Folding by Numbers: Primary Sequence Statistics and Their Use in Studying Protein Folding

Abstract
:1. Introduction
2. Statistical Analyses of Protein Primary Sequences
2.1. The Randomness of the Primary Sequence
2.2. Binary Patterns Within Primary Sequences
2.3. Analyzing the Primary Sequence Using Information Theory
3. Primary Sequence and Secondary Structure
3.1. Amino Acid Conformational Propensities
3.2. Residue Coupling
4. Primary Sequence and Tertiary Structure
4.1. Natively Disordered Proteins
4.2. Domain Boundary Prediction
4.3. Domain Structural Class Prediction
5. A Novel Example: Residue Patterning in β-Strands
5.1. Methods
5.2. Results and Discussion
6. Concluding Remarks
“… the limitations in all statistical approaches to protein structure must be kept in mind: proteins are biologically evolved molecules with a particular structure tailored to a particular function. Only average properties of protein structures can be understood by statistical methods, but not the highly individual character of each protein” [53].
References and Notes
- Anfinsen, CB; Haber, E; Sela, M; White, FH, Jr. The kinetics of formation of native ribonuclease during oxidation of the reduced polypeptide chain. Proc. Natl. Acad. Sci. USA 1961, 47, 1309–1314. [Google Scholar]
- Rossmann, MG; Argos, P. Protein folding. Ann. Rev. Biochem 1981, 50, 497–532. [Google Scholar]
- Levinthal, C. Are there pathways for protein folding? J. Chem. Phys 1968, 65, 44–45. [Google Scholar]
- Fetrow, JS; Giamonna, A; Kolinski, A; Sholnick, J. The protein folding problem: a biophysical enigma. Curr. Pharm. Biotechnol 2002, 3, 329–347. [Google Scholar]
- Dill, KA; Ozkan, SB; Shell, MS; Weikl, TR. The protein folding problem. Annu. Rev. Biophys 2008, 37, 289–316. [Google Scholar]
- Dill, KA; Fiebig, KM; Chan, HS. Cooperativity in protein-folding kinetics. Proc. Natl. Acad. Sci. USA 1993, 90, 1942–1946. [Google Scholar]
- Onuchic, JN; Wolynes, PG. Theory of protein folding. Curr. Opin. Struct. Biol 2004, 14, 70–75. [Google Scholar]
- Wolynes, PG. Energy landscapes and solved protein-folding problems. Phil. Trans. R. Soc. A 2005, 363, 453–467. [Google Scholar]
- Marqusee, S; Robbins, VH; Baldwin, RL. Unusually stable helix formation in short alaninebased peptides. Proc. Natl. Acad. Sci. USA 1989, 86, 5286–5290. [Google Scholar]
- Fersht, AR. Characterizing transition states in protein folding: an essential step in the puzzle. Curr. Opin. Struct. Biol 1994, 5, 79–84. [Google Scholar]
- Englander, SW. Protein folding intermediates and pathways studied by hydrogen exchange. Annu. Rev. Biophys. Biomol. Struct 2000, 29, 213–238. [Google Scholar]
- Swanson, R; Tsai, J. Pretty good guessing: protein structure prediction at CASP5. J. Bacteriol 2003, 185, 3990–3993. [Google Scholar]
- Schueler-Furman, O; Wang, C; Bradley, P; Misura, K; Baker, D. Progress in modeling of protein structures and interactions. Science 2005, 310, 638–642. [Google Scholar]
- Kryshtafovych, A; Fidelis, K; Moult, J. CASP progress report. Proteins 2007, 69(Suppl 8), 194–207. [Google Scholar]
- Eaton, WA; Muñoz, V; Hagen, SJ; Jas, GS; Lapidus, LJ; Henry, ER; Hofrichter, J. Fast kinetics and mechanisms in protein folding. Annu. Rev. Biophys. Biomol. Struct 2000, 29, 327–359. [Google Scholar]
- Maity, H; Maity, M; Krishna, MMG; Mayne, L; Englander, SW. Protein folding: the stepwise assembly of foldon units. Proc. Natl. Acad. Sci. USA 2005, 102, 4741–4746. [Google Scholar]
- Krantz, BA; Mayne, L; Rumbley, J; Englander, SW; Sosnick, TR. Fast and slow intermediate accumulation and the initial barrier mechanism in protein folding. J. Mol. Biol 2002, 324, 359–371. [Google Scholar]
- Bédard, S; Krishna, MM; Mayne, L; Englander, SW. Protein folding: independent unrelated pathways or predetermined pathway with optional errors. Proc. Natl. Acad. Sci. USA 2008, 105, 7182–7187. [Google Scholar]
- Dill, KA; Chan, HS. From Levinthal to pathways to funnels. Nat. Struct. Biol 1997, 4, 10–19. [Google Scholar]
- Yon, JM. Protein folding in the post-genomic era. J. Cell Mol. Med 2002, 6, 307–327. [Google Scholar]
- Gruebele, M. Downhill protein folding: evolution meets physics. C. R. Biol 2005, 328, 701–712. [Google Scholar]
- Vincent, JJ; Tai, C-H; Sathyanarayana, BK; Lee, B. Assessment of CASP6 predictions for new and nearly new fold targets. Proteins 2005, 61(Suppl 7), 67–83. [Google Scholar]
- Jones, TM; Thirup, S. Using known substructures in protein model building and crystallography. EMBO J 1986, 5, 819–822. [Google Scholar]
- Unger, R; Harel, D; Wherland, S; Sussman, JL. A 3D building blocks approach to analyzing and predicting structures of proteins. Proteins 1989, 5, 355–373. [Google Scholar]
- de Brevern, AG; Etchebest, C; Hazout, S. Bayesian probabilistic approach for predicting backbone structures in terms of protein blocks. Proteins 2000, 41, 271–287. [Google Scholar]
- Edgar, RC; Batzoglou, S. Multiple sequence alignment. Curr. Opin. Struct. Biol 2006, 16, 368–373. [Google Scholar]
- Cootes, AP; Curmi, PMG; Cunningham, R; Donnelly, C; Torda, AE. The dependence of amino acid pair correlations on structural environment. Proteins 1998, 32, 175–189. [Google Scholar]
- White, SH; Jacobs, RE. Statistical distribution of hydrophobic residues along the length of protein chains. Biophys. J 1990, 57, 911–921. [Google Scholar]
- Kauzmann, W. Some factors in the interpretation of protein denaturation. Adv. Protein Chem 1959, 14, 1–63. [Google Scholar]
- Rose, GD; Roy, S. Hydrophobic basis of packing in globular proteins. Proc. Natl. Acad. Sci. USA 1980, 77, 4643–4647. [Google Scholar]
- Murphy, LR; Wallqvist, A; Levy, RM. Simplified amino acid alphabets for protein fold recognition and implications for folding. Protein Eng 2000, 13, 149–152. [Google Scholar]
- Etchebest, C; Benros, C; Bornot, A; Camproux, A-C; de Brevern, AG. A reduced amino acid alphabet for understanding and designing protein adaptation in mutation. Eur. Biophys. J 2007, 36, 1059–1069. [Google Scholar]
- Wang, J; Wang, W. A computational approach to simplifying the protein folding alphabet. Nat. Struct. Biol 1999, 6, 1033–1038. [Google Scholar]
- Bacardit, J; Stout, M; Hirst, JD; Valencia, A; Smith, RE; Krasnogor, N. Automated alphabet reduction for protein datasets. BMC Bioinf 2009, 10, 6. [Google Scholar]
- Vazquez, S; Thomas, C; Lew, RA; Humphreys, RE. Favored and suppressed patterns on hydrophobic and nonhydrophobic amino acids in protein sequences. Proc. Natl. Acad. Sci. USA 1993, 90, 9100–9104. [Google Scholar]
- Schwartz, R; Istrail, S; King, J. Frequencies of amino acid strings in globular protein sequences indicate suppression of blocks of consecutive hydrophobic residues. Protein Sci 2001, 10, 1023–1031. [Google Scholar]
- Schwartz, R; King, J. Frequencies of hydrophobic and hydrophilic runs and alternations in proteins of known strcutre. Protein Sci 2006, 15, 102–112. [Google Scholar]
- West, MW; Hecht, MH. Binary patterning of polar and nonpolar amino acids in the sequences and structures of native proteins. Protein Sci 1995, 4, 2032–2039. [Google Scholar]
- Broome, BM; Hecht, MH. Nature disfavors sequences of alternating polar and non-polar amino acids: implications for amyloidogenesis. J. Mol. Biol 2000, 296, 961–968. [Google Scholar]
- Xiong, H; Buckwalter, BL; Shieh, HM; Hecht, MH. Periodicity of polar and nonpolar amino acids is the major determinant of secondary structure in self-assembling oligomeric peptides. Proc. Natl. Acad. Sci. USA 1995, 92, 6349–6353. [Google Scholar]
- Strait, BJ; Dewey, TG. The Shannon information entropy of protein sequences. Biophys. J 1996, 71, 148–155. [Google Scholar]
- Weiss, O; Jiménez-Montaño, MA; Herzel, H. Information content of protein sequences. J. Theor. Biol 2000, 206, 379–386. [Google Scholar]
- Shannon, CE. A mathematical theory of communication. The Bell System Tech J 1948, 27, 379–423. [Google Scholar]
- Chou, PY; Fasman, GD. Conformational parameters for amino acids in helical, β-sheet, and random coil regions calculated from proteins. Biochemistry 1974, 13, 211–222. [Google Scholar]
- Richardson, JS; Richardson, DC. Amino acid preferences for specific locations at the ends of α helices. Science 1988, 240, 1648–1652. [Google Scholar]
- Aurora, R; Rose, GD. Helix capping. Protein Sci 1998, 7, 21–38. [Google Scholar]
- Gunasekaran, K; Nagarajaram, HA; Ramakrishnan, C; Balaram, P. Stereochemical punctuation marks in protein structures: glycine and proline containing helix stop signals. J. Mol. Biol 1998, 275, 917–932. [Google Scholar]
- Penel, S; Hughes, E; Doig, AJ. Side-chain structures in the first turn of the α-helix. J. Mol. Biol 1999, 287, 127–143. [Google Scholar]
- Ermolenko, DN; Thomas, ST; Aurora, R; Gronenborn, AM; Makhatadze, GI. Hydrophobic interactions at the Ccap position of the C-capping motif of α-helices. J. Mol. Biol 2002, 322, 123–135. [Google Scholar]
- Pal, L; Chakrabarti, P; Basu, G. Sequence and structure patterns in proteins from an analysis of the shortest helices: implications for helix nucleation. J. Mol. Biol 2003, 326, 273–291. [Google Scholar]
- Wang, J; Feng, J-A. Exploring the sequence patterns in the α-helices of proteins. Protein Eng 2003, 16, 799–807. [Google Scholar]
- Fonseca, NA; Camacho, R; Magalhães, AL. Amino acid pairing at the N- and C-termini of helical segments in proteins. Proteins 2008, 70, 188–196. [Google Scholar]
- Lifson, S; Sander, C. Antiparallel and parallel β-strands differ in amino acid residue preferences. Nature 1979, 282, 109–111. [Google Scholar]
- Wouters, MA; Curmi, PMG. An analysis of side chain interactions and pair correlations within antiparallel β-sheets: the differences between backbone hydrogen-bonded and non-hydrogenbonded residue pairs. Proteins 1995, 22, 119–131. [Google Scholar]
- Zhu, H; Braun, W. Sequence specificity, statistical potentials, and three-dimensional structure prediction with self-correcting distance geometry calculations of β-sheet formation in proteins. Protein Sci 1999, 8, 326–342. [Google Scholar]
- Wilmot, CM; Thornton, JM. Analysis and prediction of the different types of β-turn in proteins. J. Mol. Biol 1988, 203, 221–232. [Google Scholar]
- Hutchinson, EG; Thornton, JM. A revised set of potentials for {beta}-turn formation in proteins. Protein Sci 1994, 3, 2207–2216. [Google Scholar]
- Guruprasad, K; Prasad, MS; Kumar, GR. Analysis of γβ, βγ, γγ, ββ multiple turns in proteins. J. Peptide Res 2000, 56, 250–263. [Google Scholar]
- Dasgupta, B; Pal, L; Basu, G; Chakrabarti, P. Expanded turn conformations: characterization and sequence-structure correspondence in α-turns, with implications in helix folding. Proteins 2004, 55, 305–315. [Google Scholar]
- Colloc’h, N; Cohen, FE. β-breakers: an aperiodic secondary structure. J. Mol. Biol 1991, 221, 603–613. [Google Scholar]
- Chan, A; Hutchinson, EG; Harris, D; Thornton, JM. Identification, classification, and analysis of beta-bulges in proteins. Protein Sci 1993, 2, 1574–1590. [Google Scholar]
- Daffner, C; Chelvanayagam, G; Argos, P. Structural characteristics and stabilizing principles of bent {beta}-strands in protein tertiary architectures. Protein Sci 1994, 3, 876–882. [Google Scholar]
- Crasto, CJ; Feng, J-A. Sequence codes for extended conformation: a neighbor-dependent sequence analysis of loops in proteins. Proteins 2001, 42, 399–413. [Google Scholar]
- Penel, S; Morrison, RG; Mortishire-Smith, RJ; Doig, AJ. Periodicity in α-helix lengths and C-capping preferences. J. Mol. Biol 1999, 293, 1211–1219. [Google Scholar]
- Presta, LG; Rose, GD. Helix signals in proteins. Science 1988, 240, 1632–1641. [Google Scholar]
- Serrano, L; Fersht, AR. Capping and α-helix stability. Nature 1989, 342, 296–299. [Google Scholar]
- Serrano, L; Sancho, J; Hirshberg, M; Ferscht, AR. α-helix stability in proteins. J. Mol. Biol 1992, 227, 544–559. [Google Scholar]
- Doig, AJ; Baldwin, RL. N- and C-capping preferences for all 20 amino acids in {alpha}-helical peptides. Protein Sci 1995, 4, 1325–1335. [Google Scholar]
- Sagermann, M; Lars-Göran, M; Baase, WA; Matthews, BW. A test of proposed rules for helix capping: implications for protein design. Protein Sci 2002, 11, 516–521. [Google Scholar]
- Kapp, GT; Richardson, JS; Oas, TG. Kinetic role of helix caps in protein folding is contextdependent. Biochemistry 2004, 43, 3814–3823. [Google Scholar]
- Bang, D; Gribenko, AV; Tereshko, V; Kossiakoff, AA; Kent, SB; Makhatadze, GI. Dissecting the energetics of protein α-helix C-cap termination through chemical protein synthesis. Nat. Chem. Biol 2006, 2, 139–143. [Google Scholar]
- Doig, AJ. Recent advances in helix-coil theory. Biophys Chem 2002. [Google Scholar]
- Wilson, CL; Boardman, PE; Doig, AJ; Hubbard, SJ. Improved prediction for N-termini of α-helices using empirical information. Proteins 2004, 57, 322–330. [Google Scholar]
- Jiménez, MA; Muñoz, V; Rico, M; Serrano, L. Helix stop and start signals in peptides and proteins. The capping box does not necessarily prevent helix elongation. J. Mol. Biol 1994, 242, 487–496. [Google Scholar]
- Shortle, D. Propensities, probabilities, and the Boltzmann hypothesis. Protein Sci 2003, 12, 1298–1302. [Google Scholar]
- Klingler, TM; Brutlag, DL. Discovering structural correlations in α-helices. Protein Sci 1994, 3, 1847–1857. [Google Scholar]
- Viguera, AR; Serrano, L. Side-chain interactions between sulfur-containing amino acids and phenylalanine in α -helices. Biochemistry 1995, 34, 8771–8779. [Google Scholar]
- Walther, D; Argos, P. Intrahelical side chain-side chain contacts: the consequences of restricted rotameric states and implications for helix engineering and design. Protein Eng 1996, 9, 471–478. [Google Scholar]
- Fernández-Recio, J; Sancho, J. Intrahelical side chain interactions in α-helices: poor correlation between energetics and frequency. FEBS Lett 1998, 429, 99–103. [Google Scholar]
- Andrew, CD; Penel, S; Jones, GR; Doig, AJ. Stabilizing nonpolar/polar side-chain interactions in the α-helix. Proteins 2001, 45, 449–455. [Google Scholar]
- von Heijne, G; Blomberg, C. The β structure: inter-strand correlations. J. Mol. Biol 1977, 117, 821–824. [Google Scholar]
- Lifson, S. Specific recognition in the tertiary structure of β-sheets of proteins. J. Mol. Biol 1980, 139, 627–639. [Google Scholar]
- Hutchinson, EG; Sessions, RB; Thornton, JM; Woolfson, DN. Determinants of strand register in antiparallel {beta}-sheets of proteins. Protein Sci 1998, 7, 2287–2300. [Google Scholar]
- Fooks, HM; Martin, ACR; Woolfson, DN; Sessions, RB; Hutchinson, EG. Amino acid pairing preferences in parallel β-sheets in proteins. J. Mol. Biol 2006, 356, 32–44. [Google Scholar]
- Mandel-Gutfreund, Y; Zaremba, SM; Gregoret, LM. Contributions of residue pairing to β- sheet formation: conservation and covariation of amino acid residue pairs on antiparallel β- strands. J. Mol. Biol 2001, 305, 1145–1159. [Google Scholar]
- Karplus, M; Weaver, DL. Protein folding dynamics: the diffusion-collision model and experimental data. Protein Sci 1994, 3, 650–668. [Google Scholar]
- Wright, PE; Dyson, HJ. Intrinsically unstructured proteins: re-assessing the4 protein structurefunction paradigm. J. Mol. Biol 1999, 293, 321–331. [Google Scholar]
- Fink, AL. Natively unfolded proteins. Curr. Opin. Struct. Biol 2005, 15, 35–41. [Google Scholar]
- Dunker, AK; Oldfield, CJ; Meng, J; Romero, P; Yang, JY; Chen, JW; Vacic, V; Obradovic, Z; Uversky, VN. The unfoldomics decade: an update on intrinsically disordered proteins. BMC Genomics 2008, 9(Suppl 2), S1. [Google Scholar]
- Uversky, VN; Gillespie, JR; Fink, AL. Why are “natively unfolded” proteins unstructured under physiologic conditions? Proteins 2000, 41, 415–427. [Google Scholar]
- Romero, P; Obradovic, Z; Li, X; Garner, EC; Brown, CJ; Dunker, AK. Sequence complexity of disordered protein. Proteins 2001, 42, 38–48. [Google Scholar]
- Dunker, AK; Lawson, JD; Brown, CJ; Williams, RM; Romero, R; Oh, JS; Oldfield, CJ; Campen, AM; Ratliff, CM; Hipps, KW; Ausio, J; Nissen, MS; Reeves, R; Kang, C; Kissinger, CR; Bailey, RW; Griswold, MD; Chiu, W; Garner, EC; Obradovic, Z. Intrinsically disordered proteins. J. Mol. Graphics Modell 2001, 19, 26–59. [Google Scholar]
- Wetlaufer, DB. Nucleation, rapid folding, and globular intrachain regions in proteins. Proc. Natl. Acad. Sci. USA 1973, 70, 697–701. [Google Scholar]
- Rigden, DJ. Use of covariance analysis for the prediction of structural domain boundaries from multiple protein sequence alignments. Protein Eng 2002, 15, 65–77. [Google Scholar]
- Dong, Q; Wang, X; Lin, L; Xu, Z. Domain boundary predictio nbased on profile domain linker propensity index. Comput. Biol. Chem 2006, 30, 127–133. [Google Scholar]
- Liu, J; Rost, B. Sequence-based prediction nof protein domains. Nucleic Acids Res 2004, 32, 3522–3530. [Google Scholar]
- Miyazaki, S; Kuroda, Y; Yokoyama, S. Identification of putative domain linkers by a neural network-application to a large sequence database. BMC Bioinf 2006, 7, 323. [Google Scholar]
- Ye, L; Liu, T; Wu, Z; Zhou, R. Sequence-based protein domain boundary prediction using BP neural network with various property profiles. Proteins 2007, 71, 300–307. [Google Scholar]
- Yoo, PD; Sikder, AR; Zhou, BB; Zomaya, AY. Improved general regression network for protein domain boundary prediction. BMC Bioinf 2008, 9(Suppl 1), 512. [Google Scholar]
- Wheelan, SJ; Marchler-Bauer, A; Bryant, SH. Domain size distributions can predict domain boundaries. Bioinformatics 2000, 16, 613–618. [Google Scholar]
- Suyama, M; Ohara, O. DomCut: prediction of inter-domain linker regions in amino acid sequences. Bioinformatics 2003, 19, 673–674. [Google Scholar]
- Galzitskaya, OV; Melnik, BS. Prediction of protein domain boundaries from sequence alone. Protein Sci 2003, 12, 696–701. [Google Scholar]
- Levitt, M; Chothia, C. Structural patterns in globular proteins. Nature 1976, 261, 552–558. [Google Scholar]
- Chou, K-C; Zhang, C-T. Prediction of protein structural classes. Crit. Rev. Biochem. Mol. Biol 1995, 30, 275–349. [Google Scholar]
- Nakashima, H; Nishikawa, K; Ooi, T. The folding type of a protein is relevant to the amino acid composition. J. Biochem 1986, 99, 153–162. [Google Scholar]
- Bu, W-S; Feng, Z-P; Zhang, Z; Zhang, C-T. Prediction of protein (domain) structural classes based on amino-acid index. Eur. J. Biochem 1999, 266, 1043–1049. [Google Scholar]
- Gu, F; Chen, H; Ni, J. Protein structural class prediction based on an improved statistical strategy. BMC Bioinf 2008, 9(Suppl 6), S5. [Google Scholar]
- Luo, R-Y; Feng, Z-P; Liu, J-K. Prediction of protein structural class by amino acid and polypeptide composition. Eur. J. Biochem 2002, 269, 4219–4225. [Google Scholar]
- Costantini, S; Facchiano, AM. Prediction of the protein structural class by specific peptide frequencies. Biochimie 2008. In press. [Google Scholar]
- Mahalanobis, PC. On the generalized distance in statistics. Proc. Natl. Inst. Sci. India 1936, 2, 49–55. [Google Scholar]
- Ventura, S; Serrano, L. Designing proteins from the inside out. Proteins 2004, 56, 1–10. [Google Scholar]
- Santiveri, CM; Jiménez, MA; Rico, M; Van Gunsteren, WF; Daura, X. β-hairpin folding and stability: molecular dynamics simulations of designed peptides in aqueous solution. J. Pept. Sci 2004, 10, 546–65. [Google Scholar]
- Muñoz, V; Thompson, PA; Hofrichter, J; Eaton, WA. Folding dynamics and mechanism of β- hairpin formation. Nature 1997, 390, 196–199. [Google Scholar]
- Noguchi, T; Matsuda, H; Akiyama, Y. PDB-REPRDB: a database of representative protein chains from the Protein Data Bank (PDB). Nucleic Acids Res 2001, 29, 219–220. [Google Scholar]
- Kabsch, W; Sander, C. Dictionary of protein secondary structure: pattern recognition of hydrogen-bonded and geometrical features. Biopolymers 1983, 22, 2577–2637. [Google Scholar]
- Chiti, F; Dobson, CM. Amyloid formation by globular proteins under native conditions. Nat. Chem. Biol 2009, 5, 15–22. [Google Scholar]
- Cohen, FE; Sternberg, MJE; Taylor, WR. Analysis and prediction of protein β-sheet structures by a combinatorial approach. Nature 1980, 285, 378–382. [Google Scholar]


{kind=link}
{kind=link}
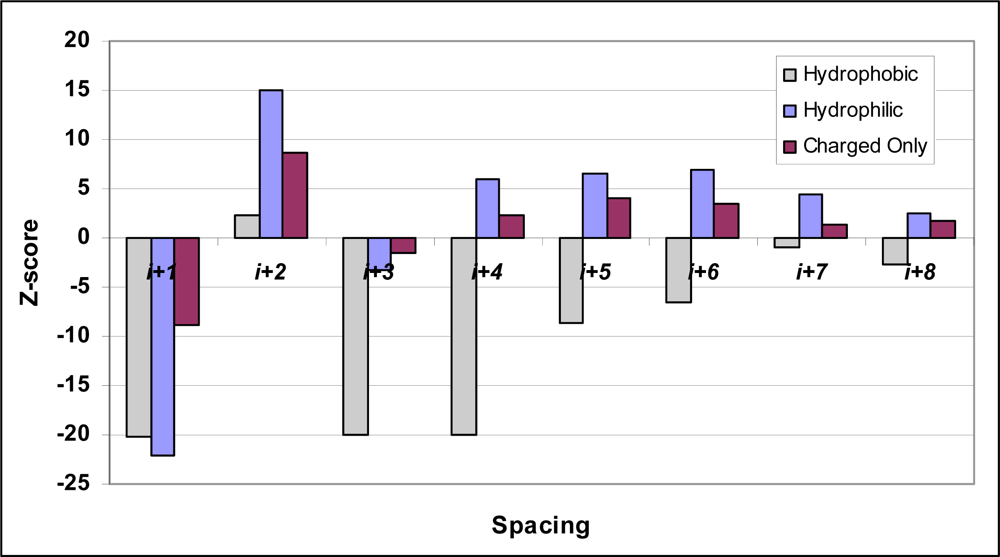
| Spacing | Hydrophobic | Hydrophilic | ||||
|---|---|---|---|---|---|---|
| Frequency | Expected | Z-score | Frequency | Expected | Z-score | |
| i+1 | 9361 | 10592.9 | −20.3 | 4579 | 5751.3 | −22.2 |
| i+2 | 8291 | 8161.8 | 2.2 | 5467 | 4716.4 | 15.1 |
| i+3 | 4803 | 5787.4 | −20.0 | 3475 | 3614.1 | −3.2 |
| i+4 | 2871 | 3759.1 | −20.1 | 2950 | 2714.0 | 5.9 |
| i+5 | 1960 | 2258.3 | −8.6 | 2197 | 1983.0 | 6.5 |
| i+6 | 1133 | 1322.7 | −6.6 | 1526 | 1339.4 | 6.8 |
| i+7 | 738 | 758.4 | −1.0 | 988 | 889.8 | 4.3 |
| i+8 | 386 | 428.4 | −2.6 | 615 | 571.8 | 2.5 |
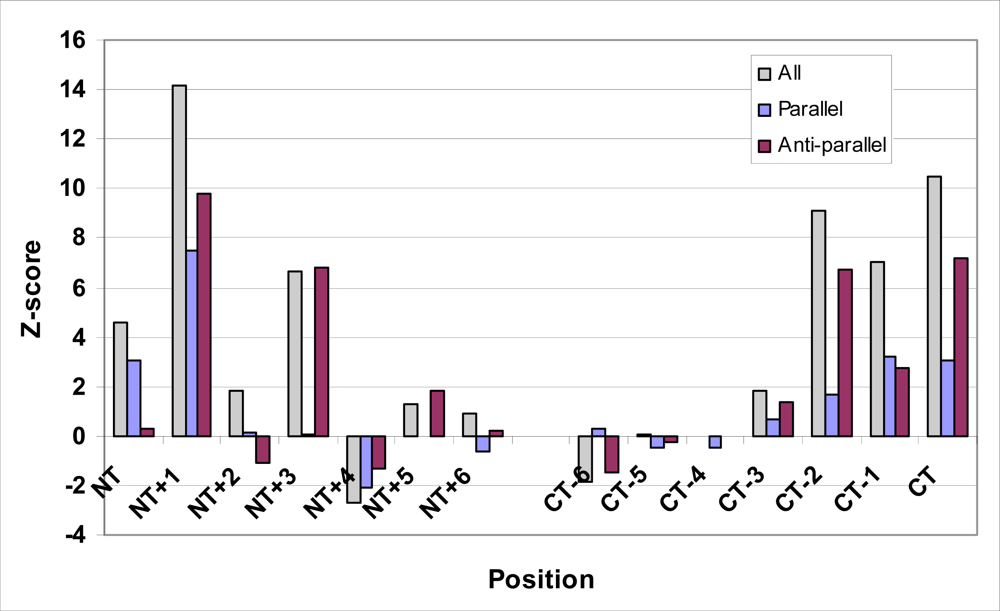
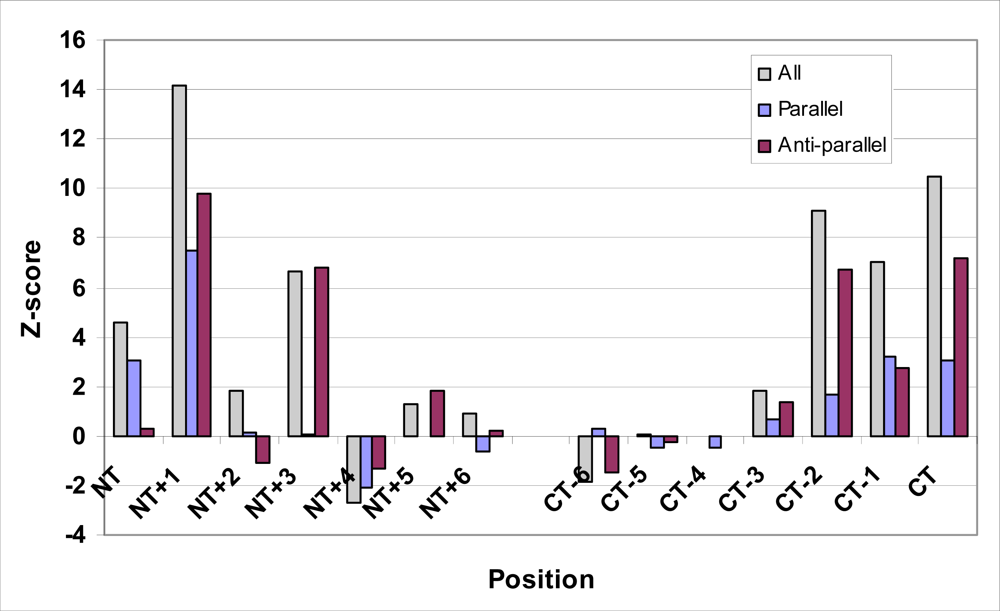
| Pairing | All Strands | Parallel Strands | Antiparallel Strands | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Freq. | Expect | Z-score | Freq. | Expect | Z-score | Freq. | Expect | Z-score | |
| NT,NT+2 | 1976 | 1835.1 | 4.6 | 802 | 748.1 | 3.0 | 952 | 944.9 | 0.3 |
| NT+1,NT+2 | 2450 | 1937.3 | 14.2 | 1004 | 853.4 | 7.5 | 1181 | 948.7 | 9.8 |
| NT+2,NT+4 | 1463 | 1408.7 | 1.8 | 522 | 519.8 | 0.1 | 718 | 743.6 | −1.1 |
| NT+3,NT+5 | 1086 | 916.2 | 6.6 | 244 | 243.2 | 0.1 | 685 | 551.9 | 6.8 |
| NT+4,NT+6 | 498 | 550.7 | −2.7 | 81 | 96.9 | −2.1 | 348 | 370.4 | −1.3 |
| NT+5,NT+7 | 345 | 324.8 | 1.3 | 31 | 31.2 | 0.0 | 264 | 239.1 | 1.8 |
| NT+6,NT+8 | 191 | 180.8 | 0.9 | 11 | 13.0 | −0.6 | 137 | 134.5 | 0.2 |
| CT-8,CT-6 | 168 | 189.7 | −1.9 | 14 | 13.1 | 0.3 | 127 | 142.1 | −1.4 |
| CT-7,CT-5 | 339 | 338.0 | 0.1 | 32 | 34.2 | −0.5 | 245 | 248.4 | −0.3 |
| CT-6,CT-4 | 571 | 571.1 | 0.0 | 102 | 105.8 | −0.5 | 379 | 379.0 | 0.0 |
| CT-5,CT-3 | 995 | 947.5 | 1.9 | 268 | 259.7 | 0.7 | 593 | 565.3 | 1.4 |
| CT-4,CT-2 | 1722 | 1439.1 | 9.1 | 568 | 539.4 | 1.7 | 910 | 753.7 | 6.7 |
| CT-3,CT-1 | 2204 | 1958.5 | 7.0 | 925 | 859.1 | 3.2 | 1029 | 961.3 | 2.7 |
| CT-2,CT | 2032 | 1719.0 | 10.5 | 789 | 735.6 | 3.0 | 1021 | 857.9 | 7.2 |
© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Wathen, B.; Jia, Z. Folding by Numbers: Primary Sequence Statistics and Their Use in Studying Protein Folding. Int. J. Mol. Sci. 2009, 10, 1567-1589. https://doi.org/10.3390/ijms10041567
Wathen B, Jia Z. Folding by Numbers: Primary Sequence Statistics and Their Use in Studying Protein Folding. International Journal of Molecular Sciences. 2009; 10(4):1567-1589. https://doi.org/10.3390/ijms10041567
Chicago/Turabian StyleWathen, Brent, and Zongchao Jia. 2009. "Folding by Numbers: Primary Sequence Statistics and Their Use in Studying Protein Folding" International Journal of Molecular Sciences 10, no. 4: 1567-1589. https://doi.org/10.3390/ijms10041567