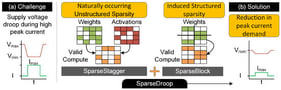
Modern deep neural network (DNN) accelerators must sustain high throughput while avoiding performance degradation from supply voltage (VDD) droop, which occurs when large arrays of multiply–accumulate (MAC) units switch concurrently and induce high peak current (
) transients on the power delivery network (PDN). In this work, we focus on
ASIC-class DNN accelerators with tightly synchronized MAC arrays rather than FPGA-based implementations, where such cycle-aligned switching is most pronounced. Conventional guardbanding and reactive countermeasures (e.g., throttling, clock stretching, or emergency DVFS) either waste energy or incur non-trivial throughput penalties. We propose SparseDroop, a unified hardware-conscious framework that proactively shapes instantaneous current demand to mitigate droop without reducing sustained computing rate. SparseDroop comprises two complementary techniques. (1) SparseStagger, a lightweight hardware-friendly droop scheduler that exploits the inherent unstructured sparsity already present in the weights and activations—it does not introduce any additional sparsification. SparseStagger dynamically inspects the zero patterns mapped to each processing element (PE) column and staggers MAC start times within a column so that high-activity bursts are temporally interleaved. This fine-grain reordering smooths
trajectories, lowers the probability and depth of transient VDD dips, and preserves cycle-level alignment at tile/row boundaries—thereby maintaining no throughput loss and negligible control overhead. (2) SparseBlock, an architecture-aware, block-wise-structured sparsity induction method that intentionally introduces additional sparsity aligned with the accelerator’s dataflow. By co-designing block layout with the dataflow, SparseBlock reduces the likelihood that all PEs in a column become simultaneously active, directly constraining
and peak dynamic power on the PDN. Together, SparseStagger’s opportunistic staggering (from existing unstructured weight zeros) and SparseBlock’s structured, layout-aware sparsity induction (added to prevent peak-power excursions) deliver a scalable, low-overhead solution that improves voltage stability, energy efficiency, and robustness, integrates cleanly with the accelerator dataflow, and preserves model accuracy with modest retraining or fine-tuning.