Abstract
The rapid development of digital technology has injected new vitality into green technological innovation within manufacturing enterprises. Proper application of digital technology during the innovation process can propel global sustainable development. Using Chinese publicly traded manufacturing firms as a sample, this study employed a constructed digital technology innovation network and OLS models to unveil the mechanisms through which digital technology application affects green technological innovation. This research reveals a significant positive impact of the breadth and depth of digital technology applications on companies’ green technological innovation performance. Green human resource allocation serves as an intermediary in this relationship. Furthermore, the embeddedness and structural embeddedness of the digital technology innovation network play a significantly positive moderating role in the relationship between digital technology applications and green human resource allocation. This discovery provides a theoretical foundation for how companies can harness digital technology to promote green innovation within China’s digital strategy. It aids manufacturing enterprises in optimizing digital technology applications, improving green human resource allocation, and facilitating the development of digital technology innovation networks, advancing more sustainable development and contributing to global environmental goals.
1. Introduction
Green technology innovation (GTI) has become a central concern for sustainable development in enterprises globally [1,2]. The peak carbon emissions and “carbon neutrality” goals, in particular, are intrinsic requirements for China’s green development and set higher environmental standards for manufacturing companies. This implies that enterprises must proactively reduce carbon emissions, enhance energy efficiency, and make remarkable strides in green innovation [3]. However, worryingly, existing research results indicate that many manufacturing companies exhibit noticeable “compliance” characteristics in their green innovation efforts [4]. Currently, many enterprises only follow the minimum environmental standards and practice passive green innovation inadvertently, which are called “shallow green” green innovation behaviors [5]. These behaviors represent a passive response to local government environmental regulations and fall far short of the high-quality green development required to meet the “dual carbon” goals [6,7]. Therefore, upgrading green innovation strategies and improving GTI performance in enterprises are urgent issues on the path to high-quality green development.
China has proposed the “Digital China” strategy in response to these urgent calls for green innovation. This strategy aims to fully utilize the advantages of digital technology. It comprehensively integrates digital technology applications into various sectors such as the economy, politics, culture, society, and ecological civilization construction, thereby driving industries towards digital transformation [8,9]. The application of digital technology has shown remarkable capabilities and provided strong support for addressing environmental issues, reducing carbon emissions, and achieving sustainable green development in specific domains. This is especially evident in green innovation [10]. It has become a critical lever for attaining the “dual carbon” goals [11,12]. Digitization can help address the issue of the low level of green technology in most manufacturing enterprises. It achieves this by improving the R&D capacity of businesses in green technology. Additionally, it encourages companies to transform from the traditional high-input, high-output, and high-energy consumption to the low-carbon, energy-saving, high-efficiency, and pollution-prevention production [1,2]. Additonally, digital technology, such as big data and AI, can be employed to explore consumer green demands, optimize enterprise resource allocation, reduce costs, and enhance the operational efficiency of enterprises. This can help to resolve the “cost and benefit” of enterprises’ green innovation dilemma and encourage upgrading the enterprise’s green innovation strategies [13,14,15] and the enhancement of innovation performance [16]. Scholars have extensively explored the impact of digital transformation [17,18], digitization [19,20], and the digital economy [1,21] on enterprise GTI. However, the mechanisms through which digital technology applications affect GTI in enterprises remain a “black box”. In implementing the “Digital China” strategy, we must fully recognize the importance of digital technology applications. This is because the widespread use of digital technology provides businesses with more opportunities for innovation and creates critical conditions for enhancing green innovation performance. The implementation of digital technology accelerates data collection, analysis, and sharing, improving efficiency, reducing costs, and aiding in more precise monitoring and control of environmental indicators. This enhances a company’s competitiveness in meeting environmental regulations and offers a new lever for innovation, encouraging the development of greener products and processes. Through digital technology, companies can respond more flexibly to ecological challenges, providing robust support for sustainable development while creating opportunities to stand out in the market. Therefore, delving into and actively adopting digital technology applications to enhance GTI performance have become an inevitable choice for businesses to succeed in the digital age and play a vital role in sustainable development.
Initially, GTI requires companies to possess a strong sense of environmental responsibility and sustainability awareness, both of which rely on the support and participation of employees [22]. Green human resource management (GHRM) includes recruitment, training, and performance evaluation, assisting the company in attracting, nurturing, and motivating employees essential to green innovation [23]. Under the “Digital China” strategy and the digital economy, companies are actively exploring digital technology to address challenges in human resource management activities during the green innovation process. They are redefining and redesigning business scenarios and management processes related to human resource management, leveraging data to enhance connectivity between internal systems and the external environment, thus supporting continuous transformation, innovation, and growth [24]. It is crucial to look into whether GHRM acts as a bridge between the application of digital technology and the innovation of green technology in businesses to better understand how digital technology influences employee behavior and internal green cultures. This will help us understand the practical effects of digital technology applications on GTI.
Furthermore, the embeddedness of digital technology innovation networks (DTINs) may influence the relationship between digital technology applications and GHRM. Digital innovation network embeddedness refers to the extent of connections and cooperation between companies and external participants during digital technology innovation [25]. Digital innovation networks provide companies with a global pool of talent and skills, enabling them to match the specific skills required in green technology flexibly and optimize the efficiency and quality of GHRM [26]. In addition, digital innovation networks can facilitate the organic integration of digital technology with green human resources through cross-industry collaboration and knowledge sharing, thereby promoting sustainable development and environmental protection goals [27]. Hence, understanding how the embeddedness of a digital innovation network moderates the impact of digital technology applications on GHRM is another crucial aspect of this study. The research questions are listed as follows:
- (1)
- How can companies improve their GTI performance and upgrade their green innovation strategies through digital technology applications?
- (2)
- What role does GHRM play in the relationship between digital technology applications and GTI performance in companies?
- (3)
- How does the embeddedness of the DTIN moderate the impact of digital technology applications on GHRM in companies?
To delve deeper into these questions, this paper first presents a theoretical literature review and feasibility design based on digital innovation, resource-based, and social network theories. Subsequently, it focuses on Chinese publicly listed manufacturing companies. Relevant patent data were obtained from the Himmpat database and the SIPO. Financial data for these companies was collected from the Wind database. Python was used to calculate indicators such as the breadth and depth of digital technology applications (DTABDs) and measure the structural and relational embeddedness of the DTIN. Finally, empirical research was conducted using an OLS model. The primary objective was to explore how the application of digital technology directly influences the performance of GTI. The study also aimed to investigate the mediating effects between digital technology applications and the allocation of green human resources. Additionally, it aimed to explore how the embedding of DTIN moderates this relationship. Through these analyses, the study aimed to elucidate further the intricate connections between the mechanisms and influencing factors of digital technology application on the performance of GTI within enterprises. This approach provides a more comprehensive understanding of this critical topic.
The contributions of this study are as follows: (1) This study has constructed a theoretical framework based on the rigid constraints of the “dual carbon” goals and the inevitable requirements of upgrading the green innovation strategy. The framework revolves around “digital technology application (features)—green human resource allocation (capabilities)—GTI performance (outcomes)”. It reveals the impact mechanism of digital technology application on the performance of green technological innovation within businesses. It comprehensively explains the relationship between the scope and depth of digital technology applications and the performance of green technological innovation by examining publicly traded companies’ patent and financial data in China’s manufacturing sector. These research findings will assist businesses in gaining a better understanding of how digital technology can play a proactive role in driving green innovation, offering crucial guidance for developing more effective green innovation strategies and driving the upgrading of green innovation strategies for enterprises.
(2) This study delves into the mediating role of green human resource allocation in the relationship between digital technology applications and green technological innovation. By analyzing employee participation in green technological innovation, a more comprehensive understanding of how businesses can support the successful implementation of digital technology applications through the reasonable allocation of human resources is gained. Specifically, it offers a more refined approach to optimizing employee recruitment, training, and incentive strategies to better meet the needs of green innovation. Managers can have a more comprehensive understanding of employee participation in green technological innovation, aligning their skills and interests to ensure they effectively support the successful implementation of digital technology. Moreover, these research findings aid in enhancing employee job satisfaction and engagement, as employees recognize the significance of their work in achieving green innovation and sustainable development goals, thereby attracting and retaining high-quality employees and further enhancing the competitiveness of enterprises.
(3) This study introduces the concept of embeddedness in the DTIN. It explores its moderating role in the relationship between digital technology applications and green human resource allocation. By studying how digital innovation networks impact the influence of digital technology applications on green human resource allocation, a more comprehensive understanding of the complex relationship between digital technology applications and green innovation is achieved. This discovery provides businesses with a broader range of strategic choices. It encourages them to engage in DTIN actively, fostering collaborative relationships to obtain valuable knowledge and resources. This contributes to developing digital innovation networks, promotes cross-sector collaboration, and facilitates knowledge sharing. Furthermore, businesses can better identify key partners and resources within the DTIN, ensuring that the relationship between digital technology applications and green innovation is mutually beneficial. Ultimately, this helps businesses advance sustainable development and environmental goals while enhancing their competitiveness in the digital age.
This paper is structured as follows: Section 2 summarizes existing research, outlining the research hypotheses. Section 3 covers research design, encompassing data sources, indicator selection, and the modeling process. In Section 4, we delve into the mechanisms through theoretical and empirical lenses, exploring the impacts of digital technology application, green human resource allocation, digital innovation network embedding, and green innovation performance. Section 5 discusses the research findings and presents the limitations. Finally, Section 6 concludes the main findings of this research.
2. Theoretical Foundation and Research Hypotheses
2.1. Digital Technology Application and Green Innovation Performance
Digital technology includes computer programming, big data, cloud computing, AI, the Internet of Things, virtual reality, and blockchain [28]. Digital technology enables data to be managed, analyzed, and utilized more efficiently, promoting innovation, automation, and intelligence [29]. The rise and application of digital technology have brought about significant transformations in a company’s production, services, and business models [30]. Companies create competitive advantages by acquiring and adopting advanced digital technology to navigate the unpredictable market environment. Some technologies may disrupt a company’s activities, such as research, development, and production [31,32]. Therefore, scholars have extensively researched digital technology applications from various perspectives. For instance, Mackert et al. (2016) [33] defined digital technology application from a legal perspective as using digital technology in manufacturing for product and service innovation. Shen (2021) [34] considered digital technology applications as the avenue for enterprises to develop digital technology and transform the potential of digital technology applications into technological breadth and depth. Shi (2023) [35] viewed digital technology applications as using digital components, infrastructure, and platforms to provide new business development. Although scholars have diverse definitions of digital technology application, they generally agree that “enterprise digital technology application refers to the process of applying various digital technologies, tools, and methods to improve operational efficiency, innovate products and services, optimize business processes, enhance customer experiences, thereby achieving corporate objectives and enhancing competitiveness”.
As scholars deepen their understanding of the concept of digital technology application, they have extensively explored the consequences of digital technology application. Yoo (2012) [36] believed that digital technology innovation is self-generating, continuously improving, and changing through digital technology. New technological resources are continually acquired and created. Usai (2021) [37] argued that the most commonly used digital technologies have a minimal impact on a company’s innovation performance because innovation results from creativity and sustained R&D efforts. Blichfeldt (2021) [38], when exploring the impact of digital technology applications on a company’s product and service innovation performance, divided digital technology applications into two dimensions—breadth and depth—and separately explained the impact of these two dimensions on innovation performance. While scholars have widely explored how digital technology applications affect innovation, few have focused on how digital technology applications affect green innovation performance. In the era of the digital economy, digital technology applications are increasingly becoming critical factors for companies to achieve GTI performance [1]. Increasingly, more companies are incorporating digital technology into their green innovation strategies to achieve goals related to resource efficiency, environmental technology innovation, and sustainability [39,40]. Companies using digital technology can better optimize resource allocation, reduce waste, increase production efficiency, and thus achieve both economic and environmental benefits.
Regarding the breadth of digital technology applications, extensive applications allow companies to comprehensively examine and optimize their resource utilization, helping them adjust their strategies and actions quickly, reduce environmental risks, and enhance green performance [41]. For example, by using digital technology to construct a visual resource management system, companies can accurately understand the utilization of resources [42], identify waste and inefficiencies, reduce resource consumption, and improve green efficiency by improving processes and implementing environmental measures [43]. Furthermore, the breadth of digital technology applications promotes collaboration and innovation across departments and fields [44]. Information and data from different domains can be integrated, facilitating new insights and innovative thinking. Therefore, this study proposes the following hypothesis:
Hypothesis H1a.
The breadth of digital technology applications positively impacts a company’s green innovation performance.
In terms of the depth of digital technology application, the deep application allows companies to conduct more detailed data analysis, identify opportunities and challenges for green innovation more accurately [45], and formulate and adjust green innovation strategies more precisely. In addition, digital simulation and simulation technology enable companies to test and validate green innovation ideas at a lower cost, reducing resource waste during experimentation [46]. Deep digital technology applications also promote intelligent optimization of internal processes within companies, improving resource utilization efficiency and energy conservation [47]. These deep digital technology applications provide more entry points and opportunities for green innovation and strengthen a company’s competitiveness in the green sector and its potential for sustainable development. Therefore, this study proposes the following hypothesis:
Hypothesis H1b.
The depth of digital technology application positively impacts a company’s green innovation performance.
2.2. The Mediating Role of Green Human Resource Allocation in the Relationship between Corporate Digital Technology Application and Green Innovation Performance
Green human resource allocation is crucial in today’s corporate sustainable development strategies [23]. As global environmental issues escalate and society’s focus on sustainability intensifies, companies are no longer solely concerned with short-term economic benefits. Instead, they emphasize long-term sustainability. In this context, green human resource allocation has become a prominent issue. It involves possessing, nurturing, and managing a workforce with environmental awareness and professional skills to drive companies toward green innovation and sustainable development goals [48]. Previous research has shown that green human resource allocation plays a significant role in a company’s sustainable development, market competitiveness, reputation and brand building, cost control, and efficiency improvement [48,49,50]. It is significant in green innovation and environmental protection. Additionally, it is an indispensable part of achieving sustainable development goals. Therefore, to support sustainable development, companies should highly prioritize green human resource allocation, formulate corresponding strategies and policies to ensure that employees’ expertise and skills in the green domain are fully developed and applied [49], promote technological innovation, assist companies in reducing their dependence on finite resources, and facilitate the implementation of a circular economy model [51].
Green human resource allocation profoundly affects a company’s green innovation performance. Firstly, green human resource allocation enhances the efficiency and quality of green innovation [49,50]. Employees with green expertise and skills are better equipped to understand and apply environmental standards and regulations, enabling them to adapt more quickly to the development of ecological technologies [48,52]. They can actively participate in the R&D of green products and services, drive the emergence of new environmental solutions, and improve the quality of green innovation to ensure that a company’s green products and services meet high eco-friendly standards. Secondly, green human resource allocation helps reduce the risks associated with green innovation. In the process of green innovation, challenges such as technological uncertainty, market risks, and regulatory changes may be faced [10]. Employees with green expertise can better identify and manage these risks, develop effective response strategies, and reduce the risk of failure in green innovation projects [53]. They are aware of the latest developments in environmental technology. They can better adapt to changes in market demand, thereby enhancing a company’s flexibility and adaptability in green innovation.
Additionally, green human resource allocation encourages employees to participate and innovate more actively [49]. Employees with environmental expertise are inclined to actively engage in green innovation projects, propose new ecological ideas and solutions, and drive the development of green innovation [54]. They take pride in the company’s green mission. They are more motivated to contribute their wisdom and creativity to green innovation, accelerating its progress.
The DTABD has significant effects on green human resource allocation. With the continuous acceleration of implementing the Digital China strategy and the enterprise’s digital transformation advancement, companies increasingly rely on the DTABD for green innovation and environmental protection [55]. Firstly, the increase in the breadth of digital technology may expand the demand for green human resource allocation. With the widespread application of digital technology in production, supply chains, and environmental monitoring, companies need more employees with knowledge and skills in digital technology [56]. These employees can better understand and apply digital tools to support the development and application of environmental technologies. Secondly, the increase in the depth of digital technology places higher demands on green human resource allocation. Deep digital technology applications typically involve advanced technologies such as data analysis, AI, and the Internet of Things, which have enormous potential for green innovation [57]. However, this requires employees to possess advanced digital technology knowledge and skills to address complex environmental issues. Companies must train and attract employees with these advanced technical skills to ensure that deep digital technology applications are fully realized in green innovation [23]. Furthermore, the increase in the breadth and depth of digital technology also accelerates the transformation of green human resource allocation [58]. Traditional green human resource allocation methods may no longer meet the demands of the digital age [49]. It is suggested that companies re-examine their employees’ skill requirements, redefine training plans, and attract new employees with digital backgrounds to adapt to the changes brought about by digital transformation. Therefore, the DTABD impacts green human resource allocation and prompts companies to rethink their GHRM strategies. Consequently, this study proposes the following hypotheses:
Hypothesis H2.
Green human resources in enterprises play a positive intermediary role in the relationship between digital technology applications and the performance of GTI in enterprises.
Hypothesis H2a.
Green human resources in enterprises play a positive intermediary role in the relationship between the breadth of digital technology applications and the performance of GTI.
Hypothesis H2b.
Green human resources in enterprises play a positive intermediary role in the relationship between the depth of digital technology applications and the performance of GTI.
2.3. The Moderating Effect of Corporate DTIN Embeddedness on the Relationship between Digital Technology Application and Corporate Green Human Resource Configuration
Digital technology innovation network (DTIN) embeddedness refers to the degree of connection and cooperation between enterprises and external stakeholders. It can be divided into two key dimensions: relational and structural embeddedness [25]. Relational embeddedness emphasizes the interaction, trust, and cooperation between enterprises and external partners, including collaborators, suppliers, and digital technology innovation communities [59]. Structural embeddedness focuses on the complexity and density of the DTIN, including the number of nodes, connection strength, and efficiency of information flow within the network [60,61]. These two dimensions interact with each other, jointly influencing the relationship between corporate digital technology applications and green human resource configuration.
On the one hand, relational embeddedness in the digital DTIN strengthens the collaborative relationships between enterprises and external partners, providing a broader range of digital technology support and resources [62]. As the DTABD increases within the enterprise, relational embeddedness helps expand the external resource pool for green innovation, further promoting the enhancement of corporate green human resource configuration [63]. This external collaboration accelerates the attraction of talent with expertise in green knowledge and skills. It facilitates cooperation and knowledge sharing in green innovation projects. On the other hand, structural embeddedness reflects the complexity and tightness of the DTIN. A more complex and tightly embedded network structure provides enterprises with a broader range of digital technology support and resources [64]. This structural embeddedness accelerates the attraction of talent with expertise in green knowledge and skills. It promotes cooperation and knowledge sharing in green innovation projects [65,66]. As the range and depth of digital technology applications continue to expand, enterprises are more likely to attain higher levels of green human resource configuration in such situations.
In summary, DTIN embeddedness is crucial in the relationship between digital technology applications and corporate green human resource configuration. This role helps strengthen the connection between digital technology applications and green innovation, driving enterprises toward sustainable development goals. Therefore, this study proposes the following hypotheses:
Hypothesis H3.
Corporate DTIN embeddedness positively moderates the relationship between digital technology applications and corporate green human resource configuration.
Hypothesis H3a.
Corporate DTIN relational embeddedness positively moderates the relationship between the DTABD and green human resource configuration. The main benefits stem from the network’s facilitation of integration, knowledge sharing, strategic consistency, and resource consolidation. This embedding fosters greater collaboration among different departments, aiding the seamless integration of digital technology and green human resource configuration. By facilitating the exchange of experiences and knowledge, the network enhances the internal agility of the enterprise, enabling it to address digital technology innovation and green initiatives more effectively. Simultaneously, network embedding helps ensure that the enterprise maintains consistent strategic goals in applying digital technology and green human resource configuration, driving resource integration, and enhancing the relationship between DTABD and green human resource configuration.
Hypothesis H3b.
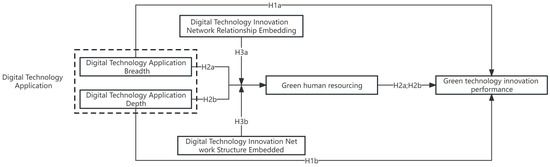
Corporate DTIN structural embeddedness positively moderates the relationship between the DTABD and green human resource configuration (Figure 1). The reason for this lies in its promotion of interdepartmental collaboration and information sharing. This embedding results in a tighter interconnection among business units, reinforcing the coordination between digital technology applications and green human resource configuration. Through internal communication and resource integration facilitated by the network structure, companies find achieving comprehensive digital technology adoption easier and adjust green human resource configuration more flexibly to adapt to environmental changes. This close structural embedding provides companies with an organic framework, fostering a more intimate and coordinated relationship between digital technology applications and green human resource configuration, ultimately enhancing the overall performance of the company’s green innovation.
Figure 1.
Overall research framework.
3. Research Design
3.1. Sample Selection and Data Sources
This empirical study focuses on Chinese publicly listed manufacturing companies from 2011 to 2020. We selected these companies as our sample for two reasons. Firstly, China, one of the biggest developing countries in the world, has a diverse industrial structure that includes manufacturing, services, and high-tech sectors, providing a wide range of samples for in-depth exploration of the relationship between digital technology adoption and green human resource allocation. Secondly, the Chinese government actively promotes green sustainable development and digital transformation, introducing a series of specific policies and targets that impose higher requirements on listed manufacturing companies. This unique policy environment and practical foundation make China an ideal setting for this research. Moreover, Chinese publicly listed manufacturing companies have enormous market share and international influence, making their experiences and development paths beneficial for other countries and regions in advancing sustainable development goals. Therefore, selecting Chinese publicly listed manufacturing companies for empirical research is reasonable and contributes to a profound understanding and practical application.
Chinese publicly listed manufacturing companies and their financial data are obtained from the Wind database. Wind is a leading financial data service provider that delivers comprehensive financial market data to users, covering various asset classes such as stocks, bonds, futures, and funds. The database provides real-time market data and includes rich historical data, enabling users to conduct comprehensive market analyses and reviews. In addition, Wind offers financial statement data for listed companies, supporting users in conducting company financial analysis. With powerful data analysis tools, users can engage in sophisticated market research and quantitative analysis. Moreover, Wind provides macroeconomic indicators and industry data, offering economic information at the macro level. Through professional services and diverse data offerings, Wind provides reliable decision support for investment institutions and financial practitioners, empowering them to make informed investment strategies.
Corporate social responsibility (CSR) data were taken from Hexun.com. Hexun.com, as one of China’s leading financial information service providers, is committed to delivering comprehensive and timely financial information, market data, and analytical reports to a broad audience of investors and professionals. The content on Hexun.com covers various financial markets, including stocks, funds, bonds, foreign exchange, macroeconomic indicators, industry dynamics, and financial commentary. The website offers real-time market quotes, financial news, insights from professional analysts, and an interactive user community, providing users with a comprehensive financial information platform. Notably, Hexun.com has gained recognition for releasing comprehensive social responsibility scores for Chinese-listed companies, serving as a metric for evaluating corporate social responsibility performance. We utilized Python software to extract annual social responsibility data from Hexun.com for each listed company. The patent data were collected from the Chinese National Intellectual Property Administration and the Himmpat database.
The steps used were as follows: Firstly, in the stock module of the Wind Database, choose the “Multidimensional Data for Stocks” option. Select all listed companies in the “Market Type” option within the available range. Choose indicators such as enterprise type to identify the Chinese-listed manufacturing companies. Next, within the database indicators, select data for enterprise finance, enterprise age, enterprise size, ownership nature, pollution attributes, debt-to-equity ratio, enterprise growth, and industry classification, exporting them to Excel. Subsequently, perform calculations on the exported Excel data based on different indicator formulas and transform them into panel data.
Secondly, based on the list of specific names of Chinese manufacturing companies obtained from the Wind database, we retrieved patent data for each company from the Himmpat patent database. Due to the Chinese patent regulations stipulating an 18-month delay in the publication of invention patents, we collected data up to 2020 to ensure accuracy. Specifically, we constructed a patent retrieval formula, “Applicant = Company Name, Patent Application Time from 2011 to 2020,” to retrieve specific patent data for each listed company. We captured each patent’s application number, publication number, title, applicant, inventor, application date, IPC classification code, CPC classification code, and citation information. Subsequently, we split the applicant field in the obtained patent dataset. We precisely matched the list of Chinese manufacturing companies and their stock codes to eliminate data where “the original applicant and patentee are non-target companies, but the current patentee is the target company”. Each patent was assigned a unique stock code to ease subsequent data integration. The preprocessed dataset accumulated over 860,000 entries.
Thirdly, we utilized tools such as Python to conduct a detailed analysis of the green patent information for each listed company, including the number of inventors and patent applications related to green technologies. We employed the widely used CPC patent classification system to identify green patents based on categories Y02 and Y04. Specifically, leveraging a dataset of 860,000 patents, we utilized Python to extract data from the CPC column that included Y02 or Y04, facilitating the quantification of green patents. Subsequently, we split and consolidated inventor information from the extracted green patents to precisely calculate each company’s annual count of green inventors. This process not only aids in understanding a company’s performance in green innovation, but also establishes a reliable foundation for subsequent data analysis.
Fourthly, we extracted the patent numbers cited by each application and obtained more than 900,000 cited patent numbers. We then searched the database for these cited patents, extracting IPC classification codes, application numbers, and application years for each. This information is used to measure the dimensions of digital technology applications in subsequent analysis. For the definition of digital technology, this paper processes data according to the definition in the “Reference Relationship Table of the Core Industry Classification of the Digital Economy and the International Patent Classification (2023)” issued by China National Intellectual Property Administration [67,68]. We follow the degree centrality measurement mentioned in existing work [69] to calculate network centrality metrics in structure and relational embeddings. According to a previous study, inter-firm cooperation ties often persist for 3–5 years [70]. Therefore, the innovation network of listed enterprises involved in digital technology innovation during 2011–2020 is divided into ten periods in this study using a 3-year rolling time window. Specifically, when calculating the relationship embedding indicators and structural embedding of the innovation network using Python, we leveraged the powerful NetworkX network analysis library. Firstly, through NetworkX, we flexibly and efficiently constructed the digital technology innovation network, mapping each company as a node and representing their collaborative relationships with edges. The relationship embedding in this innovation network goes beyond a simple reflection of connections between companies; it is further refined to quantify the number of collaboration partners, providing in-depth insights into the collaborative network features of digital technology innovation. Regarding structural embedding, we relied on the rich algorithms offered by the NetworkX library in Python, particularly centrality metrics such as degree centrality. Degree centrality not only measures the level of connectivity for each company within the digital technology innovation network, but also reveals their importance and influence in the network structure by examining the number of adjacent nodes. This form of structural embedding not only offers a clear understanding of the position of each company within the innovation network, but also provides robust support for understanding their roles and contributions in collaborative relationships.
Finally, we used Python to merge the obtained and calculated patent indicators with enterprise financial and other indicators based on the consistency of stock listing codes and years. Unmatched companies with stock codes and companies that did not apply for patents during the observation period were excluded. After that, we obtained a sample of 1760 companies.
3.2. Variable Explanations
- (1)
- Independent Variable—Digital Technology Application
Drawing on Blichfeldt (2021) [38], this study divided digital technology applications into breadth and depth. Specifically, the digital technology application breadth (DTAB) measures the variety of digital technologies a company employs in its GTI processes. This metric measures how widely a corporation uses different digital technologies, such as the Internet of Things (IoT), artificial intelligence, blockchain, big data analytics, and virtual reality, to advance the development of green technologies. A higher DTAB indicates that a company extensively utilizes diverse digital technology to drive environmental innovation.
The digital technology application depth (DTAD) focuses on the proportion of specific digital technologies a company applies in GTI. This dimension highlights the critical role of digital technology in a company’s GTI. A high DTAD means that digital technology plays a significant and influential role in a company’s GTI, contributing substantially to innovation.
- (2)
- Dependent Variable—GTI Performance
A company’s innovation achievements in environmental protection and sustainable development are primarily manifested through the invention of green-related new technologies, products, or methods that are granted unique invention patents. Green invention patents represent a company’s outstanding contributions to environmentally friendly innovations, signifying the company’s active commitment to goals such as resource efficiency, pollution reduction, and energy conservation [71]. Following Liang (2022) [72], this study measures a company’s performance in green innovation using the natural logarithm of the number of green invention patent applications submitted by the company. This objective metric verifies the company’s influence and innovation level in environmental innovation. A higher number of green invention patents indicates that the company has achieved significant results in GTI, providing a competitive advantage and contributing to the industry’s overall sustainability.
- (3)
- Mediating Variable—Green Human Resource
Green human resources are a crucial component of green resource management, reflecting employees’ expertise and capabilities in green knowledge, skills, technological innovation, and environmental management [73]. To measure the level of green human resources, this study adopts a measurement method based on the quantity of green technology research and development personnel, similar to Li et al. (2019) [74]. Specifically, we rely on enterprise patent data from the Himmpat database to calculate the number of inventors involved in green technology inventions subject to patent applications each year and take the natural logarithm of this number. This measurement method accurately reflects the company’s green human resource allocation level. It enhances the comparability and interpretability of the research results, improving understanding of the dynamic interaction between applications of digital technology and green innovation.
- (4)
- Moderating Variable—Digital Technology Innovation Network Embedding
This study comprehensively measures the DTIN embedding of enterprises, focusing primarily on two key dimensions: DTIN relationship embedding (NR) and DTIN structure embedding (NS).
NR focuses on the interactive relationships among enterprises within the DTIN. This dimension primarily assesses the degree of trust and reciprocity among enterprises, often measured by the strength of relationships. Strong connections between network members indicate more potential for information sharing and teamwork, essential for information searching, knowledge sharing, and collaborative development. In this study, we adopt the “number of collaborations between the target enterprise and its partners in the network” to measure DTIN relationship embedding [69]. Specifically, we take the natural logarithm of the number of collaborations between the target enterprise and its partners in the network plus one as the measurement indicator, reflecting the strength of the enterprise’s relationships within the DTIN.
Alternatively, NS focuses on the impact of a company’s relative position within the DTIN. This study employs the degree centrality index to measure this dimension, indicating a company’s connectivity within the network [75]. The higher a company’s degree of centrality, the more central it is within the network. The formula for calculating degree centrality is C(ni) = d(ni)/(n − 1), where n represents the total number of nodes, and d(ni) represents the number of times node ni is connected to other nodes. This index reflects the structural embedding of enterprises within the DTIN, which is their relative importance within the network. By measuring these two key dimensions, this study can comprehensively understand the degree of embedding of enterprises within the DTIN, including their interactive relationships with partners and their position within the network structure. This aids in a deeper exploration of the relationship between digital technology applications (including breadth and depth) and green human resource allocation, and investigates its impact on green innovation performance.
- (5)
- Control Variables
Drawing from existing research, this paper primarily controls for the following variables. Firm age: The natural logarithm of the years from the establishment year to the observation year. Firm size: The natural logarithm of the company’s total assets. Ownership nature: Assign a value of 1 if the company is state-owned; otherwise, assign a value of 0. Pollution attribute: Takes the value 1 for heavily polluting companies and 0 otherwise. Financial leverage means the asset–liability ratio, calculated as the total liabilities divided by total assets. Firm growth: Calculated as the operating income difference between the current and prior periods divided by the prior period’s operating income. Corporate social responsibility: The natural logarithm of the corporate social responsibility score obtained from Hexun.com (Table 1).

Table 1.
Variables mentioned in this study.
3.3. Model Design
The design draws upon data obtained from Chinese-listed manufacturing companies from 2011 to 2020. This study employs an ordinary least squares (OLS) mixed-effects model to scrutinize the connections among digital technology applications, green human resource allocation, enterprise DTIN embedding, and green innovation performance. Specifically, we designate digital technology application as the independent variable, GTI performance as the dependent variable, green human resource as the mediator variable, and enterprise DTIN embedding as the moderating variable. The ensuing empirical model is constructed as follows.
Firstly, we propose the following model to analyze how digital technology applications affect green innovation performance, corresponding to hypotheses H1a and H1b:
GIN is the dependent variable representing a company’s green innovation performance. DTA is the independent variable representing digital technology applications, including the DTABD. Controls refer to the control variables, including firm age, firm size, ownership nature, pollution attribute, asset-liability ratio, firm growth, industry affiliation, and corporate social responsibility. “i” and “t” respectively represent companies and years, and i,t denotes the residual terms.
Secondly, when investigating the mediating effect of a company’s green human resource allocation, as hypothesized in H2a and H2b, this study employs a three-step method to test the effect of green human resource allocation. The specific model is as follows:
GH is the mediating variable of green human resource allocation; other variables are mentioned above.
Third, we propose Model (5) to examine the moderating effect of enterprise DTIN embedding on the relationship between digital technology applications and green human resource allocation, as hypothesized in H3a and H3b:
N is the moderating variable of DTIN embedding, including the relational and structural embedding of the DTIN. N*DTA represents the interaction between enterprise DTIN embedding and digital technology applications. Other variables are mentioned above.
4. Results
4.1. Statistical Description and Correlation Analysis
Table 2 presents the statistical results of the main variables. Overall, these variables’ standard deviations fall within the usual range, proving that outlier values have little impact on them. Regarding GTI performance across firms, the maximum is 7.02, belonging to Zhuhai Gree Electric Appliances, while the minimum is 0.693, with an average value of 1.421. Regarding digital technology applications among firms engaged in green innovation, the minimum and maximum values for the breadth of digital technology applications are 0 and 14, respectively, with a mean value of 3.048. For the depth of digital technology application, the minimum and maximum values are 0 and 1, respectively, with a mean value of 0.446. This indicates significant variations in the DTABD among firms engaged in green innovation.
Table 2.
Statistical description of relevant variables.
The mean value for allocating green human resources is 2.35, with a minimum value of 0.693 and a maximum value of 7.906, respectively. As for the enterprise’s DTIN embedding, the minimum value for relationship embedding is 0 and the maximum is 9.008. For structural embedding, the minimum value is 0 and the maximum is 5.006. We further examined the correlations between the variables. Pearson correlation analysis in Table 3 reveals significant relationships among the main variables. Additionally, this study conducted variance inflation factor (VIF) tests for the variables, with the minimum VIF being 1.01, the maximum being 2.11, and the average being 1.51. The data can be used for regression analysis because all VIF values are substantially below 10, which indicates that multicollinearity problems are absent.
Table 3.
The results of Pearson correlation analysis.
4.2. Main Effects Analysis
This study used the OLS model to reveal the impact of digital technology applications on GTI performance in enterprises (Table 4). In this table, without including any control variables, the regression findings of the DTABD on GTI performance are shown in columns (1) and (5). The regression results are shown in columns (2) and (6) by including control variables. The regression results are displayed in columns (3) and (7) while controlling for time dummy variables. The regression results using the control industry dummy variables are shown in columns (4) and (8). Column (4) shows that, after adjusting for other factors, there is a 0.105 *** correlation between the performance of green innovation in listed businesses and the breadth of digital technology applications. This indicates a positive correlation between the breadth of digital technology applications and green innovation performance, confirming hypothesis H1a. Column (8) shows that when controlling other variables, the regression coefficient between the depth of digital technology application and GTI performance in listed companies is 0.247 ***. This suggests a positive correlation between the depth of digital technology application and green innovation performance, confirming hypothesis H1b. These findings reveal the pivotal role of digital technology applications in enhancing corporate green innovation performance. Fostering the breadth and depth of digital technology applications can significantly improve green innovation performance, which is crucial in achieving sustainability objectives. In summary, this study offers practical guidance to businesses for maximizing digital technology applications to drive green innovation, enabling them to excel in the digital era and positively impact globally.
Table 4.
Main effects test results.
4.3. Mediation Effects Analysis
To further reveal the mechanism of how digital technology application affects GTI performance in enterprises, this study determined the mediation effects of enterprise green human resource allocation. Table 5 presents the test results. The study employed hierarchical regression analysis to examine the significance of the mediation effect of corporate social responsibility. This method includes three steps:
Table 5.
Mediation effects test results.
Step 1: Testing the relationship between digital technology applications and green innovation performance. Columns (1) and (2) in Table 5 examine the relationship between the independent variables (DTABD) and the dependent variable (green innovation performance), respectively. It was found that both the DTABD measures have a significant positive relationship with GTI performance in listed companies, indicating that digital technology application enhances green innovation performance.
Step 2: Testing the relationship between digital technology applications and enterprise green human resource allocation. Columns (3) and (4) in Table 5 examine the relationship between the DTABD and enterprise green human resource allocation, respectively. It was found that both the breadth and DTABD have a significant positive relationship with enterprise green human resource allocation.
Step 3: Testing the relationship between the independent variable (digital technology applications), the mediator variable (enterprise green human resource allocation), and the dependent variable (green innovation performance). The results remain significant according to columns (5) and (6) in Table 5. This suggests that corporate green human resource allocation mediates the performance of green innovation and digital technology applications. Hypotheses H2a and H2b of this study are confirmed. In summary, the research results underscore the mediating role of green human resource allocation in the relationship between digital technology applications and corporate green innovation performance, providing valuable insights into the underlying mechanisms. These findings assist businesses in better planning their digital technology application strategies and offer essential clues for implementing green innovation. This enables companies to stand out and make a more significant impact in the digital era.
4.4. Moderation Effects Analysis
In order to determine the influence of DTIN embedding on the relationship between digital technology applications and corporate green human resource allocation, this study examined the moderating effects of DTIN embedding. Table 6 presents the test results.
Table 6.
Moderation effects test results.
In columns (1) and (2) of Table 6, the effects of the DTABD on enterprise green human resource allocation are examined. In column (3), the interaction term (NS*DTAB) between the breadth of digital technology applications and enterprise DTIN structural embedding is found to have a significantly positive impact on enterprise green human resource allocation, with a regression coefficient of 0.0975 **. In column (4), the interaction term (NS*DTAD) between the depth of digital technology applications and enterprise DTIN structural embedding also significantly impacts enterprise green human resource allocation, with a regression coefficient of 1.258 **. In column (5), the interaction term (NR*DTAB) between the breadth of digital technology applications and enterprise DTIN relational embedding significantly impacts enterprise green human resource allocation, with a regression coefficient of 0.0359 **. Enterprise green human resource allocation is found to be highly impacted by the interaction term (NR*DTAD) between the depth of digital technology applications and enterprise DTIN relational embedding, with a regression coefficient of 0.409 ** (Table 6). Therefore, enterprise DITN embedding positively moderates the relationship between digital technology applications and enterprise green human resource allocation, confirming hypotheses H3a and H3b. In summary, the findings emphasize the pivotal role of DTIN embedding in enhancing the link between digital technology applications and corporate green human resource allocation. These insights contribute to a better understanding of the intricate mechanisms at play and guide businesses in optimizing their strategies to promote green innovation and contribute positively in the digital era.
4.5. Robustness Tests
To further examine the robustness of the conclusions, this study conducted two robustness tests using lagged independent variables and changes in sample size regression. Firstly, we examined the effects of lagged digital technology application breadth and depth on enterprise GTI performance after delaying the DTABD by one and two periods. The results showed that the regression remained significant and robust.
Secondly, this study employed the method of changing the sample size. After applying a 5% trimming to the dependent variable (enterprise green innovation performance), we conducted a regression analysis of digital technology application and enterprise green innovation performance. The results remained significantly positive (Table 7).
Table 7.
The results of the robustness test.
These robustness tests further reinforce the credibility of our research findings, indicating that the positive impact of digital technology applications on corporate GTI performance remains consistent and reliable in different contexts. These findings provide more robust evidence for businesses to confidently adopt digital technology application strategies, driving their green innovation efforts and making a more significant contribution to sustainable development.
5. Discussion
5.1. The Impact of Digital Technology Application on Green Innovation Performance
Through empirical research on Chinese-listed companies, this study successfully reveals the significant positive impact of the breadth and depth of digital technology applications on corporate green innovation performance, providing a new theoretical perspective for understanding the role and effectiveness of enterprises in green innovation in the digital era. Specifically, drawing inspiration from the viewpoints of Su (2021) [11] and Sestino (2023) [12], we incorporate the theoretical framework of digital technology application into empirical research to clarify the mechanisms by which digital technology applications function in corporate green innovation.
Regarding the breadth of digital technology applications, we find a significantly positive relationship between greater breadth and corporate green innovation performance, further confirming Blichfeldt’s (2021) [38] theory of the breadth of digital technology applications. The concept of breadth encompasses the diversity and extent of adopting various types of digital technologies, providing a more comprehensive perspective on resource utilization for companies and accelerating the development and application of environmental protection technologies [76]. Through the diversified use of digital technologies, companies can utilize extensive data analysis to identify resource waste and inefficiencies, improve processes, and implement environmental measures to enhance green efficiency, better meet environmental demands, and drive the realization of green innovation performance [77]. On the other hand, regarding the depth of digital technology applications, we find that a higher depth of digital technology applications also has a significantly positive impact on corporate green innovation performance, aligning with Blichfeldt’s (2021) proposed theory of the depth of digital technology applications [38]. The depth measures the importance of digital technology in corporate green technological innovation, implying more sophisticated data analysis and more accurate formulation and adjustment of green innovation strategies [38]. Additionally, digital simulation and simulation technologies enable companies to test and validate green innovation ideas at lower costs [78] through intelligent optimization of internal processes [79], further improving resource utilization efficiency and energy savings. These in-depth applications of digital technologies provide companies with more entry points and opportunities for green innovation, thereby enhancing competitiveness and the potential for sustainable development in the green field.
Precisely, for example, in the production process of Pangang Group Vanadium Titanium Resources Co., Ltd. (Panzhihua, China), through the use of extensive data analysis, the company can monitor equipment energy consumption in real time, identify devices with energy waste, and reduce energy consumption by adjusting working parameters or performing timely maintenance. Moreover, through digital technology, Guangzhou Jia Cheng International Logistics Co., Ltd. (Guangzhou, China) can optimize supply chain management, reduce logistics costs, and minimize environmental impact during transportation. Additionally, manufacturing companies such as Beijing Holychip Communication Technology Co., Ltd. (Beijing, China) have demonstrated significant achievements in the deep application of digital technology. Companies can use digital simulation and simulation technologies to test new green innovation solutions before production. This virtual testing environment significantly reduces the cost of trial and error, enabling companies to be more flexible in experimenting with and optimizing innovative ideas, thereby facilitating the rapid application of green technologies.
5.2. The Mediating Role of Green Human Resource Configuration in the Relationship between Digital Technology Application and Green Innovation Performance
Green innovation has become a core theme for the sustainable development of businesses, particularly in addressing global climate change and environmental protection, prompting companies to continually seek innovative solutions [1,2]. Simultaneously, the rapid development of digital technology has provided significant opportunities for enterprises to more efficiently and precisely drive green innovation. In this context, our study introduces the Resource-Based View (RBV) theory, revealing the relationship between the application of digital technology and the performance of green innovation through the lens of green human resource allocation. RBV posits that a unique combination of resources within a company can construct competitive advantages, encompassing various forms of capital, including human resources. Our research findings indicate that green human resource allocation plays an intermediary role in the relationship between the application of digital technology and the performance of green innovation, providing profound insights. This intermediary role elucidates that in the digital era, green human resource allocation acts as a bridge, connecting the widespread application of digital technology with the efficacy of green innovation. This discovery not only aids in a better understanding of how companies operate and perform in green innovation, but also offers new empirical support for applying RBV theory in sustainable development. Through its theoretical contribution, this study expands the understanding of the relationship between digital technology and green innovation, providing a more affluent theoretical foundation for future research.
Firstly, as a mediating variable, green human resource configuration reflects the bridging role of employees between digital technology and green innovation. Employees with green expertise are more likely to understand and apply digital technology, especially digital tools and platforms related to environmental technology [80]. They can better utilize digital technology to promote green innovation because they deeply understand ecological standards, regulations, and industry best practices [81]. This understanding and application capability allows companies to develop and launch green products and services more efficiently, thereby improving green innovation efficiency [81].
Secondly, green human resource configuration also helps reduce risks in green innovation. Green innovation has multiple risks and uncertainties, such as technology, markets, and regulations [10]. Employees with green expertise can better cope with these challenges by more accurately identifying and assessing potential risk factors [53]. They can also formulate response strategies more quickly to adapt to the changing environment [54]. Therefore, green human resource configuration contributes to increasing the flexibility and adaptability of companies in the green innovation process.
Additionally, green human resource configuration stimulates employee involvement and innovation willingness. Employees with green expertise are more likely to participate actively in green innovation projects, propose new environmental concepts, and offer solutions [49]. They take pride in the company’s green mission and are motivated to contribute their wisdom and creativity to green innovation [54]. This active involvement and willingness to innovate help drive the development of green innovation because it often requires cross-departmental cooperation and collective intelligence. Green human resource configuration also contributes to improving the sustainability of green innovation. Employees with green expertise can drive current green innovation projects and provide solutions for future environmental challenges [23,24]. They can continuously learn and adapt to new environmental technologies, helping companies stay at the forefront of sustainable development. This sustainability means that companies can constantly engage in green innovation rather than just making a temporary effort. Therefore, companies should focus on training and developing green human resources to fully unleash their potential, improve the efficiency and quality of green innovation, reduce risks, stimulate employee involvement and innovation willingness, and achieve sustainable green innovation. Take BYD Company Limited as an example. The company is a well-known mainland Chinese manufacturer specializing in new energy vehicles and batteries. BYD has achieved remarkable success in green innovation, leveraging digital technology to promote sustainable development. Through digitized design and manufacturing processes, BYD can more efficiently produce electric vehicles and advanced battery technology, addressing environmental challenges and enhancing energy utilization efficiency. Green human resources play a crucial role in this process, as the company focuses on recruiting and nurturing employees with expertise in green practices. These employees comprehend and apply digital technology innovations in new energy vehicles and actively participate in green innovation projects, providing sustainable solutions for the company. BYD’s successful practices highlight the synergistic relationship between digital technology applications and green human resource management, setting an example for enterprises in sustainable development through green innovation. Future research can further explore the mechanisms of green human resource configuration in different industries and cultural backgrounds, providing more accurate guidance and suggestions for companies.
5.3. The Moderating Role of Enterprise DTIN Embedding in the Relationship between Digital Technology Application and Green Human Resource Configuration
In this digital age, enterprise digital technology innovation has become critical in gaining a competitive advantage and achieving sustainable development. At the same time, green human resource allocation is also considered crucial for enterprises to succeed in the environmental protection field [23]. However, our research has revealed an important finding: the relationship embedding and structural embedding of the enterprise’s digital technology innovation network have a moderating effect on the relationship between digital technology application and green human resource allocation. This finding provides a new perspective for a deeper understanding of the complex relationships among digital technology, green resources, and innovation. At this juncture, we introduce the Resource Dependence Theory, which emphasizes that enterprises depend on resources in their environment, and resource acquisition and utilization have profound effects on the behavior and performance of enterprises. Digital technology and green resources can be seen as essential resources for enterprises, and the relationship embedding and structural embedding of the digital technology innovation network affect how enterprises acquire and integrate these resources. The Resource Dependence Theory helps explain how enterprises adjust green human resource allocation through the relationship embedding and structural embedding of the digital technology innovation network, thereby influencing innovation and performance in the environmental protection field. In terms of theoretical contribution, our study extends the application scope of the Resource Dependence Theory in the digital era, providing a new theoretical perspective of the relationship between green innovation and digital technology innovation. Through theoretical integration, we understand the interactions among digital technology, green resources, and enterprise innovation, offering valuable guidance for enterprises to balance technological innovation and environmental protection demands in the digital age.
First, we explore how the relational embedding of DTIN moderates the relationship between digital technology applications and green human resource configuration. Relational embedding typically involves trust and reciprocity among network members [59]. Our research shows that when companies establish strong trust relationships and achieve high reciprocity within the DTIN, the positive relationship between digital technology applications and green human resource configuration becomes more significant. Because employees are more eager to participate actively in green innovation activities and businesses are more likely to exchange information and resources connected to digital technology applications in these circumstances, the degree of green human resource configuration is increased. [65]. This finding emphasizes the importance of building trust and promoting reciprocity within the DTIN, which can be achieved through facilitating cooperation, sharing information, and sharing resources [26].
Secondly, we focus on how the structural embedding of DTIN moderates the relationship between digital technology applications and green human resource configuration. Structural embedding pertains to a company’s relative position within the network, typically measured using indicators such as degree centrality [60,61]. Our research reveals that when companies have a higher degree of centrality within the DTIN, the positive relationship between digital technology applications and green human resource configuration becomes more significant because companies at the network’s core usually possess more resources and information, enabling them to effectively promote digital technology applications. Furthermore, attracting and retaining employees with green expertise is more accessible, thus enhancing green human resource configuration [64]. This finding suggests that companies should actively engage in DTIN to secure a more favorable position within the network while establishing strong trust relationships and promoting reciprocal cooperation [26]. In order to increase employee engagement and capabilities in digital technology applications and green innovation, businesses should prioritize the training and development of green human resources. By doing this, they can create a positive feedback loop between the configuration of green human resources and digital technology applications. For example, Guangzhou Automobile Group Co., Ltd. (Guangzhou, China) has consolidated its relationship embeddedness in the digital technology innovation network by establishing strong trust relationships and fostering highly reciprocal cooperation. Internally within the network, the company emphasizes cultivating high trust among members and fostering closer collaborative relationships by sharing information and resources related to digital technology applications. This relationship embeddedness lays a solid foundation for the positive relationship between digital technology applications and the configuration of green human resources within the company.
Furthermore, Guangzhou Automobile Group actively enhances its structural embeddedness within the digital technology innovation network, positioning itself advantageously. The company ensures a higher degree of centrality within the network, becoming one of the core entities. Through this strategic positioning, Guangzhou Automobile Group can more effectively drive the application of digital technology, making it easier to attract and retain employees with expertise in green technologies, further elevating the level of green human resources configuration. The successful practices of Guangzhou Automobile Group highlight how enterprises in the digital era can achieve synergistic enhancement of digital technology applications and green human resource configuration by actively embedding themselves in digital technology innovation networks and optimizing network structures. This strategy provides robust support for innovation and performance in the environmental protection domain. It offers a feasible example for other enterprises seeking to balance technological innovation and environmental sustainability in the digital era.
6. Conclusions and Recommendations
6.1. Conclusions
The results of this study reveal complex and significant interrelationships among digital technology applications, green human resource configuration, DTIN embedding, and green technological innovation. It provides profound insights into the development of enterprises in the digital and green innovation domains. The main conclusions of this study are as follows:
(1) Our findings underscore the pivotal role of digital technology in shaping green innovation performance, both in terms of breadth and depth. Expanding on this, it is evident that a broader and more profound integration of digital technology yields a substantial positive impact on a company’s ability to innovate in environmentally sustainable ways. This emphasizes the strategic significance of digital technology in steering the trajectory of green innovation. In practical terms, companies are strongly encouraged to proactively embrace digital technology, incorporating it comprehensively across their green innovation initiatives. This holistic adoption is critical to unlocking heightened levels of efficiency and effectiveness in their endeavors toward green innovation. To support this transition, governments and relevant organizations can play a facilitating role by actively promoting the widespread adoption of digital technologies, particularly in the context of green innovation. Supportive measures may encompass targeted digital technology training programs, financial incentives, tax breaks, and optimization of human resource configurations. The collaborative efforts of enterprises, governments, and organizations are instrumental in fostering an environment conducive to the seamless integration of digital technology. This collaboration is crucial for achieving superior green innovation performance and advancing sustainability goals.
(2) Green human resources are pivotal in mediating the intricate connection between digital technology applications and green innovation performance. In essence, they act as a critical bridge, fortifying the positive influence of digital technology applications on green technology innovation (GTI) performance by providing specialized green expertise, skills, and unwavering support. This discovery underscores the strategic significance of prioritizing green human resource configuration within companies. To optimize the impact of digital technology applications on green innovation performance, enterprises are urged to proactively foster and refine their employees’ green knowledge and skills. This proactive approach ensures that the workforce possesses the essential competencies to apply digital technology to effectively pursue heightened green innovation performance. Collaborative initiatives between the government and businesses are instrumental in achieving this goal. By jointly investing in training and development programs, they can enhance employees’ proficiency in green practices, laying the groundwork for more adept application of digital technologies. This concerted effort aligns with the companies’ pursuit of superior green innovation performance and contributes to broader sustainability objectives. Furthermore, recognizing that the full potential of green human resource configuration can be harnessed through strategic embedding within digital technology innovation networks, enterprises should place a premium on optimizing their network structures. This involves actively participating in and shaping digital technology innovation networks, fostering collaborative relationships, and contributing to exchanging knowledge and best practices. By doing so, companies can create an environment conducive to synergizing green human resources with digital technologies, ultimately enhancing green innovation performance.
(3) This study also reveals that the relational embedding and structural embedding of the enterprise DITN have a moderating effect on the relationship between digital technology applications and green human resource configuration. Relational and structural embedding jointly influence the positive effects of digital technology applications on green human resource configuration. This means businesses must excel in digital technology applications and actively engage in the DTIN. Through close collaboration with government and industry organizations, establishing strong trust relationships, and strategically positioning themselves within the network, businesses can promote the construction and development of the DTIN. This balance and coordination enhance the relationship between digital technology applications and green human resource configuration, promoting green innovation more effectively. Specifically, relationship embedding emphasizes close connections and trust-based relationships with other organizations, allowing enterprises to gain insights into the latest technology trends, market demands, and best practices. This aids businesses in better understanding how to adjust their digital technology applications to support green innovation, thus expediting the positive impact of digital technology adoption on green human resource configuration. Additionally, strong relationship embedding promotes the establishment of partnerships for collaborative development of innovative solutions, resource sharing, and joint resolution of challenges related to GTI. On the other hand, structural embedding focuses on an enterprise’s position and role within the DTIN. Enterprises with advantageous positions typically have more opportunities to influence other participants and control the flow of resources and information. They can actively participate in and lead the formulation of industry standards, steering the DTIN toward supporting GTI. Favorable structural embedding also enables enterprises to more effectively coordinate different resources and capabilities to better meet the needs of green innovation.
(4) This study’s conclusions apply to publicly listed manufacturing companies in China and have broad global relevance. Although our research primarily focused on Chinese enterprises, the principles and mechanisms proposed have significant guiding implications for businesses in other countries and regions. Globally, companies are confronted with shared challenges in digitization and green innovation. The interconnections and patterns revealed in this study offer valuable lessons for enterprises navigating this terrain. Firstly, businesses in other countries can draw upon the successful experiences of Chinese companies in applying digital technologies. By maximizing the breadth and depth of digital technology applications, enterprises can elevate their levels of green innovation performance, thereby achieving tremendous success in sustainable development. This principle is universally applicable, providing a general guideline for companies worldwide to balance technological innovation and environmental sustainability in the digital age. Secondly, international organizations and businesses can collaborate with Chinese enterprises and government entities to share experiences applying digital technologies and green innovation. Such cross-border collaboration not only contributes to driving global green technological innovation but also facilitates the exchange of knowledge among nations, enhancing the collective ability of global businesses to address the challenges of digitization and green innovation. On the other hand, businesses and governments outside China can derive inspiration from the successful experiences within the country. By learning and adapting practices from Chinese enterprises, particularly in digital technology innovation networks and green human resource management, companies in other countries can better understand how to propel green innovation in the digital era. This cross-cultural learning fosters a more comprehensive approach for global enterprises to tackle the intricate challenges of digitization and green innovation.
6.2. Recommendations
- (1)
- Multi-level Application of Digital Technology:
Intelligent monitoring and optimization: Utilize digital technology for comprehensive monitoring of production and operations, identifying and rectifying issues of low environmental efficiency through extensive data analysis. This includes recognizing high-energy-consuming processes, reducing waste, and optimizing the supply chain to enhance the overall environmental performance of the enterprise. Simulation and virtual testing: Employ digital simulation and virtualization techniques to reduce testing costs for green innovation projects. Through digital simulation, companies can rapidly and cost-effectively validate new green innovation ideas, thereby reducing the risk of project failures.
- (2)
- Development of a Green Expert Team:
Green skills training: Elevate employees’ green expertise through training programs, enabling them to better understand and apply digital technology. Cultivate employees’ profound understanding of environmental standards, regulations, and industry best practices to enhance the practical application of digital technology in green innovation. Cross-department collaboration mechanism: Establish mechanisms that facilitate collaboration among different teams, ensuring that employees with green expertise actively participate in green innovation projects. Collaboration between different departments enhances the enterprise’s flexibility and adaptability, reducing risks during the green innovation process.
- (3)
- Active Engagement in Digital Technology Innovation Networks:
Building trust relationships: Establish robust trust relationships within digital technology innovation networks, encouraging the free flow of information and resources. Emphasize a spirit of cooperation within the network, sharing information and resources related to digital technology applications to support green human resource configuration. Optimizing network structure: Strive to occupy advantageous positions within digital technology innovation networks, ensuring the enterprise has a higher degree of centrality. This helps more effectively drive the application of digital technology, attracting and retaining employees with green expertise, thereby elevating the level of green human resource configuration.
7. Research Limitations
Despite the significant findings, this study has several limitations. Firstly, the sample in this study only includes Chinese-listed companies. The regional and cultural differences may limit the generalizability of the research results. Companies in different countries and regions may face different market environments, levels of policy support, and cultural backgrounds, which could influence the relationships among digital technology applications, green human resource configuration, and the DITN. Future research can expand the sample range to cover multiple countries and regions for a more comprehensive understanding. Secondly, this study relies on self-reported data from companies, which carries the risk of self-reporting bias. Although we have taken various approaches to reduce the likelihood of this bias, we have not eliminated the bias. Future research could consider incorporating objective performance data or third-party evaluations to validate the research results. Thirdly, this study focused on the relationships among digital technology applications, green human resource configuration, and the DITN without considering the potential influence of other factors. For example, market competition, government policies, industry characteristics, and other factors may also impact green innovation.
Author Contributions
Conceptualization, J.L. and C.W.; methodology, Q.W.; software, J.L.; validation, Q.W. and C.W.; formal analysis, J.L.; investigation, C.W.; resources, Q.W.; data curation, J.L. and Q.W.; writing—original draft preparation, J.L. and C.W.; writing—review and editing, C.W.; visualization, Q.W.; supervision, Q.W.; funding acquisition, J.L. and C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Guangdong Higher Education Society’s “14th Five-Year Plan” 2022 Higher Education Research Project: Research on the Innovation of Training Models and Mechanisms for Complex Health Education Management Talents in the Context of New Liberal Arts Construction: 22GYB169. Dongguan City College 2020 Young Teachers’ Development Fund Focused Project: A Practical Study of Social Work Intervention in Community Traditional Culture Conservation from the Perspective of Cultural Sociology”.
Data Availability Statement
The data from this study is already in the figures and tables in the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Elahi, E.; Khalid, Z.; Zhang, Z.X. Understanding farmers’ intention and willingness to install renewable energy technology: A solution to reduce the environmental emissions of agriculture. Appl. Energy 2022, 309, 118459. [Google Scholar] [CrossRef]
- Tyfield, D.; Ely, A.; Geall, S. Low Carbon Innovation in China: From Overlooked Opportunities and Challenges to Transitions in Power Relations and Practices. Sustain. Dev. 2015, 32, 206–216. [Google Scholar] [CrossRef]
- Aguilera-Caracuel, J.; Ortiz-de-Mandojana, N. Green Innovation and Financial Performance: An Institutional Approach. Organ. Environ. 2013, 26, 365–385. [Google Scholar] [CrossRef]
- Shukla, G.P.; Adil, G.K. A conceptual four-stage maturity model of a firm’s green manufacturing technology alternatives and performance measures. J. Manuf. Technol. Manag. 2021, 32, 1444–1465. [Google Scholar] [CrossRef]
- Mardani, A.; Streimikiene, D.; Zavadskas, E.K.; Cavallaro, F.; Nilashi, M.; Jusoh, A.; Zare, H. Application of Structural Equation Modeling (SEM) to Solve Environmental Sustainability Problems: A Comprehensive Review and Meta-Analysis. Sustainability 2017, 9, 1814. [Google Scholar] [CrossRef]
- Ding, C.; Liu, C.; Zheng, C.; Li, F. Digital Economy, Technological Innovation and High-Quality Economic Development: Based on Spatial Effect and Mediation Effect. Sustainability 2022, 14, 216. [Google Scholar] [CrossRef]
- Gu, W.; Wang, J.; Hua, X.; Liu, Z. Entrepreneurship and high-quality economic development: Based on the triple bottom line of sustainable development. Int. Entrep. Manag. J. 2021, 17, 1–27. [Google Scholar] [CrossRef]
- Chang, S.E.; Chen, Y.C.; Lu, M.F. Supply chain re-engineering using blockchain technology: A case of smart contract based tracking process. Technol. Forecast. Soc. Chang. 2019, 144, 1–11. [Google Scholar] [CrossRef]
- Barrett, M.; Davidson, E.; Prabhu, J.; Vargo, S.L. Service Innovation in the Digital Age: Key Contributions and Future Directions. MIS Q. 2015, 39, 135–154. Available online: https://www.jstor.org/stable/26628344 (accessed on 11 December 2022). [CrossRef]
- Yuan, B.L.; Cao, X.Y. Do corporate social responsibility practices contribute to green innovation? The mediating role of green dynamic capability. Technol. Soc. 2022, 68, 101868. [Google Scholar] [CrossRef]
- Su, J.; Su, K.; Wang, S. Does the Digital Economy Promote Industrial Structural Upgrading?—A Test of Mediating Effects Based on Heterogeneous Technological Innovation. Sustainability 2021, 13, 10105. [Google Scholar] [CrossRef]
- Sestino, A.; Kahlawi, A.; De Mauro, A. Decoding the data economy: A literature review of its impact on business, society and digital transformation. Eur. J. Innov. Manag. 2023, 1–26. [Google Scholar] [CrossRef]
- Shen, Y.; Zhang, X.U. Intelligent manufacturing, green technological innovation and environmental pollution. J. Innov. Knowl. 2023, 8, 100384. [Google Scholar] [CrossRef]
- Wu, Y.; Li, H.; Luo, R.; Yu, Y. How digital transformation helps enterprises achieve high-quality development? Empirical evidence from Chinese listed companies. Eur. J. Innov. Manag. 2023, 1–27. [Google Scholar] [CrossRef]
- Wu, H.T.; Hao, Y.; Ren, S.I.; Yang, X.; Xie, G. Does internet development improve green total factor energy efficiency? Evidence from China. Energy Policy 2021, 153, 112247. [Google Scholar] [CrossRef]
- Hanaysha, J.R.; Al-Shaikh, M.E.; Joghee, S.; Alzoubi, H.M. Impact of Innovation Capabilities on Business Sustainability in Small and Medium Enterprises. FIIB Bus. Rev. 2022, 11, 67–78. [Google Scholar] [CrossRef]
- Xue, L.; Zhang, Q.; Zhang, X.; Li, C. Can Digital Transformation Promote Green innovation performance? Sustainability 2022, 14, 7497. [Google Scholar] [CrossRef]
- Bo, S.; Liu, Y.Y. The impact of digital transformation on corporate financialization: The mediating effect of Green innovation performance. Innov. Green Dev. 2023, 2, 100032. [Google Scholar] [CrossRef]
- Li, D.; Shen, W. Can Corporate Digitalization Promote Green Innovation? The Moderating Roles of Internal Control and Institutional Ownership. Sustainability 2021, 13, 13983. [Google Scholar] [CrossRef]
- Hao, X.L.; Li, Y.H.; Ren, S.Y.; Wu, H.; Hao, Y. The role of digitalization on green economic growth: Does industrial structure optimization and green innovation matter? J. Environ. Manag. 2023, 325, 116504. [Google Scholar] [CrossRef]
- Dou, Q.; Gao, X. The double-edged role of the digital economy in firm green innovation: Micro-evidence from Chinese manufacturing industry. Environ. Sci. Pollut. Res. 2022, 29, 67856–67874. [Google Scholar] [CrossRef] [PubMed]
- Jawad, A.; Mustafa, S. Impact of knowledge management practices on green innovation and corporate sustainable development: A structural analysis. J. Clean. Prod. 2019, 229, 611–620. [Google Scholar]
- Singh, S.K.; Giudice, M.D.; Chierici, R.; Graziano, D. Green innovation and environmental performance: The role of green transformational leadership and green human resource management. Technol. Forecast. Soc. Change 2020, 150, 119762. [Google Scholar] [CrossRef]
- Correani, A.; De Massis, A.; Frattini, F.; Petruzzelli, A.M.; Natalicchio, A. Implementing a Digital Strategy: Learning from the Experience of Three Digital Transformation Projects. Calif. Manag. Rev. 2020, 62, 37–56. [Google Scholar] [CrossRef]
- Costa, J.; João, C.O.M. Open Innovation 4.0 as an Enhancer of Sustainable Innovation Ecosystems. Sustainability 2020, 12, 8112. [Google Scholar] [CrossRef]
- Guo, B.; Wang, Y.; Zhang, H.; Liang, C.; Feng, Y.; Hu, F. Impact of the digital economy on high-quality urban economic development: Evidence from Chinese cities. Econ. Model. 2023, 120, 106194. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, Z.; Boadu, F.; Tang, H.J. How does digital transformation affect agricultural enterprises’ pro-land behavior: The role of environmental protection cognition and cross-border search. Technol. Soc. 2022, 70, 101991. [Google Scholar] [CrossRef]
- Li, J.; Herdem, M.S.; Nathwani, J.; Wen, J.Z. Methods and applications for Artificial Intelligence, Big Data, Internet of Things, and Blockchain in smart energy management. Energy AI 2023, 11, 100208. [Google Scholar] [CrossRef]
- Fatima, S.; Desouza, K.C.; Dawson, G.S. National strategic artificial intelligence plans: A multi-dimensional analysis. Econ. Anal. Policy 2020, 67, 178–194. [Google Scholar] [CrossRef]
- Claudia, L.; Arnold, P. Reflections on societal and business model transformation arising from digitization and big data analytics: A research agenda. J. Strateg. Inf. Syst. 2015, 24, 149–157. [Google Scholar]
- Pratono, A.H. Multiple flexible suppliers and competitive advantage during market turbulence: The role of digital capabilities. J. Enterp. Inf. Manag. 2023, 1–19. [Google Scholar] [CrossRef]
- Zhao, N.Y.; Hong, J.T.; Lau, K.H. Impact of supply chain digitalization on supply chain resilience and performance: A multi-mediation model. Int. J. Prod. Econ. 2023, 259, 108817. [Google Scholar] [CrossRef]
- Mackert, M.; Mabry-Flynn, A.; Champlin, S.; Donovan, E.E.; Pounders, K. Health literacy and health information technology adoption: The potential for a new digital divide. J. Med. Internet Res. 2016, 18, e264. [Google Scholar] [CrossRef] [PubMed]
- Shen, L.; Zhang, X.; Liu, H. Digital technology adoption, digital dynamic capability, and digital transformation performance of textile industry: Moderating role of digital innovation orientation. Manag. Decis. Econ. 2021, 43, 2038–2054. [Google Scholar] [CrossRef]
- Shi, J.R.; Jiang, Z.H.; Liu, Z.Y. Digital Technology Adoption and Collaborative Innovation in Chinese High-Speed Rail Industry: Does Organizational Agility Matter? IEEE Trans. Eng. Manag. 2023, 1–14. [Google Scholar] [CrossRef]
- Yoo, Y.; Henfridsson, O.; Lyytinen, K. Research commentary—The new organizing logic of digital innovation: An agenda for information systems research. Inf. Syst. Res. 2010, 21, 724–735. [Google Scholar] [CrossRef]
- Usai, A.; Fiano, F.; Messeni Petruzzelli, A.; Paoloni, P.; Briamonte, M.F.; Orlando, B. Unveiling the impact of the adoption of digital technologies on firms’ innovation performance. J. Bus. Res. 2021, 133, 327–336. [Google Scholar] [CrossRef]
- Blichfeldt, H.; Faullant, R. Performance effects of digital technology adoption and product & service innovation-A process-industry perspective. Technovation 2021, 105, 102275. [Google Scholar]
- Bradu, P.; Biswas, A.; Nair, C.; Sreevalsakumar, S.; Patil, M.; Kannampuzha, S.; Mukherjee, A.G.; Wanjari, U.R.; Renu, K.; Vellingiri, B.; et al. Recent advances in green technology and Industrial Revolution 4.0 for a sustainable future. Environ. Sci. Pollut. Res. 2022, 1–32. [Google Scholar] [CrossRef]
- Yadav, S.; Samadhiya, A.; Kumar, A.; Majumdar, A.; Garza-Reyes, J.A.; Luthra, S. Achieving the sustainable development goals through net zero emissions: Innovation-driven strategies for transitioning from incremental to radical lean, green and digital technologies. Resour. Conserv. Recycl. 2023, 197, 107094. [Google Scholar] [CrossRef]
- Valtteri, R.; Leena, A.S.; Väisänen, J.M. Digital technologies catalyzing business model innovation for circular economy—Multiple case study. Resour. Conserv. Recycl. 2021, 164, 105155. [Google Scholar]
- Niu, Y.F.; Ying, L.M.; Yang, J. Organizational business intelligence and decision making using big data analytics. Inf. Process. Manag. 2021, 58, 102725. [Google Scholar] [CrossRef]
- Rosário, A.T.; Dias, J.C. Sustainability and the Digital Transition: A Literature Review. Sustainability 2022, 14, 4072. [Google Scholar] [CrossRef]
- Sworowska-Baranowska, A. Knowledge pluralisation in for-common-good science: Cross-disciplinary, cross-institutional and cross-sectoral research in Environmental Conservation in Poland. Forum Sci. Oeconomia 2022, 2, 45–72. [Google Scholar]
- Baesens, B.; Bapna, R.; Marsden, J.R.; Vanthienen, J.; Zhao, J.L. Transformational Issues of Big Data and Analytics in Networked Business. MIS Q. 2016, 40, 807–818. [Google Scholar] [CrossRef]
- Chor, H.T. Chapter 1—A historical perspective on industrial production and outlook. In Digital Manufacturing; Elsevier: Amsterdam, The Netherlands, 2022; pp. 1–56. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Y.; Wang, W.L. How does digital transformation drive green total factor productivity? Evidence from Chinese listed enterprises. J. Clean. Prod. 2023, 406, 136954. [Google Scholar] [CrossRef]
- Ahmad, S. Green Human Resource Management: Policies and practices. Cogent Bus. Manag. 2015, 2, 1030817. [Google Scholar] [CrossRef]
- Renwick, D.W.S.; Redman, T.; Maguire, S. Green Human Resource Management: A Review and Research Agenda. Int. J. Manag. Rev. 2012, 15, 1–14. [Google Scholar] [CrossRef]
- Ren, S.; Tang, G.; Jackson, S.E. Green human resource management research in emergence: A review and future directions. Asia Pac. J. Manag. 2018, 35, 769–803. [Google Scholar] [CrossRef]
- Junaid, A.; Nabila, A.; Nicola, S.M. Green human resource management and environmental performance: The role of green innovation and environmental strategy in a developing country. Bus. Strategy Environ. 2022, 32, 1782–1798. [Google Scholar]
- Saumyaranjan, S.; Anil, K.; Arvind, U. How do green knowledge management and Green innovation performance impact corporate environmental performance? Understanding the role of green knowledge acquisition. Bus. Strategy Environ. 2023, 32, 551–569. [Google Scholar]
- Arfi, W.B.; Hikkerova, L.; Sahut, J.M. External knowledge sources, green innovation and performance. Technol. Forecast. Soc. Chang. 2018, 129, 210–220. [Google Scholar] [CrossRef]
- Zhang, W.Y.; Zhang, W.; Daim, T.U. The voluntary green behavior in Green innovation performance: The dual effects of green human resource management system and leader green traits. J. Bus. Res. 2023, 165, 114049. [Google Scholar] [CrossRef]
- Li, G.X.; Zhang, R.; Feng, S.; Wang, Y. Digital finance and sustainable development: Evidence from environmental inequality in China. Bus. Strategy Environ. 2022, 31, 3574–3594. [Google Scholar] [CrossRef]
- Peter, J.S.; Vivid, C.L. Information technology as a facilitator for enhancing dynamic capabilities through knowledge management. Inf. Manag. 2004, 41, 933–945. [Google Scholar]
- Magdalena, R.; Schöggl, J.P.; Baumgartner, R.J. Application of digital technologies for sustainable product management in a circular economy: A review. Bus. Strategy Environ. 2023, 32, 1159–1174. [Google Scholar]
- Feng, S.; Chong, Y.; Yu, H.; Ye, X.; Li, G. Digital financial development and ecological footprint: Evidence from green-biased technology innovation and environmental inclusion. J. Clean. Prod. 2022, 380, 135069. [Google Scholar] [CrossRef]
- Han, Y. The Effect of Network Embedding on Innovation Performance: Based on the Moderating Effect of Knowledge Distance. Front. Bus. Econ. Manag. 2022, 3, 64–68. [Google Scholar] [CrossRef]
- Liao, B.; Li, L. Urban green innovation efficiency and its influential factors: The Chinese evidence. Environ. Dev. Sustain. 2023, 25, 6551–6573. [Google Scholar] [CrossRef]
- Zhang, R.; Tai, H.; Cheng, K.T.; Cao, Z.; Dong, H.; Hou, J. Analysis on Evolution Characteristics and Dynamic Mechanism of Urban Green Innovation Network: A Case Study of Yangtze River Economic Belt. Sustainability 2022, 14, 297. [Google Scholar] [CrossRef]
- Rycroft, R.W. Does cooperation absorb complexity? Innovation networks and the speed and spread of complex technological innovation. Technol. Forecast. Soc. Chang. 2007, 74, 565–578. [Google Scholar] [CrossRef]
- Wang, C.; Chin, T.; Lin, J.H. Openness and firm innovation performance: The moderating effect of ambidextrous knowledge search strategy. J. Knowl. Manag. 2020, 24, 301–323. [Google Scholar] [CrossRef]
- Zhang, L.; Xiong, K.; Gao, X.; Yang, Y. Factors influencing innovation performance of China’s high-end manufacturing clusters: Dual-perspective from the digital economy and the innovation networks. Front. Psychol. 2022, 13, 1012228. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.; Yang, H.; Yin, S. Insight into the Balancing Effect of a Digital Green Innovation (DGI) Network to Improve the Performance of DGI for Industry 5.0: Roles of Digital Empowerment and Green Organization Flexibility. Systems 2022, 10, 97. [Google Scholar] [CrossRef]
- Meng, S.; Wang, P.; Yu, J. Going Abroad and Going Green: The Effects of Top Management Teams’ Overseas Experience on Green Innovation in the Digital Era. Int. J. Environ. Res. Public Health 2022, 19, 14705. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Lv, W. Research on the Impact of Green Innovation Network Embeddedness on Corporate Environmental Responsibility. Int. J. Environ. Res. Public Health 2023, 20, 3433. [Google Scholar] [CrossRef] [PubMed]
- Ge, C.; Lv, W.; Wang, J. The Impact of Digital Technology Innovation Network Embedding on Firms’ Innovation Performance: The Role of Knowledge Acquisition and Digital Transformation. Sustainability 2023, 15, 6938. [Google Scholar] [CrossRef]
- Phelps, C.C. A longitudinal study of the influence of alliance network structure and composition on firm exploratory innovation. Acad. Manag. J. 2010, 53, 890–913. [Google Scholar] [CrossRef]
- Guan, J.C.; Zuo, K.R.; Chen, K.H. Does country level R&D efficiency benefit from the collaboration network structure. Res. Policy 2016, 45, 770–784. [Google Scholar]
- Su, J.; Wei, Y.; Wang, S.; Liu, Q. The impact of digital transformation on the total factor productivity of heavily polluting enterprises. Sci. Rep. 2023, 13, 6386. [Google Scholar] [CrossRef]
- Liang, J.; Yu, N.; Zhang, L.; Zhao, L. Study on the impact of multi-partner R&D partnership on innovation performance—The moderating role of geographical area. Sci. Technol. Manag. Res. 2022, 42, 65–72. [Google Scholar]
- Song, W.; Yu, H.; Xu, H. Effects of green human resource management and managerial environmental concern on green innovation. Eur. J. Innov. Manag. 2021, 24, 951–967. [Google Scholar] [CrossRef]
- Li, G.; Wang, X.; Su, S.; Su, Y. How green technological innovation ability influences enterprise competitiveness. Technol. Soc. 2019, 59, 101136. [Google Scholar] [CrossRef]
- Liu, X.L.; Ji, X.H.; Yang, B.X. Research on the construction and application of urban innovation ecosystem evaluation system—An analysis based on the pilot city of ‘Total Innovation Reform’. Sci. Technol. Manag. 2022, 43, 63–84. [Google Scholar]
- Tseng, M.L.; Tran, T.P.T.; Ha, H.M.; Bui, T.-D.; Lim, M.K. Sustainable industrial and operation engineering trends and challenges Toward Industry 4.0: A data driven analysis. J. Ind. Prod. Eng. 2021, 38, 581–598. [Google Scholar] [CrossRef]
- Yin, S.; Yu, Y. An adoption-implementation framework of digital green knowledge to improve the performance of digital green innovation practices for industry 5.0. J. Clean. Prod. 2022, 363, 132608. [Google Scholar] [CrossRef]
- Gupta, N.; Prusty, B.R.; Alrumayh, O.; Almutairi, A.; Alharbi, T. The Role of Transactive Energy in the Future Energy Industry: A Critical Review. Energies 2022, 15, 8047. [Google Scholar] [CrossRef]
- Yin, S.; Zhang, N.; Ullah, K.; Gao, S. Enhancing Digital Innovation for the Sustainable Transformation of Manufacturing Industry: A Pressure-State-Response System Framework to Perceptions of Digital Green Innovation and Its Performance for Green and Intelligent Manufacturing. Systems 2022, 10, 72. [Google Scholar] [CrossRef]
- Lyu, W.; Liu, J. Artificial Intelligence and emerging digital technologies in the energy sector. Appl. Energy 2021, 303, 117615. [Google Scholar] [CrossRef]
- Shahzad, M.; Qu, Y.; Zafar, A.U.; Appolloni, A. Does the interaction between the knowledge management process and sustainable development practices boost corporate green innovation? Bus. Strategy Environ. 2021, 30, 4206–4222. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).