- Perspective

The Innovative Potential of Artificial Intelligence Applied to Patient Registries to Implement Clinical Guidelines
- Sebastiano Gangemi,
- Alessandro Allegra and
- Giorgio Walter Canonica
- + 3 authors
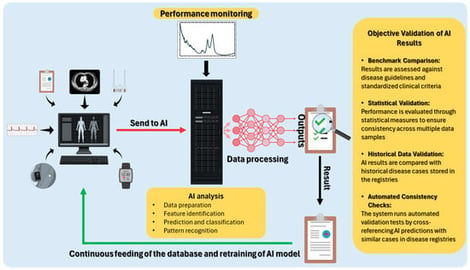
Guidelines provide specific recommendations based on the best available medical knowledge, summarizing and balancing the advantages and disadvantages of various diagnostic and treatment options. Currently, consensus methods are the best and most common practices in creating clinical guidelines, even though these approaches have several limitations. However, the rapid pace of biomedical innovation and the growing availability of real-world data (RWD) from clinical registries (containing data like clinical outcomes, treatment variables, imaging, and laboratory results) call for a complementary paradigm in which recommendations are continuously stress-tested against high-quality, interoperable data and auditable artificial intelligence (AI) pipelines. AI, based on information retrieved from patient registries, can optimize the process of creating guidelines. In fact, AI can analyze large volumes of data, ensuring essential tasks such as correct feature identification, prediction, classification, and pattern recognition of all information. In this work, we propose a four-phase lifecycle, comprising data curation, causal analysis and estimation, objective validation, and real-time updates, complemented by governance and machine learning operations (MLOps). A comparative analysis with consensus-only methods, a pilot protocol, and a compliance checklist are provided. We believe that the use of AI will be a valuable support in drafting clinical guidelines to complement expert consensus and ensure continuous updates to standards, providing a higher level of evidence. The integration of AI with high-quality patient registries has the potential to substantially modernize guideline development, enabling continuously updated, data-driven recommendations.
7 February 2026