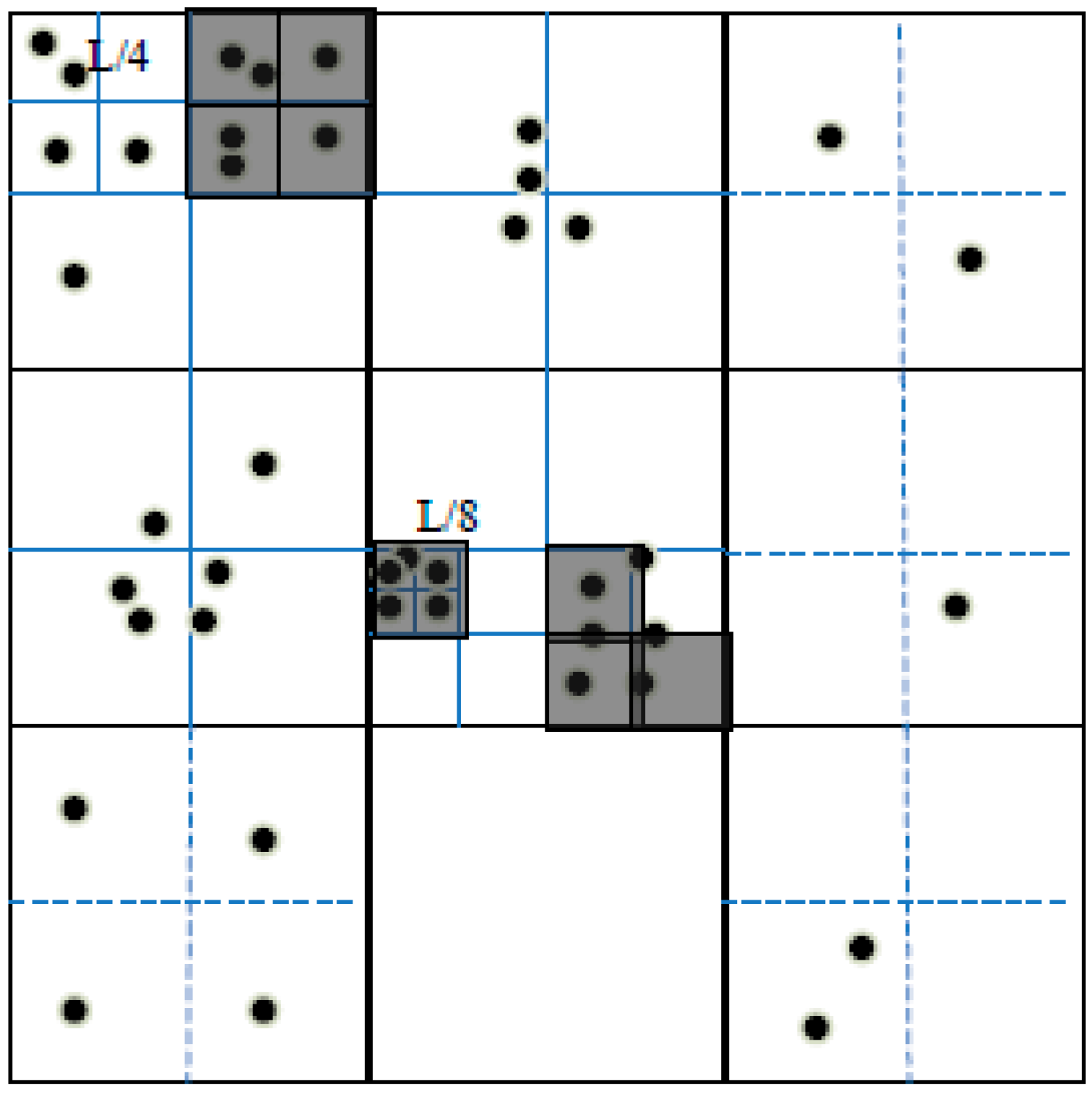
Under the smaller and more credible trajectory space generated by TS-EE, sparse trajectory prediction based on multiple entropy measures (STP-ME) combines Location entropy and time entropy with the second-order Markov model to do sparse trajectory prediction.
4.3. Second-Order Markov Model for Trajectory Prediction
A number of studies [
7,
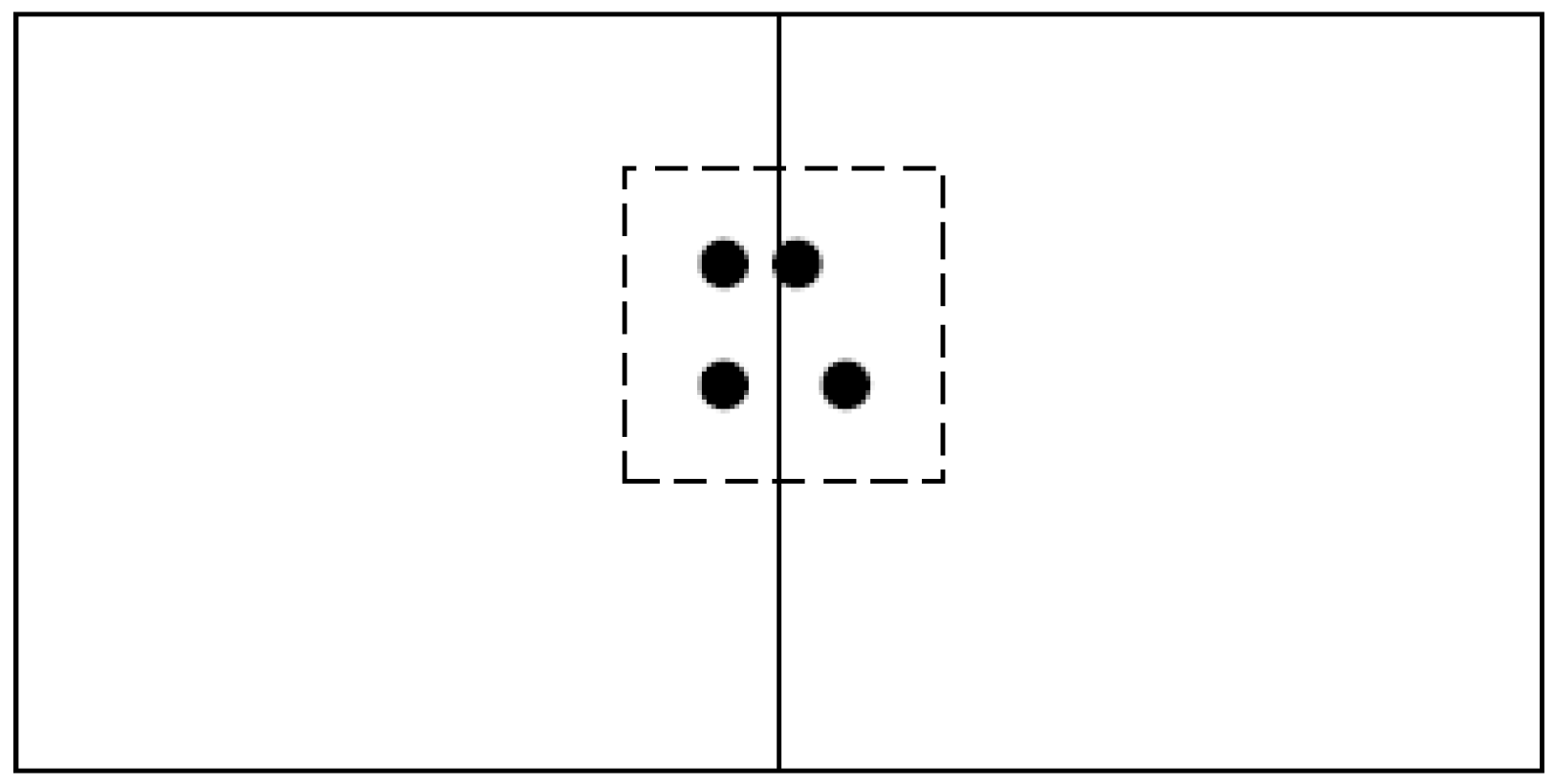
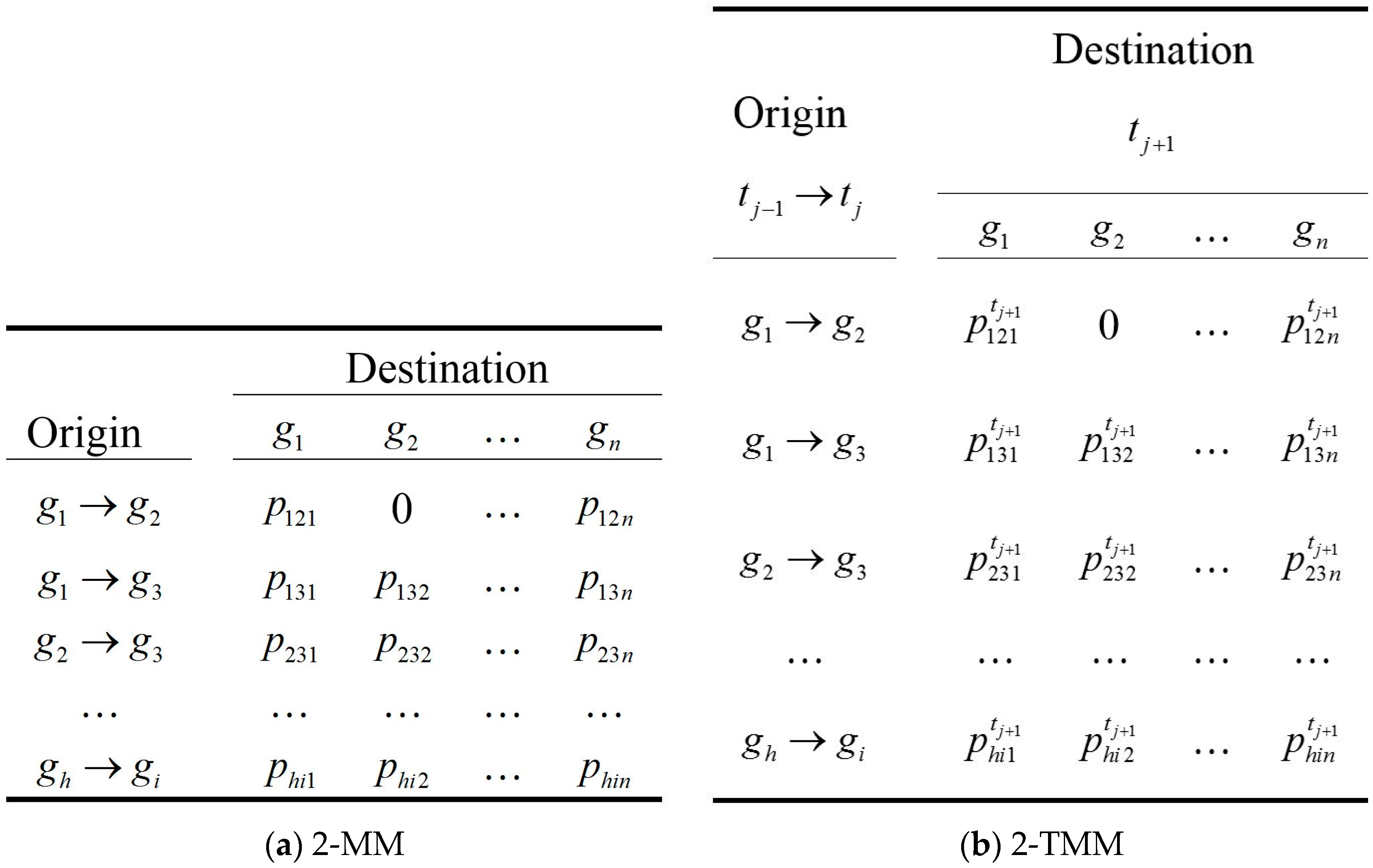
8] have established that the second-order Markov model (2-MM) has the best accuracies, up to 95%, for predicting human mobility, and that higher-order MM (>2) is not necessarily more accurate, but is often less precise. However, the 2-MM always utilizes historical geo-spatial trajectories to train a transition probability matrix and in 2-MM (see
Figure 3a) the probability of each destination is computed based only on the present and immediate past grids of interest that a user visited without using temporal information. Despite being quite successful in predicting human mobility, existing works share some major drawbacks. Firstly, the majority of the existing works are time-unaware in the sense that they neglect the temporal dimension of users’ mobility (such as time of the day) in their models. Consequently, they can only tell where, but not when, a user is likely to visit a location. Neglecting the temporal dimension can have severe implications on some applications that heavily rely on temporal information for the effective function. For example, in homeland security, temporal information is vital in predicting the anticipated movement of a suspect if a potential crime is to be averted. Secondly, no existing works have focused on the popularity of locations and timeslots with considering locations users are interested in and in which timeslots users are active. Trajectory prediction accuracy would be improved by computing user’s popularity of different locations and timeslots quantitatively; for example, people are most likely to go shopping or walking in the park after work. We propose the second-order Markov model with Temporal information (2-TMM, see
Figure 3b) for trajectory prediction based on location entropy and time entropy. Specifically, using Bayes rule, we find the stationary distribution of posterior probabilities of visiting locations during specified timeslots. We then build a second-order mobility transition matrix and combine location entropy and time entropy with a second-order Markov chain model for predicting most likely next location that the user will visit in the next timeslot, using the location entropy, the time entropy, the transition matrix, and the stationary posterior probability distributions.
Let
denote a finite set of grids partitioned by SIGP. Additionally, let
be a set of predefined timeslots in a day. Thus,
denotes a finite set of historical grids with temporal information visited by user
u. Assuming
Table 1 represents statistics of historical visit behaviors of all users,
Table 1a corresponds to trajectories’ historical visits to grids without considering temporal information, and
Table 1b corresponds to trajectories’ historical visits to grids during specified timeslots, where
.
Definition 1. Given a finite set of grids with time visited by trajectories, the visit probability, denoted by of a grid , is a numerical estimate of the likelihood that users will visit grid during . We express a visit probability of grid in terms of two component probabilities coined as (i) grid feature-correlated visit probability (GVP), and (ii) temporal feature-correlated visit probability (TVP). GVP of a grid denoted by , is a prior probability of visit to expressed as a ratio of number of times trajectories visited to the total number of visits to all grids in the trajectories’ grid history.
Table 2a exemplifies GVP probabilities computed from
Table 1a. TVP of
during
, denoted by
, is a conditional probability that a visit occurred during
given that
is visited by trajectories.
Table 2b shows TVP probabilities obtained from
Table 1b.
In line with Definition 1, we compute the visit probability of a semantic location by applying the Bayes’ rule to GVP and TVP. Accordingly, the visit probability of
during timeslot
is given by:
where
.
and
are defined in Definition 1.
Applying Equation (7) to
Table 2 yields visit probabilities for grids visited during each timeslot in
Table 3. Each column in
Table 3 is a probability vector showing a distribution of
for each
during
, where
.
Definition 2. A second-order Markov chain model is a discrete stochastic process with limited memory in which the probability of visiting a grid during timeslot only depends on tags of two grids visited during timeslots .
In line with Definition 2, the probability that a trajectory’s destination will be a grid during timeslot can be expressed as .
Definition 3. A transition probability with respect to 2-TMM is the probability that a trajectory will move to a destination grid during timeslot given that the user has successively visited locations having tags and during timeslots and , respectively.
We denote a transition from grids
and
during timeslots
and
, respectively, to a destination grid
during timeslot
by
. The transition probability is computed as:
where
is the tag of any location at
. We predict the destination grid
of the most likely next grid and its probability by computing right hand side of Equation (9):
Let probability vectors
and
represent distributions of visit probabilities of grids during timeslots
and
, respectively. We represent the initial probability distribution of 2-TMM by the joint distribution of
and
given by
. Given the initial probability distribution and the matrix of transition probabilities, and the location entropy and time entropy computed, the prediction destination of a target query trajectory is calculated by using:




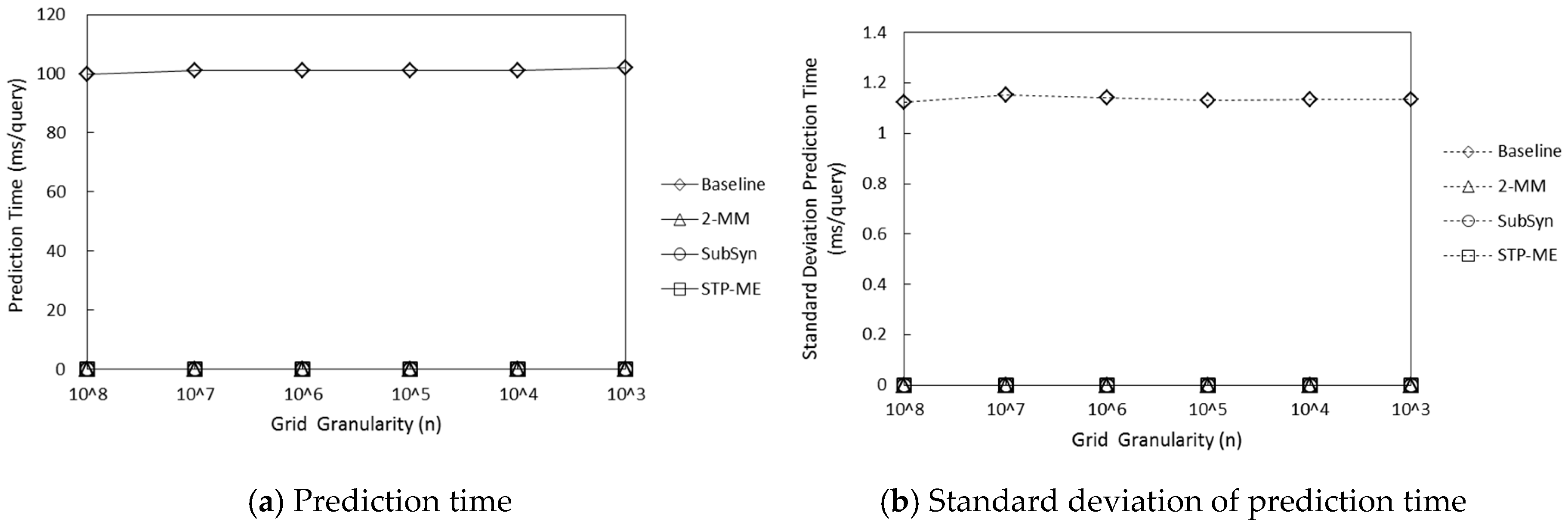
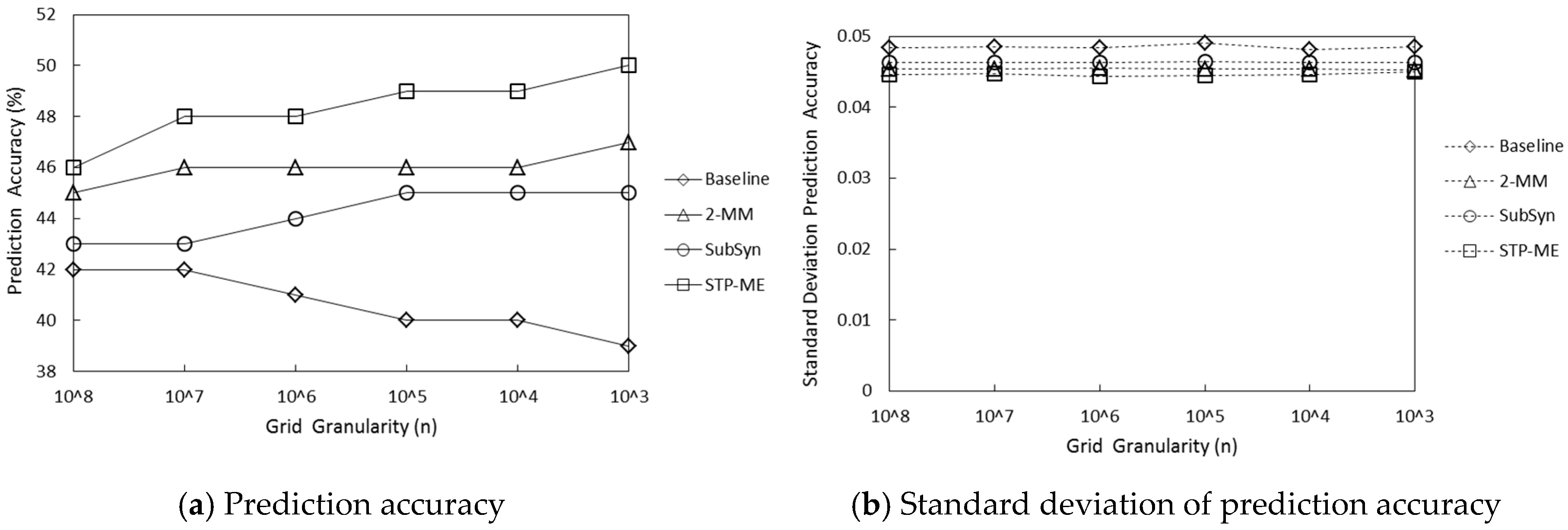
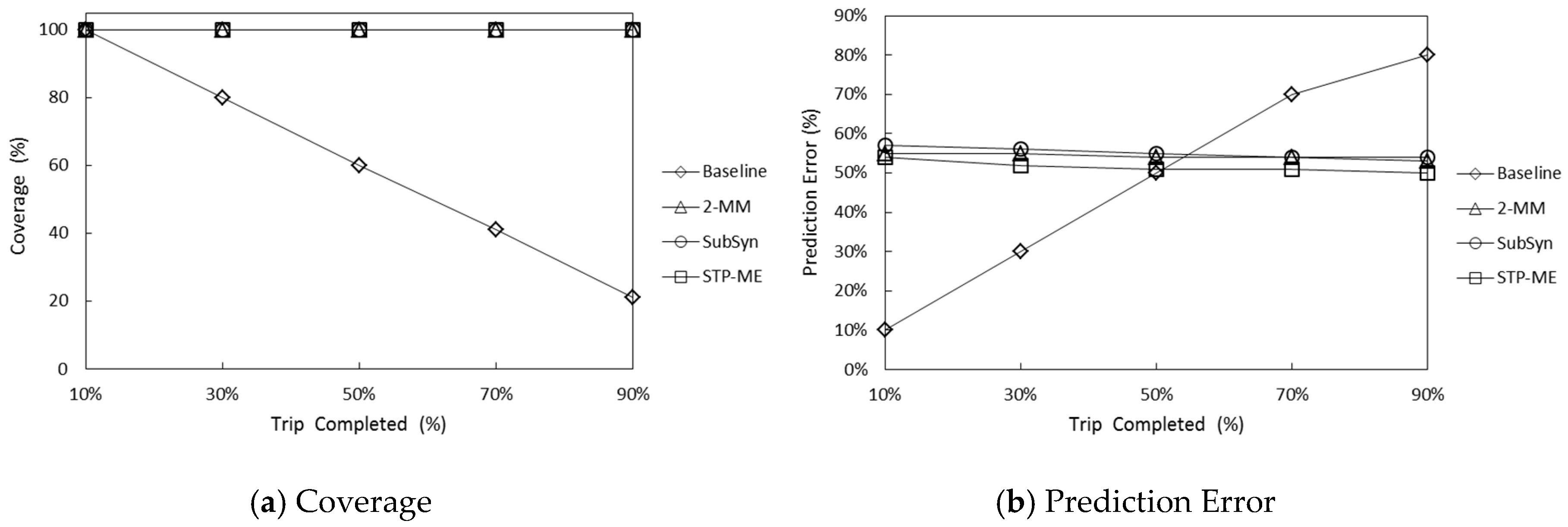

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}