
Controllable Music Playlist Generation Based on Knowledge Graph and Reinforcement Learning †


Abstract
:1. Introduction
2. Related Works
2.1. Music Playlist Generation
2.2. Knowledge Graph-Based Recommendation
3. Preliminary
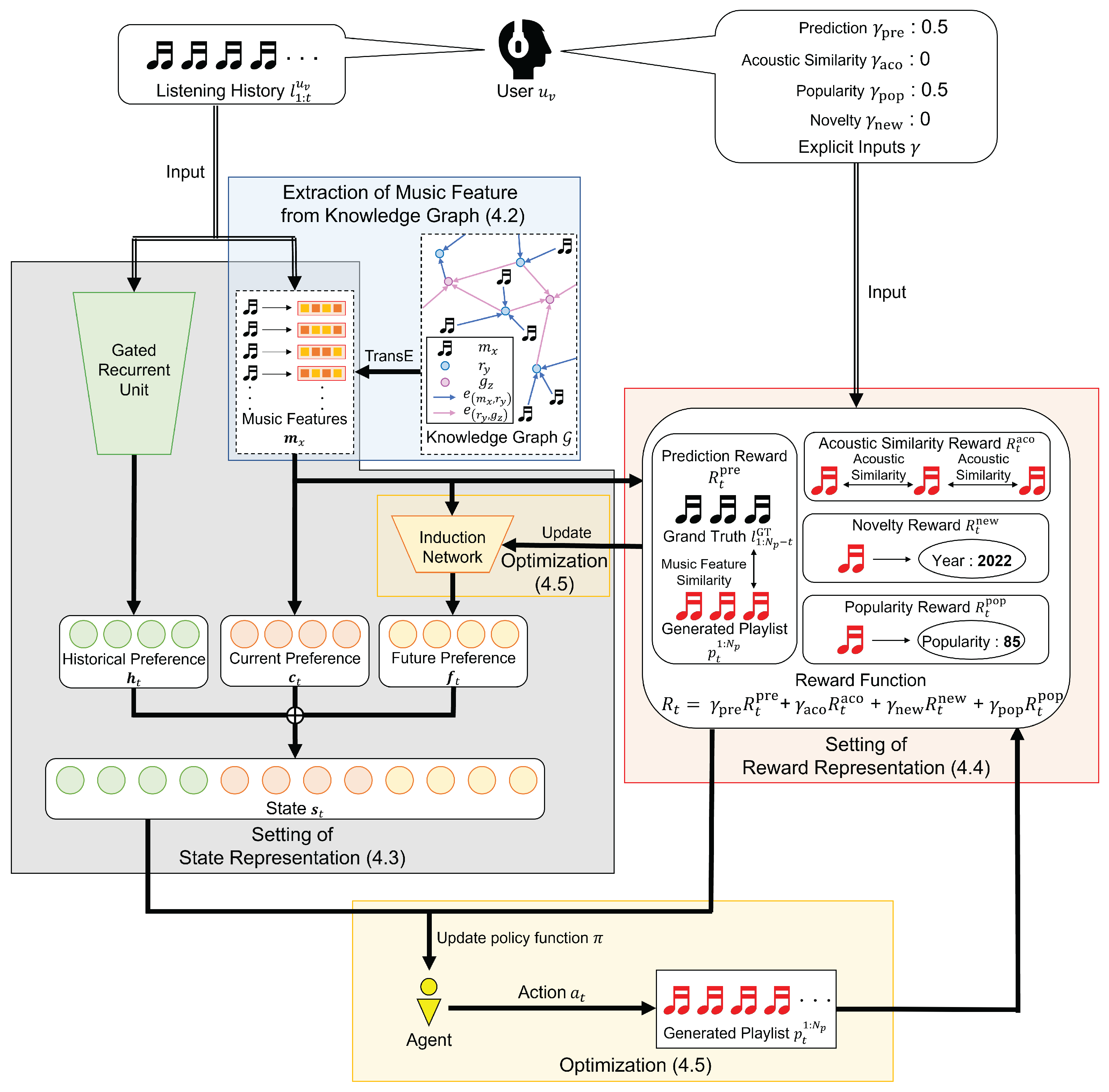
- NotationA scenario of a music playlist generation consists of a target user’s listening history and his/her explicit inputs. Let denote a set of users and denote a set of music tracks in a database. For each target user being the number of target users) ∈ , we set ( being the number of music tracks in the listening history of a target user ) to denote the listening history of the target user . Specifically, denotes the music track that the target user listened to first. In addition to the listening history of a target user, our model uses the target user’s explicit inputs for the parameter of the reward function in RL. Furthermore, a KG is provided for the task of music playlist generation, where each record is a triplet consisting of two entities and their relationships. The set of music tracks can be arranged in the KG. Based on the KG, we can obtain associated knowledge information of music tracks, e.g., an artist of a music track or genres of an artist.
- Task definitionWe used RL to generate music playlists. Based on the above notations, our model generates a music playlist and recommends it to a target user. The main advantage of our model is that it can predict the target user preferences based on the user’s listening history and guide the target user to the new types of music tracks based on the user’s explicit inputs.
- Markov decision processMDP is an important principle of RL. First, we briefly introduce the MDP. Generally, the MDP can be described by a quintuple 〈, , , , 〉:
- Statedenotes a set of states, and each ∈ represents the information state of an agent in the environment.
- Actiondenotes a set of actions, and each ∈ denotes the actions that the agent can take with respect to the environment.
- Transition functiondenotes a transition function for updating the state according to the action and current state, i.e., = (, ).
- Reward functiondenotes a reward function, e.g., if the agent performs in state , it gives an immediate reward (, ).
- Policydenotes the agent’s action policy. Generally, it is modeled using a probability distribution over possible actions.
- Based on the above five definitions, we obtained the optimal policy through repeated trial and error.
4. Proposed Method
4.1. Formulation of Markov Decision Process
4.2. Extraction of Music Feature from Knowledge Graph
4.3. Setting of State Representation
4.3.1. Historical Preference State Representation
4.3.2. Current Preference State Representation
4.3.3. Future Preference State Representation
4.3.4. Final State Representation
4.4. Setting of Reward Function
4.4.1. Prediction Reward
4.4.2. Guiding Reward
- Acoustic Similarity RewardConventionally, playlists with smooth track transitions are effective in increasing users’ satisfaction [17,54]. We design a reward based on the similarity of acoustic features of music tracks for users who prefer playlists with highly smooth track transitions. Specifically, the acoustic similarity reward is calculated using the cosine similarity of the acoustic feature of the -th and “”-th music tracks in the generated playlist and defined as follows:where denotes the acoustic feature of the music track .
- Popularity RewardWe assume that users who are unfamiliar with music or who are meek often listen to music based on its popularity. Many music streaming services have gained popularity by recommending popular music tracks to users who do not know what types of music they like. This means that popular music can attract users’ attention. To accommodate users who want to listen to popular songs, we use the value of popularity obtained from the Spotify API (https://developer.spotify.com/documentation/web-api/, accessed on 12 May 2022) in the popularity reward , which is defined as follows:where denotes the function that returns the popularity values of music track obtained from Spotify API and denotes the music track with the highest popularity value in the database.
- Novelty RewardMany music-savvy users may want to focus on the latest music. Notably, Shih et al. argues that it is important to consider the novelty of music tracks in the playlist [42]. We design the reward based on the year in which music tracks were released so that the generated playlist contains more new music tracks. The novelty reward is defined as follows:where denotes the function that returns the year of the music track, and denote the oldest and the newest music tracks in the database, respectively.
4.4.3. Final Reward Function
4.5. Optimization
4.5.1. Training with Policy Gradient
4.5.2. Training the Induction Network
5. Experiment
5.1. Experimental Setting
- CM1:The method is based on GRU [53] trained by only the target users’ listening history
- CM2 [17]:The playlist generation method is based on the exploration of the graph constructed from the acoustic similarities of the music tracks
- CM3 [49]:The method is based on a deep RL-based music recommendation model that uses the KG constructed from users’ listening history and acoustic features of music tracks
- CM4 [36]:The method is based on the item recommendation model and uses RL-based KG reasoning to explain recommendation results
- Acoustic Similarity MetricTo measure the similarity of acoustic features of successive music tracks in the generated playlist, we designed as follows:where denotes the number of music tracks in the playlist generated for the target user , and denotes the acoustic feature of -th music track in the playlist generated for the target user .
- Popularity MetricTo evaluate whether the generated playlist consists of music tracks with high popularity, we used the average values as the popularity metric. The popularity metric is defined as follows:where denotes the music track in the playlist generated for the target user .
- Novelty MetricTo evaluate whether new music tracks are included in the generated playlist, we used the average of the year that the music tracks were released as a novelty metric. The novelty metric is defined as follows:
5.2. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Matt, C.; Hess, T.; Benlian, A. Digital transformation strategies. Bus. Inf. Syst. Eng. 2015, 57, 339–343. [Google Scholar] [CrossRef]
- Yang, Y.H.; Lin, Y.C.; Su, Y.F.; Chen, H.H. A regression approach to music emotion recognition. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 448–457. [Google Scholar] [CrossRef]
- Sakurai, K.; Togo, R.; Ogawa, T.; Haseyama, M. Music playlist generation based on reinforcement learning using acoustic feature map. In Proceedings of the IEEE 9th Global Conference on Consumer Electronics, Kobe, Japan, 13–16 October 2020; pp. 942–943. [Google Scholar]
- Swanson, K. A Case Study on Spotify: Exploring Perceptions of the Music Streaming Service. MEIEA J. 2013, 13, 207–230. [Google Scholar] [CrossRef]
- Korver, J. Facing the music: The Current State of Streaming Services in The Music Industry. Ph.D. Thesis, Florida Southern College, Lakeland, FL, USA, 2019. [Google Scholar]
- Paul, D.; Kundu, S. A Survey of Music Recommendation Systems with a Proposed Music Recommendation System. In Emerging Technology in Modelling and Graphics; Springer: Berlin/Heidelberg, Germany, 2020; pp. 279–285. [Google Scholar]
- Pichl, M.; Zangerle, E.; Specht, G. Understanding playlist creation on music streaming platforms. In Proceedings of the IEEE International Symposium on Multimedia, San Jose, CA, USA, 11–13 December 2016; pp. 475–480. [Google Scholar]
- Eriksson, M. The editorial playlist as container technology: On Spotify and the logistical role of digital music packages. J. Cult. Econ. 2020, 13, 415–427. [Google Scholar] [CrossRef]
- Liebman, E.; Saar-Tsechansky, M.; Stone, P. The Right Music at the Right Time: Adaptive Personalized Playlists Based on Sequence Modeling. MIS Q. 2019, 43, 765–786. [Google Scholar] [CrossRef]
- Schedl, M.; Zamani, H.; Chen, C.W.; Deldjoo, Y.; Elahi, M. Recsys challenge 2018: Automatic playlist continuation. In Proceedings of the Late-Breaking/Demos 18th International Society for Music Information Retrieval Conference, Suzhou, China, 23–27 October 2017. [Google Scholar]
- Music Biz Consumer Insights. Available online: https://musicbiz.org/news/playlists-overtake-albums-listenership-says-loop-study/ (accessed on 2 May 2022).
- Andric, A.; Haus, G. Automatic playlist generation based on tracking user’s listening habits. Multimed. Tools Appl. 2006, 29, 127–151. [Google Scholar] [CrossRef]
- Dias, R.; Gonçalves, D.; Fonseca, M.J. From manual to assisted playlist creation: A survey. Multimed. Tools Appl. 2017, 76, 14375–14403. [Google Scholar] [CrossRef]
- Volkovs, M.; Rai, H.; Cheng, Z.; Wu, G.; Lu, Y.; Sanner, S. Two-stage model for automatic playlist continuation at scale. In ACM Recommender Systems Challenge; ACM: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Gatzioura, A.; Vinagre, J.; Jorge, A.M.; Sànchez-Marrè, M. A hybrid recommender system for improving automatic playlist continuation. IEEE Trans. Knowl. Data Eng. 2019, 33, 1819–1830. [Google Scholar] [CrossRef]
- Oliver, N.; Kreger-Stickles, L. PAPA: Physiology and Purpose-Aware Automatic Playlist Generation. In Proceedings of the 7th International Society for Music Information Retrieval Conference, Victoria, BC, Canada, 8–12 October 2006. [Google Scholar]
- Sakurai, K.; Togo, R.; Ogawa, T.; Haseyama, M. Music Playlist Generation Based on Graph Exploration Using Reinforcement Learning. In Proceedings of the IEEE 3rd Global Conference on Life Sciences and Technologies, Nara, Japan, 9–11 March 2021; pp. 53–54. [Google Scholar]
- Vall, A. Listener-inspired automated music playlist generation. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 387–390. [Google Scholar]
- Kaya, M.; Bridge, D. Automatic playlist continuation using subprofile-aware diversification. In ACM Recommender Systems Challenge; ACM: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Nabizadeh, A.H.; Jorge, A.M.; Tang, S.; Yu, Y. Predicting user preference based on matrix factorization by exploiting music attributes. In Proceedings of the 9th International Conference on Computer Science & Software Engineering, Porto, Portugal, 20–22 July 2016; pp. 61–66. [Google Scholar]
- Choi, K.; Fazekas, G.; Sandler, M. Towards playlist generation algorithms using rnns trained on within-track transitions. arXiv 2016, arXiv:1606.02096. [Google Scholar]
- Irene, R.T.; Borrelli, C.; Zanoni, M.; Buccoli, M.; Sarti, A. Automatic playlist generation using convolutional neural networks and recurrent neural networks. In Proceedings of the 27th European Signal Processing Conference, A Coruña, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Pauws, S.; Eggen, B. PATS: Realization and user evaluation of an automatic playlist generator. In Proceedings of the 2nd International Society for Music Information Retrieval Conference, Paris, France, 13–17 October 2002; pp. 222–230. [Google Scholar]
- Lee, J.H.; Bare, B.; Meek, G. How Similar Is Too Similar?: Exploring Users’ Perceptions of Similarity in Playlist Evaluation. In Proceedings of the 11th International Society for Music Information Retrieval Conference, Utrecht, The Netherlands, 9–13 August 2010; pp. 109–114. [Google Scholar]
- Wang, P.; Fan, Y.; Xia, L.; Zhao, W.X.; Niu, S.; Huang, J. KERL: A knowledge-guided reinforcement learning model for sequential recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 209–218. [Google Scholar]
- Huang, L.; Fu, M.; Li, F.; Qu, H.; Liu, Y.; Chen, W. A deep reinforcement learning based long-term recommender system. Knowl.-Based Syst. 2021, 213, 106706. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Liebman, E.; Saar-Tsechansky, M.; Stone, P. Dj-mc: A reinforcement-learning agent for music playlist recommendation. arXiv 2014, arXiv:1401.1880. [Google Scholar]
- Hu, B.; Shi, C.; Liu, J. Playlist recommendation based on reinforcement learning. In Proceedings of the International Conference on Intelligence Science, Shanghai, China, 25–28 October 2017; pp. 172–182. [Google Scholar]
- He, R.; McAuley, J. Fusing similarity models with markov chains for sparse sequential recommendation. In Proceedings of the IEEE 16th International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016; pp. 191–200. [Google Scholar]
- Ge, Y.; Zhao, S.; Zhou, H.; Pei, C.; Sun, F.; Ou, W.; Zhang, Y. Understanding echo chambers in e-commerce recommender systems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 2261–2270. [Google Scholar]
- Nguyen, T.T.; Hui, P.M.; Harper, F.M.; Terveen, L.; Konstan, J.A. Exploring the filter bubble: The effect of using recommender systems on content diversity. In Proceedings of the 23rd international Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 677–686. [Google Scholar]
- Nickel, M.; Murphy, K.; Tresp, V.; Gabrilovich, E. A review of relational machine learning for knowledge graphs. IEEE 2015, 104, 11–33. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Xian, Y.; Fu, Z.; Muthukrishnan, S.; De Melo, G.; Zhang, Y. Reinforcement knowledge graph reasoning for explainable recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 285–294. [Google Scholar]
- Bonnin, G.; Jannach, D. Automated generation of music playlists: Survey and experiments. ACM Comput. Surv. 2014, 47, 1–35. [Google Scholar] [CrossRef]
- Monti, D.; Palumbo, E.; Rizzo, G.; Lisena, P.; Troncy, R.; Fell, M.; Cabrio, E.; Morisio, M. An ensemble approach of recurrent neural networks using pre-trained embeddings for playlist completion. In ACM Recommender Systems Challenge; ACM: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Vall, A.; Quadrana, M.; Schedl, M.; Widmer, G. The importance of song context and song order in automated music playlist generation. arXiv 2018, arXiv:1807.04690. [Google Scholar]
- Kim, J.; Won, M.; Liem, C.C.; Hanjalic, A. Towards seed-free music playlist generation: Enhancing collaborative filtering with playlist title information. In ACM Recommender Systems Challenge; ACM: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Yang, H.; Zhao, Y.; Xia, J.; Yao, B.; Zhang, M.; Zheng, K. Music playlist recommendation with long short-term memory. In Proceedings of the International Conference on Database Systems for Advanced Applications, Chiang Mai, Thailand, 22–25 April 2019; pp. 416–432. [Google Scholar]
- Shih, S.Y.; Chi, H.Y. Automatic, personalized, and flexible playlist generation using reinforcement learning. arXiv 2018, arXiv:1809.04214. [Google Scholar]
- Sun, Z.; Yang, J.; Zhang, J.; Bozzon, A.; Huang, L.K.; Xu, C. Recurrent knowledge graph embedding for effective recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; pp. 297–305. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Zhang, Z.; Cui, P.; Zhu, W. Deep learning on graphs: A survey. IEEE Trans. Knowl. Data Eng. 2020, 34, 249–270. [Google Scholar] [CrossRef] [Green Version]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A survey on knowledge graph-based recommender systems. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Song, W.; Duan, Z.; Yang, Z.; Zhu, H.; Zhang, M.; Tang, J. Explainable knowledge graph-based recommendation via deep reinforcement learning. arXiv 2019, arXiv:1906.09506. [Google Scholar]
- Sakurai, K.; Togo, R.; Ogawa, T.; Haseyama, M. Deep Reinforcement Learning-based Music Recommendation with Knowledge Graph Using Acoustic Features. ITE Trans. Media Technol. Appl. 2022, 10, 8–17. [Google Scholar] [CrossRef]
- Zhou, S.; Dai, X.; Chen, H.; Zhang, W.; Ren, K.; Tang, R.; He, X.; Yu, Y. Interactive recommender system via knowledge graph-enhanced reinforcement learning. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 179–188. [Google Scholar]
- Wang, X.; Xu, Y.; He, X.; Cao, Y.; Wang, M.; Chua, T.S. Reinforced negative sampling over knowledge graph for recommendation. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 99–109. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Ben-Elazar, S.; Lavee, G.; Koenigstein, N.; Barkan, O.; Berezin, H.; Paquet, U.; Zaccai, T. Groove radio: A bayesian hierarchical model for personalized playlist generation. In Proceedings of the ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 445–453. [Google Scholar]
- Turnbull, B.W. The empirical distribution function with arbitrarily grouped, censored and truncated data. J. R. Stat. Soc. Ser. B (Methodol.) 1976, 38, 290–295. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.W.; Lamere, P.; Schedl, M.; Zamani, H. Recsys challenge 2018: Automatic music playlist continuation. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; pp. 527–528. [Google Scholar]
- Ferraro, A.; Kim, Y.; Lee, S.; Kim, B.; Jo, N.; Lim, S.; Lim, S.; Jang, J.; Kim, S.; Serra, X.; et al. Melon Playlist Dataset: A public dataset for audio-based playlist generation and music tagging. In Proceedings of the 46th IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 536–540. [Google Scholar]
- Jannach, D.; Lerche, L.; Kamehkhosh, I. Beyond “hitting the hits” Generating coherent music playlist continuations with the right tracks. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; pp. 187–194. [Google Scholar]



{kind=link}
{kind=link}
| Parameter | ||||
|---|---|---|---|---|
| PM-A | 0.5 | 0.5 | 0 | 0 |
| PM-P | 0.5 | 0 | 0.5 | 0 |
| PM-N | 0.5 | 0 | 0 | 0.5 |
| PM-AP | 0.33 | 0.33 | 0.33 | 0 |
| PM-AN | 0.33 | 0.33 | 0 | 0.33 |
| PM-PN | 0.33 | 0 | 0.33 | 0.33 |
| PM-ALL | 0.25 | 0.25 | 0.25 | 0.25 |
| Metric | nDCG@k [] | Hit Rate@k [%] | ||||
|---|---|---|---|---|---|---|
| k = 1 | k = 5 | k = 10 | k = 1 | k = 5 | k = 10 | |
| PM-A | 18.2 | 24.7 | 26.2 | 18.2 | 30.9 | 37.9 |
| PM-P | 19.3 | 25.6 | 27.9 | 19.3 | 33.4 | 40.4 |
| PM-N | 18.2 | 26.1 | 26.8 | 18.2 | 32.9 | 39.6 |
| PM-AP | 17.5 | 23.5 | 24.8 | 17.5 | 29.8 | 36.8 |
| PM-AN | 17.0 | 24.9 | 24.5 | 17.0 | 27.2 | 34.2 |
| PM-PN | 18.7 | 22.1 | 24.6 | 18.7 | 30.5 | 38.1 |
| PM-ALL | 18.0 | 23.0 | 24.1 | 18.0 | 29.0 | 36.0 |
| CM1 | 10.2 | 13.9 | 17.2 | 10.2 | 21.8 | 28.8 |
| CM2 [17] | 0.00 | 0.52 | 0.40 | 0.00 | 0.43 | 1.03 |
| CM3 [49] | 3.42 | 5.30 | 6.22 | 3.42 | 6.71 | 11.5 |
| CM4 [36] | 3.59 | 4.30 | 5.94 | 3.59 | 7.05 | 12.0 |
| Metrics | |||
|---|---|---|---|
| PM-A | 0.90 | 19.0 | 2001.9 |
| PM-P | 0.57 | 52.8 | 2012.4 |
| PM-N | 0.64 | 37.6 | 2013.4 |
| PM-AP | 0.81 | 50.6 | 2006.6 |
| PM-AN | 0.86 | 27.2 | 2011.4 |
| PM-PN | 0.65 | 48.0 | 2012.8 |
| PM-ALL | 0.73 | 42.0 | 2009.8 |
| CM1 | 0.56 | 41.2 | 2005.4 |
| CM2 [17] | 0.97 | 19.3 | 2004.2 |
| CM3 [49] | 0.65 | 38.6 | 2006.6 |
| CM4 [36] | 0.60 | 40.7 | 2007.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sakurai, K.; Togo, R.; Ogawa, T.; Haseyama, M. Controllable Music Playlist Generation Based on Knowledge Graph and Reinforcement Learning. Sensors 2022, 22, 3722. https://doi.org/10.3390/s22103722
Sakurai K, Togo R, Ogawa T, Haseyama M. Controllable Music Playlist Generation Based on Knowledge Graph and Reinforcement Learning. Sensors. 2022; 22(10):3722. https://doi.org/10.3390/s22103722
Chicago/Turabian StyleSakurai, Keigo, Ren Togo, Takahiro Ogawa, and Miki Haseyama. 2022. "Controllable Music Playlist Generation Based on Knowledge Graph and Reinforcement Learning" Sensors 22, no. 10: 3722. https://doi.org/10.3390/s22103722
APA StyleSakurai, K., Togo, R., Ogawa, T., & Haseyama, M. (2022). Controllable Music Playlist Generation Based on Knowledge Graph and Reinforcement Learning. Sensors, 22(10), 3722. https://doi.org/10.3390/s22103722