
Improved YOLOv8 and SAHI Model for the Collaborative Detection of Small Targets at the Micro Scale: A Case Study of Pest Detection in Tea


Abstract
1. Introduction
- The visual features of small targets may be unclear due to less important feature information and low image resolution;
- In object detection tasks, extracting effective features is crucial. The quality of feature extraction directly affects the accuracy of detection results. Compared with large-scale targets, the features of small targets are more difficult to extract, which brings certain difficulties to the detection task. In the detection model, after the pooling operation, some important features of small targets may be lost, thus increasing the challenge of detection;
- In complex environments, small-target detection is hindered by factors like illumination, occlusion, and aggregation, which make it challenging to differentiate the target from the background or similar targets. Consequently, addressing complex background interference is a crucial challenge in small-target detection.
2. Materials and Methods
2.1. Introduction to YOLOv8
2.2. Improving YOLOv8 Network Structure
- In order to solve the problem of detecting small targets in high-resolution images while maintaining a high level of memory utilization, slicing-aided fine-tuning and slicing-aided hyper inference (SAHI) are introduced to slice the input network image, resulting in larger pixel regions for small-target objects, improving the effectiveness of network inference and fine-tuning, and providing more detailed features for subsequent models;
- A new lightweight network architecture based on gradient path planning, Generalized Efficient Layer Aggregation Network (GELAN), has been designed to replace the C2f module in the backbone network, simplify the backbone network structure, enhance its feature extraction capabilities, and achieve model lightweighting;
- Secondly, in the neck network of YOLOv8, the MS structure is used for feature fusion. In the first stage of the encoder, the smallest kernel convolution is used, while the largest kernel convolution is used in the final stage, which is consistent with the increment of feature resolution. This improves the extraction of fine-grained and coarse-grained semantic information, enhances the multi-scale feature representation ability of the encoder, and further improves the performance of the model in identifying different scales, complex backgrounds, and small targets;
- On the basis of these improvements, an inner-MPDIoU is used as the loss function for the model bounding box regression to further enhance its learning ability for small-target samples.
2.3. Slicing-Aided Module
2.3.1. Slicing-Aided Fine-Tuning
2.3.2. Slicing-Aided Hyper Inference
2.4. Generalized ELAN
2.5. Transformer
2.6. Neck Improvement
2.7. Inner-MPDIOU
3. Results and Discussion
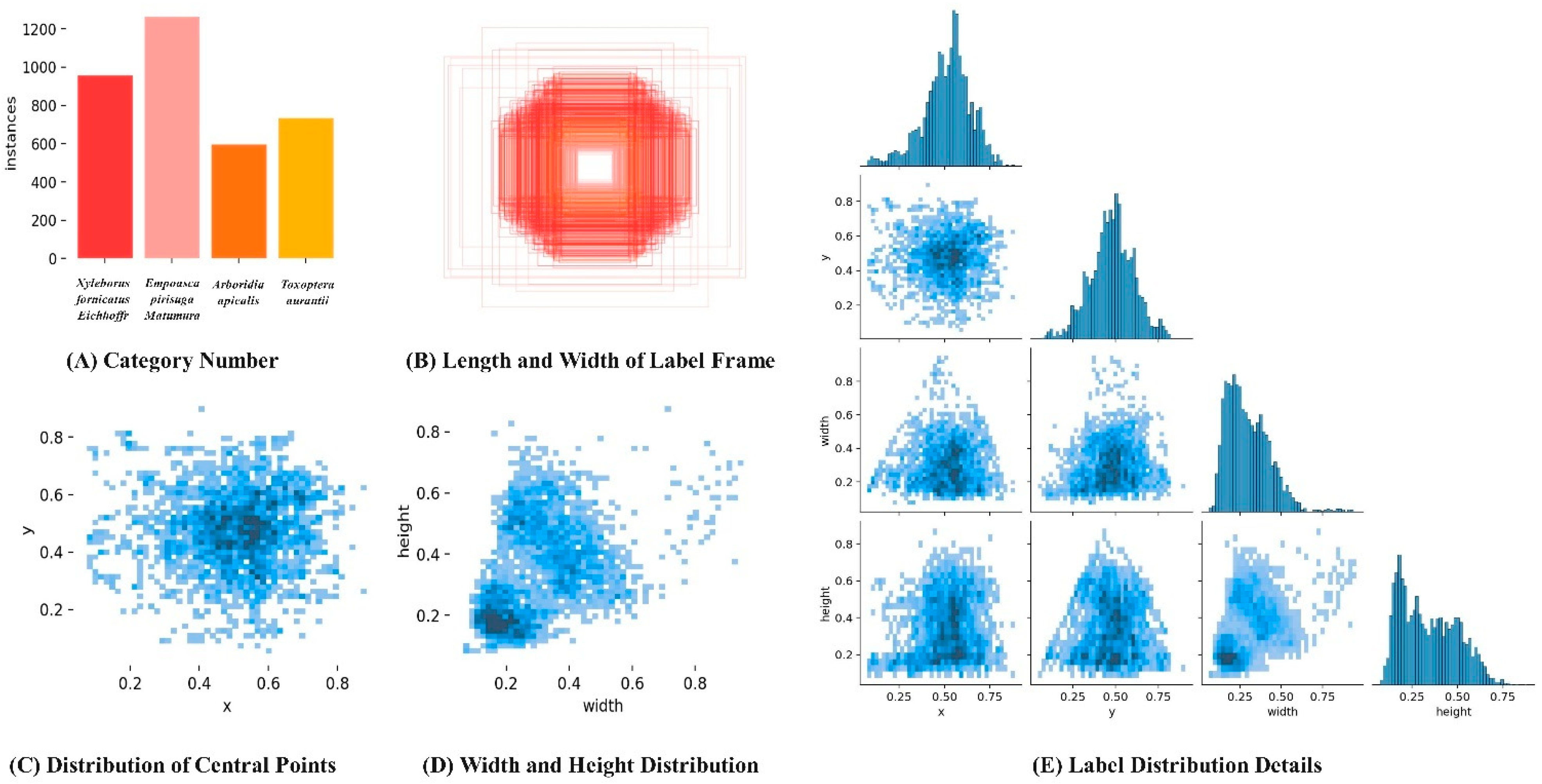
3.1. Dataset and Experimental Environment
3.2. Evaluation Indicators
3.3. Performance Analysis of Tea Pest Detection Model Based on Improved YOLOv8
3.4. Comparative Experiments on Detection of Different Models
3.5. Ablation Experiment
4. Conclusions
- In response to the problem of a large proportion of background information in images, the SAHI-assisted inference algorithm is applied to the detection network, which increases the detection effect of small targets in local areas through slicing. This provides a novel method for small-target image analysis and meets the demand for high-resolution images under normal shooting.
- The methods for improving the model’s small-object detection capability include designing GELAN and MS as well as introducing a bi-level routing attention mechanism and loss function. GELAN is designed as the backbone network, utilizing PGI to solve information bottleneck problems, ensuring that the feedforward level of the main branch preserves important features while keeping the model lightweight. The neck layer introduces a multi-scale building block to enhance the real-time object detector’s ability to extract multi-scale features and improve the inference speed. The BiFormer dual-layer routing attention mechanism and C2f module can guide the network to focus on receptive field information at different scales and for different key pest characteristics. At the same time, adopting inner-MPDIoU instead of the CIOU calculation method accelerates the boundary box regression process and promotes an improvement of the model’s generalization ability.
- We constructed a dedicated tea pest dataset and conducted practical tests on our model and other mainstream models for four scenarios: a single target under normal lighting, multiple targets under normal lighting, a single target under low lighting, and multiple targets under low lighting. The experimental results show that the detection performance of our model is good in these four scenarios, with an mAP@0.5 score that reaches 98.17%, which is 17.04%, 11.23%, 5.78%, 3.75%, and 2.71% higher than those of Faster R-CNN, SSD, YOLOv5, YOLOv7, and YOLOv8, respectively.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fu, C.; Yan, W.; Yuan, Y.; Yang, J.; Liu, S.; Wan, S.; Dong, Y. The current situation, problems and countermeasures of the cultivation of tea geographical indication products cultivation in Yunnan Province. Qual. Saf. Agro-Prod. 2023, 3, 89–93. [Google Scholar] [CrossRef]
- Drew, L. The growth of tea. Nature 2019, 566, S2–S4. [Google Scholar] [CrossRef]
- Singh, V.; Misra, A. Detection of plant leaf diseases using image segmentation and soft computing techniques. Inf. Process. Agric. 2017, 4, 41–49. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Bengio, Y.; Lecun, Y.; Hinton, G. Deep Learning for AI. Commun. ACM 2021, 64, 58–65. [Google Scholar] [CrossRef]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A survey of deep learning and its applications: A new paradigm to machine learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Too, E.C.; Li, Y.; Njuki, S.; Liu, Y. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar] [CrossRef]
- Shaopeng, J.; Hongju, G.; Xiao, H. Research progress on image recognition technology of crop pests and diseases on deep learning. Trans. Chin. Soc. Agric. Mach. 2019, 50, 313–317. [Google Scholar]
- Wang, C.; Han, Q.; Li, C.; Li, J.; Kong, D.; Wang, F.; Zou, X. Assisting the Planning of Harvesting Plans for Large Strawberry Fields through Image-Processing Method Based on Deep Learning. Agriculture 2024, 14, 560. [Google Scholar] [CrossRef]
- Zhang, G.; Tian, Y.; Yin, W.; Zheng, C. An Apple Detection and Localization Method for Automated Harvesting under Adverse Light Conditions. Agriculture 2024, 14, 485. [Google Scholar] [CrossRef]
- Feng, L.; Wu, B.; Zhu, S.; Wang, J.; Su, Z.; Liu, F.; He, Y.; Zhang, C. Investigation on data fusion of multisource spectral data for rice leaf diseases identification using machine learning methods. Front. Plant Sci. 2020, 11, 577063. [Google Scholar] [CrossRef]
- Conrad, A.O.; Li, W.; Lee, D.-Y.; Wang, G.-L.; Rodriguez-Saona, L.; Bonello, P. Machine learning-based presymptomatic detection of rice sheath blight using spectral profiles. Plant Phenomics 2020, 2020, 1–10. [Google Scholar] [CrossRef]
- Ganatra, N.; Patel, A. A multiclass plant leaf disease detection using image processing and machine learning techniques. Int. J. Emerg. Technol. 2020, 11, 1082–1086. [Google Scholar]
- Ibañez, S.C.; Monterola, C.P. A Global Forecasting Approach to Large-Scale Crop Production Prediction with Time Series Transformers. Agriculture 2023, 13, 1855. [Google Scholar] [CrossRef]
- Jing, J.; Zhai, M.; Dou, S.; Wang, L.; Lou, B.; Yan, J.; Yuan, S. Optimizing the YOLOv7-Tiny Model with Multiple Strategies for Citrus Fruit Yield Estimation in Complex Scenarios. Agriculture 2024, 14, 303. [Google Scholar] [CrossRef]
- Kumar, C.; Mubvumba, P.; Huang, Y.; Dhillon, J.; Reddy, K. Multi-stage corn yield prediction using high-resolution UAV multispectral data and machine learning models. Agronomy 2023, 13, 1277. [Google Scholar] [CrossRef]
- Chen, J.; Hu, X.; Lu, J.; Chen, Y.; Huang, X. Efficient and Lightweight Automatic Wheat Counting Method with Observation-Centric SORT for Real-Time Unmanned Aerial Vehicle Surveillance. Agriculture 2023, 13, 2110. [Google Scholar] [CrossRef]
- Shah, S.A.; Lakho, G.M.; Keerio, H.A.; Sattar, M.N.; Hussain, G.; Mehdi, M.; Vistro, R.B.; Mahmoud, E.A.; Elansary, H.O. Application of drone surveillance for advance agriculture monitoring by android application using convolution neural network. Agronomy 2023, 13, 1764. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: To-wards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Kundur, N.C.; Mallikarjuna, P.B. Insect Pest Image Detection and Classification using Deep Learning. Int. J. Adv. Comput. Sci. Appl. IJACSA 2022, 13, 411–421. [Google Scholar] [CrossRef]
- Deng, Z.; Wang, P.; Song, X.; Wang, C.; Chen, J.; Wu, L. Research on Granary Pest Detection Based on SSD. J. Comput. Eng. Appl. 2020, 56, 214–218. [Google Scholar]
- Faisal, M.S.A.B. A pest monitoring system for agriculture using deep learning. Res. Prog. Mech. Manuf. Eng. 2021, 2, 1023–1034. [Google Scholar]
- Liu, C.; Chen, H.; Zeng, X.; Xiang, T.; Kou, X. Farmland Pest Detection Based on YOLO-V5l and ResNet50. Artif. Intell. Robot. Res. 2022, 11, 236. [Google Scholar]
- Hong, J.; Xin, H.; Lu, H.; Liu, R.; Chen, L.; Chen, Z. Tobacco insect recognition in cigarette factory using YOLOV3 model. Tob. Sci. Technol. 2020, 53, 77. [Google Scholar]
- Liu, J.; Wang, X. Tomato Diseases and Pests Detection Based on Improved Yolo V3 Convolutional Neural Network. Front. Plant Sci. 2020, 11, 521544. [Google Scholar] [CrossRef]
- Lin, W.; Zhang, J.; He, N. Real-time detection method of dendrolimus superans-infested larix gmelinii trees based on improved YOLO v4. Trans. Chin. Soc. Agric. Mach. 2023, 54, 304–312+393. [Google Scholar]
- Li, W.; Zhang, W.; Zhou, W.; Han, T.; Wang, P.; Liu, H.; Xiong, M.; Sun, Y. Research and Application of Lightweight Yolov7-TSA Network in Tea Disease Detection and Identification. J. Henan Agric. Sci. 2023, 52, 162–169. [Google Scholar]
- Fuentes, A.; Yoon, S.; Kim, S.C.; Park, D.S. A robust deep-learning-based detector for real-time tomato plant diseases and pests recognition. Sensors 2017, 17, 2022. [Google Scholar] [CrossRef]
- Dai, M.; Dorjoy, M.H.; Miao, H.; Zhang, S. A new pest detection method based on improved YOLOv5m. Insects 2023, 14, 54. [Google Scholar] [CrossRef]
- Alam Soeb, J.; Jubayer, F.; Tarin, T.A.; Al Mamun, M.R.; Ruhad, F.M.; Parven, A.; Mubarak, N.M.; Karri, S.L.; Meftaul, I.M. Tea leaf disease detection and identification based on YOLOv7 (YOLO-T). Sci. Rep. 2023, 13, 6078. [Google Scholar] [CrossRef]
- Deng, J.; Yang, C.; Huang, K.; Lei, L.; Ye, J.; Zeng, W.; Zhang, J.; Lan, Y.; Zhang, Y. Deep-Learning-Based Rice Disease and Insect Pest Detection on a Mobile Phone. Agronomy 2023, 13, 2139. [Google Scholar] [CrossRef]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12595–12604. [Google Scholar]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. Sod-mtgan: Small object detection via multi-task generative adversarial network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 206–221. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10213–10224. [Google Scholar]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small object detection using context and attention. In Proceedings of the 2021 international Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021; pp. 181–186. [Google Scholar]
- Liu, Y.; Yang, F.; Hu, P. Small-object detection in UAV-captured images via multi-branch parallel feature pyramid networks. IEEE Access 2020, 8, 145740–145750. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, W.; Zhao, Y.; Song, T.H.; Shin, H. DW-yolo: An efficient object detector for drones and self-driving vehicles. Arab. J. Sci. Eng. 2023, 48, 1427–1436. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Sarasaen, C.; Chatterjee, S.; Breitkopf, M.; Rose, G.; Nürnberger, A.; Speck, O. Finetuning deep learning model parameters for improved superresolution of dynamic MRI with prior-knowledge. Artif. Intell. Med. 2021, 121, 102196. [Google Scholar] [CrossRef]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Cai, Y.; Zhou, Y.; Han, Q.; Sun, J.; Kong, X.; Li, J.; Zhang, X. Reversible column networks. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Wang, L.; Lee, C.-Y.; Tu, Z.; Lazebnik, S. Training deeper convolutional networks with deep supervision. arXiv 2015, arXiv:1505.02496. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Yeh, I.-H. Designing network design strategies through gradient path analysis. J. Inf. Sci. Eng. JISE 2023, 39, 975–995. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Long Beach, CA, USA, 2017; pp. 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16×16 words: Transformers for image recognition at scale. In Proceedings of the 9th International Conference on Learning Representations ICLR, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with Transformers. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Glasgow, UK, 2020; pp. 213–229. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. Cspnet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. Pp-yoloe: An evolved version of yolo. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI: New York, NY, USA, 2020; p. 12993. [Google Scholar]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.S. Alpha-IoU: A family of power intersection over union losses for bounding box regression. Adv. Neural Inf. Process. Syst. 2021, 34, 20230–20242. [Google Scholar]
- Zhang, H.; Xu, C.; Zhang, S. Inner-IoU: More Effective Intersection over Union Loss with Auxiliary Bounding Box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Siliang, M.; Yong, X. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Bari, B.S.; Islam, N.; Rashid, M.; Hasan, J.; Razman, M.A.M.; Musa, R.M.; Ab Nasir, A.F.; Majeed, A.P.A. A real-time approach of diagnosing rice leaf disease using deep learning-based faster R-CNN framework. PeerJ Comput. Sci. 2021, 7, e432. [Google Scholar] [CrossRef]
- Lyu, Z.; Jin, H.; Zhen, T.; Sun, F.; Xu, H. Small Object Recognition Algorithm of Grain Pests Based on SSD Feature Fusion. IEEE Access 2021, 9, 43202–43213. [Google Scholar] [CrossRef]
- Önler, E. Real time pest detection using YOLOv5. Int. J. Agric. Nat. Sci. 2021, 14, 232–246. [Google Scholar]
- Jia, L.; Wang, T.; Chen, Y.; Zang, Y.; Li, X.; Shi, H.; Gao, L. MobileNet-CA-YOLO: An improved YOLOv7 based on the MobileNetV3 and attention mechanism for Rice pests and diseases detection. Agriculture 2023, 13, 1285. [Google Scholar] [CrossRef]
- Zhang, L.; Ding, G.; Li, C.; Li, D. DCF-Yolov8: An Improved Algorithm for Aggregating Low-Level Features to Detect Agricultural Pests and Diseases. Agronomy 2023, 13, 2012. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P/% | R/% | F1/% | AP1 | AP2 | AP3 | AP4 | mAP@0.5/% |
|---|---|---|---|---|---|---|---|---|
| YOLOv8 | 93.83 | 95.22 | 94.52 | 95.73 | 94.66 | 96.35 | 95.14 | 95.46 |
| Improved YOLOv8 | 96.32 | 97.95 | 97.13 | 98.54 | 97.18 | 98.71 | 98.25 | 98.17 |
| Model | P/% | R/% | F1/% | mAP@0.5/% | FPS/s |
|---|---|---|---|---|---|
| Faster R-CNN | 79.11 | 76.14 | 77.60 | 81.13 | 39 |
| SSD | 81.08 | 84.64 | 82.82 | 86.94 | 58 |
| YOLOv5 | 86.32 | 86.99 | 86.65 | 92.39 | 67 |
| YOLOv7 | 87.91 | 87.60 | 87.75 | 94.42 | 74 |
| YOLOv8 | 93.83 | 95.22 | 94.52 | 95.46 | 76 |
| Improved YOLOv8 | 96.32 | 97.95 | 97.13 | 98.17 | 95 |
| Model | GELAN | MS | BRA | Inner IOU | P/% | R/% | mAP@0.5/% | FPS/s |
|---|---|---|---|---|---|---|---|---|
| YOLOv8 | - | - | - | - | 93.83 | 95.22 | 95.46 | 76 |
| +G | √ | - | - | - | 91.51 | 91.47 | 95.97 | 85 |
| +M | - | √ | - | - | 93.81 | 90.61 | 96.25 | 72 |
| +B | - | - | √ | - | 92.26 | 93.08 | 96.58 | 95 |
| +G +M | √ | √ | - | - | 93.70 | 96.52 | 97.75 | 99 |
| +G +B | √ | - | √ | - | 95.12 | 94.61 | 97.24 | 82 |
| +M +B | - | √ | √ | - | 95.69 | 95.92 | 97.78 | 74 |
| +M +B +I | - | √ | √ | √ | 95.79 | 96.68 | 97.93 | 97 |
| +G +M +B +I | √ | √ | √ | √ | 96.32 | 97.95 | 98.17 | 95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, R.; Gao, Q.; Qian, Y.; Sun, J.; Li, T. Improved YOLOv8 and SAHI Model for the Collaborative Detection of Small Targets at the Micro Scale: A Case Study of Pest Detection in Tea. Agronomy 2024, 14, 1034. https://doi.org/10.3390/agronomy14051034
Ye R, Gao Q, Qian Y, Sun J, Li T. Improved YOLOv8 and SAHI Model for the Collaborative Detection of Small Targets at the Micro Scale: A Case Study of Pest Detection in Tea. Agronomy. 2024; 14(5):1034. https://doi.org/10.3390/agronomy14051034
Chicago/Turabian StyleYe, Rong, Quan Gao, Ye Qian, Jihong Sun, and Tong Li. 2024. "Improved YOLOv8 and SAHI Model for the Collaborative Detection of Small Targets at the Micro Scale: A Case Study of Pest Detection in Tea" Agronomy 14, no. 5: 1034. https://doi.org/10.3390/agronomy14051034
APA StyleYe, R., Gao, Q., Qian, Y., Sun, J., & Li, T. (2024). Improved YOLOv8 and SAHI Model for the Collaborative Detection of Small Targets at the Micro Scale: A Case Study of Pest Detection in Tea. Agronomy, 14(5), 1034. https://doi.org/10.3390/agronomy14051034