1. Introduction
A circular random variable takes values on the unit circle, and its density function must be periodic. Generally, a circular random variable represents an angle in the interval , and it is important to model many random phenomena in different areas, such as in meteorology for the wind direction, in biology for the dihedral angles defining the spatial structure of a protein, in ecology for camera trap data that records the time of the day at which different animals are observed and in many other examples in other disciplines.
The circular distributions based on nonnegative trigonometric sums (NNTS) developed by ref. [
1] are flexible distributions capable of modelling circular data that present multimodality and/or skewness (asymmetry). Fernández-Durán and Gregorio-Domínguez in [
2] developed an efficient optimisation algorithm for manifolds to obtain maximum likelihood estimates of the parameters of an NNTS model. This algorithm was implemented by using the
R package
[
3]. The NNTS family of distributions includes the uniform distribution as a special case (
M = 0). One of the most important hypothesis tests in the study of circular statistics is testing for circular uniformity [
4,
5]. In addition, for absolutely continuous circular density functions, the circular uniform density is closed under summation, that is, the sum of independent circular uniformly distributed random variables has a circular uniform distribution [
5]. Additionally, if at least one member of the sum of independent circular random variables is uniformly distributed, then the sum of these random variables is also circular uniformly distributed. This is a consequence of the characteristic function of a circular uniformly distributed random variable,
, defined for
as:
where
is an indicator function that takes the value of one for
and zero otherwise.
There are many different tests for circular uniformity, such as the Rayleigh test, Watson’s test, Kuiper’s test, and Rao’s spacing test, among others [
6,
7,
8]. Many of these tests were designed with unimodal distributions as an alternative hypothesis and presented low power when applied to multimodal datasets. The Hermans-Rasson test, Bogdan test and Pycke test consider multimodal circular distributions as alternative hypotheses and have more power to detect deviations from circular uniformity when applied to multimodal circular data [
9,
10,
11]. In this study, two tests are developed with alternative hypotheses NNTS distributions to account for the cases that present multimodality but also asymmetry. The NNTS tests are based on the maximum likelihood method: The first test is based on the standardised maximum likelihood estimator, and the second is based on the generalised likelihood ratio statistic. The power of the NNTS tests was compared to that of the Hermans-Rasson and Pycke tests. The results of the sums of NNTS random variables allow us to identify NNTS densities that are close to the uniform distribution, and we use these results to compare the power of the tests in simulated datasets where the degree of closeness to the circular uniform distribution can be controlled. This study is divided into seven sections, including the introduction. In the second section, mathematical formulas for the characteristic function of an NNTS circular random variable are developed. In the third section, the NNTS family is shown to be closed under summation; that is, the sum of independent NNTS circular random variables is also NNTS distributed, and how to obtain the parameters of the NNTS density of the sum and numerical examples with graphs is explained. In the fourth section, the two proposed circular uniformity tests, taking an NNTS distribution as an alternative hypothesis are developed. Considering the parameter space of NNTS densities, the null circular uniformity distribution corresponds to a parameter on the boundary of the parameter space. Then, the regularity conditions of maximum likelihood estimation are not satisfied because the parameters of the NNTS densities are estimated by maximum likelihood, and the critical values of the NNTS circular uniformity test are obtained by simulation. Ref. [
12] showed the inconsistency of the bootstrap method when the parameter is on the boundary of the parameter space. Alternative bootstrap methods have been developed by Cavaliere, Nielsen and Rahbek to apply the bootstrap method when some or all the elements of the parameter vector are on the boundary of the parameter space [
13,
14]. They applied the proposed modified bootstrap method to the family of ARCH models for modelling the volatility of financial time series. These modified bootstrap methods require the simulation of bootstrap samples from the model in which the parameter estimates are specified with a shrinkage towards the boundary values at an appropriate rate. In this paper, since the null hypothesis with parameters on the boundary of the parameter space is completely specified, we considered a simpler approach in which we sampled from the null circular uniform distribution, calculated the test statistic and repeated this process for many null samples to estimate the critical values at significance levels of 10%, 5% and 1%. This procedure is repeated for samples of different sizes. The estimated critical values for different sample sizes are used in a regression model to obtain interpolated values of the critical values for any sample size, as suggested by Cuddington and Navidi [
15]. Finally, we obtained a regression formula for the critical values for any sample size that satisfies the asymptotic values of the critical values of the test statistic observed for very large simulated samples sizes. In the fifth section, the power of the NNTS circular uniformity tests is examined by considering the results of the sums of the NNTS random variables in the third section to consider alternative circular distributions that are close to the null circular uniform distribution. The practical application of the proposed tests to real data on the time of occurrence of earthquakes and the flying orientation of home pigeons is presented in the sixth section. Finally, in the seventh section, conclusions are presented.
2. Characteristic Function of an NNTS Circular Random Variable
A circular random variable
is defined as a random variable with unit circle support. These random variables are relevant when modelling seasonal patterns in many different scientific areas. Let
be a circular random variable with an NNTS distribution with support interval
with a density function defined as the squared norm of a sum of complex trigonometric terms:
where
and
. Complex parameter vector
with complex numbers
and
, where
and
are the real and imaginary parts of the complex number
, respectively. The parameter vector
must satisfy
where
is the squared norm of the complex number
. Given this parameter constraint,
must be a positive real number related to the density concentration around its modes. The parameter set is a subset of the surface of a complex unit hypersphere in the space of complex numbers of dimension
,
because
and
produce the same NNTS density. In addition, the vector of parameters
written in reverse order, produces the same NNTS density. For identifiability, we considered the parameter vectors
with
positive and
. The number of terms in the sum
M is an additional parameter that determines the maximum number of modes of the NNTS density function. By increasing
M, it is possible to increase the number of modes and/or the concentration around the modes in the NNTS density function. The case
corresponds to a circular uniform distribution,
. The NNTS density satisfies the periodicity constraint for a circular density
for any integer
r.
The characteristic function of a circular random variable,
, is defined as
The characteristic function of an NNTS circular random variable is obtained as
then
where
is an indicator function that takes the value of one if
and zero otherwise. This result is obtained because the integral
is zero for
and equal to
for
. Rearranging the terms in Equation (
5), we obtain
Thus, the characteristic function of an NNTS circular random variable takes values on the integers , and these values are functions of the vector of parameters .
3. Distribution of the Sum of Independent NNTS Circular Random Variables
Let
be independent NNTS circular random variables with parameter vectors
,
, …,
and
, respectively. For independent random variables, the characteristic function of
,
, satisfies
In particular, for the case of two summands,
,
and for the NNTS case,
Extending this result to the case of
S summands, the characteristic function of the sum
of the independent NNTS circular random variables is given by
Thus, the NNTS family of circular distributions is closed under summation; that is, the sum of independent NNTS circular random variables is an NNTS circular random variable with parameter and parameter , which is a function of the vectors of parameters , .
To obtain the vector of parameters
, the following system of
equations involving the real parameter
is considered.
for
and the norm equation
By considering the real and imaginary parts in Equations (
8) and (
9), this system of
nonlinear real equations can be solved numerically. In particular, one can use the
R package
considering the vector with one in its first entry and zeroes in the other entries that correspond to the uniform distribution case as initial values [
16].
For the sum of more than two NNTS circular random variables, the result for two random variables can be applied recursively.
3.1. Case
If both summands are NNTS random variables with
, then the density function of their sum can be obtained analytically as follows: By considering the squared norm in the equations defined in Equation (
8), we obtain
Substituting these equations into Equation (
9), the following equation for
is obtained:
which is equivalent to the following biquadratic equation on
:
with the largest positive solution given by
Once the value of
is determined, the values of
can be obtained by using the system of equations in Equation (
8).
Thus, for the sum of two NNTS circular random variables with
1, the
c parameters are given by
and
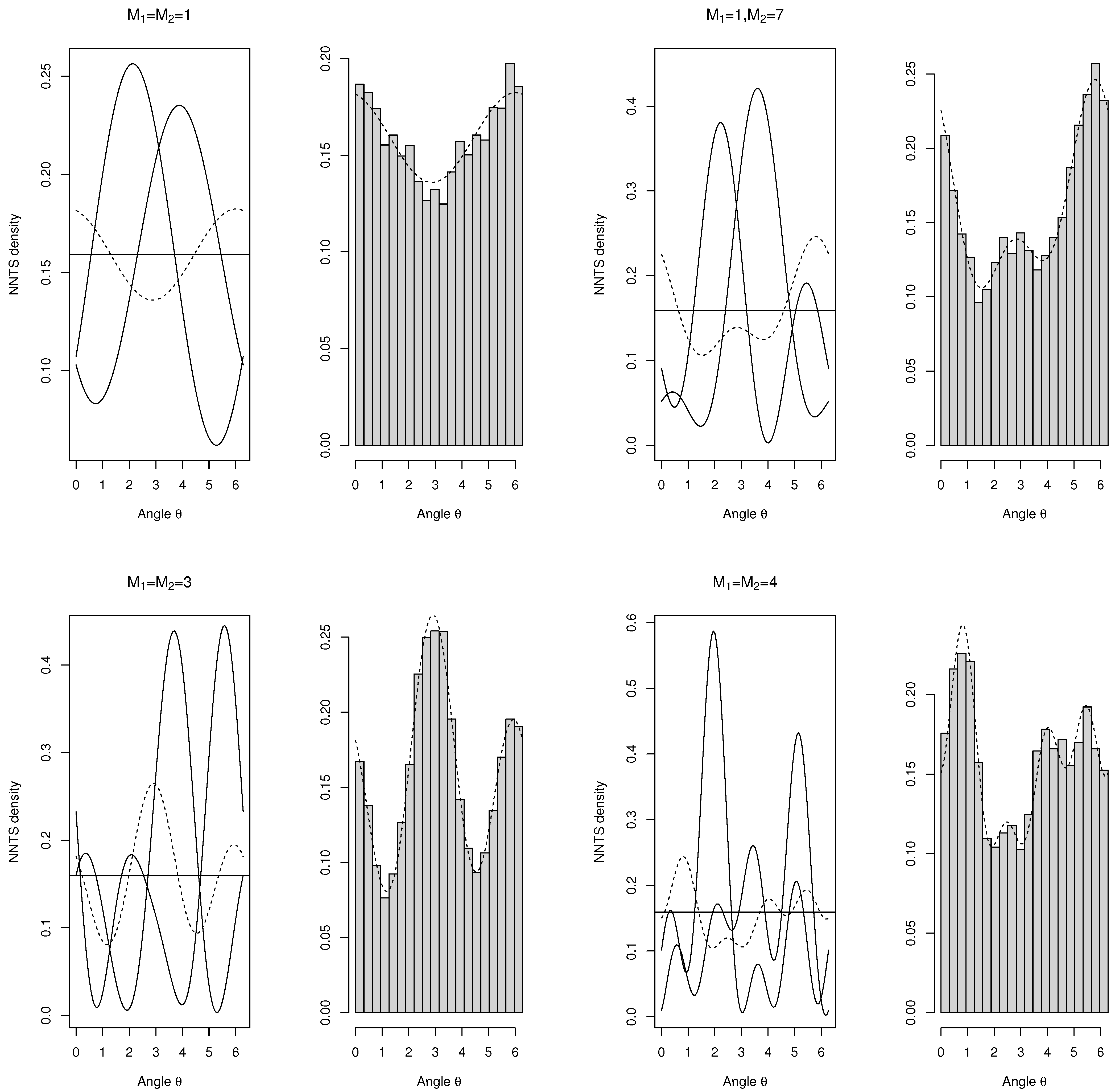
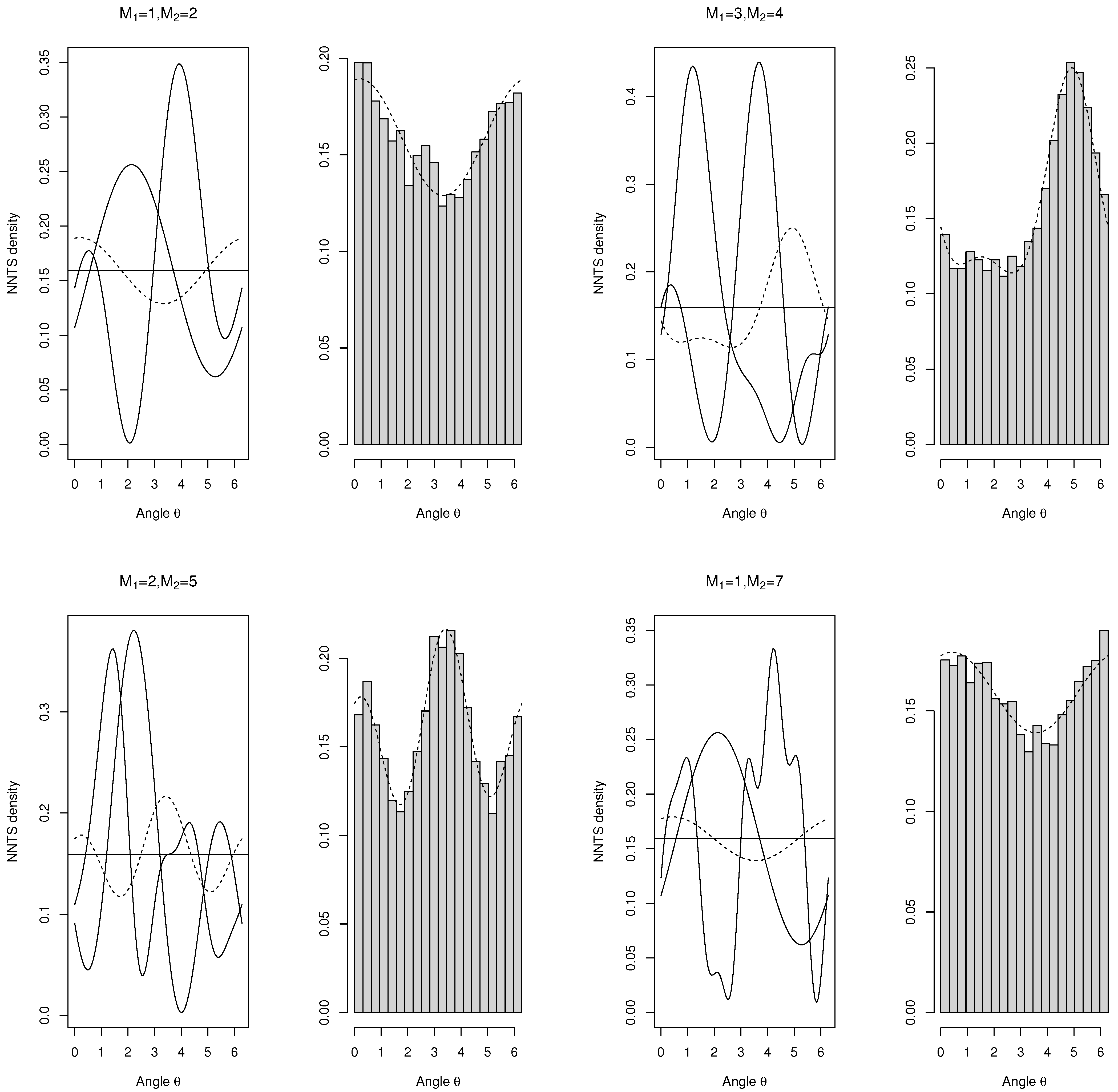
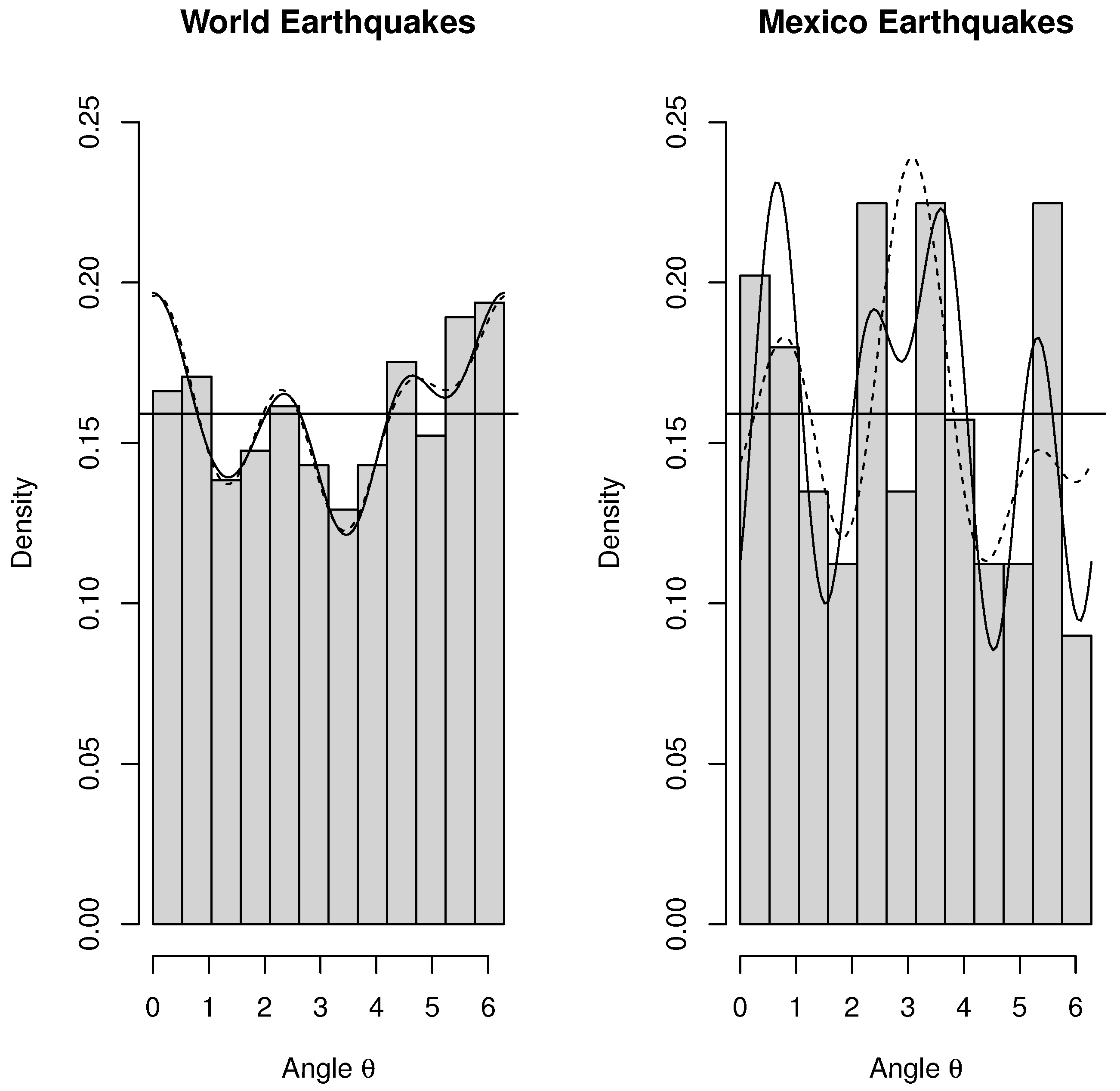
3.2. Numerical Examples
In the case of the sum of two NNTS circular random variables with different values of
M,
Figure 1 and
Figure 2 show the density functions of the two random variables and their sum. In addition, the horizontal line corresponding to the circular uniform density (
) was included to appreciate the convergence of the sum to the circular uniform density. The plots on the right of
Figure 1 and
Figure 2 include the histograms of 1000 realisations from the sum of the two univariate NNTS densities; considering realisations from each of the summands and then their sum (modulus 2
), the NNTS density of the sum is superimposed on the histograms.
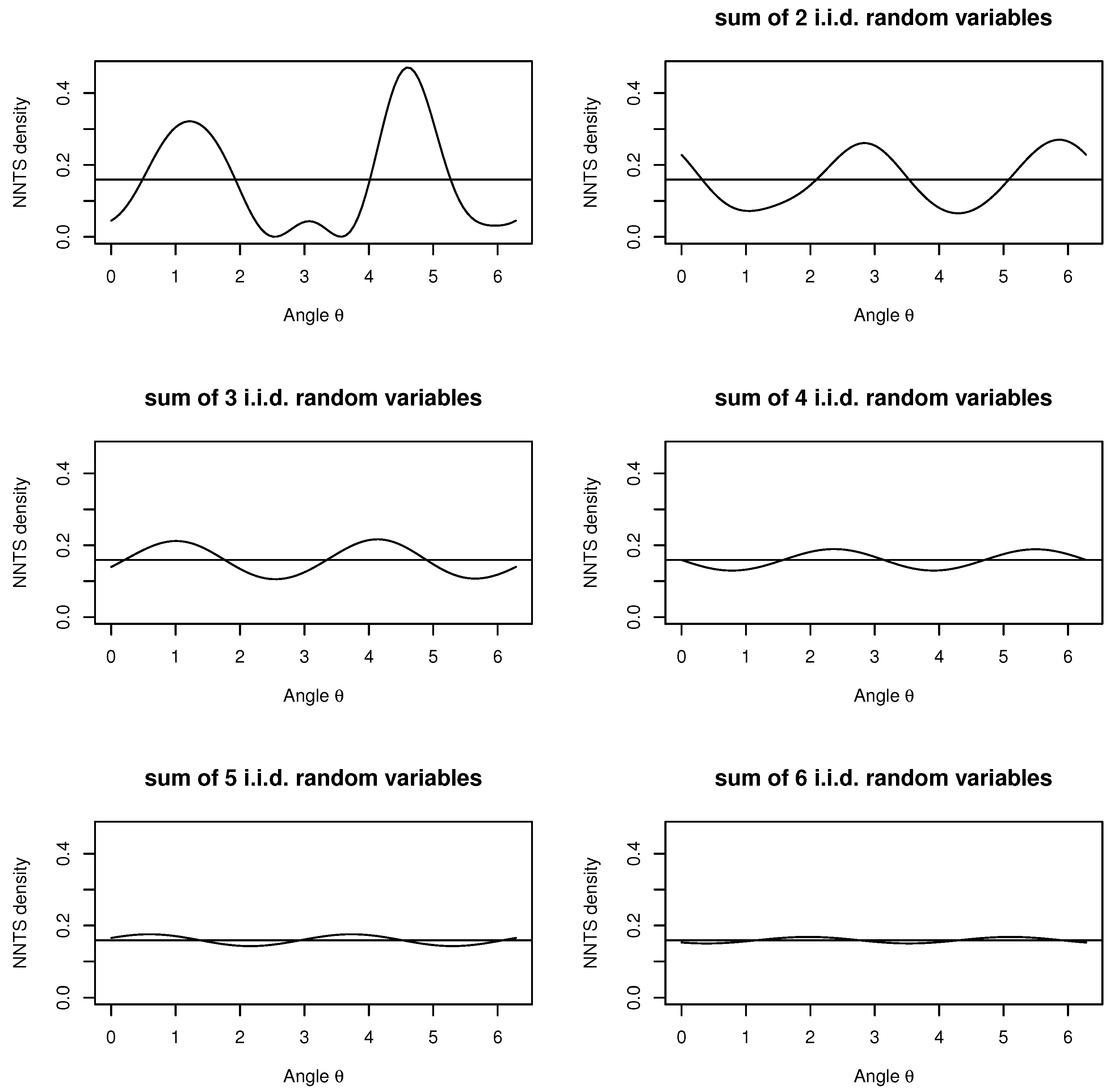
Figure 3 presents, for a simulated case with
, the plots of the NNTS densities for the case of independent and identically distributed random variables, in which we add recursively to obtain the density function of the sum of 2, 3, 4, 5, and 6 random variables. From
Figure 3, it is clear how the convergence to the circular uniform distribution occurs very fast, with the sum of three or more random variables appearing almost circularly uniformly distributed.
4. Two Circular Uniformity Tests with NNTS as Alternative Hypotheses
Many tests for circular uniformity have been reported in the literature. Among the most used in practice, one finds the Rayleigh test against a unimodal alternative, Kuiper’s test, Watson’s test, and the range test among many others [
4,
5,
17]. As noted by Fisher, circular uniformity tests depend on the specification of the model in the alternative hypothesis, and one wants to have an alternative model that has a different number of modes to detect any departure from uniformity ([
4], p. 65). Given that the family of NNTS circular distributions is nested, that is, all models with
are particular cases of NNTS circular distributions with
with
, NNTS circular distributions are suitable models for detecting any departure from uniformity for a sufficiently large sample size. Various studies have been conducted on the low power of many circular uniformity tests. For example, ref. [
18] compared the power of the Rayleigh test, Watson’s test, Kuiper’s test, Rao’s spacing test, Bogdan test, and Hermans-Rasson test. Their main conclusions are that the Rayleigh test is preferred for unimodal departures from circular uniformity and that for multimodal departures from circular uniformity, the Hermans-Rasson test is recommended when considering mixtures of von Mises distributions as alternative models and eight different sample sizes (10, 15, 20, 25, 30, 40, 80, and 100). In the case of symmetric multimodality, the transformation of the data to a unimodal distribution and application of the Rayleigh test is recommended. Later, Landler et al. compared the power of the Rayleigh test, the Hermans-Rasson original test, a modification of the Hermans-Rasson test, and the Pycke test when considered as alternative model mixtures of von Mises distributions with modes equally distributed in the interval
with different proportions assigned to the different elements of the mixture and a sample size of 60 [
19]. The final recommendations are to use the Rayleigh tests for unimodal departures from circular uniformity, the original Hermans-Rasson test for alternative distributions with at least two modes, and when the sample size is large and one considers at least two modes in the alternative distribution, the recommendation is to use the Pycke test instead. In addition, they point to the difficulty of testing for circular uniformity when the number of modes is greater than two and the alternative distribution is unknown and recommend substantially increasing the sample size and running the Pycke test with the constraint that the observed angles are supposed to show a high concentration around the modes. Given these results, we compared the power of the two proposed NNTS tests against four different tests: the Rayleigh test, the original and modified Hermans-Rasson tests, and the Pycke test. For a random sample of angles
, the test statistic, as presented in [
19], of the original Hermans-Rasson test is
the modified Hermans-Rasson test is
while the Pycke test is
The Hermans-Rasson tests belong to the family of circular uniformity tests of Beran, also known as Sobolev’s tests, in which the mean resultant length of the observations is p-fold wrapped on the unit circle, which is equivalent to considering the powers of the unit complex vectors with arguments given by the observed angles and calculating their mean resultant lengths, thereby obtaining weighted sums of Rayleigh statistics for different powers [
5,
20]. Like this study, ref. [
11] considered multimodal alternative distributions that correspond to Fourier transformations that are equivalent to NNTS densities but Pycke did not consider the constraints in the parameter space to obtain a valid density function that is positive and integrates to one. Pycke found that the distribution of his test statistic is of a nonstandard form and corresponds to a weighted sum of chi-square distributions in which the weights are unknown complex functions of the observations [
11]. Given the convergence of the distribution of the sum of circular random variables to the circular uniform distribution and, for the case of NNTS circular random variables, it is possible to investigate and compare the properties of the proposed NNTS test for cases where the parameter vector is close to the value specified to the null hypothesis. A circular uniformity test with NNTS distributions as alternative hypotheses exploits the flexibility of NNTS densities, which can model very different patterns for the alternative distribution in terms of the number of modes and asymmetry. For the NNTS test, the null and alternative hypotheses were specified as follows:
or, equivalently,
In terms of the
parameter vector of an NNTS density with a fixed value of
, the null and alternative hypotheses are as follows:
This hypothesis test is nonregular because the null hypothesis specifies the parameter vector on the boundary of the parameter space, and the maximum likelihood asymptotic results under regularity conditions do not apply. In particular, the likelihood ratio test statistic does not converge in distribution to a chi-squared distribution, and common bootstrap procedures are not applicable. Because the null hypothesis corresponds to the circular uniform distribution, the critical values of the NNTS test are obtained by simulating samples from the circular uniform distribution and, for each sample, fitting the NNTS model specified under the alternative hypothesis by maximum likelihood to calculate the value of the test statistic. For the first NNTS test for circular uniformity (
), we considered test statistic the standardised maximum likelihood estimator,
, of the vector of parameters
defined as:
where
is the Hermitian (conjugate and transpose) of the vector
and
is the observed information that is proportional to the Hessian matrix that includes the second derivatives of the log-likelihood function, and for the NNTS density, it is equal to the projection matrix [
2]
where
n is the sample size and
is the
identity matrix. Because
is a projection matrix that is not an identity matrix, it is not invertible, making this a nonregular maximum likelihood estimation problem. Then,
By partitioning the maximum likelihood estimator as
with
and considering that
, one obtains
and
. Then,
depends only on the first component of the maximum likelihood vector and, intuitively, because the sum of the norms of the components of the parameter vector, , should be equal to one, measures (scaled by the sample size) how far is of being equal to one that corresponds to the circular uniform distribution case.
Table 1 lists the critical values for
obtained by the simulation for significance levels of 10%, 5%, and 1% for different sample sizes. We used a total of 10,000 simulated samples to obtain critical values. Given the recommendations in [
15] for the number of simulated samples to produce critical values, the critical values in
Table 1 and
Table 2 are reported with a precision of 0.1.
The second maximum likelihood NNTS test for circular uniformity is based on the generalised likelihood ratio statistic defined as
where
is the maximised likelihood under the alternative hypothesis
, which corresponds to the maximised likelihood of the NNTS model with
. Again, because the maximum likelihood of the NNTS model does not satisfy the regularity conditions under the null hypothesis of uniformity, the critical values are obtained by simulation and are included in
Table 2 for various values of
M (1, 2, …, 7), significance levels
(10%, 5%, and 1%), and various sample sizes. Again, given the nonregular maximum likelihood estimation for NNTS models under the null hypothesis (
), the statistic
does not converge to a chi-squared distribution for large sample sizes, and commonly used bootstrap procedures are not applicable.
Table 2 contains a larger number of sample sizes than
Table 1 since, as shown later in the paper, the
NNTS2 has more power than the
NNTS1 test and is recommended for use in practice. Running in parallel for different simulated samples in different cores of the processor, ten thousand simulated datasets are used to estimate the critical values of the
statistic took, for sample sizes of 500, from approximately 38 min for
to approximately 68 min for
in an 8 core CPU at a speed of 3 GHz.
Following MacKinnon,
Table 3 includes the fitted regression models to interpolate the critical values for any sample size with a precision of 0.1 (one decimal place) [
21,
22]. In this case, the regression models for the critical values considered as explanatory variables the reciprocal of the sample size and the NNTS parameter
M and their interaction and the reciprocal of the squared sample size. The interaction between the squared sample size and
M was not significant for all the considered models. Initially, a single regression model for all the values of
M was considered, but for the cases
1 and
2, it did not present a good fit. Then, two separate regression models were fitted for the cases
1 and
2, in which only the sample size and
M had significant coefficients. For the other considered values of
M, 3 to 7, a common regression model was sufficient. As shown in
Table 3, the fitted regression models had a good fit since their coefficients of determination are very high and their maximum absolute and relative errors are quite small. The relative errors are less than 2.1% for the model with
1 and less than 1.3% for the other models (
). Given these results, the critical values for all sample sizes can be interpolated for any sample size by using the fitted regression models. Given the observed precision of the regression models, in the case of an observed
NNTS2 statistic,
, with a value that differs from the interpolated critical value by less than 0.1, the test can be considered inconclusive.
Table 3 also includes the sample sizes at which the interpolated critical values by regression reach the asymptotic critical values observed in the simulations in
Table 2. From these identified sample sizes, the asymptotic values obtained in the simulation are used in the implementation of the test. These asymptotic critical values were determined in the simulations by identifying many consecutive sample sizes at which the critical values obtained by simulation did not change. For the fitting of the regression models, we considered only the first two consecutive sample sizes at which the critical values did not change. From the simulations and by considering the critical values as a decreasing function of the sample size, the minimum sample size to apply the
NNTS2 test for
3 was found to be
which implies that we have at least 5 observations for each of the 2
M NNTS parameters to be estimated. For cases
1 and
2, we found that the required minimum sample sizes are 15 and 25, respectively.
5. Power and Size Comparisons
We compared the Rayleigh (RT), modified Hermans-Rasson (HRmT), Pycke (PT), and NNTS (
and
) tests in terms of their power and size by simulating samples from the null circular uniform distribution and the alternative NNTS distribution for sample sizes (
SS) of 25, 50, 100, 200, and 500. We compared the power of the tests for significance levels
of 10%, 5%, and 1%. The
R package
was used to calculate the test statistic of the Rayleigh test [
23]. The Hermans-Rasson and Pycke tests were performed by using the
R package
[
19,
24]. Finally, for the
and
the
R package
was used [
3]. To speed up the calculation of the NNTS tests, the computations were implemented in parallel by using the
R package
in an 8 core CPU at a speed of 3 GHz [
25].
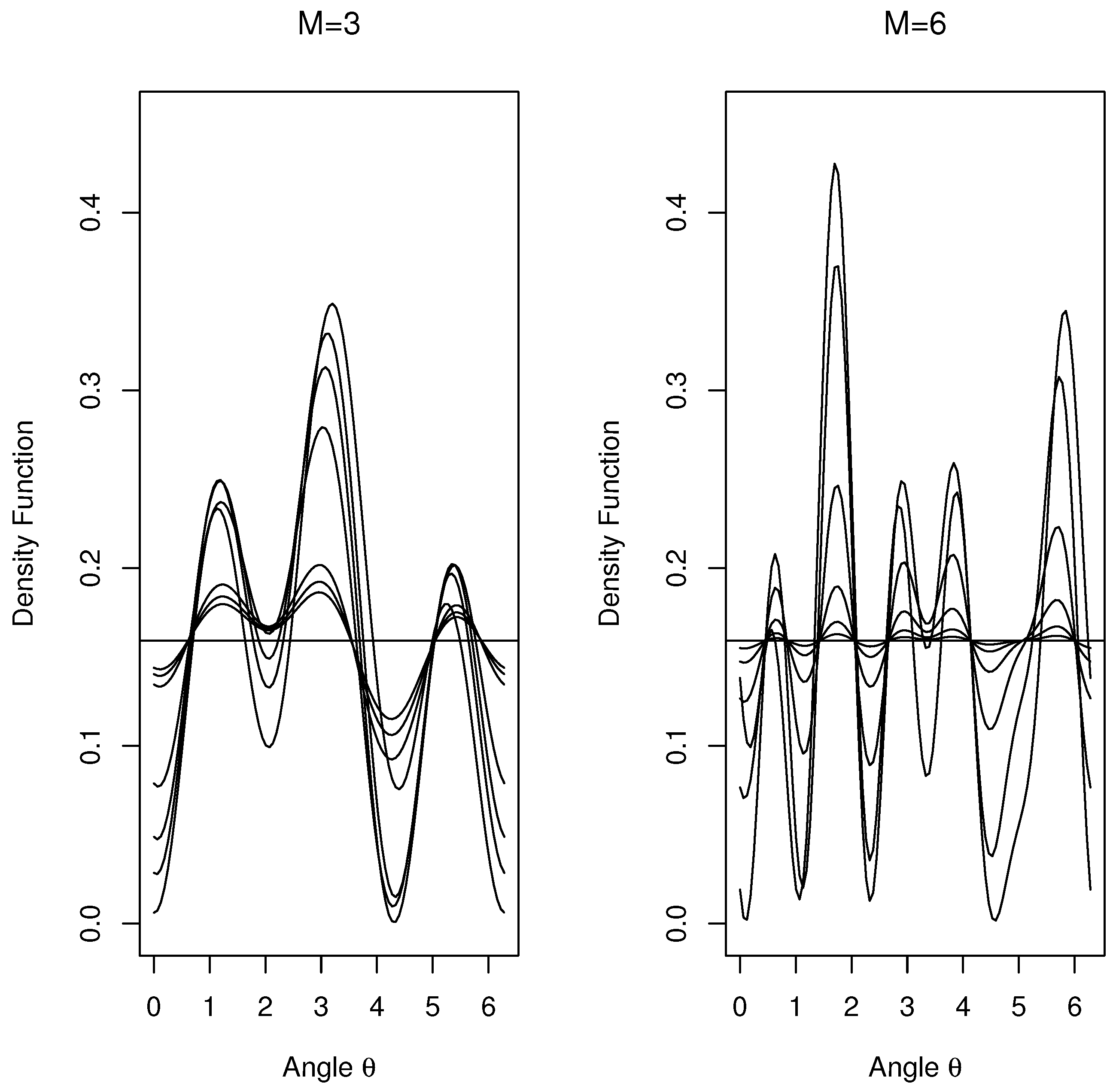
Figure 4 shows plots of the two NNTS alternative models with
and
. For each of the two NNTS alternative models, we considered various values of the parameter
to obtain alternative models that are close to the null circular uniform distribution. As shown in
Figure 4, by increasing the value of parameter
, we obtain distributions that are closer to the circular uniform distribution. In terms of size, when simulating samples from the null circular uniform distribution and applying the tests, all the considered tests obtained an adequate observed frequency of rejection of the null hypothesis that was practically identical to the significance level. We used 1000 simulated samples from the null and alternative models in our simulations, and the frequencies corresponding to the observed power are reported in rounded percentages ranging from 0% to 100%.
Table 4,
Table 5 and
Table 6 contain the results for the power of the tests by using the observed frequencies, in percentage, for rejecting the null hypothesis of circular uniformity when simulating random samples from the alternative model with
with eight different values of parameter
. The considered eight cases of the
parameter range from 0.59 to 0.9959, with
values near one representing densities closer to the circular uniform distribution, as shown in the left plot in
Figure 4. Basically, in all cases and sample sizes where the power takes an acceptable value, the Hermans-Rasson (HRmT) test presented lower power than that for the Pycke (PT) test, and we then compared the NNTS (
and
) tests against the Pycke (PT) test. For the sample size of 25, the Pycke test has the largest power, although it is below 0.6. For cases 1 to 5 and sample sizes of 25 and 50, the
with
had the largest power, followed by the
test with
, which was followed by the Pycke test. In many cases and sample sizes, the
test with
has a very similar power to the Pycke test. This implies that when applying the generalised likelihood ratio
test, there is some flexibility in the selection of the
M value to be used in the test; in case of doubt between
and
, it is recommended using
to avoid a situation in which a smaller
M is used and the power decreases considerably, as shown for the power values for the
test with
or
. For the largest sample sizes of 200 and 500 in
Table 5 and
Table 6,
and
present similar power values, showing that the two tests are equivalent for large sample sizes and significance levels of 5% and 1%, respectively. This convergence was achieved earlier for sample sizes of 100, 200, and 500 for a significance level of 10%, as shown in
Table 4.
For cases 6, 7 and 8 and sample sizes of 25, 50, and 100, none of the tests showed acceptable power, implying that a larger sample size is required to detect small deviations from circular uniformity. For example, for case 6 with
, one obtains acceptable power for the
test with
only for a sample size equal to 500. As suggested by one of the reviewers, we tried an automatic implementation of the
test in which the alternative model was considered the best AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) NNTS model. For the case of the AIC alternative model, the simulations showed that the size of the test is larger than the specified significance level, although the power increases with respect to the
test, making the
AIC test unsuitable for practical application. For the
BIC test, the opposite effect is observed: the size of the test is correct, but the power is reduced, as shown in
Table 4,
Table 5 and
Table 6.
Table 7 presents a comparison of the generalised likelihood ratio
test with
and
and the Pycke test for simulated data from the NNTS alternative model with
and six cases with values of the parameter
from 0.5072892 to 0.9999601 presented in the right plot in
Figure 4. For cases 4, 5 and 6, it is clear from the low power of the tests that sample sizes larger than 500 are required to detect very small deviations from circular uniformity implied by the
values that are very close to one. For cases 1, 2 and 3, the
tests with
are the ones that almost in all cases, present the largest power followed by the
test with
, and this test is followed by the Pycke test. The difference between the powers of the
test and the Pycke test can be large, as shown in case 3. Again, the use of the
test is recommended, and the value of
M can be larger than the true value, and still one obtains a larger power than that for the Pycke test. As shown in
Table 8, we confirm that the
test outperforms or has a similar power to the Hermans-Rasson (HRmT) and Pycke (PT) tests when the alternative model corresponds to a model different from a member of the NNTS family. In
Table 8, the observed frequency of rejection for some cases of the von Mises distribution, a mixture of two von Mises distributions and wrapped Cauchy alternative models are presented.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}