
An End-to-End Artificial Intelligence of Things (AIoT) Solution for Protecting Pipeline Easements against External Interference—An Australian Use-Case

Abstract
:1. Introduction
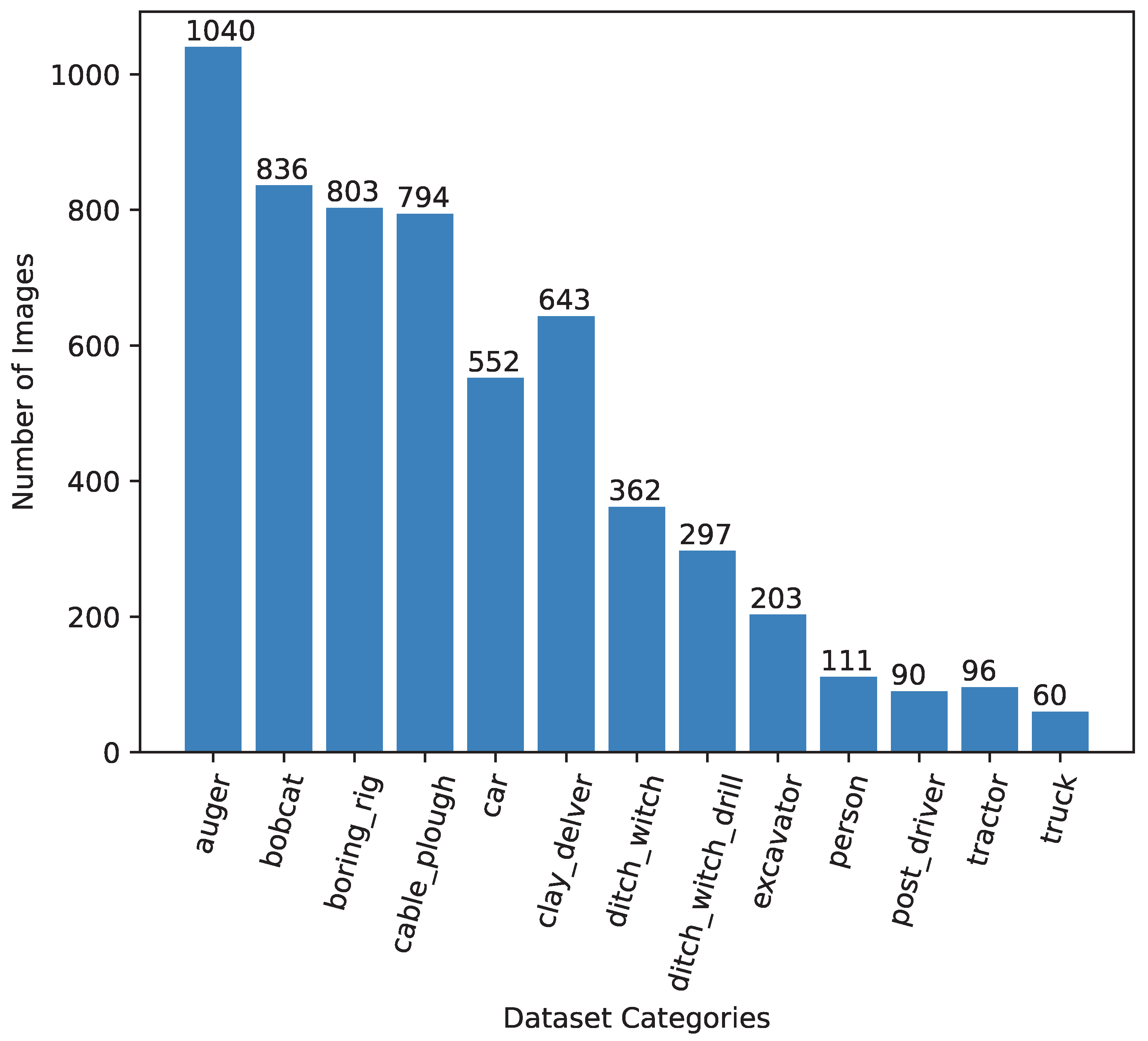
- The development of the custom Pipe-VisTA dataset consisting of 10,181 images to facilitate the training of the computer vision object-detection model.
- The development of an end-to-end interference-threat-detection solution by designing a smart visual sensor based on AIoT capable of processing the live video from a camera using an edge computer equipped with the trained object-detection model (e.g., YOLOv4, DINO) to detect the potential interference threat and transmitting the alert message to the pipeline operator using LoRaWAN in real time to avoid an accident.
- The installment and field validation of the developed solution for the SEA Gas use-case to assess the actual real-world performance of the proposed system.
2. Pipeline Visual Threat Assessment (Pipe-VisTA) Dataset
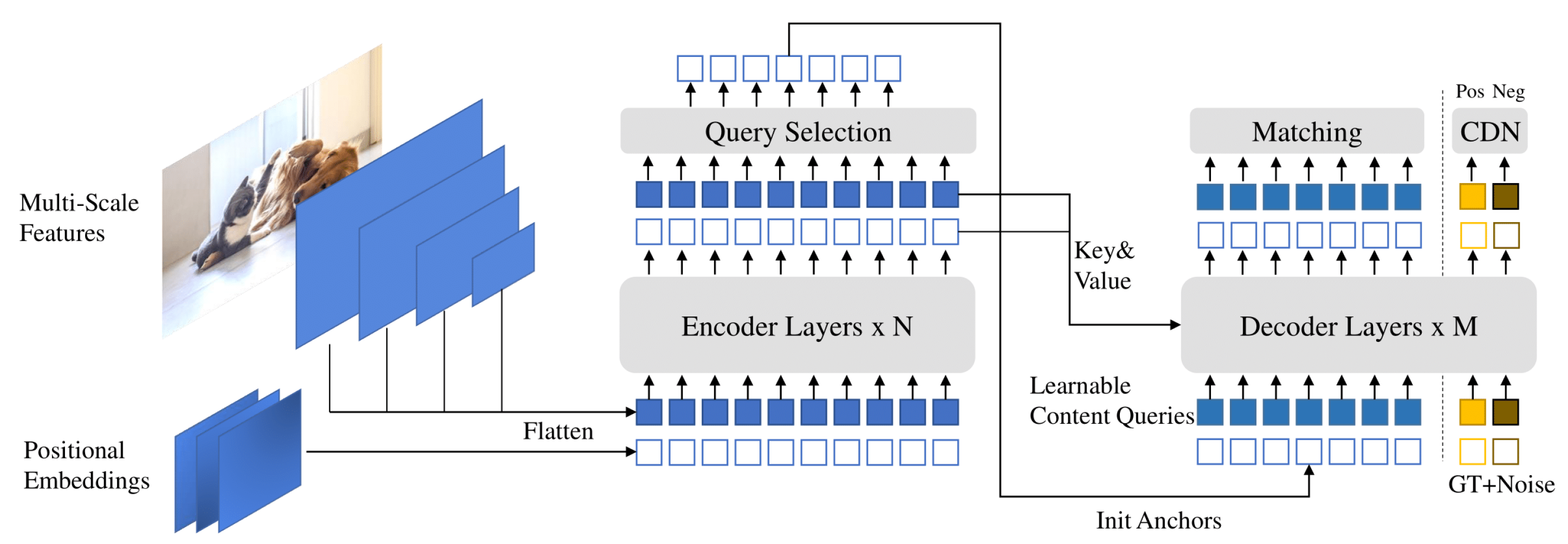
3. The Proposed AIoT Smart Sensing Solution
- A standard web camera to capture the remote site images to be processed by the AI model for potential threat detection.
- An NVIDIA Jetson Nano 4G edge computer (i.e., ARM-based embedded device to accelerate the AI computations) equipped with the trained AI model (e.g., YOLOv4, DINO) to detect external interference threats.
- A radio module to handle the wireless LoRaWAN communications and transmit the results of the AI model.
- A solar-based battery system to power the AIoT sensing device in remote areas.
- A Fleet Portal to transmit the alert via Fleet’s satellite network, which enables connectivity between the cloud and terrestrial network elements and enables coverage in areas with no other connectivity options.
- A dashboard to host the transmitted alert(s) accessible by the operators and managers to be informed in a timely manner about any potential threat. The alters reach Nebula from the Fleet network, the control platform where the data are aggregated and enabling all network management operations to be performed.
- Turn the power on, and wake up the device.
- Acquire the image from the camera
- Process the image using the trained AI model on the edge computer to identify the potential external interference threat.
- If a threat is detected, transmit the alert (i.e., type of threat, timestamp, device_id) to the Fleet Portal using the LoRaWAN protocol.
- Transit to hibernation mode to save power.
4. Training and Evaluation of Threat-Detection AI Model
4.1. Theoretical Background to Object-Detection Models
4.1.1. You Only Look Once Version 4 (YOLOv4)
4.1.2. DETR with Improved deNoising anchOr Boxes (DINO)
4.2. Training Protocols and Evaluation Measures
4.3. Results
5. Field Testing and Validation
5.1. Hardware Testing
- The alerts were successfully generated by the AIoT device during the field tests and went through a Portal, forwarding the data and alerts to the user interface. The LoRaWAN data transmission was reliable for the tests.
- In order for the AIoT device to remain operational when powered using batteries (12 V, 12 Ah) and the solar panel (10 W), the device was configured to be in hibernation mode and to wake up every 15 min to monitor the area in its field of view. The wakeup, detection, and hibernation operational flow for the device was successfully validated during the tests.
- The AIoT device was designed to be waterproof; however, minor condensation appeared on rare occasions specifically on days with large temperature variations.
- The temperature, humidity, and battery life sensors of the AIoT device were regularly transmitted via LoRaWAN messages to monitor the device health. The payload of the message contains the temperature in Celsius, the relative humidity in percentage, and the battery voltage. The field tests reported no unusual behavior from the sensors.
5.2. AI Model’s Performance
6. AIoT Solution Deployment: SEA Gas Use-Case
7. Implication and Recommendations
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SMS | Safety Management Study |
| AIoT | Artificial Intelligence of Things |
| CNN | convolutional neural network |
| YOLO | You Only Look Once |
| SORT | Simple Online Real-time Tracking |
| ACID | Alberta Construction Image Dataset |
| DINO | DETR with Improved deNoising anchOr boxes |
| Pipe-VisTA | Pipeline Visual Threat Assessment |
| LPWAN | Low-Power Wide-Area |
| CSP | Cross-Stage Partial |
| SPP | Spatial Pyramid Pooling |
| MSE | mean-squared error |
| NMS | Non-Maximal Suppression |
| IoU | Intersection over Union |
| TAO | Train Adapt Optimize |
| GPU | Graphical Processing Unit |
| mAP | Mean Average Precision |
References
- Vairo, T.; Pontiggia, M.; Fabiano, B. Critical aspects of natural gas pipelines risk assessments. A case-study application on buried layout. Process Saf. Environ. Prot. 2021, 149, 258–268. [Google Scholar] [CrossRef]
- Jo, Y.D.; Crowl, D.A. Individual risk analysis of high-pressure natural gas pipelines. J. Loss Prev. Process Ind. 2008, 21, 589–595. [Google Scholar] [CrossRef]
- Bariha, N.; Mishra, I.M.; Srivastava, V.C. Hazard analysis of failure of natural gas and petroleum gas pipelines. J. Loss Prev. Process Ind. 2016, 40, 217–226. [Google Scholar] [CrossRef]
- Jo, Y.D.; Ahn, B.J. Analysis of hazard areas associated with high-pressure natural-gas pipelines. J. Loss Prev. Process Ind. 2002, 15, 179–188. [Google Scholar] [CrossRef]
- Liang, W.; Hu, J.; Zhang, L.; Guo, C.; Lin, W. Assessing and classifying risk of pipeline third-party interference based on fault tree and SOM. Eng. Appl. Artif. Intell. 2012, 25, 594–608. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Abbassi, R.; Yang, M.; Zhang, R.; Chen, G. Dynamic probability assessment of urban natural gas pipeline accidents considering integrated external activities. J. Loss Prev. Process Ind. 2021, 69, 104388. [Google Scholar] [CrossRef]
- Hu, J.; Zhang, L.; Liang, W.; Guo, C. Intelligent risk assessment for pipeline third-party interference. J. Press. Vessel. Technol. 2012, 134, 011701. [Google Scholar] [CrossRef]
- Adewumi, R.; Agbasi, O.; Sunday, E.; Robert, U. An Industry Perception and Assessment of Oil and Gas Pipeline Third-Party Interference. J. Int. Environ. Appl. Sci. 2023, 18, 17–32. [Google Scholar]
- APGA. AS 2885: The Standard for High Pressure Pipeline Systems. 1987. Available online: https://www.apga.org.au/2885-standard-high-pressure-pipeline-systems (accessed on 2 February 2024).
- Ariavie, G.O.; Oyekale, J.O. Risk Assessment of Third-Party Damage Index for Gas Transmission Pipeline around a Suburb in Benin City, Nigeria. Int. J. Eng. Res. Afr. 2015, 16, 166–174. [Google Scholar] [CrossRef]
- Beller, M.; Steinvoorte, T.; Vages, S. Inspecting challenging pipelines. Aust. Pipeliner Off. Publ. Aust. Pipelines Gas Assoc. 2018, 175, 56–59. [Google Scholar]
- Maslen, S. Learning to prevent disaster: An investigation into methods for building safety knowledge among new engineers to the Australian gas pipeline industry. Saf. Sci. 2014, 64, 82–89. [Google Scholar] [CrossRef]
- Papadakis, G.A. Major hazard pipelines: A comparative study of onshore transmission accidents. J. Loss Prev. Process Ind. 1999, 12, 91–107. [Google Scholar] [CrossRef]
- Biezma, M.; Andrés, M.; Agudo, D.; Briz, E. Most fatal oil & gas pipeline accidents through history: A lessons learned approach. Eng. Fail. Anal. 2020, 110, 104446. [Google Scholar]
- Iqbal, H.; Tesfamariam, S.; Haider, H.; Sadiq, R. Inspection and maintenance of oil & gas pipelines: A review of policies. Struct. Infrastruct. Eng. 2017, 13, 794–815. [Google Scholar]
- Brunetti, A.; Buongiorno, D.; Trotta, G.F.; Bevilacqua, V. Computer vision and deep learning techniques for pedestrian detection and tracking: A survey. Neurocomputing 2018, 300, 17–33. [Google Scholar] [CrossRef]
- Mpouziotas, D.; Karvelis, P.; Tsoulos, I.; Stylios, C. Automated Wildlife Bird Detection from Drone Footage Using Computer Vision Techniques. Appl. Sci. 2023, 13, 7787. [Google Scholar] [CrossRef]
- Iqbal, U.; Bin Riaz, M.Z.; Barthelemy, J.; Perez, P. Quantification of visual blockage at culverts using deep learning based computer vision models. Urban Water J. 2022, 20, 26–38. [Google Scholar] [CrossRef]
- Iqbal, U.; Barthelemy, J.; Perez, P.; Davies, T. Edge-Computing Video Analytics Solution for Automated Plastic-Bag Contamination Detection: A Case from Remondis. Sensors 2022, 22, 7821. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.; Kim, H.; Hong, Y.W.; Byun, H. Detecting construction equipment using a region-based fully convolutional network and transfer learning. J. Comput. Civ. Eng. 2018, 32, 04017082. [Google Scholar] [CrossRef]
- Roberts, D.; Golparvar-Fard, M. End-to-end vision-based detection, tracking and activity analysis of earthmoving equipment filmed at ground level. Autom. Constr. 2019, 105, 102811. [Google Scholar] [CrossRef]
- Xiao, B.; Kang, S.C. Vision-based method integrating deep learning detection for tracking multiple construction machines. J. Comput. Civ. Eng. 2021, 35, 04020071. [Google Scholar] [CrossRef]
- Xiao, B.; Kang, S.C. Development of an image data set of construction machines for deep learning object detection. J. Comput. Civ. Eng. 2021, 35, 05020005. [Google Scholar] [CrossRef]
- Labelbox. Labelbox: The Leading Training Data Platform for Data Labeling. Available online: https://labelbox.com (accessed on 3 September 2023).
- Haxhibeqiri, J.; De Poorter, E.; Moerman, I.; Hoebeke, J. A survey of LoRaWAN for IoT: From technology to application. Sensors 2018, 18, 3995. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- MMDet. DINO. Available online: https://github.com/open-mmlab/mmdetection/tree/main/configs/dino (accessed on 2 January 2024).
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| auger | person | boring_rig | bobcat |
| excavator | tractor | ditch_witch | post_driver |
| cable_plough | ditch_witch_drill | clay_delver | truck |
| car |
| Focal Length | 1.58 mm | Pixel Size | 1.12 m × 1.12 m |
| FOV | 136 Degree | Operating Temperature | −20 °C–+60 °C |
| Active Pixels | 3280 (H) × 2464 (V) | Operating Voltage | 3 V |
| Dimensions (LWH) | 150 mm × 25 mm × 15.3 mm |
| Parameter | YOLOv4 | DINO |
|---|---|---|
| Backbone | CSPDarkNet53 | Fan Tiny |
| Training Epochs | 1000 | 200 |
| Batch Size | 8 | 4 |
| Base Learning Rate | 1e−4 | 2e−4 |
| Number of Classes | 13 | 13 |
| Optimizer | Adam | – |
| Category | YOLOv4 | DINO | |||
|---|---|---|---|---|---|
| Validation mAP | Test mAP | Validation mAP | Test mAP | ||
| auger | 0.777 | 0.808 | 0.822 | 0.839 | |
| bobcat | 0.669 | 0.642 | 0.392 | 0.260 | |
| boring_rig | 0.710 | 0.746 | 0.823 | 0.851 | |
| cable_plough | 0.639 | 0.632 | 0.716 | 0.749 | |
| car | 0.549 | 0.532 | 0.672 | 0.675 | |
| clay_delver | 0.169 | 0.197 | 0.256 | 0.331 | |
| ditch_witch | 0.772 | 0.700 | 0.754 | 0.925 | |
| ditch_witch_drill | 0.892 | 0.735 | 0.758 | 0.920 | |
| excavator | 0.600 | 0.649 | 0.694 | 0.900 | |
| person | 0.523 | 0.531 | 0.691 | 0.676 | |
| post_driver | 0.644 | 0.598 | 0.684 | 0.626 | |
| tractor | 0.767 | 0.762 | 0.829 | 0.903 | |
| truck | 0.492 | 0.507 | 0.628 | 0.571 | |
| Mean | 0.631 | 0.618 | 0.671 | 0.712 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iqbal, U.; Barthelemy, J.; Michal, G. An End-to-End Artificial Intelligence of Things (AIoT) Solution for Protecting Pipeline Easements against External Interference—An Australian Use-Case. Sensors 2024, 24, 2799. https://doi.org/10.3390/s24092799
Iqbal U, Barthelemy J, Michal G. An End-to-End Artificial Intelligence of Things (AIoT) Solution for Protecting Pipeline Easements against External Interference—An Australian Use-Case. Sensors. 2024; 24(9):2799. https://doi.org/10.3390/s24092799
Chicago/Turabian StyleIqbal, Umair, Johan Barthelemy, and Guillaume Michal. 2024. "An End-to-End Artificial Intelligence of Things (AIoT) Solution for Protecting Pipeline Easements against External Interference—An Australian Use-Case" Sensors 24, no. 9: 2799. https://doi.org/10.3390/s24092799