
Discrimination of Transgenic Canola (Brassica napus L.) and their Hybrids with B. rapa using Vis-NIR Spectroscopy and Machine Learning Methods

 ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. Results
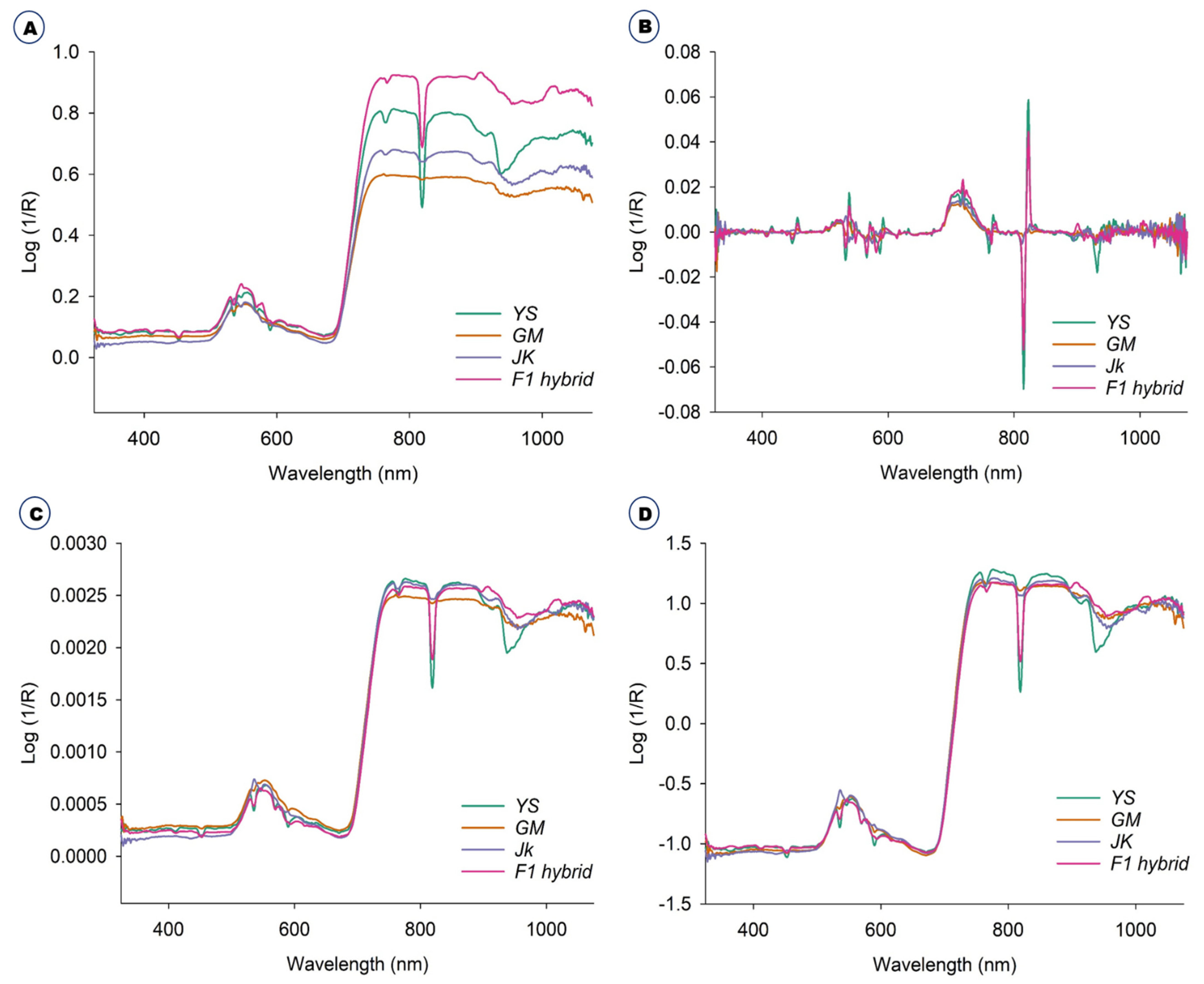
2.1. Diffuse Reflectance Spectroscopic Analysis and Preprocessing
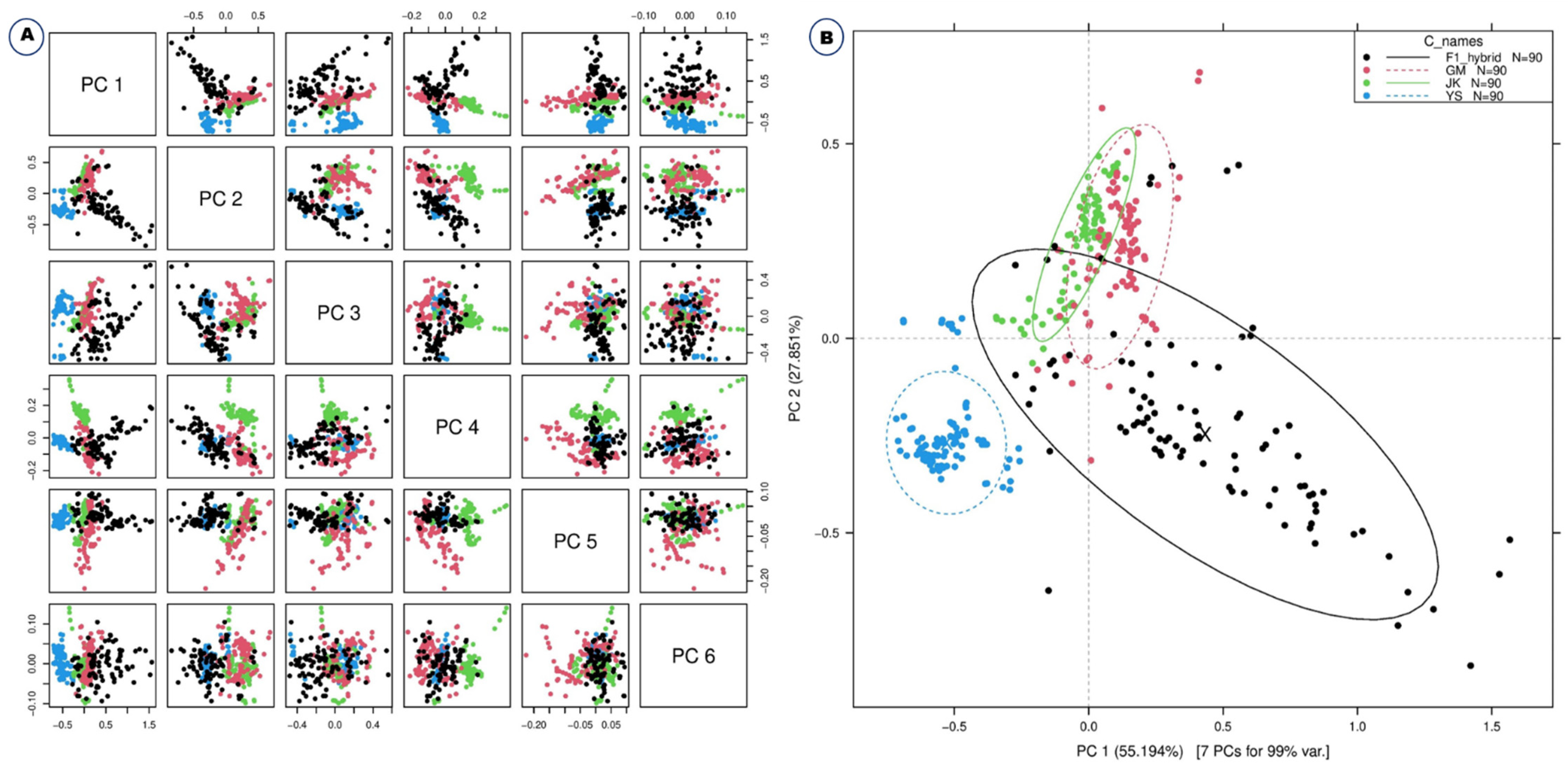
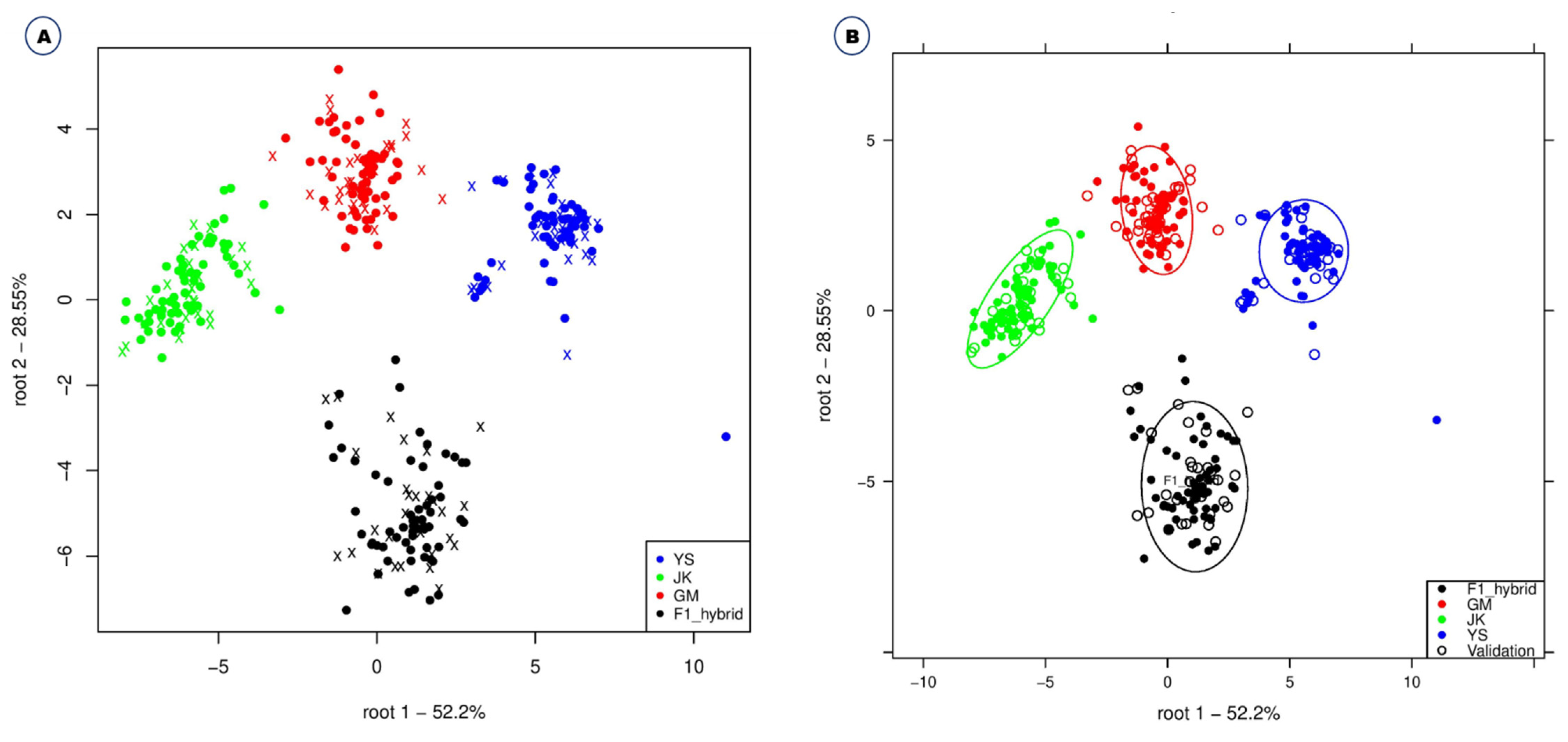
2.2. Machine Learning Classification Methods
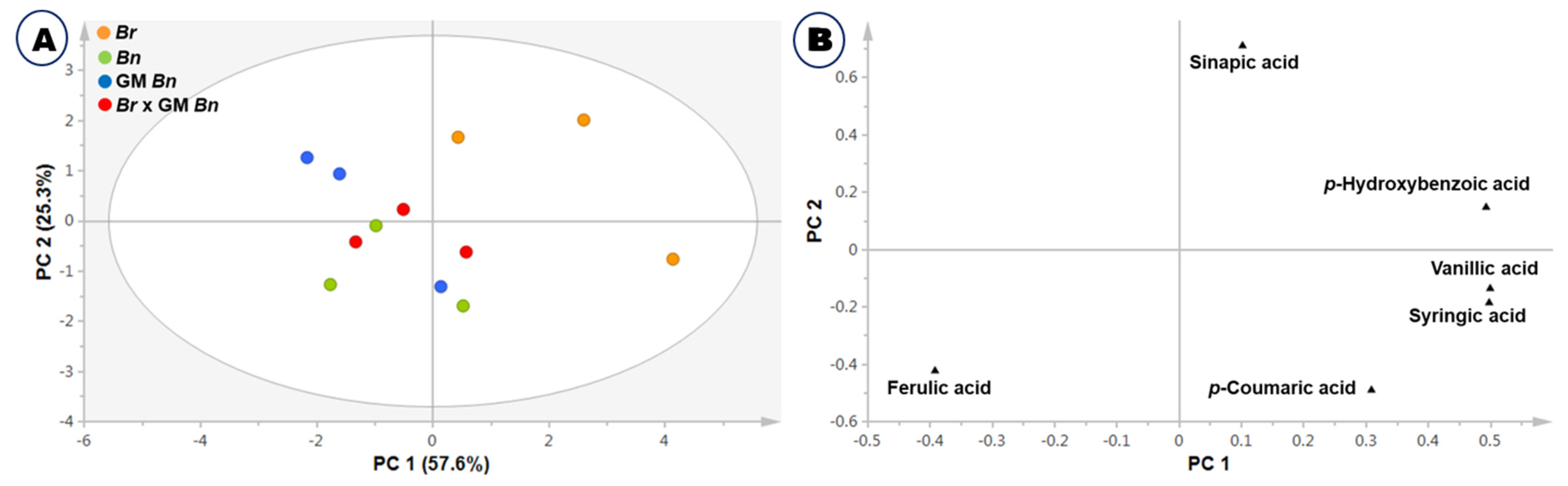
2.3. Phenolic Acid Composition Analysis
2.4. Partial Least Squares Regression (PLSR) Prediction of Phenolic Compounds
3. Discussion
4. Materials and Methods
4.1. Plant Materials
4.2. Spectral Measurement and Preprocessing
4.3. Modelling Methods and Statistical Analysis
4.4. Assessment of Phenolic Acid Contents
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- USDA. Oilseeds: World Markets and Trade; USDA: Washington, DC, USA, 2020. Available online: https://www.fas.usda.gov/data/oilseeds-world-markets-and-trade (accessed on 18 October 2021).
- Chen, R.; Shimono, A.; Aono, M.; Nakajima, N.; Ohsawa, R.; Yoshioka, Y. Genetic diversity and population structure of feral rapeseed (Brassica napus L.) in Japan. PLoS ONE 2020, 15, e0227990. [Google Scholar] [CrossRef]
- Chalhoub, B.; Denoeud, F.; Liu, S.; Parkin, I.A.P.; Tang, H.; Wang, X.; Chiquet, J.; Belcram, H.; Tong, C.; Samans, B.; et al. Early allopolyploid evolution in the post-Neolithic Brassica napus oilseed genome. Science 2014, 345, 950–953. [Google Scholar] [CrossRef] [PubMed]
- Lu, K.; Wei, L.; Li, X.; Wang, Y.; Wu, J.; Liu, M.; Zhang, C.; Chen, Z.; Xiao, Z.; Jian, H.; et al. Whole-genome resequencing reveals Brassica napus origin and genetic loci involved in its improvement. Nat. Commun. 2019, 10, 1154. [Google Scholar] [CrossRef]
- Sun, F.; Fan, G.; Hu, Q.; Zhou, Y.; Guan, M.; Tong, C.; Li, J.; Du, D.; Qi, C.; Jiang, L.; et al. The high-quality genome of Brassica napus cultivar ‘ZS 11’reveals the introgression history in semi-winter morphotype. Plant J. 2017, 92, 452–468. [Google Scholar] [CrossRef] [PubMed]
- Zou, J.; Mao, L.; Qiu, J.; Wang, M.; Jia, L.; Wu, D.; He, Z.; Chen, M.; Shen, Y.; Shen, E.; et al. Genome-wide selection footprints and deleterious variations in young Asian allotetraploid rapeseed. Plant Biotechnol. J. 2019, 17, 1998–2010. [Google Scholar] [CrossRef]
- Séguin-Swartz, G.; Beckie, H.J.; Warwick, S.I.; Roslinsky, V.; Nettleton, J.A.; Johnson, E.N.; Falk, K.C. Pollen-mediated gene flow between glyphosate-resistant Brassica napus canola and B. juncea and B. carinata mustard crops under large-scale field conditions in Saskatchewan. Can. J. Plant Sci. 2013, 93, 1083–1087. [Google Scholar] [CrossRef]
- Sohn, S.I.; Oh, Y.J.; Lee, K.R.; Ko, H.C.; Cho, H.S.; Lee, Y.H.; Chang, A. Characteristics analysis of F1 hybrids between genetically modified Brassica napus and B. rapa. PLoS ONE 2016, 11, e0162103. [Google Scholar] [CrossRef]
- Tu, Y.K.; Chen, H.W.; Tseng, K.Y.; Lin, Y.C.; Kuo, B.J. Morphological and genetic characteristics of F1 hybrids introgressed from Brassica napus to B. rapa in Taiwan. Bot. Stud. 2020, 61, 1. [Google Scholar] [CrossRef]
- Vigeolas, H.; Waldeck, P.; Zank, T.; Geigenberger, P. Increasing seed oil content in oilseed rape (Brassica napus L.) by over-expression of a yeast glycerol-3-phosphate dehydrogenase under the control of seed-specific promoter. Plant Biotechnol. J. 2007, 5, 431–441. [Google Scholar] [CrossRef]
- Zhu, M.; Monroe, J.G.; Suhail, Y.; Villiers, F.; Mullen, J.; Pater, D.; Hauser, F.; Jeon, B.W.; Bader, J.S.; Kwak, J.M.; et al. Molecular and systems approaches towards drought-tolerant canola crops. New Phytol. 2016, 210, 1169–1189. [Google Scholar] [CrossRef]
- Miki, B.L.; Labbé, H.; Hattori, J.; Ouellet, T.; Gabard, J.; Sunohara, G.; Charest, P.J.; Iyer, V.N. Transformation of Brassica napus canola cultivars with Arabidopsis thaliana acetohydroxyacid synthase genes and analysis of herbicide resistance. Theor. Appl. Genet. 1990, 80, 449–458. [Google Scholar] [CrossRef]
- Szydłowska-Czerniak, A. Rapeseed and its products—sources of bioactive compounds: A review of their characteristics and analysis. Crit. Rev. Food Sci. Nutr. 2011, 53, 307–330. [Google Scholar] [CrossRef] [PubMed]
- Beckie, H.J.; Hall, L.M.; Simard, M.-J.; Leeson, J.Y.; Willenborg, C.J. A framework for postrelease environmental monitoring of second-generation crops with novel traits. Crop Sci. 2010, 50, 1587–1604. [Google Scholar] [CrossRef]
- Wilkinson, M.J.; Timmons, A.M.; Charters, Y.; Dubbels, S.; Robertson, A.; Wilson, N.; Scott, S.; O’Brien, E.; Lawson, H.M. Problems of risk assessment with genetically modified oilseed rape. In Proceedings of the Brighton Crop Protection Conference Weeds, Brighton, UK, 20–23 November 1995; pp. 1035–1044. [Google Scholar]
- Yoshimura, Y.; Beckie, H.J.; Matsuo, K. Transgenic oilseed rape along transportation routes and port of Vancouver in western Canada. Environ. Biosaf. Res. 2006, 5, 67–75. [Google Scholar] [CrossRef]
- Ahmed, F.E. Detection of genetically modified organisms in foods. Trends Biotechnol. 2002, 20, 215–223. [Google Scholar] [CrossRef]
- Sohn, S.-I.; Pandian, S.; Oh, Y.-J.; Zaukuu, J.-L.Z.; Kang, H.-J.; Ryu, T.-H.; Cho, W.-S.; Cho, Y.-S.; Shin, E.-K.; Cho, B.-K. An overview of near infrared spectroscopy and its applications in the detection of genetically modified organisms. Int. J. Mol. Sci. 2021, 22, 9940. [Google Scholar] [CrossRef]
- Cozzolino, D.; Smyth, H.E.; Gishen, M. Feasibility study on the use of visible and near-infrared spectroscopy together with chemometrics to discriminate between commercial white wines of different varietal origins. J. Agric. Food Chem. 2003, 51, 7703–7708. [Google Scholar] [CrossRef]
- Roussel, S.A.; Hardy, C.L.; Hurburgh, C.R., Jr.; Rippke, G.R. Detection of Roundup Ready™ soybeans by near-infrared spectroscopy. Appl. Spectrosc. 2001, 55, 1425–1430. [Google Scholar] [CrossRef]
- Luna, A.S.; da Silva, A.P.; Pinho, J.S.; Ferré, J.; Boqué, R. Rapid characterization of transgenic and non-transgenic soybean oils by chemometric methods using NIR spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2013, 100, 115–119. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Zhao, Y.; Zhang, C.; Cheng, P.; He, Y. Discrimination of transgenic maize kernel using NIR hyperspectral imaging and multivariate data analysis. Sensors 2017, 17, 1894. [Google Scholar] [CrossRef] [PubMed]
- Ning, K.; Ding, C.; Zhu, W.; Zhang, W.; Dong, Y.; Shen, Y.; Su, X. Comparative metabolomic analysis of the cambium tissue of non-transgenic and multi-gene transgenic poplar (Populus × euramericana ‘Guariento’). Front. Plant Sci. 2018, 9, 1201. [Google Scholar] [CrossRef]
- Peiris, K.H.; Wu, X.; Bean, S.R.; Perez-Fajardo, M.; Hayes, C.; Yerka, M.K.; Jagadish, S.V.; Ostmeyer, T.; Aramouni, F.M.; Tesso, T.; et al. Near infrared spectroscopic evaluation of starch properties of diverse sorghum populations. Processes 2021, 9, 1942. [Google Scholar] [CrossRef]
- Ge, G.; Zheng, X.; Wu, J.; Ye, Z.; Shi, C. Analysis of the conditional correlations from different genetic systems between the protein content and the appearance quality traits of indica rice. J. Genet. Gen. 2007, 34, 129–137. [Google Scholar] [CrossRef]
- Huang, H.; Yu, H.; Xu, H.; Ying, Y. Near infrared spectroscopy for on/in-line monitoring of quality in foods and beverages: A review. J. Food Eng. 2008, 87, 303–313. [Google Scholar] [CrossRef]
- Beć, K.B.; Grabska, J.; Huck, C.W. Near-infrared spectroscopy in bio-applications. Molecules 2020, 25, 2948. [Google Scholar] [CrossRef]
- Rinnan, Å.; Van Den Berg, F.; Engelsen, S.B. Review of the most common pre-processing techniques for near-infrared spectra. TrAC Trends Anal. Chem. 2009, 28, 1201–1222. [Google Scholar] [CrossRef]
- Fernández-Cabanás, V.M.; Garrido-Varo, A.; Pérez-Marín, D.; Dardenne, P. Evaluation of pretreatment strategies for near-infrared spectroscopy calibration development of unground and ground compound feeding stuffs. Appl. Spectrosc. 2006, 60, 17–23. [Google Scholar] [CrossRef] [PubMed]
- Cordella, C.; Moussa, I.; Martel, A.-C.; Sbirrazzuoli, N.; Lizzani-Cuvelier, L. Recent developments in food characterization and adulteration detection: Technique-oriented perspectives. J. Agric. Food Chem. 2002, 50, 1751–1764. [Google Scholar] [CrossRef]
- Xie, L.; Ying, Y.; Ying, T.; Yu, H.; Fu, X. Discrimination of transgenic tomatoes based on visible/near-infrared spectra. Anal. Chim. Acta 2007, 584, 379–384. [Google Scholar] [CrossRef] [PubMed]
- Smith, H.L.; McAusland, L.; Murchie, E.H. Don’t ignore the green light: Exploring diverse roles in plant processes. J. Exp. Bot. 2017, 68, 2099–2110. [Google Scholar] [CrossRef]
- Delwiche, S.R.; Reeves, J.B.; Reeves, I.J. The effect of spectral pre-treatments on the partial least squares modelling of agricultural products. J. Near Infrared Spectrosc. 2004, 12, 177–182. [Google Scholar] [CrossRef]
- Hao, Y.; Geng, P.; Wu, W.; Wen, Q.; Rao, M. Identification of rice varieties and transgenic characteristics based on near-infrared diffuse reflectance spectroscopy and chemometrics. Molecules 2019, 24, 4568. [Google Scholar] [CrossRef] [PubMed]
- Handbook of Near-Infrared Analysis; Burns, D.A., Ciurczak, E.W., Eds.; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Gestal, M.; Gómez-Carracedo, M.P.; Andrade, J.M.; Dorado, J.; Fernández, E.; Prada, D.; Pazos, A. Classification of apple beverages using artificial neural networks with previous variable selection. Anal. Chim. Acta 2004, 524, 225–234. [Google Scholar] [CrossRef]
- Xie, L.; Ying, Y.; Ying, T. Classification of tomatoes with different genotypes by visible and short-wave near-infrared spectroscopy with least-squares support vector machines and other chemometrics. J. Food Eng. 2009, 94, 34–39. [Google Scholar] [CrossRef]
- Sohn, S.-I.; Oh, Y.-J.; Pandian, S.; Lee, Y.-H.; Zaukuu, J.-L.Z.; Kang, H.-J.; Ryu, T.-H.; Cho, W.-S.; Cho, Y.-S.; Shin, E.-K. Identification of Amaranthus species using visible-near-infrared (vis-NIR) spectroscopy and machine learning methods. Remote Sens. 2021, 13, 4149. [Google Scholar] [CrossRef]
- Podsedek, A. Natural antioxidants and antioxidant capacity of Brassica vegetables: A review. LWT-Food Sci. Technol. 2007, 40, 1–11. [Google Scholar] [CrossRef]
- Cartea, M.E.; Francisco, M.; Soengas, P.; Velasco, P. Phenolic compounds in Brassica vegetables. Molecules 2011, 16, 251–280. [Google Scholar] [CrossRef] [PubMed]
- Brglez Mojzer, E.; Knez Hrnčič, M.; Škerget, M.; Knez, Ž.; Bren, U. Polyphenols: Extraction methods, antioxidative action, bioavailability and anticarcinogenic effects. Molecules 2016, 21, 901. [Google Scholar] [CrossRef]
- Khattab, R.; Eskin, M.; Aliani, M.; Thiyam, U. Determination of sinapic acid derivatives in canola extracts using high-performance liquid chromatography. J. Am. Oil Chem. Soc. 2010, 87, 147–155. [Google Scholar] [CrossRef]
- Velasco, P.; Francisco, M.; Moreno, D.A.; Ferreres, F.; García-Viguera, C.; Cartea, M.E. Phytochemical fingerprinting of vegetable Brassica oleracea and Brassica napus by simultaneous identification of glucosinolates and phenolics. Phytochem. Anal. 2011, 22, 144–152. [Google Scholar] [CrossRef] [PubMed]
- Dowell, F.E.; Maghirang, E.B.; Graybosch, R.A.; Berzonsky, W.A.; Delwiche, S.R. Selecting and sorting waxy wheat kernels using near-infrared spectroscopy. Cereal Chem. 2009, 86, 251–255. [Google Scholar] [CrossRef]
- Wu, D.; Yong, H.; Shuijuan, F. Short-wave near-infrared spectroscopy analysis of major compounds in milk powder and wavelength assignment. Anal. Chim. Acta 2008, 610, 232–242. [Google Scholar] [CrossRef] [PubMed]
- Abedini, R.; Ghanegolmohammadi, F.; PishkamRad, R.; Pourabed, E.; Jafarnezhad, A.; Shobbar, Z.-S.; Shahbazi, M. Plant dehydrins: Shedding light on structure and expression patterns of dehydrin gene family in barley. J. Plant Res. 2017, 130, 747–763. [Google Scholar] [CrossRef] [PubMed]
- Park, S.Y.; Lee, S.Y.; Yang, J.W.; Lee, J.S.; Oh, S.D.; Oh, S.; Lee, S.M.; Lim, M.H.; Park, S.K.; Jang, J.S.; et al. Comparative analysis of phytochemicals and polar metabolites from colored sweet potato (Ipomoea batatas L.) tubers. Food Sci. Biotechnol. 2016, 25, 283–291. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
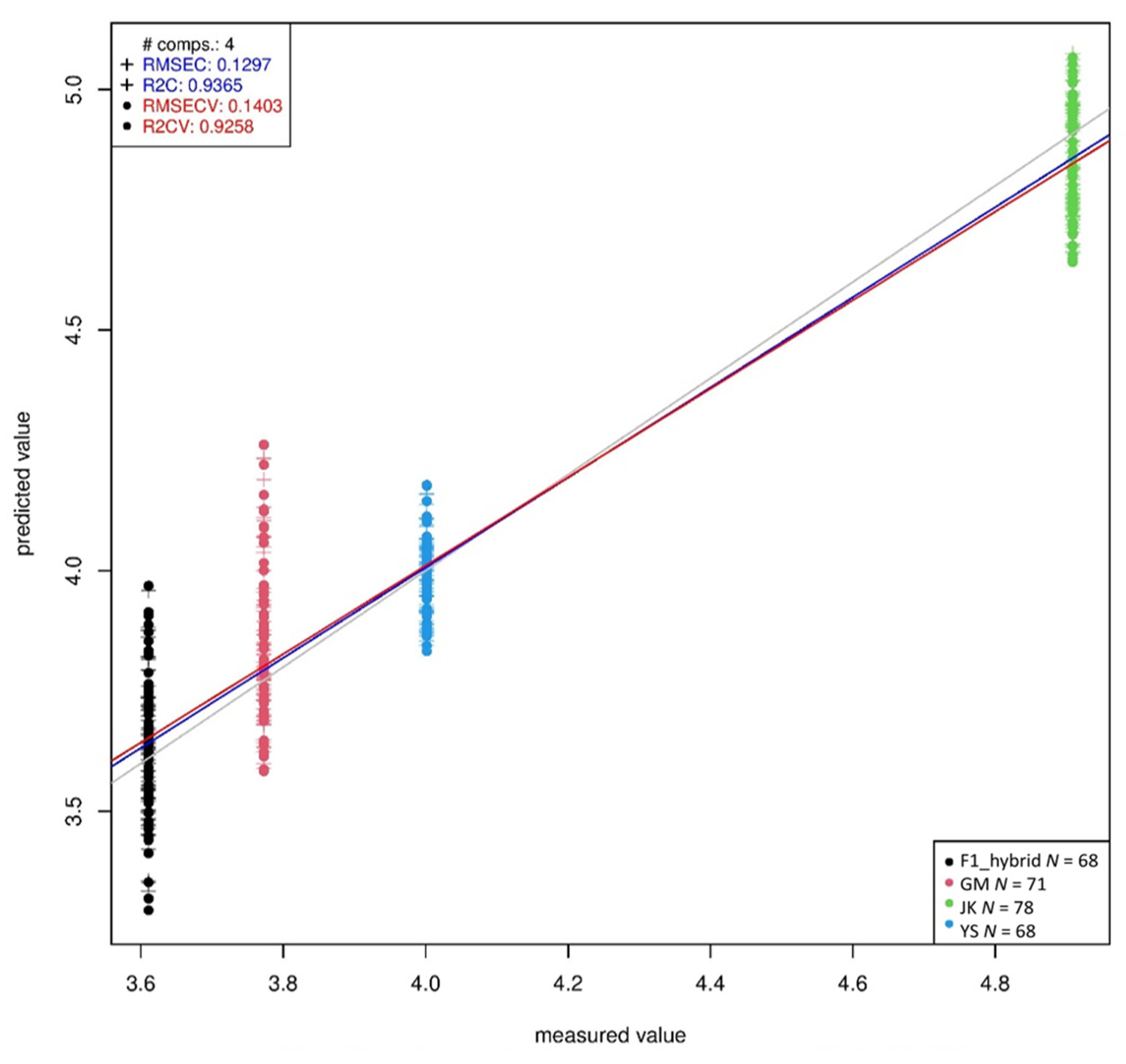{kind=link}
{kind=link}
| S. No | Model | Preprocessing | Average Accuracy (%) | Run Time (ms) |
|---|---|---|---|---|
| 1. | Linear Discriminant Analysis | Raw spectra | 78.3 | - |
| Normalization | 98.6 | - | ||
| Standard Normal Variate | 98.6 | - | ||
| Savitzky-Golay | 99.8 | - | ||
| 2. | Support Vector Machine | Raw spectra | 98.4 | 21,417 |
| Normalization | 79.6 | 41,166 | ||
| Standard Normal Variate | 98.4 | 22,074 | ||
| Savitzky-Golay | 100.0 | 30,556 | ||
| 3. | Generalized Linear Model | Raw spectra | 85.4 | 32,905 |
| Normalization | 87.1 | 19,854 | ||
| Standard Normal Variate | 90.3 | 26,768 | ||
| Savitzky-Golay | 97.9 | 14,038 | ||
| 4. | Gradient Boosted Trees | Raw spectra | 95.2 | 841,966 |
| Normalization | 97.3 | 790,162 | ||
| Standard Normal Variate | 97.3 | 988,233 | ||
| Savitzky-Golay | 98.9 | 990,738 | ||
| 5. | Naive Bayes | Raw spectra | 70.5 | 6546 |
| Normalization | 74.2 | 6535 | ||
| Standard Normal Variate | 81.2 | 6210 | ||
| Savitzky-Golay | 91.4 | 6661 | ||
| 6. | Fast Large Margin | Raw spectra | 93.6 | 37,002 |
| Normalization | 71.2 | 38,845 | ||
| Standard Normal Variate | 96.2 | 37,597 | ||
| Savitzky-Golay | 98.9 | 17,611 | ||
| 7. | Raw spectra | 79.0 | 31,558 | |
| Random Forest | Normalization | 86.6 | 30,336 | |
| Standard Normal Variate | 90.9 | 31,411 | ||
| Savitzky-Golay | 91.4 | 31,590 | ||
| 8. | Convolutional Neural Network (Deep Learning) | Raw spectra | 91.4 | 7529 |
| Normalization | 98.9 | 7123 | ||
| Standard Normal Variate | 97.9 | 5850 | ||
| Savitzky-Golay | 96.8 | 5450 |
| Model | Species Accuracy (% ± SE) | ||||
|---|---|---|---|---|---|
| Raw Spectra | Normalization | Savitzky-Golay | SNV | Significance | |
| Naive Bayes | 74.2 ± 9.5 | 74.5 ± 3.3 b | 91.8 ± 3.1 | 82.7 ± 4.9 | ns |
| Generalized Linear Model | 86.7 ± 3.7 | 87.2 ± 2 ab | 97.3 ± 1.5 | 91.3 ± 6.3 | ns |
| Fast Large Margin | 94.1 ± 4.4 A | 73.1 ± 4.4 Bb | 99.2 ± 0.8 A | 96.3 ± 3 A | ** |
| Convolutional Neural Network | 92.8 ± 3.5 | 99.2 ± 0.8 a | 96.9 ± 3.1 | 98 ± 1.2 | ns |
| Gradient Boosted Trees | 76.1 ± 12.4 | 85.6 ± 6.4 ab | 85.2 ± 6.3 | 59.6 ± 22 | ns |
| Random Forest | 80.8 ± 6 | 87.2 ± 2.3 ab | 92.9 ± 3.5 | 91.5 ± 3.3 | ns |
| Support Vector Machine | 98.4 ± 1.6 A | 80 ± 3.6 Bb | 100 ± 0 A | 98.3 ± 1.7 A | ** |
| significance | ns | ** | ns | ns | |
| Source | df | SS | MS | F-Value | p-Value |
|---|---|---|---|---|---|
| Preprocessing (P) | 3 | 0.186074 | 0.062025 | 4.07 | 0.0095 |
| Model (M) | 6 | 0.494012 | 0.082335 | 5.4 | <0.0001 |
| P × M | 18 | 0.426077 | 0.023671 | 1.55 | 0.0925 |
| Error | 84 | 1.280539 | 0.015245 | ||
| Total | 111 | 2.386702 |
| Savitzky-Golay/ SVM | Classified as | Average Accuracy (%) | |||
| B. napus | B. rapa | GM B. napus | F1 hybrid | ||
| B. napus | 43 | 0 | 0 | 0 | 100 |
| GM B. napus | 0 | 42 | 0 | 0 | 100 |
| B. rapa | 0 | 0 | 44 | 0 | 100 |
| F1 hybrid | 0 | 0 | 0 | 56 | 100 |
| Class recall (%) | 100 | 100 | 100 | 100 | |
| Normalize/ Convolutional Neural Network | Classified as | Average Accuracy (%) | |||
| B. napus | B. rapa | GM B. napus | F1 hybrid | ||
| B. napus | 42 | 0 | 0 | 0 | 100 |
| GM B. napus | 0 | 44 | 0 | 0 | 100 |
| B. rapa | 0 | 0 | 40 | 0 | 100 |
| F1 hybrid | 0 | 0 | 2 | 58 | 96.67 |
| Class recall (%) | 100 | 100 | 95.24 | 100 | |
| Savitzky-Golay/ Fast Large Margin | Classified as | Average Accuracy (%) | |||
| B. napus | B. rapa | GM B. napus | F1 hybrid | ||
| B. napus | 42 | 0 | 0 | 0 | 100 |
| GM B. napus | 0 | 44 | 0 | 0 | 100 |
| B. rapa | 0 | 0 | 40 | 0 | 100 |
| F1 hybrid | 0 | 0 | 2 | 58 | 96.67 |
| Class recall (%) | 100 | 100 | 95.24 | 100 | |
| S. No | Phenolic Acids | B. napus L. (Youngsan) (ug/g ± SD) | GM B. napus L. (TG#39) (ug/g ± SD) | B. rapa L. (Jangang) (ug/g ± SD) | B. rapa X GM B. napus (F1 hybrid) (ug/g ± SD) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Soluble | Insoluble | Total | Soluble | Insoluble | Total | Soluble | Insoluble | Total | Soluble | Insoluble | Total | ||
| 1 | p-hydroxybenzoic acid | 2.2 ± 0.4 | 1.1 ± 0.3 | 3.3 ± 0.6 | 2.3 ± 0.1 | 0.9 ± 0.1 | 3.1 ± 0.3 | 4.1 ± 0.7 | 1.3 ± 0.3 | 5.4 ± 1.0 | 2.2 ± 0.4 | 1.3 ± 0.8 | 3.5 ± 0.8 |
| 2 | vanillic acid | 3.0 ± 0.6 | 1.0 ± 0.2 | 4.0 ± 0.7 | 2.7 ± 0.3 | 1.1 ± 0.2 | 3.8 ± 0.5 | 3.9 ± 0.8 | 1.0 ± 0.2 | 4.9 ± 0.9 | 2.6 ± 0.6 | 1.0 ± 0.1 | 3.6 ± 0.5 |
| 3 | syringic acid | 0.3 ± 0.2 | 0.3 ± 0.2 | 0.6 ± 0.3 | 0.3 ± 0.2 | 0.3 ± 0.2 | 0.6 ± 0.3 | 0.6 ± 0.3 | 0.4 ± 0.3 | 1.0 ± 0.4 | 0.3 ± 0.2 | 0.3 ± 0.04 | 0.6 ± 0.2 |
| 4 | p-coumaric acid | 56.1 ± 14.4 | 6.9 ± 0.7 | 63.0 ± 13.8 | 28.1 ± 17.1 | 5.5 ± 0.9 | 33.7 ± 18.0 | 49.9 ± 15.7 | 12.7 ± 1.5 | 62.6 ± 15.0 | 56.2 ± 6.4 | 6.1 ± 4.2 | 62.3 ± 10.5 |
| 5 | ferulic acid | 1498.8 ± 184.2 | 110.4 ± 17.6 | 1609.2 ± 197.5 | 1255.9 ± 120.6 | 128.1 ± 8.3 | 1384.0 ± 125.7 | 891.5 ± 51.4 | 49.4 ± 9.2 | 940.9 ± 60.5 | 1167.8 ± 132.1 | 86.3 ± 10.2 | 1254.1 ± 140.5 |
| 6 | sinapic acid | 877.3 ± 138.9 | 26.5 ± 4.8 | 903.77 ± 140.38 | 935.8 ± 427.3 | 37.2 ± 14.6 | 973.06 ± 441.83 | 1439.2 ± 518.4 | 35.2 ± 8.6 | 1474.3 ± 511.6 | 923.6 ± 73.0 | 35.2 ± 6.0 | 958.80 ± 78.64 |
| Phenolic Compound | Latent Variable | R2 | RMSEC (ug/g) | R2CV | RMSECV (ug/g) |
|---|---|---|---|---|---|
| p-hydroxybenzoic acid | 4 | 0.93 | 0.26 | 0.91 | 0.28 |
| Vanillic acid | 4 | 0.94 | 0.13 | 0.93 | 0.14 |
| Syringic acid | 4 | 0.92 | 0.04 | 0.91 | 0.05 |
| p-coumaric acid | 4 | 0.91 | 3.68 | 0.89 | 4.03 |
| Ferulic acid | 4 | 0.94 | 58.91 | 0.93 | 64.34 |
| Sinapic acid | 4 | 0.94 | 57.89 | 0.93 | 63.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sohn, S.-I.; Pandian, S.; Zaukuu, J.-L.Z.; Oh, Y.-J.; Park, S.-Y.; Na, C.-S.; Shin, E.-K.; Kang, H.-J.; Ryu, T.-H.; Cho, W.-S.; et al. Discrimination of Transgenic Canola (Brassica napus L.) and their Hybrids with B. rapa using Vis-NIR Spectroscopy and Machine Learning Methods. Int. J. Mol. Sci. 2022, 23, 220. https://doi.org/10.3390/ijms23010220
Sohn S-I, Pandian S, Zaukuu J-LZ, Oh Y-J, Park S-Y, Na C-S, Shin E-K, Kang H-J, Ryu T-H, Cho W-S, et al. Discrimination of Transgenic Canola (Brassica napus L.) and their Hybrids with B. rapa using Vis-NIR Spectroscopy and Machine Learning Methods. International Journal of Molecular Sciences. 2022; 23(1):220. https://doi.org/10.3390/ijms23010220
Chicago/Turabian StyleSohn, Soo-In, Subramani Pandian, John-Lewis Zinia Zaukuu, Young-Ju Oh, Soo-Yun Park, Chae-Sun Na, Eun-Kyoung Shin, Hyeon-Jung Kang, Tae-Hun Ryu, Woo-Suk Cho, and et al. 2022. "Discrimination of Transgenic Canola (Brassica napus L.) and their Hybrids with B. rapa using Vis-NIR Spectroscopy and Machine Learning Methods" International Journal of Molecular Sciences 23, no. 1: 220. https://doi.org/10.3390/ijms23010220
APA StyleSohn, S.-I., Pandian, S., Zaukuu, J.-L. Z., Oh, Y.-J., Park, S.-Y., Na, C.-S., Shin, E.-K., Kang, H.-J., Ryu, T.-H., Cho, W.-S., & Cho, Y.-S. (2022). Discrimination of Transgenic Canola (Brassica napus L.) and their Hybrids with B. rapa using Vis-NIR Spectroscopy and Machine Learning Methods. International Journal of Molecular Sciences, 23(1), 220. https://doi.org/10.3390/ijms23010220