
Research on PointPillars Algorithm Based on Feature-Enhanced Backbone Network



Abstract
1. Introduction
- Enhancing features of pseudo-images generated through the algorithm via channel attention, spatial attention, and 1 × 1 2D convolution.
- FasterNet [10], a more lightweight network, replaces the feature extraction network, resulting in a significant reduction in module parameters. This replacement not only enhances detection accuracy but also decreases the number of parameters required.
- Replacing the original model’s inverse convolution technique involves the implementation of two up-sampling methods and feature enhancement using proximity scale sampling methods.
2. Related Work
2.1. Point-Based, Voxel-Based Approach to Target Detection
2.2. Feature Extraction Networks
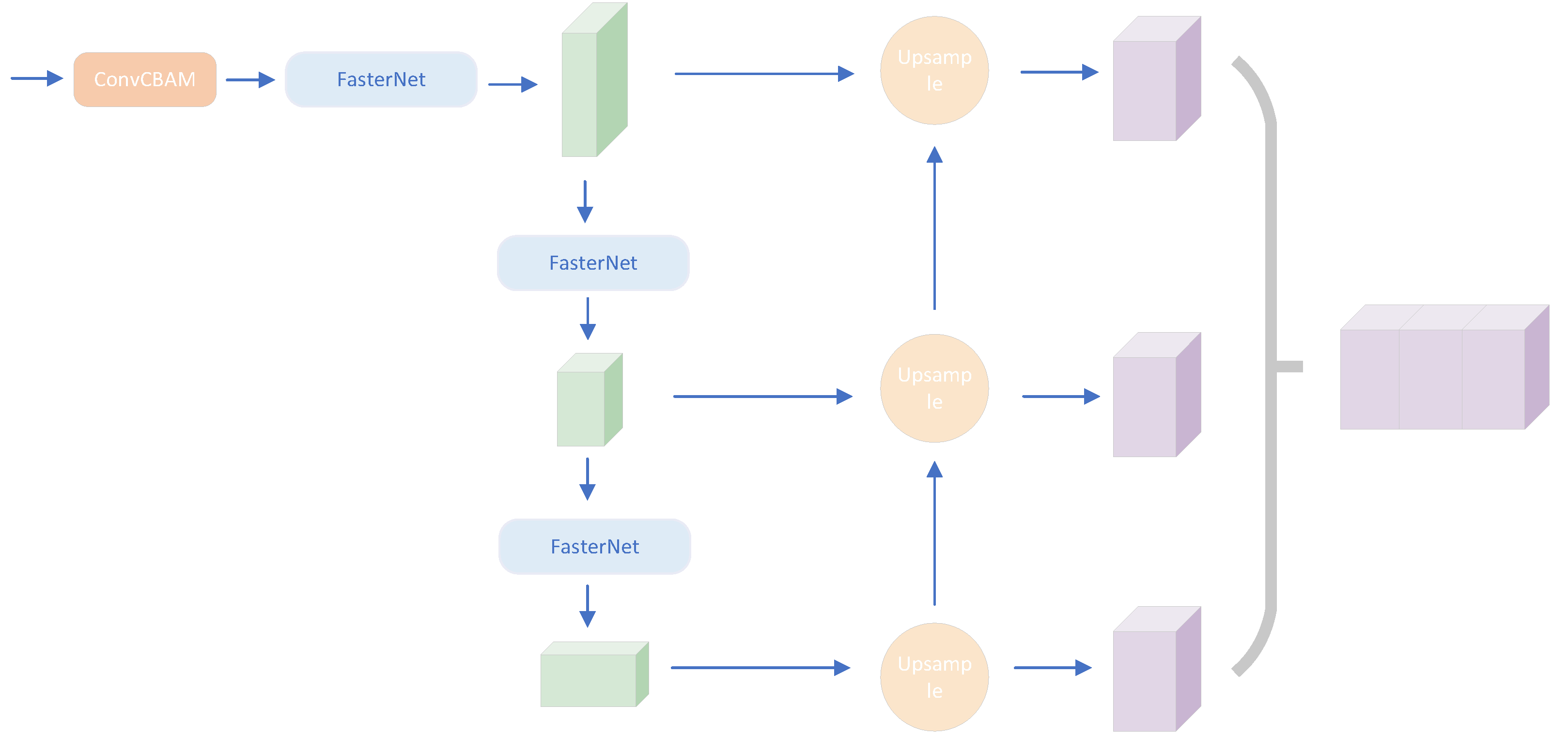
3. Feature-Enhanced Backbone Network
3.1. PointPillars
- Point cloud input. The original input point cloud is entered, and the point cloud is augmented using data augmentation methods, including random inversion and random scaling, to improve model performance.
- Columnarization of point cloud. A square box is created based on X-Y, with Z as the vertical dimension of point columns. Each column comprises multiple points, and a basic PointNet network is then employed to project the original point cloud onto a 2D plane, generating a sparse 2D pseudo-image that assists in subsequent feature learning. Technical abbreviations are explained when first employed [5].
- Feature extraction. A 2D convolutional neural network down-samples the pseudo-image several times, creating feature maps with varying resolutions and channels. The down-sampling-generated feature maps are up-sampled using inverse convolution to the same channel and resolution feature maps, and subsequently merged to form the final map.
- Detection head output. The feature map is fed to the SSD (Single Shot MultiBox Detector) detection head to perform the target’s classification and the regression of the enclosing frame, obtaining the object’s position and type. SSD is a deep learning model used for detecting multiple image targets simultaneously. It achieves this by applying multiple anchor frames (anchors) on different levels of the feature map. PointPillars applies the same idea to point cloud data for target detection.
3.2. FasterNet Lightweight Feature Extraction Network
- Block depth settings correspond to PointPillars.
- Add Embedding before each block for down-sampling.
- The activation function uses GELU as suggested by FasterNet, and PointPillars remains unchanged using RELU. GELU is an activation function based on the Gaussian distribution. It has the advantage of avoiding the gradient vanishing problem, as the gradient does not become very small when the input value is relatively large or small. Additionally, the GELU function has a non-zero derivative when the input value is negative, which helps to avoid the neuron death problem. This improves the running effect when the computational complexity is low.
3.3. Attention-Based Feature Enhancement
3.4. Carafe and Dysample Sampling on the Proximity Scale
- Large sensory field: Unlike previous approaches, such as bilinear interpolation, Carafe can aggregate contextual information within a large receptive field.
- Content-aware: Instead of using a fixed kernel for all samples, Carafe supports instance-specific content-aware processing and can dynamically generate adaptive kernels.
- Lightweight and fast: Carafe has low computational overhead and can be easily integrated into existing framework networks.
4. Results
4.1. Experimental Results and Analysis
4.2. Ablation Experiments
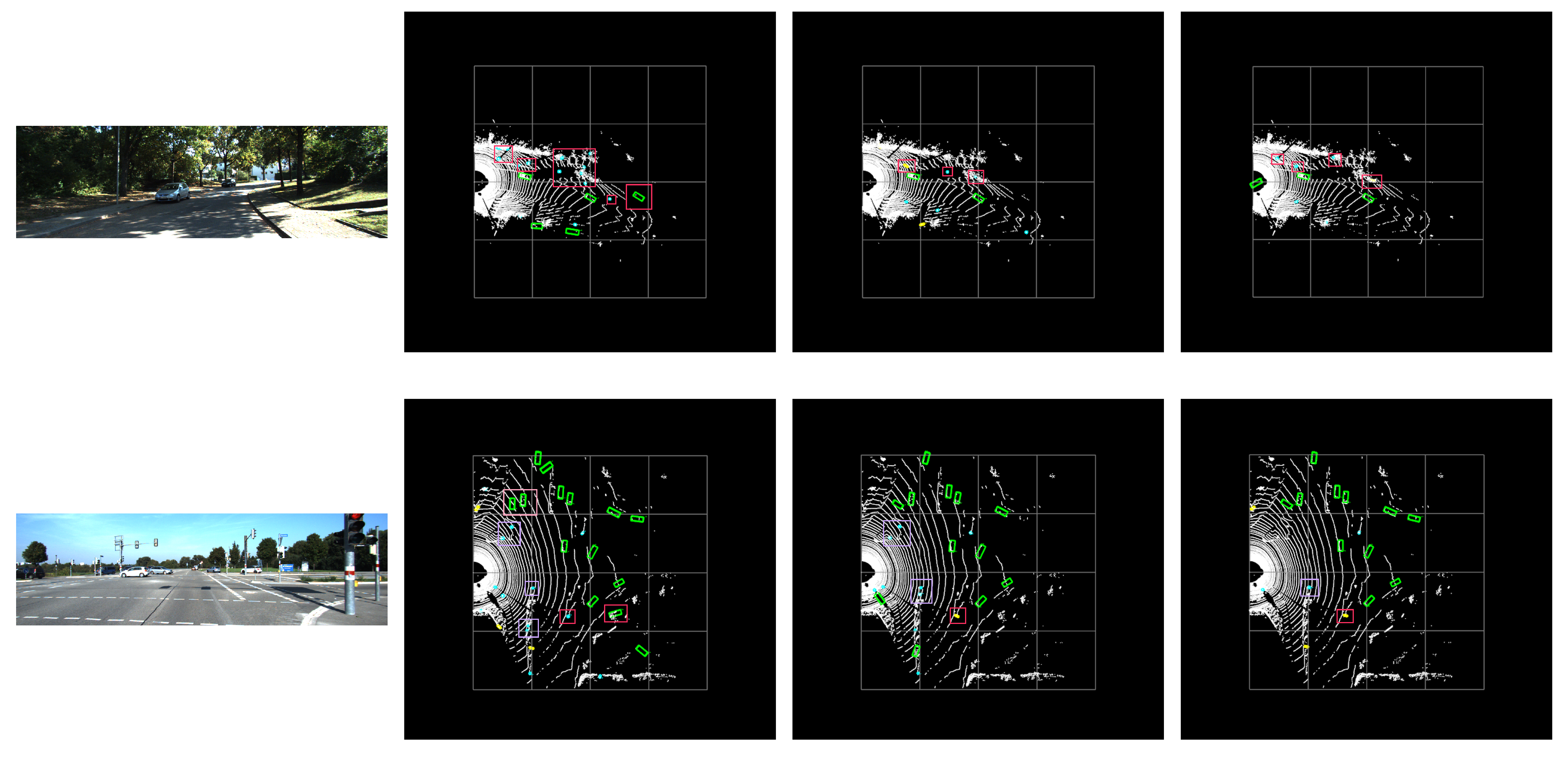
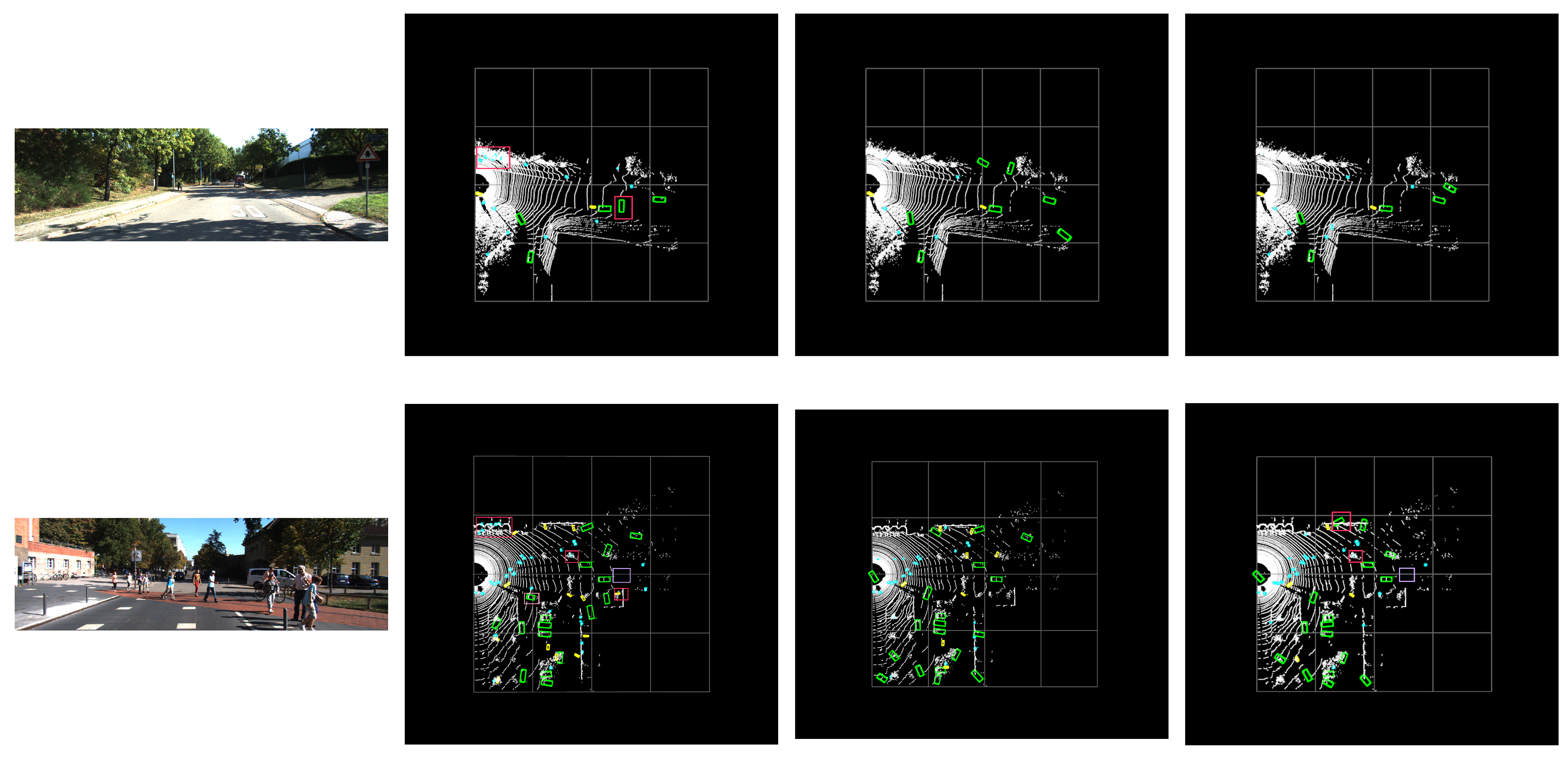
4.3. Visualization Analysis
- In the initial scene, PointPillars identifies the far-off iron house as a vehicle, which the algorithm in the optimization is able to avoid. Additionally, there are more trees on the left side, and PointPillars recognizes the number as people, which is significantly reduced compared to PointPillars in the optimized algorithm, although there is also a misdetection.
- In the second scenario, PointPillars made a mistake during multi-check by identifying the iron ladder near the car as a car. This error was avoided in the optimized scenario. Multi-checks occurred near the point in PointPillars and PP Carafe, mistaking the road sign for a person. The optimized scheme shows the direction of the two cars in the upper left at a more accurate angle. The three scenarios resulted in a false pickup on the right against the red streetlight army.
- The third scenario is straightforward. All three scenarios detected the bicycle following the car. PointPillars produced one multi-detection (a lateral car) for the car directly in front and none in the optimized scenario. PointPillars is especially problematic for the false detection of trees on the left side. In the optimized scenario, PP Carafe produces only one multidetection, and PP Dysample identifies the number on the left side intact.
- The fourth scenario is complex, involving multiple object types. PointPillars still experiences significant multi-detection issues on the left side. In all three scenarios, there are missed detections directly in front. PP Dysample has more severe detection errors on the left side, and one vehicle lacks direction discrimination. For the nearby vehicles, the optimized scheme improves the vehicle facing angle significantly, resulting in much better direction prediction than PointPillars.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, F.; Jin, W.; Fan, C.; Zou, L.; Chen, Q.; Li, X.; Jiang, H.; Liu, Y. PSANet: Pyramid Splitting and Aggregation Network for 3D Object Detection in Point Cloud. Sensors 2020, 21, 136. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 26 July 2017. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, Q.; Che, H.; Liu, J.; Liu, R. Small object 3D detection algorithm based on lidar point cloud. In Proceedings of the 2023 IEEE 3rd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 26–28 May 2023. [Google Scholar] [CrossRef]
- Chen, D.; Yu, W.; Gao, Y. LIDAR 3D target detection based on improved PointPillars. Adv. Lasers Optoelectron. 2023, 60, 1028012. [Google Scholar]
- Lee, M.; Kim, H.; Park, S.; Yoon, M.; Lee, J.; Choi, J.; Kang, M.; Choi, J. PillarAcc: Sparse PointPillars Accelerator for Real-Time Point Cloud 3D Object Detection on Edge Devices. arXiv 2023, arXiv:2305.07522. [Google Scholar]
- Nakamura, R.; Enokida, S. Robust 3D Object Detection for Moving Objects Based on PointPillars. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 4–8 January 2022. [Google Scholar]
- Li, X.; Liang, B.; Huang, J.; Peng, Y.; Yan, Y.; Li, J.; Shang, W.; Wei, W. Pillar-Based 3D Object Detection from Point Cloud with Multiattention Mechanism. Wirel. Commun. Mob. Comput. 2023, 2023, 5603123. [Google Scholar] [CrossRef]
- Konrad Lis, T.K. Encyclopedia of Parallel Computing; Springer Science & Business Media B.V.: New York, NY, USA, 2022. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don‘t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Wei-Qin, Z.; Ni, R.; Yang, B. PointPillars+3D Target Detection Based on Attention Mechanisms. Jiangsu Univ. J. Nat. Sci. Ed. 2020, 41, 268–273. [Google Scholar]
- Zamanakos, G.; Tsochatzidis, L.; Amanatiadis, A.; Pratikakis, I. A comprehensive survey of LIDAR-based 3D object detection methods with deep learning for autonomous driving. Comput. Graph. 2021, 99, 153–181. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, W.; Zhu, D.; Luo, H.; Li, Y. 3D Target Detection by Fusing Point Attention Mechanisms in LiDAR Point Clouds. J. Photonics 2023, 52, 213–223. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chapala, H.; Sujatha, B. ResNet: Detection of Invasive Ductal Carcinoma in Breast Histopathology Images Using Deep Learning. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tao, Z.; Su, J. Research on object detection algorithm of 3D point cloud PointPillar based on attention mechanism. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Lecture Notes in Computer Science, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Cheng, D.; Meng, G.; Cheng, G.; Pan, C. SeNet: Structured Edge Network for Sea—Land Segmentation. IEEE Geosci. Remote Sens. Lett. 2017, 11211, 247–251. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-wise Spatial Attention Network for Scene Parsing. In Proceedings of the Computer Vision—ECCV 2018, Lecture Notes in Computer Science, Munich, Germany, 8–14 September 2018; pp. 270–286. [Google Scholar] [CrossRef]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to Upsample by Learning to Sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-Aware ReAssembly of FEatures. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PointPillar | Total Params | Total Mult-Adds (G) | Params Size (MB) | Estimated Size (MB) |
|---|---|---|---|---|
| PointPillars | 4,207,616 | 29.63 | 444.66 | 513.02 |
| OurFasterNet | 2,339,712 | 3.96 | 91.55 | 152.78 |
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| MV3D | 86.02 | 76,88 | 68.59 | N/A | N/A | N/A | N/A | N/A | N/A |
| VoxelNet | 89.35 | 79.26 | 77.39 | 46.13 | 40.74 | 38.11 | 66.70 | 54.76 | 50.55 |
| SECOND | 88.07 | 79.37 | 77.95 | 55.10 | 46.27 | 44.76 | 73.67 | 56.04 | 48.78 |
| PointPillars | 90.74 | 86.57 | 84.05 | 55.89 | 48.86 | 44.42 | 81.44 | 63.63 | 59.29 |
| PP Carafe | 91.55 | 87.76 | 85.04 | 58.97 | 51.88 | 48.47 | 85.64 | 66.15 | 61.59 |
| PP Dysample | 91.78 | 87.79 | 85.08 | 59.28 | 51.76 | 47.28 | 84.74 | 66.01 | 61.79 |
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| MV3D | 71.09 | 62.35 | 55.12 | N/A | N/A | N/A | N/A | N/A | N/A |
| VoxelNet | 78.47 | 66.13 | 57.73 | 39.48 | 34.67 | 31.50 | 63.56 | 48.36 | 45.73 |
| SECOND | 83.69 | 73.98 | 66.67 | 51.88 | 43.65 | 37.29 | 71.15 | 54.58 | 46.90 |
| PointPillars | 85.40 | 75.14 | 72.71 | 48.16 | 41.58 | 37.07 | 76.76 | 59.74 | 55.53 |
| PP Carafe | 87.95 | 78.59 | 75.20 | 51.63 | 44.35 | 41.13 | 83.27 | 62.61 | 57.95 |
| PP Dysample | 87.89 | 78.13 | 73.44 | 50.62 | 43.28 | 39.01 | 81.69 | 63.46 | 58.96 |
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| SECOND | 87.84 | 81.54 | 71.59 | 52.56 | 43.59 | 38.98 | 81.97 | 59.20 | 56.14 |
| PointPillars | 94.75 | 91.27 | 88.29 | 46.34 | 42.96 | 39.68 | 86.15 | 70.35 | 65.98 |
| PP Carafe | 95.57 | 92.03 | 90.56 | 54.73 | 49.20 | 47.73 | 87.65 | 70.22 | 65.58 |
| PP Dysample | 95.47 | 91.79 | 88.90 | 53.98 | 48.42 | 45.44 | 86.40 | 70.08 | 66.01 |
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| root | 90.74 | 86.57 | 84.05 | 55.89 | 48.86 | 44.42 | 81.44 | 63.63 | 59.29 |
| Attention | 91.67 | 87.75 | 85.18 | 56.19 | 49.89 | 46.16 | 85.05 | 65.91 | 61.41 |
| FasterNet | 92.63 | 88.32 | 86.91 | 56.19 | 49.95 | 45.82 | 88.09 | 67.98 | 63.46 |
| Carafe | 92.05 | 87.80 | 85.13 | 55.55 | 49.12 | 44.86 | 85.07 | 67.49 | 62.85 |
| Dysample | 91.78 | 87.79 | 85.08 | 59.28 | 51.76 | 47.28 | 84.74 | 66.01 | 61.79 |
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| root | 85.40 | 75.14 | 72.71 | 48.16 | 41.58 | 37.07 | 76.76 | 59.74 | 55.53 |
| Attention | 86.52 | 76.24 | 73.09 | 49.81 | 43.13 | 39.13 | 79.88 | 60.48 | 56.57 |
| FasterNet | 88.73 | 78.76 | 75.58 | 50.69 | 43.98 | 39.25 | 83.41 | 61.94 | 57.69 |
| Carafe | 86.92 | 75.47 | 72.31 | 48.37 | 42.13 | 37.35 | 79.88 | 62.50 | 58.23 |
| Dysample | 87.89 | 78.13 | 73.44 | 50.72 | 43.28 | 39.01 | 81.69 | 63.46 | 58.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shu, X.; Zhang, L. Research on PointPillars Algorithm Based on Feature-Enhanced Backbone Network. Electronics 2024, 13, 1233. https://doi.org/10.3390/electronics13071233
Shu X, Zhang L. Research on PointPillars Algorithm Based on Feature-Enhanced Backbone Network. Electronics. 2024; 13(7):1233. https://doi.org/10.3390/electronics13071233
Chicago/Turabian StyleShu, Xiaoning, and Liang Zhang. 2024. "Research on PointPillars Algorithm Based on Feature-Enhanced Backbone Network" Electronics 13, no. 7: 1233. https://doi.org/10.3390/electronics13071233
APA StyleShu, X., & Zhang, L. (2024). Research on PointPillars Algorithm Based on Feature-Enhanced Backbone Network. Electronics, 13(7), 1233. https://doi.org/10.3390/electronics13071233