Optimized Design of EdgeBoard Intelligent Vehicle Based on PP-YOLOE+


Abstract
1. Introduction
2. Related Work
2.1. Two-Stage Detection Methods
2.2. Single-Stage Detection Methods
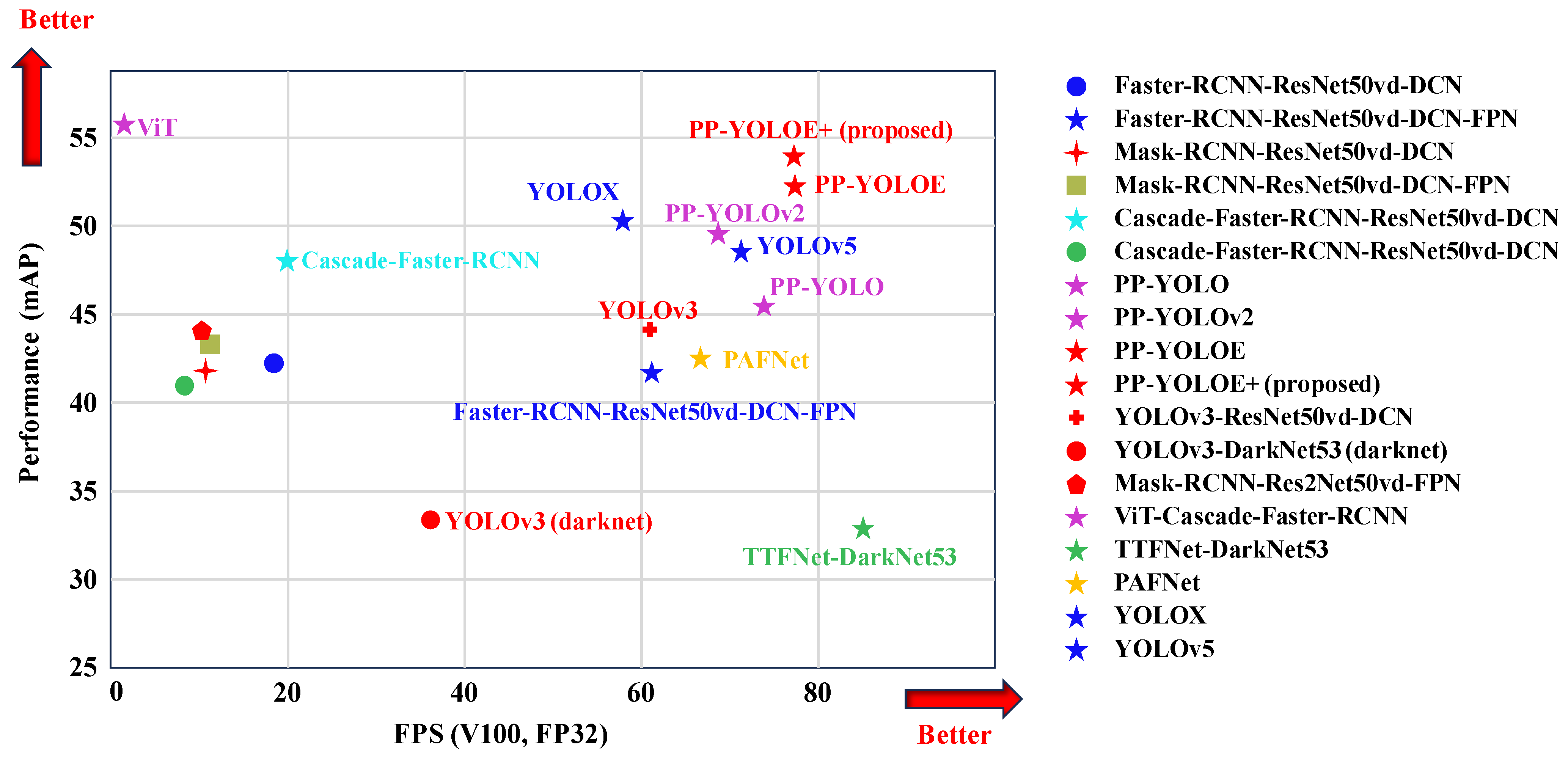
3. The PP-YOLOE+ Model
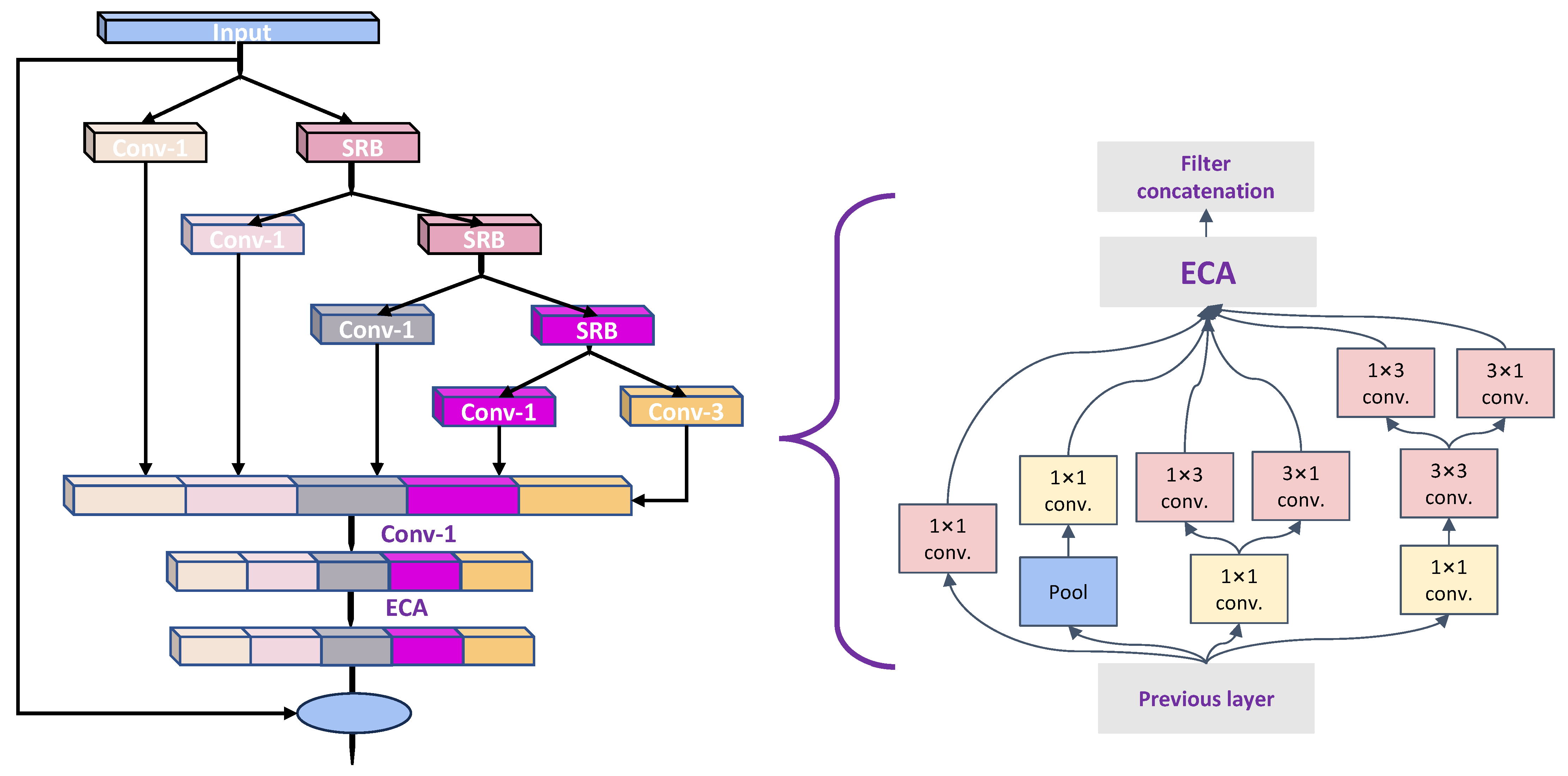
3.1. Backbone Network
3.2. Parameter Optimization for the PP-YOLOE+ Model
4. Design and Implementation of Intelligent Vehicle Model Based on EdgeBoard
4.1. Overview of System Structure
4.2. Comprehensive Hardware Design of the System
4.3. Designing Algorithmic Control for EdgeBoard-Integrated Intelligent Vehicle Systems
4.3.1. Pos-PID Controller
4.3.2. Roc-PID Controller
- (1)
- It produces incremental outputs, thus minimizing the impact of incorrect operations, which can be deactivated through logical decisions if needed.
- (2)
- The transition between manual and automatic modes is smooth, promoting seamless switches. Moreover, in case of a computer failure, the output channel or the actuator’s capacity to latch signals preserves the initial value.
- (3)
- The algorithm does not necessitate cumulative calculations. The control increment Δu(k) is determined solely by the latest k sample values, facilitating improved control quality via weighted methods.
5. Experimental Results and Analysis
5.1. Datasets
5.2. Model Evaluation Metrics
- -
- TP (true positives) represents the number of positive samples accurately identified as positive.
- -
- TN (true negatives) describes the number of negative samples accurately identified as negative.
- -
- FP (false positives) marks the number of negative samples incorrectly identified as positive.
- -
- FN (false negatives) signifies the number of positive samples incorrectly identified as negative.
5.3. Tests for Detecting Targets on the Road
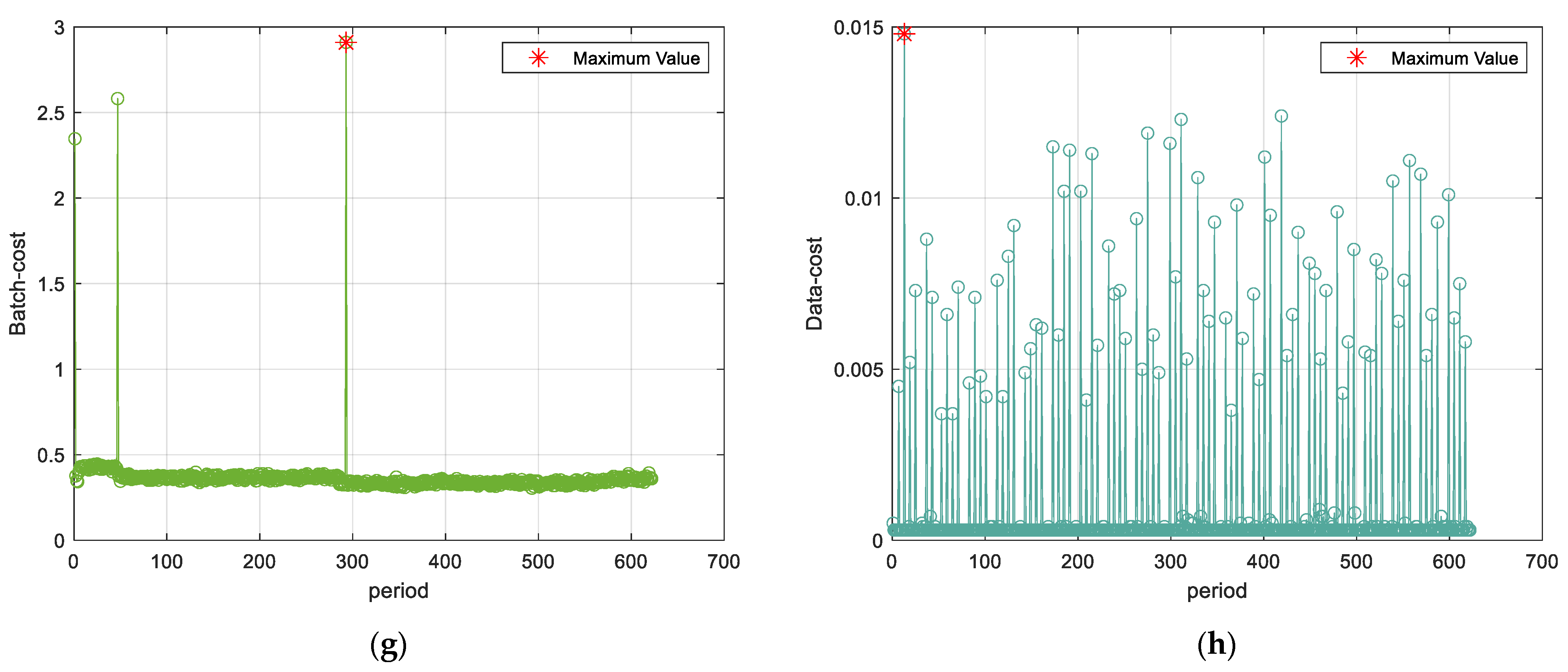
5.4. Experimental Outcomes
5.5. Comparison Experiments
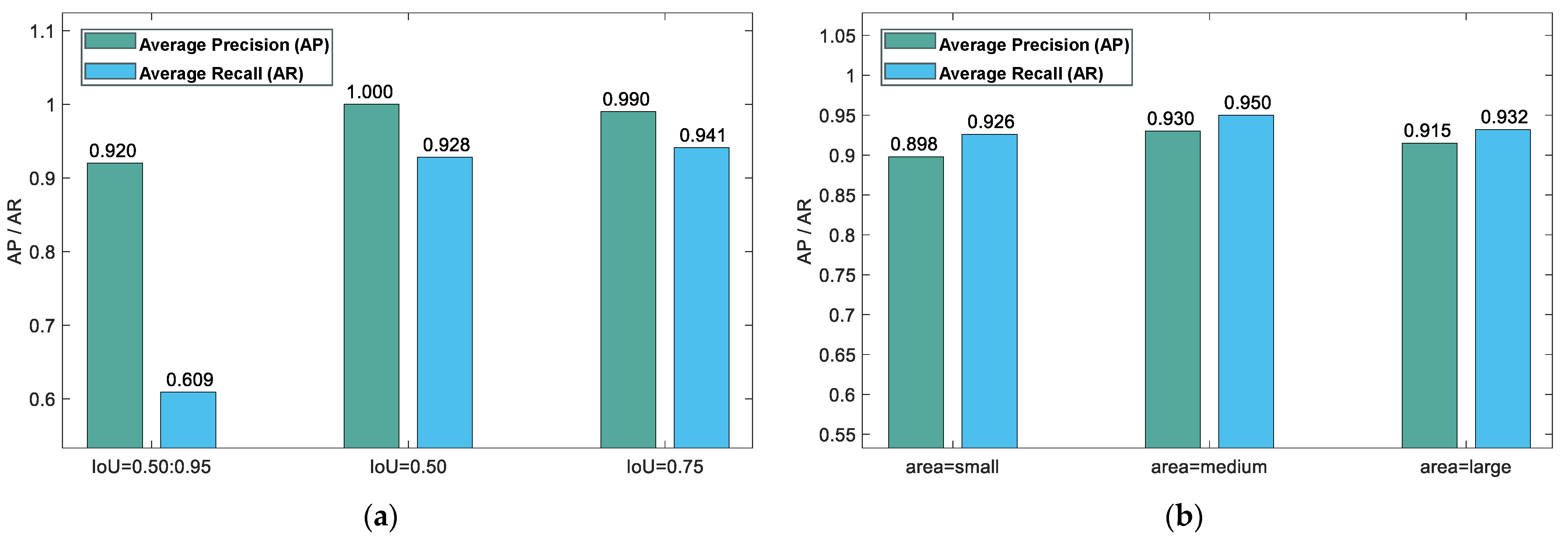
5.6. Model Evaluation
- (1)
- Calculating mAP across ten distinct IoU thresholds, spanning from 0.5 to 0.95 in steps of 0.05, and averaging them to obtain the AP measure according to the COCO dataset standard.
- (2)
- Computing AP with an IoU benchmark of 0.5, corresponding to the evaluation standard of the PASCAL VOC dataset.
- (3)
- Evaluating mAP with an IoU cutoff of 0.75, reflecting a more rigorous assessment due to the increased necessary overlap between the forecasted and true bounding boxes.
- (4)
- Determining mAP for small (area < 322), medium (322 < area < 962), and large objects (area > 962) to evaluate model performance across object sizes.
- (5)
- Calculating the average recall (AR) with a limit of 1, 10, and 100 bounding rectangles per image, which demonstrates the model’s recall capability.
- (6)
- Calculating mean average recall (mAR) for small, medium, and large objects, offering insight into the model’s recall efficiency across different object scales.
5.7. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Jia, Y.; Tong, X.; Li, Z. Research on pedestrian detection and deepsort tracking in front of intelligent vehicle based on deep learning. Sustainability 2022, 14, 9281. [Google Scholar] [CrossRef]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An evolved version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Yang, Z.; Zhao, C.; Maeda, H.; Sekimoto, Y. Development of a large-scale roadside facility detection model based on the Mapillary Dataset. Sensors 2022, 22, 9992. [Google Scholar] [CrossRef] [PubMed]
- Humayun, M.; Ashfaq, F.; Jhanjhi, N.Z.; Alsadun, M.K. Traffic management: Multi-scale vehicle detection in varying weather conditions using yolov4 and spatial pyramid pooling network. Electronics 2022, 11, 2748. [Google Scholar] [CrossRef]
- Choi, J.Y.; Han, J.M. Deep Learning (Fast R-CNN)-Based Evaluation of Rail Surface Defects. Appl. Sci. 2024, 14, 1874. [Google Scholar] [CrossRef]
- Zhang, H.; Li, X.; Yuan, H.; Liang, H.; Wang, Y.; Song, S. A Multi-Angle Appearance-Based Approach for Vehicle Type and Brand Recognition Utilizing Faster Regional Convolution Neural Networks. Sensors 2023, 23, 9569. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Yoshimura, T.; Horima, Y.; Sugimori, H. A preprocessing method for coronary artery stenosis detection based on deep learning. Algorithms 2024, 17, 119. [Google Scholar] [CrossRef]
- Zhai, S.; Shang, D.; Wang, S.; Dong, S. DF-SSD: An improved SSD object detection algorithm based on DenseNet and feature fusion. IEEE Access 2020, 8, 24344–24357. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An improved YOLOv2 for vehicle detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef]
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Liu, Y.T.; Jiang, X.Y.; Hartomo, K.D. Yolo V4 for advanced traffic sign recognition with synthetic training data generated by various GAN. IEEE Access 2021, 9, 97228–97242. [Google Scholar] [CrossRef]
- Sanjay Kumar, K.K.R.; Subramani, G.; Thangavel, S.K.; Parameswaran, L. A mobile-based framework for detecting objects using ssd-mobilenet in indoor environment. In Proceedings of the International Conference on Big Data, Cloud Computing, and Data Science Engineering (ICBDCC), Singapore, 26 July 2021; pp. 65–76. [Google Scholar]
- Mikic, I.; Cosman, P.C.; Kogut, G.T.; Trivedi, M.M. Moving shadow and object detection in traffic scenes. In Proceedings of the International Conference on Pattern Recognition (ICPR), Barcelona, Spain, 3–7 September 2000; pp. 321–324. [Google Scholar]
- Kamboj, D.; Vashisth, S.; Arora, S. A Novel Approach for Traffic Sign Detection: A CNN-Based Solution for Real-Time Accuracy. Int. J. Intell. Syst. Appl. Eng. 2024, 12, 400–409. [Google Scholar]
- Parmar, Y.; Natarajan, S.; Sobha, G. Deeprange: Deep-learning-based object detection and ranging in autonomous driving. IET Intell. Transp. Syst. 2019, 13, 1256–1264. [Google Scholar] [CrossRef]
- Oh, S.I.; Kang, H.B. Object detection and classification by decision-level fusion for intelligent vehicle systems. Sensors 2017, 17, 207. [Google Scholar] [CrossRef]
- Meyer, M.; Kuschk, G. Deep learning based 3d object detection for automotive radar and camera. In Proceedings of the European Radar Conference (EuRAD), Paris, France, 2–4 October 2019; pp. 133–136. [Google Scholar]
- Aradhya, H.V.R. Object detection and tracking using deep learning and artificial intelligence for video surveillance applications. Int J Adv Comput Sci Appl. 2019, 10, 12. [Google Scholar]
- Fang, S.; Zhang, B.; Hu, J. Improved mask R-CNN multi-target detection and segmentation for autonomous driving in complex scenes. Sensors 2023, 23, 3853. [Google Scholar] [CrossRef] [PubMed]
- Nie, J.; Yan, J.; Yin, H.; Ren, L.; Meng, Q. A multimodality fusion deep neural network and safety test strategy for intelligent vehicles. IEEE Trans. Intell. Veh. 2020, 6, 310–322. [Google Scholar] [CrossRef]
- Mahmood, Z.; Khan, K.; Khan, U.; Adil, S.H.; Ali, S.S.A.; Shahzad, M. Towards automatic license plate detection. Sensors 2022, 22, 1245. [Google Scholar] [CrossRef]
- Tan, L.; Lv, X.; Lian, X.; Wang, G. YOLOv4_Drone: UAV image target detection based on an improved YOLOv4 algorithm. Comput. Electr. Eng. 2021, 93, 107261. [Google Scholar] [CrossRef]
- Tao, J.; Wang, H.; Zhang, X.; Li, X.; Yang, H. An object detection system based on YOLO in traffic scene. In Proceedings of the International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 21–22 October 2017; pp. 315–319. [Google Scholar]
- Wang, X.; Hua, X.; Xiao, F.; Li, Y.; Hu, X.; Sun, P. Multi-object detection in traffic scenes based on improved SSD. Electronics 2018, 7, 302. [Google Scholar] [CrossRef]
- Lam, C.T.; Ng, B.; Chan, C.W. Real-time traffic status detection from on-line images using generic object detection system with deep learning. In Proceedings of the International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 October 2019; pp. 1506–1510. [Google Scholar]
- Ye, L.; Wang, D.; Yang, D.; Ma, Z.; Zhang, Q. VELIE: A Vehicle-Based Efficient Low-Light Image Enhancement Method for Intelligent Vehicles. Sensors 2024, 24, 1345. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.; Lu, Y.; Wang, Y.; Jiang, H. IDOD-YOLOV7: Image-Dehazing YOLOV7 for Object Detection in Low-Light Foggy Traffic Environments. Sensors 2023, 23, 1347. [Google Scholar] [CrossRef] [PubMed]
- Sudha, D.; Priyadarshini, J. An intelligent multiple vehicle detection and tracking using modified vibe algorithm and deep learning algorithm. Int. J. Soft Comput. 2020, 24, 17417–17429. [Google Scholar] [CrossRef]
- Cao, J.; Song, C.; Song, S.; Peng, S.; Wang, D.; Shao, Y.; Xiao, F. Front vehicle detection algorithm for smart car based on improved SSD model. Sensors 2020, 20, 4646. [Google Scholar] [CrossRef] [PubMed]
- Qu, Y.; Wan, B.; Wang, C.; Ju, H.; Yu, J.; Kong, Y.; Chen, X. Optimization algorithm for steel surface defect detection based on PP-YOLOE. Electronics 2023, 12, 4161. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, X.; Guo, J.; Zhou, P. Surface defect detection of strip-steel based on an improved PP-YOLOE-m detection network. Electronics 2022, 11, 2603. [Google Scholar] [CrossRef]
- Huang, Y.Q.; Zheng, J.C.; Sun, S.D.; Yang, C.F.; Liu, J. Optimized YOLOv3 algorithm and its application in traffic flow detections. Appl. Sci. 2020, 10, 3079. [Google Scholar] [CrossRef]
- Mahaur, B.; Mishra, K.K. Small-object detection based on YOLOv5 in autonomous driving systems. Pattern Recognit. Lett. 2023, 168, 115–122. [Google Scholar] [CrossRef]
- Jin, Z.; An, P.; Yang, C.; Shen, L. Fast QTBT partition algorithm for intra frame coding through convolutional neural network. IEEE Access 2018, 6, 54660–54673. [Google Scholar] [CrossRef]
- Xia, C.; Wang, X.; Lv, F.; Hao, X.; Shi, Y. ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions. arXiv 2024, arXiv:2403.07392. [Google Scholar]
- Patil, R.S.; Jadhav, S.P.; Patil, M.D. Review of Intelligent and Nature-Inspired Algorithms-Based Methods for Tuning PID Controllers in Industrial Applications. JRC 2024, 5, 336–358. [Google Scholar]
- Borase, R.P.; Maghade, D.K.; Sondkar, S.Y.; Pawar, S.N. A review of PID control, tuning methods and applications. Int. J. Dyn. Control. 2021, 9, 818–827. [Google Scholar] [CrossRef]
- Carlucho, I.; De Paula, M.; Villar, S.A.; Acosta, G.G. Incremental Q-learning strategy for adaptive PID control of mobile robots. Expert Syst. Appl. 2017, 80, 183–199. [Google Scholar] [CrossRef]
- Yu, G.; Chang, Q.; Lv, W.; Xu, C.; Cui, C.; Ji, W.; Dang, Q.; Deng, K.; Wang, G.; Du, Y.; et al. PP-PicoDet: A better real-time object detector on mobile devices. arXiv 2021, arXiv:2111.00902. [Google Scholar]
- Dong, K.; Liu, T.; Zheng, Y.; Shi, Z.; Du, H.; Wang, X. Visual Detection Algorithm for Enhanced Environmental Perception of Unmanned Surface Vehicles in Complex Marine Environments. J. Intell. Robot. Syst. 2024, 110, 1. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Advantages | Disadvantages |
|---|---|---|
| CNN-SSD [13] | Introduce variability convolution | Complexity of degree calculation |
| YOLOv4 [23] | Hollow convolution; ULSAM; soft-NMS | High computational resource |
| YOLO [24] | Combining R-FCN and histograms | Low parameter detection accuracy |
| AP-SSD [25] | Gabor feature extraction; SSD enhancement | Computational complexity |
| YOLOv3 [26] | Lightweight object detection framework | Poor visual effect |
| MAP [14] | Fading memory estimation | Low robustness complexity |
| CNN [15] | Multiclass object detection classifier | Low detection rate |
| VELIE [27] | Combining the integrated U-Net of Swin Vision Transformer and gamma transform | Gaps in detail enhancement |
| IDOD-YOLOv7 [28] | Combined AOD and SAIP; high accuracy | Poor practice results |
| Range-layer CNN [16] | High detection speed and low cost | Lack safety and reliability in autonomous driving |
| EYOLOv3 [29] | Kalman filter and particle filter; high efficiency | Large amount of data |
| SSD [30] | Structure, training method, and loss function | Suboptimal detection performance |
| Feature | PP-YOLOE | PP-YOLOE+ |
|---|---|---|
| Backbone | CSPRepResStage | CSPRepResNet and new CSPPAN structure |
| Dynamic Label Assignment | Basic dynamic label assignment | Advanced TAL for optimized classification and localization |
| Detection Head | ET-head with layer attention and basic alignment modules | ET-head replaced layer attention with ESE block, and more efficient alignment modules |
| Number | Epoch | Momentum | Learning Rate | Trainreader Batch Size |
|---|---|---|---|---|
| 1 | 80 | 0.85 | 0.001 | 8, 2, 1 |
| 2 | 100 | 0.95 | 0.00095 | 8, 4, 1 |
| 3 | 150 | 0.90 | 0.0009 | 8, 4, 2 |
| 4 | 180 | 0.95 | 0.001 | 4, 2, 1 |
| 5 | 250 | 0.90 | 0.0011 | 4, 4, 1 |
| 6 | 300 | 0.95 | 0.00088 | 4, 4, 2 |
| Metric | PP-YOLOE | PP-YOLOE+ |
|---|---|---|
| mAP (%) | 52.5 | 54.9 |
| AP accuracy (%) | 50.5 | 59.6 |
| FPS | 78 | 160 |
| Convergence Time (h) | 16 | 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, C.; Liu, X.; Wang, J.; Cheng, Y. Optimized Design of EdgeBoard Intelligent Vehicle Based on PP-YOLOE+. Sensors 2024, 24, 3180. https://doi.org/10.3390/s24103180
Yao C, Liu X, Wang J, Cheng Y. Optimized Design of EdgeBoard Intelligent Vehicle Based on PP-YOLOE+. Sensors. 2024; 24(10):3180. https://doi.org/10.3390/s24103180
Chicago/Turabian StyleYao, Chengzhang, Xiangpeng Liu, Jilin Wang, and Yuhua Cheng. 2024. "Optimized Design of EdgeBoard Intelligent Vehicle Based on PP-YOLOE+" Sensors 24, no. 10: 3180. https://doi.org/10.3390/s24103180
APA StyleYao, C., Liu, X., Wang, J., & Cheng, Y. (2024). Optimized Design of EdgeBoard Intelligent Vehicle Based on PP-YOLOE+. Sensors, 24(10), 3180. https://doi.org/10.3390/s24103180