Abstract
Global demand for cumene is rising day by day due to its broad applications in the production of numerous types of polymers like nylon-6, epoxy resins, and polycarbonates. Efforts to enhance process design and operation efficiency are ongoing. However, addressing process uncertainties remains a significant challenge for stable process industry operations. Artificial neural networks (ANNs) have proven to be powerful tools for modelling and predicting complex chemical processes, offering substantial potential for improving the quality and quantity of cumene production. In the present study, a data-based model was used for the prediction of the molar flow and mole fraction of cumene in the final product stream. A steady-state Aspen plus model was set to a dynamic mode by deliberately introducing ±10% variability in process conditions. This dynamic model served as the foundation for generating a comprehensive dataset. Two ANN models were developed using the dataset for the prediction of the molar flow and mole fraction of cumene. During the rigorous testing phase, the models demonstrated outstanding performance, as evidenced by their correlation coefficient values of 0.99216 and 0.99412 for the molar flow and mole fraction of cumene, respectively. These high correlation coefficients provide compelling evidence of the models’ robust and precise predictive capabilities, highlighting their potential for real-world application. This study paves the way for Al integration in the process industry, making a significant step toward embracing industry 4.0.
1. Introduction
Cumene ranks among the top-five essential chemical reagents produced globally on a large scale, primarily due to its extensive application in the production of phenol and acetone. These two compounds play pivotal roles in meeting approximately 80% of the global plastic demand, with cumene serving as the cornerstone for about 98% of acetone and phenol production [1]. The soaring worldwide cumene demand is projected to reach USD 17.63 billion by 2025 [2]. This research delves into optimizing the design of the cumene production process to achieve greater efficiency and thus minimize the consumption of raw materials and utilities and ensure the production of high-quality products. Computational methods have proven to be invaluable in the quest for attaining efficient process design and operations, leading to a significant reduction in the need for extensive experimental work [3]. These methods include response surface methodology, multi-objective optimization (MOO), regression analysis, analysis of variance (ANOVA), and machine learning. The domain of cumene production has been extensively explored using computational methods, focusing on several critical aspects [4]. These aspects encompass process modification, yield quality, environmental impact, optimization, and process control [5,6,7]. Previous studies primarily employed AI for optimizing production processes, controlling processes, and conducting economic and environmental analyses. However, no studies have been carried out on using AI to predict both the quality and yield of cumene. Computational methods serve as a versatile toolbox for addressing these multifaceted challenges and driving advancements in cumene production. In this study, ANN models were employed to predict the quality and yield of cumene under uncertain process conditions, enabling the management of uncertainties and enhancing process efficiency.
2. Materials and Methods
2.1. Process Description
Figure 1 shows a schematic representation of the cumene production process. The process is categorized into three primary segments: preheating, reaction, and separation sections. Preheating and reaction section: In the initial phase of the cumene production process, propene and benzene, in conjunction with the recycled benzene from the separation section, undergo heating. This is achieved by harnessing the heat of the outlet stream from the reactor. This process involves passing the feeds (Feed-1 and MixFeed-2) through heat exchangers (E-2 and E-1) to elevate their temperatures. Once the feeds are mixed, they are further heated in a furnace until reaching the required temperature for the chemical reactions. The preheated mixture is subsequently introduced into the reactor, where alkylation and trans-alkylation reactions are initiated. The effluent from the reactor is directed through heat exchangers, where it undergoes heat exchange with the incoming feed streams. To further reduce the temperature of the output, it passes through a water boiler. Separation section: The output from the reactor is then directed into the depropanizer column, which carries out separation based on boiling points. This process results in the production of unreacted propylene and inert propane as the top product, for which a side product is fuel gas. The bottom product contains benzene, cumene, and DIPB, and, prior to entering the benzene column, it is passed through a heat exchanger. In the benzene column, the unreacted benzene is extracted as the top product, while the cumene and DIPB are collected as bottom product. Undesirable DIPB is managed as waste in the cumene recovery column process, with the valuable cumene being extracted from the top.
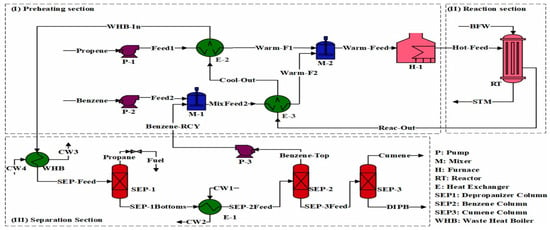
Figure 1.
Process diagram of cumene production process [2].
2.2. Artificial Neural Network
An artificial neural network is a computational model with many interconnected elements that take in information and produce results based on predefined activation functions [8]. An ANN typically has three layers: an input, a hidden layer, and an output. These layers contain interconnected neurons that help the network understand and model intricate and nonlinear processes. The input layer is where the network receives information or data. The hidden layers are responsible for digging deeper into the information, trying to make sense of it. Neurons in these layers take an input, process it using their predefined rules, and generate an output. The output layer is the final step, responsible for presenting the network’s ultimate results. Mean squared error (MSE) and coefficient of correlation (R) can be used to evaluate an ANN’s performance [9]. In this study, they were calculated using Equations (1) and (2), respectively.
3. Results and Discussion
Uncertainty was intentionally introduced into the process parameters to generate a variety of data samples, encompassing an input with uncertain process parameters and an output representing the molar flow and mole fraction of cumene in the product stream. To generate these data samples, a ±10% uncertainty was applied to nine key input variables, which included the mole fraction of propylene and propane, the flow rate of propene and benzene, the outlet pressure of pumps 1 and 2, and the outlet temperatures of E-1, E-2, and WHB, with upper and lower bonds ranging from 0.994 to 0.855, 0.1449 to 0.0050, 0.0309 to 0.0267, 0.0305 to 0.0260, 2,694,867.42 to 2,215,322.235, 2,769,212.25 to 2,305,397.063, 393.83.84 to 327.270, 684.0317 to 566.8795, and 448.54 to 387.436, respectively. These uncertain values resulted in notable changes, as depicted in Figure 2.
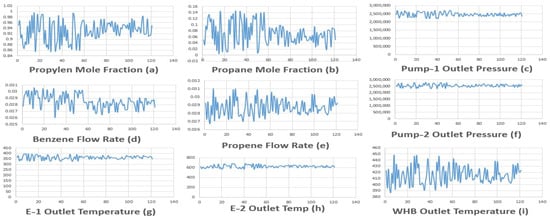
Figure 2.
Uncertainty in process variables.
Two distinct ANN models were developed using a dataset comprising 200 samples. Among these, 120 were allocated for model training, 25 were used for validation, and 25 were used for model testing. Both ANN models underwent training using the Levenberg–Marquardt backpropagation (trainlm) training algorithm, with the networks’ behavior being regulated through the Tansig activation function. Furthermore, an additional 30 data samples were employed to evaluate the models’ ability to generalize beyond their training data. The ANN model developed for predicting the mole fraction of cumene exhibited strong performance, with an R value of 0.99412 for testing, and its MSE value was impressively low, measuring 2.9877 × 10−6 for testing, 8 as shown in Figure 3b. Similarly, the ANN model developed for predicting the molar flow of cumene also performed admirably. It achieved an R value of 0.99412 for testing. The MSE value was notably low, measuring 0.0967 for testing, as depicted in Figure 3a. These results showcase the models’ robust predictive abilities, indicating their proficiency in estimating the quality and yield of cumene in the product stream.
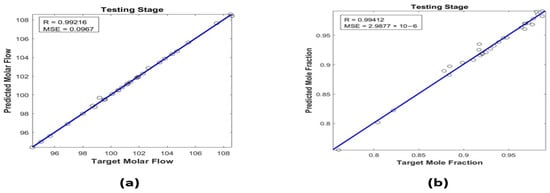
Figure 3.
Predicted vs. actual molar flow (a) and mole fraction (b).
4. Conclusions
This study presents the application of ANN models to predict both the quality and yield of cumene in the outlet stream by using the Aspen plus and MATLAB environment. Two distinct ANN models were developed for the prediction of the molar flow and mole fraction of cumene in outlet stream by utilizing the same set of input parameters. During testing, these models exhibited exceptional performance, with correlation coefficient values of 0.99216 and 0.99412 in the testing stage, respectively. These values attest to the ANN models’ accuracy and reliability in forecasting cumene’s properties. This research emphasizes the significant potential of ANN models as valuable tools for process optimization and control in cumene production. The use of these models has demonstrated their ability to not only forecast the quality and yield of cumene but also contribute to enhancing the operational efficiency of the cumene production process.
Author Contributions
Conceptualization, A.A.; methodology, A.A. and M.Z.; software, A.A. and M.Z.; validation, A.A., M.Z. and H.S.; formal analysis, A.A., M.Z. and H.S.; investigation, A.A., M.Z. and H.S.; resources, A.A.; data curation, A.A.; writing—original draft preparation, A.A., M.Z. and H.S.; writing—review and editing, A.A., M.Z. and H.S.; visualization, A.A. and M.Z.; supervision, A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Dataset available on request from the authors.
Conflicts of Interest
Author Asad Ayub (A.A.) was employed by the company E-Triangle Automation Company, NSTP, H-12, Islamabad 44000, Pakistan. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Ramazanov, K.R. Increase of efficiency of cumene process of receiving phenol and acetone. Eur. Sci. Technol. 2013, 775–786. [Google Scholar] [CrossRef]
- Samad, A.; Saghir, H.; Ahmad, I.; Ahmad, F.; Caliskan, H.J.E. Thermodynamic analysis of cumene production plant for identification of energy recovery potentials. Energy 2023, 270, 126840. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef] [PubMed]
- Sivaranjani, T.; Xavier, S.; Periandy, S. NMR, FT-IR, FT-Raman, UV spectroscopic, HOMO–LUMO and NBO analysis of cumene by quantum computational methods. J. Mol. Struct. 2015, 1083, 39–47. [Google Scholar] [CrossRef]
- Junqueira, P.G.; Mangili, P.V.; Santos, R.O.; Santos, L.S.; Prata, D.M. Economic and environmental analysis of the cumene production process using computational simulation. Chem. Eng. Process. Process Intensif. 2018, 130, 309–325. [Google Scholar] [CrossRef]
- Flegiel, F.; Sharma, S.; Rangaiah, G.P. Development and multiobjective optimization of improved cumene production processes. Mater. Manuf. Process. 2015, 30, 444–457. [Google Scholar] [CrossRef]
- Norouzi, H.; Hasani, M.; Haddadi-Sisakht, B.; Mostoufi, N.J. Economic design and optimization of zeolite-based cumene production plant. Chem. Eng. Commun. 2014, 201, 1270–1293. [Google Scholar] [CrossRef]
- Al-Shathr, A.; Shakor, Z.M.; Majdi, H.S.; AbdulRazak, A.A.; Albayati, T.M. Comparison between artificial neural network and rigorous mathematical model in simulation of industrial heavy naphtha reforming process. Catalysts 2021, 11, 1034. [Google Scholar] [CrossRef]
- Zhang, X.; Kano, M.; Matsuzaki, S. A comparative study of deep and shallow predictive techniques for hot metal temperature prediction in blast furnace ironmaking. Comput. Chem. Eng. 2019, 130, 106575. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).