
Unlocking Preclinical Alzheimer’s: A Multi-Year Label-Free In Vitro Raman Spectroscopy Study Empowered by Chemometrics
 , , , and
, , , and
Abstract
:1. Introduction
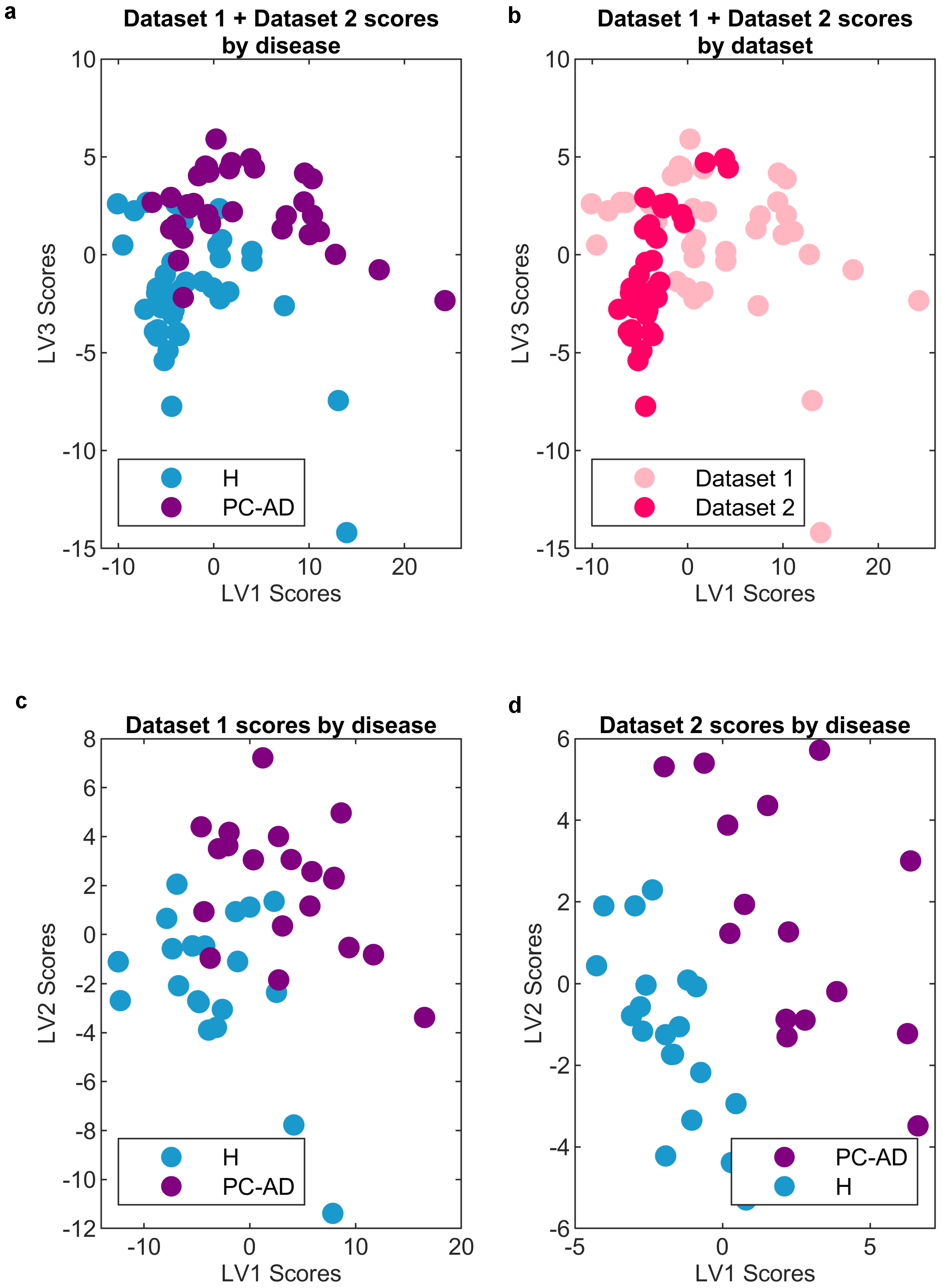
2. Results and Discussion
3. Materials and Methods
3.1. Dataset Creation
3.2. Raman Measurements and Sample Preparation
3.3. Modeling Workflow
3.3.1. Data Preprocessing
3.3.2. Feature Extraction Methods for Identification of Discriminative Molecules in Preclinical AD’s Discrimination
3.3.3. PLS-DA Model Development and Evaluation Metrics
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AD | Alzheimer’s disease |
| PC | Preclinical |
| MCI | Mild cognitive impairment |
| PC-AD | Preclinical Alzheimer’s disease |
| IWG | International working group |
| ATN | Amyloid, tau, and neurodegeneration |
| A | Amyloid beta |
| CSF | Cerebrospinal fluid |
| PET | Positron emission tomography |
| ELISA | Enzyme-linked immunosorbent assays |
| MS | Mass spectrometry |
| MRI | Magnetic resonance imaging |
| GAP | Gipuzkoa Alzheimer project |
| H | Healthy individuals |
| SNV | Standard normal variate |
| VIP | Variables in projection |
| SR | Selectivity ratio |
| PLS-DA | Partial least squares discriminant analysis |
| RMSECV | Root mean square error of cross-validation |
| LV | Latent variable |
| AUC-ROC | Area under the receiver operating characteristic curve |
| PS | Phosphatidylserine |
References
- Pais, M.; Martinez, L.; Ribeiro, O.; Loureiro, J.; Fernandez, R.; Valiengo, L.; Canineu, P.; Stella, F.; Talib, L.; Radanovic, M.; et al. Early diagnosis and treatment of Alzheimer’s disease: New definitions and challenges. Braz J. Psychiatry 2020, 42, 431–441. [Google Scholar] [CrossRef]
- Park, J.; Jang, S.; Gwak, J.; Kim, B.C.; Lee, J.J.; Choi, K.Y.; Lee, K.H.; Jun, S.C.; Jang, G.J.; Ahn, S. Individualized diagnosis of preclinical Alzheimer’s Disease using deep neural networks. Expert Syst. Appl. 2022, 210, 118511. [Google Scholar] [CrossRef]
- Mayeux, R. Alzheimer’s Disease Biomarkers—Timing Is Everything. N. Engl. J. Med. 2024, 390, 761–763. [Google Scholar] [CrossRef]
- Hubbard, B.M.; Fenton, G.W.; Anderson, J.M. A quantitative histological study of early clinical and preclinical Alzheimer’s disease. Neuropathol. Appl. Neurobiol. 1990, 16, 111–121. [Google Scholar] [CrossRef]
- Dubois, B.; Hampel, H.; Feldman, H.H.; Scheltens, P.; Aisen, P.; Andrieu, S.; Bakardjian, H.; Benali, H.; Bertram, L.; Blennow, K.; et al. Preclinical Alzheimer’s disease: Definition, natural history, and diagnostic criteria. Alzheimer’s Dement. 2016, 12, 292–323. [Google Scholar] [CrossRef]
- Rafii, M.S.; Sperling, R.A.; Donohue, M.C.; Zhou, J.; Roberts, C.; Irizarry, M.C.; Dhadda, S.; Sethuraman, G.; Kramer, L.D.; Swanson, C.J.; et al. The AHEAD 3-45 Study: Design of a prevention trial for Alzheimer’s disease. Alzheimer’s Dement. 2022, 19, 1227–1233. [Google Scholar] [CrossRef]
- Dubois, B.; Villain, N.; Frisoni, G.B.; Rabinovici, G.D.; Sabbagh, M.; Cappa, S.; Bejanin, A.; Bombois, S.; Epelbaum, S.; Teichmann, M.; et al. Clinical diagnosis of Alzheimer’s disease: Recommendations of the International Working Group. Lancet Neurol. 2021, 20, 484–496. [Google Scholar] [CrossRef]
- Jia, J.; Ning, Y.; Chen, M.; Wang, S.; Yang, H.; Li, F.; Ding, J.; Li, Y.; Zhao, B.; Lyu, J.; et al. Biomarker Changes during 20 Years Preceding Alzheimer’s Disease. N. Engl. J. Med. 2024, 390, 712–722. [Google Scholar] [CrossRef]
- Ashton, N.J.; Brum, W.S.; Di Molfetta, G.; Benedet, A.L.; Arslan, B.; Jonaitis, E.; Langhough, R.E.; Cody, K.; Wilson, R.; Carlsson, C.M.; et al. Diagnostic Accuracy of a Plasma Phosphorylated Tau 217 Immunoassay for Alzheimer Disease Pathology. JAMA Neurol. 2024, 81, 255–263. [Google Scholar] [CrossRef]
- Aisen, P.S.; Cummings, J.; Jack, C.R.; Morris, J.C.; Sperling, R.; Frölich, L.; Jones, R.W.; Dowsett, S.A.; Matthews, B.R.; Raskin, J.; et al. On the path to 2025: Understanding the Alzheimer’s disease continuum. Alzheimer’s Res. Ther. 2017, 9, 60. [Google Scholar] [CrossRef]
- Jack, C.R., Jr.; Bennett, D.A.; Blennow, K.; Carrillo, M.C.; Dunn, B.; Haeberlein, S.B.; Holtzman, D.M.; Jagust, W.; Jessen, F.; Karlawish, J.; et al. NIA-AA Research Framework: Toward a biological definition of Alzheimer’s disease. Alzheimer’s Dement. 2018, 14, 535–562. [Google Scholar] [CrossRef]
- Ralbovsky, N.M.; Halámková, L.; Wall, K.; Anderson-Hanley, C.; Lednev, I.K. Screening for Alzheimer’s Disease Using Saliva: A New Approach Based on Machine Learning and Raman Hyperspectroscopy. J. Alzheimer’s Dis. 2019, 71, 1351–1359. [Google Scholar] [CrossRef]
- Long, J.M.; Coble, D.W.; Xiong, C.; Schindler, S.E.; Perrin, R.J.; Gordon, B.A.; Benzinger, T.L.S.; Grant, E.; Fagan, A.M.; Harari, O.; et al. Preclinical Alzheimer’s disease biomarkers accurately predict cognitive and neuropathological outcomes. Brain 2022, 145, 4506–4518. [Google Scholar] [CrossRef]
- Milà-Alomà, M.; Ashton, N.J.; Shekari, M.; Salvadó, G.; Ortiz-Romero, P.; Montoliu-Gaya, L.; Benedet, A.L.; Karikari, T.K.; Lantero-Rodriguez, J.; Vanmechelen, E.; et al. Plasma p-tau231 and p-tau217 as state markers of amyloid-β pathology in preclinical Alzheimer’s disease. Nat. Med. 2022, 28, 1797–1801. [Google Scholar] [CrossRef]
- Jack, C.R., Jr.; Bennett, D.A.; Blennow, K.; Carrillo, M.C.; Feldman, H.H.; Frisoni, G.B.; Hampel, H.; Jagust, W.J.; Johnson, K.A.; Knopman, D.S.; et al. A/T/N: An unbiased descriptive classification scheme for Alzheimer disease biomarkers. Neurology 2016, 87, 539–547. [Google Scholar] [CrossRef]
- Koychev, I.; Jansen, K.; Dette, A.; Shi, L.; Holling, H. Blood-Based ATN Biomarkers of Alzheimer’s Disease: A Meta-Analysis. J. Alzheimer’s Dis. 2021, 79, 177–195. [Google Scholar] [CrossRef]
- Alcolea, D.; Delaby, C.; Muñoz, L.; Torres, S.; Estellés, T.; Zhu, N.; Barroeta, I.; Carmona-Iragui, M.; Illán-Gala, I.; Santos-Santos, M.Á.; et al. Use of plasma biomarkers for AT(N) classification of neurodegenerative dementias. J. Neurol. Neurosurg. Psychiatry 2021, 92, 1206–1214. [Google Scholar] [CrossRef]
- Porsteinsson, A.P.; Isaacson, R.S.; Knox, S.; Sabbagh, M.N.; Rubino, I. Diagnosis of Early Alzheimer’s Disease: Clinical Practice in 2021. J. Prev. Alzheimer’s Dis. 2021, 8, 371–386. [Google Scholar] [CrossRef]
- Jack, C.R., Jr.; Knopman, D.S.; Jagust, W.J.; Petersen, R.C.; Weiner, M.W.; Aisen, P.S.; Shaw, L.M.; Vemuri, P.; Wiste, H.J.; Weigand, S.D.; et al. Tracking pathophysiological processes in Alzheimer’s disease: An updated hypothetical model of dynamic biomarkers. Lancet Neurol. 2013, 12, 207–216. [Google Scholar] [CrossRef]
- Blennow, K.; Mattsson, N.; Schöll, M.; Hansson, O.; Zetterberg, H. Amyloid biomarkers in Alzheimer’s disease. Trends Pharmacol. Sci. 2015, 36, 297–309. [Google Scholar] [CrossRef]
- Duits, F.H.; Martinez-Lage, P.; Paquet, C.; Engelborghs, S.; Lleó, A.; Hausner, L.; Molinuevo, J.L.; Stomrud, E.; Farotti, L.; Ramakers, I.H.; et al. Performance and complications of lumbar puncture in memory clinics: Results of the multicenter lumbar puncture feasibility study. Alzheimer’s Dement. 2016, 12, 154–163. [Google Scholar] [CrossRef]
- Gonzalez-Ortiz, F.; Kirsebom, B.E.; Contador, J.; Tanley, J.E.; Selnes, P.; Gísladóttir, B.; Pålhaugen, L.; Suhr Hemminghyth, M.; Jarholm, J.; Skogseth, R.; et al. Plasma brain-derived tau is an amyloid-associated neurodegeneration biomarker in Alzheimer’s disease. Nat. Commun. 2024, 15, 2908. [Google Scholar] [CrossRef]
- Lausted, C.; Lee, I.; Zhou, Y.; Qin, S.; Sung, J.; Price, N.D.; Hood, L.; Wang, K. Systems approach to neurodegenerative disease biomarker discovery. Annu. Rev. Pharmacol. Toxicol. 2013, 54, 457–481. [Google Scholar] [CrossRef]
- Wang, H.; Dey, K.K.; Chen, P.C.; Li, Y.; Niu, M.; Cho, J.H.; Wang, X.; Bai, B.; Jiao, Y.; Chepyala, S.R.; et al. Integrated analysis of ultra-deep proteomes in cortex, cerebrospinal fluid and serum reveals a mitochondrial signature in Alzheimer’s disease. Mol. Neurodegener. 2020, 15, 43. [Google Scholar] [CrossRef]
- Kuhar, N.; Sil, S.; Verma, T.; Umapathy, S. Challenges in application of Raman spectroscopy to biology and materials. RSC Adv. 2018, 8, 25888–25908. [Google Scholar] [CrossRef]
- Xu, Y.; Pan, X.; Li, H.; Cao, Q.; Xu, F.; Zhang, J. Accuracy of Raman spectroscopy in the diagnosis of Alzheimer’s disease. Front. Psychiatry 2023, 14, 1112615. [Google Scholar] [CrossRef]
- Paraskevaidi, M.; Morais, C.L.M.; Halliwell, D.E.; Mann, D.M.A.; Allsop, D.; Martin-Hirsch, P.L.; Martin, F.L. Raman Spectroscopy to Diagnose Alzheimer’s Disease and Dementia with Lewy Bodies in Blood. ACS Chem. Neurosci. 2018, 9, 2786–2794. [Google Scholar] [CrossRef]
- Carlomagno, C.; Cabinio, M.; Picciolini, S.; Gualerzi, A.; Baglio, F.; Bedoni, M. SERS-based biosensor for Alzheimer disease evaluation through the fast analysis of human serum. J. Biophotonics 2020, 13, e201960033. [Google Scholar] [CrossRef]
- Ryzhikova, E.; Ralbovsky, N.M.; Sikirzhytski, V.; Kazakov, O.; Halamkova, L.; Quinn, J.; Zimmerman, E.A.; Lednev, I.K. Raman spectroscopy and machine learning for biomedical applications: Alzheimer’s disease diagnosis based on the analysis of cerebrospinal fluid. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 248, 119188. [Google Scholar] [CrossRef]
- Cialla-May, D.; Krafft, C.; Rösch, P.; Deckert-Gaudig, T.; Frosch, T.; Jahn, I.J.; Pahlow, S.; Stiebing, C.; Meyer-Zedler, T.; Bocklitz, T.; et al. Raman Spectroscopy and Imaging in Bioanalytics. Anal. Chem. 2022, 94, 86–119. [Google Scholar] [CrossRef]
- Khristoforova, Y.; Bratchenko, L.; Bratchenko, I. Raman-Based Techniques in Medical Applications for Diagnostic Tasks: A Review. Int. J. Mol. Sci. 2023, 24, 15605. [Google Scholar] [CrossRef]
- Pezzotti, G. Raman spectroscopy in cell biology and microbiology. J. Raman Spectrosc. 2021, 52, 2348–2443. [Google Scholar] [CrossRef]
- Chesney, R.W. Taurine: Its biological role and clinical implications. Adv. Pediatr. 1985, 32, 1–42. [Google Scholar] [CrossRef]
- Jang, H.; Lee, S.; Choi, S.L.; Kim, H.Y.; Baek, S.; Kim, Y. Taurine Directly Binds to Oligomeric Amyloid-β and Recovers Cognitive Deficits in Alzheimer Model Mice. In Taurine 10; Lee, D.H., Schaffer, S.W., Park, E., Kim, H.W., Eds.; Springer: Dordrecht, The Netherlands, 2017; pp. 233–241. [Google Scholar]
- Lanznaster, D.; Tasca, C.I. Targeting the guanine-based purinergic system in Alzheimer’s disease. Neural Regen. Res. 2017, 12, 212–213. [Google Scholar]
- Ma, X.; Li, X.; Wang, W.; Zhang, M.; Yang, B.; Miao, Z. Phosphatidylserine, inflammation, and central nervous system diseases. Front. Aging Neurosci. 2022, 14, 975176. [Google Scholar] [CrossRef]
- Xu, Z.J.; Li, Q.; Ding, L.; Shi, H.H.; Xue, C.H.; Mao, X.Z.; Wang, Y.M.; Zhang, T.T. A comparative study of the effects of phosphatidylserine rich in DHA and EPA on Aβ-induced Alzheimer’s disease using cell models. Food Funct. 2021, 12, 4411–4423. [Google Scholar] [CrossRef]
- Ecay-Torres, M.; Estanga, A.; Tainta, M.; Izagirre, A.; Garcia-Sebastian, M.; Villanua, J.; Clerigue, M.; Iriondo, A.; Urreta, I.; Arrospide, A.; et al. Increased CAIDE dementia risk, cognition, CSF biomarkers, and vascular burden in healthy adults. Neurology 2018, 91, e217–e226. [Google Scholar] [CrossRef]
- Tainta, M.; Iriondo, A.; Ecay-Torres, M.; Estanga, A.; de Arriba, M.; Barandiaran, M.; Clerigue, M.; Garcia-Sebastian, M.; Villanua, J.; Izagirre, A.; et al. Brief cognitive tests as a decision-making tool in primary care. A population and validation study. Neurologia, 2022; in press. [Google Scholar] [CrossRef]
- Guo, S.; Popp, J.; Bocklitz, T. Chemometric analysis in Raman spectroscopy from experimental design to machine learning-based modeling. Nat. Protoc. 2021, 16, 5426–5459. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Whittaker, E.T. On a New Method of Graduation. Proc. Edinb. Math. Soc. 1922, 41, 63–75. [Google Scholar] [CrossRef]
- Randolph, T.W. Scale-based normalization of spectral data. Cancer Biomark 2006, 2, 135–144. [Google Scholar] [CrossRef]
- Lopez, E.; Etxebarria-Elezgarai, J.; Amigo, J.M.; Seifert, A. The importance of choosing a proper validation strategy in predictive models. A tutorial with real examples. Anal. Chim. Acta 2023, 1275, 341532. [Google Scholar] [CrossRef]
- Inc, E.R. Selectvars. Available online: https://wiki.eigenvector.com/index.php?title=Selectvars (accessed on 8 March 2018).
- Ballabio, D.; Consonni, V. Classification tools in chemistry. Part 1: Linear models. PLS-DA. Anal. Methods 2013, 5, 3790–3798. [Google Scholar] [CrossRef]
- Barker, M.; Rayens, W. Partial least squares for discrimination. J. Chemom. 2003, 17, 166–173. [Google Scholar] [CrossRef]
- Gottfries, J.; Blennow, K.; Wallin, A.; Gottfries, C.G. Diagnosis of dementias using partial least squares discriminant analysis. Dementia 1995, 6, 83–88. [Google Scholar] [CrossRef]
- Christin, C.; Hoefsloot, H.C.; Smilde, A.K.; Hoekman, B.; Suits, F.; Bischoff, R.; Horvatovich, P. A Critical Assessment of Feature Selection Methods for Biomarker Discovery in Clinical Proteomics. Mol. Cell. Proteom. 2013, 12, 263–276. [Google Scholar] [CrossRef]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-Validation. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 532–538. [Google Scholar]
- Rudolph, P.E. Permutation Tests. A Practical Guide to Resampling Methods for Testing Hypotheses; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 1994; 228p, ISBN 3-540-94097-9. [Google Scholar]
- van der Voet, H. Comparing the predictive accuracy of models using a simple randomization test. Chemom. Intell. Lab. Syst. 1994, 25, 313–323. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wavenumber (cm−1) | Biomarkers | Description [32] |
|---|---|---|
| 727 | Nucleic acids | Phosphatidylserine, hypotaurine, guanine |
| 956 | Proteins, carbohydrates | of the phosphate group, guanine |
| 998 | Monophosphate group | |
| 1009 | Phenylalanine | Tryptophan |
| 1039 | Proteins, carbohydrates | Taurine |
| 1045 | Hypotaurine | |
| 1046 | Hypotaurine, taurine | |
| 1051 | Taurine | |
| 1065 | Hypotaurine |
| Cohort | Matrix | AUC | Accuracy | Sensitivity | Specificity | LVs | Variables |
|---|---|---|---|---|---|---|---|
| Dataset 1 | 40 × 93 | 0.99 | 0.93 | 0.95 | 0.92 | 4 | 93 |
| Dataset 2 | 35 × 50 | 1.00 | 0.97 | 0.93 | 0.98 | 3 | 50 |
| Dataset 1 + | 75 × 213 | 0.98 | 0.93 | 0.91 | 0.94 | 6 | 213 |
| Dataset 2 Dataset 1 + Dataset 2 in common | 75 × 9 | 0.61 | 0.53 | 0.63 | 0.51 | 2 | 9 |
| Dataset 1 + Dataset 2 thr@30 1 | 75 × 168 | 0.99 | 0.96 | 0.93 | 0.96 | 6 | 168 |
| Status | Total | Male/Female | Age | ||
|---|---|---|---|---|---|
| Dataset 1 | Healthy | 20 | 40 | 10/10 | 59.5 ± 6.8 |
| Preclinical | 20 | 10/10 | 65.4 ± 5.1 | ||
| Dataset 2 | Healthy | 20 | 35 | 11/9 | 65.7 ± 6.1 |
| Preclinical | 15 | 10/5 | 68.5 ± 6.2 | ||
| Dataset 1 + | Healthy | 40 | 75 | 21/19 | 62.7 ± 7.1 |
| Dataset 2 | Preclinical | 35 | 20/15 | 66.7 ± 7.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopez, E.; Etxebarria-Elezgarai, J.; García-Sebastián, M.; Altuna, M.; Ecay-Torres, M.; Estanga, A.; Tainta, M.; López, C.; Martínez-Lage, P.; Amigo, J.M.; et al. Unlocking Preclinical Alzheimer’s: A Multi-Year Label-Free In Vitro Raman Spectroscopy Study Empowered by Chemometrics. Int. J. Mol. Sci. 2024, 25, 4737. https://doi.org/10.3390/ijms25094737
Lopez E, Etxebarria-Elezgarai J, García-Sebastián M, Altuna M, Ecay-Torres M, Estanga A, Tainta M, López C, Martínez-Lage P, Amigo JM, et al. Unlocking Preclinical Alzheimer’s: A Multi-Year Label-Free In Vitro Raman Spectroscopy Study Empowered by Chemometrics. International Journal of Molecular Sciences. 2024; 25(9):4737. https://doi.org/10.3390/ijms25094737
Chicago/Turabian StyleLopez, Eneko, Jaione Etxebarria-Elezgarai, Maite García-Sebastián, Miren Altuna, Mirian Ecay-Torres, Ainara Estanga, Mikel Tainta, Carolina López, Pablo Martínez-Lage, Jose Manuel Amigo, and et al. 2024. "Unlocking Preclinical Alzheimer’s: A Multi-Year Label-Free In Vitro Raman Spectroscopy Study Empowered by Chemometrics" International Journal of Molecular Sciences 25, no. 9: 4737. https://doi.org/10.3390/ijms25094737