Approximations of Shannon Mutual Information for Discrete Variables with Applications to Neural Population Coding


1
Key Laboratory of Cognition and Intelligence and Information Science Academy of China Electronics Technology Group Corporation, Beijing 100086, China
2
Department of Biomedical Engineering, Johns Hopkins University School of Medicine, Baltimore, MD 21205, USA
*
Authors to whom correspondence should be addressed.
Entropy 2019, 21(3), 243; https://doi.org/10.3390/e21030243
Submission received: 15 December 2018
/
Revised: 11 February 2019
/
Accepted: 28 February 2019
/
Published: 4 March 2019
(This article belongs to the Special Issue The 20th Anniversary of Entropy - Recent Advances in Entropy and Information-Theoretic Concepts and Their Applications)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Although Shannon mutual information has been widely used, its effective calculation is often difficult for many practical problems, including those in neural population coding. Asymptotic formulas based on Fisher information sometimes provide accurate approximations to the mutual information but this approach is restricted to continuous variables because the calculation of Fisher information requires derivatives with respect to the encoded variables. In this paper, we consider information-theoretic bounds and approximations of the mutual information based on Kullback-Leibler divergence and Rényi divergence. We propose several information metrics to approximate Shannon mutual information in the context of neural population coding. While our asymptotic formulas all work for discrete variables, one of them has consistent performance and high accuracy regardless of whether the encoded variables are discrete or continuous. We performed numerical simulations and confirmed that our approximation formulas were highly accurate for approximating the mutual information between the stimuli and the responses of a large neural population. These approximation formulas may potentially bring convenience to the applications of information theory to many practical and theoretical problems.
1. Introduction
Information theory is a powerful tool widely used in many disciplines, including, for example, neuroscience, machine learning, and communication technology [1,2,3,4,5,6,7]. As it is often notoriously difficult to effectively calculate Shannon mutual information in many practical applications [8], various approximation methods have been proposed to estimate the mutual information, such as those based on asymptotic expansion [9,10,11,12,13], k-nearest neighbor [14], and minimal spanning trees [15]. Recently, Safaai et al. proposed a copula method for estimation of mutual information, which can be nonparametric and potentially robust [16]. Another approach for estimating the mutual information is to simplify the calculations by approximations based on information-theoretic bounds, such as the Cramér–Rao lower bound [17] and the van Trees’ Bayesian Cramér–Rao bound [18].
In this paper, we focus on mutual information estimation based on asymptotic approximations [19,20,21,22,23,24]. For encoding of continuous variables, asymptotic relations between mutual information and Fisher information have been presented by several researchers [19,20,21,22]. Recently, Huang and Zhang [24] proposed an improved approximation formula, which remains accurate for high-dimensional variables. A significant advantage of this approach is that asymptotic approximations are sometimes very useful in analytical studies. For instance, asymptotic approximations allow us to prove that the optimal neural population distribution that maximizes the mutual information between stimulus and response can be solved by convex optimization [24]. Unfortunately this approach does not generalize to discrete variables since the calculation of Fisher information requires partial derivatives of the likelihood function with respect to the encoded variables. For encoding of discrete variables, Kang and Sompolinsky [23] represented an asymptotic relationship between mutual information and Chernoff information for statistically independent neurons in a large population. However, Chernoff information is still hard to calculate in many practical applications.
Discrete stimuli or variables occur naturally in sensory coding. While some stimuli are continuous (e.g., the direction of movement, and the pitch of a tone), others are discrete (e.g., the identities of faces, and the words in human speech). For definiteness, in this paper, we frame our questions in the context of neural population coding; that is, we assume that the stimuli or the input variables are encoded by the pattern of responses elicited from a large population of neurons. The concrete examples used in our numerical simulations were based on Poisson spike model, where the response of each neuron is taken as the spike count within a given time window. While this simple Poisson model allowed us to consider a large neural population, it only captured the spike rate but not any temporal structure of the spike trains [25,26,27,28]. Nonetheless, our mathematical results are quite general and should be applicable to other input–output systems under suitable conditions to be discussed later.
In the following, we first derive several upper and lower bounds on Shannon mutual information using Kullback-Leibler divergence and Rényi divergence. Next, we derive several new approximation formulas for Shannon mutual information in the limit of large population size. These formulas are more convenient to calculate than the mutual information in our examples. Finally, we confirm the validity of our approximation formulas using the true mutual information as evaluated by Monte Carlo simulations.
2. Theory and Methods
2.1. Notations and Definitions
Suppose the input is a K-dimensional vector, , which could be interpreted as the parameters that specifies a stimulus for a sensory system, and the outputs is an N-dimensional vector, , which could be interpreted as the responses of N neurons. We assume N is large, generally . We denote random variables by upper case letters, e.g., random variables X and R, in contrast to their vector values and . The mutual information between X and R is defined by
where , , and denotes the expectation with respect to the probability density function . Similarly, in the following, we use and to denote expectations with respect to and , respectively.
If and are twice continuously differentiable for almost every , then for large N we can use an asymptotic formula to approximate the true value of I with high accuracy [24]:
which is sometimes reduced to
where denotes the matrix determinant, is the stimulus entropy,
and
is the Fisher information matrix.
Here, is equivalent to Chernoff divergence of order [30]. It is well known that in the limit .
We define
where in we have and and assume for all .
In the following, we suppose takes M discrete values, , , and for all m. Now, the definitions in Equations (9)–(11) become
Furthermore, we define
where
Here, notice that, if is uniformly distributed, then by definition and become identical. The elements in set are those that make take the minimum value, excluding any element that satisfies the condition . Similarly, the elements in set are those that minimize excluding the ones that satisfy the condition .
2.2. Theorems
In the following, we state several conclusions as theorems and prove them in Appendix A.
Theorem 1.
The mutual information I is bounded as follows:
Theorem 2.
Theorem 3.
If there exist and such that
for discrete stimuli , where , and , then we have the following asymptotic relationships:
and
Theorem 4.
Suppose and are twice continuously differentiable for , , , where and and denote partial derivatives and , and is positive definite with , where denotes matrix Frobenius norm,
and . If there exist an such that
for all and , where is the complementary set of , then we have the following asymptotic relationships:
where
and with .
Remark 1.
We see from Theorems 1 and 2 that the true mutual information I and the approximation both lie between and , which implies that their values may be close to each other. For discrete variable , Theorem 3 tells us that and are asymptotically equivalent (i.e., their difference vanishes) in the limit of large N. For continuous variable , Theorem 4 tells us that and are asymptotically equivalent in the limit of large N, which means that and I are also asymptotically equivalent because and I are known to be asymptotically equivalent [24].
Remark 2.
To see how the condition in Equation (33) could be satisfied, consider the case where has only one extreme point at for and there exists an such that for . Now, the condition in Equation (33) is satisfied because
where by assumption we can find an for any given . The condition in Equation (34) can be satisfied in a similar way. When , is the Bhattacharyya distance [31]:
and we have
where is the Hellinger distance [32] between and :
By Jensen’s inequality, for we get
By Theorem 4,
2.3. Approximations for Mutual Information
In this section, we use the relationships described above to find effective approximations to true mutual information I in the case of large but finite N. First, Theorems 1 and 2 tell us that the true mutual information I and its approximation lie between lower and upper bounds given by: and . As a special case, I is also bounded by . Furthermore, from Equations (2) and (36) we can obtain the following asymptotic equality under suitable conditions:
Hence, for continuous stimuli, we have the following approximate relationship for large N:
Consider the special case for . With the help of Equation (18), substitution of into Equation (52) yields
where and the second approximation follows from the first-order Taylor expansion assuming that the term is sufficiently small.
The theoretical discussion above suggests that and are effective approximations to true mutual information I in the limit of large N. Moreover, we find that they are often good approximations of mutual information I even for relatively small N, as illustrated in the following section.
3. Results of Numerical Simulations
Consider Poisson model neuron whose responses (i.e., numbers of spikes within a given time window) follow a Poisson distribution [24]. The mean response of neuron n, with , is described by the tuning function , which takes the form of a Heaviside step function:
where the stimulus with , , and the centers , , ⋯, of the N neurons are uniformly spaced in interval , namely, with for , and for . We suppose that the discrete stimulus x has possible values that are evenly spaced from to T, namely, . Now, the Kullback-Leibler divergence can be written as
Thus, we have when , when and , and when and . Therefore, in this case, we have
More generally, this equality holds true whenever the tuning function has binary values.
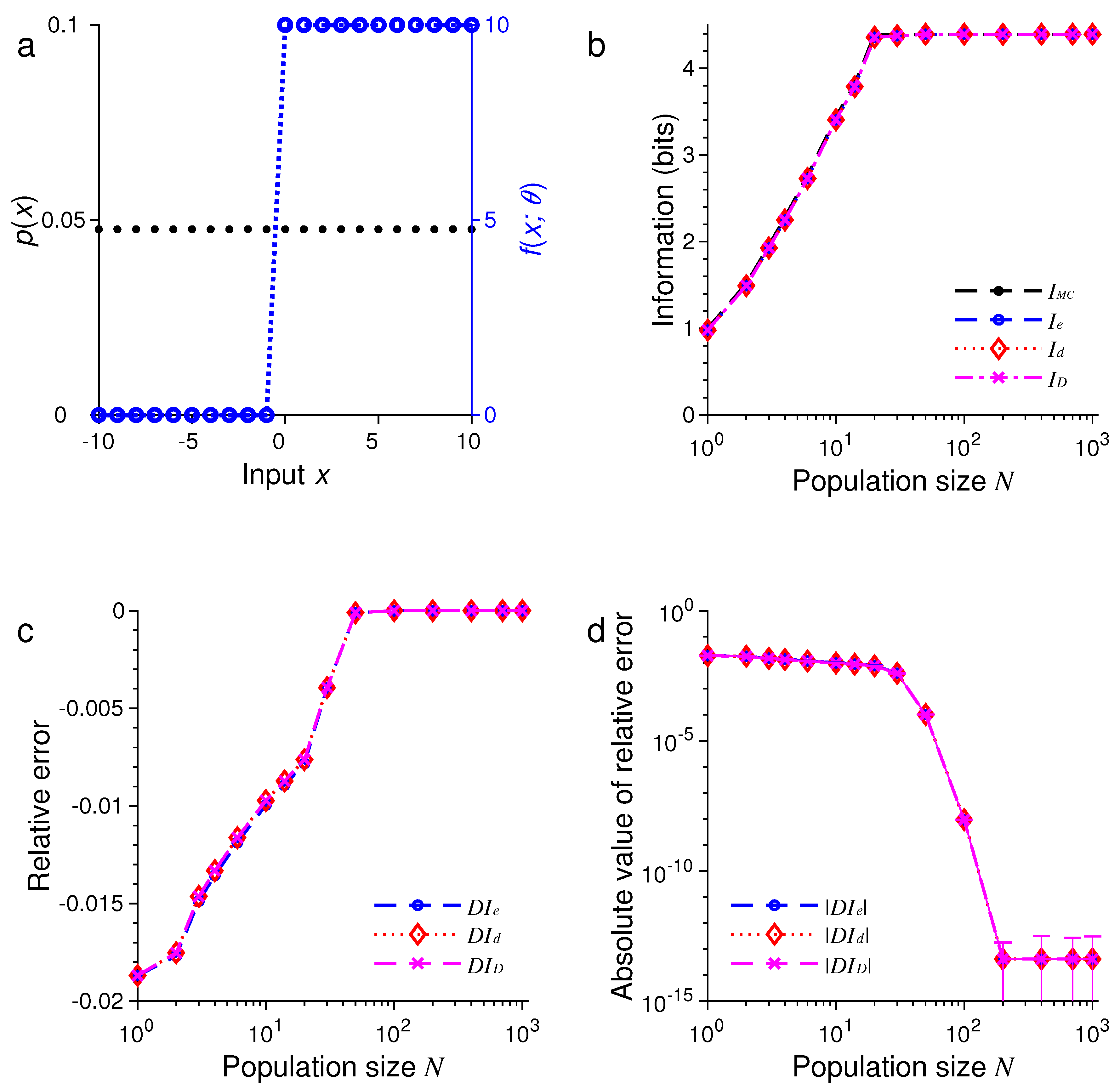
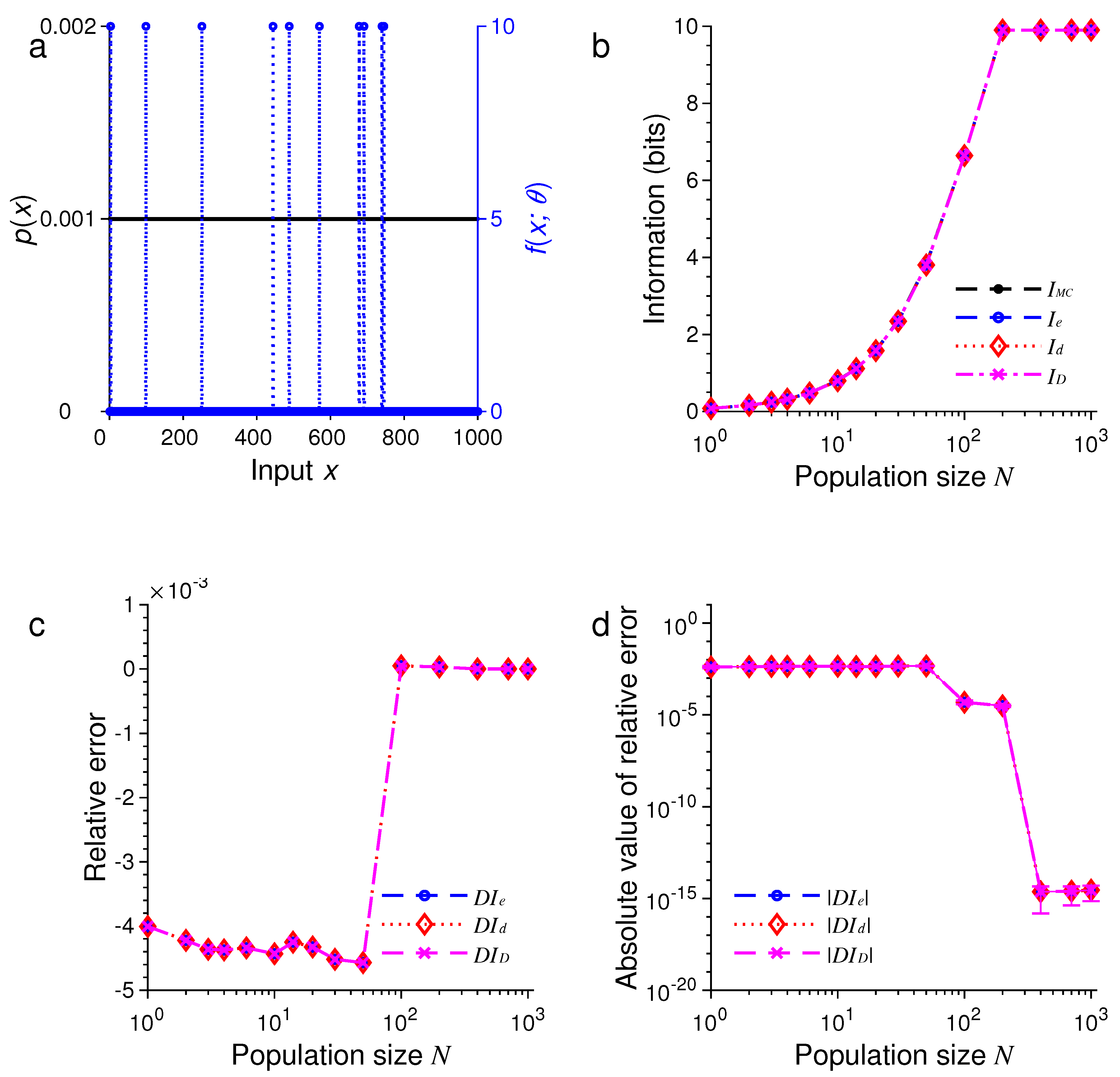
In the first example, as illustrated in Figure 1, we suppose the stimulus has a uniform distribution, so that the probability is given by . Figure 1a shows graphs of the input distribution and a representative tuning function with the center .
To assess the accuracy of the approximation formulas, we employed Monte Carlo (MC) simulation to evaluate the mutual information I [24]. In our MC simulation, we first sampled an input from the uniform distribution , then generated the neural responses by the conditional distribution based on the Poisson model, where , 2, ⋯, . The value of mutual information by MC simulation was calculated by
where
To assess the precision of our MC simulation, we computed the standard deviation of repeated trials by bootstrapping:
where
and is the -th entry of the matrix with samples taken randomly from the integer set , 2, ⋯, by a uniform distribution. Here, we set , and .
For different , we compared with , and , as illustrated in Figure 1b–d. Here, we define the relative error of approximation, e.g., for , as
and the relative standard deviation
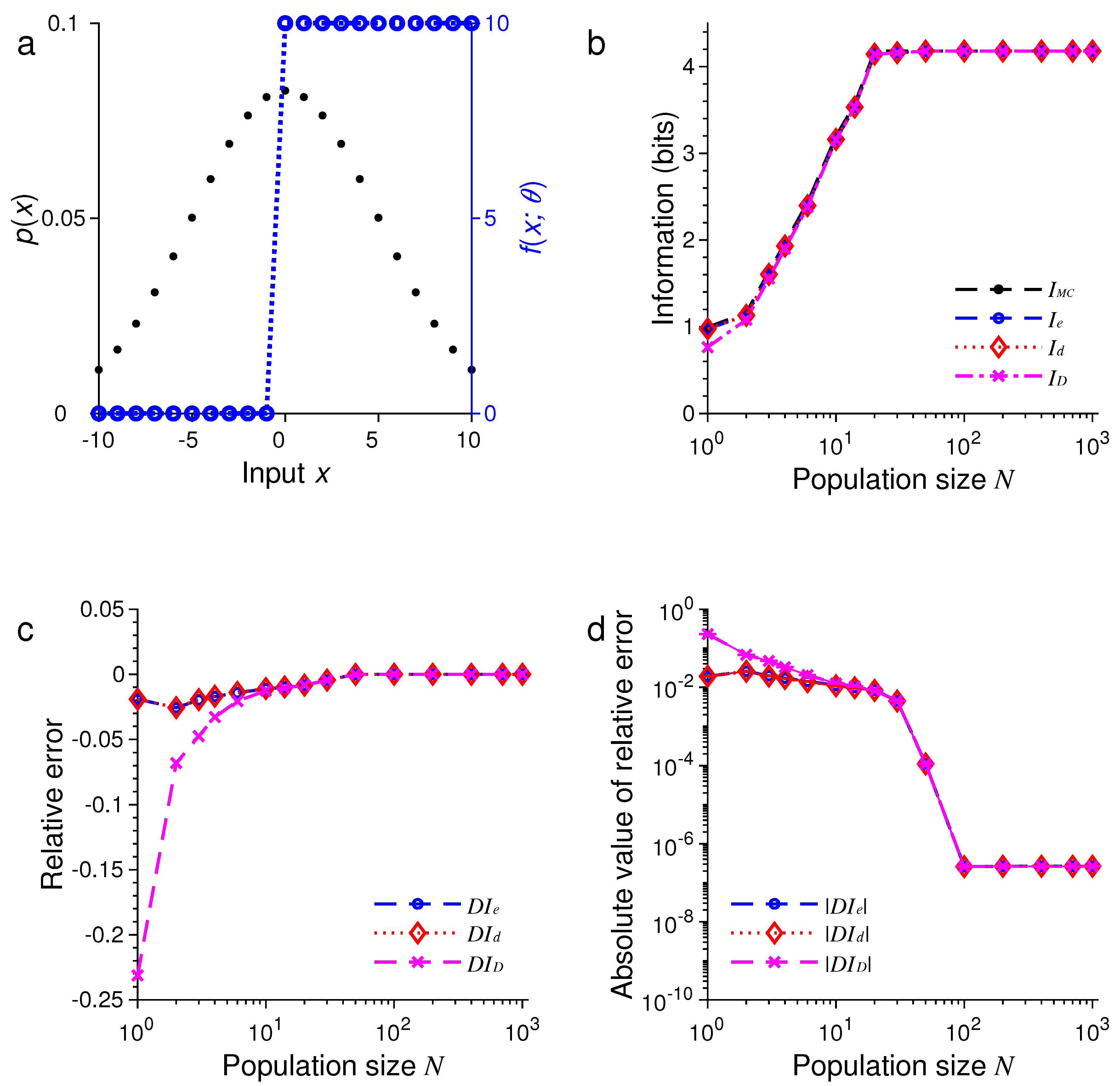
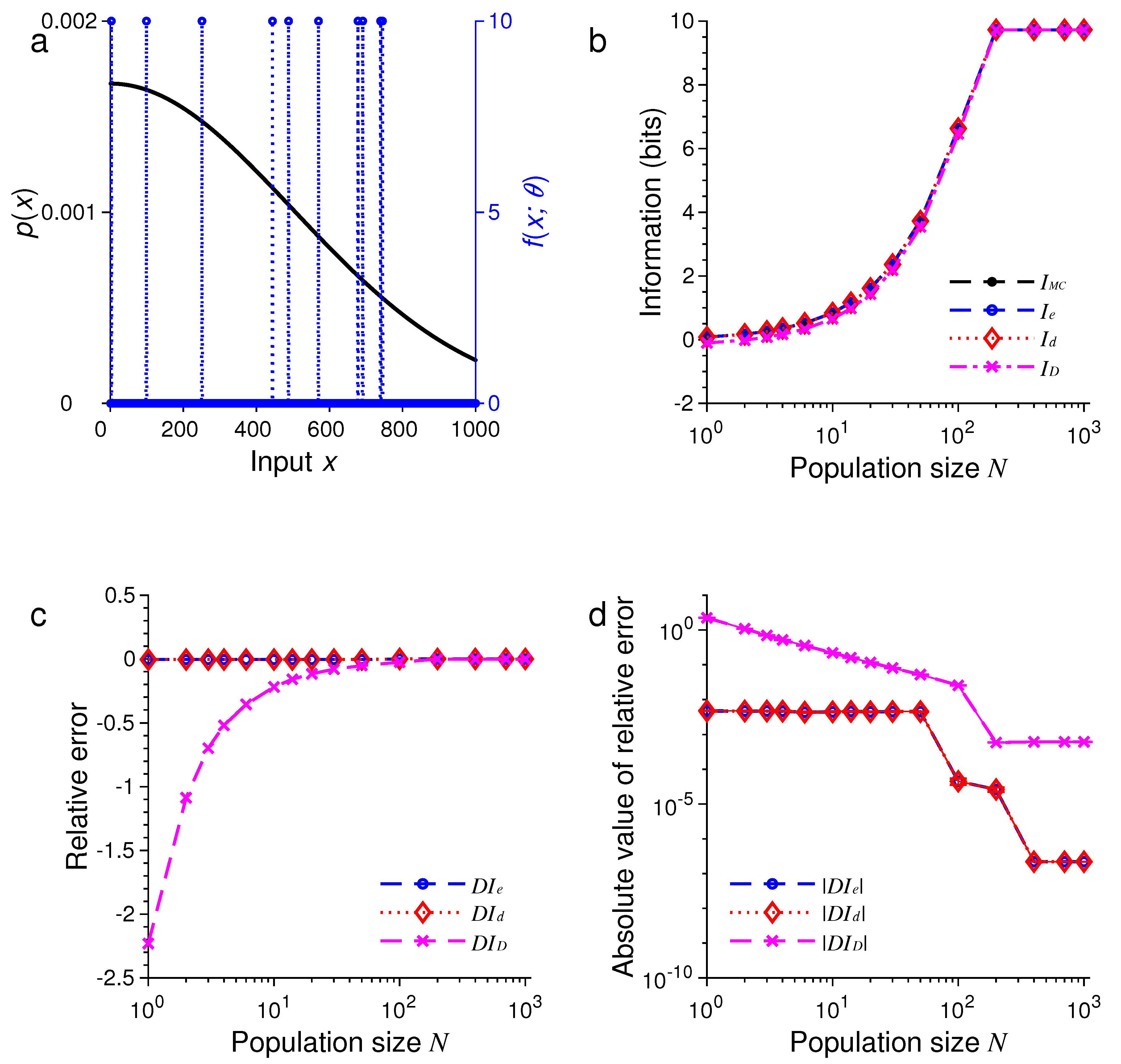
For the second example, we only changed the probability distribution of stimulus while keeping all other conditions unchanged. Now, is a discrete sample from a Gaussian function:
where is the normalization constant and . The results are illustrated in Figure 2.
Next, we changed each tuning function to a rectified linear function:
Figure 3 and Figure 4 show the results under the same conditions of Figure 1 and Figure 2 except for the shape of the tuning functions.
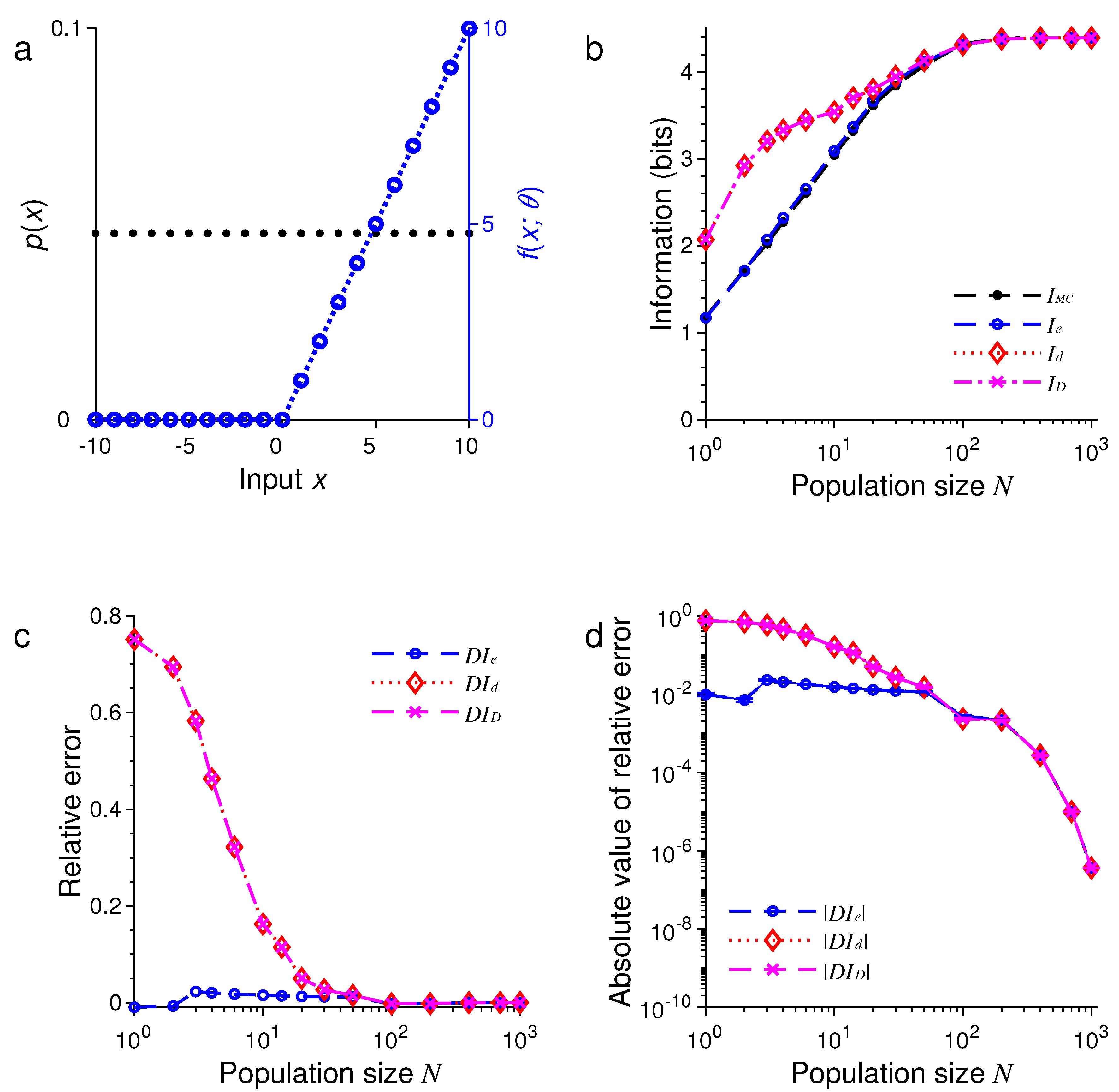
Finally, we let the tuning function have a random form:
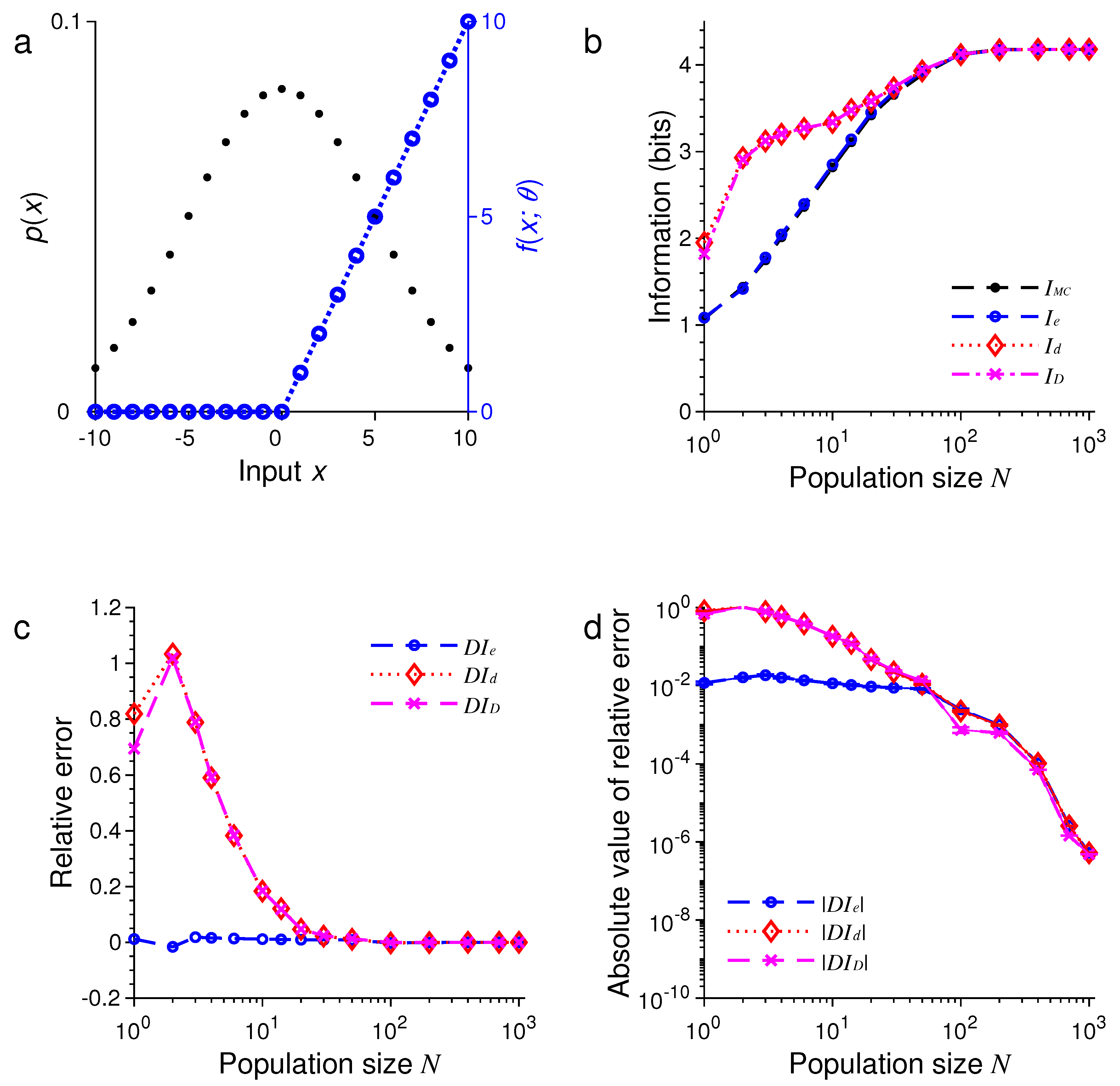
where the stimulus , , the values of are distinct and randomly selected from the set with . In this example, we may regard as a list of natural objects (stimuli), and there are a total of N sensory neurons, each of which responds only to K randomly selected objects. Figure 5 shows the results under the condition that is a uniform distribution. In Figure 6, we assume that is not flat but a half Gaussian given by Equation (64) with .
In all these examples, we found that the three formulas, namely, , and , provided excellent approximations to the true values of mutual information as evaluated by Monte Carlo method. For example, in the examples in Figure 1 and Figure 5, all three approximations were practically indistinguishable. In general, all these approximations were extremely accurate when .
In all our simulations, the mutual information tended to increase with the population size N, eventually reaching a plateau for large enough N. The saturation of information for large N is due to the fact that it requires at most bits of information to completely distinguish all M stimuli. It is impossible to gain more information than this maximum amount regardless of how many neurons are used in the population. In Figure 1, for instance, this maximum is bits, and in Figure 5, this maximum is bits.
For relatively small values of N, we found that tended to be less accurate than or (see Figure 5 and Figure 6). Our simulations also confirmed two analytical results. The first one is that when the stimulus distribution is uniform; this result follows directly from the definitions of and and is confirmed by the simulations in Figure 1, Figure 3, and Figure 5. The second result is that (Equation (56)) when the tuning function is binary, as confirmed by the simulations in Figure 1, Figure 2, Figure 5, and Figure 6. When the tuning function allows many different values, can be much more accurate than and , as shown by the simulations in Figure 3 and Figure 4. To summarize, our best approximation formula is because it is more accurate than and , and, unlike and , it applies to both discrete and continuous stimuli (Equations (10) and (13)).
4. Discussion
We have derived several asymptotic bounds and effective approximations of mutual information for discrete variables and established several relationships among different approximations. Our final approximation formulas involve only Kullback-Leibler divergence, which is often easier to evaluate than Shannon mutual information in practical applications. Although in this paper our theory is developed in the framework of neural population coding with concrete examples, our mathematical results are generic and should hold true in many related situations beyond the original context.
We propose to approximate the mutual information with several asymptotic formulas, including in Equation (10) or Equation (13), in Equation (15) and in Equation (18). Our numerical experimental results show that the three approximations , and were very accurate for large population size N, and sometimes even for relatively small N. Among the three approximations, tended to be the least accurate, although, as a special case of , it is slightly easier to evaluate than . For a comparison of and , we note that is the universal formula, whereas is restricted only to discrete variables. The two formulas and become identical when the responses or the tuning functions have only two values. For more general tuning functions, the performance of was better than in our simulations.
As mentioned before, an advantage of of is that it works not only for discrete stimuli but also for continuous stimuli. Theoretically speaking, the formula for is well justified, and we have proven that it approaches the true mutual information I in the limit of large population. In our numerical simulations, the performance of was excellent and better than that of and . Overall, is our most accurate and versatile approximation formula, although, in some cases, and are slightly more convenient to calculate.
The numerical examples considered in this paper were based on an independent population of neurons whose responses have Poisson statistics. Although such models are widely used, they are appropriate only if the neural responses can be well characterized by the spike counts within a fixed time window. To study the temporal patterns of spike trains, one has to consider more complicated models. Estimation of mutual information from neural spike trains is a difficult computational problem [25,26,27,28]. In future work, it would be interesting to apply the asymptotic formulas such as to spike trains with small time bins each containing either one spike or nothing. A potential advantage of the asymptotic formula is that it might help reduce the bias caused by small samples in the calculation of the response marginal distribution or the response entropy because here one only needs to calculate the Kullback-Leibler divergence , which may have a smaller estimation error.
Finding effective approximation methods for computing mutual information is a key step for many practical applications of the information theory. Generally speaking, Kullback-Leibler divergence (Equation (7)) is often easier to evaluate and approximate than either Chernoff information (Equation (44)) or Shannon mutual information (Equation (1)). In situations where this is indeed the case, our approximation formulas are potentially useful. Besides applications in numerical simulations, the availability of a set of approximation formulas may also provide helpful theoretical tools in future analytical studies of information coding and representations.
As mentioned in the Introduction, various methods have been proposed to approximate the mutual information [9,10,11,12,13,14,15,16]. In future work, it would be useful to compare different methods rigorously under identical conditions in order to asses their relative merits. The approximation formulas developed in this paper are relatively easy to compute for practical problems. They are especially suitable for analytical purposes; for example, they could be used explicitly as objective functions for optimization or learning algorithms. Although the examples used in our simulations in this paper are parametric, it should be possible to extend the formulas to nonparametric problem, possibly with help of the copula method to take advantage of its robustness in nonparametric estimations [16].
Author Contributions
W.H. developed and proved the theorems, programmed the numerical experiments and wrote the manuscript. K.Z. verified the proofs and revised the manuscript.
Funding
This research was supported by an NIH grant R01 DC013698.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. The Proofs
Appendix A.1. Proof of Theorem 1
By Jensen’s inequality, we have
and
In this section, we use integral for variable , although our argument is valid for both continuous variables and discrete variables. For discrete variables, we just need to replace each integral by a summation, and our argument remains valid without other modification. The same is true for the response variable .
To prove the upper bound, let
where satisfies
By Jensen’s inequality, we get
To find a function that minimizes , we apply the variational principle as follows:
where is the Lagrange multiplier and
Setting and using the constraint in Equation (A4), we find the optimal solution
Thus, the variational lower bound of is given by
Appendix A.2. Proof of Theorem 2
Appendix A.3. Proof of Theorem 3
For the lower bound , we have
where
Now, consider
where
Appendix A.4. Proof of Theorem 4
Consider the Taylor expansion for around . Assuming that is twice continuously differentiable for any , we get
where
and
For later use, we also define
where
Since is continuous and symmetric for , for any , there is a such that
for all , where . Then, we get
and with Jensen’s inequality,
where is a positive constant, ,
and
Now, we evaluate
Performing integration by parts with , we find
for some constant .
Note that
Now, we have
Since is arbitrary, we can let it go to zero. Therefore, from Equations (25), (A29) and (A34), we obtain the upper bound in Equation (35).
The Taylor expansion of around is
In a similar manner as described above, we obtain the asymptotic relationship (37):
Notice that and the equality holds when . Thus, we have
The proof of Equation (36) is similar. This completes the proof of Theorem 4.
References
- Borst, A.; Theunissen, F.E. Information theory and neural coding. Nat. Neurosci. 1999, 2, 947–957. [Google Scholar] [CrossRef] [PubMed]
- Pouget, A.; Dayan, P.; Zemel, R. Information processing with population codes. Nat. Rev. Neurosci. 2000, 1, 125–132. [Google Scholar] [CrossRef] [PubMed]
- Laughlin, S.B.; Sejnowski, T.J. Communication in neuronal networks. Science 2003, 301, 1870–1874. [Google Scholar] [CrossRef] [PubMed]
- Brown, E.N.; Kass, R.E.; Mitra, P.P. Multiple neural spike train data analysis: State-of-the-art and future challenges. Nat. Neurosci. 2004, 7, 456–461. [Google Scholar] [CrossRef] [PubMed]
- Bell, A.J.; Sejnowski, T.J. The “independent components” of natural scenes are edge filters. Vision Res. 1997, 37, 3327–3338. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Zhang, K. An Information-Theoretic Framework for Fast and Robust Unsupervised Learning via Neural Population Infomax. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Huang, W.; Huang, X.; Zhang, K. Information-theoretic interpretation of tuning curves for multiple motion directions. In Proceedings of the 2017 51st Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2017. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information, 2nd ed.; Wiley-Interscience: New York, NY, USA, 2006. [Google Scholar]
- Miller, G.A. Note on the bias of information estimates. Inf. Theory Psychol. Probl. Methods 1955, 2, 100. [Google Scholar]
- Carlton, A. On the bias of information estimates. Psychol. Bull. 1969, 71, 108. [Google Scholar] [CrossRef]
- Treves, A.; Panzeri, S. The upward bias in measures of information derived from limited data samples. Neural Comput. 1995, 7, 399–407. [Google Scholar] [CrossRef]
- Victor, J.D. Asymptotic bias in information estimates and the exponential (Bell) polynomials. Neural Comput. 2000, 12, 2797–2804. [Google Scholar] [CrossRef] [PubMed]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Bandyopadhyay, S.; Ganguly, A.R.; Saigal, S.; Erickson, D.J., III; Protopopescu, V.; Ostrouchov, G. Relative performance of mutual information estimation methods for quantifying the dependence among short and noisy data. Phys. Rev. E 2007, 76, 026209. [Google Scholar] [CrossRef] [PubMed]
- Safaai, H.; Onken, A.; Harvey, C.D.; Panzeri, S. Information estimation using nonparametric copulas. Phys. Rev. E 2018, 98, 053302. [Google Scholar] [CrossRef]
- Rao, C.R. Information and accuracy attainable in the estimation of statistical parameters. Bull. Calcutta Math. Soc. 1945, 37, 81–91. [Google Scholar]
- Van Trees, H.L.; Bell, K.L. Bayesian Bounds for Parameter Estimation and Nonlinear Filtering/Tracking; John Wiley: Piscataway, NJ, USA, 2007. [Google Scholar]
- Clarke, B.S.; Barron, A.R. Information-theoretic asymptotics of Bayes methods. IEEE Trans. Inform. Theory 1990, 36, 453–471. [Google Scholar] [CrossRef] [Green Version]
- Rissanen, J.J. Fisher information and stochastic complexity. IEEE Trans. Inform. Theory 1996, 42, 40–47. [Google Scholar] [CrossRef]
- Brunel, N.; Nadal, J.P. Mutual information, Fisher information, and population coding. Neural Comput. 1998, 10, 1731–1757. [Google Scholar] [CrossRef] [PubMed]
- Sompolinsky, H.; Yoon, H.; Kang, K.J.; Shamir, M. Population coding in neuronal systems with correlated noise. Phys. Rev. E 2001, 64, 051904. [Google Scholar] [CrossRef] [PubMed]
- Kang, K.; Sompolinsky, H. Mutual information of population codes and distance measures in probability space. Phys. Rev. Lett. 2001, 86, 4958–4961. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Zhang, K. Information-theoretic bounds and approximations in neural population coding. Neural Comput. 2018, 30, 885–944. [Google Scholar] [CrossRef] [PubMed]
- Strong, S.P.; Koberle, R.; van Steveninck, R.R.D.R.; Bialek, W. Entropy and information in neural spike trains. Phys. Rev. Lett. 1998, 80, 197. [Google Scholar] [CrossRef]
- Nemenman, I.; Bialek, W.; van Steveninck, R.D.R. Entropy and information in neural spike trains: Progress on the sampling problem. Phys. Rev. E 2004, 69, 056111. [Google Scholar] [CrossRef] [PubMed]
- Panzeri, S.; Senatore, R.; Montemurro, M.A.; Petersen, R.S. Correcting for the sampling bias problem in spike train information measures. J. Neurophysiol. 2017, 98, 1064–1072. [Google Scholar] [CrossRef] [PubMed]
- Houghton, C. Calculating the Mutual Information Between Two Spike Trains. Neural Comput. 2019, 31, 330–343. [Google Scholar] [CrossRef] [PubMed]
- Rényi, A. On measures of entropy and information. In Fourth Berkeley Symposium on Mathematical Statistics and Probability; The Regents of the University of California, University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Chernoff, H. A measure of asymptotic efficiency for tests of a hypothesis based on the sum of observations. Ann. Math. Stat. 1952, 23, 493–507. [Google Scholar] [CrossRef]
- Bhattacharyya, A. On a measure of divergence between two statistical populations defined by their probability distributions. Bull. Calcutta Math. Soc. 1943, 35, 99–109. [Google Scholar]
- Beran, R. Minimum Hellinger distance estimates for parametric models. Ann. Stat. 1977, 5, 445–463. [Google Scholar] [CrossRef]
Figure 1.
A comparison of approximations , and against obtained by Monte Carlo method for one-dimensional discrete stimuli. (a) Discrete uniform distribution of the stimulus (black dots) and the Heaviside step tuning function with center (blue dashed lines); (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.
Figure 1.
A comparison of approximations , and against obtained by Monte Carlo method for one-dimensional discrete stimuli. (a) Discrete uniform distribution of the stimulus (black dots) and the Heaviside step tuning function with center (blue dashed lines); (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.

Figure 2.
A comparison of approximations , and against . The situation is identical to that in Figure 1 except that the stimulus distribution is peaked rather flat (black dots in (a)). (a) Discrete Gaussian-like distribution of the stimulus (black dots) and the Heaviside step tuning function with center (blue dashed lines); (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.
Figure 2.
A comparison of approximations , and against . The situation is identical to that in Figure 1 except that the stimulus distribution is peaked rather flat (black dots in (a)). (a) Discrete Gaussian-like distribution of the stimulus (black dots) and the Heaviside step tuning function with center (blue dashed lines); (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.

Figure 3.
A comparison of approximations , and against . The situation is identical to that in Figure 1 except for the shape of the tuning function (blue dashed lines in (a)). (a) Discrete uniform distribution of the stimulus (black dots) and the rectified linear tuning function with center (blue dashed lines); (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.
Figure 3.
A comparison of approximations , and against . The situation is identical to that in Figure 1 except for the shape of the tuning function (blue dashed lines in (a)). (a) Discrete uniform distribution of the stimulus (black dots) and the rectified linear tuning function with center (blue dashed lines); (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.

Figure 4.
A comparison of approximations , and against . The situation is identical to that in Figure 3 except that the stimulus distribution is peaked rather flat (black dots in (a)). (a) Discrete Gaussian-like distribution of the stimulus (black dots) and the rectified linear tuning function with center (blue dashed lines); (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.
Figure 4.
A comparison of approximations , and against . The situation is identical to that in Figure 3 except that the stimulus distribution is peaked rather flat (black dots in (a)). (a) Discrete Gaussian-like distribution of the stimulus (black dots) and the rectified linear tuning function with center (blue dashed lines); (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.

Figure 5.
A comparison of approximations , and against . The situation is similar to that in Figure 1 except that the tuning function is random (blue dashed lines in (a)); see Equation (66). (a) Discrete uniform distribution of the stimulus (black dots) and the random tuning function ; (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.
Figure 5.
A comparison of approximations , and against . The situation is similar to that in Figure 1 except that the tuning function is random (blue dashed lines in (a)); see Equation (66). (a) Discrete uniform distribution of the stimulus (black dots) and the random tuning function ; (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.

Figure 6.
A comparison of approximations , and against . The situation is identical to that in Figure 5 except that the stimulus distribution is not flat (black dots in (a)). (a) Discrete Gaussian-like distribution of the stimulus (black dots) and the random tuning function ; (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.
Figure 6.
A comparison of approximations , and against . The situation is identical to that in Figure 5 except that the stimulus distribution is not flat (black dots in (a)). (a) Discrete Gaussian-like distribution of the stimulus (black dots) and the random tuning function ; (b) The values of , , and depend on the population size or total number of neurons N; (c) The relative errors , and for the results in (b); (d) The absolute values of the relative errors , and as in (c), with error bars showing standard deviations of repeated trials.

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Huang, W.; Zhang, K. Approximations of Shannon Mutual Information for Discrete Variables with Applications to Neural Population Coding. Entropy 2019, 21, 243. https://doi.org/10.3390/e21030243
AMA Style
Huang W, Zhang K. Approximations of Shannon Mutual Information for Discrete Variables with Applications to Neural Population Coding. Entropy. 2019; 21(3):243. https://doi.org/10.3390/e21030243
Chicago/Turabian StyleHuang, Wentao, and Kechen Zhang. 2019. "Approximations of Shannon Mutual Information for Discrete Variables with Applications to Neural Population Coding" Entropy 21, no. 3: 243. https://doi.org/10.3390/e21030243
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.