
AI-Driven Privacy in Elderly Care: Developing a Comprehensive Solution for Camera-Based Monitoring of Older Adults

Abstract
Featured Application
Abstract
1. Introduction
2. Related Works
2.1. Camera Surveillance Systems
2.2. Artificial Intelligence in Elderly Care
2.3. Subject Anonymization
3. Materials and Methods
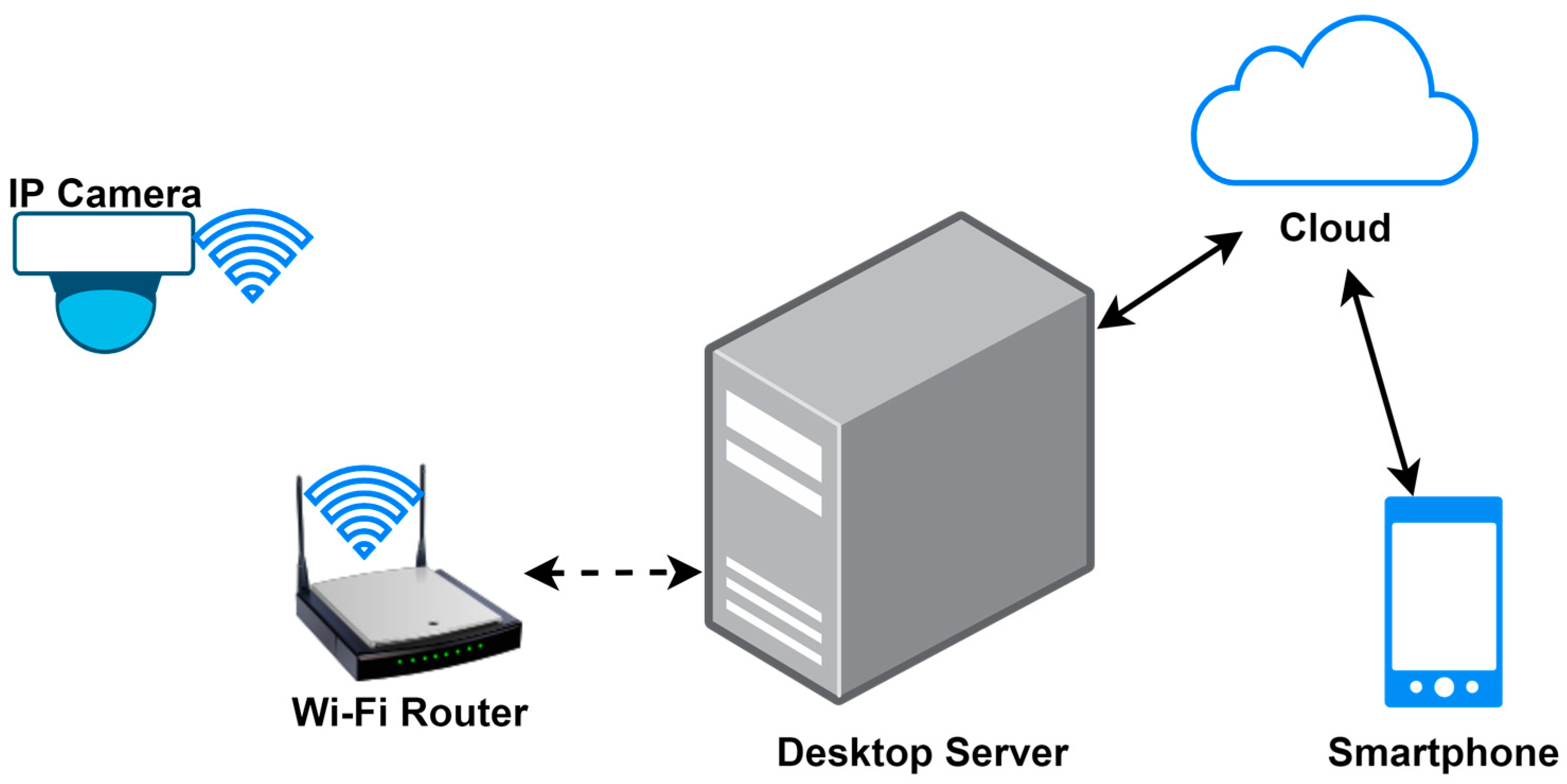
3.1. System Design
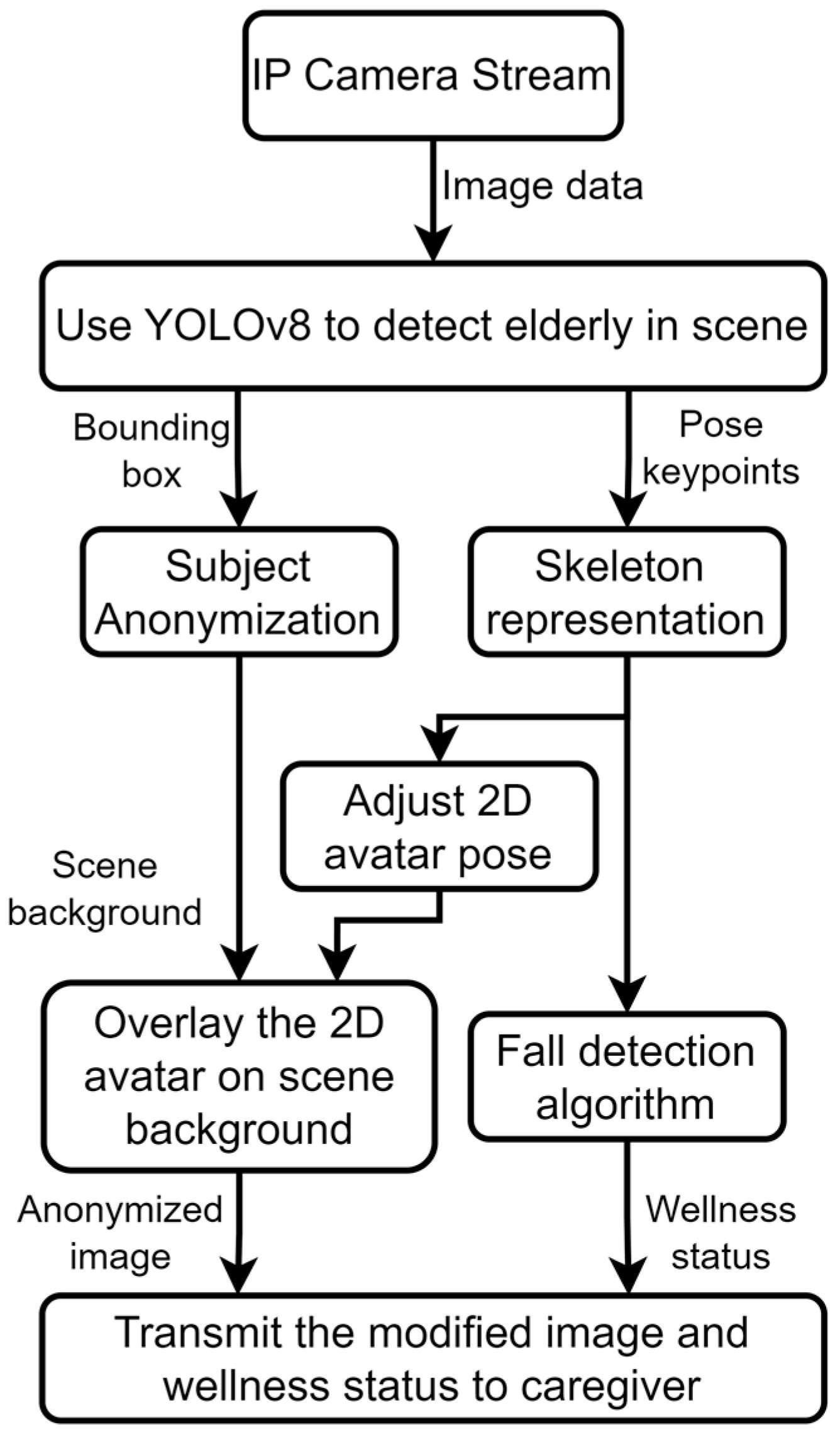
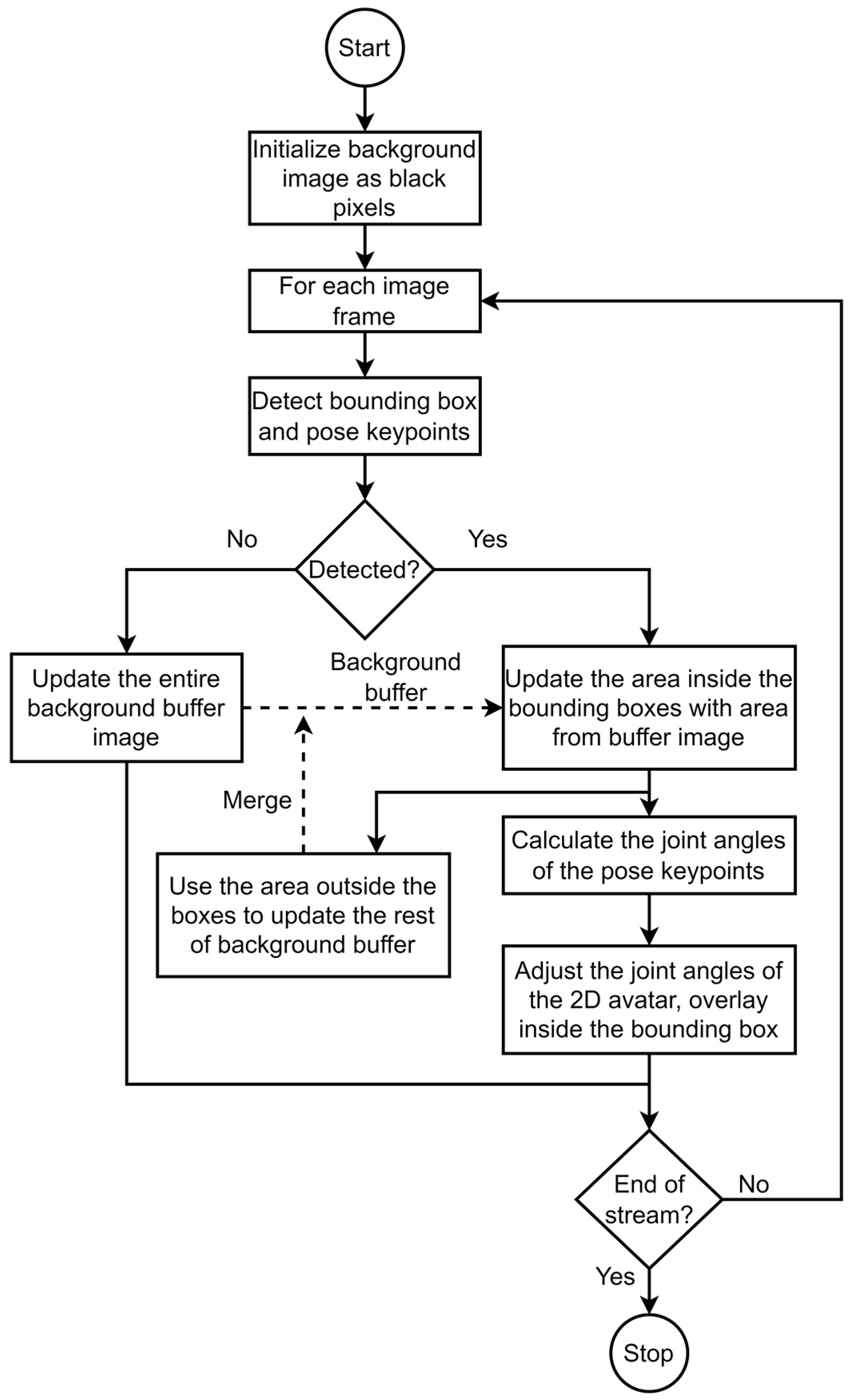
3.2. Person Detection and Subject Anonymization
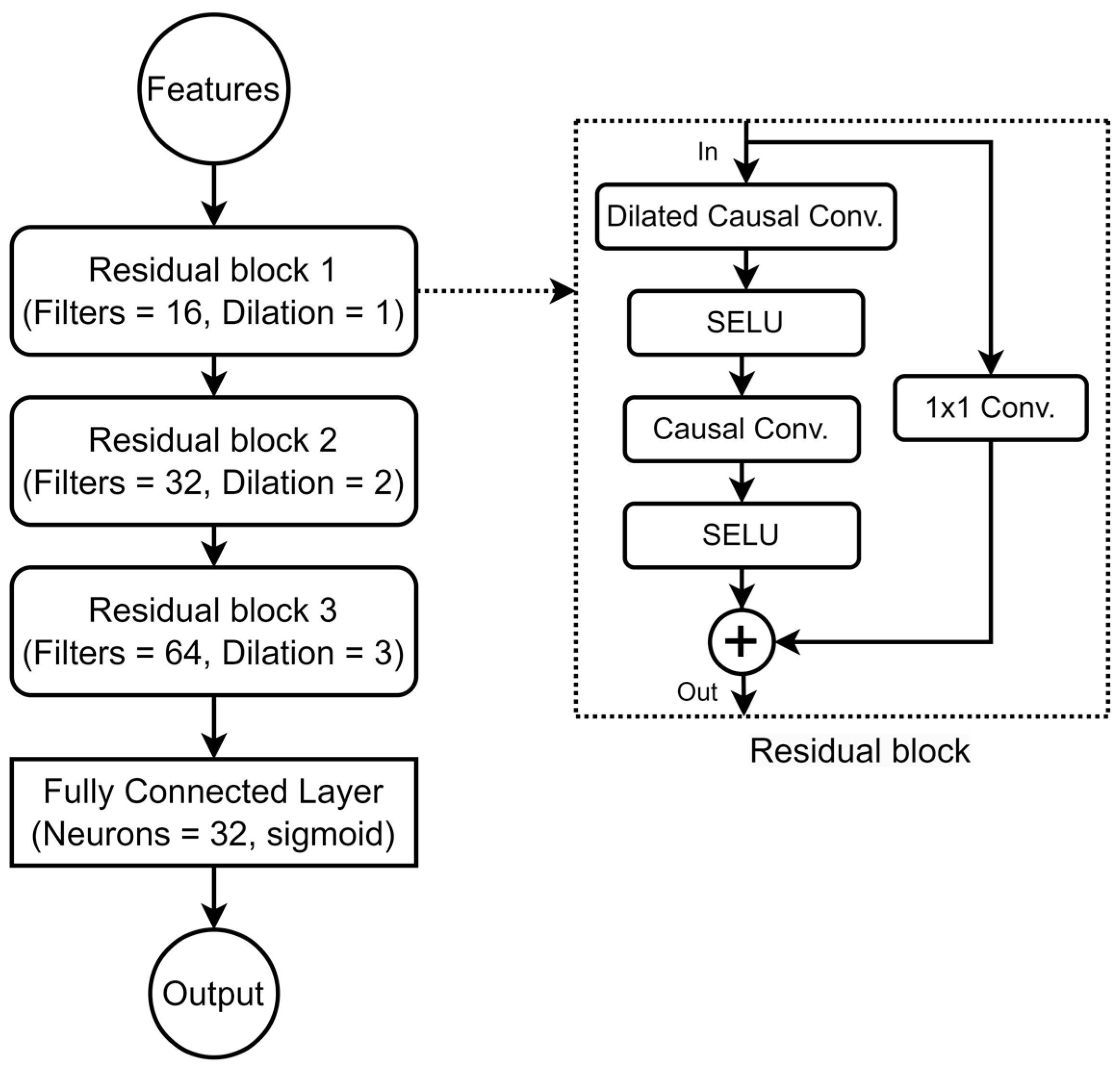
3.3. Fall Detection Method
4. Results
4.1. Dataset
4.2. Subject Anonymization
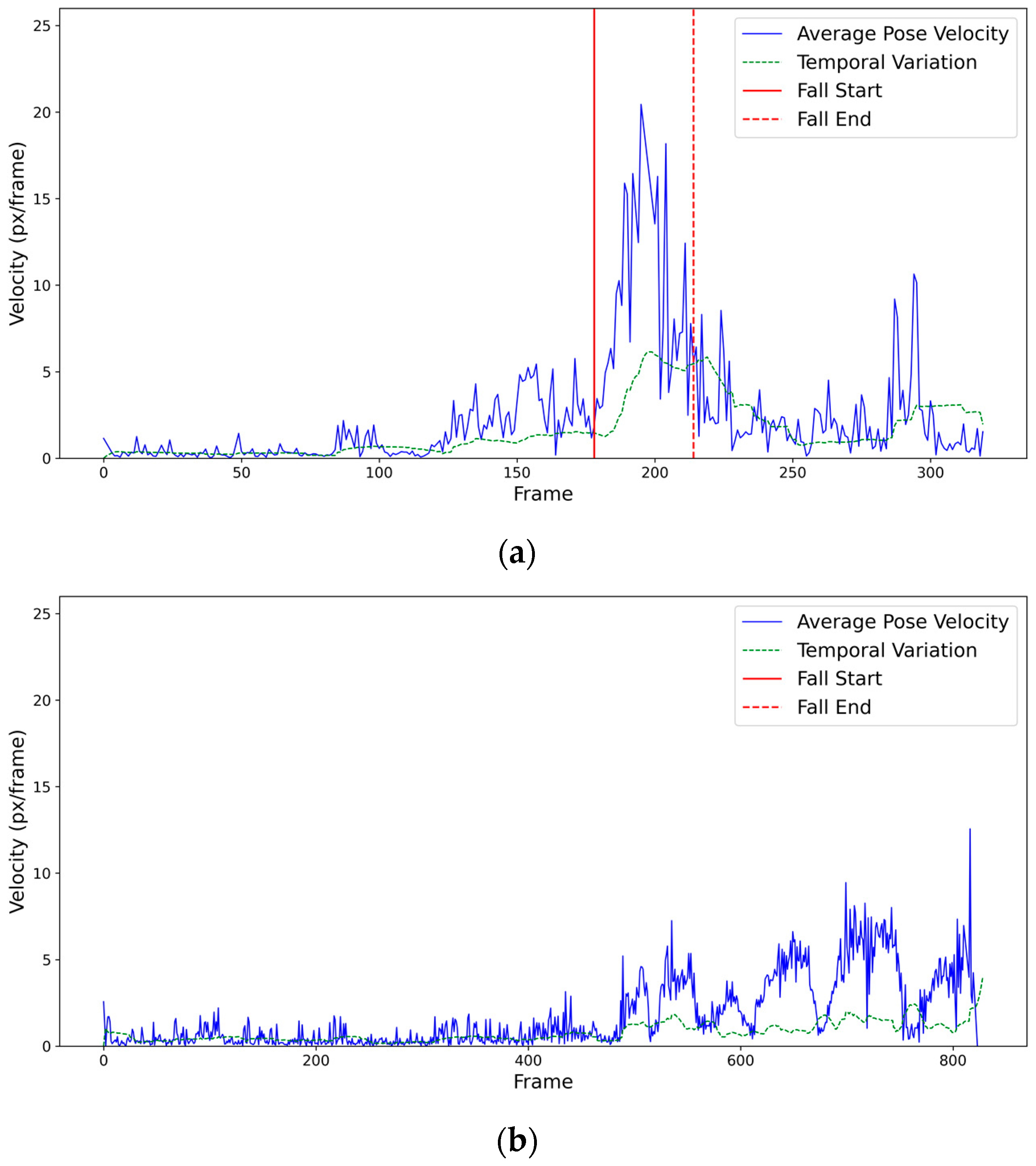
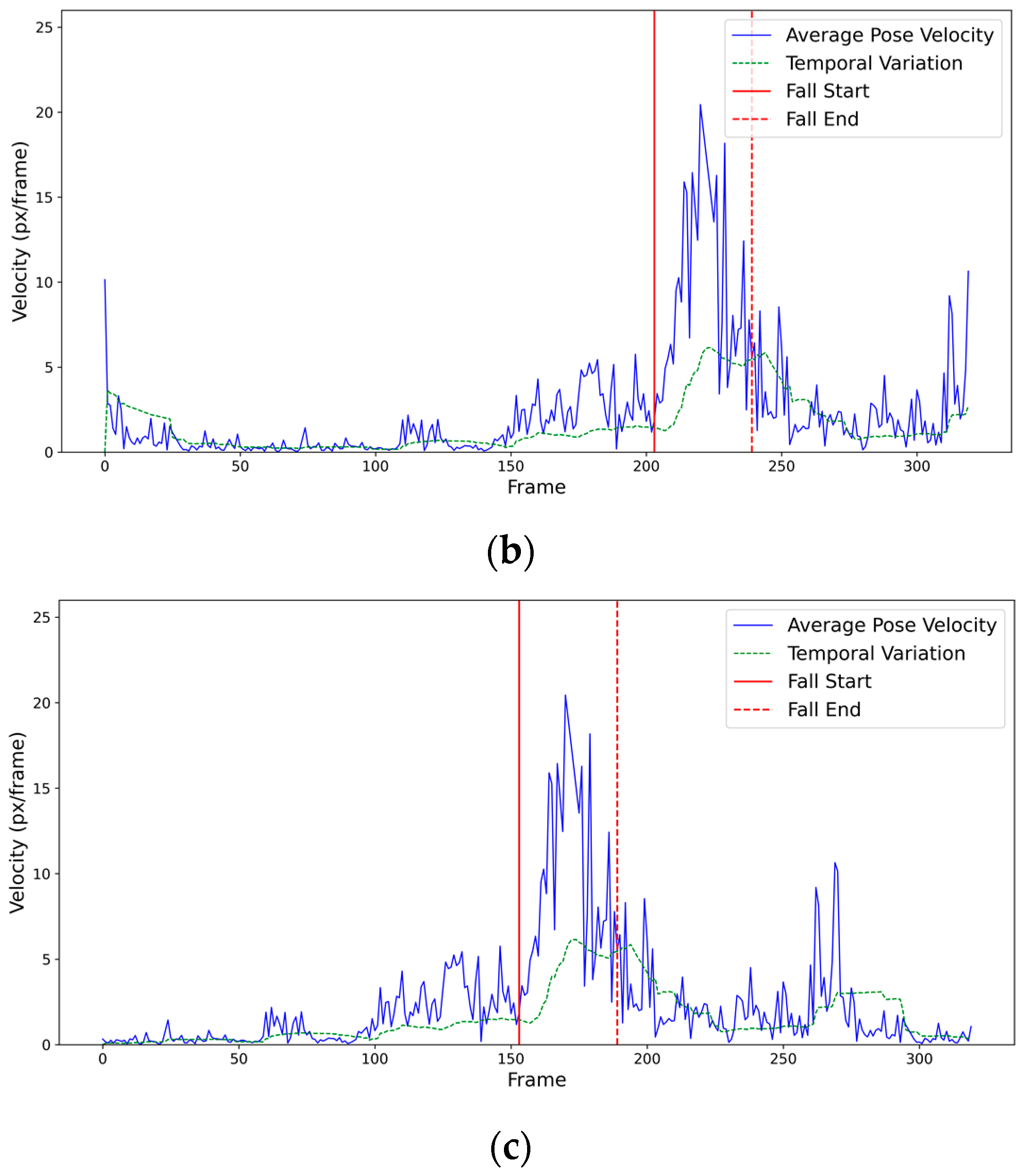
4.3. Fall Detection
- Accuracy: The percentage of items correctly classified, calculated as (TP + TN)/(TP + TN + FP + FN).
- Precision: The proportion of true-positive identifications among all positive predictions, calculated as TP/(TP + FP).
- Recall/sensitivity: The true-positive rate or the model’s ability to identify positive instances accurately, calculated as TP/(TP + FN).
- Specificity: Often used together with recall, specificity measures the true-negative rate or the model’s ability to correctly identify negative instances, calculated as TN/(TN + FP).
- F1-Score: This denotes the harmonic mean between precision and recall, calculated as 2 × (Precision × Recall)/(Precision + Recall)
4.4. System Latency
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Population Division of the Department of Economic and Social Affairs. World Population Prospects 2022; United Nations: New York, NY, USA, 2022; ISBN 978-92-1-148373-4. [Google Scholar]
- World Health Organization. WHO Global Report on Falls Prevention in Older Age; World Health Organization: Geneva, Switzerland, 2007. [Google Scholar]
- Osborne, T.F.; Veigulis, Z.P.; Arreola, D.M.; Vrublevskiy, I.; Suarez, P.; Curtin, C.; Schalch, E.; Cabot, R.C.; Gant-Curtis, A. Assessment of a Wearable Fall Prevention System at a Veterans Health Administration Hospital. Digit. Health 2023, 9, 20552076231187727. [Google Scholar] [CrossRef] [PubMed]
- Ren, L.; Peng, Y. Research of Fall Detection and Fall Prevention Technologies: A Systematic Review. IEEE Access 2019, 7, 77702–77722. [Google Scholar] [CrossRef]
- Hamm, J.; Money, A.G.; Atwal, A.; Paraskevopoulos, I. Fall Prevention Intervention Technologies: A Conceptual Framework and Survey of the State of the Art. J. Biomed. Inform. 2016, 59, 319–345. [Google Scholar] [CrossRef] [PubMed]
- Rastogi, S.; Singh, J. Human Fall Detection and Activity Monitoring: A Comparative Analysis of Vision-Based Methods for Classification and Detection Techniques. Soft Comput. 2022, 26, 3679–3701. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Lin, F.-S. Exploring Older Adults’ Willingness to Install Home Surveil-Lance Systems in Taiwan: Factors and Privacy Concerns. Healthcare 2023, 11, 1616. [Google Scholar] [CrossRef] [PubMed]
- Buzzelli, M.; Albé, A.; Ciocca, G. A Vision-Based System for Monitoring Elderly People at Home. Appl. Sci. 2020, 10, 374. [Google Scholar] [CrossRef]
- Jansen, B.; Deklerck, R. Home Monitoring of Elderly People with 3D Camera Technology. In Proceedings of the First BENELUX Biomedical Engineering Symposium, Brussels, Belgium, 7–8 December 2006. [Google Scholar]
- Feng, W.; Liu, R.; Zhu, M. Fall Detection for Elderly Person Care in a Vision-Based Home Surveillance Environment Using a Monocular Camera. Signal Image Video Process. 2014, 8, 1129–1138. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, H.; Liu, Z.; Yuan, Y.; Guan, X. Fall Detection System Based on Infrared Array Sensor and Multi-Dimensional Feature Fusion. Meas. J. Int. Meas. Confed. 2022, 192, 110870. [Google Scholar] [CrossRef]
- Ramanujam, E.; Padmavathi, S. Real Time Fall Detection Using Infrared Cameras and Reflective Tapes under Day/Night Luminance. J. Ambient Intell. Smart Environ. 2021, 13, 285–300. [Google Scholar] [CrossRef]
- Park, J.; Chen, J.; Cho, Y.K.; Kang, D.Y.; Son, B.J. CNN-Based Person Detection Using Infrared Images for Night-Time Intrusion Warning Systems. Sensors 2020, 20, 34. [Google Scholar] [CrossRef]
- Cosar, S.; Yan, Z.; Zhao, F.; Lambrou, T.; Yue, S.; Bellotto, N. Thermal Camera Based Physiological Monitoring with an Assistive Robot. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 5010–5013. [Google Scholar] [CrossRef]
- Riquelme, F.; Espinoza, C.; Rodenas, T.; Minonzio, J.-G.; Taramasco, C. eHomeSeniors Dataset: An Infrared Thermal Sensor Dataset for Automatic Fall Detection Research. Sensors 2019, 19, 4565. [Google Scholar] [CrossRef] [PubMed]
- Fernando, Y.P.N.; Gunasekara, K.D.B.; Sirikumara, K.P.; Galappaththi, U.E.; Thilakarathna, T.; Kasthurirathna, D. Computer Vision Based Privacy Protected Fall Detection and Behavior Monitoring System for the Care of the Elderly. In Proceedings of the 2021 26th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vasteras, Sweden, 7–10 September 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Nini, B.; Sabokrou, M.; Hadid, A. Vision-Based Human Activity Recognition: A Survey. Multimed. Tools Appl. 2020, 79, 30509–30555. [Google Scholar] [CrossRef]
- Nikouei, S.Y.; Chen, Y.; Song, S.; Xu, R.; Choi, B.Y.; Faughnan, T.R. Real-Time Human Detection as an Edge Service Enabled by a Lightweight CNN. In Proceedings of the 2018 IEEE International Conference on Edge Computing (EDGE), San Francisco, CA, USA, 2–7 July 2018; pp. 125–129. [Google Scholar] [CrossRef]
- Chen, Y.; Kong, X.; Meng, L.; Tomiyama, H. An Edge Computing Based Fall Detection System for Elderly Persons. Procedia Comput. Sci. 2020, 174, 9–14. [Google Scholar] [CrossRef]
- Kim, S.; Park, J.; Jeong, Y.; Lee, S.E. Intelligent Monitoring System with Privacy Preservation Based on Edge AI. Micromachines 2023, 14, 1749. [Google Scholar] [CrossRef] [PubMed]
- Williams, A.; Xie, D.; Ou, S.; Grupen, R.; Hanson, A.; Riseman, E. Distributed Smart Cameras for Aging in Place. In Proceedings of the ACM SenSys Workshop on Distributed Smart Cameras, Boulder, CO, USA, 31 October 2006. [Google Scholar]
- Samkari, E.; Arif, M.; Alghamdi, M.; AlGhamdi, M.A. Human Pose Estimation Using Deep Learning: A Systematic Literature Review. Mach. Learn. Knowl. Extr. 2023, 5, 1612–1659. [Google Scholar] [CrossRef]
- BenGamra, M.; Akhloufi, M.A. A Review of Deep Learning Techniques for 2D and 3D Human Pose Estimation. Image Vis. Comput. 2021, 114, 104282. [Google Scholar] [CrossRef]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 2938–2946. [Google Scholar]
- Bazarevsky, V.; Grishchenko, I.; Raveendran, K.; Zhu, T.; Zhang, F.; Grundmann, M. BlazePose: On-Device Real-Time Body Pose Tracking. arXiv 2020, arXiv:2006.10204. [Google Scholar]
- Li, S.; Man, C.; Shen, A.; Guan, Z.; Mao, W.; Luo, S.; Zhang, R.; Yu, H. A Fall Detection Network by 2D/3D Spatio-Temporal Joint Models with Tensor Compression on Edge. ACM Trans. Embed. Comput. Syst. 2022, 21, 1–19. [Google Scholar] [CrossRef]
- Egawa, R.; Miah, A.S.M.; Hirooka, K.; Tomioka, Y.; Shin, J. Dynamic Fall Detection Using Graph-Based Spatial Temporal Convolution and Attention Network. Electronics 2023, 12, 3234. [Google Scholar] [CrossRef]
- Noor, N.; Park, I.K. A Lightweight Skeleton-Based 3D-CNN for Real-Time Fall Detection and Action Recognition. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Paris, France, 2–6 October 2023; pp. 2171–2180. [Google Scholar] [CrossRef]
- Min, W.; Yao, L.; Lin, Z.; Liu, L. Support Vector Machine Approach to Fall Recognition Based on Simplified Expression of Human Skeleton Action and Fast Detection of Start Key Frame Using Torso Angle. IET Comput. Vis. 2018, 12, 1133–1140. [Google Scholar] [CrossRef]
- Kong, X.; Kumaki, T.; Meng, L.; Tomiyama, H. A Skeleton Analysis Based Fall Detection Method Using ToF Camera. Procedia Comput. Sci. 2021, 187, 252–257. [Google Scholar] [CrossRef]
- De Miguel, K.; Brunete, A.; Hernando, M.; Gambao, E. Home Camera-Based Fall Detection System for the Elderly. Sensors 2017, 17, 2864. [Google Scholar] [CrossRef] [PubMed]
- Lafuente-Arroyo, S.; Martín-Martín, P.; Iglesias-Iglesias, C.; Maldonado-Bascón, S.; Acevedo-Rodríguez, F.J. RGB Camera-Based Fallen Person Detection System Embedded on a Mobile Platform. Expert Syst. Appl. 2022, 197, 116715. [Google Scholar] [CrossRef]
- Alam, E.; Sufian, A.; Dutta, P.; Leo, M. Vision-Based Human Fall Detection Systems Using Deep Learning: A Review. Comput. Biol. Med. 2022, 146, 105626. [Google Scholar] [CrossRef] [PubMed]
- Gutiérrez, J.; Rodríguez, V.; Martin, S. Comprehensive Review of Vision-Based Fall Detection Systems. Sensors 2021, 21, 947. [Google Scholar] [CrossRef] [PubMed]
- Hbali, Y.; Hbali, S.; Ballihi, L.; Sadgal, M. Skeleton-Based Human Activity Recognition for Elderly Monitoring Systems. IET Comput. Vis. 2018, 12, 16–26. [Google Scholar] [CrossRef]
- Nguyen, H.-C.; Nguyen, T.-H.; Scherer, R.; Le, V.-H. Deep Learning for Human Activity Recognition on 3D Human Skeleton: Survey and Comparative Study. Sensors 2023, 23, 5121. [Google Scholar] [CrossRef] [PubMed]
- Alaoui, A.Y.; ElFkihi, S.; Thami, R.O.H. Fall Detection for Elderly People Using the Variation of Key Points of Human Skeleton. IEEE Access 2019, 7, 154786–154795. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, T. Enhancing Elderly Care: Efficient and Reliable Real-Time Fall Detection Algorithm. Digit. Health 2024, 10, 20552076241233690. [Google Scholar] [CrossRef]
- Hoang, V.H.; Lee, J.W.; Piran, M.J.; Park, C.S. Advances in Skeleton-Based Fall Detection in RGB Videos: From Handcrafted to Deep Learning Approaches. IEEE Access 2023, 11, 92322–92352. [Google Scholar] [CrossRef]
- Xiao, H.; Peng, K.; Huang, X.; Roitberg, A.; Li, H.; Wang, Z.; Stiefelhagen, R. Toward Privacy-Supporting Fall Detection via Deep Unsupervised RGB2Depth Adaptation. IEEE Sens. J. 2023, 23, 29143–29155. [Google Scholar] [CrossRef]
- Cao, Y.; Erdt, M.; Robert, C.; Naharudin, N.B.; Lee, S.Q.; Theng, Y.L. Decision-Making Factors Toward the Adoption of Smart Home Sensors by Older Adults in Singapore: Mixed Methods Study. JMIR Aging 2022, 5, e34239. [Google Scholar] [CrossRef] [PubMed]
- Gochoo, M.; Alnajjar, F.; Tan, T.-H.; Khalid, S. Towards Privacy-Preserved Aging in Place: A Systematic Review. Sensors 2021, 21, 3082. [Google Scholar] [CrossRef]
- Demiris, G.; Hensel, B.K.; Skubic, M.; Rantz, M. Senior Residents’ Perceived Need of and Preferences for “Smart Home” Sensor Technologies. Int. J. Technol. Assess. Health Care 2008, 24, 120–124. [Google Scholar] [CrossRef]
- Pirzada, P.; Wilde, A.; Doherty, G.H.; Harris-Birtill, D. Ethics and Acceptance of Smart Homes for Older Adults. Informatics Health Soc. Care 2022, 47, 10–37. [Google Scholar] [CrossRef]
- Gochoo, M.; Tan, T.H.; Velusamy, V.; Liu, S.H.; Bayanduuren, D.; Huang, S.C. Device-Free Non-Privacy Invasive Classification of Elderly Travel Patterns in a Smart House Using PIR Sensors and DCNN. IEEE Sens. J. 2018, 18, 390–400. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Khaksar, W.; Torresen, J. Ambient Sensors for Elderly Care and Independent Living: A Survey. Sensors 2018, 18, 2027. [Google Scholar] [CrossRef]
- Camp, N.; Lewis, M.; Hunter, K.; Johnston, J.; Zecca, M.; Di Nuovo, A.; Magistro, D. Technology Used to Recognize Activities of Daily Living in Community-Dwelling Older Adults. Int. J. Environ. Res. Public Health 2021, 18, 163. [Google Scholar] [CrossRef] [PubMed]
- Pham, S.; Yeap, D.; Escalera, G.; Basu, R.; Wu, X.; Kenyon, N.J.; Hertz-Picciotto, I.; Ko, M.J.; Davis, C.E. Wearable Sensor System to Monitor Physical Activity and the Physiological Effects of Heat Exposure. Sensors 2020, 20, 855. [Google Scholar] [CrossRef]
- Randazzo, V.; Ferretti, J.; Pasero, E. A Wearable Smart Device to Monitor Multiple Vital Parameters—VITAL ECG. Electronics 2020, 9, 300. [Google Scholar] [CrossRef]
- Shu, F.; Shu, J. An Eight-Camera Fall Detection System Using Human Fall Pattern Recognition via Machine Learning by a Low-Cost Android Box. Sci. Rep. 2021, 11, 2471. [Google Scholar] [CrossRef]
- Gaikwad, S.; Bhatlawande, S.; Shilaskar, S.; Solanke, A. A Computer Vision-Approach for Activity Recognition and Residential Monitoring of Elderly People. Med. Nov. Technol. Devices 2023, 20, 100272. [Google Scholar] [CrossRef]
- Korshunov, P.; Ebrahimi, T. Using Warping for Privacy Protection in Video Surveillance. In Proceedings of the 2013 18th International Conference on Digital Signal Processing (DSP), Fira, Greece, 1–3 July 2013; pp. 1–6. [Google Scholar]
- Winkler, T.; Rinner, B. Security and Privacy Protection in Visual Sensor Networks: A Survey. ACM Comput. Surv. 2014, 47, 1–42. [Google Scholar] [CrossRef]
- Padilla-López, J.R.; Chaaraoui, A.A.; Flórez-Revuelta, F. Visual Privacy Protection Methods: A Survey. Expert Syst. Appl. 2015, 42, 4177–4195. [Google Scholar] [CrossRef]
- Rakhmawati, L.; Wirawan; Suwadi. Image Privacy Protection Techniques: A Survey. In Proceedings of the TENCON 2018—2018 IEEE Region 10 Conference, Jeju, Republic of Korea, 28–31 October 2018; pp. 76–80. [Google Scholar] [CrossRef]
- Fan, L. Image Pixelization with Differential Privacy. In Data and Applications Security and Privacy XXXII. DBSec 2018. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 10980, pp. 148–162. [Google Scholar] [CrossRef]
- Zin, T.T.; Htet, Y.; Akagi, Y.; Tamura, H.; Kondo, K.; Araki, S.; Chosa, E. Real-Time Action Recognition System for Elderly People Using Stereo Depth Camera. Sensors 2021, 21, 5895. [Google Scholar] [CrossRef]
- Tateno, S.; Meng, F.; Qian, R.; Hachiya, Y. Privacy-Preserved Fall Detection Method with Three-Dimensional Convolutional Neural Network Using Low-Resolution Infrared Array Sensor. Sensors 2020, 20, 5957. [Google Scholar] [CrossRef]
- Rafferty, J.; Synnott, J.; Nugent, C.; Morrison, G.; Tamburini, E. Fall Detection Through Thermal Vision Sensing. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016; Volume 10070, pp. 84–90. ISBN 9783319487984. [Google Scholar]
- Terven, J. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Xiao, X.; Feng, X. Multi-Object Pedestrian Tracking Using Improved YOLOv8 and OC-SORT. Sensors 2023, 23, 8439. [Google Scholar] [CrossRef]
- Chen, H.; Zhou, G.; Jiang, H. Student Behavior Detection in the Classroom Based on Improved YOLOv8. Sensors 2023, 23, 8385. [Google Scholar] [CrossRef]
- Wang, X.; Gao, H.; Jia, Z.; Li, Z. BL-YOLOv8: An Improved Road Defect Detection Model Based on YOLOv8. Sensors 2023, 23, 8361. [Google Scholar] [CrossRef]
- Bao, J.; Li, S.; Wang, G.; Xiong, J.; Li, S. Improved YOLOV8 Network and Application in Safety Helmet Detection. J. Phys. Conf. Ser. 2023, 2632, 012012. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Ma, F.; Li, J.; Huang, Y. Single-Stage Pose Estimation and Joint Angle Extraction Method for Moving Human Body. Electronics 2023, 12, 4644. [Google Scholar] [CrossRef]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Shen, Z.; Zhang, Y.; Lu, J.; Xu, J.; Xiao, G. SeriesNet:A Generative Time Series Forecasting Model. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, J.H.; Lin, G.F.; Chang, M.J.; Huang, I.H.; Chen, Y.R. Real-Time Water-Level Forecasting Using Dilated Causal Convolutional Neural Networks. Water Resour. Manag. 2019, 33, 3759–3780. [Google Scholar] [CrossRef]
- Chuya-Sumba, J.; Alonso-Valerdi, L.M.; Ibarra-Zarate, D.I. Deep-Learning Method Based on 1D Convolutional Neural Network for Intelligent Fault Diagnosis of Rotating Machines. Appl. Sci. 2022, 12, 2158. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D Convolutional Neural Networks and Applications: A Survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Cheng, C.; Zhang, C.; Wei, Y.; Jiang, Y.G. Sparse Temporal Causal Convolution for Efficient Action Modeling. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 592–600. [Google Scholar] [CrossRef]
- Hamad, R.A.; Kimura, M.; Yang, L.; Woo, W.L.; Wei, B. Dilated Causal Convolution with Multi-Head Self Attention for Sensor Human Activity Recognition. Neural Comput. Appl. 2021, 33, 13705–13722. [Google Scholar] [CrossRef]
- Hou, S.; Wang, C.; Zhuang, W.; Chen, Y.; Wang, Y.; Bao, H.; Chai, J.; Xu, W. A Causal Convolutional Neural Network for Multi-Subject Motion Modeling and Generation. Comput. Vis. Media 2023, 10, 45–59. [Google Scholar] [CrossRef]
- Jain, P.K.; Choudhary, R.R.; Singh, M.R. A Lightweight 1-D Convolution Neural Network Model for Multi-Class Classification of Heart Sounds. In Proceedings of the 2022 International Conference on Emerging Techniques in Computational Intelligence (ICETCI), Hyderabad, India, 25–27 August 2022; pp. 40–44. [Google Scholar] [CrossRef]
- Li, F.; Liu, M.; Zhao, Y.; Kong, L.; Dong, L.; Liu, X.; Hui, M. Feature Extraction and Classification of Heart Sound Using 1D Convolutional Neural Networks. EURASIP J. Adv. Signal Process. 2019, 2019, 59. [Google Scholar] [CrossRef]
- Jiang, Z.; Lai, Y.; Zhang, J.; Zhao, H.; Mao, Z. Multi-Factor Operating Condition Recognition Using 1D Convolutional Long Short-Term Network. Sensors 2019, 19, 5488. [Google Scholar] [CrossRef]
- Chen, C.-C.; Liu, Z.; Yang, G.; Wu, C.-C.; Ye, Q. An Improved Fault Diagnosis Using 1D-Convolutional Neural Network Model. Electronics 2021, 10, 59. [Google Scholar] [CrossRef]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. Adv. Neural Inf. Process. Syst. 2017, 2017, 972–981. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Kwolek, B.; Kepski, M. Human Fall Detection on Embedded Platform Using Depth Maps and Wireless Accelerometer. Comput. Methods Programs Biomed. 2014, 117, 489–501. [Google Scholar] [CrossRef]
- Charfi, I.; Miteran, J.; Dubois, J.; Atri, M.; Tourki, R. Optimized Spatio-Temporal Descriptors for Real-Time Fall Detection: Comparison of Support Vector Machine and Adaboost-Based Classification. J. Electron. Imaging 2013, 22, 041106. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Accuracy [%] | Precision [%] | Sensitivity [%] | Specificity [%] | F1-Score |
|---|---|---|---|---|---|
| LE2I | 98.86 | 90.02 | 91.11 | 99.35 | 0.905 |
| URFD | 96.23 | 97.18 | 92.56 | 98.40 | 0.948 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.-Y.; Lin, F.-S. AI-Driven Privacy in Elderly Care: Developing a Comprehensive Solution for Camera-Based Monitoring of Older Adults. Appl. Sci. 2024, 14, 4150. https://doi.org/10.3390/app14104150
Wang C-Y, Lin F-S. AI-Driven Privacy in Elderly Care: Developing a Comprehensive Solution for Camera-Based Monitoring of Older Adults. Applied Sciences. 2024; 14(10):4150. https://doi.org/10.3390/app14104150
Chicago/Turabian StyleWang, Chang-Yueh, and Fang-Suey Lin. 2024. "AI-Driven Privacy in Elderly Care: Developing a Comprehensive Solution for Camera-Based Monitoring of Older Adults" Applied Sciences 14, no. 10: 4150. https://doi.org/10.3390/app14104150
APA StyleWang, C.-Y., & Lin, F.-S. (2024). AI-Driven Privacy in Elderly Care: Developing a Comprehensive Solution for Camera-Based Monitoring of Older Adults. Applied Sciences, 14(10), 4150. https://doi.org/10.3390/app14104150