameters β. By denoting , with diag(·) standing for a diagonal matrix, we have the variance-covariance matrix Σy of the measurements y in (7) as follows:
As a result of (10), we can apply the weighted LS method to (7) and obtain the following minimization problem:
Differentiating (11) with respect to the unknown parameters β and letting it equal zero, we have:
The weighted LS estimate β̂WLS of (14) is obviously nonlinear with respect to the measurements y, even though the functional models are linear in the unknown parameters β, since the matrix D̂y and the elements of the second term on the right hand side of (14) are all the nonlinear functions of the weighted LS estimate β̂WLS itself. In general, we can only use numerical methods to solve for β̂WLS. Statistically, Xu and Shimada [33] proved that the weighted LS estimate β̂WLS is biased, even though are linear; this is fundamentally different from the weighted LS estimation in a linear model with additive random errors. They also derived the bias of β̂WLS, and further proved that the bias of the weighted LS estimate β̂WLS is solely due to the fact that the variance-covariance matrix Σy of the measurements y is the function of the unknown parameters β. In other words, the nonzero partial derivatives P̂i in (13) or (14) should be totally responsible for the bias of the weighted LS estimate β̂WLS [33,46]. In the case of linear models with additive random errors, since the variance-covariance matrix of measurements is independent of the unknown parameters, all P̂i are equal to zero. Therefore, they suggested removing the second term on the right hand of (14) and constructed an unbiased estimate as follows:
We should note that formula (15) is the same as that derived by using the quasi-likelihood method, which nevertheless requires the class of exponential distributions in order for quasi-likelihood to be equivalent to maximum likelihood [27]. However, in this paper, we do not assume any distribution for the measurements y. Actually, the estimate (15) is obtained solely from applying the weighted LS principle, indicating that more complicated adjustment with multiplicative errors can also be solved by using the conventional LS estimation principle.
3. Error Analysis of Quantities in the Model with Multiplicative Errors
Since Xu and Shimada [33] only focused on the estimation of parameters and numerical simulations to compute the biases and accuracy of the estimated parameters, we will complement their study by providing an analytical error analysis of the adjusted quantities. We should point out that error analysis is well documented in linear models with additive random errors, but nothing along the same line has ever been available in association with measurements contaminated by multiplicative errors, at least, to our best knowledge. Alternatively, one may carry out an error analysis with an approximate variance-covariance matrix of the measurements, as can be seen in geodetic adjustment of distance networks; but such an analysis cannot serve as a solid theoretical foundation of statistical inference in models with multiplicative errors, the extent of approximation will depend on the model itself, the stochastic model of measurements and prior knowledge on the unknown parameters. In this section, we will only assume the first and second central moments for the measurements y and will derive the accuracy formulae of the estimated quantities for the three LS-based estimation methods. We will limit ourselves to the first order approximation. We should note that some of the theoretical formulae to be given below may contain the unknown parameters, which should be substituted by their approximate values or estimates in practical computation.
3.1. Accuracy of the Estimated Parameters
Applying the error propagation law to the ordinary LS estimate (9) and after taking the variance-covariance matrix (10) into account, we can readily obtain the variance-covariance matrix of β̂LS as follows:
Unlike the ordinary LS estimate β̂LS, (14) and (15) have clearly shown that both the weighted LS estimate β̂WLS and the bias-corrected weighted LS estimate β̂bc are nonlinear with respect to the measurements y. In order to derive their accuracy formulae, we will have to represent β̂WLS and β̂bc in terms of the random errors ε and then follow the definition of variance to derive the variance-covariance matrices of β̂WLS and β̂bc. In this paper, we will limit ourselves to the first order approximation for accuracy assessment. Since the weighted LS estimate β̂WLS is not an unbiased estimate, we will also have to take its bias into account. In other words, we will have to compute the mean squared error matrix of β̂WLS for proper error analysis.
In order to derive the bias of the weighted LS estimate β̂WLS, Xu and Shimada [33] Taylor-expanded β̂WLS with respect to the random errors ε and then truncated the expansion up to the second order term, which is directly written as follows:
We now apply the error propagation law to (17a) up to the first order approximation of ε and as a result, obtain the first order approximation of the variance-covariance matrix of the weighted LS estimate β̂WLS as follows:
Denoting the bias of β̂WLS by E(bβ), we can finally obtain the mean squared error matrix as follows:
3.2. Accuracy of the Adjusted Measurements
By using the ordinary LS estimate β̂LS in (9), we can readily compute the corresponding LS adjusted values of the measurements:
In the similar manner, based on the weighted LS estimate and the bias-corrected weighted LS estimate and by using the formulae (19) and (20), we can directly obtain the adjusted measurements computed from the weighted LS estimate and the bias-corrected weighted LS estimate, and their mean squared error (MSE) and variance-covariance matrices, respectively, as follows:
3.3. Accuracy of the Corrections of Measurements
As is well known, the corrections of measurements are important quantities in practical data processing and quality assessment/control. We denote the corrections of measurements as follows:
By linearizing (24a), (25a) and (26a) with respect to the random errors ε, and after applying the error propagation law to the linearized corrections of measurements, we can then derive their corresponding variance-covariance matrices:
Because the weighted LS estimate is biased, the corresponding corrections of measurements should also be biased. The bias of VWLS can be directly computed from the bias of the weighted LS estimate β̂WLS. Thus, for proper error evaluation, we have to compute the MSE matrix:
3.4. The Covariances of the Adjusted Quantities
In practical data processing, we are also interested in computing the cross-covariance matrices of the original measurements, the estimated parameters, the adjusted measurements and the corrections of measurements. With the three LS-based methods in hand, if we follow the above lines of thought for the variance-covariance matrices of these quantities, we can then easily derive and obtain their covariances. If we further limit ourselves to the linear approximation in terms of the random errors ε, then the weighted LS estimate and the bias-corrected weighted LS estimate should lead to the same covariance representations. Thus, by omitting the details of derivations, we simply list the cross-covariance matrices among the measurements, the estimated parameters, the adjusted measurements and the corrections of measurements for the ordinary LS and the bias-corrected weighted LS estimates in Table 1.
4. The Estimates of Variance of Unit Weight with the Three LS-Based Methods
The variance of unit weight is one of the most important quantities in statistical quality evaluation and hypothesis testing. Since the measurements are not equally weighted, the conventional estimator of the variance of unit weight by using the ordinary LS residuals of measurements and the redundant number of (n–t) is not unbiased [48]. To estimate the variance of unit weight, we have to start with the naïve or weighted sum of square of the corrections of measurements, find its mathematical expectation in terms of the variance of unit weight σ2 and then estimate σ2.In what follows, we will derive the estimates of the variance of unit weight in association with the three LS-based methods.
From the formula (24b), we can readily derive the mathematical expectation of the sum of square of the ordinary LS corrections of measurements:
If we use the weighted sum of square of the corrections of measurements in (28a), then the corresponding mathematical expectation can be rewritten as follows:
For the weighted LS and bias-corrected weighted LS methods, if the bias of the weighted LS estimate is not significant, both methods should lead to almost the same estimates of the variance of unit weight. In the similar manner to the derivation of the estimate of the variance of unit weight in association with the ordinary LS method, we can readily use (25b) and (26b) to obtain the estimates of the variance of unit weight by using the weighted LS and the bias-corrected weighted LS estimates, which are simply listed, respectively, as follows:
5. Numerical Examples and Practical Effect on the Estimate of Volume from LiDAR-Type DEM
DEM has been playing an increasing role in hazard assessment (see e.g., [39–41]). A precise DEM will reduce the uncertainty of hazard mapping and could help make the operation and management of disaster rescue and support more focused. LiDAR has been widely used to construct DEM (see e.g., [37,39,40,43–45]). Although LiDAR measurements have been proved, both theoretically and experimentally, to be of multiplicative random errors (see e.g., [49–51]), they have been treated as if they were of additive error nature in DEM construction. Thus, this section is to serve two major purposes through numerical simulations: (i) to investigate the effect of LiDAR-type measurements on DEM construction; and (ii) to collectively use the error analysis and the estimates of the variance of unit weight given in the previous two sections to estimate the errors of the volume of landslide mass, since a precise estimate of the volume of a landslide from the constructed DEM can be important in practical hazard evaluation.
In this section, we will follow the website http://geology.com/usgs/landslides/with information on landslides and choose a rotational landslide model to simulate our numerical examples. A landslide of rotational type may create a curved surface. If the reader is interested in the worldwide damaging landslides in the 20th and 21st centuries, she/he may refer to the website http://landslides.usgs.gov/learning/majorls.php of the United States Geological Survey (USGS) for more information, with a landslide ranging from a few to many thousands millions cubic meter. The largest landslide in record seems to be the 1920 Haiyuan landslide, with an area of 50,000 square km and causing 100,000 plus deaths, due to the Haiyuan earthquake of magnitude M8.5, according to the above USGS website.
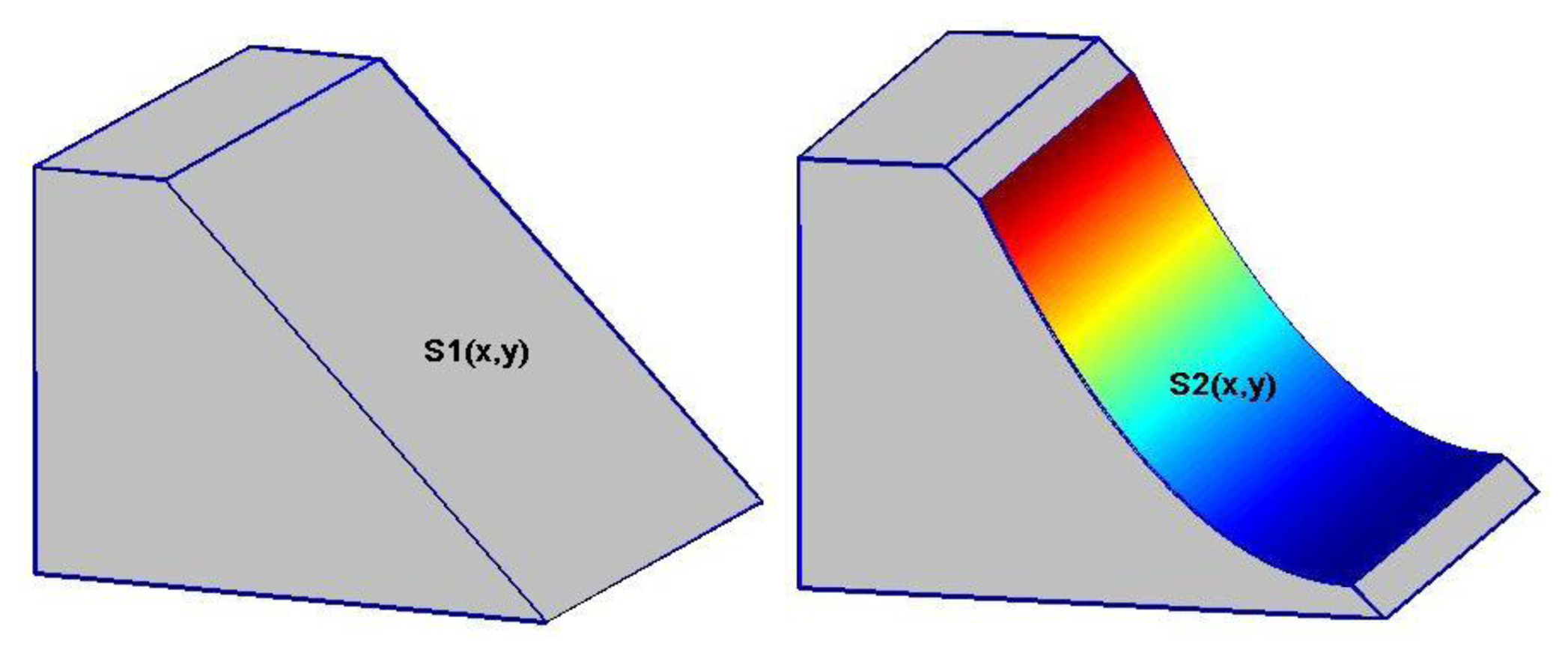
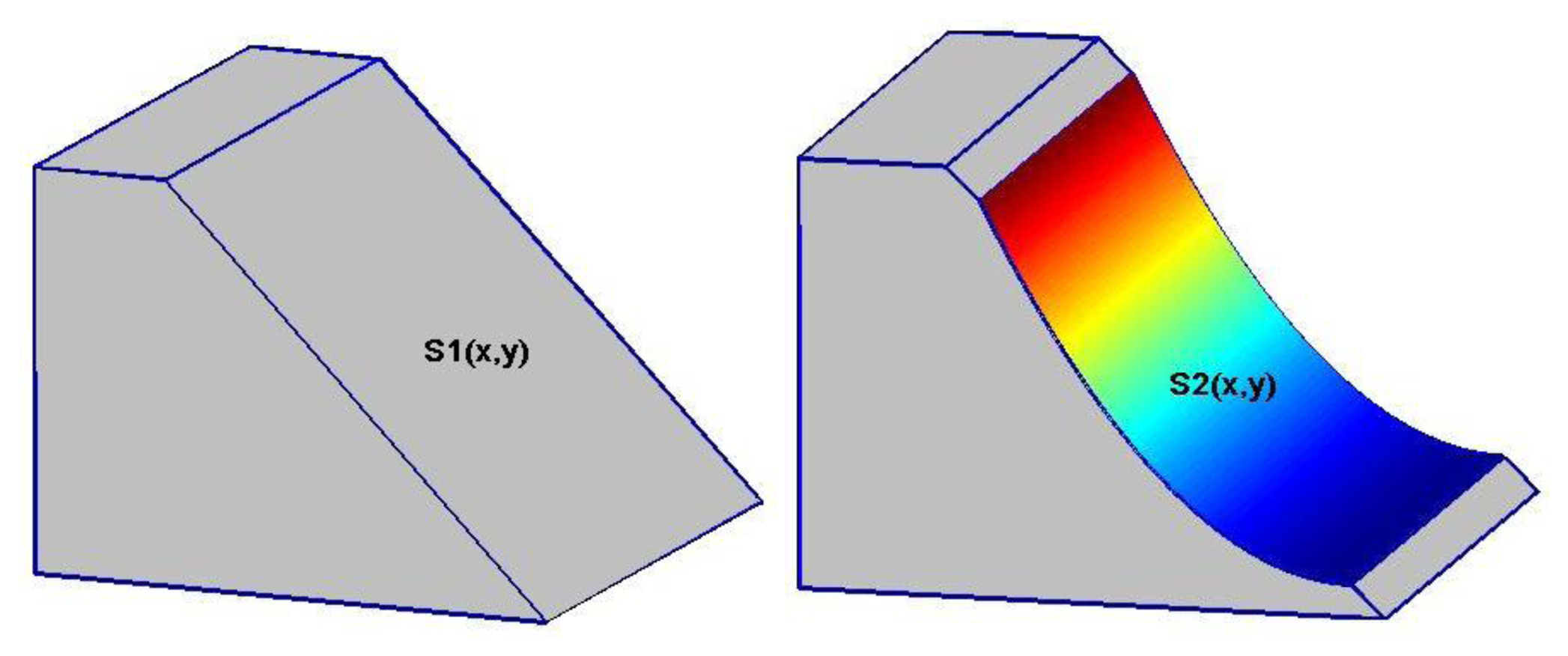
To start with the simulation, we first assume a simple mountain of trapezoidal prism, with a slope of 50°, a height of 700 m and the length of 500 m. We then assume that a landslide occurs along the slope of the mountain, say due to a large earthquake. The design of landslide examples may be illustrated in Figure 1, with the left panel showing the original trapezoidal mountain and the right panel corresponding to the same mountain after the landslide. The volume of landslide mass can be computed by the following integration:
We now assume that DEMs are constructed by using airborne LiDAR before and after the landslide occurs, respectively. The height of flight is fixed at 900 m and the trajectory of the flight is assumed to be free of errors. For simplicity of simulation, we may also assume that the slope plane S1(x, y) before the landslide is sufficiently precise and treated as error-free. Since the surface function S2(x, y) has only six unknown parameters to be estimated for the complete reconstruction of the DEMs after the landslide, we use the uniform distribution to generate 30 LiDAR points for S2(x, y); this number of points is sufficiently large to estimate the variance of unit weight reliably. The standard deviation of multiplicative errors is equal to 0.5 per cent, i.e., σ = 0.005, which is transformed into an equivalent standard deviation of unit weight of 1.268 m for the LiDAR ranging measurements.
With the simulated LiDAR data at hand, we can then estimate the surface S2(x, y) by using each of the three estimation methods given in Section 2 and further compute the estimated volume of the mass due to the landslide, which can be symbolically written as follows:
Listed in Table 2 are the true and estimated volumes of the simulated landslide mass by the three methods. It is clear from Table 2 that the bias-corrected weighted LS method leads to a difference of 38,664 m3 from the true value and performs better than the ordinary and weighted LS methods. The difference between the true volume and that estimated from the ordinary LS method is 80,790 m3, about the double of the difference by using the bias-corrected weighted LS method; a landslide with a size of this difference by itself is sufficiently large to cause severe damaging, when compared to the large landslides of the 20th and 21st centuries listed in the USGS website http://landslides.usgs.gov/learning/majorls.php. Nevertheless, the example has indicated that all the three methods can lead to good results, if the measurements are sufficiently precise.
In order to evaluate the errors of the estimated volume by each of the three methods, we apply the results of error analysis in Section 3 and the estimates of variance of unit weight in Section 4 to the estimate of volume (35) and readily obtain the error estimates for the estimated volumes of landslide mass. By the ordinary LS method one usually means to use (AT A)−1 σ̂2 to represent the accuracy, which is incorrect statistically. In fact, if one would do so, one would end up with a standard deviation of 65,130, which is only about 40 per cent of the correct standard deviation, as will be seen later. The correct error analysis for the ordinary LS method with multiplicative errors should follow Section 3, since too optimistic an incorrect estimate can be disastrous in disaster evaluation. For example, if the magnitude of the 2011 Tohoku mega-earthquake would have not been incorrectly under-estimated by more than one unit, most lives (even if not all) may have survived from the tsunami.
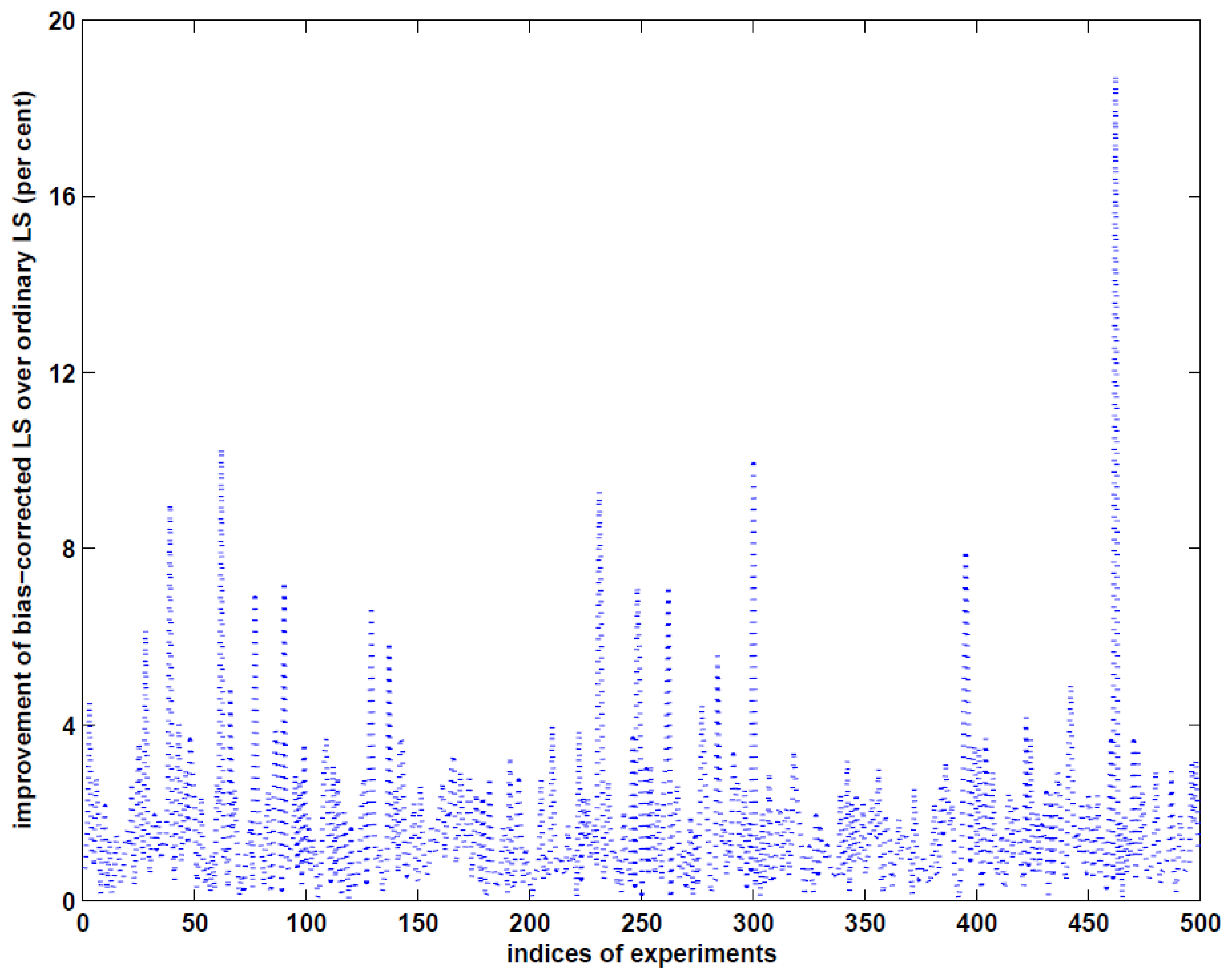
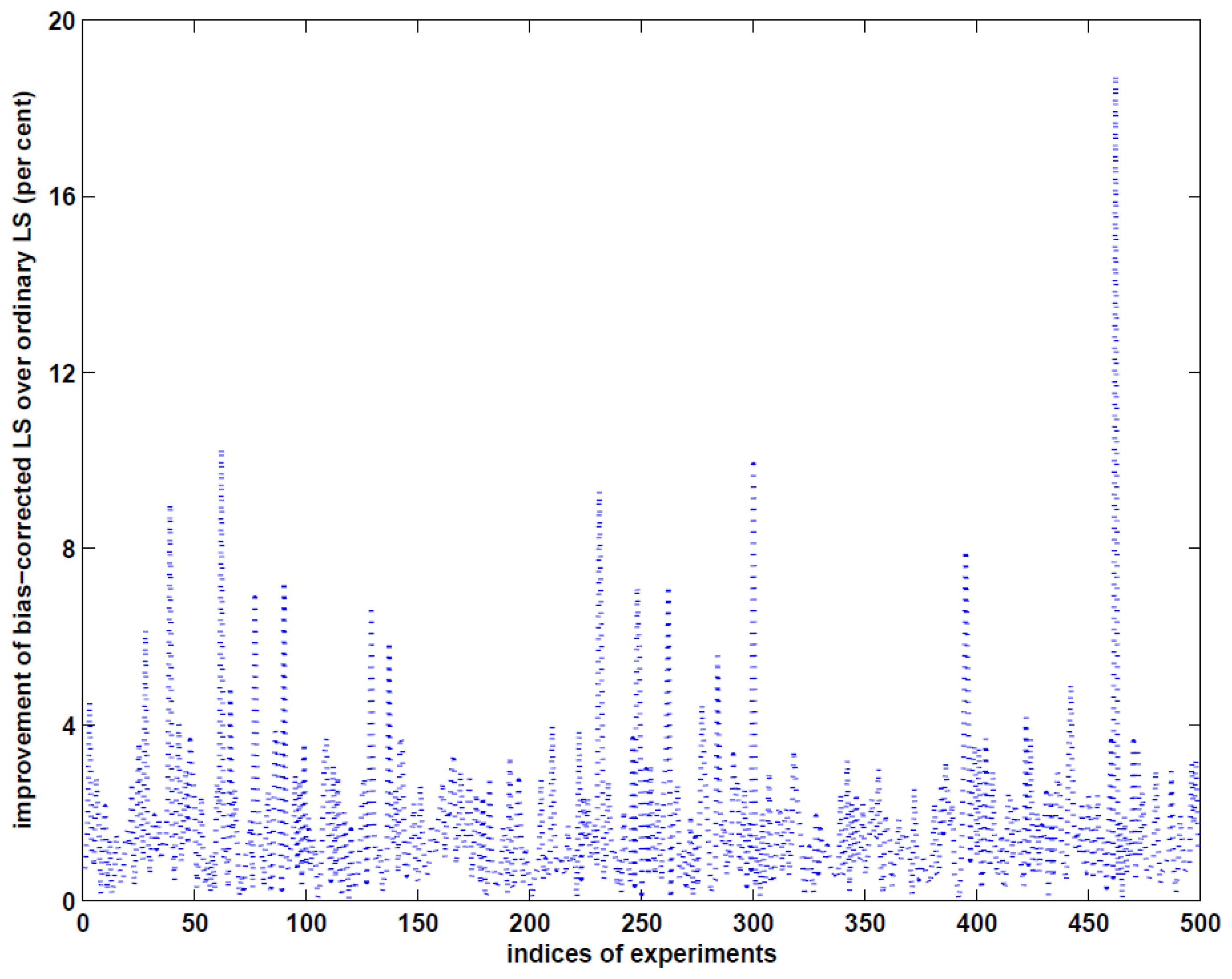
More precisely, to estimate the accuracy of the estimated volume of the landslide, we first estimate the variance of unit weight by using (28b–c) for the ordinary LS method, (30) and (31) for the weighted LS and the bias-corrected weighted LS methods, respectively, and then compute the variance-covariance matrix of the estimated parameters in the case of the ordinary LS and bias-corrected weighted LS methods and the MSE matrix in the case of the weighted LS method. With these results at hand, we can finally apply the error propagation law to (35) and obtain the accuracy of the estimated volume of the landslide by each of the three methods. The MSE roots (RMSE) of the estimated volumes are given in row RMSE of Table 2. Obviously, the RMSE value by the bias-corrected weighted LS method is the smallest, which is nevertheless only better than the ordinary LS method by about 3.5 per cent in this specific example. The results of this example indicate that if LiDAR measurements are sufficiently precise, the three methods are able to precisely estimate the volume of landslide mass with sufficiently good accuracy. One may wonder whether the improvement of the bias-corrected weighted LS method over the ordinary LS method is marginally small. To answer this question, we simulate 500 independent examples with 30 different sampling points and repeat the above procedure to compute the RMSE values. The accuracy improvement of volume estimation with the bias-corrected weighted LS method over the ordinary LS method is shown in Figure 2. Depending on the locations of the measurements, the maximum improvement reaches about 19 per cent, which can have a significant consequence in hazard evaluation. Since the LiDAR measurements are assumed to be very precise, the biases of the estimated parameters from the weighted LS method are very small, as can be seen from the RMSE value in Table 2 in this example.
6. Concluding Remarks
Adjustment has been founded on the basis of observational models with additive random errors to process data in geoscience. The most important feature of an observational model with additive errors is that random errors do not change with the size of a signal or a measurement. However, with the advance of modern space observation technology, we realize that some of random errors change with the sizes of measurements, which may be attributed to the random nature of physical media along the path of observation. For example, GPS, VLBI and EDM baselines, InSAR and LiDAR measurements all show the feature of multiplicative random errors in the sense that their accuracy always contains one term that is proportional to the length of the baseline or the strength of signal. Theoretically speaking, the theory and methods developed on the basis of observational models with additive errors cannot meet the need of models with multiplicative errors. New theory and methods have to be developed accordingly. Xu and Shimada [33] demonstrated that the LS principle can be used to adjust observational models with multiplicative errors, unless the induced bias in the weighted LS estimate can be removed.
This paper has substantially extended the work by Xu and Shimada [33] by supplementing a complete error analysis for the quantities of interest. We have derived the cross-covariance matrices among such quantities. Since the variance of unit weight has been one of the most important quantities in statistical analysis of measurements and hypothesis testing, we have also constructed five estimators that correspond to the ordinary LS, the weighted LS and the bias-corrected weighted LS methods. Although LiDAR measurements have been known, theoretically and experimentally, to be of multiplicative error nature (see e.g., [37,39,43–45]), they have been used to reconstruct DEM as if they were of additive random errors. We have simulated an example of reconstructing DEM from LiDAR-type measurements and investigated the effect on volume estimation from the reconstructed DEM. The results have shown that all the three methods can well reconstruct the DEM, if measurements are sufficiently precise. The bias-corrected LS method can perform much better than the ordinary LS method, with a maximum improvement of about 19 per cent from 500 independent repetitions of the example experiment. Such an improvement could be important in hazard evaluation of landslides, for example.
Acknowledgments
This work is supported by the Chinese National Science Foundation (Projects Nos. 41204006, 41374016, 41231174) and a Grant-in-Aid for Scientific Research (C25400449). The authors thank two reviewers very much for their constructive comments, which help further improve the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ewing, C.E.; Mitchell, M.M. Introduction to Geodesy; Elsevier: New York, NY, USA, 1970; Chapter 7. [Google Scholar]
- Airy, G.B. On the Algebraical and Numerical Theory of Errors of Observations and the Combination of Observations; Macmillan: Cambridge, UK, 1861; pp. 92–103. [Google Scholar]
- Helmert, F.R. Die Ausgleichungsrechnung nach der Methode der kleinsten Quadrate; Zweite Auflage Teubner: Leipzig, Germany, 1907; pp. 358–363. [Google Scholar]
- Rao, C.R.; Kleffe, J. Estimation of Variance Components and Applications; North-Holland: Amsterdam, The Netherlands, 1988. [Google Scholar]
- Koch, K.R. Parameter Estimation and Hypothesis Testing in Linear Models, 2nd ed.; Springer: Berlin, Germany, 1999; pp. 225–237. [Google Scholar]
- Xu, P.L. Iterative generalized cross-validation for fusing heteroscedastic data of inverse ill-posed problems. Geophys. J. Int. 2009, 179, 182–200. [Google Scholar]
- Huber, P.J. Robust estimation of a location parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; Wiley: New York, NY, USA, 1987. [Google Scholar]
- Barnett, V.; Lewis, T. Outliers in Statistical Data, 3rd ed.; Wiley: Chichester, UK, 1994. [Google Scholar]
- Baarda, W. A Testing Procedure for Use in Geodetic Networks; Netherlands Geodetic Commission: Delft, The Netherlands, 1968; Volume 2, No. 5. [Google Scholar]
- Xu, P.L. Sign-constrained robust least squares, subjective breakdown point and the effect of weights of observations on robustness. J. Geod. 2005, 79, 146–159. [Google Scholar]
- Yang, Y.X. Robust estimation for dependent observations. Manuscr. Geod. 1994, 19, 10–17. [Google Scholar]
- Gui, Q.; Zhang, J. Robust biased estimation and its applications in geodetic adjustments. J. Geod. 1998, 72, 430–435. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar]
- Curlander, J.C.; McDonough, R.N. Synthetic Aperture Radar; Wiley: New York, NY, USA, 1991. [Google Scholar]
- Parkinson, B.W.; Spilker, J.J., Jr. Global Positioning System: Theory and Applications; American Institute Aeronautics Astronautics: Washington, DC, USA, 1996; Volume 1. [Google Scholar]
- Hofmann-Wellenhof, B.; Lichtenegger, H.; Collins, J. GPS—Theory and Practice; Springer-Verlag: Berlin, Germany, 1992. [Google Scholar]
- Xu, P.L. Voronoi cells, probabilistic bounds and hypothesis testing in mixed integer linear models. IEEE Trans. Inf. Theory 2006, 52, 3122–3138. [Google Scholar]
- MacDoran, P.F. Satellite emission radio interferometric Earth surveying series—GPS geodetic system. Bull. Geod. 1979, 53, 117–138. [Google Scholar]
- Seeber, G. In Satellite Geodesy, 2nd ed.; De Gruyter: Berlin, Germany. 2003; Chapter 7.4. [Google Scholar]
- Goodman, J.W. Some fundamental properties of speckle. J. Opt. Soc. Am. 1976, 66, 1145–1150. [Google Scholar]
- Ulaby, F.; Kouyate, F.; Brisco, B.; Williams, T. Textural information in SAR images. IEEE Trans. Geosci. Remote Sens. 1986, 24, 235–245. [Google Scholar]
- Oliver, C.J. Information from SAR images. J. Phys. D: Appl. Phys. 1991, 24, 1493–1514. [Google Scholar]
- Xu, P.L. Despeckling SAR-type multiplicative noise. Int. J. Remote Sens. 1999, 20, 2577–2596. [Google Scholar]
- López-Martínez, C.; Pottier, E. On the extension of multidimensional speckle noise model from single-look to multilook SAR image. IEEE Trans. Geosci. Remote Sens. 2007, 45, 305–320. [Google Scholar]
- López-Martínez, C.; Fabregas, X.; Pipia, L. Forest parameter estimation in the Pol-InSAR context employing the ultiplicative-additive speckle noise model. ISPRS J. Photogram. Remote Sens. 2011, 66, 597–607. [Google Scholar]
- Wedderburn, R.W.M. Quasi-likelihood functions, generalized linear models, and the Gauss-Newton method. Biometrika 1974, 61, 439–447. [Google Scholar]
- McCullagh, P.; Nelder, J.A. Generalized Linear Models, 2nd ed.; Chapman and Hall: London, UK, 1989. [Google Scholar]
- Tjur, T. Nonlinear regression, quasi likelihood, and overdispersion in generalized linear models. Am. Stat. 1998, 52, 222–227. [Google Scholar]
- Matthews, G.B. Theory and methods: A maximum likelihood estimation procedure for the generalized linear model with restrictions. S. Afr. Stat. J. 1998, 32, 119–144. [Google Scholar]
- Paul, S.; Saha, K.K.T. The generalized linear model and extensions: A review and some biological and environmental applications. Environmetrics 2007, 18, 421–443. [Google Scholar]
- Björkall, S.; Hössjer, O.; Ohlsson, E.; Verrall, R. A generalized linear model with smoothing effects for claims reserving. Insur. Math. Econ. 2011, 49, 27–37. [Google Scholar]
- Xu, P.L.; Shimada, S. Least squares parameter estimation in multiplicative noise models. Commun. Stat. 2000, B29, 83–96. [Google Scholar]
- Akima, H. Algorithm 760: Rectangular-grid-data surface fitting that has the accuracy of a bicubic polynomial. ACM Trans. Math. Softw. 1996, 22, 357–361. [Google Scholar]
- Zimmerman, D.; Pavlik, C.; Ruggles, A.; Armstrong, M.P. An experimental comparison of ordinary and universal kriging and inverse distance weighting. Math. Geol. 1999, 31, 375–390. [Google Scholar]
- Kidner, D.B. Higher-order interpolation of regular grid digital elevation models. Int. J. Remote Sens. 2003, 24, 2981–2987. [Google Scholar]
- Kobler, A.; Pfeifer, N.; Ogrinc, P.; Todorovski, L.; Ostir, K.; Dzeroski, S. Repetitive interpolation: A robust algorithm for DTM generation from Aerial Laser Scanner Data in forested terrain. Remote Sens. Environ. 2007, 108, 9–23. [Google Scholar]
- Chen, C.; Li, Y. A robust multiquadric method for digital elevation model construction. Math. Geosci. 2013, 45, 297–319. [Google Scholar]
- Hu, H.; Fernandez-Steeger, T.M.; Dong, M.; Azzam, R. Numerical modeling of LiDAR-based geological model for landslide analysis. Autom. Constr. 2012, 24, 184–193. [Google Scholar]
- Jaboyedoff, M.; Oppikofer, T.; Abellan, A.; Derron, M.; Loye, A.; Metzger, R.; Pedrazzini, A. Use of LIDAR in landslide investigations: A review. Nat. Hazards 2012, 61, 5–28. [Google Scholar]
- Stefanescu, E.R.; Bursik, M.; Cordoba, G.; Dalbey, K.; Jones, M.D.; Patra, A.K.; Pieri, D.C.; Pitman, E.B.; Sheridan, M.F. Digital elevation model uncertainty and hazard analysis using a geophysical flow model. Proc. R. Soc. A 2012, 468, 1543–1563. [Google Scholar]
- Yang, Z.; Teller, J.T. Using LiDAR digital elevation model data to map Lake Agassiz beaches, measure their isostatically-induced gradients, and estimate their ages. Quat. Int. 2012, 260, 32–42. [Google Scholar]
- Leigh, C.L.; Kidner, D.B.; Thomas, M.C. The use of LiDAR in digital surface modelling: Issues and errors. Trans. GIS 2009, 13, 345–361. [Google Scholar]
- Liu, X. Airborne LiDAR for DEM generation: Some critical issues. Prog. Phys. Geogr. 2008, 32, 31–49. [Google Scholar]
- Hladik, C.; Alber, M. Accuracy assessment and correction of a LIDAR-derived salt marsh digital elevation model. Remote Sens. Environ. 2012, 121, 224–235. [Google Scholar]
- Xu, P.L.; Shi, Y.; Peng, J.H.; Liu, J.N.; Shi, C. Adjustment of geodetic measurements with mixed multiplicative and additive random errors. J. Geod. 2013, 87, 629–643. [Google Scholar]
- Magnus, J.; Neudecker, H. Matrix Differential Calculus with Applications in Statistics and Econometrics; Wiley and Sons: New York, NY, USA, 1988; Chapter 8. [Google Scholar]
- Xu, P.L. The effect of incorrect weights on estimating the variance of unit weight. Stud. Geophys. Geod. 2013, 57, 339–352. [Google Scholar]
- Flamant, P.H.; Menzies, R.T.; Kavaya, M.J. Evidence for speckle effects on pulsed CO2 lidar signal returns from remote targets. Appl. Opt. 1984, 23, 1412–1417. [Google Scholar]
- Wang, J.Y.; Pruitt, P.A. Effects of speckle on the range precision of a scanning lidar. Appl. Opt. 1992, 31, 801–808. [Google Scholar]
- Hill, A.C.; Harris, M.; Ridley, K.C.; Jakeman, E.; Lutzmann, P. Lidar frequency modulation vibrometry in the presence of speckle. Appl. Opt. 2003, 42, 1091–1100. [Google Scholar]

{kind=link}
{kind=link}
| Covariance | Ordinary LS Method | Bias-Corrected Weighted LS Method |
|---|---|---|
| cov(β̂,y) | (XTX)−1XTDyσ2 | |
| cov(ŷ,y) | X(XTX)−1XTDyσ2 | |
| cov(V,y) | [X(XTX)−1XT−I]Dyσ2 | |
| cov(ŷ, β̂) | X(XTX)−1XTDyX(XTX)−1σ2 | |
| cov(V, β̂) | [X(XTX)−1XT−I]DyX(XTX)−1σ2 | 0 |
| cov(V, ŷ) | [X(XTX)−1XT−I]DyX(XTX)−1XTσ2 | 0 |
| Methods | True | OLS | BCLS | WLS |
|---|---|---|---|---|
| Volume (m3) | 2.45686 × 107 | 2.46494 × 107 | 2.46073 × 107 | 2.46105 × 107 |
| RMSE (m3) | 1.640 × 105 | 1.582 × 105 | 1.583 × 105 | |
| σ (m) | 1.268 | 1.251 | 1.245 | 1.245 |
The abbreviations OLS, BCLS and WLS stand for the ordinary LS, bias-corrected and weighted LS methods, Volume for the volume of the landslide mass, and RMSE for the root mean squared errors of the estimated volumes of the landslide mass. σ is the standard deviation of unit weight.
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Shi, Y.; Xu, P.; Peng, J.; Shi, C.; Liu, J. Adjustment of Measurements with Multiplicative Errors: Error Analysis, Estimates of the Variance of Unit Weight, and Effect on Volume Estimation from LiDAR-Type Digital Elevation Models. Sensors 2014, 14, 1249-1266. https://doi.org/10.3390/s140101249
Shi Y, Xu P, Peng J, Shi C, Liu J. Adjustment of Measurements with Multiplicative Errors: Error Analysis, Estimates of the Variance of Unit Weight, and Effect on Volume Estimation from LiDAR-Type Digital Elevation Models. Sensors. 2014; 14(1):1249-1266. https://doi.org/10.3390/s140101249
Chicago/Turabian StyleShi, Yun, Peiliang Xu, Junhuan Peng, Chuang Shi, and Jingnan Liu. 2014. "Adjustment of Measurements with Multiplicative Errors: Error Analysis, Estimates of the Variance of Unit Weight, and Effect on Volume Estimation from LiDAR-Type Digital Elevation Models" Sensors 14, no. 1: 1249-1266. https://doi.org/10.3390/s140101249